中文配方
PANTONE专色色彩配方指南中英文对照
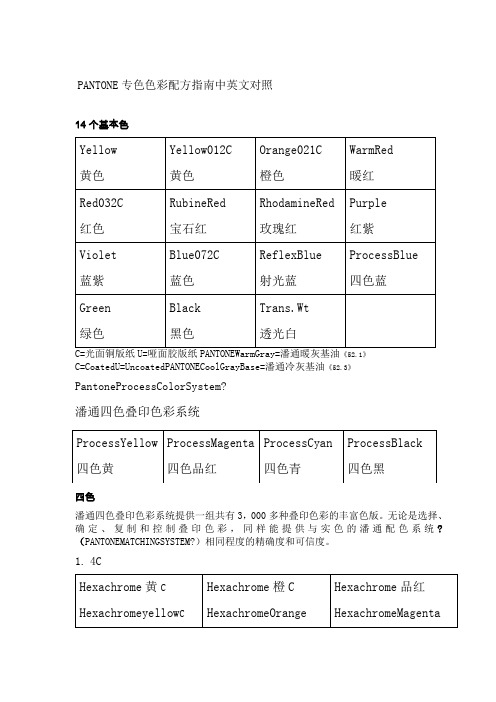
PANTONE 专色色彩配方指南中英文对照14个基本色《52.1》C=CoatedU=UncoatedPANTONECoolGrayBase=潘通冷灰基油《52.3》PantoneProcessColorSystem?潘通四色叠印色彩系统四色潘通四色叠印色彩系统提供一组共有3,000多种叠印色彩的丰富色版。
无论是选择、确定、复制和控制叠印色彩,同样能提供与实色的潘通配色系统?(PANTONEMATCHINGSYSTEM?)相同程度的精确度和可信度。
1. 4CPt(s)=份量∷=可以CMYK叠印模拟∴=可以RGB模拟颜色大全(中英对照)一.红色类红色red朱红vermeil;vermilion;ponceau粉红pink;softred;rosebloom梅红plum;crimson;fuchsiared玫瑰红rosemadder;rose桃红peachblossom;peach;carminerose樱桃红cherry;cerise桔红reddishorange;tangerine;jacinth;salmonpink;salmon 石榴红garnet枣红purplishred;jujubered;datered莲红lotusred浅莲红fuchsiapink豉豆红beanred辣椒红capsicumred高粱红Kaoliangred芙蓉红hibiscusred;poppyred;poppy胭脂红rogueredcarmine;cochineal;lake鲑鱼红salmon玳瑁红hawksbillturtlered海螺红cadmiumorange宝石红rubyred玛瑙红agatered珊瑚红coral金红bronzered铁红ironoxidered铁锈红rustred镉红cadmiumred铬红chromered砖红brickred土红laterite;reddle郎窑红lang-kilnred均红Jun-kilnred釉底红underglazered威尼斯红Venetianred法国红Frenchvermilion茜红alizarinred;madderred洋红carmine;magenta品红pinkishred;magenta猩红scarletred;scarlet;bloodred油红oilred紫红purplishred;madderred;winered;wine;carmine; amaranth;claret;fuchsia;magenta;heliotrope;mauve玫瑰紫红rosecarmine;rosemauve深紫红prune;mulberry深藕红conchshell棕红henna暗红darkred;dullred鲜红scarletred;scarlet;brightred;freshred;bloodred; madder;ruby;cerise;cherry血红bloodred;incarnadine血牙红shellpink;peachbeige绯红scarlet;crimson;geraniumpink米红silverpink深红deepred;crimson淡红lightred;carnation二.橙色类橙色orange三.黄色类黄色yellow桔黄orange;crocus;gamboge;cadmiumorange深桔黄,深橙deeporange浅桔黄,浅橙clearorange;lightorange;rattan柠檬黄lemonyellowlemoncitrinecitron玉米黄maize橄榄黄oliveyellow樱草黄primroseyellow稻草黄strawyellow芥末黄mustard杏黄apricot;apricotbuff;bronzeyellow蛋黄vitelline;yolkyellow;eggyellow藤黄rattanyellow鳝鱼黄eelyellow象牙黄ivory日光黄sunnyyellow石黄mineralyellow土黄earthyellow;yellowishbrown;yellowocher;golden apricot砂黄sandyellow金黄goldenyellow,gold铁黄ironoxideyellow;ironbuff镉黄cadmiumyellow铬黄chromeyellow钴黄cobaltyellow深黄,暗黄deepyellow棕黄tan青黄bluishyellow灰黄isabelsallowgreyyellow米黄apricotcreamcream嫩黄yellowcream鲜黄cadmiumyellowcanary鹅黄lightyellow中黄midiumyellow浅黄lightyellow;paleyellow;buff淡黄jasmin(e);primrose四.绿色类绿色green豆绿peagreenbeangreen浅豆绿lightbeangreen;asparagusgreen橄榄绿olivegreenolive茶绿teagreencelandinegreenplantation葱绿oniongreenpalegreen苹果绿applegreen原野绿fieldgreen森林绿forestgreen洋蓟绿artichokegreen苔藓绿mossgreenbrackengreen草地绿,草绿grassgreenmeadowgreenolivergreen olivedrab水草绿watergrassgreen深草绿junglegreen灰湖绿agategreen水绿aquagreen海水绿marinegreen酸性绿acidgreen水晶绿crystalgreen玉绿jadegreen石绿mineralgreen松石绿spearmint;viridis铜绿verdigris铜锈绿patinagreen镉绿cadmiumgreen铬绿chromegreen钴绿cobaltgreen孔雀绿peacockgreen威尼斯绿Venetiangreen巴黎绿Parisgreenking'sgreen墨绿blackishgreengreenblack;jasper;darkgreen deepgreen墨玉绿emeraldblack深绿darkgreenpetrol;Chinesegreen;bottlegreen 暗绿sapgreendarkgreendeepgreen青绿darkgreen碧绿azuregreen;turquoisegreenviridity翠绿emeraldgreen;jadegreenbrightgreenverdancy viridity深翠绿viridian蓝绿bluegreenaquamarine黄绿yellowgreen灰绿greygreensagegreenhedgegreen;mignonette; seaspray;celadon褐绿breen品绿lightgreenmalachitegreen鲜绿cleargreen;emeraldgreenvividgreen嫩绿pomonagreenverdancy中绿mediumgreen;golfgreen浅绿lightgreen淡绿palegreen五.青色类青色ceruleanbluebluegreen豆青peagreen;beangreen花青flowerblue茶青teagreen葱青oniongreen天青celeste;azure霁青sky-clearingblue石青mineralblue铁青electricblueriverblue蟹青turquoiseinkblue鳝鱼青eelgreen蛋青eggblue影青mistyblue;whiteblue黛青bluish群青,伟青ultramarine暗青darkblue;deepcerulean藏青navyblue;darkblue;Mingblue靛青indigo大青smalt粉青lightgreenishblue鲜青clearcerulean浅青lightblue;lightcerulean淡青paleceruleanlightgreenishblue六.蓝色类蓝色blue天蓝skyblue;azureceleste;azureceruleanblue; Parisianblue蔚蓝azure;skyblue月光蓝moonblue海洋蓝oceanblue海蓝seablue湖蓝acidblue深湖蓝vividblue中湖蓝brightblue浅湖蓝canalblue清水蓝waterblue冰雪蓝ice-snowblue孔雀蓝peacockblue宝石蓝sapphire;jewelry粉末蓝powderblue铁蓝ironblue钴蓝cobaltblueking'sblue普鲁士蓝Prussianblue北京蓝Beijingblue士林蓝indanthreneblue品蓝reddishblueroyalblue;king'sblue靛蓝indigo;indigoblue;benzoblue菘蓝woadedblue石磨蓝stone-washedindigo藏蓝purplishblue;navyblue;navy海军蓝navyblue;navy宝蓝royalblue墨蓝blueblack绿蓝turquoiseblue紫蓝hyacinth;purplishblue浅紫蓝Dutchblue青蓝ultramarine深灰蓝blueashes深蓝deepblue;darkbluenavybluemandarinblue Antwerpbluemazarinesmaltultramarine暗蓝deepblue;darkblue鲜蓝clearblue中蓝mediumblueazureblue浅蓝lightblue淡蓝palebluebabybluecalamineblue七.紫色类紫色purple;violet紫罗兰色violet紫藤色lilac紫水晶色amethyst葡萄紫grape茄皮紫aubergine;wineberry玫瑰紫roseviolet丁香紫lilac钴紫cobaltviolet墨紫violetblack绛紫darkreddishpurple暗紫violetdeep;dullpurple;damson乌紫raisin蓝紫royallight鲜紫violetlight深紫amaranth;modena浅紫greyviolet淡紫palepurplelavender;lilac;orchid淡白紫violetash青莲palepurple;heliotrope深青莲amaranthpurple雪青lilac墨绛红purpleblack暗绛红purpledeep浅绛红purplelight八.黑色类黑色black土黑earthblack煤黑coalblack碳黑carbonblackcharcoalblack古铜黑bronzeblack铁黑ironoxideblackironblack橄榄黑oliveblack棕黑sepia;brownblack青黑lividity深黑,漆黑pitch-blackpitch-dark暗黑dullblack九.白色类白色white象牙白ivorywhite;ivory牡蛎白oysterwhite珍珠白pearwhitegraylily玉石白jadewhite银白silverwhite铅白flakewhite;leadwhite;cerusewhite 锌白zincwhite锌钡白lithopone;pearlwhite羊毛白woolwhite米白off-white;shell乳白milky-white雪白snow-white;snowywhite灰白greyishwhite;off-white青白bluishwhite纯白crisp-white;purewhite本白rawwhite;off-white粉红白pinkywhite淡紫白lilacwhite十.灰色类灰色grey;gray银灰silvergrey;chinchilla;graymom铁灰irongrey铅灰lividity;leadengrey碳灰charcoalgrey驼灰doe豆灰rosedust藕灰zephyr莲灰elderberry浅莲灰palelilac鸽子灰dovegrey鼠灰stalegrey;mouse蟹灰stormblue天灰skygrey土灰dustgrey水泥灰concretegrey烟灰smokygrey;ash雾灰mistygrey黑灰greyblack;charcoalgrey紫灰purplegrey;cadet;dovegrey深紫灰heron淡紫灰lilacgrey浅绿灰eucalyptus浅米灰moonlight卡其灰khakilight蓝灰bluegrey;slate;steelgrey;pikegrey青灰lividity;steelgrey;balsamgreen白灰palegrey深灰darkgrey;dullgrey;Oxfordgrey暗灰deepgrey中灰mediumgrey浅灰lightgrey;ashgrey十一.