总结:线性回归分析的基本步骤
线性回归的求解方法

线性回归的求解方法线性回归是一种广泛应用于机器学习和数据分析领域的数学方法,它能从现有数据中分析出变量间的关系,从而预测未来的结果。
该方法在各行各业都得到了广泛应用,包括经济学、工程学、医学、生物学等领域。
本文将主要介绍线性回归的求解方法,包括最小二乘法和梯度下降法。
一、最小二乘法最小二乘法是一种常见的线性回归求解方法,它的基本思想是找到一条直线,使得这条直线与数据点之间的距离最短。
距离通常是指欧几里得距离或曼哈顿距离。
具体来说,最小二乘法的公式如下:$$\hat{\beta} = (X^TX)^{-1}X^TY$$其中,$\hat{\beta}$表示回归系数的向量,$X$表示自变量的矩阵,$Y$表示因变量的向量。
最小二乘法的求解过程包括以下几个步骤:1. 将自变量和因变量分别存储在矩阵$X$和向量$Y$中。
2. 计算$X^TX$的逆矩阵,如果逆矩阵不存在,则说明矩阵$X$线性相关,需要进行特征分解或奇异值分解来处理。
3. 计算$\hat{\beta}$的值,即$(X^TX)^{-1}X^TY$。
最小二乘法的优点在于简单易懂,求解速度较快。
但是,它也存在一些缺点,例如当数据集中存在极端值时,该方法会对这些极端值敏感。
二、梯度下降法与最小二乘法相比,梯度下降法在面对大规模数据时能够更好地处理。
梯度下降法的基本思想是根据误差的方向和大小不断更新回归系数的值,以达到最小化误差的目的。
梯度下降法的公式如下:$$\beta_{new}=\beta_{old}-\alpha\frac{\partial RSS}{\partial\beta}$$其中,$\beta_{new}$表示迭代后的回归系数向量,$\beta_{old}$表示迭代前的回归系数向量,$\alpha$表示学习率,$RSS$表示残差平方和。
梯度下降法的求解过程包括以下几个步骤:1. 初始化回归系数向量$\beta$和学习率$\alpha$。
2. 计算回归函数的预测值$y$3. 计算误差$e=y-y_{true}$4. 计算残差平方和$RSS=\sum_{i=1}^{n}e_i^2$5. 计算参数向量的梯度$\frac{\partial RSS}{\partial \beta}$6. 更新参数向量:$\beta_{new}=\beta_{old}-\alpha\frac{\partial RSS}{\partial \beta}$7. 通过迭代不断更新参数,直到误差达到最小值。
线性回归精确分析讲课文档

(6)指定作图时各数据点的标志变量(case labels)
11
第十一页,共76页。
一元线性回归分析操作
(二) statistics选项 (1)基本统计量输出
– Estimates:默认.显示回归系数相关统计量.
– confidence intervals:每个非标准化的回归系数95%的置信
起的因变量y的平均变动
(二)多元线性回归分析的主要问题
– 回归方程的检验
– 自变量筛选 – 多重共线性问题
18
第Hale Waihona Puke 八页,共76页。多元线性回归方程的检验
(一)拟和优度检验:
(1)判定系数R2:
– R是y和xi的复相关系数(或观察值与预测值的相关系数),测定了因变量 y与所有自变量全体之间线性相关程度
第二十三页,共76页。
23
多元线性回归分析中的自变量筛选
(二)自变量向前筛选法(forward): • 即:自变量不断进入回归方程的过程. • 首先,选择与因变量具有最高相关系数的自变量进入方程,
并进行各种检验;
• 其次,在剩余的自变量中寻找偏相关系数最高的变量进入回归方 程,并进行检验;
– 默认:回归系数检验的概率值小于PIN(0.05)才可以进入方程.
6
第六页,共76页。
一元线性回归方程的检验
(一)拟和优度检验:
(3)统计量:判定系数
– R2=SSR/SST=1-SSE/SST. – R2体现了回归方程所能解释的因变量变差的比例;1-R2则体现
了因变量总变差中,回归方程所无法解释的比例。
– R2越接近于1,则说明回归平方和占了因变量总变差平方和的绝大
如何进行回归分析:步骤详解(四)

回归分析是统计学中一种重要的分析方法,用于研究两个或更多变量之间的关系。
它可以帮助我们了解变量之间的因果关系,预测未来的趋势,以及检验假设。
在实际应用中,回归分析被广泛用于经济学、社会学、医学等领域。
下面将详细介绍如何进行回归分析的步骤。
第一步:确定研究的目的和问题在进行回归分析之前,首先需要明确研究的目的和问题。
例如,我们想要了解某个因变量与几个自变量之间的关系,或者我们想要预测未来的趋势。
明确研究目的和问题可以帮助我们选择合适的回归模型和变量。
第二步:收集数据接下来,我们需要收集相关的数据。
数据可以是实验数据、调查数据或者是已有的数据集。
在收集数据的过程中,需要保证数据的质量和完整性,以及避免数据的缺失和错误。
同时,还需要考虑数据的样本量和代表性,以确保结果的可靠性和有效性。
第三步:选择合适的回归模型在确定了研究目的、问题和收集了相关数据之后,接下来需要选择合适的回归模型。
常见的回归模型包括线性回归模型、多元线性回归模型、逻辑回归模型等。
选择合适的回归模型需要考虑多个因素,包括变量之间的关系、数据类型、模型的假设和可解释性等。
第四步:建立回归模型在选择了合适的回归模型之后,接下来需要建立回归模型。
建立回归模型的过程包括确定因变量和自变量之间的关系、估计模型的参数、检验模型的拟合度等。
在建立回归模型的过程中,需要考虑模型的解释能力和预测能力,以及模型的稳健性和可靠性。
第五步:评估回归模型建立回归模型之后,需要对模型的拟合度进行评估。
常用的评估方法包括确定系数(R-squared)、残差分析、假设检验等。
评估回归模型的过程可以帮助我们了解模型的解释能力和预测能力,以及检验模型的假设和稳健性。
第六步:解释结果和做出推断最后,根据回归模型的结果,我们可以对变量之间的关系进行解释和推断。
通过对回归系数的解释和显著性检验,我们可以了解自变量与因变量之间的关系,以及变量对因变量的影响程度。
同时,还可以利用回归模型进行预测和假设检验,以支持决策和推断。
回归分析方法总结全面

