最新差分进化算法
差分进化算法

差分进化算法简介差分进化算法是一种优化算法,源于遗传算法,通过模拟生物进化的过程来解决优化问题。
它不同于传统的遗传算法,是基于个体间的差异性来实现优化的。
差分进化算法的原理差分进化算法的基本原理是通过在候选解向量上进行简单算术运算来生成新的解向量,并通过比较这些解向量的适应度来更新种群。
差分进化算法包括三个关键步骤:1. 初始化种群: 初始种群是随机生成的一组解向量。
2. 变异操作: 通过选择多个解向量,并对它们进行简单算术运算来产生新的解向量。
3. 交叉和选择: 通过比较原解向量和新解向量的适应度来决定是否更新种群。
差分进化算法的优势1.不需要求导: 差分进化算法不需要求解目标函数的梯度,适用于解决非线性、非光滑和高维优化问题。
2.全局最优: 由于其能够维持种群的多样性,因此差分进化算法往往可以找到全局最优解。
3.较少参数设置: 差分进化算法相对于其他优化算法来说,参数配置相对较少,并且对初始参数不敏感。
差分进化算法的应用差分进化算法被广泛应用于各种领域,包括工程优化、机器学习、信号处理等。
1. 工程优化: 在电力系统、通信网络、管道设计等领域,差分进化算法被用来优化系统设计和参数。
2. 机器学习: 在神经网络训练、特征选择、模型调优等方面,差分进化算法常用于搜索最优解。
3. 信号处理: 在图像处理、语音识别、生物信息学等领域,差分进化算法被应用于信号处理和数据分析。
结论差分进化算法作为一种优化算法,通过模拟生物进化的过程,能够有效地解决各种优化问题。
其独特的优势使其在工程、机器学习、信号处理等领域广泛应用。
未来随着算法的不断改进和扩展,差分进化算法将发挥更大的作用,为解决复杂问题提供新的解决方案。
参考文献1.Storn, R., & Price, K. (1997). Differential evolution—a simple and efficient heuristic for global optimization over continuous spaces. Journal of global optimization, 11(4), 341-359.2.Das, S., & Suganthan, P. N. (2011). Differential evolution: a survey of the state-of-the-art. IEEE Transactions on evolutionary computation, 15(1), 4-31.。
nsga 差分进化算法

