notepad++正则表达式替换字符串详解
notepad++正则表达式的用法

notepad++正则表达式的用法Notepad++ 是一款常用的文本编辑器,支持使用正则表达式进行搜索和替换。
以下是Notepad++ 中正则表达式的一些常见用法:1. 普通字符匹配:- `abc`: 匹配包含"abc" 的文本。
2. 元字符:- `.`: 匹配任意单个字符。
- `^`: 匹配行的开头。
- `$`: 匹配行的结尾。
- `\b`: 匹配单词的边界。
- `\d`: 匹配数字字符。
- `\w`: 匹配字母、数字或下划线。
- `\s`: 匹配空白字符。
3. 字符类:- `[abc]`: 匹配包含字符'a'、'b' 或'c' 的文本。
- `[^abc]`: 匹配不包含字符'a'、'b' 或'c' 的文本。
4. 重复限定符:- `*`: 匹配前一个元素零次或多次。
- `+`: 匹配前一个元素一次或多次。
- `?`: 匹配前一个元素零次或一次。
- `{n}`: 匹配前一个元素恰好n 次。
- `{n,}`: 匹配前一个元素至少n 次。
- `{n,m}`: 匹配前一个元素至少n 次且不超过m 次。
5. 分组和捕获:- `(abc)`: 将"abc" 视为一个整体进行匹配,可以在替换时使用。
- `\1`, `\2`, ...: 反向引用,引用前面捕获的分组。
6. 特殊字符转义:- `\.`: 匹配实际的点字符。
- `\\`: 匹配实际的反斜杠字符。
7. 零宽断言:- `(?=...)`: 正向先行断言,匹配某个位置之后的文本。
- `(?!...)`: 负向先行断言,匹配某个位置之后不是指定文本的文本。
8. 替换:-在搜索框中使用正则表达式,然后在替换框中使用捕获组(例如`\1`, `\2`)进行替换。
示例:-查找所有以数字开头的行:`^\d.*$`-匹配包含"cat" 或"dog" 的文本:`cat|dog`-匹配重复的单词:`\b(\w+)\b.*\b\1\b`请注意,Notepad++ 使用的正则表达式语法基于PCRE(Perl Compatible Regular Expressions),并且在实际使用中可能会根据文本编辑器版本有轻微的变化。
nodepad 正则表达式

nodepad 正则表达式
正则表达式是用来描述字符串模式的一种文字语言,在Notepad++ 中,可以通过搜索菜单的'查找/替换'功能(Ctrl+F)来实现正则表达式的使用。
一般而言,Notepad++ 内置的正则表达式使用 POSIX 标准的语法来定义字符模式。
以下是一些常用的正则表达式用法:
1. 匹配单个字符:
使用下面的正则表达式可以匹配单个字符:
.
- 匹配任何字符,包括换行符。
2. 匹配字符类:
使用下面的正则表达式可以匹配一组字符:
[characters]
- 匹配所有括号内的字符。
3. 匹配重复字符:
使用下面的正则表达式可以匹配重复元素:
{min,max}
- 匹配最少 min 个,最多 max 个前面的字符或字符类。
4. 否定字符类:
使用下面的正则表达式可以对某种字符类进行否定:
[^characters]
- 否定括号内的字符类,也就是搜索括号内以外的字符。
5. 匹配关键字:
使用下面的正则表达式可以匹配文本中出现的关键字: /keyword/
- 匹配文本中括号内的关键字。
正则表达式notepad++搜索替换驼峰下划线

正则表达式notepad++搜索替换驼峰下划线
目标:将icp_double_record_info转为icpDoubleRecordInfo 方法1:
匹配:(\w)_(\w)
替换:\1\U\2\E
\U表示将匹配项转为大写(Upper)。
\L表示将匹配项转为大写(Lower)。
\0表示全部匹配。
\1表示第一个匹配分组,也可以用$1。
\E表示结束(End)匹配的大小写转换。
\2表示第二个匹配分组,也可以用$2。
\b表示单词边界。
\w表示字母。
这个\1 \2...... 都要和正则表达式集合()一起使用
\1表示引用第一个圆括号内匹配到的内容
\2表示引用第二个圆括号内匹配到的内容
可以理解为变量,或占位符。
小括号的作用
[a-z][A-Z]*
可以匹配到任意长度的大小写字母组合。
例如:XXXaaaBBBccc ([a-z][A-Z])*
和上面的区别是这个只能匹配到偶数个,例如AAAbb,他只能匹配到前面4个,AAAb。
即,2个为一组,若干组。
中括号和*的搭配注意点
[123][456] 例如123456,会匹配到34,
[123][456]* 例如123456,会匹配到1,2,3456,[123]*[456]* 例如142356,会匹配到14,2,356。
notepad++正则表达式通配符的用法

文章标题:探索Notepad++正则表达式通配符的用法一、引言在计算机科学领域中,正则表达式是一种强大的文本处理工具,它可以帮助我们在海量数据中快速准确地查找、替换和匹配特定的文本模式。
Notepad++作为一款备受欢迎的文本编辑器,其内置的正则表达式引擎更是为用户提供了便捷灵活的文本处理能力。
本文将深入探索Notepad++中正则表达式通配符的使用方法,希望能够帮助读者更好地利用这一强大工具。
二、基础知识在使用Notepad++的正则表达式功能之前,首先需要了解几个基本概念和通配符的用法。
在正则表达式中,通配符是用来匹配文本中的特定字符或字符序列的符号,常见的通配符包括“*”、“.”、“+”、“?”等。
1. “*”通配符在正则表达式中,“*”通配符用于匹配零个或多个之前的字符。
在Notepad++中,可以使用“.*”来匹配任意长度的任意字符序列。
2. “.”通配符“.”通配符用于匹配任意一个字符,在Notepad++中可以使用“.”来匹配任意单个字符。
3. “+”通配符“+”通配符用于匹配一个或多个之前的字符,在Notepad++中可以使用“.+”来匹配至少一个字符的序列。
4. “?”通配符“?”通配符用于匹配零个或一个之前的字符,在Notepad++中可以使用“a?”来匹配“a”或空字符。
三、深入探索在Notepad++中,正则表达式通配符的使用不仅局限于简单的字符匹配,还可以进行更加灵活和复杂的文本操作。
下面将围绕特定主题或概念展开更加深入的探讨。
1. 使用通配符匹配特定文本在日常文本处理中,我们经常需要根据特定的文本模式进行查找和替换操作。
在Notepad++中,可以使用正则表达式通配符来进行精确匹配,例如使用“\d”匹配数字、“\w”匹配单词字符、“\s”匹配空白字符等。
2. 使用通配符进行高级查找与替换除了基本的字符匹配外,正则表达式通配符还可以进行高级的文本查找和替换操作。
例如可以使用“^”匹配行首、“$”匹配行尾、“\b”匹配单词边界等,这些通配符可以帮助我们更加精确地定位文本。
正则表达式:Notepad++查找两段特殊字符之间文字并在该目标字符后面添加字符

