递归神经网络英文课件-Chapter 2 Machine learning basics
MLP神经网络PPT课件

• structure • universal theorem • MLP for classification • mechanism of MLP for classification
– nonlinear mapping – binary coding of the areas
i, j
Ep i jk
O k1 i
• Situation for k M
E p i jM
E p O j M
O j M i jM
( y j OjM ) f '(ijM )
• Situation for k M
Ep
i jk
l
E p il k1
il k1 O j k
O j k i jk
l
• We ended by looking at some practical issues that didn’t arise for the single layer networks
Structure of an MLP
• it is composed of several layers • neurons within each layer are not connected • ith layer is only fully connected to the (i+1)jth layer • Signal is transmitted only in a feedforward manner
ij (xi )
• It is impractical
– the functions Ej(.) and ij (.) are not the simple weighted sums passed through
神经网络课件2

Computation of actual response
y(n) sgn[ wT (n)x(n)]
Adaptation of Weight Vector
w(n 1) w(n) [d (n) y(n)]x(n)
1 if x(n) belongs to class C1 d ( n) { 1 if x(n) belongs to class C 2 Continuation
Perceptron Convergence Theorem(II)
Using modified signal-flow graph
bias
b(n) is treated as synaptic weight driven by fixed input +1 w0 ( n) is b(n) linear combiner output
m
of bias b is merely to shift decision boundary away from origin synaptic weights adapted on iteration by iteration basis
Perceptron(II)
Decision regions separated by a hyperplane
Perceptron
The simplest form of a neural network consists of a single neuron with adjustable synaptic weights and bias. performs pattern classification with only two classes perceptron convergence theorem :
Machine Learning.ppt

History of ML(1990s & beyond)
What’s hot now? Reinforcement learning; Bayesian learning; automatic bias selection; inductive logic programming (mostly in Europe); applications to robotics; adaptive software agents; voting, bagging, boosting, and stacking.
.. ..
x1
x1+x2+1=0
2x2=0 x1
step 4 input (x1,x2) = (-1,1) , t = -1
ww120211((11))11 b 0 (1) 1
step 5 input (x1,x2) = (-1,-1) , t = -1
w1 1 (1) (1) 2 w2 1 (1) (1) 2 b 1 (1) 2
Machine Learning <T,P,E>:
Computer automatically improves
at task T(任务) according to performance metric P(性能) through experience E(经验)
--- Tom Mitchell
T: Driving on four-lane highways using vision sensors
P: Average distance traveled before a human-judged error
E: A sequence of images and steering commands recorded while observing a human driver.
神经网络学习PPT课件

d ||X1 X 2|| ( X1 X 2 )( X1-X 2 )T
摘自《Talking Nets: An Oral History of Neural Networks》封面
2008-2009学年第1学期
1
神经网络基础
公元前400年左右,柏拉图和亚里士多德就曾对 人类认知、记忆、思维进行过研究;
19世纪末,出现了神经元学说;美国生物学家W. James在《Physiology》一书中提到,“人脑中 两个基本单元靠得较近时,一个单元的兴奋会传 到另一个单元;
2008-2009学年第1学期
16
“感知器”无法解决线性不可分问题;
1969年,Minsky和Papert指出了“感知器”的 这种局限性,例如,“感知器”无法实现“异或”
逻辑。
逻辑“与”
逻辑“异或”
x1
x2
y
x1
x2
y
0
0
0
0
0
0
0
1
0
0
1
1
1
0
0
1
0
1
1
1
1
1
1
0
2008-2009学年第1学期
输入一个实际例子,让ANN分析并给出结果。
2008-2009学年第1学期
12
“感知器”是怎么训练的呢?
假设每个样本含 n 个属性,用向量(x1, x2, …, xn)表示;若 X 为样本变量, X∈Rn;
wij 是 xi 到神经元 j 的连接权值, Wj 是神经元 j 的输入连 接的权值向量,即Wj =(w1j , w2j , …, wnj );
第i层神经元netij层神经元的数目20082009学年第1学神经网络学习bp算法中的前向计算ijijnetijij特征函数必须是有界连续可微的如sigmoid函数20082009学年第1学期神经网络学习bp算法中的反向计算ijkijkijkijkijk输出层神经元j的状态误差ijk的调整量20082009学年第1学期神经网络学习bp算法中的反向计算续ikik神经网络学习bp学习算法的特点对于n层网络结构学习后可得到n1个超曲面组成复合曲面从而实现复杂的分类任务
《ANN神经网络》课件

