编译技术课程设计A实验报告(华北电力大学科技学院)
编译技术实验报告词法(3篇)

第1篇一、实验目的本次实验旨在通过实践加深对编译技术中词法分析阶段的理解,掌握词法分析的基本原理和方法,能够实现一个简单的词法分析器,并对源代码进行初步的符号化处理。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse IDE4. 实验素材:实验提供的C语言源代码三、实验原理词法分析是编译过程中的第一个阶段,其主要任务是将源代码中的字符序列转换成一系列的词法单元(Token)。
词法单元是构成源程序的基本单位,如标识符、关键字、运算符等。
词法分析的基本原理如下:1. 字符流:从源代码中逐个读取字符,形成字符流。
2. 状态转换:根据字符流中的字符,在有限状态自动机(FSM)中转换状态。
3. 词法单元生成:当状态转换完成后,生成对应的词法单元。
4. 错误处理:在分析过程中,如果遇到无法识别的字符或状态,进行错误处理。
四、实验步骤1. 设计词法分析器:根据C语言的语法规则,设计有限状态自动机,定义状态转换图。
2. 实现状态转换函数:根据状态转换图,实现状态转换函数,用于将字符流转换为词法单元。
3. 实现词法单元生成函数:根据状态转换结果,生成对应的词法单元。
4. 测试词法分析器:使用实验提供的C语言源代码,测试词法分析器的正确性。
五、实验结果与分析1. 词法分析器设计:根据C语言的语法规则,设计了一个包含26个状态的状态转换图。
状态转换图包括以下状态:- 初始状态:用于开始分析。
- 标识符状态:用于分析标识符。
- 关键字状态:用于分析关键字。
- 运算符状态:用于分析运算符。
- 数字状态:用于分析数字。
- 字符串状态:用于分析字符串。
- 错误状态:用于处理非法字符。
2. 状态转换函数实现:根据状态转换图,实现了状态转换函数。
该函数用于将字符流转换为词法单元。
3. 词法单元生成函数实现:根据状态转换结果,实现了词法单元生成函数。
该函数用于生成对应的词法单元。
《编译技术》课程设计

《编译技术》课程设计一、课程目标知识目标:1. 理解编译技术的概念、原理及作用,掌握编译程序的基本结构;2. 掌握词法分析、语法分析、语义分析及中间代码生成的相关方法;3. 了解目标代码生成、代码优化及运行时存储管理的基本原理。
技能目标:1. 能够运用编译技术进行简单程序的设计与调试;2. 能够运用编译原理对实际问题进行分析,提出解决方案;3. 能够运用相关工具和软件进行编译过程的实践操作。
情感态度价值观目标:1. 培养学生对编译技术学科的兴趣,激发学生主动学习的热情;2. 培养学生严谨的科学态度和良好的团队协作精神;3. 增强学生对我国计算机事业发展的自豪感,树立为祖国信息技术事业作贡献的信念。
课程性质:本课程属于计算机科学与技术专业核心课程,以理论与实践相结合的方式进行教学。
学生特点:学生具备一定的编程基础和计算机科学理论知识,具有较强的逻辑思维能力。
教学要求:结合课程性质、学生特点,注重理论与实践相结合,强调动手实践,培养学生的编译技术实际应用能力。
通过课程学习,使学生能够掌握编译技术的基本知识,具备一定的编译程序设计与调试能力。
同时,注重培养学生的团队合作精神和价值观。
将课程目标分解为具体的学习成果,以便后续的教学设计和评估。
二、教学内容1. 编译技术基础:包括编译程序的作用、编译过程概述、编译程序的组成及结构。
- 教材章节:第1章 编译技术概述2. 词法分析:涉及词法分析器的功能、词法规则、状态转换图、词法分析程序设计。
- 教材章节:第2章 词法分析3. 语法分析:介绍语法分析器的功能、上下文无关文法、递归下降分析、LL(1)分析法、自底向上的语法分析、算符优先分析。
- 教材章节:第3章 语法分析4. 语义分析:语义分析任务、属性文法、语法制导翻译、类型检查、中间代码生成。
- 教材章节:第4章 语义分析5. 代码优化与目标代码生成:包括代码优化方法、基本块优化、目标代码生成、指令选择、寄存器分配。
华北电力大学编译实验报告

课程设计报告( 2013 -- 2014年度第 1 学期)名称:编译技术课程设计题目:词法分析器设计算符优先分析程序设计基于算符优先分析方法的语法制导翻译程序设计院系:计算机系班级:学号:学生姓名:指导教师:设计周数:1周成绩:日期:2014 年 1 月 3 日一、课程设计的目的与要求1.词法分析器设计的目的与要求1.1 词法分析器设计的实验目的本实验是为计算机科学与技术专业、网络工程专业、信息安全专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。
通过这个实验,使学生应用编译程序设计的原理和技术设计出词法分析器,了解扫描器的组成结构,不同种类单词的识别方法。
能使得学生在设计和调试编译程序的能力方面有所提高。
为将来设计、分析编译程序打下良好的基础。
1.2 词法分析器设计的实验要求设计一个扫描器,该扫描器是一个子程序,其输入是源程序字符串,每调用一次识别并输出一个单词符号。
为了避免超前搜索,提高运行效率,简化扫描器的设计,假设该程序设计语言中,基本字(也称关键词)不能做一般标识符用,如果基本字、标识符和常数之间没有确定的运算符或界符作间隔,则用空白作间隔。
单词符号及其内部表示如表1-1所示,单词符号中标识符由一个字母后跟多个字母、数字组成,常数由多个十进制数字组成。
单词符号的内部表示,即单词的输出形式为二元式:(种别编码,单词的属性值)。
表1-1 单词符号及其内部表示2.算符优先分析程序设计的目的和要求2.1 算符优先分析程序设计的实验目的本实验是为计算机科学与技术等专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。
通过这个实验,使学生应用编译程序设计的原理和技术, 设计、编写和调试算符优先分析程序,了解算符优先分析程序的组成结构,掌握实现通用算符优先分析算法的方法。
能使得学生在设计和调试编译程序的能力方面有所提高。
编译原理课程设计报告 编译器

《编译技术》课程设计实验报告实验名称:编译器程序说明:下载请好评姓名:向难学号:200812110106班级:计算机系08本一班2010年11月12日目录一、课设要求 (3)二、总体设计思想 (4)三、详细算法设计 (4)四、流程框图 (5)五、函数相关说明 (9)1. 所有函数一览 (9)2. void emit(char *res,char *num1,char *op,char *num2) (9)3. char *newTemp() (10)4. int merge(int p1,int p2) (10)5. void backpatch(int p,int t) (11)6. void fuzhi() (11)7. void tiaojian(int *nChain) (12)8. void xunhuan() (13)六、程序运行结果 (15)七、编译器使用说明 (17)八、心得与体会 (17)九、源程序清单 (18)一、课设要求用C语言对下述文法和单词表定义的语言设计编制一个编译器。
(1)单词符号及种别表(2)语法结构定义<程序> ::= main()<语句块><语句块> ::= ‘{‘<语句串>’}’//程序用括号括起来<语句串>::=<语句>{;<语句>};<语句>::=<赋值语句>|<条件语句>|<循环语句><赋值语句>::=ID=<表达式> //赋值语句用”=”号<条件语句>::=if<条件><语句块> //条件怎么没有括号,囧(自己加1个)<循环语句>::=do <语句块>while <条件><条件>::=<表达式><关系运算符><表达式> //没有布尔运算,还算简单<表达式> ::= <项>{ +<项>|-<项>}<项> ::= <因子>{*<因子>|/<因子>}<因子> ::=ID|num|(<表达式>)num::=( +|-|ε) 数字*(.数字数字* | ε)( e ( +|-|ε) 数字数字*|ε)ID::=字母(字母|d数字)*字母::=a|b|c…|z|A|B|C…|Z数字::=0|1|2…|9<关系运算符> ::= <|<=|>|>=|==|!=二、总体设计思想采用递归下降(自上而下)的语法制导翻译法。
《编译技术》课程设计

《编译技术》课程设计一、教学目标本课程的教学目标是使学生掌握编译技术的基本原理和方法,能够运用编译原理分析和设计简单的编译器。
具体目标如下:1.知识目标:–掌握编译原理的基本概念,如文法、语法分析、语义分析、中间代码生成、目标代码生成等。
–了解编译器的基本结构和工作原理。
–熟悉编译器的优化技术。
2.技能目标:–能够使用编译原理的方法和技巧分析简单的程序代码。
–能够运用编译原理设计和实现简单的编译器。
–能够对编译器进行基本的优化。
3.情感态度价值观目标:–培养学生的抽象思维和逻辑思维能力。
–培养学生对编译技术的兴趣和热情,使学生认识到编译技术在软件工程中的重要性。
二、教学内容本课程的教学内容主要包括编译原理的基本概念、编译器的基本结构和工作原理、编译器的实现技术和优化技术。
具体安排如下:1.编译原理的基本概念:–语言、文法、语法分析、语义分析等基本概念。
2.编译器的基本结构和工作原理:–编译器的基本组成部分,如词法分析器、语法分析器、语义分析器、中间代码生成器、目标代码生成器等。
–编译器的工作流程,包括词法分析、语法分析、语义分析、中间代码生成、目标代码生成等阶段。
3.编译器的实现技术:–词法分析器的实现技术,如正则表达式、有限自动机等。
–语法分析器的实现技术,如递归下降分析、LL分析、LR分析等。
–语义分析器的实现技术,如类型检查、符号表管理等。
4.编译器的优化技术:–常见的优化技术,如常量折叠、死代码消除、循环优化等。
三、教学方法本课程采用讲授法、讨论法、案例分析法和实验法等多种教学方法,以激发学生的学习兴趣和主动性。
1.讲授法:通过讲解编译原理的基本概念、基本技术和方法,使学生掌握编译技术的核心知识。
2.讨论法:学生进行课堂讨论,引导学生思考和探索编译技术的问题,培养学生的抽象思维和逻辑思维能力。
3.案例分析法:分析典型的编译器设计案例,使学生了解编译器的实际应用和实现技巧。
4.实验法:让学生动手设计和实现简单的编译器,培养学生的实际操作能力和创新能力。
编译实习报告