正则表达式:Notepad++查找两段特殊字符之间文字并在该目标字符后面添加字符今日在工作中使用Notepad++处理json文件时遇到一个正则表达式查找并添加字符的问题:问题描述:我们工作团队人员需要迁移一个平台的文章内容到另一个平台,使用富文本编辑器进行复制迁移,其中文本链接需要手工添加,但由于提前没做要求,大家都没有设置链接的跳转目标页,也就是都是默认的在本网页打开新链接,在用户体验中属于不良好体验。
而且链接数目较多,再次逐一添加确实耽误了人力,所以就想办法在所有文章源文件(json格式)中批量处理,既:1、确定查找目标字符串:所有以 href= 开头以 > 结尾的字符片段;2、在每个查找到的字符串后添加的理想代码字符target=\"_blank\" ,由于是在json文件中所以要注意使用反斜杠 \ 的转义字符表示方式;原字符示例:text_example<a href=\"/\">link_text_example</a>......text_example<ahref=\"px/\">link_text_example</a>......解决方案:1、查找的正则表达式:(?<=href=)(.*?)(?=>)2、替换的正则表达式:($1)( target=\\"_blank\\")3、图示:修改后字符示例:text_example<ahref=\"/\" target=\"_blank\">link_text_example</a>......text_example<ahref=\"px/\" target=\"_blank\">link_text_example</a>......。
notepad正则语法

notepad正则语法Notepad是Windows操作系统中的一个文本编辑器,它支持使用正则表达式进行搜索和替换操作。
在Notepad中,你可以使用正则表达式来查找特定模式的文本,并且可以使用这些模式来进行替换操作。
在Notepad中,正则表达式的语法遵循标准的正则表达式规则,包括以下一些常见的用法:1. 普通字符匹配,普通字符(例如字母、数字、标点符号)在正则表达式中表示它们自身。
2. 元字符,元字符是具有特殊含义的字符,例如"."表示匹配任意字符,"^"表示匹配行的开头,"$"表示匹配行的结尾。
3. 字符类,用方括号"[]"表示,可以匹配其中任意一个字符,例如"[abc]"可以匹配字符a、b或c。
4. 量词,用来指定匹配次数,例如""表示零次或多次匹配,"+"表示一次或多次匹配,"?"表示零次或一次匹配。
5. 分组和捕获,用小括号"()"表示,可以将匹配的内容分组并进行捕获。
在Notepad中,你可以通过使用这些正则表达式的语法来进行文本的搜索和替换操作。
例如,你可以使用"."来匹配任意字符,使用"^"和"$"来匹配行的开头和结尾,使用"[]"来匹配指定范围的字符,使用""、"+"和"?"来指定匹配次数,使用"()"来进行分组和捕获。
总之,在Notepad中使用正则表达式可以帮助你更加灵活和高效地进行文本处理操作,但需要注意在使用时要小心谨慎,确保正则表达式的准确性和合理性。
希望这些信息能够帮助到你对Notepad正则语法的理解。
正则表达式replace 的用法

正则表达式replace 的用法
Replace 方法的简单介绍
Replace 方法是JavaScript 中的一种字符串操作方法,它可以将字符串中的指定内容替换成另外一个内容。
它有两种使用形式:
1. 使用字符串替换:replace(要替换的字符串,替换成什么字符串)
2. 使用正则表达式替换:replace(要替换的正则表达式,替换成什么字符串)
使用正则表达式替换时,可以替换字符串中满足正则表达式规则的字符,比如:将字符串中的“a”全部替换成“b”,可以使用replace (/a/g,“b”)的方式来实现。
同时,使用正则表达式替换还可以引用替换字符串中的内容,比如:将字符串中的a替换成它本身加上b,可以使用replace(/a/g,“$&b”)的方式来实现。
此外,replace 方法还可以使用函数作为参数,并将函数返回的内容作为替换字符串,例如:将字符串中的a替换成它本身加上b再加上一个随机数,可以使用replace(/a/g,function(){return $&b + Math.random()})的方式来实现。
综上所述,replace 方法是一种非常强大的字符串操作方法,能够
帮助我们轻松实现字符串的替换操作,在开发中有着广泛的使用场景。
notepad匹配规则

notepad匹配规则Notepad是一款广泛使用的文本编辑器,它具有简洁、高效的特点。
本文将围绕Notepad的匹配规则展开,并分为以下几个部分进行探讨:正则表达式、搜索与替换、文本格式化和文本编辑技巧。
一、正则表达式正则表达式是Notepad中的一项强大的匹配规则,它可以帮助我们在文本中进行高级的搜索和替换操作。
正则表达式是一种由字符和特殊符号组成的模式,可以用来匹配和处理文本。
例如,我们可以使用正则表达式来查找所有以大写字母开头的单词。
在Notepad中,我们可以使用"^([A-Z][a-z]+)\b"来进行匹配。
其中,"^"表示匹配行的开头,"([A-Z][a-z]+)"表示匹配一个以大写字母开头,后面跟着至少一个小写字母的单词,"\b"表示匹配单词的边界。
二、搜索与替换除了正则表达式,Notepad还提供了简单而强大的搜索与替换功能。
通过使用搜索与替换功能,我们可以快速地定位到特定的文本,并进行相应的替换操作。
例如,我们可以使用搜索与替换功能将文本中的"apple"替换为"orange"。
在Notepad中,我们可以按下Ctrl + H打开搜索与替换对话框,然后在"Find what"中输入"apple",在"Replace with"中输入"orange",最后点击"Replace All"按钮即可完成替换操作。
三、文本格式化Notepad还提供了一些简单的文本格式化功能,可以帮助我们快速地调整文本的外观。
例如,我们可以使用文本格式化功能将文本中的所有字母转换为大写。
在Notepad中,我们可以按下Ctrl + Shift + U将选中的文本转换为大写。
四、文本编辑技巧除了上述功能,Notepad还提供了一些实用的文本编辑技巧,可以让我们更加高效地编辑文本。
Notepad正则表达式剖析

