带参数Shell脚本执行SQL语句
Shell脚本编写的高级技巧使用变量和参数传递数据

Shell脚本编写的高级技巧使用变量和参数传递数据Shell脚本编写的高级技巧:使用变量和参数传递数据Shell脚本是一种在Linux和Unix操作系统下使用的命令行解释器,它允许用户通过编写脚本来自动执行一系列命令。
变量和参数是Shell脚本中非常重要的概念,它们可以用来存储和传递数据,使脚本更加灵活和可重用。
本文将介绍一些Shell脚本编写的高级技巧,重点讨论变量和参数的使用。
一、变量的定义和使用在Shell脚本中,变量是用于存储数据的容器。
定义变量的格式为“变量名=值”,其中变量名不能以数字开头,可以包含字母、数字和下划线。
值可以是字符串、数字和其他类型的数据。
1. 字符串变量:示例:```name="John"echo "My name is $name"```输出:```My name is John```2. 数字变量:在Shell脚本中,不需要事先声明变量的类型,直接赋值即可。
示例:```age=25echo "I am $age years old"```输出:```I am 25 years old```3. 环境变量:Shell脚本还能够访问和使用系统的环境变量。
系统的环境变量是在操作系统启动时设置的,它们可以存储一些系统级别的配置信息。
示例:```echo "My home directory is $HOME"echo "My current working directory is $PWD"```输出:```My home directory is /home/userMy current working directory is /home/user/scripts```二、参数的传递和使用Shell脚本可以通过命令行参数接收外部传递的数据,这样可以使脚本更具通用性。
shell调用oracle语句

shell调用oracle语句Shell脚本可以通过调用Oracle语句与数据库进行交互。
在以下内容中,我们将讨论如何使用Shell脚本调用Oracle语句来执行一些常见的数据库操作,如查询数据、插入数据、更新数据和删除数据等。
1. 连接到Oracle数据库在Shell脚本中,可以使用`sqlplus`命令与Oracle数据库建立连接,如下所示:```shell#!/bin/bash# 设置数据库连接信息ORACLE_SID=<ORACLE_SID>ORACLE_USER=<ORACLE_USER>ORACLE_PASSWORD=<ORACLE_PASSWORD># 连接Oracle数据库sqlplus -S$ORACLE_USER/$ORACLE_PASSWORD@$ORACLE_SID << EOF-- 执行SQL语句-- ...EOF```其中,`$ORACLE_SID`是Oracle实例的标识符,`$ORACLE_USER`和`$ORACLE_PASSWORD`是数据库用户的用户名和密码。
2. 查询数据在Shell脚本中,可以使用`select`语句查询Oracle数据库中的数据,如下所示:```shellsqlplus -S$ORACLE_USER/$ORACLE_PASSWORD@$ORACLE_SID << EOF-- 查询数据SELECT * FROM employees WHERE department_id = 10; EOF```以上示例中,查询了`employees`表中`department_id`为10的所有记录。
3. 插入数据在Shell脚本中,可以使用`insert into`语句向Oracle数据库中插入数据,如下所示:```shellsqlplus -S$ORACLE_USER/$ORACLE_PASSWORD@$ORACLE_SID<< EOF-- 插入数据INSERT INTO employees (id, name, salary) VALUES (1, 'John', 5000);COMMIT;EOF```以上示例中,向`employees`表中插入了一条记录,插入的字段包括`id`、`name`和`salary`。
使用shell脚本进行数据库操作

使用shell脚本进行数据库操作Shell脚本是一种可以在Unix、Linux和其他操作系统中运行的脚本语言,它可以帮助我们自动化执行各种任务。
在数据库管理和操作中,Shell脚本也可以发挥重要作用。
本文将介绍如何使用Shell脚本进行数据库操作,包括连接数据库、执行SQL语句、导入导出数据等常见操作。
一、连接数据库在使用Shell脚本进行数据库操作之前,首先需要连接数据库。
不同的数据库系统可能具有不同的连接命令,下面以MySQL数据库为例。
要连接MySQL数据库,可以使用以下命令:```shell#!/bin/bashMYSQL_USER="your_username"MYSQL_PASSWORD="your_password"mysql -u $MYSQL_USER -p$MYSQL_PASSWORD -e "useyour_database"```上述脚本首先定义了两个变量`MYSQL_USER`和`MYSQL_PASSWORD`,分别存储数据库的用户名和密码。
然后通过`mysql`命令连接数据库,并使用`-u`参数指定用户名,`-p`参数指定密码,`-e`参数执行指定的SQL语句。
其中,`use your_database`是一个示例,你可以根据实际情况修改为你要连接的数据库。
二、执行SQL语句连接数据库后,我们可以使用Shell脚本执行各种SQL语句,例如创建表、插入数据、更新数据等。
```shell#!/bin/bashMYSQL_USER="your_username"MYSQL_PASSWORD="your_password"mysql -u $MYSQL_USER -p$MYSQL_PASSWORD -e "useyour_database; create table your_table (id int, name varchar(255)); insert into your_table values (1, 'John'); select * from your_table"```上述脚本在连接数据库后,执行了三条SQL语句:创建表`your_table`,插入一条数据,然后查询表中的数据。
shell -s 用法

shell -s 用法什么是Shell脚本?Shell脚本是一种简化的编程语言,用于自动化执行在操作系统的Shell 环境下运行的一系列命令。
Shell脚本是由一系列命令和控制结构组成的文字文件,它可以被操作系统解释器逐行执行。
Shell脚本可以用于快速、高效地执行复杂的任务,如自动备份文件、批量处理数据等。
Shell脚本的用途Shell脚本可以用于多种用途,例如:1. 系统管理:管理员可以使用Shell脚本来配置和管理操作系统,例如安装软件包、定时任务调度等。
2. 数据处理:Shell脚本可以用于批量处理大量数据,例如日志分析、数据格式转换等。
3. 自动化任务:Shell脚本可以用于自动执行常见的任务,例如备份文件、发送电子邮件等。
4. 工作流程管理:Shell脚本可以用于连接多个命令和程序,形成复杂的工作流程,例如数据流处理、任务调度等。
Shell脚本的基本语法和用法Shell脚本的基本语法包括注释、变量、常量、条件判断、循环和函数等。
下面逐步介绍Shell脚本的用法:1. 注释:Shell脚本中的注释以"#"开头,用于解释代码的作用。
注释可以提高脚本的可读性,也方便其他人阅读和理解脚本。
2. 变量:变量用于存储和引用数据。
在Shell脚本中,变量名以""符号开头,可以是字母、数字、下划线的组合,不区分大小写。
变量可以通过赋值语句进行初始化,例如:`name="John"`。
变量的值可以通过""符号进行引用,例如:`echo name`。
3. 常量:常量是指在脚本中固定不变的值。
在Shell脚本中,可以使用`readonly`命令将变量声明为常量,例如:`readonly PI=3.14159`。
常量的值不能被修改。
4. 条件判断:Shell脚本可以根据条件的真假来执行不同的代码。
常用的条件判断命令有`if`、`else`、`elif`等。
Shell脚本编写的高级技巧使用命令行参数和交互式输入进行脚本的定制化

Shell脚本编写的高级技巧使用命令行参数和交互式输入进行脚本的定制化Shell脚本是一种在类Unix系统中广泛使用的脚本语言,它提供了一种自动化执行操作系统命令和任务的方式。
在Shell脚本编写过程中,使用命令行参数和交互式输入可以使脚本更加灵活和定制化。
本文将介绍Shell脚本编写的一些高级技巧,详细阐述如何利用命令行参数和交互式输入来实现脚本的定制化。
一、命令行参数的使用命令行参数是在执行Shell脚本时传递给脚本的参数,通过这些参数可以定制脚本的行为。
在Shell脚本中,可以使用$1、$2等特殊变量来获取命令行参数的值。
以下是一个示例:```#!/bin/bashecho "欢迎使用脚本定制工具!"echo "脚本名称:$0"echo "参数1:$1"echo "参数2:$2"```在执行该脚本时,可以通过命令行传入参数:```$ ./custom.sh 参数1 参数2```执行结果如下:```欢迎使用脚本定制工具!脚本名称:./custom.sh参数1:参数1参数2:参数2```通过命令行参数,我们可以根据用户的需求定制脚本的行为。
例如,在一个备份脚本中,可以使用命令行参数指定要备份的目录,备份到的目标目录等。
二、交互式输入的使用除了命令行参数,Shell脚本还可以通过交互式输入与用户进行交互,进一步定制脚本的行为。
在Shell脚本中,可以使用`read`命令获取用户输入的值。
