基于噪声信道模型统计机器翻译的学习笔记
《自然语言处理》课程教学分析与实践

关键词:自然语言处理;实践教学;认知驱动;编程巩固;人工智能
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)18-0160-02
开放科学(资源服务)标识码(OSID):
Analysis and Practice of“Natural Language Processing”Course Teaching
4.1“认知驱动”教学
“认知驱动”教学法,即基于学生认知的教学方法。不同于 传统教学方法以教师的角度去执行,该方法从学生的角度去执 行,以学生现有的认知水平为起点并规划学习的内容,让学生 根据自己对自然语言处理的现有认知去探索研究某一子领域 内容,教师在此过程中扮演了观察者以及评估者的角色。”认知 驱动“教学法一方面可以提高学生学习的兴趣和积极性,培养 学生在学习过程中的独立思考能力和创新思维,另一方面可以
帮助教师掌握每一位学生的知识基础,基于因材施教的理念为 学生设计不同的教学策略。
例如,在讲解“文本处理”方法时让每一位学生根据自己的 现有认知表述什么是文本处理,如何对文本进行处理。有些同 学数学基础较强,可以将文本处理的过程用数学公式形式化描 述,还有些同学编程能力较强,用伪代码算法框架描述了文本 处理的流程。
Key words: natural language processing; practical teaching; cognitive drive; programming consolidation; artificial intelligence
1 引言
《自然语言处理》课程属于人工智能专业选修课,是一门融 语言学、计算机科学、数学于一体的科学,它研究能实现人与计 算机之间用自然语言进行有效通信的各种理论和方法,是计算 机科学领域与人工智能领域中的一个重要方向[1-2]。《自然语言 处理》课程理论性较强、知识体系庞大,其主要教学内容包括: 词法分析、句法分析、语义分析、文本分类、对话系统,统计机器 翻译等,传统的教学方法只能使学生了解自然语言处理的理论 知识,难以理论联系实际并灵活运用,此外,固有的理论教学模 式降低了学生学习的兴趣和积极性,也无法培养学生的创造性 思维。针对上述传统教学体系存在的问题,本文在先前的改革 实践教学研究[3-7]的基础上提出了新的“认知驱动+编程巩固”教 学方法,达到了现代教育对教师与时俱进、因材施教的要求。
Moses_shuxi

熟悉Moses流程一.1.Prepare data①Tokenisation:This means that spaces have to be inserted between words and punctuation。
举例:tokenizer.perl -l en<news-commentary-v8.fr-en.en > news-commentary-v8.fr-en.tok.en举例:tokenizer.perl -l fr<news-commentary-v8.fr-en.fr > news-commentary-v8.fr-en.tok.fr②Truecasing:The initial words in each sentence are converted to their most probable casing。
This helps reduce data sparsity。
举例:train-truecaser.perl --model truecase-model.en --corpus news-commentary-v8.fr-en.tok.entruecase.perl --model truecase-model.en<news-commentary-v8.fr-en.tok.en >news-commentary-v8.fr-en .true.en举例:train-truecaser.perl --model truecase-model.fr --corpus news-commentary-v8.fr-en.tok.frtruecase.perl --model truecase-model.fr<news-commentary-v8.fr-en.tok.fr >news-commentary-v8.fr-en. ture.fr③Cleaning:Long sentences and empty sentences are removedas they can cause problems with the training pipeline,and obviously mis-aligned sentences are removed。
噪声估计算法范文

噪声估计算法范文噪声估计算法是指通过对信号进行分析和处理,估计出信号中的噪声成分的方法。
在实际应用中,噪声是不可避免的,它会干扰信号的传输和处理,影响信号质量和系统性能。
因此,准确地估计噪声的特性对于信号处理和系统设计具有重要意义。
本文将介绍几种常用的噪声估计算法。
1.统计估计法:统计估计法是一种基于统计分析方法的噪声估计算法。
该方法通过对信号进行统计分析,计算出信号的一些统计特性,如均值、方差等,然后根据这些特性来估计噪声的性质。
例如,对于高斯白噪声,可以使用样本均值和样本方差来估计其均值和方差。
该方法简单易用,但对信号的统计特性有一定的要求。
2.自回归模型法:自回归模型法是一种基于自回归模型的噪声估计算法。
该方法通过对信号进行自回归建模,利用自回归模型的参数来估计噪声的自相关性。
常用的自回归模型包括AR模型和ARMA模型。
该方法在信号存在较强自相关性时效果比较好,但对信号的自相关性有一定的要求。
3.小波变换法:小波变换法是一种基于小波变换的噪声估计算法。
该方法通过对信号进行小波分解,得到信号的小波系数,然后根据小波系数的特性来估计噪声的性质。
常用的小波变换包括离散小波变换(DWT)和连续小波变换(CWT)。
该方法在时频域分析中常用,可以对不同频率的噪声进行估计。
4. 光谱估计法:光谱估计法是一种基于频域分析的噪声估计算法。
该方法通过对信号进行频谱分析,得到信号的频谱特性,然后根据频谱特性来估计噪声的频谱密度。
常用的光谱估计方法包括传统的周期图法和现代的最小二乘法、Yule-Walker方法、扩展最小二乘法等。
该方法在频域分析和信号处理中广泛应用,可以对不同频率的噪声进行估计。
以上是几种常用的噪声估计算法,每种算法都有其适用的场景和优缺点。
在具体应用中,可以根据实际需求选择合适的算法,并结合实际情况进行参数调整和优化,以获得准确的噪声估计结果。
噪声估计在通信、音频处理、图像处理等领域都有广泛的应用,对于提高系统性能和信号质量具有重要意义。
噪声回归结构-概述说明以及解释