Notepad++快捷键&正则表达式替换字符串&插件使用介绍发布者:lovelclxf 时间:04-21 阅读数:798点评:Notepad++绝对是windows下进行程序编辑的神器之一,要更快速的使用以媲美VIM,必须灵活掌握它的快捷键,下面对notepad++默认的快捷键做个整理(其中有颜色的为常用招数)Notepad++绝对是windows下进行程序编辑的神器之一,要更快速的使用以媲美VIM,必须灵活掌握它的快捷键,下面对notepad++默认的快捷键做个整理(其中有颜色的为常用招数):1. 文件相关快捷键动作定义Ctrl-O 打开文件Ctrl-N 新建文件Ctrl-S 保存文件Ctrl-Alt-S 文件另存为Ctrl-Shift-S 保存所有打开文件Ctrl-P 打印Alt-F4 退出程序Ctrl-Tab 文件标签跳转,跳至下一个打开文件Ctrl-Shift-Tab 文件标签跳转,跳至上一个打开文件Ctrl-W 关闭当前文件2.编辑相关快捷键动作定义Ctrl-C 复制Ctrl-Insert 同上,复制Ctrl-Shift-T 复制当前行至剪贴板Ctrl-X 剪切Shift-Delete 同上,剪切Ctrl-V 粘帖Shift-Insert 同上,粘帖Ctrl-Z 撤销上一次操作Alt-Backspace 同上Ctrl-Y 重做,注:撤销后,重做刚刚撤销的动作Ctrl-A 全选Alt-Shift-方向键或Alt + 鼠标左键列选择模式Ctrl + 鼠标左键非连续性的多区域选择ALT-C 列编辑器Ctrl-D 复制当前行至下方,或者复制选中区域至其后Ctrl-T 复制当前行至剪贴板(注:帮助中说是将当前行与上一行交换位置)Ctrl-Alt-T 与上一行进行交换Ctrl-Shift-Up 将当前行上移一行Ctrl-Shift-Down 将当前行下移一行Ctrl-L 删除当前行Ctrl-I -(注:帮助中是分割多行,不过最新版中不起作用)Ctrl-J 合并多行(注:使用时要选择中需要合并的行)Ctrl-G 跳转至某行对话框Ctrl-Q 添加/删除注释Ctrl-Shift-Q 区块添加/删除注释Tab (selection of one or more fulllines)插入TabShift-Tab (selection of one or morefull lines)删除位置之前的TabCtrl-BackSpace 删除当前位置至单词开始的内容Ctrl-Delete 删除当前位置至单词结尾的内容Ctrl-Shift-BackSpace 删除当前位置至行首的内容Ctrl-Shift-Delete 删除当前位置至行尾的内容Ctrl-U 转换为小写Ctrl-Shift-U 转换为大写Ctrl-B 跳转至配对的括号Ctrl-Space 触发函数自动完成列表Ctrl-Shift-Space 触发函数参数提示Ctrl-Enter 触发关键字自动完成列表Ctrl-Alt-R 整个页面文字方向从右到左Ctrl-Alt-L 整个页面文字方向从左到右(注:在安装了zencoding后,此快捷键可能被覆盖)Enter 回车Shift-Enter 同上建议添加一个快捷键用来复制当前行至下一行:在设置->快捷键管理中,选择scintilla commands中,找到SCI_LINEDUPLICATE,给它指定一个快捷键,例如Ctrl+M3.搜索相关快捷键动作定义Ctrl-F 打开搜索对话框Ctrl-H 打开替换搜索对话框F3 搜索下一个结果Shift-F3 搜索上一个结果Ctrl-Shift-F 文件中搜索F7 调到寻找结果Ctrl-Alt-F3 快速查找下一个Ctrl-Alt-Shift-F3 快速查找上一个Ctrl-F3 选定并寻找下一个Ctrl-Shift-F3 选定并寻找上一个F4 下一次寻找结果Shift-F4 上一次寻找结果Ctrl-Shift-I 增量查找Ctrl-n 跳至下一个结果,用第n个风格标识(n为1~5,0是默认风格)Ctrl-Shift-n 跳至上一个结果,用第n个风格标识(n为1~5,0是默认风格)Ctrl-F2 收缩展开标签F2 跳至下一个标签处Shift-F2 跳至上一个标签处4.显示相关快捷键定义内容Ctrl-(Keypad-/Keypad+)或者Ctrl+鼠放大/缩小页面标滚轮Ctrl-Keypad/ 回复到原始页面大小F11 开关全屏显示(显示标签页)F12 开关全屏显示(不显示标签页)Ctrl-Alt-F 收缩当前折叠Ctrl-Alt-Shift-F 展开当前折叠Alt-0 收缩所有折叠Alt-(1~8) 展开相应层折叠Alt-Shift-0 展开所有折叠Alt-Shift-(1~8) 展开所有层次折叠5.运行相关快捷键定义内容F5 打开运行窗口Alt-F1 获得PHP帮助Alt-F2 用Google搜索Alt-F3 用Wiki搜索哦Alt-F5 在本标签页中打开当前目录中,与光标位置文本同名的文件Alt-F6 在新标签页中打开当前目录中,与光标位置文本同名的文件Ctrl-Alt-Shift-R 在Chrome中打开Ctrl-Alt-Shift-X 在Firefox中打开Ctrl-Alt-Shift-I 在IE中打开Ctrl-Alt-Shift-F 在Safari中打开Ctrl-Alt-Shift-O 通过Outlook发送当前文件[转]notepad++正则表达式替换字符串详解表达式说明\t 制表符.\n 新行.. 匹配任意字符.| 匹配表达式左边和右边的字符. 例如, “ab|bc” 匹配“ab” 或者“bc”.[] 匹配列表之中的任何单个字符. 例如, “[ab]” 匹配“a” 或者“b”. “[0-9]” 匹配任意数字.[^] 匹配列表之外的任何单个字符. 例如, “[^ab]” 匹配“a” 和“b” 以外的字符. “[^0-9]” 匹配任意非数字字符.* 其左边的字符被匹配任意次(0次,或者多次). 例如“be*” 匹配“b”, “be” 或者“bee”.+ 其左边的字符被匹配至少一次(1次,或者多次). 例如“be+” 匹配“be” 或者“bee” 但是不匹配“b”.其左边的字符被匹配0次或者1次. 例如“be?” 匹配“b” 或者“be” 但是不匹配“bee”.^ 其右边的表达式被匹配在一行的开始. 例如“^A” 仅仅匹配以“A” 开头的行.” 仅仅匹配以“e” 结尾的行.() 影响表达式匹配的顺序,并且用作表达式的分组标记.\ 转义字符. 如果你要使用“\” 本身, 则应该使用“\\”.例子:原始串str[1]abc[991];str[2]abc[992];str[11]abc[993];str[22]abc[994];str[111]abc[995];str[222]abc[996]; str[1111]abc[997]; str[2222]abc[999];目标串:abc[1];abc[2];abc[11];abc[22];abc[111];abc[222];abc[1111];abc[2222];处理:查找串:strabc替换串:abc[\1]【1】正则表达式应用——替换指定内容到行尾原始文本如下面两行abc aaaaa123 abc 444希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”即上面的文本最终替换为:abc efg123 abc efg解决:①在替换对话框,查找内容里输入“abc.*”②同时勾选“正则表达式”复选框,然后点击“全部替换”按钮其中,符号的含义如下:“.” =匹配任意字符“*” =匹配0次或更多注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
正则表达式(十二)——字符串的替换

