在windows下安装hadoop
windows配置hadoop环境变量

windows配置hadoop环境变量1.⾸先需要下载 hadoop的tar.gz包,⽬前最新版本是2.9.0 下载地址:⽂件共享在最下⾯/releases.html前提是JDK必须配置成功我的hadoop是在如图解压在E盘下解压完之后⼤概是2G多需要⼀点时间啊2.修改etc\hadoop下的⽂件(注意以下配置⽂件下所有的地址都是从Linux集群中的hadoop jar粘贴复制过来的) 4个配置⽂件core-site.xml<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-2.8.0/tmp</value> //linux集群中的地址</property></configuration>mapred-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.address</name><value>master:19888</value></property></configuration>hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name>node.secondary.http-address</name><value>master:50090</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>.dir</name><value>file:/usr/local/hadoop-2.8.0/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop-2.8.0/hdfs/data</value></property></configuration>yarn-site.xml<?xml version="1.0"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property></configuration>3.配置环境变量此电脑--属性--⾼级系统设置--环境变量新建系统变量变量名:HADOOP_HOME变量值:你的hadoop位置 E:\hadoop\hadoop-2.8.0\hadoop-2.8.0编辑Path系统路径 %HADOOP_HOME%\bin然后⼀路确定下来4.编辑hadoop的⽂件如下打开 \etc\hadoop\hadoop-enc.cmd⽂件,修改JAVA_HOME为你⾃⼰的jdk路径。
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
Win10系统安装Hadoop与Hbase

目录1. 前言 (2)2. 准备工作 (2)2.1. 下载Hadoop (2)2.2. 下载hadoop-common (3)2.3. 下载Hbase (3)2.4. 下载JDK (4)3. 环境配置 (4)3.1. 将下载好的3个压缩包分别解压缩 (4)3.2. 覆盖文件 (6)3.3. 安装JDK (7)3.3.1. 配置JAVA环境变量 (8)3.3.2. 测试JDK安装是否成功 (11)4. 配置Hadoop (11)4.1. hadoop-env.cmd (12)4.2. core-site.xml (13)4.3. hdfs-site.xml (14)4.4. 创建mapred-site.xml (15)4.5. yarn-site.xml (18)5. 启动Hadoop (20)5.1. 以管理员身份运行CMD命令提示符 (20)5.2. 切换到hadoop目录 (21)5.3. 运行hadoop-env.cmd脚本 (21)5.4. 格式化HDFS文件系统 (21)5.5. 启动HDFS (22)5.6. 遇到异常 (23)5.6.1. 解决方案 (23)5.7. 停止Hadoop (25)6. 配置Hbase (26)6.1. 编辑hbase-site.xml (26)6.2. 编辑hbase-env.cmd (27)7. 启动Hbase (28)8. Hbase Shell (31)8.1. 用shell连接HBase (31)8.2. 使用shell (31)8.2.1. 创建表 (31)8.2.2. Scan表 (32)8.2.3. Get一行 (33)8.2.4. 删除表 (33)8.2.5. 关闭shell (34)8.2.6. 停止Hbase (34)9. Java API Hbase (35)1.前言工作需要,现在开始做大数据开发了,通过下面的配置步骤,你可以在win10系统中,部署出一套hadoop+hbase,便于单机测试调试开发。
hadoop搭建与eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――罗利辉1.前言1.1 目标目的很简单,为进行研究与学习,部署一个hadoop运行环境,并搭建一个hadoop开发与测试环境。
具体目标是:✓在ubuntu系统上部署hadoop✓在windows 上能够使用eclipse连接ubuntu系统上部署的hadoop进行开发与测试1.2 软硬件要求注意:Hadoop版本和Eclipse版本请严格按照要求。
现在的hadoop最新版本是hadoop-0.20.203,我在windows上使用eclipse(包括3.6版本和3.3.2版本)连接ubuntu上的hadoop-0.20.203环境一直没有成功。
但是开发测试程序是没有问题的,不过需要注意权限问题。
如果要减少权限问题的发生,可以这样做:ubuntu上运行hadoop的用户与windows 上的用户一样。
1.3 环境拓扑图ubuntu 192.168.69.231ubuntu2192.168.69.233 ubuntu1192.168.69.2322.Ubuntu 安装安装ubuntu11.04 server系统,具体略。
我是先在虚拟机上安装一个操作系统,然后把hadoop也安装配置好了,再克隆二份,然后把主机名与IP修改,再进行主机之间的SSH配置。
如果仅作为hadoop的运行与开发环境,不需要安装太多的系统与网络服务,或者在需要的时候通过apt-get install进行安装。
不过SSH服务是必须的。
3.Hadoop 安装以下的hadoop安装以主机ubuntu下进行安装为例。
3.1 下载安装jdk1.6安装版本是:jdk-6u26-linux-i586.bin,我把它安装拷贝到:/opt/jdk1.6.0_263.2 下载解压hadoop安装包是:hadoop-0.20.2.tar.gz。
3.3 修改系统环境配置文件切换为根用户。
●修改地址解析文件/etc/hosts,加入3.4 修改hadoop的配置文件切换为hadoop用户。
hadoop安装配置指南

