林子雨大数据技术原理及应用第四章课后作业答案
大学生mooc大数据技术原理与应用(林子雨)题库答案

⼤学⽣mooc⼤数据技术原理与应⽤(林⼦⾬)题库答案作者:解忧书店 JieYouBookshop 第1章⼤数据概述1单选(2分)第三次信息化浪潮的标志是:A.个⼈电脑的普及B.云计算、⼤数据、物联⽹技术的普及C.虚拟现实技术的普及D.互联⽹的普及正确答案:B你选对了2单选(2分)就数据的量级⽽⾔,1PB数据是多少TB?A.2048B.1000C.512D.1024正确答案:D你选对了3单选(2分)以下关于云计算、⼤数据和物联⽹之间的关系,论述错误的是:A.云计算侧重于数据分析B.物联⽹可以借助于云计算实现海量数据的存储C.物联⽹可以借助于⼤数据实现海量数据的分析D.云计算、⼤数据和物联⽹三者紧密相关,相辅相成正确答案:A你选对了4单选(2分)以下哪个不是⼤数据时代新兴的技术:A.SparkB.HadoopC.HBaseD.MySQL正确答案:D你选对了每种⼤数据产品都有特定的应⽤场景,以下哪个产品是⽤于批处理的:A.MapReduceB.DremelC.StormD.Pregel正确答案:A你选对了6单选(2分)每种⼤数据产品都有特定的应⽤场景,以下哪个产品是⽤于流计算的:A.GraphXB.S4C.ImpalaD.Hive正确答案:B你选对了7单选(2分)每种⼤数据产品都有特定的应⽤场景,以下哪个产品是⽤于图计算的:A.PregelB.StormC.CassandraD.Flume正确答案:A你选对了8单选(2分)每种⼤数据产品都有特定的应⽤场景,以下哪个产品是⽤于查询分析计算的:A.HDFSB.S4C.DremelD.MapReduce正确答案:C你选对了9多选(3分)数据产⽣⽅式⼤致经历了三个阶段,包括:A.运营式系统阶段B.感知式系统阶段C.移动互联⽹数据阶段正确答案:ABD你选对了10多选(3分)⼤数据发展的三个阶段是:A.低⾕期B.成熟期C.⼤规模应⽤期D.萌芽期正确答案:BCD你选对了11多选(3分)⼤数据的特性包括:A.价值密度低B.处理速度快C.数据类型繁多D.数据量⼤正确答案:ABCD你选对了12多选(3分)图领奖获得者、著名数据库专家Jim Gray博⼠认为,⼈类⾃古以来在科学研究上先后经历了哪⼏种范式:A.计算科学B.数据密集型科学C.实验科学D.理论科学正确答案:ABCD你选对了13多选(3分)⼤数据带来思维⽅式的三个转变是:A.效率⽽⾮精确B.相关⽽⾮因果C.精确⽽⾮全⾯D.全样⽽⾮抽样正确答案:ABD你选对了14多选(3分)⼤数据主要有哪⼏种计算模式:。
林子雨大数据技术原理与应用答案(全)

林子雨大数据技术原理及应用课后题答案大数据第一章大数据概述课后题 (1)大数据第二章大数据处理架构Hadoop课后题 (5)大数据第三章Hadoop分布式文件系统课后题 (10)大数据第四章分布式数据库HBase课后题 (16)大数据第五章NoSQl数据库课后题 (22)大数据第六章云数据库课后作题 (28)大数据第七章MapReduce课后题 (34)大数据第八章流计算课后题 (41)大数据第九章图计算课后题 (50)大数据第十章数据可视化课后题 (53)大数据第一章课后题——大数据概述1.试述信息技术发展史上的3次信息化浪潮及其具体内容。
第一次信息化浪潮1980年前后个人计算机开始普及,计算机走入企业和千家万户。
代表企业:Intel,AMD,IBM,苹果,微软,联想,戴尔,惠普等。
第二次信息化浪潮1995年前后进入互联网时代。
代表企业:雅虎,谷歌阿里巴巴,百度,腾讯。
第三次信息浪潮2010年前后,云计算大数据,物联网快速发展,即将涌现一批新的市场标杆企业。
2.试述数据产生方式经历的几个阶段。
经历了三个阶段:运营式系统阶段数据伴随一定的运营活动而产生并记录在数据库。
用户原创内容阶段Web2.0时代。
感知式系统阶段物联网中的设备每时每刻自动产生大量数据。