正则表达式(⼗⼆)——字符串的替换1、查找字符串中的字串1package com.wy.regular;23import java.util.regex.Matcher;4import java.util.regex.Pattern;56public class RegularTest {78public static void main(String[] args) {9/**10 * 字符串的替换 replacement11*/12 Pattern pattern = pile("java");13 Matcher matcher = pattern.matcher("java Java JAVa JaVa I love JAVA you hate Java");14// 查找所有的Java15while (matcher.find()) {16 pri(matcher.group());// 只有⼀个java17 }18 }1920public static void pri(Object object){21 System.out.println(object);22 }23 }2、忽略⼤⼩写1package com.wy.regular;23import java.util.regex.Matcher;4import java.util.regex.Pattern;56public class RegularTest {78public static void main(String[] args) {9/**10 * 字符串的替换 replacement13 * 使⽤compile(String regex, int flags)⽅法14 * CASE_INSENSITIVE ⼤⼩写不敏感,忽略⼤⼩写15*/16 Pattern pattern = pile("java", Pattern.CASE_INSENSITIVE);17 Matcher matcher = pattern.matcher("java Java JAVa JaVa I love JAVA you hate Java");18/**19 * 查找所有的Java,结果是:20 * java21 * Java22 * JAVa23 * JaVa24 * JAVA25 * Java26*/27while (matcher.find()) {28 pri(matcher.group());29 }30 }3132public static void pri(Object object){33 System.out.println(object);34 }35 }3、替换成⼤写1package com.wy.regular;23import java.util.regex.Matcher;4import java.util.regex.Pattern;56public class RegularTest {78public static void main(String[] args) {9/**10 * 字符串的替换 replacement11 * 使⽤compile(String regex, int flags)⽅法12 * CASE_INSENSITIVE ⼤⼩写不敏感,忽略⼤⼩写13*/14 Pattern pattern = pile("java", Pattern.CASE_INSENSITIVE);15 Matcher matcher = pattern.matcher("java Java JAVa JaVa I love JAVA you hate Java");16// 替换所有的Java为⼤写17 pri(matcher.replaceAll("JAVA"));// 打印结果:JAVA JAVA JAVA JAVA I love JAVA you hate JAVA18 }1920public static void pri(Object object){21 System.out.println(object);22 }23 }4、单数个替换为⼤写,双数个替换为⼩写1package com.wy.regular;23import java.util.regex.Matcher;4import java.util.regex.Pattern;56public class RegularTest {78public static void main(String[] args) {9/**10 * 字符串的替换 replacement11 * 使⽤compile(String regex, int flags)⽅法12 * CASE_INSENSITIVE ⼤⼩写不敏感,忽略⼤⼩写13*/14 Pattern pattern = pile("java", Pattern.CASE_INSENSITIVE);15 Matcher matcher = pattern.matcher("java Java JAVa JaVa I love JAVA you hate Java tail");16// 单数个替换为⼤写,双数个替换为⼩写17 StringBuffer buffer = new StringBuffer();18int i = 0;19while (matcher.find()) {20 i++;21if (i%2==0) {22 matcher.appendReplacement(buffer, "java");23 } else{24 matcher.appendReplacement(buffer, "JAVA");25 }26 }27 pri(buffer);// 结果:JAVA java JAVA java I love JAVA you hate java,没有结尾的tail28 matcher.appendTail(buffer);// 添加最后的字符串29 pri(buffer);// 结果:JAVA java JAVA java I love JAVA you hate java tail30 }3132public static void pri(Object object){33 System.out.println(object);34 }35 }。
notepad++正则表达式替换字符串详解

notepad++正则表达式替换字符串详解则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。
EditPlus的查找,替换,文件中查找支持以下的正则表达式:表达式说明/t 制表符./n 新行.. 匹配任意字符.| 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配"ab" 或者"bc".[] 匹配列表之中的任何单个字符. 例如, "[ab]" 匹配 "a" 或者 "b". "[0-9]" 匹配任意数字.[^] 匹配列表之外的任何单个字符. 例如, "[^ab]" 匹配 "a" 和 "b" 以外的字符. "[^0-9]" 匹配任意非数字字符.* 其左边的字符被匹配任意次(0次,或者多次). 例如"be*" 匹配"b", "be" 或者 "bee".+ 其左边的字符被匹配至少一次(1次,或者多次). 例如 "be+" 匹配 "be" 或者 "bee" 但是不匹配 "b".其左边的字符被匹配0次或者1次. 例如 "be?" 匹配 "b" 或者 "be" 但是不匹配 "bee".^ 其右边的表达式被匹配在一行的开始. 例如"^A" 仅仅匹配以"A" 开头的行.$ 其左边的表达式被匹配在一行的结尾. 例如 "e$" 仅仅匹配以 "e" 结尾的行.() 影响表达式匹配的顺序,并且用作表达式的分组标记./ 转义字符. 如果你要使用 "/" 本身, 则应该使用 "//".例子:原始串str[1]abc[991];str[2]abc[992];str[11]abc[993];str[22]abc[994];str[111]abc[995];str[222]abc[996];str[1111]abc[997];str[2222]abc[999];目标串:abc[1];abc[2];abc[11];abc[22];abc[111];abc[222];abc[1111];abc[2222];处理:查找串:str/[([0-9]+)/]abc/[[0-9]+/]替换串:abc[/1]【1】正则表达式应用——替换指定内容到行尾原始文本如下面两行abc aaaaa123 abc 444希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”即上面的文本最终替换为:abc efg123 abc efg解决:①在替换对话框,查找内容里输入“abc.*”②同时勾选“正则表达式”复选框,然后点击“全部替换”按钮其中,符号的含义如下:“.” =匹配任意字符“*” =匹配0次或更多注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
使用正则表达式进行文本处理的技巧与方法

使用正则表达式进行文本处理的技巧与方法正则表达式是一种强大的文本处理工具,它可以帮助我们快速有效地处理各种文本数据。
无论是在编程领域还是数据分析领域,正则表达式都是一项必备技能。
本文将介绍一些使用正则表达式进行文本处理的技巧与方法。
一、了解正则表达式的基本语法正则表达式是一种用于匹配、查找和替换文本的模式。
在使用正则表达式之前,我们需要了解一些基本的语法规则。
例如,使用"."表示匹配任意字符,使用"*"表示匹配前面的字符任意次数,使用"^"表示匹配字符串的开头,使用"$"表示匹配字符串的结尾等等。
二、使用正则表达式进行字符串匹配正则表达式最常见的用途之一就是进行字符串匹配。
我们可以使用正则表达式来判断一个字符串是否符合某种模式。
例如,我们可以使用正则表达式匹配一个邮箱地址,判断一个字符串是否是有效的手机号码等等。
三、使用正则表达式进行文本提取除了字符串匹配,正则表达式还可以用于提取文本中的特定内容。
例如,我们可以使用正则表达式提取一个网页中的所有链接,提取一段文本中的所有日期等等。
通过灵活运用正则表达式,我们可以快速高效地从大量文本数据中提取所需信息。
四、使用正则表达式进行文本替换正则表达式不仅可以用于匹配和提取文本,还可以用于替换文本中的特定内容。
例如,我们可以使用正则表达式将一段文本中的所有数字替换为"#",将一段文本中的所有空格替换为下划线等等。
通过使用正则表达式进行文本替换,我们可以快速完成一些批量处理的任务。
五、使用正则表达式进行文本分割有时候,我们需要将一段文本按照特定的规则进行分割。
正则表达式可以帮助我们实现这一目标。
例如,我们可以使用正则表达式将一个长句子分割为多个短句,将一个文本文件按照空行进行分割等等。
通过使用正则表达式进行文本分割,我们可以更好地组织和处理文本数据。
六、使用正则表达式进行文本格式化正则表达式还可以用于对文本进行格式化。
使用正则表达式进行文本处理的技巧