神经网络的训练过程和算法
1 BP算法
2 Adam算法
通过反向传播算法,根据输出误差和梯度下 降法更新网络参数,目标是最小化误差函数。
结合了Ad ag r ad 和RM Sp ro p 优点的一种有效 的优化算法,自适应的调节学习率,以加快 训练速度。
神经网络的激活函数和正则化方法
激活函数
每个神经元的输出需要通过激活函数进行非线性映 射,目前比较流行的有sig mo id 、t an h 和ReLU等。
神经元和生物神经元的异同
1 神经元
是神经网络的基本单位,是一种用于计算的抽象模型,只有输入和输出,以及需要学习 的权重和偏置。
2 生物神经元
是神经系统的基本单位,由轴突、树突、细胞体和突触等结构组成,与其他神经元具有 复杂的生物学表现和相互作用。
神经网络的优势和局限性
优势
具有自主学习、自适应、非线性和可并行处理等优 势,能够处理高维度数据和复杂的非线性问题。
参考文献和拓展阅读建议
参考文献: 1. Bishop, C. M . (1995). Neural Networks for Pattern Recognition. Oxford University Press. 2. Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. M IT Press. 3. LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep Learning. Nature, 521, 436-444. 拓展阅读建议: 1. 《深度学习》白板推导与Python实战 2. 《Python深度学习》实践指南 3. 《自然语言处理综论》 4. 《计算机视觉综论》
NEURALNETWORKS培训课件.ppt

Introduction
Biological neural networks are much more complicated in their elementary structures than the mathematical models we use for ANNs.
techniques A neural network is a processing device, either an algorithm, or actual hardware, whose
design was motivated by the design and functioning of human brains and components thereof. Most neural networks have some sort of "training" rule whereby the weights of connections
The Brain
The Brain as an Information Processing System The human brain contains about 10 billion nerve cells, or neurons. On average, each neuron is connected to other neurons through about 10 000 synapses. (The actual figures vary greatly, depending on the local neuroanatomy.)
Neural networks are a powerful technique to solve many real world problems. They have the ability to learn from experience in order to improve their performance and to adapt themselves to changes in the environment. In addition to that they are able to deal with incomplete information or noisy data and can be very effective especially in situations where it is not possible to define the rules or steps that lead to the solution of a problem.
神经网络

T
αt sign wtT x
gt (x)
G
G(x) = sign
t =1
• two layers of weights:
wt and α
• two layers of sign functions:
in gt and in G
what boundary can G implement?
−
−
+ + + +
−
−
+ + + +
−
−
−
−
−
−
−
8 perceptrons
16 perceptrons
target boundary
• ‘convex set’ hypotheses implemented: dVC → ∞, remember? :-) • powerfulness: enough perceptrons ≈ smooth boundary
linear regression
h(x) = s
x0 x1 x2 xd s h(x)
logistic regression
h(x) = θ(s)
x0 x1 x2 xd s h(x)
err = 0/1
err = squared
err = cross-entropy
will discuss ‘regression’ with squared error
2
G(x) = sign
t =0 1 2 3 4
αt gt (x)
to implement OR(g1 , g2 )?
神经网络ppt课件

