语料库课程(一)笔记解析
专业的语料库使用技巧

专业的语料库使用技巧语料库是在语言学和应用语言学研究中非常重要的工具。
它是大规模文本的集合,可以用来研究语言的使用情况和规律。
对于语言学研究者、翻译人员、教师和学生来说,掌握语料库的使用技巧是必不可少的。
本文将介绍一些专业的语料库使用技巧,帮助读者更好地利用语料库进行学习和研究。
一、选择合适的语料库选择合适的语料库是使用语料库的第一步。
不同的语料库有不同的特点和用途,因此我们需要根据具体的需求选择合适的语料库。
常见的语料库包括:1. 综合性语料库:这些语料库收录了各种类型的文本,涵盖了不同的话题和领域。
例如,BNC(British National Corpus)是一个英语综合性语料库,适合于对英语的整体使用情况进行研究。
2. 学科专业语料库:这些语料库针对特定学科的使用情况进行了收集和整理。
例如,法律语料库和医学语料库分别用于研究法律和医学领域的语言使用。
3. 历时语料库:这些语料库收录了不同时期的文本,可以用来研究语言的演变。
例如,COHA(Corpus of Historical American English)是一个用来研究美国英语历史演变的语料库。
二、设置搜索条件在使用语料库进行检索时,我们需要设置适当的搜索条件,以便找到所需的文本。
以下是一些常用的搜索条件:1. 词汇:我们可以输入一个或多个词汇,以搜索包含这些词汇的文本。
还可以设置搜索词的位置(如句首、句中、句末)和词性(如名词、动词、形容词等)。
2. 短语:除了单个词汇,我们还可以搜索特定的短语。
短语搜索可以通过添加引号来实现,以确保搜索结果仅包含完整的短语。
3. 上下文:为了更精确地定位所需的文本,我们可以指定搜索词的上下文。
上下文可以是一个特定的句子、段落或文档。
4. 语言特征:语料库通常提供一些基于语言特征的搜索选项,如词频、词汇搭配、句法关系等。
这些选项可以帮助我们更深入地了解和研究语言的使用。
三、分析搜索结果搜索结果的分析是使用语料库的关键步骤之一。
第4章:自然语言语料库与词汇知识库

No.95, Zhongguancun Beijing 100080, ChinaNLPR4.1 基本概念NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念输入输出处理模块大规模语言数据:•模型参数训练•知识获取NLP中知识库包括:•词汇语义库语言数据库或知识库•词法、句法规则库•常识库等等NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念语料库(corpus)¾语料库(corpus)就是存放语言材料的仓库(语言数据库)。
基于语料库进行语言学研究-语料库语言学(corpus linguistics)NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念语料库语言学根据篇章材料对语言的研究称为语料库语言学。
-[Aijmer, 1991]基于现实生活中语言运用的实例进行的语言研究称为语料库语言学。
-[McEnery, 1996]以语料为语言描写的起点或以语料为验证有关语言的假说的方法称为语料库语言学。
-[Crystal, 1991] NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念两种解释:不是新术语:利用语料库对语言的某个方面进行研究,或者发现某些规律性知识。
是新术语:对现行语言学理论进行批评,提出新的理论。
NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念“语料库语言学已经成为语言研究的主流。
基于语料库的研究不再是计算机专家的独有领域,它正在对语言研究的许多领域产生愈来愈大的影响。
”-J. Thomas等人为祝贺语料库语言学的主要奠基人和倡导者G. Leech六十岁生日而出版的语料库语言学研究论文集的开场白[丁信善,1998]。
NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.1 基本概念语料库语言学研究的内容:语料库的建设与编纂语料库的加工和管理技术语料库的使用NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR4.2 语料库技术的发展NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.2语料库技术的发展三个阶段20世纪50年代中期之前:早期¾语料库在语言研究中被广泛使用:语言习得、方言学、语言教学、句法和语义、音系研究等NLPR, CAS-IA 2007-4-3宗成庆:《自然语言理解》讲义NLPR 4.2语料库技术的发展1957~20世纪80年代初期:沉寂时期¾1957年Chomsky的《句法理论》及其以后一系列著作的发表,根本改变了语料库语言学的发展状况。
常见语料库使用入门