以下是一个示例:```#!/bin/bashecho "欢迎使用脚本定制工具!"read -p "请输入您的姓名:" nameecho "您好,$name!"```执行该脚本时,脚本会提示用户输入姓名,并将输入的姓名输出。
例如:```$ ./custom.sh请输入您的姓名:张三您好,张三!```通过交互式输入,我们可以获取用户的输入值,并根据这些值来定制脚本的行为。
Linux脚本中调用SQL,RMAN脚本

Linux脚本中调⽤SQL,RMAN脚本Linux/Unix shell脚本中调⽤或执⾏SQL,RMAN 等为⾃动化作业以及多次反复执⾏提供了极⼤的便利,因此通过Linux/Unix shell来完成的相关⼯作,也是DBA必不可少的技能之⼀。
本⽂针对Linux/Unix shell脚本调⽤sql, rman 脚本给出了相关⽰例。
⼀、由shell脚本调⽤sql,rman脚本1. 1、shell脚本调⽤sql脚本2. #⾸先编辑sql⽂件3. oracle@SZDB:~> more dept.sql4. connect scott/tiger5. spool /tmp/dept.lst6. set linesize 100 pagesize 807. select * from dept;8. spool off;9. exit;10.11. #编辑shell脚本⽂件,在shell脚本内调⽤sql脚本12. oracle@SZDB:~> more get_dept.sh13. #!/bin/bash14.15. # set environment variable16.17. if [ -f ~/.bashrc ]; then18. . ~/.bashrc19. fi20.21. export ORACLE_SID=CNMMBO22. sqlplus -S /nolog @/users/oracle/dept.sql #注意此处执⾏sql脚本的⽅法 -S 表⽰以静默⽅式执⾏23. exit24.25. #授予脚本执⾏权限26. oracle@SZDB:~> chmod 775 get_dept.sh27.28. -->执⾏shell脚本29. oracle@SZDB:~> ./get_dept.sh30.31. DEPTNO DNAME LOC32. ---------- -------------- -------------33. 10 ACCOUNTING NEW YORK34. 20 RESEARCH DALLAS35. 30 SALES CHICAGO36. 40 OPERATIONS BOSTON37.38. 2、shell脚本调⽤rman脚本39. #⾸先编辑RMAN脚本40. oracle@SZDB:~> more rman.rcv41. RUN {42. CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;43. CONFIGURE BACKUP OPTIMIZATION ON;44. CONFIGURE CONTROLFILE AUTOBACKUP ON;45. CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/users/oracle/bak/%d_%F';46. ALLOCATE CHANNEL CH1 TYPE DISK MAXPIECESIZE=4G;47. ALLOCATE CHANNEL CH2 TYPE DISK MAXPIECESIZE=4G;48. SET LIMIT CHANNEL CH1 READRATE=10240;49. SET LIMIT CHANNEL CH1 KBYTES=4096000;50. SET LIMIT CHANNEL CH2 READRATE=10240;51. SET LIMIT CHANNEL CH2 KBYTES=4096000;52. CROSSCHECK ARCHIVELOG ALL;53. DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;54. BACKUP55. DATABASE FORMAT '/users/oracle/bak/%d_FULL__%U';56. SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';57. BACKUP ARCHIVELOG ALL FORMAT '/users/oracle/bak/%d_LF_%U' DELETE INPUT;58. DELETE NOPROMPT OBSOLETE;59. RELEASE CHANNEL CH1;60. RELEASE CHANNEL CH2;63. #编辑shell脚本⽂件,在shell脚本内调⽤rman脚本64. oracle@SZDB:~> more rman_bak.sh65. #!/bin/bash66.67. # set environment variable68.69. if [ -f ~/.bashrc ]; then70. . ~/.bashrc71. fi72.73. export ORACLE_SID=CNMMBO74. $ORACLE_HOME/bin/rman target / cmdfile=/users/oracle/rman.rcv log=/users/oracle/bak/rman.log75. exit76.77. #授予脚本执⾏权限78. oracle@SZDB:~> chmod 775 rman_bak.sh79.80. #执⾏shell脚本81. oracle@SZDB:~> ./rman_bak.sh⼆、嵌⼊sql语句及rman到shell脚本1. 1、直接将sql语句嵌⼊到shell脚本2. oracle@SZDB:~> more get_dept_2.sh3. #!/bin/bash4. # Author : Robinson Cheng5. # Blog : /robinson_06126.7. # set environment variable8.9. if [ -f ~/.bashrc ]; then10. . ~/.bashrc11. fi12.13. export ORACLE_SID=CNMMBO14. sqlplus -S /nolog <<EOF #EOF在此表⽰当输⼊过程中碰到EOF后,整个sql脚本输⼊完毕15. connect scott/tiger16. spool /tmp/dept.lst17. set linesize 100 pagesize 8018. select * from dept;19. spool off;20. exit; #退出sqlplus 环境21. EOF22. exit #推出shell脚本23.24. #授予脚本执⾏权限25. oracle@SZDB:~> chmod u+x get_dept_2.sh26.27. #执⾏shell脚本28. oracle@SZDB:~> ./get_dept_2.sh29.30. DEPTNO DNAME LOC31. ---------- -------------- -------------32. 10 ACCOUNTING NEW YORK33. 20 RESEARCH DALLAS34. 30 SALES CHICAGO35. 40 OPERATIONS BOSTON36.37. 2、直接将sql语句嵌⼊到shell脚本(⽅式⼆,使⽤管道符号>代替spool来输出⽇志)38. oracle@SZDB:~> more get_dept_3.sh39. #!/bin/bash40.41. # set environment variable42.43. if [ -f ~/.bashrc ]; then44. . ~/.bashrc47. export ORACLE_SID=CNMMBO48. sqlplus -S /nolog 1>/users/oracle/dept.log 2>&1 <<EOF49. connect scott/tiger50. set linesize 80 pagesize 8051. select * from dept;52. exit;53. EOF54. cat /users/oracle/dept.log55. exit56.57. #另⼀种实现⽅式,将所有的sql语句输出来⽣成sql脚本后再调⽤58. oracle@SZDB:~> more get_dept_4.sh59. #!/bin/bash60.61. # set environment variable62.63. if [ -f ~/.bashrc ]; then64. . ~/.bashrc65. fi66.67. export ORACLE_SID=CNMMBO68. echo "conn scott/tiger69. select * from dept;70. exit;" >/users/oracle/get_dept.sql71. sqlplus -silent /nolog @get_dept.sql 1>/users/oracle/get_dept.log 2>&172. cat get_dept.log73. exit74.75. 3、将rman脚本嵌⼊到shell脚本76. oracle@SZDB:~> more rman_bak_2.sh77. #!