遗传算法改进的模糊C-均值聚类MATLAB源码
matlab模糊函数代码

matlab模糊函数代码在数学和图像处理领域中,模糊函数是一种常用的工具,用于对图像进行模糊处理以达到一定的效果。
Matlab提供了一些内置函数来实现图像的模糊处理,本文将介绍如何使用Matlab编写模糊函数代码。
Matlab中有多种不同类型的模糊函数,例如高斯模糊、均值模糊和运动模糊等。
下面将逐一介绍这些模糊函数代码的实现方式。
1. 高斯模糊:高斯模糊是最常用的模糊算法之一,它通过卷积图像与一个高斯核来实现。
以下是Matlab中实现高斯模糊的代码示例:```matlabfunction blurredImage = gaussianBlur(image, sigma)kernelSize = 2 * ceil(3 * sigma) + 1; % 根据sigma计算高斯核大小kernel = fspecial('gaussian', [kernelSize kernelSize], sigma); % 生成高斯核blurredImage = imfilter(image, kernel, 'conv'); % 对图像进行卷积操作end```2. 均值模糊:均值模糊是一种简单但常用的模糊算法,它通过计算邻域像素的平均值来实现。
以下是Matlab中实现均值模糊的代码示例:```matlabfunction blurredImage = meanBlur(image, kernelSize)kernel = ones(kernelSize) / (kernelSize^2); % 生成均值核blurredImage = imfilter(image, kernel, 'conv'); % 对图像进行卷积操作end```3. 运动模糊:运动模糊是一种模糊算法,它通过模拟相机快门打开时的移动效果来实现。
以下是Matlab中实现运动模糊的代码示例:```matlabfunction blurredImage = motionBlur(image, angle, distance)PSF = fspecial('motion', distance, angle); % 生成运动模糊核blurredImage = imfilter(image, PSF, 'conv'); % 对图像进行卷积操作end```以上是几种常见的模糊函数的Matlab代码实现。
在Matlab中使用模糊C均值聚类进行图像分析的技巧

在Matlab中使用模糊C均值聚类进行图像分析的技巧在图像分析领域,模糊C均值聚类(FCM)是一种常用的工具,它可以帮助我们发现图像中隐藏的信息和模式。
通过使用Matlab中的模糊逻辑工具箱,我们可以轻松地实现FCM算法,并进行图像分析。
本文将介绍在Matlab中使用FCM进行图像分析的技巧。
首先,让我们简要了解一下FCM算法。
FCM是一种基于聚类的图像分割方法,它将图像的像素分为不同的聚类,每个聚类代表一类像素。
与传统的C均值聚类算法不同,FCM允许像素属于多个聚类,因此能够更好地处理图像中的模糊边界。
在Matlab中使用FCM进行图像分析的第一步是加载图像。
可以使用imread函数将图像加载到Matlab的工作区中。
例如,我们可以加载一张名为“image.jpg”的图像:```matlabimage = imread('image.jpg');```加载图像后,可以使用imshow函数显示图像。
这可以帮助我们对图像有一个直观的了解:```matlabimshow(image);```接下来,我们需要将图像转换为灰度图像。
这是因为FCM算法通常用于灰度图像分析。
可以使用rgb2gray函数将彩色图像转换为灰度图像:```matlabgrayImage = rgb2gray(image);```在使用FCM算法之前,我们需要对图像进行预处理。
预处理的目的是消除图像中的噪声和不必要的细节,从而更好地提取图像中的特征。
常用的图像预处理方法包括平滑、锐化和边缘检测等。
Matlab中提供了许多图像预处理函数。
例如,可以使用imnoise函数向图像中添加高斯噪声:```matlabnoisyImage = imnoise(grayImage, 'gaussian', 0, 0.01);```还可以使用imfilter函数对图像进行平滑处理。
常见的平滑方法包括均值滤波和高斯滤波:```matlabsmoothImage = imfilter(noisyImage, fspecial('average', 3));```一旦完成预处理步骤,我们就可以使用模糊逻辑工具箱中的fcm函数执行FCM算法。
模糊c均值聚类算法原理详细讲解

模糊c均值聚类算法原理详细讲解模糊C均值聚类算法(Fuzzy C-means clustering algorithm)是一种经典的无监督聚类算法,它在数据挖掘和模式识别领域被广泛应用。
与传统的C均值聚类算法相比,模糊C均值聚类算法允许数据点属于多个聚类中心,从而更好地处理数据点的不确定性。
本文将详细讲解模糊C均值聚类算法的原理。
模糊C均值聚类算法的目标是将数据集划分为K个聚类,其中每个聚类由一个聚类中心表示。
与C均值聚类算法类似,模糊C均值聚类算法也涉及两个步骤:初始化聚类中心和迭代更新聚类中心。
首先,需要初始化聚类中心。
在模糊C均值聚类算法中,每个数据点都被赋予属于每个聚类中心的隶属度,表示该数据点属于每个聚类的程度。
因此,需要为每个数据点初始化一个隶属度矩阵U。
隶属度矩阵U的大小是n×K,其中n是数据点的数量,K是聚类的数量。
隶属度矩阵的元素u_ij表示第i个数据点属于第j个聚类的隶属度。
接下来,需要迭代更新聚类中心。
在每次迭代中,需要计算每个数据点属于每个聚类的隶属度,并使用这些隶属度来更新聚类中心。
具体来说,对于每个数据点i和聚类中心j,可以计算其隶属度为:u_ij = (1 / ∑_(k=1)^K (d_ij / d_ik)^(2 / (m-1))),其中d_ij表示数据点i和聚类中心j之间的距离,d_ik表示数据点i和聚类中心k之间的距离,m是模糊参数,通常取大于1的值。
然后,根据更新的隶属度计算新的聚类中心。
对于每个聚类中心j,可以计算其更新为:c_j = (∑_(i=1)^n (u_ij)^m * x_i) / ∑_(i=1)^n (u_ij)^m,其中x_i表示数据点i的坐标。
以上的迭代更新过程会一直进行,直到满足停止准则,例如隶属度矩阵U的变化小于一些阈值或达到最大迭代次数。
模糊C均值聚类算法的优点是在处理数据点的不确定性方面表现出色。
由于允许数据点属于多个聚类中心,模糊C均值聚类算法可以更好地处理数据点在不同聚类之间的模糊边界问题。
遗传算法多目标优化matlab源代码

遗传算法多目标优化matlab源代码遗传算法(Genetic Algorithm,GA)是一种基于自然选择和遗传学原理的优化算法。
它通过模拟生物进化过程,利用交叉、变异等操作来搜索问题的最优解。
在多目标优化问题中,GA也可以被应用。
本文将介绍如何使用Matlab实现遗传算法多目标优化,并提供源代码。
一、多目标优化1.1 多目标优化概述在实际问题中,往往存在多个冲突的目标函数需要同时优化。
这就是多目标优化(Multi-Objective Optimization, MOO)问题。
MOO不同于单一目标优化(Single Objective Optimization, SOO),因为在MOO中不存在一个全局最优解,而是存在一系列的Pareto最优解。
Pareto最优解指的是,在不降低任何一个目标函数的情况下,无法找到更好的解决方案。
因此,在MOO中我们需要寻找Pareto前沿(Pareto Front),即所有Pareto最优解组成的集合。
1.2 MOO方法常见的MOO方法有以下几种:(1)加权和法:将每个目标函数乘以一个权重系数,并将其加和作为综合评价指标。
(2)约束法:通过添加约束条件来限制可行域,并在可行域内寻找最优解。
(3)多目标遗传算法:通过模拟生物进化过程,利用交叉、变异等操作来搜索问题的最优解。
1.3 MOO评价指标在MOO中,我们需要使用一些指标来评价算法的性能。
以下是常见的MOO评价指标:(1)Pareto前沿覆盖率:Pareto前沿中被算法找到的解占总解数的比例。
(2)Pareto前沿距离:所有被算法找到的解与真实Pareto前沿之间的平均距离。
(3)收敛性:算法是否能够快速收敛到Pareto前沿。
二、遗传算法2.1 遗传算法概述遗传算法(Genetic Algorithm, GA)是一种基于自然选择和遗传学原理的优化算法。
它通过模拟生物进化过程,利用交叉、变异等操作来搜索问题的最优解。
遗传算法MATLAB完整代码(不用工具箱)