3.试述大数据的4个基本特征。
数据量大(Volume)据类型繁多(Variety)处理速度快(Velocity)价值密度低(Value)4.试述大数据时代的“数据爆炸”特性。
大数据摩尔定律:人类社会产生的数据一直都在以每年50%的速度增长,即每两年就增加一倍。
5.科学研究经历了那四个阶段?实验比萨斜塔实验理论采用各种数学,几何,物理等理论,构建问题模型和解决方案。
例如:牛一,牛二,牛三定律。
计算设计算法并编写相应程序输入计算机运行。
数据以数据为中心,从数据中发现问题解决问题。
6.试述大数据对思维方式的重要影响。
全样而非抽样效率而非精确相关而非因果7.大数据决策与传统的基于数据仓库的决策有什么区别?数据仓库以关系数据库为基础,在数据类型和数据量方面存在较大限制。
厦门大学林子雨编著

厦门大学林子雨编著《大数据技术原理与应用》教材配套上机练习熟悉MongoDB的基本操作(版本号:2016年3月14日版本)主讲教师:林子雨厦门大学数据库实验室二零一六年三月目录目录1作业题目 (1)2作业目的 (1)3作业性质 (1)4作业考核方法 (1)5作业提交日期与方式 (1)6实验平台 (1)7实验内容和要求 (1)8实验报告 (2)附录1:任课教师介绍 (2)附录2:课程教材介绍 (2)附录3:中国高校大数据课程公共服务平台介绍 (3)厦门大学林子雨编著《大数据技术原理与应用》教材配套上机练习熟悉MongoDB的基本操作上机练习说明主讲教师:林子雨E-mail: ziyulin@ 个人主页:/linziyu1作业题目熟悉MongoDB的基本操作。
2作业目的1. 理解NoSQL数据库和关系型数据库的区别;2. 熟练使用MongoDB操作常用的Shell命令;3作业性质课后作业,必做,作为课堂平时成绩。
4作业考核方法提交上机实验报告,任课老师根据上机实验报告评定成绩。
5作业提交日期与方式林子雨编著《大数据技术原理与应用》教材第五章NoSQL数据库内容结束后的下一周周六晚上9点之前提交。
6实验平台操作系统:LinuxMongoDB版本:3.0以上版本7实验内容和要求1.根据上面给出的表格,用MongoDB设计student学生表格。
a)设计完后,用find指令浏览表的所有数据。
b)查询学号为95002 的所有信息。
给出截图。
c)删除姓名为liuchen的数据d)将学号为95001的年龄改为22岁8 实验报告附录1:任课教师介绍林子雨(1978-),男,博士,厦门大学计算机科学系助理教授,主要研究领域为数据库,实时主动数据仓库,数据挖掘.主讲课程:《大数据技术基础》办公地点:厦门大学海韵园科研2号楼E-mail: ziyulin@个人主页:/linziyu数据库实验室网站: 附录2:课程教材介绍《大数据技术原理与应用——概念、存储、处理、分析与应用》,由厦门大学计算机科学系教师林子雨博士编著,是中国高校第一本系统介绍大数据知识的专业教材。
大数据技术原理与应用 林子雨版 课后习题答案(精编文档).doc

【最新整理,下载后即可编辑】第一章1.试述信息技术发展史上的3次信息化浪潮及具体内容。
2.试述数据产生方式经历的几个阶段答:运营式系统阶段,用户原创内容阶段,感知式系统阶段。
3.试述大数据的4个基本特征答:数据量大、数据类型繁多、处理速度快和价值密度低。
4.试述大数据时代的“数据爆炸”的特性答:大数据时代的“数据爆炸”的特性是,人类社会产生的数据一致都以每年50%的速度增长,也就是说,每两年增加一倍。
5.数据研究经历了哪4个阶段?答:人类自古以来在科学研究上先后历经了实验、理论、计算、和数据四种范式。
6.试述大数据对思维方式的重要影响答:大数据时代对思维方式的重要影响是三种思维的转变:全样而非抽样,效率而非精确,相关而非因果。
7.大数据决策与传统的基于数据仓库的决策有什么区别答:数据仓库具备批量和周期性的数据加载以及数据变化的实时探测、传播和加载能力,能结合历史数据和实时数据实现查询分析和自动规则触发,从而提供对战略决策和战术决策。