噪声回归结构-概述说明以及解释1.引言1.1 概述概述噪声回归是一种用于处理噪声数据的统计建模方法。
在实际应用中,数据往往会受到各种噪声的影响,如测量误差、不完整数据等,导致数据的准确性和可靠性下降。
噪声回归的目标就是通过建立合适的模型,将噪声数据转化为可靠的信息,从而提高数据处理和分析的效果。
噪声回归的核心思想是通过对噪声数据的建模来还原真实的数据信息。
它基于对噪声的统计特性进行分析和模型拟合,通过相关的数学方法和算法,对噪声数据进行处理和去噪,从而得到更加准确和可靠的数据结果。
噪声回归的应用领域广泛,涵盖了多个学科和行业。
在工程领域,噪声回归被广泛应用于信号处理、图像处理、声音处理等领域,用于提高信号质量和准确度。
在金融领域,噪声回归可以应用于风险评估、股价预测等方面,提高预测和决策的可靠性。
在医学领域,噪声回归可用于医学图像处理、生物信号处理等,提高医学数据的准确性和可靠性。
虽然噪声回归具有很多优势,但也存在一定的局限性。
首先,噪声回归的效果受到模型的选择和参数的设置的影响,选择不合适或参数设置不当可能导致结果的不准确。
其次,噪声回归处理的复杂度往往较高,需要使用一些高级的数学理论和算法,对于非专业人士来说较难理解和应用。
此外,噪声回归方法对数据分布的假设较为敏感,如果数据违背了假设,可能会导致结果的失真。
随着科技的不断进步和应用需求的提出,噪声回归仍然具有很大的发展潜力。
未来发展方向主要包括改进噪声建模方法,提出更加高效和准确的模型拟合算法,以及深入研究噪声的统计特性和分布规律,以应对更加复杂和多样化的噪声情况。
此外,噪声回归方法的推广和应用也是一个重要的方向,通过提供更加易用和智能化的噪声回归工具,使更多的人能够受益于噪声回归的技术优势。
综上所述,噪声回归是一种处理噪声数据的有效方法,具有广泛的应用前景和发展潜力。
在各个领域的实际应用中,合理选择噪声模型和适当的算法,将噪声数据转化为可靠的信息,对于提高数据的准确性和可靠性具有重要意义。
920094-人工智能导论(第4版)-第10章 自然语言理解

10.1.2 自然语言理解研究的产生与发展
1. 萌芽时期(20世纪40年代末50年代初)
2. 以关键词匹配技术为主的时期 (A2.0D世ona纪ld B6o0ot年h &代W.始We)aver M. Chomsky 形式语言和文法
3. 以句法6语8年义B.分Ra析ph技ae术l:为语主义检的索时系期统(SIR20世纪70年代后)
24
第10章 自然语言理解及其应用
10.1 自然语言理解的概念与发展历史 10.2 语言处理过程的层次 10.3 机器翻译
✓10.4 语音识别
25
10.4.1 语言识别的概念
▪ 机器翻译用印刷文本作为输入,能清楚地区分单个 单词和单词串 。
▪ 语音识别用语音作为输入,口语对话与语音信号中 语言提取的不同:
10.3.1 机器翻译方法概述 10.3.2 翻译记忆
17
10.3.1 机器翻译方法概述
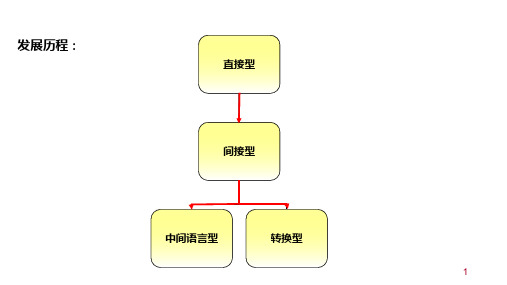
发展历程:
直接型
间接型
中间语言型
转换型
18
10.3.1 机器翻译方法概述
▪ 1. 直译式翻译系统(direct translation MT systems) 通过快速的分析和双语词典,将原文译出。
▪ 2. 规则式翻译系统(rule-based MT systems) 先分析原文内容,产生原文的句法结构,再转换成译 文的句法结构,最后再生成译文。
特点:切分单词容易,找出词素复杂。
词法分析算法举例:
repeat look for word in dictionary
if not found then modify the word
例:importable分为 import-able或
im-port-able
基于隐马尔可夫模型的机器翻译研究

基于隐马尔可夫模型的机器翻译研究机器翻译是一项依赖于计算机技术的研究,旨在将一种自然语言(源语言)转换成另一种自然语言(目标语言)。
随着人工智能技术的日益发展,机器翻译技术不断完善,其应用领域也越来越广。
与传统的基于规则和统计分析的机器翻译方法相比,基于隐马尔可夫模型(Hidden Markov Model,HMM)的机器翻译方法在语音识别、自然语言处理等领域具有广泛的应用前景。
一、HMM的基本原理HMM是一种基于概率模型的非监督学习算法,是统计机器学习中的经典算法之一。
它被广泛应用于语音识别、文本分类、自然语言处理等领域。
HMM模型由初始概率分布、状态转移概率矩阵、状态观测概率矩阵三部分组成。
假设一个序列的每一个元素到底处于哪一个状态是未知的,仅知道每个状态发射对应观测值的概率。
HMM的目标是根据观测序列,推断出最有可能的隐含状态序列。
这个过程被称为解码。
二、HMM在机器翻译中的应用随着人们生活方式的改变和经济全球化的发展,人们在跨文化交流和国际贸易中越来越需要进行语言翻译。
机器翻译技术的发展不断推动着这项工作的进步。
基于HMM的机器翻译使用的是隐含语言模型,它能够学习源语言和目标语言之间的映射关系,从而实现准确、高速的机器翻译。
HMM作为一种基本的语音识别算法,最早被应用于机器翻译中的语音翻译问题。
由于语音翻译涉及到多个层面的信息,包括声音、语法、词法和语义等方面,所以使用HMM将声学模型和语言模型进行结合,可以有效地提高翻译的准确性。
三、HMM机器翻译技术的优缺点基于HMM的机器翻译技术,虽然能够有效地提高翻译的准确性,但也存在一些不足之处。
比如说,HMM是一种传统方法,它对于长句和复杂句子的处理效果并不好。
此外,HMM模型需要存储大量的概率矩阵,计算速度相对较慢,同时需要大量的训练数据。
不过,尽管存在这些缺点,基于HMM的机器翻译技术仍然具有其独特的优点。
HMM能够精确地识别语音,在音信号处理方面有着广泛的应用。
AWGN信道中的信噪比估计算法

