利用SPSS进行Logistic回归分析
请教:如何在SPSS中进行多项Logistic回归分析?

请教:如何在SPSS中进行多项Logistic回归分析?
展开全文
既然你会了二分类变量的Logistic回归分析,那因变量有三个或者三个以上分类就不难了!在SSPS软件上,单项和多项Logistic Regression 的菜单紧挨着,要是多变量多项 Logistic Regression 选多项 Logistic Regression 分析就行了!但注意以下几个事项:
1,要分清从属变量和独立变量,从属变量是被影响因子---比如:0 不发病 1 发病,而独立变量就是那些影响因子。
2,在选多项Logistic Regression 分析,独立变量里可能还包括因子变量和共同变量两种,前者是计数资料,后者是计量资料。
这一点非常重要,在SSPS软件上输入时要注意。
3,从属变量和因子变量里还要注意主次成分,也就是排序,比如:你是判断发病危险还是判断不发病的可能性(与从属变量排序有关),你是判断吸烟对疾病有无危险还是判断吸烟对疾病有无保护(与因子变量排序有关)。
也不知道你明白了没有?总之,统计就是这么抽象,只有自己在实战中才能真正理解!。
多因素logistic回归分析spss

多因素logistic回归分析spssLogistic回归分析是一种用来研究影响离散变量的因素的方法,该方法的输出是一个logistic模型,这一模型可以用于预测变量的值,即预测该变量的值有多高的概率会取各种可能的取值。
简言之,logistic回归分析的主要目的是把客观的结果(例如,是否改变某个政策,是否感染某种疾病等)变成可预测的离散变量,以便分析影响客观结果的各种因素。
Spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量(例如,是否改变某个政策,是否感染某种疾病等)的多个因素之间的关联。
该分析需要有一个组合变量作为自变量,以及一个离散变量作为因变量。
例如,如果您要研究性别和年龄两个因素如何影响某种疾病的发生率,那么性别和年龄两个因素就是组合变量,而疾病的发生率则是因变量。
1.建立变量和分类(上述示例中需要建立性别和年龄两个变量,以及分类变量的可能的取值)。
2.执行logistic回归分析。
打开spss,并在“分析”菜单中打开多元分析,然后点击“逻辑回归”,并选择您要研究的变量和分类。
3.生成回归模型和检验其统计学意义。
在spss中,您可以使用类似“回归系数”之类的描述性统计学方法来估算回归模型,并可以使用“p-值”来判断回归模型中各变量的统计学意义。
4.Interpret模型。
根据p值判断各变量的统计学意义,进而分析影响离散变量的多个因素之间的关联。
四、总结Logistic回归分析是一种用来研究影响离散变量的因素的方法,spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量的多个因素之间的关联,spss中步骤:建立变量和分类,执行logistic回归分析,生成回归模型和检验其统计学意义,Interpret模型。
SPSS的Logistics回归

SPSS的Logistics回归实验⽬的学会使⽤SPSS的简单操作,Logistic回归。
实验要求使⽤SPSS。
实验内容实验步骤 (1)⼆项分类Logistic回归SPSS分析,使⽤Hosmer和Lemeshow于1989年研究低出⽣体重婴⼉的影响因素作为演⽰例⼦。
结果变量为“是否娩出低出⽣体重⼉”,考虑影响因素有8个,详见Logistics_step.sav⽂件。
本例题主要演⽰“⾃变量的筛选与逐步回归”。
操作如下:点击【分析】→【回归】→【⼆元Logistics回归】,在打开的对话框中,把待结果变量LOW选⼊【因变量】中,将变量LWT,AGE,SMOKE,PTL,HT,UI,FTV,RACE选⼊【协变量】中。
点击【分类】,把RACE选⼊【分类协变量】→【第⼀个】→【变化量】→【继续】,【块】⾥的【⽅法(M)】选【向前:LP】,【选项】→【Exp(B)的置信区间】→【继续】,单击【运⾏】。
主要分析结果如下:分类变量编码频率参数编码(1)(2)种族⽩⼈96.000.000⿊⼈26 1.000.000其他种族67.000 1.000 上表输出race在产⽣哑变量时的编码情况,以⽩⼈为参照⽔平。
未包括在⽅程中的变量得分⾃由度显著性步骤 0变量产妇体重 4.6161.032产妇年龄 2.4071.121产妇在妊娠期间是否吸烟 4.9241.026本次妊娠前早产次数7.2671.007是否患有⾼⾎压 4.3881.036应激性 4.2051.040随访次数.9341.334种族 5.0052.082种族(1) 1.7271.189种族(2) 1.7971.180总体统计29.1409.001 输出的是拟合包含常数项和任⼀⾃变量的Logistics回归模型检验统计量、⾃由度及P值。
其中race产⽣两个哑变量,因此其总⾃由度为2。
由上表可以发现,本次妊娠前早产次数(ptl)的score统计量最⼤,P=0.007,⼩于SPSS默认选⼊变量的标准(0.05)因此下⼀步将它⾸先选⼊模型。
SPSS做Logistic回归步骤