大数据决策可以面向类型繁多的、非结构化的海量数据进行决策分析。
8.举例说明大数据的基本应用答:9.举例说明大数据的关键技术答:批处理计算,流计算,图计算,查询分析计算10.大数据产业包含哪些关键技术。
答:IT基础设施层、数据源层、数据管理层、数据分析层、数据平台层、数据应用层。
11.定义并解释以下术语:云计算、物联网答:云计算:云计算就是实现了通过网络提供可伸缩的、廉价的分布式计算机能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人类和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
12.详细阐述大数据、云计算和物联网三者之间的区别与联系。
第二章1.试述hadoop和谷歌的mapreduce、gfs等技术之间的关系答:Hadoop的核心是分布式文件系统HDFS和MapReduce,HDFS 是谷歌文件系统GFS的开源实现,MapReduces是针对谷歌MapReduce的开源实现。
林子雨大数据技术原理与应用答案(全)
林子雨大数据技术原理及应用课后题答案大数据第一章大数据概述课后题 (1)大数据第二章大数据处理架构Hadoop课后题 (5)大数据第三章Hadoop分布式文件系统课后题 (10)大数据第四章分布式数据库HBase课后题 (16)大数据第五章NoSQl数据库课后题 (22)大数据第六章云数据库课后作题 (28)大数据第七章MapReduce课后题 (34)大数据第八章流计算课后题 (41)大数据第九章图计算课后题 (50)大数据第十章数据可视化课后题 (53)大数据第一章课后题——大数据概述1.试述信息技术发展史上的3次信息化浪潮及其具体内容。
第一次信息化浪潮1980年前后个人计算机开始普及,计算机走入企业和千家万户。
代表企业:Intel,AMD,IBM,苹果,微软,联想,戴尔,惠普等。
第二次信息化浪潮1995年前后进入互联网时代。
代表企业:雅虎,谷歌阿里巴巴,百度,腾讯。
第三次信息浪潮2010年前后,云计算大数据,物联网快速发展,即将涌现一批新的市场标杆企业。
2.试述数据产生方式经历的几个阶段。
经历了三个阶段:运营式系统阶段数据伴随一定的运营活动而产生并记录在数据库。
用户原创内容阶段Web2.0时代。
感知式系统阶段物联网中的设备每时每刻自动产生大量数据。
3.试述大数据的4个基本特征。
数据量大(Volume)据类型繁多(Variety)处理速度快(Velocity)价值密度低(Value)4.试述大数据时代的“数据爆炸”特性。
大数据摩尔定律:人类社会产生的数据一直都在以每年50%的速度增长,即每两年就增加一倍。
5.科学研究经历了那四个阶段?实验比萨斜塔实验理论采用各种数学,几何,物理等理论,构建问题模型和解决方案。
例如:牛一,牛二,牛三定律。
计算设计算法并编写相应程序输入计算机运行。
数据以数据为中心,从数据中发现问题解决问题。
6.试述大数据对思维方式的重要影响。
全样而非抽样效率而非精确相关而非因果7.大数据决策与传统的基于数据仓库的决策有什么区别?数据仓库以关系数据库为基础,在数据类型和数据量方面存在较大限制。
数据库原理与应用教程(第三版)第四章课后习题答案
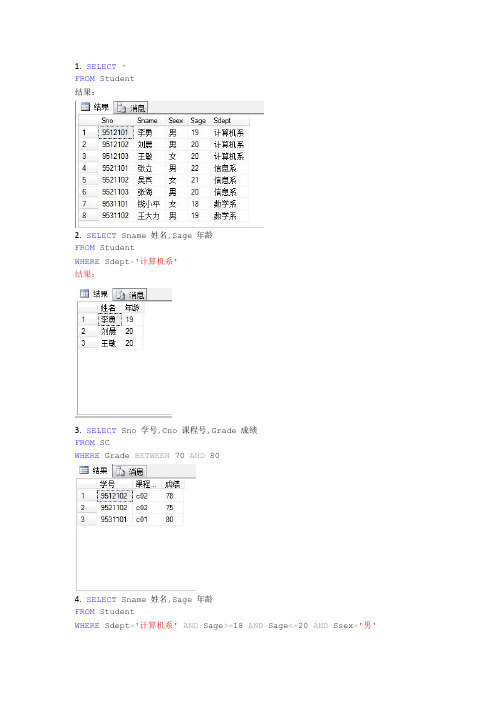