nsga 差分进化算法NSGA 差分进化算法简介NSGA 差分进化算法,是一种多目标优化算法,以 Pareto 前沿为基础,采用差分进化的方式进行求解。
其主要特点是可以快速准确地寻找到Pareto 前沿上最优的解集。
通过对解集的划分和排序,可以得到一系列最优解,支持决策者做出决策。
具体方法NSGA 差分进化算法的具体实现步骤如下:1. 随机初始化种群,根据评价函数对个体进行排序,得到 Pareto 前沿上的最优解(帕累托前沿);2. 采用差分进化的方式进行交叉变异,生成新的个体;3. 根据评价函数对新的个体进行排序,得到 Pareto 前沿上的最优解;4. 判断新个体与已有个体的关系,合并优势个体,删除劣势个体;5. 重复2-4步骤,直到满足停止条件。
NSGA 差分进化算法的优点1. 高效:NSGA 差分进化算法具有高效性,可快速找到 Pareto 前沿上的最优解;2. 稳定:在多样性维护的前提下,算法稳定,易于收敛;3. 支持决策:可基于 Pareto 前沿,为决策者提供多种最优方案选择。
应用场景由于该算法高效、稳定且支持决策,所以,NSGA 差分进化算法的应用范围非常广泛。
例如:1. 工艺优化:在制造领域,可以利用该算法进行工艺优化,从而提高生产效率和质量;2. 设计问题:在工程设计领域,可以利用该算法进行最优设计,从而降低成本;3. 决策支持:在决策支持系统中,可以利用该算法为决策者提供多种最优方案供选择。
总结NSGA 差分进化算法是一种多目标优化算法。
该算法具有高效性、稳定性和支持决策的特点,是一种常用的优化算法。
在工艺优化、工程设计和决策支持等领域得到了广泛的应用。
差分进化算法DE-DifferentialEvolution
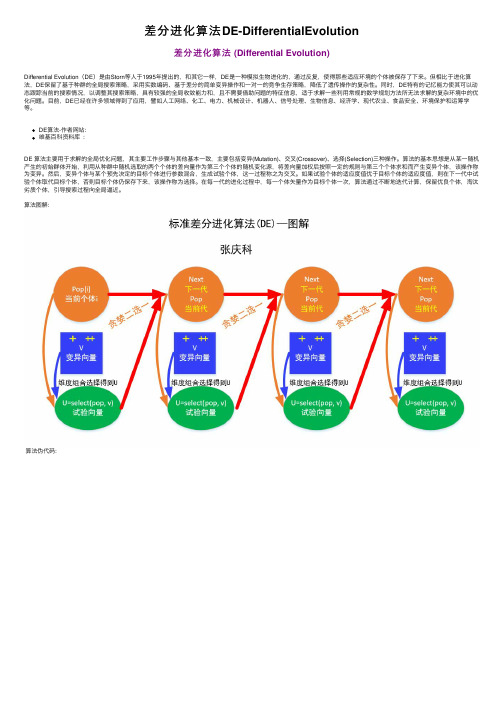
差分进化算法DE-DifferentialEvolution差分进化算法 (Differential Evolution)Differential Evolution(DE)是由Storn等⼈于1995年提出的,和其它⼀样,DE是⼀种模拟⽣物进化的,通过反复,使得那些适应环境的个体被保存了下来。
但相⽐于进化算法,DE保留了基于种群的全局搜索策略,采⽤实数编码、基于差分的简单变异操作和⼀对⼀的竞争⽣存策略,降低了遗传操作的复杂性。
同时,DE特有的记忆能⼒使其可以动态跟踪当前的搜索情况,以调整其搜索策略,具有较强的全局收敛能⼒和,且不需要借助问题的特征信息,适于求解⼀些利⽤常规的数学规划⽅法所⽆法求解的复杂环境中的优化问题。
⽬前,DE已经在许多领域得到了应⽤,譬如⼈⼯⽹络、化⼯、电⼒、机械设计、机器⼈、信号处理、⽣物信息、经济学、现代农业、⾷品安全、环境保护和运筹学等。
DE算法-作者⽹站:维基百科资料库 :DE 算法主要⽤于求解的全局优化问题,其主要⼯作步骤与其他基本⼀致,主要包括变异(Mutation)、交叉(Crossover)、选择(Selection)三种操作。
算法的基本思想是从某⼀随机产⽣的初始群体开始,利⽤从种群中随机选取的两个个体的差向量作为第三个个体的随机变化源,将差向量加权后按照⼀定的规则与第三个个体求和⽽产⽣变异个体,该操作称为变异。
然后,变异个体与某个预先决定的⽬标个体进⾏参数混合,⽣成试验个体,这⼀过程称之为交叉。
如果试验个体的适应度值优于⽬标个体的适应度值,则在下⼀代中试验个体取代⽬标个体,否则⽬标个体仍保存下来,该操作称为选择。
在每⼀代的进化过程中,每⼀个体⽮量作为⽬标个体⼀次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局逼近。
算法图解:算法伪代码:算法C代码:1//********************************************************/2// DE/rand/1/bin --差分进化算法-(基本类型)3//********************************************************/456 #include <stdlib.h>7 #include <stdio.h>8 #include <time.h>9 #include <float.h>1011/* Function definitions */1213double func(double *);14int usage(char *);1516/* Random number generator defined by URAND should return17double-precision floating-point values uniformly distributed18over the interval [0.0, 1.0) */1920#define URAND ((double)rand()/((double)RAND_MAX + 1.0))2122/* Definition for random number generator initialization */2324#define INITRAND srand(time(0))2526/* Usage for the program */2728int usage(char *str)29 {30 fprintf(stderr, "Usage: %s [-h] [-u] [-s] [-N NP (20*D)] ", str);31 fprintf(stderr, "[-G Gmax (1000)]\n");32 fprintf(stderr, "\t[-C crossover constant, CR (0.9)]\n");33 fprintf(stderr, "\t[-F mutation scaling factor, F (0.9)]\n");34 fprintf(stderr, "\t[-o <outputfile>]\n\n");35 fprintf(stderr, "\t-s does not initialize random number generator\n");36 exit(-1);37 }383940int main(int argc, char **argv)41 {42 register int i, j, k, r1, r2, r3, jrand, numofFE = 0;43extern int D;44extern double Xl[], Xu[];4546int NP = 20 * D, Gmax = 1000, c, index = -1, s = 1;4748double **popul, **next, **ptr, *iptr, *U, CR = 0.9, F = 0.9,4950 min_value = DBL_MAX, totaltime = 0.0;5152char *ofile = NULL;5354 FILE *fid;55 clock_t starttime, endtime;565758/* Parse command line arguments given by user */5960for (i = 1; i < argc; i++)61 {62if (argv[i][0] != '-')63 usage(argv[0]);6465 c = argv[i][1];6667switch (c)68 {69case'N':70if (++i >= argc)71 usage(argv[0]);7273 NP = atoi(argv[i]);74break;75case'G':76if (++i >= argc)77 usage(argv[0]);7879 Gmax = atoi(argv[i]);80break;81case'C':82if (++i >= argc)83 usage(argv[0]);8485 CR = atof(argv[i]);86break;87case'F':88if (++i >= argc)89 usage(argv[0]);9091 F = atof(argv[i]);92break;93case'o':94if (++i >= argc)95 usage(argv[0]);9697 ofile = argv[i];98break;99case's': /* Flag for using same seeds for */100 s = 0; /* different runs */101break;102case'h':103case'u':104default:105 usage(argv[0]);106 }107 }108109if (s) INITRAND;110111/* Printing out information about optimization process for the user */ 112113 printf("Program parameters: ");114 printf("NP = %d, Gmax = %d, CR = %.2f, F = %.2f\n",115 NP, Gmax, CR, F);116117 printf("Dimension of the problem: %d\n", D);118119120/* Starting timer */121122 starttime = clock();123124125/* Allocating memory for current and next populations, intializing126 current population with uniformly distributed random values and127 calculating value for the objective function */128129130// NP:种群⼤⼩, Gmax:迭代次数, CR:交叉概率, F:扰动向量的缩放因⼦131132//当前种群133 popul = (double **)malloc(NP*sizeof(double *));134if (popul == NULL) perror("malloc");135136//下代种群137 next = (double **)malloc(NP*sizeof(double *));138if (next == NULL) perror("malloc");139140//当前种群popul[NP][D+1]141for (i = 0; i < NP; i++)142 {143//个体维度空间分配144 popul[i] = (double *)malloc((D + 1)*sizeof(double));145if (popul[i] == NULL) perror("malloc");146147//初始化维度值148for (j = 0; j < D; j++)149 popul[i][j] = Xl[j] + (Xu[j] - Xl[j])*URAND;150151//最后的元素内存放该个体的适应度值152 popul[i][D] = func(popul[i]);153154 numofFE++;//统计评估次数155156//下⼀代个体空间分配157 next[i] = (double *)malloc((D + 1)*sizeof(double));158if (next[i] == NULL) perror("malloc");159 }160161/* 为实验向量分配空间--Allocating memory for a trial vector U */ 162163 U = (double *)malloc((D + 1)*sizeof(double));164if (U == NULL) perror("malloc");165166167/* The main loop of the algorithm */168169for (k = 0; k < Gmax; k++)170 {171172for (i = 0; i < NP; i++) /* Going through whole population */173 {174175/* Selecting random indeces r1, r2, and r3 to individuls of176 the population such that i != r1 != r2 != r3 */177178//1.选择三个互不相同的随机个体r1,r2,r3179do180 {181 r1 = (int)(NP*URAND);182 } while (r1 == i);183184do185 {186 r2 = (int)(NP*URAND);187 } while (r2 == i || r2 == r1);188do189 {190 r3 = (int)(NP*URAND);191 } while (r3 == i || r3 == r1 || r3 == r2);192193 jrand = (int)(D*URAND);194195/* Mutation and crossover */196//2. 执⾏变异和交叉操作197for (j = 0; j < D; j++)198 {199//执⾏⼆项式交叉200if (URAND < CR || j == jrand)201 {202//试验向量部分来⾃变异后的向量203 U[j] = popul[r3][j] + F*(popul[r1][j] - popul[r2][j]);204 }205else206//试验向量部分来⾃个体i207 U[j] = popul[i][j];208 }209//3. 计算新⽣成向量的适应度值210 U[D] = func(U);211212 numofFE++;213214/* Comparing the trial vector 'U' and the old individual215 'next[i]' and selecting better one to continue in the216 next population.注意:空间的交替变换和使⽤ */217218//贪婪策略从试验向量U和当前个体i中选择⼀个好的放⼊到下⼀代个体中219if (U[D] <= popul[i][D])//新向量好220 {221222//试验向量U⽜逼, next指向当前的试验向量U,u指向next, ⽅法:指针交换223 iptr = U;224 U = next[i];225 next[i] = iptr;226 }227else//原始向量⽜逼, next指向个体i, ⽅法: 直接拷贝228 {229for (j = 0; j <= D; j++)230 next[i][j] = popul[i][j];231 }232233 } /* End of the going through whole population */234235236/* Pointers of old and new populations are swapped */237//指针交换,各指针指向的空间发⽣变化238 ptr = popul;239 popul = next;240 next = ptr;241242 } /* End of the main loop */243244245/* Stopping timer */246247 endtime = clock();248 totaltime = (double)(endtime - starttime);249250251/* If user has defined output file, the whole final population is252 saved to the file */253254if (ofile != NULL)255 {256if ((fid = (FILE *)fopen(ofile, "a")) == NULL)257 {258 fprintf(stderr, "Error in opening file %s\n\n", ofile);259 usage(argv[0]);260 }261262for (i = 0; i < NP; i++)263 {264for (j = 0; j <= D; j++)265 fprintf(fid, "%.15e ", popul[i][j]);266 fprintf(fid, "\n");267 }268 fclose(fid);269 }270271/* Finding best individual */272273for (i = 0; i < NP; i++)274 {275if (popul[i][D] < min_value)276 {277 min_value = popul[i][D];278 index = i;279 }280 }281282/* Printing out information about optimization process for the user */283284 printf("Execution time: %.3f s\n", totaltime / (double)CLOCKS_PER_SEC);285 printf("Number of objective function evaluations: %d\n", numofFE);286287 printf("Solution:\nValues of variables: ");288for (i = 0; i < D; i++)289 printf("%.15f ", popul[index][i]);290291 printf("\nObjective function value: ");292 printf("%.15f\n", popul[index][D]);293294295/* Freeing dynamically allocated memory */296297for (i = 0; i < NP; i++)298 {299free(popul[i]);300free(next[i]);301 }302free(popul);303free(next);304free(U);305306return(0);307 }经典⽂献:[1] Storn, R., "Designing Nonstandard Filters with Differential Evolution, IEEE Signal Processing Magazine, january 2005, pp. 103 - 106.[2] Storn, R., "Sytem Design by Constraint Adaptation and Differential Evolution", IEEE Trans. on Evolutionary Computation, 1999, Vol. 3, No. 1, pp. 22 - 34.[3] Storn, R. and Price, K., "Differential Evolution - a Simple and Efficient Heuristic for Global Optimization over Continuous Spaces", Journal of Global Optimization, Kluwer Academic Publishers, 1997, Vol. 11, pp. 341 - 359.[4] Gitsels, M. and Storn, R., Internet-Videotelephonie nach dem H.323-Standard, ITG-Fachbericht 144, 7. Dortmunder Fernsehseminar, pp. 87 - 92.[5] Storn, R., , Technical Report TR-96-046, ICSI, November 1996, .[6] Storn, R., , Technical Report TR-96-039, ICSI, November 1996, .[7] Price, K. and Storn, R., "Differential Evolution: Numerical Optimization Made Easy", Dr. Dobb's Journal, April 97, pp. 18 - 24.[8] Storn, R., NAFIPS 1996, Berkeley, pp. 519 - 523.[9] Storn, R. and Price, K., IEEE Conference on Evolutionary Computation, Nagoya, 1996, pp. 842 - 844.[10] Storn, R., (IEEE Signal Processing Letters, Vol. 3, No. 8, August 1996, pp. 242 - 244), Technical Report TR-95-061, ICSI, September 1995, .[11] Storn, R., IEEE International Conference on Evolutionary Computation ICEC 96, pp. 268 - 273, Technical Report TR-95-026, ICSI, May 1995, .[12] Storn, R., , Technical Report TR-95-018, ICSI, May 1995, .[13] Storn, R. and Price, K., , Technical Report TR-95-012, ICSI, March 1995, . Anyone who is interested in trying Differential Evolution (DE) might access the .[14] Storn, R., "A Debug/Trace Tool for C SW Projects", Dr. Dobb's Journal, February 1997, pp. 22 - 26.[15] Storn, R., "Constrained Optimization", Dr. Dobb's Journal, May 1995, pp. 119 - 123.[16] Christ, J., Storn, R. and Lueder, E., " New Shortlength DFTs for the Prime Factor Implementation on DSP Architectures", Frequenz, 1995, Band 49, Issue 1-2, pp. 8 - 10.[17] Ballay, H. and Storn, R., "A Tool for Checking C Coding Conventions", C User's Journal, july 94, pp. 41 - 50..[18] Storn, R., "A Hashing Function Based on Algebraic Coding", submitted for publication in the I.E.E. Proceedings~E, Computers and Digital Techniques.[19] Storn, R., "A Radix-2 FFT-Pipeline Architecture With Reduced Noise to Signal Ratio", I.E.E. Proceedings~F, Radar and Signal Processing, 1994.[20] Storn, R. , "Datensicherung mit Prüfsummen", ST-Computer, 1994.[21] Storn, R., "Some Results in Fixed Point Error Analysis of the Bruun-FFT Algorithm, IEEE Trans. on Signal Processing, Vol. 41, No. 7, July 93, pp. 2371 - 2375.[22] Storn, R. , "Statistische Optimierung", ST-Computer, Issues 12/1992 and 1/1993.[23] Storn, R. , "On the Bruun Algorithm and its Inverse", Frequenz, Vol. 3-4, 1992, pp. 110 -116.[24] Storn, R. , "Logische Schaltungen und deren Vereinfachung nach Quine-McCluskey", ST-Computer, Issues 3, 4 and 5, 1990.[25] Storn, R. , "A novel Radix-2 Pipeline Architecture for the Computation of the DFT", IEEE Proc. of the ISCAS 1988, pp. 1899 -1902.[26] Storn, R. , "On the Reduction of Arithmetic Complexity in the Chirp-Transform", Proc. ECCTD, 1987, pp. 239 -244.[27] Storn, R. , "Ein Primfaktor-Algorithmus für die diskrete Hartley-Transformation", 9. DFG-Kolloquium über digitale Signalverarbeitung, 1986, pp. 79 -82.[28] Storn, R. , "Fast Algorithms for the Discrete Hartley Transform", AEÜ, Band 40, Heft 4, 1986, pp. 233 -240.[29] Storn, R. , "Dreieck-Quadratur-Oszillator. Nur ein zeitbestimmendes Glied erforderlich", Elektronik, Issue 5, 1982, p. 74.[30] Storn, R. , "Constant Current Adapter", Elektor, Issue 7/8, 1981.[31] Storn, R. , "De Luxe Transistor Tester", Elektor, Issue 7/8, 1979. (The corresponding circuit was among the winners of the european circuit design contest "EUROTRONIK").BOOKS[1] Price K., Storn R., Lampinen J., Differential Evolution - A Practical Approach to Global Optimization, Springer, Berlin, 2005.[2] Contributor for Babu, B.V., Onwubolu, G. (Editors), New Optimization Techniques in Engineering, Springer, Berlin, 2004.[3] Contributor for Corne, D., Dorigo., M, and Glover., F. (Editors), New Ideas in Optimization, McGraw-Hill, 1999.。
差分进化算法任务分解

