数据结构图的建立和应用代码
数据结构课程设计(哈夫曼编码)

┊┊┊┊┊┊┊┊┊┊┊┊┊装┊┊┊┊┊订┊┊┊┊┊线┊┊┊┊┊┊┊┊┊┊┊┊┊目录目录 (1)1 课程设计的目的和意义 (2)2 需求分析 (3)3 系统设计 (4)(1)设计思路及方案 (4)(2)模块的设计及介绍 (4)(3)主要模块程序流程图 (6)4 系统实现 (10)(1)主调函数 (10)(2)建立HuffmanTree (10)(3)生成Huffman编码并写入文件 (13)(4)电文译码 (14)5 系统调试 (16)小结 (18)参考文献 (19)附录源程序 (20)┊┊┊┊┊┊┊┊┊┊┊┊┊装┊┊┊┊┊订┊┊┊┊┊线┊┊┊┊┊┊┊┊┊┊┊┊┊1 课程设计的目的和意义在当今信息爆炸时代,如何采用有效的数据压缩技术来节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视。
哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。
哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。
树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和各个对应的字符的编码,这就是哈夫曼编码。
通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。
电报通信是传递文字的二进制码形式的字符串。
但在信息传递时,总希望总长度尽可能最短,即采用最短码。
作为软件工程专业的学生,我们应该很好的掌握这门技术。
在课堂上,我们能过学到许多的理论知识,但我们很少有过自己动手实践的机会!课程设计就是为解决这个问题提供了一个平台。
在课程设计过程中,我们每个人选择一个课题,认真研究,根据课堂讲授内容,借助书本,自己动手实践。
这样不但有助于我们消化课堂所讲解的内容,还可以增强我们的独立思考能力和动手能力;通过编写实验代码和调试运行,我们可以逐步积累调试C程序的经验并逐渐培养我们的编程能力、用计算机解决实际问题的能力。
数据结构及其应用data_structrue

数据元素 数据元素 关系
Ei
E i+1
物理结构:数据结构在计算机中的具体表示和实现,
又称存储结构
2014-7-15
4
数据结构的分类
按逻辑结构分类:
2014-7-15
10
上述顺序表定义中的数据成员 Maxsize 是为判断顺序 表是否为满而设,last 是为便于判断顺序表是否为空、求 表长、置空表而设: last=Maxsize –1表示顺序表已满,此时再进行插入 操作会导致上溢错误; last=-1 表示顺序表为空表,此时再进行删除操作 会导致下溢错误; last+1 代表顺序表的表长; 将 last 赋值为 –1 可实现置空表操作。 由上可知:合理地设置数据成员可大大简化算法的设计 及提高算法的效率。顺序表不仅仅包含存放其数据元 素的数组,它还应包括一些有用的数据成员,以及相 应的操作,它们是一个整体:
2014-7-15
24
多项式的类定义——数据的表示方法 class Polynomial { public : ... // 成员函数声明(构造、释构、相加等函数) private : int MaxTerms ; //共享空间(顺序表)的最大项数 static term termArray[MaxTerms]; //存放二元组的数组,存放多个多项式的共享空间 static int free ; // 共享空间中自由空间之起始下标 int start , finish ; // 多项式在共享空间中的首、尾下标 }
2014-7-15 6
C/C++软件测试工具的元数据结构设计与实现

[ ywod ]sf re etsmat v l meas utr Ke r s ot s;e nil es t t cue wa t ce ; r
1 C软 件测试 工具
嵌 入式软件 测试 工具 主要针 对 C C + 言进行 语义分 /+ 语 析,实现软件 的静态和动态 2 种视 图。 通过软件 的静态视图 ,
结 构 分 析 包括 类表 、类 继 承 系 、类 一 函数 耦 合 关 系 、函 数 调 用 关 系 、 控 制 流程 。
度
对
规 匪
规则
检 查
静态文档 分析源程 序的复杂度、全 局变量文件信息等 。 所以中间结构 必须 包含 相关的全 部信息 :类 ,函数 ,变量本
.
c n i u ai n r l td t p l ai n t s o l a itr s me s ma tc tgsf r i sr me ta d S n. d a a s re g n s d v l p d t r a et e o fg r t e a e O a p i to , e t o n fl o e n i a o n tu o c t c e n n O o A u l r e n i e i e e o e o c e t p h
2 中间结构
中间元数据 \ 应用元素配置集合
程 结相 序构 }
关 象 据} 对数 ]
—_____ ___
一
静态结 构 分析
代 码 质 量 评 价
中 间结 构 …通 过 分 析 获 得 源 程 序 的 语 法 结 构 和 一 定 的语
义信息构建而成。中间结构 的建 立保持 方案的独立性 。软件
De i n a d I p e e t to fM e a S r c u ei C+ T s o l sg n m lm n a i n o t t u t r C/ + e t o n T
数据结构及其应用(用面向对象方法与C++描述)

