Cache命中率分析工具的使用(附源代码)
Cache安装使用

5TERMINAL使用(3)
常用操作
4运行Routine: 不传参数:d Tag^Routine,或d ^Routine 假如:文件名为Test.mac 的Routine内容为:
GetTime w $ZD($p($h,",",1),3)_" "_$ZT($p($h,",",2)) 在Terminal中运行结果为:
课后练习(2)
7创建命名空间和远程数据库 8建立定时任务,查看任务的运行情况 9创建csp Application 10新建一个Routine,打印出输入整数的3次方 11新建一个类方法,交换两个整数a和b的值,并进行调 试 12导入导出Global 13导入导出Routine 14导入导出类定义、工程
1CACHÉ介绍(4)
Caché SQL存取
SQL 网关(SQL Gateway)功能使得 Caché应用程序能从关系型数据 库中 存取数据;关系型数据库转移到 Caché上 Caché可以兼容所有这些使用 SQL 的应用程序 DDL 文件中的关系型表格定义来创建数据结构
1CACHÉ介绍(5)
1CACHÉ介绍(7)
Caché 完整的开发环境 提供开发、调试、部署的环境, 提供插件工具对外部接口的引用。 提供导入导出代码工具
2CACHÉ安装(1)
安装准备 1安装文件 2License:cache.key 安装要求
注意:安装文件路径不能包含中文
2CACHÉ安装(2)
可采用多种方式数据建模:对象、表格、或者多维数组 Studio、DDL、 Rational Rose 多种技术编写数据库和业务逻辑 Cache ObjectScript 、CachéBasic、JAVA、.Net
Cache实验

Caches实验杨祯 15281139实验目的1.阅读分析附件模拟器代码2.通过读懂代码加深了解cache的实现技术3.结合书后习题1进行测试4.通过实验设计了解参数(cache和block size等)和算法(LRU,FIFO 等)选择的优化配置与组合,需要定性和定量分析,可以用数字或图表等多种描述手段配合说明。
阅读分析模拟器代码课后习题stride=132下直接相连映射1)实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0 array[132]的块地址为132/4=33 映射到cache的块号为33%16=1第一次访问cache中的0号块与1号块时,会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下直接相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0array[131]的块地址为131/4=32 映射到cache的块号为32%16=0 第一次访问cache中的0号时,一定会发生强制性失效,次数为1;之后因为cache中块号为0的块不断地被替换写入,此时发生的是冲突失效,冲突失效次数为19999,则发生的失效次数为19999+1=20000 所以misscount=20000 missrate=20000/(2*10000)=1实验验证stride=132下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[132]的块地址为132/4=33 映射到cache的组号为33%8=1第一次访问cache中的0号块与1号块时,一定会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[131]的块地址为131/4=32 映射到cache的组号为32%8=0 第一次访问cache中的0组时,一定会发生强制性失效,因为1组中有2个块,不妨假设array[0]对应0组中的第0块,array[131]对应0组中的第1块,则强制失效次数为1;之后因为 array[0]与array[131]都在0组,不会发生失效则发生的失效次数为2次,命中次数为19998,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000实验验证实验分析(1)block块大小与Cache容量对Cache效率的影响实验以Hitrate作为衡量指标,在直接相连映射,组相连度为1,project.txt 为500个1---100的随机数。
Cache性能分析
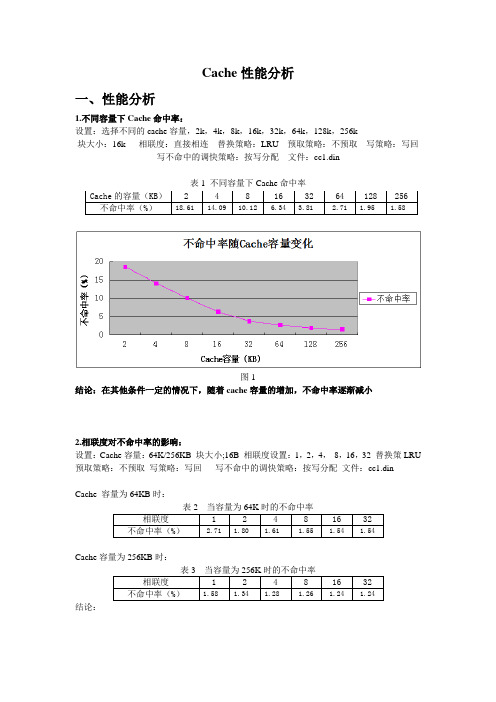
Cache 性能分析一、性能分析1.不同容量下Cache 命中率:设置:选择不同的cache 容量,2k ,4k ,8k ,16k ,32k ,64k ,128k ,256k块大小:16k 相联度:直接相连 替换策略:LRU 预取策略:不预取 写策略:写回写不命中的调快策略:按写分配 文件:cc1.din表1 不同容量下Cache 命中率图1结论:在其他条件一定的情况下,随着cache 容量的增加,不命中率逐渐减小2.相联度对不命中率的影响:设置:Cache 容量:64K/256KB 块大小;16B 相联度设置:1,2,4, 8,16,32 替换策LRU 预取策略:不预取 写策略:写回 写不命中的调快策略:按写分配 文件:cc1.dinCache 容量为64KB 时:表2 当容量为64K 时的不命中率相联度 1 2 4 8 16 32不命中率(%)2.71 1.80 1.61 1.55 1.54 1.54Cache 容量为256KB 时:表3 当容量为256K 时的不命中率相联度 1 2 4 8 16 32不命中率(%)1.58 1.34 1.28 1.26 1.24 1.24 结论:Cache 的容量(KB ) 2 4 8 16 32 64 128 256不命中率(%)18.61 14.09 10.12 6.34 3.81 2.71 1.95 1.58图2结论:(1)当Cache容量一定时,随着相联度的不断增加,不命中率逐渐减小,但是当相联度增加到一定程度时,不命中率保持不变。
(2)当关联度相同时,Cache容量越大,不命中率越小,当关联度增加到一定程度时,不命中率和Cache容量大小无关。
3.Cache块大小对命中率的影响:设置:Cahce块大小(B):16,32,64,128,256 Cache容量设置(KB):2,8,32,128,512相联度:直接相联预取策略:不预取写策略:写回写不命中的调快策略:按写分配文件:eg.din表4 不同Cache行大小情况下Cache的不命中率块大小(B)Cache的容量(KB)2 8 32 128 51216 7.80% 7.40% 7.20% 7.20% 7.20%32 5.40% 5.00% 4.70% 4.70% 4.70%64 4.00% 3.40% 3.10% 3.10% 3.10%128 4.40% 3.30% 2.40% 2.40% 2.40%256 6.50% 5.10% 2.30% 1.90% 1.90%图3结论:(1)在Cache容量一定时,Cache 不命中率随着Cache行的增加先减小后增加。
java cache的hitcount函数

