数据库设计规范编码规范
数据库编码规范

数据库编码规范V1.02022-8-28目的范围术语设计概要命名规范(逻辑对象)数据库对象命名脚本注释数据库操作原则常用字段命名(参考)1)目的为了统一公司软件开辟的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。
2)范围本规范合用于开辟组全体人员,作用于软件项目开辟的数据库设计、维护阶段<3)术语数据库对象:在数据库软件开辟中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。
普通对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。
4)设计概要设计环境<数据库:ORACLE9i、MSSQLSERVER2000 等,操作系统:LINUX7.1 以上版本,显示图形操作界面;RedHat9 以上版本WINDOWS2000SERVER 以上设计使用工具手使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说明。
对于SQLServer 尽量使用企业管理器对数据库进行设计,并且要求对表,字段编写详细的说明(这些将作为扩展属性存入SQLServer 中) 手通过PowerDesigner 定制word 格式报表,并导出word 文档,作为数据字典保存。
(PowerDesignerv10 才具有定制导出word 格式报表的功能)<对于SQLServer 一旦在企业管理器进行数据库设计时加入扩展属性,就可以通过编写简单的工具将数据字典导出。
4 编写数据库建数据库、建数据库对象、初始化数据脚本文件设计原则4 采用多数据文件手禁止使用过大的数据文件,unix 系统不大于2GB,window 系统不超过500MB$oracle 数据库中必须将索引建立在索引表空间里。
数据库设计规范与命名规则

数据库设计规范、技巧与命名规范一、数据库设计过程数据库技术是信息资源管理最有效的手段。
数据库设计是指:对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。
数据库设计的各阶段:A、需求分析阶段:综合各个用户的应用需求(现实世界的需求)。
B、在概念设计阶段:形成独立于机器和各DBMS产品的概念模式(信息世界模型),用E-R图来描述。
C、在逻辑设计阶段:将E-R图转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式。
然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(VIEW)形成数据的外模式。
D、在物理设计阶段:根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。
1. 需求分析阶段需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。
需求分析的重点:调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。
需求分析的方法:调查组织机构情况、各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。
常用的调查方法有:跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。
分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。
自顶向下的结构化分析方法(Structured Analysis,简称SA方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。
数据流图表达了数据和处理过程的关系。
系统中的数据则借助数据字典(Data Dictionary,简称DD)来描述。
2. 概念结构设计阶段通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。
概念模型用于信息世界的建模。
概念模型不依赖于某一个DBMS支持的数据模型。
概念模型可以转换为计算机上某一DBMS 支持的特定数据模型。
主题数据库设计规则

主题数据库设计规则
主题数据库设计规则主要包括以下内容:
1. 规范化与反规范化:规范化的优点是减少数据冗余,节约存储空间,减少相应逻辑和物理的I/O次数,同时加快增、删、改的速度。
出于性能和方便管理的考虑,原则上表设计应满足第三范式,有时为了提高某些查询或应用的性能而可以破坏规范规则,即反规范化。
2. 数据表分类:数据表按照不同业务逻辑,分为不同的类别。
主要有以下类别:基本数据表、标准编码表、业务数据表、系统信息表、统计数据表、临时处理表和其他类型表。
3. 统一选择表字符集为utf8,表名必须有详细描述。
4. 一般情况可以选择MyISAM存储引擎,如果需要事务支持必须使用InnoDB存储引擎。
以上内容仅供参考,如需更多信息,建议查阅数据库相关书籍或咨询数据库领域专业人士。
编码规范

系统开发编码规范作者:日期:2011-5-29一、中英文对照以及简拼:二、Java源程序的编码规范1.命名:1)类名的定义:类名采用英文中具有实际意义的名词单词组合或是英文名词简拼的组合,并根据类所在的MVC层的名字作为后缀名,系统中嵌入了Fire WorkFlow工作流,为了将业务类和工作流类区分开,在类名开始添加Biz定义为业务类,添加Flow定义为工作流类。
例如:设计一个类作为投保处理,该类所在层为Dao层,且是业务类,该类接口为:BizAppPlyDao,类命名为:BizAppPlyDaoImpl,2)方法的命名:方法名采用英文中具有实际意义动宾结构的单词组合的形式,例如该方法保存一个投保单则命名为saveAppPly3)包的命名:包名都要小写,现有系统所有包名都以com.xxx.aaa开头,后续名称为模块名+层名,工具类放在util包下,如果某包下所有的类都是自定义接口的实现类,则该包要在所实现接口的包下面,并命名为impl。
例如:com.xxx.aaa.app.service,com.xxx.aaa.app.service.impl2.注释:1)类注释:必须包含该类的描述,例如功能信息,注明作者(可以同svn的账户名),创建时间,版本号等。
2)方法注释:必须包含该方法的用途,参数介绍,返回值介绍,抛出异常等信息3)行注释:代码的关键行、判断分支、关键算法、复杂语法、关键字段或是修改别人代码的新添内容必须写详细的注释说明如果关键算法不能立即实现注释上加// TODO4)添加注释模版按照注释模版的格式填写。
(附模版文件)三、数据库表和字段命名规范1.数据库表命名数据库表大体分为公共信息表(Common),业务数据表(Biz)、工作流表(Flow),公共信息表以Common开头,业务数据表以Biz开头,工作流表已Flow开头,各个单词间以“_”下划线隔开,并采用与保存数据相关的英文单词,例如业务保单数据信息表的命名为:Biz_Ply_Information2.表中字段的命名字段的命名为英文单词(简拼)的组合,各个单词间以“_”下划线隔开,采用与保存数据相关的英文单词,例如保单号为:ply_no注意:在设计数据库和创建数据库、创建表或是修改数据表,添加字段等都要添加comment注释3.Sql编写规范1)关键字大写,表明、字段名小写,别名用驼峰命名法。
mysql 编码规则

MySQL编码规则是指MySQL数据库中字符集和排序规则的设置。
字符集定义了存储在数据库中的字符数据的类型,而排序规则定义了对这些字符数据的比较和排序方式。
MySQL支持多种字符集和排序规则,其中最常用的是utf8字符集和utf8_general_ci排序规则。
utf8字符集可以存储任何Unicode字符,而utf8_general_ci排序规则则按照字典顺序对字符进行排序。
在MySQL中,可以通过以下命令查看当前数据库的编码规则:
```
SHOW VARIABLES LIKE 'character%';
SHOW VARIABLES LIKE 'collation%';
```
如果需要修改编码规则,可以使用以下命令:
```
ALTER DATABASE database_name CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
```
其中,database_name是要修改编码规则的数据库名称,table_name是要修改编码规则的数据表名称。
编码规范

