Hadoop入门—Linux下伪分布式计算的安装与wordcount的实例展示
Hadoop环境搭建及wordcount实例运行
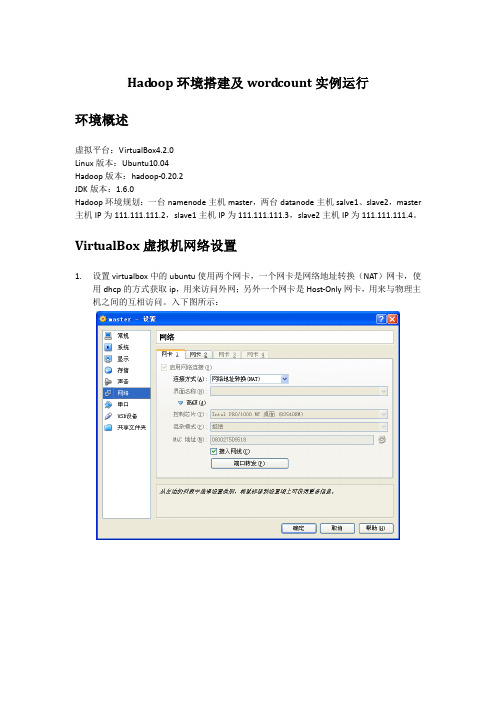
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
Hadoop伪分布式安装

Hadoop伪分布式安装1.安装Hadoop(伪分布式)
上传Hadoop
将hadoop-2.9.2.tar.gz 上传到该目录
解压
ls
将Hadoop添加到环境变量
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出vim
验证环境变量是否正确hadoop version
修改配置文件hadoop-env.sh
保存并退出vim
修改配置文件core-site.xml
保存并退出vim
修改配置文件hdfs-site.xml
</property>
保存并退出vim
格式化HDFS
hdfs namenode -format
格式化成功的话,在/bigdata/data目录下可以看到dfs目录
启动NameNode
启动DataNode
查看NameNode管理界面
在windows使用浏览器访问http://bigdata:50070可以看到HDFS的管理界面
如果看不到,(1)检查windows是否配置了hosts;
位于C:\Windows\System32\drivers\etc\hosts
关闭HDFS的命令
2.配置SSH免密登录生成密钥
回车四次即可生成密钥
复制密钥,实现免密登录
根据提示需要输入“yes”和root用户的密码
新的HDFS启停命令
免密登录做好以后,可以使用start-dfs.sh和stop-dfs.sh命令启停HDFS,不再需要使用hadoop-daemon.sh脚本
stop-dfs.sh
注意:第一次用这个命令可能还是需要输入yes,按提示输入即可。
hadoop集群搭建实训报告

实训项目名称:搭建Hadoop集群项目目标:通过实际操作,学生将能够搭建一个基本的Hadoop集群,理解分布式计算的概念和Hadoop生态系统的基本组件。
项目步骤:1. 准备工作介绍Hadoop和分布式计算的基本概念。
确保学生已经安装了虚拟机或者物理机器,并了解基本的Linux命令。
下载Hadoop二进制文件和相关依赖。
2. 单节点Hadoop安装在一台机器上安装Hadoop,并配置单节点伪分布式模式。
创建Hadoop用户,设置环境变量,编辑Hadoop配置文件。
启动Hadoop服务,检查运行状态。
3. Hadoop集群搭建选择另外两台或更多机器作为集群节点,确保网络互通。
在每个节点上安装Hadoop,并配置集群节点。
编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等。
配置SSH无密码登录,以便节点之间能够相互通信。
4. Hadoop集群启动启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager 等。
检查集群状态,确保所有节点都正常运行。
5. Hadoop分布式文件系统(HDFS)操作使用Hadoop命令行工具上传、下载、删除文件。
查看HDFS文件系统状态和报告。
理解HDFS的数据分布和容错机制。
6. Hadoop MapReduce任务运行编写一个简单的MapReduce程序,用于分析示例数据集。
提交MapReduce作业,观察作业的执行过程和结果。
了解MapReduce的工作原理和任务分配。
7. 数据备份和故障恢复模拟某一节点的故障,观察Hadoop集群如何自动进行数据备份和故障恢复。
8. 性能调优(可选)介绍Hadoop性能调优的基本概念,如调整副本数、调整块大小等。
尝试调整一些性能参数,观察性能改善情况。
9. 报告撰写撰写实训报告,包括项目的目标、步骤、问题解决方法、实验结果和总结。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
hadoop伪分布式 实验报告模板 -回复

