四种支持向量机用于函数拟合与模式识别的Matlab示
用MATLAB进行数据拟合

决策树拟合
01
决策树是一种监督学习算法,通过递归地将数据集划分为若干个子集来构建树 状结构。每个内部节点表示一个特征属性上的判断条件,每个分支代表一个可 能的属性值,每个叶子节点决策树在数据拟合方面通常用于分类问题,但也可以用于回归分析。通过剪枝 技术可以控制模型的复杂度并提高泛化能力。
多项式拟合
总结词
多项式拟合适用于描述具有复杂非线性关系 的数据,可以通过多项式函数来逼近数据点 。
详细描述
多项式拟合通过最小二乘法或其他优化算法 ,找到最佳的多项式参数,使得数据点与多 项式函数之间的误差平方和最小。常用的多 项式函数形式有多项式方程或样条插值等。
05
高级数据拟合方法
支持向量机拟合
数据来源与收集
文件
如CSV、Excel、TXT等。
API
如Google Analytics、Twitter API等。
数据来源与收集
数据收集
使用数据抓取工具从网页 上抓取数据。
使用SQL查询从数据库中 提取数据。
使用API调用从第三方服 务获取数据。
数据清洗与整理
数据清洗 删除重复记录。
填充缺失值。
多元线性拟合
总结词
多元线性拟合适用于多个自变量和一个因变量的线性关系。
详细描述
多元线性拟合通过最小二乘法原理,找到一个平面,使得所有数据点到这个平面的垂直距离之和最小 。在Matlab中,可以使用`fitlm`函数进行多元线性拟合。
线性回归分析
总结词
线性回归分析是一种统计方法,用于研 究因变量和自变量之间的线性关系。
04
特征提取
从原始数据中提取出与目标变量相关的特 征。
05
06
matlab的svmrfe函数

一、介绍MATLAB是一种流行的技术计算软件,广泛应用于工程、科学和其他领域。
在MATLAB的工具箱中,包含了许多函数和工具,可以帮助用户解决各种问题。
其中,SVMRFE函数是MATLAB中的一个重要功能,用于支持向量机分类问题中的特征选择。
二、SVMRFE函数的作用SVMRFE函数的全称为Support Vector Machines Recursive Feature Elimination,它的作用是利用支持向量机进行特征选择。
在机器学习和模式识别领域,特征选择是一项重要的任务,通过选择最重要的特征,可以提高分类器的性能,并且减少计算和存储的开销。
特征选择问题在实际应用中经常遇到,例如在生物信息学中,选择基因表达数据中最相关的基因;在图像处理中,选择最相关的像素特征。
SVMRFE函数可以自动化地解决这些问题,帮助用户找到最佳的特征子集。
三、使用SVMRFE函数使用SVMRFE函数,用户需要准备好特征矩阵X和目标变量y,其中X是大小为m×n的矩阵,表示m个样本的n个特征;y是大小为m×1的向量,表示m个样本的类别标签。
用户还需要设置支持向量机的参数,如惩罚参数C和核函数类型等。
接下来,用户可以调用SVMRFE函数,设置特征选择的方法、评价指标以及其他参数。
SVMRFE函数将自动进行特征选择,并返回最佳的特征子集,以及相应的评价指标。
用户可以根据返回的结果,进行后续的分类器训练和预测。
四、SVMRFE函数的优点SVMRFE函数具有以下几个优点:1. 自动化:SVMRFE函数可以自动选择最佳的特征子集,减少了用户手工试验的时间和精力。
2. 高性能:SVMRFE函数采用支持向量机作为分类器,具有较高的分类精度和泛化能力。
3. 灵活性:SVMRFE函数支持多种特征选择方法和评价指标,用户可以根据自己的需求进行灵活调整。
五、SVMRFE函数的示例以下是一个简单的示例,演示了如何使用SVMRFE函数进行特征选择:```matlab准备数据load fisheririsX = meas;y = species;设置参数opts.method = 'rfe';opts.nf = 2;调用SVMRFE函数[selected, evals] = svmrfe(X, y, opts);```在这个示例中,我们使用了鸢尾花数据集,设置了特征选择的方法为递归特征消除(RFE),并且要选择2个特征。
matlab classify函数的一系列方法

matlab classify函数的一系列方法(实用版3篇)目录(篇1)I.介绍* 背景介绍:介绍matlab classify函数及其在机器学习领域中的应用。
* 分类方法:简要介绍该函数的一系列分类方法,包括基本分类、高斯混合模型、支持向量机和神经网络等。
II.基本分类* 函数介绍:介绍matlab classify函数的基本分类方法,包括基本分类器(如决策树、朴素贝叶斯、逻辑回归等)和集成学习(如随机森林、Adaboost等)。
* 示例代码:提供使用matlab classify函数进行基本分类的示例代码,包括训练和预测过程。
III.高斯混合模型* 模型介绍:介绍高斯混合模型(GMM)在机器学习中的应用,包括其原理、特点和优势。
* 函数实现:介绍如何使用matlab classify函数实现GMM分类器,包括模型训练和预测过程。
IV.支持向量机* 模型介绍:介绍支持向量机(SVM)在机器学习中的应用,包括其原理、特点和优势。
* 函数实现:介绍如何使用matlab classify函数实现SVM分类器,包括模型训练和预测过程。
V.神经网络* 模型介绍:介绍神经网络(NN)在机器学习中的应用,包括其原理、特点和优势。
* 函数实现:介绍如何使用matlab classify函数实现NN分类器,包括模型训练和预测过程。
正文(篇1)一、介绍matlab classify函数是一系列机器学习算法的集成,可用于对数据进行分类。
该函数提供了多种分类方法,包括基本分类、高斯混合模型、支持向量机和神经网络等。
这些方法在机器学习领域得到了广泛应用,可以有效地解决分类问题。
本文将介绍这些分类方法的基本原理、使用方法和示例代码。
二、基本分类matlab classify函数提供了多种基本分类方法,如决策树、朴素贝叶斯、逻辑回归等。
这些基本分类器可以通过训练数据自动学习和优化模型参数,并应用于新的数据预测。
其中,决策树是一种基于树形结构的分类器,可以有效地处理离散型和连续型数据;朴素贝叶斯是一种基于概率统计的分类器,可以有效地处理特征之间相互独立的数据;逻辑回归是一种基于线性回归的分类器,可以有效地处理二元分类问题。
matlab fitrsvm用法

