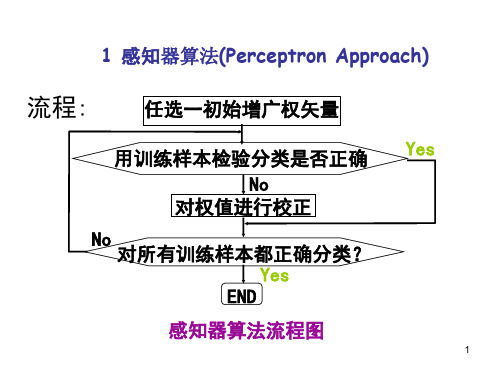
感知器算法
感知器算法原理

感知器算法原理
感知器算法是一种人工神经网络的算法,它的主要原理是通过学习一
组样本数据,来预测新数据的类别。
感知器算法最早由Frank Rosenblatt在1957年提出,它是一种二元线性分类器,它的输入为
一组实数,输出为0或1。
感知器算法的工作原理非常简单,它将输入向量与一组权重系数进行
内积计算,并将结果与一个阈值进行比较。
如果结果大于阈值,则输
出为1,否则输出为0。
如果感知器的输出与实际输出不一致,那么算法就会根据误差进行权重的调整,直到误差收敛或达到预设的最大迭
代次数。
感知器算法的收敛性是有保证的,如果数据是线性可分的,那么感知
器算法一定能够找到一个最优的线性分类超平面,使得样本分类正确。
但如果数据是非线性可分的,那么感知器算法可能无法收敛。
感知器算法有一些缺点,比如它只能处理线性可分的数据,可能会牺
牲一些分类精度,对于高维数据来说,它需要大量的计算和存储资源,而且对于非平衡数据集来说,它可能会产生误导性的结果。
为了克服
这些缺点,人们提出了许多改进的感知器算法,比如多层感知器、支
持向量机、Adaboost等,这些算法可以更好地处理非线性数据,提
高分类精度。
总的来说,感知器算法是一种简单而有效的分类算法,它的原理易于理解,实现也比较简单,但在现实应用中需要注意其局限性。
在选择分类算法时,需要根据具体的数据特征和需求来选择合适的算法。
单层感知器算法及其训练过程探究

单层感知器算法及其训练过程探究随着人工智能和机器学习技术的发展,单层感知器算法因为其简单和易于理解的特点成为了很多人学习和掌握机器学习初步知识的入门之路。
本文将介绍单层感知器算法及其训练过程探究。
一、单层感知器算法单层感知器是一种线性分类模型,也是神经网络的一种。
它通过一些列数值计算和激活函数的运用,将输入的向量映射到某个输出的标签值,用于相应的分类任务中。
单层感知器算法的基本流程是:输入向量 x 经过线性函数运算 h(x) = w*x+b 之后,再经过激活函数 g(h(x)) ,得到分类的输出 y。
其中,w 是权重,b 是偏差量。
在训练过程中,单层感知器通过反向传播算法对权重和偏差量进行不断调整,从而不断提高分类准确率。
二、单层感知器的训练过程单层感知器的训练过程可以分为以下几步:1. 准备数据准备数据是机器学习的第一步,也是单层感知器训练的必要条件。
通常,我们需要用一些已经标记好标签的数据集,输入向量 x 和对应的标签 y,作为算法的训练数据集。
2. 初始化权重和偏差量在开始训练之前,需要初始化权重 w 和偏差量 b。
通常,我们可以使用随机的小数值来初始化它们。
3. 计算误差并更新参数单层感知器的权重和偏差量通过随机初始化后,就可以开始输入训练集数据,并对其进行分类。
如果分类结果与真实标签不一致,则需要通过误差计算来调整权重和偏差。
通常,我们可以使用代价函数作为误差计算的准则,常见的代价函数有均方误差MSE 和交叉熵 CE. 通过代价函数计算出误差值,再通过反向传播算法对权重和偏差量进行更新,不断调整,直到误差值最小化。
4. 不断迭代在更新了权重和偏差量之后,需要再次用训练集测试,并根据误差值调整权重和偏差,直到误差值达到预设精度或者达到最大迭代次数停止。
三、总结单层感知器算法作为神经网络中的一种基本算法,其训练过程简单,易于理解,对于初学者来说是一种入门机器学习和神经网络的良好途径。
总之,单层感知器是机器学习和深度学习的起点,学习它可以让我们更好地理解更复杂的神经网络和机器学习算法,为未来更高级的研究打下坚实的基础。
delta规则