编译实习报告一、实习背景随着计算机技术的不断发展,编译技术在软件开发和计算机科学领域中起着至关重要的作用。
为了更好地了解编译原理在实际应用中的具体实现,提高自己的实际动手能力,我参加了为期三个月的编译实习项目。
在实习期间,我深入学习了编译原理的基本知识,并参与了编译器的开发与优化过程。
二、实习内容1. 编译原理学习在实习的第一阶段,我系统地学习了编译原理的基本知识,包括文法、语法分析、中间代码生成、代码优化和目标代码生成等。
通过学习,我掌握了编译器的基本组成部分及其工作原理,为后续的实践操作打下了坚实的基础。
2. 编译器开发在实习的第二阶段,我参与了编译器的开发过程。
首先,我使用C语言编写了一个简单的编译器前端,实现了源代码的词法分析和语法分析。
在此基础上,我进一步实现了中间代码的生成和代码优化模块。
最后,我完成了目标代码的生成和运行。
整个过程中,我深刻体会到了编译原理在实际应用中的重要性。
3. 编译器优化在实习的第三阶段,我主要负责编译器的优化工作。
通过对中间代码的分析和调整,我实现了常数折叠、死代码消除和循环优化等优化策略。
经过优化,编译器生成的目标代码在运行效率和内存占用方面都有了显著的提升。
三、实习收获1. 知识运用通过实习,我将所学的编译原理知识运用到了实际项目中,提高了自己的实际动手能力。
同时,实习过程中遇到的问题也促使我不断深入学习相关知识,提高了自己的理论水平。
2. 团队协作在实习过程中,我与团队成员密切配合,共同解决问题。
这使我更加明白了团队协作的重要性,也锻炼了我的沟通与协作能力。
3. 工程实践实习过程中,我独立完成了编译器的开发与优化任务,掌握了工程实践的基本方法。
这对我今后从事软件开发工作具有很大的帮助。
四、实习总结通过这次编译实习,我对编译原理有了更深入的了解,并在实际项目中积累了宝贵的经验。
同时,实习过程中的挑战和困难也让我明白了自身存在的不足,为我今后的学习和工作指明了方向。
华北电力大学科技学院通信原理实验-数字基带传输编译码

内
容
1.用示波器分别观测AMI编码输入的数据和编码输出的数据,观察记录波形,验证AMI编码规则;用示波器分别观测AMI编码输入的数据和译码输出的数据,观察记录AMI译码波形与输入信号波形。
2.用示波器分别观测HDB3编码输入的数据和编码输出的数据,记录波形,验证HDB3编码规则;用示波器分别观HDB3测编码输入数据和译码输出数据,观察记录HDB3译码波形与输入信号波形。
实
验
数
据
记
录
第2页
实
验
结
果
及
分
析
问
题
及
答
案
问题1:本实验输入信号采用的单极性码,可较好的恢复出位时钟信号,如果输入信号采用的是双极性码,是否能观察到恢复的位时钟信号,为什么?
答案:
问题2:比较两种编码的优劣,说说为什么实际通信系统采用HDB3码。
答案:
问题3:不归零码和归零码的特点是什么?
答案:
收
获
本实验输入信号采用的单极性码可较好的恢复出位时钟信号如果输入信号采用的是双极性码是否能观察到恢复的位时钟信号为什么
华北电力大学科技学院
实验报告
|
|
实验名称
课程名称
|
|
专业班级:电信13K学生姓名:
学 号:31成 绩:
指导教师:王劭龙实验日期:
华北电力大学科技学院实验报告
院/系:同组人:
实验名称
数字基带据记录
后面其他
所用仪器
设备
示波器RIGOL DS1102E,LTE-TX-06A通信原理综合实验箱
实验目的
要求
1.掌握AMI码、HDB3码的编译规则。
2.理解AMI码、HDB3码的码变换过程。
编译原理实验报告-样例

一、实验目的
分析PL/0编译程序的总体结构、代码生成的方法和过程;具体写出一条语句的中间代码生成过程。
二、设备与环境
PC兼容机、Windows操作系统、Turbo Pascal软件等。
三、实验内容
1.分析PL/0程序的Block子程序,理清PL/0程序结构和语句格式。画出ock子程序的流程图,写出至少两条PL/0程序语句的语法格式。
题解正确
其他:
评价教师签名:
年月日
华北科技学院计算机系综合性实验
实验报告
课程名称编译原理
实验学期2008至2009学年第二学期
学生所在系部计算机系
年级三专业班级计算机B062班
学生姓名XXX学号************
任课教师王养廷
实验成绩
计算机系制
《编译原理》课程综合性实验报告
开课实验室:软件开发室2009年5月14日
实验题目
分析中间代码生成程序
四、实验结果及分析
(一)Block子程序分析
(二)代码生成的方法和过程:
(三)编写一个简单的PL/0程序
(四)分析上述程序中c:=2*(l+w);的代码生成过程
教师评价
编译技术实验报告模板---更新
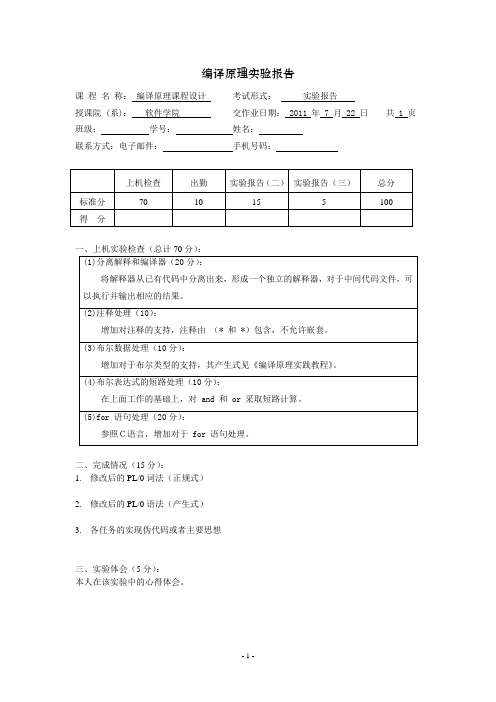
编译原理实验报告课程名称:编译原理课程设计考试形式:实验报告授课院 (系):软件学院交作业日期: 2011 年 7 月 22 日共 1 页班级:学号:姓名:联系方式:电子邮件:手机号码:二、完成情况(15分):1.修改后的PL/0词法(正规式)2.修改后的PL/0语法(产生式)3.各任务的实现伪代码或者主要思想三、实验体会(5分):本人在该实验中的心得体会。
注意:此页无需打印,阅读后可以删除此页。
大作业说明:[1]请大家按照本格式来写实验作业。
(方便批改,谢谢!)[2]请大家不要修改原文字的字体、字号。
(方便批改,谢谢!)[3]你自己所陈述文字的字体、字号可以任选。
[4]请准备纸版作业(实验报告)和电子版作业(上机实验和实验报告)。
[5]纸版作业和电子版作业缺一不可,少了哪个均无法通过本考试。
[6]如果某题一页回答内容超出一页范围(例如第2题),可以扩展至多页。
大作业分数说明:[7]期末成绩:=实验报告得分+ 平时成绩[8]本次大作业卷面满分为100分。
[9]平时成绩满分为80分,包括出勤(10分)、上机检查(70分)。
[10]实验报告占20分。
[11]出勤分数为10分,每天不定时考察一次出勤。
[12]实验报告字数不得少于1000字。
关于作业上交的说明:[13]纸版作业请打印,如果图不容易画,可以打印后手工画图。
[14]纸版作业上交时间:2011年7月22日上午上课时间(8点至11点)。
[15]纸版作业上交要求:请各位同学本人上交自己的纸版作业。
(不收代交作业)[16]电子版作业上交时间:2011年7月22日上午。
(不晚于纸版作业时间,可提前提交)[17]电子版作业命名格式:班级-学号-姓名-作业题目.doc(或wps均可)。
例如:0901-200996001-喜洋洋-校园某服务系统.doc如果上传作业后又进行了作业更新,则新文件名后加入更新日期即可。
例如:班级-学号-姓名-作业题目-更新日期.doc[18]电子版作业提交地址:ftp://210.30.96.4/UPLOAD/Liu_xinyue_Upload/有问题请咨询:[19]如有任何问题,欢迎大家邮件咨询xinyue_dlut@,我会继续补充此处的说明。
《编译技术》课程设计

《编译技术》课程设计一、教学目标本课程的教学目标是使学生掌握编译技术的基本原理和方法,包括词法分析、语法分析、语义分析、中间代码生成、目标代码生成和优化等主要环节。
通过本课程的学习,学生应能理解并应用编译原理解决实际问题,提高软件开发和维护的效率。
在知识目标方面,学生应掌握编译器的基本架构和各个阶段的主要算法。
在技能目标方面,学生应能够使用现有的编译器工具,并根据实际需要进行简单的编译器设计和实现。
在情感态度价值观目标方面,学生应培养对软件工程的热爱和敬业精神,提高团队合作能力和创新意识。
二、教学内容本课程的教学内容主要包括编译原理的基本概念、编译器的各个阶段以及相关的算法和优化技术。
具体包括:1. 编译原理的基本概念,如编译器的作用、编译过程和编译器的基本架构;2. 词法分析,如词法规则、词法分析器的设计和实现;3. 语法分析,如语法规则、语法分析树和分析算法;4. 语义分析,如类型检查、语义分析和错误处理;5. 中间代码生成,如三地址码和中间代码优化;6. 目标代码生成和优化,如指令选择、代码生成和优化技术。
三、教学方法为了实现本课程的教学目标,我们将采用多种教学方法,包括讲授法、讨论法、案例分析法和实验法等。
在教学过程中,我们将注重理论教学与实践相结合,通过生动的案例和实际的编译器工具使学生更好地理解和应用编译原理。
同时,我们将鼓励学生积极参与课堂讨论,提高他们的思考能力和创新意识。
此外,我们还将通过实验课程让学生亲自动手设计和实现简单的编译器,提高他们的实践能力和团队合作能力。
四、教学资源为了支持本课程的教学内容和教学方法,我们将准备一系列教学资源,包括教材、参考书、多媒体资料和实验设备。
教材方面,我们选择《编译原理》一书作为主教材,同时推荐《现代编译原理》等参考书供学生自主学习。
多媒体资料方面,我们将提供课件、教学视频和相关的学术论文等,以丰富学生的学习体验。
实验设备方面,我们将提供计算机实验室,让学生能够在实验课程中亲自动手实践编译原理。
华北电力大学科技学院数字信号处理课程设计

课程设计(综合实验)报告( 2015-- 2016年度第一学期)名称:数字信号处理课程设计题目:MATLAB编程院系:信息工程系班级:13K2学号:31学生姓名:指导教师:孙老师设计周数: 2成绩:日期:2015年12月18日一、课程设计(综合实验)的目的与要求一、 目的与要求1. 掌握《数字信号处理基础》课程的基本理论;2. 掌握应用MATLAB 进行数字信号处理的程序设计方法。
二、 主要内容设计题目及设计要求:已知低通数字滤波器的性能指标如下:0.26p ωπ=,0.75dB p R =,0.41s ωπ=,50dB s A =要求:1. 选择合适的窗函数,设计满足上述指标的数字线性相位FIR 低通滤波器。
用一个图形窗口,包括四个子图,分析显示滤波器的单位冲激响应、相频响应、幅频响应和以dB 为纵坐标的幅频响应曲线。
2. 用双线性变换法,设计满足上述指标的数字Chebyshev I型低通滤波器。
用一个图形窗口,包括三个子图,分析显示滤波器的幅频响应、以dB 为纵坐标的幅频响应和相频响应。
3. 已知模拟信号1234()2sin(2)5sin(2)8cos(2)7.5cos(2)x t f t f t f t f t ππππ=+++其中10.12f kHz =,2 4.98f kHz =,3 3.25f kHz =,4 1.15f kHz =,取采样频率10s f kHz =。
