线性 偏倚研究
测量系统分析MSA简介

1、稳定性研究
➢Xbar-R法
➢取一个样本并建立相对于可朔源标准的基准值
➢定期〔天,周〕测量标准样本3-5次,样本容量和 频率应该基于对测量系统的了解
➢将数据按时间顺序画在x&R或X&s控制图上
➢结果分析:
➢
建立控制限并用标准控制图分析评价
失控或不稳定状态。
稳定性练习
10/16 48.6
10/22 48.4
被管理的 过程
测量
测量过程 测量值
分析
入
作业 一般的过程〔放羊式过程〕
输出
对产品决策的影响
➢第一类错误〔生产者风险/假警报〕 ➢ 一个好的零件有时被误判为“不合格〞
➢第二类错误〔消费者风险/漏判率〕 ➢ 一个不合格的零件有时被误判为“合格〞
对产品决策的影响
➢ 减少过程变差,没有零件产生在Ⅱ区
48.5
48.7
48.3
48.0
48.9 48.0
49.2
49.0
48.3
47.7
48.7
48.4
48.7
48.9
48.5
Sample StDev
Sample Mean
49.6 49.2 48.8 48.4 48.0
1
0.8 0.6 0.4 0.2 0.0
1
稳定性案例- Xbar-R法
Xbar-S Chart of C1
评价疑心有测量缺陷的量具的依据
维修前后测量设备的比较
计算过程变差所需的方法,以及生产过程的可接受性水平
作出量具的特性曲线的必要信息。
以上一切是为了满足ISO/TS 6949的相关要求:
“7.6.1 测量系统分析
临床研究中常见偏倚及其控制

临床研究中常见偏倚及其控制临床研究中常见偏倚及其控制1.引言在临床研究中,偏倚(bias)是一个非常重要的概念。
它指的是在研究过程中可能导致研究结果与真实情况不一致的因素。
控制偏倚是确保研究结果的可靠性和有效性的关键步骤。
本文将介绍临床研究中常见的偏倚类型及其控制方法。
2.偏倚类型2.1 选择偏倚(Selection bias)选择偏倚是指参与研究的样本群体与目标总体不完全一致,从而导致研究结果的错误。
控制选择偏倚的方法包括:- 随机抽样:通过随机选择样本,减少选择偏倚的可能性。
- 匹配:在研究设计阶段根据特定标准选取对照组样本,使其与受试组样本在某些特征上匹配,减少选择偏倚的影响。
- 敏感性分析:通过分析不同样本选择策略下的研究结果,评估选择偏倚的影响程度。
2.2 测量偏倚(Measurement bias)测量偏倚是指在对研究对象进行测量时,存在的误差或倾向性,导致测量结果与实际情况存在偏差。
控制测量偏倚的方法包括: - 标准化测量工具:使用标准化的测量工具或问卷,确保测量结果的准确性和可比性。
- 培训和校准:对参与测量的研究人员进行培训和校准,提高测量的一致性和准确性。
- 双盲设计:在实验研究中,采用双盲设计,使研究人员和受试者在不知道实际处理情况的情况下进行评估,减少主观判断的干扰。
2.3 回忆偏倚(Recall bias)回忆偏倚是指在调查研究中,受试者对过去事件的回忆存在偏差,导致研究结果的失真。
控制回忆偏倚的方法包括: - 限定回溯时期:对受试者进行限定回溯时期,减少过远过近的回忆,提高回忆的准确性。
- 不透露假设:在调查过程中,不透露研究者的假设和研究目的,减少受试者对回忆的主观干扰。
- 避免听证:避免向受试者介绍其他受试者的回忆情况,以免互相影响。
3.控制偏倚的方法3.1 随机化随机化是控制偏倚的重要手段,它可以通过评估和平衡干扰因素的分布,减少干扰因素对研究结果的影响。
在临床研究中,常用的随机化方法有简单随机化、分层随机化、区组随机化等。
测量系统-偏倚研究