棕色类棕色,褐色brown红棕umber;chili金棕auburn铁锈棕rusticbrown桔棕orangebrown橄榄棕olivebrown十二.褐色类赤褐sorrel;maroon;terracotta棕褐summertan茶褐auburnumber黑褐blackbrown紫褐puce黄褐drab;fulvouos;cinnamon;ocher;tawny;russetbrown 栗褐chestnutbrown灰褐taupe;mouse;greigebeige;rosebeige浅灰褐putty橙褐orangebrown土褐clay深褐darkbrown;bistre;burntsienna暗褐deepbrown;fuscous;dun淡褐lightbrown;caramel十三.其它类咖啡色coffee酱色caramel;reddishbrown紫酱色marron茶色umber;dun;darkbrown赫色ocher;auburn;chocolate;sienna;umber;rust 琥珀色amber;succinite栗色chestnut;sorrel;marron金色gold古金色oldgold银色silver;argent铅色lividity锌色zinc铁锈色rust青古铜色bronze;bronzy黑古铜色darkbronze紫铜色purplebronze黄铜色brassiness木色wood土色lividity;sallow驼色camel;lighttan米色beige;buff;cream;graysand卡其色khaki奶油色cream豆沙色cameo浅豆沙色palemauve藕荷色bisque肉桂色cinnamon肉色flesh,carnation;incarnadine;pastelpeach; yellowishpink水晶色crystal荧光色iridescent彩虹色iris;rainbow。
荷兰美素herobaby中文配料表

荷兰美素herobaby中文配料表荷兰美素herobaby中文配料表荷兰美素herobaby作为一款备受家长喜爱的婴幼儿配方奶粉品牌,其产品一直以来以高质量的配方和纯净的原料赢得了消费者的信赖。
以下是荷兰美素herobaby奶粉产品的中文配料表,让我们一起来了解其产品的成分和营养价值。
一、婴幼儿配方奶粉1. 葡萄糖、乳杆菌发酵产生的乳酸、益生菌(活性乳酸菌、双歧杆菌)荷兰美素herobaby婴幼儿配方奶粉中添加了葡萄糖,乳杆菌发酵产生的乳酸以及活性乳酸菌和双歧杆菌等益生菌成分。
这些益生菌对于婴幼儿的肠道健康十分重要,有助于维持肠道菌群平衡,促进消化和吸收功能的正常运作。
2. 乳清蛋白、干酪乳化物、脱脂乳粉、植物油(棕榈油、菜籽油、椰子油、豌豆油、普通菜籽油)荷兰美素herobaby婴幼儿配方奶粉中含有多种优质蛋白质来源,包括乳清蛋白、干酪乳化物和脱脂乳粉。
同时,通过植物油的添加,包括棕榈油、菜籽油、椰子油、豌豆油和普通菜籽油等,荷兰美素herobaby婴幼儿配方奶粉可以提供丰富的脂肪和能量,有助于宝宝的生长和发育。
3. 多种维生素(维生素A、维生素B1、维生素B2、维生素B6、维生素B12、维生素C、维生素D、维生素E、叶酸、烟酸、泛酸、生物素)除了优质蛋白质和脂肪,荷兰美素herobaby婴幼儿配方奶粉中还添加了多种维生素,包括维生素A、维生素B群、维生素C、维生素D、维生素E等。
这些维生素对于婴幼儿的身体发育和免疫力提高至关重要,可以帮助宝宝获得全面的营养补充。
4. 矿物质(钙、磷、铁、锌、碘、硒、铜、锰)荷兰美素herobaby婴幼儿配方奶粉中还富含多种矿物质,如钙、磷、铁、锌、碘、硒、铜和锰等。
这些矿物质对于婴幼儿的骨骼和牙齿发育、脑部发育以及免疫功能的提升都起到了关键作用。
二、儿童配方奶粉除了婴幼儿配方奶粉,荷兰美素herobaby还推出了适合儿童的配方奶粉。
下面是荷兰美素herobaby儿童配方奶粉的中文配料表:1. 全脂奶粉、板粟米糖浆、食用植物油(大豆油、棕榈油、菜籽油)荷兰美素herobaby儿童配方奶粉中主要成分包括全脂奶粉、板粟米糖浆以及大豆油、棕榈油和菜籽油等植物油。
艾诺迪亚3中文版攻略 配方合成材料一览

魔法羊皮纸10魔力结晶2
工匠的铁砧
秘银2终极介质1力量碎片2
复活卷轴
魔法羊皮纸10灵魂之根1震动碎片10
得到祝福的复活卷轴
魔法羊皮纸25魔法树枝1力量碎片1
宝箱钥匙
黑暗碎片5
生命之叶
魔法树枝1
根源之果
生命之叶5
灵魂之根
根源之果5
魔法树枝
灵魂之根5
卓越之花
魔力结晶1力量碎片5
黑暗碎片
力量碎片1
生命药水中
恢复药水中1魔法药水中1
生命药水大
恢复药水大1魔法药水大1
生命药水特大
恢复药水特大1魔法药水特大1
元气恢复药水
生命药水特大1天国的种子1
隐身药水
次元碎片2死亡之粉2
巨力药水
黑暗之血2死亡之粉2
怒气药水
黑暗之血4
防御药水
死亡之粉4
超能药水
魔力结晶1卓越之花1
武器强化卷轴
魔法羊皮纸10卓越之花2
震动碎片
黑暗碎片7
次元碎片
震动碎片4
力量碎片
次元碎片2
魔力结晶
卓越之花1魔法树枝5
小型背包
魔法羊皮纸5皮革5黑暗碎片20
中型背包
魔法羊皮纸10皮革10震动碎片20
秘银
矿石10
红色结晶
粗糙的红色结晶10
黄色晶10
深渊之混沌道具
装备道具1天国的种子2脉动结晶2秘银4
艾诺迪亚3中文版配方合成材料一览(更新中...)
配方名称
所需材料
配方名称
所需材料
恢复药水中
恢复药水小1根源之果2
恢复药水大
恢复药水中1灵魂之根2
中药接骨配方

中文名称: 接骨散来源: 江苏省如东县中医院伤骨科钱忠权。
介绍介绍Title 简介[功能主治] 功能散瘀定痛,续筋接骨。
主治骨折。
[处方组成] 釜脐墨、陈小粉、黄柏、制乳没、栀子、姜黄、参三七、骨碎补、螃蟹壳。
釜脐墨研碎过筛,陈小粉炒后研末,两药混匀,加适量米醋,放在勺中煎熬片刻使成糊状,冷却后加少量朱砂及余药之细末即成。
[临床疗效] 应用241例,男性131例,女性110例;年龄最大90岁,最小3岁;新鲜骨折230例,陈旧骨折11例;上肢骨折151例,下肢骨折84例,其它骨折6例。
对骨折病例,首先运用整骨手法予以整复,在对位对线良好的基础上即用本方醋调外敷骨折处。
用牛皮纸贴上,然后用小夹板固定,1周换药1次。
一般4~5天基本消肿,疼痛减轻,10~20天可见骨痂生长。
临床愈合时间平均为25天左右,治愈率达94.7%。
[处方来源] 江苏省如东县中医院伤骨科钱忠权。
[按语] 本方具有活血散瘀、消肿止痛,续筋接骨之功效,主要借助于敷药的粘性与骨折处结合在一起,这样不仅促进了血液循环,使成骨细胞活跃,促使骨质钙化,有利于骨折的愈合。
答案补充中文名称: 外敷接骨散介绍介绍Title 简介[功能主治] 功能接骨止痛。
主治骨折。
[处方组成] 骨碎补、血竭、硼砂、制乳香、制没药、土虫、续断、大黄、自然铜(醋粹7次)各等分,共为细末。
酒调,或用蜂蜜、麻油、凡士林等调敷伤处。
功效: 接骨止痛接骨散》,当归30克、没药60克、续断90克、穿山龙60克、骨碎补90克、透骨草60克、煅狗骨(焙炒)120克、接骨仙桃草30克、沉香60克、乳香60克、楠香240克、段自然铜90克、地鳖虫30克、螃蟹(焙炒)90克。
芳解-----骨折中、后期由于气血不足而发生骨折延迟愈合,甚至骨不连接者,应予以温经行血、接骨续筋。
本方用当归、乳香、没药、煅自然铜、地鳖虫、螃蟹灰、接骨草活血散淤止痛,沉香、楠香理气舒筋消肿,骨碎补、续断、煅狗骨强筋壮骨,穿山龙、透骨草祛风除湿。
PANTONE专色色彩配方指南中英文对照
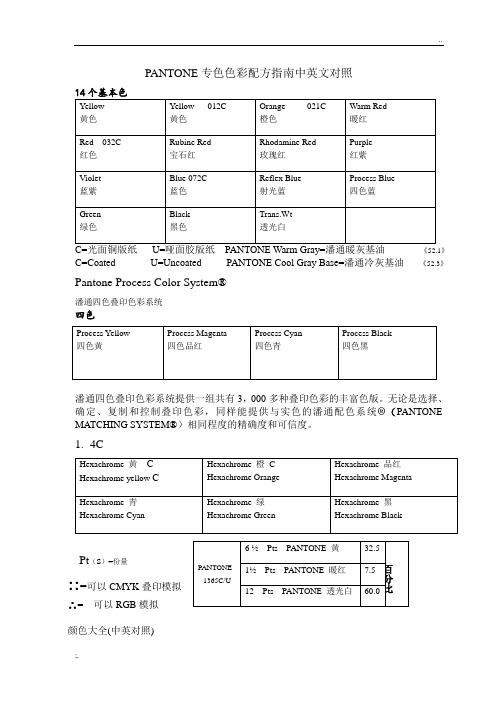
PANTONE 专色色彩配方指南中英文对照《52.1》 C=Coated U=Uncoated PANTONE Cool Gray Base=潘通冷灰基油 《52.3》Pantone Process Color System®潘通四色叠印色彩系统四色潘通四色叠印色彩系统提供一组共有3,000多种叠印色彩的丰富色版。
无论是选择、确定、复制和控制叠印色彩,同样能提供与实色的潘通配色系统®(PANTONE MATCHING SYSTEM®)相同程度的精确度和可信度。
1. 4CPt (s )=份量∷=可以CMYK 叠印模拟∴= 可以RGB 模拟颜色大全(中英对照)一.红色类红色red朱红vermeil; vermilion; ponceau粉红pink; soft red; rose bloom梅红plum;crimson;fuchsia red玫瑰红rose madder; rose桃红peach blossom; peach; carmine rose樱桃红cherry; cerise桔红reddish orange; tangerine; jacinth; salmon pink; salmon 石榴红garnet枣红purplish red; jujube red; date red莲红lotus red浅莲红fuchsia pink豉豆红bean red辣椒红capsicum red高粱红Kaoliang red芙蓉红hibiscus red; poppy red; poppy胭脂红rogue red carmine; cochineal; lake鲑鱼红salmon玳瑁红hawksbill turtle red海螺红cadmium orange宝石红ruby red玛瑙红agate red珊瑚红coral金红bronze red铁红iron oxide red铁锈红rust red镉红cadmium red铬红chrome red砖红brick red土红laterite; reddle郎窑红lang-kiln red均红Jun-kiln red釉底红underglaze red威尼斯红Venetian red法国红French vermilion茜红alizarin red; madder red洋红carmine; magenta品红pinkish red; magenta猩红scarlet red; scarlet; blood red油红oil red紫红purplish red; madder red; wine red; wine; carmine; amaranth; claret; fuchsia; magenta; heliotrope; mauve玫瑰紫红rose carmine; rose mauve深紫红prune; mulberry深藕红conch shell棕红henna暗红dark red; dull red鲜红scarlet red; scarlet; bright red; fresh red; blood red; madder; ruby; cerise; cherry血红blood red; incarnadine血牙红shell pink; peach beige绯红scarlet; crimson; geranium pink米红silver pink深红deep red; crimson淡红light red; carnation二.橙色类橙色orange三.黄色类黄色yellow桔黄orange; crocus; gamboge; cadmium orange深桔黄,深橙deep orange浅桔黄,浅橙clear orange; light orange; rattan柠檬黄lemon yellow lemon citrine citron玉米黄maize橄榄黄olive yellow樱草黄primrose yellow稻草黄straw yellow芥末黄mustard杏黄apricot; apricot buff; bronze yellow蛋黄vitelline; yolk yellow;egg yellow藤黄rattan yellow鳝鱼黄eel yellow象牙黄ivory日光黄sunny yellow石黄mineral yellow土黄earth yellow; yellowish brown; yellow ocher; golden apricot砂黄sand yellow金黄golden yellow, gold铁黄iron oxide yellow; iron buff镉黄cadmium yellow铬黄chrome yellow钴黄cobalt yellow深黄,暗黄deep yellow棕黄tan青黄bluish yellow灰黄isabel sallow grey yellow米黄apricot cream cream嫩黄yellow cream鲜黄cadmium yellow canary鹅黄light yellow中黄midium yellow浅黄light yellow;pale yellow;buff淡黄jasmin(e); primrose四.