pooleddb的用法
Python数据库读写分离技术

Python数据库读写分离技术Python数据库读写分离技术摘要本论文介绍了Python数据库读写分离技术的概念和实现原理。
通过将数据库的读和写分别部署在不同的服务器或节点上,可以提高系统的可靠性和扩展性。
本文重点讨论了该技术的应用场景、优势以及实现方法,并提出了一些值得注意的问题。
最后,我们通过实例分析的方法验证了该技术的有效性。
关键词:Python、数据库、读写分离、可靠性、扩展性引言数据库作为现代企业信息化过程中最常用的存储与管理涉密信息的技术,其读写性能常常是系统性能的重要瓶颈之一。
为了保障企业信息系统的正常运行,企业需要不断优化数据库技术。
对于大型企业和高并发访问量的系统,数据库读写分离技术是一项非常重要的技术。
数据库读写分离技术是将数据库的读和写分别部署在不同的服务器或节点上,以提高系统的可靠性和扩展性。
Python作为一种高效、灵活、易学易用的编程语言,非常适合用来开发企业级应用,因此,使用Python实现数据库读写分离技术,成为很多企业的首选方案。
本文将重点介绍Python数据库读写分离的实现原理,包括设计思路、应用场景、优势以及实现方法等,以期为广大Python程序员提供一些有益的参考。
1.设计思路在实际生产环境中,高并发访问的情况经常出现。
如果把数据库的所有请求都交给单一的服务器来处理,势必会导致服务器性能的瓶颈,从而影响到整个系统的响应速度。
为了解决这种情况,可以把数据库的读写功能分离到不同的服务器或节点上。
一般情况下,写入操作通常是少量的,但是需要保证100%的数据可靠性,因此很适合放在主服务器上处理。
而读取数据则相对比较频繁,所以可以把读操作放在从属服务器中处理。
通过对数据库读写的分离,主服务器可以快速处理写请求,并对所有从属服务器进行同步和备份,保证数据的一致性和可靠性。
而从属服务器则只需要处理读请求,可以采用多个节点组成一个分布式缓存系统,提高系统的性能和响应速度,降低延迟。
pooleddb的用法

pooleddb的用法
Pooleddb(也称为Pool Databases)是一种用于管理和存储数据的数据库系统。
它通过将数据分布在多个节点上,实现了数据的高可用性和可伸缩性。
下面将介绍一些关于Pooleddb的基本用法和功能。
首先,Pooleddb可以支持多个节点同时访问和管理数据库。
这些节点可以分布在不同的物理服务器上,通过网络连接进行通信。
这种分布式架构使得Pooleddb 可以在数据库节点发生故障时实现自动故障转移,保证数据的可用性。
其次,Pooleddb提供了一种灵活的数据模型,可以轻松地存储和查询各种类型的数据。
它支持事务处理和ACID(原子性、一致性、隔离性和持久性)特性,确保数据的完整性和可靠性。
另外,Pooleddb还提供了多种数据访问接口,包括SQL和NoSQL。
这使得开发人员可以根据自身需求选择合适的接口进行数据操作。
同时,Pooleddb还支持数据分片和数据复制功能,以实现数据的水平扩展和备份。
在实际应用中,Pooleddb可以用于各种场景,如Web应用程序、企业应用、物联网等。
它可以处理大量的并发读写请求,提供高性能和低延迟的数据访问。
同时,Pooleddb还支持数据的在线扩容,可以根据需求动态增加或减少节点,以适应数据量的变化。
总之,Pooleddb是一种功能强大的分布式数据库系统,具有高可用性、可伸缩性和灵活的数据模型。
通过使用Pooleddb,开发人员可以轻松地管理和存储海量数据,实现高性能和可靠的数据访问。
python使用dbutils的PooledDB连接池,操作数据库

python使⽤dbutils的PooledDB连接池,操作数据库1、使⽤dbutils的PooledDB连接池,操作数据库。
这样就不需要每次执⾏sql后都关闭数据库连接,频繁的创建连接,消耗时间2、如果是使⽤⼀个连接⼀直不关闭,多线程下,插⼊超长字符串到数据库,运⾏⼀段时间后很容易出现OperationalError: (2006, ‘MySQL server has gone away’)这个错误。
使⽤PooledDB解决。
# coding=utf-8"""使⽤DBUtils数据库连接池中的连接,操作数据库OperationalError: (2006, ‘MySQL server has gone away’)"""import jsonimport pymysqlimport datetimefrom DBUtils.PooledDB import PooledDBimport pymysqlclass MysqlClient(object):__pool = None;def__init__(self, mincached=10, maxcached=20, maxshared=10, maxconnections=200, blocking=True,maxusage=100, setsession=None, reset=True,host='127.0.0.1', port=3306, db='test',user='root', passwd='123456', charset='utf8mb4'):""":param mincached:连接池中空闲连接的初始数量:param maxcached:连接池中空闲连接的最⼤数量:param maxshared:共享连接的最⼤数量:param maxconnections:创建连接池的最⼤数量:param blocking:超过最⼤连接数量时候的表现,为True等待连接数量下降,为false直接报错处理:param maxusage:单个连接的最⼤重复使⽤次数:param setsession:optional list of SQL commands that may serve to preparethe session, e.g. ["set datestyle to ...", "set time zone ..."]:param reset:how connections should be reset when returned to the pool(False or None to rollback transcations started with begin(),True to always issue a rollback for safety's sake):param host:数据库ip地址:param port:数据库端⼝:param db:库名:param user:⽤户名:param passwd:密码:param charset:字符编码"""if not self.__pool:self.__class__.__pool = PooledDB(pymysql,mincached, maxcached,maxshared, maxconnections, blocking,maxusage, setsession, reset,host=host, port=port, db=db,user=user, passwd=passwd,charset=charset,cursorclass=pymysql.cursors.DictCursor)self._conn = Noneself._cursor = Noneself.__get_conn()def__get_conn(self):self._conn = self.__pool.connection();self._cursor = self._conn.cursor();def close(self):try:self._cursor.close()self._conn.close()except Exception as e:print edef__execute(self, sql, param=()):count = self._cursor.execute(sql, param)print countreturn count@staticmethoddef__dict_datetime_obj_to_str(result_dict):"""把字典⾥⾯的datatime对象转成字符串,使json转换不出错"""if result_dict:result_replace = {k: v.__str__() for k, v in result_dict.items() if isinstance(v, datetime.datetime)}result_dict.update(result_replace)return result_dictdef select_one(self, sql, param=()):"""查询单个结果"""count = self.__execute(sql, param)result = self._cursor.fetchone()""":type result:dict"""result = self.__dict_datetime_obj_to_str(result)return count, resultdef select_many(self, sql, param=()):"""查询多个结果:param sql: qsl语句:param param: sql参数:return: 结果数量和查询结果集"""count = self.__execute(sql, param)result = self._cursor.fetchall()""":type result:list"""[self.__dict_datetime_obj_to_str(row_dict) for row_dict in result]return count, resultdef execute(self, sql, param=()):count = self.__execute(sql, param)return countdef begin(self):"""开启事务"""self._conn.autocommit(0)def end(self, option='commit'):"""结束事务"""if option == 'commit':self._conn.autocommit()else:self._conn.rollback()if__name__ == "__main__":mc = MysqlClient()sql1 = 'SELECT * FROM shiji WHERE id = 1'result1 = mc.select_one(sql1)print json.dumps(result1[1], ensure_ascii=False)sql2 = 'SELECT * FROM shiji WHERE id IN (%s,%s,%s)'param = (2, 3, 4)print json.dumps(mc.select_many(sql2, param)[1], ensure_ascii=False)如果独⽴使⽤pymysql数据库,最好是配合DButils库。
pooleddb的用法