回归分析方法总结全面回归分析是一种常用的统计分析方法,用于建立一个或多个自变量与因变量之间的关系模型,并进行预测和解释。
在许多研究领域和实际应用中,回归分析被广泛使用。
下面是对回归分析方法的全面总结。
1.简单线性回归分析:简单线性回归分析是最基本的回归分析方法之一,用于建立一个自变量和一个因变量之间的线性关系模型。
它的方程为Y=a+bX,其中Y是因变量,X是自变量,a是截距,b是斜率。
通过最小二乘法估计参数a和b,可以用于预测因变量的值。
2. 多元线性回归分析:多元线性回归分析是在简单线性回归的基础上扩展的方法,用于建立多个自变量和一个因变量之间的线性关系模型。
它的方程为Y = a + b1X1 + b2X2 + ... + bnXn,其中n是自变量的个数。
通过最小二乘法估计参数a和bi,可以用于预测因变量的值。
3.对数线性回归分析:对数线性回归分析是在简单线性回归或多元线性回归的基础上,将自变量或因变量取对数后建立的模型。
这种方法适用于因变量和自变量之间呈现指数关系的情况。
对数线性回归分析可以通过最小二乘法进行参数估计,并用于预测因变量的对数。
4.多项式回归分析:多项式回归分析是在多元线性回归的基础上,将自变量进行多项式变换后建立的模型。
它可以用于捕捉自变量和因变量之间的非线性关系。
多项式回归分析可以通过最小二乘法估计参数,并进行预测。
5.非线性回归分析:非线性回归分析是一种更一般的回归分析方法,用于建立自变量和因变量之间的非线性关系模型。
这种方法可以适用于任意形式的非线性关系。
非线性回归分析可以通过最小二乘法或其他拟合方法进行参数估计,用于预测因变量的值。
6.逐步回归分析:逐步回归分析是一种变量选择方法,用于确定最重要的自变量对因变量的解释程度。
它可以帮助选择最佳的自变量组合,建立最合适的回归模型。
逐步回归分析可以根据其中一种准则(如逐步回归F检验、最大似然比等)逐步添加或删除自变量,直到最佳模型被找到为止。
总结:线性回归分析的基本步骤
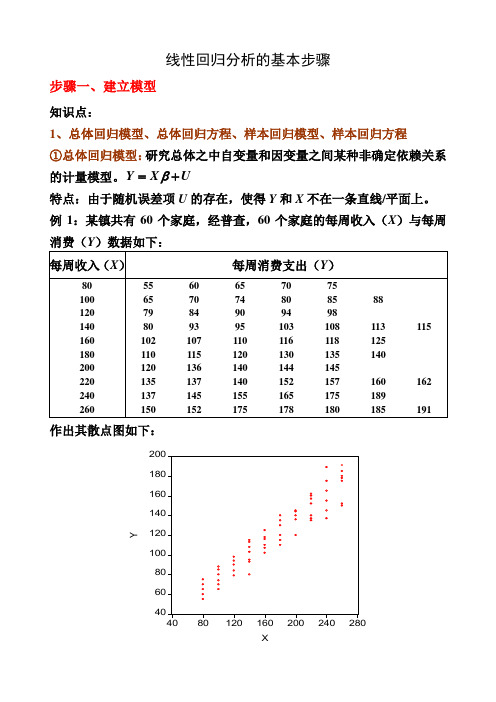
线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X U β=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:作出其散点图如下:②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。
总体回归方程的求法:以例1的数据为例,求出E (Y |X 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入()01|i i i E Y X X ββ=+可得:01001177100171372000.6ββββββ=+=⎧⎧⇒⎨⎨=+=⎩⎩以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。
如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型ˆY X e β=+就称为样本回归模型。
④样本回归方程(线):通过样本数据估计出ˆβ,得到样本观测值的拟合值与解释变量之间的关系方程ˆˆY X β=称为样本回归方程。
如下图所示:⑤四者之间的关系:ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。
完整的线性回归算法流程