java cache的hitcount函数以下是一篇关于Java缓存的hitcount函数的文章:Java Cache的hitcount函数:将缓存性能提升到一个新的水平引言:在当今的软件开发中,性能是一个至关重要的因素。
为了提高性能,开发人员通常会使用各种优化技术。
其中之一就是缓存。
缓存是一种存储在内存中的临时数据存储器,用于存储频繁访问的数据,以提高数据访问速度。
在Java编程语言中,我们经常使用缓存来加快代码的执行速度。
在本文中,我们将重点讨论一个名为hitcount的函数,以及如何使用它来改进缓存性能。
1. 什么是缓存?在计算机科学中,缓存是一种高速数据存储器,用于存储经常被访问的数据,以便在将来的访问中提供更快的访问速度。
缓存可以存储各种类型的数据,例如数据库查询结果、网络请求结果或计算结果。
当代码需要访问这些数据时,它首先检查缓存,如果数据已经存储在缓存中,则直接从缓存中获取数据,从而避免了耗时的访问原始数据源的过程。
2. 缓存的好处使用缓存可以带来许多好处。
首先,它显着提高了代码的执行速度。
由于缓存数据存储在内存中,而内存的访问速度通常比磁盘或网络访问速度快得多,因此缓存能够提供更快的数据访问速度。
其次,使用缓存可以减轻数据源的负载。
当代码频繁访问数据源时,缓存可以减少与数据源的交互次数,从而减少了对数据源的压力。
最后,缓存还可以降低网络延迟。
如果数据源位于远程服务器上,通过缓存将数据存储在本地内存中,可以避免网络传输延迟,并且可以更快地访问数据。
3. hitcount函数的作用hitcount函数是一个用于统计缓存命中次数的函数。
当代码从缓存中获取数据时,它会调用hitcount函数,该函数会记录缓存命中的次数。
通过统计缓存命中次数,开发人员可以评估缓存的性能。
如果缓存命中次数较高,说明缓存效果良好,数据几乎都从缓存中获取。
相反,如果缓存命中次数较低,可能意味着缓存策略需要进行优化或者数据不适合缓存。
实验4 Cache性能分析

实验4 Cache性能分析4.1 实验目的1.加深对Cache的基本概念、基本组织结构以及基本工作原理的理解;2.掌握Cache的容量、相联度、块大小对Cache性能的影响;3.掌握降低Cache不命中率的各种方法,以及这些方法对Cache性能提高的好处;4.理解LRU与随机法的基本思想以及它们对Cache性能的影响;4.2 实验平台实验平台采用Cache模拟器My Cache。
4.3 实验内容及步骤首先要掌握My Cache模拟器的使用方法。
4.3.1 Cache的容量对不命中率的影响1.启动MyCache模拟器。
2.用鼠标单击“复位”按钮,把各参数设置为默认值。
3.选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
4.选择不同的Cache容量,包括2KB、4KB、8KB、16KB、32KB、64KB、128KB和256KB。
分别执行模拟器(单击“执行到底”按钮即可执行),然后在表5.1中记录各种情况下的不命中率。
地址流文件名:5.以容量为横坐标,画出不命中率随Cache容量变化而变化的曲线,并指明地址流文件名。
6.根据该模拟结果,你能得出什么结论?4.3.2 相联度对不命中率的影响1.用鼠标单击“复位”按钮,把各参数设置为默认值。
此时的Cache的容量为64KB。
2.选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
3.选择不同的Cache相联度,包括直接映像、2路、4路、8路、16路和32路。
分别执行模拟器(单击“执行到底”按钮即可执行),然后在表5.2中记录各种情况下的不命中率。
地址流文件名:4.把Cache的容量设置为256KB,重复3的工作,并填写表5.3。
5.以相联度为横坐标,画出在64KB和256KB的情况下不命中率随Cache相联度变化而变化的曲线,并指明地址流文件名。
run-clang-tidy用法