Pooleddb的用法1. 什么是Pooleddb?Pooleddb是一个用于管理分布式数据库的工具。
它是一个开源项目,旨在简化和优化数据库的部署和管理。
Pooleddb提供了一种简单且高效的方式来管理大规模的数据库集群,使得数据库的水平扩展变得更加容易。
2. Pooleddb的特点2.1 分布式架构Pooleddb使用分布式架构,将数据库分散在多个节点上。
每个节点都可以独立地处理查询和事务,从而提高数据库的性能和可伸缩性。
2.2 自动故障恢复Pooleddb具有自动故障恢复的能力。
当某个节点发生故障时,Pooleddb会自动将数据迁移到其他正常节点上,确保数据库的高可用性。
2.3 数据一致性Pooleddb采用分布式一致性算法,确保所有节点上的数据保持一致。
它使用副本机制来存储数据,并使用一致性协议来保证数据的一致性。
2.4 负载均衡Pooleddb通过负载均衡算法将查询请求均匀地分配到不同的节点上,从而提高数据库的性能和吞吐量。
它可以根据节点的负载情况自动调整查询的分配策略。
2.5 扩展性Pooleddb可以很容易地扩展数据库的规模。
只需添加更多的节点,就可以增加数据库的容量和性能。
3. Pooleddb的安装和配置3.1 安装Pooleddb要安装Pooleddb,可以按照以下步骤进行操作:1.下载Pooleddb的安装包。
2.解压安装包到指定的目录。
3.运行安装脚本,按照提示完成安装过程。
3.2 配置Pooleddb安装完成后,需要对Pooleddb进行配置,以便正确地运行数据库集群。
配置文件通常位于安装目录的config文件夹中。
可以根据需要修改配置文件中的参数,以适应特定的环境和需求。
4. Pooleddb的使用4.1 创建数据库要创建一个新的数据库,可以使用Pooleddb提供的命令行工具。
可以使用以下命令创建一个名为”mydb”的数据库:pooleddb create mydb4.2 连接数据库要连接到Pooleddb中的数据库,可以使用以下命令:pooleddb connect mydb4.3 执行查询连接到数据库后,可以执行各种查询操作。
policydb解析

policydb解析全文共四篇示例,供读者参考第一篇示例:PolicyDB是一种用于编程的数据库,它可以帮助开发人员在应用程序中实现访问控制策略。
PolicyDB在很多操作系统中得到应用,比如Linux、UNIX等。
通过PolicyDB,开发人员可以定义不同用户和角色在系统中的权限和访问控制策略,从而保护系统的安全性。
PolicyDB的解析是指系统如何解释和执行通过PolicyDB定义的策略。
这个过程涉及到策略管理、权限校验等方面。
在很多操作系统中,PolicyDB的解析是由内核模块来实现的。
内核模块会解析PolicyDB中定义的策略规则,并根据这些规则来对系统中的用户进行权限控制。
在PolicyDB中,策略规则通常由主体(subject)、对象(object)和动作(action)组成。
主体指的是拥有访问权限的用户或角色,对象指的是要访问的资源,动作指的是用户对资源执行的操作。
通过定义这些规则,开发人员可以灵活地控制不同用户对系统资源的访问权限。
PolicyDB的解析过程通常包括以下几个步骤:1. 策略加载和解析:系统会在启动时加载PolicyDB中定义的策略规则,并解析这些规则,将其存储在内存中以便后续的访问控制操作。
2. 访问控制:当用户发起访问请求时,内核模块会根据PolicyDB 中定义的规则对请求进行访问控制。
如果请求符合规则,则可以执行相应的操作;否则会被拒绝。
3. 策略管理:在系统运行过程中,开发人员可能需要对PolicyDB 中的策略进行修改和更新。
内核模块会提供相应的管理接口,使开发人员能够灵活地管理策略。
4. 日志记录:为了方便系统管理员对系统权限的监控和调整,PolicyDB通常会记录访问控制的日志。
管理员可以通过查看日志来了解系统中用户的访问情况,及时探测异常访问行为。
PolicyDB的解析是系统安全性的重要保障之一。
通过合理地定义策略规则和有效地解析这些规则,可以有效地保护系统资源不受非法访问。
剩余产量模型

平衡渔获量与平均资源生物量及捕捞死亡系数三者之间的关系
上图中,通过原点直线的斜率为F。设对某渔业的捕捞死 亡系数F1(图中OP直线的斜率),若当时的平均资源生物量为 B2,而此时的实际渔获量为SB2,大于所对应的平衡渔获量QB1, 使资源量水平下降而向B1靠拢;若当时资源量水平为B3,则此 时的实际渔获量为RB3,小于其所对应的平衡渔获量QB1 ,资源 量水平上升而向B1靠拢。可见如果逐年均以稳定的F进行捕捞, 则资源群体将会通过自身的再生产起调节作用,使资源量水平 处在该捕捞水平所对应的平衡资源量水平。如果捕捞努力量逐 年变动,则渔业将永远达不到任何平衡点。
表达式。其推导过程与上节所述的相同,具体如下:
Ye
rm
B
( rm B
) B 2或Ye
KB
B
K
2
B
Ye
B F
( B rm
)F 2或Ye
B F
F2
K
Ye
qB
f
( q2B rm
)
f
2或Ye
qB
f
(qf
)2
K
Ye af bf 2 Ye f a bf
fmsy a 2b 和MSY a2 4b
若资源相对的瞬间增长率 1 dB 用f (B)表示,当资源生物量 B dt
极小时,这个函数值最高,但当资源生物量增长到最大值B时, f (B)逐步下降到0 (图6-1,6-2,6-3)。
函数表达式:f (B) 1 dB , f (B)与B成线性关系, B dt
则f (B) r KB,因B B时f (B) 0,得r KB, 故资源生物量的绝对增长率为:f (B) BK(B B) KBB KB2。 可见资源生物量B的绝对增加量与B呈抛物线关系,在B 2 处 得到极值(MSY),而在这条抛物线上的任一点均处在平衡状态。
解决mysql服务器在无操作超时主动断开连接的情况

解决mysql服务器在⽆操作超时主动断开连接的情况我们在使⽤mysql服务的时候,正常情况下,mysql的设置的timeout是8个⼩时(28800秒),也就是说,如果⼀个连接8个⼩时都没有操作,那么mysql会主动的断开连接,当这个连接再次尝试查询的时候就会报个”MySQL server has gone away”的误,但是有时候,由于mysql服务器那边做了⼀些设置,很多情况下会缩短这个连接timeout时长以保证更多的连接可⽤。
有时候设置得⽐较变态,很短,30秒,这样就需要客户端这边做⼀些操作来保证不要让mysql主动来断开。
查看mysql的timeout使⽤客户端⼯具或者Mysql命令⾏⼯具输⼊show global variables like '%timeout%';就会显⽰与timeout相关的属性,这⾥我⽤docker模拟了⼀个测试环境。
mysql> show variables like '%timeout%';+-----------------------------+----------+| Variable_name | Value |+-----------------------------+----------+| connect_timeout | 10 || delayed_insert_timeout | 300 || have_statement_timeout | YES || innodb_flush_log_at_timeout | 1 || innodb_lock_wait_timeout | 50 || innodb_rollback_on_timeout | OFF || interactive_timeout | 30 || lock_wait_timeout | 31536000 || net_read_timeout | 30 || net_write_timeout | 60 || rpl_stop_slave_timeout | 31536000 || slave_net_timeout | 60 || wait_timeout | 30 |+-----------------------------+----------+13 rows in setwait_timeout:服务器关闭⾮交互连接之前等待活动的秒数,就是你在你的项⽬中进⾏程序调⽤interactive_timeout: 服务器关闭交互式连接前等待活动的秒数,就是你在你的本机上打开mysql的客户端,cmd的那种使⽤pymysql进⾏查询我在数据库⾥随便创建了⼀个表,插⼊两条数据mysql> select * from person;+----+------+-----+| id | name | age |+----+------+-----+| 1 | yang | 18 || 2 | fan | 16 |+----+------+-----+2 rows in set我使⽤pymysql这个库对其进⾏查询操作,很简单#coding:utf-8import pymysqldef mytest():connection = pymysql.connect(host='localhost',port=3306,user='root',password='123456',db='mytest',charset='utf8')cursor = connection.cursor()cursor.execute("select * from person")data = cursor.fetchall()cursor.close()for i in data:print(i)cursor.close()connection.close()if __name__ == '__main__':mytest()可以正确的得到结果(1, 'yang', 18)(2, 'fan', 16)连接超时以后的查询上⾯可以正常得到结果是由于当创建好⼀个链接以后,就⽴刻进⾏了查询,此时还没有超过它的超时时间,如果我sleep⼀段时间,看看什么效果。
python3实现mysql数据库连接池的示例代码