使用正则表达式进行文本处理的技巧正则表达式是一种强大的文本处理工具,可以在文本中进行匹配、替换和提取等操作。
在实际应用中,合理运用正则表达式可以提高工作效率和代码简洁性。
下面将介绍一些常用的正则表达式技巧。
1. 匹配数字- \d:匹配任意数字- \d+:匹配一个或多个连续的数字- \d{n}:匹配恰好n个连续的数字- \d{n,}:匹配至少n个连续的数字2. 匹配字母和数字- \w:匹配任意字母或数字- \w+:匹配一个或多个连续的字母或数字- \w{n}:匹配恰好n个连续的字母或数字- \w{n,}:匹配至少n个连续的字母或数字3. 匹配特殊字符- \s:匹配空白字符,包括空格、制表符和换行符等- \S:匹配非空白字符- \b:匹配单词的边界- \B:匹配非单词的边界- .:匹配任意字符(除了换行符)4. 匹配重复字符- {n}:匹配前一个字符恰好n次- {n,}:匹配前一个字符至少n次- {n,m}:匹配前一个字符至少n次但不超过m次 - *:匹配前一个字符零次或多次- +:匹配前一个字符一次或多次- ?:匹配前一个字符零次或一次5. 匹配多种选择- []:匹配方括号内的任意一个字符- [abc]:匹配a、b或c中的任意一个字符- [a-z]:匹配任意小写字母- [A-Z]:匹配任意大写字母- [0-9]:匹配任意数字- [^abc]:匹配除了a、b、c之外的任意字符6. 匹配位置- ^:匹配字符串的开头- $:匹配字符串的结尾- \A:匹配字符串的开头(忽略多行模式)- \Z:匹配字符串的结尾(忽略多行模式)- \b:匹配单词的边界- \B:匹配非单词的边界7. 匹配分组- ():创建一个匹配组- |:匹配两个或多个表达式之一8. 替换文本- re.sub(pattern, repl, string):使用repl替换string中与pattern匹配的内容9. 提取数据- re.findall(pattern, string):提取string中所有与pattern匹配的内容- re.search(pattern, string):在string中搜索与pattern匹配的内容(只返回第一个匹配结果)- re.match(pattern, string):从string的开头开始匹配与pattern的内容(只返回第一个匹配结果)10. 其他常用方法- re.split(pattern, string):根据pattern将string分割成列表- re.finditer(pattern, string):在string中搜索与pattern匹配的所有内容,并返回迭代器以上是关于正则表达式的一些常用技巧,通过合理运用这些技巧,可以轻松实现各种文本处理操作。
notepad正则表达式替换字符...