完整的线性回归算法流程英文回答:Linear regression is a popular algorithm used for predicting continuous numerical values based on a set of input variables. It assumes a linear relationship between the input variables and the target variable. The algorithm aims to find the best-fit line that minimizes the sum of the squared differences between the predicted and actual values.The complete workflow of a linear regression algorithm can be divided into several steps:1. Data Collection: Gather the dataset that contains the input variables and the corresponding target variable. The dataset should be representative and have enough samples to train the model effectively.2. Data Preprocessing: Clean the dataset by handlingmissing values, outliers, and any other data quality issues. This step may also involve feature selection or extractionto improve the model's performance.3. Splitting the Dataset: Divide the dataset into two parts: training set and test set. The training set is usedto train the model, while the test set is used to evaluate its performance. Typically, the dataset is split into a70:30 or 80:20 ratio.4. Feature Scaling: Perform feature scaling if necessary. Linear regression is sensitive to the scale ofthe input variables, so it is important to normalize or standardize them to a similar range.5. Model Training: Train the linear regression model using the training set. The model learns the coefficients and intercept that define the best-fit line.6. Model Evaluation: Evaluate the performance of the trained model using the test set. Common evaluation metrics for linear regression include mean squared error (MSE),root mean squared error (RMSE), and coefficient of determination (R-squared).7. Model Optimization: If the model's performance is not satisfactory, consider optimizing it by adjusting hyperparameters or trying different variations of the algorithm. This step may involve techniques like regularization or feature engineering.8. Model Deployment: Once the model is optimized and meets the desired performance, it can be deployed for making predictions on new, unseen data. The deployment can be in the form of an API, a web application, or any other suitable format.Overall, the linear regression algorithm follows a systematic approach of data collection, preprocessing, training, evaluation, optimization, and deployment to build an effective predictive model.中文回答:线性回归是一种常用的算法,用于基于一组输入变量预测连续数值。
线性回归分析

一元线性回归分析1.理论回归分析是通过试验和观测来寻找变量之间关系的一种统计分析方法。
主要目的在于了解自变量与因变量之间的数量关系。
采用普通最小二乘法进行回归系数的探索,对于一元线性回归模型,设(X1,Y1),(X2,Y2),…,(X n,Y n)是取至总体(X,Y)的一组样本。
对于平面中的这n个点,可以使用无数条曲线来拟合。
要求样本回归函数尽可能好地拟合这组值。
综合起来看,这条直线处于样本数据的中心位置最合理。
由此得回归方程:y=β0+β1x+ε其中Y为因变量,X为解释变量(即自变量),ε为随机扰动项,β0,β1为标准化的偏斜率系数,也叫做回归系数。
ε需要满足以下4个条件:1.数据满足近似正态性:服从正态分布的随机变量。
2.无偏态性:∑(εi)=03.同方差齐性:所有的εi 的方差相同,同时也说明εi与自变量、因变量之间都是相互独立的。
4.独立性:εi 之间相互独立,且满足COV(εi,εj)=0(i≠j)。
最小二乘法的原则是以“残差平方和最小”确定直线位置。
用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。
最常用的是普通最小二乘法(OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。
线性回归分析根据已有样本的观测值,寻求β0,β1的合理估计值^β0,^β1,对样本中的每个x i,由一元线性回归方程可以确定一个关于y i的估计值^y i=^β0+^β1x i,称为Y关于x的线性回归方程或者经验回归公式。
^β0=y-x^β1,^β1=L xy/L xx,其中L xx=J12−x2,L xy=J1−xy,x=1J1 ,y=1J1 。
再通过回归方程的检验:首先计算SST=SSR+SSE=J1^y−y 2+J1−^y2。
其中SST为总体平方和,代表原始数据所反映的总偏差大小;SSR为回归平方和(可解释误差),由自变量引起的偏差,放映X的重要程度;SSE为剩余平方和(不可解释误差),由试验误差以及其他未加控制因子引起的偏差,放映了试验误差及其他随机因素对试验结果的影响。
(整理)总结:线性回归分析的基本步骤
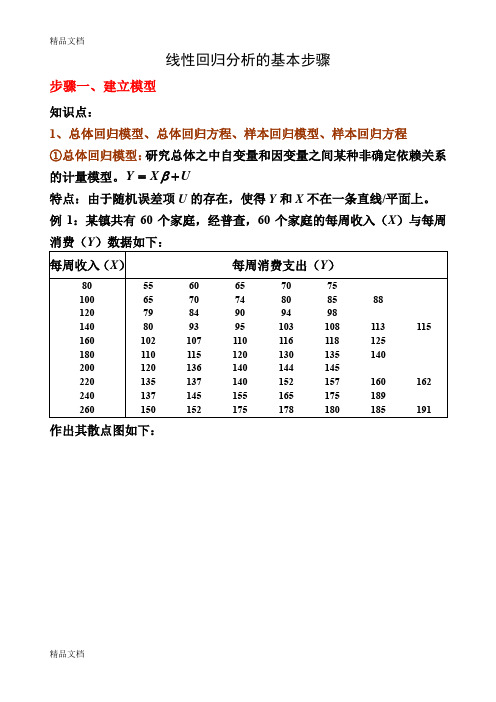
线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X U β=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:作出其散点图如下:②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。
总体回归方程的求法:以例1的数据为例,求出E (Y |X 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入()01|i i i E Y X X ββ=+可得:01001177100171372000.6ββββββ=+=⎧⎧⇒⎨⎨=+=⎩⎩以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。
如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型ˆY X e β=+就称为样本回归模型。
④样本回归方程(线):通过样本数据估计出ˆβ,得到样本观测值的拟合值与解释变量之间的关系方程ˆˆY X β=称为样本回归方程。
如下图所示:⑤四者之间的关系:ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y和自变量X之间的近似于真实的非确定型依赖关系。
线性回归分析思路总结