python3实现mysql数据库连接池的⽰例代码DBUtils是⼀套Python数据库连接池包,并允许对⾮线程安全的数据库接⼝进⾏线程安全包装。
DBUtils来⾃Webware for Python。
DBUtils提供两种外部接⼝:PersistentDB :提供线程专⽤的数据库连接,并⾃动管理连接。
PooledDB :提供线程间可共享的数据库连接,并⾃动管理连接。
需要库1、DBUtils pip install DBUtils2、pymysql pip install pymysql/MySQLdb创建DButils组件db_config.py 配置⽂件# -*- coding: UTF-8 -*-import pymysql# 数据库信息DB_TEST_HOST = "127.0.0.1"DB_TEST_PORT = 3306DB_TEST_DBNAME = "ball"DB_TEST_USER = "root"DB_TEST_PASSWORD = "123456"# 数据库连接编码DB_CHARSET = "utf8"# mincached : 启动时开启的闲置连接数量(缺省值 0 开始时不创建连接)DB_MIN_CACHED = 10# maxcached : 连接池中允许的闲置的最多连接数量(缺省值 0 代表不闲置连接池⼤⼩)DB_MAX_CACHED = 10# maxshared : 共享连接数允许的最⼤数量(缺省值 0 代表所有连接都是专⽤的)如果达到了最⼤数量,被请求为共享的连接将会被共享使⽤DB_MAX_SHARED = 20# maxconnecyions : 创建连接池的最⼤数量(缺省值 0 代表不限制)DB_MAX_CONNECYIONS = 100# blocking : 设置在连接池达到最⼤数量时的⾏为(缺省值 0 或 False 代表返回⼀个错误<toMany......> 其他代表阻塞直到连接数减少,连接被分配) DB_BLOCKING = True# maxusage : 单个连接的最⼤允许复⽤次数(缺省值 0 或 False 代表不限制的复⽤).当达到最⼤数时,连接会⾃动重新连接(关闭和重新打开)DB_MAX_USAGE = 0# setsession : ⼀个可选的SQL命令列表⽤于准备每个会话,如["set datestyle to german", ...]DB_SET_SESSION = None# creator : 使⽤连接数据库的模块DB_CREATOR = pymysqldb_dbutils_init.py 创建数据池初始化from DBUtils.PooledDB import PooledDBimport db_config as config"""@功能:创建数据库连接池"""class MyConnectionPool(object):__pool = None# def __init__(self):# self.conn = self.__getConn()# self.cursor = self.conn.cursor()# 创建数据库连接conn和游标cursordef __enter__(self):self.conn = self.__getconn()self.cursor = self.conn.cursor()# 创建数据库连接池def __getconn(self):if self.__pool is None:self.__pool = PooledDB(creator=config.DB_CREATOR,mincached=config.DB_MIN_CACHED,maxcached=config.DB_MAX_CACHED,maxshared=config.DB_MAX_SHARED,maxconnections=config.DB_MAX_CONNECYIONS,blocking=config.DB_BLOCKING,maxusage=config.DB_MAX_USAGE,setsession=config.DB_SET_SESSION,host=config.DB_TEST_HOST,port=config.DB_TEST_PORT,user=config.DB_TEST_USER,passwd=config.DB_TEST_PASSWORD,db=config.DB_TEST_DBNAME,use_unicode=False,charset=config.DB_CHARSET)return self.__pool.connection()# 释放连接池资源def __exit__(self, exc_type, exc_val, exc_tb):self.cursor.close()self.conn.close()# 关闭连接归还给链接池# def close(self):# self.cursor.close()# self.conn.close()# 从连接池中取出⼀个连接def getconn(self):conn = self.__getconn()cursor = conn.cursor()return cursor, conn# 获取连接池,实例化def get_my_connection():return MyConnectionPool()制作mysqlhelper.pyfrom db_dbutils_init import get_my_connection"""执⾏语句查询有结果返回结果没有返回0;增/删/改返回变更数据条数,没有返回0"""class MySqLHelper(object):def __init__(self):self.db = get_my_connection() # 从数据池中获取连接def __new__(cls, *args, **kwargs):if not hasattr(cls, 'inst'): # 单例cls.inst = super(MySqLHelper, cls).__new__(cls, *args, **kwargs)return cls.inst# 封装执⾏命令def execute(self, sql, param=None, autoclose=False):"""【主要判断是否有参数和是否执⾏完就释放连接】:param sql: 字符串类型,sql语句:param param: sql语句中要替换的参数"select %s from tab where id=%s" 其中的%s就是参数 :param autoclose: 是否关闭连接:return: 返回连接conn和游标cursor"""cursor, conn = self.db.getconn() # 从连接池获取连接count = 0try:# count : 为改变的数据条数if param:count = cursor.execute(sql, param)else:count = cursor.execute(sql)mit()if autoclose:self.close(cursor, conn)except Exception as e:passreturn cursor, conn, count# 执⾏多条命令# def executemany(self, lis):# """# :param lis: 是⼀个列表,⾥⾯放的是每个sql的字典'[{"sql":"xxx","param":"xx"}....]' # :return:# """# cursor, conn = self.db.getconn()# try:# for order in lis:# sql = order['sql']# param = order['param']# if param:# cursor.execute(sql, param)# else:# cursor.execute(sql)# mit()# self.close(cursor, conn)# return True# except Exception as e:# print(e)# conn.rollback()# self.close(cursor, conn)# return False# 释放连接def close(self, cursor, conn):"""释放连接归还给连接池"""cursor.close()conn.close()# 查询所有def selectall(self, sql, param=None):try:cursor, conn, count = self.execute(sql, param)res = cursor.fetchall()return resexcept Exception as e:print(e)self.close(cursor, conn)return count# 查询单条def selectone(self, sql, param=None):try:cursor, conn, count = self.execute(sql, param)res = cursor.fetchone()self.close(cursor, conn)return resexcept Exception as e:print("error_msg:", e.args)self.close(cursor, conn)return count# 增加def insertone(self, sql, param):try:cursor, conn, count = self.execute(sql, param)# _id = strowid() # 获取当前插⼊数据的主键id,该id应该为⾃动⽣成为好 mit()self.close(cursor, conn)return count# 防⽌表中没有id返回0# if _id == 0:# return True# return _idexcept Exception as e:print(e)conn.rollback()self.close(cursor, conn)return count# 增加多⾏def insertmany(self, sql, param):""":param sql::param param: 必须是元组或列表[(),()]或((),()):return:"""cursor, conn, count = self.db.getconn()try:cursor.executemany(sql, param)mit()return countexcept Exception as e:print(e)conn.rollback()self.close(cursor, conn)return count# 删除def delete(self, sql, param=None):try:cursor, conn, count = self.execute(sql, param)self.close(cursor, conn)return countexcept Exception as e:print(e)conn.rollback()self.close(cursor, conn)return count# 更新def update(self, sql, param=None):try:cursor, conn, count = self.execute(sql, param)mit()self.close(cursor, conn)return countexcept Exception as e:print(e)conn.rollback()self.close(cursor, conn)return countif __name__ == '__main__':db = MySqLHelper()# # 查询单条# sql1 = 'select * from userinfo where name=%s'# args = 'python'# ret = db.selectone(sql=sql1, param=args)# print(ret) # (None, b'python', b'123456', b'0')# 增加单条# sql2 = 'insert into userinfo (name,password) VALUES (%s,%s)' # ret = db.insertone(sql2, ('old2','22222'))# print(ret)# 增加多条# sql3 = 'insert into userinfo (name,password) VALUES (%s,%s)' # li = li = [# ('分省', '123'),# ('到达','456')# ]# ret = db.insertmany(sql3,li)# print(ret)# 删除# sql4 = 'delete from userinfo WHERE name=%s'# args = 'xxxx'# ret = db.delete(sql4, args)# print(ret)# 更新# sql5 = r'update userinfo set password=%s WHERE name LIKE %s'# args = ('993333993', '%old%')# ret = db.update(sql5, args)# print(ret)python3 实现mysql数据库连接池原理python编程中可以使⽤MySQLdb进⾏数据库的连接及诸如查询/插⼊/更新等操作,但是每次连接mysql数据库请求时,都是独⽴的去请求访问,相当浪费资源,⽽且访问数量达到⼀定数量时,对mysql的性能会产⽣较⼤的影响。
pooleddb 参数

