黄庆明 模式识别与机器学习 第三章 作业
模式识别作业题(2)

答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
λ11 P(ω1 | x) + λ12 P(ω2 | x) < λ21 P(ω1 | x) + λ22 P(ω2 | x) ( λ21 - λ11 ) P (ω1 | x) >( λ12 - λ22 ) P (ω2 | x) ( λ21 - λ11 ) P (ω1 ) P ( x | ω1 ) >( λ12 - λ22 ) P (ω2 ) P ( x | ω2 ) p( x | ω1 ) (λ 12 − λ 22) P(ω2 ) > 即 p( x | ω2 ) ( λ 21 − λ 11) P (ω1 )
6、设总体分布密度为 N( μ ,1),-∞< μ <+∞,并设 X={ x1 , x2 ,… xN },分别用最大似然 估计和贝叶斯估计计算 μ 。已知 μ 的先验分布 p( μ )~N(0,1)。 解:似然函数为:
∧Байду номын сангаас
L( μ )=lnp(X|u)=
∑ ln p( xi | u) = −
i =1
N
模式识别第三章作业及其解答
《机器学习》第一次作业——第一至三章学习记录和心得

《机器学习》第⼀次作业——第⼀⾄三章学习记录和⼼得第⼀章、模式识别基本概念1.什么是模式识别模式识别划分为“分类”和“回归”两种形式分类(Classification)输出量是离散的类别表达,即输出待识别模式所属的类别⼆类/多类分类回归(Regression)输出量是连续的信号表达(回归值),输出量维度:单个/多个维度回归是分类的基础:离散的类别值是由回归值做判别决策得到的。
模式识别根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。
模式识别本质上是⼀种推理(inference)过程。
2.模式识别的数学表达数学解释模式识别可以看做⼀种函数映射f(x),将待识别模式x从输⼊空间映射到输出空间。
函数f(x)是关于已有知识的表达。
注:f(x)可能是可解析表达的,也可能是不可解析表达的,其输出值可能是确定值也可能是概率值输⼊空间原始输⼊数据x所在的空间。
空间维度:输⼊数据的维度。
输出空间输出的类别/回归值y所在的空间。
空间维度:1维、类别的个数(>2)、回归值的维度。
模型关于已有知识的⼀种表达⽅式,即函数f(x)。
模型通过机器学习得到。
3.特征向量的相关性点积能够度量特征向量两两之间的相关性即识别模式之间是否相似。
可以表征两个特征向量的共线性,即⽅向上的相似程度。
点积为0,说明两个向量是正交的(orthogonal)。
投影向量x到y的投影(projection)︰将向量x垂直投射到向量y⽅向上的长度(标量)。
投影的含义:向量x分解到向量y⽅向上的程度。
能够分解的越多,说明两个向量⽅向上越相似。
残差向量特征向量的欧⽒距离两个特征向量之间的欧式距离:表征两个向量之间的相似程度(综合考虑⽅向和模长)。
4.机器学习基本概念训练样本每个训练样本,都是通过采样得到的⼀个模式,即输⼊特征空间中的⼀个向量;通常是⾼维度(即 很⼤),例如⼀幅图像。
训练样本可以认为是尚未加⼯的原始知识,模型则是经过学习(即加⼯整理归纳等)后的真正知识表达。
模式识别与机器学习 作业 中科院 国科大 来源网络 (3)

{ double sum=0.0; for(int j=0;j<T;j++) sum+=a[j]*C[j][i]; res[i]=sum; } } int main() { int T; int w1_num,w2_num; double w1[10][5],w2[10][5],m1[5]={0},m2[5]={0},C1[5][5]={0},C2[5][5]={0}; cin>>T>>w1_num>>w2_num; for(int i=0;i<w1_num;i++) { for(int j=0;j<T;j++) { cin>>w1[i][j]; m1[j]+=w1[i][j]; } } for(int i=0;i<w2_num;i++) { for(int j=0;j<T;j++) { cin>>w2[i][j]; m2[j]+=w2[i][j]; } } for(int i=0;i<w1_num;i++) m1[i]=m1[i]/w1_num; for(int i=0;i<w2_num;i++) m2[i]=m2[i]/w2_num; for(int i=0;i<w1_num;i++) { double res[5][5],a[5]; for(int j=0;j<T;j++) a[j]=w1[i][j]-m1[j]; get_matrix(T,res,a); for(int j=0;j<T;j++) { for(int k=0;k<T;k++) C1[j][k]+=res[j][k]; }
模式识别第三章

3 回归的线性模型至此,本书都聚焦在无监督学习,包括的议题有密度估计和数据聚类。
我们现在转向监督学习,并从回归开始。
回归的目的是:对给定的输入变量的D 维向量x 值,预测一个或更多连续目标变量t 值。
我们在第一章考虑多项式曲线拟合时,已经遇到过一个回归问题的例子。
多项式是线性回归模型的一大类函数中一个具体的例子,它也有含可调参数的线性函数的性质,并将组成本章的焦点。
最简单的线性回归模型也是输入变量的线性函数。
但是,通过取输入变量的一组给定的非线性函数的线性组合,我们可以获得更有用的函数类,称为基函数。
这样的模型是参数的线性函数,它们有简单的解析性,并且关于输入变量仍是非线性的。
给定一个训练数据集合,它有N 个观察值{}n x ,其中n=1,…,N ,以及对应的目标值{}n t ,目的是给定一个新的x 预测t 的值。
最简单方法是直接构造一个适当的函数()y x ,对一个新输入x ,它的值组成对应的t 的预测值。
更一般地,从概率角度考虑,我们想建立一个预测分布()p t x ,因为它表示了对x 的每一个值,t 值的不确定性。
