基于嵌入式Linux多线程聊天系统的设计与实现
课程设计(论文)基于linux嵌入式的聊天室系统设计

专业方向课程设计任务书(嵌入式方向)题目: 基于linux嵌入式的聊天室系统设计初始条件:1. 软帝嵌入式ARM9开发教学设备;2. PC机及相关应用软件;要求完成的主要任务:1. 了解TCP方面socket编程。
2. 实现客户端与服务器端的聊天功能。
3. 撰写课程设计说明书。
4. 课程设计说明书要求:引言、设计要求、系统结构、原理设计、各个模块的设计与实现、软件设计、调试过程、体会及总结、参考文献、源程序。
说明书使用A4纸打印或手写。
指导教师签名:年月日摘要本系统建立在嵌入式系统网络平台上,系统的设计使用了面向对象技术和面向对象的设计原则。
系统采用C/S与B/S结合的结构,客户端与客户端以及客户端与服务器端之间通过Socket传送消息。
使用嵌入式C++语言编写,开发工具采用linux下的Qt环境。
服务器设计与实现过程中,采用了多线程技术,可以在单个程序当中同时运行多个不同的线程,执行不同的任务。
大大增强了程序对服务器资源的利用。
在Linux下编写并调试服务器端程序和客户端程序,实现了客户、服务器之间的连接和通信。
关键字:Linux ;Qt;TCP/IP;多人聊天目录目录............................................................................................................................................. 3第一章总体方案设计 ................................................................................................................. 41.1 系统实现原理 ............................................................................................................ 41.2. 总体方案设计............................................................................................................. 41.2.1 服务器流程图.................................................................................................. 51.2.2 客户端流程图.................................................................................................. 6第二章软件功能实现 ................................................................................................................. 7............................................................................................................................................. 7网络套接字(socket).............................................................................................. 7C/S结构 ........................................................................................ 错误!未定义书签。
嵌入式linux开发课程设计

嵌入式linux开发课程设计一、课程目标知识目标:1. 理解嵌入式Linux系统的基本概念、原理和架构。
2. 掌握嵌入式Linux开发环境的搭建与使用。
3. 学习嵌入式Linux内核配置、编译与移植方法。
4. 掌握常见的嵌入式Linux设备驱动编程技术。
技能目标:1. 能够独立搭建嵌入式Linux开发环境。
2. 熟练运用Makefile、交叉编译工具链进行代码编译。
3. 能够编写简单的嵌入式Linux设备驱动程序。
4. 学会分析并解决嵌入式Linux开发过程中的常见问题。
情感态度价值观目标:1. 培养学生对嵌入式系统开发的兴趣,提高学习积极性。
2. 培养学生的团队协作意识,增强沟通与表达能力。
3. 培养学生勇于克服困难,面对挑战的精神。
分析课程性质、学生特点和教学要求:本课程为高年级专业课程,要求学生具备一定的C语言基础和计算机硬件知识。
课程性质为理论与实践相结合,注重培养学生的实际动手能力。
针对学生特点,课程目标设定了明确的知识点和技能要求,旨在使学生能够掌握嵌入式Linux开发的基本方法,为后续项目实践和职业发展奠定基础。
课程目标分解为具体学习成果:1. 学生能够阐述嵌入式Linux系统的基本概念、原理和架构。
2. 学生能够自主搭建嵌入式Linux开发环境,并进行简单的程序编译与运行。
3. 学生能够编写简单的嵌入式Linux设备驱动程序,并实现相应的功能。
4. 学生能够针对嵌入式Linux开发过程中遇到的问题,提出合理的解决方案,并进行实际操作。
二、教学内容1. 嵌入式Linux系统概述- 嵌入式系统基本概念- 嵌入式Linux的发展历程- 嵌入式Linux系统的特点与优势2. 嵌入式Linux开发环境搭建- 交叉编译工具链的安装与配置- 嵌入式Linux文件系统制作- 常用开发工具的使用(如Makefile、GDB)3. 嵌入式Linux内核与驱动- 内核配置与编译- 内核移植方法- 常见设备驱动编程(如字符设备、块设备、网络设备)4. 实践项目与案例分析- 简单嵌入式Linux程序编写与运行- 设备驱动程序编写与调试- 分析并解决实际问题(如系统性能优化、故障排查)教学内容安排与进度:1. 嵌入式Linux系统概述(2课时)2. 嵌入式Linux开发环境搭建(4课时)3. 嵌入式Linux内核与驱动(6课时)4. 实践项目与案例分析(8课时)本教学内容基于课程目标,结合教材章节内容,注重理论与实践相结合,旨在培养学生的实际动手能力和解决问题的能力。
linux基于线程通信技术聊天室的设计与实现 -回复

linux基于线程通信技术聊天室的设计与实现-回复Linux基于线程通信技术聊天室的设计与实现聊天室是一种常见的在线交流工具,它允许用户在不同地点之间进行实时对话。
为了实现一个基于线程通信技术的Linux聊天室,我们可以选择使用已有的进程间通信(IPC)机制中的一种,例如共享内存或消息队列。
本文将一步一步回答有关该主题的问题,为您介绍如何设计并实现一个Linux聊天室。
第一步:确定需求和设计目标在开始设计之前,我们需要明确聊天室的需求和设计目标。
在这里,我们希望实现一个具有以下特点的聊天室:1. 实时通信:聊天室应该能够在用户之间进行实时的消息传递。
2. 多用户支持:聊天室应该允许多个用户同时登录和交谈。
3. 可扩展性:聊天室应该可以轻松地添加更多的用户和功能,以适应不同的需求。
4. 兼容性:聊天室应该支持Linux操作系统,并能够在不同的平台上运行。
第二步:选择合适的线程通信技术在设计线程通信聊天室时,我们可以选择使用多种IPC机制,如共享内存、消息队列、命名管道等。
根据聊天室的设计目标,我们可以选择使用共享内存和消息队列来实现聊天室的通信功能。
共享内存允许多个进程访问同一块内存区域,从而实现数据的共享。
通过在内存中创建一个共享缓冲区,我们可以在其中存储消息数据,并通过读写指针来实现消息的传递。
每个用户可以通过从共享内存中读取数据来接收其他用户发送的消息,并可以通过写入数据到共享内存来发送自己的消息。
消息队列是另一种常用的IPC机制,它可以实现进程之间的异步通信。
通过创建一个消息队列,每个用户可以将自己的消息发送到队列中,并从队列中接收其他用户发送的消息。
这种方式比共享内存更灵活,可以轻松地实现多用户的消息传递。
在这里,我们可以选择使用共享内存来存储聊天室的消息数据,并使用消息队列来处理消息的传递。
第三步:设计线程通信聊天室的架构在设计聊天室的架构时,我们需要考虑以下几个方面:1. 服务器:设计一个服务器线程,用于接收和处理用户的连接请求,并将消息分发给其他在线用户。
基于ARM的嵌入式LINUX系统中GUI的研究和实现