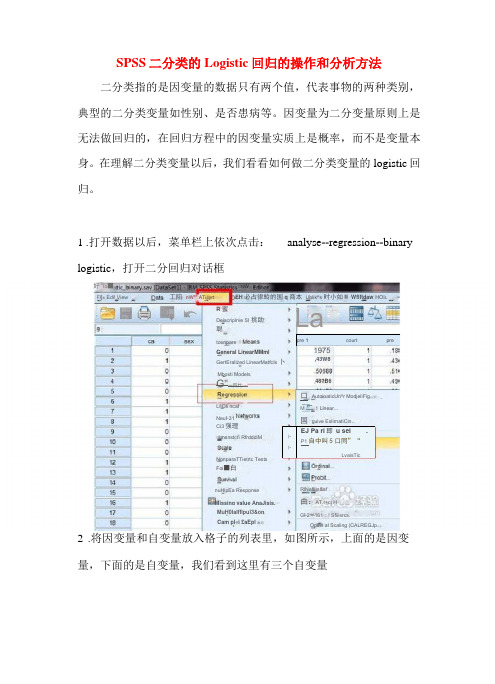
SPSS 二分类的Logistic 回归的操作和分析方法二分类指的是因变量的数据只有两个值,代表事物的两种类别, 典型的二分类变量如性别、是否患病等。
因变量为二分变量原则上是 无法做回归的,在回归方程中的因变量实质上是概率,而不是变量本 身。
在理解二分类变量以后,我们看看如何做二分类变量的logistic 回归。
1 .打开数据以后,菜单栏上依次点击: analyse --regression --binary logistic ,打开二分回归对话框2 .将因变量和自变量放入格子的列表里,如图所示,上面的是因变 量,下面的是自变量,我们看到这里有三个自变量pre 1courtpre卜 卜EJ Pa ri 即 u sei.P1自中叫5口同”“LvaisTic好 Io ■网 □N W□imsnstcri RfrdddiMNonparaTTietrtc Tests Foi ■白MuH0lalfflpul3&on Deiscriplrve SI 挑助聪LfiOli ncaf - Neuf-31 nuHlpEa ResponseMissing value AnaJisis. EH 必占律蛉的国q 商本 Ublik^s 时小如M Wflftdaw HOI LFl[« Edi! View工陷 nW"" ATiilyrtCam pl«i £aEpl 骷与Opsin al Scaling (CALREGJp..R 蜜GertEralized LinearMatfcIs 卜 Mbosti ModelsRlNafllin&af .曲:AT.r+ci HC] 2^^161;! Sfiiisrcs.tosnpareGeneral LinearMMml 48?B6Ci3强理 G"一四忙—一 3 La,43W8口 AutoioaticUn^r ModjeliFig..M 二1 Linear...国 guive EslirnatiCin...C>ep«n (lferit3 .设置回归方法,这里选择最简单的方法:enter ,它指的是将所有的 变量一次纳入到方程。
如何用SPSS做logistic回归分析解读
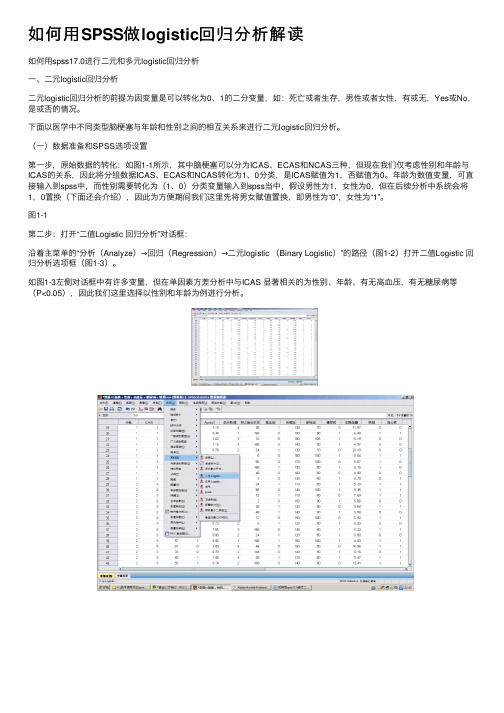
如何⽤SPSS做logistic回归分析解读如何⽤spss17.0进⾏⼆元和多元logistic回归分析⼀、⼆元logistic回归分析⼆元logistic回归分析的前提为因变量是可以转化为0、1的⼆分变量,如:死亡或者⽣存,男性或者⼥性,有或⽆,Yes或No,是或否的情况。
下⾯以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进⾏⼆元logistic回归分析。
(⼀)数据准备和SPSS选项设置第⼀步,原始数据的转化:如图1-1所⽰,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输⼊到spss中,⽽性别需要转化为(1、0)分类变量输⼊到spss当中,假设男性为1,⼥性为0,但在后续分析中系统会将1,0置换(下⾯还会介绍),因此为⽅便期间我们这⾥先将男⼥赋值置换,即男性为“0”,⼥性为“1”。
图1-1第⼆步:打开“⼆值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→⼆元logistic (Binary Logistic)”的路径(图1-2)打开⼆值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素⽅差分析中与ICAS 显著相关的为性别、年龄、有⽆⾼⾎压,有⽆糖尿病等(P<0.05),因此我们这⾥选择以性别和年龄为例进⾏分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选⼊因变量(Dependent)中,⽽将性别和年龄选⼊协变量(Covariates)框中,在协变量下⽅的“⽅法(Method)”⼀栏中,共有七个选项。
采⽤第⼀种⽅法,即系统默认的强迫回归⽅法(进⼊“Enter”)。
接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所⽰进⾏设置。
如何用spss17.0进行二元和多元logistic回归分析

如何用spss17.0进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图 1-1第二步:打开“二值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic(Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
采用第一种方法,即系统默认的强迫回归方法(进入“Enter”)。
接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所示进行设置。
spss的logistic分析教程

Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