/bin/bash78.79. # set environment variable80.81. if [ -f ~/.bashrc ]; then82. . ~/.bashrc83. fi84.85. export ORACLE_SID=CNMMBO86. $ORACLE_HOME/bin/rman log=/users/oracle/bak/rman.log <<EOF87. connect target /88. RUN {89. CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;90. CONFIGURE BACKUP OPTIMIZATION ON;91. CONFIGURE CONTROLFILE AUTOBACKUP ON;92. CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/users/oracle/bak/%d_%F';93. ALLOCATE CHANNEL CH1 TYPE DISK MAXPIECESIZE=4G;94. ALLOCATE CHANNEL CH2 TYPE DISK MAXPIECESIZE=4G;95. SET LIMIT CHANNEL CH1 READRATE=10240;96. SET LIMIT CHANNEL CH1 KBYTES=4096000;97. SET LIMIT CHANNEL CH2 READRATE=10240;98. SET LIMIT CHANNEL CH2 KBYTES=4096000;99. CROSSCHECK ARCHIVELOG ALL;100. DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;101. BACKUP102. DATABASE FORMAT '/users/oracle/bak/%d_FULL__%U';103. SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';104. BACKUP ARCHIVELOG ALL FORMAT '/users/oracle/bak/%d_LF_%U' DELETE INPUT;105. DELETE NOPROMPT OBSOLETE;106. RELEASE CHANNEL CH1;107. RELEASE CHANNEL CH2;108. }109. EXIT;110. EOF111. exit112.113. #授予脚本执⾏权限114. oracle@SZDB:~> chmod u+x rman_bak_2.sh115.116. #执⾏shell脚本117. oracle@SZDB:~> ./rman_bak_2.sh118. RMAN> RMAN> 2> 3> 4> 5> 6> 7> 8> 9> 10> 11> 12> 13> 14> 15> 16> 17> 18> 19> 20> 21> RMAN> oracle@SZDB:~>。
命令行shell用于SQLite

命令⾏shell⽤于SQLite转SQLite 库包含了⼀个简单的命令⾏实⽤⼯具命名sqlite3 (或sqlite3exe 在windows 上), 它允许⽤户⼿动输⼊并执⾏SQL 命令针对⼀个SQLite 数据库此⽂档提供了有关如何使⽤简要介绍sqlite3 程序使⽤⼊门要启动"sqlite3 程序时, 只需键⼊"sqlite3 ", 后跟该⽂件SQLite , 该数据库如果该⽂件不存在, 则⾃动"sqlite3 程序将提⽰您要输⼊SQL在SQL 语句类型(由⼀个semicolon) 终⽌, SQL 按"enter ", 将会被执⾏例如, 要创建⼀个新的名为"ex1 "SQLite 数据库使⽤⼀个"tbl1 名为的表", 可能会这样做:$sqlite3 ex1SQLite 版本3611输⼊"帮助"有关说明⽤"; "输⼊SQL 语句终⽌sqlite > create table tbl1(one varchar(10) , 两个smallint) ;sqlite > insert into tbl1 values( ''hello! '', 10) ;sqlite > insert into tbl1 values( ''goodbye '' , 20) ;sqlite > select *from tbl1 ;hello!|10goodbye|20sqlite >通过键⼊以下命令可以终⽌sqlite3 程序您的系统End-Of-File 字符(通常为Control-D)使⽤中断字符(通常是⼀个Control-C) 停⽌长时间运⾏的SQL 语句请确认您键⼊⼀个分号!的每个SQL 命令结束时, sqlite3 程序时查找⼀个分号知道您的SQL 命令如果省略分号, sqlite3 将给您继续符如果提⽰, 等待输⼊更多⽂本添加到当前SQL 命令此功能允许您要输⼊SQL 横跨多⾏例如:sqlite > CREATE TABLE tbl2 (...> f1 varchar(30 )主键,...> f2 ⽂本....> f3 实数...> );sqlite >除: 仅使⽤SQLITE_MASTER 表将显⽰"数据库模式中的⼀个SQLite 数据库是存储在⼀个特殊的表格"sqlite_master "可以为特殊sqlite_master 表执⾏"SELECT "语句就像任何其他表在SQLite 数据库例如:$sqlite3 ex1SQLite 版本3611输⼊"帮助"有关说明sqlite > select *from sqlite_master ;类型=表名称=tbl1tbl_name =tbl1rootpage =3sql =create table tbl1(one varchar(10) , 两个smallint )sqlite >但不能执⾏DROP TABLE, UPDATE, INSERT 或DELETE 对sqlite_master 表在sqlite_master 表⾃动为您创建或更新从数据库中删除表及索引不能⼿动修改sqlite_master 表此模式的TEMPORARY 表没有存储在TEMPORARY "sqlite_master "表中的表是不可见的应⽤程序, 创建该表的应⽤程序此模式的TEMPORARY 表是存储在另⼀个特殊的表格"sqlite_temp_master """sqlite_temp_master "表是临时本⾝特殊命令来sqlite3在⼤多数情况下, sqlite3 上读取的输⼊, 并把它们拖到SQLite 库为执⾏但是, 如果⼀个输⼊⾏以点号("") 该⾏, 然后是截取和nocase sqlite3 程序本⾝"时, 通常使⽤这些"dot 命令来更改输出的格式, 或要执⾏的某些⾃带的查询的查询语句有关服务器可⽤的点命令, 您可以输⼊"帮助"在任意时间例如:sqlite > 帮助备份? DB? FILE 备份DB (默认"main ")来FILEbail ON|OFF 停⽌后, ⼀个错误默认OFF列表名的数据库和⽂件附加数据库转储? TABLE? 转储到数据库中SQL ⽂字格式回⾳式ON|OFF 打开或关闭命令回显exit 退出该程序解释ON|OFF 关闭或输出模式适合于EXPLAINgenfkey ? OPTIONS? 选项有:--no-drop : 请不要删除旧fkey 触发器--ignore-errors : 忽略表提供fkey 错误--exec : ⽴即执⾏⽣成的SQL请参阅⽂件tool/genfkeyREADME 在源分发以获得进⼀步的信息header(s )ON|OFF 关闭或显⽰的标题help 显⽰此消息导⼊FILE TABLE 在FILE TABLE⽤于分隔索引TABLE 只显⽰指定的TABLE 上的所有索引iotrace FILE 启⽤I/O 诊断⽇志记录设置为FILE加载FILE ? ENTRY? 加载扩展库模式MODE ? TABLE? 设置输出模式其中MODE 是以下值之⼀:csv 以逗号分隔的值列居中的列(参见宽度)html HTML < 表格> 代码为TABLE 插⼊SQL insert 语句⾏每⾏对应⼀个值列表中的值⽤分号分隔分隔字符串标签tab-separated 值tcl TCL 列表元素nullvalue 将STRING 打印STRING 代替NULL 值输出FILENAME 发送输出以FILENAME输出stdout 发送输出到屏幕提⽰MAIN CONTINUE 替换标准提⽰quit 退出该程序在FILENAME 读取FILENAME 执⾏SQL还原? DB? FILE 还原DB 内容(默认的"main ")从FILE架构? TABLE? 显⽰CREATE 语句输出模式和使⽤的分隔符STRING 更改分隔符导⼊显⽰显⽰当前的不同设置的值表? PATTERN? 列表中的名称相匹配的表LIKE 图案MS 请尝试打开MS 表锁定毫秒后超时定时器ON|OFF 关闭或CPU 计时器测量宽度NUM NUM设置"column 列宽"模式sqlite >更改输出格式在sqlite3 程序能够显⽰查询的结果在⼋种不同的格式: "csv ""column ""html ""insert ""line ""list ""tabs "和"tcl "可以使⽤"模式"点命令要切换这些输出格式输出模式的默认设置是"list "在"位置"中, 每个记录列表写⼊⼀次查询中每⼀⾏输出和记录是⼀个特定的分隔符分隔的字符串默认分隔符是⼀个管道符号("| ")列出模式时特别有⽤创建⼀个查询的输出发送给其他程序(例如⽤于其他处理的AWK)sqlite > 模式列表sqlite > select *from tbl1 ;hello|10goodbye|20sqlite >可以使⽤"分隔符"点命令更改分隔符为列表模式例如, 要将插⼊⼀个逗号和空格, 您也可以这样做:sqlite > 分隔符", "sqlite > select *from tbl1 ;"你好, 10再见, 20sqlite >在"line "模式下, 每⼀个列与数据库中的某⾏都在单独⼀⾏每⾏由等号列名, 并进⾏适当的更改连续记录通过⼀个空⾏分隔下⾯是⼀个例⼦模式⾏的输出:sqlite > 模式⾏sqlite > select *from tbl1 ;⼀个=hello两个=10⼀个=再见两个=20sqlite >在列模式中, 每个记录都在单独的⼀⾏中对齐与数据列例如:sqlite > 模式列sqlite > select *from tbl1 ;⼀个两个---------- ----------hello 10再见20sqlite >默认情况下, 每个列⾄少为10 个字符宽数据太⼤以适合列被截断使⽤"可以调整列宽宽度&w"命令像这样:sqlite > 宽度12 6sqlite > select *from tbl1 ;⼀个两个------------ ------hello 10再见20sqlite >"宽度&w"命令在以上⽰例中第⼀列的宽度设为指定值.