通常,人们较多地考虑神经网络的互连结构。本 节将按照神经网络连接模式,对神经网络的几种 典型结构分别进行介绍
12
2.2.1 单层感知器网络
单层感知器是最早使用的,也是最简单的神经 网络结构,由一个或多个线性阈值单元组成
这种神经网络的输入层不仅 接受外界的输入信号,同时 接受网络自身的输出信号。 输出反馈信号可以是原始输 出信号,也可以是经过转化 的输出信号;可以是本时刻 的输出信号,也可以是经过 一定延迟的输出信号
此种网络经常用于系统控制、 实时信号处理等需要根据系 统当前状态进行调节的场合
x1
…… …… ……
…… yi …… …… …… …… xi
再励学习
再励学习是介于上述两者之间的一种学习方法
19
2.3.2 学习规则
Hebb学习规则
这个规则是由Donald Hebb在1949年提出的 他的基本规则可以简单归纳为:如果处理单元从另一个处
理单元接受到一个输入,并且如果两个单元都处于高度活 动状态,这时两单元间的连接权重就要被加强 Hebb学习规则是一种没有指导的学习方法,它只根据神经 元连接间的激活水平改变权重,因此这种方法又称为相关 学习或并联学习
9
2.1.2 研究进展
重要学术会议
International Joint Conference on Neural Networks
IEEE International Conference on Systems, Man, and Cybernetics
World Congress on Computational Intelligence
复兴发展时期 1980s至1990s
machine-learning-机器学习PPT课件

两个可能的测试结果
1. + (阳性)
2. – (阴性)
先验知识
P(癌症) = 0.008 P(非癌) = 0.992 P(+|癌) = 0.98
P(-|癌) = 0.02 P(-|非癌) = 0.97 P(+|非癌) = 0.03
假定一个患者的测试结#43;) 和 P(ㄱcancer |+)
2021/3/12
21
P(vj) : 不同目标值的概率
P(Play Tennis = yes) = 9/14 = .64 P(Play Tennis = no) = 5/14 = .36
P(aj|vj) : 条件概率
P(Wind = strong | Play Tennis = yes) = 3/9 = .33 P(Wind = strong | Play Tennis = no) = 3/5 = .60 P(yes)P(sunny|yes)P(cool|yes)P(high|yes)P(strong|yes)=0.0053 P(no) P(sunny|no) P(cool|no) P(high|no) P(strong|no)= .0206 vNB = no
•P(+|cancer) P(cancer)=0.0078
•P(+|ㄱcancer) P(ㄱcancer)=0.0298
所以 hMAP = ㄱcancer
2021/3/12
17
最可能的分类结果是考虑各个假设的加权和,权重就 是他们各自的后验概率 最优分类器平均性能最好 当假设空间很大时,计算待价很大
2021/3/12
22
贝叶斯信任网络是一个概率图模型,通过一个有向无环图 表示一系列变量及其条件独立关系
深学习循环神经网络PPT课件

Linear Separable Problem
AND
0
1
0
0
x1
x2
y
000
100
010
111
OR
1
1
0 1
111
XOR
1
0
0 1
x1
x2
y
000
101
011
110
12
Single Layer Perceptrons
XOR
1
0
0 1
For XOR problem: 1. introducing one additional neuron in a special way; 2. using differentiable activation function;
最简单的神经网络: Perceptrons
8
Single Layer Perceptrons
Rosenblatt, 1957
x1
x2
w1
y
• ••
w2
b
wM
xM
y f (u) signwi xi b
1 if u 0 y 1 if u 0
1 if u 0 f (u) w1x1 w2x2 b 1 if u 0
吸收了HMM模型的有限序列关联的思想。 神经网络的隐藏层结构能够更好的表达有限的观察值背后的复杂分布。
22
递归神经网络模型
时序扩展
23
Recurrent Neural Network
RNN是一类扩展的人工神经网络,它是为了对序列数据进行建模而产生的。 针对对象:序列数据。例如文本,是字母和词汇的序列;语音,是音节的序列;
人工智能英语 Unit 2 Machine Learning