AWGN信道中的信噪比估计算法一、本文概述本文旨在探讨和分析在加性白高斯噪声(AWGN)信道中的信噪比(SNR)估计算法。
AWGN信道是一种理想的通信信道模型,其中噪声是加性的、白色的,并且服从高斯分布。
在实际的无线通信系统中,SNR是一个关键的参数,它直接影响到通信系统的性能和可靠性。
因此,准确地估计SNR对于优化系统性能、提高通信质量和实现可靠的数据传输至关重要。
本文将首先介绍AWGN信道的基本概念和特性,包括噪声的统计特性和其对信号的影响。
随后,将详细讨论几种常用的SNR估计算法,如基于统计特性的估计算法、基于信号处理的估计算法以及基于机器学习的估计算法等。
这些算法各有优缺点,适用于不同的应用场景和信道条件。
本文还将对这些SNR估计算法的性能进行评估和比较,包括它们的估计精度、计算复杂度以及鲁棒性等方面。
通过仿真实验和理论分析,我们将揭示各种算法在不同SNR水平和信道条件下的表现,并为实际应用中的SNR估计提供有益的参考和指导。
本文还将探讨SNR估计算法在无线通信系统中的应用,如信道编码、调制解调、信号检测等方面。
通过合理的SNR估计,可以有效地提高通信系统的性能,实现更可靠的数据传输和更高的频谱效率。
本文将对AWGN信道中的SNR估计算法进行全面而深入的探讨,旨在为无线通信领域的研究和实践提供有益的参考和启示。
二、AWGN信道中的信噪比估计方法概述在加性白高斯噪声(AWGN)信道中,信噪比(SNR)估计是一项关键任务,它对于无线通信系统的性能优化、错误控制以及信号恢复等方面具有重要影响。
SNR估计的准确性直接影响到接收机的性能,因此,开发高效、准确的SNR估计算法一直是无线通信领域的研究热点。
在AWGN信道中,SNR通常定义为信号功率与噪声功率的比值。
由于噪声是白噪声,即其功率谱密度在所有频率上都是恒定的,因此SNR可以简化为信号幅度与噪声幅度的比值。
然而,在实际通信系统中,由于信号受到多种干扰和失真的影响,准确估计SNR变得十分困难。
汉英统计翻译系统中未登录词的处理方法

汉英统计翻译系统中未登录词的处理方法*周可艳,宗成庆中国科学院 自动化研究所 模式识别国家重点实验室 100080E-mail: {kyzhou, cqzong}@摘 要:在统计机器翻译系统的解码过程中,经常会出现训练语料中没有的“未登录词”,这些词的出现严重地影响了解码器的速度和整个系统的性能,为此,本文通过对未登录词现象及其同义词的分析,提出并实现了一种针对统计翻译系统中未登录词的处理方法,该方法利用汉语同义词知识对源语言句子中未登录词的语义进行解释,使其具备初步的词义消歧能力。
实验表明在训练语料规模有限的情况下,充分利用语义知识,在某种程度上可以解决未登录词问题。
关键字:统计机器翻译,未登录词处理,同义词Dealing with OOV Words in Chinese-to-English StatisticalMachine Translation SystemKeyan Zhou, Chengqing ZongNational Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, 100080E-mail: {kyzhou,cqzong}@Abstract: In statistical machine translation (SMT) system, there are always OOV (Out-of-Vocabulary) words which have never appeared in the training set. These OOV words seriously slow the speed of decoding and weaken the performance of system. This paper first gives the analysis on OOV words in the Chinese-to-English MT system, and then proposes an approach to dealing with the OOV problem to improve the performance of the system. In our approach, the knowledge of Chinese synonym is used to explain the OOV words and make the word sense disambiguation. The experimental results have shown that our approach may resolve the OOV problem in some extent and improve the performance of the system. Key words: SMT, OOV word, synonym1. 引言基于噪声信道模型的统计翻译方法是基于语料库的翻译方法的一种,这种方法对翻译建立数学模型,从大规模语料库中学习模型的参数,然后对句子进行翻译。
统计语言模型

例子
p(我是一个学生) p(我,是,一, 个,学生) p(我) p(是 | 我) p(一 | 我,是) p(个 | 我,是,一) p(学生 | 我,是,一, 个)
Markov链
有限的记忆能力
不考虑太“旧”的历史
只记住前n-1个词,
称为n-1阶Markov链近似
这里:C()为 在训练语料库中出现次数。
模型作用:计算概率。P(wn
|
w1w2 ... wn 1 )
c(w1w2...wn ) c( w1w2 ... wn 1 )
模型训练:在训练语料库中统计获得n-gram的频度信息
参数训练系统
语料 库
分词
分词 语料
参数 估计
语言 模型
系统 词表
wi i n1
的出现概率为:
p GT
(wiin1
)
r*
r*
r 0
。 nr 不能为零,本身需要平滑。
Good-Turing 估计公式中缺乏利用低元模型对高元模型进行插值的思想,它通
常不单独使用,而作为其他平滑算法中的一个计算工具。
3、线性插值平滑 (Linear Interpolation)
p(我是一个学生) p(我,是,一, 个,学生) p(我) p(是 | 我) p(一 | 我,是) p(个 | 是,一) p(学生 | 一, 个)
N-gram模型
N-gram模型:相当于n-1阶Markov链。
“n-gram” = n个词构成的序列, w 1w 2...w n
I
I
P(O)
I
信源-信道模型的应用
信源-信道模型
第三章信道与噪声

第三章信道与噪声通信原理电子教案第3章信道与噪声学习目标:信道的数学描述方法;恒参信道/随参信道及其传输特性;加性高斯白噪声;信道容量的概念。
重点难点:调制信道模型;编码信道模型;恒参信道对信号传输的影响;加性高斯白噪声;Shannon信道容量公式。
随参信道对信号传输的影响;起伏噪声;噪声等效带宽;连续信道的信道容量“三要素”。
随参信道特性的改善。
课外作业: 3-5,3-11,3-16,3-19,3-20本章共分4讲《通信原理》第九讲知识要点:信道等义、广义信道、狭义信道,调制信道和编码信道。
§3.1 信道定义与数学模型1、信道定义信道是指以传输媒质为基础的信号通道。
信道即允许信号通过,又使信号受到限制和损害。
研究信道的目的:建立传播预测模型;为实现信道仿真器提供基础。
狭义信道仅指信号的传输媒质,这种信道称为狭义信道;广义信道不仅是传输媒质,而且包括通信系统中的一些转换装置,这种信道称为广义信道。
狭义信道按照传输媒质的特性可分为有线信道和无线信道两类。
有线信道包括明线、对称电缆、同轴电缆及光纤等。
广义信道按照它包括的功能,可以分为调制信道、编码信道等。
图3-1 调制信道和编码信道2、信道的数学模型信道的数学模型用来表征实际物理信道的特性,它对通信系统的分析和设计是十分方便的。
下面我们简要描述调制信道和编码信道这两种广义信道的数学模型。
1. 调制信道模型图3-2 调制信道模型二端口的调制信道模型其输出与输入的关系有一般情况下,可表示为信道单位冲击响应与输入信号的卷积,即或其中,依赖于信道特性。
对于信号来说,可看成是乘性干扰,而为加性干扰。
在实际使用的物理信道中,根据信道传输函数的时变特性的不同可以分为两大类:一类是基本不随时间变化,即信道对信号的影响是固定的或变化极为缓慢的,这类信道称为恒定参量信道,简称恒参信道;另一类信道是传输函数随时间随机快变化,这类信道称为随机参量信道,简称随参信道。
基于统计的机器翻译