2019/4/1
19
确定偏倚的指南 -控制图法
确定的水平依赖于敏感度水平,而敏感度水平是用来评价/控 制该生产过程并且与产品/生产过程的损失函数(敏感度曲线)相关 联。如果水平不是用默认值0.05(95%置信度)则必须得到顾客的 同意。
2019/4/1
20
控制图法举例
对一个基准值 6.01的零件进行稳定性研究(见MSA手册p72页图 9),所有样本(20个子组)的 总平均值是 6.021。因而计算偏倚 值为 0.011。 使用电子表格和统计软件,研究者产生了数值分析结果(见表 4)。 因为0落在偏倚置信区间(- 0.0800 ,0.1020)内,过程小组 可以假设测量偏倚是可以接受的,同时假定实际使用不会导致附加 变差源。
2019/4/1
9
确定偏倚的指南 - 独立样件法
4.计算该评价人n个读数的均值。 公式如右:
5.计算可重复性标准偏差。 其中 d*2可以从附录c中查 到,g=1,m=n。
2019/4/1
10
确定偏倚的指南 - 独立样件法
6.确定偏倚的t统计量: 偏倚=观测测量平均值-基准值 其中σ r=σ 重复性 7.如果0落在围绕偏倚值1-置信区间以内, 偏倚在水平是可接受的。 d2,d*2和v可以在附录c中查到,g=1,m=n。
偏倚的分析程序 1.1按生产过程所要求的检验项目、内容和检验规定,从生产过程中 选取一个零件作为样品。 1.2 首先确定所检查零件特性的基准值。基准值应尽可能通过更高 一级的计量装置或在工具室、 全尺寸检验设备上确定。确定的读数应与量具R&R研究中的评价人 的观察平均值(Xa 、Xb、Xc)进行比较。
2019/4/1
11
独立样件法 —范例
标准差
MSA测量系统(稳定性、偏移和线性研究)分析报告

XXXX作业文件文件编号:JT/C-7.6J-003版号:A/0(MSA)测量系统分析稳定性、偏移和线性研究作业指导书批准:吕春刚审核:尹宝永编制:邹国臣受控状态:分发号:2006年11月15日发布2006年11月15日实施量具的稳定性、偏移、线性研究作业指导书JT/C-7.6J-0031目的为了配备并使用与要求的测量能力相一致的测量仪器,通过适当的统计技术,对测量系统的五个特性进行分析,使测量结果的不确定度已知,为准确评定产品提高质量保证。
2适用范围适用于公司使用的所有测量仪器的稳定性、偏移和线性的测量分析。
3职责3.1检验科负责确定过程所需要的测量仪器,并定期校准和检定,对使用的测量系统分析,对存在的异常情况及时采取纠正预防措施。
3.2工会负责根据需要组织和安排测量系统技术应用的培训。
3.3生产科配合对测量仪器进行测量系统分析。
4术语4.1偏倚偏倚是测量结果的观测平均值与基准值(标准值)的差值。
4.2稳定性(飘移)稳定性是测量系统在某持续时间内测量同一基准或零件的单一特性时获得的测量值总变差。
4.3线性线性是在量具预期的工作量程内,偏倚值的变差。
4.4重复性重复性是由一个评价人,采用一种测量仪器,多次测量同一零件的同一特性获得的测量值的变差。
4.5再现性再现性是由不同的评价人,采用相同的测量仪器,测量同一零件的同一特性的测量平均值的变差。
5测量系统分析作业准备5.1确定测量过程需要使用的测量仪器以及测量系统分析的范围。
a)控制计划有要求的工序所使用的测量仪器;b)有SPC控制要求的过程,特别是有关键/特殊特性的产品及过程;c)新产品、新过程;d)新增的测量仪器;e)已经作过测量系统分析,重新修理后。
5.2公司按GB/T10012标准要求,建立公司计量管理体系,确保建立的测量系统的可靠性。
6分析研究过程 6.1稳定性分析研究1)取一样件,并建立其可追溯到相关标准的参考值。
如果无法取得这样的样件,则选择一个落在产品测量范围中间的生产零件,指定它为基准样件进行稳定性分析。
如何进行MSA量具线性和偏倚的研究

如何进行MSA量具线性和偏倚的研究
1、测量系统没有偏倚最好,如果有,我们希望是线性偏倚,这样可以对测量系统进行修正。
如果存在偏倚又不存在线性,那么这个测量系统是不合格的。
2、为了说明如何进行量具线性和偏倚的研究,我们使用盈质统计分析软件打开一个包含测量数据的Excel文件。
这是5种规格的部件,分别检测它们的厚度,每种部件进行12次测量,要求分析测量系统是否有偏倚和线性。
3、点击“测量系统分析”菜单下的“量具线性和偏倚”。
4、部件号选择“部件编号”这一列,参考值选择“标准值(毫米)”这一列,测量结果选择“测量结果(毫米)”这一列,过程变异或6倍历史标准差有则填,没有则不填。
5、点击确定,可得到量具线性和偏倚的分析结果及图形。
6、从右侧的图形可以清楚看到,测量系统存在正偏倚。
7、再来看左侧的分析结果,量具偏倚,整体偏倚为0.408208,P值为0,表明这是显著的偏倚。
那么来看一下这种偏倚是否有线性,主要看量具线性中的斜率,其P值大于0.05,表明它是不显著的,所以不存在线性。
综上所述,该测量系统存在偏倚却不存在线性,需要更换或调整再评估。
7、如果已知过程变异或6倍历史标准差为0.36,可以更清晰地在图上看到存在偏倚,不存在线性。
8、分析结果的量具偏倚中求得平均偏倚为113.4%,线性百分率只有0.039。
9、如需查看完整视频或了解更多信息,请百度搜索“盈质统计分析软件”查看。
临床研究中常见偏倚及其控制