delta规则Delta规则,也称为delta学习规则或感知器算法,是一个经典的人工神经网络学习算法。
这个算法主要用于训练一个由具有权重的神经元构成的网络,使得网络能够正确地预测给定的输入和输出。
当神经元收到一个输入时,它会计算输入与其权重的加权和作为神经元的激活函数输入。
激活函数通常采用一些非线性的函数,例如sigmoid函数,以产生更高的复杂性。
Delta规则的核心思想是基于误差的学习,即对于给定的输入,通过比较神经元的实际输出和期望输出之间的差异来调整权重。
这个差异被称为误差项,也可以被看作是网络预测与实际结果之间的差异。
具体来说,Delta规则可以被描述为下面的步骤:1.随机初始化权重。
2.使用网络进行预测。
3.计算误差项。
4.根据误差项调整权重。
5.重复以上步骤,直到误差收敛或达到预定的迭代次数。
在第一步中,权重的初始值通常被设置为随机值,以便训练开始时网络能够探索许多可能的解决方案。
在第二步中,网络接收输入并根据初始的权重计算输出。
这个输出通常与期望输出不同,因此满足误差项的条件。
在第三步中,误差项被计算为期望输出与实际输出之间的差异。
这个差异可以使用一个成本函数来度量。
在第四步中,权重被通过误差项的反向传播来调整,即越大的误差项产生更多的权重调整。
在第五步中,程序使用新的权重再次执行第二至第四步,以获得更准确的输出结果。
这个过程持续进行直到误差足够小,或达到规定的迭代次数。
需要注意的是,Delta规则的效率和准确度很大程度上取决于两个因素:学习速率和激活函数。
学习速率决定了神经元根据误差项调整权重的幅度,如果学习速率太大,网络可能会无法收敛;如果太小,网络的训练过程可能会变得过于缓慢。
激活函数对网络所能解决的问题的复杂度具有重要的影响。
如果激活函数是线性的,那么神经网络只能处理线性可分问题,并且不能处理高度非线性的问题。
总之,Delta规则是一种简单而有效的网络训练算法,它在许多机器学习应用中被广泛使用。
感知器算法的基本原理与应用

感知器算法的基本原理与应用感知器算法是一种简单而有效的机器学习算法,于1957年被Frank Rosenblatt所提出。
在过去几十年里,感知器算法一直被广泛应用在识别模式,分类数据和垃圾邮件过滤等领域。
本文将会介绍感知器算法的基本原理,如何使用感知器完成模式分类,以及如何优化感知器算法。
感知器算法的基本原理感知器算法基于神经元(Perceptron)模型构建,神经元模型的基本原理是对输入信号进行加权,然后通过激活函数的计算输出结果。
通常情况下,神经元被认为是一个输入层节点,一个或多个输入是接收的,以及一个输出层。
感知器算法的核心思想是,给定一组输入和对应的输出(通常成为标签),通过多个迭代来调整模型中的权重,以最大限度地减少模型的误差,并尽可能准确地预测未知输入的输出。
感知器算法的主要流程如下:1. 初始化感知器参数,包括权重(最初为随机值)和偏置(通常为零)。
2. 对于每个输入,计算预测输出,并将预测输出与实际标签进行比较。
3. 如果预测输出与实际标签不同,则更新权重和偏置。
更新规则为$\omega_{j} \leftarrow \omega_{j} + \alpha(y-\hat{y})x_{j}$,其中$x_{j}$是输入的第$j$个特征,$\alpha$是学习率(控制权重和偏置的更新量),$y$是实际标签,而$\hat{y}$是预测输出。
4. 重复步骤2和步骤3,直到满足停止条件(例如,经过N次重复迭代后误差不再显著降低)。
如何使用感知器完成分类让我们考虑一个简单的情况:我们要学习使用感知器进行两类别(正面和负面)的文本情感分类。
我们可以将文本转换为一组数字特征,例如文本中出现特定单词的频率或数量,并将每个文本的情感作为输入,正面或负面情感被记为1或0。
我们可以将感知器视为一个二元分类器,用它来预测每个输入文本的情感值。
对于每个输入,我们计算出感知器的输出,并将其与实际情感进行比较。
如果它们没有匹配,那么我们将使用上面提到的更新规则调整每个特征的权重,重复该过程,直到达到收敛为止。
感知器算法

y = f (∑ wi xi − θ )
i =1
d
而且f为一阶跃函数, 而且 为一阶跃函数,即: 为一阶跃函数
d 1, ∑ wi xi − θ ≥ 0 i =1 y = f ( x) = = sgn( w0T x − θ ) d −1, w x − θ < 0 ∑ i i i =1
四、感知器训练算法在多类问题中的应用 就第二章中的第三种情况为例说明) (就第二章中的第三种情况为例说明) 判决规则:对于c种类型 存在k个判决函 种类型, 判决规则:对于 种类型,存在 个判决函 数 d j ( x)( j = 1, 2,⋯, k ) ,若 di ( x) > d j ( x)( j = 1, 2,⋯ , k , j ≠ i) , x ∈ ωi 则判: 则判: 假设k=c, 多类问题的感知器算法的步骤如下: 多类问题的感知器算法的步骤如下: 假设 (1) 赋给初值: 赋给初值: 赋初值,选择正常数c, 给 Wi 赋初值,选择正常数 把训练样本 变成增广型, 变成增广型,k=0; x (2) 输入训练样本 xk,k ∈{x1 , x2 ,⋯, xn },假定 x ∈ ωi ;
训练样本
x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101
W(K)Tx
+ + + 0 0 + 0 + + + -
(3) 计算 个判决函数值: 计算c个判决函数值 个判决函数值:
di ( xk ) = [Wi (k )]T xk , i = 1, 2,⋯ , c
感知器的训练算法