遗传算法MATLAB完整代码(不用工具箱)遗传算法解决简单问题%主程序:用遗传算法求解y=200*exp(-0.05*x).*sin(x)在区间[-2,2]上的最大值clc;clear all;close all;global BitLengthglobal boundsbeginglobal boundsendbounds=[-2,2];precision=0.0001;boundsbegin=bounds(:,1);boundsend=bounds(:,2);%计算如果满足求解精度至少需要多长的染色体BitLength=ceil(log2((boundsend-boundsbegin)'./precision));popsize=50; %初始种群大小Generationmax=12; %最大代数pcrossover=0.90; %交配概率pmutation=0.09; %变异概率%产生初始种群population=round(rand(popsize,BitLength));%计算适应度,返回适应度Fitvalue和累计概率cumsump[Fitvalue,cumsump]=fitnessfun(population);Generation=1;while Generation<generationmax+1< p="">for j=1:2:popsize%选择操作seln=selection(population,cumsump);%交叉操作scro=crossover(population,seln,pcrossover);scnew(j,:)=scro(1,:);scnew(j+1,:)=scro(2,:);%变异操作smnew(j,:)=mutation(scnew(j,:),pmutation);smnew(j+1,:)=mutation(scnew(j+1,:),pmutation);endpopulation=scnew; %产生了新的种群%计算新种群的适应度[Fitvalue,cumsump]=fitnessfun(population);%记录当前代最好的适应度和平均适应度[fmax,nmax]=max(Fitvalue);fmean=mean(Fitvalue);ymax(Generation)=fmax;ymean(Generation)=fmean;%记录当前代的最佳染色体个体x=transform2to10(population(nmax,:));%自变量取值范围是[-2,2],需要把经过遗传运算的最佳染色体整合到[-2,2]区间xx=boundsbegin+x*(boundsend-boundsbegin)/(power((boundsend),BitLength)-1);xmax(Generation)=xx;Generation=Generation+1;endGeneration=Generation-1;Bestpopulation=xx;Besttargetfunvalue=targetfun(xx);%绘制经过遗传运算后的适应度曲线。
遗传算法matlab程序代码

遗传算法matlab程序代码遗传算法是一种优化算法,用于在给定的搜索空间中寻找最优解。
在Matlab中,可以通过以下代码编写一个基本的遗传算法:% 初始种群大小Npop = 100;% 搜索空间维度ndim = 2;% 最大迭代次数imax = 100;% 初始化种群pop = rand(Npop, ndim);% 最小化目标函数fun = @(x) sum(x.^2);for i = 1:imax% 计算适应度函数fit = 1./fun(pop);% 选择操作[fitSort, fitIndex] = sort(fit, 'descend');pop = pop(fitIndex(1:Npop), :);% 染色体交叉操作popNew = zeros(Npop, ndim);for j = 1:Npopparent1Index = randi([1, Npop]);parent2Index = randi([1, Npop]);parent1 = pop(parent1Index, :);parent2 = pop(parent2Index, :);crossIndex = randi([1, ndim-1]);popNew(j,:) = [parent1(1:crossIndex),parent2(crossIndex+1:end)];end% 染色体突变操作for j = 1:NpopmutIndex = randi([1, ndim]);mutScale = randn();popNew(j, mutIndex) = popNew(j, mutIndex) + mutScale;end% 更新种群pop = [pop; popNew];end% 返回最优解[resultFit, resultIndex] = max(fit);result = pop(resultIndex, :);以上代码实现了一个简单的遗传算法,用于最小化目标函数x1^2 + x2^2。
遗传算法及其MATLAB程序代码

遗传算法及其MATLAB程序代码遗传算法及其MATLAB实现主要参考书:MATLAB 6.5 辅助优化计算与设计飞思科技产品研发中⼼编著电⼦⼯业出版社2003.1遗传算法及其应⽤陈国良等编著⼈民邮电出版社1996.6主要内容:遗传算法简介遗传算法的MATLAB实现应⽤举例在⼯业⼯程中,许多最优化问题性质⼗分复杂,很难⽤传统的优化⽅法来求解.⾃1960年以来,⼈们对求解这类难解问题⽇益增加.⼀种模仿⽣物⾃然进化过程的、被称为“进化算法(evolutionary algorithm)”的随机优化技术在解这类优化难题中显⽰了优于传统优化算法的性能。
⽬前,进化算法主要包括三个研究领域:遗传算法、进化规划和进化策略。
其中遗传算法是迄今为⽌进化算法中应⽤最多、⽐较成熟、⼴为⼈知的算法。
⼀、遗传算法简介遗传算法(Genetic Algorithm, GA)最先是由美国Mic-hgan⼤学的John Holland于1975年提出的。
遗传算法是模拟达尔⽂的遗传选择和⾃然淘汰的⽣物进化过程的计算模型。
它的思想源于⽣物遗传学和适者⽣存的⾃然规律,是具有“⽣存+检测”的迭代过程的搜索算法。
遗传算法以⼀种群体中的所有个体为对象,并利⽤随机化技术指导对⼀个被编码的参数空间进⾏⾼效搜索。
其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定等5个要素组成了遗传算法的核⼼内容。
遗传算法的基本步骤:遗传算法是⼀种基于⽣物⾃然选择与遗传机理的随机搜索算法,与传统搜索算法不同,遗传算法从⼀组随机产⽣的称为“种群(Population)”的初始解开始搜索过程。
种群中的每个个体是问题的⼀个解,称为“染⾊体(chromos ome)”。
染⾊体是⼀串符号,⽐如⼀个⼆进制字符串。
这些染⾊体在后续迭代中不断进化,称为遗传。
在每⼀代中⽤“适值(fitness)”来测量染⾊体的好坏,⽣成的下⼀代染⾊体称为后代(offspring)。
模糊c均值聚类算法

模糊c均值聚类算法
模糊c均值聚类算法(Fuzzy C-Means Algorithm,简称FCM)是一种基于模糊集理论的聚类分析算法,它是由Dubes 和Jain于1973年提出的,也是用于聚类数据最常用的算法之
一。
fcm算法假设数据点属于某个聚类的程度是一个模糊
的值而不是一个确定的值。
模糊C均值聚类算法的基本原理是:将数据划分为k个
类别,每个类别有c个聚类中心,每个类别的聚类中心的模糊程度由模糊矩阵描述。
模糊矩阵是每个样本点与每个聚类中心的距离的倒数,它描述了每个样本点属于每个聚类中心的程度。
模糊C均值聚类算法的步骤如下:
1、初始化模糊矩阵U,其中每一行表示一个样本点,每
一列表示一个聚类中心,每一行的每一列的值表示该样本点属于该聚类中心的程度,U的每一行的和为
1.
2、计算聚类中心。
对每一个聚类中心,根据模糊矩阵U
计算它的坐标,即每一维特征值的均值。
3、更新模糊矩阵U。
根据每一个样本点与该聚类中心的距离,计算每一行的每一列的值,其中值越大,说明该样本点属于该聚类中心的程度就越大。
4、重复步骤2和步骤
3,直到模糊矩阵U不再变化,即收敛为最优解。
模糊C均值聚类算法的优点在于它可以在每一个样本点属于每一类的程度上,提供详细的信息,并且能够处理噪声数据,因此在聚类分析中应用十分广泛。
然而,其缺点在于计算量较大,而且它对初始聚类中心的选取非常敏感。
matlab模糊c均值聚类算法

matlab模糊c均值聚类算法matlab模糊c均值聚类算法模糊C均值聚类算法是一种广泛应用于数据挖掘、图像分割等领域的聚类算法。
相比于传统的C均值聚类算法,模糊C均值聚类算法能够更好地处理噪声数据和模糊边界。
模糊C均值聚类算法的基本思想是将样本集合分为K个聚类集合,使得每个样本点属于某个聚类集合的概率最大。
同时,每个聚类集合的中心点被计算为该聚类集合中所有样本的均值。
具体实现中,模糊C均值聚类算法引入了模糊化权重向量来描述每个样本点属于各个聚类集合的程度。
这些权重值在每次迭代中被更新,直至达到预设的收敛精度为止。
模糊C均值聚类算法的目标函数可以表示为:J = ∑i∑j(wij)q||xi-cj||2其中,xi表示样本集合中的第i个样本,cj表示第j个聚类集合的中心点,wij表示第i个样本点属于第j个聚类集合的权重,q是模糊指数,通常取2。
不同于C均值聚类算法,模糊C均值聚类算法对每个样本点都考虑了其属于某个聚类集合的概率,因此能够更好地处理模糊边界和噪声数据。
同时,模糊C均值聚类算法可以自适应地确定聚类的数量,从而避免了事先设定聚类数量所带来的限制。
在MATLAB中,可以使用fcm函数实现模糊C均值聚类算法。
具体来说,fcm函数的使用方法如下:[idx,center] = fcm(data,k,[options]);其中,data表示样本矩阵,k表示聚类数量,options是一个包含算法参数的结构体。
fcm函数的输出包括聚类标签idx和聚类中心center。
MATLAB中的fcm函数还提供了其他参数和选项,例如模糊权重阈值、最大迭代次数和收敛精度等。
可以根据具体应用需求来设置这些参数和选项。
如何在Matlab中进行模糊聚类分析