差分进化算法任务分解差分进化算法的任务分解差分进化 (DE) 算法是一种强大的进化算法,用于解决复杂的优化问题。
它基于自然选择和群体搜索的原则,在优化过程中逐步迭代。
DE 算法的任务分解涉及以下关键步骤:1. 初始化群体DE 算法从随机初始化的个体群体开始。
每个个体代表一种潜在的解决方案,由一组决策变量定义。
群体大小通常根据问题的复杂性和所需的精度来确定。
2. 计算目标函数对于每个个体,DE 算法评估其目标函数值,该值衡量该个体对优化问题的适应性。
目标函数是算法用于引导搜索过程的优化目标。
3. 变异变异是 DE 算法的关键操作,它通过结合不同个体的特征来生成新的个体。
变异有不同的策略,例如差分变异、当前对最佳变异和随机差分变异。
4. 交叉交叉操作将变异后的个体与父个体结合,以产生子个体。
交叉有不同的方法,例如指数交叉和二项交叉。
交叉概率控制子个体接受变异个体特征的程度。
5. 选择选择操作确定哪些个体将成为下一代群体的一部分。
DE 算法通常采用基于贪婪的方法,选择具有最佳目标函数值的个体。
6. 迭代变异、交叉和选择操作重复进行,生成新的个体群体。
这个迭代过程持续进行,直到满足终止条件,例如达到最大迭代次数或达到预定的目标函数值。
7. 精炼在某些情况下,DE 算法完成后,可以使用局部搜索或其他优化技术对最佳个体进行精炼。
这有助于进一步提高解决方案的质量。
任务分解的优势任务分解为 DE 算法的实现提供了几个优势:模块化:任务分解允许将 DE 算法分解为更小的、可管理的模块,这简化了实现和维护。
可扩展性:任务分解使算法易于扩展,添加新功能或修改现有功能。
可重用性:算法的模块化设计允许在其他优化问题中重复使用DE 算法的组件。
性能优化:任务分解可以帮助识别和优化算法中性能瓶颈的特定区域。
结论任务分解是 DE 算法实现的关键方面。
它通过将算法分解为更小的、可管理的步骤,提供了模块化、可扩展性、可重用性和性能优化等优势。
《2024年差分进化算法的优化及其应用研究》范文