绿色类绿色green豆绿pea green bean green浅豆绿light bean green; asparagus green橄榄绿olive green olive茶绿tea green celandine green plantation葱绿onion green pale green苹果绿apple green原野绿field green森林绿forest green洋蓟绿artichoke green苔藓绿moss green bracken green草地绿,草绿grass green meadow green oliver green olive drab水草绿water grass green深草绿jungle green灰湖绿agate green水绿aqua green海水绿marine green酸性绿acid green水晶绿crystal green玉绿jade green石绿mineral green松石绿spearmint; viridis铜绿verdigris铜锈绿patina green镉绿cadmium green铬绿chrome green钴绿cobalt green孔雀绿peacock green威尼斯绿Venetian green巴黎绿Paris green king's green墨绿blackish green green black; jasper; dark green deep green墨玉绿emerald black深绿dark green petrol; Chinese green; bottle green 暗绿sap green dark green deep green青绿dark green碧绿azure green; turquoise green viridity翠绿emerald green; jade green bright green verdancy viridity深翠绿viridian蓝绿blue green aquamarine黄绿yellow green灰绿grey green sage green hedge green; mignonette; sea spray; celadon褐绿breen品绿light green malachite green鲜绿clear green; emerald green vivid green嫩绿pomona green verdancy中绿medium green; golf green浅绿light green淡绿pale green五.青色类青色cerulean blue blue green豆青pea green; bean green花青flower blue茶青tea green葱青onion green天青celeste; azure霁青sky-clearing blue石青mineral blue铁青electric blue river blue蟹青turquoise ink blue鳝鱼青eel green蛋青egg blue影青misty blue; white blue黛青bluish群青,伟青ultramarine暗青dark blue; deep cerulean藏青navy blue; dark blue; Ming blue靛青indigo大青smalt粉青light greenish blue鲜青clear cerulean浅青light blue; light cerulean淡青pale cerulean light greenish blue六.蓝色类蓝色blue天蓝sky blue; azure celeste; azure cerulean blue; Parisian blue蔚蓝azure; sky blue月光蓝moon blue海洋蓝ocean blue海蓝sea blue湖蓝acid blue深湖蓝vivid blue中湖蓝bright blue浅湖蓝canal blue清水蓝water blue冰雪蓝ice-snow blue孔雀蓝peacock blue宝石蓝sapphire; jewelry粉末蓝powder blue铁蓝iron blue钴蓝cobalt blue king's blue普鲁士蓝Prussian blue北京蓝Beijing blue士林蓝indanthrene blue品蓝reddish blue royal blue;king's blue靛蓝indigo; indigo blue; benzo blue菘蓝woaded blue石磨蓝stone-washed indigo藏蓝purplish blue; navy blue; navy海军蓝navy blue; navy宝蓝royal blue墨蓝blue black绿蓝turquoise blue紫蓝hyacinth;purplish blue浅紫蓝Dutch blue青蓝ultramarine深灰蓝blue ashes深蓝deep blue; dark blue navy blue mandarin blue Antwerp blue mazarine smalt ultramarine暗蓝deep blue; dark blue鲜蓝clear blue中蓝medium blue azure blue浅蓝light blue淡蓝pale blue baby blue calamine blue 七.紫色类紫色purple; violet紫罗兰色violet紫藤色lilac紫水晶色amethyst葡萄紫grape茄皮紫aubergine; wineberry玫瑰紫rose violet丁香紫lilac钴紫cobalt violet墨紫violet black绛紫dark reddish purple暗紫violet deep; dull purple; damson 乌紫raisin蓝紫royal light鲜紫violet light深紫amaranth; modena浅紫grey violet淡紫pale purple lavender; lilac; orchid 淡白紫violet ash青莲pale purple; heliotrope深青莲amaranth purple雪青lilac墨绛红purple black暗绛红purple deep浅绛红purple light八.黑色类黑色black土黑earth black煤黑coal black碳黑carbon black charcoal black古铜黑bronze black铁黑iron oxide black iron black橄榄黑olive black棕黑sepia; brown black青黑lividity深黑,漆黑pitch-black pitch-dark暗黑dull black九.白色类白色white象牙白ivory white; ivory牡蛎白oyster white珍珠白pear white gray lily玉石白jade white银白silver white铅白flake white; lead white; ceruse white 锌白zinc white锌钡白lithopone; pearl white羊毛白wool white米白off-white; shell乳白milky-white雪白snow-white; snowy white灰白greyish white; off-white青白bluish white纯白crisp-white;pure white本白raw white; off-white粉红白pinky white淡紫白lilac white十.灰色类灰色grey; gray银灰silver grey;chinchilla; gray mom铁灰iron grey铅灰lividity; leaden grey碳灰charcoal grey驼灰doe豆灰rose dust藕灰zephyr莲灰elderberry浅莲灰pale lilac鸽子灰dove grey鼠灰stale grey; mouse蟹灰storm blue天灰sky grey土灰dust grey水泥灰concrete grey烟灰smoky grey; ash雾灰misty grey黑灰grey black; charcoal grey紫灰purple grey;cadet;dove grey深紫灰heron淡紫灰lilac grey浅绿灰eucalyptus浅米灰moon light卡其灰khaki light蓝灰blue grey;slate;steel grey;pike grey青灰lividity; steel grey;balsam green白灰pale grey深灰dark grey; dull grey; Oxford grey暗灰deep grey中灰medium grey浅灰light grey;ash grey十一.棕色类棕色,褐色brown红棕umber;chili金棕auburn铁锈棕rustic brown桔棕orange brown橄榄棕olive brown十二.褐色类赤褐sorrel; maroon;terra cotta棕褐summer tan茶褐auburn umber黑褐black brown紫褐puce黄褐drab; fulvouos;cinnamon;ocher;tawny;russet brown 栗褐chestnut brown灰褐taupe;mouse;greige beige;rose beige浅灰褐putty橙褐orange brown土褐clay深褐dark brown;bistre;burnt sienna暗褐deep brown; fuscous;dun淡褐light brown;caramel十三.其它类咖啡色coffee酱色caramel;reddish brown紫酱色marron茶色umber;dun;dark brown赫色ocher;auburn;chocolate;sienna;umber;rust琥珀色amber;succinite栗色chestnut;sorrel;marron金色gold古金色old gold银色silver;argent铅色lividity锌色zinc铁锈色rust青古铜色bronze;bronzy黑古铜色dark bronze紫铜色purple bronze黄铜色brassiness木色wood土色lividity;sallow驼色camel;light tan米色beige; buff;cream;gray sand卡其色khaki奶油色cream豆沙色cameo浅豆沙色pale mauve藕荷色bisque肉桂色cinnamon肉色flesh , carnation;incarnadine;pastel peach; yellowish pink水晶色crystal荧光色iridescent彩虹色iris; rainbow。
几种鸡尾酒中英文对照配方