以12 并第三列的宽度为6要查看所有其他列宽可以给出任意数量的参数来"在必要时宽度&w"以指定的列宽的任意多个列在您的查询结果如果指定列的宽度值为0然后的列宽⾃动调整是最多只能有三个数字: 10页眉的宽度⾸⾏的宽度, 并将该数据这将使列宽self-adjusting每⼀列的宽度设置此auto-adjusting 默认值为0值标志所在列的列标出现在前两⾏输出可以使⽤"打开和关闭header"点命令在上⾯的⽰例中, 列标签都在已开启您也可以这样做:sqlite > 页眉处于关闭状态sqlite > select *from tbl1 ;hello 10再见20sqlite >另⼀个有⽤的输出模式是"insert "在插⼊模式下, 则输出将会在格式化为看起来像是SQL INSERT 语句可以使⽤insert 模式来⽣成可以⽤来输⼊数据到不同的数据库当指定插⼊模式, 您要创建⼀个额外的参数的名称输⼊的表不存档例如:sqlite > 插⼊new_table 模式sqlite > select *from tbl1 ;INSERT INTO ''new_table "VALUES( ''hello '', 10);INSERT INTO ''new_table "VALUES( ''goodbye '', 20);sqlite >最后⼀个输出模式为"html "在此模式下, sqlite3 写⼊查询的结果作为XHTML 表开始< TABLE > 和终⽌< /TABLE > 都不进⾏写⼊但所有罪< TR > s< TH > s和< TD > s是html输出的模式为CGI _ganglia.py 标为很有⽤将结果写⼊⼀个⽂件默认情况下, sqlite3 会发送: 使⽤"可以更改此"命令的输出只需将输出⽂件的名称为⼀个参数输出命令及所有后续查询结果将写⼊该⽂件使⽤"输出stdout "以开始写⼊标准输出例如:sqlite > 模式列表sqlite > 分隔符|sqlite > 输出test_file_1⽂本⽂件txtsqlite > select *from tbl1 ;sqlite > 退出$cat test_file_1⽂本⽂件txthello|10goodbye|20$提交到数据库模式指定sqlite3 程序提供了⼏个⽅便命令会⾮常有⽤启动时, 模式的数据库服务器名⽆效⽂档这些命令执⾏不能执⾏某些其他⽅式这些命令都提供了纯粹作为⼀种快捷⽅式例如, 来查看数据库中的表的列表, 可以输⼊"表"sqlite > 表tbl1tbl2sqlite >"列表模式下表"命令类似于设置然后执⾏以下查询:SELECT 名称FROM sqlite_masterWHERE IN 类型('able '', ''view ")AND NOT LIKE '��qlite_% "UNION ALLSELECT 名称FROM sqlite_temp_masterWHERE IN 类型('able '', ''view '' )ORDER BY 1实际上, 如果您这样的源代码树sqlite3 程序(在列表中找到⽂件src/shellc )您将发现完全符合上⾯的查询"⽤于分隔索引的⼯作⽅式类似"命令来列出所有索引的表中"⽤于分隔索引"命令接受⼀个参数, 它是该名称表的索引不正确last, 但不能有,为"架构"命令不带参数, 则"架构"命令显⽰原始CREATE TABLE 和CREATE INDEX 语句被⽤来⽣成当前的数据库如果允许⽤户名称"架构",它展⽰了在原始CREATE 语句⽤于将该表和全部如果它的索引我们有:sqlite > 架构create table tbl1(one varchar(10) , 两个smallint )CREATE TABLE tbl2 (f1 varchar(30 )主键,f2 ⽂本.f3 实数)sqlite > 架构tbl2CREATE TABLE tbl2 (f1 varchar(30 )主键,f2 ⽂本.f3 实数)sqlite >"架构"命令完成设置效果相同的列表模式, 则输⼊以下查询:SELECT sql FROM(SELECT *FROM sqlite_master UNION ALLSELECT *FROM sqlite_temp_master )WHERE type!= ''meta "ORDER BY tbl_name , 请输⼊DESC, 名或者, 如果您给出的参数"架构", 因为您只想要为单个表架构, 该查询是这个样⼦:SELECT sql FROM(SELECT *FROM sqlite_master UNION ALLSELECT *FROM sqlite_temp_master )WHERE type!= ''meta "AND sql NOT NULL AND 名称NOT LIKE '��qlite_% "ORDER BY substr(type, 2, 1) , 名称您可以提供⼀个参数bcp命令如果您, 查询是这个样⼦:SELECT sql FROM(SELECT *FROM sqlite_master UNION ALLSELECT *FROM sqlite_temp_master )WHERE tbl_name LIKE ''%s "AND type!= ''meta "AND sql NOT NULL AND 名称NOT LIKE '��qlite_% "ORDER BY substr(type, 2, 1) , 名称在查询中的"%s "被替换参数这允许您查看模式对于某些⼦集的数据库sqlite > 架构%abc%沿着这些同样的, ⽽"表"命令也接受⼀个模式作为其第⼀个参数如果您给出参数设为表格命令, ⼀个"% "追加和instr 与LIKE ⼦句添加到查询这允许您仅列出这些表, 以匹配特定样式"databases "命令显⽰了所有在当前连接打开的数据库总是⾄少有2第⼀个为"main ", 则原始数据库中打开第⼆个是"temp ", 该数据库⽤于临时表可能还有其他数据库中列出的数据库附加使⽤ATTACH 语句第⼀个输出列是附加到的名称, 第⼆个列是外部⽂件的⽂件名sqlite > 数据库将整个数据库转换为⼀个ASCII ⽂本的⽂件使⽤"转储命令将整个数据库的内容复制到单个ASCII ⽂本⽂件该⽂件可以转换回数据库的管道其返回到sqlite3 .请在存档复制⼀个很好的⽅式与此数据库:$echo ''转储"| sqlite3 ex1 | gzip -c> ex1转储gz这⽣成⼀个名为ex1转储gz包含createbackup 所需要的⼀切东西的数据库, 或另⼀个机器上createbackup数据库时, 只需输⼊:$zcat ex1转储gz| sqlite3 ex2⽂字格式为纯SQL 因此, 您还可以使⽤转储命令将导出到在应⽤程序配置中设置的SQLite 数据库到其他常⽤的SQL 数据库引擎像这样:$数据库集群ex2$sqlite3 ex1转储| psql ex2其他点命令"解释"点可以使⽤下⾯的命令将输出模式设置为"column "并设置列宽设置为合理的每个值都在⼀个EXPLAIN 命令的输出EXPLAIN命令是⼀个SQLite-specific SQL 扩展插件后台模式如果任何常规SQL scs 的EXPLAIN, 然后键⼊SQL 命令被解析, 但不执⾏虚拟机指令序列的条件时,将已被⽤于执⾏SQL 命令返回查询结果, 如下所⽰: 例如:sqlite > 解释sqlite > 解释tbl1 删除, 其中两个< 20 ;addr opcode p1 p2 p3---- ------------ ----- ----- -------------------------------------0ListOpen 001打开01tbl12下⼀页0╟93〗字段014整数20 05ge 026键007ListWrite 008goto 029noop 0010 ListRewind 0011 ListRead 01412 删除0013 goto 01114 ListClose 00"超时"命令设定的时间sqlite3 程序将等待对⽂件的锁定来清除它正试图访问⼀个错误返回之前将超时的默认值零, 以便⽴即返回⼀个错误如果任何所需的数据库表或索引已被锁定最后, 我们提及"退出"命令导致sqlite3 程序退出使⽤sqlite3 在shell 脚本使⽤sqlite3 在shell 脚本的⼀种⽅法是使⽤"echo "或""cat "来⽣成⼀个⽂件中的⼀系列命令然后调⽤的单元测试将从⽣成的命令⽂件的输⼊此依旧⽆法正常运⾏的是⼤多数情况下但作为附加的⽅便, sqlite3 允许单个SQL 命令在命令⾏输⼊的值为第⼆个参数在数据库的名称当启动sqlite3 程序时, 使⽤两个参数第⼆个参数将被传递到SQLite 库为处理在标准输出上打印查询的结果在列表中.模式和这种机制是专为帮助sqlite3 易于使⽤的程序, 如"awk "结合使⽤例如:$sqlite3 ex1 '��elect *从tbl1 "|> awk '{printf " < tr > < td > %s < td > %sn",$1,$2 }'< tr > < td > hello < td > 10< tr > < td > 再见< td > 20$结束shell 命令SQLite 命令通常由分号终⽌在shell 也可以使⽤word "GO "(不区分⼤⼩写), 也可以是⼀个斜杠字符"/ "变得杂乱结束命令以下是由SQL server 和oracle , 值定义这些⽆法⼯作sqlite3_exec( )通过shell , 因为这些转换为⼀个分号传递到该功能之前将sqlite3 编译程序从源源代码到命令⾏sqlite3 接⼝中的单个名为"shell可以确定c"从SQLite ⽹站⾸先编译此⽂件(⼀起使⽤⽣成可执⾏⽂件例如: gcc -osqlite3 shellc sqlite3c -ldl -lpthread。