《差分进化算法的优化及其应用研究》篇一一、引言差分进化算法(Differential Evolution Algorithm,简称DEA)是一种全局优化算法,其通过模拟自然进化过程,以种群为基础进行迭代搜索,具有强大的全局寻优能力和较快的收敛速度。
该算法被广泛应用于各类复杂的优化问题中,包括但不限于工程优化、函数优化以及智能控制等。
本文将首先简要介绍差分进化算法的原理及特性,随后对其优化方法和应用进行深入的研究探讨。
二、差分进化算法的基本原理与特性差分进化算法基于差分算子和突变、交叉、选择等进化思想,是一种典型的自适应搜索算法。
它利用群体搜索的策略来搜索多维空间,可以灵活地处理离散或连续的问题。
在寻优过程中,通过引入多种不同的进化操作和随机策略,使算法具有较强的全局搜索能力和局部寻优能力。
三、差分进化算法的优化方法(一)参数优化差分进化算法的参数设置对算法性能具有重要影响。
为了获得更好的优化效果,通常需要根据问题的特性进行参数优化。
比如根据问题的规模、搜索空间的性质和复杂性来选择适当的变异系数(F)和交叉概率(Cr)等。
这些参数的设置决定了种群中的个体变异和遗传的概率大小,直接影响着算法的寻优效率和性能。
(二)策略改进在策略上,我们可以通过多种改进方法提升差分进化算法的搜索能力。
如采用自适应参数策略,使得参数可以根据算法的执行情况进行动态调整;或者在搜索过程中引入新的策略和思路,如并行计算策略等。
这些策略改进可以提高算法在处理复杂问题时的效率,使算法在解决不同问题上更具通用性和适应性。
四、差分进化算法的应用研究(一)工程优化在工程领域,差分进化算法广泛应用于机械设计、电力系统的调度优化等问题中。
通过引入差分进化算法的优化策略,可以在设计过程中实现最优化的设计方案,从而提高工程的性能和效率。
(二)函数优化在函数优化问题中,差分进化算法具有较好的全局搜索能力和收敛速度。
通过引入不同的变异策略和交叉策略,可以有效地解决多模态函数和复杂函数的优化问题。
一种新的差分进化算法

Abtat o o l u c oswt i i e s n , e ieet lE o tn a o tm ( D s c:F rcmpe fn t n i hg dm ni sa N w D f r i vl i l rh r x i h h o f na u o gi N E)b sd o h a ac f ae n te vr ne o i
E m i l x oi 0 3 a o. n. — a :u i j2 0 @yhoc e li a . o n DE NG ex,AO n qa ,I X a-i t 1 e i ee t leouinag rtm. mp trE g ern n pi t n , Z-i C Du — inL U ioj, . w df rni v lt loi Co ue n i eiga dAp l ai s e aN a o h n c o
维普资讯
4 2 0 .4 2 ) 0 0 8 4 (4
C m u rE gne n n p lai s o p t n ier g a dA pi t n 计算机 工程与应用 e i c o
一
种新 的差 分进化 算法
娜。
ห้องสมุดไป่ตู้
邓 泽喜 , 一 曹敦 虔 z刘 晓冀 z李 , ,
摘
要: 针对 高维复杂 函数的优化问题 , 出了一种新的差分进 化算法( D 。该算 法在运行 中根据选代 次数 自动地调 整交叉概 提 N E)
率 因子 , 而在搜 索的初始阶段提 高种群 多样性 , 从 而在搜 索后期加强局部搜索能力。 对几种经典函数 的测试表明 , 算法 不仅具有 新
一种新的差分进化算法 12.23 ###(具体差分进化算法)

( 1)
g
ggg
g
g
式中: xgbest 为种群中适应度 最 好 的 个 体 ; xa 、xb 、xc 和 xd 为 xgbest 与
不同的 4 个互不相同的个体;F 为缩放因子, 其取值范围为
g
g
( 0, 1.2], 相当于 xgbest 的一个噪音版本, F 越大, xgbest 变异 越 多 , 对
此, DE 与其他算法一样, 容易早熟收敛, 陷入局部最优。
为了加快收敛速率, 避免早熟收敛, 人们提出了多种方法,
其 中 文 献[4]提 出 了 自 适 应 二 次 变 异 差 分 进 化 算 法 , 该 文 提 出
了一种时变交叉概率因子 CR 的方法, 设 CRmin 为 最 小 交 叉 概 率, CRmax 为最大交叉概率, g 为当前迭代次数, G 为最大迭代次
g
决定 xT 中哪位由 xm 贡献, 哪位由 xi 贡献。 交叉操作的方程为:
#xmj
xTj = g
rand( ) ≤CR
( 2)
xij rand( ) ≥CR
其 中 , j=1, 2, … , d, 式 中 : rand( ) 为 一[0, 1]之 间 的 均 匀 随 机 数 , j
表示第 j 个变量( 基因) , D 为变量的维数。由式( 2) 可知, CR 越
1 引言
差 分 进 化 算 法( Differential Evolution, DE) 是 Dainer Storn 和 Kenneth Price 于 1995 年 共 同 提 出 的 一 种 采 用 浮 点 矢 量 编 码, 在连续空间中进行启发式随机搜索的优化算法[1]。近年来, 差分进化算法作为一种性能卓越的优化算法正受到日益关注, 其应用领域也越来越广。近年来的研究已越来越多地表明, DE 对函数优化有强大的生命力, 特别是对一些规模大、维数高、非 线性和不可微等特性的函数进行优化[2-3], 与其他进 化 算 法 一 样 易陷入局部最优, 存在早熟收敛现象。目前的解决方法主要是 增加种群的规模, 但这样会明显增加算法的运算量, 而且也不 能从根本上克服早熟收敛的问题。为提高 DE 的性能 , 许 多 学 者提出了改进的办法。本文以几种典型的 Benchmarks 函数为 测试算例, 提出了一种重构交叉概率因子 CR 差分进 化 算 法 , 协调好全局搜索能力与局部搜索能力, 快速收敛, 高效避免早 熟收敛问题, 实验结果表明, 解的质量好, 算法高效可行。
差分进化算法调参