临床研究中常见偏倚及其控制临床研究是医学领域发展的重要驱动力,旨在探索疾病的治疗方法、改善患者生活质量以及促进医学知识的积累。
然而,在临床研究过程中,常常会出现各种偏倚,影响研究的可靠性和准确性。
本文将探讨临床研究中常见的偏倚及其控制方法。
在临床研究中,偏倚是指在研究过程中出现的系统性误差,导致研究结果偏离真实情况。
偏倚通常源于研究设计、实施、数据分析以及结果解释等环节。
以下是一些常见的偏倚类型:1、选择偏倚:选择研究对象时,研究队列的代表性不足,导致研究结果不能推广到更大的人群。
例如,一项仅针对男性患者的研究结果可能不适用于女性患者。
2、信息偏倚:在收集或记录数据时出现误差,导致信息质量下降。
例如,在观察性研究中,患者未能准确报告其生活方式或病史可能导致信息偏倚。
3、检测偏倚:在测量或评估研究变量时出现的误差,导致测量结果不准确。
例如,在评估药物疗效时,若未采用双盲试验,医生可能主观地调整剂量或给予额外治疗,从而影响结果的客观性。
4、失访偏倚:在研究过程中,研究对象由于各种原因未能完成试验或未能提供必要的数据,导致数据分析不完整。
例如,在长期研究中,患者因病情恶化退出试验,可能导致研究结果的不完整性。
为了控制上述偏倚,研究人员可采取以下措施:1、研究设计阶段:明确研究目的和纳入标准,制定详细的研究方案,并采用随机、对照、双盲等设计方法,以减少偏倚的发生。
2、数据分析阶段:采用适当的统计方法对数据进行处理和分析,以减少偏倚的影响。
例如,通过匹配对照组、增加样本量或进行敏感性分析等方法来控制选择偏倚。
3、实施阶段:确保研究过程的标准化和规范化,提高数据质量。
例如,制定详细的操作流程和培训研究人员,以减少信息和质量偏倚。
4、长期随访和失访管理:在研究设计中考虑失访情况,制定相应的应对策略,如定期与研究对象保持联系、进行随访等。
总之,偏倚是临床研究中常见的问题,对研究结果的可靠性和准确性产生负面影响。
临床研究中的偏倚及控制讲解

临床研究中的偏倚及控制讲解临床研究是评估新药治疗效果或疾病预防策略有效性等的重要手段,但由于研究设计和实施过程中的一些因素的存在,可能会引入偏倚(bias),导致研究结果的误差。
为了减小偏倚对研究结果的影响,研究人员需要在研究设计和分析中进行偏倚的控制。
本文将就临床研究中的常见偏倚及其控制方法进行讲解。
1. 选择偏倚(Selection Bias)选择偏倚是由于研究对象的选择不是随机的,而是与研究目标相关的因素导致的偏倚。
为了控制选择偏倚,应采取以下措施:-采用随机分组方法:通过随机分组,可以使得研究对象的分组与其自身特征无关,从而减小选择偏倚的风险。
-需要制定明确的入组和排除标准:研究对象的选择应该严格遵守预定的入组和排除标准,避免人为的选择操作。
-多中心研究:多中心研究可以增加样本的代表性,从而减小选择偏倚的可能。
2. 配置偏倚(Allocation Bias)配置偏倚是指由于随机分组的不完全或不严格导致的偏倚。
为了控制配置偏倚,应采取以下措施:-采用适当的随机化方法:应采用随机数字生成、随机封号等方法以实现随机分组,从而减小分组差异的可能性。
-实施隐藏分组:应确保在研究对象入组前,研究人员无法预测下一个分组的具体分组方法,以保证分组的随机性。
-进行双盲或者三盲研究:盲法是控制配置偏倚的有效手段之一,可以减少研究人员对研究对象的知情和预期。
3. 报告偏倚(Reporting Bias)报告偏倚是由于一些研究结果未被完整地报告或被错误地报告而引入的偏倚。
为了控制报告偏倚,应采取以下措施:-注册研究计划:在开始临床研究之前,应该注册研究计划,并明确预先确定的主要研究结局指标,以减小结果报告的选择性。
-完整报告结果:无论结果是积极的还是消极的,都需要完整地报告,以确保研究结果的透明和客观性。
-准确描述研究方法:应该准确地描述研究的设计和方法,包括分析方法和样本大小等,避免结果解读的误导。
4. 记忆偏倚(Recall Bias)记忆偏倚是由于研究对象回忆自身的信息时,受到主观记忆和偏好的影响而引入的偏倚。
线性偏倚研究报告解读