由这个条件分布,我们可以为任意的新x 值预测t ,这相当于最小化一个适当选择的损失函数的期望。
如在第1.5.5所讨论的,通常选择损失函数的平方作为实值变量的损失函数,因为它的最优解由t 的条件期望给出。
对模式识别来说,虽然线性模型作为实用的技术有显著的限制,特别是涉及到高维输入空间的问题,但是它们具有好的解析性质,并且是以后章节要讨论的更复杂模型的基础。
3.1 线性基函数模型最简单的线性回归模型是输入变量的线性组合:011(,)D D y w w x w x =+++x w L (3.1) 其中1(,,)T D x x =x L ,这就是通常简称的线性回归。
此模型的关键特征是:它是参数0,,D w w L 的一个线性函数。
但同时它也是输入变量i x 的一个线性函数,这对模型产生了很大的限制。
模式识别Chapter 3归纳.ppt

最新.课件
11
Discriminant functions
yk (x)
1 2
(x
k
)
t
k
1
(
x
k )
d 2
ln
2
1 2
ln
| k
| ln
p(ck )
Case 1 k 2I
yk
(x)
1
2
k t
x
kt k
ln
p(ck
)
yk (x) wkt x wk0
wk
1
2
k , wk 0
ktk
最新.课件
21
Introduction
we could design an optional classifier if we knew the priori probabilities and the class-conditional densities
Unfortunately, we rarely, if ever, have this kind of completely knowledge about the probabilistic structure
Feature space, feature point in space
Classification
-- Bayesian decision theory
-- Discriminant function
-- Decision region, Decision boundary
最新.课件
15
Example
Drawbacks -- the number of parameters grows with the size of the data -- slow
模式识别(3-2)

0
x为其它
解:此为多峰情况的估计
-2.5 -2 0
2x
设窗函数为正态
(u) 1 exp[ 1 u2], hN h1
2
2
N
❖
用
Parzen
窗 法 估 计 两 个 均 匀 分 布 的 实 验
h1 0.25 10.0
1.0 0.1 0.01 0.001 10.0 1.0 0.1 0.01 0.001 10.0 1.0 0.1 0.01 0.001 10.0 1.0 0.1 0.01 0.001
Parse窗口估计
例2:设待估计的P(x)是个均值为0,方差为1的正态密度
函数。若随机地抽取X样本中的1个、 16个、 256个作为
学习样本xi,试用窗口法估计PN(x)。 解:设窗口函数为正态的, σ=1,μ=0
(| x xi |)
1
exp[
1
(
|
x
xi
|
2
)]
设hN h1
hN
2
2 hN
N
0.01
0.001 10.0
1.0
0.1
0.01
0.001 10.0
1.0
0.1
0.01
0.001 10.0
1.0
0.1
0.01
0.001 2 0 2
h1 1 2 0 2
h1 4 2 0 2
Parse窗口估计
讨论:由图看出, PN(x)随N, h1的变化情况 ①正当态N=形1时状,的P小N(丘x),是与一窗个函以数第差一不个多样。本为中心的
概率密度估计
数学期望: E(k)=k=NP
∴对概率P的估计: P k。
N
模式识别_作业3

作业一:设以下模式类别具有正态概率密度函数: ω1:{(0 0)T , (2 0)T , (2 2)T , (0 2)T }ω2:{(4 4)T , (6 4)T , (6 6)T , (4 6)T }(1)设P(ω1)= P(ω2)=1/2,求这两类模式之间的贝叶斯判别界面的方程式。
(2)绘出判别界面。
答案:(1)模式的均值向量m i 和协方差矩阵C i 可用下式估计:2,111==∑=i x N m i N j ij i i2,1))((11=--=∑=i m x m x N C i N j Ti ij i ij i i 其中N i 为类别ωi 中模式的数目,x ij 代表在第i 个类别中的第j 个模式。
由上式可求出:T m )11(1= T m )55(2= ⎪⎪⎭⎫ ⎝⎛===1 00 121C C C ,⎪⎪⎭⎫⎝⎛=-1 00 11C 设P(ω1)=P(ω2)=1/2,因C 1=C 2,则判别界面为:24442121)()()(2121211112121=+--=+--=----x x m C m m C m x C m m x d x d T T T(2)作业二:编写两类正态分布模式的贝叶斯分类程序。
程序代码:#include<iostream>usingnamespace std;void inverse_matrix(int T,double b[5][5]){double a[5][5];for(int i=0;i<T;i++)for(int j=0;j<(2*T);j++){ if (j<T)a[i][j]=b[i][j];elseif (j==T+i)a[i][j]=1.0;elsea[i][j]=0.0;}for(int i=0;i<T;i++){for(int k=0;k<T;k++){if(k!