差分进化算法调参差分进化算法(Differential Evolution, DE)是一种常用的全局优化算法,也是一种遗传算法的变体。
差分进化算法通过引入差分操作和变异策略,能够有效地参数空间中的全局最优解。
然而,差分进化算法中存在一些需要进行调参的参数,对于不同的问题可能需要不同的参数设置。
本文将探讨差分进化算法中需要调参的参数,并介绍一些常用的调参方法。
首先是种群大小,种群大小决定了算法的收敛速度和能力。
一般来说,种群大小越大,算法收敛的速度越慢,但能力越强。
对于大部分问题,种群大小可以设置在50-200之间。
如果问题的维度较高,适当增加种群大小可能会提高能力。
接下来是差分策略,差分策略决定了个体之间的差异程度。
常用的差分策略有rand/1、rand/2和best/1等。
其中,rand表示随机选择个体,best表示选择当前最优个体。
例如,rand/1表示随机选择一个个体作为目标向量,然后从剩下的个体中随机选择两个个体,通过目标向量和这两个个体的差异来生成变异向量。
在实践中,差分策略可以根据问题的特点进行选择。
然后是变异因子F,变异因子F控制了变异的幅度。
较小的F会使变异向量与目标向量更加类似,而较大的F会使变异向量的差异更大。
变异因子F一般取值在[0,2]之间,过大的F可能导致算法过度探索,而过小的F可能导致算法陷入局部最优解。
对于不同的问题,适当调整变异因子F可能会产生更好的效果。
最后是交叉概率CR,交叉概率CR决定了变异向量与目标向量之间的交叉程度。
较小的CR会使得目标向量的信息更多地保留下来,而较大的CR会增加新生成的变异向量的信息。
交叉概率CR一般取值在[0,1]之间,过小的CR可能会导致算法难以收敛,而过大的CR可能会导致算法失去能力。
对于不同的问题,可以通过调整交叉概率CR来调整算法的探索和利用能力。
对于以上参数,可以通过以下几种常用的调参方法进行优化。
首先是网格法,即通过指定一系列参数值的网格,对所有可能的参数组合进行评估和比较,选择最优的参数组合。
差分进化算法pdf

差分进化算法pdf差分进化算法是一种基于群体智能的优化算法,其主要目的是在给定的问题中快速找到最优解。
相对于传统的进化算法,差分进化算法的主要优势在于其对于高维度问题的表现力更加出色。
以下是差分进化算法的具体步骤:1. 初始化种群在差分进化算法中,我们需要首先初始化一个种群,将其放在搜索空间中,以便进行进化。
每个个体都是由一个特定的向量组成,表示搜索空间中的一个点。
我们可以通过随机抽样的方式来初始化种群中每一个个体的向量值。
2. 差分算子差分运算符是差分进化算法的核心组成部分。
其主要功能是根据种群中已有的个体,构造并生成新的解向量。
在差分算子中,我们选取两个可行解x和y,然后通过差分算子构建新的解向量z。
具体地,z的构造方式如下:z = x + F(y-x)其中F是参数范围在[0,2]之间的可调整的参数,其作用是控制差分算子对y-x的影响程度。
3. 交叉运算符在差分进化算法中,交叉运算符主要用来融合一个个体的特征向量与由差分算子生成的新的特征向量。
具体来说,交叉运算符可以通过在两个向量矩阵中分别随机选取一些位置,并将这些位置标记为“父向量”和“子向量”来实现。
然后,我们可以根据随机选取的位置进行特征向量的融合。
4. 选择算子选择算子主要用来筛选种群中的优质解向量,并将其作为下一次进化的种子。
在差分进化算法中,我们可以根据优化的目标函数来度量一个解向量的质量。
具体来说,我们需要对整个种群中的解向量进行评估,并选取其中表现最优秀的个体作为下一次进化的种子。
总之,差分进化算法是一种非常高效的搜索算法,在很多领域中已经得到了广泛的应用。
相信通过学习差分进化算法的操作步骤以及其内在的优化机制,我们可以更好地理解并应用这个优秀的算法。
kmeans 差分进化算法

kmeans 差分进化算法
差分进化算法是一种基于种群的优化方法。
它模拟了生物进化过程中的突变和交叉操作,并通过不断改进种群中的个体来寻找最优解。
在使用差分进化算法优化K均值算法时,需要将聚类中心向量编码成差分进化算法的染色体,通过不断变异和交叉操作来改进聚类
中心向量的选择,从而达到更好的聚类效果。
具体地,K均值算法的流程是:首先选择k个随机的聚类中心,然后将每个数据点分
配到距其最近的聚类中心所在的簇中,更新每个簇的聚类中心位置,直到收敛。
与此相反,使用差分进化算法优化K均值算法的流程是:将聚类中心向量编码成染色体,每个染色体
代表着k个聚类中心的位置。
然后,初始化种群中的染色体,通过差分变异算子对其进行
变异操作,修改染色体中的聚类中心位置。
接着,使用交叉算子对不同个体之间的聚类中
心进行交叉操作,改进聚类中心的选择。
最后,使用适应度函数评估染色体的质量,选择
最优染色体作为k个聚类中心的位置。
相比于传统K均值算法,使用差分进化算法优化K均值算法的优势在于,它可以有效
地选择更优的聚类中心,更准确地划分数据集。
因为差分进化算法是一种基于种群的优化
算法,能够通过多次迭代搜索整个解空间,并根据适应度函数的评估结果选择最优解。
另外,差分进化算法的全局搜索能力也比K均值算法更强,不容易陷入局部最优解中,从而
有助于提高聚类的准确性和稳定性。
总之,差分进化算法是一种有效的优化算法,可以用来改善K均值算法的初始化问题。
通过结合这两种算法,可以得到更准确、更稳定的聚类结果,提高数据挖掘和机器学习的
应用效果。
差分进化算法(DE)进行最优化处理