文 章 编 号 :0 3—15 (0 6)5— 0 3—0 10 2 1 20 0 0 2 4
基 于 A M 的嵌 入 式 L N R I UX 系统 中 GU 的研 究 和 实现 I
张兴财, 康 , 杨 崔 向
( 阳理工大学 信息科学与工程分院 , 沈 辽宁 沈阳 106 ) 118
所示 . 术角度 讲, 现有 的 G I U 系统都存 在一定 的缺 陷, 构 如 图 l
Mco no s i Wi w 平台原来是面向 P r d c环境的, 于系 对 统资源的要求 较高, 尽管经剪裁后可 以适 应对于 静态空问的要求 , 但对动态空 间的要求依然很难 ,
A I 程接 口 P 编
2 自主开发 G I U 系统
消息驱动下形成整体 , 构成系统. 在分析和设计 的 过程中, 采用 O A O D进行分析设计 , O/O 形成一个
移植性好 、 易于扩展和重定义的系统结 嵌入式 G I U 的总体设计思想是 : 所有操作 由 层次清楚 、 嵌入式 G I U 的整体框架和体 系结构如 图 2所 对象和消息驱动, 通过对现有 G I U 的分析 , 多种 构. 对
嵌 入 式 GUI 设 备抽 象层
系 统 硬 件
垒 星
图 形 显示 设
l
垒 星
输 入 设 备
其功能受 到极 大削弱 ; tE bde Q/ m edd平 台尽管
较为成熟, 但真正在商 品化产 品中使 用时会面临 很高的授权费用 , 无形 中增加 了产品的成本 , 使得
1 基于嵌入式 Ln x的 G I系统 底 iu U 层 实现 基 础
一
个能够 移植 到多种硬 件平 台上 的嵌 入式
linux基于线程通信技术聊天室的设计与实现 -回复

linux基于线程通信技术聊天室的设计与实现-回复Linux基于线程通信技术聊天室的设计与实现1. 引言(100字)在当今互联网时代,聊天室成为人们分享信息和交流思想的重要工具。
本文将介绍如何利用Linux中的线程通信技术实现一个基于线程通信的聊天室。
2. 设计与实现概述(200字)为了实现基于线程通信的聊天室,我们需要使用Linux中的线程库和进程间通信机制。
我们将设计一个多线程的服务器端和多线程的客户端,服务器端用于接收和处理客户端的请求,客户端用于向服务器发送消息和接收其他客户端的消息。
3. 服务器端设计与实现(500字)服务器端首先需要创建一个主线程,用于监听与接收客户端的连接请求。
一旦有客户端连接请求到达,主线程将创建一个新的工作线程,处理该客户端的请求。
在服务器端,我们可以使用线程锁和条件变量等线程同步机制,防止多个线程并发访问共享资源,实现线程间的安全通信。
我们可以创建一个线程池,用于管理工作线程,当有新的连接请求到达时,从线程池中获取一个空闲的线程进行处理。
我们使用线程锁来保护线程池中线程的访问,确保在某一时刻只有一个线程可以获取到线程资源。
为了实现服务器与客户端的实时通信,我们可以使用Linux中的socket 编程接口。
服务器将创建一个socket,绑定到特定的IP地址和端口上,然后开始监听来自客户端的连接请求。
一旦有连接请求到达,服务器将接受该连接并创建一个新的线程来处理客户端请求。
服务器通过socket接口读取客户端发来的消息,再将消息广播给其他连接到服务器的客户端。
4. 客户端设计与实现(500字)客户端需要创建一个连接到服务器端的socket,并提供用户界面用于发送和接收消息。
客户端主线程需要同时处理用户输入和服务器发来的消息。
客户端需要使用线程同步机制,确保在用户输入消息时,不会和服务器发来的消息产生竞争。
我们可以使用互斥锁来保护消息队列,当用户输入消息时,需要先获取互斥锁以确保消息队列的一致性。
多人聊天系统的设计与实现

多人聊天系统的设计与实现1.系统设计:a.客户端设计:客户端需要有用户界面用于用户输入和显示聊天内容。
用户界面应该支持多人聊天,因此可以设计为一个聊天室的形式,让用户能够选择加入不同的聊天室。
客户端还需要处理消息的发送和接收,并将接收到的消息显示在用户界面上。
b.服务器设计:服务器用于协调客户端之间的通信。
服务器需要根据客户端的请求,将消息发送给指定的客户端。
服务器还需要管理聊天室的创建和销毁,以及处理用户的连接和断开。
2.系统实现:a. 客户端实现:客户端可以使用常见的编程语言(如Python、Java、C++等)进行实现。
客户端需要使用套接字(socket)进行与服务器的通信,并实现发送和接收消息的功能。
客户端还需要设计用户界面以便于用户进行输入和显示聊天内容。
b.服务器实现:服务器也可以使用常见的编程语言进行实现。
服务器需要使用套接字进行与客户端的通信,并维护一个客户端列表用于管理连接的客户端。
服务器需要处理客户端的连接和断开,并根据客户端的请求发送相应的消息给指定的客户端。
3.其他功能的设计与实现:a.聊天记录保存:可以设计一个数据库用于保存聊天记录,以便于用户离线时能够查看历史消息。
b.文件传输:可以设计一个文件传输功能,允许用户发送和接收文件。
c.图片和表情支持:可以设计一个图片和表情支持的功能,允许用户发送和接收图片和表情。
d.用户认证与权限管理:可以设计一个用户认证和权限管理的功能,以确保只有经过认证的用户才能加入聊天室,并按照权限进行相关操作。
e.客户端扩展性:可以设计客户端的扩展性,以便于在未来可以添加更多的功能和插件。
以上是多人聊天系统的设计与实现的一个基本框架和示例。
具体的实现方式和细节可以根据具体的需求来设计和开发。
电子信息专业毕业设计题目汇总表(硬件方向)
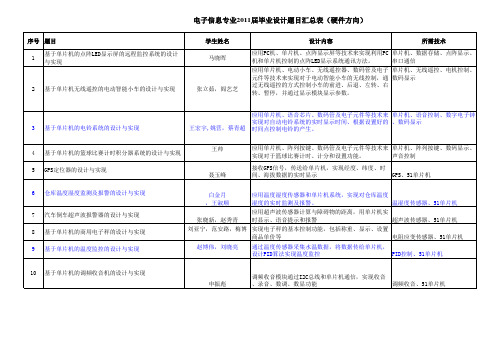
通过软件模拟实现对I2C总线协议的解释;利用I2C总线 进行多路温度的采集、存储、显示及相关硬件电路设 计。 51单片机
21
基于单片机的自行车测速系统的设计与实现 程明月,董哲 实现速度的检测;键盘输入;显示时间速度;硬件电 路的设计。 51单片机 实现强、弱两种洗涤工作状态和4种洗衣工作程序, 即标准程序、经济程序、单独程序和排水程序及硬件 电路设计。 51单片机
13
基于单片机的MP3播放器的设计与实现
齐树雄
以单片机为主控芯片和VS1003B硬件音频解码芯片, 加LCD、U盘等组成一部MP3,主要实现功能:音乐 播放、图片浏览、电子书阅读、万年历支持SD卡和U 盘的访问。包括单片机电路,U盘模块电路,SD卡接 口电路,时钟电路,字库存储电路,USB供电及电压 转换电路,音频解码电路。软件部分包括主程序和各 模块底层电路。 单片机编程,下载,调试;音频编码解码技 建立交叉编译环境;系统启动bootloader的编写;采 用GNU交叉编译内核;Linux2.6内核的移植和根文件 系统的移植。 操作系统Linux2.6核心代码,ARM
预期成果
硬件实物
技术论文与相关测试 文档
技术论文与相关文档
技术论文与相关测试 文档
技术论文与相关测试 文档
技术论文与核心/扩展 电路板(原理图)
2
基于单片机无线遥控的电动智能小车的设计与实现
张立茹,阎艺芝
3
基于单片机的电铃系统的设计与实现
王宏宇,姚营,蔡青超
应用单片机、语音芯片、数码管及电子元件等技术来 单片机、语音控制、数字电子钟 实现对自动电铃系统的实时显示时间、根据设置好的 、数码显示 时间点控制电铃的产生。 应用单片机、阵列按键、数码管及电子元件等技术来 单片机、阵列按键、数码显示、 实现对于篮球比赛计时、计分和设置功能。 声音控制 接收GPS信号,传送给单片机,实现经度、纬度、时 间、海拔数据的实时显示 GPS、51单片机
Linux系统线程创建及同步互斥方法简要说明(供查考)