感知器的训练算法
已知两个训练模式集分别属于ω1类和ω2类,权向量的初始值为w(1),可任意取值。
若0x )k (w ,x k T 1k >∈ω,若0x )k (w ,x k T 2k ≤∈ω,则在用全部训练模式集进行迭代训练时,第k 次的训练步骤为:
- 若1k x ω∈且0x )k (w k T ≤,则分类器对第k 个模式x k 做了错误分类,此时应校正权向量,使得w(k+1) = w(k) + Cx k ,其中C 为一个校正增量。
- 若2k x ω∈且0x )k (w k T >,同样分类器分类错误,则权向量应校正如下:w(k+1) = w(k) - Cx k
- 若以上情况不符合,则表明该模式样本在第k 次中分类正确,因此权向量不变,即:w(k+1) = w(k)
若对2x ω∈的模式样本乘以(-1),则有:
0x )k (w k T ≤时,w(k+1) = w(k) + Cx k
此时,感知器算法可统一写成:
⎩⎨⎧≤+>=+0
x )k (w if Cx )k (w 0x )k (w if )k (w )1k (w k T k k T。
感知器算法的实验报告

一、实验背景感知器算法是一种简单的线性二分类模型,由Frank Rosenblatt于1957年提出。
它是一种基于误分类项进行学习,以调整权重来拟合数据集的算法。
感知器算法适用于线性可分的数据集,能够将数据集中的样本正确分类。
本次实验旨在通过编程实现感知器算法,并使用iris数据集进行验证。
通过实验,我们能够熟悉感知器算法的基本原理,了解其优缺点,并掌握其在实际应用中的使用方法。
二、实验目的1. 理解感知器算法的基本原理;2. 编程实现感知器算法;3. 使用iris数据集验证感知器算法的性能;4. 分析感知器算法的优缺点。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 机器学习库:Scipy、Numpy、Matplotlib、sklearn四、实验步骤1. 导入必要的库```pythonimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.model_selection import train_test_split```2. 读取iris数据集```pythoniris = datasets.load_iris()X = iris.datay = iris.target```3. 将数据集划分为训练集和测试集```pythonX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)```4. 编写感知器算法```pythondef perceptron(X, y, w, b, learning_rate):for i in range(len(X)):if np.dot(X[i], w) + b <= 0:w += learning_rate y[i] X[i]b += learning_rate y[i]return w, b```5. 训练感知器模型```pythonlearning_rate = 0.1max_iter = 100w = np.zeros(X.shape[1])b = 0for _ in range(max_iter):w, b = perceptron(X_train, y_train, w, b, learning_rate)```6. 评估感知器模型```pythondef predict(X, w, b):return np.sign(np.dot(X, w) + b)y_pred = predict(X_test, w, b)accuracy = np.mean(y_pred == y_test)print("感知器算法的准确率:", accuracy)```7. 可视化感知器模型```pythondef plot_decision_boundary(X, y, w, b):plt.figure(figsize=(8, 6))plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired,edgecolors='k', marker='o')x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))Z = np.dot(np.c_[xx.ravel(), yy.ravel()], w) + bZ = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.4)plt.xlabel("Sepal length (cm)")plt.ylabel("Sepal width (cm)")plt.title("Perceptron Decision Boundary")plt.show()plot_decision_boundary(X_train, y_train, w, b)```五、实验结果与分析1. 感知器算法的准确率为约0.9,说明感知器算法在iris数据集上表现良好。
感知器算法原理