线性偏倚研究报告解读线性偏倚研究报告解读引言在统计学和机器学习中,线性偏倚是一个重要的概念。
它指的是在使用线性模型对数据进行拟合时,模型的输出与真实值之间存在一定的偏差。
本文将解读一份研究报告,其中探讨了线性偏倚的性质以及可能的影响。
研究背景线性偏倚是机器学习领域的一个热门研究方向,因为它在实际应用中经常出现,并且可能会导致模型的性能下降。
了解线性偏倚的性质和来源,可以帮助我们更好地理解模型的表现和改进模型的拟合能力。
研究目的本研究的目的是探究线性偏倚的性质,并通过实验验证一些假设。
通过对研究结果的解读,我们可以更好地了解线性偏倚对模型性能的影响,并提出可能的解决方案。
研究方法本次研究采用了以下方法来对线性偏倚进行分析。
数据收集研究者使用了一个包含1000个样本的数据集,每个样本包含多个特征和一个目标变量。
这些样本是通过调查问卷收集而来,涵盖了不同年龄、性别和收入水平的人群。
线性拟合研究者使用了线性回归模型对数据进行拟合。
他们选择了一组特征作为自变量,并将目标变量作为因变量,使用最小二乘法求解最佳参数。
偏差分析在拟合模型后,研究者进行了偏差分析。
他们比较了模型预测值与真实值之间的差异,并计算了平均偏差和方差。
此外,他们还通过绘制残差图和残差分布图来可视化偏差的分布情况。
影响因素探索在分析偏差的性质后,研究者进一步探索了可能的影响因素。
他们使用了模型解释方法来计算每个特征对目标变量的贡献程度,并分析了特征与偏差之间的相关性。
结果与讨论偏差的性质根据研究结果,线性偏倚在该数据集中普遍存在。
模型的预测值整体上偏离了真实值,表现出了一定的系统性偏差。
平均偏差为0.2,方差为0.1,说明模型对部分样本的预测结果相对稳定,但对另一部分样本的预测结果变化较大。
偏差的分布通过绘制残差图和残差分布图,我们可以观察到偏差的分布情况。
图中显示,偏差的分布大致呈正态分布,但在一些特定范围内偏差较大。
这可能是由于数据特征的分布不均匀或模型无法很好地拟合某些关键特征。
偏倚和线性分析报告

偏倚及线性分析报告
量具名称
量具编号
临床研究中的偏倚及控制讲解

临床研究中的偏倚及控制讲解在医学领域,临床研究对于推动医学进步、改善医疗质量至关重要。
然而,在临床研究的过程中,偏倚的存在可能会导致研究结果的不准确和不可靠,从而影响临床决策和患者的治疗效果。
因此,了解和控制临床研究中的偏倚是至关重要的。
一、什么是临床研究中的偏倚偏倚,简单来说,就是在研究过程中,由于各种因素的影响,导致研究结果偏离了真实情况。
在临床研究中,偏倚可能来自研究设计、研究对象的选择、数据的收集和分析等多个环节。
常见的偏倚类型包括选择偏倚、信息偏倚和混杂偏倚。
选择偏倚发生在研究对象的选择过程中。
例如,如果研究某种疾病的治疗效果,但只选择了病情较轻的患者,那么得出的治疗效果可能会过于乐观,无法反映真实情况。
信息偏倚则与数据的收集有关。
比如,患者回忆病史时不准确,或者医生在诊断和评估时存在主观偏差,都可能导致信息偏倚。
混杂偏倚是指除了研究因素之外,还有其他因素同时影响了研究结果。
比如,在研究吸烟与肺癌的关系时,如果没有考虑到空气污染这个混杂因素,可能会得出错误的结论。
二、偏倚产生的原因1、研究设计不合理研究方案不完善,如样本量不足、对照组选择不当、随访时间过短等,都可能导致偏倚的产生。
2、研究对象的选择偏差如果纳入和排除标准不明确,或者在招募研究对象时存在倾向性,就可能导致研究对象不能代表总体人群,从而产生偏倚。
3、测量误差在收集数据时,使用的测量工具不准确、测量方法不一致或者观察者的主观判断差异,都可能引入测量误差,进而导致偏倚。
4、随访丢失在长期的随访研究中,部分研究对象失去联系或拒绝继续参与,导致数据不完整,也可能产生偏倚。
5、数据分析方法不当错误的统计分析方法或不合理的数据分析策略,可能会放大或掩盖偏倚的影响。
三、偏倚对临床研究的影响偏倚会严重影响临床研究的质量和可靠性。
如果研究结果存在偏倚,可能会导致错误的临床决策,浪费医疗资源,甚至对患者的健康造成危害。
例如,一项关于某种新药物疗效的研究,如果因为选择偏倚只纳入了对药物反应良好的患者,可能会高估药物的疗效,从而使医生在临床实践中过度使用该药物,而实际上它对大多数患者可能并没有那么有效。
偏倚与线性研究

