关联分析:进阶概念课件
关联规则和关联分析PPT讲稿

age ( X , "30...39") income ( X , "42k...48k") buys ( X , "computer") – 根据规则中涉及的数据维
• 单维关联规则
• (仅涉及buys这个维)
b•uy多s维( X关联, "规c则omputer") buys ( X , "software")
C1 1st scan
30 A, B, C, E
40
B, E
C2
L2 Itemset sup
{A, C} 2
{B, C} 2
{B, E} 3
{C, E} 2
Itemset sup
{A}
2 L1
{B}
3
{C}
3
{D}
1
{E}
3
Itemset sup
{A}
2
{B}
3
{C}
3
{E}
3
Itemset sup {A, B} 1 {A, C} 2 {A, E} 1 {B, C} 2 {B, E} 3 {C, E} 2
购买的item A,B,C A,C A,D B,E,F
• confiden假ce (设A 最B小) 支P(B持| A度) 为P(5A0%B),/ P(A)
最小置信度为50%,则
有如下关联规则
– A C (50%, 66.6%)
– C A (50%, 100%)
当前你正在浏览到的事第十二页PPTT,共三十六页。
{A}
75%
{B}
50%
{C}
关联分析基本概念与算法ppt课件
2/5 频繁项集(Frequent Itemset) – 满足最小支持度阈值( minsup )的
先验原理( Apriori principle)
先验原理:
– 如果一个项集是频繁的,则它的所有子集一定也是频繁 的
相反,如果一个项集是非频繁的,则它的所有超集 也一定是非频繁的:
– 这种基于支持度度量修剪指数搜索空间的策略称为基于 支持度的剪枝(support-based pruning)
– 这种剪枝策略依赖于支持度度量的一个关键性质,即一 个项集的支持度决不会超过它的子集的支持度。这个性 质也称为支持度度量的反单调性(anti-monotone)。
4
Bread, Milk, Diaper, Beer
关联规则的强度
5
Bread, Milk, Diaper, Coke
– 支持度 Support (s) 确定项集的频繁程度
Example:
{M,iD lkia}p e Bree
– 置信度 Confidence (c) 确定Y在包含X的事 务中出现的频繁程度
Brute-force 方法:
– 把格结构中每个项集作为候选项集
– 将每个候选项集和每个事务进行比较,确定每个候选项集 的支持度计数。
Transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
关联分析基本概念与算法

关联分析基本概念与算法关联分析(Association Analysis)是一种在大规模数据集中寻找项集之间有意义关联关系的数据挖掘技术。
它的基本任务是发现数据集中的项目之间的频繁关联模式(Frequent Pattern)和关联规则(Association Rule)。
1.频繁关联模式频繁关联模式是指在数据集中经常同时出现的项集。
如果一个项集的支持度大于等于用户事先设定的最小支持度阈值,则称该项集为频繁项集。
频繁关联模式的发现是关联分析的核心任务。
2.关联规则关联规则是指一个集合中的一个子集在给定另一个集合的条件下出现的概率。
关联规则可以表示为X->Y,其中X和Y分别为项集。
关联规则呈现了一个条件和结论之间的关系。
根据关联规则中的置信度(Confidence)和支持度(Support)等指标,可以对规则进行排序和筛选。
3.支持度与置信度支持度(Support)是指一个项集在数据集中出现的频次。
在关联分析中,项集的支持度是指该项集在数据集中出现的概率。
置信度(Confidence)是指一个关联规则的可信程度。
在关联分析中,置信度表示当一个项集出现时,另一项集也会同时出现的概率。
为了发现频繁关联模式和关联规则,关联分析算法中常用的两种方法是Apriori算法和FP-Growth算法。
1. Apriori算法Apriori算法是一种基于候选生成和剪枝的算法。
该算法的基本思想是通过迭代计算递增长度的候选项集,然后按照最小支持度筛选出频繁项集,从而生成频繁关联模式。
Apriori算法的过程如下:(1)初始化,生成所有的单个项集;(2)通过计算支持度筛选出频繁一项集;(3)进一步生成候选二项集,并利用剪枝策略和支持度进行筛选,得到频繁二项集;(4)迭代生成更高阶的候选项集,并以频繁(k-1)项集为基础进行筛选,直到没有更高阶的频繁项集为止。
2. FP-Growth算法FP-Growth算法是一种基于频繁模式树(FP-Tree)的算法。
4关联分析PPT课件