Linux系统线程创建及同步互斥方法简要说明(供查考)1、.POSIX线程函数的定义在头文件pthread.h中,所有的多线程程序都必须通过使用#include<pthread.h>包含这个头文件2、用gcc编译多线程程序时,必须与pthread函数库连接。
可以使用以下两种方式编译(建议使用第一种)(1)gcc –D_REENTRANT -o 编译后的目标文件名源文件名-lpthread例如:gcc –D_REENTRANT -o pthread_create pthread_create.c -lpthread (执行该编译结果的方式为:./pthread_create)(2)gcc -pthread -o 编译后的文件名源文件名例如:gcc -pthread -o example example.c一、需要用到的函数的用法提示1、创建线程函数pthread_t a_thread; /*声明a_thread变量,用来存放创建的新线程的线程ID(线程标识符)*/int res=pthread_create(&a_thread,NULL,thread_function,NULL);/*创建一个执行函数thread_function的新线程,线程ID存放在变量a_thread */ 2、退出线程函数pthread_exit(NULL);/*那个线程在执行中调用了该方法,那个线程就退出*/创建和退出线程实例3、连接(等待)线程函数int error;int *exitcodeppthread_t tid; /*用来表示一个已经存在的线程*/error=pthread_join(tid,&exitcodep); /*执行该方法的线程将要一直等待,直到tid 表示的线程执行结束,exitcodep 存放线程tid退出时的返回值*/4、返回线程ID的函数pthread_t t/*声明表示线程的变量t */t=pthread_self( ) /*返回调用该方法的线程的线程ID*/5、判断两个线程是否相等的函数(pthread_equal)int pthread_equal(pthread_t t1, pthread_t t2);/*判断线程t1与线程t2是否线程ID相等*/二、线程同步1、使用互斥量同步线程(实现互斥)(1)互斥量的创建和初始化pthread_mutex_t a_mutex=PTHREAD_MUTEX_INITIALIZER/*声明a_mutex为互斥量,并且初始化为PTHREAD_MUTEX_INITIALIZER */ (2)锁定和解除锁定互斥量pthread_mutex_t a_mutex=PTHREAD_MUTEX_INITIALIZER/*声明互斥量a_mutex*/int rc=pthread_mutex_lock(&a_mutex) /*锁定互斥量a_mutex*/ ………………………………/*锁定后的操作*/int rd= pthread_mutex_unlock(&a_mutex) /*解除对互斥量a_mutex的锁定*/例子:利用互斥量来保护一个临界区pthread_mutex_t a_mutex=PTHREAD_MUTEX_INITIALIZER;pthread_mutex_lock(&a_mutex) /*锁定互斥量a_mutex*//*临界区资源*/pthread_mutex_unlock(&a_mutex) /*解除互斥量a_mutex的锁定*/(3)销毁互斥量Int rc=pthread_mutex_destory(&a_mutex) /*销毁互斥量a_mutex*/2、用条件变量同步线程(实现真正的同步)条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待"条件变量的条件成立"而挂起;另一个线程使"条件成立"(给出条件成立信号)。
Linux下嵌入式设备串口通信的多线程实现

关键词:嵌入式;编程:多线程;共享数据 区;互斥锁 。
— l Ol m e ‘nR t om m um- t on Js r‘ r s us l m e nt le c l - ‘ l l i ca - Ol e i ● ■oo t l aI ● ng
m ulihr a nde nux o m be tt e d u rLi n e dde v c s d de i e
DU x u ZHENG i i Zhi i Hax n
( pr n o pia adEet nc q i ns Deat t f t l n lc o i up me O c r E met ,
设 置 A类数 据采 集模 式 的各 种命 令先 保存 在 串 口 1 发送 队列 中 ,通 信模 块再 择机 发送 出去 。串 口 2依 次主 动 呼叫各 下位 机 ,要求 传送 B类 采集 数据 ,收 到数据 后 保存 到 串 口 2的接收 数据 缓 冲 队列 中 。显示模 块 定 时从该 队列 中获 取数 据 ,刷新 屏幕 显示 。同时打 印数据 和系 统报 警控 制 信 息也 通过 串 口 2发 送 出去 。对该 口挂 接各 设备 的控 制命 令先 暂存 到本 端 口发送 队列 中 ,适 当 时机再 发送 。当中央 主机 要求 联 网数据 时 ,接收 到 的命令 先保 存到 串 口 3接 收 队列 中, 由主 处
1引言
在某 嵌入 式设 备开 发项 目中,根据 系统 总体 设计 ,要求 AR 主处理 器 的三个 串 口能 同时 M 工 作 以完成 必须 的通 信功 能 。其 中串 口 1 串口 2用 于接 收数据 采集 结 果 ,串 口 3实现数 据联 和
实验九 嵌入式Linux QT程序设计