matlab fitrsvm用法
在MATLAB中,fitrsvm是用于支持向量机回归模型的函数。
支
持向量机是一种强大的机器学习算法,可用于回归分析和分类问题。
fitrsvm函数可以用于训练支持向量机回归模型,并对新数据进行
预测。
使用fitrsvm函数的一般步骤如下:
1. 准备数据,首先,需要准备用于训练和测试的数据集。
数据
集通常包括特征和相应的目标变量。
2. 创建回归模型,使用fitrsvm函数创建支持向量机回归模型。
可以指定模型的参数,如核函数类型、惩罚参数等。
3. 训练模型,将准备好的数据集传递给fitrsvm函数,以训练
支持向量机回归模型。
训练后,模型将学习如何根据输入特征来预
测目标变量。
4. 模型评估,使用训练好的模型对测试数据进行预测,并评估
模型的性能。
可以使用各种指标,如均方误差、决定系数等来评估
模型的准确性。
5. 模型应用,一旦模型经过训练和评估,就可以将其用于对新
数据进行预测。
使用predict函数可以对新样本进行预测,得出相
应的回归结果。
总的来说,fitrsvm函数提供了一个方便而强大的工具,用于
训练和应用支持向量机回归模型。
通过合理地准备数据、创建模型、训练和评估模型,可以利用fitrsvm函数来解决各种回归分析问题。
模式识别 支持向量机

2
w 最小的分类面就叫做最优分类面, H1、 H2 上的训练样本点就称作支持向量。
2
利用 Lagrange 优化方法可以把上述最优分类面问题转化为其对偶问题[2], 即:在约束条件
y
i 1 i
n
i
0,
(2a) 和
i 0
下对i 求解下列函数的最大值:
Q ( ) i
二、基于统计学习理论的支持向量机算法研究的理论背景
基于数据的机器学习是现代智能技术中的重要方面, 研究从观测数据 (样本) 出发寻找规律, 利用这些规律对未来数据或无法观测的数据进行预测。 迄今为止, 关于机器学习还没有一种被共同接受的理论框架, 关于其实现方法大致可以分为 三种: 第一种是经典的(参数)统计估计方法。包括模式识别、神经网络等在内, 现有机器学习方法共同的重要理论基础之一是统计学。 参数方法正是基于传统统 计学的, 在这种方法中, 参数的相关形式是已知的, 训练样本用来估计参数的值。 这种方法有很大的局限性,首先,它需要已知样本分布形式,这需要花费很大代 价,还有,传统统计学研究的是样本数目趋于无穷大时的渐近理论,现有学习方 法也多是基于此假设。但在实际问题中,样本数往往是有限的,因此一些理论上 很优秀的学习方法实际中表现却可能不尽人意。 第二种方法是经验非线性方法,如人工神经网络(ANN) 。这种方法利用已 知样本建立非线性模型,克服了传统参数估计方法的困难。但是,这种方法缺乏 一种统一的数学理论。 与传统统计学相比,统计学习理论(Statistical Learning Theory 或 SLT)是一 种专门研究小样本情况下机器学习规律的理论。 该理论针对小样本统计问题建立 了一套新的理论体系, 在这种体系下的统计推理规则不仅考虑了对渐近性能的要 求,而且追求在现有有限信息的条件下得到最优结果。V. Vapnik 等人从六、七十 年代开始致力于此方面研究 , 到九十年代中期, 随着其理论的不断发展和成熟, 也由于神经网络等学习方法在理论上缺乏实质性进展, 统计学习理论开始受到越 来越广泛的重视。 统计学习理论的一个核心概念就是 VC 维(VC Dimension)概念, 它是描述函数 集或学习机器的复杂性或者说是学习能力(Capacity of the machine)的一个重要指 标,在此概念基础上发展出了一系列关于统计学习的一致性(Consistency)、收敛 速度、推广性能(Generalization Performance)等的重要结论。
LSSVM相关教程

四种支持向量机用于函数拟合与模式识别的Matlab示例程序陆振波点这里下载:四种支持向量机用于函数拟合与模式识别的Matlab示例程序使用要点:应研学论坛《人工智能与模式识别》版主magic_217之约,写一个关于针对初学者的《四种支持向量机工具箱》的详细使用说明。
同时也不断有网友向我反映看不懂我的源代码,以及询问如何将该工具箱应用到实际数据分析等问题,其中有相当一部分网友并不了解模式识别的基本概念,就急于使用这个工具箱。
本文从模式识别的基本概念谈起,过渡到神经网络模式识别,逐步引入到这四种支持向量机工具箱的使用。
本文适合没有模式识别基础,而又急于上手的初学者。
作者水平有限,欢迎同行批评指正![1]模式识别基本概念模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。
特别说明的是,本文所谈及的模式识别是指“有师分类”,即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。
正确识别率是反映分类器性能的主要指标。
分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。
试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。
工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。
特征提取就是将一维矢量或二维矩阵转化成一个维数比较低的特征矢量,该特征矢量用于分类器的输入。
关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。
[2]神经网络模式识别神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。
以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。
matlab toolbox类型