编码规范概述
编码规范的必要性
① 有助于程序的维护,降低软件生命周期成本,符 合项目管理的规律 ② 使团队中相关人员的流动对项目的影响尽可能小, 有利于项目的控制与管理; ③ 提高程序的可读性,有利于相关设计人员交流, 提高软件质量; ④ 容易发现代码的问题,调试时比较容易 ⑤ 体现公司形象
实例讲解
• C#的编码规范
– 代码格式
代码的格式包括缩进、换行、空行、空格等,为了不影响编码的效率,在此只作如下规定: • 空格、空行不做严格的固定,以使代码清晰为基本原则。空行不影响程序的运行,但可 以使代码看起来清晰,增加可读性,因此可以适当的多用。 • 代码的缩进建议使用tab键进行控制,tab键的大小设置为4个空格。每个层次都要进行缩 进。 如:
if (isOverFlow) { return false; }
• 换行,掌握的原则是不要使一行代码特别的长,再不产生严重歧义或增加阅读难度的情 况下,尽量控制在120列之内,以方便代码的打印。另外,换行的原则是,在逗号后,操 作符前换行,换行与首行要保持一个单位的缩进。 如: string strSql = “SELECT ID,NAME,SEX,BIRTHDAY,” + “BELONGCLASSID,BELONGGRADEID “ + “FROM STUDENTINFO”; • { }必须单独在一行上,且上下对齐。 • if,while,do,try-catch-finally等语句后必须有{},即使里面只有一条语句或为空,且遵循 { }单独成行的原则。
实例讲解
• C#的编码规范
– 注释(续)
• 特别注意,如果是在已经发行版本的基础上添加、修改、删除代码,则需要将原先的代 码注释掉,而不是直接删除掉,然后添加自己的代码。如: 添加新代码的注释: //add by [姓名] yyyyMMdd xxx // add by [姓名] yyyyMMdd 修改代码的注释: //update by [姓名] yyyyMMdd // xxx yyy // update by [姓名] yyyyMMdd 删除代码的注释: //delete by [姓名] yyyyMMdd //xxx // delete by [姓名] yyyyMMdd
数据库设计指南

数据库设计指南1. 设计原则1.1. 关于范式如无性能上的必要原因,应该考虑遵循关系数据库理论,达到较高的范式匹配(3NF),避免数据冗余,明确数据间的关系。
如果对性能有较高要求,或者在特定场景达成业务目标的便利性收益高于数据管理影响,可以设计适当的突破范式要求。
1.2. 字符集和编码应当采用Unicode字符集和UTF8编码,此为PostgreSQL 数据库服务器默认设置,并且,如果在创建数据库(实例)时没有特别指定,也将是数据库(实例)的默认设置。
如果有强烈的中华多文字支持要求,如简体汉字、繁体汉字、少数民族文字、日文、韩文等,可以使用GB18030字符集和编码,不建议使用GB2312、GBK。
1.3. 数据库服务器和数据库一个操作系统中只部署 1 个数据库服务器软件。
一个数据库服务器中可以创建多个数据库。
1.4. 表空间对于PostgreSQL 来说,在同一个磁盘分区上建立多个表空间没有太多实际意义。
从合理利用磁盘性能和空间角度,可以分别建立不同的表空间,如:•在高IO 性能的磁盘分区上创建的表空间,可以用来存放经常访问的表和索引。
•在便宜和较低IO 性能的磁盘分区上创建的表空间,可以用来存放很少使用或性能要求不高的归档数据的表。
对于容器部署的数据库,容器内可以使用默认表空间pg_default(路径$PGDATA/base),并映射到容器外宿主机的特定路径下。
非容器部署的数据库,建议在指定的路径下创建表空间。
多个数据库可以共用同一个表空间。
注意: PostgreSQL 中的表空间与 Oracle 不一样,创建PostgreSQL 表空间只要指定名称与数据库文件的目录,而没有具体的大小。
PostgreSQL 表空间不适用“自动扩容”这个概念,存储不足时可以通过扩展表空间所在存储容量,或者在不同存储设备/分区中新建表空间并指定新表使用新表空间来达到扩容目的。
1.5. Schema建议为子系统、业务模块或用户分配对应的schema。
数据库设计规范_编码规范

数据库设计规范_编码规范数据库设计规范包括数据库表结构的设计原则和数据库编码规范。
数据库表结构的设计原则包括表的命名规范、字段的命名规范、主键和外键的设计、索引的使用、约束的定义等。
数据库编码规范包括SQL语句的书写规范、存储过程和函数的命名规范、变量和参数的命名规范、注释的使用等。
1.表的命名规范-表名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:user_info。
- 表名使用单数形式,如:user、order。
2.字段的命名规范-字段名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 字段名使用小写字母,使用下划线(_)作为单词之间的分隔符,如:user_name。
- 字段名要具有描述性,可以清楚地表示其含义,如:user_name、user_age。
3.主键和外键的设计-每张表应该有一个主键,用于唯一标识表中的记录。
- 主键字段的命名为表名加上“_id”,如:user_id。
- 外键字段的命名为关联的表名加上“_id”,如:user_info_id,指向user_info表的主键。
4.索引的使用-对于经常用于查询条件或连接条件的字段,可以创建索引,提高查询性能。
-索引的选择要权衡查询性能和写入性能之间的平衡。
-不宜为每个字段都创建索引,避免索引过多导致性能下降。
5.约束的定义-定义必要的约束,保证数据的完整性和一致性。
-主键约束用于保证唯一性和数据完整性。
-外键约束用于保证数据的一致性和关联完整性。
6.SQL语句的书写规范-SQL关键字使用大写字母,表名和字段名使用小写字母。
-SQL语句按照功能和逻辑进行分行和缩进,提高可读性。
-使用注释清晰地描述SQL语句的功能和用途。
7.存储过程和函数的命名规范-存储过程和函数的命名要具有描述性,可以清楚地表示其功能和用途。
-使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:get_user_info。
数据库设计中的命名规范与约定