要求:(1)以10s f kHz =对()x t 进行取样,得到()x n 。
用一个图形窗口,包括两个子图,分别显示()x t 以及()x n (0511n ≤≤)的波形;(2)用FFT 对()x n 进行谱分析,要求频率分辨率不超过5Hz 。
求出一个记录长度中的最少点数x N ,并用一个图形窗口,包括两个子图,分别显示()x n 以及()X k 的幅值;(3)用要求1中设计的线性相位低通数字滤波器对()x n 进行滤波,求出滤波器的输出1()y n ,并用FFT 对1()y n 进行谱分析,要求频率分辨率不超过5Hz 。
编译技术实验报告

编译技术实验报告
编译技术实验报告是每个程序员与编程相关的任务中都非常重要的一部分,它能让他们更好的深入理解为什么程序能在机器上运行,以及它在什么情况下会失去有效性。
编译技术实验报告是一个程序的思考、测试和分析的下一步,以确保程序的性能得到可靠的运行和改进。
首先,程序员在编辑器中使用语言来构建程序。
然后,使用编译器将源代码生成可执行文件,将源代码翻译成机器可以理解的语言,使其在机器上可以运行代码。
在它完成后,程序员就可以通过编译技术实验报告,测试程序是否正确、优化其性能、增强其可用性、甚至查找隐藏的错误等。
特别是在编写嵌入式程序时,编译技术实验报告尤为重要,因为它可以在发布时发现隐藏的Bug,而没有这一步就无法确保程序的完美运行。
此外,编译技术实验报告还可以帮助程序员发现程序的内在缺陷,例如发现变量的重复初始化、变量的名称未定义或程序函数将活动超出其规格等。
这样可以保证程序在发布时无bug可言,从而提高程序的可用性。
总之,编译技术实验报告是一种在程序发布之前及时发现并修复Bug的重要手段。
它可以提高程序的性能、便捷性和有效性,使其达到最佳的运行状态。
无论程序员采用何种程序设计语言,在发布前都一定要注意进行实验报告,严格检查程序中可能存在的bug。
这样可以确保程序能够顺利发布,且不会因Bug引起用户不满。
编译实验报告

《编译原理课程设计》总结报告:实验目的:设计SNL语言的词法分析器和语法分析器实验内容:1. 非确定有限自动机的实现2. 单词的结构和分类3. 直接转向法实现词法分析器4. Snl语言的predict集5. 语法分析程序的LL(1)实现词法语法程序设计思路与步骤:词法分析器:1. 单词分类(保留字、标识、常数、运算符、界限符、)2. 单词的token表示3. 选择词法分析器的接口4. DFA的构造和实现5. 词法分析器的实现语法分析器:1. 选择语法分析方法——LL(1)2. 求snl文法predict集3. 实现语法树节点的数据结构4. 构造文法LL(1)程序数据结构和算法设计:词法分析器:数据结构://token结构public class TokenNode {private int lineNum; // 行号private LexType lex; // 单词类型private StringBuffer sem; // 单词语义//属性的get、set方法public int getLineNum() {return lineNum;}public void setLineNum(int lineNum) { this.lineNum = lineNum;}public LexType getLex() {return lex;}public void setLex(LexType lex) {this.lex = lex;}public StringBuffer getSem() {return sem;}public void setSem(StringBuffer sem) {this.sem = sem;}public boolean equals(Object obj) {// TODO Auto-generated method stubif (obj != null)if (obj instanceof TokenNode) {TokenNode that = (TokenNode) obj;if (lineNum == that.getLineNum() && lex.equals(that.getLex())) if (sem.equals(that.getSem()))return true;}return false;}}算法实现:while ((line = br.readLine()) != null) {// 当前行号lineNum++ 当前行内容lineline += "\n";// 补充换行linePos = 0;// 当前所在行位置lineLength = line.length();// 0,1,2....lineLength-1char cur;// 待接收字符state = Values.START;// 处理状态while (state != Values.DONE) {cur = line.charAt(linePos);save = true;// 初始默认保存switch (state) {case Values.START:// 当前处于单词的开端,待接收字符cur start(cur);break;case Values.INCOMMENT:// 注释comment(cur);break;case Values.INASSIGN:// 处于单词赋值位置assign(cur);break;case Values.INRANGE:// 处于下标位置range(cur);break;case Values.INNUM:// 处于数字位置num(cur);break;case Values.INCHAR:// 字符mchar(cur);break;case Values.INID:// 标识符id(cur);break;case Values.DONE:// 结束break;default:System.out.printf("Bug here linePosition : %d char : %c ", linePos, cur);state = Values.DONE;curNode.setLex(LexType.ERROR);Values.Error = true;break;}// 字符cur判断结束if (save == true) {chs.append(cur);}if (state == Values.DONE) {// 单词识别结束// 判断标识符是否为保留字if (curNode.getLex() == LexType.ID) {if (reservedWords.containsKey(chs.toString())) {curNode.setLex(reservedWords.get(chs.toString()));}}curNode.setLineNum(Values.lineNum);curNode.setSem(chs);bw.write(curNode.toString());bw.newLine();bw.flush();tokenlist.add(new Tokennode(curNode));Values.TokenNum++;chs.delete(0, chs.length());// 清空StringBuffer 存储本行下一单词state = Values.START;}linePos++;// 当前字符cur识别结束,跳转至下一字符if (linePos >= lineLength)break;} // 当前状态Values.lineNum++;} // 当前行语法分析器:数据结构:语法树节点、操作数节点、操作符节点:public class Treenode {private Treenode[] child;// 子节点指针private Treenode sibling;// 兄弟节点指针private int lineNum;// 源代码行号private NodeKind nodekind;// 节点类型private Kind kind; // 具体类型private int idNum; // 相同类型的变量个数private StringBuffer[] name;// 节点中标识符名称private Attr attr;// 记录语法树节点的 数组属性、过程属性 、表达式属性 、}public class Attr {private ArrayAttr arrayAttr;private ProcAttr procAttr;private ExpAttr expAttr;private StringBuffer type_name;// 当节点为声明类型,且类型是由类型标识符表示时有效}符号栈节点:public class StackNode {private int flag; // 内容标志 flag为1,表示栈中内容为非终极符; flag为2,表示栈中内容为终极符private NTtype var;// 内容非终极符部分终极符部分}算法实现(LL(1)分析法):int pnum = 0;// 记录选中的产生式编号CreatLL1Table();Push(1, NontmlType.Program.ordinal());// 文法开始符压入符号栈rootPointer = newRootNode();// 语法树根节点生成,并初始化子节点PushPA(rootPointer.getChild(2));PushPA(rootPointer.getChild(1));PushPA(rootPointer.getChild(0));curNode = tokenlist.get(curTokenindex);// 取出token序列curTokenindex++;Values.lineNum = curNode.getLineNum();while (!nodeStack.isEmpty()) {// 符号栈非空if (readSatckflag() == 2) {stacktopT = readstackT();if (stacktopT == curNode.getLex()) {Pop();curNode =tokenlist.get(curTokenindex);curTokenindex++;Values.lineNum =curNode.getLineNum();} else {syntaxErr("unexcepted token -> ");System.out.println(curNode.getSem());System.exit(1);// 遇到语法错误,直接退出}} else {// 根据非终极符和栈中符号进行预测stacktopN = readStackN();pnum = LL1Table[stacktopN.ordinal()] [curNode.getLex().ordinal()];Pop();predict(pnum);// System.out.println("the tree: ");// MTree.readTree(rootPointer);}}if (!(curNode.getLex().equals(LexType.ENDFILE)))syntaxErr("Code ends before file \n");MTree.printTree(rootPointer);编译原理是学过的比较难的专业课之一,能够掌握初级的词法和语法分析器原理并亲手编写编译器非常的自豪。