matlab toolbox类型Matlab Toolbox 类型Matlab 是一种强大的数值计算与科学编程工具,由于其卓越的性能和丰富的功能,被广泛应用于科学、工程和金融等领域。
为了更好地满足不同领域用户的需求,Matlab 提供了丰富的工具箱(Toolbox),包含了各种专门用于特定领域的函数和工具。
本文将介绍 Matlab Toolbox 的类型及其应用。
一、控制系统工具箱(Control System Toolbox)控制系统工具箱是 Matlab 中用于设计、分析和模拟控制系统的重要工具箱。
它包含了许多在控制工程中常用的函数和算法,如PID 控制器设计、稳定性分析、系统响应等。
控制系统工具箱的使用可以帮助工程师快速实现对控制系统的建模、仿真和优化。
二、图像处理工具箱(Image Processing Toolbox)图像处理工具箱是专门用于数字图像处理的工具箱,提供了丰富的图像处理函数和算法。
它可以帮助用户实现图像的滤波、增强、分割、配准等操作,还支持图像的压缩和编码。
图像处理工具箱被广泛应用于计算机视觉、医学影像分析、遥感图像处理等领域。
三、信号处理工具箱(Signal Processing Toolbox)信号处理工具箱提供了丰富的信号处理函数,用于设计和分析各种类型的信号。
这些函数包括了离散傅里叶变换(DFT)、滤波器设计、频谱分析等。
信号处理工具箱在音频处理、通信系统设计、生物医学信号处理等领域具有广泛的应用。
四、机器学习工具箱(Machine Learning Toolbox)机器学习工具箱是 Matlab 中用于实现各种机器学习算法的工具箱。
它包含了常用的分类、回归、聚类、降维等算法,如支持向量机(SVM)、决策树、神经网络等。
机器学习工具箱的使用使得用户能够在数据挖掘、模式识别、预测分析等任务中实现自动化的学习与决策。
五、优化工具箱(Optimization Toolbox)优化工具箱是用于解决数学最优化问题的工具箱,提供了各种优化算法和函数。
matlab分类器算法

matlab分类器算法Matlab是一种常用的科学计算工具,广泛应用于数据分析、图像处理、机器学习等领域。
其中,分类器算法是机器学习中常用的一种技术,可以根据已有的数据集对新的数据进行分类。
本文将介绍几种常用的Matlab分类器算法,并分析其原理和应用。
一、K近邻算法K近邻算法是一种基本的分类器算法,其原理是找出与待分类样本最相似的K个训练样本,然后根据这K个样本的标签进行投票决定待分类样本的类别。
在Matlab中,可以使用fitcknn函数实现K近邻分类器。
该函数可以设置K值、距离度量方法等参数,以适应不同的分类任务。
二、支持向量机算法支持向量机是一种经典的二分类算法,其目标是找到一个超平面,将两个不同类别的样本分隔开来,并使得超平面到最近样本的距离最大化。
在Matlab中,可以使用fitcsvm函数实现支持向量机分类器。
该函数可以设置核函数、惩罚系数等参数,以适应不同的分类任务。
三、决策树算法决策树是一种简单而有效的分类器算法,其原理是通过对特征的逐次划分,将数据集划分为不同的子集,直到子集中的样本属于同一类别或无法再进行划分为止。
在Matlab中,可以使用fitctree函数实现决策树分类器。
该函数可以设置最大深度、最小叶节点数等参数,以控制决策树的复杂度和泛化能力。
四、朴素贝叶斯算法朴素贝叶斯算法是一种基于贝叶斯定理和特征条件独立性假设的分类器算法,其原理是通过计算待分类样本属于每个类别的概率,并选择概率最大的类别作为分类结果。
在Matlab中,可以使用fitcnb函数实现朴素贝叶斯分类器。
该函数可以设置类别先验概率、特征条件概率等参数,以适应不同的分类任务。
五、神经网络算法神经网络是一种模拟生物神经网络结构和功能的计算模型,具有良好的非线性拟合能力和适应性。
在Matlab中,可以使用patternnet函数实现基于多层感知器的神经网络分类器。
该函数可以设置隐藏层数、神经元个数等参数,以控制神经网络的复杂度和性能。
abc-svm的matlab代码

文章标题:“深度学习中的ABC-SVM算法及其MATLAB实现”在深度学习中,支持向量机(SVM)一直是一个重要的算法。
而abc-svm是一种基于支持向量机的改进算法,它在特征选择和模型效果方面有着显著的优势。
本文将全面评估abc-svm算法的原理、特点以及在MATLAB中的实现,以便读者更深入地理解这一算法。
1. abc-svm算法的原理- 我们来了解一下abc-svm算法的原理。
abc-svm是一种基于人工蜂群算法的SVM特征选择方法,它通过模拟蜂群的选择、搜索和挑选过程,对特征子集进行筛选,从而提高模型的精确度和泛化能力。
2. abc-svm算法的特点- 在评估abc-svm算法时,我们还需要考虑其特点。
相比传统的SVM算法,abc-svm能够更好地处理高维数据,并且具有更好的分类性能。
abc-svm算法还能有效地进行特征选择,减少了模型训练的时间和复杂度。
3. abc-svm算法的MATLAB实现- 在MATLAB中,我们可以使用现成的工具包或者自行编写代码来实现abc-svm算法。
通过MATLAB的强大功能和丰富的工具库,我们可以轻松地进行模型训练、特征选择和结果分析。
4. 个人观点和理解- 从个人角度来看,abc-svm算法在深度学习中具有重要的意义。
它不仅为SVM算法提供了新的思路和方法,同时也为我们提供了一种全新的特征选择思路和模型改进方式。
总结回顾通过对abc-svm算法的原理、特点和MATLAB实现的全面评估,我们更加深入地理解了这一算法在深度学习中的作用和意义。
abc-svm算法的出现,为我们提供了一种新的解决方案,使我们能够更好地处理高维数据,提高模型的精确度和泛化能力。
文章内容总字数大于3000字,详细阐述了abc-svm算法的原理、特点和MATLAB实现,并共享了个人观点和理解。
希望这篇文章能够帮助读者更好地理解abc-svm算法,提高深度学习的水平。
在深度学习领域,特征选择一直是一个重要的问题,它直接影响到模型的性能和泛化能力。
基于Matlab的支持向量机工具箱