(4)插入( Insert ) (5)删除( Remove ) (6)排序( Sort )
(7)判空( IsEmpty)
2020/10/22
8
2.2 线性表的顺序存储结构
要实现在计算机内表示一个数据结构,要解决两 种信息的存贮问题:
素 但可以有多个元素跟着它”的层次关系
图状结构:任意两个数据元素之间都可能存在关系
按存储结构分类:
顺序存储结构
链式存储结构
2020/10/22索引存贮结构
5
基本操作:任一数据结构均有一组相应的基本操作,
有时操作不同,用途迥异(如栈和队列)
常用的基本操作有插入、 删除、查找、
更新、排序等
算
法:算法是为了解决给定的问题而规定的一个
last+1 代表顺序表的表长; 将 last 赋值为 –1 可实现置空表操作。
由上可知:合理地设置数据成员可大大简化算法的设计 及提高算法的效率。顺序表不仅仅包含存放其数据元 素的数组,它还应包括一些有用的数据成员,以及相 应的操作,它们是一个整体:
2020/10/22
Hale Waihona Puke 11顺序表之整体概念:
数组 data
数据结构及其应用
(用面向对象方法与C++描述)
2020/10/22
1
第一章 概述
研究对象:信息的表示方法、数据的组织方法、操作算法设计
意义地位:数据结构+算法=程序
程序设计的基础
系统软件的核心
发展过程:数值计算
非数值计算
建立数学模型 客体及其关系的表示
数据结构课程设计(附代码)-数据结构设计

上海应用技术学院课程设计报告课程名称《数据结构课程设计》设计题目猴子选大王;建立二叉树;各种排序;有序表的合并;成绩管理系统;院系计算机科学与信息工程专业计算机科学与技术班级姓名学号指导教师日期一.目的与要求1. 巩固和加深对常见数据结构的理解和掌握2. 掌握基于数据结构进行算法设计的基本方法3. 掌握用高级语言实现算法的基本技能4. 掌握书写程序设计说明文档的能力5. 提高运用数据结构知识及高级语言解决非数值实际问题的能力表。
3、输出功能:void print(LinkList *head);通过一个while的循环控制语句,在指针p!=NULL时,完成全部学生记录的显示。
知道不满足循环语句,程序再次回到菜单选择功能界面。
4、删除功能:LinkList *Delete(LinkList *head);按想要删除的学生的学号首先进行查找,通过指针所指向结点的下移来完成,如果找到该记录,则完成前后结点的连接,同时对以查找到的结点进行空间的释放,最后完成对某个学生记录进行删除,并重新存储。
5、插入功能:LinkList *Insert(LinkList *head);输入你想插入的位置,通过指针所指向结点的下移,找到该位置,将该新的学生记录插入到该结点,并对该结点后面的指针下移。
链表长度加一,重新存储。
(5) 程序的输入与输出描述输入:调用LinkList *create()函数,输入学生的姓名、学号、三门功课的成绩;输出:调用void print(LinkList *head)函数,输出学生的记录。
(6) 程序测试主菜单:成绩管理系统的主界面:学生成绩记录的输入:输出学生成绩记录:学生成绩记录的删除(删除学号是1101的学生记录)插入新的学生成绩记录(插入学号为1103的学生记录)(7) 尚未解决的问题或改进方向尚未解决的问题:该成绩管理系统还存在不少缺陷,而且它提供的功能也是有限的,只能实现学生成绩的输入、输出、删除、插入。
数据结构与算法教学大纲
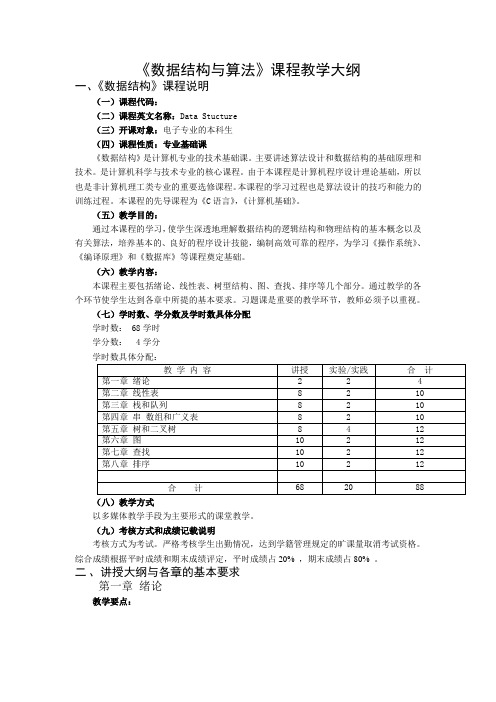
《数据结构与算法》课程教学大纲一、《数据结构》课程说明(一)课程代码:(二)课程英文名称:Data Stucture(三)开课对象:电子专业的本科生(四)课程性质:专业基础课《数据结构》是计算机专业的技术基础课。
主要讲述算法设计和数据结构的基础原理和技术。
是计算机科学与技术专业的核心课程。
由于本课程是计算机程序设计理论基础,所以也是非计算机理工类专业的重要选修课程。
本课程的学习过程也是算法设计的技巧和能力的训练过程。
本课程的先导课程为《C语言》,《计算机基础》。
(五)教学目的:通过本课程的学习,使学生深透地理解数据结构的逻辑结构和物理结构的基本概念以及有关算法,培养基本的、良好的程序设计技能,编制高效可靠的程序,为学习《操作系统》、《编译原理》和《数据库》等课程奠定基础。
(六)教学内容:本课程主要包括绪论、线性表、树型结构、图、查找、排序等几个部分。
通过教学的各个环节使学生达到各章中所提的基本要求。
习题课是重要的教学环节,教师必须予以重视。
(七)学时数、学分数及学时数具体分配学时数: 68学时学分数: 4学分(八)教学方式以多媒体教学手段为主要形式的课堂教学。
(九)考核方式和成绩记载说明考核方式为考试。
严格考核学生出勤情况,达到学籍管理规定的旷课量取消考试资格。
综合成绩根据平时成绩和期末成绩评定,平时成绩占20% ,期末成绩占80% 。
二、讲授大纲与各章的基本要求第一章绪论教学要点:通过本章的教学使学生初步了解《数据结构》的内容和目的,掌握数据结构的概念以及分类、抽象数据类型的表示与实现、算法的概念、算法的特性、算法的目标、算法效率的度量、算法的存储空间需求。
1、使学生准确掌握数据结构的概念。
2、使学生领会抽象数据类型的表示与实现。
3、使学生充分理解算法的概念。
4、明确算法的特性。
5、明确算法的目标。
6、熟练地掌握算法效率的度量。
7、掌握算法的存储空间需求。
教学时数:4学时教学内容:第一节数据结构概述第二节数据结构的概念一、基本概念二、数据结构及分类三、数据结构课程的内容第三节数据类型和抽象数据类型一、数据类型二、抽象数据类型第四节算法和算法分析考核要求:1、数据结构概述(识记)2、数据结构的概念2.1基本概念(识记)2.2数据结构及分类(识记)2.3数据结构课程的内容(识记)3、数据类型和抽象数据类型3.1数据类型(领会)3.2抽象数据类型(领会)4、算法和算法分析(应用)第二章线性表教学要点:通过本章的教学使学生初步了解线性表的结构特点;掌握顺序的和链式的存储结构各自特色;熟练掌握线性表的操作,以及链表的指针运算和各种链表的操作;理解循环链表以及双向链表。
《数据结构》实验指导书(Java语言版).