hadoop伪分布式实验报告模板-回复什么是Hadoop伪分布式, 以及如何进行实验的报告。
实验报告模板:一、引言(100-200字)在大数据时代,Hadoop作为一个开源的分布式计算框架,被广泛应用于数据处理和分析领域。
Hadoop伪分布式是搭建在单台机器上的分布式环境的模拟实验环境,可以帮助学习者理解和掌握Hadoop的基本概念、架构和操作方法。
本实验报告将详细介绍Hadoop伪分布式的搭建和实验过程,并总结所获得的经验和教训。
二、目的和背景(200-300字)Hadoop伪分布式的实验目的是为了让学习者能够在一台机器上模拟分布式环境,学习和掌握Hadoop的基本操作和流程。
通过这个实验,学习者可以深入了解Hadoop的整体架构,包括HDFS(Hadoop分布式文件系统)和MapReduce计算框架,以及相关的工具和命令。
三、实验环境和工具(200-300字)在本次实验中,我们使用以下工具和环境进行Hadoop伪分布式搭建和实验:1. Hadoop2.10.0:作为分布式计算框架的核心组件,用于数据存储和处理;2. JDK 1.8:用于支持Hadoop的Java编程环境;3. VirtualBox 6.0:用于创建虚拟机环境,模拟分布式部署;4. Ubuntu 18.04 LTS:作为操作系统,提供稳定和可靠的环境;5. SSH工具:用于在虚拟机之间进行远程登录和通信。
四、实验步骤(800-1000字)1. 下载和安装Hadoop:根据Hadoop官方网站上的说明,下载适合的Hadoop版本并进行安装。
解压缩Hadoop安装包,并配置相应的环境变量。
2. 配置SSH无密登录:为了方便虚拟机之间的通信和远程登录,需要进行SSH无密登录的配置。
生成SSH密钥对,并将公钥分发到所有虚拟机中。
3. 配置Hadoop伪分布式:编辑Hadoop的配置文件,主要包括core-site.xml、hdfs-site.xml和mapred-site.xml。
熟悉常用的linux操作和hadoop操作实验报告

熟悉常用的linux操作和hadoop操作实验报告本实验主要涉及两个方面,即Linux操作和Hadoop操作。
在实验过程中,我深入学习了Linux和Hadoop的基本概念和常用操作,并在实际操作中掌握了相关技能。
以下是我的实验报告:一、Linux操作1.基本概念Linux是一种开放源代码的操作系统,它允许用户自由地使用、复制、分发和修改系统。
Linux具有更好的性能、更高的安全性和更好的可定制性。
2.常用命令在Linux操作中,一些常用的命令包括:mkdir:创建目录cd:更改当前目录ls:显示当前目录中的文件cp:复制文件mv:移动文件rm:删除文件pwd:显示当前所在目录chmod:更改文件权限chown:更改文件所有者3.实验操作在实验中,我对Linux的文件系统、文件权限、用户与组等进行了学习和操作。
另外,我还使用Linux命令实现了目录创建、文件复制、删除等操作。
二、Hadoop操作1.基本概念Hadoop是一种开源框架,用于处理大规模数据和分布式计算。
它使用Hadoop分布式文件系统(HDFS)来存储数据,使用MapReduce来处理大规模数据集。
2.常用命令在Hadoop操作中,一些常用的命令包括:hdfs dfs:操作HDFS文件系统hadoop fs:操作Hadoop分布式文件系统hadoop jar:运行Hadoop任务hadoop namenode -format:格式化文件系统start-all.sh:启动所有Hadoop服务3.实验操作在实验中,我熟悉了Hadoop的安装过程、配置过程和基本概念。
我使用Hadoop的命令对文件系统进行操作,如创建、删除、移动文件等。
此外,我还学会了使用MapReduce处理大规模数据集。
总结通过本次实验,我巩固了Linux和Hadoop操作的基本知识和技能。
我深入了解了Linux和Hadoop的基本概念和常用操作,并学会了使用相关命令进行实际操作。
hadoop伪分布式搭建实验报告心得