数据库设计中的命名规范与约定在数据库设计和开发过程中,命名规范与约定起着至关重要的作用。
准确、一致且易于理解的命名可以提高代码的可读性和可维护性,减少开发人员之间的沟通成本,同时还能规范化操作,提高工作效率。
本文将介绍数据库设计中常见的命名规范和约定。
1. 表名规范:表名应该具有描述性,能够清晰地反映出该表存储数据的实际含义。
通常,表名使用名词复数形式,并采用下划线或驼峰命名法进行分隔。
例如,使用"users"表示用户信息表,"order_items"表示订单明细表。
2. 字段名规范:字段名应该具有描述性,能够清楚地表示字段所存储的数据内容。
命名应该避免使用缩写、缺乏含义的名称或过于通用的名称。
建议使用名词或名词短语,使用下划线或驼峰命名法进行分隔。
例如,使用"first_name"表示用户的名字,“price”表示商品价格。
3. 主键命名:主键字段通常是唯一标识表中每个记录的字段。
主键字段的命名规范是将表名加上后缀"_id",例如,对于用户表"users",主键字段可以命名为"user_id"。
4. 外键命名:外键字段通常用于关联两个表之间的关系,可以用于查询相关数据。
外键字段的命名规范是将被关联的表的表名加上后缀"_id"。
例如,对于订单表"orders"和用户表"users",关联用户的外键字段可以命名为"user_id"。
5. 索引命名:索引是提高数据库查询效率的重要方式之一。
在命名索引时,应明确表示所涉及的字段或字段组合,建议在字段名之前加上前缀"idx_"。
例如,使用"idx_last_name"表示基于姓氏进行的索引。
6. 视图命名:视图是根据查询语句创建的虚拟表,可以简化复杂查询操作。
mysql 建库常用编码

mysql 建库常用编码
在MySQL中,常用的字符集和校对规则取决于您的需求和所处理的数据。
以下是一些常用的字符集和校对规则:
1. utf8:支持大部分国际字符,如果只是英文和部分特殊字符,可以选择utf8。
2. utf8mb4:这是utf8的超集,支持更多的国际字符,包括emoji等。
如果需要存储emoji或某些其他特殊字符,建议使用utf8mb4。
3. latin1:这是一个单字节的字符集,支持西欧语言。
4. gbk:支持简体中文。
5. gb2312:支持简体和部分繁体中文。
6. big5:支持繁体中文。
当您创建数据库或表时,可以指定字符集和校对规则。
例如:
```sql
CREATE DATABASE mydb DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
```
或者为特定的表指定:
```sql
CREATE TABLE mytable (id INT, name VARCHAR(255)) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
```
请注意,选择正确的字符集和校对规则对于确保数据的正确存储和检索非常重要。
在处理多语言数据时,应特别注意这一点。
数据库设计规范_编码规范

数据库设计规范_编码规范1.命名规范:表名、字段名和约束名应该具有描述性,遵循一致的命名规则。
避免使用保留字作为名称,使用下划线或驼峰命名法。
2.数据类型选择:选择合适的数据类型来存储数据,避免过大或过小的数据类型。
这有助于减小数据库的存储空间,提高查询性能。
3.主键和外键:每个表都应该有一个主键来唯一标识每条记录。
外键用于建立表之间的关系,确保数据的一致性和完整性。
4.表的范式:根据具体需求,遵循规范化设计原则。
将数据分解为多个表,减少数据冗余和更新异常。
5.索引设计:根据查询需求和数据量,设计适当的索引。
避免过多或不必要的索引,以减小索引维护的开销。
6.分区设计:对大型表进行分区,将数据分散存储在不同的物理磁盘上,提高查询性能。
7.安全性设计:为数据库设置适当的权限和访问控制,限制不必要的用户访问和操作。
数据库编码规范:1.编码一致性:统一使用同一种编码方式,如UTF-8,避免不同编码之间的转换问题。
2.参数化查询:使用参数化查询语句,预编译SQL语句。
这样可以防止SQL注入攻击,提高查询性能。
3.事务管理:使用事务控制语句(如BEGIN、COMMIT和ROLLBACK)来管理数据库事务,确保数据的一致性和完整性。
4.错误处理:在代码中捕获和处理数据库错误和异常,提高系统的容错性。
5.SQL语句编写:编写简洁且优化的SQL语句,避免使用多个嵌套的子查询,使用JOIN操作符进行表之间的关联。
6.数据库连接管理:优化数据库连接,避免频繁地打开和关闭数据库连接。
7.缓存机制:对于频繁查询的数据,使用缓存机制来减少数据库的压力。
8.日志记录:记录数据库操作日志,包括增删改查的操作,以便后续的问题跟踪和审计。
综上所述,数据库设计规范和编码规范对于确保数据库系统的性能、安全性和可维护性至关重要。
遵循这些规范能够提高数据库系统的效率和可靠性,减少潜在的问题和风险。
因此,在进行数据库设计和编码时,应该遵循这些规范。
ORACLE数据库设计规范

1 命名原则约定ü? 是指对数据库、数据库对象如表、字段、索引、序列、存储过程等的命名约定;ü? 命名使用富有意义的英文词汇,尽量避免使用缩写,多个单词组成的,中间以下划线分割ü? 避免使用Oracle的保留字如LEVEL、关键字如TYPE(见Oracle保留字和关键字);ü? 各表之间相关列名尽量同名;ü? 除数据库名称长度为1-8个字符,其余为1-30个字符,Database link名称也不要超过30个字符;ü? 命名只能使用英文字母,数字和下划线;?表名规则如下:命名规则为xxx_yyy_TableName。
xxx表示开发公司的名称,最多五个字母构成,尽量用简称;yyy表示子系统中的子模块的名称(可以没有), 最多五个字母构成,尽量用简称;TableName为表含义, 最多十个字母构成,尽量用简称?TableName规则如下:ü? 使用英文单词或词组作为表名,不得使用汉语拼音ü? 用名词和名词短语作表名ü? 不使用复数?正确的命名,例如:fiber_sys_userfiber_biz_order?存储过程规则如下:命名规则为xxx_yyy_StoredProcedureName。
xxx表示开发公司的名称,最多五个字母构成,尽量用简称;yyy表示子系统中的子模块的名称(可以没有), 最多五个字母构成,尽量用简称;StoredProcedureName为存储过程含义,最多十个字母构成,尽量用简称?StoredProcedureName规则如下:ü? 用动词或动词短语来命名,并带有宾语ü? 需要符合用Pascal 命名规则。
ü? 尽量谨慎地使用缩写ü? 尽量不要和关键字重合ü? 不要用任何名前缀 (例如 U,B)ü? StoredProce dureName内不使用下划线ü? 当操作依赖条件时,一般结尾使用 By+条件?存储过程正确的命名,例如:sys_InsertUsersys_SearchUserByUserIDsys_DeleteUserByUserID?视图规则如下:ü? 视图的命名采用xxx_yyy_ViewName_v。
数据库标准规范(两篇)