支持度 0 0 0 0 0 0
20 20
0 0 0 0 0 0 0
关联规则挖掘的基本概念
所有频繁项集及其支持度
项集 啤酒 面包 牛奶 花生酱 面包、花生酱
支持度(%) 40 80 40 60 60
假设最小支持度 设定为40%
关联规则挖掘的基本概念
所有最大频繁项集及其支持度(黄色标识)
项集 啤酒 面包 牛奶 花生酱 面包、花生酱
关联规则挖掘的步骤
1.产生所有 频繁项集
2.产生相应 强关联规则
这些项集的频度 至少应等于(预先 设置的)最小支持 度
Confidence(X→Y),即
Confi(dXe nYc)eSupp(XorYt) Supp(Xo)rt
关联规则挖掘的基本概念
支持度和可信度
用户定义的一个可信度阈值,表示规则的最低 最小可信度 可靠性,记作minconf
支持度和可 信度的作用
淘汰无用的关联规则
强关联规则:同时满足最小支持度和最小可信度阀值的规则。 (两个阀值的取值都在0%~100%之间)
支持度定义:假定X是一个项集,D是一个事务集合或事务数据库, 称D中包含X的交易的个数与D中总的交易个数之比为X在D中的支持 度,记作Support (X),即
Sup(p X)o|r|{d tD|Xd|| ||D||
关联规则挖掘的基本概念
支持度和可信度
由用户定义的衡量项集频繁程度的一个阈值, 最小支持度 记作minsup
关联规则挖掘的基本概念
数据集、事务、项
❖ 事务数据库 ▪ 关联规则挖掘的数据集记为D ▪ D={t1,t2,…tk…tn},由一系列具有唯一标 识tid的事务组成
关联规则挖掘的基本概念
05 新QC七大手法-关联图法(内容完整,PPT颜值高)

关联图的注意事项
1. 要针对复杂的因果关系 2. 原因查找从人、机、料、法、环、测等方面考虑 3. 针对找到的原因排序时适当的调换位置 4. 中间关键因素也要作为主因对待
关联图法
关联图法
● 定义 就是把关系复杂而相互纠缠的问题及其因素,用箭
头连接起來的一种图示分析工具,从而找出主要因 素和专案的方法。
关联图的概念图 一次原因
问 题 点 一次原因 一次原因
二次原因 二次原因 二次原因 二次原因
三次原因 三次原因 三次原因 三次原因 三次原因
关联图法
● 适用范围 用于纷繁复杂的因果纠缠分析 用于现场问题的掌握 用于市场调查及抱怨分析 用于方针管理的展开
工程1 活动要项1
2
工程2 3
4
工程3 5
6
7
工程4
8
9
关联图的作法
决定题目 — 以标记写出主题; 小组组成 — 集合有关部门人员组成小组; 资料收集 — 运用脑力激荡,寻找原因; 用简明通俗的语言作卡片; 连接因果关系制作关联图; 修正图形—讨论不足,修改箭头; 找出重要专案、原因并以标记区别; 形成文章—整理成文章使別人易懂; 提出改善对策;
关联图的判别方法
❖箭头只进不出是问题;
问题
❖箭头只出不进是主因;
主要因素
❖箭头有进有出是中间因素
中间因素
❖出多于进的中间因素是关键中间因素
关联图的优缺点
优点 1. 化繁为简,一目了然 2. 容易找到问题“罩门”,很快进入改善作业 3. 相关成员易捐弃成见 ,打破先入为主观念 4. 可短时间做到跨部门合作
关联图法
关联性分析课件

1. 它们在客观上是有一定联系的; 特点: 2. 在观察时是独立地去测量的;
3.这两个随机变量都服从正态分布; 例如:父子的身高(X)、儿子的身高(Y)
X1 Y1 、X2 Y2 、 X3 Y3 、 … 、 Xn Yn
相关分析和回归分析
是否有联系,联系的方 向、程度如何?
相关或关联
定量指示相关或关联的 指标:如相关系数
定量描述其 依存关系
回归分析
依存性 (relationship)
数学模型:如Y=f (x)
如何保证一份作关联性研究的样本合格?
抽样研究
保证样本的合格性
随机抽样 保证样本间相互独立
关联性分析
9.1 概述 9.2 两个连续型随机变量的相关分析 9.3 两个分类变量间的关联分析
(b)
(d)
(f)
(h)
散点图能直观地看出两变量是否存在相关关系。故研 究两变量关系应先绘散点图,再量化两者的关系。
Positive Correlation
Negative Correlation
Zero Correlation
Curvilinear relationship
(a)
(c)
Linear Relationship
相关系数反应线性相关性:
Y
Y
5.0
Y
7.5
Y
6
2.2
4.5
Y
7.0
2.0
5
4.0
1.8
6.5
4
3.5
1.6 3.0
6.0
3
1.4
2.5
5.5
1.2
2
2.0
1.0
第5章 关联分析