Hadoop伪分布式搭建实验报告心得一、实验目的1. 掌握Hadoop的基本原理和架构。
2. 学习并实践Hadoop的伪分布式环境的搭建。
3. 熟悉Hadoop的基本操作和管理。
二、实验环境1. 操作系统:CentOS 7.x2. Hadoop版本:2.x3. Java版本:1.8三、实验步骤1. 安装JDK首先需要在服务器上安装Java开发工具包(JDK),可以从Oracle官网下载对应版本的JDK安装包,然后按照提示进行安装。
2. 配置环境变量编辑/etc/profile文件,添加以下内容:```bashexport JAVA_HOME=/usr/local/java/jdk1.8.0_xxxexport PATH=$JAVA_HOME/bin:$PATH```使配置生效:```bashsource /etc/profile```3. 下载并解压Hadoop从Apache官网下载Hadoop的tar包,然后解压到指定目录,例如:/usr/local/hadoop。
4. 配置Hadoop环境变量编辑~/.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP_HOME/bin:$PATH```使配置生效:```bashsource ~/.bashrc```5. 配置Hadoop的核心配置文件复制一份hadoop-env.sh.template文件到hadoop-env.sh,并修改其中的JAVA_HOME 为实际的JDK路径。
编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```6. 格式化HDFS文件系统在Hadoop安装目录下执行以下命令:```bashhadoop namenode -format```7. 启动Hadoop集群执行以下命令启动Hadoop集群:```bashstart-all.sh```8. 验证Hadoop集群状态执行以下命令查看Hadoop集群状态:```bashjps | grep Hadoop```如果看到NameNode、SecondaryNameNode、DataNode等进程,说明Hadoop集群已经成功启动。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Linux系统下Hadoop运行环境搭建

Linux系统下Hadoop运⾏环境搭建1.安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost2.卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看3.安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls新建⼀个app⽂件夹,命令:mkdir app将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/libexport PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version4.安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
物联网数据处理实验指导书

《物联网数据处理》实验指导书实验一:熟悉常用的Linux操作(2学时)一、实验目的与要求1、熟悉安装和配置Linux。
2、熟悉常用的Linux操作。
6、总结在调试过程中的错误。
二、实验类型验证型三、实验原理及说明通过实际操作,使学生对Linux的使用有一个更深刻的理解;熟悉Linux的开发环境及程序结构。
四、实验仪器安装操作系统:Linux五、实验内容和步骤熟悉常用的Linux操作请按要求上机实践如下linux基本命令。
cd命令:切换目录(1)切换到目录/usr/local(2)去到目前的上层目录(3)回到自己的主文件夹ls命令:查看文件与目录(4)查看目录/usr下所有的文件mkdir命令:新建新目录(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在(6)创建目录a1/a2/a3/a4rmdir命令:删除空的目录(7)将上例创建的目录a(/tmp下面)删除(8)删除目录a1/a2/a3/a4,查看有多少目录存在cp命令:复制文件或目录(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1(10)在/tmp下新建目录test,再复制这个目录内容到/usrmv命令:移动文件与目录,或更名(11)将上例文件bashrc1移动到目录/usr/test(12)将上例test目录重命名为test2rm命令:移除文件或目录(13)将上例复制的bashrc1文件删除(14)rm -rf 将上例的test2目录删除cat命令:查看文件内容(15)查看主文件夹下的.bashrc文件内容tac命令:反向列示(16)反向查看主文件夹下.bashrc文件内容more命令:一页一页翻动查看(17)翻页查看主文件夹下.bashrc文件内容head命令:取出前面几行(18)查看主文件夹下.bashrc文件内容前20行(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行tail命令:取出后面几行(20)查看主文件夹下.bashrc文件内容最后20行(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据touch命令:修改文件时间或创建新文件(22)在/tmp下创建一个空文件hello并查看时间(23)修改hello文件,将日期调整为5天前chown命令:修改文件所有者权限(24)将hello文件所有者改为root帐号,并查看属性find命令:文件查找(25)找出主文件夹下文件名为.bashrc的文件tar命令:压缩命令tar -zcvf /tmp/etc.tar.gz /etc(26)在/目录下新建文件夹test,然后在/目录下打包成test.tar.gz(27)解压缩到/tmp目录tar -zxvf /tmp/etc.tar.gzgrep命令:查找字符串(28)从~/.bashrc文件中查找字符串'examples'(29)配置Java环境变量,在~/.bashrc中设置(30)查看JA V A_HOME变量的值六、注意事项命令的名称。
hadoop伪分布式安装实验总结