线性回归分析是一种研究影响关系的方法,在实际研究里非常常见。
不管你有没有系统学习过,对于线性回归,相信多少都有那么一点了解。
即使如此,在实际分析时,还是会碰到很多小细节,让我们苦思冥想,困扰很久,以致拖慢进度,影响效率。
因此本文就一起梳理下回归分析的分析流程,闲话少说,我们开始吧。
回归分析实质上就是研究一个或多个自变量X对一个因变量Y(定量数据)的影响关系情况。
当自变量为1个时,是一元线性回归,又称作简单线性回归;自变量为2个及以上时,称为多元线性回归。
在SPSSAU里均是使用【通用方法】里的【线性回归】实现分析的。
SPSSAU-线性回归1.数据类型线性回归要求因变量Y(被解释变量)一定是定量数据。
如果因变量Y为定类数据,可以用【进阶方法】中的【logit回归】。
对于引入模型的自变量,通常没有个数要求。
但从经验上看,不要一次性放入太多自变量。
如果同时自变量太多,容易引起共线性问题。
建议根据专业知识进行选择,同时样本量不能过少,通常要满足样本个数是自变量的20倍以上。
如果自变量为定类数据,需要对变量进行哑变量处理,可以在SPSSAU的【数据处理】→【生成变量】进行设置。
具体设置步骤查看SPSSAU有关哑变量的文章:什么是虚拟变量?怎么设置才正确?控制变量,可以是定量数据,也可以是定类数据。
一般来说更多是定类数据,如:性别,年龄,工作年限等人口统计学变量。
通常情况下,不需要处理,可以直接和自变量一起放入X 分析框分析即可。
3. 正态性检验理论上,回归分析的因变量要求需服从正态分布,SPSSAU 提供多种检验正态性的方法。
如果出现数据不正态,可以进行对数处理。
若数据为问卷数据,建议可跳过正态性检验这一步。
原因在于问卷数据属于等级数据,很难保证正态性,且数据本身变化幅度就不大,即使对数处理效果也不明显。
4.散点图和相关分析一般来说,回归分析之前需要做相关分析,原因在于相关分析可以先了解是否有关系,回归分析是研究有没有影响关系,有相关关系但并不一定有回归影响关系。
总结线性回归分析的基本步骤

总结线性回归分析的基本步骤线性回归分析是一种统计方法,用于研究两个或更多变量之间的关系。
它的基本思想是通过构建一个线性函数来描述因变量与自变量之间的关系,并使用最小二乘法估计未知参数。
下面是线性回归分析的基本步骤:1.收集数据:首先,我们需要收集有关自变量和因变量的数据。
这些数据可以通过实验、观察或调查获得。
数据应该涵盖自变量和因变量的所有可能值,并且应该尽可能全面和准确。
2.绘制散点图:一旦我们收集到数据,我们可以使用散点图来可视化自变量和因变量之间的关系。
散点图展示了每个观测值的自变量与相应因变量的值之间的关系图形。
通过观察散点图,我们可以初步判断变量之间的关系类型,如直线、曲线或没有明显关系。
3.选择模型:在进行线性回归分析之前,我们需要选择适当的模型。
线性回归模型的形式为Y=β0+β1X1+β2X2+...+βnXn+ε,其中Y是因变量,X1,X2,...Xn是自变量,β0,β1,β2,...βn是未知参数,ε是误差项。
我们假设因变量与自变量之间的关系是线性的。
4.估计参数:在线性回归模型中,我们的目标是估计未知参数β0,β1,β2,...βn。
我们使用最小二乘法来估计这些参数,最小二乘法的目标是通过最小化残差平方和来选择最佳拟合直线,使预测值与观测值之间的差异最小化。
5.评估模型:一旦我们估计出参数,我们需要评估模型的拟合程度。
常见的评估指标包括残差分析、方差分析、回归系数的显著性检验、确定系数和调整确定系数。
这些指标可以帮助我们判断模型的有效性和可靠性。
6.解释结果:在得到合理的回归模型之后,我们可以使用回归方程来进行预测和解释结果。
通过回归系数可以了解自变量对因变量的影响程度和方向。
同时,我们可以进行假设检验,确定哪些自变量对因变量是显著的。
7.模型修正和改进:一旦我们获得了回归模型,我们可以进一步修正和改进模型。
这可以通过添加更多的自变量或删除不显著的自变量来完成。
同时,我们还可以使用交互项、多项式项或转换变量来探索更复杂的关系。
线性回归分析

1
在研究问题时,我们考虑一个变量受其他变量的影响时,把这变量称为因变 量,记为Y ,其他变量称为自变量,记为 X ,这时相关系数可记作:
行元素构成的行向量,上式对 k 1,2, , K 都成立,bk 正是被解释变量观测值Yi 的
线性组合,也就是多元线性回归参数的最小二乘估计是线性估计。 (2)无偏性:
多元线性回归的最小二乘估计也是无偏估计,即参数最小二乘估计的数学期 望都等于相应参数的真实值,最小二乘估计向量的数学期望等于参数真实值的向 量,参数真实值是参数估计量的概率分布中心。
i
bk zki )](1) 0, bk zki )](z1i ) 0,
2[Yi (b0 b1z1i bk zki )](zki ) 0
i
同时成立时,V 有最小值。对这个方程组整理,可得到如下的正规方程组:
4
b0 Y (b1z1 bK zK ), S11b1 S12b2 S1KbK S10,
(2)成立为前提)。 (4) 对应不同观测数据的误差项不相关,即
Cov(i , j ) E[(i E(i ))( j E( j ))] E(i j 0) 对任意的 i j 都成立(假设(1) 成立为前提)。
(5) 解释变量 Xi (i 1, 2, ,r)是确定性变量而非随机变量。当存在多个解释 变量 (r 1) 时假设不同解释变量之间不存在线性关系,包括严格的线性关系和强 的近似线性关系。
Yi 0 1X1i 2 X2i 3X3i k Zki i ,其中 i 是随机误差项。
如何进行回归分析:步骤详解