基于sparksql调用shell脚本运行SQL

基于sparksql调⽤shell脚本运⾏SQL[Author]: kwu基于sparksql调⽤shell脚本运⾏SQL,sparksql提供了类似hive中的 -e , -f ,-i的选项1、定时调⽤脚本#!/bin/sh# upload logs to hdfsyesterday=`date --date='1 days ago' +%Y%m%d`/opt/modules/spark/bin/spark-sql -i /opt/bin/spark_opt/init.sql --master spark://10.130.2.20:7077 --executor-memory 6g --total-executor-cores 45 --conf spark.ui.port=4075 -e "\insert overwrite table st.stock_realtime_analysis PARTITION (DTYPE='01' )select t1.stockId as stockId,t1.url as url,t1.clickcnt as clickcnt,0,round((t1.clickcnt / (case when t2.clickcntyesday is null then 0 else t2.clickcntyesday end) - 1) * 100, 2) as LPcnt,'01' as type,t1.analysis_date as analysis_date,t1.analysis_time as analysis_timefrom (select stock_code stockId,concat('/', stock_code,'.shtml') url,count(1) clickcnt,substr(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'),1,10) analysis_date,substr(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'),12,8) analysis_timefrom dms.tracklog_5minwhere stock_type = 'STOCK'and day =substr(from_unixtime(unix_timestamp(), 'yyyyMMdd'), 1, 8)group by stock_codeorder by clickcnt desc limit 20) t1left join (select stock_code stockId, count(1) clickcntyesdayfrom dms.tracklog_5min awhere stock_type = 'STOCK'and substr(datetime, 1, 10) = date_sub(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'),1)and substr(datetime, 12, 5) <substr(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'), 12, 5)and day = '${yesterday}'group by stock_code) t2on t1.stockId = t2.stockId;"\sqoop export --connect jdbc:mysql://10.130.2.245:3306/charts --username guojinlian --password Abcd1234 --table stock_realtime_analysis --fields-terminated-by '\001' --columns "stockid,url,clickcnt,splycnt,lpcnt,type" --export-dir /dw/st/stock init.sql内容为载⼊udf:add jar /opt/bin/UDF/hive-udf.jar;create temporary function udtf_stockidxfund as 'com.hexun.hive.udf.stock.UDTFStockIdxFund';create temporary function udf_getbfhourstime as 'com.hexun.hive.udf.time.UDFGetBfHoursTime';create temporary function udf_getbfhourstime2 as 'com.hexun.hive.udf.time.UDFGetBfHoursTime2';create temporary function udf_stockidxfund as 'com.hexun.hive.udf.stock.UDFStockIdxFund';create temporary function udf_md5 as 'mon.HashMD5UDF';create temporary function udf_murhash as 'mon.HashMurUDF';create temporary function udf_url as 'com.hexun.hive.udf.url.UDFUrl';create temporary function url_host as 'com.hexun.hive.udf.url.UDFHost';create temporary function udf_ip as 'com.hexun.hive.udf.url.UDFIP';create temporary function udf_site as 'com.hexun.hive.udf.url.UDFSite';create temporary function udf_UrlDecode as 'com.hexun.hive.udf.url.UDFUrlDecode';create temporary function udtf_url as 'com.hexun.hive.udf.url.UDTFUrl';create temporary function udf_ua as 'eragent.UDFUA';create temporary function udf_ssh as 'eragent.UDFSSH';create temporary function udtf_ua as 'eragent.UDTFUA';create temporary function udf_kw as 'com.hexun.hive.udf.url.UDFKW';create temporary function udf_chdecode as 'com.hexun.hive.udf.url.UDFChDecode';设置ui的port--conf spark.ui.port=4075默觉得4040,会与其它正在跑的任务冲突,这⾥改动为4075设定任务使⽤的内存与CPU资源--executor-memory 6g --total-executor-cores 45原来的语句是⽤hive -e 运⾏的,改动为spark后速度⼤加快了。
批处理(bat)开发和执行SQL语句----osql、isql、sqlcmd

批处理(bat)开发和执⾏SQL语句----osql、isql、sqlcmdSQL Server 命令⾏执⾏语句,似乎有⼏个选择⽅案:osql,isql和sqlcmd。
但是他们之间⼜有什么区别呢?这⾥我也从⽹上找了⼀些资料,⼤概如下:⼀楼推荐使⽤sqlcmd,它是功能最齐全的产品。
sqlcmd:SQL Server的最新,最狂热的命令⾏界⾯。
isql:与SQL Server进⾏命令⾏通信的较旧的DB-Library(本机SQL Server协议)⽅式。
osql:与SQL Server进⾏命令⾏通信的基于ODBC的旧⽅法。
编辑:⾃从⼏年前我回答这个问题以来,时代已经发⽣了变化。
现在,您还可以在PowerShell中使⽤invoke-sqlcmd cmdlet。
如果您习惯使⽤PowerShell或计划编写任何复杂程序的脚本,请改⽤它。
⼆楼我不确定你问题的范围是什么,但我相信:isql使⽤DB-Library与服务器通信,在SQL2000之后不再包含它osql使⽤ODBC与服务器进⾏通信,SQL2005之后将不再包含ODBCsqlcmd该实⽤⼯具使⽤ ODBC 执⾏ TRANSACT-SQL 批处理,⽬前是推荐的命令⾏⼯具。
三楼如果你有SQL SERVER 2005,最好使⽤SQLCMD⽽不是OSQL或ISQL,否则使⽤OSQL⽽不是ISQL。
微软之前宣布ISQL即将退出。
果然,ISQL不包含在SQL Server 2005 RTM中。
OSQL最终也将逐步淘汰,尽管它仍然包含在SQL Server 2005⼆进制安装中。