Hadoop安装、配置指南一、环境1、软件版本Hadoop:hadoop-0.20.2.Hive:hive-0.5.0JDK:jdk1.6以上版本2、配置的机器:主机[服务器master]:192.168.10.121 hadoop13从机[服务器slaves]:192.168.10.68 hadoop4在本文中,在命令或二、先决条件1、配置host:打开/etc/host文件,添加如下映射192.168.10.121 hadoop13 hadoop13192.168.10.68 hadoop4 hadoop42、配置SSH自动登陆1)以ROOT用户,登陆到[服务器master]上执行,如下操作:ssh-keygen -t rsa //一路回车cd ~/.sshcat id_rsa.pub >> authorized_keysscp -r ~/.ssh [服务器slaves]:~/2)以ROOT用户,登陆到[服务器slaves]上执行,如下操作:scp -r ~/.ssh [服务器master]:~/3)测试SSH是否配置成功在主服务器中执行如下命令:ssh [服务器master]ssh 192.168.10.68成功显示结果:Last login: Thu Aug 26 14:11:27 2010 from 在从服务器中执行如下命令:ssh [服务器slaves]ssh 192.168.10.121成功显示结果Last login: Thu Aug 26 18:23:58 2010 from 三、安装hadoop1、JDK安装,解压到/usr/local/jdk1.6.0_17,并配置/etc/profile环境export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarJDK路径:/usr/local/jdk/jdk1.7.0export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar/usr/local/jdk/jdk1.7.02、下载Hadoop 并解压到[服务器master]的/root/zwmhadoop目录下tar zxvf hadoop-0.20.2.tar.gz四、配置hadoop1.配置主机[服务器master]到zwm hadoop/hadoop-0.20.2/ hadoop 目录下,修改以下文件:1)配置conf/hadoop-env.sh文件,在文件中添加环境变量,增加以下内容:export JAVA_HOME=/usr/local/jdk1.6.0_17export HADOOP_HOME=/root/zwmhadoop/hadoop-0.20.2/2)配置conf/core-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://192.168.10.121:9000</value>//你的namenode的配置,机器名加端口<description>The nam e of the default file system. Either the literal string "local" o r a host:port for DFS.</description></property></configuration>3)配置conf/hdfs-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.t m p.dir</name><value>/root/zwmhadoop/t m p</value>//Hadoop的默认临时路径,这个最好配置,然后在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的t mp目录即可。
Hadoop大数据平台安装实验(详细步骤)(虚拟机linux)

大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。
《大数据技术原理与操作应用》第3章习题答案

第三章单选题1、下列选项中,若是哪个节点关闭了,就无法访问Hadoop集群()。
•A、namenode•B、datanode•C、secondary namenode•D、yarn参考答案:A答案解析:暂无解析2、下列说法中,关于客户端从HDFS中读取数据的说法错误的是()。
•A、客户端会选取排序靠前的DataNode来依次读取Block块•B、客户端会把最终读取出来所有的Block块合并成一个完整的最终文件•C、客户端会选取排序靠后的DataNode来依读取Block块•D、如果客户端本身就是DataNode,那么将从本地直接获取数据参考答案:C答案解析:暂无解析3、下列选项中,用于检验数据完整性的信息的是()。
•A、心跳机制•B、ACK机制•C、选举机制•D、垃圾回收机制参考答案:B答案解析:暂无解析4、下列选项中,关于HDFS说法错误的是()。
•A、HDFS是Hadoop的核心之一•B、HDFS源于Google的GFS论文•C、HDFS用于存储海量大数据•D、HDFS是用于计算海量大数据参考答案:D答案解析:暂无解析5、下列选项中,用于存放部署Hadoop集群服务器的是()。
•A、namenode•B、datanode•C、rack•D、metadata参考答案:C答案解析:Rack是用来存放部署Hadoop集群服务器的机架。
6、下列选项中,用于删除HDFS上文件夹的方法是()。
•A、delete()•B、rename()•C、mkdirs()•D、copyToLocalFile()参考答案:A答案解析:FileSystem对象调用delete()方法可以删除文件夹,delete()方法接收两个参数,第一个参数表示要删除的文件夹路径,第二个参数用于设置是否递归删除目录。
7、下列选项中,关于HDFS的架构说法正确的是()。
•A、HDFS采用的是主备架构•B、HDFS采用的是主从架构•C、HDFS采用的是从备架构•D、以上说法均错误参考答案:B答案解析:HDFS采用主从架构(Master/Slave架构)。
Hadoop开发环境搭建(Win8 + Eclipse + Linux)