回归分析是一种统计学方法,用来分析两个或多个变量之间的关系。
它可以帮助我们理解变量之间的相关性,并进行预测和控制。
在实际应用中,回归分析被广泛用于经济学、社会学、医学等领域。
下面我将详细介绍如何进行回归分析的步骤,希望能对初学者有所帮助。
第一步:确定研究的目的和问题在进行回归分析之前,首先需要明确研究的目的和问题。
你需要想清楚你想要研究的变量是什么,以及你想要回答的问题是什么。
比如,你想要研究收入和教育水平之间的关系,那么你的目的就是确定这两个变量之间的相关性,并回答是否教育水平对收入有影响。
第二步:收集数据一旦确定了研究的目的和问题,接下来就需要收集相关的数据。
数据可以通过调查、实验、观察等方式获取。
在收集数据的过程中,需要注意数据的质量和完整性。
确保数据的准确性对于回归分析的结果至关重要。
第三步:进行描述性统计分析在进行回归分析之前,通常会先进行描述性统计分析。
这可以帮助我们对数据的基本特征有一个初步的了解,比如平均值、标准差、分布情况等。
描述性统计分析可以帮助我们确定变量之间的大致关系,为后续的回归分析奠定基础。
第四步:建立回归模型建立回归模型是回归分析的核心步骤。
在建立回归模型时,需要确定自变量和因变量,并选择合适的回归方法。
常见的回归方法包括线性回归、多元线性回归、逻辑回归等。
在选择回归方法时,需要考虑自变量和因变量之间的关系,以及数据的分布情况。
第五步:进行回归分析一旦建立了回归模型,接下来就可以进行回归分析了。
回归分析的主要目的是确定自变量和因变量之间的关系,并评估回归模型的拟合程度。
在进行回归分析时,需要注意检验回归模型的显著性、自变量的影响程度以及模型的预测能力。
第六步:解释回归结果进行回归分析后,需要解释回归结果。
这包括解释自变量对因变量的影响程度,以及回归模型的可解释性。
在解释回归结果时,需要注意避免过度解释或误导性解释,确保解释的准确性和可信度。
第七步:进行敏感性分析在完成回归分析后,通常会进行敏感性分析。
化学数据的一元线性回归分析

化学数据的一元线性回归分析
一元线性回归分析是一种统计分析方法,用于确定两个变量之间的线性关系。
它可以用来研究化学数据,以确定某种化学反应的反应速率是否与某种变量(如温度)成线性关系。
一元线性回归分析的步骤如下:
1. 选择一个变量(X),它可以是温度、pH值或其他变量,用于衡量化学反应的反应速率。
2. 收集数据,记录X和反应速率(Y)的值。
3. 计算X和Y的均值,以及X和Y的协方差和方差。
4. 计算回归系数,即斜率,用于表示X和Y之间的线性关系。
5. 根据回归系数,构建一元线性回归方程,用于预测X和Y之间的关系。
6. 根据回归方程,预测X和Y之间的关系,并验证预测结果的准确性。
线性回归分析的基本步骤

:酒类经营许可证数量(张) :酒类广告投入(万元)
已知 , 对角线上的元素分别为 , ,
, , ,回归方程的残差平方和
1)先验地,你认为各自变量回归系数的符号为什么
2)请完成以下方差分析表:
方差来源
平方和(SS)
自由度
均方值
离差平方和TSS
回归平方和RSS
RSS的自由度为k=2
4)求
解: ,
②回归方程的显著性检验(F检验)
目的:检验模型中的因变量与自变量之间是否存在显著的线性关系
步骤:1、提出假设:
2、构造统计量:
3、给定显著性水平 ,确定拒绝域
4、计算统计量值,并判断是否拒绝原假设
例3:就例2中的数据,给定显著性水平 ,对回归方程进行显著性检验。
解:由于统计量值 ,
残差平方和ESS
3)计算 值
4)对4个自变量进行显著性检验,并分析其经济含义;
5)给出 置信水平为95%的区间估计;
6)对方程进行显著性检验;
3、求出 的置信度为 的置信区间
例5:根据例4的数据,求出 的置信度为95%的置信区间。
解:由于 ,故 的置信度为95%的置信区间为:
3、经济意义检验
目的:检验回归参数的符号及数值是否与经济理论的预期相符。
例6:根据26个样本数据建立了以下回归方程用于解释美国居民的个人消费支出:
其中:Y为个人消费支出(亿元);X1为居民可支配收入(亿元);X2为利率(%)
表示,利率提高1个百分点,个人消费支出将减少亿元。
截距项表示居民可支配收入和利率为零时的个人消费支出为亿元,它没有明确的经济含义。
3)检验 是否显著不为1;( )
线性回归分析法