run-clang-tidy用法run-clang-tidy是一个用于运行Clang-Tidy静态分析工具的实用程序。
它提供了一种便捷的方法来检查和改进C++代码的质量和可读性。
本文将详细介绍run-clang-tidy的用法,以便读者了解如何在其项目中使用此工具进行代码检查和改进。
1. 什么是Clang-Tidy?Clang-Tidy是一个基于Clang的静态分析工具,用于检查C++代码中的潜在问题和一般性错误。
它使用编译器内部的静态分析框架,并提供了大量的检查规则,以帮助开发人员识别常见的编码错误和潜在问题。
2. 为什么使用run-clang-tidy?使用Clang-Tidy可以帮助开发人员在编译时检测可能导致运行时错误、内存泄漏、未定义行为和性能问题的代码。
它能够捕获一些编译器可能会忽略的问题,并提供相应的建议和修复建议,帮助开发人员改进代码质量。
run-clang-tidy是一个方便的工具,它简化了使用Clang-Tidy的过程。
3. 安装run-clang-tidy要使用run-clang-tidy,您需要安装LLVM和Clang。
您可以从官方网站(4. 配置run-clang-tidy在您的C++项目中,您需要创建一个名为`.clang-tidy`的文件来配置run-clang-tidy。
这个文件描述了您希望运行的Clang-Tidy检查和选项。
您可以根据您的项目需求自定义配置。
以下是一个示例`.clang-tidy`文件的内容:Checks: 'modernize-*'CheckOptions:- { key: modernize-use-auto, value: false }- { key: modernize-loop-convert, value: false }上述示例配置了一些在现代化转换方面的检查,如`modernize-use-auto`和`modernize-loop-convert`。
cachefs使用方法

cachefs使用方法Cachefs是一个用于Linux系统的内核文件系统,它允许用户将磁盘上的文件缓存到内存中,以提高文件读取的速度。
Cachefs 的使用方法涉及几个步骤:1. 安装Cachefs,首先,您需要确保您的Linux内核支持Cachefs,并且已经安装了Cachefs的用户空间工具。
您可以通过包管理器来安装Cachefs,或者从源代码进行编译安装。
2. 配置Cachefs,一旦Cachefs安装完成,您需要进行一些配置。
您可以编辑Cachefs的配置文件,通常是在/etc/cachefilesd.conf中。
您可以指定要缓存的目录、缓存的大小、缓存的策略等。
3. 启动Cachefs,在配置完成后,您需要启动Cachefs服务。
您可以使用systemctl或service命令来启动Cachefs服务。
一旦Cachefs服务启动,它将开始监视您指定的目录,并将文件缓存到内存中。
4. 监控Cachefs,一旦Cachefs开始运行,您可以使用cachefilesdctl工具来监视Cachefs的运行情况。
您可以查看缓存命中率、缓存大小等信息。
5. 测试Cachefs,最后,您可以测试Cachefs的性能。
您可以通过读取经常访问的文件来测试Cachefs是否能够加速文件读取。
您还可以通过监视系统资源使用情况来评估Cachefs对内存和CPU 的影响。
需要注意的是,Cachefs的使用方法可能会因Linux发行版和Cachefs版本而有所不同,因此在使用Cachefs之前,请务必查阅相应的文档和指南以获取准确的使用方法。
希望这些信息能够帮助您更好地理解Cachefs的使用方法。
缓存命中率测试标准