感知器算法原理
感知器是一种最简单的人工神经网络模型,它模拟了人类大脑神经元的工作原理,能够实现简单的分类任务。
感知器算法的原理是基于线性分类器的思想,通过不断迭代更新权重和偏置,使得感知器能够找到一个能够将输入数据正确分类的超平面。
在本文中,我们将详细介绍感知器算法的原理及其应用。
首先,让我们来了解一下感知器的结构。
感知器由输入层、权重、偏置、激活
函数和输出层组成。
输入层接收外部输入数据,每个输入数据都有一个对应的权重,权重表示了输入数据对输出的影响程度。
偏置用于调整模型的灵活性,激活函数则用于引入非线性因素,输出层则输出最终的分类结果。
感知器算法的原理是基于误差驱动的学习规则,即通过不断调整权重和偏置,
使得感知器的输出尽可能接近真实标签。
具体来说,感知器接收输入数据,计算加权和并经过激活函数处理得到输出,然后与真实标签进行比较,如果预测错误,则根据误差调整权重和偏置,直到达到一定的精度要求。
在实际应用中,感知器算法可以用于解决二分类问题,如判断一张图片是猫还
是狗,或者判断一封邮件是垃圾邮件还是正常邮件。
感知器算法的优点是简单易懂,训练速度快,适用于线性可分的数据集。
然而,感知器也存在一些局限性,比如无法解决非线性可分的问题,对噪声敏感等。
总之,感知器算法是一种简单而有效的分类算法,它通过模拟人脑神经元的工
作原理,实现了简单的分类任务。
在实际应用中,感知器算法可以用于解决二分类问题,具有训练速度快等优点。
然而,感知器也存在一些局限性,需要根据具体问题选择合适的算法。
希望本文能够帮助您更好地理解感知器算法的原理及其应用。
多层感知器算法在数据分类中的应用论文素材

多层感知器算法在数据分类中的应用论文素材多层感知器算法在数据分类中的应用多层感知器(Multilayer Perceptron,简称MLP)是一种常见的人工神经网络模型,在数据分类领域得到了广泛应用。
本论文将介绍MLP算法的基本原理和在数据分类中的应用。
一、MLP算法的基本原理多层感知器算法是一种前向人工神经网络(Feedforward Artificial Neural Network)模型。
它由输入层、隐藏层和输出层构成,每个层由多个人工神经元(Artificial Neuron)组成。
1. 输入层:接收原始数据作为神经网络的输入,并负责传递数据到下一层。
2. 隐藏层:它是介于输入层和输出层之间的一层或多层,用于提取输入数据的特征信息。
每个神经元都通过一定的连接权重将输入传递给下一层。
3. 输出层:对于分类问题,输出层的神经元数量通常与分类的类别数量相同,每个神经元对应一个类别。
根据传递到输出层的信号强度,可以确定数据属于哪个类别。
在MLP算法中,每个神经元都由一个激活函数(Activation Function)来处理输入信号。
常用的激活函数包括Sigmoid函数、ReLU 函数和Softmax函数等。
MLP算法通过不断调整连接权重和阈值,使得神经网络能够学习并改进自己的性能。
训练过程通常采用反向传播算法(Backpropagation Algorithm)来更新网络参数。
二、MLP算法在数据分类中的应用MLP算法在数据分类中具有广泛的应用,尤其在图像和文本分类领域取得了显著的成果。
1. 图像分类图像分类是指将输入的图像划分到不同的类别,比如人脸识别、车辆检测等。
MLP算法可以用于图像特征提取和分类。
通过在隐藏层中设计合适的神经元数量和激活函数,MLP模型能够学习到图像的高级特征,从而提高分类的准确性。
2. 文本分类文本分类是将一段文本划分到不同的类别,比如垃圾邮件过滤、情感分析等。
MLP算法可以将文本表示为向量形式,并通过隐藏层学习到文本的语义信息。
机器学习算法--Perceptron(感知器)算法

机器学习算法--Perceptron(感知器)算法概括Perceptron(感知器)是⼀个⼆分类线性模型,其输⼊的是特征向量,输出的是类别。
Perceptron的作⽤即将数据分成正负两类的超平⾯。
可以说是机器学习中最基本的分类器。
模型Perceptron ⼀样属于线性分类器。
对于向量X=x1,x2,...x n,对于权重向量(w)相乘,加上偏移(b),于是有:f(x)=N∑i=1w i x i+b设置阈值threshold之后,可以的到如果f(x)>threshold,则y(标签)设为1如果f(x)<threshold,则y(标签)设为0即,可以把其表⽰为:y=sign(w T x+b)参数学习我们已经知道模型是什么样,也知道Preceptron有两个参数,那么如何更新这两个参数呢?⾸先,我们先Preceptron的更新策略:1. 初始化参数2. 对所有数据进⾏判断,超平⾯是否可以把正实例点和负实例点完成正确分开。
3. 如果不⾏,更新w,b。
4. 重复执⾏2,3步,直到数据被分开,或者迭代次数到达上限。
那么如何更新w,b呢?我们知道在任何时候,学习是朝着损失最⼩的地⽅,也就是说,我的下⼀步更新的策略是使当前点到超平⾯的损失函数极⼩化。
在超平⾯中,我们定义⼀个点到超平⾯的距离为:(具体如何得出,可以⾃⾏百度~~~ ),此外其中1|w|是L2范数。
意思可表⽰全部w向量的平⽅和的开⽅。
1‖w‖w T x+b 这⾥假设有M个点是误差点,那么损失函数可以是:L(w,b)=−1‖w‖∑x i∈M yi(w T x+b)当然,为了简便计算,这⾥忽略1|w|。
1|w|不影响-y(w,x+b)正负的判断,即不影响学习算法的中间过程。
因为感知机学习算法最终的终⽌条件是所有的输⼊都被正确分类,即不存在误分类的点。
则此时损失函数为0,则可以看出1|w|对最终结果也⽆影响。
既然没有影响,为了简便计算,直接忽略1|w|。
fisher感知器算法的原理