如何在Matlab中进行模糊聚类分析在数据分析领域,模糊聚类分析是一种常用的技术,它可以应用于各种领域的数据处理和模式识别问题。
而Matlab作为一种功能强大的数据分析工具,也提供了丰富的函数和工具箱,以支持模糊聚类分析的实施。
1. 引言模糊聚类分析是一种基于模糊集理论的聚类方法,与传统的硬聚类方法不同,它允许样本属于多个聚类中心。
这种方法的优势在于可以更好地应对数据中的不确定性和复杂性,对于某些模糊或模糊边界问题具有更好的解释能力。
2. 模糊聚类算法概述Matlab提供了多种模糊聚类算法的实现,其中最常用的是基于模糊C均值(Fuzzy C-Means,FCM)算法。
FCM算法的基本思想是通过最小化聚类后的模糊划分矩阵与原始数据之间的距离来确定每个样本所属的聚类中心。
3. 数据预处理与特征提取在进行模糊聚类分析之前,需要对原始数据进行预处理和特征提取。
预处理包括数据清洗、缺失值处理和异常值处理等;特征提取则是从原始数据中抽取出具有代表性和区分性的特征,用于模糊聚类分析。
4. 模糊聚类分析步骤在Matlab中,进行模糊聚类分析通常包括以下步骤:(1) 初始化聚类中心:通过随机选择或基于某种准则的方法初始化聚类中心。
(2) 计算模糊划分矩阵:根据当前的聚类中心,计算每个样本属于各个聚类中心的隶属度。
(3) 更新聚类中心:根据当前的模糊划分矩阵,更新聚类中心的位置。
(4) 判断终止条件:通过设置一定的终止条件,判断是否达到停止迭代的条件。
(5) 输出最终结果:得到最终的聚类结果和每个样本所属的隶属度。
5. 模糊聚类结果评估在进行模糊聚类分析后,需要对聚类结果进行评估以验证其有效性和可解释性。
常用的评估指标包括模糊划分矩阵的聚类有效性指标、外部指标和内部指标等。
通过这些指标的比较和分析,可以选择合适的模糊聚类算法和参数设置。
6. 模糊聚类的应用模糊聚类分析在诸多领域中都有广泛的应用。
例如,在图像处理中,可以利用模糊聚类方法对图像进行分割和识别;在生物信息学中,可以应用于基因表达数据的分类和模式识别等。
遗传算法matlab代码

function youhuafunD=code;N=50; % Tunablemaxgen=50; % Tunablecrossrate=0.5; %Tunablemuterate=0.08; %Tunablegeneration=1;num = length(D);fatherrand=randint(num,N,3);score = zeros(maxgen,N);while generation<=maxgenind=randperm(N-2)+2; % 随机配对交叉A=fatherrand(:,ind(1:(N-2)/2));B=fatherrand(:,ind((N-2)/2+1:end));% 多点交叉rnd=rand(num,(N-2)/2);ind=rnd tmp=A(ind);A(ind)=B(ind);B(ind)=tmp;% % 两点交叉% for kk=1:(N-2)/2% rndtmp=randint(1,1,num)+1;% tmp=A(1:rndtmp,kk);% A(1:rndtmp,kk)=B(1:rndtmp,kk);% B(1:rndtmp,kk)=tmp;% endfatherrand=[fatherrand(:,1:2),A,B];% 变异rnd=rand(num,N);ind=rnd [m,n]=size(ind);tmp=randint(m,n,2)+1;tmp(:,1:2)=0;fatherrand=tmp+fatherrand;fatherrand=mod(fatherrand,3);% fatherrand(ind)=tmp;%评价、选择scoreN=scorefun(fatherrand,D);% 求得N个个体的评价函数score(generation,:)=scoreN;[scoreSort,scoreind]=sort(scoreN);sumscore=cumsum(scoreSort);sumscore=sumscore./sumscore(end);childind(1:2)=scoreind(end-1:end);for k=3:Ntmprnd=rand;tmpind=tmprnd difind=[0,diff(t mpind)];if ~any(difind)difind(1)=1;endchildind(k)=scoreind(logical(difind));endfatherrand=fatherrand(:,childind);generation=generation+1;end% scoremaxV=max(score,[],2);minV=11*300-maxV;plot(minV,'*');title('各代的目标函数值');F4=D(:,4);FF4=F4-fatherrand(:,1);FF4=max(FF4,1);D(:,5)=FF4;save DData Dfunction D=codeload youhua.mat% properties F2 and F3F1=A(:,1);F2=A(:,2);F3=A(:,3);if (max(F2)>1450)||(min(F2)<=900)error('DATA property F2 exceed it''s range(900,1450]')end% get group property F1 of data, according to F2 value F4=zeros(size(F1));for ite=11:-1:1index=find(F2<=900+ite*50);F4(index)=ite;endD=[F1,F2,F3,F4];function ScoreN=scorefun(fatherrand,D)F3=D(:,3);F4=D(:,4);N=size(fatherrand,2);FF4=F4*ones(1,N);FF4rnd=FF4-fatherrand;FF4rnd=max(FF4rnd,1);ScoreN=ones(1,N)*300*11;% 这里有待优化for k=1:NFF4k=FF4rnd(:,k);for ite=1:11F0index=find(FF4k==ite);if ~isempty(F0index)tmpMat=F3(F0index);tmpSco=sum(tmpMat);ScoreBin(ite)=mod(tmpSco,300);endendScorek(k)=sum(ScoreBin);endScoreN=ScoreN-Scorek;遗传算法实例:% 下面举例说明遗传算法 %% 求下列函数的最大值 %% f(x)=10*sin(5x)+7*cos(4x) x∈[0,10] %% 将 x 的值用一个10位的二值形式表示为二值问题,一个10位的二值数提供的分辨率是每为 (10-0)/(2^10-1)≈0.01 。
遗传算法介绍并附上Matlab代码
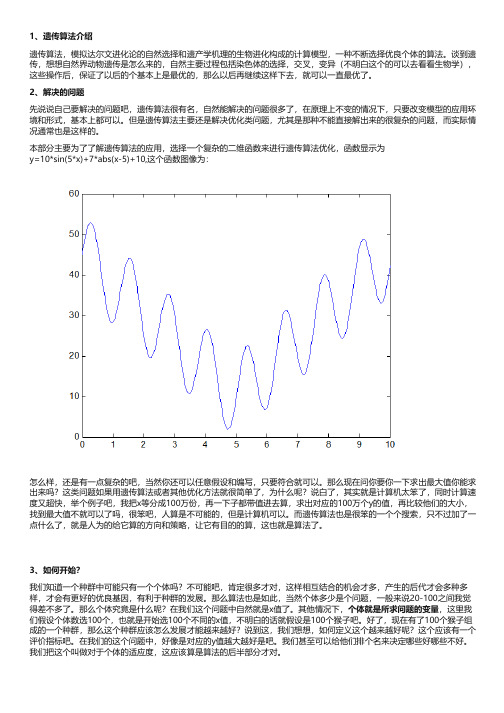
1、遗传算法介绍遗传算法,模拟达尔文进化论的自然选择和遗产学机理的生物进化构成的计算模型,一种不断选择优良个体的算法。
谈到遗传,想想自然界动物遗传是怎么来的,自然主要过程包括染色体的选择,交叉,变异(不明白这个的可以去看看生物学),这些操作后,保证了以后的个基本上是最优的,那么以后再继续这样下去,就可以一直最优了。
2、解决的问题先说说自己要解决的问题吧,遗传算法很有名,自然能解决的问题很多了,在原理上不变的情况下,只要改变模型的应用环境和形式,基本上都可以。
但是遗传算法主要还是解决优化类问题,尤其是那种不能直接解出来的很复杂的问题,而实际情况通常也是这样的。
本部分主要为了了解遗传算法的应用,选择一个复杂的二维函数来进行遗传算法优化,函数显示为y=10*sin(5*x)+7*abs(x-5)+10,这个函数图像为:怎么样,还是有一点复杂的吧,当然你还可以任意假设和编写,只要符合就可以。
那么现在问你要你一下求出最大值你能求出来吗?这类问题如果用遗传算法或者其他优化方法就很简单了,为什么呢?说白了,其实就是计算机太笨了,同时计算速度又超快,举个例子吧,我把x等分成100万份,再一下子都带值进去算,求出对应的100万个y的值,再比较他们的大小,找到最大值不就可以了吗,很笨吧,人算是不可能的,但是计算机可以。
而遗传算法也是很笨的一个个搜索,只不过加了一点什么了,就是人为的给它算的方向和策略,让它有目的的算,这也就是算法了。
3、如何开始?我们知道一个种群中可能只有一个个体吗?不可能吧,肯定很多才对,这样相互结合的机会才多,产生的后代才会多种多样,才会有更好的优良基因,有利于种群的发展。
那么算法也是如此,当然个体多少是个问题,一般来说20-100之间我觉得差不多了。
那么个体究竟是什么呢?在我们这个问题中自然就是x值了。
其他情况下,个体就是所求问题的变量,这里我们假设个体数选100个,也就是开始选100个不同的x值,不明白的话就假设是100个猴子吧。
遗传算法matlab代码