Hadoop开发环境搭建(Win8+Linux)常见的Hadoop开发环境架构有以下三种:1、Eclipse与Hadoop集群在同一台Windows机器上。
2、Eclipse与Hadoop集群在同一台Linux机器上。
3、Eclipse在Windows上,Hadoop集群在远程Linux机器上。
点评:第一种架构:必须安装cygwin,Hadoop对Windows的支持有限,在Windows 上部署hadoop会出现相当多诡异的问题。
第二种架构:Hadoop机器运行在Linux上完全没有问题,但是有大部分的开发者不习惯在Linux上做开发。
这种架构适合习惯使用Linux的开发者。
第三种架构:Hadoop集群部署在Linux上,保证了稳定性,Eclipse在Windows 上,符合大部分开发者的习惯。
本文主要介绍第三种Hadoop开发环境架构的搭建方法。
Hadoop开发环境的搭建分为两大块:Hadoop集群搭建、Eclipse环境搭建。
其中Hadoop集群搭建可参考官方文档,本文主要讲解Eclipse环境搭建(如何在Eclipse 中查看和操作HDFS、如何在Eclipse中执行MapReduce作业)。
搭建步骤:1、搭建Hadoop集群(Linux、JDK6、Hadoop-1.1.2)2、在Windows上安装JDK6+3、在Windows上安装Eclipse3.3+4、在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件(如果没有,则需自行编译源码)5、在Eclipse上配置Map/Reduce Location搭建Hadoop集群此步骤可参考Hadoop官方文档在Windows上安装JDK此步骤可参考官方文档在Window上安装Eclipse此步骤可参考官方文档在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件Hadoop-1.1.2的发布包里面没有hadoop-eclipse-plugin-1.1.2.jar,开发者必须根据所在的环境自行编译hadoop-eclipse-plugin-1.1.2.jar插件。
Windows平台上安装Hadoop-0.20.203.0版本方法

Windows平台上安装Hadoop-0.20.203.0版本方法 目的这篇文档的目的旨在说明在Windows平台上、利用Cygwin模拟Linux环境下,完成单机上Hadoop-0.20.203.0版的安装与使用。
同时也旨在解决你在安装hadoop过程中出现JA V A_HOME is not set或是bin/java No such file or directory错误的问题。
先决条件1支持平台。
Win32平台是作为开发平台支持的。
由于分布式操作尚未在Win32平台上充分测试,所以还不作为一个生产平台被支持。
2所需软件2.1Java TM1.6.x,必须安装且版本要为1.6及以上,建议选择Sun公司发行的Java版本。
2.2Cygwin,提供Shell支持。
本文使用最新版1.7.x,要选择安装Openssh、Openssl等。
2.3Hadoop-0.20.203.0 最新的稳定版。
安装支持软件1安装Java安装下载的Java 1.6.x,使用jdk-6u27-windows-i586.exe安装,安装路径比如为:C:\Java\jdk1.6.0_27。
安装完成后,配置环境变量如下:设置JA V A_HOME变量值为:C:\Java\jdk1.6.0_27设置CLASSPATH 变量值为:.;%JA V A_HOME%\lib\dt.jar;%JA V A_HOME%\lib\tools.jar向path变量中添加路径,添加%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin2安装Cygwin安装Cygwin,可以从官网上下载最新的cygwin1.7.9-1进行安装。
本人把下载的setup.exe 放在C:\Cygwin-localPackage文件夹中,该文件用于存储安装选项网络下载的源文件,双击setup.exe进行安装。
安装流程如下:图1 图2注:图2 中选择install from internet图3 图4注:图3确定安装路径如C:\cygwin;图4选择下载文件存放的路径如C:\Cygwin-localPackage图5 图6图6 选择下载安装文件的站点,本文选择默认的第一个站点。
hadoop安装指南(非常详细,包成功)

➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
使用idea在windows上连接远程hadoop开发

使⽤idea在windows上连接远程hadoop开发⼀.前置环境准备1.下载⼀份hadoop本地解压,配置HADOOP_HOME的环境变量idea运⾏时会读这个环境变量然后找到他⾥⾯的bin⽂件,其实不需要启动只要有bin这个⽬录就⾏,不然会报错找不到HADOOP_HOME这个环境变量2.bin⾥⾯缺少了winutils.exe和hadoop.dll 需要额外下载也可以不下载hadoop直接下载这个bin把环境变量配置成这个bin的上⼀级⽬录3.将hadoop.dll 复制到C:\Windows\System32中否则会报 Exception in thread"main"ng.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z⼆.构建项⽬ 1.导⼊jar<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>3.1.0</version></dependency>2.拷贝源码中WordCount.java 位置在 hadoop-3.1.0-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-jobclient\src\test\java\org\apache\hadoop\mapred⽬录中我这个稍有改动/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** /licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/import java.io.IOException;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.Mapper;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reducer;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/*** This is an example Hadoop Map/Reduce application.* It reads the text input files, breaks each line into words* and counts them. The output is a locally sorted list of words and the* count of how often they occurred.** To run: bin/hadoop jar build/hadoop-examples.jar wordcount* [-m <i>maps</i>] [-r <i>reduces</i>] <i>in-dir</i> <i>out-dir</i>*/public class WordCount extends Configured implements Tool {/*** Counts the words in each line.* For each line of input, break the line into words and emit them as* (<b>word</b>, <b>1</b>).*/public static class MapClass extends MapReduceBaseimplements Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value,OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {String line = value.toString();StringTokenizer itr = new StringTokenizer(line," \t\n\r\f,.:;?![]'");while (itr.hasMoreTokens()) {word.set(itr.nextToken().toLowerCase());output.collect(word, one);}}}/*** A reducer class that just emits the sum of the input values.*/public static class Reduce extends MapReduceBaseimplements Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterator<IntWritable> values,OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {int sum = 0;while (values.hasNext()) {sum += values.next().get();}if(sum>4){output.collect(key, new IntWritable(sum));}}}static int printUsage() {System.out.println("wordcount [-m <maps>] [-r <reduces>] <input> <output>"); ToolRunner.printGenericCommandUsage(System.out);return -1;}/*** The main driver for word count map/reduce program.* Invoke this method to submit the map/reduce job.* @throws IOException When there is communication problems with the* job tracker.*/public int run(String[] args) throws Exception {JobConf conf = new JobConf(getConf(), WordCount.class);conf.setJobName("wordcount");// the keys are words (strings)conf.setOutputKeyClass(Text.class);// the values are counts (ints)conf.setOutputValueClass(IntWritable.class);conf.setMapperClass(MapClass.class);conf.setCombinerClass(Reduce.class);conf.setReducerClass(Reduce.class);List<String> other_args = new ArrayList<String>();for(int i=0; i < args.length; ++i) {try {if ("-m".equals(args[i])) {conf.setNumMapTasks(Integer.parseInt(args[++i]));} else if ("-r".equals(args[i])) {conf.setNumReduceTasks(Integer.parseInt(args[++i]));} else {other_args.add(args[i]);}} catch (NumberFormatException except) {System.out.println("ERROR: Integer expected instead of " + args[i]);return printUsage();} catch (ArrayIndexOutOfBoundsException except) {System.out.println("ERROR: Required parameter missing from " +args[i-1]);return printUsage();}}// Make sure there are exactly 2 parameters left.if (other_args.size() != 2) {System.out.println("ERROR: Wrong number of parameters: " +other_args.size() + " instead of 2.");return printUsage();}FileInputFormat.setInputPaths(conf, other_args.get(0));FileOutputFormat.setOutputPath(conf, new Path(other_args.get(1)));JobClient.runJob(conf);return 0;}public static void main(String[] args) throws Exception {int res = ToolRunner.run(new Configuration(), new WordCount(), new String[]{"D:\\my.txt","D:\\out"});System.exit(res);}}运⾏可能会报权限不⾜的问题,编辑服务器etc/hadoop/hdfs-site.xml 将 dfs.permissions修改为false 重启即可<property><name>dfs.permissions</name><value>false</value></property>好啦现在运⾏控制台没有任何报错去D盘看看D盘已经⽣成了out⽂件夹打开out 发现⾥⾯有四个⽂件⽐服务器本地执⾏多了两个.crc⽂件我们先看看part-00000已经出来统计结果了。
Hadoop完全分布式详细安装过程
Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
Hadoop集群搭建详细简明教程