概念:不同于基于规则的机译系统由词典和语法规则库构成翻译知识库, 基于语料库的机译系统是以语料库(P121-P122)的应用为核心,由经过 划分并具有标注的语料库构成知识库,以统计规律为主。
分类: (1)基于统计(Statistics-based)的机器翻译 (2)基于实例(Example-based)的机器翻译 发展时期: 20世纪80年代(计算机技术和互联网技术的迅猛发展) 代表人物: 香农:香农模式,噪声信道模型 P122 机器翻译之父:1947年Weaver提出的“解码思想”
应用:Google 的在线翻译已为人熟知,其背后的技术即为基于统计的机 器翻译方法,基本运行原理是通过搜索大量的双语网页内容,将其作为 语料库,然后由计算机自动选取最为常见的词与词的对应关系,最后给 出翻译结果。 此外,常用的,基于统t提供的一项文段和网页全文翻译功能网站,作 为Bing服务品牌的一部分。
TM所面对的用户通常是“专家”,既懂双语,又懂专业。
挑剔者的挖苦与讽刺: “MT?不是machine translation, 而是mad translations to bed at 11 in the evening. 相似句子: Mother gets up at 6 in the morning. 母亲早上六点起床。 重组调整:父亲晚上11点上床。
我给玛丽一支笔——I gave Mary a pen. 我给汤姆一本书——I gave Tom a book.
基本思想:在已经收集的双语实例库中找出 与待翻译部分最相似的翻译实例,再对实例 的译文通过替换,删除或增加等一系列变形 操作,实现翻译。
基于实例的机器翻译系统主要由两个数据库(实例 库和同义词库)以及两个模式(检索模式和调整模 式)组成。
机器翻译

机器翻译1 概述机器翻译(machine translation),又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。
它是自然语言处理(Natural Language Processing)的一个分支,与计算语言学(Computational Linguistics )、自然语言理解( Natural Language Understanding)之间存在着密不可分的关系。
2 国内外现状机器翻译思想的萌芽关于用机器来进行语言翻译的想法,远在古希腊时代就有人提出过了。
在17世纪,一些有识之士提出了采用机器词典来克服语言障碍的想法。
笛卡(Descartes)和莱布尼兹(Leibniz)都试图在统一的数字代码的基础上来编写词典。
在17世纪中叶,贝克(Cave Beck)、基尔施(Athanasius Kircher)和贝希尔(Johann JoachimBecher)等人都出版过这类的词典。
由此开展了关于“普遍语言”的运动。
维尔金斯(JohnWilkins)在《关于真实符号和哲学语言的论文》(An Essay towards a Real Character andPhilosophical Language, 1668)中提出的中介语(Interlingua)是这方面最著名的成果,这种中介语的设计试图将世界上所有的概念和实体都加以分类和编码,有规则地列出并描述所有的概念和实体,并根据它们各自的特点和性质,给予不同的记号和名称。
本世纪三十年代之初,亚美尼亚裔的法国工程师阿尔楚尼(G.B. Artsouni)提出了用机器来进行语言翻译的想法,并在1933年7月22日获得了一项“翻译机”的专利,叫做“机械脑”(mechanical brain)。
这种机械脑的存储装置可以容纳数千个字元,通过键盘后面的宽纸带,进行资料的检索。
阿尔楚尼认为它可以应用来记录火车时刻表和银行的帐户,尤其适合于作机器词典。
噪声对神经网络训练效果的影响

噪声对神经网络训练效果的影响一、噪声对神经网络训练的基本概念神经网络是一种受人脑结构启发的计算模型,它通过模拟人脑神经元的连接和交互来处理信息。
在机器学习和深度学习领域,神经网络被广泛应用于各种任务,如图像识别、自然语言处理等。
然而,在实际应用中,数据往往不可避免地包含噪声,这些噪声可能会对神经网络的训练效果产生显著影响。
1.1 噪声的定义与类型噪声是指数据中存在的非信息性或错误性成分,它可以是随机的或系统性的。
在神经网络训练中,常见的噪声类型包括高斯噪声、椒盐噪声、脉冲噪声等。
高斯噪声是最常见的噪声类型,它遵循正态分布;椒盐噪声则表现为图像上的随机黑白像素点;脉冲噪声则可能由硬件故障或传输错误引起。
1.2 噪声对神经网络的影响噪声的存在可能会对神经网络的训练过程产生多种影响。
首先,噪声可能会增加数据的不确定性,导致模型在训练过程中难以收敛。
其次,噪声可能会误导模型学习到错误的特征,从而影响模型的泛化能力。
此外,噪声还可能增加模型的过拟合风险,因为模型可能过度拟合到噪声而非数据的真实分布。
1.3 神经网络对噪声的敏感性不同类型的神经网络对噪声的敏感性不同。
例如,深度神经网络通常具有更好的容错能力,因为它们可以通过多层结构捕捉数据中的复杂模式。
然而,即使是深度网络也可能在面对高噪声数据时表现不佳。
此外,网络的架构、激活函数的选择、优化算法等因素也会影响模型对噪声的敏感性。
二、噪声对神经网络训练效果的实证分析为了深入理解噪声对神经网络训练效果的影响,可以通过实证分析来探讨不同噪声条件下模型性能的变化。
以下是一些可能的研究方向和分析方法。
2.1 数据集与噪声注入选择适合的基准数据集,如MNIST、CIFAR-10等,然后在这些数据集上注入不同类型和程度的噪声。
通过控制噪声的注入方式,可以系统地研究噪声对模型性能的影响。
2.2 模型架构与训练策略设计不同的神经网络架构,包括不同层数、不同类型的激活函数和正则化技术。
机器翻译研究综述(DOC)