Lead-in
Part I
Part I
Task 1 The following are common terms used in machine learning. Please match them with their Chinese translation. Look them up in a dictionary if necessary.
Part II
Types of machine learning Depending upon the nature of the data and the desired outcome, machine learning are divided into 4 primary types. Supervised machine learning Addressing datasets with labels or structure,data acts as a teacher and “trains” the machine, increasing in its ability to make a prediction or decision.
Part I
Task 2 Listen to the short passage and choose the proper words to fill in the blanks.
In the past, humans built algorithmic bots by giving them instructions that humans could 1________. If this, than that. But many problems are just too big and complex for a human to write simple instructions for. There are countless videos on Tiktok, which ones should the users see as 2______________? There’s a a huge amount of financial transactions a second, which ones are fraudulent? For this beautiful dress, what is the 3 ________ price this user will pay right now?
深度学习系列(6):递归神经网络
定义δp 为误差函数E相对于父父节点p的加权输入入netp 的导数,即:
δp =
设netp 是父父节点的加权输入入,则
∂E ∂netp c1 +b [ c2 ] ⎡ netc11 ⎤ ⎢ ⎥ wp1c21 · ·· ⎤ ⎢ netc12 ⎥ ⎥ wp2c21 · ·· ⎥ ⎢ · · · ⎥ ⎢ ⎥ netc21 ⎥ ··· ⎥ ⎢ ⎥⎢ ⎥ wpnc21 · ·· ⎦ ⎢ netc22 ⎥ ⎣ ··· ⎦
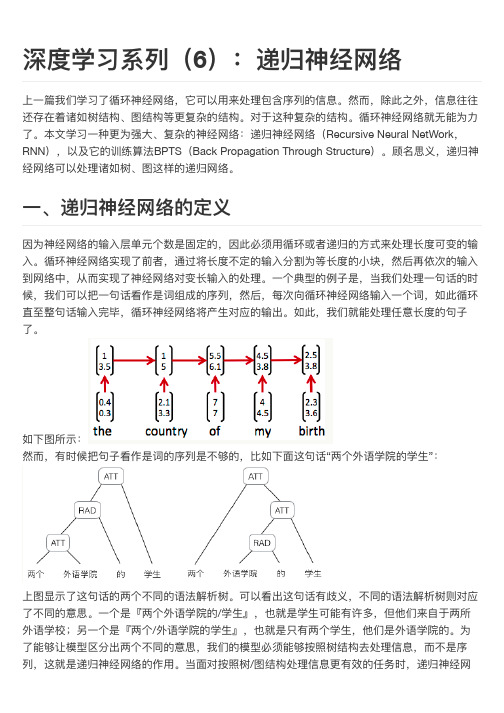
如下图所示: 然而而,有时候把句句子子看作是词的序列列是不不够的,比比如下面面这句句话“两个外语学院的学生生”:
上图显示了了这句句话的两个不不同的语法解析树。可以看出这句句话有歧义,不不同的语法解析树则对应 了了不不同的意思。一一个是『两个外语学院的/学生生』,也就是学生生可能有许多,但他们来自自于两所 外语学校;另一一个是『两个/外语学院的学生生』,也就是只有两个学生生,他们是外语学院的。为 了了能够让模型区分出两个不不同的意思,我们的模型必须能够按照树结构去处理理信息,而而不不是序 列列,这就是递归神经网网络的作用用。当面面对按照树/图结构处理理信息更更有效的任务时,递归神经网网
深度学习系列列(6):递归神经网网络
上一一篇我们学习了了循环神经网网络,它可以用用来处理理包含序列列的信息。然而而,除此之外,信息往往 还存在着诸如树结构、图结构等更更复杂的结构。对于这种复杂的结构。循环神经网网络就无无能为力力力 了了。本文文学习一一种更更为强大大、复杂的神经网网络:递归神经网网络(Recursive Neural NetWork, RNN),以及它的训练算法BPTS(Back Propagation Through Structure)。顾名思义,递归神 经网网络可以处理理诸如树、图这样的递归网网络。
神经网络之——递归神经网络PPT演示课件