Linux 操作系统安装
利用 vmware 安装 Linux 虚拟机,选择 CentOS 操作系统
搭建机器配置说明
本人机器是 thinkpadt410,i7 处理器,8G 内存,虚拟机配置为 2G 内存,大家可以 按照自己的机器做相应调整,但虚拟机内存至少要求 1G。
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图: 选择“软驱”,点击“remove”移除软驱:
选择光驱,选择 CentOS ISO 镜像,如下图: 最后点击“Close”,回到“硬件配置页面”,点击“Finsh”即可,如下图: 下图为创建all or upgrade an existing system”
执行 java –version 命令 会出现上图的现象。 从网站上下载 jdk1.6 包( jdk-6u21-linux-x64-rpm.bin )上传到虚拟机上 修改权限:chmod u+x jdk-6u21-linux-x64-rpm.bin 解压并安装: ./jdk-6u21-linux-x64-rpm.bin (默认安装在/usr/java 中) 配置环境变量:vi /etc/profile 在该 profile 文件中最后添加:
选择“Skip”跳过,如下图:
选择“English”,next,如下图: 键盘选择默认,next,如下图:
选择默认,next,如下图:
输入主机名称,选择“CongfigureNetwork” 网络配置,如下图:
选中 system eth0 网卡,点击 edit,如下图:
选择网卡开机自动连接,其他不用配置(默认采用 DHCP 的方式获取 IP 地址), 点击“Apply”,如下图:
Windows 下配置 Eclipse 连接 Hadoop 开发环境
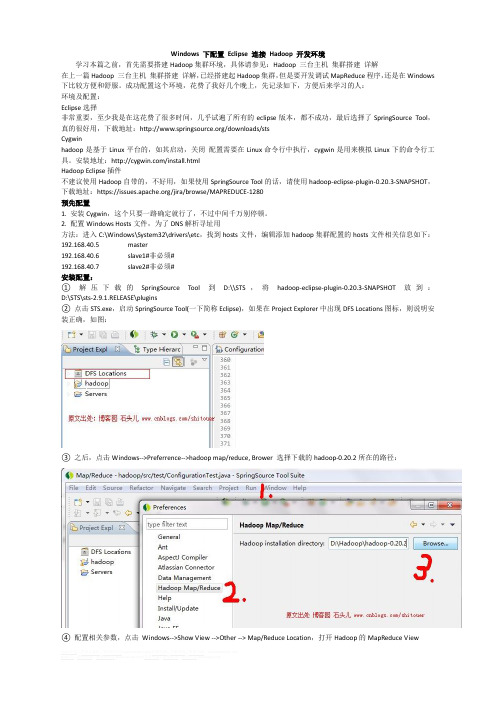
Windows 下配置Eclipse 连接Hadoop 开发环境学习本篇之前,首先需要搭建Hadoop集群环境,具体请参见:Hadoop 三台主机集群搭建详解在上一篇Hadoop 三台主机集群搭建详解,已经搭建起Hadoop集群,但是要开发调试MapReduce程序,还是在Windows 下比较方便和舒服。
成功配置这个环境,花费了我好几个晚上,先记录如下,方便后来学习的人:环境及配置:Eclipse选择非常重要,至少我是在这花费了很多时间,几乎试遍了所有的eclipse版本,都不成功,最后选择了SpringSource Tool,真的很好用,下载地址:/downloads/stsCygwinhadoop是基于Linux平台的,如其启动,关闭配置需要在Linux命令行中执行,cygwin是用来模拟Linux下的命令行工具。
安装地址:/install.htmlHadoop Eclipse插件不建议使用Hadoop自带的,不好用,如果使用SpringSource Tool的话,请使用hadoop-eclipse-plugin-0.20.3-SNAPSHOT,下载地址:https:///jira/browse/MAPREDUCE-1280预先配置1. 安装Cygwin,这个只要一路确定就行了,不过中间千万别停顿。
2. 配置Windows Hosts文件,为了DNS解析寻址用方法:进入C:\Windows\System32\drivers\etc,找到hosts文件,编辑添加hadoop集群配置的hosts文件相关信息如下:192.168.40.5master192.168.40.6slave1#非必须#192.168.40.7slave2#非必须#安装配置:①解压下载的SpringSource Tool到D:\\STS,将hadoop-eclipse-plugin-0.20.3-SNAPSHOT放到:D:\STS\sts-2.9.1.RELEASE\plugins②点击STS.exe,启动SpringSource Tool(一下简称Eclipse),如果在Project Explorer中出现DFS Locations图标,则说明安装正确,如图:③之后,点击Windows-->Preferrence-->hadoop map/reduce, Brower 选择下载的hadoop-0.20.2所在的路径:④配置相关参数,点击Windows-->Show View -->Other --> Map/Reduce Location,打开Hadoop的MapReduce View点击Ok之后,出现如下图⑤上一步你不应该看到hadoopLoc, 应该什么都没有,右键点击空白处-->New Hadoop Location, 你会看到一个填写MapReduce Location参数的一个界面:其中:Location Name:这个不用在意,就是对这个MapReduce的标示,只要能帮你记忆即可Map/Reduce Master 部分相关定义:Host:上一节搭建的集群中JobTracker所在的机器的IP地址port:JobTracker的端口两个参数就是mapred-site.xml中mapred.job.tracker的ip和端口DFS Master部分:Host:就是上一节集群搭建中Namenode所在机器IPPort:就是namenode的端口这两个参数是在core-site.xml里里面的ip和端口User Name:就是搭建Hadoop集群是所用的用户名,我这里用的是root⑥填写完以上信息以后,关闭Eclipse,然后重新启动。
windows下搭建hadoop开发环境(Eclipse)