单样本 T: measurement
mu = 6 与≠ 6 的检验
平均值
变量 N 平均值标准差标准误 95% 置信区间 T P
measurement 15 6.0067 0.2120 0.0547 (5.8893, 6.1241) 0.12 0.905
结论:
图形显示H0在置信区间中,单样本的T检验,P值为0.905大于0.05,不能拒绝原假设,该测量系统的偏倚是可以接受的。
单样本 T: 面粉重量
mu = 20 与≠ 20 的检验
平均值
变量 N 平均值标准差标准误 95% 置信区间 T P
面粉重量 16 20.0669 0.1026 0.0257 (20.0122, 20.1216) 2.61 0.020
结论:
图形显示H0在置信区间之外,单样本的T检验,P值为0.02小于0.05,拒绝原假设,该测量系统的偏倚是不能接受的。
结论:
图形显示偏倚为0的线未包含在置信区间中,与置信区间交叉。
常量与斜率P值为0,小于0.05,拒绝原假设。
平均偏倚P值为0.04,小于0.05,拒绝原假设。
该测量系统的偏倚与线性是不能接受的。
结论:
图形显示偏倚为0的线完全在置信区间中。
常量与斜率P值大于0.05,不能拒绝原假设。
平均偏倚P值为0.0064,大于0.05,不能拒绝原假设。
该测量系统的偏倚与线性是可以接受的。
一文解析临床研究中的偏倚及控制方法

一文解析临床研究中的偏倚及控制方法临床研究中的偏倚是指研究结果偏离真实情况的可能性。
偏倚可能导致对研究问题的有偏估计,因此在临床研究中,需要采取一系列的控制方法来降低偏倚的影响。
首先,随机化是控制偏倚的一种重要方法。
随机化是指通过随机的方式将研究对象分配到干预组和对照组,从而降低可能出现的系统性偏差。
随机化可以有效地减少干扰因素对结果的影响,使得干预与对照组之间的差异更有可能是由于干预措施引起的。
其次,对照组的选择和配对也是控制偏倚的重要手段。
对照组的选择要符合研究目的,通常可以选择与干预组相似的人群作为对照组,以确保与干预组的比较更具可比性。
在一些情况下,使用配对的对照组可以进一步减少存在的混杂因素,例如通过相同年龄、性别等进行配对。
此外,盲法是降低偏倚的常用方法之一、单盲或双盲试验可以减少研究人员和受试者对治疗干预或评估结果的期望,从而减少主观因素对结果的影响。
特别是在主观结果评估中,如疼痛感受、生活质量等,采用盲法能够更客观地评估干预效果。
此外,适当的样本大小计算也是控制偏倚的重要手段。
样本大小的确定要根据研究目的、研究设计和预期效应大小来确定。
适当的样本大小可以提高研究的统计能力,减少因样本小而引起的偏倚。
在临床研究中,有时还会使用隐性随访和揭示研究设计等方法来降低偏倚。
通过隐性随访,研究者可以减少与干预相关的期望、降低受试者的依从性,从而更真实地反映干预效果。
而揭示研究设计是指研究结束后,将研究组别和干预方式对受试者进行揭示,这样可以降低研究者和受试者在干预期间的偏倚。
此外,在临床研究中,还存在一些专门用于控制偏倚的设计和分析方法,如多重比较校正、倾向评分匹配、子集分析等。
这些方法可以进一步减少混杂因素的影响,提高研究结果的可靠性。
总之,临床研究中的偏倚是不可忽视的因素,它可能导致研究结果的偏离。
为了降低偏倚的影响,采取一系列控制方法是十分必要的,如随机化、对照组选择和配对、盲法、适当的样本大小计算等,可以有效地减少偏倚的影响,提高研究结果的可靠性和可解释性。
一文解析临床研究中的偏倚及控制方法