pooleddb 参数pooleddb是一款功能强大的数据库管理工具,它提供了简单易用的界面和强大的功能,可以帮助用户轻松地管理数据库。
在使用pooleddb时,参数是非常重要的,它们决定了数据库的连接、操作和性能等方面。
本文将介绍pooleddb的常用参数及其含义和用法。
一、连接参数连接参数是用于建立与数据库的连接的参数。
以下是pooleddb中常用的连接参数:1.主机名和端口号:这是数据库的地址信息,用于指定数据库所在的主机名和端口号。
主机名通常是服务器的IP地址或域名,而端口号通常是数据库所使用的端口。
例如,“localhost:3306”表示连接到本地主机上的MySQL数据库。
2.用户名和密码:这是用于连接数据库的用户名和密码,需要正确填写才能连接到数据库。
用户名和密码通常在数据库服务器上设置,并且只有具有相应权限的用户才能使用它们进行连接。
3.数据库名称:在成功连接到数据库后,可以选择要操作的数据库。
在pooleddb中,可以通过下拉菜单或手动输入来选择数据库名称。
二、操作参数操作参数是用于执行数据库操作的各种参数。
以下是pooleddb中常用的操作参数:1.查询语言:pooleddb支持多种查询语言,如SQL、NoSQL等。
选择适当的查询语言可以影响查询结果的呈现方式和性能。
2.查询语句:可以在pooleddb中输入或粘贴查询语句,执行相应的数据库操作。
查询语句可以是SQL语句或其他类型的查询,具体取决于所选的查询语言。
3.结果集格式:可以选择结果集的显示格式,如表格、列表等。
这有助于用户更方便地查看结果,并根据需要对其进行处理。
三、性能参数性能参数是用于优化数据库性能的各种参数。
以下是pooleddb中常用的性能参数:1.缓存大小:pooleddb提供了缓存功能,可以提高查询速度和性能。
通过调整缓存大小,可以控制缓存中存储的数据量,从而影响查询性能。
2.并发连接数:并发连接数是同时连接到数据库的连接数上限。
Python3多线程(连接池)操作MySQL插入数据