机器翻译综述1.引言1.1机器翻译的历史现代机器翻译的研究应该是从20世纪50年代开始,但是早在这以前很多人已经提出了相应的想法,甚至是远在古希腊时期就有人提出要用机器来进行语言翻译的想法。
在1946年,美国宾夕法尼亚大学的两位科学家设计并制造了世界上第一台电子计算机。
与此同时,英国工程师同美国洛克菲勒基金会副总裁韦弗在讨论计算机的应用范围时,就提出了利用计算机实现语言的自动翻译的想法。
在1949年,韦弗发表了一份名为《翻译》的备忘录,正式提出了机器翻译问题。
他提出了两个主要观点:第一,他认为翻译类似于解读密码的过程。
第二,他认为原文与译文“说的是同样的事情”,因此,当把语言A翻译为语言B时,就意味着从语言A出发,经过某一“通用语言”或“中间语言”,可以假定是全人类共同的。
在这一段时间由于学者的热心倡导,实业界的大力支持,美国的机器翻译研究一时兴盛起来。
1964年,美国科学院成立语言自动处理咨询委员会,调查机器翻译的研究情况,给出了“在目前给机器翻译以大力支持还没有多少理由”的结论,随后机器翻译的研究就陷入了低潮期。
直到70年代以后机器翻译的研究才重新进入了一个复苏期,随后机器翻译的发展又迎来了繁荣期1.2机器翻译的主要内容经过50多年的发展,在机器翻译领域中出现了很多的研究方法,总结如下:●直接翻译方法●句法转换方法●中间语言方法●基于规则的方法●基于语料库的方法➢基于实例的方法(含模板、翻译记忆方法)➢基于统计的方法在当前的研究中,更多的是基于统计的方法进行的,因为基于统计的方法可以充分的利用计算机的计算能力,并且并不需要过多的语言学知识作为支撑,可以让更多的计算机科学家投入到实用系统的研究中,极大的促进了统计机器翻译的发展。
下面对各个方法逐一的进行介绍。
2.机器翻译主要方法2.1直接翻译方法所谓直接翻译方法就是从句子的表层出发,将单词、词组、短语甚至是句子直接置换成目标语言译文,有时进行一些简单的词序调整实现翻译,并不进行深层次的句法和语义分析。
规则化和模型选择(Regularization and model selection)

规则化和模型选择(Regularization and model selection)1 问题模型选择问题:对于一个学习问题,可以有多种模型选择。
比如要拟合一组样本点,可以使用线性回归,也可以用多项式回归。
那么使用哪种模型好呢(能够在偏差和方差之间达到平衡最优)?还有一类参数选择问题:如果我们想使用带权值的回归模型,那么怎么选择权重w公式里的参数?形式化定义:假设可选的模型集合是,比如我们想分类,那么SVM、logistic 回归、神经网络等模型都包含在M中。
2 交叉验证(Cross validation)我们的第一个任务就是要从M中选择最好的模型。
假设训练集使用S来表示来训练每一个,训练出参数后,也就可以得到假设函数。
(比如,线性模型中得到得到了假设函数)遗憾的是这个算法不可行,比如我们需要拟合一些样本点,使用高阶的多项式回归肯定比线性回归错误率要小,偏差小,但是方差却很大,会过度拟合。
因此,我们改进算法如下:的样例作为训练集作为测试集在,得到假设函数在上测试每一个,得到相应的经验错误选择具有最小经验错误这种方法称为hold-out cross validation或者称为简单交叉验证。
由于测试集是和训练集中是两个世界的,因此我们可以认为这里的经验错误接近于泛化错误(generalization error)。
这里测试集的比例一般占全部数据的1/4-1/3。
30%是典型值。
还可以对模型作改进,当选出最佳的模型后,再在全部数据S上做一次训练,显然训练数据越多,模型参数越准确。
简单交叉验证方法的弱点在于得到的最佳模型是在70%的训练数据上选出来的,不代表在全部训练数据上是最佳的。
还有当训练数据本来就很少时,再分出测试集后,训练数据就太少了。
{,然后在训练子集中选择出{}),使用这个子集训练后,得到假设函数。
最后使用剩下的一份作测试,得到经验错误(个经验错误,那么对于一个选出平均经验错误率最小的,然后使用全部的再做一次训练,得到最后的这个方法称为k-fold cross validation(k-折叠交叉验证)。
神经网络在噪声识别中的应用研究

神经网络在噪声识别中的应用研究神经网络是一种生物启发式的计算模型,它模拟了人脑神经元之间的信息传递过程。
神经网络在模式识别、分类、预测等领域内应用广泛,其中噪声识别是其重要应用之一。
噪声是现代社会中不可避免的问题之一。
噪声严重影响人们的生活质量,而且很难完全消除。
因此,开发有效的噪声识别系统是当前亟待解决的问题。
传统的噪声识别系统常常采用声学模型或统计学模型。
声学模型利用声学特征提取器提取音频特征,然后使用隐马尔可夫模型 (HMM) 或高斯混合模型 (GMM)进行分类。
统计学模型则利用贝叶斯分类器或支持向量机(SVM) 等算法进行分类。
然而,传统的噪声识别系统存在一些问题。
一方面,声学模型和统计学模型需要提取人工特征,这个过程需要耗费大量的人力和时间,并且人工特征提取过程中很难消除噪声的影响。
另一方面,传统的分类器在面临复杂问题时容易产生过拟合现象。
神经网络具有自动学习的能力,可以直接从原始音频中提取特征。
神经网络由输入层、隐藏层和输出层组成。
输入层接收音频特征向量,隐藏层处理输入并提取特征,输出层输出分类结果。
神经网络可以通过训练来自适应地调整权重和偏差,以逐步提高预测准确度。
当前,神经网络在噪声识别中的应用研究已经取得了一些进展。
许多学者利用神经网络来建立噪声识别系统,通过实验验证了其优越性。
例如,一些研究者提出了基于卷积神经网络 (CNN) 的噪声识别方法。
他们设计了多个卷积核,每个卷积核可以提取不同的特征。
卷积神经网络在音频分类问题上具有很好的效果,在许多数据集上实现了较高的准确度。
除此之外,一些学者提出了基于循环神经网络 (RNN) 的噪声识别方法。
他们认为,RNN 可以捕捉到音频信号的序列信息,因此可以更好地应对噪声干扰。
他们还利用了LSTM(长短时记忆)网络来建立模型,实现了在噪声条件下的语音识别。
该方法还应用于噪声消除和语音增强领域。
综上所述,神经网络在噪声识别中的应用研究已经成为趋势。
语音识别算法中的声学建模方法总结