%% Differential Evolution Algorithm(DE) 差分演化算法%% min f(x,y)=3*(1-x).^2.*exp(-x.^2-(y+1).^2)-10*(x/5-x.^3-y.^5).*exp(-x.^2-y.^2)-exp(-(x+1).^2-y.^2)/3;%% Clear screenclear all;close all;clc;%% 初始化(Initialization)tic; %程序运行计时error=1e-3; %允许误差popsize=30; %种群数量maxgen=50; %最大迭代次数(最大进化代数)nvars=2; %决策变量个数F=0.5; %变异缩放因子CRmin=0.2;CRmax=0.8; %交叉概率因子最值(初始全局搜索能力强,进化后期局部搜索能力强)k=1; %初始化迭代次数x=-3+(3+3)*rand(popsize,nvars); %初始化x变量best_trace=[]; %存储寻优路径%% 目标函数(Objective function)%用虚拟函数定义适应度函数以便将子函数文件与主程序文件放在一起%目标函数为:z=3*(1-x).^2.*exp(-x.^2-(y+1).^2)-10*(x/5-x.^3-y.^5).*exp(-x.^2-y.^2)-exp(-(x+1).^2-y.^2)/3%虚拟函数命令定义适应度函数如下fitness=@(x)3*(1-x(1))^2*exp(-x(1)^2-(x(2)+1)^2)-10*(x(1)/5-x(1)^3-x(2)^5).*exp(-x(1)^2-x(2)^2)-exp(-(x(1)+1)^2-x(2)^2)/3;%% 主程序(Main procedure)%% Step1 对初始种群进行评价(适应度函数值)f=zeros(1,popsize);for i=1:popsizef(i)=fitness(x(i,:));end[d1,d2]=min(f);best_fx=x(d2,:);best_fval=d1;best_trace=[best_trace best_fval];if abs(best_fval)<=errorreturn;end%% Step2 变异交叉选择过程(mutation,crossover,selection)u=zeros(1,2);while (abs(best_fval)>error) %这里的判断条件需要修改(否则迭代次数一直保持最高次)CR=CRmin+k*(CRmax-CRmin)/maxgen; %交叉概率因子% x1=x;for i=1:popsize %变异、交叉、选择操作(Mutation and Crossover)% temp=randperm(popsize,3); %生成3个无重复的整数-randperm% temp1=temp(1);temp2=temp(2);temp3=temp(3);temp1=ceil(popsize*rand);temp2=ceil(popsize*rand);temp3=ceil(popsize*rand);while(temp1==temp2)||(temp1==temp3)||(temp2==temp3)||(temp1==i)||(temp2 ==i)||(temp3==i)temp1=ceil(popsize*rand);temp2=ceil(popsize*rand);temp3=ceil(popsize*rand);endv=x(temp3,:)+F*(x(temp1,:)-x(temp2,:)); %Mutationif v(1)>3||v(1)<-3 %边界控制v(1)=-3+(3+3)*rand;endif v(2)>3||v(2)<-3v(2)=-3+(3+3)*rand;endfor j=1:nvars %Crossoverif (rand<=CR)||j==ceil(nvars*rand)u(1,j)=v(j);elseu(1,j)=x(i,j);endendif fitness(u)<f(i) %Selectionx(i,:)=u;f(i)=fitness(x(i,:));endend% x=x1;[d1,d2]=min(f); %判断是否为最优解if d1<best_fvalbest_fval=d1;best_fx=x(d2,:);endbest_trace=[best_trace best_fval];k=k+1;if k>=maxgenbreak;endendbest_fxbest_fvaltoc; %程序计时结束t1=linspace(-3,3,200);t2=t1;[T1,T2]=meshgrid(t1,t2);Z=3*(1-T1).^2.*exp(-T1.^2-(T2+1).^2)-10*(T1/5-T1.^3-T2.^5).*exp(-T1.^2-T2.^2)-exp(-(T1+1).^2-T2.^2)/3;subplot(2,1,1)mesh(T1,T2,Z)hold onplot3(best_fx(1),best_fx(2),best_fval,'rp','LineWidth',4)subplot(2,1,2)plot(1:k,best_trace,'--','linewidth',2)。
基于自适应集成的差分进化算法

基于自适应集成的差分进化算法自适应集成的差分进化算法(Adaptive Ensemble Differential Evolution, AEDE)是一种进化计算算法,用于解决优化问题。
它结合了差分进化算法和集成学习的思想,并引入自适应机制来提高算法的性能。
本文将详细介绍AEDE算法的原理、流程和应用。
一、差分进化算法简介差分进化算法(Differential Evolution, DE)是一种常用的优化算法,以其简单的原理和强大的搜索能力而受到广泛关注。
它通过模拟生物进化中的变异、交叉和选择等过程,逐代地搜索最优解。
DE算法主要包括以下几个步骤:1.初始化种群:随机生成一组初始个体作为种群。
2.变异操作:对每个个体进行变异操作,生成新的个体。
3.交叉操作:将变异个体与原个体进行交叉操作,生成试验个体。
4.选择操作:通过比较试验个体和原个体的适应度,选择适应度较好的个体作为下一代种群。
二、集成学习简介集成学习(Ensemble Learning)是一种将多个学习器集成起来,共同完成学习任务的方法。
它通过将多个学习器的预测结果进行加权或投票等方式进行综合,从而得到更准确的预测结果。
集成学习一般包括以下几种主要方法:1.投票法:通过对多个学习器的预测结果进行多数投票或加权投票,从而得到最终的预测结果。
2.平均法:通过对多个学习器的预测结果进行平均操作,从而得到最终的预测结果。
3.堆叠法:通过将多个学习器的预测结果作为输入,训练一个元学习器来得到最终的预测结果。
三、自适应集成的差分进化算法原理AEDE算法是将差分进化算法和集成学习相结合的一种进化计算算法。
它通过引入自适应机制,来动态调整算法的参数,从而提高算法的性能。
具体而言,AEDE算法的自适应机制包括以下几个方面:1.自适应变异策略:在差分进化算法中,变异操作的策略对算法的性能有重要影响。
AEDE算法通过自适应地选择变异策略,来提高算法的搜索能力。
差分进化优化算法

差分进化优化算法
差分进化算法(Differential Evolution, DE)是一种高效的全局优化算法,主要应用于实数编码的连续问题。
该算法基于群体搜索策略,通过种群中个体的协作和竞争来实现对解空间的搜索和优化。
在差分进化算法中,每个解向量代表一个潜在的解,通过比较解向量之间的差异,算法可以逐渐接近最优解。
差分进化算法的基本流程如下:
1.初始化种群:在解空间内随机生成一定数量的解向量作
为初始种群。
2.变异操作:根据一定的变异策略,对种群中的每个解向
量进行变异操作,生成新的解向量。
3.交叉操作:根据一定的交叉策略,将种群中的解向量进
行交叉操作,生成新的解向量。
4.选择操作:比较新生成的解向量和原种群中的解向量,
选择较优的解向量进入下一代种群。
5.终止条件:重复上述步骤,直到满足终止条件(如达到
预设的最大迭代次数或找到满足精度要求的最优解)。
差分进化算法的优点包括简单易实现、全局搜索能力强、对初始种群和参数设置要求较低等。
然而,该算法也存在一些局限性,如对于多峰函数优化问题可能陷入局部最优解、对于大规模问题计算量大等。
针对这些问题,研究者们已经提出了一些改进的差分进化算法,如自适应差分进化算法、混合差分进化算法等。
差分进化优化算法 -回复