编译原理课设实验报告

《编译技术》课程设计报告实验名称编译器设计姓名学号班级本课设的任务是完成一个完整的编译器,处理用户提交的符合所定文法的源程序代码,生成四元式中间代码,进而翻译成等价的X86平台上汇编语言的目标程序。
编译程序的工作过程划分为下列5个过程:词法分析,语法分析,语义分析和中间代码生成,代码优化,目标代码生成。
其中,词法分析阶段的基本任务是从以字符串表示的源程序中识别出具有独立意义的单词符号,并以二元组的形式输出,以作为语法分析阶段的输入。
语法分析阶段的基本任务是将词法分析阶段产生的二元组作为输入,根据语言的语法规则,识别出各种语法成分,并判断该单词符号序列是否是该语言的一个句子。
语义分析的任务是首先对每种语法单位进行静态的语义审查,然后分析其含义,并用另一种语言形式 (本课设采用四元式) 来描述这种语义。
代码优化的任务是对前阶段产生的中间代码进行等价变换或改造,以期获得更为高效即省时间和空间的目标代码。
目标代码生成的任务是将中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码(本课设生成汇编指令代码)。
在词法分析阶段,通过DOS环境手动输入字符串序列(以’#’作为结束标志)作为带分析的源程序,调用词法扫描子程序将字符串以二元组的形式输出(若有不属于该语言单词符号出现,则进行出错处理),词法扫描子程序包括了对源程序的预处理(忽略多余空格、回车换行符等空白字符),以及对单词的识别和分类,以形成(单词种别,单词自身的值)形式的二元组,并将用户自定义变量信息存入程序变量信息表。
在语法分析阶段,采用自上而下的递归下降分析法,从文法的开始符号出发,根据文法规则正向推导出给定句子。
根据递归下降分析函数编写规则来编写相应的函数,在各个函数的分析过程中调用词法分析程序中的扫描程序,发出“取下一个单词符号”的命令,以取得下一个单词符号作语法分析。
在语义分析和中间代码生成阶段,采用语法制导翻译法,使用属性文法为工具来描述程序设计语言的语义。
编译学原理实验报告

一、实验目的1. 理解编译原理的基本概念和编译过程。
2. 掌握编译器各个阶段的功能和实现方法。
3. 通过实际操作,加深对编译原理的理解和应用。
二、实验环境1. 操作系统:Windows 102. 编译器:C++编译器3. 开发环境:Visual Studio三、实验内容1. 词法分析2. 语法分析3. 语义分析4. 中间代码生成5. 代码优化6. 目标代码生成四、实验步骤1. 词法分析(1)设计词法分析器:根据实验要求,设计一个词法分析器,能够将源代码中的字符序列转换成一个个词法符号。
(2)实现词法分析器:使用C++编写词法分析器代码,实现字符序列到词法符号的转换。
(3)测试词法分析器:编写测试用例,验证词法分析器的正确性。
2. 语法分析(1)设计语法分析器:根据实验要求,设计一个语法分析器,能够识别源代码中的语法结构。
(2)实现语法分析器:使用C++编写语法分析器代码,实现语法结构的识别。
(3)测试语法分析器:编写测试用例,验证语法分析器的正确性。
3. 语义分析(1)设计语义分析器:根据实验要求,设计一个语义分析器,能够对源代码中的语义进行验证。
(2)实现语义分析器:使用C++编写语义分析器代码,实现语义验证。
(3)测试语义分析器:编写测试用例,验证语义分析器的正确性。
4. 中间代码生成(1)设计中间代码生成器:根据实验要求,设计一个中间代码生成器,能够将源代码转换成中间代码。
(2)实现中间代码生成器:使用C++编写中间代码生成器代码,实现源代码到中间代码的转换。
(3)测试中间代码生成器:编写测试用例,验证中间代码生成器的正确性。
5. 代码优化(1)设计代码优化器:根据实验要求,设计一个代码优化器,能够对中间代码进行优化。
(2)实现代码优化器:使用C++编写代码优化器代码,实现中间代码的优化。
(3)测试代码优化器:编写测试用例,验证代码优化器的正确性。
6. 目标代码生成(1)设计目标代码生成器:根据实验要求,设计一个目标代码生成器,能够将优化后的中间代码转换成目标代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程设计报告( 2011-- 2012年度第1学期)名称:编译技术课程设计A 院系:科技学院信息工程系班级:软件09k2学号:0919********学生姓名:闫雪峰指导教师:郭丰娟设计周数: 2成绩:日期:2011年12 月6日《编译技术课程设计A》任务书一、目的与要求1. 理解和掌握编译程序设计原理及常用的技术,建立编译程序的整体概念;2. 理解和掌握编译程序词法分析、语法分析、语义分析、中间代码生成和目标代码生成等几个关键环节原理和实现算法;3. 掌握软件模块设计技能;熟悉并能较好地利用软件开发环境独立编程、调试和分析程序运行情况,逐渐形成创新思维和从事系统软件的研究和开发能力。
二、主要内容定义一个简化的类C语言—L语言作为源语言,重点针对词法分析、语法分析、语义分析、中间代码生成和目标代码生成等几个关键环节进行编程和调试训练,最终设计实现L语言的编译程序。
通过调试L编译程序,了解一般编译程序的总体框架,掌握编译各阶段程序的构造,理解和掌握错误处理方法及符号表的组织方式,理解和掌握语法制导翻译方法。
还可以适当扩展L语言成分,并对相应的编译程序进行扩充。
可使用C、VC++等语言编程实现。
具体内容包括:1.由单词的语法规则出发、画出识别单词的状态转换图,然后用程序实现扫描器设计。
2.设计、编写和调试算法优先分析程序,了解算法优先分析器的组成结构以及对文法的要求,掌握实现通用算法优先分析算法的方法。
3.在算符优先分析文法的基础上进行翻译工作,生成四元式表;4.设计一个简单的代码生成器,该代码生成器以基本块为单位,依次将每条中间代码变换成相应的目标代码。
5.综合以上实验的结果,并进行集成与设计,开发出一个小型编译程序。
对于各项主要内容的实现细节描述和指导,请参考《计算机综合实践指导》编译技术的相关内容。
三、进度计划四、设计(实验)成果要求至少完成简单变量定义语句及包含算术运算符的赋值语句的整个编译过程,统一使用课程设计报告书,文字清楚、工整。
五、考核方式实验结果(60%)+实验报告(30%)+实验过程表现(10%)学生姓名:指导教师:年月日一、课程设计(综合实验)的目的与要求实验整体思想:a)词法分析总体概述:由单词的语法规则出发、画出识别单词的状态转换图,然后用程序实现扫描器设计。
具体要求:设计一个扫描器,该扫描器是一个子程序,其输入是源程序字符串,每调用一次,就输出一个以内部形式表示的单词符号。
(1)单词符号及其内部表示注:其中关键字保留,不支持将关键字作为变量名。
(2)输入预处理1.词法分析器工作的第一步就是输入源程序文本。
2.预处理工作会剔除源程序中多余的空格(将多个空格换行符合并成一个)。
3.能识别//*** 这样的单行注视将其过滤掉。
4.将固定字长的过滤过字节放到循环扫缓冲区,并记录扫描位置,下次继续从上次扫描结尾继续扫描取固定字长。
5.本程序设计为255个字节,最大单个标识符长度不能超过255个字节。
(3)输入缓冲区设计扫描缓冲去一分为二。
每半个缓冲区可容纳256个字符,两个半区互补。
如果搜索指示器从单词起点出发搜索到半区边缘尚未到达单词的终点,那么就调用预处理程序,另其把后序的256个字符装进另半区(4)缓冲区中字符的存放其中如下代码在缓冲区里的存放a=b+c;(5)识别单词符号的状态装换图b)语法分析总体概述:采用自下而上规约过程,根据算符优先文法。
具体要求:设计、编写和调试算法优先分析程序,了解算法优先分析器的组成结构以及对文法的要求,掌握实现通用算法优先分析算法的方法。
(1)算符优先文法定义算符优先文法是一种自下而上的分析方法,其文法的特点是文法的产生式中不含两个相邻的非终结符。
自上而下的分析方法,通常要求文法的产生式不含左递归,如LL(I)文法就是一种可以自上而下分析的文法。
假定G是不含ε- 产生式的算符文法。
对于任何一对终结符a、b,我们说:(1)a等于b 当且仅当文法G中含有形如P→ ···ab···或P→···aQb···的产生式;(2)a小于b 当且仅当G中含有形如P→···aR···的产生式,而R(+=>)b···或R(+=>)Qb···;(3)a大于 b 当且仅当G中含有形如P→···Rb···的产生式,而R(+=>)···a或R(+=>)···aQ;如果一个算符文法G中的任何终结符对(a,b)之多满足下述三个条件之一:a=b,a<b,a>b则称G是一个算符优先文法。
(2) 文法S->D;ED->T spe L;T->keyL->varE->Evar=F;|var=F;F->M+F|M|M-FM->M*T|M|M/T|TT->L|const(3)优先表程序采用递归方式求的优先关系表(4)符号栈1.每次入站判断栈顶终结符和栈外终结符的有限关系,小于等于就入栈,大于规约2.每次规约比较靠近栈顶的第二个终结符和栈顶终结符的有限关系,若小于规约第二个终结符到栈顶。
3.每次规约查找文发表进行规约。
4.二、课程设计(综合实验)总结或结论1.1通过实验掌握了词法分析和语法分析的设计以及制导过程如何生成四元式。