public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one);
} } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } 5.2 配置运行参数 Run As -> Open Run Dialog... 选择 WordCount 程序,在 Arguments 中配置运行参数:
Hadoop,HBase,hive安装步骤

Hadoop,ZooKeeper,HBase,hive(HQL) 安装步骤Hadoop安装:首先我们统一一下定义,在这里所提到的Hadoop是指Hadoop Common,主要提供DFS(分布式文件存储)与Map/Reduce的核心功能。
Hadoop在windows下还未经过很好的测试,所以推荐大家在linux(cent os 6.X)下安装使用。
准备安装Hadoop集群之前我们得先检验系统是否安装了如下的必备软件:ssh和Jdk1.6(因为Hadoop需要使用到Jdk中的编译工具,所以一般不直接使用Jre)。
可以使用yum install rsync来安装rsync。
一般来说ssh是默认安装到系统中的。
Jdk1.6的安装方法下载linux版本的java,#mkdir /usr/java#cd /usr/java#chmod a+x jdk-6u27-linux-i586.bin#./jdk-6u27-linux-i586.bin安装完成后,设臵环境变量:在etc/profile中设臵#export JAVA_HOME=/usr/java/jdk1.6.0_27#exportCLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOM E/lib/tools.jar#export PATH=$PATH:$JAVA_HOME/bin设臵完成后,使用reboot或者source /etc/profile确保以上准备工作完了之后我们就开始安装Hadoop软件,假设我们用三台机器做Hadoop集群,分别是:192.168.0.141、192.168.0.142和192.168.0.143(下文简称141,142和143),且都使用root用户。
这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。
Host配臵一个很简单的测试办法就是ping一下主机名,比如在ww-1上ping ww-2,如果能ping通就OK!若不能正确解析,可以修改/etc/hosts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode机器的IP地址。
Windows10安装Hadoop2.10的过程总结

Windows10安装Hadoop2.10的过程总结 1. 配置JAVA_HOME环境和Hadoop环境: 2. 配置bin 3. 进⼊Hadoop中/etc/hadoop下 配置hdfs-site.xml增加:<property><!-- 单节点,所以配置成1 --><name>dfs.replication</name><value>1</value></property><!-- 指定Hadoop辅助名称节点主机配置,即:2NN配置 --><property><name>node.secondary.http-address</name><value>localhost:50090</value></property><!-- 配置前台访问页⾯ --><property><name>node.http.address</name><value>slave1:50070</value></property> 配置core-site.xml⽂件:<property><name>fs.defaultFS</name><value>hdfs://node1:9820</value></property><property><name>hadoop.tmp.dir</name><value>/I:/BigData</value></property> 4. 配置hadoop-env.cmd 的JAVA_HOME环境变量:set JAVA_HOME=E:\Java\Java8 5. 运⾏命令: hdfs namenode -format 运⾏没报错即可-------------------------报错---------------------------------------------------1. 运⾏ hdfs namenode -format 报错,异常:格式化失败,将此⽂件放到bin下2. 报错org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z将hadoop.dll放到java的bin⽬录下即可到此这篇关于Windows 10 安装 Hadoop 2.10的⽂章就介绍到这了,更多相关Windows 10 安装 Hadoop 内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章,希望⼤家以后多多⽀持!。
Hadoop分布式详细安装步骤