一元线性回归分析和多元线性回归分析一元线性回归分析1.简单介绍当只有一个自变量时,称为一元回归分析(研究因变量y 和自变量x 之间的相关关系);当自变量有两个或多个时,则称为多元回归分析(研究因变量y 和自变量1x ,2x ,…,n x 之间的相关关系)。
如果回归分析所得到的回归方程关于未知参数是线性的,则称为线性回归分析;否则,称为非线性回归分析。
在实际预测中,某些非线性关系也可以通过一定形式的变换转化为线性关系,所以,线性回归分析法成为最基本的、应用最广的方法。
这里讨论线性回归分析法。
2.回归分析法的基本步骤回归分析法的基本步骤如下: (1) 搜集数据。
根据研究课题的要求,系统搜集研究对象有关特征量的大量历史数据。
由于回归分析是建立在大量的数据基础之上的定量分析方法,历史数据的数量及其准确性都直接影响到回归分析的结果。
(2) 设定回归方程。
以大量的历史数据为基础,分析其间的关系,根据自变量与因变量之间所表现出来的规律,选择适当的数学模型,设定回归方程。
设定回归方程是回归分析法的关键,选择最优模型进行回归方程的设定是运用回归分析法进行预测的基础。
(3) 确定回归系数。
将已知数据代入设定的回归方程,并用最小二乘法原则计算出回归系数,确定回归方程。
这一步的工作量较大。
(4) 进行相关性检验。
相关性检验是指对已确定的回归方程能够代表自变量与因变量之间相关关系的可靠性进行检验。
一般有R 检验、t 检验和F 检验三种方法。
(5) 进行预测,并确定置信区间。
通过相关性检验后,我们就可以利用已确定的回归方程进行预测。
因为回归方程本质上是对实际数据的一种近似描述,所以在进行单点预测的同时,我们也需要给出该单点预测值的置信区间,使预测结果更加完善。
3. 一元线性回归分析的数学模型用一元线性回归方程来描述i x 和i y 之间的关系,即i i i x a a y ∆++=10 (i =1,2,…,n )(2-1)式中,i x 和i y 分别是自变量x 和因变量y 的第i 观测值,0a 和1a 是回归系数,n 是观测点的个数,i ∆为对应于y 的第i 观测值i y 的随机误差。
总结:线性回归分析的基本步骤

线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X U β=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:作出其散点图如下:②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。
总体回归方程的求法:以例1的数据为例,求出E (Y |X 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入()01|i i i E Y X X ββ=+可得:01001177100171372000.6ββββββ=+=⎧⎧⇒⎨⎨=+=⎩⎩以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。
如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型ˆY X e β=+就称为样本回归模型。
④样本回归方程(线):通过样本数据估计出ˆβ,得到样本观测值的拟合值与解释变量之间的关系方程ˆˆY X β=称为样本回归方程。
如下图所示:⑤四者之间的关系:ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。
回归分析步骤

回归分析步骤
回归分析是一种统计学方法,用于检查一个或多个变量之间的关系。
它以模型形式来描述这种关系,从而推断出变量可能的响应。
回归分析对研究者、市场调研者和有组织的企业决策的有效方法,能够帮助研究者和决策者了解单指标和多指标系统之间的关系,从而作出正确的决策。
回归分析也能够检验预测性因素或跟踪个体行为模式的变化。
一般来说,回归分析由以下几个步骤组成:
第一步,确定拟合目标变量和解释变量。
拟合目标变量是我们希望使用回归分析来预测的变量,而解释变量则是用来解释拟合目标变量值的变量。
第二步,使用统计技巧来确定回归模型的类型。
通过观察数据,可以找到最适合拟合数据的模型类型。
常见的模型类型包括线性回归、局部加权回归和多项式回归。
第三步,获取模型估计值。
通过使用统计工具,可以根据解释变量的值预测拟合目标变量的值。
估算的参数包括斜率、截距和R2。
第四步,模型诊断。
诊断模型是检查模型是否具有拟合数据的能力。
可以使用残差、可视化图形和空间变化来诊断模型。
第五步,模型检验。
使用模型来预测新数据,以验证模型是否有效。
第六步,模型选择。
选择最佳模型,以满足研究目标。
第七步,模型实施。
实施模型,并使用模型的结果来制定策略、
调整决策并监测其结果。
以上就是回归分析的步骤。
到此,我们可以认识到,回归分析不仅仅是一种统计技术,而是一种可以用来研究和预测变量之间关系的有效方法。
正确地使用回归分析可以帮助研究者和决策者更好地理解和利用现有数据,以解决重要的管理、经济和社会问题。
如何进行回归分析:步骤详解(九)

回归分析是一种统计方法,用于研究自变量和因变量之间的关系。
它可以帮助我们理解和预测变量之间的相互影响,是许多领域中常用的分析方法,比如经济学、社会学和市场营销等。
本文将详细介绍如何进行回归分析,包括数据准备、模型选择、结果解释等步骤。
1. 数据准备首先,进行回归分析的第一步是收集并准备数据。
数据应包括自变量和因变量,自变量是用来预测因变量的变量。
确保数据的准确性和完整性非常重要,因为分析的结果将直接受到数据质量的影响。
在准备数据时,需要注意处理缺失值、异常值和离群点,确保数据的可靠性和有效性。
2. 模型选择在进行回归分析之前,需要选择适当的回归模型。
常用的回归模型包括简单线性回归、多元线性回归、逻辑回归等。
简单线性回归用于研究两个变量之间的线性关系,多元线性回归则可以考虑多个自变量对因变量的影响。
逻辑回归则用于处理因变量为二元变量的情况。
选择合适的回归模型需要根据研究问题和数据特点来进行判断,适当的模型选择将有助于提高回归分析的准确性和解释性。
3. 模型拟合选择好回归模型之后,接下来要进行模型的拟合。
拟合模型的目的是找到最佳的拟合曲线或平面,使得模型能够最好地描述自变量和因变量之间的关系。
最常用的方法是最小二乘法,它可以帮助我们找到使残差平方和最小的拟合曲线或平面。
拟合模型后,需要对模型的适配度进行检验,比如F检验、R方值等,以评价模型的拟合效果。
4. 结果解释当模型拟合完成后,需要对回归分析的结果进行解释。
在解释结果时,需要注意自变量和因变量之间的因果关系,以及回归系数的意义和解释。
回归系数表示自变量对因变量的影响程度,可以帮助我们理解变量之间的关系。
此外,也需要注意结果的显著性检验,以确定模型是否具有统计显著性。
5. 模型诊断最后,进行回归分析时,还需要进行模型诊断,以评估模型的稳健性和有效性。
模型诊断主要包括残差分析、多重共线性检验、异方差性检验等。
这些诊断可以帮助我们发现模型的不足之处,进一步改进模型,提高回归分析的准确性和可靠性。
根据线性回归的计算方法