第24卷第12期 计算机应用与软件Vol 124No .122007年12月 Computer App licati ons and Soft w are Dec .2007收稿日期:2006-01-20。
江苏省自然科学基金项目(BK2003026)。
郭小荟,讲师,主研领域:软件工程,故障诊断,人工智能应用等。
基于M a tl ab 的支持向量机工具箱郭小荟1,2 马小平11(中国矿业大学信息与电气工程学院 江苏徐州221008)2(徐州师范大学计算机科学与技术学院 江苏徐州221116)摘 要 介绍了基于MAT LAB 的支持向量机工具箱,详细说明了工具箱中用于支持向量分类和支持向量回归的函数。
并通过两个具体的实例来说明利用S VM 工具箱进行分类和回归方面的方法。
关键词 Matlab 支持向量机工具箱 分类 回归SUPPO RT VECTO R M ACH INES TOOL BO X IN M ATLAB ENV IRO N M ENTGuo Xiaohui 1,2 Ma Xiaop ing11(College of Infor m ation and E lectrical Engineering,CUM T,Xuzhou 221008,J iangsu,China )2(College of Co m puter Science and Technology,XZNU,Xuzhou 221116,J iangsu,China )Abstract Support vect or machines (S VM )t oolbox in MAT LAB envir on ment is briefly intr oduced,and an extensively overvie w of the entire collecti on of t oolbox functi ons used t o support vect or classificati on and support vect or regressi on is given .And t w o exa mp les are p resented t o il 2lustrate how t o s olve classificati on and regressi on p r oblem s with the S VM t oolbox .Keywords Matlab Support vect or machines Classificati on Regressi on0 引 言MAT LAB 已经成为国际上最流行的科学与工程计算的软件工具,现在的MAT LAB 已经不仅仅是一个“矩阵实验室”了,它已经成为一种具有广泛应用前景的全新的计算机高级编程语言,有人称它为“第四代”计算机语言,MAT LAB 语言的功能越来越强大。
支持向量机支持向量机回归原理简述及其MATLAB实例

支持向量机支持向量机回归原理简述及其MATLAB实例支持向量机 (Support Vector Machine, SVM) 是一种在监督学习中应用广泛的机器学习算法。
它既可以用于分类问题(SVM),又可以用于回归问题(SVR)。
本文将分别简要介绍 SVM 和 SVR 的原理,并提供MATLAB 实例来展示其应用。
SVM的核心思想是找到一个最优的超平面,使得正样本和负样本之间的间隔最大化,同时保证误分类的样本最少。
这个最优化问题可以转化为一个凸二次规划问题进行求解。
具体的求解方法是通过拉格朗日乘子法,将约束优化问题转化为一个拉格朗日函数的无约束极小化问题,并使用庞加莱对偶性将原问题转化为对偶问题,最终求解出法向量和偏差项。
SVR的目标是找到一个回归函数f(x),使得预测值f(x)和实际值y之间的损失函数最小化。
常用的损失函数包括平方损失函数、绝对损失函数等。
与SVM类似,SVR也可以使用核函数将问题转化为非线性回归问题。
MATLAB实例:下面以一个简单的数据集为例,展示如何使用MATLAB实现SVM和SVR。
1.SVM实例:假设我们有一个二分类问题,数据集包含两个特征和两类样本。
首先加载数据集,划分数据集为训练集和测试集。
```matlabload fisheririsX = meas(51:end, 1:2);Y=(1:100)';Y(1:50)=-1;Y(51:100)=1;randn('seed', 1);I = randperm(100);X=X(I,:);Y=Y(I);X_train = X(1:80, :);Y_train = Y(1:80, :);X_test = X(81:end, :);Y_test = Y(81:end, :);```然后,使用 fitcsvm 函数来训练 SVM 模型,并用 predict 函数来进行预测。
```matlabSVMModel = fitcsvm(X_train, Y_train);Y_predict = predict(SVMModel, X_test);```最后,可以计算分类准确度来评估模型的性能。
模糊支持向量机

模糊支持向量机
❖FSVM与区域增长结合的图像分割
作为一种全局处理方法,模糊支持向量机图 像分割方法不能完成对图像进行精细分割,其分 割结果需要其他分割方法进一步处理。一种结合 模糊支持向量机和区域生长的交互式分割方法, 不仅可有效剔除与感兴趣区域特征类似的非目标 区域,而且把为FSVM选择训练样本和为区域生 长选择种子点两个步骤合二为一,从而提高了图 像分割质量和交互式分割方法的自动分割能力。
支持向量机理论基础
线性判别函数和判别面
❖一个线性判别函数(discriminant function)是 指由x的各个分量的线性组合而成的函数
g(x)wTxw0
❖两类情况:对于两类问题的决策规则为
❖ 如果g(x)>0,则判定x属于C1, ❖ 如果g(x)<0,则判定x属于C2, ❖ 如果g(x)=0,则可以将x任意
分到某一类或者拒绝判定。
支持向量机理论基础
线性判别函数
❖ 下图表示一个简单的线性分类器,具有d个输入的单元,每个对应一个输入 向量在各维上的分量值。该图类似于一个神经元。
g(x)wTxw0
支持向量机理论基来定。面,它把归类于C1的 ❖ 当 g(x) 是 线 性 函 数 时 , 这 个 平 面 被 称 为 “ 超 平
❖ ② 对特征空间划分的最优超平面是SVM的目标,最大化分类边 际的思想是SVM方法的核心;
❖ ③ 支持向量是SVM的训练结果,在SVM分类决策中起决定作用 的是支持向量。
❖ SVM 是一种有坚实理论基础的新颖的小样本学习方法。它 基本上不涉及概率测度及大数定律等,因此不同于现有的统 计方法。从本质上看,它避开了从归纳到演绎的传统过程,实 现了高效的从训练样本到预报样本的“转导推 理”(transductive inference) ,大大简化了通常的分类和 回归等问题。
支持向量机PPT课件