考虑到历史SQL Server发布周期,OSQL可能会在2010年向我们提出申请。
SQLCMD具有以下许多优点:1)表现明智2)SQLCMD⽀持参数化变量3)SQLCMD⽀持⾃定义编辑器4):XML [ONOFF]5):错误STDERRSTDOUT6):Perftrace STDERRSTDOUT7)远程专⽤管理连接(DAC)出处:如何开发SQLCMD程序呢?开发SQLCMD程序的流程是什么?根据上⾯的描述,我想你已经知道⾃⼰需要使⽤什么命令了。
使用Shell脚本进行命令行参数解析的技巧

使用Shell脚本进行命令行参数解析的技巧Shell脚本是一种在Unix或Linux系统上编写的脚本语言,它通过命令行界面执行一系列操作。
为了增加脚本的灵活性和适应不同的使用场景,我们经常需要在命令行中传递参数给Shell脚本。
本文将介绍一些使用Shell脚本进行命令行参数解析的技巧,帮助您更好地利用Shell脚本进行编程和自动化任务。
1. 使用$#获取参数数量在Shell脚本中,我们可以使用$#来获取命令行中传递的参数数量。
例如,如果您的脚本名为script.sh,执行命令如下:```shell./script.sh arg1 arg2 arg3```那么在脚本中使用$#将返回3,表示有3个参数被传递进来。
2. 使用$*或$@获取所有参数除了获取参数的数量,我们还可以使用$*或$@来获取所有的命令行参数。
这两个变量的区别在于,$*将所有的参数看作一个字符串,而$@将每个参数看作一个独立的字符串。
下面是一个示例,展示了如何使用$*和$@遍历所有的命令行参数:```shellfor arg in "$*"doecho $argdone``````shellfor arg in "$@"doecho $argdone```3. 使用$0获取脚本名称有时候,在Shell脚本中需要获取脚本的名称,以便在输出或日志中使用。
此时可以使用$0来获取当前脚本的文件名。
下面是一个示例,展示了如何使用$0获取脚本名称并输出:```shellecho "当前脚本的名称是:$0"```4. 使用$1、$2等获取特定位置的参数在命令行中传递的参数可以使用$1、$2等来获取。
其中$1表示第一个参数,$2表示第二个参数,以此类推。
下面是一个示例,展示了使用$1和$2获取命令行中的特定参数:```shellecho "第一个参数:$1"echo "第二个参数:$2"```5. 使用getopt进行高级参数解析在一些复杂的脚本中,我们可能需要更加灵活地解析命令行参数,包括可选参数和参数的值。
PowerShell应用之-批量执行SQL脚本

PowerShell应⽤之-批量执⾏SQL脚本这⼀篇,我们来实现PowerShell 2.0在SQL Server中的⼀个应⽤,是批量执⾏SQL脚本。
在接下来的内容,将使⽤到下⾯的命令或类库。
Sort-Objectout-nullWrite-Error$_System.IO.DirectoryInfomon.ServerConnection创建测试环境为了更能说明PowerShell脚本的应⽤,我们这⾥创建个测试环境,模拟⼀个要升级的SQL脚本⽂件;⾸先,要创建两个数据库『TestingDB01』和『TestingDB02』:View Codeuse masterGoif db_id('TestingDB01') Is Not nullDrop Database TestingDB01GoCreate Database TestingDB01Goif db_id('TestingDB02') Is Not nullDrop Database TestingDB02GoCreate Database TestingDB02Go在Microsoft SQL Server Management Studio(MSSMS)中执⾏上⾯的创建数据库SQL语句。
接下来我们创建三个SQL脚本⽂件:1. 01_ TestingDB_CreateTB&InitializeData.sql2. 02_ TestingDB_Procedures_0001.sql3. 03_ TestingDB_Procedures_0002.sql第1个脚本,应⽤于创建数据表和初始化数据使⽤,第2、3个脚本,只要是存储过程的脚本⽂件,其中有1个存储过程包含有动态的SQL语句,每⼀个脚本都包含有对数据库『TestingDB01』和『TestingDB02』的脚本。
这些脚本制作是模拟真实环境中的升级脚本,列举常见的脚本内容样本。
SQLServer用powershell实现多台服务器批量执行SQL脚本

SQLServer⽤powershell实现多台服务器批量执⾏SQL脚本 在运维⼯作中,会遇到很多重复性的操作。
对于单台服务器重复性的⼯作,可以⽤job实现定期的处理;⽽对于多台服务器相同的需求,我们就可以利⽤powershell来进⾏批量的操作,对多台服务器进⾏批量相同的操作。
本⽂重点分析这种⽅案的实现过程,⽽不纠结于对每台服务器具体执⾏的SQL脚本,所以在例⼦中以简单的SQL脚本为例:在中⼼服务器上执⾏⼀个powershell脚本,即可以收集所有服务器的信息。
对类似于定期出report的任务,还可以将该powershell脚本设置成计划任务。
⾸先将需要执⾏批量操作的服务器放在⽂本⽂件Serverlist.txt中: 中⼼服务器:10.120.100.101 10.120.100.1 10.120.100.2 10.120.100.3 以下所有创建的⽂件应该和Serverlist.txt放在⼀个⽂件夹中! ⼀.编写SQL脚本实现需求,并保存.SQL⽂件: 脚本1-(脚本⽂件名1.Create_DB&Table.sql):在每台服务器创建收集数据的数据库和表 --默认设置创建⽤于收集信息的专⽤数据库 CREATE DATABASE [Info_stats] CONTAINMENT = NONE ON PRIMARY ( NAME = N'Info_stats', FILENAME = N'D:\SQLServer\Data\Info_stats.mdf' , SIZE = 4096KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'Info_stats_log', FILENAME = N'D:\SQLServer\Data\Info_stats_log.ldf' , SIZE = 1024KB , FILEGROWTH = 10%) GO --在该数据库中创建本例⼦中需要⽤到的表 Use [Info_stats]; Create table DBName (Servername nvarchar(100), DBName nvarchar(100)) 脚本2-(脚本⽂件名2.Select_DBName.sql):查询所有⽤户数据库名字并存放在该服务器上的[Info_stats]-DBName表中 select name from sysdatabases where name not in(N'master', N'model', N'msdb', N'tempdb', N'distribution', N'DWDiagnostics',N'DWConfiguration',N'DWQueue', N'resource',N'ReportServer',N'ReportServerTempDB') 脚本3-(脚本⽂件名3.Copy Info to Centre.sql):将查询出的该服务器的信息同步到中⼼服务器: Set nocount on; use [Info_stats]; truncate table [Info_stats].[dbo].[DBName]; insert into [Info_stats].[dbo].[DBName] select * from ( select top 1* from OPENDATASOURCE( 'SQLOLEDB', 'Data Source=10.120.100.1;Integrated Security=SSPI' ).[Info_stats].[dbo].[DBName] order by Check_Date desc) c union select * from ( select top 1* from OPENDATASOURCE( 'SQLOLEDB', 'Data Source=10.120.100.2;Integrated Security=SSPI' ).[Info_stats].[dbo].[DBName] order by Check_Date desc) c union ( select * from ( select top 1* from OPENDATASOURCE( 'SQLOLEDB', 'Data Source=10.120.100.3;Integrated Security=SSPI' ).[Info_stats].[dbo].[DBName] order by Check_Date desc)z) Set nocount off; 注意:在中⼼服务器上需要打开‘Ad Hoc Distributed Queries’的选项,才可以使⽤OPENDATASOURCE来同步查询结果到中⼼服务器 ⼆.开始powershell脚本的准备: 1.创建调⽤(1.Create_DB&Table.sql)的powershell脚本,⽤于第⼀次执⾏时使⽤: 脚本名:Create_DB&Table.ps1 $PSScriptRoot = Split-Path -Parent $MyInvocation.MyCommand.Definition $Serverlist="$PSScriptRoot\Serverlist.txt" $Create_table="$PSScriptRoot\1.Create_DB&Table.sql" Foreach ($server in GC $Serverlist) { Invoke-Sqlcmd -ServerInstance $server -InputFile $Create_table } 2.