=i){double t=a[k][i]/a[i][i];for(int j=0;j<(2*T);j++){double x=a[i][j]*t;a[k][j]=a[k][j]-x;}}}}for(int i=0;i<T;i++){double t=a[i][i];for(int j=0;j<(2*T);j++)a[i][j]=a[i][j]/t;}for(int i=0;i<T;i++)for(int j=0;j<T;j++)b[i][j]=a[i][j+T];}void get_matrix(int T,double result[5][5],double a[5]) {for(int i=0;i<T;i++){for(int j=0;j<T;j++){result[i][j]=a[i]*a[j];}}}void matrix_min(int T,double a[5][5],int bb){for(int i=0;i<T;i++){for(int j=0;j<T;j++)a[i][j]=a[i][j]/bb;}}void getX(int T,double res[5],double a[5],double C[5][5]) {for(int i=0;i<T;i++)double sum=0.0;for(int j=0;j<T;j++)sum+=a[j]*C[j][i];res[i]=sum;}}int main(){int T;int w1_num,w2_num;double w1[10][5],w2[10][5],m1[5]={0},m2[5]={0},C1[5][5]={0},C2[5][5]={0};cin>>T>>w1_num>>w2_num;for(int i=0;i<w1_num;i++){for(int j=0;j<T;j++){cin>>w1[i][j];m1[j]+=w1[i][j];}}for(int i=0;i<w2_num;i++){for(int j=0;j<T;j++){cin>>w2[i][j];m2[j]+=w2[i][j];}}for(int i=0;i<w1_num;i++)m1[i]=m1[i]/w1_num;for(int i=0;i<w2_num;i++)m2[i]=m2[i]/w2_num;for(int i=0;i<w1_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w1[i][j]-m1[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C1[j][k]+=res[j][k];}matrix_min(T,C1,w1_num);for(int i=0;i<w2_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w2[i][j]-m2[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C2[j][k]+=res[j][k];}}matrix_min(T,C2,w2_num);inverse_matrix(T,C1);inverse_matrix(T,C2);double XX[5]={0},C_C1[5]={0},C_C2[5]={0};double m1_m2[5];for(int i=0;i<T;i++){m1_m2[i]=m1[i]-m2[i];}getX(T,XX,m1_m2,C1);getX(T,C_C1,m1,C1);getX(T,C_C2,m2,C1);double resultC=0.0;for(int i=0;i<T;i++)resultC-=C_C1[i]*C_C1[i];for(int i=0;i<T;i++)resultC+=C_C2[i]*C_C2[i];resultC=resultC/2;cout<<"判别函数为:"<<endl;cout<<"d1(x)-d2(x)=";for(int i=0;i<T;i++)cout<<XX[i]<<"x"<<i+1;if(resultC>0)cout<<"+"<<resultC<<endl;elseif(resultC<0)cout<<resultC<<endl;return 0;}运行截图:。
中科院 国科大 黄庆明 模式识别与机器学习 期末考点 复习

SVR:一般形式及其对偶问题 Multi-class SVM:一对多。 VC dimension:一般而言, VC 维 越大, 学习能力就 越强,学习也越复杂;可以通过 VC 维 计算学习风 险的上界
概念 K-means:形式化,思想 高斯混合模型及EM算法(思想,步骤)
模式识别系统的基本构成
数据 获取 预处理
分类器设 计
特征提取和 选择
分类决 策
机器学习的基本构成
环境 学习 知识库 执行与评价
数据聚类 统计分类 结构模式识别 神经网络 监督学习 无监督学习 半监督学习 集成学习 增强学习 深度学习
在贝叶斯分类器中,构造分类器需要知道类概率密 度函数。
流形学习
◦ ◦ ◦ ◦ ◦ Multidimensional Scaling(MDS): 点对距离 Kernel PCA Isomap:保持内在几何结构(测地距离) LLE:映射到低维空间时要保持局部线性结构 LPP:保持局部结构
半监督学习 假设:平滑假设 Disagreement-based 方法:Co-training Low-density separation方法:transductive SVM Graph-based SSL:加入不同的正则项得到不同的 方法
分类方法
◦ 感知器算法:
perceptron criterion 随机梯度下降求解 缺点
分类方法
◦ Logistic regression
MLE+SGD求解 多类logistic regression: Cross Entropy Loss Function
《模式识别与机器学习》习题和参考答案

(μ i , i ), i 1, 2 ,可得
r (x) ln p(x | w 1) ln p(x | w 2)
d
1
1
(x μ1 ) 1 (x μ1 ) ln 2 ln | |
2
2
2
d
1
1
(x μ 2 ) 1 (x μ 2 ) ln 2 ln | |
(2-15)可简化为
1
gi ( x) (x μi ) 1 (x μi ).