If a1 a2, then
at, a1 at, a2 for any t 0
L
35
Trajectories
da(t) ga(t), p(t),t
dt
If a1 a2, then
at, a1 at, a2 for any t 0
L
36
A Simple Example
L
46
/people/seung/index.html
L
47
Linear RNNs
H. S. Seung, How the brain keeps the eyes still, Proc. Natl. Acad. Sci. USA, vol. 93, pp. 13339-13344, 1996
x(t ) x(t) x(t) f wx(t) b
L
28
From Discrete Computing to Continuous Computing
x(t ) x(t) x(t) f wx(t) b
0
dx(t) x(t) f wx(t) b
dt
L
29
Continuous Computing RNNs
dx(t) x(t) f wx(t) b
dt
L
30
Recurrent NNs
RNN model:
da(t) ga(t), p(t),t
dt
Network time
Network state
Network input
x(k 1) f wx(k) b
L
18
Discrete Time RNNs
Machine Learning

sky sunny cloudy rainy ? 4 airtemp warm cold ? 3 humidity normal high ? 3 wind strong weak ? 3 water warm cool ? 3 forecast same change ? 3
15
Prototypical task
• Data produced by "target". • Hypothesis learned from data in order to "explain", "model" or "control" the target. • Generalisation ability is essential.
• Finding all consistent hypotheses: candidate
elimination algorithm
• Generalising the hypothesis space: the role of
inductive bias
14
Induction and inference
6
Approaches
• • • • • • • • • • Decision tree learning Association rule learning Artificial neural networks Genetic programming Inductive logic programming Support vector machines Clustering Bayesian networks Reinforcement learning …
零基础入门深度学习(7) - 递归神经网络

[关闭]零基础入门深度学习(7) - 递归神经网络机器学习深度学习入门无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就out了?现在救命稻草来了,《零基础入门深度学习》系列文章旨在讲帮助爱编程的你从零基础达到入门级水平。
零基础意味着你不需要太多的数学知识,只要会写程序就行了,没错,这是专门为程序员写的文章。
虽然文中会有很多公式你也许看不懂,但同时也会有更多的代码,程序员的你一定能看懂的(我周围是一群狂热的Clean Code程序员,所以我写的代码也不会很差)。
文章列表零基础入门深度学习(1) - 感知器零基础入门深度学习(2) - 线性单元和梯度下降零基础入门深度学习(3) - 神经网络和反向传播算法零基础入门深度学习(4) - 卷积神经网络零基础入门深度学习(5) - 循环神经网络零基础入门深度学习(6) - 长短时记忆网络(LSTM)零基础入门深度学习(7) - 递归神经网络往期回顾在前面的文章中,我们介绍了循环神经网络,它可以用来处理包含序列结构的信息。
然而,除此之外,信息往往还存在着诸如树结构、图结构等更复杂的结构。
对于这种复杂的结构,循环神经网络就无能为力了。
本文介绍一种更为强大、复杂的神经网络:递归神经网络(Recursive Neural Network, RNN),以及它的训练算法BPTS (Back Propagation Through Structure)。
顾名思义,递归神经网络(巧合的是,它的缩写和循环神经网络一样,也是RNN)可以处理诸如树、图这样的递归结构。
在文章的最后,我们将实现一个递归神经网络,并介绍它的几个应用场景。
递归神经网络是啥因为神经网络的输入层单元个数是固定的,因此必须用循环或者递归的方式来处理长度可变的输入。
递归神经网络