2、编写 Hello 程序
1) 在/opt/uptech 目录下,建立一个名为 hello 的目录,在目录下建立一个名为 hello.cpp 的 c++源文件。编写 hello.cpp 文件,文件内容如下:
[root@PCForARM hello]# cat hello.cpp #include <QApplication> #include <QLabel>
进行修改。 y 可以随意设置程序界面的外观。 y 可以方便地为程序连接数据库。 y 可以使程序本地化。 y 可以将程序与 Java 集成。 y 嵌入式系统地要求是小而快速,而 QtE 就能帮助开发者为满足这些要求开发强壮地应
用程序。 y QtE 是模块化和可裁剪地。开发者可以选取他所需要的一些特性,而裁剪掉所不需要的。
这样,通过选择所需要的特性,QtE 的映像变得很小,最小只有 600K 左右。 y 同 Qt 一样,QtE 也是用 C++写的,虽然这样会增加系统资源消耗,但是却为开发者提
供了清洗的程序框架,使开发者能够迅速上手,并且能够方便地编写自定义的用户界面 程序。
图 9-3 QT/Embedded 通过 Qt API 与 Linux I/O 设施直接交互,成为嵌入式 linux 端口。同 Qt/X11 相比,QT/Embedded 很节省内存,其不需要一个 X 服务器或是 Xlib 库,它在底层摈弃了 Xlib,采用 framebuffer(帧缓存)作为底层图形接口。同时,将外部输入设备抽象为 keyboard 和 mouse 输入事件。QT/Embedded 的应用程序可以直接写内核缓冲帧,这可避免开发者使 用繁琐的 Xlib/Server 系统。
基于嵌入式Linux的多线程远程监控系统设计与实现

( xem n Dpr etf i agAruu l oe Xnag 6OO C i ) Epr et eam n oXn n g c ta Clg i n 4O , h a i t y i l r l e, y 4 n
A b t a t: efc so edsu s nfrtec s ntee vrn n ftel u weso t n o t l ee up n s r c W o u nt ic si o ae:i n i me to n x, c u dc nr q ime t h o h h o h i a ot h
程监控方案 , 用户可以通过 It t ne 远程 管理与操纵被监控设备 , me 实现大规模 的监控与便捷的数据发布相结合。
关键词 : 嵌入式 L u ; i x远程监控; b n We 服务; 多线程
中图分 类号 :N 1. T 992 文献 标识码 : A
文章编 号 :0 8 9 6 20 )20 3 -2 10 - 1 (0 7 0 -1 20 4
在 信息化 、 字化社 会浪潮 的推 动下 , 数 大容 量 、 低 用户 通过 互联 网发 来 的请 求 , 以达 到 远 程 监 控 的 目 成本 、 方便 快捷 的远程监 控方式 显得 日益重要 。传统 的 。这种方式 不但 广泛适 用于各种 距离 的监控 , 由 且
的远程 监控方法是 依靠 串行总 线来完 成上 位机 ( C 于嵌 入式设 备本身 的特点 使得该方 式无论 在成本 、 P) 易
T ed s n a di l n 0 ess m fmut l tra ae n Iee e d iu h ei n g mpe t rI t o lpe h e db sdO mbd e Ln x me f h y e i h d
基于ARM-linux嵌入式系统运行参数的配置方法和实现

智 能家 电以及 消费 电子 等领 域 …。 尤其 是 lu i x操作 系统 的发 展 更新 系 统 参数 。 若 需要 则 将 更 新参 数 存 入指 定 的文 件 中 ,供 应 n 使 得嵌 入式 系统 得 以 更普 遍 的 应 用。 其 中专 用 性 强 是嵌 入 式 系 用程 序 的读 取 。 同时调 用 s e 脚 本 完成 本 地 l 参数 的配 置。 hl l P等
方 案一 :选 择在 A M 板 上 电后 检测 串口或者 网络状 态判 断 无法 正 常地 发送 数 据 。鉴 于 上 述 问题 ,我 们 尝 试 了 网络 通 信 方 R 是 否 要 更新 系统 参 数 ,若 需 要 则进 入 配 置模 式 ,配 置完 成 后 将 式进行 参 数 的配置 。 ★ 基 金项 目:河南 省科 技 厅基础 研 究项 目 ( 0 3 0 1 1 2) 120 40 6
统 一 个 很突 出的 特点 。 不 仅 表现 在 其 软 硬件 系 统 的 设计 与实 际
的数 也 不
具体 的 文件 读 写存 储工 作可 由操作 系统 完成 ,并且 l u i x的文 件 n 系统 也具 有掉 电非 易失 的特 点 ,这种 方 法省 去 了对 f s 驱 动 的 lh a
为 多 线程 方式 ,可 同时 响应 多个 客 户 的请 求 。嵌 入 式 设 备作 为
配 置 完成 命 令 后 ,嵌 入 式 设备 将调 用相 关 脚 本 完成 系统 参数 的
ce t ,当 其上 电运 行 后 向固定 端 口发 送 s ce 请 求 ,若 服 配 置 ,若 配置 成 功则 发送 l 置成 功 命令 ;若 未 成 功 ,则重 新 ln端 i okt P配
我们 将 围绕 这两种 方式 进 行进 ~步 的讨论 。
linux下多人聊天室