2
(2-17)
将上式展开,忽略与 i 无关的项 x 1x ,判别函数进一步简化为
1
gi (x) ( 1μi ) x μi 1μi .
2
(2-18)
此时判别函数是 x 的线性函数,决策面是一个超平面。当决策区域 Ri 与 R j 相邻时,
190%
(2-13)
最小风险贝叶斯决策会选择条件风险最小的类别,即 h( x) 1 。
3.
给出在两类类别先验概率相等情况下,类条件概率分布是相等对角协方差
矩阵的高斯分布的贝叶斯决策规则,并进行错误率分析。
答:
(1)首先给出决策面的表达式。根据类条件概率分布的高斯假设,可以
得到
p(x | w i )
2
2
2
1
1
1 ||
(x μ1 ) 1 (x μ1 ) (x μ 2 ) 1 (x μ 2 ) ln
2
2
2 ||
1
(μ 2 μ1 ) 1x (μ1 1μ1 μ 2 1μ 2 ).
2
(2-28)
中科院_黄庆明_模式识别_考试试卷总结_国科大

的
k j
来计算:
kh
w
hj
k j
j
因此,算出
kh
后,
k h
也就求出了。
如果前面还有隐蔽层,用
k h
再按上述方法计算
kl
和
k l
,以此类
推,一直将输出误差δ一层一层推算到第一隐蔽层为止。各层的δ
求得后,各层的加权调节量即可按上述公式求得。由于误差
k j
相当
于由输出向输入反向传播,所以这种训练算法成为误差反传算法
第四步:返回第二步,重复计算及合并,直到得到满意的分类结
果。(如:达到所需的聚类数目,或 D(n)中的最小分量超过给定阈值
D 等。)
聚类准则函数
(1)最短距离法:设 H 和 K 是两个聚类,则两类间的最短距离定义
为:
DH,K min{ d u,v}, u H, v K 其中,du,v 表示 H 类中的样本 xu 和 K 类中的样本 xv 之间的距离, DH,K 表示 H 类中的所有样本和 K 类中的所有样本之间的最小距 离。
k j
y
k j
)
2
1 2
{T
k j
k, j
F[
h
whj F (
i
wih xik )]}2
为了使误差函数最小,用梯度下降法求得最优的加权,权值先从
输出层开始修正,然后依次修正前层权值,因此含有反传的含义。
根据梯度下降法,由隐蔽层到输出层的连接的加权调节量为:
w
hj
E w hj
模式试卷总结
一、 模式
1.什么是模式:广义地说,存在于时间和空间中可观察的物体,如果我们可以区 别它们是否相同或是否相似,都可以称之为模式。 模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有 时间和空间分布的信息。 2.模式的直观特性:可观察性、可区分性、相似性 3.模式识别的分类:监督学习、概念驱动或归纳假说;非监督学习、数据驱动或 演绎假说。 4.模式分类的主要方法:数据聚类、统计分类、结构模式识别、神经网络。
模式识别习题及答案

第一章 绪论1.什么是模式?具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的___信息__。
2.模式识别的定义?让计算机来判断事物。
3.模式识别系统主要由哪些部分组成?数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第二章 贝叶斯决策理论1.最小错误率贝叶斯决策过程? 答:已知先验概率,类条件概率。
利用贝叶斯公式得到后验概率。
根据后验概率大小进行决策分析。
2.最小错误率贝叶斯分类器设计过程?答:根据训练数据求出先验概率类条件概率分布 利用贝叶斯公式得到后验概率如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3.最小错误率贝叶斯决策规则有哪几种常用的表示形式? 答:4.贝叶斯决策为什么称为最小错误率贝叶斯决策?答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式答:∑====mj Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)⎩⎨⎧∈>=<211221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑===Mj j j i i i i i A P A B P A P A B P B P A P A B P B A P 1)()|()()|()()()|()|(= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布?答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。
模式识别与机器学习_作业_中科院_国科大_来源网络 (1)
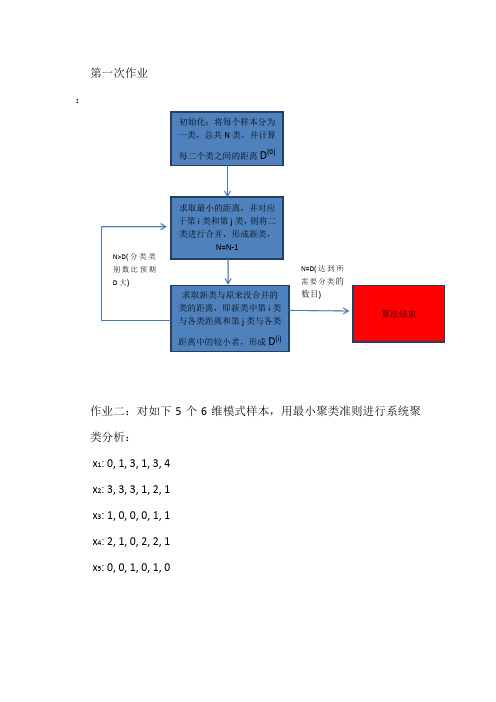
初始化:将每个样本分为 一类,总共 N 类,并计算 每二个类之间的距离 D
(0)
求取最小的距离,并对应 于第 i 类和第 j 类, 则将二 类进行合并,形成新类, N=N-1
N>D( 分 类 类 别数比预期 D 大) N=D( 达 到 所 需要分类的
求取新类与原来没合并的 类的距离,即新类中第 i 类 与各类距离和第 j 类与各类 距离中的较小者,形成 D