一般也不用管它。
选好主面板以后,单击分类(右上角),打开分类对话框。
在这个对话框里边,左边的协变量的框框里边有你选好的自变量,右边写着分类协变量的框框则是空白的。
你要把协变量里边的字符型变量和分类变量选到分类协变量里边去(系统会自动生成哑变量来方便分析,什么事哑变量具体参照前文)。
SPSS—回归—二元Logistic回归案例分析

SPSS—回归—⼆元Logistic回归案例分析数据分析真不是⼀门省油的灯,搞的⼈晕头转向,⽽且涉及到很多复杂的计算,还是书读少了,⼩学毕业的我,真是死了不少脑细胞,学习⼆元Logistic回归有⼀段时间了,今天跟⼤家分享⼀下学习⼼得,希望多指教!⼆元Logistic,从字⾯上其实就可以理解⼤概是什么意思,Logistic中⽂意思为“逻辑”但是这⾥,并不是逻辑的意思,⽽是通过logit变换来命名的,⼆元⼀般指“两种可能性”就好⽐逻辑中的“是”或者“否”⼀样,Logistic 回归模型的假设检验——常⽤的检验⽅法有似然⽐检验(likelihood ratio test)和 Wald检验)似然⽐检验的具体步骤如下:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL02:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InL13:最后⽐较两个对数似然函数值的差异,若两个模型分别包含l个⾃变量和P个⾃变量,记似然⽐统计量G的计算公式为 G=2(InLP - InLl). 在零假设成⽴的条件下,当样本含量n较⼤时,G统计量近似服从⾃由度为 V = P-l 的 x平⽅分布,如果只是对⼀个回归系数(或⼀个⾃变量)进⾏检验,则 v=1.wald 检验,⽤u检验或者X平⽅检验,推断各参数βj是否为0,其中u= bj / Sbj, X的平⽅=(bj / Sbj), Sbj 为回归系数的标准误这⾥的“⼆元”主要针对“因变量”所以跟“曲线估计”⾥⾯的Logistic曲线模型不⼀样,⼆元logistic回归是指因变量为⼆分类变量是的回归分析,对于这种回归模型,⽬标概率的取值会在(0-1),但是回归⽅程的因变量取值却落在实数集当中,这个是不能够接受的,所以,可以先将⽬标概率做Logit变换,这样它的取值区间变成了整个实数集,再做回归分析就不会有问题了,采⽤这种处理⽅法的回归分析,就是Logistic 回归设因变量为y, 其中“1” 代表事件发⽣, “0”代表事件未发⽣,影响y的 n个⾃变量分别为 x1, x2 ,x3 xn等等记事件发⽣的条件概率为 P那么P= 事件未发⽣的概理为 1-P事件发⽣跟”未发⽣的概率⽐为( p / 1-p ) 事件发⽣⽐,记住Odds将Odds做对数转换,即可得到Logistic回归模型的线性模型:还是以教程“blankloan.sav"数据为例,研究银⾏客户贷款是否违约(拖⽋)的问题,数据如下所⽰:上⾯的数据是⼤约700个申请贷款的客户,我们需要进⾏随机抽样,来进⾏⼆元Logistic回归分析,上图中的“0”表⽰没有拖⽋贷款,“1”表⽰拖⽋贷款,接下来,步骤如下:1:设置随机抽样的随机种⼦,如下图所⽰:选择“设置起点”选择“固定值”即可,本⼈感觉200万的容量已经⾜够了,就采⽤的默认值,点击确定,返回原界⾯、2:进⾏“转换”—计算变量“⽣成⼀个变量(validate),进⼊如下界⾯:在数字表达式中,输⼊公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置⼀个“选择条件”点击“如果”按钮,进⼊如下界⾯:如果“违约”变量中,确实存在缺失值,那么当使⽤"missing”函数的时候,它的返回值应该为“1”或者为“true",为了剔除”缺失值“所以,结果必须等于“0“ 也就是不存在缺失值的现象点击 ”继续“按钮,返回原界⾯,如下所⽰:将是“是否曾经违约”作为“因变量”拖⼊因变量选框,分别将其他8个变量拖⼊“协变量”选框内,在⽅法中,选择:forward.LR⽅法将⽣成的新变量“validate" 拖⼊"选择变量“框内,并点击”规则“设置相应的规则内容,如下所⽰:设置validate 值为1,此处我们只将取值为1的记录纳⼊模型建⽴过程,其它值(例如:0)将⽤来做结论的验证或者预测分析,当然你可以反推,采⽤0作为取值记录点击继续,返回,再点击“分类”按钮,进⼊如下页⾯在所有的8个⾃变量中,只有“教育⽔平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育⽔平分为:初中,⾼中,⼤专,本科,研究⽣等等, 参考类别选择:“最后⼀个” 在对⽐中选择“指⽰符” 点击继续按钮,返回再点击—“保存”按钮,进⼊界⾯:在“预测值"中选择”概率,在“影响”中选择“Cook距离” 在“残差”中选择“学⽣化”点击继续,返回,再点击“选项”按钮,进⼊如下界⾯:分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别⽤值“1“和“0”代替,在“分类变量编码”中教育⽔平分为5类,如果选中“为完成⾼中,⾼中,⼤专,⼤学等,其中的任何⼀个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究⽣“ 