南京工程学院嵌入式系统开发课程设计专业:计算机科学与技术(嵌入式)班级:计算机091学号:202090134姓名:陈之魁设计题目:局域网多人聊天室开发日期:2012年12目录1.绪论 (4)1.1研究背景 (4)介绍 (4)2.需求分析 (6)2.1功能需求: (6)3.应用技术 (7)3.1TCP和UDP通信的概念 (7)3.1.1 UDP通信 (7)3.1.2 TCP通信 (7)客户/服务器模型 (8)网络套接字(SOCKET)的概念 (9)多线程的概念 (9)4.工作原理 (10)4.1L INUX提供的有关S OCKET的系统调用 (10)4.2实验过程说明(使用TCP/IP) (12)5.系统设计 (14)6.详细设计与实现 (14)主要功能实现如下 (14)6.1.1 登陆模块 (14)6.1.2 查看在线用户 (15)6.1.3 私聊模块 (15)6.1.4 群聊信息 (16)7. 主要代码 (16)7.1 COMMON.H 所有服务器的头文件及出现的函数 (16)17237.4 MAKEFILE 服务器函数的编译命令 (28)8.实验结果 (29)登录 (29)私聊 (29)群聊 (30)显示在线用户列表 (31)9.总结 (32)1.绪论1.1 研究背景在网络无所不在的今天,在Internet上,有ICQ、MSN、Gtalk、OICQ等网络聊天软件,极大程度上方便了处于在世界各地的友人之间的相互联系,也使世界好像一下子缩小了,不管你在哪里,只要你上了网,打开这些软件,就可以给你的朋友发送信息,不管对方是否也同时在线,只要知道他有号码。
Linux 操作系统作为一个开源的操作系统被越来越多的人所应用,它的好处在于操作系统源代码的公开化!只要是基于GNU公约的软件你都可以任意使用并修改它的源代码。
但对很多习惯于Windows操作系统的人来说,Linux的操作不够人性化、交互界面不够美观,这给Linux操作系统的普及带来了很大的阻碍。
linux多线程的实现方式

linux多线程的实现方式Linux是一种支持多线程的操作系统,它提供了许多不同的方式来实现多线程。
本文将介绍Linux多线程的几种实现方式。
1. 线程库Linux提供了线程库,包括POSIX线程库(Pthreads)和LinuxThreads。
Pthreads是一种由IEEE组织制定的标准线程库,它提供了一组线程API,可以在不同的操作系统上实现。
LinuxThreads 是Linux内核提供的线程实现,不同于Pthreads,它不是标准线程库,但具有更好的性能。
使用线程库可以方便地创建和管理线程,线程库提供了许多API 函数,例如pthread_create(),pthread_join(),pthread_mutex_lock()等,可以在程序中使用这些API函数来实现多线程。
2. 多进程在Linux中,多进程也是一种实现多线程的方式。
每个进程都可以有自己的线程,进程之间也可以通过IPC机制进行通信。
多进程的优点是可以更好地利用多核CPU,因为每个进程都可以在不同的CPU核心上运行。
但是,多进程的开销比多线程大,因为每个进程都需要拥有自己的地址空间和运行环境。
3. 线程池线程池是一种常见的多线程实现方式。
线程池中有多个线程可以处理任务,任务可以通过任务队列来进行分发。
当任务到达时,线程池中的线程会从任务队列中取出任务并处理。
线程池的优点是可以重复利用线程,减少创建和销毁线程的开销。
线程池还可以控制线程的数量,避免过多线程导致的性能下降。
4. 协程协程是一种轻量级线程,它不需要操作系统的支持,可以在用户空间中实现。
协程基于线程,但是不需要线程上下文切换的开销,因为协程可以在同一个线程内进行切换。
协程的优点是可以更好地利用CPU,因为不需要线程上下文切换的开销。
协程还可以更好地控制并发性,因为协程的切换是由程序员控制的。
总结Linux提供了多种实现多线程的方式,每种方式都有其优点和缺点。
在选择多线程实现方式时,需要考虑到应用程序的特点和需求,选择最适合的实现方式。
毕业设计论文--聊天系统的设计与实现

毕业设计论⽂--聊天系统的设计与实现南京航空航天⼤学本科毕业论⽂题⽬基于JAVA的聊天系统的设计与实现年级专业班级学号学⽣姓名指导教师职称论⽂提交⽇期基于JAVA的聊天系统的设计与实现摘要⽹络聊天⼯具已经作为⼀种重要的信息交流⼯具,受到越来越多的⽹民的青睐。
⽬前,出现了很多⾮常不错的聊天⼯具,其中应⽤⽐较⼴泛的有Netmeeting、腾讯QQ、MSN-Messager等等。
该系统开发主要包括⼀个⽹络聊天服务器程序和⼀个⽹络聊天客户程序两个⽅⾯。
前者通过Socket套接字建⽴服务器,服务器能读取、转发客户端发来信息,并能刷新⽤户列表。
后者通过与服务器建⽴连接,来进⾏客户端与客户端的信息交流。
其中⽤到了局域⽹通信机制的原理,通过直接继承Thread类来建⽴多线程。
开发中利⽤了计算机⽹络编程的基本理论知识,如TCP/IP协议、客户端/服务器端模式(Client/Server 模式)、⽹络编程的设计⽅法等。
在⽹络编程中对信息的读取、发送,是利⽤流来实现信息的交换,其中介绍了对实现⼀个系统的信息流的分析,包含了⼀些基本的软件⼯程的⽅法。
经过分析这些情况,该聊天⼯具采⽤Eclipse为基本开发环境和java语⾔进⾏编写,⾸先可在短时间内建⽴系统应⽤原型,然后,对初始原型系统进⾏不断修正和改进,直到形成可⾏系统关键词:即时通讯系统 B/S C/S MySQL Socket SwingThe Design and Implementation of Instant Messaging System Based on JavaAbstractAlong with the fast development of Internet, the network chating tool has already become one kind of important communication tools and received more and more web cams favor. At present, many extremely good chating tools have appeared . for example, Netmeeting, QQ, MSN-Messager and so on. This system development mainly includes two aspects of the server procedure of the network chat and the customer procedure of the network chat. The former establishes the server through the Socket, the server can read and deliver the information which client side sends, and can renovate the users tabulation. The latter make a connection with the server, carries on communication between the client side and the client side. With the LAN correspondence mechanism principle, through inheritting the Thread kind to establish the multithreading directly. In the development, it uses the elementary theory knowledge which the computer network programmes. for example, TCP/IP agreement, Client/Server pattern, network programming design method and so on. In the network programming, it realizes reading and transmission of the information, that is,informaton flows realize the information exchange, introduce information flow analysis for realizing a system, in which containes some basic software engineering methods. After analyzes these situations, this chating tool takes Eclipse as the basic development environment and compiles in java language. first, it will establish the system application prototype in a short time. then, for the initial prototype system, it needs constantly revised and improved, until a viable system.Keywords:Instant Messaging System; B/S ; C/S ;MySQL ;Socket; Swing;⽬录第1章引⾔ (1)1.1 开发背景 (1)1.2 开发⽬的和意义 (1)1.3 论⽂研究内容 (2)第2章即时通讯系统的相关研究 (3)2.1 C/S开发模式 (3)2.2 B/S开发模式 (3)2.3即时通讯原理 (4)2.4 Java web 、Struts2、AJAX、JavaScript应⽤技术 (4) 2.5 MySQL数据库应⽤技术 (4)2.6 Socket通信技术 (4)2.7 开发环境的搭建 (5)第3章系统分析 (5)3.1 系统基本功能描述 (5)3.2 可⾏性分析 (6)3.3 系统需求分析 (6)3.3.1功能分析 (6)第4章系统设计 (8)4.1 数据库设计 (8)4.2 系统模块设计 (9)4.2.1 聊天系统⼯作原理图 (9)4.2.2 系统功能模块图: (10)4.2.3 系统⽤例图: (10)4.2.4 活动图: (11)4.3 系统类设计 (13)4.3.1 Message类的设计 (14)4.2.2 截图类的设计 (15)4.2.3 聊天记录类的设计 (16)4.2.4 服务器线程类设计 (17)第5章系统实现 (17)5.1 实现概况 (17)5.2 注册模块 (18)5.2.1 流程图 (18)5.2.2 关键代码 (18)5.3 登录模块 (20)5.3.1 流程图 (20)5.3.2 关键代码 (20)5.4 聊天模块 (25)5.4.1 流程图 (25)5.4.2 关键代码 (25)5.5 ⽂件模块 (29)5.5.1 流程图 (29)5.5.2 关键代码 (30)5.6 ⽤户管理模块 (36)5.6.1 流程图 (36)5.6.2 关键代码 (36)5.7 其他功能的实现 (39)5.7.1 截图功能的实现 (39)5.7.2 聊天记录功能的实现 (40)5.7.3 服务端线程的实现 (42)5.8 ⽤户界⾯的设计 (43)结语 (46)参考⽂献 (47)致谢 ......................................................................................... 错误!未定义书签。
linux多线程编程实验心得