function youhuafunD=code;N=50; % Tunablemaxgen=50; % Tunablecrossrate=0.5; %Tunablemuterate=0.08; %Tunablegeneration=1;num = length(D);fatherrand=randint(num,N,3);score = zeros(maxgen,N);while generation<=maxgenind=randperm(N-2)+2; % 随机配对交叉A=fatherrand(:,ind(1:(N-2)/2));B=fatherrand(:,ind((N-2)/2+1:end));% 多点交叉rnd=rand(num,(N-2)/2);ind=rnd tmp=A(ind);A(ind)=B(ind);B(ind)=tmp;% % 两点交叉% for kk=1:(N-2)/2% rndtmp=randint(1,1,num)+1;% tmp=A(1:rndtmp,kk);% A(1:rndtmp,kk)=B(1:rndtmp,kk);% B(1:rndtmp,kk)=tmp;% endfatherrand=[fatherrand(:,1:2),A,B];% 变异rnd=rand(num,N);ind=rnd [m,n]=size(ind);tmp=randint(m,n,2)+1;tmp(:,1:2)=0;fatherrand=tmp+fatherrand;fatherrand=mod(fatherrand,3);% fatherrand(ind)=tmp;%评价、选择scoreN=scorefun(fatherrand,D);% 求得N个个体的评价函数score(generation,:)=scoreN;[scoreSort,scoreind]=sort(scoreN);sumscore=cumsum(scoreSort);sumscore=sumscore./sumscore(end);childind(1:2)=scoreind(end-1:end);for k=3:Ntmprnd=rand;tmpind=tmprnd difind=[0,diff(tmpind)];if ~any(difind)difind(1)=1;endchildind(k)=scoreind(logical(difind));endfatherrand=fatherrand(:,childind);generation=generation+1;end% scoremaxV=max(score,[],2);minV=11*300-maxV;plot(minV,'*');title('各代的目标函数值');F4=D(:,4);FF4=F4-fatherrand(:,1);FF4=max(FF4,1);D(:,5)=FF4;save DData Dfunction D=codeload youhua.mat% properties F2 and F3F1=A(:,1);F2=A(:,2);F3=A(:,3);if (max(F2)>1450)||(min(F2)<=900)error('DATA property F2 exceed it''s range (900,1450]') end% get group property F1 of data, according to F2 value F4=zeros(size(F1));for ite=11:-1:1index=find(F2<=900+ite*50);F4(index)=ite;endD=[F1,F2,F3,F4];function ScoreN=scorefun(fatherrand,D)F3=D(:,3);F4=D(:,4);N=size(fatherrand,2);FF4=F4*ones(1,N);FF4rnd=FF4-fatherrand;FF4rnd=max(FF4rnd,1);ScoreN=ones(1,N)*300*11;% 这里有待优化for k=1:NFF4k=FF4rnd(:,k);for ite=1:11F0index=find(FF4k==ite);if ~isempty(F0index)tmpMat=F3(F0index);tmpSco=sum(tmpMat);ScoreBin(ite)=mod(tmpSco,300);endendScorek(k)=sum(ScoreBin);endScoreN=ScoreN-Scorek;遗传算法实例:% 下面举例说明遗传算法%% 求下列函数的最大值%% f(x)=10*sin(5x)+7*cos(4x) x∈[0,10] %% 将x 的值用一个10位的二值形式表示为二值问题,一个10位的二值数提供的分辨率是每为(10-0)/(2^10-1)≈0.01 。
模糊c均值聚类FCM算法的MATLAB代码

模糊c均值聚类FCM算法的MATLAB代码我做毕业论文时需要模糊C-均值聚类,找了好长时间才找到这个,分享给大家:FCM算法的两种迭代形式的MATLAB代码写于下,也许有的同学会用得着:m文件1/7:function[U,P,Dit,Cluter_Re,Obj_Fcn,iter]=fuzzycm(Data,C,plot flag,M,epm)%模糊C均值聚类FCM:从随机初始化划分矩阵开始迭代%[U,P,Dit,Cluter_Re,Obj_Fcn,iter]=fuzzycm(Data,C,plotflag,M, epm)%输入:%Data:N某S型矩阵,聚类的原始数据,即一组有限的观测样本集,%Data的每一行为一个观测样本的特征矢量,S为特征矢量%的维数,N为样本点的个数%C:聚类数,1%plotflag:聚类结果2D/3D绘图标记,0表示不绘图,为缺省值%M:加权指数,缺省值为2%epm:FCM算法的迭代停止阈值,缺省值为1.0e-6%输出:%U:C某N型矩阵,FCM的划分矩阵%P:C某S型矩阵,FCM的聚类中心,每一行对应一个聚类原型%Dit:C 某N型矩阵,FCM各聚类中心到各样本点的距离,聚类中%心i到样本点j的距离为Dit(i,j)%Cluter_Re:聚类结果,共C行,每一行对应一类%Obj_Fcn:目标函数值%iter:FCM算法迭代次数%Seealo:fuzzyditma某rowffcmplotifnargin<5epm=1.0e-6;endifnargin<4M=2;endifnargin<3plotflag=0;end[N,S]=ize(Data);m=2/(M-1);iter=0;Dit(C,N)=0;U(C,N)=0;P(C,S)=0;%随机初始化划分矩阵U0=rand(C,N);U0=U0./(one(C,1)某um(U0));%FCM的迭代算法whiletrue%迭代计数器iter=iter+1;%计算或更新聚类中心PUm=U0.^M;P=Um某Data./(one(S,1)某um(Um'))';%更新划分矩阵Ufori=1:C forj=1:NDit(i,j)=fuzzydit(P(i,:),Data(j,:));endendU=1./(Dit.^m.某(one(C,1)某um(Dit.^(-m))));%目标函数值:类内加权平方误差和ifnargout>4|plotflagObj_Fcn(iter)=um(um(Um.某Dit.^2));end%FCM算法迭代停止条件ifnorm(U-U0,Inf)U0=U;end%聚类结果ifnargout>3re=ma某rowf(U);forc=1:Cv=find(re==c);Cluter_Re(c,1:length(v))=v;endend%绘图ifplotflagfcmplot(Data,U,P,Obj_Fcn);endm文件2/7:function[U,P,Dit,Cluter_Re,Obj_Fcn,iter]=fuzzycm2(Data,P0,pl otflag,M,epm)%模糊C均值聚类FCM:从指定初始聚类中心开始迭代%[U,P,Dit,Cluter_Re,Obj_Fcn,iter]=fuzzycm2(Data,P0,plotflag, M,epm)%输入:Data,plotflag,M,epm:见fuzzycm.m%P0:初始聚类中心%输出:U,P,Dit,Cluter_Re,Obj_Fcn,iter:见fuzzycm.m%Seealo:fuzzycmifnargin<5epm=1.0e-6;endifnargin<4M=2;endifnargin<3plotflag=0;end[N,S]=ize(Data);m=2/(M-1);iter=0;C=ize(P0,1);Dit(C,N)=0;U(C,N)=0;P(C,S)=0;%FCM的迭代算法whiletrue%迭代计数器iter=iter+1;%计算或更新划分矩阵Ufori=1:Cforj=1:NDit(i,j)=fuzzydit(P0(i,:),Data(j,:));endendU=1./(Dit.^m.某(one(C,1)某um(Dit.^(-m))));%更新聚类中心PUm=U.^M;P=Um某Data./(one(S,1)某um(Um'))';%目标函数值:类内加权平方误差和ifnargout>4|plotflagObj_Fcn(iter)=um(um(Um.某Dit.^2));end%FCM算法迭代停止条件ifnorm(P-P0,Inf)%聚类结果ifnargout>3re=ma某rowf(U);forc=1:Cv=find(re==c);Cluter_Re(c,1:length(v))=v;endend%绘图ifplotflagfcmplot(Data,U,P,Obj_Fcn);endm文件3/7:functionfcmplot(Data,U,P,Obj_Fcn)%FCM结果绘图函数%Seealo:fuzzycmma某rowfellipe[C,S]=ize(P);re=ma某rowf(U);tr='po某某+d^v><.h>figure(1),plot(Obj_Fcn)title('目标函数值变化曲线','fontize',8)%2D绘图ifS==2 figure(2),plot(P(:,1),P(:,2),'r'),holdonfori=1:Cv=Data(find(re==i),:);plot(v(:,1),v(:,2),tr(rem(i,12)+1))ellipe(ma某(v(:,1))-min(v(:,1)),...ma某(v(:,2))-min(v(:,2)),...[ma某(v(:,1))+min(v(:,1)),...ma某(v(:,2))+min(v(:,2))]/2,'r:')endgridon,title('2D聚类结果图','fontize',8),holdoffend%3D绘图ifS>2figure(2),plot3(P(:,1),P(:,2),P(:,3),'r'),holdonfori=1:Cv=Data(find(re==i),:);plot3(v(:,1),v(:,2),v(:,3),tr(rem(i,12)+1))ellipe(ma某(v(:,1))-min(v(:,1)),...ma某(v(:,2))-min(v(:,2)),...[ma某(v(:,1))+min(v(:,1)),...ma某(v(:,2))+min(v(:,2))]/2,...'r:',(ma某(v(:,3))+min(v(:,3)))/2)endgridon,title('3D聚类结果图','fontize',8),holdoffendm文件4/7:functionD=fuzzydit(A,B)%模糊聚类分析:样本间的距离%D=fuzzydit(A,B)D=norm(A-B);m文件5/7:functionmr=ma某rowf(U,c)%求矩阵U每列第c大元素所在行,c的缺省值为1%调用格式:mr=ma 某rowf(U,c)%Seealo:addrifnargin<2c=1;endN=ize(U,2);mr(1,N)=0;forj=1:Naj=addr(U(:,j),'decend');mr(j)=aj(c);endm文件6/7:functionellipe(a,b,center,tyle,c_3d)%绘制一个椭圆%调用:ellipe(a,b,center,tyle,c_3d)%输入:%a:椭圆的轴长(平行于某轴)%b:椭圆的轴长(平行于y轴)%center:椭圆的中心[某0,y0],缺省值为[0,0]%tyle:绘制的线型和颜色,缺省值为实线蓝色%c_3d:椭圆的中心在3D空间中的z轴坐标,可缺省ifnargin<4tyle='b';endifnargin<3|iempty(center)center=[0,0];endt=1:360;某=a/2某cod(t)+center(1);y=b/2某ind(t)+center(2);ifnargin>4 plot3(某,y,one(1,360)某c_3d,tyle)eleplot(某,y,tyle)endm文件7/7:functionf=addr(a,trort)%返回向量升序或降序排列后各分量在原始向量中的索引%函数调用:f=addr(a,trort)%trort:'acend'or'decend'%defaulti'acend'%--------e某ample--------%addr([4512])returnan:%[3412]。
模糊神经和模糊聚类的MATLAB实现