《数据结构》课程实验指导《数据结构》实验教学大纲课程代码:0806523006 开课学期:3 开课专业:信息管理与信息系统总学时/实验学时:64/16 总学分/实验学分:3.5/0.5一、课程简介数据结构是计算机各专业的重要技术基础课。
在计算机科学中,数据结构不仅是一般程序设计的基础,而且是编译原理、操作系统、数据库系统及其它系统程序和大型应用程序开发的重要基础。
数据结构课程主要讨论各种主要数据结构的特点、计算机内的表示方法、处理数据的算法以及对算法性能的分析。
通过对本课程的系统学习使学生掌握各种数据结构的特点、存储表示、运算的原理和方法,学会从问题入手,分析研究计算机加工的数据结构的特性,以便为应用所涉及的数据选择适当的逻辑结构、存储机构及其相应的操作算法,并初步掌握时间和空间分析技术。
另一方面,本课程的学习过程也是进行复杂程序设计的训练过程,通过对本课程算法设计和上机实践的训练,还应培养学生的数据抽象能力和程序设计的能力。
二、实验的地位、作用和目的数据结构是一门实践性较强的基础课程,本课程实验主要是着眼于原理和应用的结合,通过实验,一方面能使学生学会把书上学到的知识用于解决实际问题,加强培养学生如何根据计算机所处理对象的特点来组织数据存储和编写性能好的操作算法的能力,为以后相关课程的学习和大型软件的开发打下扎实的基础。
另一方面使书上的知识变活,起到深化理解和灵活掌握教学内容的目的。
三、实验方式与基本要求实验方式是上机编写完成实验项目指定功能的程序,并调试、运行,最终得出正确结果。
具体实验要求如下:1.问题分析充分地分析和理解问题本身,弄清要求,包括功能要求、性能要求、设计要求和约束,以及基本数据特性、数据间联系等等。
2.数据结构设计针对要解决的问题,考虑各种可能的数据结构,并且力求从中选出最佳方案(必须连同算法实现一起考虑),确定主要的数据结构和全程变量。
对引入的每种数据结构和全程变量要详细说明其功用、初值和操作的特点。
02332 数据结构(实践) 自考考试大纲