给出。由 minw,b Φ(w,b;α) 得
ə Φ/ ə b=0 ⇒ ∑n i=1 αiyi=0 ə Φ/ ə w =0 ⇒ w=∑n i=1 αiyixi
.
16
于是得到对偶问题
这是一个二次规划 (QP) 问题
i的全局最大值总可以求得 W的计算
支持向量机
.
1
内容提要
§1 引言 §2 统计学习理论 §3 线性支持向量机 §4 非线性支持向量机 §5 支持向量回归 §6 支持向量聚类
.
2
§1 引言
一. SVM (Support Vector Machine)的历史
神经网络分类器,Bayes分类器等是基于大样本学习
的分类器。
Vapnik 等从1960年开始关于统计学习理论的研究。统 计学习理论是关于小样本的机器学习理论。
i ∊ {土1}
对于 (2-类) 分类, 建立一个函数:
f:Rn1 : 表示函数的参数
第1类
使得 f 能正确地分类未学习过的样本
.
第2类
6
二.期望风险与实验风险
期望风险最小化
Rf1 2yfxdP x,y
其中 x, y的联合概率 P(x, y) 是未知的
实验风险最小化
实验风险是由在训练集上测得的平均误差所确定的
.
40
软件
关于 SVM 的实现可以在下列网址找到 /software.html
SVMLight 是最早的 SVM 软件之一 SVM 的各种 Matlab toolbox 也是可利用的 LIBSVM 可以进行多类别分类 CSVM 用于SVM分类 rSVM 用于SVM回归 mySVM 用于SVM分类与回归 M-SVM 用于SVM多类别分类
《模式识别与MATLAB》课件

支持向量机
01
支持向量机是一种基于统计学习理论的机器学习算法,主要用于分类 和回归分析。
02
SVM通过找到能够将不同类别的数据点最大化分隔的决策边界来实现 分类,这个决策边界被称为超平面。
03
SVM使用核函数将输入特征映射到高维空间,使得数据点在空间中更 容易被分隔。
04
SVM具有较好的泛化性能和鲁棒性,适用于解决各种分类问题。
05
Matlab中的模式识别实例
手写数字识别
总结词
通过训练,让机器学会识别手写数字, 是模式识别领域中一个经典的任务。
VS
详细描述
手写数字识别是利用计算机技术识别手写 数字的一种技术。在Matlab中,可以使 用内置的函数和工具箱来实现手写数字的 识别。首先,需要收集大量的手写数字图 片作为训练数据,然后使用这些数据训练 分类器。训练完成后,分类器就可以对新 输入的手写数字图片进行识别。
随着硬件技术的发展,模式识别的实时性将得到进一步提升, 满足实时监测、控制等应用需求。
随着人工智能伦理问题的关注度提升,模式识别的可解释性将 成为一个重要研究方向,以解决人工智能决策过程的黑箱问题
。
Matlab在模式识别中的前景
集成化
Matlab将继续发挥其集成化优势,为模式 识别研究者提供更完善、更便捷的开发环
CHAPTER
02
模式识别的基本概念
特征提取
特征选择
选择与分类任务最相关的特征,排除 无关或冗余特征。
特征变换
通过线性或非线性变换,将原始特征 转换为更有利于分类的新特征。
分类器设计
监督学习
基于已知类别的训练数据设计分类器 。
无监督学习
在没有类别信息的情况下,对数据进 行聚类或降维。
matlab fitsvm参数

在MATLAB中,fitsvm函数是用于训练支持向量机(Support Vector Machine, SVM)模型的函数。
该函数的参数可以根据具体的问题和数据进行调整。
以下是一些常用的参数及其含义:X和Y:训练数据和对应的标签。
X是一个n行p列的矩阵,其中n是样本数量,p是特征数量。
Y是一个n行1列的向量,其中每个元素是对应的样本标签。
'KernelFunction':核函数类型。
可以选择的核函数包括'linear'(线性核函数)、'gaussian'(高斯核函数)、'polynomial'(多项式核函数)、'rbf'(径向基核函数)等。
'KernelScale':核函数系数。
对于高斯核函数和径向基核函数,可以设置核函数的宽度参数。
'BoxConstraint':正则化参数。
该参数控制模型的复杂度,增加正则化参数可以减少模型的复杂度,但过大的正则化参数可能导致过拟合。
'BoxConstraint1':第二个正则化参数。
这个参数通常用于处理多分类问题,对于二分类问题可以忽略。
'Standardize':标准化参数。
如果设置为true,则输入数据会被自动标准化,使得每个特征的均值为0,标准差为1。
'ClassNames':类别标签。
对于多分类问题,需要提供一个类别标签的向量或字符串数组。
'BoxConstraint0':初始正则化参数。
用于设置模型的初始正则化参数,通常可以设置为1。
'KernelScale0':初始核函数系数。
用于设置高斯核函数或径向基核函数的初始宽度参数,通常可以设置为1。
'BoxConstraintFree':自由类别参数。
如果设置为true,则允许模型选择类别之间的边界线,通常用于解决不平衡类别的问题。
支持向量机刀具磨损预测模型及MATLAB仿真