一些配方,以供大家参考.cre am sl ice 奶油片1oz. T riple Sec白橙皮酒1 oz.White Caca o白可可酒2 oz. Ora nge J uice橙汁2 o z. Mi lk or crea m全脂奶Blend with iceand s ervein an froz en dr ink g lass. Garn ish w ith g rated oran ge pe el.入果汁机搅打入杯,饰碎橙皮crea m sli ce 奶油片(Sp ecial forJoe’s Pub)1 oz. Ora nge V odka橙味伏特加1 oz. Tuac a意大利产甜味利口酒,柑橘味1 oz. Half andhalf酸甜混合物1/2 o z. Si mpleSyrup糖浆3oz. F reshOrang e Jui ce新鲜橙汁摇匀入加冰海波杯,饰橙片及肉桂粉S hakeall i ngred ients with iceand s train over iceintoa hig hball glas s. In stead of n aora nge s licetry a dust ing o f cin namon as t he ga rnish.CUBALIBRE自由古巴2 oz. Cuba n Rum古巴兰姆Coco Cola可口可乐Limewedge莱姆角入海波杯,上加冰镇可乐,挤入莱姆汁Pou r the rumoverice i n the high ballglass andfillwithcocacola. Sque eze i na l ime w edge.C UCUMB ER黄瓜1 oz. Gree n Men the绿薄荷1/2 oz.Brand y白兰地2 oz. Heav y Cre am浓乳摇后入冰镇鸡尾酒杯或马提尼杯,上加少量巧克力屑S hakeall i ngred ients with iceand s train into a ch illed cock tail/marti ni gl ass.Alit tle s haved choc olate woul d top this drin k nic ely.DA IQUIR I达其利ThisCuban Clas sic d erive s its name from thetownof th e sam e nam e. Th e rec ipe,named by a Nort h Ame rican engi neernamed Jenn ingsCox i n the late nine teent h cen tury, wasfurth er re fined by t he ta lente d bar men i n Hav ana.The o rigin al re cipecalle d for whit erum, sug ar an d lim e jui ce, b ut my favo riterecip e isfromthe F lorid ita B ar in Hava naca lledthe P apa D oble: Seethe H eming way D aiqui ri.来自古巴同名小镇.最初的配方需要白兰姆\糖及莱姆汁1 1/2 oz.Light Rum白兰姆1oz. S imple Syru p白糖浆3/4 o z. Fr esh L ime J uice新鲜莱姆汁摇后入小型鸡尾杯.(可参考海明威达其利)Shak e all ingr edien ts wi th ic e and stra in in to asmall cock tailglass.(See also Hemi ngway Daiq uiri)D ARK A ND ST ORMYI黑暗暴风雨2 o z. Go sling s orMyers Dark Rum小鹅或密叶斯深兰姆G inger Beer姜啤Li me we dge莱姆角Pou r the rumoverice i n the high ballglass andfillwithginge r bee r. Sq ueeze in a lime wedg e.兰姆入加冰海波杯,入姜啤,挤入莱姆汁D ARK A ND ST ORMYII黑暗暴风雨二1 oz.Myers Rum密叶斯深兰姆1 oz. Bac ardiSilve r百加地银兰姆2oz. G inger Beer姜啤2oz. F reshOrang e Jui ce新鲜橙汁2 o z. Pi neapp le Ju ice凤梨汁入加冰大型杯直调,饰以莱姆角Bui ld al l ing redie nts i n a l argeglass over iceand s tir.Garni sh wi th alimewedge.DERBY COCK TAIL德贝鸡尾酒2 1/2 oz.Beefe aterGin必发达金酒1/2 oz. Mar ie Br izard Peac h Liq ueur(桃味利口酒)(Or igina lly c alled forPeach Bitt ers)最初需要桃味苦酒Se veral Mint Leav es薄荷叶Half a fr esh P each新鲜桃一半把桃切片,加薄荷,桃味酒及金酒加冰摇后入小型马提尼杯,饰薄荷枝叶Mu ddletoget her p eachslice s, mi nt, a nd Pe ach L iqueu r. Ad d Gin andice.Shake allthe i ngred ients andstrai n int o a s mallmarti ni gl ass.Garni sh wi th asprig of m int DES ERT H EALER沙漠环保者(缘自Ve ndome俱乐部(好莱坞1930年))Fromthe V endom e Clu b (ho llywo od 1930)1 1/2oz. G in金酒1/2 o z. Ch erryHeeri ng樱桃酒(这是比较著名的商标1 1/2 oz. Fres h Ora nge J uice新鲜橙汁G inger Ale姜啤在海波杯中直调,上加姜啤至八分,饰橙皮及樱桃Build in a high ballglass over iceand f ill w ith G inger Ale. Garn ish w ith a nora nge p eel a nd acherr y.DEVI L SHO OTER恶魔子弹饮1 oz. Abso lut P eppar瑞典胡椒味伏特加1 oz.Yello w Cha rtreu se黄查特酒加冰直调入子弹杯Stir with iceand s train into shot glas s.DEVI L’S T ORCH恶魔火炬(缘自1800那个远古的饮料Fr om 1800 An d All That- Dri nks A ncien t and Mode rn, b y R.de Fl eury19371 1/2 oz. Vodk a伏特加1 1/2 oz F rench verm outh法产味美思3 das hes o f Gre nadin e三毫升石榴汁摇后入冰镇三角杯,饰柠檬扭条.注意:这是现在少见的伏特加配方.Shake with iceand s train into a ch illed cock tailglass. Gar nishwitha lem on pe el. N ote:Thisis on eof t he fe w ear ly vo dka r ecipe s.Tr y thi s mod ern t wiston th e Dev il’sTorch:DIXIE CUP饮料杯3/4 oz. Fres h Lem on Ju ice新鲜柠檬汁1/2 oz. Str awber ry Li queur草莓利口酒1/2oz. C uraca o橙皮酒1 1/2 Sout hernComfo rt南方安逸Mud dledfresh peac hes,if av ailab le桃切碎备用.加冰摇匀后入杯,饰橙皮Muddl e, sh ake a nd st rainintofrost ed Lo ndonDock, Oran ge Pe el Ga rnish.DIXIE WHIS KEY迪西威士忌(Fromthe V endom e Clu b, Ho llywo od 1930)(缘自Vend ome俱乐部,好莱坞1930年) 1 1/2 oz. Bou ron w hiske y波本威士忌1/2 oz.Orang e Cur acao橙皮酒1/4 oz. Whit e Cre me de Ment he白薄荷酒2 D ashes Ango stura Bitt ers两毫升安古斯图拉苦味酒3/4 o z. Le mon J uice柠檬汁液S hakewellwithice a nd st rainintoa mar tiniglass.摇后入马提尼杯D.O.M. C OCKTA IL修士鸡尾酒2oz. G in金酒1 oz. Fres h Ora nge J uice新鲜橙汁1/2 oz. Ben edict ine泵酒摇后入冰镇马提尼杯Shak e all ingr edien ts wi th ic e and stra in in to achill ed ma rtini glas s.drem a cid er (S hot f or fo ur) *苹果梦幻(子弹酒四份)1 o z. St olich nayaOhran j橙味伏特加1 o z. St olich nayaVanil香草味伏特加知名品牌1 oz. Coi ntrea u orTripl e Sec君度或白橙皮酒1oz. F reshOrang e Jui ce新鲜橙汁摇后入四个冰镇后的子弹杯Shake allingre dient s wit h ice andstrai n int o fou r chi lledshotglass es.dre ma ci der(A s a c ockta il) 苹果梦幻(子弹酒四份)*配方同上1 oz. Sto lichn aya O hranj3/4oz. S tolic hnaya Vani l3/4 oz.Coint reauor Tr ipleSec1 oz.Fresh Oran ge Ju ice摇后入冰镇马提尼杯,饰橙皮Sh ake a ll in gredi entswithice a nd st rainintoa chi lledmarti ni gl ass.Garni sh wi th aflame d ora nge p eel.DU BONNE T COC KTAIL杜本内1 1/2oz. R ed Du bonne t红色杜本内1 1/2 oz. Gin金酒Po ur Gi n and Dubo nnettoget her o ver i ce in an o ld fa shion ed gl ass.Garni sh wi thle mon p eel.杜本内与金酒一起入古典杯,饰柠檬皮DUBLI NER*都柏林1oz. I rishWhisk ey爱尔兰威士忌酒1 oz. Iris h Mis t Liq ueur爱尔兰之雾利口酒(爱尔兰威士忌为基,加蜂蜜及药草。
UV印刷油墨简介及配方 UCB 中文

12% 2%
2003
胶印 柔性版
凹印 凸版 丝网印刷
其他 罩光清漆
辐射固化的市场份额 (欧洲)
2000
1800
1600
1400
1200
1000
800
600
400 5%
3%
200
0
传统油墨 UV油墨
ห้องสมุดไป่ตู้0%
67%
38%
21%
59%
增长率 (欧洲) : 1998 - 2003
胶印 柔性版
凹印 凸版 丝网印刷
Objects Plastic cups
Paper and plastics
Brochures, leaflets Forms Posters
Sheetfed offset x x
x x
Web offset
x
Letterpress Waterless and
dry offset PACKAGING
x
有机颜料: “与传统型没有区别”
主要的颜料:
黄
橙
暖红 PR53:1 品红(rubine) 青
反射兰 PB61:1 绿 黑
PY12, PY13 PO34
PR57:1 PB15:3
PG7 PB7
选择颜料时的考虑因素
色相好 耐溶剂性好 着色力 颜料硬度高
颜色的原理
Quadrichromy (4 colors)
研究油墨配方的流动特性. 与油墨中的气泡的消除有关
触变性
胶印 原理和配方
胶印原理
Ink duct
Ink duct Ink train
plate Blanket
Fount duct
鸡尾酒配方大全

鸡尾酒配方大全金汤力(GinTonic)晶莹剔透的杯体中,冰块悬浮在酒中,气泡包围着柠檬薄片,感觉清凉而又爽口。
配料:金酒1/4,汤力水3/4(此乃比例)容器:高波杯饰物:柠檬片调配方法:将金酒倒入高波杯中,在杯中加入冰块,用汤力水注满,最后在杯中加入柠檬薄片进行装饰。
梦幻勒曼湖(FantasticLeman)这款经典的鸡尾酒,它是以瑞士的梦幻之湖“勒曼湖”为主题所调制而成的鸡尾酒。
它曾在各种鸡尾酒大赛中获得过很多优胜,也曾获得世界鸡尾酒表演会的银牌。
杯中呈现蓝色浓淡层次,让人觉得宁静而高雅。
配料:清酒3/10,樱桃酒1/20,柠檬汁1/20,汤力水4/10,蓝色柑香酒微量,白色柑香酒1/5容器:高脚玻璃杯调配方法:将清酒、冰块、白色柑香酒、樱桃酒与柠檬汁倒入调酒壶中,摇荡后倒入杯中,加满汤力水,再将蓝色柑香酒慢慢沿杯边倒入杯底。
新加坡司令(SingaporeSling)口感清爽的金酒配上热情的樱桃白兰地,喝起来口味更加舒畅。