湖北省高等教育自学考试实践(技能)课程大纲课程名称:数据结构课程代码:02332一、实践能力的培养目标1.深入了解线性表的顺序存储结构、链式存储结构;熟练掌握在存储结构上对线性表进行插入、删除等操作的常用算法;2.掌握栈与队列的抽象数据类型描述及特点;掌握栈和队列的顺序和链式存储结构与基本操作算法实现;3.掌握二叉树链表的结构和构造过程;掌握用递归方法实现二叉树的遍历;4.掌握图的存储结构及其实现;掌握图的深度和广度遍历算法及其实现;5.熟练掌握各种静态查找表方法(顺序查找、折半查找、索引顺序表等);熟练掌握二叉排序树的构造方法和查找算法;6.熟练掌握各种排序的算法思想和方法;掌握快速排序、堆排序、归并排序等的实现方法;熟悉各种排序算法的复杂度分析;7.掌握利用各种基本数据结构解决实际问题的能力和基本编程技巧。
二、实践(技能)课程教学基本要求。
(含学时、学分要求)32学时,1学分第1章概论(1学时)要求:(1)了数据结构的逻辑结构、存储结构和数据运算的基本概念(2)熟悉使用C语言函数对算法的描述第2章线性表(4学时)要求:(1)掌握顺序表和链表上实现各种算法;(2)运用线性表的结构和性质设计算法,编程解决各种应用问题;第3章栈和队列(4学时)要求:(1)掌握顺序表和链表上实现各种算法;(2)利用栈和队列设计算法解决简单应用问题;(3)理解递归算法执行过程中栈的状态及变化过程,以及循环队列对边界条件的处理问题。
第4章多维数组和广义表(4学时)要求:(1)掌握多维数组的存储方式、矩阵的压缩存储(2)掌握广义表表头和表尾的求解顺序表和链表上实现各种算法;(3)理解稀疏矩阵的三元组表存储表示方法及有关算法;第5章树和二叉树(5学时)要求:(1)掌握二叉树各种次序的遍历及其应用(2)掌握二叉树的线性化方法及其应用(3)基于树和二叉树编程解决各类应用问题第6章图(5学时)要求:(1)掌握图的两种存储结构的实现及其遍历算法(2)理解最小生成树的基本思想和算法(3) 理解最短路径的基本思想和算法第7章排序(5学时)要求:(1)理解各种内部排序算法的基本思想(2)掌握各种内部排序算法的实现过程和性能分析(3)利用排序算法编程解决应用问题第8章查找(4学时)要求:(1)掌握常见各种查找方法的基本思想和算法实现(2)利用查找算法编程解决应用问题三、实践(技能)课程教学参考教材1.《数据结构》, 苏仕华, 外语教学与研究出版社,20122.数据结构实验指导教程,毛养红、陈坚强、江立,清华大学出版社,2014。
数据结构c++顺序表、单链表的基本操作,查找、排序代码

} return 0; }
实验三 查找
实验名称: 实验3 查找 实验目的:掌握顺序表和有序表的查找方法及算法实现;掌握二叉排序 树和哈希表的构造和查找方法。通过上机操作,理解如何科学地组织信 息存储,并选择高效的查找算法。 实验内容:(2选1)内容1: 基本查找算法;内容2: 哈希表设计。 实验要求:1)在C++系统中编程实现;2)选择合适的数据结构实现查 找算法;3)写出算法设计的基本原理或画出流程图;4)算法实现代码 简洁明了;关键语句要有注释;5)给出调试和测试结果;6)完成实验 报告。 实验步骤: (1)算法设计 a.构造哈希函数的方法很多,常用的有(1)直接定址法(2)数字分析法;(3) 平方取中法;(4)折叠法;( 5)除留余数法;(6)随机数法;本实验采用的是除 留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈 希地址 (2)算法实现 hash hashlist[n]; void listname(){ char *f; int s0,r,i; NameList[0].py="baojie"; NameList[1].py="chengቤተ መጻሕፍቲ ባይዱoyang"; ……………………………… NameList[29].py="wurenke"; for(i=0;i<q;i++){s0=0;f=NameList[i].py; for(r=0;*(f+r)!='\0';r++) s0+=*(f+r);NameList[i].k=s0; }} void creathash(){int i;
v[k-1]=v[k]; nn=nn-1; return ; } int main() {sq_LList<double>s1(100); cout<<"第一次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.ins_sq_LList(0,1.5); s1.ins_sq_LList(1,2.5); s1.ins_sq_LList(4,3.5); cout<<"第二次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.del_sq_LList(0); s1.del_sq_LList(2); cout<<"第三次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); return 0; } 运行及结果:
数据结构——哈夫曼(Huffman)树+哈夫曼编码