int INDEX[10]; //初始分类是以哪些点 int main() { cin>>SCALE; cin>>N>>K; for(int j=0;j<SCALE;j++) { for(int i=1;i<=N;i++) { cin>>XX[i][j]; } } for(int i=0;i<K;i++) cin>>INDEX[i]; doubledist[1000][10]; int classes[10][1000]={0}; doublemeanX[10][10],newMeanX[10][10]; intiindex[10]={0}; for(int i=0;i<K;i++) { for(int j=0;j<SCALE;j++) {
0 23 5 24 26 23 0 24 15 5 5 24 0 7 3 (0) , 1、 计算 D = 因为 x3 与 x5 的距离最近, 则 24 15 7 0 12 26 5 3 12 0
将 x3 与 x5 分为一类。同时可以求出 x1,x2,x4 与 x3,5 的距离,如 x1 到 x3,5 的距离为 x1 到 x3 的距离与 x1 与 x5 的距离中取最小的 一个距离。
模式识别作业第三章2

第三章作业3.5 已知两类训练样本为设,用感知器算法求解判别函数,并绘出判别界面。
解:matlab程序如下:clear%感知器算法求解判别函数x1=[0 0 0]';x2=[1 0 0]';x3=[1 0 1]';x4=[1 1 0]';x5=[0 0 1]';x6=[0 1 1]';x7=[0 1 0]';x8=[1 1 1]';%构成增广向量形式,并进行规范化处理x=[0 1 1 1 0 0 0 -1;0 0 0 1 0 -1 -1 -1;0 0 1 0 -1 -1 0 -1;1 1 1 1 -1 -1 -1 -1];plot3(x1(1),x1(2),x1(3),'ro',x2(1),x2(2),x2(3),'ro',x3(1),x3(2),x3( 3),'ro',x4(1),x4(2),x4(3),'ro');hold on;plot3(x5(1),x5(2),x5(3),'rx',x6(1),x6(2),x6(3),'rx',x7(1),x7(2),x7( 3),'rx',x8(1),x8(2),x8(3),'rx');grid on;w=[-1,-2,-2,0]';c=1;N=2000;for k=1:Nt=[];for i=1:8d=w'*x(:,i);if d>0w=w;t=[t 1];elsew=w+c*x(:,i);t=[t -1];endendif i==8&t==ones(1,8)w=wsyms x yz=-w(1)/w(3)*x-w(2)/w(3)*y-1/w(3);ezmesh(x,y,z,[0.5 1 2]);axis([-0.5,1.5,-0.5,1.5,-0.5,1.5]); title('感知器算法')break;elseendend运行结果:w =3-2-31判别界面如下图所示:若有样本;其增广;则判别函数可写成:若,则,否则3.6 已知三类问题的训练样本为试用多类感知器算法求解判别函数。
黄庆明 模式识别与机器学习 第三章 作业

T
d2(7)= w2 (7) x①=(0 0 0)(-1 -1 1) =0
T
T
d3(7)= w3 (7) x①=(2 2 -2)(-1 -1 1) =-6
T
T
因 d1(7)>d2(7),d1(7)>d3(7),分类结果正确,故权向量不变。 由于第五、六、七次迭代中 x①、x②、x③均已正确分类,所以权向量的解为: T w1=(-1 -1 -1) T w2=(0 0 0) T w3=(2 2 -2) 三个判别函数: d1(x)=- x1 -x2-1 d2(x)=0 d3(x)=2x1+2x2-2
·采用梯度法和准则函数
J ( w, x, b)
1 8x
2
[( wT x b) wT x b ]2
式中实数 b>0,试导出两类模式的分类算法。
J 1 ( wT x b) | wT x b | * x - x * sign(wT x b) 2 w 4 | | x ||
用二次埃尔米特多项式的势函数算法求解以下模式的分类问题 ω1: {(0 1)T, (0 -1)T} ω2: {(1 0)T, (-1 0)T} (1)
1 ( x) 1 ( x1 , x2 ) H 0 ( x1 ) H 0 ( x2 ) 1 2 ( x) 2 ( x1 , x2 ) H 0 ( x1 ) H1 ( x2 ) 2 x2 3 ( x) 3 ( x1 , x2 ) H 0 ( x1 ) H 2 ( x2 ) 4 x22 2 4 ( x) 4 ( x1 , x2 ) H1 ( x1 ) H 0 ( x2 ) 2 x1 5 ( x) 5 ( x1 , x2 ) H1 ( x1 ) H1 ( x2 ) 4 x1 x2 6 ( x) 6 ( x1 , x2 ) H1 ( x1 ) H 2 ( x2 ) 2 x1 (4 x22 2) 7 ( x) 7 ( x1 , x2 ) H 2 ( x1 ) H 0 ( x2 ) 4 x12 2 8 ( x) 8 ( x1 , x2 ) H 2 ( x1 ) H1 ( x2 ) 2 x2 (4 x12 2) 9 ( x) 9 ( x1 , x2 ) H 2 ( x1 ) H 2 ( x2 ) (4 x12 2)(4 x22 2)