数据库标准规范(二)引言:数据库是当代信息系统中关键的存储和管理数据的工具,数据库标准规范的制定对于确保数据的一致性、完整性和可靠性至关重要。
本文将详细阐述数据库标准规范的五个大点,包括数据库设计、数据模型、数据操作、数据存储和数据安全。
概述:在数据库标准规范中,数据库设计是基础,决定了整个数据库系统的架构和功能。
数据模型定义了数据的结构和属性,数据操作确定了对数据库的增删改查操作,数据存储指定了数据的物理存储方式,数据安全保证了数据库的安全性和可用性。
正文内容:一、数据库设计1. 定义数据库设计的目标和要求,包括数据的一致性、可扩展性和易用性。
2. 建立数据库的概念模型,包括实体关系模型、关系模型和层次模型。
3. 制定数据库设计的规范和准则,确保数据库结构的一致性和易维护性。
4. 设计数据库的表结构,包括表的字段、属性和约束等。
5. 定义数据库的索引和视图,提高数据库的查询和操作效率。
二、数据模型1. 介绍常用的数据模型,包括层次模型、网络模型、关系模型和面向对象模型。
2. 选择合适的数据模型,根据数据库的特点和应用需求进行权衡。
3. 设计数据模型的实体和属性,确保数据的准确性和完整性。
4. 定义数据模型之间的关系,包括一对一、一对多和多对多关系。
5. 使用标准的建模工具和方法,对数据模型进行建模和验证。
三、数据操作1. 定义数据操作的目标和要求,包括数据的增加、删除、修改和查询。
2. 设计数据操作的接口和功能,提供简单易用的操作方式。
3. 制定数据操作的规范和约束,确保数据的一致性和安全性。
4. 优化数据操作的性能,提高查询和更新的效率。
5. 实现数据操作的事务管理和并发控制,确保数据的一致和可靠。
四、数据存储2. 设计数据的物理存储结构,包括数据文件、表空间和数据块等。
3. 制定数据存储的规范和准则,确保数据的安全和可靠。
4. 实施数据存储的备份和恢复策略,保护数据的完整性和可用性。
5. 优化数据存储的性能,提高数据访问的效率和响应速度。
项目开发规范(编码规范、命名规范、安全规范、前端优化、源码提交规范、代码维护规范、产品发布规范)

项⽬开发规范(编码规范、命名规范、安全规范、前端优化、源码提交规范、代码维护规范、产品发布规范)第⼀节:编码过程的命名约定(编码命名规范)==========================================================================================================================PHP编码规范=============================================================================================================================PSR(PHP Standard Recommendations,PHP标准规范)是由PHP FIG组织制定的PHP规范,是PHP开发的实践标准。
主要包含基础编码规范、编码风格规范、⽇志接⼝规范、缓存接⼝规范、HTTP消息接⼝规范等。
1. 【必须】代码必须使⽤4个空格符⽽不是「Tab 键」进⾏缩进。
使⽤空格⽽不是「tab键缩进」的好处在于,避免在⽐较代码差异、打补丁、重阅代码以及注释时产⽣混淆。
并且,使⽤空格缩进,让对齐变得更⽅便。
2. 【必须】类的属性和⽅法必须添加访问修饰符(private、protected 以及 public),abstract 以及 final 必须声明在访问修饰符之前,⽽static 必须声明在访问修饰符之后。
3. 【必须】PHP所有关键字必须全部⼩写。
常量 true 、false 和 null 也必须全部⼩写。
4. 【不该】类的属性和⽅法不该使⽤下划线作为前缀,来区分是 protected 或 private。
⽬录和⽂件⽬录使⽤⼩写+下划线。
(参考linux⽬录命名,全部⼩写,linux⽬录单词间没有分隔符,如/var/spool/clientqueue,/etc/inittab,/bin/dnsdomainname等)类的⽂件名均以命名空间定义,并且命名空间的路径和类库⽂件所在路径⼀致。
数据库设计格式规范