notepad++正则表达式替换字符串详解(Note pad + + regular expression substitution string details)Notepad + + regular expression substitution string detailsThe 2010-08-30 who wereRegular expressions are a query string, which contains the general characters and some special characters, special characters can be extended to find the ability of the string, the regular expression in the find and replace the role of strings can not be ignored, it can improve the work efficiency.EditPlus's lookups, substitutions, and files find support for the following regular expressions:Expression description\ t TAB.New line \ n.To match any character.| matches the left and right characters of the expression. For example, "ab | BC" matches "ab" or "BC".[] any single character that match the list. For example, "[ab]" match "a" or "b". "[0-9]" match any number.(^) match the list of any single character. For example, "[^ab]" match "a" and "b" character. "[^ 0-9]" match anynon-numeric characters.* the character on the left is matched to any number of times (0, or many times). For example, "be *" matches "b", "be" or "bee".The characters on the left are matched at least once (one or more times). For example, "be +" matches "be" or "bee" but does not match "b".The characters on the left are matched 0 or 1 times, such as "be? Match "b" or "be" but not "bee".^ the expression in the right hand be matched in the beginning of A line. For example "^ A" only matching lines starting with "A".The expression on the left is matched to the end of a line, such as "e $" only matches the line ending with" e ".() affects the order of expression matching and is used as a grouping marker for expressions.If you want to use "\" itself, you should use "\ \".Example:The original stringABC STR [1] [991];STR ABC [992], [2] ABC STR [11] [993]; ABC STR [22] [994]; ABC STR [111] [995]; ABC STR [222] [996]; ABC STR [1111] [997]; ABC STR [2222] [999]; The target list:ABC [1];ABC [2];ABC [11];ABC [22].ABC [111];ABC [222];ABC [1111];ABC [2222];Processing:Find string: STR \ [0-9] +) \] ABC \ [0-9] + \]Substitution string: ABC [\ 1][1] regular expression applications - replace the specified content to the end of the rowThe original text is two lines belowABC aaaaaABC 123 to 444I hope that each time I encounter ABC, I will replace the "ABC" and the subsequent to the end of the line "ABC efg".The above text is eventually replaced by:ABC efg123 ABC efgSolution:In the replace dialog box, find the content to enter "ABC. *"Check the "regular expression" check box, then click the "fullreplace" buttonThe meaning of the symbol is as follows:". "= matches any character"*" = match 0 or moreNote: in fact, the regular expression substitution, here are just some questions are finishing, a purely in the regular expression itself, can lead to thousands of exceptions.[2] regular expression application - digital substitutionWant to putasdadas123asdasdas456asdasdasd789asdasdReplace with:Asdadas [123] asdasdas [456] asdasdasd [789] asdasdIn the replace dialog box, check the "regular expression" check box;Enter "[0-9] [0-9] [0-9]" in the lookup content, without quotation marks"Replace:" [\ 0\1\2] ", without quotation marksRange for the range you operate and then choose to replace it.In fact, this is also a special case of regular expression, "[0-9]" means any special case that matches between 0 and 9, and "[a-z]" means to match any special case between a and zThe above repeats "[0-9]", indicating the three consecutive digits"\ 0" represents the first "[0-9]" corresponding prototype, and "\ 1" represents the second "[0-9]" corresponding prototype, and so on"[" and"] "for the simple character, add" [" or "] ", if the input "other, 0, 1, 2 other", then replace the results as follows:Asdadas other 123 other asdasdas other 456 other asdasdasd other 789 other asdasdFunction enhancement (by jiuk2k) :If you find content "[0-9] [0-9] [0-9]" instead of "[0-9] * [0-9]", corresponding to 1 or 123 or 12345 or...You customize it as neededThere's a lot more to it, so you can take a closer look at the syntax of regular expressions[3] regular expression application - deletes the specified character at the end of each lineBecause these characters also appear in the row, you can't use a simple replacementSuch as12345, 1265345,2345Need to delete the "345" at the end of each lineThe also calculate regular expression usage, actually see regular expressions should be relatively simple, but now that have this problem, that of the regular expression also have a cognitive process, the solution is as followsSolution:In the replace dialog box, enable the regular expression check boxEnter "$345" in the find contentsHere, "$" represents a matching from the tailIf from the beginning of a line matching, can be used to implement the "^", but EditPlus has another function can be easily delete rows first stringA. Select the row to operateB. edit - format - delete line commentsC. Enter the first character of the line to be cleared in the pop-up dialog box[4] regular expression applications - replace multiple rows with a half - Angle bracketThe following code is included in hundreds of pages:\ nReplace the dialog box with the "regular expression" option[5] regular expression application - delete empty rowStart EditPlus to open the pending text type file.Select the "replace" command of the "find" menu, and the text replace dialog box pops up. Select the regular expression check box to indicate that we want to use regular expressions in find and replace. Then, select the "current file" in the "replace scope" to indicate the current file operation.Click the button on the right of the "find content" combo box, and the drop-down menu appears.The following operation adds the regular expression, which represents the empty row to be found. Skills (hint: empty line only includes Spaces, tabs, carriage return, and have to be oneof the three symbols as the beginning of a line, and end with a carriage return, to find the empty lines of the key structure represents empty lines of regular expressions).Enter a regular expression in the "search" directly "^ t] [\ * \ n", pay attention to before the \ t have Spaces.(1) select "since the beginning of a line matching", "find" characters "^" appear in the combo box, said to find the string in the beginning of a line row must appear in the text.(2) select "characters" in the scope, then will increase after the "^" a pair of parentheses "[]", the insertion point in brackets. In the regular expression, the parentheses indicate that the characters in the text match any of the characters in parentheses.(3) press the space bar to add the space character. A space character is a component of an empty row.(4) select "TAB" and add "\ t" that represents tabs.(5) move the cursor, move the current insertion point to "] "and then select" match 0 or more ", which adds the asterisk character "*". An asterisk indicates that the preceding brackets "[]" have zero or more characters in a row.(6) select the "newline" and insert "\ n", indicating the return card.The "replace" combo box remains empty, indicating that thecontents found are deleted. Click "replace" button to delete empty lines individually, or click "replace all" button to delete all the empty line (note: EditPlus sometimes have a "replace" cannot one-time completely delete empty problems, may be a program BUG, need to press a few times more button).1. In the course of sinicization, it is often encountered that such statements need to be translated:Code:"Error adding the post!" ;"Error adding the comment!" ;"Error adding the user! ;If there are a lot of similar files a single translation is obviously very tired and very boring.In fact, you can do this with the replace function in Editplus, and select the regular expression check box in the replace dialog box:Find the original file:Code:"Error adding ([^! | |;] *)"Replace:Code:"An error occurred while adding \ 1What happens after this substitution? The result is:Code:"An error occurred while adding the post!" ;"An error occurred while adding the comment!" ;"An error occurred while increasing the user!" ;Ok,What would you do next? Of course, replace the post, the comment, and the user with the word you want to translate. Get the final result:Code:"An error occurred while adding posts!" ;"An error occurred while adding comments!" ;"An error occurred while increasing the user!" ;2. The words to be extracted are in the middle, such as:Code:Can not be deleted becauseCan not be added becauseCan not be updating becauseCan be used this way:With the replace function in Editplus, select the regular expression check box in the replace dialog box:Find the original file:Code:Can not be because (^) (*)Replace:Code:Can't be \ 1 becauseWhat happens after this substitution? The result is:Code:Can't be deleted becauseCan't be added becauseIt can't be redone becauseThe remaining steps are as above.The improvement of efficiency is obvious in the case of high sinification and monotonous period.Explain: [[^! | | ";] *) mean is not equal to! And "and"; Any one of them means that all characters except these three characters will be selected (the replacement area);\ 1 is the new location where the selected replacement area is located (copy to this new location).3. Often the manual cleaning the inside of the line to delete text file blank lines, it can be done to Editplus better, use replace feature in Editplus, in replace dialog box select the "regular expressions" check box:Find the original file:Code:^ t] [\ * \ nThe replacement section is empty, and you can delete the blank line.Abandon, abandon, abandonAbandonment 'b9nd2nm2nt [2] n. Give upAbbreviation [2 bri: vi 'ei62n] n. abbreviations Abeyance [2 'bei2ns] nAbide [2 'baid] v. abide by itAbility [2 'biliti] n. abilityI'm able to do itAbnormal [9b 'n0: m2l]Aboard the ship1.Find: (^ [a zA - Z0-0 \] +) (\ [* * \] +) (. *) Replacement: @ @ @ @ @ \ "1", "\ 2", "\" 3,Effect:"[2 'b9nd2n]" "[2' b9nd2n]" [2 'b9nd2n]"@ @ @ @ @ "abandonment", "" b9nd2nm2nt [2]", "n. give up",@ @ @ @ @ "abbreviation", "[2 bri: vi 'ei62n]", "n. abbreviated","Abeyance", "[2 ' 'bei2ns]", "n.@ @ @ @ abide "@", "' baid [2]", "v. abide by",@ @ @ @ @ "ability", "' biliti [2]", "n",@ @ @ @ @ "able", "[' eibl]",[/ b] [/ b] [/ b]"Abnormal", "[9b 'n0: m2l]","The "aboard", "[2 'b0: d]","2.Find: \ nReplacement:Note: the replacement content is emptyEffect:@ @ @ @ @ "abandon", "" 'b9nd2n [2]", "v. abandoned, give up", @ @ @ @ @ "abandonment", ""' b9nd2nm2nt [2]", "n. give up", @ @ @ @ @ "abbreviation", "[2 bri: vi 'ei62n]", "n. abbreviated", @ @ @ @ @ "abeyance", ""' bei2ns [2]", "n. postponed, suspended," @ @ @ @ abide "@", "' baid [2]", "v. comply with" @ @ @ @ @ "ability", "' biliti [2]", "n. ability", @ @ @ @ @"able", ""," [' eibl] adj. Have the ability, can do, "@ @ @ @ @" abnormal ", "[9 'n0 b: m2l]", "adj. Unusual, abnormal," @ @ @ @ aboard "@", "[2' b0: d]", "adv. The ship (car)," @ @ @ @ @ "abolish" and "' b0li6 [2]", "v. in addition to scrap, cancel," @ @ @ @ abolition "@", "b2 'li62n [9]", "n. abolished, cancel"3.Find: @ @ @ @ @Replacement: \ nEffect:"[2 ' 'b9nd2n]" [2' b9nd2n]""Abandonment", "' b9nd2nm2nt [2]", "n. give up","Abbreviation", "[2 bri: vi 'ei62n]", "n. abbreviated","Abeyance", "[2 ' 'bei2ns]", "n."Abide", "' baid [2]", "v. abide by","Ability", "' biliti [2]", "n",[/ b] [/ b] [/ b] [/ b] [/ b] [/ b] [b] [b] [b] [b] [b] [b] [b] [b] [b] [b] [b] [b]"Abnormal", "[9b 'n0: m2l],""Aboard", "[2 'b0: d],""[2 ' 'b0li6]" [2' "b0li6]" "v.4. Task completion。
Notepad++几个常用删除类正则表达式汇总(收藏)
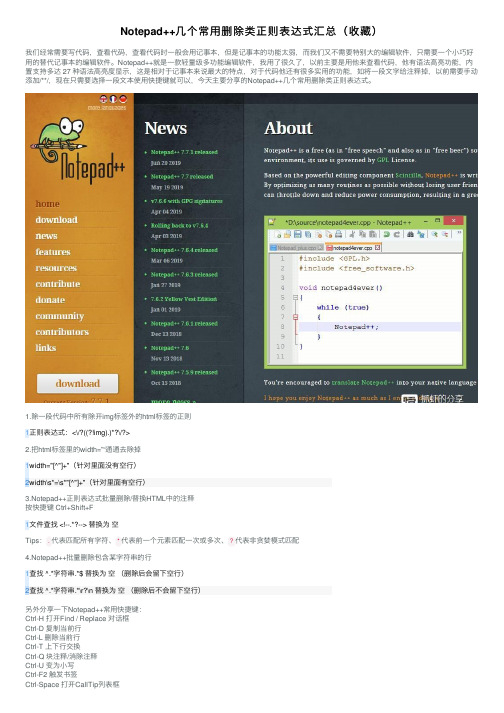
Notepad++⼏个常⽤删除类正则表达式汇总(收藏)我们经常需要写代码,查看代码,查看代码时⼀般会⽤记事本,但是记事本的功能太弱,⽽我们⼜不需要特别⼤的编辑软件,只需要⼀个⼩巧好⽤的替代记事本的编辑软件。
Notepad++就是⼀款轻量级多功能编辑软件,我⽤了很久了,以前主要是⽤他来查看代码,他有语法⾼亮功能,内置⽀持多达 27 种语法⾼亮度显⽰,这是相对于记事本来说最⼤的特点,对于代码他还有很多实⽤的功能,如将⼀段⽂字给注释掉,以前需要⼿动添加/**/,现在只需要选择⼀段⽂本使⽤快捷键就可以,今天主要分享的Notepad++⼏个常⽤删除类正则表达式。
1.除⼀段代码中所有除开img 标签外的html 标签的正则1正则表达式:<\/?((?!img).)*?\/?>2.把html 标签⾥的width=”“通通去除掉12width="[^"]+"(针对⾥⾯没有空⾏)width\s*=\s*"[^"]+"(针对⾥⾯有空⾏)3.Notepad++正则表达式批量删除/替换HTML 中的注释按快捷键 Ctrl+Shift+F1⽂件查找 <!--.*?--> 替换为 空Tips :.代表匹配所有字符、*代表前⼀个元素匹配⼀次或多次、?代表⾮贪婪模式匹配4.Notepad++批量删除包含某字符串的⾏12查找 ^.*字符串.*$ 替换为 空 (删除后会留下空⾏)查找 ^.*字符串.*\r?\n 替换为 空 (删除后不会留下空⾏)另外分享⼀下Notepad++常⽤快捷键:Ctrl-H 打开Find / Replace 对话框Ctrl-D 复制当前⾏Ctrl-L 删除当前⾏Ctrl-T 上下⾏交换Ctrl-Q 块注释/消除注释Ctrl-U 变为⼩写Ctrl-F2 触发书签Ctrl-Space 打开CallTip 列表框Ctrl-Space 打开CallTip列表框Ctrl-Shift-U 变为⼤写Ctrl-Shift-F 在⽂件中找F2 到前⼀个书签F3 找下⼀个F5 打开run对话框F11 全屏Shift-F3 找上⼀个Shift-F2 到下⼀个书签Shift-Tab (selection of several lines) 移除Space Alt-0 折叠全部Alt-Shift-0 展开全部Tab (selection of several lines) 加⼊Space。
Notepad++中查找替换「换行符」