差分进化优化算法-回复什么是差分进化优化算法?差分进化优化算法(Differential Evolution,简称DE)是基于种群的进化算法,属于一种全局优化算法。
DE算法由于其简单性和高效性,被广泛应用于解决各种复杂的优化问题,包括函数优化、参数估计、特征选择等。
DE算法的基本思想是通过模拟生物进化的过程,通过对候选解进行自然选择、交叉和变异等操作来搜索最优解。
差分进化算法利用种群中个体之间的差异来产生新的解向量,从而在搜索空间中进行有效的探索,并最终找到最优解。
DE算法的步骤如下:1. 初始化种群:随机生成一定数量的解向量作为初始种群。
2. 选择操作:根据某种适应度评价函数,对每个解向量进行评估,选择适应度较高的个体作为父代。
3. 变异操作:对于每个父代个体,通过从种群中随机选择另外两个个体,并计算它们的差值,将它们与父代个体进行相加来生成新的变异个体。
4. 交叉操作:将变异个体与父代个体进行交叉操作,生成一个子代个体。
5. 选择操作:根据适应度评价函数,对父代个体和子代个体进行比较,选择适应度更高的个体作为下一代父代。
6. 终止条件:重复执行变异、交叉和选择操作直到满足终止条件,例如达到最大迭代次数或适应度函数收敛。
差分进化优化算法的关键是如何选择合适的变异策略和交叉策略。
常用的变异策略有rand/1、best/1和rand/2等,而交叉策略通常为二进制交叉。
DE算法的优点在于其简单性、鲁棒性和全局寻优能力。
由于DE算法的不断演化和改进,已经出现了很多变种和改进算法,例如自适应差分进化算法、多目标差分进化算法等,为不同类型的问题提供了更好的求解方案。
总结一下,差分进化优化算法是一种全局优化算法,通过模拟生物进化的过程,通过选择、变异和交叉等操作来搜索最优解。
它具有简单性、鲁棒性和全局寻优能力,被广泛应用于解决各种复杂的优化问题。
差分进化算法详细介绍

差分进化算法详细介绍差分进化算法(Differential Evolution, DE)是一种全局优化算法,它通过模拟生物进化过程来解决优化问题。
差分进化算法在解决连续优化问题中具有很好的性能,并且在其他领域也得到了广泛的应用。
差分进化算法最初由Storn和Price于1995年提出,它的基本思想是通过不断迭代的方式,从初始的一组候选解中寻找最优解。
在每一次迭代中,差分进化算法通过引入变异、交叉和选择操作来更新候选解的集合,从而逐步靠近最优解。
差分进化算法的核心是三个操作:变异、交叉和选择。
首先,通过变异操作,差分进化算法从当前的候选解集合中随机选择三个不同的个体,然后利用它们之间的差异生成一个新的个体。
这一步骤可以通过以下公式表示:$$v_i = x_{r1} + F \cdot (x_{r2} - x_{r3})$$其中,$v_i$是新生成的个体,$x_{r1}$、$x_{r2}$、$x_{r3}$分别是随机选择的三个个体,$F$是变异因子。
接下来,通过交叉操作,差分进化算法将新生成的个体与原来的个体进行交叉,生成一个中间个体。
交叉操作可以通过以下公式表示:$$u_i = \begin{cases} v_i, & \text{if } rand_j \leq CR \text{ or } j= rand_k \\ x_{ij}, & \text{otherwise} \end{cases}$$其中,$u_i$是交叉后生成的个体,$rand_j$是一个随机数,$CR$是交叉概率,$rand_k$是一个随机整数。
通过选择操作,差分进化算法从新生成的个体和原来的个体中选择出最优的个体。
选择操作通常采用贪婪策略,即选择具有更好适应度的个体作为下一代的候选解。
差分进化算法的优点是简单易于实现,并且不需要太多的参数调整。
它能够在较短的时间内找到较好的解,并且对问题的搜索空间没有特定的要求。
差分进化算法 de

差分进化算法 de
差分进化算法(Differential Evolution,DE)是一种用于全
局优化的启发式优化算法。
它是基于群体搜索的算法,通常用于解
决连续型优化问题。
DE算法最初由Storn和Price在1997年提出,它模拟了自然界中的进化过程,通过不断迭代寻找最优解。
DE算法的基本原理是通过维护一个种群,利用差分操作来产生
新的个体,然后通过比较新个体和原有个体的适应度来更新种群。
在每次迭代中,DE算法通过交叉和变异操作来生成新的个体,并根
据适应度函数来决定是否接受新个体。
这样不断迭代,直到达到停
止条件为止,从而找到最优解或者近似最优解。
DE算法相对于其他优化算法的优势在于其简单性和高效性。
它
不需要对目标函数进行求导,也不需要事先对问题的特性有深入的
了解,因此适用于各种优化问题。
同时,DE算法具有较好的全局搜
索能力,能够有效避免陷入局部最优解。
然而,DE算法也存在一些缺点,比如对参数的选择比较敏感,
需要进行一定的调参才能达到较好的性能。
此外,对于高维优化问题,DE算法的收敛速度可能会受到影响。
总的来说,差分进化算法作为一种全局优化算法,在实际应用中具有一定的优势和局限性,需要根据具体问题的特点来选择合适的优化算法。
差分进化算法与蒙特卡洛算法

差分进化算法与蒙特卡洛算法差分进化算法与蒙特卡罗算法是两种优化算法,都有着各自的特点和应用场景。
一、差分进化算法差分进化算法(Differential Evolution,DE)是一种基于群体智能的优化算法,目标是在搜索空间中找到最优解。
其基本思想是通过差分算子对多个个体进行加权差分,生成新的个体,并通过比较新旧个体的适应度值来筛选出新的优秀个体。
因此,差分进化算法可以应用于解决许多优化问题,如函数最小化、参数优化、机器学习、数据挖掘等。
差分进化算法的过程包括以下几个步骤:1. 初始化种群,即根据问题的要求,初始化一组随机的可行解,作为初始个体群体。
2. 评估适应度,根据目标函数计算每个个体的适应度值。
3. 变异操作,根据差分进化算子,对种群中的每个个体进行变异,生成新的个体。
4. 交叉操作,对新生成的个体与原个体进行交叉,生成新的后代个体。
5. 选择操作,利用一定的选择策略,选择优秀的后代个体,替代原有个体集合,继续迭代。
6. 迭代停止,当符合停止条件时,算法停止。
差分进化算法的主要优点是其简单性、可靠性和高效性。
相对于其他一些优化算法,差分进化算法所需要的参数较少,而且较为鲁棒,适应性较强。
此外,差分进化算法的全局搜索能力也很强,不容易出现早熟现象。
二、蒙特卡罗算法蒙特卡罗算法是一种随机模拟算法,它通过随机采样的方式,以概率统计的方法获得目标问题的解。
蒙特卡罗算法的核心思想是:通过统计样本的随机分布,得到目标的特征,从而获得目标的近似值。
蒙特卡罗算法常用于解决复杂的优化问题、模拟和数据处理等问题。
蒙特卡罗算法的过程包括以下几个步骤:1. 参数选取,选取适当的参数,如样本量、采样方法、随机分布等。
2. 随机生成样本,按照预定的参数进行随机采样。
3. 计算参数,根据采样的样本数据,统计目标函数的特征指标,如均值、方差等。
4. 分析结果,对统计得到的结果进行分析、评估。
5. 判断终止,根据一定的停止条件,判断算法是否需要终止。
交叉概率差分进化算法