频率分别代表了处在某个教育⽔平的个数,总和应该为 489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“⽅程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029⼏乎接近,是因为我对数据进⾏的向下舍⼊的关系,所以数据会稍微偏⼩,B和Exp(B) 是对数关系,将B进⾏对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中⾃由度为1, sig为0.000,⾮常显著1:从“不在⽅程中的变量”可以看出,最初模型,只有“常数项”被纳⼊了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, ⽽其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了⼀个平⽅)下⾯来举例说明这个计算过程:(“年龄”⾃变量的得分为例)从“分类表”中可以看出:有129⼈违约,违约记为“1” 则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五⼊)计算过程采⽤的是在 EXCEL ⾥⾯计算出来的,截图如下所⽰:从“不在⽅程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采⽤的是:向前步进的⽅法,在“模型系数的综合检验”表中可以看出:所有的SIG ⼏乎都为“0” ⽽且随着模型的逐渐步进,卡⽅值越来越⼤,说明模型越来越显著,在第4步后,终⽌,根据设定的显著性值和⾃由度,可以算出卡⽅临界值,公式为:=CHIINV(显著性值,⾃由度) ,放⼊excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR⽅和 Nagelkerke R⽅拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最⼤似然平⽅的对数值都⽐较⼤,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR⽅的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含⾃变量的检验)再根据公式:即可算出:Cox&SnellR⽅的值!提⽰:将Hosmer 和 Lemeshow 检验和“随机性表” 结合⼀起来分析1:从 Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡⽅统计量为:11.919,⽽临界值为:CHINV(0.05,8) =15.507卡⽅统计量< 临界值,从SIG ⾓度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
详解利用SPSS进行Logistic_回归分析
第8 章利用SPSS 进行Logistic 回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类。
首先用实例讲述二值logistic 回归,然后进一步说明多值logistic 回归。
在阅读这部分内容之前,最好先看看有关SPSS 软件操作技术的教科书。
§8.1 二值logistic 回归8.1.1 数据准备和选项设置我们研究2005 年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
第一步:整理原始数据。
这些数据不妨录入Excel 中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005 年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes 表示,否则用No 表示(图8-1-1)图8-1-1 原始数据(Excel 中,局部)将数据拷贝或者导入SPSS 的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31 个地区的数据(SPSS 中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic K”的路径(图8-1-3)打开二值Logistic 回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic 回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
Spss软件之logistic回归分析

Logistic regression analysis
(二) 模型参数的意义 如果把logistic模型中的 P看作是在某一暴露状态下发
病的概率,则 β0:表示所有暴露剂量为0时发病与不发病概率之比的 自然对数,反映了疾病的基准状态。 βj :表示当因素 Xj 改变一个单位时logit(P)的改变量。
G 2(ln L1 ln L0)