hadoop伪分布式安装实验总结
1. 确保系统满足要求:在开始安装之前,确保系统满足Hadoop的最低要求,包括适当的操作系统版本、Java环境和相关的依赖项。
确保在安装过程中没有缺少任何必要的软件包或依赖项。
2. 下载和安装Hadoop:从官方网站下载Hadoop的稳定版本。
解压缩下载的文件,并将其放置在适当的位置。
设置相应的环境变量,以便系统能够识别Hadoop的安装路径。
3. 配置Hadoop:编辑Hadoop配置文件,主要包括core-site.xml、hdfs-site.xml和mapred-site.xml。
在这些文件中,指定Hadoop集群的相关配置,如HDFS的名称节点、数据节点、日志目录的位置以及其他必要的属性。
4. 格式化HDFS:在启动Hadoop之前,需要对HDFS进行初始化。
使用命令hdfs namenode -format初始化名称节点。
这一步会清空HDFS上的所有数据,所以请确保在使用时备份重要数据。
5. 启动Hadoop:使用start-all.sh脚本启动Hadoop服务。
该脚本会启动HDFS和MapReduce 服务。
在启动过程中,系统会显示Hadoop的日志输出,如果有任何错误或警告信息,请注意排查并解决。
6. 测试安装:使用hadoop fs -ls命令来验证HDFS是否运行正常。
该命令应该列出HDFS 上的文件和目录列表。
您还可以运行简单的MapReduce任务来验证MapReduce服务的运行情况。
Hadoop大数据平台安装实验(详细步骤)(虚拟机linux)

大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。
(完整版)Hadoop安装教程_伪分布式配置_CentOS6.4_Hadoop2.6.0

Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0都能顺利在CentOS 中安装并运行Hadoop。
环境本教程使用CentOS 6.4 32位作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS)。
如果用的是Ubuntu 系统,请查看相应的Ubuntu安装Hadoop教程。
本教程基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1, Hadoop 2.4.1等。
Hadoop版本Hadoop 有两个主要版本,Hadoop 1.x.y 和Hadoop 2.x.y 系列,比较老的教材上用的可能是0.20 这样的版本。
Hadoop 2.x 版本在不断更新,本教程均可适用。
如果需安装0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
新版是兼容旧版的,书上旧版本的代码应该能够正常运行(我自己没验证,欢迎验证反馈)。
装好了CentOS 系统之后,在安装Hadoop 前还需要做一些必备工作。
创建hadoop用户如果你安装CentOS 的时候不是用的“hadoop” 用户,那么需要增加一个名为hadoop 的用户。
首先点击左上角的“应用程序” -> “系统工具” -> “终端”,首先在终端中输入su,按回车,输入root 密码以root 用户登录,接着执行命令创建新用户hadoop:如下图所示,这条命令创建了可以登陆的hadoop 用户,并使用/bin/bash 作为shell。
CentOS创建hadoop用户接着使用如下命令修改密码,按提示输入两次密码,可简单的设为“hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:如下图,找到root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:为hadoop增加sudo权限添加上一行内容后,先按一下键盘上的ESC键,然后输入:wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
hadoop基本架构及系统安装和程序开发实验报告