交叉概率差分进化算法
交叉概率差分进化算法是一种用于优化问题的进化算法,与其他经典的遗传算法不同,交叉概率差分进化算法具有较快的收敛速度和更高的优化性能。
一、基本概念
交叉概率差分进化算法是基于进化算法的一种优化算法。
差分进化算法是一种从种群中产生差分向量并利用差分向量来更新目标向量的算法。
交叉概率差分进化算法是一种改进的差分进化算法,通过引入交叉概率来控制算法的搜索方向。
二、算法步骤
1. 初始化:生成种群,设置交叉概率、变异概率、最大迭代次数等参数。
2. 适应度计算:将初始种群的每个个体应用于优化问题,计算适应度函数值,以便评估和比较每个个体。
3. 差分向量生成:根据生成的种群和变异概率,生成一些差分向量。
4. 交叉操作:根据交叉概率,将差分向量和种群中的某些个体进行交叉操作。
5. 新种群生成:根据交叉结果和适应度函数进行新种群的生成。
6. 更新种群:将新生成的种群作为下一代种群。
7. 迭代次数判定:当达到最大迭代次数或者满足停止条件时,停止迭代过程。
8. 输出结果:输出最优解或者最优个体。
三、优化应用
交叉概率差分进化算法经常用于解决多目标优化问题、非线性规划问题、组合优化问题、图像处理、机器学习等各种优化领域。
四、总结
交叉概率差分进化算法虽然与其他的进化算法类似,但其本身具
有更高的优化性能和更快的收敛速度。
它适用于许多实际问题的求解,并被广泛应用于优化领域。
因此,我们在优化问题的求解过程中,可以尝试使用交叉概率差
分进化算法,以提高效率和准确性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
这一轮仍然不会发生变异。于是,得第三代种群S3:
s1=11100(28), s2=01001(9), s3=11000(24), s4=10011(19)
表1.3.3 第三代种群S4中各染色体的情况
假设这一轮选择-复制操作中,种群S2中的4个染色体都被选中(因为选择概 率毕竟只是一种几率,所以4个染色体恰好都被选中的情况是存在的),我们得到 群体:
s1’=11001(25), s2’=01100(12), s3’=11011(27), s4’=10000(16)
然后,做交叉运算,让s1’与s2’,s3’与s4’ 分别交换后三位基因,得
s1’’=11001(25), s2’’=01100(12), s3’’=11011(27), s4’’=10000(16) 变异 设变异率pm=0.001。这样,群体S1中共有540.001=0.02位基因可以变异。 0.02位显然不足1位,所以本轮遗传操作不做变异。
现在,我们得到了第二代种群S2: s1=11001(25), s2=01100(12), s3=11011(27), s4=10000(16)
估 计 被 选 中 次 数 1 2 0 1
选择-复制 设从区间[0, 1]中产生4个随机数如下:
r1=0.450126, r2=0.110347, r3=0.572496, r4=0.98503 按赌轮选择法,染色体s1, s2, s3, s4的被选中次数依次为:1, 2, 0, 1。于是,经复制 得群体:
解
(1) 定义适应度函数,编码染色体。由上面的分析,函数f(x)=x2就可作为空间U上 的适应度函数。显然y=x2是一个单调增函数,其取最大值的点x=31是个整数。另一 方面, 5位二进制数也刚好能表示区间[0, 31]中的全部整数。所以, 我们就仅取 [0,31]中的整数来作为参加进化的个体,并且用5位二进制数作为个体x的基因型 编码, 即染色体。
计算S1中各染色体的适应度、选择概率、积累概率等并列于表4.1中。
表1.3.1 第一代种群S1中各染色体的情况
染 色 体
s1=01101 s2=11000 s3=01000 s4=10011
适 应 度 169 576 64 361
选 择 概 率 0.14 0.49 0.06 0.31
积 累 概 率 0.14 0.63 0.69 1.00
分析 可以看出,只要能在区间[0,31]中找到函数值最大的点a,则函数y=x2的 最大值也就可以求得。于是, 原问题转化为在区间[0, 31]中寻找能使y取最大值 的点a的问题。显然, 对于这个问题, 任一点x∈[0, 31]都是可能解, 而函数值f(x)= x2也就是衡量x能否为最佳解的一种测度。那么,用遗传算法的眼光来看, 区间[0, 31]就是一个(解)空间,x就是其中的个体对象, 函数值f(x)恰好就可以作为x的适应度 。这样, 只要能给出个体x的适当染色体编码, 该问题就可以用遗传算法来解决。
s1’=11000(24), s2’=01101(13), s3’=11000(24), s4’=10011(19)
可以看出,在第一轮选择中适应度最高的染色体s2被选中两次,因而被复制两 次;而适应度最低的染色体s3一次也没有选中而遭淘汰。
交叉 设交叉率pc=100%,即S1中的全体染色体都参加交叉运算。设s1’与s2’配 对,s2’与s4’配对。分别交换后两位基因,得新染色体:
表 1.3.2 第二代种群S2中各染色体的情况
染 色 体
s1=11001 s2=01100 s3=11011 s4=10000
适 应 度 625 144 729 256
选 择 概 率 0.36 0.08 0.41 0.15
积 累 概 率 0.36 0.44 0.85 1.00
估 计 被 选 中 次 数 1 0 2 1
单击增加标题内容
种群
适应度
编码
遗传操作
演化 算法 共有 的对 象元 素
选择优秀个 体,复制成 为新的群体
初始化种群;
评价种群适应
2
度
1
决定的参加 交叉的染色 体数,配对 进行交叉操 作,并用产 生的新染色 体代替原染 色体
3
进行变异操 作
得到新的子
4 种群
5
遗传算法
1.3 遗传算法应用举例
例: 利用遗传算法求解区间[0,31]上的二次函数y=x2的最大值。
染 色 体
s1=11100 s2=01001 s3=11000 s4=10011
适 应 度 784 81 576 361
选 择 概 率 0.44 0.04 0.32 0.20
积 累 概 率 0.44 0.48 0.80 1.00
估 计 被 选 中 次 数 2 0 1 1
设这一轮的选择-复制结果为:
(2) 设定种群规模 , 产生初始种群 。我们将种群规模设定为 4,取染色体 s1=01101(13),s2=11000(24),s3=01000(8), s4=10011(19)组成初始种群S1。
(3) 计算各代种群中的各染色体的适应度, 并进行遗传操作,直到适应度最高 的染色体(该问题中显然为“11111”=31)出现为止。
差分进化算法
1.2基本遗传 算法
2.1 DE的来源
1.1GA的基本
1.3 举例和应用
2.2DE的标准算
概念
法
单击增加标题内容
GA
遗传算法(Genetic Algorithm)它 是由美国的J.Holland教授1975年首 先提出的模拟达尔文生物进化论的 自然选择和遗传学机理的生物进化 过程的计算模型,是一种通过模拟 自然进化过程搜索最优解的方法。 这个过程将导致种群像自然进化一 样的后生代种群比前代更加适应于 环境,末代种群中的最优个体经过 解码(decodiห้องสมุดไป่ตู้g),可以作为问题 近似最优解。
s1’=11100(28), s2’=11100(28), s3’=11000(24), s4’=10011(19)
然后,做交叉运算,让s1’与s4’,s2’与s3’ 分别交换后两位基因,得
s1’’=11111(31), s2’’=11100(28), s3’’=11000(24), s4’’=10000(16)