1. SELECT*FROM Student结果:2. SELECT Sname 姓名,Sage 年龄FROM StudentWHERE Sdept='计算机系'结果:3. SELECT Sno 学号,Cno 课程号,Grade 成绩FROM SCWHERE Grade BETWEEN 70 AND 804. SELECT Sname 姓名,Sage 年龄FROM StudentWHERE Sdept='计算机系'AND Sage>=18 AND Sage<=20 AND Ssex='男'5. SELECT MAX(Grade)最高分数FROM SCWHERE Cno='c01'6. SELECT MAX(Sage)最大年龄,MIN(Sage)最小年龄FROM StudentWHERE Sdept='计算机系'7. SELECT Sdept 系名,COUNT(*)学生人数FROM StudentGROUP BY Sdept8. SELECT Cname 课程名,COUNT(*)选课门数,MAX(Grade)最高分FROM Course,SCGROUP BY Cname9. SELECT Sno 学号,COUNT(*)选课门数,SUM(Grade)总成绩FROM SCGROUP BY SnoORDER BY'选课门数'ASC10. SELECT Sno 学号,SUM(Grade)总成绩FROM SCGROUP BY SnoHAVING SUM(Grade)>20010.CREAT TABLE BOOK(Snobook nchar(6) PRIMARY KEY,Snamebook nvarchar(30) NBOT NULL,Writer char(10) NOT NULL,Time smalldatetime,Price numeric(3,1))CREAT TABLE BOOKSHOP(Snoshop nchar(6) PRIMARY KEY,Snameshop nvarchar(30) NOT NULL,Tel char(8)CHECK(Tel =0 AND Tel <=9),Place nchar(40),Snoemail char(6))CREAT TABLE BOOKSELL(Snobook nchar(6) NOT NULL,Snoshop nchar(6) NOT NULL,Selltime smalltime NOT NULL,Snosell tinyint,PRIMARY KEY (Snobook, Snoshop, Selltime),FOREIGN KEY (Snobook) REFERENCES BOOK(Snobook), FOREIGN KEY (Snoshop) REFERENCES BOOK(BOOKSHOP) )11.ALTER TABLE BOOKADD Nomber intADD CONSTRAINT DF-NomberCHECK (Nomber>1000)12.ALTER TABLE BOOKSHOPDROP COLUMN Tel13.ALTER TABLE BOOKSELLALTER COLUMN Snosell int。
厦门大学林子雨编著

厦门大学林子雨编著《大数据技术原理与应用》教材配套上机练习熟悉常用的HDFS操作(版本号:2016年1月24日版本)主讲教师:林子雨厦门大学数据库实验室二零一六年一月目录目录1作业题目 (1)2作业目的 (1)3作业性质 (1)4作业考核方法 (1)5作业提交日期与方式 (1)6实验平台 (1)7实验内容和要求 (1)8实验报告 (2)附录1:任课教师介绍 (2)附录2:课程教材介绍 (2)附录3:中国高校大数据课程公共服务平台介绍 (4)厦门大学林子雨编著《大数据技术原理与应用》教材配套上机练习熟悉常用的HDFS操作上机练习说明主讲教师:林子雨E-mail: ziyulin@ 个人主页:/linziyu1作业题目熟悉常用的HDFS操作。
2作业目的(1)理解HDFS在Hadoop体系结构中的角色;(2)熟练使用HDFS操作常用的Shell命令;(3)熟悉HDFS操作常用的Java API。
3作业性质课后作业,必做,作为课堂平时成绩。
4作业考核方法提交上机实验报告,任课老师根据上机实验报告评定成绩。
5作业提交日期与方式林子雨编著《大数据技术原理与应用》教材第三章分布式文件系统HDFS内容结束后的下一周周六晚上9点之前提交。