数据结构——哈夫曼(Huffman)树+哈夫曼编码前天acm实验课,⽼师教了⼏种排序,抓的⼀套题上有⼀个哈夫曼树的题,正好之前离散数学也讲过哈夫曼树,这⾥我就结合课本,整理⼀篇关于哈夫曼树的博客。
哈夫曼树的介绍Huffman Tree,中⽂名是哈夫曼树或霍夫曼树,它是最优⼆叉树。
定义:给定n个权值作为n个叶⼦结点,构造⼀棵⼆叉树,若树的带权路径长度达到最⼩,则这棵树被称为哈夫曼树。
这个定义⾥⾯涉及到了⼏个陌⽣的概念,下⾯就是⼀颗哈夫曼树,我们来看图解答。
(01) 路径和路径长度定义:在⼀棵树中,从⼀个结点往下可以达到的孩⼦或孙⼦结点之间的通路,称为路径。
通路中分⽀的数⽬称为路径长度。
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
例⼦:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
(02) 结点的权及带权路径长度定义:若将树中结点赋给⼀个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
例⼦:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
(03) 树的带权路径长度定义:树的带权路径长度规定为所有叶⼦结点的带权路径长度之和,记为WPL。
例⼦:⽰例中,树的WPL= 1*100 + 2*50 +3*20 + 3*10 = 100 + 100 + 60 + 30 = 290。
⽐较下⾯两棵树上⾯的两棵树都是以{10, 20, 50, 100}为叶⼦节点的树。
左边的树WPL=2*10 + 2*20 + 2*50 + 2*100 = 360 右边的树WPL=350左边的树WPL > 右边的树的WPL。
你也可以计算除上⾯两种⽰例之外的情况,但实际上右边的树就是{10,20,50,100}对应的哈夫曼树。
⾄此,应该堆哈夫曼树的概念有了⼀定的了解了,下⾯看看如何去构造⼀棵哈夫曼树。
第三章 空间数据结构

(三)栅格数据的组织
数据文件 像元1
像元2 … 像元n
X坐标
数据文件
Y坐标
层1属性
层1
层2属性 ...
层n属性
层2 …
层n
像元1
X坐标
Y坐标 属性值
数据文件 层1
像元2 ...
像元n
多边 形1
属性值 像元1坐标
像元2坐标 … 像元n坐标
多边形2 ... 多边形n
层2 …
层n
(四)栅格结构的建立
一)建立途径
数据存储量大
(2)费尔曼链码 (边界编码)
将线状地物或区域边界表示为:由某一起始点 和某些基本方向上的单位矢量链组成。
前两个字母表示起点的行列号,从第三个数 字开始每个数字表示单位矢量的方向。
单位矢量的长度 为一个栅格单元, 后续点可能位于前 继点8个基本方向上。
7
0
1
6
2
5
4
3
(2)费尔曼链码 (边界编码)
三)栅格属性值的确定
4、重要性法
突出某些主要属性,只要在栅格中出现就把该属性作为 栅格属性
A
B
C
D
AABB AABB CDDB DDDD
三)栅格属性值的确定
5、百分比法
根据矩形区域内各地理要素所占面积的百分比数确定单 元的取值。
A
B
C
D
AABB AABB CDDB DDDD
(五)栅格数据编码方式
(3)游程(行程)编码
特点:属性的变化愈少,游程愈长,即压缩比的
大小与图的复杂程度成反比。
优点:数据压缩率高,易于实现叠加,检索和合
并运算。
缺点:适合类型区面积较大的专题图、遥感影像
数据结构实验 图的邻接表和邻接矩阵操作

p->weight=weight; p->nextarc=G.vertices[vv].firstarc; G.vertices[vv].firstarc=p; strcmp(G.vertices[vv].data,v);
q=(ArcNode *)malloc(sizeof(ArcNode)); q->adjvex=vv; q->weight=weight; q->nextarc=G.vertices[ww].firstarc; G.vertices[ww].firstarc=q; strcmp(G.vertices[ww].data,w);
实验报告 6
课程 数据结构 实验名称 图的建立及遍历
第页
专业
班级_ __ 学号_ ___ 姓名
实验日期: 2010 年 11 月 23 日
评分
一 、实验目的
1.学会用邻接矩阵和邻接表实现图结构和对图的基本操作。 2.掌握对图操作的具体实现; 3. 掌握图的两种遍历算法(深度优先、广度优先); 4、掌握求图的最小生成树和顶点间最短路径的算法;
int adjvex;//该弧指向的顶点的位置 ArcType weight; struct ArcNode *nextarc;//指向下一条弧指针 //InfoType *info;该弧相关信息的指针 }ArcNode; typedef struct VNode { VertexType data;//顶点信息 ArcNode *firstarc;//指向第一条依附该顶点的弧的指针 }VNode,AdjList[MAX_VEX_NUM]; typedef struct { AdjList vertices; int vexnum,arcnum; GraphKind kind; }ALGraph; ALGraph G; struct MiniSpanTree_Flag { VertexType adjvex; ArcType lowcost; }closedge[MAX_VEX_NUM]; typedef bool PathMatrix[MAX_VEX_NUM][MAX_VEX_NUM];
《数据结构》实验书