fisher感知器算法的原理Fisher感知器算法是一种模式识别算法,用于解决二分类问题。
它基于Fisher线性判别分析(Fisher Linear Discriminant Analysis,简称FLDA)的原理。
FLDA通过将数据投影到低维空间,使得同一类别的样本尽可能靠近,不同类别的样本尽可能分开。
具体来说,FLDA的目标是最大化类间方差与最小化类内方差的比值。
Fisher感知器算法将FLDA应用于二分类任务中。
它假设数据可以通过一个线性函数进行分类,即假设存在一个权重向量w 和偏置b,使得对于每个样本x,如果w·x + b > 0,则将其分类为正类,否则分类为负类。
Fisher感知器算法的训练过程如下:1. 初始化权重向量w和偏置b。
2. 选择一个样本x,计算 w·x + b 的值。
3. 如果 w·x + b > 0,并且x属于正类,则保持w和b不变。
4. 如果 w·x + b > 0,并且x属于负类,则将w向量朝负梯度方向调整,使得 w·x + b 变小。
5. 如果 w·x + b < 0,并且x属于负类,则保持w和b不变。
6. 如果 w·x + b < 0,并且x属于正类,则将w向量朝正梯度方向调整,使得 w·x + b 变大。
7. 重复步骤2-6,直到收敛或达到最大迭代次数。
在训练过程中,Fisher感知器算法会根据样本点的分类结果对参数进行调整,以找到一个能够最大化类间方差与最小化类内方差的超平面,从而实现对数据的最优分类。
感知器算法1

3.5 感知器算法对于线性判别函数,当模式的维数已知时判别函数的形式实际上就已经定了下来,如二维 121122T()x x d w x w x w ==++(,),X X三维123112233T,()+x x x d w x w x w x w==++(,),X X剩下的问题也就是确定权向量W ,只要求出权向量,分类器的设计即告完成。
非线性判别函数也有类似的问题。
本章的后续部分将主要讨论一些基本的训练权向量的算法,或者说学习权向量的算法,它们都是都是用于设计确定性分类器的迭代算法。
1. 概念理解在学习感知器算法之前,首先要明确几个概念。
1)训练与学习训练是指利用已知类别的模式样本指导机器对分类规则进行反复修改,最终使分类结果与已知类别信息完全相同的过程。
从分类器的角度来说,就是学习的过程。
学习分为监督学习和非监督学习两大类。
非监督学习主要用于学习聚类规则,没有先验知识或仅有极少的先验知识可供利用,通过多次学习和反复评价,结果合理即可。
监督学习主要用于学习判别函数,判别函数的形式已知时,学习判别函数的有关参数;判别函数的形式未知时,则直接学习判别函数。
训练与监督学习方法相对应,需要掌握足够的与模式类别有关的先验信息,这些先验信息主要通过一定数量的已知类别的模式样本提供,这些样本常称作训练样本集。
用训练样本集对分类器训练成功后,得到了合适的判别函数,才能用于分类。
前面在介绍线性判别函数的同时,已经讨论了如何利用判别函数的性质进行分类,当然,前提是假定判别函数已知。
2)这种分类器只能处理确定可分的情况,包括线性可分和非线性可分。
只要找到一个用于分离的判别函数就可以进行分类。
由于模式在空间位置上的分布是可分离的,可以通过几何方法把特征空间分解为对应不同类别的子空间,故又称为几何分类器。
当不同类别的样本聚集的空间发生重叠现象时,这种分类器寻找分离函数的迭代过程将加长,甚至振荡,也就是说不收敛,这时需要用第4章将要介绍的以概率分类法为基础的概率分类器进行分类。
神经元算法权重计算公式