linux多线程编程实验心得在进行Linux多线程编程实验后,我得出了一些心得体会。
首先,多线程编程是一种高效利用计算机资源的方式,能够提高程序的并发性和响应性。
然而,它也带来了一些挑战和注意事项。
首先,线程同步是多线程编程中需要特别关注的问题。
由于多个线程同时访问共享资源,可能会引发竞态条件和数据不一致的问题。
为了避免这些问题,我学会了使用互斥锁、条件变量和信号量等同步机制来保护共享数据的访问。
其次,线程间通信也是一个重要的方面。
在实验中,我学会了使用线程间的消息队列、管道和共享内存等方式来实现线程间的数据传递和协作。
这些机制可以帮助不同线程之间进行有效的信息交换和协调工作。
此外,线程的创建和销毁也需要注意。
在实验中,我学会了使用pthread库提供的函数来创建和管理线程。
同时,我也了解到线程的创建和销毁是需要谨慎处理的,过多或过少的线程都可能导致系统资源的浪费或者性能下降。
在编写多线程程序时,我还学会了合理地划分任务和资源,以充分发挥多线程的优势。
通过将大任务拆分成多个小任务,并将其分配给不同的线程来并行执行,可以提高程序的效率和响应速度。
此外,我还学会了使用调试工具来分析和解决多线程程序中的问题。
通过使用gdb等调试器,我可以观察线程的执行情况,查找潜在的错误和死锁情况,并进行相应的修复和优化。
总结起来,通过实验我深刻认识到了多线程编程的重要性和挑战性。
合理地设计和管理线程,正确处理线程同步和通信,以及使用调试工具进行分析和修复问题,都是编写高效稳定的多线程程序的关键。
通过不断实践和学习,我相信我能够更好地应用多线程编程技术,提升程序的性能和可靠性。
linux基于线程通信技术聊天室的设计与实现

linux基于线程通信技术聊天室的设计与实现Linux基于线程通信技术的聊天室设计与实现聊天室作为常见的网络应用程序之一,在实现过程中需要考虑到多用户同时访问、数据传输的实时性和数据安全性等方面的问题。
本文将基于Linux 操作系统的线程通信技术,逐步介绍设计和实现一个基于线程的聊天室的方法。
第一步:设计聊天室的基本框架一个典型的聊天室一般有服务器和多个客户端组成。
服务器负责接收和分发消息,而客户端则负责与服务器建立连接并发送和接收消息。
在本次实现中,我们将使用基于线程的通信技术,即服务器和每个客户端都以一个线程的形式运行。
第二步:服务器的设计与实现服务器程序主要包括以下功能:1. 创建套接字并绑定地址;2. 监听客户端的连接请求;3. 接收客户端的连接,并为每个连接创建一个线程,通过该线程与对应的客户端进行通信;4. 分发和接收消息。
首先,在服务器程序中,我们需要创建一个套接字来接收连接请求,可以使用socket()系统调用来实现此功能。
在代码中,你可以用以下代码创建套接字:cint sockfd = socket(AF_INET, SOCK_STREAM, 0);然后,我们还需要绑定服务器的地址信息,并监听来自客户端的连接请求。
cstruct sockaddr_in serv_addr;bzero((char *) &serv_addr, sizeof(serv_addr));serv_addr.sin_family = AF_INET;serv_addr.sin_addr.s_addr = INADDR_ANY;serv_addr.sin_port = htons(portno);bind(sockfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)); listen(sockfd, 5);接下来,我们需要创建一个线程,为每个连接的客户端分别处理通信。
基于Linux的局域网聊天系统设计

文章编 号 : 1 6 7 4 . 4 5 7 8 ( 2 0 1 4 ) O 1 - 0 0 6 7 — 0 3
软 件 技 术
基于 L i n u x的 局 域 网聊 天 系统 设 计
杜金祥 ,杜宇轩。
( 1 . 太原工业学院 自 动化 系, 山西 太原 0 3 0 0 0 8 ; 2 . 四川大学 物理科学与技术学院, 四川 成都 6 1 0 2 0 7 )
高可靠性 、 高时效性 、 功能强大 的局 域网即时聊天系统 。
l 标示符 l 协议头 l 账号/ 密码 l 账号 l 内容 特别说 明 : 基本协议结 构只用 于客户 登陆 和注册 使用 。 此基本 协议 结构在使 用时没有 的信息块 均 以显示 内容 的字
1 系统 总体 设计
要采用L i n u x作 为软 件 开 发 平 台 , 以 C语 言作 为 编 程语 言 , 利用V I 、 G C C编 辑 工 具 编 译 , 采用c / S架构 实现 。 关键 词 : L i n u x ,局域 网,聊 天系统 ,T C P / I P
中图分类号 : I l 6 . 8
件 更 是 少 之 又少 。
I 堡 重 竺J 兰J !l 查 翌l 望 翌l 兰 些J 竺 竺J 丝 型j
客户与服务器 传送其他信息 内容另有协议 帧 , 交互 式协 议结 构如表 2所 示。
表 2 交互 式 协 议 结 构
基于上述情 况 , 为 了力求使局域 网通信 网络技 术的优势 得 到充 分发挥 , 同时基 于局域 网聊天 软件匮 乏的 现状 , 我们 采用 L i n u x作 为软件 开发平 台 , 以 c语言 作为 编程 语 言 , 利 用V I 、 G C C编辑工具编译 , 采用 C / S架构 , 设 计一款低 成本 、
嵌入式多线程应用程序设计实验