Python3多线程(连接池)操作MySQL插⼊数据⽬录多线程(连接池)操作MySQL插⼊数据1.主要模块2.创建连接池3.数据预处理4.线程任务5.启动多线程6.完整⽰例7.思考/总结多线程(连接池)操作MySQL插⼊数据针对于此篇博客的收获⼼得:⾸先是可以构建连接数据库的连接池,这样可以多开启连接,同⼀时间连接不同的数据表进⾏查询,插⼊,为多线程进⾏操作数据库打基础多线程根据多连接的⽅式,需求中要完成多语⾔的⼊库操作,我们可以启⽤多线程对不同语⾔数据进⾏并⾏操作在插⼊过程中,⼀条⼀插⼊,⽐较浪费时间,我们可以把数据进⾏积累,积累到⼀定的条数的时候,执⾏⼀条sql命令,⼀次性将多条数据插⼊到数据库中,节省时间cur.executemany1.主要模块DBUtils : 允许在多线程应⽤和数据库之间连接的模块套件Threading : 提供多线程功能2.创建连接池PooledDB 基本参数:mincached : 最少的空闲连接数,如果空闲连接数⼩于这个数,Pool⾃动创建新连接;maxcached : 最⼤的空闲连接数,如果空闲连接数⼤于这个数,Pool则关闭空闲连接;maxconnections : 最⼤的连接数;blocking : 当连接数达到最⼤的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会⼀直等待,直到当前连接数⼩于最⼤连接数,如果这个值是False,会报错;def mysql_connection():maxconnections = 15 # 最⼤连接数pool = PooledDB(pymysql,maxconnections,host='localhost',user='root',port=3306,passwd='123456',db='test_DB',use_unicode=True)return pool# 使⽤⽅式pool = mysql_connection()con = pool.connection()3.数据预处理⽂件格式:txt共准备了四份虚拟数据以便测试,分别有10万, 50万, 100万, 500万⾏数据MySQL表结构如下图:数据处理思路 :每⼀⾏⼀条记录,每个字段间⽤制表符 “\t” 间隔开,字段带有双引号;读取出来的数据类型是 Bytes ;最终得到嵌套列表的格式,⽤于多线程循环每个任务每次处理10万⾏数据;格式 : [ [(A,B,C,D), (A,B,C,D),(A,B,C,D),…], [(A,B,C,D), (A,B,C,D),(A,B,C,D),…], [], … ]import reimport timest = time.time()with open("10w.txt", "rb") as f:data = []for line in f:line = re.sub("\s", "", str(line, encoding="utf-8"))line = tuple(line[1:-1].split("\"\""))data.append(line)n = 100000 # 按每10万⾏数据为最⼩单位拆分成嵌套列表result = [data[i:i + n] for i in range(0, len(data), n)]print("10万⾏数据,耗时:{}".format(round(time.time() - st, 3)))# 10万⾏数据,耗时:0.374# 50万⾏数据,耗时:1.848# 100万⾏数据,耗时:3.725# 500万⾏数据,耗时:18.4934.线程任务每调⽤⼀次插⼊函数就从连接池中取出⼀个链接操作,完成后关闭链接;executemany 批量操作,减少 commit 次数,提升效率;def mysql_insert(*args):con = pool.connection()cur = con.cursor()sql = "INSERT INTO test(sku,fnsku,asin,shopid) VALUES(%s, %s, %s, %s)"try:cur.executemany(sql, *args)mit()except Exception as e:con.rollback() # 事务回滚print('SQL执⾏有误,原因:', e)finally:cur.close()con.close()5.启动多线程代码思路 :设定最⼤队列数,该值必须要⼩于连接池的最⼤连接数,否则创建线程任务所需要的连接⽆法满⾜,会报错 :pymysql.err.OperationalError: (1040, ‘Too many connections')循环预处理好的列表数据,添加队列任务如果达到队列最⼤值或者当前任务是最后⼀个,就开始多线程队执⾏队列⾥的任务,直到队列为空;def task():q = Queue(maxsize=10) # 设定最⼤队列数和线程数# data : 预处理好的数据(嵌套列表)while data:content = data.pop()t = threading.Thread(target=mysql_insert, args=(content,))q.put(t)if (q.full() == True) or (len(data)) == 0:thread_list = []while q.empty() == False:t = q.get()thread_list.append(t)t.start()for t in thread_list:t.join()6.完整⽰例import pymysqlimport threadingimport reimport timefrom queue import Queuefrom DBUtils.PooledDB import PooledDBclass ThreadInsert(object):"多线程并发MySQL插⼊数据"def __init__(self):start_time = time.time()self.pool = self.mysql_connection()self.data = self.getData()self.mysql_delete()self.task()print("========= 数据插⼊,共耗时:{}'s =========".format(round(time.time() - start_time, 3))) def mysql_connection(self):maxconnections = 15 # 最⼤连接数pool = PooledDB(pymysql,maxconnections,host='localhost',user='root',port=3306,passwd='123456',db='test_DB',use_unicode=True)return pooldef getData(self):st = time.time()with open("10w.txt", "rb") as f:data = []for line in f:line = re.sub("\s", "", str(line, encoding="utf-8"))line = tuple(line[1:-1].split("\"\""))data.append(line)n = 100000 # 按每10万⾏数据为最⼩单位拆分成嵌套列表result = [data[i:i + n] for i in range(0, len(data), n)]print("共获取{}组数据,每组{}个元素.==>> 耗时:{}'s".format(len(result), n, round(time.time() - st, 3))) return resultdef mysql_delete(self):st = time.time()con = self.pool.connection()cur = con.cursor()sql = "TRUNCATE TABLE test"cur.execute(sql)mit()cur.close()con.close()print("清空原数据.==>> 耗时:{}'s".format(round(time.time() - st, 3)))def mysql_insert(self, *args):con = self.pool.connection()cur = con.cursor()sql = "INSERT INTO test(sku, fnsku, asin, shopid) VALUES(%s, %s, %s, %s)"try:cur.executemany(sql, *args)mit()except Exception as e:con.rollback() # 事务回滚print('SQL执⾏有误,原因:', e)finally:cur.close()con.close()def task(self):q = Queue(maxsize=10) # 设定最⼤队列数和线程数st = time.time()while self.data:content = self.data.pop()t = threading.Thread(target=self.mysql_insert, args=(content,))q.put(t)if (q.full() == True) or (len(self.data)) == 0:thread_list = []while q.empty() == False:t = q.get()thread_list.append(t)t.start()for t in thread_list:t.join()print("数据插⼊完成.==>> 耗时:{}'s".format(round(time.time() - st, 3)))if __name__ == '__main__':ThreadInsert()插⼊数据对⽐共获取1组数据,每组100000个元素.== >> 耗时:0.374's清空原数据.== >> 耗时:0.031's数据插⼊完成.== >> 耗时:2.499's=============== 10w数据插⼊,共耗时:3.092's ===============共获取5组数据,每组100000个元素.== >> 耗时:1.745's清空原数据.== >> 耗时:0.0's数据插⼊完成.== >> 耗时:16.129's=============== 50w数据插⼊,共耗时:17.969's ===============共获取10组数据,每组100000个元素.== >> 耗时:3.858's清空原数据.== >> 耗时:0.028's数据插⼊完成.== >> 耗时:41.269's=============== 100w数据插⼊,共耗时:45.257's ===============共获取50组数据,每组100000个元素.== >> 耗时:19.478's清空原数据.== >> 耗时:0.016's数据插⼊完成.== >> 耗时:317.346's=============== 500w数据插⼊,共耗时:337.053's ===============7.思考/总结思考 :多线程+队列的⽅式基本能满⾜⽇常的⼯作需要,但是细想还是有不⾜;例⼦中每次执⾏10个线程任务,在这10个任务执⾏完后才能重新添加队列任务,这样会造成队列空闲.如剩余1个任务未完成,当中空闲数 9,当中的资源时间都浪费了;是否能⼀直保持队列饱满的状态,每完成⼀个任务就重新填充⼀个.到此这篇关于Python3 多线程(连接池)操作MySQL插⼊数据的⽂章就介绍到这了,更多相关Python3 多线程插⼊MySQL数据内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
[227]python数据库连接池DBUtils.PooledDB
![[227]python数据库连接池DBUtils.PooledDB](https://img.taocdn.com/s3/m/49869307876fb84ae45c3b3567ec102de3bddf52.png)
[227]python数据库连接池DBUtils.PooledDBDBUtils 是⼀套⽤于管理数据库连接池的包,为⾼频度⾼并发的数据库访问提供更好的性能,可以⾃动管理连接对象的创建和释放。
最常⽤的两个外部接⼝是 PersistentDB 和 PooledDB,前者提供了单个线程专⽤的数据库连接池,后者则是进程内所有线程共享的数据库连接池。
简介DBUtils是⼀套Python数据库连接池包,并允许对⾮线程安全的数据库接⼝进⾏线程安全包装。
DBUtils来⾃Webware for Python。
DBUtils提供两种外部接⼝:PersistentDB :提供线程专⽤的数据库连接,并⾃动管理连接。
PooledDB :提供线程间可共享的数据库连接,并⾃动管理连接。
实测证明 PersistentDB 的速度是最⾼的,但是在某些特殊情况下,数据库的连接过程可能异常缓慢,⽽此时的PooledDB则可以提供相对来说平均连接时间⽐较短的管理⽅式。
使⽤⽅法连接池对象只初始化⼀次,⼀般可以作为模块级代码来确保。
PersistentDB的连接例⼦:import DBUtils.PersistentDBpersist=DBUtils.PersistentDB.PersistentDB(dbpai=MySQLdb,maxusage=1000,**kwargs)这⾥的参数dbpai指使⽤的底层数据库模块,兼容DB-API的。
maxusage则为⼀个连接最⼤使⽤次数,参考了官⽅例⼦。
后⾯的**kwargs 则为实际传递给MySQLdb的参数。
获取连接: conn=persist.connection() 实际编程中⽤过的连接直接关闭 conn.close() 即可将连接交还给连接池。
PooledDB使⽤⽅法同PersistentDB,只是参数有所不同。
dbapi :数据库接⼝mincached :启动时开启的空连接数量maxcached :连接池最⼤可⽤连接数量maxshared :连接池最⼤可共享连接数量maxconnections :最⼤允许连接数量blocking :达到最⼤数量时是否阻塞maxusage :单个连接最⼤复⽤次数setsession :⽤于传递到数据库的准备会话,如 [”set name UTF-8″] 。
JDBC优化与批量处理技巧