递归神经网络概述一、引言人工神经网络的发展历史己有60多年,是采用物理可实现的系统模仿人脑神经细胞的结构和功能,是在神经生理学和神经解剖学的基础上,利用电子技术、光学技术等模拟生物神经网络的结构和功能原理而发展起来的一门新兴的边缘交叉学科,(下面简称为神经网络,NeuralNetwork)。
这些学科相互结合,相互渗透和相互推动。
神经网络是当前科学理论研究的主要“热点”之一,它的发展对目前和未来的科学技术的发展将有重要的影响。
神经网络的主要特征是:大规模的并行处理、分布式的信息存储、良好的自适应性、自组织性、以及很强的学习能力、联想能力和容错能力。
神经网络在处理自然语言理解、图像识别、智能机器人控制等方面具有独到的优势。
与冯·诺依曼计算机相比,神经网络更加接近人脑的信息处理模式。
自从20世纪80年代,Hopfield首次提出了利用能量函数的概念来研究一类具有固定权值的神经网络的稳定性并付诸电路实现以来,关于这类具有固定权值神经网络稳定性的定性研究得到大量的关注。
由于神经网络的各种应用取决于神经网络的稳定特性,所以,关于神经网络的各种稳定性的定性研究就具有重要的理论和实际意义。
递归神经网络具有较强的优化计算能力,是目前神经计算应用最为广泛的一类神经网络模型。
根据不同的划分标准,神经网络可划分成不同的种类。
按连接方式来分主要有两种:前向神经网络和反馈(递归)神经网络。
前向网络主要是函数映射,可用于模式识别和函数逼近。
递归神经网络因为有反馈的存在,所以它是一个非线性动力系统,可用来实现联想记忆和求解优化等问题。
由于神经网络的记亿信息都存储在连接权上,根据连接权的获取方式来划分,一般可分为有监督神经网络、无监督神经网络和固定权值神经网络。
有监督学习是在网络训练往往要基于一定数量的训练样木。
在学习和训练过程中,网络根据实际输出与期望输出的比较,进行连接权值和阂值的调节。
通常称期望输出为教师信号,是评价学习的标准。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Xiaogang Wang
Machine Lzation
We care more about the performance of the model on new, previously unseen examples
The training examples usually cannot cover all the possible input configurations, so the learner has to generalize from the training examples to new cases
y ∗ = arg max P(y = k |x)
k
(Duda et al. Pattern Classification 2000) Xiaogang Wang
Machine Learning Basics
cuhk
Regression
Predict real-valued output f : RD → RM
Mean squared error (MSE) for linear regression
MSEtrain
=
1 N
||wt x(itrain) − yi(train)||22
i
Cross entropy (CE) for classification
CEtrain
=
1 N
log P(y = yi(train)|x(itrain))
wMSEtrain = 0 ⇒ w||X(train)w − y(train)||22 = 0 w = (X(train)t X(train))−1X(train)t y(train) where X(train) = [x(1train), . . . , x(Ntrain)] and y(train) = [y1(train), . . . , yN(train)].
1 Performancetest = M
M
Error(f (x(i test)), yi(test))
i =1
We hope that both test examples and training examples are drawn from p(x, y ) of interest, although it is unknown
i
Why not use classification errors #{f (x(itrain)) = yi(train)}?
cuhk
Xiaogang Wang
Machine Learning Basics
Optimization
The choice of the objective function should be good for optimization Take linear regression as an example
GEf = p(x, y )Error(f (x), y )
x,y
cuhk
Xiaogang Wang
Machine Learning Basics
Generalization
However, in practice, p(x, y ) is unknow. We assess the generalization performance with a test set {x(i test), yi(test)}
Decision boundary, parameters of P(y |x), and w in linear regression
Optimize an objective function on the training set. It is a performance measure on the training set and could be different from that on the test set.
Generalization error: the expected error over ALL examples
To obtain theoretical guarantees about generalization of a machine learning algorithm, we assume all the samples are drawn from a distribution p(x, y ), and calculate generalization error (GE) of a prediction function f by taking expectation over p(x, y )
f (x) is decided by the decision boundary As an variant, f can also predict the probability distribution over classes given x, f (x) = P(y |x). The category is predicted as
Machine Learning Basics
Xiaogang Wang
Machine Learning Basics
cuhk
Machine Learning
Xiaogang Wang
Machine Learning Basics
cuhk
Classification
f (x) predicts the category that x belongs to f : RD → {1, . . . , K }
Example: linear regression
D
y = wt x = wd xd + w0
d =1
(Bengio et al. Deep Learning 2014)
Xiaogang Wang
Machine Learning Basics
cuhk
Training
Training: estimate the parameters of f from {(x(itrain), yi(train))}