hadoop基本架构及系统安装和程序开发实验报告实验报告:Hadoop基本架构及系统安装和程序开发一、实验目的本实验旨在帮助学习者掌握Hadoop的基本架构、系统安装及程序开发。
通过实际操作,使学习者能够深入理解Hadoop的工作原理,并掌握其在大数据处理中的应用。
二、实验内容1. Hadoop基本架构:了解Hadoop的分布式存储系统HDFS和计算框架MapReduce的基本原理;熟悉YARN的资源管理和调度功能。
2. Hadoop系统安装:在本地计算机上安装Hadoop,配置环境变量,并测试Hadoop集群的连通性。
3. Hadoop程序开发:编写简单的MapReduce程序,实现对文本数据的处理;学习使用Hive和HBase等工具进行数据存储和查询。
三、实验步骤1. 准备环境:确保本地计算机安装了Java开发环境,并配置好相应的环境变量。
2. 下载Hadoop:从Apache官网下载Hadoop的稳定版本,并解压到本地计算机。
3. 配置Hadoop:编辑Hadoop的配置文件,设置相关参数,如HDFS的块大小、端口号等。
4. 安装与配置:将Hadoop安装目录添加到系统的环境变量中,并配置网络设置,以确保Hadoop集群中的节点可以相互通信。
5. 启动与测试:启动Hadoop集群,包括NameNode、DataNode、ResourceManager和NodeManager等节点。
使用命令行工具测试集群的连通性。
6. 编写MapReduce程序:编写一个简单的MapReduce程序,实现对文本数据的处理。
例如,统计文本中每个单词的出现次数。
学习使用Hadoop 的API进行程序开发。
7. 使用Hive和HBase:学习使用Hive进行数据仓库的构建和查询;了解HBase的基本原理和使用方法,实现对结构化数据的存储和查询。
四、实验总结通过本次实验,学习者对Hadoop的基本架构、系统安装和程序开发有了较为深入的了解和实践经验。
实验6:Mapreduce实例——WordCount

实验6:Mapreduce实例——WordCount实验⽬的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会⾃⼰编写WordCount程序进⾏词频统计实验原理MapReduce采⽤的是“分⽽治之”的思想,把对⼤规模数据集的操作,分发给⼀个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
简单来说,MapReduce就是”任务的分解与结果的汇总“。
1.MapReduce的⼯作原理在分布式计算中,MapReduce框架负责处理了并⾏编程⾥分布式存储、⼯作调度,负载均衡、容错处理以及⽹络通信等复杂问题,现在我们把处理过程⾼度抽象为Map与Reduce两个部分来进⾏阐述,其中Map部分负责把任务分解成多个⼦任务,Reduce部分负责把分解后多个⼦任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map⽅法。
通过在map⽅法中添加两句把key值和value值输出到控制台的代码,可以发现map⽅法中输⼊的value值存储的是⽂本⽂件中的⼀⾏(以回车符为⾏结束标记),⽽输⼊的key值存储的是该⾏的⾸字母相对于⽂本⽂件的⾸地址的偏移量。
然后⽤StringTokenizer类将每⼀⾏拆分成为⼀个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map⽅法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce⽅法。
Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输⼊到reduce⽅法中,reduce⽅法只要遍历values并求和,即可得到某个单词的总次数。
伪分布的实验报告

一、实验名称伪分布式实验二、实验目的1. 了解伪分布式Hadoop的基本原理和架构;2. 掌握Hadoop伪分布式环境的搭建步骤;3. 熟悉Hadoop伪分布式环境下HDFS和YARN的基本操作。
三、实验原理伪分布式Hadoop是一种简化版的分布式计算环境,它将所有的Hadoop服务(如HDFS、YARN、MapReduce等)运行在一个单台机器上。
在这种环境下,可以方便地研究Hadoop的分布式存储和计算机制,而不需要购买和维护多台服务器。
伪分布式Hadoop主要由以下几个组件组成:1. Hadoop分布式文件系统(HDFS):负责存储海量数据;2. Yet Another Resource Negotiator(YARN):负责资源管理和任务调度;3. MapReduce:Hadoop的并行计算框架。
四、实验环境1. 操作系统:Linux;2. Java开发环境:JDK 1.8;3. Hadoop版本:Hadoop 3.3.4。
五、实验步骤1. 安装Java开发环境(1)下载JDK 1.8安装包;(2)解压安装包至指定目录;(3)配置环境变量,使Java命令可以在任意位置执行。
2. 安装Hadoop(1)下载Hadoop 3.3.4安装包;(2)解压安装包至指定目录;(3)配置Hadoop环境变量,使Hadoop命令可以在任意位置执行;(4)配置Hadoop配置文件。
3. 配置Hadoop配置文件(1)编辑`hadoop-env.sh`文件,设置JDK路径;(2)编辑`core-site.xml`文件,配置HDFS的存储路径;(3)编辑`hdfs-site.xml`文件,配置HDFS副本数量等参数;(4)编辑`mapred-site.xml`文件,配置MapReduce相关参数;(5)编辑`yarn-site.xml`文件,配置YARN相关参数。
4. 格式化HDFS在Hadoop命令行中执行以下命令:```hdfs dfs -format```5. 启动Hadoop服务在Hadoop命令行中执行以下命令:```start-dfs.shstart-yarn.sh```6. 验证Hadoop服务在浏览器中访问`http://localhost:50070`,查看HDFS的Web界面;在浏览器中访问`http://localhost:8088`,查看YARN的Web界面。
Hadoop大数据开发基础教案Hadoop教案MapReduce入门编程教案