【例5.1】对于表5.1所示的事务数据库,设min_sup=2,产生 所有频繁项集的过程如图5.1所示,最后L4=Ф,算法结束,产生的 所有频繁项集为L1∪L2∪L3。
C1 L1 项集 {i1} {i2} {i3} {i4} {i5} C2 项集 {i1,i2} {i1,i3} {i1,i4} 由 L1 产生候选 C2 {i1,i5} {i2,i3} {i2,i4} {i2,i5} {i3,i4} {i3,i5} {i4,i5} C3 项集 {i1,i2,i3} {i1,i2,i5} 由 L2 产生候选 C3 {i1,i3,i5} {i2,i3,i4} {i2,i3,i5} {i2,i4,i5} C4 由 L3 产生候选 C4 项集 {i1,i2,i3,i5} 扫描 D,对每个候 选项集计数 扫描 D,对每个候 选项集计数 扫描 D,对每个候 选项集计数 计数 6 7 6 2 2 C2 项集 {i1,i2} {i1,i3} {i1,i4} {i1,i5} {i2,i3} {i2,i4} {i2,i5} {i3,i4} {i3,i5} {i4,i5} C3 项集 {i1,i2,i3} {i1,i2,i5} {i1,i3,i5} {i2,i3,i4} {i2,i3,i5} {i2,i4,i5} C4 项集 {i1,i2,i3,i5} 计数 1 将候选项集计数与最 小支持度计数比较 L4=Ф 计数 2 2 1 0 1 0 将候选项集计数与最 小支持度计数比较 L3 项集 {i1,i2,i3} {i1,i2,i5} 计数 2 2 计数 4 4 1 2 4 2 2 0 1 0 将候选项集计数与最 小支持度计数比较 L2 项集 {i1,i2} {i1,i3} {i1,i5} {i2,i3} {i2,i4} {i2,i5} 计数 4 4 2 4 2 2 项集 {i1} {i2} {i3} {i4} {i5} 计数 6 7 6 2 2 扫描 D,对每个候 选项集计数 将候选项集计数与最 小支持度计数比较
第4章 关联分析

购物篮数据的二元0/1表示
TID 面包 牛奶 尿布 啤酒 鸡蛋 可乐 1 2 3 4 5 1 1 0 1 1 1 0 1 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 0 0 0 1 0 1
5
4.1.2 关联分析中的基本概念
项集(Itemset) 包含0个或多个项的集合 例: {Milk, Bread, Diaper} k-项集:包含k个项的集合 例: {Milk, Bread, Diaper}是个3-项集 每个事务T由事务标识符TID标识,它是项的集合 例: TID(4)={Bread, Milk, Diaper , Coke} 任务相关数据D是事务数据的集合
例如:
7
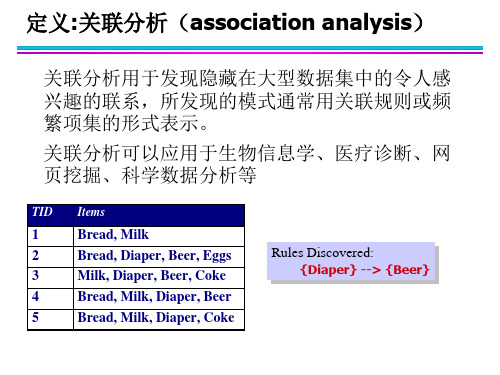
关联规则
关联规则(Association Rule) 关联规则是形如AB的蕴含表达 式, 其中A和B是不相交的项集 例如: {Milk, Diaper} {Beer} 关联规则的强度 • 支持度 Support (s) 确定项集的频繁程度 • 置信度 Confidence (c) 确定B在包含A的事务中出现 的频繁程度
包含特定项集的事务个数
例如: ({Milk, Bread,Diaper}) = 2 支持度(Support)
包含项集的事务数与总事务数的比值
s({Milk, Bread, Diaper}) = 2/5 频繁项集(Frequent Itemset) 满足最小支持度阈值( minsup )的所有项集
第4章 关联分析
问题定义
频繁项集的产生
关联规则的产生 关联模式的评估 关联分析中的事务数据处理 多层关联规则
序列模式
1
4.1 问题定义
关联分析