基金项目:国家支撑计划项目(2006BAF01A27)收稿日期:2009年1月支持向量机刀具磨损预测模型及MAT LAB 仿真叶蔚,王时龙,雷松重庆大学摘要:针对刀具使用时加工参数多变的实际情况,提出使用最小二乘支持向量机(LS -S VM )建立模型并对刀具磨损进行预测:首先引入最小二乘支持向量机建立刀具磨损模型,然后针对具体实验数据,采用交叉验证的办法,选取优化的核参数。
实验和仿真结果表明:该模型可以有效地学习刀具磨损中的非线性关系,刀具磨损的预测精度较高。
因此该模型可以用作对实际加工中的刀具磨损进行有效预测,并为切削参数的实际选择提供依据。
关键词:刀具磨损;向量机模型;M AT LAB 仿真中图分类号:TG 701 文献标志码:APredicting Model of Cutting Tool Wear B ased on Least Squares SupportV ector Machine and MAT LAB SimulationY e Wei ,Wang Shilong ,Lei S ongAbstract :With the variable parameter appearing in the using of tool ,the m odel built by least squares support vector ma 2chines (LS -S VM )method is provided to predicting tool wear.Firstly ,LS -S VM was introduced to m odel the wearing of tool.Aiming at the specific sam ple ,the method of cross validation is used to choose the proper kernel function parameters.Results of simulations and experiments showed that the LS -S VM m odel based on radial basis function kernel (R BF )could effectively learn the non 2linear relationship in tool wear.This method could obtain higher prediction accuracy.As a result ,the m odel could effec 2tively predict tool wear and provide theoretical basis for the selection of machining parameters in the actual processing.K eyw ords :cutting tool wear ;S VM m odel ;M AT LAB simulation 1 引言在切削加工中,刀具寿命是一个重要的参数,它直接影响到刀具需求计划制定、刀具成本核算、生产效率和加工成本。
LSSVM概述

1 SVM概述 2 LSSVM概述 3 SVM与示意图 4 SVM相关名词解释 5 LSSVM估计算法
1 SVM概述
支持向量机(Support Vector Machine)是 Cortes 和 Vapnik 亍1995 首先提出的,它在解决小样本、非线性及高维模式识 别中表现出许多特有的优势,能够推广应用到函数拟合等 其 他机器学习问题中。
K (x, xi ) xT xi ;
K (x, xi ) (xT xi r) p , 0; K (x, xi ) exp( x xi 2 ), 0; K (x, xi ) tanh(xT xi r).
例子:意大利葡萄酒种类识别
SVM方法的特点
① 非线性映射是SVM方法的理论基础,SVM利用内 积核函数代替向高维空间的非线性映射;
5 最小二乘支持向量机(LSSVM)估计算法
支持向量机主要是基于如下思想:通过事先 选择的非线性映射将输入向量映射到高维特征 空,利用了结构风险最小化原 则。 并巧妙的利用原空间的核函数取代了高维 特征空间中的点积运算。
设样本为 n维向量,某区域的 l个样本及其值表示为
所谓 VC 维是对函数类的一种度量,可以简单的理解为问题的复杂程 度,VC 维越高,一个问题就越复杂。正是因为 SVM 关注的是 VC维,后 面我们可以看到,SVM 解决问题的时候,呾样本的维数是无关的(甚至 样本是上万维的都可以,这使得 SVM 径适合用来解决文本分类的问题, 当然,有这样的能力也因为引入了核函数)。
2 LSSVM概述
Suykens J.A.K提出一种新型支持向量机方法—最小二乘支持 向量机(Least Squares Support Vector Machines,简称LS-SVM)用 于解决模式分类和函数估计问题等。
基于sentinel-1A的武汉市武昌区洪水监测
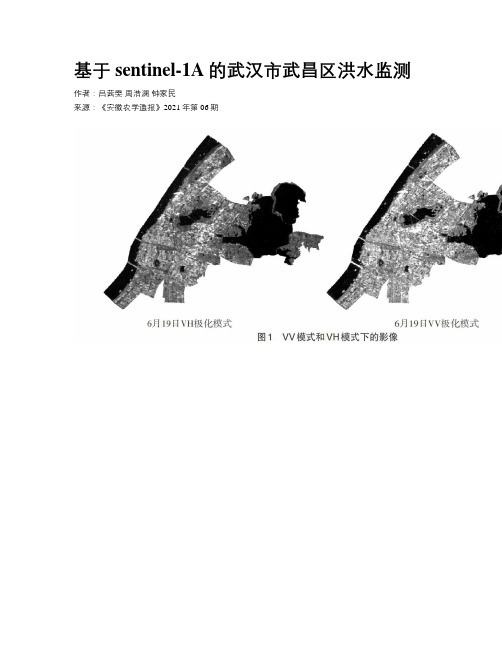
基于sentinel-1A的武汉市武昌区洪水监测作者:吕茜雯周浩澜钟家民来源:《安徽农学通报》2021年第06期摘要:洪水淹没范围的提取精度是城市内涝监测的关键问题之一。
洪水一般发生在阴雨天气,利用光学遥感影像存在大量云层阻挡,无法有效监测洪水淹没区域,而星载合成孔径雷达(SAR)可以穿透云层,获得类似光学的高分辨率雷达图像,可全天候观测。
基于哨兵1号数据,对武汉市武昌区灾前影像采用基于监督分类和非监督分类共5种方法对水体进行了提取。
结果表明:支持向量机法的提取精度最高;利用该方法对灾后影像进行提取,对灾前灾后影像进行差值运算,得到城市洪水的淹没范围。
利用雷达影像进行洪水监测对抗洪救灾和改进城市洪水模型具有重要意义。
关键词:遥感;城市洪水;提取中图分类号 P237;P407 文献标识码 A 文章编号 1007-7731(2021)06-0124-03洪水是全球最常见和最广泛的自然灾害之一,能造成巨大的经济损失和人员伤亡,因此洪水事件监测至关重要。
合成孔径雷达(SAR)传感器能够穿透通常在洪水时出现的云,并且能够在夜间和白天成像,是洪水检测的首选。
合成孔径雷达(SAR)传感器因其全天候的检测能力而经常用于成像洪水,现已具有足够的分辨率来成像城市洪水。
从图像中提取的洪水范围,可用于洪水救济管理和改进城市洪水淹没建模。
2020年6月30日武汉市遭遇暴雨和特大暴雨,部分沿河地势低洼地区受淹较为严重。
为此,笔者选取武汉市武昌区作为研究区域,采用哨兵1号数据对该区域暴雨前后的洪水淹没范围进行了监测分析。
1 材料与方法1.1 研究区概况武汉市位于江汉平原东部、长江中下游,除少数山丘和湖泊外,地面标高多在20~24m,部分地区地势低于长江多年平均洪水位23.87m。
武汉市城区雨水主要通过排涝泵站抽排到长江,每年梅雨季节降水集中,易发生洪涝灾害。
1.2 数据预处理选用sentinel-1A雷达数据,选用Level-1地距影像(GRD,Ground Range Detected),成像方式为干涉宽幅(IW,Interferometric Wide swath),极化方式为VV和VH。
浅谈模式识别中的支持向量机技术分析肿瘤基因表达数据