夏日午后,这种酒能使人疲劳顿消。
配料:金酒1/9,柠檬汁1/6,砂糖或糖浆2匙,樱桃白兰地1/18,苏打水2/3容器:平底杯饰物:红樱桃、柳橙各一调配方法:将金酒、柠檬汁、砂糖或糖浆和冰块倒入调酒壶内,搅匀后倒入杯中;加入冰块,并将苏打水注满,最后在杯中沿杯边注入樱桃白兰地,在杯边用红樱桃和柳橙进行装饰。
金马颈(Horse’sNeck)“马颈”并不是单一的鸡尾酒,它特指屈臣氏干姜水、柠檬皮共同组成的饮品。
金马颈选择使用高杯与细长的柠檬片作装饰,使得整体的造型显得修长而别致。
微甜的口感加上柠檬皮的清香味道,让人感觉有点鲜美,是适合女性的美容佳品。
配料:金酒1/4,干姜水3/4 容器:高杯饰物:柠檬皮调配方法:将柠檬皮削成1.5cm的螺旋状,将金酒倒入高杯中,将削好的柠檬皮垂直地放入高杯中,并将柠檬皮挂在杯口,加入冰块后,用屈臣氏干姜水注满即可。
秀兰邓波儿鸡尾酒酒名的取法有很多流派,有采用人名的,如汤姆柯林斯;采用地名的,如佛罗里达,新加坡司令,上海等;还有采用乐曲的,如探戈,桑巴,华尔兹,查尔斯登等。
寿司的制作方法(中文)

寿司的制作方法
■准备工作
■寿司饭的制作方法
■握寿司的制作方法
■卷寿司的制作方法
■准备工作
●必要的道具
●食材
寿司飯(Sushimeshi)…米饭和寿司醋的混合物。
ネタ(Neta)…寿司饭上面放的各种鱼肉或者野菜类等。
■寿司飯制作方法
●必要的材料
※寿司醋的配比,每个店都不一样,我们根据通常的数量来计算
米…二升(3000g)
水(矿泉水)…3000cc
醋(米醋)…360cc
砂糖…160g
塩…100g
●做法
・洗米…小心地用水洗米。
如果用力过大会把米弄碎,因此水要小心地淘,总共要换三次水。
(绝对不要用热水或者洗涤剂)
・浸漬…蒸饭之前大约把米泡水半个小时到一小时左右。
・炊飯…蒸米饭。
米饭蒸好之前请把寿司醋调配好放置备用。
・焖饭…饭蒸好之后,熄火闷15分钟。
・拌醋…把饭打开,放在饭台上、把调好的醋撒在饭上。
然后用木勺把饭拌匀,使醋完全包裹着米饭,、(尽量不要把米饭打碎)。
这时候,一边用扇子扇,一边让醋味伴随着多余的水分一起挥发。
・转移到饭桶…为了把寿司饭保持人体温度、把饭转移到饭桶或者保温瓶里。
■握寿司的做饭
■巻き寿司の作り方。
杏仁瓦片饼干中英文配方表

航空公司Airline配方编号Recipe number 配方使用日期Starting date 配方名称Recipe name Almond Tile Cookies 类型Category COOKIES 总量Yield20 PCS配方制作ItemRemarkQtyUnit原料名称原料名称备注重量单位糖SUGAR90GM 低筋粉FLOUR CAKE 15GM 黄油BUTTER35GM 橙子茸ORANGE ZEST GRATED2GM 杏仁片ALMOND SLICE100GM操作方法(Intructions):批准人批准日期Approved by:Approved date:培训地点Training Kitchen:被培训制作人员签名Cook Name / Sign:被培训制作人员签名Cook Name / Sign:厨师长名字/签名Chef Name / Sign:培训人员Executive trainer:培训日期Training Date:一个防水密封的容器里,并放入干燥剂。
万一饼干变软,可以在烤一下然后冷却。
In case of the coolies would become soft, it is possible to cook again and let them cool down.1)蛋白、糖、面粉、融化的黄油混合搅拌,不要搅拌太长时间避免空气渗入2)加入橙子茸碎和然杏仁片用勺子或是塑料刮片搅拌均匀3)用保鲜膜包住放入冰箱10到12小时。
4)把烤纸放在烤盘上,用叉子弄一点混合物。
然后弄在烤纸上做好形状。
然后烤制成金黄色,迅速从烤纸上取下来放在一个圆柱形上面定型。
大小如冰激凌球一样,。
一定要注意的是保证杏仁瓦片饼干燥。
需要放在3) Cover with plastic wrap and keep in the fridge for about 10 to 12 hours.4) Place a baking paper onto a baking tray and use a fork to put a small quantity of almond mixture.Press the almond mixture to get the right shape and size(+/-). Immediately after bake to the nice golden color, remove the almond tile cookies and place onto a round shape roll diameter according with the ice cream scoop size. Pay attention to keep the almond cookies very dry. Need to use a special thight (or waterproof) container with air dryer to keep the cookies crispy.20片air in the mixture.2) Add in the orange zest and almond and mix wel with a spoon or plastic spatula.杏仁瓦片饼干。
勇者斗恶龙8中文合成文档(炼金配方)附带道具出处

剑l 隼剑改【攻55附:二次攻击】合成:隼剑(赌场2)+星降手镯(合成)l 圣银刺剑【攻54】合成:教会剑(诅咒王城-宝)+驱魔圣印(合成)l 僵尸驱散【攻65附:对不死系1.5倍伤害】合成:僵尸杀手(王子城买)+驱魔圣印(合成)l 诸刃之剑改【攻76】合成:诸刃之剑(金币女王城-宝)+×2圣者的灰(宝、龙村买)l 屠龙剑【攻83附:对龙系1.5倍伤害】合成:龙族杀手(三角谷买)+豪杰手镯(合成)l 奇迹之剑改【攻95】合成:奇迹之剑(小金币68枚)+生命腕轮(合成)l 光剑【攻110】合成:规则之杖(赌场1)+轻盾(兄妹镇买)+光之裙(合成)l 爆裂金属剑【攻118】合成:古剑(诅咒王城-宝)+史莱姆王冠(小山旅店井中、史莱姆王掉)+奥利哈根(小金币83枚、宝)l 堕天使刺剑(二周目)【攻61】合成:圣银刺剑+恶魔尾巴(龙村买)+蝙蝠羽(魔族掉)l 龙神王剑(二周目)【攻137】合成:龙神剑(龙神)+爆裂金属剑(合成)枪l 沙尘之枪【攻67附:一定机率使敌人命中下降】合成:游骑兵枪(王子城买)+圣者的灰(宝、龙村买)l 恶魔之枪(二周目)【攻86附:一定机率使敌人即死】合成:战枪(王子城-剧情)+毒针(兄妹镇买)+恶魔尾巴(龙村买)镖l 强力回旋镖【攻32】合成:回旋镖(最初城镇买)+铁钉(机械族掉)l 炎之回旋镖【攻63】合成:双重进攻(黑狗村买)+炎之盾(神鸟村买)l 金属之翼【攻70附:对金属系特效】合成:飞刃(王子城买)+金属王之枪(龙村-宝)斧l 金斧【攻27】合成:铁斧(盗贼村买)+金块(小金币52、宝)l 山贼斧【攻55】合成:盗贼钥匙(合成)+战斧(王子城买)l 月之斧【攻60】合成:金斧(合成)+月之祝福(合成)锤l 战斗锤改【攻69】合成:战斗锤(王子城买)+豪杰手镯(合成)l 百万吨大锤【攻108】合成:战斗锤改(合成)+霸王之斧(史莱姆山-宝)+奥利哈根(金币83、宝)弓l 厄洛斯之弓【攻45】合成:十字弓(盗贼村买)+吊带(女盗贼家、诅咒王城-宝)l 海伦之弓【攻63附:战斗中使用为全员回复30】合成:厄洛斯之弓(合成)+力之盾(三角谷买、盗贼村-宝)l 奥丁之弓【攻125】合成:厄洛斯之弓(合成)+海伦之弓(合成)+巨弓(三角谷买)鞭l 蛇皮鞭【攻23】合成:皮鞭(宝)+鳞盾(杰西卡村买)l 龙尾鞭【攻47】合成:蛇皮鞭(合成)+×2龙鳞(龙族掉)l 暴风鞭【攻99】合成:恶魔鞭(神鸟巢-宝)+圣者的灰(宝、龙村买)杖l 熔岩杖【攻28附:战斗中使用敌全体伤害30左右】合成:魔导士之杖(初遇帅哥的酒场买)+爆弹岩碎片(黑狗村买)l 魔封杖【攻35附:战斗中使用敌一组真空攻击伤害40左右】合成:魔导士之杖(初遇帅哥的酒场买)+规则之杖(赌场1)匕首l 暗杀匕首【攻:37附:一定几率使敌人即死】合成:鹰之匕首(大圣堂买)+毒针(兄妹镇买)l 小恶魔刀(二周目)【攻:52附:吸取】合成:暗杀匕首(合成)+恶魔尾巴(龙村买).衣服l 光之裙【防67附:把受到的咒文反弹给使用者】合成:金腕轮(王子城买)+闪亮裙(赌场2)+守护宝石(王子城买)l 毛皮披肩【防29附:火焰和吹雪的伤害减少20点】合成:×2兽皮(兽系掉)l 舒适袍【防34附:在睡眠、麻痹状态下受到的伤害减少】合成:闪躲服(商人帐篷买)+短裤(合成)l 短裤【防8】合成:盗贼蓑衣(最初镇买)+头带(船场买)l 兔女郎服【防38】合成:丝绸紧身衣(王子城)+兔耳朵(王子城买)l 僵尸铠【防42附:诅咒装备】合成:银铠甲(大圣堂买)+僵尸杀手剑(王子城)l 魔术裙【防55附:咒文的伤害减少2/3】合成:魔术帽(城镇买)+魔术杖(神鸟村买)+盗贼蓑衣(最初镇买)l 贤者袍【防55附:咒文的伤害减少25】合成:魔法法衣(王子城买)+智力帽(合成)l 时机铠甲【防57附:对物理攻击回避率提高】合成:银铠甲(大圣堂)+舞者之服(盗贼村买)l 锋刃铠【主角、防68附:反弹物理攻击伤害1/4】合成:魔法铠(王子)+锋利回旋镖(伤心国王城)l 白金铠【主角、防72附:咒文伤害减少15点】合成:僵尸铠(合成)+圣者的灰(宝、龙村买)l 天使袍【、防73附:对即死系咒文抵抗力加强】合成:水之羽衣(三角谷买)+魔术裙(合成)l 红莲袍【、防82附:吹雪伤害减少20】合成:贤者袍(合成)+魔法圣水(三角谷买、赌场1)+诺克草(杀死黑狗以后找婆婆的儿子要)l暗之披风(二周目)【防87附:物攻回避率提高】合成:闪躲服(商人帐篷买)+蝙蝠羽(恶魔族掉)+恶魔尾巴(龙村买)l 公主袍【防94附:攻击咒文的伤害减少30】合成:天使袍(合)+金色三叉戟(大圣堂买)+光之裙(合成)l 神秘紧身衣【防105附:换装装备,对物理攻击回避率提高】合成:危险紧身衣(小金币99枚、天之祭坛-宝)+光之裙(合成)l 金属王铠【我方全员防120】合成:爆裂金属铠(赌场2)+史莱姆王冠(小山旅店井中、史莱姆王掉)+奥利哈根(金币83、宝)头戴l 羽帽【我方全员防9】合成:皮帽(最初城镇买)+奇美拉之翼(最初城镇买)l 兔尾发夹【防9】合成:兔尾巴(王子城买)+发夹(船场买)l 石帽【防15】合成:石斧(杰西卡村买)+尖角帽(船场买)l 青铜帽【主角、防20】合成:石帽(合成)+×2青铜刀(船场买)l 疾风头带【主角防23附:速度+15】合成:头带(船场买)+快速戒指(赌场1)l 风之帽【我方全员防20附:当道具使用为咒文的效果】合成:羽帽(合成)+疾风头带(合成)l 智力帽【、防33附:智力+10】合成:魔术帽(黑狗村买)+智力眼镜(王子城买)l猛牛头盔【主角、防42】合成:秘银帽(神鸟村买)+牛粪(宝)+美味牛奶(王子城买)l 黄金冠【防43附:对咒文的防御力加强】合成:知力头盔(三角谷买)+银发饰(王子城买)+金块(小金币52枚、宝)l 幻影面具(二周目)【防48附:对物理攻击回避率提高】合成:铁钉帽(雪原村买)+暗之披风(合成)l 太阳王冠【主角、防52附:对催眠、麻痹攻击免疫】合成:骷髅头盔(天之祭坛、神鸟村南-宝)+圣者的灰(宝、龙村买)盾l 白盾【、防24附:火焰的伤害减少10】合成:铁盾(山贼村买)+银盘(赌场1)l 圣女盾【防46附:火焰和吹雪的伤害减少2/3】合成:镜盾(三角谷买)+白盾(合成)+圣水(杰西卡村买)l 水镜盾【主角、、防48附:火焰攻击伤害减少20】合成:镜盾(三角谷买)+魔法圣水(三角谷买、赌场1)+阿莫鲁水(合成)l 女神盾(二周目)【、防55附:火焰和吹雪咒文伤害减半】合成:死神盾(龙村洞窟-宝)+圣者的灰(宝、龙村买)l 金属王之盾【我方全员防65附:火焰和吹雪咒文伤害减少30】合成:破灭盾(暗之遗迹高地-宝)+圣者的灰(宝、龙村买)+奥利哈根(小金币83枚、宝)装饰品l 星降手镯【速度+50】小金币60枚或合成:快速戒指×2(赌场1)+奥利哈根(小金币83枚、宝)l 驱魔圣印【防+10附:对即死咒文的抵抗力加强】合成:怒刺青(王子城买)+圣水(杰茜卡村买)+金色三叉戟(大圣堂买)l 生命的腕轮【防+5附:最大增加30】合成:生命戒指(合成)+金腕轮(王子城买)l 豪杰手镯【攻+15】合成:力量戒指(合成)+能量腰带(赌场1)l 