缓存命中率测试标准一、引言缓存命中率是衡量缓存系统性能的重要指标之一。
高缓存命中率表示缓存系统能够高效地提供数据,减轻后端数据库的负载,从而提升系统的响应速度和并发能力。
本文将从缓存命中率的定义和计算方法、测试环境搭建、测试数据准备和测试指标分析等方面,对缓存命中率的测试标准进行探讨。
二、缓存命中率的定义和计算方法2.1 定义缓存命中率是指在一定时间内,缓存系统中所命中的缓存请求数占总请求数的比例。
通常用百分比表示,高命中率表示大部分数据都能从缓存中获取,反之表示缓存系统效果较差。
2.2 计算方法缓存命中率的计算方法有多种,以下是常用的两种方法:2.2.1 单位时间内的命中率单位时间内的命中率计算非常简单,直接将命中的请求数除以总请求数即可,如下所示:命中率 = (命中的请求数 / 总请求数) × 100%2.2.2 滑动窗口平均命中率滑动窗口平均命中率是计算一定时间范围内的命中率的方法。
它利用滑动窗口记录最近一段时间的缓存命中情况,并根据窗口的长度计算平均命中率。
计算公式如下:平均命中率 = (滑动窗口内的命中请求数 / 滑动窗口内的总请求数) × 100%三、测试环境搭建为了进行缓存命中率的测试,我们需要搭建一个合适的测试环境。
下面是测试环境的搭建步骤:1.准备一台运行缓存系统的服务器,可以使用开源的缓存软件,比如Redis、Memcached等。
2.准备一台运行数据库的服务器,用于模拟后端数据库。
3.在测试客户端上安装相应的测试工具,比如Apache JMeter、Redis-benchmark等。
四、测试数据准备进行缓存命中率测试需要准备一定量的测试数据,以模拟实际的应用场景。
以下是测试数据准备的步骤:1.创建一个包含大量数据的数据库表,可以使用工具生成测试数据,确保数据具有一定的规模和分布。
2.将部分数据加载到缓存系统中,以模拟实际应用中缓存系统的初始化。
3.编写测试脚本或使用测试工具,模拟用户对数据的读取和更新操作。
Cache的命中率和替换策略

Cache的命中率和替换策略C^hE的命中率命中率扌旨CPU所要访问的信息在Cache中的比率;而将所要访问的信息不在€眈11芒中的比率称为失敢率•增加echg的目的,就是在性能上使主存的平均读出时I可尽可能接近ciich也的读出时间“ E此,ciicli巳的命中率应撰近于由于程序访问的局部性滾这是可能的。
在一个程序执行期间:设表示cache完威存馭的总次数,Nn*表示主存完風存取的总次数、h定义为命中率*则有:h=Ne/N卄u若1表示命中时的cacheiy问时问,—表示未命中时的至存访问时间,l・h表示不命中芈,则cache/主存系统的平均访问时间J为:t尸h J+ (I -hjt^我们追求的目标是:以较小的碰伴代价使mcti"主存系统的平均访问时间©越接近-越好.设Ut/t*一表示主存慢于5chE的倍率F芒表示访问效丄聲,则有二e=t</tn=t1/ht t+(l-h)tin=l/r+(l-r)h=l/h4-(l-h)r为捉葯访问效率:命屮率h越接近丄越好” r值以5——J.0为宜丁不宜太大口侖中率h与#呈序的行为,('日cli疋的容愛、纽织考式* 块的丸小有关.例:CPU执行一』殳程序时,cache完成存取的次数为丄900矢,主存完戚存取的次数为丄00次,已Bracht吞取周期为50ns, 主存存取周期为250ns, 求cache/主存系统的效率和平均访问时间。
解:h=N c/(N v+N in)=1900/(1900+100)=0.95r=t m/t c=250ns/50ns=5e=_l/(r+( 1 -r)h)=l/(5+( 1 -5) x 0.95)=83.3% t a=t c/e=50ns/0.833=60ns 例:已知Cache存储周期为40ns,主存存倚周期为200ns, Cache / 主存系统平均访问时间为50ns,求Cache的命中卑是多少?解:因为ta=htc+(l-h)tm所以h=(ta-tm)/(tc-tm)=(50-200)/(40-200)=15/丄6替换策略当一个新的主存块要调入到cache,而允许存放此块的行位置都被其它主存块占满时,就要产生替换,因为cache工作原理要求它应尽量保存最新的数据。
cache以及命中率

cache以及命中率cache n. 高速缓冲存储器一种特殊的存储器子系统,其中复制了频繁使用的数据以利于快速访问。
存储器的高速缓冲存储器存储了频繁访问的RAM 位置的内容及这些数据项的存储地址。
当处理器引用存储器中的某地址时,高速缓冲存储器便检查是否存有该地址。
如果存有该地址,则将数据返回处理器;如果没有保存该地址,则进行常规的存储器访问。
因为高速缓冲存储器总是比主RAM 存储器速度快,所以当RAM 的访问速度低于微处理器的速度时,常使用高速缓冲存储器。
Cache的出现是基于两种因素:首先,是由于CPU的速度和性能提高很快而主存速度较低且价格高,第二就是程序执行的局部性特点。
因此,才将速度比较快而容量有限的SRAM构成Cache,目的在于尽可能发挥CPU的高速度。
很显然,要尽可能发挥CPU的高速度就必须用硬件实现其全部功能。
Cache与主存之间可采取多种地址映射方式,直接映射方式是其中的一种。
在这种映射方式下,主存中的每一页只能复制到某一固定的Cache页中。
由于Cache块(页)的大小为16B,而Cache容量为16KB。
因此,此Cache可分为1024页。
可以看到,Cache的页内地址只需4位即可表示;而Cache的页号需用10位二进制数来表示;在映射时,是将主存地址直接复制,现主存地址为1234E8F8(十六进制),则最低4位为Cache的页内地址,即1000,中间10位为Cache的页号,即1010001111。
Cache的容量为16KB决定用这14位编码即可表示。
题中所需求的Cache的地址为10100011111000。
Cache中的内容随命中率的降低需要经常替换新的内容。
替换算法有多种,例如,先入后出(FILO)算法、随机替换(RAND)算法、先入先出(FIFO)算法、近期最少使用(LRU)算法等。
这些替换算法各有优缺点,就以命中率而言,近期最少使用(LRU)算法的命中率最高。
浏览器缓存缓存用于存储一些临时的文件。
计算机高速缓冲存储器(Cache)命中率的分析