一文解析临床研究中的偏倚及控制方法在临床科研过程中,我们都致力于一点,就是让分析所得的关联性(association)尽量接近病因性(causation)。
除了应用统计学方法以外,非常重要的就是从根本上分析造成偏倚(bias)的原因并控制误差和偏倚。
正如LinkLab前文所提及的,我们需要重点分析和排除的误差包括:随机误差和系统误差(bias),以及发现和解释效应修正(effect modification)。
其中随机误差是随机分布且不可预测的,因此除了增加样本量或重复测量取均值外别无他法。
但对于系统误差和效应修正却可以得到控制或解释,帮助理解所得结论。
系统误差包括:混淆偏倚(confounding)、选择偏倚(selection bias)和信息偏倚(information bias)。
其中,信息偏倚(information bias)是指在研究的实施阶段中从研究对象获取研究所需的信息时产生的系统误差,其原因是由于诊断疾病、测量暴露或结局的方法有问题,导致被比较各组间收集的信息有差异而引入的误差。
本文将不对其进行描述。
阅读此文前强烈建议您阅读LinkLab 2015年11月6日《流行病学也好玩(四):一种方法教会你理清科研思路》,之后就能轻松理解清楚误差和偏倚,以及有效的解决方法。
混淆偏倚(confounding)E:暴露变量(exposure);Y:结果变量(outcome);C:混淆因素在研究暴露与疾病的联系时,C作为混淆因素(confounder)必须满足:1)与exposure相关联;2)与outcome相关联且不是因为exposure;3)不在E和Y的因果链上。
但并不是满足这三个条件就是混淆因素。
由于混杂变量的存在,造成了观察到的联系强度偏离了实际情况,则称为混杂偏倚。
小测试:假设A=exposure,Y=outcome,哪些图的L不是混淆因素呢?答案就是最后一个图。
混淆因素严重干扰我们对于risk的估计,所以必须想办法控制这些variable。
量具线性和偏倚研究 的主要结果
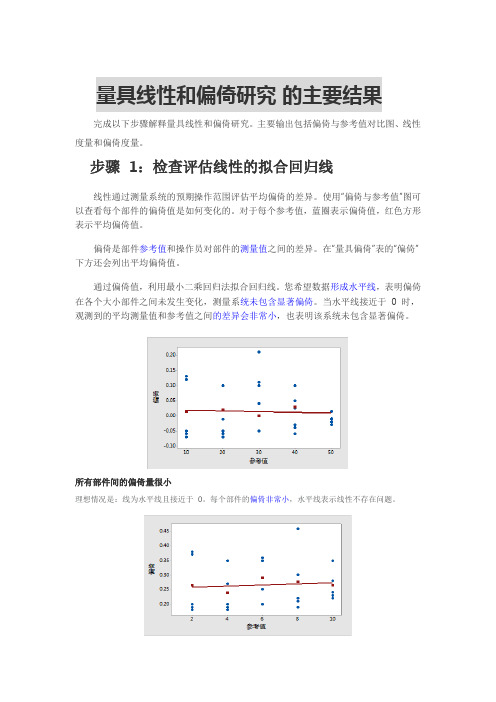
量具线性和偏倚研究的主要结果完成以下步骤解释量具线性和偏倚研究。
主要输出包括偏倚与参考值对比图、线性度量和偏倚度量。
步骤1:检查评估线性的拟合回归线线性通过测量系统的预期操作范围评估平均偏倚的差异。
使用“偏倚与参考值”图可以查看每个部件的偏倚值是如何变化的。
对于每个参考值,蓝圈表示偏倚值,红色方形表示平均偏倚值。
偏倚是部件参考值和操作员对部件的测量值之间的差异。
在“量具偏倚”表的“偏倚”下方还会列出平均偏倚值。
通过偏倚值,利用最小二乘回归法拟合回归线。
您希望数据形成水平线,表明偏倚在各个大小部件之间未发生变化,测量系统未包含显著偏倚。
当水平线接近于0 时,观测到的平均测量值和参考值之间的差异会非常小,也表明该系统未包含显著偏倚。
所有部件间的偏倚量很小理想情况是:线为水平线且接近于0。
每个部件的偏倚非常小,水平线表示线性不存在问题。
线性看起来没问题标绘线接近水平,表明平均偏倚相对稳定,且不依赖于参考值。
在此示例中,所有部件的测量值高于其相应参考部件的测量值。
(红线大于0.2,在0线以上)较小部件较大部件线性看起来有问题标绘线是倾斜的。
在本示例中,较小部件的测量值高于其对应参考部件值的测量值。
而较大部件的测量值往往低于其对应参考部件值的测量值。
步骤2:确定量具线性是否有统计意义一般而言,拟合线的斜率越接近于零,量具的线性将越好。
理想情况下,拟合线将为水平线且接近于0。
使用拟合线斜率(量具线性斜率)的p 值来确定线性是否有统计意义。
➢如果p 值大于0.05,则可以推断线性不存在且可以评估偏倚。
使用平均偏倚的p 值评估平均偏倚是否显著不同于0。
➢如果p 值小于或等于0.05,则可以推断出存在线性问题。
您可以评估每个单独参考值的偏倚而非整体偏倚。
当存在显著线性时将无法评估整体偏倚,因为不同参考值上的偏倚是不同的。
换句话说,当线性具有显著统计意义时,将仅解释单个参考水平的偏倚p 值。
主要结果:量具线性P在这些结果中,斜率的p 值是0.000,表明斜率是显著的,且在测量系统中存在线性。
线性和偏倚分析