Hadoop大数据开发基础教案Hadoop教案MapReduce入门编程教案第一章:Hadoop概述1.1 Hadoop简介了解Hadoop的发展历程理解Hadoop的核心价值观:可靠性、可扩展性、容错性1.2 Hadoop生态系统掌握Hadoop的主要组件:HDFS、MapReduce、YARN理解Hadoop生态系统中的其他重要组件:HBase、Hive、Pig等1.3 Hadoop安装与配置掌握Hadoop单机模式安装与配置掌握Hadoop伪分布式模式安装与配置第二章:HDFS文件系统2.1 HDFS简介理解HDFS的设计理念:大数据存储、高可靠、高吞吐掌握HDFS的基本架构:NameNode、DataNode2.2 HDFS操作命令掌握HDFS的基本操作命令:mkdir、put、get、dfsadmin等2.3 HDFS客户端编程掌握HDFS客户端API:Configuration、FileSystem、Path等第三章:MapReduce编程模型3.1 MapReduce简介理解MapReduce的设计理念:将大数据处理分解为简单的任务进行分布式计算掌握MapReduce的基本概念:Map、Shuffle、Reduce3.2 MapReduce编程步骤掌握MapReduce编程的四大步骤:编写Map函数、编写Reduce函数、设置输入输出格式、设置其他参数3.3 典型MapReduce应用掌握WordCount案例的编写与运行掌握其他典型MapReduce应用:排序、求和、最大值等第四章:YARN资源管理器4.1 YARN简介理解YARN的设计理念:高效、灵活、可扩展的资源管理掌握YARN的基本概念:ResourceManager、NodeManager、ApplicationMaster等4.2 YARN运行流程掌握YARN的运行流程:ApplicationMaster申请资源、ResourceManager 分配资源、NodeManager执行任务4.3 YARN案例实战掌握使用YARN运行WordCount案例掌握YARN调优参数设置第五章:Hadoop生态系统扩展5.1 HBase数据库理解HBase的设计理念:分布式、可扩展、高可靠的大数据存储掌握HBase的基本概念:表结构、Region、Zookeeper等5.2 Hive数据仓库理解Hive的设计理念:将SQL查询转换为MapReduce任务进行分布式计算掌握Hive的基本操作:建表、查询、数据导入导出等5.3 Pig脚本语言理解Pig的设计理念:简化MapReduce编程的复杂度掌握Pig的基本语法:LOAD、FOREACH、STORE等第六章:Hadoop生态系统工具6.1 Hadoop命令行工具掌握Hadoop命令行工具的使用:hdfs dfs, yarn命令等理解命令行工具在Hadoop生态系统中的作用6.2 Hadoop Web界面熟悉Hadoop各个组件的Web界面:NameNode, JobTracker, ResourceManager等理解Web界面在Hadoop生态系统中的作用6.3 Hadoop生态系统其他工具掌握Hadoop生态系统中的其他工具:Azkaban, Sqoop, Flume等理解这些工具在Hadoop生态系统中的作用第七章:MapReduce高级编程7.1 二次排序理解二次排序的概念和应用场景掌握MapReduce实现二次排序的编程方法7.2 数据去重理解数据去重的重要性掌握MapReduce实现数据去重的编程方法7.3 自定义分区理解自定义分区的概念和应用场景掌握MapReduce实现自定义分区的编程方法第八章:Hadoop性能优化8.1 Hadoop性能调优概述理解Hadoop性能调优的重要性掌握Hadoop性能调优的基本方法8.2 HDFS性能优化掌握HDFS性能优化的方法:数据块大小,副本系数等8.3 MapReduce性能优化掌握MapReduce性能优化的方法:JVM设置,Shuffle优化等第九章:Hadoop实战案例9.1 数据分析案例掌握使用Hadoop进行数据分析的实战案例理解案例中涉及的技术和解决问题的方法9.2 数据处理案例掌握使用Hadoop进行数据处理的实战案例理解案例中涉及的技术和解决问题的方法9.3 数据挖掘案例掌握使用Hadoop进行数据挖掘的实战案例理解案例中涉及的技术和解决问题的方法第十章:Hadoop项目实战10.1 Hadoop项目实战概述理解Hadoop项目实战的意义掌握Hadoop项目实战的基本流程10.2 Hadoop项目实战案例掌握一个完整的Hadoop项目实战案例理解案例中涉及的技术和解决问题的方法展望Hadoop在未来的发展和应用前景重点和难点解析重点环节1:Hadoop的设计理念和核心价值观需要重点关注Hadoop的设计理念和核心价值观,因为这是理解Hadoop生态系统的基础。
简述hadoop伪分布式环境搭建流程