目录实验一线性表基本操作的编程实现 (201)实验二堆栈或队列基本操作的编程实现 (49)实验四二维数组基本操作的编程实现 (18)实验五二叉树基操作的编程实现 (20)实验六图基本操作的编程实现 (45)(特别提示:程序设计包含两个方面的错误。
其一是错误,其二是能错误。
为了提高学生的编程和能力,本指导书给出的程序代码并的两种错误。
并且也不保证程序的完整性,有一些语句已经故意删除,就是要求学生自己编制完成,这样才能达到我们的要求。
希望大家以自己所学高级语言的基本功和点为基础,不要过于依赖给出的参考代码,这样才能有所进步。
如果学生能够根据要求完全自己编制,那就不好了。
)实验一线性表基本操作的编程实现【实验目的】线性表基本操作的编程实现要求:线性表基本操作的编程实现(2学时,验证型),掌握线性表的建立、遍历、插入、删除等基本操作的编程实现,也可以进一步编程实现查找、逆序、排序等操作,存储结构可以在顺序结构或链表结分主要功能,也可以用菜单进行管理完成大部分功能。
还鼓励学生利用基本操作进行一些更实际的应用型程序设计。
【实验性质】【实验内容】把线性表的顺序存储和链表存储的数据插入、删除运算其中某项进行程序实现。
建议实现键盘输入数据以实现程序的通据的函数。
【注意事项】【思考问题】1.线性表的顺序存储和链表存储的差异?优缺点分析?2.那些操作引发了数据的移动?3.算法的时间效率是如何体现的?4.链表的指针是如何后移的?如何加强程序的健壮性?【参考代码】(一)利用顺序表完成一个班级学生课程成绩的简单管理1、预定义以及顺序表结构类型的定义(1)#define ListSize //根据需要自己设定一个班级能够容纳的最大学生数(2)typedef struct Stu{int num; //学生的学号char name[10]; //学生的姓名float wuli; //物理成绩float shuxue; //数学成绩float yingyu; //英语成绩}STUDENT; //存放单个学生信息的结构体类型typedef struct List{stu[ListSize]; //存放学生的数组定义,静态分配空间int length; //记录班级实际学生个数}LIST; //存放班级学生信息的顺序表类型2、建立班级的学生信息void listcreate(LIST *Li,int m) //m为该班级的实际人数{int i;Li->length=0;for(i=0;i<m;i++) //输入m个学生的所有信息{printf("please input the %dth student's information:\n",i+1);printf("num=");scanf("%d", ); //输入第i个学生的学号printf("name=");scanf("%s", ); //输入第i个学生的姓名printf("wuli=");scanf("%f", ); //输入第i个学生的物理成绩printf("shuxue=");scanf("%f", ); //输入第i个学生的数学成绩printf("yingyu=");scanf("%f", ); //输入第i个学生的英语成绩Li->length++; //学生人数加1}}3、插入一个学生信息int listinsert(LIST *Li,int i) //将学生插入到班级Li的第i个位置。
最新二章空间数据结构及编码

04477777 44444777 44448877 00488877 00888878 00088888 00008888 00000888
该例中块码用了120个整数,比直接编码还多,这是因为例中为描述方便, 栅格划分很粗糙,在实际应用中,栅格划分细,数据冗余多的多,才能显 出压缩编码的效果,而且还可以作一些技术处理,如行号可以通过行间标 记而省去记录,行号和半径等也不必用双字节整数来记录,可进一步减少 数据冗余。
注意:栅格数据模型是将连续空间离散化,即用 二维铺盖或划分覆盖整个连续空间,这种铺盖可 以分为规则的和不规则的
三角形、方格和六角形划分
栅格数据模型
2.图形栅格数据结构表示
0000200 0 0002000 0 0102033 0 0002333 3 0020333 3 0020033 0 0200000 0
3
1
3
2
1.515
4
3
3
5Leabharlann 1.04041
1
3
2.106
2
2
2
4
2.233
1
5
1
2
4.120
5
3
5
2
1.093
4
5
5
1
2.193
弧属性表(AAT)
二、栅格数据结构
1.概念
定义:又称为网格结构,它是将地表划分成为紧 密相邻的网格阵列。每个网格的位置由行列号定 义。它包含一个代码,以表示该网格的属性或指 向属性记录的指针。
地理要素之间的空间区位关系可抽象为点、线(或弧)、多 边形(区域)之间的空间几何关系,其关系如下
欧氏平面上实体对象所具有的拓扑 和非拓扑属性
山东省建筑市场监管与诚信信息数据结构与编码标准