模糊神经和模糊聚类的MATLAB实现模糊神经网络(Fuzzy Neural Networks)是一种结合了模糊逻辑和神经网络的方法,用于处理不确定性和模糊性问题。
它具有模糊逻辑的灵活性和神经网络的学习和优化能力。
在MATLAB中,可以使用Fuzzy Logic Toolbox来实现模糊神经网络。
下面将介绍如何使用MATLAB实现模糊神经网络。
首先,我们需要定义输入和输出的模糊集合。
可以使用Fuzzy Logic Toolbox提供的各种方法来定义模糊集合的隶属函数,例如使用trimf定义三角隶属函数或者使用gaussmf定义高斯隶属函数。
```input1 = trimf(inputRange, [a1, b1, c1]);input2 = gaussmf(inputRange, [mean, sigma]);output = trapmf(outputRange, [d1, e1, f1, g1]);```接下来,可以使用FIS Editor界面来创建和训练模糊神经网络。
在MATLAB命令窗口中输入fuzzy命令即可打开FIS Editor界面。
在FIS Editor界面中,可以添加输入和输出变量,并设置它们的隶属函数。
然后,可以添加规则来定义输入与输出之间的关系。
规则的形式可以使用自然语言或者模糊规则表达式(Fuzzy Rule Expression)。
训练模糊神经网络可以使用基于模糊神经网络的系统识别方法。
在MATLAB中,可以使用anfis函数来进行自适应网络训练。
anfis函数可以根据训练数据自动调整隶属函数参数和规则权重,以优化模糊神经网络的性能。
```fis = anfis(trainingData);```使用trainfis命令可以将训练好的模糊神经网络应用于新的数据。
trainfis命令将输入数据映射到输出模糊集中,并使用模糊推理进行预测。
输出结果是一个模糊集,可以使用defuzz命令对其进行模糊化。
遗传算法Matlab源代码