神经元算法权重计算公式神经元是大脑的基本功能单元,它们通过神经元之间的连接来传递信息。
在人工神经网络中,神经元模拟了生物神经元的功能,它们通过连接的权重来传递和处理信息。
神经元算法权重计算公式是一种用来调整神经元连接权重的方法,它可以帮助神经网络学习和适应不同的输入数据。
神经元算法权重计算公式的基本思想是通过不断地调整连接权重,使得神经元的输出与期望输出尽可能接近。
这个过程可以通过梯度下降算法来实现,梯度下降算法是一种优化算法,它通过计算误差函数的梯度来调整连接权重,使得误差函数最小化。
下面我们将介绍几种常见的神经元算法权重计算公式。
1. 感知器算法。
感知器算法是一种简单的神经元算法,它通过不断地调整连接权重来使得神经元的输出与期望输出尽可能接近。
感知器算法的权重更新公式如下:Δw = η (d y) x。
其中,Δw是连接权重的变化量,η是学习率,d是期望输出,y是实际输出,x是输入。
通过不断地迭代更新连接权重,感知器算法可以逐渐逼近期望输出。
2. 反向传播算法。
反向传播算法是一种常用的神经元算法,它通过计算误差函数的梯度来调整连接权重。
反向传播算法的权重更新公式如下:Δw = -η ∂E/∂w。
其中,Δw是连接权重的变化量,η是学习率,E是误差函数,w是连接权重。
通过计算误差函数对连接权重的偏导数,反向传播算法可以找到使得误差函数最小化的连接权重。
3. 遗传算法。
遗传算法是一种启发式优化算法,它通过模拟生物进化的过程来调整连接权重。
遗传算法的权重更新公式如下:Δw = α (w1 w2)。
其中,Δw是连接权重的变化量,α是变异率,w1和w2是两个随机选择的连接权重。
通过不断地随机变异和选择,遗传算法可以找到最优的连接权重。
总结。
神经元算法权重计算公式是神经网络学习的基础,它通过不断地调整连接权重来使得神经元的输出与期望输出尽可能接近。
感知器算法、反向传播算法和遗传算法是几种常见的神经元算法权重计算公式,它们各自有着不同的优缺点,可以根据具体的问题选择合适的算法。
感知器算法原理

感知器算法原理感知器算法是一种二分类的分类算法,基于线性模型的思想。
其原理是通过输入的特征向量和权重向量的线性组合,经过阈值函数进行判别,实现对样本的分类。
具体来说,感知器算法的输入为一个包含n个特征的特征向量x=(x₁, x₂, ..., xn),以及对应的权重向量w=(w₁, w₂, ..., wn),其中wi表示特征xi对应的权重。
感知器算法的目标是找到一个超平面,将正负样本正确地分离开来。
如果超平面上方的点被判为正样本,超平面下方的点被判为负样本,则称超平面为正类超平面;反之,则称超平面为负类超平面。
感知器算法的具体步骤如下:1. 初始化权重向量w和阈值b。
2. 对于每个样本(xᵢ, yᵢ),其中xᵢ为特征向量,yᵢ为样本的真实标签。
3. 计算样本的预测输出值y_pred=sign(w·x + b),其中·表示向量内积操作,sign为符号函数,将预测值转化为+1或-1。
4. 如果预测输出值与真实标签不一致(y_pred ≠ yᵢ),则更新权重向量w和阈值b:- w:=w + η(yᵢ - y_pred)xᵢ- b:=b + η(yᵢ - y_pred),其中η为学习率,用于控制权重的更新速度。
5. 重复步骤3和4,直到所有样本都被正确分类,或达到预定的迭代次数。
感知器算法的核心思想是不断地通过训练样本来优化权重向量和阈值,使得模型能够将正负样本准确地分开。
然而,感知器算法只对线性可分的问题有效,即存在一个超平面能够完全分开正负样本。
对于线性不可分问题,感知器算法无法收敛。
因此,通常需要通过特征工程或使用其他复杂的分类算法来解决线性不可分的情况。
感知器算法的基本步骤