6实验平台操作系统:LinuxHadoop版本:2.6.0或以上版本JDK版本:1.6或以上版本Java IDE:Eclipse7实验内容和要求首先,编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同任务:(1)向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;(2)从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;(3)将HDFS中指定文件的内容输出到终端中;(4)显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;(5) 给定HDFS 中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;(6) 提供一个HDFS 内的文件的路径,对该文件进行创建和删除操作。
大大数据技术原理与指导应用 林子雨版 课后习题问题详解

第一章1.试述信息技术发展史上的3次信息化浪潮及具体容。
2.试述数据产生方式经历的几个阶段答:运营式系统阶段,用户原创容阶段,感知式系统阶段。
3.试述大数据的4个基本特征答:数据量大、数据类型繁多、处理速度快和价值密度低。
4.试述大数据时代的“数据爆炸”的特性答:大数据时代的“数据爆炸”的特性是,人类社会产生的数据一致都以每年50%的速度增长,也就是说,每两年增加一倍。
5.数据研究经历了哪4个阶段?答:人类自古以来在科学研究上先后历经了实验、理论、计算、和数据四种式。
6.试述大数据对思维方式的重要影响答:大数据时代对思维方式的重要影响是三种思维的转变:全样而非抽样,效率而非精确,相关而非因果。
7.大数据决策与传统的基于数据仓库的决策有什么区别答:数据仓库具备批量和周期性的数据加载以及数据变化的实时探测、传播和加载能力,能结合历史数据和实时数据实现查询分析和自动规则触发,从而提供对战略决策和战术决策。
大数据决策可以面向类型繁多的、非结构化的海量数据进行决策分析。
8.举例说明大数据的基本应用答:9.举例说明大数据的关键技术答:批处理计算,流计算,图计算,查询分析计算10.大数据产业包含哪些关键技术。
答:IT基础设施层、数据源层、数据管理层、数据分析层、数据平台层、数据应用层。
11.定义并解释以下术语:云计算、物联网答:云计算:云计算就是实现了通过网络提供可伸缩的、廉价的分布式计算机能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人类和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
12.详细阐述大数据、云计算和物联网三者之间的区别与联系。
第二章1.试述hadoop和谷歌的mapreduce、gfs等技术之间的关系答:Hadoop的核心是分布式文件系统HDFS和MapReduce,HDFS是谷歌文件系统GFS的开源实现,MapReduces是针对谷歌MapReduce的开源实现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大数据技术原理与应用第四章课后作业
黎狸
1.试述在Hadoop体系架构中HBase与其他组成部分的相互关系。
HBase利用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算;利用Zookeeper作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力; Sqoop为HBase的底层数据导入功能,Pig 和Hive为HBase提供了高层语言支持,HBase是BigTable的开源实现。
2.请阐述HBase和BigTable的底层技术的对应关系。
3.请阐述HBase和传统关系数据库的区别。
4.HBase有哪些类型的访问接口?