下面我们来看一下,生产者写入缓冲区和消费者从缓冲区读数的具体流程,生产者首先要 获得互斥锁,并且判断写指针+1后是否等于读指针,如果相等则进入等待状态,等候条件 变 量notfull;如果不等则向缓冲区中写一个整数,并且设置条件变量为notempty,最后 释 放互斥锁。消费者线程与生产者线程类似,这里就不再过多介绍了。流程图如下:
}
4.主要的多线程API 在本程序的代码中大量的使用了线程函数,如
pthread_cond_signal、 pthread_mutex_init、pthread_mutex_lock等等,这些函数的作用是 什么,在哪里定义的, 我们将在下面的内容中为大家做一个简单的介绍,并且为其中比较重 要的函数做一些详细 的说明。
/* 等待缓冲区非空*/ while (b->writepos == b->readpos) { printf("wait for not empty\n"); pthread_cond_wait(&b->notempty, &b->lock); } /* 读数据并且指针前移 */ data = b->buffer[b->readpos]; b->readpos++; if (b->readpos >= BUFFER_SIZE) b->readpos = 0; /* 设置缓冲区非满信号*/ pthread_cond_signal(&b->notfull);
pthread_mutex_unlock(&b->lock); return data; } /*--------------------------------------------------------*/ #define OVER (-1) struct prodcons buffer; /*--------------------------------------------------------*/ void * producer(void * data) { int n;
Linux下的多线程编程实例解析