3 影 响 C ce 中率要 与 C c e中块 的大 小 、 的大 小 、 a h ah ah 组 C c e容 量 和 C c e中数 据 的替 换 算 法 和 地 ah 址 流 的簇 聚性 有关 . 3 1 C ce命 中率 与 C c e 量 的关系 . ah ah 容 如 果 C U每 次需要 访 问 的数 据都存 在 于 C ce中 , P ah 也就 是 每次访 问 C c e ah 都命 中 , 么 C c e的容量 就 那 ah
解 决 了 C U和主存 速度 不 匹配 的 问题 , ah P C c e的大 小 、 容量 的 组织方 式 、 问方 法等 直 接影 响 了 C U处理 数 访 P
据 的速 度 .
1 计算 机 存储 器体 系层 的次 结构 介 绍 计算 机 的存 储体 系是 为 了满 足人 们对 计算 机存 储 器 “ 量 大 、 度 快 、 容 速 价格 低 ” 的要 求 而设 计 的. 储 体 存
V0 . No 3 1 2l . Se 201 p. 2
计 算 机 高 速 缓 冲 存 储 器 ( a h ) 中率 的分 析 C ce 命
席 红 旗
( 南教 育 学 院 信 息 技 术 系 , 南 郑 , 4 0 4 ) 河 河 k 50 6 m 1
摘 要 : C c e的 容 量 、 间逻 辑 组 织 结 构 的 组 大 小 、 大 小 、 据 的 替 换 算 法 和 写 入 C c e的数 据 地 址 流 对 从 ah 空 块 数 ah
Cache命中率分析工具的使用(附源代码)

题目:安装一种Cache命中率分析工具,并现场安装、演示。
一、什么是CPU-CacheCPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
CPU包含多个核心,每个核心又有独自的一级缓存(细分成代码缓存和数据缓存)和二级缓存,各个核心之间共享三级缓存,并统一通过总线与内存进行交互。
二、关于Cache Line整个Cache被分成多个Line,每个Line通常是32byte或64byte,Cache Line是Cache和内存交换数据的最小单位,每个Cache Line包含三个部分Valid:当前缓存是否有效Tag:对应的内存地址Block:缓存数据三、Cache命中率分析工具选择1、Linux平台:Valgrind分析工具;2、Windows平台如下:java的Jprofiler;C++的VisualStudio2010及以后的版本中自带profile工具;Application Verifier;intel vtune等。
四、选用Valgrind分析工具在Linux-Ubuntu14.04环境下实验1.Valgrind分析工具的常用命令功能:memcheck:检查程序中的内存问题,如泄漏、越界、非法指针等。
callgrind:检测程序代码的运行时间和调用过程,以及分析程序性能。
cachegrind:分析CPU的cache命中率、丢失率,用于进行代码优化。
helgrind:用于检查多线程程序的竞态条件。
massif:堆栈分析器,指示程序中使用了多少堆内存等信息。
cache命中率实验报告

矩阵乘程序的cache失效率实验
实验目的:
使用project4中实现的cache验证结论:对于矩阵乘程序,当矩阵规模N=512(或1024)时,数据cache的失效率高于N=513(或1025)时的。
实验环境:
Dev-c++。
实验内容:
使用for循还将地址流保存到二位数组中,随后模拟矩阵乘运算的过程,计算当N=512、513、1024、1025时cache的命中率(源代码中N为DATA)。
方法一是通过真实执行矩阵乘运算来计算cache命中率,而方法二仅仅是模拟取地址的过程,可见方法二的操作包含在方法一的操作中,故显然方法二的时间比方法一的时间短。
实验非常重要的一项内容就是优化算法,使得程序执行时间变短,为此,我分别采用了三种方法来计算地址流:
1、使用三个大小为N的矩阵,其将其内容循环赋值为a、b、c的地址然后依次对相应地址进行访问。
该方法的优点是算数运算较少,且简单直接,但是执行时间较长。
2、将地址流写入文件,然后读取文件内容进行访问。
但是在实际操作时发现,由于矩阵太过庞大,导致文件过大无法实现(当矩阵大小为1025时,我发现txt文件大小为10G 多而且还在不断变大,所以就果断的杀掉还在执行的程序,并且放弃了这种方法)。
3、不将地址流保存,而是在访问过程中计算地址流,但是由于算数运算过多,时间也并不快。
综上考虑,仍然使用第一种方法实现本实验。
结果检验:
由于算法实现问题,导致程序执行需要较长时间,但是从结果上依然能够证明当矩阵规模N=512(或1024)时,数据cache的失效率高于N=513(或1025)时的。
Cache命中率