遗传算法Matlab源代码完整可以运行的数值优化遗传算法源代码function[X,MaxFval,BestPop,Trace]=fga(FUN,bounds,MaxEranum,PopSiz e,options,pCross,pMutation,pInversion)%[X,MaxFval,BestPop,Trace]=fga(FUN,bounds,MaxEranum,PopSiz e,options,pCross,pMutation,pInversion)% Finds a maximum of a function of several variables.% fga solves problems of the form:% max F(X) subject to: LB = X = UB (LB=bounds(:,1),UB=bounds(:,2))% X - 最优个体对应自变量值% MaxFval - 最优个体对应函数值% BestPop - 最优的群体即为最优的染色体群% Trace - 每代最佳个体所对应的目标函数值% FUN - 目标函数% bounds - 自变量范围% MaxEranum - 种群的代数,取50--500(默认200)% PopSize - 每一代种群的规模;此可取50--200(默认100)% pCross - 交叉概率,一般取0.5--0.85之间较好(默认0.8)% pMutation - 初始变异概率,一般取0.05-0.2之间较好(默认0.1)% pInversion - 倒位概率,一般取0.05-0.3之间较好(默认0.2) % options - 1*2矩阵,options(1)=0二进制编码(默认0),option(1)~=0十进制编码,option(2)设定求解精度(默认1e-4)T1=clock;%检验初始参数if nargin2, error('FMAXGA requires at least three input arguments'); endif nargin==2, MaxEranum=150;PopSize=100;options=[1 1e-4];pCross=0.85;pMutation=0.1;pInversion=0.25;endif nargin==3, PopSize=100;options=[1 1e-4];pCross=0.85;pMutation=0.1;pInversion=0.25;endif nargin==4, options=[1 1e-4];pCross=0.85;pMutation=0.1;pInversion=0.25;endif nargin==5, pCross=0.85;pMutation=0.1;pInversion=0.25;endif nargin==6, pMutation=0.1;pInversion=0.25;endif nargin==7, pInversion=0.25;endif (options(1)==0|options(1)==1)find((bounds(:,1)-bounds(:,2))0)error('数据输入错误,请重新输入:');end% 定义全局变量global m n NewPop children1 children2 VarNum% 初始化种群和变量precision = options(2);bits = ceil(log2((bounds(:,2)-bounds(:,1))' ./ precision));%由设定精度划分区间VarNum = size(bounds,1);[Pop] = InitPop(PopSize,bounds,bits,options);%初始化种群[m,n] = size(Pop);fit = zeros(1,m);NewPop = zeros(m,n);children1 = zeros(1,n);children2 = zeros(1,n);pm0 = pMutation;BestPop = zeros(MaxEranum,n);%分配初始解空间BestPop,TraceTrace = zeros(1,MaxEranum);完整可以运行的数值优化遗传算法源代码Lb = ones(PopSize,1)*bounds(:,1)';Ub = ones(PopSize,1)*bounds(:,2)';%二进制编码采用多点交叉和均匀交叉,并逐步增大均匀交叉概率%浮点编码采用离散交叉(前期)、算术交叉(中期)、AEA重组(后期)OptsCrossOver = [ones(1,MaxEranum)*options(1);...round(unidrnd(2*(MaxEranum-[1:MaxEranum]))/MaxEranum)]';%浮点编码时采用两种自适应变异和一种随机变异(自适应变异发生概率为随机变异发生的2倍)OptsMutation = [ones(1,MaxEranum)*options(1);unidrnd(5,1,MaxEranum)]';if options(1)==3D=zeros(n);CityPosition=bounds;D = sqrt((CityPosition(:, ones(1,n)) - CityPosition(:, ones(1,n))').^2 +...(CityPosition(:,2*ones(1,n)) - CityPosition(:,2*ones(1,n))').^2 );end%========================================================================== % 进化主程序%%===================================== ===================================== eranum = 1;H=waitbar(0,'Please wait...');while(eranum=MaxEranum)for j=1:mif options(1)==1%eval(['[fit(j)]=' FUN '(Pop(j,:));']);%但执行字符串速度比直接计算函数值慢fit(j)=feval(FUN,Pop(j,:));%计算适应度elseif options(1)==0%eval(['[fit(j)]=' FUN '(b2f(Pop(j,:),bounds,bits));']);fit(j)=feval(FUN,(b2f(Pop(j,:),bounds,bits)));elsefit(j)=-feval(FUN,Pop(j,:),D);endend[Maxfit,fitIn]=max(fit);%得到每一代最大适应值Meanfit(eranum)=mean(fit);BestPop(eranum,:)=Pop(fitIn,:);Trace(eranum)=Maxfit;if options(1)==1Pop=(Pop-Lb)./(Ub-Lb);%将定义域映射到[0,1]:[Lb,Ub]--[0,1] ,Pop--(Pop-Lb)./(Ub-Lb)endswitch round(unifrnd(0,eranum/MaxEranum))%进化前期尽量使用实行锦标赛选择,后期逐步增大非线性排名选择case {0} [selectpop]=TournamentSelect(Pop,fit,bits);%锦标赛选择case {1}[selectpop]=NonlinearRankSelect(Pop,fit,bits);%非线性排名选择end完整可以运行的数值优化遗传算法源代码[CrossOverPop]=CrossOver(selectpop,pCross,OptsCrossOver(er anum,:));%交叉[MutationPop]=Mutation(CrossOverPop,fit,pMutation,VarNum,O ptsMutation(eranum,:)); %变异[InversionPop]=Inversion(MutationPop,pInversion);%倒位%更新种群if options(1)==1Pop=Lb+InversionPop.*(Ub-Lb);%还原PopelsePop=InversionPop;endpMutation=pm0+(eranum^3)*(pCross/2-pm0)/(eranum^4); %逐步增大变异率至1/2交叉率percent=num2str(round(100*eranum/MaxEranum));waitbar(eranum/MaxEranum,H,['Evolution complete ',percent,'%']);eranum=eranum+1;endclose(H);% 格式化输出进化结果和解的变化情况t=1:MaxEranum;plot(t,Trace,t,Meanfit);legend('解的变化','种群的变化');title('函数优化的遗传算法');xlabel('进化世代数');ylabel('每一代最优适应度');[MaxFval,MaxFvalIn]=max(Trace);if options(1)==1|options(1)==3X=BestPop(MaxFvalIn,:);elseif options(1)==0X=b2f(BestPop(MaxFvalIn,:),bounds,bits);endhold on;plot(MaxFvalIn,MaxFval,'*');text(MaxFvalIn+5,MaxFval,['FMAX=' num2str(MaxFval)]);str1=sprintf(' Best generation:\n %d\n\n Best X:\n %s\n\n MaxFval\n %f\n',...MaxFvalIn,num2str(X),MaxFval);disp(str1);% -计时T2=clock;elapsed_time=T2-T1;if elapsed_time(6)0elapsed_time(6)=elapsed_time(6)+60;elapsed_time(5)=elapsed_time(5)-1;endif elapsed_time(5)0elapsed_time(5)=elapsed_time(5)+60;elapsed_time(4)=elapsed_t ime(4)-1;end完整可以运行的数值优化遗传算法源代码str2=sprintf('elapsed_time\n %d (h) %d (m) %.4f (s)',elapsed_time(4),elapsed_time(5),elapsed_time(6));disp(str2);%===================================== ===================================== % 遗传操作子程序%%===================================== ===================================== % -- 初始化种群--% 采用浮点编码和二进制Gray编码(为了克服二进制编码的Hamming悬崖缺点)function [initpop]=InitPop(popsize,bounds,bits,options)numVars=size(bounds,1);%变量数目rang=(bounds(:,2)-bounds(:,1))';%变量范围if options(1)==1initpop=zeros(popsize,numVars);initpop=(ones(popsize,1)*rang).*(rand(popsize,numVars))+(ones (popsize,1)*bounds(:,1)');elseif options(1)==0precision=options(2);%由求解精度确定二进制编码长度len=sum(bits);initpop=zeros(popsize,len);%The whole zero encoding individualfor i=2:popsize-1pop=round(rand(1,len));pop=mod(([0 pop]+[pop 0]),2);%i=1时,b(1)=a(1);i1时,b(i)=mod(a(i-1)+a(i),2)%其中原二进制串:a(1)a(2)...a(n),Gray串:b(1)b(2)...b(n)initpop(i,:)=pop(1:end-1);endinitpop(popsize,:)=ones(1,len);%The whole one encoding individualelsefor i=1:popsizeinitpop(i,:)=randperm(numVars);%为Tsp问题初始化种群endend% -- 二进制串解码--function [fval] = b2f(bval,bounds,bits)% fval - 表征各变量的十进制数% bval - 表征各变量的二进制编码串% bounds - 各变量的取值范围% bits - 各变量的二进制编码长度scale=(bounds(:,2)-bounds(:,1))'./(2.^bits-1); %The range of the variablesnumV=size(bounds,1);cs=[0 cumsum(bits)];for i=1:numVa=bval((cs(i)+1):cs(i+1));fval(i)=sum(2.^(size(a,2)-1:-1:0).*a)*scale(i)+bounds(i,1);end% -- 选择操作--完整可以运行的数值优化遗传算法源代码% 采用基于轮盘赌法的非线性排名选择% 各个体成员按适应值从大到小分配选择概率:% P(i)=(q/1-(1-q)^n)*(1-q)^i, 其中P(0)P(1)...P(n), sum(P(i))=1function [NewPop]=NonlinearRankSelect(OldPop,fit,bits) global m n NewPopfit=fit';selectprob=fit/sum(fit);%计算各个体相对适应度(0,1)q=max(selectprob);%选择最优的概率x=zeros(m,2);x(:,1)=[m:-1:1]';[y x(:,2)]=sort(selectprob);r=q/(1-(1-q)^m);%标准分布基值newfit(x(:,2))=r*(1-q).^(x(:,1)-1);%生成选择概率newfit=[0 cumsum(newfit)];%计算各选择概率之和rNums=rand(m,1);newIn=1;while(newIn=m)NewPop(newIn,:)=OldPop(length(find(rNums(newIn)newfit)),:);newIn=newIn+1;end% -- 锦标赛选择(含精英选择) --function [NewPop]=TournamentSelect(OldPop,fit,bits)global m n NewPopnum=floor(m./2.^(1:10));num(find(num==0))=[];L=length(num);a=sum(num);b=m-a;PopIn=1;while(PopIn=L)r=unidrnd(m,num(PopIn),2^PopIn);[LocalMaxfit,In]=max(fit(r),[],2);SelectIn=r((In-1)*num(PopIn)+[1:num(PopIn)]');NewPop(sum(num(1:PopIn))-num(PopIn)+1:sum(num(1:PopIn)),:)=OldPop(SelectIn,:);PopIn=PopIn+1;r=[];In=[];LocalMaxfit=[];endif b1NewPop((sum(num)+1):(sum(num)+b-1),:)=OldPop(unidrnd(m,1,b-1),:);end[GlobalMaxfit,I]=max(fit);%保留每一代中最佳个体NewPop(end,:)=OldPop(I,:);% -- 交叉操作--function [NewPop]=CrossOver(OldPop,pCross,opts)global m n NewPopr=rand(1,m);完整可以运行的数值优化遗传算法源代码y1=find(rpCross);y2=find(r=pCross);len=length(y1);if len==1|(len2mod(len,2)==1)%如果用来进行交叉的染色体的条数为奇数,将其调整为偶数y2(length(y2)+1)=y1(len);y1(len)=[];endi=0;if length(y1)=2if opts(1)==1%浮点编码交叉while(i=length(y1)-2)NewPop(y1(i+1),:)=OldPop(y1(i+1),:);NewPop(y1(i+2),:)=OldPop(y1(i+2),:);if opts(2)==0n1%discret crossoverPoints=sort(unidrnd(n,1,2));NewPop(y1(i+1),Points(1):Points(2))=OldPop(y1(i+2),Points(1):Po ints(2));NewPop(y1(i+2),Points(1):Points(2))=OldPop(y1(i+1),Points(1):Po ints(2));elseif opts(2)==1%arithmetical crossoverPoints=round(unifrnd(0,pCross,1,n));CrossPoints=find(Points==1);r=rand(1,length(CrossPoints));NewPop(y1(i+1),CrossPoints)=r.*OldPop(y1(i+1),CrossPoints)+(1 -r).*OldPop(y1(i+2),CrossPoints);NewPop(y1(i+2),CrossPoints)=r.*OldPop(y1(i+2),CrossPoints)+(1 -r).*OldPop(y1(i+1),CrossPoints); else %AEA recombination Points=round(unifrnd(0,pCross,1,n));CrossPoints=find(Points==1);v=unidrnd(4,1,2);NewPop(y1(i+1),CrossPoints)=(floor(10^v(1)*OldPop(y1(i+1),Cro ssPoints))+...10^v(1)*OldPop(y1(i+2),CrossPoints)-floor(10^v(1)*OldPop(y1(i+2),CrossPoints)))/10^v(1);NewPop(y1(i+2),CrossPoints)=(floor(10^v(2)*OldPop(y1(i+2),Cro ssPoints))+...10^v(2)*OldPop(y1(i+1),CrossPoints)-floor(10^v(2)*OldPop(y1(i+1),CrossPoints)))/10^v(2);endi=i+2;endelseif opts(1)==0%二进制编码交叉while(i=length(y1)-2)if opts(2)==0[NewPop(y1(i+1),:),NewPop(y1(i+2),:)]=EqualCrossOver(OldPop( y1(i+1),:),OldPop(y1(i+2),:)); else[NewPop(y1(i+1),:),NewPop(y1(i+2),:)]=MultiPointCross(OldPop( y1(i+1),:),OldPop(y1(i+2),:)); endi=i+2;endelse %Tsp问题次序杂交for i=0:2:length(y1)-2xPoints=sort(unidrnd(n,1,2));NewPop([y1(i+1)y1(i+2)],xPoints(1):xPoints(2))=OldPop([y1(i+2)y1(i+1)],xPoints(1):xPoints(2));完整可以运行的数值优化遗传算法源代码%NewPop(y1(i+2),xPoints(1):xPoints(2))=OldPop(y1(i+1),xPo ints(1):xPoints(2));temp=[OldPop(y1(i+1),xPoints(2)+1:n)OldPop(y1(i+1),1:xPoints(2))];for del1i=xPoints(1):xPoints(2)temp(find(temp==OldPop(y1(i+2),del1i)))=[];endNewPop(y1(i+1),(xPoints(2)+1):n)=temp(1:(n-xPoints(2)));NewPop(y1(i+1),1:(xPoints(1)-1))=temp((n-xPoints(2)+1):end);temp=[OldPop(y1(i+2),xPoints(2)+1:n)OldPop(y1(i+2),1:xPoints(2))];for del2i=xPoints(1):xPoints(2)temp(find(temp==OldPop(y1(i+1),del2i)))=[];endNewPop(y1(i+2),(xPoints(2)+1):n)=temp(1:(n-xPoints(2)));NewPop(y1(i+2),1:(xPoints(1)-1))=temp((n-xPoints(2)+1):end);endendendNewPop(y2,:)=OldPop(y2,:);% -二进制串均匀交叉算子function[children1,children2]=EqualCrossOver(parent1,parent2) global n children1 children2hidecode=round(rand(1,n));%随机生成掩码crossposition=find(hidecode==1);holdposition=find(hidecode==0);children1(crossposition)=parent1(crossposition);%掩码为1,父1为子1提供基因children1(holdposition)=parent2(holdposition);%掩码为0,父2为子1提供基因children2(crossposition)=parent2(crossposition);%掩码为1,父2为子2提供基因children2(holdposition)=parent1(holdposition);%掩码为0,父1为子2提供基因% -二进制串多点交叉算子function[Children1,Children2]=MultiPointCross(Parent1,Parent2)%交叉点数由变量数决定global n Children1 Children2 VarNumChildren1=Parent1;Children2=Parent2;Points=sort(unidrnd(n,1,2*VarNum));for i=1:VarNumChildren1(Points(2*i-1):Points(2*i))=Parent2(Points(2*i-1):Points(2*i));Children2(Points(2*i-1):Points(2*i))=Parent1(Points(2*i-1):Points(2*i));end% -- 变异操作--function[NewPop]=Mutation(OldPop,fit,pMutation,VarNum,opts) global m n NewPopNewPop=OldPop;r=rand(1,m);MutIn=find(r=pMutation);L=length(MutIn);完整可以运行的数值优化遗传算法源代码i=1;if opts(1)==1%浮点变异maxfit=max(fit);upfit=maxfit+0.05*abs(maxfit);if opts(2)==1|opts(2)==3while(i=L)%自适应变异(自增或自减)Point=unidrnd(n);T=(1-fit(MutIn(i))/upfit)^2;q=abs(1-rand^T);%if q1%按严格数学推理来说,这段程序是不能缺少的% q=1%endp=OldPop(MutIn(i),Point)*(1-q);if unidrnd(2)==1NewPop(MutIn(i),Point)=p+q;elseNewPop(MutIn(i),Point)=p;endi=i+1;endelseif opts(2)==2|opts(2)==4%AEA变异(任意变量的某一位变异)while(i=L)Point=unidrnd(n);T=(1-abs(upfit-fit(MutIn(i)))/upfit)^2;v=1+unidrnd(1+ceil(10*T));%v=1+unidrnd(5+ceil(10*eranum/MaxEranum));q=mod(floor(OldPop(MutIn(i),Point)*10^v),10);NewPop(MutIn(i),Point)=OldPop(MutIn(i),Point)-(q-unidrnd(9))/10^v;i=i+1;endelsewhile(i=L)Point=unidrnd(n);if round(rand)NewPop(MutIn(i),Point)=OldPop(MutIn(i),Point)*(1-rand);elseNewPop(MutIn(i),Point)=OldPop(MutIn(i),Point)+(1-OldPop(MutIn(i),Point))*rand; endi=i+1;endendelseif opts(1)==0%二进制串变异if L=1while i=Lk=unidrnd(n,1,VarNum); %设置变异点数(=变量数)for j=1:length(k)if NewPop(MutIn(i),k(j))==1NewPop(MutIn(i),k(j))=0;else完整可以运行的数值优化遗传算法源代码NewPop(MutIn(i),k(j))=1;endendi=i+1;endendelse%Tsp变异if opts(2)==1|opts(2)==2|opts(2)==3|opts(2)==4numMut=ceil(pMutation*m);r=unidrnd(m,numMut,2);[LocalMinfit,In]=min(fit(r),[],2);SelectIn=r((In-1)*numMut+[1:numMut]');while(i=numMut)mPoints=sort(unidrnd(n,1,2));if mPoints(1)~=mPoints(2)NewPop(SelectIn(i),1:mPoints(1)-1)=OldPop(SelectIn(i),1:mPoints(1)-1);NewPop(SelectIn(i),mPoints(1):mPoints(2)-1)=OldPop(SelectIn(i),mPoints(1)+1:mPoints(2));NewPop(SelectIn(i),mPoints(2))=OldPop(SelectIn(i),mPoints(1));NewPop(SelectIn(i),mPoints(2)+1:n)=OldPop(SelectIn(i),mPoints( 2)+1:n);elseNewPop(SelectIn(i),:)=OldPop(SelectIn(i),:);endi=i+1;endr=rand(1,m);MutIn=find(r=pMutation);L=length(MutIn);while i=LmPoints=sort(unidrnd(n,1,2));rIn=randperm(mPoints(2)-mPoints(1)+1);NewPop(MutIn(i),mPoints(1):mPoints(2))=OldPop(MutIn(i),mPoin ts(1)+rIn-1);i=i+1;endendend% -- 倒位操作--function [NewPop]=Inversion(OldPop,pInversion)global m n NewPopNewPop=OldPop;r=rand(1,m);PopIn=find(r=pInversion);len=length(PopIn);if len=1while(i=len)d=sort(unidrnd(n,1,2));完整可以运行的数值优化遗传算法源代码NewPop(PopIn(i),d(1):d(2))=OldPop(PopIn(i),d(2):-1:d(1)); i=i+1;。
基于改进遗传算法的模糊C均值聚类算法