Hadoop是一个能够处理大规模数据的分布式系统框架,它能够在集裙中运行并管理大量的数据。
在学习和使用Hadoop时,搭建一个伪分布式环境是非常有必要的。
伪分布式环境搭建流程如下:1. 准备环境在开始搭建Hadoop伪分布式环境之前,首先需要安装并配置好Java 环境。
Hadoop是基于Java开发的,所以Java环境是必不可少的。
2. 下载Hadoop首先在官全球信息站下载Hadoop的最新版本,然后解压到指定的目录。
解压后的目录就是Hadoop的安装目录。
3. 配置Hadoop环境变量在解压得到的Hadoop安装目录中,找到etc/hadoop目录,这是Hadoop的配置文件目录。
在该目录下,打开hadoop-env.sh文件,设置JAVA_HOME变量为你的Java安装路径。
4. 配置Hadoop的核心文件在etc/hadoop目录下,打开core-site.xml文件,设置Hadoop的核心配置信息。
包括Hadoop的基本参数、HDFS的URL位置区域等。
5. 配置Hadoop的HDFS文件系统同样在etc/hadoop目录下,打开hdfs-site.xml文件,设置Hadoop的HDFS配置信息。
包括数据的存储路径、副本数量等。
6. 配置Hadoop的MapReduce框架在etc/hadoop目录下,打开mapred-site.xml.template文件,设置Hadoop的MapReduce配置信息。
包括MapReduce框架的工作目录、框架的框架数据存储路径等。
7. 配置Hadoop的主节点和从节点在etc/hadoop目录下,打开slaves文件,配置Hadoop的主节点和从节点信息。
可以设置本地主机为主节点,也可以配置其他从节点的IP位置区域。
8. 格式化HDFS在命令行中输入命令:hdfs namenode -format,即可格式化HDFS 文件系统。
这一步是为了清空HDFS文件系统中的旧数据,重新初始化HDFS。
Hadoop之WordCount详解

Hadoop之WordCount详解花了好长时间查找资料理解、学习、总结这应该是⼀篇⽐较全⾯的MapReduce之WordCount⽂章了耐⼼看下去1,创建本地⽂件在hadoop-2.6.0⽂件夹下创建⼀个⽂件夹data,在其中创建⼀个text⽂件mkdir datacd datavi hello再在当前⽂件夹中创建⼀个apps⽂件夹,⽅便后续传jar包mkdir apps将⽂本⽂件传到HDFS的根⽬录下bin/hdfs dfs -put data/hello /2,程序打jar包并上传到apps⽬录3,执⾏Hadoop命令bin/hadoop jar apps/WordClass-***.jar /hello /out4,查看输出结果将HDFS根⽬录下的/out输出⽂件传到本地⽬录中查看,通常有两个⽂件:5,WordCount程序详解这部分是最重要的,但是也是最容易让⼈犯晕的部分,涉及到许多mapreduce的原理,但是学习就是这样,你越难吃透的东西,通常越重要先把程序贴上来:package cn.hx.test;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountApp {//⾃定义的mapper,继承org.apache.hadoop.mapreduce.Mapperpublic static class MyMapper extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable>{@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)throws IOException, InterruptedException {String line = value.toString();//split 函数是⽤于按指定字符(串)或正则去分割某个字符串,结果以字符串数组形式返回,这⾥按照"\t"来分割text⽂件中字符,即⼀个制表符,这就是为什么我在⽂本中⽤了空格分割,导致最后的结果有很⼤的出⼊。
《大数据技术》Hadoop安装和HDFS常见的操作实验报告二