1) 标准化和规范化数据的标准化有助于消除数据库中的数据冗余。
标准化有好几种形式,但Third Normal Form(3NF)通常被认为在性能、扩展性和数据完整性方面达到了最好平衡。
简单来说,遵守3NF 标准的数据库的表设计原则是:“One Fact in One Place”即某个表只包括其本身基本的属性,当不是它们本身所具有的属性时需进行分解。
表之间的关系通过外键相连接。
它具有以下特点:有一组表专门存放通过键连接起来的关联数据。
举例:某个存放客户及其有关定单的3NF 数据库就可能有两个表:Customer和Order。
Order表不包含定单关联客户的任何信息,但表内会存放一个键值,该键指向Customer表里包含该客户信息的那一行。
事实上,为了效率的缘故,对表不进行标准化有时也是必要的。
2) 数据驱动采用数据驱动而非硬编码的方式,许多策略变更和维护都会方便得多,大大增强系统的灵活性和扩展性。
举例,假如用户界面要访问外部数据源(文件、XML 文档、其他数据库等),不妨把相应的连接和路径信息存储在用户界面支持表里。
还有,如果用户界面执行工作流之类的任务(发送邮件、打印信笺、修改记录状态等),那么产生工作流的数据也可以存放在数据库里。
角色权限管理也可以通过数据驱动来完成。
事实上,如果过程是数据驱动的,你就可以把相当大的责任推给用户,由用户来维护自己的工作流过程。
3) 考虑各种变化在设计数据库的时候考虑到哪些数据字段将来可能会发生变更。
举例,姓氏就是如此(注意是西方人的姓氏,比如女性结婚后从夫姓等)。
所以,在建立系统存储客户信息时,在单独的一个数据表里存储姓氏字段,而且还附加起始日和终止日等字段,这样就可以跟踪这一数据条目的变化。
2.数据库涉及字符规范采用26个英文字母(区分大小写)和0-9这十个自然数,加上下划线'_'组成,共63个字符.不能出现其他字符(注释除外).注意事项:1) 以上MYSQL数据库命名都不得超过30个字符的系统限制.变量名的长度限制为29(不包括标识字符@).2) 数据对象、变量的命名都采用英文字符,禁止使用中文命名.绝对不要在对象名的字符之间留空格.3) 小心保留词,要保证你的字段名没有和保留词、数据库系统或者常用访问方法冲突5) 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性.假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了.3.数据库MYSQL数据库命名规范数据库,数据表一律使用前缀正式数据库名使用小写英文以及下划线组成,尽量说明是那个应用或者系统在使用的.比如:1.web_19floor_net2.web_car备份数据库名使用正式库名加上备份时间组成,如:1.web_19floor_net_200704032.web_car_200704034.数据库表MYSQL数据库命名规范数据表名使用小写英文以及下划线组成,尽量说明是那个应用或者系统在使用的.相关应用的数据表使用同一前缀,如论坛的表使用cdb_前缀,博客的数据表使用supe_前缀,前缀名称一般不超过5字比如:1.web_user2.web_group3.supe_userspace备份数据表名使用正式表名加上备份时间组成,如:1.web_user_200704032.web_group_200704033.supe_userspace_200704035.字段MYSQL数据库命名规范字段名称使用单词组合完成,首字母小写,后面单词的首字母大写,最好是带表名前缀.如 web_user 表的字段:erIderNameerPassword表与表之间的相关联字段要用统一名称,如 web_user 表里面的 userId 和 web_group 表里面的 userId 相对应6.字段类型规范规则:用尽量少的存储空间来存数一个字段的数据.比如能用int的就不用char或者varchar能用tinyint的就不用int能用varchar(20)的就不用varchar(255)时间戳字段尽量用int型,如created:表示从'1970-01-01 08:00:00'开始的int秒数,采用英文单词的过去式;gmtCreated:表示datetime类型的时间,即形如'1980-01-01 00:00:00'的时间串,Java中对应的类型为Timestamp7.数据库设计文档规范所有数据库设计要写成文档,文档以模块化形式表达.大致格式如下:'-------------------------------------------' 表名: web_user' 作者: Aeolus(傻鱼)' 日期: 2007-04-11' 版本: 1.0' 描述:保存用户资料' 具体内容:' UserID int,自动增量用户代码' UserName char(12) 用户名字' ......'--------------------------------------------8.索引使用原则:1) 逻辑主键使用唯一的成组索引,对系统键(作为存储过程)采用唯一的非成组索引,对任何外键列采用非成组索引.考虑数据库的空间有多大,表如何进行访问,还有这些访问是否主要用作读写.2) 大多数数据库都索引自动创建的主键字段,但是可别忘了索引外键,它们也是经常使用的键,比如运行查询显示主表和所有关联表的某条记录就用得上.3) 不要索引blob/text等字段,不要索引大型字段(有很多字符),这样作会让索引占用太多的存储空间.4) 不要索引常用的小型表不要为小型数据表设置任何键,假如它们经常有插入和删除操作就更别这样作了.对这些插入和删除操作的索引维护可能比扫描表空间消耗更多的时间.9.sql语句规范所有sql关键词全部大写,比如SELECT,UPDATE,FROM,ORDER,BY等,所有的表名和库名都要用``包含如:SELECT COUNT(*) FROM `cdb_members` WHERE `userName` = 'aeolus';10.其他设计技巧1) 避免使用触发器触发器的功能通常可以用其他方式实现.在调试程序时触发器可能成为干扰.假如你确实需要采用触发器,你最好集中对它文档化.2) 使用常用英语(或者其他任何语言)而不要使用编码或者拼音首字母缩写在创建下拉菜单、列表、报表时最好按照英语名排序.假如需要编码或者拼音首字母缩写,可以在旁边附上用户知道的英语.3) 保存常用信息让一个表专门存放一般数据库信息非常有用.在这个表里存放数据库当前版本、最近检查/修复(对Access)、关联设计文档的名称、客户等信息.这样可以实现一种简单机制跟踪数据库,当客户抱怨他们的数据库没有达到希望的要求而与你联系时,这样做对非客户机/服务器环境特别有用.4) 包含版本机制在数据库中引入版本控制机制来确定使用中的数据库的版本.时间一长,用户的需求总是会改变的.最终可能会要求修改数据库结构.把版本信息直接存放到数据库中更为方便.5) 编制文档对所有的快捷方式、MYSQL数据库命名规范、限制和函数都要编制文档.采用给表、列、触发器等加注释的数据库工具.对开发、支持和跟踪修改非常有用.对数据库文档化,或者在数据库自身的内部或者单独建立文档.这样,当过了一年多时间后再回过头来做第2 个版本,犯错的机会将大大减少.6) 测试、测试、反复测试建立或者修订数据库之后,必须用用户新输入的数据测试数据字段.最重要的是,让用户进行测试并且同用户一道保证选择的数据类型满足商业要求.测试需要在把新数据库投入实际服务之前完成.7) 检查设计在开发期间检查数据库设计的常用技术是通过其所支持的应用程序原型检查数据库.换句话说,针对每一种最终表达数据的原型应用,保证你检查了数据模型并且查看如何取出数据.。
编码规范v1