JDBC优化与批量处理技巧JDBC(Java Database Connectivity)是Java语言中用于访问关系型数据库的接口,也是Java EE中常用的数据访问方式之一。
在Java EE应用开发中,JDBC是必备的技能之一。
在使用JDBC时,需要注意代码的执行效率和效果。
本文主要介绍JDBC的优化和批量处理技巧,以提高代码的执行效率和效果。
一、JDBC优化技巧1.1 使用PreparedStatement代替Statement在使用JDBC时,有两种方式用于执行SQL语句,即Statement和PreparedStatement。
在执行单条语句时,两者的效果差不多。
但是在执行大量语句时,PreparedStatement的效率比Statement更高。
这是因为PreparedStatement能够预编译SQL语句,而Statement无法预编译。
预编译SQL语句可以减少数据库的负担,提高代码执行效率。
下面是一个使用PreparedStatement的例子:```javaPreparedStatement ps = conn.prepareStatement("SELECT * FROM users WHERE name = ?");ps.setString(1, "John");ResultSet rs = ps.executeQuery();```1.2 使用连接池连接池是一种基于数据库连接池技术的优化方式,可以避免在每次执行数据库操作时都要重新连接数据库的问题。
使用连接池可以有效地减少数据库的负荷和资源消耗。
Java EE中提供了多种连接池技术,例如Apache DBCP、C3P0等。
下面是一个使用C3P0连接池的例子:```javaComboPooledDataSource ds = new ComboPooledDataSource();ds.setDriverClass("com.mysql.jdbc.Driver");ds.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");ds.setUser("user");ds.setPassword("pwd");Connection conn = ds.getConnection();```1.3 批量操作在Java EE应用中,经常需要执行批量操作,例如批量插入数据、批量删除数据等。
pooleddb的用法

pooleddb的用法摘要:1.引言2.pooleddb 的定义和用途3.pooleddb 的安装和配置4.pooleddb 的基本操作5.pooleddb 的高级功能6.pooleddb 的应用场景7.总结正文:pooleddb 是一款用于数据库分库分表的库,它可以帮助开发者更方便地管理和操作分布式数据库。
本文将详细介绍pooleddb 的用法。
1.引言随着互联网的发展,越来越多的应用需要处理大规模的数据。
为了提高数据库的性能和稳定性,开发者们通常会选择将数据分散存储在多个服务器上,这就需要使用到分布式数据库技术。
pooleddb 就是一款非常实用的分布式数据库中间件,它支持多种数据库,如MySQL、PostgreSQL、SQL Server 等。
2.pooleddb 的定义和用途pooleddb 是一个用于连接、管理和操作分布式数据库的库。
它的主要功能包括:分库分表、数据路由、负载均衡、高可用、读写分离等。
通过使用pooleddb,开发者可以更轻松地搭建和管理分布式数据库系统。
3.pooleddb 的安装和配置pooleddb 支持多种编程语言,如Java、Python、Golang 等。
以Java 为例,首先需要在项目中引入pooleddb 的依赖,然后配置相关的数据库连接信息。
具体安装和配置方法可参考官方文档。
4.pooleddb 的基本操作pooleddb 提供了丰富的API 供开发者使用。
以下是一些基本操作示例:- 连接数据库:`Connection connection = DataSourceBuilder.create().build();`- 执行SQL 语句:`Statement statement =connection.createStatement();`- 查询数据:`ResultSet resultSet = statement.executeQuery("SELECT * FROM table_name");`- 更新数据:`statement.executeUpdate("UPDATE table_name SET column_name = value WHERE condition");`5.pooleddb 的高级功能除了基本操作外,pooleddb 还提供了许多高级功能,如事务管理、乐观锁、多数据源等。
adddbcontextpool adddbcontext

adddbcontextpool adddbcontext如何添加并使用DbContext池。
在进行数据库操作时,使用Entity Framework是一种非常常见的选择。
而在使用Entity Framework时,管理DbContext实例的创建和销毁也是非常重要的一部分。
过多地创建DbContext实例会导致性能下降,并增加数据库服务器的负担。
为了解决这个问题,可以使用DbContext池来管理DbContext实例的创建和回收,从而提高性能和资源利用率。
本文将逐步介绍如何添加和使用DbContext池,以帮助读者更好地进行数据库操作。
一、添加DbContext池的NuGet包首先,在项目中添加DbContext池的NuGet包是必须的。
在Visual Studio中,可以通过右键单击项目-> NuGet包管理器-> 管理NuGet 包来打开NuGet包管理器。
在搜索框中输入“Microsoft.EntityFrameworkCore.SqlServer”并安装该包。
这是SqlServer数据库提供程序的实现,可以根据实际需要选择其他数据库提供程序。
二、创建DbContext类接下来,我们需要创建一个派生自DbContext的类,以用于对数据库进行操作。
在项目中创建一个新的类文件,然后添加如下代码:csharpusing Microsoft.EntityFrameworkCore;public class MyDbContext : DbContext{public MyDbContext(DbContextOptions<MyDbContext> options) : base(options){}所有的DbSet、配置等都在这里定义}在该类中,我们继承了DbContext,并创建了一个构造函数,用于接受DbContextOptions类型的参数。
DbContextOptions包含了一些配置选项,比如数据库连接字符串等。
【python】数据库连接池---PooledDB

【python】数据库连接池---PooledDB不⽤数据库连接池的写法:import MySQLdbconn= MySQLdb.connect(host='localhost',user='root',passwd='pwd',db='myDB',port=3306)cur=conn.cursor()SQL="select*from table1"r=cur.execute(SQL)r=cur.fetchall()cur.close()conn.close()使⽤ PooledDBfrom DBUtils.PooledDB import PooledDBimport pymysqlimport xlwtimport osimport threadingimport zipfileclass CreateExcel(object):"""查询数据库,并⽣成excel ⽂档"""def __init__(self, mysql_info):self.mysql_info = mysql_infoself.pool = PooledDB(pymysql, 5, host=self.mysql_info['host'], user=self.mysql_info['user'],password=self.mysql_info['password'], db=self.mysql_info['db'], port=self.mysql_info['port'],charset='utf-8')连接参数定义:1. mincached,最少的空闲连接数,如果空闲连接数⼩于这个数,pool会创建⼀个新的连接2. maxcached,最⼤的空闲连接数,如果空闲连接数⼤于这个数,pool会关闭空闲连接3. maxconnections,最⼤的连接数,4. blocking,当连接数达到最⼤的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会⼀直等待,直到当前连接数⼩于最⼤连接数,如果这个值是False,会报错,5. maxshared 当连接数达到这个数,新请求的连接会分享已经分配出去的连接这⾥的 5 应该是默认的连接数吧在uwsgi中,每个http请求都会分发给⼀个进程,连接池中配置的连接数都是⼀个进程为单位的(即上⾯的最⼤连接数,都是在⼀个进程中的连接数),⽽如果业务中,⼀个连接池对性能的提升表现在:1.在程序创建连接的时候,可以从⼀个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度2.关闭连接的时候,把连接放回连接池,⽽不是真正的关闭,所以可以减少频繁地打开和关闭连接。
pool的用法_pool的用法总结大全

pool的用法_pool的用法总结大全n.水池,石油层,(液体等的)一滩,共同储金vi.使形成池塘或水洼,淤积,合伙经营,采(煤等)变形:过去式:pooled;现在分词:pooling;过去分词:pooled;pool用法pool可以用作名词pool是及物动词,后接金钱、财物、资源或思想、意见等名词作宾语。
pool用作名词的用法例句Afringeoftreesstoodroundthepool.池塘四周耸立着一圈树木。
Theystrippedoffandjumpedintothepool.他们脱掉衣服,跳进了池子。
Thereisaswimmingpoolinthepark.公园里有一个游泳池。
pool用作名词的用法例句Tosavegas,manypeoplejoinedthecarpool.为节省汽油,许多人参加车辆共乘。
Let'spoolourmoneytobuyacar.让我们合资来买一辆汽车。
Theyhadplannedtopooltheirearningstostartahome.他们计划着把他们两个人赚得的钱凑起来建立一个家庭。
pool可以用作动词pool是及物动词,后接金钱、财物、资源或思想、意见等名词作宾语。
pool用作动词的用法例句Let'spoolourmoneytobuyacar.让我们合资来买一辆汽车。
Theyhadplannedtopooltheirearningstostartahome.他们计划着把他们两个人赚得的钱凑起来建立一个家庭。
Nowthedropsrunandpooltogether.此刻水珠流动而聚集在一起。
pool用法例句1、Shewasstandingbyapool,abouttodivein.她站在水池旁边,正要往里跳。
2、Hedrankthirstilyfromthepoolundertherock.他饥渴地喝着岩石下水潭中的水。
3、Herememberedmowingthelawn,loungingaroundtheswimmingpool.他还记得修剪草坪、在泳池边闲荡的情景。
混合截面数据