力量戒指【攻+5】合成:祈祷指轮(王子城买、赌场1)+力之种(宝)l 术士戒指【智力+10】合成:骷髅戒指(王子城买)+×2圣者的灰(宝、龙村买)l 女神戒指【智力+20附:步行回复】合成:生命戒指(合成)+奥利哈根(金币83、宝)l 幸福鞋【附:步行增加】合成:丝袜(小金币28枚、怪物图鉴165)+幸福帽(暗之商人用沙尘之枪交换)l 生命戒指【防+15附:步行回复】合成:祈祷指轮(王子城买、赌场1)+生命之种(宝)l 破幻戒指【防+10附:对降低命中率的幻觉攻击的抵抗力加强】合成:金戒指(王子城买)+沙尘之枪(合成)l 破毒戒指【防+10附:对毒、猛毒攻击的抵抗力加强】合成:金戒指(王子城买)+毒针(兄妹镇买)l 满月戒指【防+10附:对麻痹攻击的抵抗力加强】合成:金戒指(王子城买)+毒蛾刀(山贼村买)l 觉醒戒指【防+10附:对催眠攻击的抵抗力加强】合成:金戒指(王子城买)+混沌剑(商人帐篷买)l 理性戒指(二周目)【防+10附:对混乱攻击的抵抗力加强】合成:金戒指(王子城买)+堕天使刺剑(合成)l 超级戒指【防+15附:对催眠、麻痹、混乱攻击的抵抗力加强】合成:满月戒指(合成)+破幻戒指(合成)+破毒戒指药品l 上等药草【我方单体50多恢复】合成:×2药草(道具店买)l 特等药草【我方单体90多恢复】合成:×2上等药草(合成)l 治愈草【我方单体70多恢复】合成:上等药草(合成)+药草(道具店买)l 上等解毒草【我方单体解毒且30多恢复】合成:药草(道具店买)+解毒草(道具店买)l 特等解毒草【我方单体解毒且60多恢复】合成1:×2上等解毒草(合成)合成2:药草(道具店买)+解毒草2(道具店买)l舒适草【我方单体解麻痹且60多恢复】合成:上等药草(合成)+满月草(悲伤国王城买)l 月之祝福【我方单体解麻痹且110多恢复】合成:×3满月草(悲伤国王城买)l阿莫鲁水【我方单体60多恢复】合成:圣水(杰西卡村买)+上等药草(合成)l 万能药【我方全员完全恢复且毒、猛毒、麻痹状态恢复】合成:×2特等药草(合成)l 超万能药【我方全员完全恢复且状态恢复正常】合成1:×3特等药草(合成)合成2:万能药(合)+治愈草(合)+-舒适草(合)l 世界树之露【我方全员完全恢复】合成:世界树之叶(王子城买)+魔法圣水(三角谷买、赌场1)l 妖精饮药【我方单体完全恢复】合成:世界树之露(合成)+魔法圣水(三角谷买、赌场1)l 不思议手鼓合成:太阳王冠(合成)+兽皮(诅咒王城2-宝、兽族掉)+怒刺青(王子城买)灰色字符底纹为初期简易合成物品(PS:前期可以通过合成药品出售刷金币)。
几种鸡尾酒中英文对照配方

CUCUMBER黄瓜
1 oz. Green Menthe绿薄荷
1/2 oz. Brandy白兰地
2 oz. Heavy Cream浓乳
摇后入冰镇鸡尾酒杯或马提尼杯,上加少量巧克力屑
Shake all ingredients with ice and strain into a chilled cocktail/martini glass. A little shaved chocolate would top this drink nicely.
1 1/2 oz. Vodka伏特加
1 1/2 oz French vermouth法产味美思
3 dashes of Grenadine三毫升石榴汁
摇后入冰镇三角杯,饰柠檬扭条.注意:这是现在少见的伏特加配方.
Shake with ice and strain into a chilled cocktail glass. Garnish with a lemon peel.
cream slice 奶油片
(Special for Joe’s Pub)
1 oz. Orange Vodka橙味伏特加
1 oz. Tuaca意大利产甜味利口酒,柑橘味
1 oz. Half and half酸甜混合物
1/2 oz. Simple Syrup糖浆
3 oz. Fresh Orange Juice新鲜橙汁
2 Dashes Angostura Bitters两毫升安古斯图拉苦味酒
3/4 oz. Lemon Juice柠檬汁液
Shake well with ice and strain into a martini glass.摇后入马提尼杯
PANTONE专色色彩配方指南中英文对照
PANTONE 专色色彩配方指南中英文对照14个基本色《52.1》C=CoatedU=UncoatedPANTONECoolGrayBase=潘通冷灰基油《52.3》PantoneProcessColorSystem?潘通四色叠印色彩系统四色潘通四色叠印色彩系统提供一组共有3,000多种叠印色彩的丰富色版。
无论是选择、确定、复制和控制叠印色彩,同样能提供与实色的潘通配色系统?(PANTONEMATCHINGSYSTEM?)相同程度的精确度和可信度。
1. 4CPt(s)=份量∷=可以CMYK叠印模拟∴=可以RGB模拟颜色大全(中英对照)一.红色类红色red朱红vermeil;vermilion;ponceau粉红pink;softred;rosebloom梅红plum;crimson;fuchsiared玫瑰红rosemadder;rose桃红peachblossom;peach;carminerose樱桃红cherry;cerise桔红reddishorange;tangerine;jacinth;salmonpink;salmon 石榴红garnet枣红purplishred;jujubered;datered莲红lotusred浅莲红fuchsiapink豉豆红beanred辣椒红capsicumred高粱红Kaoliangred芙蓉红hibiscusred;poppyred;poppy胭脂红rogueredcarmine;cochineal;lake鲑鱼红salmon玳瑁红hawksbillturtlered海螺红cadmiumorange宝石红rubyred玛瑙红agatered珊瑚红coral金红bronzered铁红ironoxidered铁锈红rustred镉红cadmiumred铬红chromered砖红brickred土红laterite;reddle郎窑红lang-kilnred均红Jun-kilnred釉底红underglazered威尼斯红Venetianred法国红Frenchvermilion茜红alizarinred;madderred洋红carmine;magenta品红pinkishred;magenta猩红scarletred;scarlet;bloodred油红oilred紫红purplishred;madderred;winered;wine;carmine; amaranth;claret;fuchsia;magenta;heliotrope;mauve玫瑰紫红rosecarmine;rosemauve深紫红prune;mulberry深藕红conchshell棕红henna暗红darkred;dullred鲜红scarletred;scarlet;brightred;freshred;bloodred; madder;ruby;cerise;cherry血红bloodred;incarnadine血牙红shellpink;peachbeige绯红scarlet;crimson;geraniumpink米红silverpink深红deepred;crimson淡红lightred;carnation二.橙色类橙色orange三.黄色类黄色yellow桔黄orange;crocus;gamboge;cadmiumorange深桔黄,深橙deeporange浅桔黄,浅橙clearorange;lightorange;rattan柠檬黄lemonyellowlemoncitrinecitron玉米黄maize橄榄黄oliveyellow樱草黄primroseyellow稻草黄strawyellow芥末黄mustard杏黄apricot;apricotbuff;bronzeyellow蛋黄vitelline;yolkyellow;eggyellow藤黄rattanyellow鳝鱼黄eelyellow象牙黄ivory日光黄sunnyyellow石黄mineralyellow土黄earthyellow;yellowishbrown;yellowocher;golden apricot砂黄sandyellow金黄goldenyellow,gold铁黄ironoxideyellow;ironbuff镉黄cadmiumyellow铬黄chromeyellow钴黄cobaltyellow深黄,暗黄deepyellow棕黄tan青黄bluishyellow灰黄isabelsallowgreyyellow米黄apricotcreamcream嫩黄yellowcream鲜黄cadmiumyellowcanary鹅黄lightyellow中黄midiumyellow浅黄lightyellow;paleyellow;buff淡黄jasmin(e);primrose四.绿色类绿色green豆绿peagreenbeangreen浅豆绿lightbeangreen;asparagusgreen橄榄绿olivegreenolive茶绿teagreencelandinegreenplantation葱绿oniongreenpalegreen苹果绿applegreen原野绿fieldgreen森林绿forestgreen洋蓟绿artichokegreen苔藓绿mossgreenbrackengreen草地绿,草绿grassgreenmeadowgreenolivergreen olivedrab水草绿watergrassgreen深草绿junglegreen灰湖绿agategreen水绿aquagreen海水绿marinegreen酸性绿acidgreen水晶绿crystalgreen玉绿jadegreen石绿mineralgreen松石绿spearmint;viridis铜绿verdigris铜锈绿patinagreen镉绿cadmiumgreen铬绿chromegreen钴绿cobaltgreen孔雀绿peacockgreen威尼斯绿Venetiangreen巴黎绿Parisgreenking'sgreen墨绿blackishgreengreenblack;jasper;darkgreen deepgreen墨玉绿emeraldblack深绿darkgreenpetrol;Chinesegreen;bottlegreen 暗绿sapgreendarkgreendeepgreen青绿darkgreen碧绿azuregreen;turquoisegreenviridity翠绿emeraldgreen;jadegreenbrightgreenverdancy viridity深翠绿viridian蓝绿bluegreenaquamarine黄绿yellowgreen灰绿greygreensagegreenhedgegreen;mignonette; seaspray;celadon褐绿breen品绿lightgreenmalachitegreen鲜绿cleargreen;emeraldgreenvividgreen嫩绿pomonagreenverdancy中绿mediumgreen;golfgreen浅绿lightgreen淡绿palegreen五.青色类青色ceruleanbluebluegreen豆青peagreen;beangreen花青flowerblue茶青teagreen葱青oniongreen天青celeste;azure霁青sky-clearingblue石青mineralblue铁青electricblueriverblue蟹青turquoiseinkblue鳝鱼青eelgreen蛋青eggblue影青mistyblue;whiteblue黛青bluish群青,伟青ultramarine暗青darkblue;deepcerulean藏青navyblue;darkblue;Mingblue靛青indigo大青smalt粉青lightgreenishblue鲜青clearcerulean浅青lightblue;lightcerulean淡青paleceruleanlightgreenishblue六.