语音识别算法中的声学建模方法总结语音识别是一种将语音信号转化为文本的技术,广泛应用于语音助手、智能音箱、电话自动接听等各种场景中。
而在语音识别算法中,声学建模方法是其中一个关键的环节。
本文将对声学建模方法进行总结,包括高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔可夫模型(Hidden Markov Model,HMM)、深度神经网络(Deep Neural Network,DNN)等方法。
首先,我们来介绍GMM方法。
GMM是一种基于统计模型的声学建模方法,它假设语音信号是由多个高斯分布组成的。
在训练过程中,我们通过最大似然估计来估计高斯分布的参数,如均值和协方差矩阵。
然后,在识别过程中,我们将输入的语音信号与每个高斯分布进行比较,选择概率最大的高斯分布作为最终的识别结果。
GMM方法常用于传统的语音识别系统中,其性能在一定程度上受到数据分布的限制。
接下来,我们介绍HMM方法。
HMM是一种基于序列建模的声学建模方法,它假设语音信号是由多个隐藏的状态序列和对应的可观测的观测序列组成的。
在训练过程中,我们通过最大似然估计来估计HMM的参数,如初始状态概率、状态转移概率和观测概率。
然后,在识别过程中,我们使用Viterbi算法来寻找最可能的状态序列,进而得到最终的识别结果。
HMM方法在语音识别中广泛应用,其优势在于对于长时序列的建模能力较好。
然而,GMM和HMM方法都存在一些问题,如GMM的参数数量较大,计算复杂度较高;HMM对于复杂的语音信号建模能力相对较弱。
因此,近年来,深度神经网络被引入到语音识别中作为一种新的声学建模方法。
深度神经网络(DNN)是一种由多层神经元构成的神经网络模型。
在语音识别中,我们可以将DNN用于声学模型的学习和预测过程中。
具体来说,我们可以将语音信号的频谱特征作为输入,通过多层的神经网络进行特征提取和模型训练,在输出层获得最终的识别结果。
相比于传统的GMM和HMM方法,DNN方法在语音识别中取得了更好的性能,其受到数据分布的限制较小,对于复杂的语音信号建模能力更强。
机器翻译研究中统计方法的局限及翻译范式更迭规律

作者简介:周柳丹,硕士在读。
研究方向:翻译理论与实践。
收稿日期:2020-8-2性能,在绝大多数语种翻译比赛上都战胜了统计机器翻译系统;2017年,几乎所有参赛的机器翻译系统都是神经机器翻译系统。
统计机器翻译系统在竞赛中渐处下风的原因是多方面的。
本文从翻译研究范式的角度对此进行探讨,主要包括:借鉴机器翻译发展史,考察三种机器翻译研究范式——基于规则的机器翻译、基于语料库的机器翻译和神经机器翻译;梳理统计方法在机器翻译中应用的史实;客观评述“语料库+统计”研究范式的局限性。
2 基于规则的机器翻译1954年,美国乔治敦大学进行了首次机器翻译实验,这标志着基于规则的机器翻译系统时代的开始。
总体上说,这些机器翻译系统所采用的主流语言学范式是基于规则的句法—语义分析。
从实验结果来看,这些系统能够处理一些受限的“子语言”,但是难以处理大规模的真实文本,因此只能在一些狭窄的专业领域得以应用。
出现上述情况的一个很重要的原因就是机器翻译系统所运用的语言规则本身存在如下两个主要问题:(1)对语言的描写不充分。
机器翻译系统所装配的语言知识数量浩大、颗粒度小。
然而,其所运用的语言规则大多由语言学家来提供,在数量和严密性方面均存在缺陷。
在那个时代,语言学家受自身经验、尤其是技术手段的限制,对语言现象的观察和理解难免具有局限性;(2)规则之间存在相互冲突。
经典的例子是PP (介词短语)附着问题。
以“I saw the lady with a telescope ”为例,句尾的介词短语有两种不同解读:当该介词短语是用来修饰a lady 时,句子意为“拿着望远镜的女生”;当修饰saw 时,句子意为“我拿着望远镜看”。
这导致了歧义现象的产生,而歧义正是机器翻译进一步发展的瓶颈。
3 基于语料库的机器翻译随着计算机性能的提升以及大规模联机语料的建成,1989年语料库被引入基于规则的机器翻译技术中。
基于语料库的机器翻译可进一步分为统计机器翻译和基于实例的机器翻译。
语音交互知识点总结