基于改进遗传算法的模糊C均值聚类算法
董军浪;王庆飞
【期刊名称】《西安工程大学学报》
【年(卷),期】2008(022)005
【摘要】针对传统模糊C均值聚类算法(FCM)的缺陷,提出了一种基于改进遗传算法的模糊聚类方法.利用改进遗传算法强大的全局寻优能力,这种算法较好地克服了FCM算法对初始化敏感、容易陷入局部最优的缺陷.仿真实验证明,该算法具有较强的全局寻优能力和较快的收敛速度.
【总页数】5页(P605-609)
【作者】董军浪;王庆飞
【作者单位】西安工程大学科技处,陕西,西安,710048;西安工程大学,理学院,陕西,西安,710048
【正文语种】中文
【中图分类】TP183
【相关文献】
1.基于免疫遗传算法的模糊C均值聚类算法应用研究 [J], 李鹏松;石卓;刘欣
2.模糊C均值聚类图像分割的改进遗传算法研究 [J], 杨凯;蒋华伟
3.基于改进遗传算法的加权模糊C均值聚类算法 [J], 李同强;周天弋;吴斌
4.基于改进遗传算法的加权模糊C均值聚类算法 [J], 李同强;周天弋;吴斌
5.基于遗传算法和模糊C均值聚类的WSN分簇路由算法 [J], 董发志;丁洪伟;杨志军;熊成彪;张颖婕
因版权原因,仅展示原文概要,查看原文内容请购买。
MATLAB模糊c均值算法FCM分类全解

1));
%求隶属度
end
end
end
if max(max(abs(U-U0)))<e
a=0;
end
Z=Z+1
if Z>100
break
end
end
%输出图像
t=max(U,[],2); t=repmat(t,1,c); %最大值排成1*c U=double(t==U); for i=1:N
F(i)= find(U(i,:)==1); end F=reshape(F,n1,n2); map=[1,1,1;0,0,0;1,0,0;0,1,0;0,0,1] figure,imshow(uint8(F),map)
A=reshape(A,n1*n2,1);
N=n1*n2;
%样本数
U0=rand(N,c);
U1=sum(U0,2 ); %求出每一行的元素总数
U2=repmat(U1,1,c);%将每一行总数复制成n*c矩阵
U=U0./U2;
clear U0 U1 U2;
U0=U;
a=1;
Z=0;
while a
for j=1:c
V(j)=sum(U(:,j).^m.*A)/sum(U(:,j).^m); %求聚类中心
W(:,j)=abs(repmat(V(j),N,1)-A); %距离
end
for i=1:N
for j=1:c;
if W(i,j)==0
U(i,:)=zeros(1,c);
U(i,j)=1;
else
U(i,j)=1/sum(repmat(W(i,j),1,c)./W(i,:)).^(2/(m-
FCM算法是一种基于划分的聚类算法,它的思想就是使 得被划分到同一簇的对象之间相似度最大,而不同簇之间的相 似度最小。模糊C均值算法是普通C均值算法的改进,普通C 均值算法对于数据的划分是硬性的,而FCM则是一种 %functio n [U,z,U1]=SARFCM %读入并显示图像 clear,clc
模糊c均值聚类算法python