1.2了解了算符优先文法的原理及具体过程。
1.3加深了c语言文件应用,加深了编程能力,深入掌握了库函数的用法。
三、参考文献[1] 陈火旺, 刘春林 编译原理. 国防工业出版社, 第三版. 2009.6附录(设计流程图、程序、表格、数据等)头文件MyHead.h#pragma once#define SBUFSIZE 256//定义扫描缓冲区的大小#define ARROPELEN 9//定义运算符数组的长度#define ARRKEYLEN 2//定义关键字数组的长度struct sBinaryRelation//返回值若为关键字或变量{int iId;//区分是什么int iSubScript;//存放操作符和关键字的偏移量,若是常量返回为常量的整型值char acTempValName[SBUFSIZE];//存放变量的值};char * apcKeyWords[]={"","int"};char apcOperator[]={' ','=','+','-','*','/','(',')',';','#'};char * apcWordList[]={"key","var","const","operate","nonTerminalSymbol","special"}; 词法分析器/*Lu语言词法分析器颜海镜 11.12.30代码已通过编译,尚未优化没次调用正确返回一个符合词法规则的单词源文件保存在.lu文件支持形如变量定义(仅支持int类型),基本加减乘除法,不支持,支持单行注视支持()可扩展:支持N个关键字,单个标识符最大支持256个字符,支持运算符扩展,支持函数名扩展int a=b+c;int a=100;//颜海镜*/#include<stdio.h>#include<stdlib.h>#include<ctype.h>#include<string.h>#include"MyHeader.h"static char acScanBufL[SBUFSIZE]={0};//扫描缓冲区static char acScanBufR[SBUFSIZE]={0};static long lnOffset=0;//偏移量,记录当前文件指针距离开头的距离char CheckChar(FILE * pfSubSourceFile,char ** ppcSubCurrent,char cSubTemp,char fcSubBlank)//检查字符功能,具有合并空格,去除回车{if(cSubTemp==EOF){return 0x20;}//判断是否到文件末尾,结束返回空格if(cSubTemp!=10&&isspace(cSubTemp))//判断是否为空格,合并多个空格为一个{if(fcSubBlank=='N'){**ppcSubCurrent=0x20;(*ppcSubCurrent)++;fcSubBlank='Y';//修改空格标志位}cSubTemp=fgetc(pfSubSourceFile);//空格的话再读入一个字符cSubTemp=CheckChar(pfSubSourceFile,ppcSubCurrent,cSubTemp,fcSubBlank);//递归检查}if(cSubTemp=='/')//判断注视{char cTemp;//临时变量,用于检查下一个是否为'/'cTemp=fgetc(pfSubSourceFile);//再读入一个字符if(cTemp=='/') //若为注视一直读入知道换行符,否则退回刚才读入的字符{while(fgetc(pfSubSourceFile)!='\n');//遇到注视,在注视结尾返回空格cSubTemp='\n';}else ungetc(cTemp,pfSubSourceFile);//退回刚才读入的字符}return cSubTemp;//返回字符}int PreProcess(char *pcSubName)//预处理子程序,完成功能每次向ScanBuffer中装入固定字长的源程序代码{static char fcFlag='L';int i;//将源程序中读入剔除空格注视等放到bufferchar * pcCurrent=0;//只是当前要赋值的字节char ** ppcCurrent=&pcCurrent;//指向指针的指针char * pcStart;//指向数组的开始,计算偏移量用char * pcTemp;//临时变量,初始化用FILE * pfSourceFile;//指向要打开的源程序文件//初始化pcCurrent确认当前要装入的缓冲区if(fcFlag=='L'){pcCurrent=acScanBufL;pcStart=acScanBufL;}else{pcCurrent=acScanBufR;pcStart=acScanBufR;}//初始化当前缓冲区为空字符pcTemp=pcCurrent;for(i=0;i<SBUFSIZE;i++){*pcTemp=0;pcTemp++;}//打开文件pfSourceFile=fopen("test.txt","r");if(pfSourceFile==NULL){printf("The file %s was not opened\n",pcSubName);//判断文件打开是否成功exit(0);//装入失败退出}else//打开成功读入{if(fseek(pfSourceFile,lnOffset,SEEK_SET))//移动文件指针到应该的位置{perror("Fseek failed");exit(1);//移动光标失败退出}while((pcCurrent-pcStart)!=SBUFSIZE)//循环读入指定长度字符{char cTemp;//临时变量cTemp=fgetc(pfSourceFile);//读入一个字符cTemp=CheckChar(pfSourceFile,ppcCurrent,cTemp,'N');//获取一个合法的字符if(cTemp==0x20){*pcCurrent=cTemp;pcCurrent++;*pcCurrent='#';//程序结束break;//判断是否到文件末尾}*pcCurrent=cTemp;//若刚才输入的不为空格也没结束则输入到缓冲区pcCurrent++;}//修改偏移量为当前偏移量,为下次读入用lnOffset=ftell(pfSourceFile);//关闭文件//修改fcFlag为下次再次装入,更改缓冲区if(fcFlag=='L') fcFlag='R';else fcFlag='L';}return 3;}int CheckOperate(char cCheck)//检查是否运算符,返回在运算符数组中的偏移量{int i;for(i=0;i<ARROPELEN;i++){if(cCheck==apcOperator[i]) return i;//返回在运算符数组中的偏移量}return 0;//不是运算符}int CheckNewLine(char cCheck,int *piSubLine)//检测字符是否为回车{if(cCheck=='\n'){(*piSubLine)++;return 1;}return 0;}int CheckKeyWords(char acCheckWords[])//检查单词是否为关键字若是返回在关键字列表中的下标,不是返回0{int i;for(i=0;i<ARRKEYLEN;i++){if(!strcmp(acCheckWords, apcKeyWords[i])) return i;}return 0;}int Error(int iSubLine)//错误处理函数,buffer质控{//打印错误信息printf("第%d行",iSubLine);lnOffset=0;//初始化文件偏移量return 0;}int CheckEndBuffer(char **ppcCheckPoint,char *pcSubName)//检测是否越界,并自动切换缓冲区,bufferL越界返回1,bufferR越界返回2,没有越界返回0{static char fcBuffer ='L';//初始化第一次扫描bufferlint iTempOffset;//临时偏移量变量fcBuffer=='L'?(iTempOffset=*ppcCheckPoint-acScanBufL):(iTempOffset=*ppcCheckPoint-acSca nBufR);//计算偏移量if(iTempOffset>=SBUFSIZE-1)//越界{{PreProcess(pcSubName);//装入Buffer*ppcCheckPoint=acScanBufR;//修改当前的指示器到下一个缓冲区的开始fcBuffer='R';//修改buffer标志,当前指针在bufferR中return 1;//bufferL越界返回1}else{PreProcess(pcSubName);//装入Buffer*ppcCheckPoint=acScanBufL;//修改当前的指示器到下一个缓冲区的开始fcBuffer='L';//修改buffer标志,当前指针在bufferL中return 2;//bufferR越界返回2}}return 0;//没有越界返回0}struct sBinaryRelation LexicalAnalyzer(char *pcSubName)//词法分析器{static char fcFirst='Y';//初始化扫描指示器为第一个元素static char *fpcStart;char **fppcStart=&fpcStart;//取fpcstart的地址static char *fpcSerching;char **fppcfpcSerching=&fpcSerching;//取fpcSerching的地址static int iLine=1;//记录当前的行数int *piLine=&iLine;//指向行数的指针struct sBinaryRelation sTempResult;//存放返回结果{PreProcess(pcSubName);fcFirst='N';fpcStart=acScanBufL;//将start和serch都指向第一个地址}while(*fpcStart==0x20){if(!CheckEndBuffer(fppcStart,pcSubName)) fpcStart++;//检查是否越界,若没越界将start 指针指向一个不为空格的字符}fpcSerching=fpcStart;//serching指向start//fpcSerching++;//serching指向start的下一个位置while(*fpcSerching!