量具线性和偏倚研究概述使用量具线性和偏倚研究可评估测量设备操作范围内的精确度。
选择覆盖量具操作范围的部件。
每个部件必须有一个参考值。
例如,一名工程师要评估量具的线性和偏倚。
该工程师选择5 个表示测量预期极差的部件。
每个选中的部件均通过布局检查进行测量以确定其主要测量值。
一个操作员使用量具随机测量每个部件12 次。
在何处可找到此分析要执行量具线性和偏倚研究,请选择统计 > 质量工具 > 量具研究 > 量具线性和偏倚研究。
何时使用备择分析●要在具有交叉数据的情况下完整分析测量系统,请使用交叉量具R&R 研究。
●要在具有嵌套数据的情况下完整分析测量系统,请使用嵌套量具R&R 研究。
量具线性和偏倚研究的数据注意事项要确保结果有效,请在收集数据、执行分析和解释结果时注意以下准则。
每个参考部件必须具有已知测量值参考值是参考部件的已知标准测量值。
在测量系统分析过程中,将参考值用作主值进行比较。
例如,您使用已知重为0.025 g 的参考部件校准天平。
应按随机顺序收集数据如果不随机收集数据,分析结果可能会有误导性。
选择表示测量实际或预期极差的部件。
跨测量实际或预期极差选择部件,可以评估您的量具是否对量具测量的所有部件大小具有相同准确度。
一个操作员应执行所有测量单个操作员应测量所有部件和所有仿行,这样来自不同操作员的量具变异才不会成为因子。
量具线性和偏倚研究示例一位工程师想要评估用于测量轴承内径的测量量具的线性和偏倚。
该工程师选择了五个表示测量预期极差的部件。
按布局检查测量每个部件以确定其主测量值,然后由一位操作员随机测量每个部件12 次。
该工程师之前使用方差分析法执行了交叉量具R&R 研究,确定该总研究变异是16.5368。
1.打开样本数据,轴承直径.MTW.轴承直径.MTW2.选择统计 > 质量工具 > 量具研究 > 量具线性和偏倚研究。
3.在部件号中,输入部件。
一文解析临床研究中的偏倚及控制方法

一文解析临床研究中的偏倚及控制方法临床研究的目标是评估医疗措施的效果和安全性,以指导临床实践或政策制定。
然而,由于人类实验的复杂性和伦理限制,临床研究中存在着多种偏倚(即误差)的可能性,这可能导致研究结论的失真。
因此,为了减少偏倚并提高研究的可靠性,在设计和进行临床研究时需要采取相应的控制方法。
一、随机分组设计:偏倚:选择性偏倚,指研究者可能倾向于将更严重的患者分配到他们认为较好的治疗方法组,或将健康状况较好的患者分配到他们认为较差的治疗方法组。
控制方法:随机分组设计能够将受试者随机分配到不同的治疗组中,以减少选择性偏倚的可能性。
通过随机分组可以保证研究组和对照组之间的可比性,控制其他潜在的干扰因素。
二、盲法:偏倚:知识偏倚,即治疗组和对照组中患者或研究者对受试者的知识或期望有所差异,从而影响了研究结果的评估。
控制方法:单盲法和双盲法是常用的方法。
单盲法指受试者不知道自己所接受的是哪种治疗方法;双盲法指受试者和研究者均不知道其所接受的治疗方法。
盲法能够降低知识偏倚对研究结果的影响,使研究结果更加客观和可靠。
三、对照组选择和匹配:偏倚:记忆偏倚,指回顾性对照研究中,受试者和对照组之间基线特征存在差异,从而影响了研究结果的比较。
控制方法:对照组的选择要与实验组相匹配,以控制其他可能的潜在干扰因素。
匹配可根据年龄、性别、病情严重程度等因素进行。
此外,区组随机设计和块随机设计是一种经常使用的对照组配对方法,可以进一步控制潜在的干扰因素。
四、分层随机:偏倚:混杂因素偏倚,即伴随其他疾病或因素而导致的干扰因素。
控制方法:分层随机法可以将混杂因素作为分层变量,使其在不同的实验组中均匀分布,从而减少混杂因素对研究结果的影响。
五、交叉设计:偏倚:演化偏倚,即研究对象在不同时期因为疾病的发展、治疗的效果等因素而导致结果的改变。
控制方法:交叉设计可以在相同受试者中比较不同治疗方法的效果,消除演化偏倚的影响。
研究对象在不同时期接受不同治疗方法,从而使得个体间的差异及干扰因素得到消除或降低。
偏倚的计算——精选推荐