模式识别与机器学习作业

•设以下模式类别具有正态概率密度函数:ω1:{(0 0)T, (2 0)T, (2 2)T, (0 2)T}ω2:{(4 4)T, (6 4)T, (6 6)T, (4 6)T}(1)设P(ω1)= P(ω2)=1/2,求这两类模式之间的贝叶斯判别界面的方程式。
(2)绘出判别界面。
解:•编写两类正态分布模式的贝叶斯分类程序。
(可选例题或上述作业题为分类模式)源程序如下:#include<iostream>using namespace std;void inverse_matrix(intT,double b[5][5]){double a[5][5];for(int i=0;i<T;i++)for(int j=0;j<(2*T);j++){ if (j<T)a[i][j]=b[i][j];elseif (j==T+i)a[i][j]=1.0;elsea[i][j]=0.0;}for(int i=0;i<T;i++){for(int k=0;k<T;k++){if(k!=i){double t=a[k][i]/a[i][i];for(int j=0;j<(2*T);j++){double x=a[i][j]*t;a[k][j]=a[k][j]-x;}}}}for(int i=0;i<T;i++){double t=a[i][i];for(int j=0;j<(2*T);j++)a[i][j]=a[i][j]/t;}for(int i=0;i<T;i++)for(int j=0;j<T;j++)b[i][j]=a[i][j+T];}voidget_matrix(intT,double result[5][5],double a[5]) {for(int i=0;i<T;i++){for(int j=0;j<T;j++){result[i][j]=a[i]*a[j];}}}voidmatrix_min(intT,double a[5][5],int bb){for(int i=0;i<T;i++){for(int j=0;j<T;j++)a[i][j]=a[i][j]/bb;}}voidgetX(intT,double res[5],double a[5],double C[5][5]) {for(int i=0;i<T;i++){double sum=0.0;for(int j=0;j<T;j++)sum+=a[j]*C[j][i];res[i]=sum;}}int main(){int T;int w1_num,w2_num;double w1[10][5],w2[10][5],m1[5]={0},m2[5]={0},C1[5][5]={0},C2[5][5]={0};cin>>T>>w1_num>>w2_num;for(int i=0;i<w1_num;i++){for(int j=0;j<T;j++){cin>>w1[i][j];m1[j]+=w1[i][j];}}for(int i=0;i<w2_num;i++){for(int j=0;j<T;j++){cin>>w2[i][j];m2[j]+=w2[i][j];}}for(int i=0;i<w1_num;i++)m1[i]=m1[i]/w1_num;for(int i=0;i<w2_num;i++)m2[i]=m2[i]/w2_num;for(int i=0;i<w1_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w1[i][j]-m1[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C1[j][k]+=res[j][k];}}matrix_min(T,C1,w1_num);for(int i=0;i<w2_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w2[i][j]-m2[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C2[j][k]+=res[j][k];}}matrix_min(T,C2,w2_num);inverse_matrix(T,C1);inverse_matrix(T,C2);double XX[5]={0},C_C1[5]={0},C_C2[5]={0}; double m1_m2[5];for(int i=0;i<T;i++){m1_m2[i]=m1[i]-m2[i];}getX(T,XX,m1_m2,C1);getX(T,C_C1,m1,C1);getX(T,C_C2,m2,C1);doubleresultC=0.0;for(int i=0;i<T;i++)resultC-=C_C1[i]*C_C1[i];for(int i=0;i<T;i++)resultC+=C_C2[i]*C_C2[i];resultC=resultC/2;cout<<"判别函数为:"<<endl;cout<<"d1(x)-d2(x)=";for(int i=0;i<T;i++)cout<<XX[i]<<"x"<<i+1;if(resultC>0)cout<<"+"<<resultC<<endl;elseif(resultC<0)cout<<resultC<<endl;return 0;}运行结果如下:。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