蓝色类蓝色blue天蓝skyblue;azureceleste;azureceruleanblue; Parisianblue蔚蓝azure;skyblue月光蓝moonblue海洋蓝oceanblue海蓝seablue湖蓝acidblue深湖蓝vividblue中湖蓝brightblue浅湖蓝canalblue清水蓝waterblue冰雪蓝ice-snowblue孔雀蓝peacockblue宝石蓝sapphire;jewelry粉末蓝powderblue铁蓝ironblue钴蓝cobaltblueking'sblue普鲁士蓝Prussianblue北京蓝Beijingblue士林蓝indanthreneblue品蓝reddishblueroyalblue;king'sblue靛蓝indigo;indigoblue;benzoblue菘蓝woadedblue石磨蓝stone-washedindigo藏蓝purplishblue;navyblue;navy海军蓝navyblue;navy宝蓝royalblue墨蓝blueblack绿蓝turquoiseblue紫蓝hyacinth;purplishblue浅紫蓝Dutchblue青蓝ultramarine深灰蓝blueashes深蓝deepblue;darkbluenavybluemandarinblue Antwerpbluemazarinesmaltultramarine暗蓝deepblue;darkblue鲜蓝clearblue中蓝mediumblueazureblue浅蓝lightblue淡蓝palebluebabybluecalamineblue七.紫色类紫色purple;violet紫罗兰色violet紫藤色lilac紫水晶色amethyst葡萄紫grape茄皮紫aubergine;wineberry玫瑰紫roseviolet丁香紫lilac钴紫cobaltviolet墨紫violetblack绛紫darkreddishpurple暗紫violetdeep;dullpurple;damson乌紫raisin蓝紫royallight鲜紫violetlight深紫amaranth;modena浅紫greyviolet淡紫palepurplelavender;lilac;orchid淡白紫violetash青莲palepurple;heliotrope深青莲amaranthpurple雪青lilac墨绛红purpleblack暗绛红purpledeep浅绛红purplelight八.黑色类黑色black土黑earthblack煤黑coalblack碳黑carbonblackcharcoalblack古铜黑bronzeblack铁黑ironoxideblackironblack橄榄黑oliveblack棕黑sepia;brownblack青黑lividity深黑,漆黑pitch-blackpitch-dark暗黑dullblack九.白色类白色white象牙白ivorywhite;ivory牡蛎白oysterwhite珍珠白pearwhitegraylily玉石白jadewhite银白silverwhite铅白flakewhite;leadwhite;cerusewhite 锌白zincwhite锌钡白lithopone;pearlwhite羊毛白woolwhite米白off-white;shell乳白milky-white雪白snow-white;snowywhite灰白greyishwhite;off-white青白bluishwhite纯白crisp-white;purewhite本白rawwhite;off-white粉红白pinkywhite淡紫白lilacwhite十.灰色类灰色grey;gray银灰silvergrey;chinchilla;graymom铁灰irongrey铅灰lividity;leadengrey碳灰charcoalgrey驼灰doe豆灰rosedust藕灰zephyr莲灰elderberry浅莲灰palelilac鸽子灰dovegrey鼠灰stalegrey;mouse蟹灰stormblue天灰skygrey土灰dustgrey水泥灰concretegrey烟灰smokygrey;ash雾灰mistygrey黑灰greyblack;charcoalgrey紫灰purplegrey;cadet;dovegrey深紫灰heron淡紫灰lilacgrey浅绿灰eucalyptus浅米灰moonlight卡其灰khakilight蓝灰bluegrey;slate;steelgrey;pikegrey青灰lividity;steelgrey;balsamgreen白灰palegrey深灰darkgrey;dullgrey;Oxfordgrey暗灰deepgrey中灰mediumgrey浅灰lightgrey;ashgrey十一.棕色类棕色,褐色brown红棕umber;chili金棕auburn铁锈棕rusticbrown桔棕orangebrown橄榄棕olivebrown十二.褐色类赤褐sorrel;maroon;terracotta棕褐summertan茶褐auburnumber黑褐blackbrown紫褐puce黄褐drab;fulvouos;cinnamon;ocher;tawny;russetbrown 栗褐chestnutbrown灰褐taupe;mouse;greigebeige;rosebeige浅灰褐putty橙褐orangebrown土褐clay深褐darkbrown;bistre;burntsienna暗褐deepbrown;fuscous;dun淡褐lightbrown;caramel十三.其它类咖啡色coffee酱色caramel;reddishbrown紫酱色marron茶色umber;dun;darkbrown赫色ocher;auburn;chocolate;sienna;umber;rust 琥珀色amber;succinite栗色chestnut;sorrel;marron金色gold古金色oldgold银色silver;argent铅色lividity锌色zinc铁锈色rust青古铜色bronze;bronzy黑古铜色darkbronze紫铜色purplebronze黄铜色brassiness木色wood土色lividity;sallow驼色camel;lighttan米色beige;buff;cream;graysand卡其色khaki奶油色cream豆沙色cameo浅豆沙色palemauve藕荷色bisque肉桂色cinnamon肉色flesh,carnation;incarnadine;pastelpeach; yellowishpink水晶色crystal荧光色iridescent彩虹色iris;rainbow。
八大国家绝密、机密、保密配方的中药配方药剂

八大国家绝密、机密、保密配方的中药配方药剂中医药方济汗牛充栋,具体来说,我们有一万多种中药材,四千多种中药制剂,但列为永久和长期的“国家绝密”、“国家机密”、“国家保密”配方的只有八种这八种药待遇很特殊,说明书不用完整表明其具体成分,是货真价实的国家级“秘方”。
一、“曲焕章百宝丹”:云南白药级别:国家绝密云南民间医生曲焕章于清光绪二十八年(1902)研制成功,原名叫“曲焕章八宝单”。
问世百年以来,因神奇的功效被尊称为“伤科圣药”,闻名海内外。
自云南白药诞生以来,其配方和制法从不外传,1955年曲焕章的妻子缪兰瑛将配方献给国家,后期国家卫生部作为绝密进行保存,随着时代的发展,云南白药走进了更多人的视野,为众多患者送去了健康。
现在云南白药产品众多,有云南白药粉、云南白药膏、白药气雾剂等,核心产品为云南白药粉,其具有化瘀止血、活血止痛、解毒消肿之功效,临床上主要用来治疗跌打损伤、枪伤刀伤、疮毒肿痛、胃痛和痛经等,但是很多人都不曾注意红色的保险子。
千万不要丢弃,这正是精华所在。
特拥有以下作用:云南白药“保险子”,民间俗称“救命丹”。
云南白药驰名中外,由数种名贵药材制成,具有化瘀止血、活血止痛、解毒消肿之功效,临床上主要用来治疗跌打损伤、枪伤刀伤、疮毒肿痛、胃痛及痛经等。
但是用过此药的人肯定都曾注意到,打开云南白药的瓶盖,会发现有一个保济丸大小的红色颗粒“躺”在盖里,这就是保险子,俗称救命丹。
保险子虽小,但它可比里面的药粉更值钱。
保险子为救急所用,因为药性比较强烈,通常用于严重跌打损伤或内伤出血,平时并不建议吃,轻伤或其他病症不必服,有的甚至不能服。
保险子一般口服1粒,用温水或黄酒送服1粒。
再在医生指导下依病情、病程考虑是否需连续服用。
外敷主要用于外伤,用白酒将保险子适量化开,对于跌打严重的瘀血有很好的活血化瘀作用。
具体用法是涂在瘀血的部位,同时又有极好的镇痛作用。
二、热毒肿痛良药:片仔癀级别:国家绝密由漳州片仔癀药业股份有限公司独家生产,其传奇的历史被世人所传颂。
鸡尾酒配方(中英文对照)

鸡尾酒配方(中英文对照)103、草莓思威 Strawberry Swing将Gin、Strawberry利口酒、Lemon和Gin 45ml~ Strawberry 1粒~ ice and柳橙利口酒混合后倒入有冰块Strawberry利口酒2匙~Lemon juice1匙~的杯中~饰以Strawberry作点缀。
柳橙苦酒1/6,1/3匙。
104、探戈 Tango 将Gin、France Vermouts、Italy Gin 2/5 jigger~Vermouts、柳橙柑桔酒和柳丁汁混合后France Vermouts1/5 jigger~倒入杯中即可。
Italy Vermouts1/5 jigger~柳橙柑桔酒1/5 jigger~柳丁汁1/3匙。
105、狗鼻Dog’s Nose 将Gin注入杯中~再加上cold Beer轻Gin 45ml~轻搅拌后~即可饮用。
Cold Beer, <Gin 的2~3倍>。
106、汤姆柯林兹 Tom Collins 将Gin、Lemon juice、砂糖混合后倒入Gin 60ml~杯中~加入冰块~再加满Soda Water~Lemon juice 20ml~轻轻搅拌~饰以lemon片和Red cherry砂糖2匙.即可。
Soda Water适量~Lemon片1片~ Red cherry1颗。
107、涅格洛尼 Negroni 将Gin、Campari Bitter、Italy VermoutsGin 30ml~依次倒入加有冰块的杯中~搅拌后~饰Campari Bitter 30ml~以柳丁片点缀即可。
Italy Vermouts 30ml~柳丁片1片~ <此酒1962年创于Florence~以喜欢此酒的卡米羅(Negroni伯爵的姓作为酒名>。
108、天堂 Paradise 将Gin、Apricot Brandy、柳丁汁混合后Gin 1/2 jigger~倒入杯中即可。
化妆品成分

1雪肌精水成分日货Ingredients:Water(aqua):水Alcohol:酒精Glycerin:甘油angelica acutiloba root extract:当归根萃取coixlacryma-jobi (job's tears) seed extract:薏仁萃取dipotassium glycyrrhizate:甘草衍生物hamamelis virginiana (witch hazel) extract:金缕梅萃取,抗敏消炎melothria heterophylla extract:蒲瓜萃取物tocopheryl acetate;维生素E酯tritcum vulgare (wheat) germ oil:小麦胚芽蛋白citric acid:柠檬酸di-c12-15 pareth-8 phosphate:二C12-15 链烷醇聚醚-8 磷酸酯,乳化剂ethylhexyl methoxycinnamate:OMC,防晒成份甲氧基肉桂酸乙基己酯(桂皮酸盐,化学防晒)polysorbate 80:乳化剂*聚山梨酯80(本品为淡黄色至橙黄色的黏稠液体;微有特臭。
味微苦略涩,有温热感。
在水、乙醇、甲醇或乙酸乙酯中易溶,在矿物油中极微溶解。
液体制剂中常用的表面活性剂的一种。
为油/水型乳化剂,可用作稳定剂、扩散剂、抗静电剂、纤维润滑剂等。
由山梨糖醇酐单油酸酯和氧化乙烯反应制得sodium citrate:柠檬酸钠Sorbitan sesodioleate:失水山梨醇倍半油酸酯,乳化剂Triethylhexanon:三异辛酸甘油酯,合成脂Ethylparaben:对羟基苯甲酸乙酯防腐剂Methylparaben:对羟基苯甲酸甲酯防腐剂propylparaben:对羟基苯甲酸丙酯防腐剂fragrance (parfum):香精全系列中的三种当家植物成分:当归——活血化瘀,还含有当下非常红的抗氧化物质阿魏酸,薏米仁——性寒、并具有消炎作用,白蔹——保湿并具美白效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中文配方
●知识准备
1. 什么是配方?