Cache命中率
在数据库的设计中,cache是极其重要的⼀个模块
命中率⾼,延迟低的cache是承受⾼QPS,低延时的关键
其中,在热点key场景下,全局cache很容易造成锁瓶颈
于是,我们可以采⽤thread local + global的两级cache,应对热点key
针对thread local cache的⼤⼩应该设置多⼤来进⾏讨论
问题
作为数据库的cache,采⽤ thread local + global 两级cache
thread local 应对热点key,global 作为普通cache (可以参考leveldb 的 cache)
问:thread local 设置多⼤的效果较好?
解答
两级cache定位不同,因此我们只 care 热点key 的命中率
数学抽象
a 代表热点key,
b 代表普通key
m 代表 a 的⼤⼩,n 代表 b 的⼤⼩
p 代表 a 的QPS,q 代表 b 的QPS
理论答案
若相邻 a 之间,b 的个数为 x ,x 的 99 分位数为 y
则 m + y * n ⼤⼩的cache,可以使命中率达到 99%
特殊地
若热key在所有key中均匀分布
则⼤于 (p * m + q * n) / p 的 cache,可以使命中率达到100%
⼀般的,若热key占10 %,key⼤⼩⼀致为10B,在设置⼤于100B的cache,可达到100%
由此可见,只考虑热点key的命中率,较⼩的cache,就能达到很好的效果。
memcached 命中率及状态说明

Connected to 172.16.32.166.
Escape character is '^]'.
stats
STAT pid 26530
STAT uptime 5807
STAT time 1258643806
STAT version 1.2.2
STAT pointer_size 64
STAT rusage_system 6850.564555
STAT curr_items 2537
STAT total_items 872539
STAT bytes 9939637
STAT curr_connections 17
STAT total_connections 6166911
STAT connection_structures 110
STAT cmd_get 68414905
STAT cmd_set 872539
STAT get_hits 67605437
STAT get_misses 809468
STAT evictions 0
STAT bytes_read 921056148171
STAT bytes_written 2323979209207
STAT limit_maxbytes 2147483648
STAT threads 1
END
pid
memcache服务器的进程ID
uptime
服务器已经运行的秒数
time
服务器当前的unix时间戳
version
memcache版本
pointer_size
当前OS的指针大小(32位系统一般是32bit)
nodejs搭建自己的简易缓存cache管理模块

nodejs搭建⾃⼰的简易缓存cache管理模块为什么要搭建⾃⼰的缓存管理模块?这个问题其实也是在问,为什么不使⽤现有的Cache存储系统,⽐如Redis,⽐如Memcached。
不是说Redis不够好,只是在处理某些场景中使⽤的Redis会显的太“笨重”了——Redis的优势之⼀在于能够供多进程共享,有完善的备份和恢复机制。
但反过来想,如果你的缓存仅供单个进程,单个Node实例使⽤,并且可以容忍缓存的丢失,承受冷启动。
那么是值得⽤不到500⾏的代码来搭建⼀个速度更快的缓存模块。
在Node中做缓存最简单的作法莫过于使⽤⼀个Object对象,将缓存以key-value的形式存⼊这个对象中,并且这么做的理由只有⼀个,就是更快的存取速度。
相⽐Redis通过TCP连接的形式与客户端进⾏通信,在程序中直接使⽤对象进⾏存储的效率会是Redis的40倍。
在⽂章的最后给出的完整的源代码中,有⼀个Redis与这个500⾏代码的性能对⽐测试:10000次的set操作,Redis使⽤的时间为12.5秒左右,平均运算次数为(operations per second)为8013 o/s,⽽如果使⽤原⽣的Object对象,10000次操作只需要0.3秒,平均运算次数为322581 o/s搭建⾃⼰的Cache模块需要解决什么问题缓存淘汰算法介于缓存只能够有限的使⽤内存,任何Cache系统都需要⼀个如何淘汰缓存的⽅案(缓存淘汰算法,等同于页⾯置换算法)。
在Node中⽆法像Redis那样设置使⽤内存⼤⼩(通过Redis中的maxmemory配置选项),所以我们只能通过设置缓存的个数(key-value对数)来间接对缓存⼤⼩进⾏控制。
但这同时也赋予了我们另⼀⾃由,就是⽤何种算法来淘汰多余的缓存,以便能提⾼命中率。
相关⼚商内容相关赞助商⾼德地图lbs专区,惊爆内容!Redis只提供五种淘汰⽅案(maxmemory-policy):volatile-lru: remove a key among the ones with an expire set, trying to remove keys not recently used(根据过期时间,移除最长时间没有使⽤过的).volatile-ttl: remove a key among the ones with an expire set, trying to remove keys with short remaining time to live(根据过期时间,移除即将过期的).volatile-random: remove a random key among the ones with an expire set(根据过期时间任意移除⼀个).allkeys-lru: like volatile-lru, but will remove every kind of key, both normal keys or keys with an expire set(⽆论是否有过期时间,根据LRU原则来移除).allkeys-random: like volatile-random, but will remove every kind of keys, both normal keys and keys with an expire set(⽆论是否有过期时间,随机移除).可见Redis的移除策略⼤部分是根据缓存的过期时间和LRU(Least Recently Used,最近最少使⽤,,其核⼼思想是“如果数据最近被访问过,那么将来被访问的⼏率也更⾼”)算法。
高性能Java缓存库—Caffeine