Notepad++中查找替换「换行符」
文章目录
•一、查找替换「换行符」
o1、设置「显示行尾符」
o2、查找并替换「换行符」
•二、扩展:查找替换「空行」、空白符
Notepad++ 是 Windows 中一款优秀的
文本编辑软件,功能非常强大。
重要说明:
1、为更好的理解本文,建议先阅读相关文章–不同操作系统中的换行符。
2、本文内容基于 Notepad++ 7.5.1 版本,为方便书写,若无特殊说明,下文中内容均指在该软件版本下的操作。
一、查找替换「换行符」
1、设置「显示行尾符」
为了更清楚的看到换行符的变化,首先进行下面设置:
视图 -> 显示符号 -> 显示行尾符
然后新建一个文本,在其中随意输入内容,会看到显示「换行符」为 CRLF,即 \r\n。
2、查找并替换「换行符」
•Ctrl + H,打开替换对话框,查找模式选中扩展或者正则表达式,使查找目标和替换为中同时支持字符串和特殊字符的匹配;
•然后在查找目标中输入 \r\n ,即可匹配到文本中的回车换行符;
•在替换为中输入要替换成的字符即可;
二、扩展:查找替换「空行」、空白符
————————————————
版权声明:本文为CSDN博主「媛测」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https:///lijing742180/java/article/details/85174564。
正则表达式之匹配替换

正则表达式之匹配替换最近做word脚注⽤到了正则表达式的匹配替换功能。
我提取rtf字符串中书签的名称,更改名称后,再替换到字符串中。
看代码:1var range = fd_Field.Result.Footnotes[1].Range;18 str_Content = Regex.Replace(str_Content, @"\\bkmk(start|end) _(\w+)}", "\\bkmk$1 _$2_" + fid + "}", RegexOptions.Multiline);1920 PasteByClipboard(range, str_Content);2122var maches=Regex.Matches(str_Content, @"\\bkmkstart _(\w+)}", RegexOptions.Multiline);2324for (int i = 1; i <= range.Paragraphs.Count; i++)25 {26if (maches.Count > 0)27 {28if (maches[i - 1].Success)29 {3031if (maches[i - 1].Groups.Count > 0)32 {33 range.Paragraphs[i].ID = maches[i - 1].Groups[1].Value;34 }35 }36 }37 }代码解释:str_Content中存储的是rtf格式的字符串,字符串中有word书签的定义,\v\bkmkstart_nf8f0c1a4cb18b4a8cae0338d4923c5cc1} 这是书签的开始位置,\v\bkmkend _nf8f0c1a4cb18b4a8cae0338d4923c5cc1}\par},这是书签的结束位置。
使用正则表达式进行替换