找出频繁项集--Apriori算法
例:
表1 交易数据库D
交易号
项集合
T100
I1,I2,I5
T200
I2,I4
T300
I2,I3
T400
I1,I2,I4
T500
I1,I3
T600
I2,I3
T700
I1,I3
T800
I1,I2,I3,I5
T900
I1,I2,I3
关联理论ppt课件

2.1 推理:语言交际的核心
首先:推理模式的输入信息不再是单一的语言表达,而是 分为两大类,即语言信息和非语言信息。
其次:推理是按一定的思维规律集语言和非语言知识于一 体的过程。在长期的语言和思维实践中,这个过程已基本 形成抽象的思维定势。推理过程分为两步,即根据语言和 非语言信息建立必要前提,后根据前提逻辑关系推导出有 关话语意图的结论。
1. 统管一切的单一的翻译理论是否可能建立尚未定论。 2. 翻译科学的划界众说纷纭。 3. 斟酌(evaluation)与决策(decision)的困难。
六. 关联理论与翻译
格特主张用关联理论研究翻译,因为关联论从能力 (competence)而不是行为(behaviour)的角度看待交际, 他试图具体说明人们大脑中的信息处理机制而不是语段 (text)本身或语段产生的过程。
关联理论中最佳关联原则第二条:在同等条件下,付出的 努力越小,关联性就越强。
二. 主要观点
Hale Waihona Puke .1 推理:语言交际的核心 在语用学领域,信码说一度为话语解释所采用,理解话语 离不开一定的解码过程。如句子语音语义的结合,并依靠 语法规则解释,但是理解话语并不是仅仅凭解释句子的语 音语义关系就可以,
六. 关联理论与翻译
Ernst August Gutt,根据关联理论对翻译进行了研究, 于1991年出版了《翻译与关联:认知与语境》,书中格特 提出了关联翻译理论。
理论基础:翻译是一个推理过程。翻译过程的研究对象是 人的大脑机制。
格特认为:可以说,过去几百年间就翻译发表的种种观点 是一大堆互相之间没有联系的说法而已。有三个原因:
Bill is not a fine friend at all. 语境:Bill has just turned down the speaker's request for help
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
概念階層
是在某個特定領域中,表示各種不同項目或概念之 多層級組織架構
定義概念階層是根據領域知識(domain knowledge) ,或以某組織定義之標準分類架構為基礎(例如,國會 圖書館之分類架構可用來組織資料的主題分類)
概念階層可使用有向無迴圈圖(directed acyclic graph )來表示, 如前頁投影片圖所示
在min-Apriori中的支持度測量有下列特性,使得它適用於 發掘文件中字的關聯:
當字的正規化次數增加時,支持度單調地增加
當包含字的文件數量增加時,支持度單調地增加
支持度有反單調的特性。舉例來說,假設一對項目集{A, B} 與 {A, B, C},由於min({A, B}) min({A, B, C}),則s({A, B}) s({A, B, C}) 。因此,在項目集中字的數量增加,則支持度單調地降低
整合概念階層至關聯分析中的主要優點如下:
在階層中較低層級之項目可能沒有足夠的支持度以出現 於任何高頻項目集中
在概念階層之低階層中所發現的規則會有過度特殊的( overly specific)傾向,且不如高階層之規則有趣
序列樣式
序列資料對於識別動態系統中再發生的特性, 或在某些事件中預測未來的發生是很有用的。 問題定義 序列樣式探勘 時間限制 替代的計算方法
一個用來減少計算時間的方式,是避免產生包含 一個以上且為相同屬性項目的候選集
處理連續屬性的方法
離散式方法(discretization-based method) 統計式方法(statistics-based method) 非離散式方法(non-discretization method)