感知器算法的基本步骤嘿,咱今儿个就来聊聊感知器算法的那些事儿哈!你知道不,这感知器算法就像是一个神奇的魔法盒子,里面装着好多奇妙的步骤呢!首先啊,得有一堆数据,就好像是一堆五颜六色的糖果,每颗糖果都有它独特的味道和特征。
然后呢,就要开始给这些数据分分类啦!这就好比把不同口味的糖果放进不同的小盒子里。
怎么分呢?这就得靠感知器算法的魔力啦!它会先观察这些数据,就像我们仔细观察糖果的颜色、形状一样。
接着,它会试着找到一些规律,一些能把这些数据区分开来的关键之处。
这可不是一件容易的事儿啊,就好像在一堆乱糟糟的东西里找线索一样。
找到规律后,它就开始行动啦!它会根据这些规律来判断新的数据该归到哪一类。
这就好像来了一颗新糖果,它能马上判断出这颗糖果该放进哪个小盒子里。
你说神奇不神奇?而且哦,这个过程就像是一场有趣的游戏,不断地尝试、调整,直到找到最合适的分类方法。
想象一下,如果没有这个神奇的感知器算法,那我们面对那么多复杂的数据该咋办呀?不就像无头苍蝇一样乱撞啦!它的基本步骤虽然听起来简单,可实际操作起来可不容易呢!得小心翼翼地处理每一个数据,就像对待珍贵的宝贝一样。
在这个过程中,可能会遇到各种问题呢。
有时候会发现分错类啦,那就得赶紧调整策略,重新再来。
有时候数据太多太复杂啦,就好像走进了一个巨大的迷宫,得慢慢摸索着找到出口。
但正是因为有了这些挑战,才让感知器算法变得更加有趣和有意义呀!它就像是一个勇敢的探险家,在数据的海洋里不断探索、前行。
总之呢,感知器算法的基本步骤就像是搭积木一样,一块一块地堆积起来,最后建成一座坚固的城堡。
虽然过程中会有困难,但只要我们用心去理解、去实践,就一定能掌握这个神奇的算法,让它为我们服务呀!所以,还等什么呢,赶紧去探索感知器算法的奥秘吧!。
感知器算法
训练样本
x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101
wkTx
+ + + 0 0 + 0 + + + -
12
k 8 , xk x4 , d ( xk ) w(k )xk 1 0 , k 9 , xk x1 , d ( xk ) w(k )xk 0 , k 10 , xk x2 , d ( xk ) w(k )xk 2 0 , k 11 , xk x3 , d ( xk ) w(k )xk 1 0 , k 12 , xk x4 , d ( xk ) w(k )xk 0 , k 13 , xk x1 , d ( xk ) w(k )xk 0 , k 14 , xk x2 , d ( xk ) w(k )xk 1 0 , k 15 , xk x3 , d ( xk ) w(k )xk 2 0 , k 16 , xk x4 , d ( xk ) w(k )xk 2 0 , k 17 , xk x1 , d ( xk ) w(k )xk 1 0 ,
13
14
解:此为线性不可分问题,利用感知器法求权向量 权向量产生循环(-1, 2, 0), (0, 2, 2), (-1, 1, 1), (-1, 1, 1) (-1, 1, 1), (0, 0, 0), (-1, 2, 0) 因此算法不收敛,我们可以取循环中任一权值,例如取 W=(0,2,2)T 则判别函数为: g(x)= 2x1+2x2 判别面方程为: g(x)= 2x1+2x2=0 所以x1+x2=0 由图看出判别面H把二类分开,但其中x2错分到ω1类, 而x1错分到ω2类,但大部分分类还是正确的。
模式识别感知器算法求判别函数

模式识别感知器算法求判别函数模式识别感知器算法(Perceptron Algorithm)是一种二分类的线性分类器算法。
它通过训练集中的数据样本来学习一组权重,将输入数据映射到一些特定类别。
判别函数是这组权重与输入数据的线性组合。
具体来说,假设我们有一个包含n个特征的输入向量x,模式识别感知器算法的判别函数可以表示为:f(x) = sign(w · x)其中,w是一组权重向量,·表示向量的内积,sign是符号函数,即如果内积结果大于等于0,结果为1,否则为-1算法的目标是找到一组权重w,使得对于所有的输入样本x,f(x)能够准确地将其分类为正类(+1)或者负类(-1),从而实现分类任务。
具体求解判别函数的过程分为两个步骤:初始化和更新权重。
1.初始化:初始权重可以设置为0向量或者一个随机的小值向量。
2.更新权重:通过迭代训练样本来逐步调整权重,直到达到收敛的条件。
a. 对于每个样本x,计算预测输出值y_pred = sign(w · x)。
c. 对于不同的特征i,更新权重w_i = w_i + η * (y - y_pred) * x_i,其中η是学习率(learning rate),控制权重的调整速度。
d.重复以上步骤直到达到收敛条件。
收敛条件可以是预先设定的最大迭代次数或者当所有的样本分类正确时停止。
在实际应用中,算法通常需要对输入数据进行预处理,例如特征缩放、特征选择等,以提高算法的性能和效果。
此外,模式识别感知器算法只能解决线性可分的问题,对于线性不可分的问题,需要使用更加复杂的算法或者进行数据转换处理。
总结起来,模式识别感知器算法的判别函数是通过一组权重与输入数据的线性组合来实现的。
该算法通过迭代训练样本来更新权重,直到达到收敛条件。
虽然该算法在处理线性可分问题中表现优秀,但对于线性不可分问题需要使用其他算法。
感知器算法原理及应用