浅谈模式识别中的支持向量机技术分析肿瘤基因表达数据摘要:肿瘤基因表达数据的模式识别是在已有数据的基础上建立分类器,并利用所建立的分类器对未知样品的状态进行判别。
肿瘤基因表达谱数据的特点是矩阵的维数不断增加,而且样本的数目却较少。
支持向量机可以处理高维数据,并且支持向量机的分类精度很高,抗噪能力也很强,使得支持向量机在肿瘤分类中有了充分的应用。
关键词:模式识别支持向量机肿瘤基因表达数据随着基因微阵列技术的出现与不断发展,大量基因表达谱数据的获取将变得越来越容易,但面对日益庞大、复杂的基因表达谱数据,已有的相关数据分析和数据挖掘方法和技术已经不能满足实际的需要。
近年来肿瘤基因表达谱技术的出现,为肿瘤学的研究提供了一种全新、系统的研究手段,并在肿瘤学的基础研究和临床应用等领域备受关注。
模式识别技术的肿瘤基因表达数据分析能有助于检测疾病的易感基因,研制个体化的治疗药物等,将对人类的医学研究提供帮助,这既具有统计学意义又具有生物学意义。
1 模式识别技术模式识别技术是机器识别、计算机识别,指计算机对物理对象进行分类,在错误概率达到最小的情况下,进行分类识别的结果尽可能与客观实际情况相符合。
模式识别技术广泛的应用于文字识别、指纹识别以及医学诊断等诸多方面,在肿瘤的基因表达数据分析上也有重要的应用[1]。
肿瘤基因表达数据的模式识别是在已有数据的基础上建立分类器,并利用所建立的分类器对未知样品的状态进行判别。
高密度芯片可以同时检测成千上万个基因的表达水平,但在很多情况下只有一小部分基因对识别是有价值的。
采用模式识别技术进行信息基因选取,是肿瘤基因表达谱分析的核心内容。
它既是建立有效分类模型的关键,也是发现肿瘤分类与分型的基因标记物以及药物治疗潜在靶点的重要手段[2]。
2 支持向量机技术在肿瘤基因表达数据分析应用2.1 支持向量机技术支持向量机是一种基于结构风险最小化准则的学习方法,有严格的统计学习理论和数学基础,算法具有全局最优性,泛化能力优于神经网络。
MATLAB机器学习
MATLAB机器学习1. MATLAB机器学习概况机器学习 ( Machine Learning ) 是一门多领域交叉学科,它涉及到概率论、统计学、计算机科学以及软件工程。
机器学习是指一套工具或方法,凭借这套工具和方法,利用历史数据对机器进行“训练”进而“学习”到某种模式或规律,并建立预测未来结果的模型。
机器学习涉及两类学习方法(如图1):有监督学习,主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的标识的预测。
有监督学习方法主要包括分类和回归;无监督学习,主要用于知识发现,它在历史数据中发现隐藏的模式或内在结构。
无监督学习方法主要包括聚类。
图1 机器学习方法MATLAB 统计与机器学习工具箱(Statistics and Machine Learning Toolbox)支持大量的分类模型、回归模型和聚类的模型,并提供专门应用程序(APP),以图形化的方式实现模型的训练、验证,以及模型之间的比较。
•分类分类技术预测的数据对象是离散值。
例如,电子邮件是否为垃圾邮件,肿瘤是癌性还是良性等等。
分类模型将输入数据分类。
典型应用包括医学成像,信用评分等。
MATLAB 提供的分类算法包括:图2 分类算法家族•回归回归技术预测的数据对象是连续值。
例如,温度变化或功率需求波动。
典型应用包括电力负荷预测和算法交易等。
回归模型包括一元回归和多元回归,线性回归和非线性回归,MATLAB 提供的回归算法有:图3 回归算法家族•聚类聚类算法用于在数据中寻找隐藏的模式或分组。
聚类算法构成分组或类,类中的数据具有更高的相似度。
聚类建模的相似度衡量可以通过欧几里得距离、概率距离或其他指标进行定义。
MATLAB 支持的聚类算法有:图4 聚类算法家族以下将通过一些示例演示如何使用 MATLAB 提供的机器学习相关算法进行数据的分类、回归和聚类。
2. 分类技术•支持向量机(SVM)SVM 在小样本、非线性及高维数据分类中具有很强的优势。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
四种支持向量机用于函数拟合与模式识别的Matlab示四种支持向量机用于函数拟合与模式识
别的Matlab示
四种支持向量机用于函数拟合与模式识别的Matlab示例程序(转)2010-08-08 10:02使用要点:
应研学论坛人工智能与模式识别版主magic_217之约,写一个关于针对初学者的四种支持向量机工具箱的详细使用说明。
同时也不断有网友向我反映看不懂我的源代码,以及询问如何将该工具箱应用到实际数据分析等问题,其中有相当一部分网友并不了解模式识别的基本概念,就急于使用这个工具箱。
本文从模式识别的基本概念谈起,过渡到神经网络模式识别,逐步引入到这四种支持向量机工具箱的使用。
本文适合没有模式识别基础,而又急于上手的初学者。
作者水平有限,欢迎同行批评指正~
模式识别基本概念 [1]
模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。
特别说明的是,本文所谈及的模式识别是指"有老师分类",即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。
正确识别率是反映分类器性能的主要指标。
分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。
试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。
工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。