谢
谢
使用时可能遇到的问题及解决办法
我们可以把时间虚拟变量也看成是一个控制变 量,在去控制了时间对于因变量的影响后, 我们就能够对不同时点观测到的数据心安理 得的用横截面的方法分析 或者我们把它看成是控制了其他可观测因素后 的这段时间里被解释变量会出现什么变化, 例子中的δ解释的就是在观测期到基期这段时 间里,控制住其他变量后,妇女生育的变化
还需要注意的问题: 所找的抽样用的总体应该足够大,否则在不 同时点随机抽样时会很容易抽到许多相同的 样本点,使混合截面数据出现综列数据的某 些特征。 所估计的方程也可能会产生误差项的异方差 问题(BP检验),可通过OLS估计后产生的 异方差的解决办法(WLS),只要把时间虚 拟变量像其他解释变量一样放进方程就可以
使用时可能遇到的问题及解决办法
Q: 混合在一起的不同时点的数据应该被“一视 同仁”么? A: 我们在处理横截面数据时会认为样本中的每 一个数据对最终结果的作用都是相同的。而 在混合截面数据中,因为受到时间的影响, 不同时点上抽样的数据可能对最终回归的结 果产生不同的影响,所以不同时点但混合在 一起数据在进行OLS时不能“一视同仁”, 而需要增加时间虚拟变量。
应用实例
把1978年的数据代入方程,则会得到 rprice=82517.23-18824.37nearinc (2653.79)(5827.71) 说明在修建焚化炉之前,靠近焚化炉位置的房价就 要低于远离焚化炉位置的房价,因此直接用1981年 的数据并不能说明新建焚化炉会压低房价 应该将实施政策前两地房价的差从政策对房价的影 响中扣除 实际的影响=-30688.27-(-18824.37)=-11863.9=δ1 Rprice=β0+δ0y81+β1nearinc+δ1y81*nearinc+u
数据库连接池技术解析
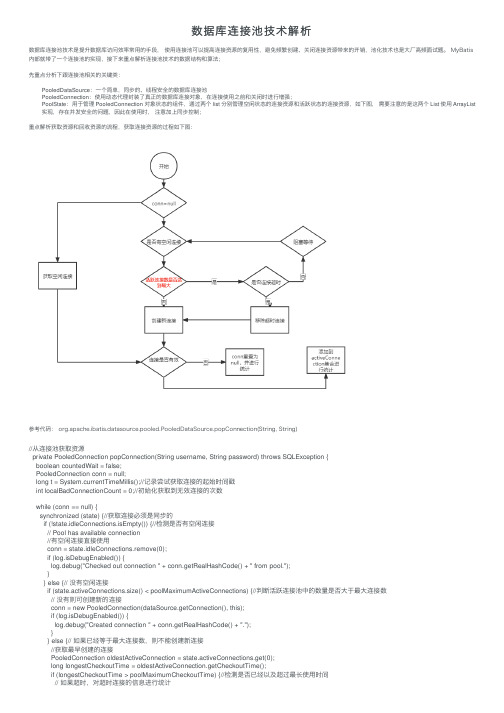
数据库连接池技术解析数据库连接池技术是提升数据库访问效率常⽤的⼿段, 使⽤连接池可以提⾼连接资源的复⽤性,避免频繁创建、关闭连接资源带来的开销,池化技术也是⼤⼚⾼频⾯试题。
MyBatis 内部就带了⼀个连接池的实现,接下来重点解析连接池技术的数据结构和算法;先重点分析下跟连接池相关的关键类:PooledDataSource:⼀个简单,同步的、线程安全的数据库连接池PooledConnection:使⽤动态代理封装了真正的数据库连接对象,在连接使⽤之前和关闭时进⾏增强;PoolState:⽤于管理 PooledConnection 对象状态的组件,通过两个 list 分别管理空闲状态的连接资源和活跃状态的连接资源,如下图,需要注意的是这两个 List 使⽤ ArrayList 实现,存在并发安全的问题,因此在使⽤时,注意加上同步控制;重点解析获取资源和回收资源的流程,获取连接资源的过程如下图:参考代码: org.apache.ibatis.datasource.pooled.PooledDataSource.popConnection(String, String)//从连接池获取资源private PooledConnection popConnection(String username, String password) throws SQLException {boolean countedWait = false;PooledConnection conn = null;long t = System.currentTimeMillis();//记录尝试获取连接的起始时间戳int localBadConnectionCount = 0;//初始化获取到⽆效连接的次数while (conn == null) {synchronized (state) {//获取连接必须是同步的if (!state.idleConnections.isEmpty()) {//检测是否有空闲连接// Pool has available connection//有空闲连接直接使⽤conn = state.idleConnections.remove(0);if (log.isDebugEnabled()) {log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");}} else {// 没有空闲连接if (state.activeConnections.size() < poolMaximumActiveConnections) {//判断活跃连接池中的数量是否⼤于最⼤连接数// 没有则可创建新的连接conn = new PooledConnection(dataSource.getConnection(), this);if (log.isDebugEnabled()) {log.debug("Created connection " + conn.getRealHashCode() + ".");}} else {// 如果已经等于最⼤连接数,则不能创建新连接//获取最早创建的连接PooledConnection oldestActiveConnection = state.activeConnections.get(0);long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();if (longestCheckoutTime > poolMaximumCheckoutTime) {//检测是否已经以及超过最长使⽤时间// 如果超时,对超时连接的信息进⾏统计state.claimedOverdueConnectionCount++;//超时连接次数+1state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;//累计超时时间增加state.accumulatedCheckoutTime += longestCheckoutTime;//累计的使⽤连接的时间增加state.activeConnections.remove(oldestActiveConnection);//从活跃队列中删除if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {//如果超时连接未提交,则⼿动回滚try {oldestActiveConnection.getRealConnection().rollback();} catch (SQLException e) {//发⽣异常仅仅记录⽇志/*Just log a message for debug and continue to execute the followingstatement like nothing happend.Wrap the bad connection with a new PooledConnection, this will helpto not intterupt current executing thread and give current thread achance to join the next competion for another valid/good databaseconnection. At the end of this loop, bad {@link @conn} will be set as null.*/log.debug("Bad connection. Could not roll back");}}//在连接池中创建新的连接,注意对于数据库来说,并没有创建新连接;conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());//让⽼连接失效oldestActiveConnection.invalidate();if (log.isDebugEnabled()) {log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");}} else {// ⽆空闲连接,最早创建的连接没有失效,⽆法创建新连接,只能阻塞try {if (!countedWait) {state.hadToWaitCount++;//连接池累计等待次数加1countedWait = true;}if (log.isDebugEnabled()) {log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");}long wt = System.currentTimeMillis();state.wait(poolTimeToWait);//阻塞等待指定时间state.accumulatedWaitTime += System.currentTimeMillis() - wt;//累计等待时间增加} catch (InterruptedException e) {break;}}}}if (conn != null) {//获取连接成功的,要测试连接是否有效,同时更新统计数据// ping to server and check the connection is valid or not//检测连接是否有效if (conn.isValid()) {//有效if (!conn.getRealConnection().getAutoCommit()) {conn.getRealConnection().rollback();//如果遗留历史的事务,回滚}//连接池相关统计信息更新conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));conn.setCheckoutTimestamp(System.currentTimeMillis());conn.setLastUsedTimestamp(System.currentTimeMillis());state.activeConnections.add(conn);state.requestCount++;state.accumulatedRequestTime += System.currentTimeMillis() - t;} else {//如果连接⽆效if (log.isDebugEnabled()) {log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection."); }state.badConnectionCount++;//累计的获取⽆效连接次数+1localBadConnectionCount++;//当前获取⽆效连接次数+1conn = null;//拿到⽆效连接,但如果没有超过重试的次数,允许再次尝试获取连接,否则抛出异常if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Could not get a good connection to the database.");}throw new SQLException("PooledDataSource: Could not get a good connection to the database.");}}}}}if (conn == null) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection."); }return conn;}回收连接资源的过程如下图:代码位置:org.apache.ibatis.datasource.pooled.PooledDataSource.pushConnection(PooledConnection)1//回收连接资源2protected void pushConnection(PooledConnection conn) throws SQLException {34synchronized (state) {//回收连接必须是同步的5 state.activeConnections.remove(conn);//从活跃连接池中删除此连接6if (conn.isValid()) {//先判断连接是否有效7//判断闲置连接池资源是否已经达到上限,并判断是由本连接池创建8if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) { 9//没有达到上限,进⾏回收10 state.accumulatedCheckoutTime += conn.getCheckoutTime();//增加累计使⽤时间11if (!conn.getRealConnection().getAutoCommit()) {12 conn.getRealConnection().rollback();//如果还有事务没有提交,进⾏回滚操作13 }14//基于该连接,创建⼀个新的连接资源,并刷新连接状态15 PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);16 state.idleConnections.add(newConn);17 newConn.setCreatedTimestamp(conn.getCreatedTimestamp());18 newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());19//⽼连接失效20 conn.invalidate();21if (log.isDebugEnabled()) {22 log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");23 }24//唤醒其他被阻塞的线程25 state.notifyAll();26 } else {//如果闲置连接池已经达到上限了,将连接真实关闭27 state.accumulatedCheckoutTime += conn.getCheckoutTime();28if (!conn.getRealConnection().getAutoCommit()) {29 conn.getRealConnection().rollback();30 }31//关闭真的数据库连接32 conn.getRealConnection().close();33if (log.isDebugEnabled()) {34 log.debug("Closed connection " + conn.getRealHashCode() + ".");35 }36//将连接对象设置为⽆效37 conn.invalidate();38 }39 } else {40if (log.isDebugEnabled()) {41 log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");42 }43 state.badConnectionCount++;44 }45 }46 }。
pool的用法总结大全5篇