当样本含量较大时,在零假设下得到的G统计量
近似服从自由度为d(d=p-l)的
2
分布。
由例13-1可以算得
lnL(X1 ) 585.326
•对于 H0:β1=0和 H0:β2=0
lnL(X1 , X2 ) 579.711
Hypothesis test
lnL(X2 ) 597.436
G1 2[lnL(X1 , X2 ) lnL(X2 )]=35.45>3.84 G2 2[lnL(X1 , X2 ) lnL(X1 )]=11.23>3.84
Hypothesis test
上面计算结果说明:在α=0.05检验水准上拒绝H0, 接受H1,说明平衡了饮酒因素的影响后,食管癌 与吸烟有显著性关系;同理,平衡了吸烟因素的 影响后,食管癌与饮酒有显著性关系。
Hypothesis test
2.Wald检验
z bj , Sbj
2
bj Sbj
2
对于大样本资料,在零假设下z 近似
服从标准正态分布,而 则近似服从
自由度=1的 分布。
2
2
Abraham Wald
Hypothesis test
似然比检验可以对自变量增减时所得到的不同回 归模型进行比较,既适合单个自变量的假设检验, 又适合多个自变量的同时检验。Wald检验比较适 合单个自变量的检验,但结果略为保守。
应用SPSS软件进行多分类Logistic回归分析

应用SPSS软件进行多分类Logistic回归分析应用SPSS软件进行多分类Logistic回归分析一、简介Logistic回归是一种常用的统计分析方法,在很多领域中都有广泛的应用。
它主要用于预测一个分类变量的可能性或概率,例如判断一个疾病的患病风险、判断学生成绩的优劣、预测金融市场的涨跌等。
本文将介绍如何使用SPSS软件进行多分类Logistic回归分析,并以一个具体案例来说明其应用。
二、SPSS软件介绍SPSS软件是统计分析的常用工具之一,它具有友好的用户界面和丰富的分析功能。
在进行Logistic回归分析时,SPSS可以帮助我们进行数据处理、模型建立、模型拟合、模型评估等步骤,并输出详细的分析结果。
三、案例描述我们假设有一份数据集,包含了500个样本和5个自变量,要根据这些自变量对样本进行多分类。
自变量包括性别、年龄、教育水平、收入和职业。
而多分类的目标变量是购买冰淇淋的偏好,包括三个分类:喜欢巧克力口味、喜欢草莓口味和喜欢香草口味。
四、数据处理首先,我们需要对数据进行处理。
SPSS可以读取各种文件格式,如Excel、CSV等。
我们将数据导入SPSS后,可以进行缺失值处理、异常值处理等预处理步骤。
这些步骤是为了保证后续的分析结果的准确性和可靠性。
五、模型建立在SPSS中,我们可以使用多分类Logistic回归模型进行建模。
它采用最大似然估计方法来估计模型参数,以便进行分类预测。
我们需要将自变量和目标变量进行指定,SPSS会自动计算出各个自变量对目标变量的系数和统计学意义。
六、模型拟合在模型拟合阶段,SPSS会对模型进行拟合优度的检验,包括卡方拟合优度检验、Hosmer-Lemeshow检验等。
这些检验可以帮助我们评估模型的拟合程度和可靠性。
如果模型的拟合程度不好,我们可以对模型进行进一步调整和改进。
七、模型评估在模型评估阶段,SPSS提供了一系列的统计指标和图表,用于评估多分类Logistic回归模型的性能。
SPSS 做Logistic 回归步骤
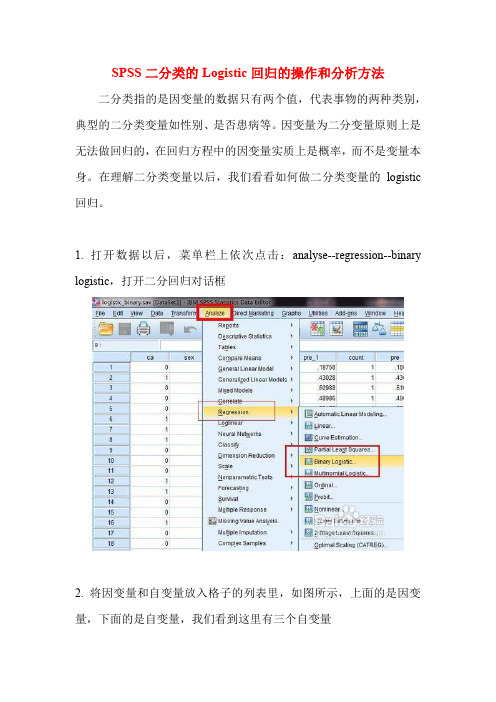
SPSS二分类的Logistic回归的操作和分析方法二分类指的是因变量的数据只有两个值,代表事物的两种类别,典型的二分类变量如性别、是否患病等。
因变量为二分变量原则上是无法做回归的,在回归方程中的因变量实质上是概率,而不是变量本身。
在理解二分类变量以后,我们看看如何做二分类变量的logistic 回归。
1. 打开数据以后,菜单栏上依次点击:analyse--regression--binary logistic,打开二分回归对话框2. 将因变量和自变量放入格子的列表里,如图所示,上面的是因变量,下面的是自变量,我们看到这里有三个自变量3.设置回归方法,这里选择最简单的方法:enter,它指的是将所有的变量一次纳入到方程。
其他方法都是逐步进入的方法,在前面的文章中有介绍,这里就不再熬述。
4. 点击ok,开始处理数据并检验回归方程,等待一会就会弹出数据结果窗口5. 看到的第一个结果是对case的描述,第一个列表告诉你有多少数据参与的计算,有多少数据是缺省值;第二个列表告诉你因变量的编码方式,得分为1代表患病,得分为0代表没有患病6. 这个列表告诉你在没有任何自变量进入以前,预测所有的case都是患病的正确率,正确率为%52.67. 下面这个列表告诉你在没有任何自变量进入以前,常数项的预测情况。
B是没有引入自变量时常数项的估计值,SE它的标准误,Wald 是对总体回归系数是否为0进行统计学检验的卡方。
8.下面这个表格结果,通过sig值可以知道如果将模型外的各个变量纳入模型,则整个模型的拟合优度改变是否有统计学意义。
sig值小于0.05说明有统计学意义9. 这个表格是对模型的全局检验,为似然比检验,供给出三个结果:同样sig值<0.05表明有统计学意义。