2.评估你的数据,对变量采用合理的类型,如一个整数在1个字节8位以内,应该 使用byte;
3.该用基本数据类型就用基本数据类型,明确告诉虚拟机你的数据类型,避免虚 拟机帮你做类型转换,如:
© 2015 冠辰世纪信息技术有限责任公司
代码检查工具和使用
5、类属性、方法注释:在类或方法的前面,类属性记载属性的功能用处,用/* 开头 描述注释,放置JavaDoc收集;类方法注释需要记载方法的功能简述、详细、输入 参数、输出值、抛出的异常、作者等,如:
© 2015 冠辰世纪信息技术有限责任公司
编码规范指南
6、类方法内部注释: ①注释应放置被注释语句的正上方或右侧; ②注释必须与被注释的语句同缩进;
8.方法内部尽量不要catch异常,让外部调用者知道出错细节;
9.方法内部对于对象参数的调用,尽量判断非null引用,除非你的设计能保证非 空对象; 10.不用的数据及时是否,如果数据库连接、集合、共享锁等; 11.不要使用技巧性比较高的表达式;
© 2015 冠辰世纪信息技术有限责任公司
怎样写规范的代码
© 2015 冠辰世纪信息技术有限责任公司
编码规范指南
命名规范
上面说道了注释规范,注释的目的在于帮助编码人员更好的理解代码、维护代 码。当然有些地方,如果命名非常规范,是可以不用注释的,下面就说说又哪 些命名规范; 1.包的命名:常用命名方式:com.公司名.产品线名.项目名.模块名,所有名称全 部小写,如下图:
© 2015 冠辰世纪信息技术有限责任公司
2、类名和接口名的命名:尽量使用完整的英文描述,首字母大写,每个英文单词的首字母 大写,其余字母小写。抽象类请以Abstract开头,接口的实现类请以Impl接口,工具类请 以Util或Utils结尾,如下列命名方式: StaffService、DefaultStaffService、AbstractEntity、StringUtils;
软件详细设计第11章编码设计与规范

命名规范
采用有意义的名称,避免使用 缩写和拼写错误的名称。
缩进和排版规范
保持代码的缩进和排版一致, 提高代码可读性。
错误处理规范
采用适当的错误处理机制,避 免程序崩溃或异常情况。
编码规范的制定和实施
制定编码规范
根据项目需求和团队实际情况,制定适合 的编码规范。可以参考行业标准和最佳实 践,结合团队特点和项目需求进行制定。
可维护性原则
代码应易于修改和维护,以提 高软件的可维护性。
可扩展性原则
代码应易于扩展和升级,以满 足未来的需求变化。
规范性原则
代码应遵循统一的编码规范和 标准,以提高代码的一致性和
可读性。
02
编码语言与工具
编程语言的种类和特点
高级语言
易于阅读和理解,但编译后执行效率较低 。常见的高级语言包括Java、Python和 C#。
选择合适的编程语言
根据项目需求选择
根据项目的规模、开发周期、性能要求等因 素选择合适的编程语言。
考虑跨平台性和可维护性
选择跨平台兼容的编程语言,以及易于维护 和扩展的编程语言。
考虑团队技能
选择团队熟悉或容易上手的编程语言,可以 提高开发效率和降低沟通成本。
性能与效率
在关键性能要求较高的场景下,选择执行效 率较高的编程语言。
用于检测代码质量、发现潜在问题和提供 改进建议,常见的代码质量分析工具包括 SonarQube和PMD。
03
编码规范与标准
编码规范的定义和作用
编码规范的定义
编码规范是规定编程语言语法、格式 和命名规则的准则,用于确保代码的 可读性、可维护性和一致性。
提高代码质量
遵循统一的编码规范,可以减少代码 错误,提高代码可读性和可维护性, 从而提高软件质量。
数据库字段命名规范

数据库字段命名规范篇一:数据库表及字段命名、设计规范数据库表及字段命名、设计规范1、命名规范1.1数据表的命名规范:1)表的前缀应该用系统或模块的英文名的缩写(全部大写或首字母大写)。
如果系统功能简单,没有划分为模块,则可以以系统英文名称的缩写作为前缀,否则以各模块的英文名称缩写作为前缀。
例如:如果有一个模块叫做BBS(缩写为BBS),那么你的数据库中的所有对象的名称都要加上这个前缀:BBS_ + 数据库对象名称,BBS_CustomerInfo标示论坛模块中的客户信息表。
2)表的名称必须易于理解,使用能表达表功能的英文单词或缩写英文单词,无论是完整英文单词还是缩写英文单词,单词首字母必须大写。
如果当前表可用一个英文单词表示的,请用完整的英文单词来表示;例如:系统资料中的客户表的表名可命名为:SYS_Customer。
如果当前表需用两个或两个以上的单词来表示时,尽量以完整形式书写,如太长可采用两个英文单词的缩写形式;例如:系统资料中的客户物料表可命名为:SYS_CustItem。
3)表的名称一般使用名词或者动宾短语4)表名称不应该取得太长(一般不超过三个英文单词)。
5)在命名表时,用单数形式表示名称。
例如,使用Employee,而不是 Employees。
6)对于有主明细的表来说。
明细表的名称为:主表的名称 + 字符Dts。
例如:采购定单的名称为:PO_Order,则采购定单的明细表为:PO_OrderDts对于有主明细的表来说,明细表必须包含两个字段:主表关键字、SN,SN字段的类型为int型,目的为与主表关键字联合组成明细表的关键字,以及标示明细记录的先后顺序,如1,2,3……。
7)表必须填写描述信息7)后台表名尽量与前台表名相同,后台独有的表应以_b作为后缀。
如r_gggd_b1.2表字段命名规范数据库字段的命名必须遵循以下规范:1)字段名称一般采用名词或动宾短语,且字段名为小写。
2)采用有意义的字段名。
数据库设计、命名、编码规范