语音交互知识点总结语音交互的基本知识点主要包括语音识别、语音合成、语音指令识别、自然语言处理等内容。
本文将对这些知识点进行详细的总结和阐述。
一、语音识别语音识别是指将人的语音信号转换为文字或命令的技术。
语音识别技术有两种基本方法:统计模型和神经网络模型。
1. 统计模型统计模型是传统的语音识别方法,它将语音信号与语音模型进行匹配,通过概率计算来确定最可能的文本输出。
统计模型主要包括音素模型、语言模型和声学模型。
音素模型是将语音信号中的音素进行分割和识别的模型,它是语音信号的基本单位。
语言模型是用来确定语音信号的文本输出的概率模型。
声学模型是用来对语音信号的频谱特征进行提取和识别的模型。
2. 神经网络模型神经网络模型是近年来发展起来的一种新型的语音识别方法。
它通过深度学习算法来对语音信号进行特征提取和识别,可以更准确地识别语音信号。
神经网络模型主要包括卷积神经网络、循环神经网络和注意力机制等技术。
二、语音合成语音合成是指将文字信息转换为语音信号的技术。
语音合成技术可以分为基于文本的语音合成和基于语音的语音合成两种方法。
1. 基于文本的语音合成基于文本的语音合成是根据输入的文本信息来生成语音信号的方法。
它主要包括文本预处理、语言模型生成、声学模型生成和语音合成器等步骤。
2. 基于语音的语音合成基于语音的语音合成是根据输入的语音信号来生成新的语音信号的方法。
它主要包括语音信号的特征提取、语音模型的训练和语音信号的合成等步骤。
三、语音指令识别语音指令识别是指通过语音信号来识别命令和指令的技术。
语音指令识别主要包括语音识别和命令识别两个过程。
语音识别是将语音信号转换为文字信息的过程,命令识别是根据提取的文本信息来识别具体的命令和指令的过程。
语音指令识别可以应用于智能音箱、智能手机、智能汽车等多个场景中,可以实现语音控制和语音交互的功能。
四、自然语言处理自然语言处理是指对自然语言进行理解和处理的技术。
自然语言处理主要包括语言模型、语义理解、对话系统等内容。
机器翻译方法概述
2
10.3.1 机器翻译方法概述
▪ 3. 中介语式翻译系统(inter-lingual MT systems) 先生成一种中介的表达方式,而非特定语言的结构; 再由中介的表达式,转换成译文。
基于规则的翻译
3
中介语式的翻译
10.3.1 机器翻译方法概述
▪ 4. 知识库式翻译系统(knowledge-based MT systems) 翻译经常需要除了词汇之外的各种知识,使用知识获取工 具(knowledge acquisition),以充实知识库的内容。
4
10.3.1 机器翻译方法概述
▪ 5. 统计式翻译系统(Statistics-based MT systems )
目前,Google翻译的大部分语言采用的都是统计机器翻 译的方法,在美国国家标准局组织的机器翻译评测中遥遥 领先。 此外,基为语言的产生构造某种合理的 统计模型,并在此统计模型基础上,定义要估计的模型参 数,并设计参数估计算法。早期的基于词的统计机器翻译 采用的是噪声信道模型,采用最大似然准则进行无监督训 练,而近年来常用的基于短语的统计机器翻译则采用区分 性训练方法,一般来说需要参考语料进行有监督训练。
发展历程:
直接型
间接型
中间语言型
转换型
1
10.3.1 机器翻译方法概述
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于噪声信道模型的SMT学习笔记理论翻译系统源语言:e(英语) 目标语言:f(法语) 从f翻译到e本来人们想说e结果在说的过程中受到类似噪声的干扰,结果说出了f。
所以我们必须得将f还原成与e最相似的语句。
这个过程就是噪声信道的模型。
统计机器翻译就是对于给定的f,找到相应的e,使P(e|f)最大,为argmax P(e|f) 。
e通过贝叶斯公式得:P(e|f) =P(e)*P(f|e)/P(f);则argmax P(e|f) = argmax P(e) * P(f|e)。
e eP(f)与e无关,所以P(f)可以忽略。
这样P(e|f)就有两个因素决定(1) P(e),(2) P(f|e);其中P(e)表示e在该语言中的流利度,也就是是否符合该语言的语法规则;P(f|e)表示e翻译成f的概率。
之所以不直接估计P(e|f),主要有两个原因:(1) 可以将e和f分别看作是疾病和症状,那么从e推出f(P(f|e))比较可行,而很难从f推出e(P(e|f))。
(2) 引入P(e),这样翻译出来的语句更像人话。
这样一个SMT系统的任务就分成了三部分:(1) 估计P(e),即语言模型(2) 估计P(f|e),即翻译模型(3) 用一个合适的算法找到一个e使得P(e) * P(f|e)最大(至少是尽可能大)。
翻译模型提供的是一些语言单词,而忽略这些单词之间的相对顺序;语言模型的作用就是找出符合该语言语法规则的顺序。
语言模型估记P(e)的值一般是基于现有的语言“数据库”,该数据库存储的是日常生活中人们所说的一些语句,这些语句通常都符合语法规则。
num(k) = k在该数据库中出现的次数。
(1)P(e)=num(e) / 数据库中语句的总数。
但是会出现一个不好的现象就是:e是一条好的语句,但是没在该数据库中出现过,所以其次数为0,从而P(e)也为0。
这样e就会被认为是差语句而被抛弃。
为了解决这个问题将引入一个平滑系数。
(2)在估计P(e)时,可以引入一个N元的概念,就是连续N个单词组成的字符串。
我们用b(y|x)表示单词y出现在单词x后的概率,即字符串xy出现的概率,b(z|xy)表示单词z出现在xy后即字符串xyz的概率,以此类推。
那么若e由单词e1,e2,e3…..en组成。
这样如果以二元模型来估计,那么P(e) = b(e1|etart)*b(e2|e1)*b(e3|e2)……*b(fnd|en);如果以三元模型来估计,那么P(e) =b(e1|etart)*b(e2|etart e1)*b(e3|e1e2)….*b(fnd|en-1en)。
引入平滑系数的作用在于当e中的子串没在数据库中出现时,不会出现为0的状况(即b(z|xy) = 0)。
b(z|xy) =num(“xyz”)/num(“yz”);用平滑系数可以将b(z|xy)= 0.95*num(“xyz”) /num( “xy”) + 0.04*num (“yz”) / num (“z”) + 0.008*num(“z”) /数据库中语句的总数+ 0.002;其中0.95,0.04,0.008,0.002就是平滑系数。
平滑系数按照不同的系统来设定不同的值,但其和必须为1。
这样即使z在整个数据库中都没出现过b(z|xy)的值为0.002而不是0,避免的(1)中的问题。
(3)在存储P(e)的值时可以用 - log (P(e)) / N 来替换P(e)的值从而避免P(e)2太小不易运算、判定。
翻译模型当给定一句f往回推出一句e,且e能很好地翻译成f。
判断e是否能很好的翻译成f就通过P(e)*P(f|e)的值来判断。
其中P(f|e)就是通过翻译模型来估计的。
以下是基于词对齐的方式讨论的。
t(x|y):表示y翻译成x的概率;n(x|y):表示单词y的产出率为x的概率;d(i|j,L,M):表示在英语句子(单词数为L)j位置的英语单词翻译成法语单词后是在法语句子(单词数为M)的i位置。