Linux下的多线程编程实例解析1 引⾔ 线程(thread)技术早在60年代就被提出,但真正应⽤多线程到操作系统中去,是在80年代中期,solaris是这⽅⾯的佼佼者。
传统的Unix也⽀持线程的概念,但是在⼀个进程(process)中只允许有⼀个线程,这样多线程就意味着多进程。
现在,多线程技术已经被许多操作系统所⽀持,包括Windows/NT,当然,也包括Linux。
为什么有了进程的概念后,还要再引⼊线程呢?使⽤多线程到底有哪些好处?什么的系统应该选⽤多线程?我们⾸先必须回答这些问题。
使⽤多线程的理由之⼀是和进程相⽐,它是⼀种⾮常"节俭"的多任务操作⽅式。
我们知道,在Linux系统下,启动⼀个新的进程必须分配给它独⽴的地址空间,建⽴众多的数据表来维护它的代码段、堆栈段和数据段,这是⼀种"昂贵"的多任务⼯作⽅式。
⽽运⾏于⼀个进程中的多个线程,它们彼此之间使⽤相同的地址空间,共享⼤部分数据,启动⼀个线程所花费的空间远远⼩于启动⼀个进程所花费的空间,⽽且,线程间彼此切换所需的时间也远远⼩于进程间切换所需要的时间。
据统计,总的说来,⼀个进程的开销⼤约是⼀个线程开销的30倍左右,当然,在具体的系统上,这个数据可能会有较⼤的区别。
使⽤多线程的理由之⼆是线程间⽅便的通信机制。
对不同进程来说,它们具有独⽴的数据空间,要进⾏数据的传递只能通过通信的⽅式进⾏,这种⽅式不仅费时,⽽且很不⽅便。
线程则不然,由于同⼀进程下的线程之间共享数据空间,所以⼀个线程的数据可以直接为其它线程所⽤,这不仅快捷,⽽且⽅便。
当然,数据的共享也带来其他⼀些问题,有的变量不能同时被两个线程所修改,有的⼦程序中声明为static的数据更有可能给多线程程序带来灾难性的打击,这些正是编写多线程程序时最需要注意的地⽅。
除了以上所说的优点外,不和进程⽐较,多线程程序作为⼀种多任务、并发的⼯作⽅式,当然有以下的优点: 1) 提⾼应⽤程序响应。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于嵌入式Linux多线程聊天系统的设计与实现学生姓名王宣达学号 S2******* 所在系(院)电子信息工程系专业名称电路与系统年级 2009级2011年8月3日中文摘要外文摘要目录1.引言 (1)2.Linux多线程聊天系统的设计思想 (3)2.1 聊天系统中服务器的设计思想 (3)2.2 聊天系统中客户端的设计思想 (3)3. Linux多线程聊天系统的实现过程 (5)3.1 多线程聊天系统中服务器端的实现过程 (5)3.2 多线程聊天系统中客户端的实现过程 (7)4.Linux多线程系统设计中出现的问题和解决的方法 (12)4.1 多线程中资源的释放问题 (12)4.2 (12)参考文献 (12)1.引言在80年代中期,线程技术就应用到了操作系统中,那时在一个进程中只允许有一个线程,这样多线程就意味着多进程,虽然实现了多任务,但是资源消耗还是非常可观的。
而到现在,多线程技术已经被许多操作系统所支持,有Windows/NT,还有Linux。
多线程和进程相比有两点优势:1.它是一种消耗资源非常少的多任务操作方式。
在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种消耗非常大的多任务工作方式。
而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,这样创建一个线程所占用的空间远远小于创建一个进程所花费的空间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间。
当然,随着系统的不同,这个差距也不不同。
2.线程间比进程间的通信机制更为便利。
对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。
线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其它线程所用,这不仅快捷,而且方便。
当然,数据的共享也带来其他一些问题,有的变量不能同时被两个线程所修改,这时就要用到互斥锁机制来保证线程间的同步。
所以在本文的多线程聊天程序的设计中,采用多线程的方式设计系统更为适宜。
其中,系统中用到的操作主要是:线程操作,设置互斥锁。
其中,线程操作包括:线程创建,退出,。
设置互斥锁包括:创建互斥锁,加锁和解锁。
但是,要实现网络聊天,系统中还要用到linux下的网络编程。
Linux下的网络编程通过socket接口实现。
socket 是一种特殊的I/O,可以实现网络上的通信机制。
Socket也是一种文件描述符。
它具有一个类似于打开文件的函数调用Socket(),该函数返回一个整型的Socket描述符,随后的连接建立、数据传输等操作都是通过该Socket实现的。
常用的Socket类型有两种:流式Socket (SOCK_STREAM)和数据报式Socket(SOCK_DGRAM)。
流式是一种面向连接的Socket,针对于面向连接的TCP服务应用;数据报式Socket是一种无连接的Socket,对应于无连接的UDP服务应用。
本文使用流式套接字,来建立服务器和客户端的通信桥梁。
其中,系统用到的API有:socket,bind,listen,accept,connect系统调用,分别完成套接字的创建,绑定本地端口和本地IP形成三元的套接字,激活监听端口并创建一个请求队列,接受客户端connect连接请求,客户端发起连接请求等功能。
2.Linux多线程聊天系统的设计思想下面是服务器和客户端的设计思想:2.1 聊天系统中服务器的设计思想服务器应用程序先创建一个socket,socket就像一个文件描述符,用来引用系统分配给服务器进程的资源,并且这部分资源只能由该进程访问,对该进程是独占的。
服务器通过使用socket系统调用的方式创建socket,创建之后该socket不能被其它进程共享。
然后,服务器进程给刚刚创建的socket绑定一个名字。
本地的socket 会分配一个在Linux文件系统中的文件名。
对于网络socket,其名称通常是与特定网络相关的服务标识(如:端口号)以便其他客户程序连接,系统能够通过这个标识符将带有特定端口的访问请求指定给服务器进程。
Socket名称的绑定是通过bind系统调用实现的。
之后,服务器进程就会等待客户对该命名的socket发起链接请求。
使用listen系统调用创建一个请求队列,最后使用accept系统调用接受请求。
定义一个用于存放已经建立起连接的用户链表,每个节点包含用户名,用户所用的套接字,还有链表指针。
当Accept系统调用接受请求后就将新生成的五元套接字填充到用户的节点中,把节点加入链表,并且创建一个线程服务该用户,然后主线程循环执行accept响应下一个connect连接请求。
2.2 聊天系统中客户端的设计思想客户端首先获取用户输入的要连接的服务器的IP和端口号,然后用socket系统调用创建一个没有命名的socket,接着使用connect系统调用建立一个到服务器端命名的socket的连接,连接建立后,socket就像一个文件描述符一样可以进行读写操作,给建立起连接的双方提供双向通信。
这里要注意的是,在与服务器通信的同时,用户也许会在终端输入信息发给服务器,所以我们要同时监控socket和用户的标准输入。
实现的方式是当连接建立以后使用select系统调用同时监听上面两个文件描述符,当其中一个可用的时候select返回,然后用FD_ISSET系统调用依次判断具体是哪个文件描述符可用,当键盘有数据可用时,我们将键盘输入的内容原封不动地通过socket发送给服务器;当socket可用时,我们就把socket里读到的内容显示到客户的屏幕。
3. Linux多线程聊天系统的实现过程下面是聊天系统的具体实现过程,以及遇到的问题和解决的方案。
3.1 多线程聊天系统中服务器端的实现过程服务器主程序的主要实现代码如下://选择通信协议为IPv4sin.sin_family=AF_INET;//系统自动选择一个网卡的ip地址sin.sin_addr.s_addr=INADDR_ANY;//选择端口号sin.sin_port=htons(port);//创建监听套接字listen_fd=socket(AF_INET,SOCK_STREAM,0);{int opt=1;setsockopt(listen_fd,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));}//绑定端口,ip到套接字ret=bind(listen_fd,(struct sockaddr *)&sin,sizeof(sin));if(ret<0){perror("bind");exit(1);}//激活监听,定义等待队列长度listen(listen_fd,T_MAX);printf("accepting connections......\n");while(1){// 接收套接字,绑定客户端IP,端口,创建五元套接字conn_fd=accept(listen_fd,(struct sockaddr *)&pin,&address_size);ptr=(node *)malloc(sizeof(node));//填充套接字ptr->sockfd=conn_fd;//填充默认名字strcpy(ptr->user_name,"unknow");ptr->next=NULL;//插入链表insert(head,ptr);pthread_create(&tid[i], NULL, (void*)thread, ptr);i++;}}下面是服务器运行起来的效果图3.2 多线程聊天系统中客户端的实现过程服务器主程序的主要实现代码如下://屏蔽信号的干扰signal(SIGPIPE,SIG_IGN);signal(SIGCHLD,SIG_IGN);printf ("Enter server ip:");fgets(ip_buf, 20, stdin);*(strchr(ip_buf, '\n')) = '\0';printf ("Enter server port:");fgets(port_buf, 10, stdin);*(strchr(port_buf, '\n')) = '\0';//把字符串转换成整型port = atoi(port_buf);bzero(&pin,sizeof(pin));pin.sin_family=AF_INET;//由于用于网络的参数是大端序列,而PC机是小端序列,所以要把传递的IP包的参数转换成网络字节序inet_pton(AF_INET,ip_buf,&pin.sin_addr);pin.sin_port=htons(port);sock_fd=socket(AF_INET,SOCK_STREAM,0);rst = connect(sock_fd,(void*)&pin,sizeof(pin));if (0 != rst){perror("connect");exit(1);}printf ("welcome to chatroom! Enter help!\n");head.sockfd=sock_fd;while (1) {fd_set rset;int tmp;FD_ZERO(&rset);//将描述符head.sockfd加入到描述符集rset中FD_SET(head.sockfd, &rset);FD_SET(fileno(stdin), &rset);//用select系统调用选择可用的文件描述符,第一个参数是读或者写,或者既不可读也不可写,中文件描述符最大的+1//第二个参数是读集合,第三个是写集合,第四个是超时时间tmp = select((head.sockfd > fileno(stdin) ? head.sockfd : fileno(stdin)) + 1, &rset, NULL, NULL, NULL);if (tmp == -1) {perror("select");continue;}if (FD_ISSET(fileno(stdin), &rset)) {if ((fgets(buff,sizeof(buff),stdin) == NULL) && ferror(stdin)) {perror("fgets");} else {send(head.sockfd,buff,strlen(buff),0);}}if (FD_ISSET(head.sockfd, &rset)) {//memset(buff,0,sizeof(buff));int n = read(head.sockfd,buff,MAX);if(n<=0) {perror("closed");exit(0);} else {write(fileno(stdout), buff, n);}}}以下是客户端程序运行过程:1.输入服务器的IP和服务器端口进入聊天程序命令行界面(因为演示时是用一台机器做服务器又做客户端,所以IP为本地回环127.0.0.1)2.注册在虚拟终端pts/1上注册一个用户在pts/2 上注册另一个用户3.登陆4.显示在线用户5.群聊用户Haoyongxin端:用户wangxuanda端:6.私聊用户wangxuanda端用户haoyongxin端4.Linux多线程系统设计中出现的问题和解决的方法4.1 多线程中资源的释放问题在Linux平台下线程的结束问题:如何让线程的资源在其结束后可以得到合理的释放。