4.4 视图名
Pascal 命名规范 视图的名称 如 = "vw_" + 视图内容标识
vw_UserPerm
4.5 触发器名
触发类型 触发标识
----------------------------------Insert Delete Update I D U
触发名=
"tr_"
+模块名称 +
相应的表名 +
查询或其它 存储过程名称 识 如 UP_Sale_Client_I =
S UP_模块名 + 下划线 + 表名 + 存储过程功能标
4.7 变量名
Pascal 命名规范
4.8 游标命名
游标应该以下面的标准来命名: 表名或者对象名字{使用此游标的对象名字}+CURSOR 例如: FiscalMonthCURSOR EmployeeListCURSOR
Sales_FK_Customer
4.12 索引命名
索引的命名应该在表空间内唯一,当查看执行计划时可以有效的对索引进行识 别.. [IX][类型(U 标识 Unique,C 标识 Clustered)][列名(s)] Ø Ø Ø Ø Ø 例如: IXUC_SalesId (clustered unique) 当对单列进行索引时,你可能需要使用列的全名. 当对多列进行索引时,要使用你所能想到的最优的缩写. 当对一个表的所有列进行索引时,使用 ALL 单词. 在多列名中使用下划线以增加可读性. 不要为索引加上序列号
6.
注释
注释可以包含在批处理中。在触发器、存储过程中包含描述性注释将大大增加文本 的可读性和可维护性。 1. 注释语法包含两种情况:单行注释、多行注释 单行注释:注释前有两个连字符(--),一般,对变量、条件子句可以采用该 类注释,在注释代码上一行。 多行注释:符号/*和*/之间的内容为注释内容。对某项完整的操作建议使用该类 注释。 2. 注释以中文为主。 实际应用中,发现以中文注释的 SQL 语句版本在英文环境中不可用。为避免后 续版本执行过程中发生某些异常错误,中文环境下用中文,外包项目一律用英 文。 3、 注释尽可能详细、全面。 创建每一数据对象前,应具体描述该对象的功能和用途。 传入参数的含义应该有所说明。如果取值范围确定,也应该一并说明。取值有 特定含义的变量(如 boolean 类型变量),应给出每个值的含义。 4、 注释简洁,同时应描述清晰。
数据库设计编码规范
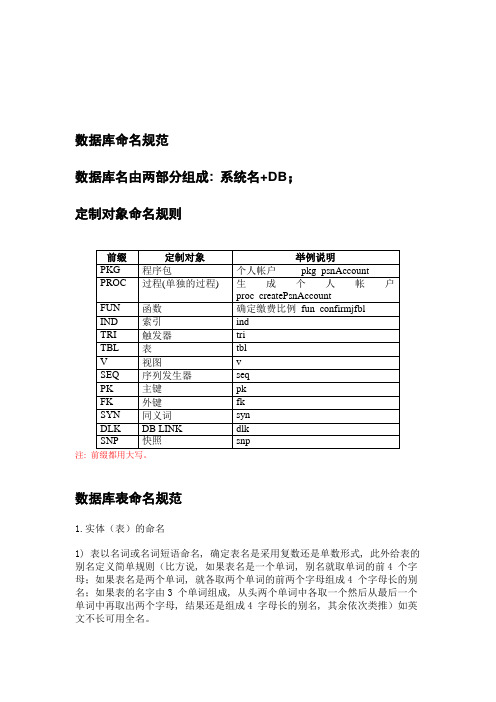
数据库命名规范数据库名由两部分组成: 系统名+DB;定制对象命名规则注:数据库表命名规范1.实体(表)的命名1) 表以名词或名词短语命名, 确定表名是采用复数还是单数形式, 此外给表的别名定义简单规则(比方说, 如果表名是一个单词, 别名就取单词的前4 个字母;如果表名是两个单词, 就各取两个单词的前两个字母组成4 个字母长的别名;如果表的名字由3 个单词组成, 从头两个单词中各取一个然后从最后一个单词中再取出两个字母, 结果还是组成4 字母长的别名, 其余依次类推)如英文不长可用全名。
对工作用表来说, 表名可以加上前缀WORK_ 后面附上采用该表的应用程序的名字。
在命名过程当中, 根据语义拼凑缩写即可。
注意, 由于ORCLE会将字段名称统一成大写或者小写中的一种, 所以要求加上下划线。
举例:定义的缩写 Sales: SAL 销售;Order: ORD 订单;Detail: DTL 明细;则销售订单明细表命名为: TBL_SAL_ORD_DTL;2) 如果表或者是字段的名称仅有一个单词, 那么建议不使用缩写, 而是用完整的单词。
举例:定义的缩写 Material MA 物品;物品表名为: TBL_Material, 而不是 MA.但是字段物品编码则是: MATERIAL_ID3) 关联类通过用下划线连接两个基本类之后, 再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母, 必须将原来的表名的进行缩写。
如果没有其他原因, 建议都使用缩写。
举例: 表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_OBJECT;表 Depart和Employee;存在多对多的关系;则关联表命名为TBL_R_DEPT_EMP 属性命名规范1.属性(列)的命名1) 采用有意义的列名, 表内的列要针对键采用一整套设计规则。
每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码, 统一命名为: ID;如果是自定义的逻辑上的编码则用缩写加“ID”的方法命名。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库编码规范1 目的?为了统一公司软件开发的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。
?2 范围?本规范适用于全体开发人员,作用于软件项目开发的数据库设计、维护阶段。
?3 术语?数据库对象:在数据库软件开发中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
?物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。
一般对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
?逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。
?4 设计概要?设计环境?a) ORACLE 11G R2数据库?ORACLE 11G R2?操作系统?LINUX 6以上版本,显示图形操作界面b) MS SQL SERVER 2005?数据库?SQL SERVER 2005 企业版?打sp3以上补丁和安全补丁??操作系统?WINDOWS 2008 SERVER设计使用工具?a)使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说明。
对于SQL Server 尽量使用企业管理器对数据库进行设计,并且要求对表,字段编写详细的说明(这些将作为扩展属性存入SQL Server中)?b)通过PowerDesigner 定制word格式报表,并导出word文档,作为数据字典保存,格式。
(PowerDesigner v10 才具有定制导出word格式报表的功能)。
对于SQL Server 一旦在企业管理器进行数据库设计时加入扩展属性,就可以通过编写简单的工具将数据字典导出。
?c) 编写数据库建数据库、建数据库对象、初始化数据脚本文件?设计原则?a) 采用多数据文件?b) 禁止使用过大的数据文件,unix系统不大于2GB,window系统不超过500MB?c) oracle数据库中必须将索引建立在索引表空间里。
?d) 基本信息表在建立时就分配足够的存储空间,禁止其自动扩展功能?e) 大文本字列、blob列要独立出一张表,此表只有id和blob(或大文本)列?f) 为每一个数据库创建独立的管理员用户,使用该用户进行设计,尽量不要使用sa或者系统管理员身份进行数据库设计。
?设计的更新?a) 在设计阶段,由数据库管理员或指定的项目组其一成员进行维护。
?b) 运行阶段,由数据库管理员进行维护。