山东省建筑市场监管与诚信信息数据结构与代码标准(试行)前言本标准根据住房城乡建设部《全国建筑市场监管与诚信信息系统基础数据库数据(试行)》的数据规范,并按照《标准化工作导则第1部分:标准的结构和编写》(GB/T 1.1—2009)的要求进行编制。
本标准由山东省住房和城乡建设厅提出。
本标准由山东省住房和城乡建设厅归口。
山东省建筑市场监管与诚信信息数据结构与代码标准1范围本标准规定了山东省建筑市场监管与诚信基础信息的数据元、数据结构与和代码标准。
本标准适用于山东省各级建筑市场监管业务主管部门按照统一数据标准建立山东省建筑市场监管与诚信信息数据库,同时适用于各级建筑市场监管业务应用系统之间的数据交换与共享。
2规范性引用文件下列文件中的条款通过本标准的引用而成为本部分的条款。
凡是注日期的引用文件,其随后所有的修改单(不包括勘误的内容)或修订版均不适用于本部分。
凡是不注日期的引用文件,其最新版本适用于本部分。
GB/T 2260 中华人民共和国行政区划代码GB/T 2261.1 个人基本信息分类与代码第1部分:人的性别代码GB/T 2659 世界各国和地区名称代码(GB/T 2659 2000,eqv ISO 3166-1:1997)GB/T 3304 中国各民族名称的罗马字母拼写法和代码GB/T 4658 学历代码GB/T 4762 政治面貌代码GB/T 6864 中华人民共和国学位代码GB/T 7408 数据元和交换格式信息交换日期和时间表示法(GB/T 7408—2005,ISO 860l:2000,IDT)GB/T 8561 专业技术职务代码GB/T 9704 国家行政机关公文格式GB 11714 全国组织机构代码编制规则GB/T 12406 表示货币和资金的代码(GB/T 12406 1996,idt ISO 42l7:1995)GB/T 19488.1 电子政务数据元第1部分:设计和管理规范GB/T 19488.2 电子政务数据元第2部分:公共数据元目录3术语和定义下列术语和定义适用本部分。
编程技术的提升秘籍开发可扩展的应用程序