10.下面的结果展示了-2log似然值和两个伪决定系数。
两个伪决定系数反应的是自变量解释了因变量的变异占因变量的总变异的比例。
他们俩的值不同因为使用的方法不同。
如何用SPSS做logistic回归分析

如何用spss17.0进行二元和多元logis tic回归分析一、二元logis tic回归分析二元logis tic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logist ic回归分析。
(一)数据准备和SP SS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NC AS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NC AS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到s pss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图1-1第二步:打开“二值Logis tic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regress ion)→二元logis tic (BinaryLogisti c)”的路径(图1-2)打开二值Log istic回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与IC AS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Depende nt)中,而将性别和年龄选入协变量(Covaria tes)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
手把手教你SPSS二分类Logistic回归分析

手把手教你SPSS二分类Logistic回归分析本教程手把手教您用SPSS做Logistic回归分析,目录如下:一、数据格式二、对数据的分析理解三、SPSS做Logistic回归分析操作步骤3.1 线性关系检验假设3.2 多重共线检验假设3.3 离群值、杠杆点和强影响点的识别3.4 Logistic回归分析四、SPSS计算结果的解释五、结果结论的撰写一、数据格式某研究者想了解年龄、性别、BMI和总胆固醇(TC)预测患心脏病(CVD)的能力,招募了100例研究对象,记录了年龄(age)、性别(gender)、BMI,测量血中总胆固醇水平(TC),并评估研究对象目前是否患有心脏病(CVD)。
部分数据如图1。
二、对问题分析使用Logistic模型前,需判断是否满足以下7项假设。
假设1:因变量(结局)是二分类变量。
假设2:有至少1个自变量,自变量可以是连续变量,也可以是分类变量。
假设3:每条观测间相互独立。
分类变量(包括因变量和自变量)的分类必须全面且每一个分类间互斥。
假设4:最小样本量要求为自变量数目的15倍,但一些研究者认为样本量应达到自变量数目的50倍。
假设5:连续的自变量与因变量的logit转换值之间存在线性关系。
假设6:自变量之间无多重共线性。
假设7:没有明显的离群点、杠杆点和强影响点。
假设1-4取决于研究设计和数据类型,本研究数据满足假设1-4。
那么应该如何检验假设5-7,并进行Logistic回归呢?三、SPSS操作3.1 检验假设5:连续的自变量与因变量的logit转换值之间存在线性关系。
连续的自变量与因变量的logit转换值之间是否存在线性关系,可以通过多种方法检验。
这里主要介绍Box-Tidwell方法,即将连续自变量与其自然对数值的交互项纳入回归方程。
本研究中,连续的自变量包括age、BMI、TC。
使用Box-Tidwell 方法时,需要先计算age、BMI、TC的自然对数值,并命名为ln_age、ln_BMI、ln_TC。
SPSS实验8-二项Logistic回归分析

SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据。
数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyze-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables Codings^Frequency Parameter coding (1)(2)收入低收入[132.000.000中收入144.000高收入155、.000性别男191.000Categorical Variables Codings ^Frequency Parameter coding (1)(2)收入低收入[132.000.000中收入144.000高收入155、.000性别男191.000女240《分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted~是否购买PercentageCorrect不购买购买Step 0是否购买】不购买2690购买1620.0)Overall Percentagea. Constant is included in the model.b. The cut value is .500—分析:上表显示了Logistic分析初始阶段(第零步)方程中只有常数项时的错判矩阵。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图 8-1-10 因变量编码