?c) 如对表结构进行修改,应先在数据字典文档进行修改,最后在数据库中进行修改。
如果修改的是数据库字典表,必须由数据库管理员进行。
?d) 编写更新的SQL代码,如果使用PowerDesigner,禁止由PowerDesigner 直接连数据库进行数据库操作(如果是更改表或者字段的说明性文字可以通过数据库管理器图形界面进行修改)?e) 修改数据库要通过SQL,禁止其它方式对数据进行修改?f) 修改数据库的SQL要添加说明后保存备查?5 命名总体原则?设定的前缀一律用小写字母?标识名称命名全部小写?整个命名的全长不得超过30个字母?全部使用字母和下划线‘_’,不能使用中文和其他字符,有特别情况允许使用末尾数字编号。
例如:t_Finace1, t_Finace2...?命名名称来自于业务,全部采用英文单词?英文单词过长可以采用通用的缩写,尽量表达出业务的含义?如需要两个以上的英文单词做标识名称,单词之间要用下划线‘_’连接?名称全是由名词组成的,名词由大范围到小范围排序取名?完成某功能的名称,如函数和过程,以动宾形式取名?6 命名规范(逻辑对象)?数据库结构命名?a) 数据库命名?数据库的命名要求使用与数据库意义相关联的英文字母,即<业务系统名称>。
?例如:china care 数据库的命名为ccnet;?客户资料数据库的命名为Customer_Info。
?b) 数据库日志设计命名?数据库日志的的命名以<数据库名>_<日志名>.log格式命名。
其中,<日志名>为有意义的数据库日志名称。
?例如:?c) 数据库配置设计命名?数据库配置设计方案是以文件形式保存的,其内容是关于特定数据库的配置项目的具体值。
?数据库配置文件的命名以:<数据库类型简写〉_<应用系统标志>格式命名。
?其中,数据库类型简写见附件2《数据库类型简写》,cfq表示该文件是数据库配置文件。
?例如:ORA_ ?d) 数据库复制与存储设计命名?数据库复制与存储设计方案是以文件形式保存的,其内容是关于特定数据库之间的复制策略的具体细节。
?数据库复制与存储设计文件的命名以:<数据库类型简写>_<应用系统标志>格式命名。
?其中,数据库类型简写见附件2《数据库类型简写》,rep表示该文件是数据库复制与存储文件。
?e) 数据库连接设计命名?数据库连接设计方案是以文件形式保存的,其内容是关于特定分布式数据库之间的连接设计的具体细节。
?数据库连接设计文件的命名以:<数据库类型简写>_<应用系统标志>_dbl. sql格式命名。
其中,数据库类型简写见附件2《数据库类型简写》,dbl 表示该文件是数据库连接设计文件。
?f) 表空间、数据文件命名(主要针对Oracle)?索引表空间:?表空间命名格式:ts<系统标识>_i?数据库文件命名格式:ts<系统标识>_i[n].dbf?临时表空间:?表空间命名格式:ts<系统标识>_t?数据库文件命名格式:ts<系统标识>_t[n].dbf?回滚表空间:?表空间命名格式:ts<系统标识>_r?数据库文件命名格式:ts<系统标识>_r[n].dbf?数据表空间:?表空间命名格式:ts<系统标识>_d?数据库文件命名格式:ts<系统标识>_d[n].dbf?注:表空间名不超过8位,n 可取00-99或0-9,根据系统数据量确定。
?数据库对象命名?a) 表?表的命名必须以“t_”(Table缩写)开头,格式为:t_[系统标识]_<数据表类型标识>_<表标识>。
?其中,[ ]表示可选项,依据实际情况而增加;<表标识> 要求与表意义相关联的英文字母,例如:t_Customers。
?数据表大致分为:业务数据表、基本编码表、辅助编码表、系统信息表、累计数据表、结算数据表、决策数据表;基本编码表用base标志?累计数据表用count标志?系统信息表用info标志 ...?例如:t_trade_base_trade_code,t_trade_info_help ...?b) 字段/域?根据业务要求进行命名,不需设定固定的前缀。
?c) 索引?针对数据库表中一个或多个字段建立的索引的命名格式应以“idx_”开头,索引列名间用_隔开,即为idx_ColumnName1_ColumnName2_…?其中,ColumnName1是数据库表中(第一个)索引字段的名称或名称简写;ColumnName2是数据库表中(第二个)索引字段的名称或名称简写;索引名的总长必需符合数据库的规定。
?例:idx_cert_number (表示在字段cert_number上创建索引)?为了避免重名索引出现,可选命名方式为 idx_<表名>_<递增号> 作为索引的命名,但是要求在数据字典中进行详细说明?d) 视图?视图的命名必须以“v_”(View 缩写)开头,格式为: v_<视图类型>_[系统标识] _<视图标识>。
?其中,视图类型参见“表的分类说明”;[系统标识_]是可选项,依据情况而增加;<视图标识> 应与视图意义相关联的英文字母。
?例:v_user_detail_info?e) 存储过程?存储过程的命名必须符合sp_[系统标识]_<存储过程标识>格式。
?其中,sp表示是存储过程;[系统标识]为可选项,依据情况而增加;<存储过程标识>是与存储过程意义相关联的英文字母,例如:USP_Query_Write_to_Disk。
?例:sp_check_user_auth(以动宾方式取名)?f) 触发器?触发器的的命名必须符合tr_<表名>_<i,u,d的任意组合> 格式。
?其中,tr表示是触发器;<i,u,d的任意组合>是与触发器意义相关联的英文字母。
?例:tr_user_info_iu (表示对user_info表进行插入、更新的触发器)?g) 函数?函数的命名必须符合fn_[系统标识]_<函数标识>格式。
?其中,fn表示是函数,[系统标识]为可选项,依情况而定;<函数标识>是与函数意义相关联的英文字母。
?例:fn_create_id(以动宾方式取名)?h) 自定义数据类型?自定义数据类型的命名格式为:ud_<自定义数据类型标识>_<数据类型>?i) Default(缺省)?Default(缺省)的命名格式一般为:df_<Default标识>;对于非绑定的默认可取系统默认的名字,请参见第点实例绑定具体字段。
?if exists (select * from sysobjects where type = 'D' and name = 'df_begin_date')?drop default ?go?go?j) Check、Constraint(约束)?约束的命名格式一般为:ck_<表名>_ <Check标识>;一些约束可直接放在生成表的语句中。
?例:ck_flag 参见第点实例,约束字段flag只能取字符‘0’到‘9’:?constraint ck_flag CHECK (flag between '0’ and '9’ )?k) Rule(规则)?规则的命名格式一般为:rl_<Rule标识>;对于非绑定规则(约束) 可取系统默认的名字,参见第10点设计实例绑定具体字段。
?例:rl_not_zero (定义一个不等于0的规则)?if exists (select * from sysobjects where type = 'R' and name = 'rl_not_zero')?drop rule ?go?create rule rl_not_zero as @i <> 0?go?l) 主键?主键的命名格式为pk_<表名>_<主键标识>。