根据线性回归的计算方法
概述
线性回归是一种常见的统计分析方法,用于建立自变量与因变
量之间的线性关系模型。
根据给定的数据集,线性回归通过最小二
乘法来估计回归方程中的参数,以求得最佳拟合线。
以下是根据线
性回归的计算方法的详细步骤。
步骤
1. 数据准备:收集并整理自变量和因变量的观测值数据。
确保
数据集中不存在缺失值或异常值,如果有需要进行数据清洗和处理。
2. 拟合回归模型:选择合适的线性回归模型,包括一元线性回
归或多元线性回归。
对于一元线性回归,只涉及一个自变量和一个
因变量;对于多元线性回归,涉及多个自变量和一个因变量。
3. 参数估计:使用最小二乘法来估计回归模型中的参数。
最小
二乘法通过最小化残差平方和,即实际观测值与模型预测值之间的
差异。
4. 模型评估:评估回归模型的拟合程度和统计显著性。
常用的评估指标包括决定系数(R-squared)、调整决定系数(Adjusted R-squared)和F统计量。
5. 预测和推断:使用估计的回归模型进行预测和推断。
根据模型得出的回归系数和截距,可以根据新的自变量观测值来预测因变量的值。
注意事项
- 在进行线性回归之前,应先进行数据探索和变量选择分析,确保选取的自变量与因变量具有一定的关联性。
- 在线性回归中,要注意解释回归系数的含义,并进行合理的解释和推断。
线性回归是一种有用的分析工具,对于建立自变量和因变量之间的关系模型具有广泛的应用。
通过了解线性回归的计算方法和步骤,可以更好地理解和应用这一统计方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
总结:线性回归分析的基本步骤-标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X U β=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:作出其散点图如下:②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。
总体回归方程的求法:以例1的数据为例由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入()01|i i i E Y X X ββ=+可得:01001177100171372000.6ββββββ=+=⎧⎧⇒⎨⎨=+=⎩⎩以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。
如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型ˆY X e β=+就称为样本回归模型。
④样本回归方程(线):通过样本数据估计出ˆβ,得到样本观测值的拟合值与解释变量之间的关系方程ˆˆY Xβ=称为样本回归方程。
如下图所示:⑤四者之间的关系:ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y和自变量X之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y和自变量X之间的近似于真实的非确定型依赖关系。
这种近似表现在两个方面:一是结构参数ˆβ是其真实值β的一种近似估计;二是残差e是随机误差项U的一个近似估计;ⅱ:总体回归方程是根据总体数据得到的,它描述的是因变量的条件均值E(Y|X)与自变量X之间的线性关系;样本回归方程是根据抽样数据得到的,它描述的是因变量Y样本预测值的拟合值ˆY与自变量X之间的线性关系。
ⅲ:回归分析的目的是试图通过样本数据得到真实结构参数β的估计值,并要求估计结果ˆβ足够接近真实值β。
由于抽样数据有多种可能,每一次抽样所得到的估计值ˆβ都不会相同,即β的估计量ˆβ是一个随机变量。
因此必须选择合适的参数估计方法,使其具有良好的统计性质。
2、随机误差项U 存在的原因: ①非重要解释变量的省略 ②人的随机行为 ③数学模型形式欠妥④归并误差(如一国GDP 的计算) ⑤测量误差等3、多元回归模型的基本假定 ①随机误差项的期望值为零()0i E U =②随机误差项具有同方差性2() 1,2,,i Var u i n σ==③随机误差项彼此之间不相关(,)0 ; ,1,2,,i j Cov u u i j i j n =≠= ④解释就变量X 1,X 2,···,X k 为确定型变量,与随机误差项彼此不相关。
(,)0 1,2,, 1,2,,ij j Cov X u i k j n ===⑤解释就变量X 1,X 2,···,X k 之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵X 为满秩矩阵:rank (X )=k +1<n ⑥随机误差项服从正态分布,即:u i ~N (0,σ2),i =1,2,···,n步骤二、参数估计知识点:1、最小二乘估计的基本原理:残差平方和最小化。
2、参数估计量:① 一元回归:1201ˆˆˆi i i x y x Y Xβββ⎧=⎪⎨⎪=-⎩∑∑② 多元回归:()1ˆT X X X Y β-'= 3、最小二乘估计量的性质(Gauss-Markov 定理):在满足基本假设的情况下,最小二乘估计量ˆβ是β的最优线性无偏估计量(BLUE 估计量)步骤三、模型检验1、经济计量检验(后三章内容)2、统计检验 ①拟合优度检验 知识点:ⅰ:拟合优度检验的作用:检验回归方程对样本点的拟合程度 ⅱ:拟合优度的检验方法:计算(调整的)样本可决系数22/R R21RSS ESSR TSS TSS==-,2/11/1ESS n k R TSS n --=--注意掌握离差平方和、回归平方和、残差平方和之间的关系以及它们的自由度。