·在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。
问该模式识别问题所需判别函数的最少数目是多少?应该是2521426*741327=+=+=++C 其中加一是分别3类 和 7类·一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1(1)设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。
(2)设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。
绘出其判别界面和多类情况2的区域。
(3)设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。
·两类模式,每类包括5个3维不同的模式,且良好分布。
如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。
) 如果线性可分,则4个建立二次的多项式判别函数,则1025 C 个·(1)用感知器算法求下列模式分类的解向量w: ω1: {(0 0 0)T , (1 0 0)T , (1 0 1)T , (1 1 0)T } ω2: {(0 0 1)T , (0 1 1)T , (0 1 0)T , (1 1 1)T }将属于ω2的训练样本乘以(-1),并写成增广向量的形式。
x ①=(0 0 0 1)T , x ②=(1 0 0 1)T , x ③=(1 0 1 1)T , x ④=(1 1 0 1)Tx ⑤=(0 0 -1 -1)T , x ⑥=(0 -1 -1 -1)T , x ⑦=(0 -1 0 -1)T , x ⑧=(-1 -1 -1 -1)T第一轮迭代:取C=1,w(1)=(0 0 0 0) T因w T (1) x ① =(0 0 0 0)(0 0 0 1) T=0 ≯0,故w(2)=w(1)+ x ① =(0 0 0 1)因w T (2) x ② =(0 0 0 1)(1 0 0 1) T =1>0,故w(3)=w(2)=(0 0 0 1)T因w T (3)x ③=(0 0 0 1)(1 0 1 1)T =1>0,故w(4)=w(3) =(0 0 0 1)T因w T (4)x ④=(0 0 0 1)(1 1 0 1)T =1>0,故w(5)=w(4)=(0 0 0 1)T因w T (5)x ⑤=(0 0 0 1)(0 0 -1 -1)T =-1≯0,故w(6)=w(5)+ x ⑤=(0 0 -1 0)T因w T (6)x ⑥=(0 0 -1 0)(0 -1 -1 -1)T =1>0,故w(7)=w(6)=(0 0 -1 0)T因w T (7)x ⑦=(0 0 -1 0)(0 -1 0 -1)T =0≯0,故w(8)=w(7)+ x ⑦=(0 -1 -1 -1)T因w T (8)x ⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T =3>0,故w(9)=w(8) =(0 -1 -1 -1)T因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。
第二轮迭代:因w T (9)x ①=(0 -1 -1 -1)(0 0 0 1)T =-1≯0,故w(10)=w(9)+ x ① =(0 -1 -1 0)T因w T (10)x ②=(0 -1 -1 0)( 1 0 0 1)T =0≯0,故w(11)=w(10)+ x ② =(1 -1 -1 1)T因w T (11)x ③=(1 -1 -1 1)( 1 0 1 1)T =1>0,故w(12)=w(11) =(1 -1 -1 1)T因w T (12)x ④=(1 -1 -1 1)( 1 1 0 1)T =1>0,故w(13)=w(12) =(1 -1 -1 1)T因w T (13)x ⑤=(1 -1 -1 1)(0 0 -1 -1)T =0≯0,故w(14)=w(13)+ x ⑤ =(1 -1 -2 0)T因w T (14)x ⑥=(1 -1 -2 0)( 0 -1 -1 -1)T =3>0,故w(15)=w(14) =(1 -1 -2 0)T因w T (15)x ⑧=(1 -1 -2 0)( 0 -1 0 -1)T =1>0,故w(16)=w(15) =(1 -1 -2 0)T因w T (16)x ⑦=(1 -1 -2 0)( -1 -1 -1 -1)T =2>0,故w(17)=w(16) =(1 -1 -2 0)T因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第三轮迭代。
第三轮迭代:w(25)=(2 -2 -2 0);因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第四轮迭代。
第四轮迭代:w(33)=(2 -2 -2 1)因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第五轮迭代。