=0x00){if(CheckNewLine(*fpcStart,piLine))//检查回车,记录行数加一{//待扩建是否将\n也算作标识符fpcStart++;fpcSerching=fpcStart;//serching指向start}else if(isalpha(*fpcStart))//第一个字符是字母,为关键字{char cTempResult[SBUFSIZE]={0};char *pcCurrent=cTempResult;//检查是否为变量或关键字while(isalnum(*fpcSerching))//下一个是字符或数字//if(isspace(*fpcSerching)) break;//若为空格结束*(pcCurrent++)=*fpcSerching;//将字符保存到临时数组,并且指针后移if(!CheckEndBuffer(fppcfpcSerching,pcSubName)) fpcSerching++; //检查是否越界,若没越界将serching++}//循环完成时fpceSerching指向当前标识符的下一个位置//将start和serching重合fpcStart=fpcSerching;//返回当前的标识符放到结构体中int KeyWordScript;//关键字的下标if((KeyWordScript=CheckKeyWords(cTempResult))!=0)//检查是否为关键字还是普通变量{sTempResult.iId=0;//标志符置为0,关键字的下标sTempResult.iSubScript=KeyWordScript;sTempResult.acTempValName[0]='\0';//赋值}else//普通变量{sTempResult.iId=1;//单词为变量int i=-1;while(cTempResult[++i]!='\0')//将变量的值赋给变量名字数组{sTempResult.acTempValName[i]=cTempResult[i];}sTempResult.acTempValName[i]=cTempResult[i];//赋值个'\0'sTempResult.iSubScript=0;//赋值//返回结构体return sTempResult;}else if(isdigit(*fpcStart))//如果是数字常量{int iTemp=0;while(*fpcSerching!=0x20)//下面字符都要是数字{if((!isdigit(*fpcSerching))&&(isalpha(*fpcSerching)))//若后面是字幕或者不是操作符{printf("词法分析:");Error(iLine);//不是数字报错printf(" %d %c非法字符\n",iTemp,*fpcSerching);}iTemp=iTemp*10+int(*fpcSerching-0x30);//将数字字符转化为整形if(!CheckEndBuffer(fppcfpcSerching,pcSubName)) fpcSerching++; //检查是否越界,若没越界将serching++//判断是否是;若下一个字符是分号或者操作符就结束if(*fpcSerching==';') break;if(CheckOperate(*fpcSerching)) break;}//循环完成时fpceSerching指向当前标识符的下一个位置fpcStart=fpcSerching;//将start和serching重合//返回当前的标识符放到结构体中sTempResult.iId=2;sTempResult.iSubScript=iTemp;return sTempResult;}else if(CheckOperate(*fpcStart)) //判断运算符{int iTempOperateOffset;//记录标识符下标iTempOperateOffset=CheckOperate(*fpcStart);//不需要因为serching本来就在start的下一个fpceSerching++;if(!CheckEndBuffer(fppcStart,pcSubName)) fpcStart=++fpcSerching;//检查serching 是否越界,若没越界将start和serching重合//返回当前的标识符放到结构体中sTempResult.iId=3;sTempResult.iSubScript=iTempOperateOffset;sTempResult.acTempValName[0]='\0';//赋值return sTempResult;}else{printf("词法分析:");Error(iLine);//不是数字报错printf(" %c非法字符\n",*fpcSerching);exit(1);//退出程序}}if(*fpcSerching!=0) printf("词法分析:未知错误\n");//若不为结束符,显示未知错误exit(1);//失败返回空int DebugLexicalAnalyzer(char *pcSubName){struct sBinaryRelation sDebugResult;//存放返回结果int i;for(i=0;i<500;i++){sDebugResult=LexicalAnalyzer(pcSubName);printf("%d %d %d %s\n",i,sDebugResult.iId,sDebugResult.iSubScript,sDebugResult.acTempV alName);}return 0;}语法分析#include"MyHeader.h"#include<stdio.h>#include<string.h>#define GRAMMARLEN 14//定义问法表长度#define FIRSTTABLELEN 12//定义优先表长度#define VTLEN 10//定义vp集的长度#define STACLSIZE 100//第一堆栈大小#define NULL {1000,1000,"end"}extern struct sBinaryRelation LexicalAnalyzer(char *pcSubName);//来自lexicalanalyzer中的函数struct sQuarternaryForm //四元式数组int iOperateScript;//操作符的下标struct sBinaryRelation sArgLeft;struct sBinaryRelation sArgRight;struct sBinaryRelation sArgResult;//next;//指向下一个};struct sVp//vt集的结构体{struct sBinaryRelation sHead;//标识符struct sBinaryRelation asVt[VTLEN];//vp集};struct sStack//栈结构体{char cType;struct sBinaryRelation sPlace;};static struct sBinaryRelation aasQuarternaryForm[GRAMMARLEN][10]={{{4,0,"start"},{4,0,"define"},{3,8,""},{4,0,"operate"},NULL},//非终结符start开始符号全部归结到start程序的开始符号start->define;operate;{{4,0,"type"},{5,0,"special"},{4,0,"name"},NULL},//define->type special name{{4,0,"type"},{0,0,""},NULL},//type->key{{4,0,"name"},{1,0,""},NULL},//name->var{{4,0,"operate"},{1,0,""},{3,1,""},{4,0,"operater"},{3,8,""},{4,0,"operate"},NULL},//op erate->var=operater;operate{{4,0,"operate"},{1,0,""},{3,1,""},{4,0,"operater"},NULL},//operate->var=operater{{4,0,"operater"},{4,0,"left"},{3,2,""},{4,0,"right"},NULL},//operater->left+right{{4,0,"operater"},{4,0,"left"},{3,3,""},{4,0,"right"},NULL},//operater->left-right {{4,0,"left"},{4,0,"left"},{3,4,""},{4,0,"other"},NULL},//left->left*other{{4,0,"left"},{4,0,"left"},{3,5,""},{4,0,"other"},NULL},//left->left/other{{4,0,"left"},{4,0,"other"},NULL},//left->other{{4,0,"other"},{4,0,"name"},NULL},//other->name{{4,0,"other"},{2,0,""},NULL}//other->const};//问法定义结束static struct sBinaryRelation asFirstTableIndex[FIRSTTABLELEN]={NULL,{3,1,"="},{3,2,"+"},{3,3,"-"},{3,4,"*"},{3,5,"/"},{3,8,";"},{0,0,"key"},{1,0,"var" },{2,0,"const"},{5,0,"spe"},{3,9,"#"}};//定义优先表索引函数数组下标即为在优先表中的下标static char acFirstTable[FIRSTTABLELEN][FIRSTTABLELEN]={{'0','=','+','-','*','/',';','0','1','2','5','3'},//{'=',0},// ={'+',0},// +{'-',0},// -{'*',0},// *{'/',0},// /{';',0},// ;{'0',0},// key{'1',0},// var{'2',0},// const{'5',0},// spe{'3',0},// #};//第7 8存放var和const的优先级char RequestVt(struct sVp asVt[],int iIndex,int iVtIndex,char fcVt)//返回要求的vt集的asVt[iIndex].sHead=aasQuarternaryForm[iIndex][0];//赋值给是谁的vt值if(fcVt=='F')//求firstvt{if (aasQuarternaryForm[iIndex][1].iId==4)//Q...