在一个固定的对齐模型中,d(i|j,L,M) =位置j到位置i 的次数/位置j到所有可能位置的次数。
有时为了使翻译的句子更通顺通常会添加一些单词,而这些单词并没有英文单词与之对应,因此引入NULL概念,认为这些“伪造”的法语单词是由NULL翻译过来的。
我们在估计出每个英语单词的产出率后,将英语句子做出处理:删除产出率为0的单词,复制产出率为1的单词,复制两遍产出率为2的单词,依此类推。
每个单词后面都可能插入NULL,设插入NULL的概率为p1,不插入的概率为p0。
由于以上参数都是基于一个特定的词对齐模型,所以我们用P(a|e,f)来表示在给定两种句子e,f的情况下使用a对齐模型的概率。
对齐模型其实是一个vector,vector的大小与法语句子的单词数相等。
其中第i个元素ai表示在法语句子中第i个位置对应的法语单词在英语句子中的位置。
则P(a | e,f) = P(a,f | e) / P(f | e)。
翻译模型得完成两个任务:(1) 估算出t,n,d,p1,p0的参数值;(2)估算出P(f|e)。
把所有可能对齐模型中e到f的概率都加起来就是P(f|e),即P(f | e) = Σ P(a,f | e),所以P(a | e,f) = P(a,f | e) /Σ P(a,f | e)a ae = 英语句子;f = 法语句子;ei = 第i个英语单词;fj = 第j个法语单词;L = 英语句子的单词数;M = 法语句子的单词数;a = 一个整型vector,表示对齐方式,vector中的值0<=ai<=L(1<=i<=M);aj = 在对齐模型a中,英语句子的第aj个单词对应于法语句子的第j个单词;eaj = 英语句子中与第j个法语单词对应的英语单词;phi-i = 在对齐模型中,英语句子的第i个单词的产出率。
L M MP(a,f | e) = Π n(phi-i | ei) * Π t(fj | eaj) * Π d(j | aj, l, m)i=1 j=1 j=1上式中并未考虑NULL的可能性,以及扭曲参数d的所有可能排列。
令 x=phi-0(NULL的产出率);M-x为实际的英文单词的产出率;通过对每个单词复制自己产出率的次数得到新的英文句子的单词数为M-x;现在要将x个NULL插入到这M-x个单词的后面,且每个单词的后面只能插入一个NULL,概率为p1;不插得概率为p0;则总共有M-x个位置可以插入这x个NULL,每个位置概率为p1,总的为p1^x;其余M-2x位置不插,每个位置概率为p0,总的为p0^M-2x。
将这x个由NULL产出的“伪”单词全排列有x!个可能,所以每个顺序的概率为1/phi-0!。
根据每个位置单词的产出率可以推出有phi-i!个等概率的相应位置的扭曲参数d。
综上所述,可以得到以下公式:P(a,f | e) = comb(M– phi0, phi0) * p0 ^ (M – 2phi0) * p1 ^ phi0 *L M M LΠ n(phi-i | ei) * Π t(fj | eaj) * Π d(j | aj, l, m) *Π phi-i! * (1 / phi0!)i=1 j=1 j:aj <> 0 i=0由于可以通过对齐模型的概率值来计算t, n, d等的参数值,也可以通过这些参数值来计算模型的概率值,所以这是一个死循环。
我们可以通过EM算法来解决这个问题。
在Model1中用EM算法就是给出初始的t(忽略其他参数值),然后通过t求P(a,f|e),然后再通过P(a,f|e)修改t,在用t修改P(a,f|e),如此反复,最后得到所有的对齐模型的概率值,其和就是P(f|e)。
同样用- log (P(f | e)) / N 来处理相应的值,以便存储。
2由于EM只能得到局部最优解而不能得到全局最优解,现在引入Viterbi Training 来改善这个问题。
1.给定初始参数;2.用已有的参数求最好(Viterbi)的对齐;3.用得到的对齐重新计算参数;4.回到第二步,直到收敛为止。
如果想在Model1的估算过程中引入扭曲参数,我们可以设计一个Model2,它的输入是Model1中的t参数的输出,而不用自己设定。
然后引入一个反失真的参数a(aj|j,L,M),其意义与d类似只是表示由j位置到aj位置的概率。
这样就可以得到:m mP(a,f | e) = Π t(fj | eaj) Π a(aj | j,L,M)j=1 j=1其中for 1 <= j <= m,aj = argmax t(fj | ei) * a(i|j,L,M)i总共有四种方法可以对P(a,f|e)进行估算,其中方法四没有弄懂。
最后的模型就是先通过Model1,然后传递参数值t给Model2,最后由Model2传输t和所估算出的P(a,f|e)给Model3,由Model3来估计基本参数值。
在每个模型中都是反复迭代的过程。
最后通过得到的参数值来估算P(f|e)。
以上讨论是基于噪声信道模型的,但现在最流行的是基于最大熵模型,接下来要弄懂基于噪声信道模型细节问题以及学习解码方法,还有学习基于最大熵模型的SMT。
问题1:在求P(e)时,用N元模型估计时,N的取值多少合适?问题2:在选词时,是否每个可能的词以及多有的词间相对顺序都得试一下,从而组成所有可能的语句,进而来判断?问题3:(2)中问题是否可以通过搜索过程中的剪枝或者使用贪心A*的搜索来减少时间复杂度?要是用A*估价函数的确定?问题4:在模型中使用反复迭代的时候每个模型中的结束条件是什么。
问题5:在Model2中方法四不懂。
l = length of English sentencem = length of French sentenceei = ith English wordfj = jth French wordt(f | e) = probability English word e translates to French word f phi-max = maximum fertility of any wordbig-gamma(n) = partition of n into a sum of integers all >= 1 (e.g., 1+2+4 is a partition of 7, and so is 1+1+1+1+3)times(partition, k) = number of times integer k appears in partition for i = 1 to lfor k = 1 to phi-maxbeta =0.0for j =1 to mbeta += [ t(fj | ei) / (1 - t(fj | ei) ]^kalpha[i,k] = (-1)^(k+1) * beta / kfor i = 1 to lr =1.0for j = 1 to mr = r * (1 - t(fj | ei))for phi = 0 to phi-maxsum =0.0for each partition p in big-gamma(phi)prod =1.0for k =1 to phiprod =prod * alpha[i,k]^times(p,k) / times(p,k)!sum += prodc(phi | ei) += r * sum问题6:有些细节上还没完全搞清楚。