创建调⽤(2.Select_DBName.sql)的powershell脚本,⽤于收集数据: 脚本名:QueryData.ps1 $PSScriptRoot = Split-Path -Parent $MyInvocation.MyCommand.Definition $Serverlist="$PSScriptRoot\Serverlist.txt" $ITSPCheck="$PSScriptRoot\2.Select_DBName.sql" Foreach ($server in GC $Serverlist) { Invoke-Sqlcmd -ServerInstance $server -InputFile $ITSPCheck } 3.创建调⽤(3.Copy Info to Centre.sql)的powershell脚本,⽤于整合数据到中⼼服务器: 脚本名:IntegrateResult.ps1 $PSScriptRoot = Split-Path -Parent $MyInvocation.MyCommand.Definition $IntegrateResult="$PSScriptRoot\3.Copy Info to Centre.sql" $Selfcheck="$PSScriptRoot\2.Select_DBName.sql" Invoke-Sqlcmd -ServerInstance $env:COMPUTERNAME -InputFile $IntegrateResult Invoke-Sqlcmd -ServerInstance $env:COMPUTERNAME -InputFile $Selfcheck 4.创建统筹powershell脚本,来按步骤调⽤以上powershell脚本: 脚本名:ExecPs.ps1 $PSScriptRoot = Split-Path -Parent $MyInvocation.MyCommand.Definition powershell.exe "$PSScriptRoot\QueryData.ps1" powershell.exe "$PSScriptRoot\IntegrateResult.ps1" 第⼀次执⾏时,会多⼀个创建数据库和表的步骤: 脚本名:ExecPs_FirstTime.ps1 $PSScriptRoot = Split-Path -Parent $MyInvocation.MyCommand.Definition powershell.exe "$PSScriptRoot\Create_DB&Table.ps1" powershell.exe "$PSScriptRoot\QueryData.ps1" powershell.exe "$PSScriptRoot\IntegrateResult.ps1" 第⼀次执⾏ExecPs_FirstTime.ps1,之后执⾏ExecPs.ps1便可收集信息到中⼼服务器,并且旧数据会保留在每个节点服务器上,中⼼服务器通过判断对最新的数据进⾏收集: 对于其他类似的需求,也可以根据本例进⾏扩展。
如何在Shell脚本中处理命令行参数

如何在Shell脚本中处理命令行参数在Shell脚本中处理命令行参数是一项非常重要的技能,它能够让我们的脚本更加灵活和可配置。
本文将介绍如何在Shell脚本中处理命令行参数,并提供一些常用的技巧和实例。
一、Shell脚本中的命令行参数在Shell脚本中,我们可以通过特殊的变量$1、$2、$3...来获取命令行参数。
其中$0表示脚本本身的名称,$1表示第一个参数,$2表示第二个参数,依此类推。
以下是一个简单的例子,展示了如何在Shell脚本中获取和使用命令行参数:```shell#!/bin/bashecho "脚本名称: $0"echo "第一个参数: $1"echo "第二个参数: $2"```当我们执行该脚本,并传入两个参数时,可以得到如下输出:```shell$ ./script.sh arg1 arg2脚本名称: ./script.sh第一个参数: arg1第二个参数: arg2```二、处理命令行参数的常用技巧1. 判断命令行参数的数量我们可以使用特殊变量$#来获取命令行参数的数量。
下面是一个示例:```shell#!/bin/bashif [ $# -eq 0 ]; thenecho "未提供命令行参数"elif [ $# -eq 1 ]; thenecho "提供了一个命令行参数"elseecho "提供了多个命令行参数"fi```2. 使用循环处理多个命令行参数如果我们需要处理多个命令行参数,可以使用循环来逐个获取和处理它们。
以下是一个示例:```shell#!/bin/bashfor arg in "$@"; doecho "参数: $arg"done```执行该脚本,并传入多个参数时,可以分别打印出每个参数。
3. 使用getopts处理带选项的命令行参数如果我们的脚本需要支持带选项的命令行参数,可以使用getopts命令来解析和处理这些选项。
SQLServer自动化运维系列——批量执行SQL脚本(PowerShell)

SQLServer⾃动化运维系列——批量执⾏SQL脚本(PowerShell)需求描述⼀般在⽣产环境中,在投产的情况下,需要批量的来执⾏SQL脚本⽂件,来完成整个投产,如果投产⽂件⽐较多的情况下,⽆疑这是⼀个⽐较痛苦的过程,所以本篇通过PowerShell脚本来批量完成。
监控脚本<#批量执⾏SQL脚本⽂件#><#===========================================#>$serverInstance="WUXUEL1"$Database="111"#$userName="sa"#$password="password01!"$ScriptPath="C:\powershell\SQLTest\"$ScriptList=""<#===========================================#>$n="`n"$r="`r"While ($ScriptList.IndexOf($n) -gt 0){$ScriptList=$ScriptList.Replace($n,";")}While ($ScriptList.IndexOf($r) -gt 0){$ScriptList=$ScriptList.Replace($r,";")}While ($ScriptList.IndexOf(" ") -gt 0){$ScriptList=$ScriptList.Replace(" ","")}While ($ScriptList.IndexOf(",") -gt 0){$ScriptList=$ScriptList.Replace(",","")}If ($ScriptList.IndexOf(".sql") –le 0){$ScriptList=""[System.IO.DirectoryInfo]$DirectoryInfo=New-Object System.IO.DirectoryInfo $ScriptPath | Sort-Objectforeach( $f In ($DirectoryInfo.GetFiles("*.sql"))){$ScriptList=$ScriptList+";"+$}}Try{[void][System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.ConnectionInfo') |out-null$ServerConnection =new-object mon.ServerConnection #$serverInstance,$userName, $password$ServerConnection.ConnectionString = "Data Source=$serverInstance;Initial Catalog=$Database;Integrated Security=True"try{$ServerConnection.BeginTransaction()Write-Host "BeginTransaction ."[System.Text.StringBuilder]$Sql=""Foreach($File In $ScriptList.Split(";")){if($File-ne ""){Write-Host $ScriptPath$File " ...start"$Sql=$Sql.AppendLine(([System.Io.File]::OpenText($ScriptPath+$File)).ReadToEnd())$ServerConnection.ExecuteNonQuery($Sql)|out-null$Sql=""Write-Host $ScriptPath$File " ...OK!"}}$mitTransaction()Write-Host "CommitTransaction ."}Catch{If ($ServerConnection.TransactionDepth -gt 0){$ServerConnection.RollBackTransaction()Write-Host "RollBackTransaction ."}Write-Error $_}}Catch{Write-Error $_}其中涉及到⼏个参数需要配置:1、批量⽂件的根⽬录路径2、此脚本⽀持两种验证⽅式:⽤户验证 & Windows验证,根据需要⾃⼰确定执⾏完成报告如下:当然,最重要的就是,如果执⾏过程中,某⼀个脚本出错的问题解决,其实只需要标⽰出错误的⽂件名称和错误的信息就可以。