第五轮迭代:w(41)=(2 -2 -2 1)因为该轮迭代的权向量对全部模式都能正确判别。
所以权向量即为(2 -2 -2 1),相应的判别函数为123()2221d x x x x =--+(2)编写求解上述问题的感知器算法程序。
见附件·用多类感知器算法求下列模式的判别函数: ω1: (-1 -1)T ω2: (0 0)T ω3: (1 1)T 将模式样本写成增广形式:x ①=(-1 -1 1)T , x ②=(0 0 1)T , x ③=(1 1 1)T取初始值w 1(1)=w 2(1)=w 3(1)=(0 0 0)T,C=1。
第一轮迭代(k=1):以x ①=(-1 -1 1)T作为训练样本。
d 1(1)=)1(1Tw x ①=(0 0 0)(-1 -1 1)T=0d 2(1)=)1(2Tw x ①=(0 0 0)(-1 -1 1)T=0d 3(1)=)1(3T w x ①=(0 0 0)(-1 -1 1)T=0因d 1(1)≯d 2(1),d 1(1)≯d 3(1),故w 1(2)=w 1(1)+x ①=(-1 -1 1)Tw 2(2)=w 2(1)-x ①=(1 1 -1)Tw 3(2)=w 3(1)-x ①=(1 1 -1)T第二轮迭代(k=2):以x ②=(0 0 1)T作为训练样本d 1(2)=)2(1Tw x ②=(-1 -1 1)(0 0 1)T=12d 3(2)=)2(3Tw x ②=(1 1 -1)(0 0 1)T=-1因d 2(2)≯d 1(2),d 2(2)≯d 3(2),故w 1(3)=w 1(2)-x ②=(-1 -1 0)Tw 2(3)=w 2(2)+x ②=(1 1 0)Tw 3(3)=w 3(2)-x ②=(1 1 -2)T第三轮迭代(k=3):以x ③=(1 1 1)T作为训练样本d 1(3)=)3(1Tw x ③=(-1 -1 0)(1 1 1)T=-2d 2(3)=)3(2Tw x ③=(1 1 0)(1 1 1)T=2d 3(3)=)3(3Tw x ③=(1 1 -2)(1 1 1)T =0因d 3(3)≯d 2(3),故w 1(4)=w 1(3) =(-1 -1 0)Tw 2(4)=w 2(3)-x ③=(0 0 -1)Tw 3(4)=w 3(3)+x ③=(2 2 -1)T第四轮迭代(k=4):以x ①=(-1 -1 1)T作为训练样本d 1(4)=)4(1Tw x ①=(-1 -1 0)(-1 -1 1)T=2d 2(4)=)4(2Tw x ①=(0 0 -1)(-1 -1 1)T=-1d 3(4)=)4(3T w x ①=(2 2 -1)(-1 -1 1)T=-5因d 1(4)>d 2(4),d 1(4)>d 3(4),故w 1(5)=w 1(4) =(-1 -1 0)Tw 2(5)=w 2(4) =(0 0 -1)Tw 3(5)=w 3(4) =(2 2 -1)T第五轮迭代(k=5):以x ②=(0 0 1)T作为训练样本d 1(5)=)5(1Tw x ②=(-1 -1 0)(0 0 1)T=0d 2(5)=)5(2Tw x ②=(0 0 -1)(0 0 1)T=-1d 3(5)=)5(3T w x ②=(2 2 -1)(0 0 1)T=-1因d 2(5) ≯d 1(5),d 2(5) ≯d 3(5),故w 1(6)=w 1(5)-x ② =(-1 -1 -1)w 2(6)=w 2(5)+x ②=(0 0 0) w 3(6)=w 3(5)-x ②=(2 2 -2)第六轮迭代(k=6):以x ③=(1 1 1)T作为训练样本d 1(6)=)6(1Tw x ③=(-1 -1 -1)(1 1 1)T=-32d 3(6)=)6(3Tw x ③=(2 2 -2)(1 1 1)T=2因d 3(6)>d 1(6),d 3(6)>d 2(6),故w 1(7)=w 1(6)w 2(7)=w 2(6) w 3(7)=w 3(6)第七轮迭代(k=7):以x ①=(-1 -1 1)T作为训练样本d 1(7)=)7(1Tw x ①=(-1 -1 -1)(-1 -1 1)T=1d 2(7)=)7(2Tw x ①=(0 0 0)(-1 -1 1)T=0d 3(7)=)7(3Tw x ①=(2 2 -2)(-1 -1 1)T =-6因d 1(7)>d 2(7),d 1(7)>d 3(7),分类结果正确,故权向量不变。
由于第五、六、七次迭代中x ①、x ②、x ③均已正确分类,所以权向量的解为:w 1=(-1 -1 -1)Tw 2=(0 0 0)Tw 3=(2 2 -2)T三个判别函数:d 1(x)=- x 1 -x 2-1 d 2(x)=0d 3(x)=2x 1+2x 2-2·采用梯度法和准则函数22])[(81),,(b x w b x w xb x w J T T ---=式中实数b>0,试导出两类模式的分类算法。
[][])sign(*x -x *||)(|||412b x w b x w b x w x w J TT T ----=∂∂|其中,⎩⎨⎧≤-->+=-010-1)(b x w if b x w if b x w sign TT T当0>-b x w T 时,则w(k+1) = w(k),此时不对权向量进行修正;当0≤-b x w T 时,则)(|||)()1(2b x w x Cx k w k w k Tk k k -+=+|,需对权向量进行校正,初始权向量w(1)的值可任选。