3. Categorical Variables Codings(分类变量编码)。我们的自变量中涉及到代表不同地 域类型的名义变量(图 8-1-11)。在我们开始的分类中,属于中部用 1 表示,否则用 0 表示。 但是,SPSS 改变了这种编码,原来的 0 改用 1 表示,原来的 1 改用 0 表示。也就是说,在 这次 SPSS 分析过程中,0 代表属于中部的地区,1 代表不属于中部的地区。记住这个分类 对后面开展预测分析非常重要。
图 8-1-6 定义分类变量选项
⒉ 设置 Save(保存)选项:决定保存到 Data View 的计算结果(图 8-1-7) 。 选中 Leverage values、DfBeta(s)、Standardized 和 Deviance 四项。 完成后,点击 Continue 继续。
4
研究生地理数学方法(实习)
Categorical Variables Codings Paramete
中部
0 1
Frequency 22 9
(1) 1.000 .000
图 8-1-11 分类变量编码
4. Classification Table(初始分类表) 。Logistic 建模如同其他很多种建模方式一样,首先 对模型参数赋予初始值,然后借助迭代计算寻找最佳值。以误差最小为原则,或者以最大似 然为原则,促使迭代过程收敛。当参数收敛到稳定值之后,就给出了我们需要的比较理想的 参数值。下面是用初始值给出的预测和分类结果(图 8-1-12) 。这个结果主要用于对比,比 较模型参数收敛前后的效果。
Percentage Correct .0 100.0 64.5
图 8-1-12 初始预测分类表
7
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
5.Variable in the Equation(初始方程中的变量) 。从这个表中可以看到系统对模型的最初 赋值方式 (图 8-1-13) 。 最开始仅仅对常数项赋值, 结果为 B=0.598 (复制到 Excel 可以看来, 更精确的数值为 0.597837) ,标准误差为 S.E.=0.375(复制到 Excel 可以看来,更精确的数值 为 0.375379) ,于是 Wald 值为
图 8-1-1 原始数据(Excel 中,局部)
将数据拷贝或者导入 SPSS 的数据窗口(Data View)中(图 8-1-2) 。
1
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
图 8-1-2 中国 31 个地区的数据(SPSS 中,局部)
第二步:打开“聚类分析”对话框。 沿着主菜单的“Analyze→Regression→Binary Logistic K ”的路径(图 8-1-3)打开二值 Logistic 回归分析选项框(图 8-1-4) 。
图 8-1-4 Logistic 回归分析选项框
第三步:选项设置。 首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调 入 Dependent(因变量)和 Covariates(协变量)列表框中(图 8-1-5) 。在本例中,将名义变 量“城市化”调入 Dependent(因变量)列表框,将“人均 GDP”和“中部”调入 Covariates (协变量)列表框中。 在 Method (方法)一栏有七个选项。采用第一种方法,即系统默认的强迫回归方法 (Enter) 。
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
第 8 章 利用 SPSS 进行 Logistic 回归分析
现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用 0 和 1 表示。如果我们采用多个因素对 0-1 表示的某种现象进行因果关系解释,就可能应用 到 logistic 回归。Logistic 回归分为二值 logistic 回归和多值 logistic 回归两类。首先用实例讲 述二值 logistic 回归,然后进一步说明多值 logistic 回归。在阅读这部分内容之前,最好先看 看有关 SPSS 软件操作技术的教科书。
⎛ B ⎞ ⎛ 0.597837 ⎞ Wald = ⎜ ⎟ =⎜ ⎟ = 2.536 . ⎝ S .E. ⎠ ⎝ 0.375379 ⎠
后面的 df 为自由度,即 df=1;Sig.为 P 值,Sig.=0.111。注意 Sig.值越低越好,一般要求小 于 0.05。当然,对于 Sig.值,我们关注的是最终模型的显示结果。Exp(E)是 B 还原之后数值, 显然
2
2
Exp( B ) = e B = e 0.597837 = 1.818 .