《大数据技术》Hadoop安装和HDFS常见的操作实验报告
三、实验过程与结论:(经调试正确的源程序(核心部分)和程序的运行结果)
1.熟悉常用的Hadoop操作
(1)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/usr/local/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/hadoop”
(2)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表
(3)将Linux系统本地的“~/.bashrc”文件上传到HDFS的test文件夹中,并查看test
(4)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下
2. 编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
3.编程实现一个类“MyFSDataInputStream”
四、实验总结:(实验中遇到的问题及解决方法,心得体会等)
通过课程的学习我知道了人类社会的数据产生方式经历3个阶段:(1)运营式系统阶段
(2)用户原创内容阶段
(3)感知式系统阶段
大数据的四个特点:
(1)数据量大(2)数量种类繁多(3)处理速度快(4)价值密度低。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
开始研究一下开源项目hadoop,因为根据本人和业界的一些分析,海量数据的分布式并行处理是趋势,咱不能太落后,虽然开始有点晚,呵呵。
首先就是安装和一个入门的小实例的讲解,这个恐怕是我们搞软件开发的,最常见也最有效率地入门一个新鲜玩意的方式了,废话不多说开始吧。
本人是在ubuntu下进行实验的,java和ssh安装就不在这里讲了,这两个是必须要安装的,好了我们进入主题安装hadoop:
1.下载hadoop-0.20.1.tar.gz:
/dyn/closer.cgi/hadoop/common/
解压:$ tar –zvxf hadoop-0.20.1.tar.gz
把Hadoop 的安装路径添加到环/etc/profile 中:
export HADOOP_HOME=/home/hexianghui/hadoop-0.20.1
export PATH=$HADOOP_HOME/bin:$PATH
2.配置hadoop
hadoop 的主要配置都在hadoop-0.20.1/conf 下。
(1)在conf/hadoop-env.sh 中配置Java 环境(namenode 与datanode 的配置相同):
$ gedit hadoop-env.sh
$ export JAVA_HOME=/home/hexianghui/jdk1.6.0_14
3.3)配置conf/core-site.xml, conf/hdfs-site.xml 及conf/mapred-site.xml(简单配置,datanode 的配置相同)
core-site.xml:
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yangchao/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name></name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:( replication 默认为3,如果不修改,datanode 少于三台就会报错)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
4.运行hadoop
首先进入hadoop所在目录,执行格式化文件系统bin/hadoop namenode –format 启动hadoop: bin/start-all.sh
用jps命令查看进程,显示:
yangchao@yangchao-VirtualBox:~/Downloads/hadoop-0.20.203.0/test-in$ jp s
5238 TaskTracker
4995 SecondaryNameNode
4836 DataNode
4687 NameNode
5077 JobTracker
7462 Jps
既是正常的,接下来要上传数据到文件系统里
还有就是使用web 接口。
访问http://localhost:50030 可以查看JobTracker 的运行状态。
访问http://localhost:50060 可以查看TaskTracker 的运行状态。
访问http://localhost:50070 可以查看NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log 等。
5.运行wordcount.java
在hadoop所在目录里有几个jar文件,其中hadoop-examples-0.20.203.0.jar就是我们需要的,它里面含有wordcount,咱们使用命令建立测试的文件
(1)先在本地磁盘建立两个输入文件file01 和file02:
$ echo “Hello World Bye World” > file01
$ e cho “Hello Hadoop Goodbye Hadoop” > file02
(2)在hdfs 中建立一个input 目录:$ hadoop fs –mkdir input
(3)将file01 和file02 拷贝到hdfs 中:
$ hadoop fs –copyFromLocal /home/hexianghui/soft/file0* input
(4)执行wordcount:
$ hadoop jar hadoop-0.20.1-examples.jar wordcount input output
(5)完成之后,查看结果:
$ hadoop fs -cat output/part-r-00000
结果为:
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
是不是很神奇的玩意呢,这是在单机上实现hadoop的应用小实例,以后有机会再来一篇真正的分布式的,前提是需要三台机器,哎离开了学校没有实验室确实不好弄了。