pool的用法总结大全pool的用法总结大全精选5篇(一)1. 名词用法:- 游泳池:I love swimming in the pool.(我喜欢在游泳池里游泳。
)- 水塘,池塘:There are some ducks swimming in the pool.(有一些鸭子在水塘里游泳。
)- 水池,沼泽:The pool was covered with algae.(水池上长满了藻类。
)- 一泡,一滩(液体的):There was a small pool of water on the floor.(地上有一小滩水。
)2. 动词用法:- 聚集,积聚:Water pooled in the low-lying areas.(水积聚在低洼地带。
)- 合作,共同出钱:We pooled our money together to buy the gift.(我们把钱合起来买礼物。
)3. 形容词用法:- 共同的,共有的:We created a pool of resources to support the project.(我们组成了一个资源共享池来支持项目。
)-(数据)汇总的,共同的:The report provides a pool of data for analysis.(这份报告提供了供分析的数据汇总。
)4. 动词短语用法:- (车辆或人)分道扬镳:The road will pool with other routes ahead.(这条路将与其他路线分道扬镳。
)- (货物)集货:They pooled the goods from multiple sources.(他们将来自多个来源的货物集中了。
)- (公司)合并:The two companies decided to pool their resources.(这两家公司决定合并资源。
)以上总结了一些pool常见的用法,具体用法还需根据上下文而定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
pooleddb的用法
【实用版】
目录
1.介绍 pooleddb
2.pooleddb 的安装与配置
3.pooleddb 的用法详解
4.pooleddb 的优点与应用场景
5.总结
正文
一、介绍 pooleddb
pooleddb 是一款高性能、轻量级的数据库连接池组件,它支持多种数据库,如 MySQL、Oracle、PostgreSQL 等。
pooleddb 的作用是管理数据库连接,避免频繁创建和销毁连接导致的性能损耗,提高系统的运行效率。
二、pooleddb 的安装与配置
在使用 pooleddb 之前,需要先对其进行安装。
pooleddb 提供了Maven 和 Gradle 两种依赖方式,开发者可以根据自己的项目需求选择相应的依赖。
Maven 依赖方式:
```
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-pool</artifactId>
<version>1.1.10</version>
</dependency>
```
Gradle 依赖方式:
```
implementation "com.alibaba:druid-pool:1.1.10"
```
在项目中引入依赖后,需要对 pooleddb 进行配置。
配置主要包括数
据源、连接池、SQL 语句等方面。
以下是一个简单的配置示例:```java
import com.alibaba.druid.pool.DruidDataSource;
public class PooleddbConfig {
public static DruidDataSource createDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("123456");
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setInitialSize(5);
dataSource.setMinIdle(5);
dataSource.setMaxActive(20);
return dataSource;
}
}
```
三、pooleddb 的用法详解
pooleddb 的用法主要分为以下几个步骤:
1.创建数据源:通过调用 PooleddbConfig 类中的createDataSource() 方法创建一个数据源实例。
2.获取连接:调用数据源实例的 getConnection() 方法获取数据库连接。
3.执行 SQL 语句:使用获取到的连接执行 SQL 语句,进行数据库操作。
4.关闭连接:操作完成后,调用连接实例的 close() 方法关闭连接。
以下是一个简单的使用示例:
```java
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class PooleddbDemo {
public static void main(String[] args) {
DruidDataSource dataSource =
PooleddbConfig.createDataSource();
try (Connection connection =
dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement("SELECT * FROM test_table");
ResultSet resultSet =
preparedStatement.executeQuery()) {
while (resultSet.next()) {
System.out.println(resultSet.getString("column_name"));
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
```
四、pooleddb 的优点与应用场景
pooleddb 的优点主要体现在以下几点:
1.提高性能:通过复用数据库连接,避免了频繁创建和销毁连接导致的性能损耗。
2.降低资源消耗:减少数据库连接的创建和销毁,降低了系统资源消耗。
3.配置简单:pooleddb 的配置较为简单,开发者可以快速上手。
4.支持多种数据库:pooleddb 支持多种数据库,如 MySQL、Oracle、PostgreSQL 等。
应用场景:pooleddb 适用于需要频繁进行数据库操作的场景,如数据迁移、批量处理等。
同时,对于连接数有限的数据库,如 Oracle,pooleddb 可以有效解决连接数不足的问题。
五、总结
pooleddb 作为一款高性能、轻量级的数据库连接池组件,在实际应用中具有广泛的应用前景。