一般來說,maxspan越長,越有可能會發現資料序列中 的樣式。然而,較長的maxspan會增加兩個不相關事件 中時間相關的可能性,而獲得不正確的樣式
maxspan限制會影響序列樣式發掘演算法中支持度計算 的步驟
Mingap與maxgap限制
可透過設定時間限制的方式限制序列中兩個連續元素之 間時間的差異,若最大時間差異(maxgap)是一週, 則一個元素中事件的發生必須與前面元素的事件發生時 間差距一週時間以內。若最小時間差異(mingap)是0 ,則在前面元素的事件發生後,另一個元素的事件必須 馬上發生
min-Apriori是另一個找尋字的關聯的方法,與傳 統關聯分析類似,項目集會被視為一群字的集合 ,而它的支持度測量是根據字之間的關聯程度
項目集的支持度可根據其對應字的正規化次數( normalized frequencies)來計算
在min-Apriori中,某一特定文章中字的關聯可以 取他們正規化次數的最小值,即 min(word1,word2) = min(0.3, 0.6) = 0.3。項目集 的支持度可以藉由整合所有文件中的關聯來計算
數量關聯規則是有趣的,只要用規則所涵蓋的交易資料 而求得的統計量,與規則不涵蓋的交易資料而求得的統 計量不同
非離散化方法
分析者在某些應用中,最感興趣的是在連續屬性( continuous attribute)中發現關聯,而不是在連續屬性 中發現離散區間的關聯
在文字探勘中,分析者最感興趣的是去發掘字之間的關 係(即data和mining),而不是字出現次數範圍間的關 係
序列樣式:問題定義
發掘序列樣式之問題的輸入為序列資料集合,每一列記 錄某一特定物件在某時間內發生的相關事件
序列樣式:問題定義
序列可由它的長度和發生事件的數量來描述,序列的長 度表示出現於序列中的元素數量,而k-sequence為一 個包含k個事件的序列
序列樣式:問題定義
在序列資料集合中元素和事件的範例
第7章 關聯分析:進階 概念
© 2008 台灣培生教育出版 (Pearson Education Taiwan)
處理類別的屬性
有很多應用是包含對稱式二元屬性和名目( nominal)屬性。例如性別、家裡有無電腦、線上 聊天、線上購物和隱私權的問題;也包含名目屬性 ,如教育層級與州名
使用關聯分析,我們可能會發現一些與網際網路使 用者有關的有趣資訊,例如
當針對年齡屬性做離散化時,區間寬度的取捨
若區間太寬,會因為信賴度不足而遺漏一些樣式 若區間太窄規則(quantitative association rule)可 被用來推論母體的統計特徵
為了產生以統計為基礎之數量關聯規則,必須指 定目標屬性以用來區分母體中感興趣的部份( interesting segments)。藉由保留目標屬性,資 料中剩餘的類別與連續屬性會用離散式的方法來 做二元化,現存的演算法如Apriori或FP-growth則 被應用於二元化資料中,以萃取高頻項目集,每 個高頻項目表示母體的一個興趣部份
離散式方法
離散是最常用以處理連續屬性的方法。這個方法是將鄰 近之連續屬性值分群至有限數值的區間中
屬性離散化中的一個重要參數是區間數量,此參數被用 來切割每一個屬性,這個參數基本上是由使用者提供, 且可被表示成區間寬度(相等區間寬度方法;等寬)、 每個區間的平均交易數量(相等次數方法;等深)、或 所需的群集數量(以分群為基礎之方法)
序列樣式:序列樣式探勘
序列樣式探勘在計算上是一個具挑戰性的工作,因為在 給定的資料序列中可能包含很多序列
序列樣式發掘:假設序列資料集合D和使用者指定之最 小支持度門檻值,序列樣式發掘可以找尋所有支持度 最小支持度門檻值得序列樣式
序列樣式:時間限制
Maxspan 限制
maxspan限制說明在整個序列中最晚與最早發生事件之 間,可允許的最大時間差異
{線上購物 = Yes} → {關心隱私權問題 = Yes}
這個規則表示:大部份線上購物的網際網路使用者 會關心他們的個人隱私
當關聯分析應用至二元化的資料上時,要考 慮的議題包括:
一些屬性值不是高頻項目,而不足以成為高頻樣 式的一部份。這個問題對於名目屬性而言(如州 名)會更明顯
和其他屬性值相較,有一些屬性值會有相當高的 次數