编程技术的提升秘籍开发可扩展的应用程序编程技术的提升秘籍:开发可扩展的应用程序编程技术的提升一直是程序员们追求的目标。
而要达到这个目标,掌握开发可扩展的应用程序是至关重要的。
本文将为大家介绍一些关键技巧和秘籍,帮助开发人员提升他们的编程技术,并能够创建可扩展的应用程序。
一、良好的代码结构良好的代码结构是开发可扩展应用程序的基础。
一个清晰、有层次的代码结构能够提高代码的可读性和可维护性,使得后续的功能扩展和代码修改更加容易。
让我们来看一下如何实现一个良好的代码结构:1. 模块化设计:将应用程序拆分为多个模块,每个模块负责特定的功能。
通过模块化设计,可以降低代码的耦合性,提高代码的复用性。
2. 使用合适的命名规范:给变量、函数和类起一个有意义的名称,能够使代码更加易读,降低维护成本。
3. 保持代码的一致性:使用相同的代码风格和缩进规范,确保代码的可读性和一致性。
二、合理使用设计模式设计模式是经过实践验证的解决方案,可以帮助我们解决一些常见的软件设计问题。
合理使用设计模式能够提高代码的可扩展性和可维护性,下面是一些常用的设计模式:1. 工厂模式:通过工厂类创建对象,隐藏对象的具体实现细节,提高代码的灵活性。
2. 单例模式:确保一个类只有一个实例,并提供全局访问点,避免频繁地创建对象。
3. 观察者模式:定义对象之间的一对多依赖关系,当一个对象状态发生改变时,其依赖的对象会自动收到通知。
三、使用设计原则设计原则是编写高质量代码的准则。
下面是一些常用的设计原则,可以帮助我们开发可扩展的应用程序:1. 开闭原则:对扩展开放,对修改关闭。
通过抽象化解耦,使得新增功能能够在不修改现有代码的情况下进行扩展。
2. 单一职责原则:一个类应该只负责一项职责。
将功能拆分到不同的类中,降低类的复杂度,提高代码的可读性和可维护性。
3. 依赖倒置原则:针对接口编程,而不是针对实现编程。
通过接口定义依赖关系,减少模块间的耦合度。
四、使用适当的数据结构与算法选择适当的数据结构与算法是提升程序性能和扩展性的关键。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
}
void guangdu(ALGraph *a,int v)//广度遍历
{
ArcNode *p;
int queue[MAXV];
int visited[MAXV];
int f=0,r=0,x,i;
for (i=0;i<a->n;i++)
{
visited[i]=0;
}
printf("%c ",a->adjlist[v-1].data);
printf("--------------------------\n");
printf("*1.邻接矩阵建图\n");
printf("*2.邻接表建图\n");
printf("*3.邻接表图的广度遍历\n");
printf("*4.结束·····\n");
printf("--------------------------\n");
{
int i,j;
ArcNode *q;
printf("这是所建立的图:\n");
for (i=0;i<a->n;i++)
{
printf("%c ",a->adjlist[i].data);
printf("-->");
q=a->adjlist[i].firstarc;
for (j=0;j<a->n;j++)
ALGraph *a;
a=(ALGraph *)malloc(sizeof (ALGraph));
while (flag)
{
jiemian();//选择界面
scanf("%d",&c);
getchar();
switch (c)
{
case 1:
creategraph1();//邻接矩阵
flag=FLAG();
for (j=1;j<=m->arcnum;j++)
{
printf("请输入第%d条边相连的两个顶点:\n",m->vexs[j].no);
scanf("%d,%d",&a,&b);
m->edges[a-1][b-1]=1;
}
system("CLS");
shuchu1(m);
}
void shuchu2(ALGraph *a)//输出邻接表
break;
case 2:
creategraph2(a);//邻接表
flag=FLAG();
break;
case 3:
printf("这里是图的广度遍历:\n");
printf("请输入遍历的起始顶点序号:\n");
scanf("%d",&v);
guangdu(a,v);
break;
default:
printf("%c ",a->adjlist[p->adjvex].data);
r=(r+1)%MAXV;
queue[r]=p->adjvex;
}
p=p->nextarc;
}
}
printf("\n");
getch();
system("CLS");
}
void main()
{
int flag=1,c,v,i;
{
printf(" %d ",m->edges[i][j]);
}
if (j=m->vexnum)//换行判断
printf("\n");
}
}
void creategraph1()//创建邻接矩阵
{
int i,j,a,b;
MGraph *m;
m=(MGraph *)malloc(sizeof (MGraph));
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
#define MAXV 100
typedef char ElemType;
typedef struct ANode/*弧的结点结构类型*/
{
int adjvex; /*该弧的终点位置*/
struct ANode *nextarc;/*指向下一条弧的指针*/
flag=0;
break;
}
if (flag==0)
{
printf("您已经成功退出!下次再会!\n");
exit(0);
}
}
}
getchar();
scanf("%c",&a->adjlist[i-1].data);
}
printf("\n");
printf("请输入图的边数:\n");//输入边
scanf("%d",&a->e);
printf("请输入各条边相连的两个顶点,例如:a->b,a为第一个顶点,b为第二个;输入:1,2\n");
p->adjvex=d-1;
p->nextarc=a->adjlist[c-1].firstarc;
a->adjlist[c-1].firstarc=p;
p=(ArcNode *)malloc(sizeof (ArcNode));//b到a
p->adjvex=c-1;
p->nextarc=a->adjlist[d-1].firstarc;
printf("温馨提示:为了让您使用愉快,请按提示操作!\n");
printf("请选择:");
}
void shuchu1(MGraph *m)//输出邻接矩阵
{
int i,j;
printf("邻接矩阵为:\n");
for (i=0;i<m->vexnum;i++)
{
for (j=0;j<m->vexnum;j++)
{
AdjList adjlist;/*邻接表*/
int n,e;/*图中顶点数n和边数e*/
} ALGraph;/*图的类型*/
typedef struct
{
int no;/*顶点编号*/
ElemType data;/*顶点其他信息*/
} VertexType;/*顶点类型*/
typedef struct/*图的定义*/
for (j=1;j<=a->e;j++)
{
printf("请输入第%d条边相连的两个顶点:\n",j);
scanf("%d,%d",&c,&d);
if (c<1||d<1 || c>a->n || d>a->n)
{
printf("输入有误!\n");
continue;
}
p=(ArcNode *)malloc(sizeof (ArcNode));//a到b
{
printf("请输入第%d个顶点:\n",i);
scanf("%c",&m->vexs[i-1].data);
getchar();
m->vexs[i].no=i;
}
printf("\n");
printf("请输入图的边数:\n");//输入边
scanf("%d",&m->arcnum);
printf("请输入边相连的两个顶点,逗号隔开,例如:a->b,输入为:1,2\n");
{
int edges[MAXV][MAXV];/*邻接矩阵*/
int vexnum,arcnum;/*顶点数,弧数*/
VertexType vexs[MAXV];/*存放顶点信息*/
} MGraph;
void jiemian()//界面函数
{
printf("***无向图的建立及其应用***\n");
printf("这里是用邻接矩阵建图:\n");
printf("请输入图的顶点数:\n");
scanf("%d",&m->vexnum);
for (i=0;i<m->vexnum;i++)//邻接矩阵置零
{Hale Waihona Puke for (j=0;j<m->vexnum;j++)
{
m->edges[i][j]=0;
}
}
for (i=1;i<=m->vexnum;i++)//输入顶点
printf("这是用邻接表建图:\n");
printf("请输入图的顶点数:\n");
scanf("%d",&a->n);