⾼性能Java缓存库—Caffeine1、介绍在本⽂中,我将介绍 — ⼀个⾼性能的 Java 缓存库。
缓存和 Map 之间的⼀个根本区别在于缓存可以回收存储的 item。
回收策略为在指定时间删除哪些对象。
此策略直接影响缓存的命中率 —— 缓存库的⼀个重要特性。
Caffeine 因使⽤了 Window TinyLfu 回收策略,提供了⼀个近乎最佳的命中率。
2、依赖我们需要在 pom.xml 中添加 caffeine 依赖:<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.5.5</version></dependency>你可以在 上找到最新版本的 caffeine。
3、填充缓存让我们来了解⼀下 Caffeine 的三种缓存填充策略:⼿动、同步加载和异步加载。
⾸先,我们为要缓存中存储的值类型写⼀个类:class DataObject {private final String data;private static int objectCounter = 0;// standard constructors/getterspublic static DataObject get(String data) {objectCounter++;return new DataObject(data);}}3.1、⼿动填充在此策略中,我们⼿动将值放⼊缓存后再检索。
初始化缓存:Cache<String, DataObject> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.MINUTES).maximumSize(100).build();现在,我们可以使⽤ getIfPresent ⽅法从缓存中获取值。
分析影响cache命中率的因素

分析影响cache命中率的因素摘要:存储器是计算机的核心部件之一。
由于CPU和主存在速度上的存在着巨大差异,现代计算机都在CPU和主存之间设置一个高速、小容量的缓冲存储器cache。
而它完全是是由硬件实现,所以它不但对应用程序员透明,而且对系统程序员也是透明的。
Cache对于提高整个计算机系统的性能有着重要的意义,几乎是一个不可缺少的部件。
关键字:cache容量;失效率;块大小;相联度;替换策略。
一、概述存储器是计算机的核心部件之一。
其性能直接关系到整个计算机系统性能的高低。
如何以合理的价格,设计容量和速度都满足计算机系统要求的存储器系统,始终是计算机系统结构设计的中关键的问题之一。
计算机软件设计者和计算机用户对于存储器容量的需求是没有止境的,他们希望容量越大越好,而且要求速度快、价格低。
仅用单一的存储器是很难达到这一需求目标的。
较好的方法是采用存储层次,用多种存储器构成存储器的层次结构。
其中“cache-主存”和“主存-辅存”层次是常见的两种层次结构,几乎所有现代的计算机都同时具有这两种层次。
我们都知道,程序在执行前,需先调入主存。
在这里主要讨论的是“cache-主存”层次。
“cache-主存”是在为了弥补主存速度的不足,这个层次的工作一般来说,完全是由硬件实现,所以它不但对应用程序员透明,而且对系统程序员也是透明的。
如前所述,为了弥补CPU和主存在速度上的巨大差异,现代计算机都在CPU和主存之间设置一个高速、小容量的缓冲存储器cache。
Cache对于提高整个计算机系统的性能有着重要的意义,几乎是一个不可缺少的部件。
Cache是按块进行管理的。
Cache和主存均被分割成大小相同的块。
信息以块为单位调入cache。
相应的,CPU的访存地址被分割成两部分:块地址和块内位移。
在这里的cache专指CPU和主存之间的cache。
对Cache的性能分析可以从三个方面进行:降低失效率、减少失效开销、减少Cache命中时间。
代码缓存命中计算