使⽤正则表达式进⾏替换string a;public string hzEncode(Match m){a += m.ToString();return a.ToString();}private void button1_Click(object sender, System.EventArgs e){// Create a regular expression that matches a series of one// or more white spaces.string pattern = @"[a-zA-Z0-9]";Regex rgx = new Regex(pattern);// Declare a string consisting of text and white spaces.string inputStr = "abcd121!#3@@";// Replace runs of white space in the input string with a// comma and a blank.string outputStr = rgx.Replace(inputStr,new MatchEvaluator(hzEncode));// Display the resulting string.Console.WriteLine("Pattern: \"{0}\"", pattern);Console.WriteLine("Input string: \"{0}\"", inputStr);Console.WriteLine("Output string: \"{0}\"", a);}1、正则表达式的三种形式⾸先我们应该知道 Perl 程序中,正则表达式有三种存在形式,他们分别是:匹配:m/<regexp>/ (还可以简写为 /<regexp>/ ,略去 m)替换:s/<pattern>/<replacement>/转化:tr/<pattern>/<replacemnt>/这三种形式⼀般都和 =~ 或 !~ 搭配使⽤(其中 "=~" 表⽰相匹配,在整条语句中读作 does,"!~" 表⽰不匹配,在整条语句中读作 doesn't),并在左侧有待处理的标量变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大家根据需要定制
相关内容还有很多,可以自己参考正则表达式的语法仔细研究一下
【3】正则表达式应用——删除每一行行尾的指定字符
因为这几个字符在行中也是出现的,所以肯定不能用简单的替换实现
比如
12345 1265345
2345
需要删除每行末尾的“345”
其中,符号的含义如下:
“.” =匹配任意字符
“*” =匹配0次或更多
注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
【2】正则表达式应用——数字替换
希望把
asdadas123asdasdas456asdasdasd789asdasd
希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”
即上面的文本最终替换为:
abc efg
123 abc efg
解决:
① 在替换对话框,查找内容里输入“abc.*”
② 同时勾选“正则表达式”复选框,然后点击“全部替换”按钮
其余步骤如上。
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*) 的意思是 不等于 ! 和 ” 和 ; 中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
\1 即被选中的替换区域所在的新位置(复制到这个新位置)。
? 其左边的字符被匹配0次或者1次. 例如 "be?" 匹配 "b" 或者 "be" 但是不匹配 "bee".
^ 其右边的表达式被匹配在一行的开始. 例如 "^A" 仅仅匹配以 "A" 开头的行.
$ 其左边的表达式被匹配在一行的结尾. 例如 "e$" 仅仅匹配以 "e" 结尾的行.
(2)选择“字符在范围中”,那么在“^”后会增加一对括号“[]”,当前插入点在括号中。括号在正则表达式中表示,文本中的字符匹配括号中任意符。空格符是空行的一个组成成分。
(4)选择“制表符”,添加代表制表符的“\t”。
(5)移动光标,将当前插入点移到“]”之后,然后选择“匹配 0 次或更多”,该操作会添加星号字符“*”。星号表示,其前面的括号“[]”内的空格符或制表符,在一行中出现0个或多个。
notepad++正则表达式替换字符串详解
2010-08-30 14:21
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它 能很好提高工作效率。
EditPlus的查找,替换,文件中查找支持以下的正则表达式:
启动EditPlus,打开待处理的文本类型文件。
①、选择“查找”菜单的“替换”命令,弹出文本替换对话框。选中“正则表达式”复选框,表明我们要在查找、替换中使用正则表达式。然后,选中“替换范围” 中的“当前文件”,表明对当前文件操作。
②、单击“查找内容”组合框右侧的按钮,出现下拉菜单。
abandon[2''b9nd2n]v.抛弃,放弃
abandonment[2''b9nd2nm2nt]n.放弃
abbreviation[2bri:vi''ei62n]n.缩写
abeyance[2''bei2ns]n.缓办,中止
abide[2''baid]v.遵守
2.要提取的单词在中间,比如:
Code:
can not be deleted because
can not be added because
can not be updating because
可以用这种方式:
在Editplus里面用 替换 功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
“Error adding ([^!|"|;]*)
替换成:
Code:
“在增加\1时发生错误
这样替换之后发生了什么?结果是:
Code:
“在增加the post时发生错误!”;
“在增加the comment时发生错误!”;
[^] 匹配列表之外的任何单个字符. 例如, "[^ab]" 匹配 "a" 和 "b" 以外的字符. "[^0-9]" 匹配任意非数字字符.
* 其左边的字符被匹配任意次(0次,或者多次). 例如 "be*" 匹配 "b", "be" 或者 "bee".
+ 其左边的字符被匹配至少一次(1次,或者多次). 例如 "be+" 匹配 "be" 或者 "bee" 但是不匹配 "b".
“在增加the user时发生错误!”;
ok,接下来你会怎么做?当然再替换一次把the post、the comment、the user替换成你要翻译的词。得到最后的结果:
Code:
“在增加帖子时发生错误!”;
“在增加评论时发生错误!”;
“在增加用户时发生错误!”;
abc[1111];
abc[2222];
处理:
查找串:str\[([0-9]+)\]abc\[[0-9]+\]
替换串:abc[\1]
【1】正则表达式应用——替换指定内容到行尾
原始文本如下面两行
abc aaaaa
123 abc 444
“[”、“]”为单纯的字符,表示添加“[”或“]”,如果输入“其它\0\1\2其它”,则替换结果为:
asdadas其它123其它asdasdas其它456其它asdasdasd其它789其它asdasd
功能增强(by jiuk2k):
如果将查找内容“[0-9][0-9][0-9]”改为“[0-9]*[0-9]”,对应1 或 123 或 12345 或 …
@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2''baid]“,”v.遵守”,
@@@@@”ability”,”[2''biliti]“,”n.能力”,
@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,
③、下面的操作添加正则表达式,该表达式代表待查找的空行。(技巧提示:空行仅包括空格符、制表符、回车符,且必须以这三个符号之一作为一行的开头,并且 以回车符结尾,查找空行的关键是构造代表空行的正则表达式)。
直接在”查找”中输入正则表达式“^[ \t]*\n”,注意\t前有空格符。
(1)选择“从行首开始匹配”,“查找内容”组合框中出现字符“^”,表示待查找字符串必须出现在文本中一行的行首。
表达式 说明
\t 制表符.
\n 新行.
. 匹配任意字符.
| 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配 "ab" 或者 "bc".
[] 匹配列表之中的任何单个字符. 例如, "[ab]" 匹配 "a" 或者 "b". "[0-9]" 匹配任意数字.
替换为:
asdadas[123]asdasdas[456]asdasdasd[789]asdasd
在替换对话框里面,勾选“正则表达式”复选框;
在查找内容里面输入“[0-9][0-9][0-9]”,不含引号
“替换为:”里面输入“[\0\1\2]”,不含引号
范围为你所操作的范围,然后选择替换即可。
ability[2''biliti]n.能力
able[''eibl]adj.有能力的,能干的
abnormal[9b''n0:m2l]adj.反常的,变态的
aboard[2''b0:d]adv.船(车)上
1.
查找: (^[a-zA-Z0-0\-]+)(\[*.*\]+)(.*)
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中 “正则表达式”复选框:
查找原文件:
Code:
^[ \t]*\n
替换部分为空就可以删除空白行了,执行一下看看:)
(6)选择“换行符”,插入“\n”,表示回车符。
④、“替换为”组合框保持空,表示删除查找到的内容。单击“替换”按钮逐个行删除空行,或单击“全部替换”按钮删除全部空行(注意:EditPlus有时 存在“全部替换”不能一次性完全删除空行的问题,可能是程序BUG,需要多按几次按钮)。
1.在汉化的时候,是否经常碰到这样的语句需要翻译:
这个也算正则表达式的用法,其实仔细看正则表达式应该比较简单,不过既然有这个问题提出,说明对正则表达式还得有个认识过程,解决方法如下
解决:
在替换对话框中,启用“正则表达式”复选框
在查找内容里面输入“345$”
这里“$”表示从行尾匹配
如果从行首匹配,可以用“^”来实现,不过 EditPlus 有另一个功能可以很简单的删除行首的字符串
替换: @@@@@”\1″,”\2″,”\3″,