HBase提供了Native Java API , HBase Shell , Thrift Gateway , REST GateWay , Pig , Hive 等访问接口。
5.请以实例说明HBase数据模型。
6.分别解释HBase中行键、列键和时间戳的概念。
①行键标识行。
行键可以是任意字符串,行键保存为字节数组。
②列族。
HBase的基本的访问控制单元,需在表创建时就定义好。
③时间戳。
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索
引。
7.请举个实例来阐述HBase的概念视图和物理视图的不同。
8.试述HBase各功能组件及其作用。
①库函数:链接到每个客户端;
②一个Master主服务器:主服务器Master主要负责表和Region的管理工作;
③③许多个Region服务器:Region服务器是HBase中最核心的模块,负责存储和
维护分配给自己的Region,并响应用户的读写请求
9.请阐述HBase的数据分区机制。
每个行区间构成一个分区,被称为“Region”,分发到不同的Region服务器上。
10.HBase中的分区是如何定位的?
通过构建的映射表的每个条目包含两项内容,一个是Regionde 标识符,另一个是Region服务器标识,这个条目就标识Region和Region服务器之间的对应关系,从而就可以知道某个Region被保存在哪个Region服务器中。
11.试述HBase的三层结构中各层次的名称和作用。
12.请阐述HBase的三层结构下,客户端是如何访问到数据的。
首先访问Zookeeper,获取-ROOT表的位置信息,然后访问-Root-表,获得.MATA.表的信息,接着访问.MATA.表,找到所需的Region具体位于哪个Region服务器,最后才会到该Region服务器读取数据。
13.试述HBase系统基本架构以及每个组成部分的作用。
(1)客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
(2)Zookeeper服务器
Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
(3)Master
主服务器Master主要负责表和Region的管理工作:管理用户对表的增加、删除、修改、查询等操作;实现不同Region服务器之间的负载均衡;在Region分裂或合并后,负责重新调整Region的分布;对发生故障失效的Region服务器上的Region进行迁移
(4)Region服务器
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
14.请阐述Region服务器向HDFS文件系统中读写数据的基本原理。
Region服务器内部管理一系列Region对象和一个HLog文件,其中,HLog是磁盘上面的记录文件,它记录着所有的更新操作。
每个Region对象又是由多个Store组成的,每个Store对象了表中的一个列族的存储。
每个Store又包含了MemStore和若干个StoreFile,其中,MemStore是在内存中的缓存。
15.试述HStore的工作原理。
每个Store对应了表中的一个列族的存储。
每个Store包括一个MenStore缓存和若干个StoreFile文件。
MenStore是排序的内存缓冲区,当用户写入数据时,系统首先把数据放入MenStore缓存,当MemStore缓存满时,就会刷新到磁盘中的一个StoreFile文件中,当单个StoreFile文件大小超过一定阈值时,就会触发文件分裂操作。
16.试述HLog的工作原理。
HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log),用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘。
17.在HBase中,每个Region服务器维护一个HLog,而不是为每个Region
都单独维护一个HLog。
请说明这种做法的优点和缺点。
优点:多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中。
缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。
18.当一台Region服务器意外终止时,Master如何发现这种意外终止情况?为
了恢复这台发生意外的Region服务器上的Region,Master应该做出那些处理(包括如何使用HLog进行恢复)?
Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master。
Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog 文件中包含了来自多个Region对象的日志记录。
系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器。
Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复。