Hadoop分布式详细安装步骤版本:0.20.2准备工作:由于Hadoop要求所有主机上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
二台机器上是这样的:都有一个coole的帐户,主目录是/home/coole两台机器(内存应在512以上,否则可能会出现计算极度缓慢的情况):一台机器名:master IP:211.87.239.181一台机器名:slave IP:211.87.239.182每台都建coole用户如果是ubuntu,为了便于用coole帐号修改系统设置和访问系统文件,推荐把coole也设为sudoers(有root 权限的用户),具体做法是用已有的sudoer登录系统,执行sudo visudo –f /etc/sudoers,并在此文件中添加以下一行:mapred ALL=(ALL) ALL一、更改主机名:1、修改/etc/sysconfig/networkNETWORKING=yesHOSTNAME=yourname (在这修改hostname,把yourname换成你想用的名字)NISDOMAIN=修改后机器211.87.239.181中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=master修改后机器211.87.239.182中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=slave2、最后在终端下执行:# hostname ***** (*****为修改后的hostname,即你想用的名字)例如#hostname master特别提示:各处修改的名字要保持一致,否则会出现问题。
3、修改每台机器的/etc/hosts,保证每台机器间都可以通过机器名解析配置etc/hosts文件,以root 身份打开/etc/hosts文件。
Master/slave做同样修改。
hadoop安装实验总结