感知器算法原理及应用随着人工智能应用领域不断扩大,越来越多的算法被使用。
其中,感知器算法是一种经典的机器学习算法,广泛应用于图像、语音、自然语言处理等领域。
本文将介绍感知器算法的原理和应用。
一、感知器算法原理感知器算法是一种以 Rosenblatt 为代表的机器学习算法,最初用于二元分类。
它的基本工作原理是通过对输入数据进行加权和,并与一个阈值进行比较,来决定输出结果。
另外,感知器算法是一种基于梯度下降优化的算法,通过不断调整权值和阈值,以使分类的效果更好。
1.1 基本模型感知器模型通常用于二元分类任务,如将一个输入数据分为两类。
模型的输入是一个特征向量 x 和一个阈值θ,这两者加权后的结果通过一个激活函数 f(x) 来得到输出 y。
感知器模型可以表示为:其中,w 是权重向量,f(x) 是激活函数,可以是阶跃函数、线性函数或者 sigmoid 函数等等。
1.2 误差更新感知器算法的关键是误差更新问题。
在二元分类任务中,我们将预测值 y 限制在 0 和 1 之间。
对于一个正确的预测 y_hat 和一个错误的预测 y,我们定义误差为:error = y_hat - y误差可以用于更新权重向量 w 和阈值θ。
为了最小化误差,我们需要在每一轮训练中更新权重和阈值,以使误差最小化。
通俗的说,就是调整权重和阈值来训练模型。
在 Rosenblatt 的感知器算法中,权重和阈值的调整如下:w = w + α(error)x其中,α 是学习率,它控制着权重和阈值的更新速率,可以视作一种步长。
它的取值通常是一个较小的正数,如 0.01。
1.3 二元分类感知器算法最初用于二元分类任务,如将输入数据分为正类和负类。
实际运用中,只有两种不同的输出可能,1 和 -1,用 y ∈{-1, 1} 来表示分类结果。
分类器的训练过程可以是迭代的,每一次迭代会调整权重和偏差,以使分类效果更好。
二、感知器算法应用感知器算法是一种简单而有效的机器学习算法,可以广泛应用于图像、语音、自然语言处理等领域,以下是几个典型的应用场景。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 词向量降维
– SVD,LSA,LDA
• Based on lexical co-occurrence
– Learning representations
• Predict surrounding words of every word • Eg. word2vec
知识点回顾: input & output vector
深度学习语言模型都有哪些?(粗略)
• 2003年,Bengio,三层的神经网络构建语言模型
– 《A Neural Probabilistic Language Model》
深度学习语言模型都有哪些?(粗略)
• 2008,Ronan Collobert 和 Jason Weston
– C&W model – 《Natural Language Processing (Almost) from Scratch》
本次目录
• • • • • • Lecture 1 知识点回顾 神经概率语言模型(Bengio 2003) Word2vec (Mikolov 2013) • (CBOW & Skip-gram) * (HS & NEG) 词向量的评价方法 Softmax分类模型(原PPT乱入) 词向量的应用场景
知识点回顾:词向量
• 2012,Huang
再探深度学习词向量表示
Advanced word vector representations
主讲人:李泽魁
目录
• Lecture 1 知识点回顾 • 神经概率语言模型(Bengio 2003) • Word2vec (Mikolov 2013)
• (CBOW & Skip-gram) * (HS & NEG)
• 词向量表示
– One-hot Representation
• “黑板”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...]
– Distributional Representation
• “黑板”表示为 [0.792, −0.177, −0.107, 0.109, −0.542, ...]
• 语言模型:判定一句话是否为自然语言
• 传统的NLP语言模型(以N-gram为例)
– 如何计算一个句子的概率?
• 机器翻译:P(high winds tonite) > P(large winds tonite) • 拼写纠错:P(about fifteen minutes from) > P(about fifteen minuets from) • 语音识别:P(I saw a van) >> P(eyes awe of an) • 音字转换:P(你现在干什么|nixianzaiganshenme) > P(你西安 在干什么|nixianzaiganshenme) • 自动文摘、问答系统、... ...
知识点回顾: Simple word2vec
• Predict surrounding words in a window of length c of every word.
知识点回顾: Word2Vec & GloVe
• Word2Vec
– Efficient Estimation of Word Representations in Vector Space. Mikolov et al. (2013)
• GloVe
– Glove: Global Vectors for Word Representation. Pennington et al. (2014) – aggregated global word-word co-occurrence statistics from a corpus
深度学习词向量的语言模型(引言)
• 其他语言模型
– 指数语言模型
• 最大熵模型MaxEnt、最大熵马尔科夫模型MEMM、条件随机域 模型CRF(平滑语法、语义的加入)
– 神经概率语言模型
• Bengio2003、Mikolov2013等
深度学习语言模型都有哪些?(粗略)
• 2000年,徐伟,神经网络训练语言模型
– 《Can Artificial Neural Networks Learn Language Models?》 – 用神经网络构建二元语言模型(即 P(wt|wt−1))的方 法
深度学习词向量的语言模型(引言)
• 传统的NLP语言模型(以N-gram为例)
– 如何计算一个2,w3,w4,w5,…,wn) • =p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1) • =p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
• 词向量的评价方法 • Softmax分类模型(原PPT乱入) • 词向量的应用场景
目录对比
cs224d Lecture 3 目录
• • • • • Lecture 1 知识点回顾 (Refresher) 词向量梯度下降&随机梯度下降 (GD & SGD) 如何评测词向量 (evaluate) Softmax分类 (softmax classification) 若干习题集 (problem set)
• 所以每个词w都有两个向量表示
– input vecter:窗口内的中心向量(center vector) v – output vector:非中心词向量(external vectors) v’
• 例如window size = 1,句子 I like learning
– like为v_like – I、learning为v’_I v’_learning
• 2008,Andriy Mnih 和 Geoffrey Hinton
– 《A scalable hierarchical distributed language model》
• 2010,Mikolov
– RNNLM – 《Recurrent neural network based language model》