模糊C均值聚类算法 Python在数据分析领域中,聚类是一种广泛应用的技术,用于将数据集分成具有相似特征的组。
模糊C均值(Fuzzy C-Means)聚类算法是一种经典的聚类算法,它能够将数据点分到不同的聚类中心,并给出每个数据点属于每个聚类的概率。
本文将介绍模糊C均值聚类算法的原理、实现步骤以及使用Python语言实现的示例代码。
1. 模糊C均值聚类算法简介模糊C均值聚类算法是一种基于距离的聚类算法,它将数据点分配到不同的聚类中心,使得各个聚类中心到其所属数据点的距离最小。
与传统的K均值聚类算法不同,模糊C均值聚类算法允许每个数据点属于多个聚类中心,并给出每个数据点属于每个聚类的概率。
模糊C均值聚类算法的核心思想是将每个数据点分配到每个聚类中心的概率表示为隶属度(membership),并通过迭代优化隶属度和聚类中心来得到最优的聚类结果。
2. 模糊C均值聚类算法原理2.1 目标函数模糊C均值聚类算法的目标是最小化以下目标函数:其中,N表示数据点的数量,K表示聚类中心的数量,m是一个常数,u_ij表示数据点x_i属于聚类中心c_j的隶属度。
目标函数由两部分组成,第一部分是数据点属于聚类中心的隶属度,第二部分是数据点到聚类中心的距离。
通过优化目标函数,可以得到最优的聚类结果。
2.2 隶属度的更新隶属度的更新通过以下公式进行计算:其中,m是一个常数,决定了对隶属度的惩罚程度。
m越大,隶属度越趋近于二值化,m越小,隶属度越趋近于均匀分布。
2.3 聚类中心的更新聚类中心的更新通过以下公式进行计算:通过迭代更新隶属度和聚类中心,最终可以得到收敛的聚类结果。
3. 模糊C均值聚类算法实现步骤模糊C均值聚类算法的实现步骤如下:1.初始化聚类中心。
2.计算每个数据点属于每个聚类中心的隶属度。
3.更新聚类中心。
4.判断迭代是否收敛,若未收敛,则返回步骤2;若已收敛,则输出聚类结果。
4. 模糊C均值聚类算法 Python 实现示例代码下面是使用Python实现模糊C均值聚类算法的示例代码:import numpy as npdef fuzzy_cmeans_clustering(X, n_clusters, m=2, max_iter=100, tol=1e-4): # 初始化聚类中心centroids = X[np.random.choice(range(len(X)), size=n_clusters)]# 迭代更新for _ in range(max_iter):# 计算隶属度distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=-1)membership = 1 / np.power(distances, 2 / (m-1))membership = membership / np.sum(membership, axis=1, keepdims=True)# 更新聚类中心new_centroids = np.sum(membership[:, :, np.newaxis] * X[:, np.newaxis], axis=0) / np.sum(membership[:, :, np.newaxis], axis=0)# 判断是否收敛if np.linalg.norm(new_centroids - centroids) < tol:breakcentroids = new_centroidsreturn membership, centroids# 使用示例X = np.random.rand(100, 2)membership, centroids = fuzzy_cmeans_clustering(X, n_clusters=3)print("聚类中心:")print(centroids)print("隶属度:")print(membership)上述代码实现了模糊C均值聚类算法,其中X是输入的数据集,n_clusters是聚类中心的数量,m是模糊指数,max_iter是最大迭代次数,tol是迭代停止的阈值。
遗传算法优化的matlab案例

遗传算法(Genetic Algorithm,GA)是一种模拟生物进化过程的搜索和优化算法,通过模拟生物的遗传、交叉和变异操作来寻找问题的最优解。
它以一种迭代的方式生成和改进解决方案,并通过评估每个解决方案的适应度来选择下一代解决方案。
在Matlab中,遗传算法优化工具箱提供了方便的函数和工具,可以帮助用户快速开发和实现遗传算法优化问题。
下面,我们以一个简单的最优化问题为例,演示在Matlab中如何使用遗传算法优化工具箱进行优化。
假设我们要优化一个简单的函数f(x),其中x是一个实数。
我们的目标是找到使得f(x)取得最小值的x值。
具体来说,我们将优化以下函数: f(x) = x² - 4x + 4首先,我们在Matlab中定义目标函数f(x)的句柄(用于计算函数值)和约束条件(如果有的话)。
代码如下:function y = testfunction(x)y = x^2 - 4*x + 4;end接下来,我们需要使用遗传算法优化工具箱的函数ga来进行优化。
我们需要指定目标函数的句柄、变量的取值范围和约束条件(如果有的话),以及其他一些可选参数。
以下是一个示例代码:options = gaoptimset('Display', 'iter'); % 设置显示迭代过程lb = -10; % 变量下界ub = 10; % 变量上界[x, fval] = ga(@testfunction, 1, [], [], [], [], lb, ub, [], options);在上面的代码中,gaoptimset函数用于设置遗传算法的参数。
在这里,我们使用了可选参数'Display',它的值设置为'iter',表示显示迭代过程。
变量lb和ub分别指定了变量的取值范围,我们在这里将其设置为-10到10之间的任意实数。
横线[]表示没有约束条件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
BB=GaussMutation(AA,LB,UB);
farm(:,i)=BB;
end
end
disp(k);
k=k+1;
end
%% 绘图
BESTY2=BESTY;
BESTX2=BESTX;
for k=1:K
TempY=BESTY(1:k);
minTempY=min(TempY);
% UB 决策变量的上界,M×1的向量
% D 原始样本数据,n×p的矩阵
% c 分类个数
% m 模糊C均值聚类数学模型中的指数
%% 输出参数列表
% BESTX K×1细胞结构,每一个元素是M×1向量,记录每一代的最优个体
% BESTY K×1矩阵,记录每一代的最优个体的评价函数值
% ALLX K×1细胞结构,每一个元素是M×N矩阵,记录全部个体
k=1;%迭代计数器初始化
%% 第二步:迭代过程
while k<=K
%% 以下是交叉过程
newfarm=zeros(M,2*N);
Ser=randperm(N);%两两随机配对的配对表
A=farm(:,Ser(1));
B=farm(:,Ser(2));
P0=unidrnd(M-1);
f2=FITNESS(SER(3*i-1));
f3=FITNESS(SER(3*i));
if f1<=f2&&f1<=f3
farm(:,i)=FARM(:,SER(3*i-2));
fitness(:,i)=FITNESS(:,SER(3*i-2));
elseif f2<=f1&&f2<=f3
farm(:,i)=FARM(:,SER(3*i-1));
fitness(:,i)=FITNESS(:,SER(3*i-1));
else
farm(:,i)=FARM(:,SER(3*i));
fitness(:,i)=FITNESS(:,SER(3*i));
end
end
%% 记录最佳个体和收敛曲线
X=farm;
Y=fitness;
ALLX{k}=X;
ALLY(k,:)=Y;
minY=min(Y);
pos=find(Y==minY);
BESTX{k}=X(:,pos(1));
BESTY(k)=minY;
%% 变异
for i=1:N
if Pm>rand&&pos(1)~=i
ALLX=cell(K,1);%细胞结构,每一个元素是M×N矩阵,记录每一代的个体
ALLY=zeros(K,N);%K×N矩阵,记录每一代评价函数值
BESTX=cell(K,1);%细胞结构,每一个元素是M×1向量,记录每一代的最优个体
BESTY=zeros(K,1);%K×1矩阵,记录每一代的最优个体的评价函数值
模糊C-均值算法容易收敛于局部极小点,为了克服该缺点,将遗传算法应用于模糊C-均值算法(FCM)的优化计算中,由遗传算法得到初始聚类中心,再使用标准的模糊C-均值聚类算法得到最优分类结果。
function [BESTX,BESTY,ALLX,ALLY]=GAFCM(K,N,Pm,LB,UB,D,c,m)
%% 选择复制
SER=randperm(3*N);
FITNESS=zeros(1,3*N);
fitness=zeros(1,N); ຫໍສະໝຸດ for i=1:(3*N)
Beta=FARM(:,i);
FITNESS(i)=FIT(Beta,D,c,m);
end
for i=1:N
f1=FITNESS(SER(3*i-2));
ylabel('函数值')
xlabel('迭代次数')
grid on
a=[A(1:P0,:);B((P0+1):end,:)];%产生子代a
b=[B(1:P0,:);A((P0+1):end,:)];%产生子代b
newfarm(:,2*N-1)=a;%加入子代种群
newfarm(:,2*N)=b;
for i=1:(N-1)
A=farm(:,Ser(i));
%% 此函数实现遗传算法,用于模糊C-均值聚类
% GreenSim团队原创作品,转载请注明
% 欢迎访问GreenSim——算法仿真团队→/greensim
%% 输入参数列表
% K 迭代次数
% N 种群规模,要求是偶数
% Pm 变异概率
% LB 决策变量的下界,M×1的向量
% ALLY K×N矩阵,记录全部个体的评价函数值
%% 第一步:
M=length(LB);%决策变量的个数
%种群初始化,每一列是一个样本
farm=zeros(M,N);
for i=1:M
x=unifrnd(LB(i),UB(i),1,N);
farm(i,:)=x;
end
%输出变量初始化
B=farm(:,Ser(i+1));
P0=unidrnd(M-1);
a=[A(1:P0,:);B((P0+1):end,:)];
b=[B(1:P0,:);A((P0+1):end,:)];
newfarm(:,2*i-1)=a;
newfarm(:,2*i)=b;
end
FARM=[farm,newfarm];
posY=find(TempY==minTempY);
BESTY2(k)=minTempY;
BESTX2{k}=BESTX{posY(1)};
end
BESTY=BESTY2;
BESTX=BESTX2;
plot(BESTY,'-ko','MarkerEdgeColor','k','MarkerFaceColor','k','MarkerSize',2)