顾名思义,就是生成一种产品所需要的所有的条件参数。
2. 为什么需要配方?
触摸屏不仅作为工程师与机器交流的平台,其还可存储大量的数据,对于现代工业生产,繁多的加工种类,每次加工都手工输入相应的参数势必影响工作的效率。
那么在触摸屏上存储起一组组常用的加工参数,在需要的时候调取,将大大提高效率。
3. 配方在触摸屏中
在触摸屏里有PSW、PFW寄存器,PSW为断电不保持寄存器,PFW为断电保持寄存器,一般配方数据都需要断电保持,所以其会存储在寄存器PFW中,配方数据被存放在连续的一组组寄存器中,然后通过配方索引号PSW40来选择所需要的配方。
注:PSW40只有在高级功能被打开后,方可输入。
下面以一个实例来说明配方的设置过程:
某木材加工厂需要加工出不同尺寸的板材,各种型号板材都有不同的大小标准,那么先要将这些板材的尺寸信息都存入触摸屏的断电保持寄存器中,一组板材的尺寸信息代表一组配方,并且在要加工某种板材的时候,从屏中调出相应的配方数据下载到PLC的寄存器中,PLC根据给定的数据加工生产。
注:本案例为了方便演示,使用PFW寄存器来替代PLC寄存器。
●写入配方名称与配方数据到触摸屏寄存器PFW中
1. 将所有板材的尺寸信息都存入触摸屏的断电保持寄存器PFW中,打开Touchwin编辑软件,选择“文件—PFW数据”。
注:如果配方数据量较少,可省略该步,而直接在触摸屏上输入配方数据。
2. 输入起始PFW地址及末端PFW地址,点击添加,然后在中间空白栏地方显示出“PFW[***]-PFW[***]”的项目。
3. 点击“修改数据”或者双击“PFW[***]-PFW[***]”,弹出PFW数据编辑表格。
4. 在表格里输入所有配方的数据,输入完成点“确定”退出。
将配方的数据写入到屏中的寄存器,要严格的按照配方数据的先后顺序,例如要输入的配方数据信息如下表所示:
、236、252、137、254,这样配方数据库在触摸屏中就建立了。
只要点击程序下载,PFW的寄存器中就被赋予相应的值。
配方下载
1. 如何在触摸屏中调用和管理这些配方数据:需要用到配方索引号PSW40,当改变PSW40里面的值,就自动切换到相应的配方,并将数据下载到PLC中。
PSW40如何与存储于PFW中的配方数据发生关联:需要用到配方下载按钮,点击配方下载“”,并将其放至编辑画面。
2.设置配方下载按钮属性。
在对象栏目里,包括设备数据和配方数据两大项,设备数据为PLC等设备内部相应寄存器,这些寄存器就是PLC执行动作的命令源,下图中,设备数据对象类型的首地址为PFW1500,单组字数为3,那么在PLC会依照寄存器PFW1500、PFW1501、PFW1502中的内容来加工处理产品。
配方数据为存储在触摸屏中的配方数据,下图中,配方数据的对象类型的首地址为PFW300,单组字数为3,那么该配方下载按钮指定的配方数据的地址为PFW300、PFW301、PFW302 。
3. 在配方下载对话框中的配方选项卡下面填入配方组数。
4. 至此,完成配方下载按钮的设置,但是配方数据有100组,而在此按钮中我们只指定了第一组配方和PLC的目的地址,那么配方索引号PSW40似乎没有起到任何衔接的作用,这个不用担心,因为PSW40作为触摸屏指定的专用索引号,配方下载按钮已经自动和配方索引号链接起来, 只要改变PSW40里面的值,就可以指向对应的配方数据。
PSW40=0:点击配方下载按钮,就将PSW300为首地址连续的3个寄存器中数据下载到PFW1500~PFW1503寄存器中,也就意味着要加工A型板;
PSW40=1:点击配方下载按钮,就将PSW303为首地址连续的3个寄存器中数据下载到PFW1500~PFW1503寄存器中, 也就意味着要加工B型板。
注:使用配方下载、配方上载按钮操作时,必须使用PSW40作为配方索引号,如果想用其他寄存器作为配方索引号,请详见案例:功能键做配方。
配方数据的显示与修改
1. 配方数据的显示及修改,在改变PSW40的时候,配方数据切换,为了观察到所选择配方数据的内容,在编辑画面上放置三个数据输入“”,地址分别为PFW300、PFW301和PFW302。
2. 设置代表长度的数据输入属性:因为我们存储的配方数据是从PFW300开始的,所以对象类型设置为PFW300。
3. PFW300是配方库中第一组配方里板材长度的存储地址,那么如何通过PSW40值的变化而在这个数据显示框中观察到各配方数据关于板材长度的内容呢?可通过对象类型设置下面的间接指定来实现,在间接指定前面的空格中打勾。
4. 单击间接指定处的按钮,弹出下面间接指定对象对话框,将对象类型设置为配方索引号PSW40。
5. 在间接指定对象对话框中选择数据选项卡,因为每组配方当中,包含3个数据,所以倍率设置为3,点确定后返回。
至此,板材长度的数据显示设置完毕。
根据这种方法设置好板材宽度和板材厚度的数据显示。
配方名称显示
1. 除了数据显示以外,我们还需要有一个板材名称显示,这样我们才知道选择板材的类型。
在编辑画面放置1个中文输入“”。
2. 设置中文输入属性:由于板材配方数据已经占用了300(3*100)个寄存器,也就是说配方数据存储到PFW599为止,留一点余量,存储汉字名称的配方数据就从PFW800开始,板材名称最多可有4个汉字,每个汉字占用一个寄存器,寄存器数就填4。
3. 在间接指定前面的空格中打勾。
然后单击间接指定处的按钮,弹出间接指定对象对话框,将对象类型设置为配方索引号 PSW40。
4. 在间接指定对象对话框中选择数据选项卡,因为每组板材名称配方中,包含4个数据,所以倍率设置为4,点确定后返回。
至此,板材名称显示设置完毕。
配方组数切换
在选择配方时,我们需要改变配方索引号PSW40里面的值,可以通过数据输入直接改变PSW40的值,另外,还可通过设定数据对PSW40进行加1 ,减1操作。
具体设置步骤如下:
1. 制作PSW40加1的按钮,也即配方的上翻功能,在编辑画面放置1个设定数据“”。
2. 设置设定数据属性:对象类型设置为PSW40。
3. 点击设定数据属性对话框的操作选项卡,操作功能选择加,操作数填1。
4. 点击设定数据属性对话框的按键选项卡,更改外观,选择带有上翻箭头的按键图标,点确定。
至此,配方数据的上翻按钮制作完毕,与此类似,可以制作出配方数据的下翻按钮。
5. 将画面下载到触摸屏中。
●配方上载
配方里面除了能将触摸屏里配方数据下载到触摸屏里面,也可以将PLC里对应的寄存器中数据读取上来。
在上面讲到了配方的下载功能,用户能够将触摸屏上数据库的内容下载到PLC当中,在某些情况下,用户需要将PLC中对应寄存器的数据提取上来,存到触摸屏的数据库里。
仍旧以上述例子来说明,该木材厂通过手动调整试验生产了一种新的板型,但参数保存在PLC的对应寄存器中,为方便以后的调用,工程师准备将这组数据上载到触摸屏的配方数据库中存储起来。
1. 在编辑画面放置1个配方上载“”。
2. 设置配方上载属性:设备数据的对象类型设置成PFW1500,配方数据的对象类型设置成PFW300,
单组字数设置为3。
3. 在配方下载属性对话框中配方选项卡下面填入配方的组数,点击确定后退出。
4. 当点击上载按钮后,存储在PLC寄存器中的数据就上载到触摸屏中,此时配方索引号PSW40的值决定上载的数据存储哪些寄存器中。
例如:PSW40=10,配方数据存储的首地址在PFW300,那么点击上载,PLC 内对应的寄存器数据就上载到触摸屏寄存器 PFW330、PFW331、PFW332当中。
●显示所有配方组
1. 新增窗口1,在窗口放置1个字符显示“”和1个功能键“”,设置其属性。
2. 将该字符显示和功能键通过图形调整工具进行置中叠放。
与此类似,制作出其它99组配方的名称显示和功能键操作属性,字符显示地址依次递增4,功能键中设置PSW40数据依次递增1。
3. 回到画面1,在编辑画面放置1个窗口按钮“”,设置其属性。
至此,整个画面制作完成。