hadoop安装实验总结Hadoop安装实验总结一、引言Hadoop是一个开源的分布式计算平台,用于存储和处理大规模数据集。
在本次实验中,我们将介绍Hadoop的安装过程,并总结一些注意事项和常见问题的解决方法。
二、安装过程1. 确定操作系统的兼容性:Hadoop支持多种操作系统,包括Linux、Windows等。
在安装之前,我们需要确认所使用的操作系统版本与Hadoop的兼容性。
2. 下载Hadoop软件包:我们可以从Hadoop的官方网站或镜像站点上下载最新的稳定版本的Hadoop软件包。
确保选择与操作系统相对应的软件包。
3. 解压缩软件包:将下载的Hadoop软件包解压缩到指定的目录下。
可以使用命令行工具或图形界面工具进行解压缩操作。
4. 配置环境变量:为了方便使用Hadoop命令行工具,我们需要配置环境变量。
在Linux系统中,可以编辑.bashrc文件,在其中添加Hadoop的安装路径。
在Windows系统中,可以通过系统属性中的环境变量设置来配置。
5. 配置Hadoop集群:在Hadoop的安装目录下,找到conf文件夹,并编辑其中的配置文件。
主要包括core-site.xml、hdfs-site.xml 和mapred-site.xml等。
根据实际需求,配置Hadoop的相关参数,如文件系统路径、副本数量、任务调度等。
6. 格式化文件系统:在启动Hadoop之前,需要先格式化文件系统。
使用命令行工具进入Hadoop的安装目录下的bin文件夹,并执行格式化命令:hadoop namenode -format。
7. 启动Hadoop集群:在命令行工具中输入启动命令:start-all.sh(Linux)或start-all.cmd(Windows)。
Hadoop集群将会启动并显示相应的日志信息。
8. 验证Hadoop集群:在启动Hadoop集群后,我们可以通过访问Hadoop的Web界面来验证集群的运行状态。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在windows下通过安装cygwin模拟linux环境,然后再安装hadoop,是一种简单方便的方式。
首先是搭建cygwin环境:一、安装cygwin二、安装sshd服务三、启动sshd服务四、配置ssh无密码登录一、此处无话可说,按照网上的文档,选择必要的组件即可。
二、1 以管理员身份运行cygwin2 输入:ssh-host-config有关键的两步:*** Query: Do you want to use a different name? (yes/no)选择yes*** Query: Create new privileged user account 'cyg_server'? (yes/no) 选择yes创建的用户名最好为新的用户名,密码最好与windows用户的密码一致三、在开始菜单运ervices.msc或其他手段进入服务列表,找到cygwin sshd服务,查看属性是否为上一步的用户名登陆的,否则更改之。
此时可能不能启动,需要在计算机右击“管理”,用户和组的管理中将上面的用户加入管理员的组,即授予管理员权限。
四、此时使用ssh服务,即输入:ssh localhost会要求输入密码,若显示为“last login:......”则说明已经正确安装ssh服务并且可以启动。
接下来是配置ssh的无密码登陆:1输入:ssh-keygen (一直回车,一般是三次回车)2 输入:cd ~/.ssh3 输入:cp id_rsa.pub authorized_keys此时输入exit退出cygwin,再次以管理员身份进入cygwin,输入ssh localhost,若没有要求输入密码便显示“last login.....”则说明成功了。
接下来是安装Hadoop:一、安装JDK二、下载hadoop及配置hadoop环境三、格式化namenode四、启动hadoop一、安装jdk只有一点要注意,路径中一定不要包含空格,最好就是字母和数字,否则后面可能会报错。
二、下载的后缀为tar.gz按照下图组织文件目录:HadoopCygwin目录位于d盘的programme目录下,将下载的hadoop置于deploy下,再解压即可得到以上目录。
下面是配置hadoop环境:1、配置hadoop-env.sh2、配置core-site.xml3、配置hdfs-site.xml4、配置mapred-site.xml上述文件都在hadoop-0.20.2下的conf目录下1.配置JDK的安装路径# The java implementation to use. Required.export JAVA_HOME=/cygdrive/d/programme/jdk/jdk1.6注意:一定要有cygdrive,然后是你的jdk在windows下的路径,不能有空格的。
2.为方便修改,拷贝hadoop-0.20.2\src\core\core-default.xml到conf目录下,并命名为core-site.xml(1)修改临时文件存放路径<property><name>hadoop.tmp.dir</name><value>/cygdrive/d/programme/HadoopCygwin/sysdata/0.20.2/tmp</value><description>A base for other temporary directories.</description></property>(2)修改文件系统的默认名称<property><name></name><value>hdfs://127.0.0.1:8888</value>注意,此处的8888是你电脑上未使用的端口号即可,下同。
<description>The name of the default file system. A URI whosescheme and authority determine the FileSystem implementation. Theuri's scheme determines the config property (fs.SCHEME.impl) namingthe FileSystem implementation class. The uri's authority is used todetermine the host, port, etc. for a filesystem.</description></property>3为方便修改,拷贝hadoop-0.20.2\src\hdfs\hdfs-default.xml到conf目录,并命名为hdfs-site.xml。
(1)修改DFS文件系统namenode存放name表的目录<property><name>.dir</name><value>/cygdrive/d/programme/HadoopCygwin/sysdata/0.20.2/name</value><description>Determines where on the local filesystem the DFS name nodeshould store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of thedirectories, for redundancy. </description></property>(2)修改DFS文件系统datanode存放数据的目录<property><name>dfs.data.dir</name><value>/cygdrive/d/programme/HadoopCygwin/sysdata/0.20.2/data</value><description>Determines where on the local filesystem an DFS data nodeshould store its blocks. If this is a comma-delimitedlist of directories, then data will be stored in all nameddirectories, typically on different devices.Directories that do not exist are ignored.</description></property>(3)修改数据存放副本数量为1(因为我们要部署的是伪分布式单节点)<property><name>dfs.replication</name><value>1</value><description>Default block replication.The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.</description></property>4.为方便修改,拷贝hadoop-0.20.2\src\mapred\mapred-default.xml文件到conf目录下,并重命名为mapred-site.xml。
(1)修改jobtracker运行的服务器和端口<property><name>mapred.job.tracker</name><value>hdfs://127.0.0.1:9999</value>注意:这里可以为:127.0.0.1:9999,若不行则加上hdfs<description>The host and port that the MapReduce job tracker runsat. If "local", then jobs are run in-process as a single mapand reduce task.</description></property>(2)修改mepreduce运行存放的即时数据文件目录<property><name>mapred.local.dir</name><value>/cygdrive/d/programme/HadoopCygwin/sysdata/0.20.2/temp</value><description>The local directory where MapReduce stores intermediatedata files. May be a comma-separated list ofdirectories on different devices in order to spread disk i/o.Directories that do not exist are ignored.</description></property>(3)修改Mapreduce存放临时文件的目录<property><name>mapred.child.tmp</name><value>/cygdrive/d/programme/HadoopCygwin/sysdata/0.20.2/temp</value><description> To set the value of tmp directory for map and reduce tasks.If the value is an absolute path, it is directly assigned. Otherwise, it is prepended with task's working directory. The java tasks are executed withoption -Djava.io.tmpdir='the absolute path of the tmp dir'. Pipes andstreaming are set with environment variable,TMPDIR='the absolute path of the tmp dir'</description></property>三、格式化namenode在hadoop的bin目录下输入:./hadoop namenode -format四、启动hadoop在hadoop的bin目录下输入:./start-all.sh若看到并且输入:./hadoop fs -ls /若看到则表明安装成功。