{if(aasQuarternaryForm[iIndex][2]!=NULL)//Qa{asVt[iIndex].asVt[iVtIndex]=aasQuarternaryForm[iIndex][2];//将a付RequestVt(asVt,iIndex,iVtIndex+1,'F');//递归调用求F(q)}else//Q{RequestVt(asVt,iIndex,iVtIndex,'F');//递归调用求F(q)}}else//a....{asVt[iIndex].asVt[iVtIndex]=aasQuarternaryForm[iIndex][1];//赋值asVt[iIndex].asVt[iVtIndex+1]=NULL;//将下一项赋值为空}return 'F';}else//求lastvt{int i=0;while(aasQuarternaryForm[iIndex][i+1]!=NUll) i++;//结束是i=....Q的下标if(aasQuarternaryForm[iIndex][i].iId==4)//...Qif(i!=1)//...aQ{asVt[iIndex].asVt[iVtIndex]=aasQuarternaryForm[iIndex][i-1];//赋值aRequestVt(asVt,iIndex,iVtIndex+1,'L');//求lastvt}else//...Q{RequestVt(asVt,iIndex,iVtIndex,'L');//求lastvt}}else//.......a{asVt[iIndex].asVt[iVtIndex]=aasQuarternaryForm[iIndex][i];//赋值aasVt[iIndex].asVt[iVtIndex+1]=NULL;//赋值NULL}return 'L';}return 'E';//出错}int RequestFirstTableScript(static struct sBinaryRelation RequestScript)//返回终结符在firsttable中的下标{int i;for(i=1;i<FIRSTTABLELEN;i++)//循环查找firsttableindex表中的每一项{if(asFirstTableIndex[i].iId==RequestScript.iId&&asFirstTableIndex[i].iSubScript==Reques tScript.iSubScript) return i;return 0;//没找到失败}int MyRequestQuarternaryFormScript(static struct sBinaryRelation RequestScript)//返回非终结符在文发表中的偏移量{int i;for(i=0;i<GRAMMARLEN;i++)//循环查找文发表{if(asFirstTableIndex[0][i]==RequestScript) return i;}return -1;//错误}int MyRequestVtLength(struct sVp RequestVtItem)//返回vt级中一项的长度{int iLength=0;while(RequestVtItem.asVt[iLength]!=NULL) iLength++;return iLength;//返回vt的长度}int CheckGrammar(char CheckChar,int iRowScript,int iLineScript)//检查优先表是否复过值从而判断问法是否正确,若未赋值返回1付过值退出{if(CheckChar==0) return 1;printf("优先表错误,非算符优先文法 %s %s 以有关系不能再有有限关系\n",asFirstTableIndex[iRowScript].acTempValName,asFirstTableIndex[iLineScript].acTempValNameexit(0);//退出return 0;}int IniFirstTable()//初始化firsttable优先表,每次规约前必须初始化{struct sVp asFirstVt[GRAMMARLEN];//firstvt的集合,每项代表一个开始符,下标和文发表兼容struct sVp asLastVt[GRAMMARLEN];//lastvt的集合int i;for(i=1;i<FIRSTTABLELEN;i++)//初始化firsttable表中的#{acFirstTable[i][FIRSTTABLELEN-1]='>';acFirstTable[FIRSTTABLELEN-1][i]='<';}acFirstTable[FIRSTTABLELEN-1][FIRSTTABLELEN-1]='=';//#和#的关系为等于for(i=0;i<GRAMMARLEN;i++)//循环求firstvt和lastvt{RequestVt(asFirstVt,i,0,'F');//求firstvtRequestVt(asLastVt,i,0,'L');//求lastvt}for(i=0;i<GRAMMARLEN;i++)//循环求优先表{int iGrammarItemLen=0;//记录每项表项长度int j;while(aasQuarternaryForm[i][iGrammarItemLen]!=NULL) iGrammarItemLen++;//求的当前表for(j=0;j<iGrammarItemLen;j++)//循环求{if(aasQuarternaryForm[i][j].iId!=4&&aasQuarternaryForm[i][j+1].iId!=4)//j和j+1都为终结符j==j+1{int ij;//j的下标int ij1;//j+1的下标ij=RequestFirstTableScript(aasQuarternaryForm[i][j]);ij1=RequestFirstTableScript(aasQuarternaryForm[i][j+1]);if(CheckGrammar(acFirstTable[ij][ij1],ij,ij1))acFirstTable[ij][ij1]='=';//有限关系相等}if((j<iGrammarItemLen-1)&&(aasQuarternaryForm[i][j].iId!=4&&aasQuarternaryForm[i][j+2]. iId!=4))//xj和xj+2都为终结符{if(aasQuarternaryForm[i][j+1]==4)//xj+1为为非终结符{int ij;//j的下标int ij2;//j+1的下标ij=RequestFirstTableScript(aasQuarternaryForm[i][j]);ij2=RequestFirstTableScript(aasQuarternaryForm[i][j+2]);if(CheckGrammar(acFirstTable[ij][ij2],ij,ij2))}}if(aasQuarternaryForm[i][j].iId!=4&&aasQuarternaryForm[i][j+1].iId==4)//xj为终结符xj+1为非终结符{int iVtIdenx;//非终结符的下标int iVtLength;//非终结符的firstvt的长度int i;iIdenx=MyRequestQuarternaryFormScript(aasQuarternaryForm[i][j+1]);//返回非终结符的在问法表中的偏移量也就是在vt中的偏移量iVtLength=MyRequestVtLength(asFirstVt[iIdenx]);for(i=0;i<iVtLength;i++)//firstvt(xj+1)的每个符号优先级大于xj{int ij;//j的下标int ij1;//j+1的下标ij=RequestFirstTableScript(aasQuarternaryForm[i][j]);//返回xj终结符在优先表中的下标ij1=RequestFirstTableScript(asFirstVt[iIdenx].asVt[i]);//返回xj+1非终结符的first中的每项在优先表中的下标if(CheckGrammar(acFirstTable[ij][ij1],ij,ij1))//判断是否优先关系已经存在{acFirstTable[ij][ij1]='<';//优先关系小于}}}if(aasQuarternaryForm[i][j].iId==4&&aasQuarternaryForm[i][j+1].iId!