在 Excel 里,利用指数函数 exp 很容易对 B 值进行还原。
Variables in the Equation
Step 0
Constant
B .598
S.E. .375
Wald 2.536
df 1
Sig. .111
a. If weight is in effect, see classification table for the total number of cases.
6
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
图 8-1-9 样品处理摘要
2. Dependent Variable Encoding(因变量编码) 。这是很重要的信息,告诉我们对不同城 市化水平地区的分类编码结果(图 8-1-10) 。我们开始根据全国各地区的平均结果 45.41 分 为两类:大于等于 45.41 的地区用 Yes 表示,否则用 No 表示。现在,图 8-1-10 显示,Yes 用 0 表示,No 用 1 表示。也就是说,在这次 SPSS 分析过程中,0 代表城市化水平高于平均 值的状态,1 代表城市化水平低于平均值的状态。记住这个分类。
图 8-1-3 打开二值 Logistic 回归分析对话框的路径
对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显
2
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
著。至于反映地区位置的分类变量,不宜一次性的全部引入,至多引入两个,比方说东部和 中部。通过尝试,发现引入中部地带为变量比较合适。因此,为了实例的典型性,我们采用 两个变量作为自变量:一是数值变量人均 GDP,二是分类变量中部地带。
5
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
图 8-1-8 Logistic 回归分析的选项设置
此外还有一个选项需要说明。一是 Classification cutoff(分类临界值) ,默认值为 0.5, 即按四舍五入的原则将概率预测值化为 0 或者 1。 如果将数值改为 0.6, 则大于等于 0.6 的概 率值才表示为 1,否则为 0。其情况余依此类推。二是 Maximum Iterations(最大迭代值) , 规定系统运算的迭代次数,默认值为 20 次,为安全起见,我们将迭代次数增加到 50。原因 是,有时迭代次数太少,计算结果不能真正收敛。三是 Include constant in model(模型中包 括常数项) ,即模型中保留截距。除了迭代次数之外,其余两个选项均采用系统默认值。 完成后,点击 Continue 继续。
3
研究生地理数学方法(实习)
Part 2 统计分析软件 SPSS
图 8-1-5 Logistic 回归分析的初步设置
接下来进行如下 4 项设置: ⒈ 设置 Categorical(分类)选项:定义分类变量(图 8-1-6) 。 将中部调入 Categorical Covariates(分类协变量)列表框,其余选项取默认值即可。完 成后,点击 Continue 继续。
a,b Classification Table
Predicted
城市化
Observed Step 0
城市化
Yes Yes No 0 0
No 11 20
Overall Percentage a. Constant is included in the model. b. The cut value is .500
Exp(B) 1.818
图 8-1-13 初始方程中的变量
6. Variable not in the Equation(不在初始方程中的变量) 。人均 GDP 和代表地理位置的 中部地带的系数初始值设为 0,这相当于,在初始模型中不考虑这两个变量(图 8-1-14) 。 表中给出了 Score 检验值及其对应的自由度 df 和 P 值,即 Sig.值。Score 检验是一种初始检 验,在建模之初根据变量之间的结构关系判断自变量与因变量之间的密切程度。Score 检验 值的计算公式为
Case Processing Summary Unweighted Cases Selected Cases
a
N Included in Analysis Missing Cases Total 31 0 31 0 31
Unselected Cases Total
Percent 100.0 .0 100.0 .0 100.0
[ Score j =
∑ x (y
i i =1 n
n
i
− y )] 2
.
i
y (1 − y )
∑ (x
i =1
-1-10 所示的编码原则,令所有的 Yes 为 0,所有的 No 为 1,容 易算出 y (1 − y ) = 0.645161(1 − 0.645161) = 0.228928 . 人均 GDP 已知,中部的编码法则已知,于是不难算出