代码缓存命中计算
代码缓存命中计算是指计算代码缓存(Code Cache)的命中率(Hit Rate)。
Code Cache是JVM中的一种区域,用来存储JIT
(Just-In-Time)编译后的本地机器代码,也称为热点代码(HotSpot)。
当一个方法被多次调用,JIT会将其编译为本地机器代码并存储在Code Cache中,从而提高程序的性能。
代码缓存命中计算可以通过以下公式进行计算:
Hit Rate = (Total Code Cache - Code Cache Free) / Total Code Cache
其中,Total Code Cache表示Code Cache的总大小,Code Cache Free表示Code Cache中空闲的空间大小。
代码缓存命中率越高,说明JIT编译的代码能够被充分利用,从
而提高程序的性能。
但是,如果Code Cache的大小不足,或者程序中存在大量不稳定的代码,可能会导致Code Cache命中率降低,从而降低程序的性能。
因此,对于大型的、长时间运行的Java应用程序,需要定期监控和调整Code Cache的大小,以确保其能够充分利用Code Cache并保持高命中率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
题目:安装一种Cache命中率分析工具,并现场安装、演示。
一、什么是CPU-Cache
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容
量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解
决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读
写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
CPU包
含多个核心,每个核心又有独自的一级缓存(细分成代码缓存和数据缓存)和二
级缓存,各个核心之间共享三级缓存,并统一通过总线与内存进行交互。
二、关于Cache Line
整个Cache被分成多个Line,每个Line通常是32byte或64byte,Cache Line
是Cache和内存交换数据的最小单位,每个Cache Line包含三个部分
Valid:当前缓存是否有效
Tag:对应的内存地址
Block:缓存数据
三、Cache命中率分析工具选择
1、Linux平台:Valgrind分析工具;
2、Windows平台如下:
java的Jprofiler;
C++的VisualStudio2010及以后的版本中自带profile工具;
Application Verifier;
intel vtune等。
四、选用Valgrind分析工具在Linux-Ubuntu14.04环境下实验
1.Valgrind分析工具的常用命令功能:
memcheck:检查程序中的内存问题,如泄漏、越界、非法指针等。
callgrind:检测程序代码的运行时间和调用过程,以及分析程序性能。
cachegrind:分析CPU的cache命中率、丢失率,用于进行代码优化。
helgrind:用于检查多线程程序的竞态条件。
massif:堆栈分析器,指示程序中使用了多少堆内存等信息。
2.Valgrind分析工具的安装:
使用Ubuntu统一安装命令:sudo apt-get install valgrind
之后等待安装完成即可。
安装界面如图(由于我已经安装了此工具,而且没有更新的版本,图上结果为无可用升级)。
五、使用Valgrind分析工具测试程序的Cache命中率
1.首先,编写两个C语言程序,主要使用对数组数据两种读写方式来测试Cache命中率的不同,同时根据程序做同一件事的运行时间来判断程序质量的好坏。
代码如下:
cache1.c :
#include <stdio.h>
#include <time.h>
#include<sys/time.h>
#define MAXROW 8000
#define MAXCOL 8000
int main () {
struct timeval startTime,endTime;
float Timeuse;
int i,j;
static int x[MAXROW][MAXCOL];
printf ("Running!\n");
gettimeofday(&startTime,NULL);
for (i=0;i<MAXROW;i++)
for (j=0;j<MAXCOL;j++)
x[i][j] = i*j;
printf("Completed!\n");
gettimeofday(&endTime,NULL);
Timeuse = 1000000*(_sec - _sec) + (_usec - _usec);
Timeuse /= 1000000;
printf("Timeuse = %f\n",Timeuse);
return 0;
}
cache2.c :
#include <stdio.h>
#include <time.h>
#include<sys/time.h>
#define MAXROW 8000
#define MAXCOL 8000
int main () {
struct timeval startTime,endTime;
float Timeuse;
int i,j;
static int x[MAXROW][MAXCOL];
printf ("Running!\n");
gettimeofday(&startTime,NULL);
for (j=0;j<MAXCOL;j++)
for (i=0;i<MAXROW;i++)
x[i][j] = i*j;
printf("Completed!\n");
gettimeofday(&endTime,NULL);
Timeuse = 1000000*(_sec - _sec) + (_usec - _usec);
Timeuse /= 1000000;
printf("Timeuse = %f\n",Timeuse);
return 0;
}
2.对以上两个程序进行Cache命中率测试:
①编译两程序:
gcc -o cache1 cache1.c
gcc -o cache2 cache2.c
②使用命令valgrind --tool=cachegrind ./cache1
测试cache1程序的Cache命中率:
③使用命令valgrind --tool=cachegrind ./cache2
测试cache2程序的Cache命中率:
3.对测试结果进行分析:
·由cache1测试结果可以看出程序cache1的D1 miss rate: 0.8%可知1级Cache的数据未命中率为0.8%,即命中率为99.2%;
·由Timeuse = 9.733398可以cache1中数组循环完成的时间是9.733398s
由cache2测试结果可以看出程序cache2的D1 miss rate: 14.2%可知1级Cache的数据未命中率为14.2%,即命中率为85.8%;
·由Timeuse = 15.708803可以cache1中数组循环完成的时间是15.708803s
综上可知cache1程序的cache命中率大于cache2,cache1循环所用时间少于cache2,即cache1程序质量比cache2好。
六、感想
这次研讨主要对Cache及Cache命中率测试工具进行了讨论,准备这次研讨时,我先查找了有关CPU Cache的资料并进行学习,加深了我对CPU Cache的理解,之后,查找了各种有关Cache命中率分析工具的资料,并选择Linux环境下的Valgrind作为此次研讨使用的工具。
在对程序进行Cache命中率的测试过程中,我对程序代码进行了设计编写,尽可能的使得程序Cache命中率变化明显,进而容易对比,容易理解。
这也让我对Valgrind工具的使用更加熟悉,也对造成Cache命中率高低的因素有了更明确的理解,深感收获很多!。