=4)//xj为非终结符,xj+1为终结符{int iVtIdenx;int iVtLength;int i;iIdenx=MyRequestQuarternaryFormScript(aasQuarternaryForm[i][j]);//返回非终结符的在问法表中的偏移量也就是在vt中的偏移量iVtLength=MyRequestVtLength(asLastVt[iIdenx]);for(i=0;i<iVtLength;i++)//firstvt(xj+1)的每个符号优先级大于xj{int ij;//j的下标int ij1;//j+1的下标ij=RequestFirstTableScript(asLastVt[iIdenx].asVt[i]);//返回xj终结符在优先表中的下标ij1=RequestFirstTableScript(aasQuarternaryForm[i][j+1]);//返回xj+1非终结符的first中的每项在优先表中的下标if(CheckGrammar(acFirstTable[ij][ij1],ij,ij1))//判断是否优先关系已经存在{acFirstTable[ij][ij1]='>';//优先关系小于}}}}}return 1;//初始化成功}char CheckTerminalPriority(struct sBinaryRelation sLeft,struct sBinaryRelation sRight)//返回参数的有限关系< > = 若为其他返回E{int iLeftOfFirstScript;int iRightOfFirstScript;iLeftOfFirstScript=RequestFirstTableScript(sLeft);iRightOfFirstScript=RequestFirstTableScript(sRight);if(acFirstTable[iLeftOfFirstScript][iRightOfFirstScript]=='<') return '<';if(acFirstTable[iLeftOfFirstScript][iRightOfFirstScript]=='>') return '>';if(acFirstTable[iLeftOfFirstScript][iRightOfFirstScript]=='=') return '=';return 'E';//返回错误标志}int FindStackTopTerminal(struct sStack asSubStack[],int iSubStackTop,int iSubStackBottom)//返回栈顶的终结符,返回值为栈顶终结符的下标{int i;for(i=iSubStackTop;i>=iSubStackBottom;i--)//从栈顶开始向栈底找{if(asSubStack[i].cType=='T') return i;}printf("语法分析:未知错误,搜寻栈顶终结符出错");exit(0);return -1;}int FindTermHead(struct sStack asSubStack[],int iSubTermTail,int iSubTempHead)//求规约中的规约头的栈下标{char cTempCheck;//临时存放终结符的优先关系iTempTermHead=FindStackTopTerminal(asSubStack,iSubTempHead,0);cTempCheck=CheckTerminalPriority(asSubStack[iSubTermTail],asSubStack[iTempTermHead]);//求的当前终结符和栈顶终结符的优先关系iSubTempHead=iTempTermHead-1;if(cTempCheck=='<')//若关系为小于{iTempTermHead=FindTermHead(asSubStack,iSubTermTail,iSubTempHead);//递归求下一个终结符}return iTempTermHead;}int MyFindGrammarTableHead(struct sStack asSubStack[],int iSubTermHead,int iSubTermTail)//查找可归约串若返回值小于grammar则查找成功若等于则失败,成功i为文法在文法表中的下标{int i;for(i=0;i<GRAMMARLEN;i++)//循环扫描整个文法表{if(aasQuarternaryForm[i][1]==asSubStack[iSubTermHead])//找到可规约头部{int j;int k=2;char cFlag='Y';for(j=iSubTermHead+1;j<=iSubTermTail;j++,k++)//循环查找后边是否相等{if(aasQuarternaryForm[i][k]==NULL)//若文法结束尚照完则错误cFlag='N';break;}if(asSubStack[j].cType=='N'&&aasQuarternaryForm[i][k].iId==4) continue;//若当前符号为非终结符且当前文法表中文法符号也为非终结符号规约if(asSubStack[j].sPlace==aasQuarternaryForm[i][k]) continue //若为终结符,且相等//执行到此与本条文法不相等cFlag='N';break;}if(cFlag=='Y') return i;//找到了i为下标}}return i;//失败返回grammar}int SyntacticAnalyzer(char *pcSubName)//语法分析器{struct sStack asStack[STACLSIZE]={NULL};struct sStack sTempItem=NULL;//临时存放可规约的字符int iStackTop=0;//栈顶int iStackBottom=0;//栈底int iStackTopTerminal;//栈顶的终结符//int iStackNearTopTerminal=iStackBottom;//靠近栈顶的非终结符//int iTopTerminalInFirstScript;//栈顶非终结符在firsttable中的下标//int iOutTerminalInFirstScript;//栈外终结符在firsttable中的下标//初始化符号栈栈底有个#asStack[0].cType='T';//终结符asStack[0].sPlace.iId=3;//为运算符asStack[0].sPlace.iSubScript=9;//#//iTopTerminalInFirstScript=FIRSTTABLELEN-1;//初始化top为#if(IniFirstTable())//如果初始化优先关系表成功{while(1)//规约{if(sTempItem==NULL)//判断sTempItem是否为空{struct sBinaryRelation sTemp;sTemp=LexicalAnalyzer(char *pcSubName);//从词法分析拿来一个字符if(sTemp.iId==4)//若是非终结符{sTempItem.cType='N';}else//是终结符{sTempItem.cType='T';}sTempItem.sPlace=sTemp;}//判断是否进站还是规约及如何规约进栈//RequestFirstTableScript(static struct sBinaryRelation RequestScript)char cTemp;iStackTopTerminal=FindStackTopTerminal(asStack,iStackTop,iStackBottom);cTemp=CheckTerminalPriority(asStack[iStackTopTerminal].sPlace,sTempItem.sPlace);//判断cTemp为大于小于还是等于或空if(cTemp=='<'||cTemp=='=')//若栈顶终结符优先级小于或等于栈外终结符入站{iStackTop++;//栈顶指针++asStack[iStackTop]=sTempItem;//入栈if(asStack[iStackTop].sPlace.iId==3&&asStack[iStackTop].sPlace.iSubScript==9) exit();//程序结束//初始化stemp为下次做准备sTempItem=NULL;}else if(cTemp=='>')//规约{//规约代码int iTermTail;//存放规约的尾int iTermHead;//存放规约的头//开始规约iTermTail=FindStackTopTerminal(asStack,iStackTop,iStackBottom);//找到栈顶部首个的终结符iTermHead=FindTermHead(asSubStack,iTermTail,iTermTail-1)+1;//找到有限关系小于等于栈顶终结符的下标iTermTail=iStackTop;//重新负值规约尾为栈顶//规约if(iTermHead==iTermTail)//若规约var这样只有一个符号的{//查找文发表看能否规约int i;char cFlag='N';for(i=0;i<GRAMMARLEN;i++)//循环扫描整个文法表{if(aasQuarternaryForm[i][1]==asStack[iTermHead].sPlace)//找到可规约头部{cFlag='Y';//设置i=文法表长度+1此时i为标志位若循环完毕i=grammar时可以规约break;}}if(cFlag=='Y')//可以规约{asStack[iTermHead].cType='N';//规约为非终结符}}else//非是一项规约a=b+c;这样的{//循环查找文发表找到规约地点int iTemp;iTemp=MyFindGrammarTableHead(asStack,iTermHead,iTermTail);//查找文发表查找可规约文法if(iTemp<GRAMMARLEN)//规约成功{//规约成功//调用函数知道产生四元式//调整堆栈asStack[iTermHead].cType='T';asStack[iTermHead].sPlace=aasQuarternaryForm[iTemp][0];iStackTop=iTermHead;//调整堆栈}else{//规约失败打印错误信息printf("规约过程中未在文法标中查到规约串");}}}else//优先关系为空错误{//报错printf("规约过程中有限关系出错");}}}return 0;}注:根据课程设计、综合实验的内容将标题任选其一。