偏倚计算的示例一名制造工程师需要对一个新的测量系统进行偏倚的分析,测量装置分析表明没有线性问题,所以工程师只做了测量系统偏倚,他的研究程序是:1.选取一个样件,得出一个可追溯到相关标准的基准值。
这个基准值是“6.0”。
2.请一个评价人,以工作状态通常的方法测量这个样件15次。
3.相对于基准值,将数据画出直方图。
评审直方图,确定是否存在特殊原因或出现异常;如果没有,继续分析。
4.计算该评价人n个读数的均值。
公式如下:x该评价人15次测量的平均值是:x=6.00675.计算可重复性标准偏差σr,既σ重复性。
其中d2*可以从《与均值极差分布相关的值》的表中查到,查出的d2*值是:3.55333注:g=1(子组容量为1),m=n=15(子组大小)。
计算结果:0.225146.确定偏倚的t统计量:t= 偏倚/σb偏倚= 测量值的平均值—基准值该评价人15次测量的偏倚值是:0.0067 σb利用下面的公式计算。
计算结果是:0.11537.根据子组的容量和子组的大小,通过173页的《与均值极差分布相关的值》表格,查找出自由度(v或df);查出的结果是df=10.88.再查表找出显著的t值。
该值是通过查《t分布分位数表》来找出的,依据自由度v(df)10.8,选α(置信度)= 0.05,α/2就是0.025,1-α/2=0.9750,则从表p=0.9750与自由度V值10.8的交叉处选值。
该表中的自由度只有10和11,没有10.8我们所要求的数,故应予以分摊。
其中10为2.22814,11为2.20099,分摊到10.8的自由度为2.20642。
8.下面开始计算;0.0067-[0.05813(2.20642)]= -0.121560.0067+[0.05813(2.20642)]=0.134969.结果评价计算结果表明,“0”落在这两个上下限计算值之间。
结论是该测量系统的偏倚是可以接受的。
陈瑞泉。
量具线性和偏倚研究的主要结果

量具线性和偏倚研究的主要结果完成以下步骤解释量具线性和偏倚研究。
主要输出包括偏倚与参考值对比图、线性度量和偏倚度量。
步骤1:检查评估线性的拟合回归线线性通过测量系统的预期操作范围评估平均偏倚的差异。
使用偏倚与参考值”图可以查看每个部件的偏倚值是如何变化的。
对于每个参考值,蓝圈表示偏倚值,红色方形表示平均偏倚值。
偏倚是部件参考值和操作员对部件的测量值之间的差异。
在量具偏倚”表的偏倚” 下方还会列出平均偏倚值。
通过偏倚值,利用最小二乘回归法拟合回归线。
您希望数据形成水平线,表明偏倚在各个大小部件之间未发生变化,测量系统未包含显著偏倚。
当水平线接近于0时,观测到的平均测量值和参考值之间的差异会非常小,也表明该系统未包含显著偏倚。
•0.15*OLin •! •库■■000 ' ■•. > 1II*. ♦ ,-01Q____ _ ___________ __ ___________ _ ____________ _ __________ __ |而।葡3b 40 50参考埴所有部件间的偏倚量很小理想情况是:线为水平线且接近于0。
每个部件的偏倚非常小,水平线表示线性不存在问题。
/竽工比壮HuaDAu D 3线性看起来没问题标绘线接近水平,表明平均偏倚相对稳定,且不依赖于参考值。
在此示例中,所有部件的测量值高于其相应参考部件的测量值。
(红线大于0.2,在0线以上)线性看起来有问题标绘线是倾斜的。
在本示例中,较小部件的测量值高于其对应参考部件值的测量值。
而较大部件的测量值往往低于其对应参考部件值的测量值。
步骤2:确定量具线性是否有统计意义一般而言,拟合线的斜率越接近于零,量具的线性将越好。
为水平线且接近于0。
使用拟合线斜率(量具线性斜率)的p 计意义。
如果p值大于0.05,则可以推断线性不存在且可以评估偏倚。
使用平均偏倚的p 值评估平均偏倚是否显著不同于0。
如果p值小于或等于0.05,则可以推断出存在线性问题。