shell 命令参数

Shell命令参数是Shell脚本编程中非常重要的一部分,它们为脚本提供了外部输入和动态行为的能力。
以下是Shell命令参数的详细介绍:1. 位置参数:- $0:脚本名称。
- $1 - $9:脚本的第一到第九个参数。
- $#:传递给脚本的参数个数。
- $*:所有位置参数的单个字符串。
- $@:所有位置参数的单独引用字符串。
2. 特殊参数:- $?:最后一条命令的退出状态。
- $!:最后一个后台命令的进程ID。
3. 环境变量:- $HOME:用户主目录。
- $PATH:执行命令时要搜索的目录列表。
- $PWD:当前工作目录。
- $USER:当前登录的用户名。
4. 逻辑运算符:--a:逻辑与。
--o:逻辑或。
- !:逻辑非。
5. 条件测试命令:- test:用于测试条件。
- [ ]:与test命令功能相同,用于测试条件。
--n:字符串不为空。
--z:字符串为空。
--eq:等于。
--ne:不等于。
--gt:大于。
--lt:小于。
--ge:大于等于。
--le:小于等于。
6. 文件测试命令:--f:测试文件是否存在且为普通文件。
--d:测试文件是否存在且为目录。
--r:测试文件是否存在且可读。
--w:测试文件是否存在且可写。
--x:测试文件是否存在且可执行。
7. 其他测试命令:--t:测试文件描述符是否指向终端。
--s:测试文件大小是否为0。
--c:测试文件是否为字符设备文件。
--b:测试文件是否为块设备文件。
这些参数和测试命令为Shell脚本提供了丰富的功能和灵活性,使得Shell脚本能够根据不同的输入和条件执行不同的操作。
Shell脚本编写的高级技巧使用数据库和SQL进行数据操作

Shell脚本编写的高级技巧使用数据库和SQL进行数据操作Shell脚本是一种在Unix或Linux操作系统中使用的脚本语言,它可以通过输入一系列的命令进行批量处理。
在Shell脚本编写的过程中,使用数据库和SQL进行数据操作的技巧可以大大提升效率和灵活性。
本文将介绍一些Shell脚本编写中使用数据库和SQL的高级技巧,帮助读者更好地进行数据操作。
1. 连接数据库在Shell脚本中连接数据库是进行数据操作的前提,常用的数据库有MySQL、Oracle和PostgreSQL等。
下面是一个连接MySQL数据库的示例代码:```shell#!/bin/bashDB_HOST="localhost"DB_USER="root"DB_PASS="password"mysql -h $DB_HOST -u $DB_USER -p$DB_PASS -e "USEdatabase_name; SQL命令"```2. 执行SQL命令连接数据库后,可以使用`mysql`命令执行SQL命令。
使用`-e`参数可以在命令行中直接输入SQL语句,例如:```shellmysql -h $DB_HOST -u $DB_USER -p$DB_PASS -e "USE database_name; SELECT * FROM table_name;"```需要注意的是,SQL语句中的分号`;`必须用双引号包含起来,以避免Shell解析时将其误认为是命令分隔符。
3. 使用变量构建SQL语句在进行数据操作时,经常需要根据不同的情况构建不同的SQL语句。
使用Shell脚本的变量可以方便地构建动态SQL语句。
```shell#!/bin/bashDB_HOST="localhost"DB_USER="root"DB_PASS="password"DB_NAME="database_name"TABLE_NAME="table_name"my_variable="some_value"sql="SELECT * FROM $DB_NAME.$TABLE_NAME WHERE column_name = '$my_variable';"mysql -h $DB_HOST -u $DB_USER -p$DB_PASS -e "$sql"```在上述示例中,通过使用Shell脚本的变量`my_variable`,可以构建出根据不同值进行查询的SQL语句。
Jenkins工程中SQL语句执行的方法
Jenkins⼯程中SQL语句执⾏的⽅法前⾔⽹上很多jenkins⼯程中基于shell或批处理⽅式调⽤sql⽂件执⾏sql命令的⽅式,⼤部分都是需要基于sql⽂件来完成的,因此在sql语句发⽣变化时需要去jenkins服务端修改对应的sql ⽂件或者通过上传的⽅式进⾏替换,对于多⼈协助相对⽐较⿇烦,为了解决此问题,本⽅法是基于groovy对mysql的操作为基础的SQL语句执⾏。
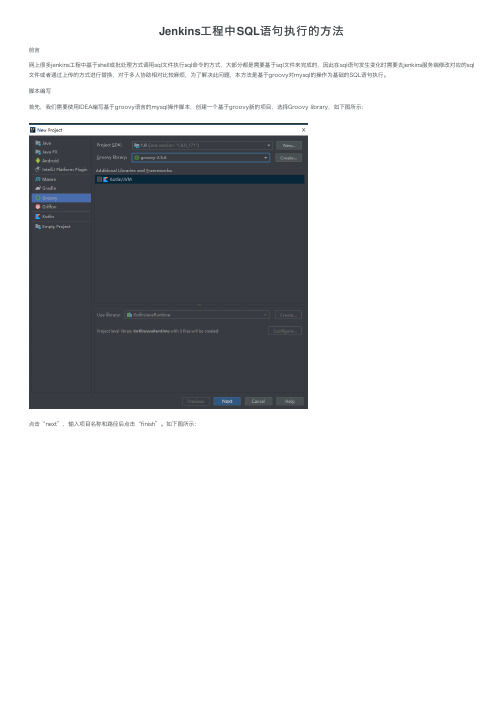
脚本编写⾸先,我们需要使⽤IDEA编写基于groovy语⾔的mysql操作脚本,创建⼀个基于groovy新的项⽬,选择Groovy library,如下图所⽰:点击“next”,输⼊项⽬名称和路径后点击“finish”。
如下图所⽰:在src⽂件夹下新建⼀个groovy script,如下图所⽰:打开新建的groovy script编写mysql操作代码,如下图所⽰:代码:运⾏后提⽰:ng.ClassNotFoundException: com.mysql.jdbc.Driver处理⽅式:下载com.mysql.jdbc_5.1.38.jar放到当前项⽬的⼯作空间中,再次运⾏测试通过。
jenkins中Groovy脚本执⾏⾸先将com.mysql.jdbc_5.1.38.jar复制到jenkins应⽤服务的\jenkins\WEB-INF\lib(tomcat中路径为\webapps\jenkins\WEB-INF\lib)中,重启服务。
在jenkins中添加groovy插件,之后构建⼀个⾃由风格的软件项⽬,在配置的“构建”中添加“Execute system Groovy script”的构建步骤,将IDEA中编写的代码拷贝到其中,如下图所⽰:保存后只需构建即可,执⾏结果如下:查看数据库对应内容已被修改。
此⽅法可以直接通过在配置中修改con.execute("delete from student_copy")内容即可实现对sql语句的维护,更加直观⽅便。
sql注入getshell原理

sql注入getshell原理SQL注入是一种针对数据库应用程序的攻击技术,攻击者通过向应用程序的输入字段中注入恶意的SQL代码,以获取未经授权的访问权限或执行未经授权的操作,甚至可以获取数据库的全部数据或直接控制服务器。
SQL注入攻击的原理是利用了应用程序在构建SQL查询语句时未对用户输入进行充分验证和过滤的漏洞。
当应用程序将用户的输入直接拼接进SQL查询语句中,并且没有进行适当的转义或参数化处理时,攻击者可以通过输入特定的字符来改变原本查询的逻辑,从而获取敏感数据或执行恶意操作。
SQL注入攻击可以分为两类:盲注和报错注入。
1.盲注:在盲注攻击中,攻击者无法直接获取数据库返回的具体信息,攻击者只能根据系统的不同响应来进行猜测和推测。
常见的盲注攻击包括布尔盲注和时间盲注。
-布尔盲注:攻击者通过构造特定的SQL查询语句,利用应用程序的返回结果来进行判断。
比如,攻击者可以通过构造查询语句,判断一些条件是否成立,从而推测出数据库中的数据。
-时间盲注:攻击者利用应用程序对一些查询操作的时间延迟来进行猜测。
例如,攻击者可以构造一个查询语句,通过引入延迟命令来判断是否存在漏洞。
2.报错注入:在报错注入中,攻击者可以利用数据库返回的错误信息来获取有关数据库结构和内容的敏感信息。
攻击者通过注入特定的SQL代码来触发应用程序的错误处理机制,从而获得有关数据库的详细错误信息。
-UNION注入:攻击者通过注入UNION操作,将查询结果合并到原始查询结果中。
通过逐渐增加UNION查询的列数和调整查询语句,攻击者可以获取到数据库的结构和内容。
-堆叠查询注入:攻击者可以在一次请求中构造多条SQL查询语句,从而执行多个查询操作。
攻击者可以通过堆叠查询注入来实现增删改查数据库的操作。
除了以上的注入技术,还有其他一些高级的注入攻击技术,如基于批量提取方式的注入、基于字符编码方式的注入、基于SQL Server的特殊语法注入等。
为了防止SQL注入攻击,开发人员应该始终遵循以下最佳实践:-使用参数化查询或预编译语句:使用参数化查询或预编译语句可以确保用户输入的数据被正确地编码和转义,从而防止恶意SQL代码的注入。
shell mysql 事务回滚写法

在MySQL中,可以使用以下步骤来执行事务回滚:
开启事务:使用START TRANSACTION 语句来开启一个新的事务。
执行SQL 语句:在事务中执行所需的SQL 语句。
判断是否需要回滚:在执行完所有SQL 语句后,使用IF 语句来判断是否需要回滚事务。
如果需要回滚,则执行以下步骤;否则,执行COMMIT 语句来提交事务。
回滚事务:使用ROLLBACK 语句来回滚事务,撤销在事务中所做的所有更改。
下面是一个示例:
START TRANSACTION;
--执行SQL 语句
INSERT INTO table1 (column1, column2) V ALUES ('value1', 'value2');
INSERT INTO table2 (column1, column2) V ALUES ('value3', 'value4');
--判断是否需要回滚
IF condition THEN
ROLLBACK;
ELSE
COMMIT;
END IF;
在上面的示例中,如果condition 为真,则执行ROLLBACK 语句来回滚事务;否则,执行COMMIT 语句来提交事务。