特征提取就是将一维矢量或二维矩阵转化成一个维
数比较低的特征矢量,该特征矢量用于分类器的输入。
关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。
[2]神经网络模式识别
神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。
以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。
将所有样本中一部分用来训练网络,另外一部分用于测试输出。
通常情况下,正确分类的第I类样本的测试输出并不是[1;0;0]或是[1;-1;-1],而是如[0.1;0;-0.2]的输出。
也是就说,认为输出矢量中最大的一个分量是1,其它分量是0或是-1就可以了。
[3]支持向量机的多类分类
支持向量机的基本理论是从二类分类问题提出的。
我想绝大部分网友仅着重于理解二类分类问题上了,我当初也是这样,认识事物都有一个过程。
二类分类的基本原理固然重要,我在这里也不再赘述,很多文章和书籍都有提及。
我觉得对于工具箱的使用而言,理解如何实现从二类分类到多类分类的过渡才是最核心的内容。
下面我仅以1-a-r算法为例,解释如何由二类分类器构造多类分类器。
二类支持向量机分类器的输出为[1,-1],当面对多类情况时,就需要把多类分类器分解成多个二类分类器。
在第一种工具箱LS_SVMlab中,文件
Classification_LS_SVMlab.m中实现了三类分类。
训练与测试样本分别为n1、
n2,它们是3 x15的矩阵,即特征矢量是三维,训练与测试样本数目均是15;由于是三类分类,所以训练与测试目标x1、x2的每一分量可以是1、2或是3,分别对应三类,如下所示:
n1=[rand(3,5),rand(3,5)+1,rand(3,5)+2];
x1=[1*ones(1,5),2*ones(1,5),3*ones(1,5)];
n2=[rand(3,5),rand(3,5)+1,rand(3,5)+2];
x2=[1*ones(1,5),2*ones(1,5),3*ones(1,5)];
1-a-r算法定义:对于N类问题,构造N个两类分类器,第i个分类器用第i类训练样本作为正的训练样本,将其它类的训练样本作为负的训练样本,此时分类器的判决函数不取符号函数sign,最后的输出是N个两类分类器输出中最大的那一类。
在文件Classification_LS_SVMlab.m的第42行:codefct='code_MOC',就是设置由二类到多类编码参数。
当第42行改写成codefct='code_OneVsAll',再去掉第53行最后的引号,按F5运行该文件,命令窗口输出有:
codebook=
1-1-1
-1 1-1
-1-1 1
old_codebook=
1 23
比较上面的old_codebook与codebook输出,注意到对于第i类,将每i类训练样本做为正的训练样本,其它的训练样本作为负的训练样本,这就是1-a-r算法定义。
这样通过设置codefct='code_OneVsAll'就实现了支持向量机的1-a-r多类算法。
其它多类算法也与之雷同,这里不再赘述。
值得注意的是:对于同一组样本,不同的编码方案得到的训练效果不尽相同,实际中应结合实际数据,选择训练效果最好的编码方案。
[4]核函数及参数选择
常用的核函数有:多项式、径向基、Sigmoid型。
对于同一组数据选择不同的核函数,基本上都可以得到相近的训练效果。
所以核函数的选择应该具有任意性。
对训练效果影响最大是相关参数的选择,如:控制对错分样本惩罚的程度的可调参数,以及核函数中的待定参数,这些参数在不同工具箱中的变量名称是不一样的。
这里仍以Classification_LS_SVMlab.m为例,在第38、39
行分别设定了gam、sig2的值,这两个参数是第63行trainlssvm函数的输入参数。
在工具箱文件夹的trainlssvm.m文件的第96、97行有这两个参数的定义: %gam:Regularization parameter
%sig2:Kernel parameter(bandwidth in the case of the'RBF_kernel') 这里gam是控制对错分样本惩罚的程度的可调参数,sig2是径向基核函数的参数。
所以在充分理解基本概念的基础上,将这些概念与工具箱中的函数说明相结合,就可以自如地运用这个工具箱了,因此所以最好的教科书是函数自带的函数说明。
最佳参数选择目前没有十分好的方法,在Regression_LS_SVMlab.m的第46至49行的代码是演示了交叉验证优化参数方法,可这种方法相当费时。
实践中可以
采用网格搜索的方法:如gam=0:0.2:1,sig2=0:0.2:1,那么gam与sig2的组合就有6x6=36种,对这36种组合训练支持向量机,然后选择正确识别率最大的一组参数作为最优的gam与sig2,如果结果均不理想,就需要重新考虑gam与sig2的范围与采样间隔了。
[5]由分类由回归的过渡
LS_SVMlab、SVM_SteveGunn这两个工具箱实现了支持向量机的函数拟合功能。
从工具箱的使用角度来看,分类与回归的最大区别是训练目标不同。
回归的训练目标是实际需要拟合的函数值;而分类的训练目标是1,2,…N(分成N类),再通过适
当的编码方案将N类分类转换成多个二类分类。
比较文件
Regression_LS_SVMlab.m与Classification_LS_SVMlab.m的前几行就可以注意到这一点。
另外,分类算法以正确分类率来作为性能指标,在回归算法中通常采用拟合的均方误差(mean square error,MSE)来作为性能指标。