计算方法:通过方差分析表计算例2:下表列出了三变量(二元)模型的回归结果:1) 样本容量为多少?解:由于TSS 的自由度为n -1,由上表知n -1=14,因此样本容量n =15。
2) 求ESS解:由于TSS =ESS +RSS ,故ESS =TSS -RSS =77 3) ESS 和RSS 的自由度各为多少解:对三变量模型而言,k =2,故ESS 的自由度为n -k -1=12 RSS 的自由度为k =2 4) 求22R R 和解:2659650.998866042RSS R TSS ===,2/110.9986/1ESS n k R TSS n --=-=-②回归方程的显著性检验(F 检验)目的:检验模型中的因变量与自变量之间是否存在显著的线性关系 步骤:1、提出假设:0121:...0:0 , 1,2,...,k j H H j kββββ====≠=至少有一2、构造统计量:/~(,1)/1RSS kF F k n k ESS n k =----3、给定显著性水平α,确定拒绝域(),1F F k n k α>--4、计算统计量值,并判断是否拒绝原假设例3:就例2中的数据,给定显著性水平1%α=,对回归方程进行显著性检验。
解:由于统计量值/65965/25140.13/177/12RSS k F ESS n k ===--,又()0.012,12 6.93F =,而()0.015140.132,12 6.93F F =>=故拒绝原假设,即在1%的显著性水平下可以认为回归方程存在显著的线性关系。
附:2R F 与检验的关系:由于()()22222/1/1/1/1RSS RSS R R RSS ESS R k TSS ESS RSS R F RSS k R n k F ESS n k ⎫==⇒=⎪⎪+-⇒=⎬---⎪=⎪--⎭又 ③解释变量的显著性检验(t 检验)目的:检验模型中的自变量是否对因变量存在显著影响。
知识点:多元回归:ˆiS β=1,1i i C ++为()1X X -'中位于第i +1行和i +1列的元素;一元回归:1ˆˆS S ββ==变量显著性检验的基本步骤:1、提出假设:01:0 :0i i H H ββ=≠2、构造统计量:ˆˆ~(1)iit t n k S ββ=--3、给定显著性水平α,确定拒绝域/2(1)tt n k α>--4、计算统计量值,并判断是否拒绝原假设 例4:根据19个样本数据得到某一回归方程如下:12ˆ58.90.20.1 (0.0092) (0.084)Y X X se =-+-试在5%的显著性水平下对变量12X X 和的显著性进行检验。
解:由于/20.025(1)(16) 2.12t n k t α--==,故t 检验的拒绝域为 2.12t>。
对自变量1X 而言,其t 统计量值为11ˆˆ0.221.74 2.120.0092t S ββ===>,落入 拒绝域,故拒绝10β=的原假设,即在5%的显著性水平下,可以认为自变量1X 对因变量有显著影响;对自变量2X 而言,其t 统计量值为22ˆˆ0.11.192.120.084t S ββ===<,未落入拒绝域,故不能拒绝20β=的原假设,即在5%的显著性水平下,可以认为自变量2X 对因变量Y 的影响并不显著。
④回归系数的置信区间目的:给定某一置信水平1α-,构造某一回归参数i β的一个置信区间,使i β落在该区间内的概率为1α- 基本步骤: 1、构造统计量ˆˆ~(1)ii i t t n k S βββ-=--2、给定置信水平1α-,查表求出α水平的双侧分位数/2(1)t n k α--3、求出i β的置信度为1α-的置信区间()ˆˆ/2/2ˆˆ,iii i t S t S ααββββ-⨯+⨯ 例5:根据例4的数据,求出1β的置信度为95%的置信区间。
解:由于0.025(16) 2.12t =,故1β的置信度为95%的置信区间为:()()0.2 2.120.0092,0.2 2.120.00920.18,0.22-⨯+⨯=3、经济意义检验目的:检验回归参数的符号及数值是否与经济理论的预期相符。
例6:根据26个样本数据建立了以下回归方程用于解释美国居民的个人消费支出:122ˆ10.960.93 2.09 ( 3.33) (249.06) ( 3.09)0.9996Y X X t R =-+---= 其中:Y 为个人消费支出(亿元);X 1为居民可支配收入(亿元);X 2为利率(%)1) 先验估计12ˆˆββ和的符号; 解:由于居民可支配收入越高,其个人消费水平也会越高,因此预期自变量X 1回归系数的符号为正;而利率越高,居民储蓄意愿越强,消费意愿相应越低,因此个从消费支出与利率应该存在负相关关系,即2ˆβ应为负。
2) 解释两个自变量回归系数的经济含义;解:1ˆ0.93β=表示,居民可支配收入每增加1亿元,其个人消费支出相应会增加0.93亿元,即居民的边际消费倾向MPC =0.93;2ˆ 2.09β=-表示,利率提高1个百分点,个人消费支出将减少2.09亿元。
截距项表示居民可支配收入和利率为零时的个人消费支出为-10.96亿元,它没有明确的经济含义。
3) 检验1β是否显著不为1;(5%α=)解:1)提出假设:0111: 1 :1H H ββ=≠2)构造统计量:111ˆˆ~(1)t t n k S βββ-=--3)给定显著性水平5%α=,查表得/20.025(1)(23) 2.07t n k t α--==,故拒绝域为 2.07t>4)计算统计量值:由于1111ˆ1ˆ1ˆˆ0.93ˆ()0.003734ˆ249.06()t S S t ββββββ=⇒=== 则111ˆˆ0.0718.75 2.070.003734t S βββ-===>,落入拒绝域。