8
公共语料库检索
国外18个知名英语语料库
01.国际英语语料库 (ICE):http: ///english-usage/ice/htm 02.美国国家语料库(ANC):/ 03.美国当代英语语料库(COCA):/ 04.美国近当代英语语料库(COHA):/coha/ 05.英国国家语料库(BNC):/bnc/ 06.柯林斯英语语料库(BOE):/wordbanks/ 07.英国英语语料库(SEU):http: ///english-usage/ 08.澳大利亚英语语料库(ACE):http: //khnt.hit.uib.no/icame/manuals/ 09.新规范语料库(NMC):http: ///
词性标记 句法标记 词义标记 篇章指代标记 韵律标记 ……
材料/工具准备阶段
若只是要词频数据, 则生语料库足够, word/wps或txt记事本 都可以建立word/wps 的“查找替换”工具 即可, txt记事本的“编辑-查 找”工具也行。
生语料库 加 工 标 注
熟语料库
“宏”
39
个人语料库创建
生 语 语 料 库
熟 语 语 料 库
3
语料库及其分类
第二节 公共语料库检索
4
公共语料库检索
统计频率
基 于 检 索
查找例句
参 数 设 置
带着 问题
收集 证据
验证分析
5
公共语料库检索
我国21个知名语料库
01.中央研究院近代汉语标记语料:.tw/Early_Mandarin/ 02.中央研究院汉籍电子文献:.tw/ftms-bin/ftmsw3 03.国家现代汉语语料库:http://124.207.106.21:8080/ 04.国家语委现代汉语语料库:/retrieval/index.html 05.树图数据库:.tw/ 06.语料库语言学在线: 07.北京大学CCL语料库:/Yuliao_Contents.Asp
北京外国语大学语料库语言学考博参考书目导师笔记重点
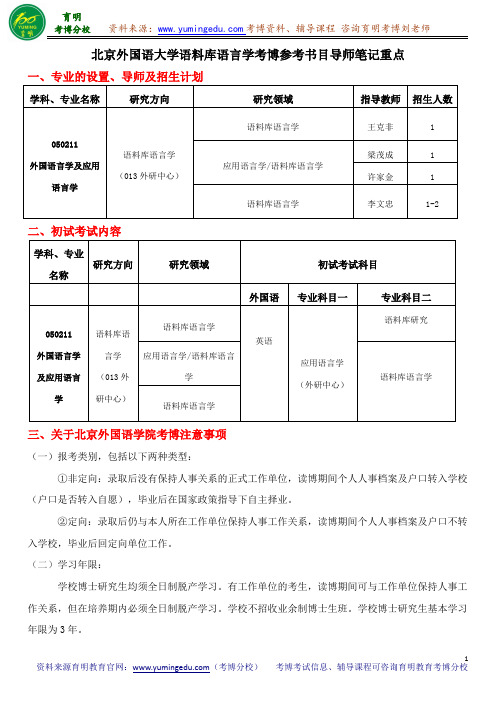
学科、专业 研究方向
名称
研究领域
初试考试科目
外国语 专业科目一
专业科目二
050211
语料库语
语料库语言学
外国语言学
言学 应用语言学/语料库语言
及应用语言 (013 外
学
学
研中心)
语料库语言学
英语
应用语言学 (外研中心)
语料库研究 语料库语言学
三、关于北京外国语学院考博注意事项
(一)报考类别,包括以下两种类型: ①非定向:录取后没有保持人事关系的正式工作单位,读博期间个人人事档案及户口转入学校
第二阶段:专题整理和讲解 在第一阶段的基础上,由专业课老师带领整理重要常考的学科专题,进行各个知识模块的深化和 凝练。以专题为突破口夯实并灵活运用理论知识。 第三阶段:时事热点和出题人的论著 对出题老师的研究重点,最新论文成果和重要的上课的笔记课件进行讲解。对本专业时政热点话 题进行分析,预测有可能出现的题型和考察角度。 第四阶段:历年真题演练和讲解 对历年真题进行最深入的剖析:分析真题来源、真题难度、真题的关联性,总结各题型的解题思 路、答题方法和技巧。全面提升学员的答题能力,把前面几个阶段掌握的理论知识转化为分数。 第五阶段:模拟练习及绝密押题 就最新的理论前沿和学科热点结合现实的热点进行拔高应用性讲解。开展高强度模拟考试,教会 考生怎么破题,怎么安排结构,怎么突出创新点等答题技巧。结合最新的内部出题信息和导师信息进 行高命中押题。
5、经济上要有一定的支撑。包括人际关系费用,找该校的对口复习资料费用,报辅导班的费用, 考试费等等,该花的最好不要省,只要是对考博成功有利的。因为这些钱对于博士生出来后的待遇来 说太微不足道了。 (二)专业课如何复习
对待专业课的认识,有些考生以为自己学了这么多年本专业,甚至发表了不少文章,专业课应该 没问题了,从而放松了对自己专业课复习的要求。其实现在博士录取时,各个环节都不能放松。即使 及格了,如果成绩较低,总分排名靠居后,也会影响导师对自己的印象。提高专业课的复习效率,育 明考博告诉大家可以分为以下两个阶段:
语料库语言学解析

1. Editorial metadata(编辑元数据)
2. Analytic metadata(分析元数据) 3. Descriptive metadata(描写元数据)
4. Administrative metadata(管理元数据)
Categories of Metadata
SAY 1 2 3 4 say says said saying
Freq. 20 15 9 2
Keywords and Key sequences
Compared (对比);Frequency (频率); Extracting (筛选)
Reference corpus (参照语料库)
A transcript of medical consultation医学讨论会手稿 (口 语)
Corpus Linguistics
语料库语言学
Presented by: Song Chao Wang Zeyu Li Zhanyu
Outline
Chapter I: Introduction
Chapter II: Analyzing Corpus Data
Chapter III: Current Issues in Corpus Linguistics
Focus of Corpora
The corpora above mainly focus on the collection of general English in use. Specialised corpora : represent a particular mode of discourse eg:1)Bergen Corpus of London Teenage Language (COLT) ; dominate academic discourse eg: 2)Michigan Corpus of Academic Spoken English (MICASE) and 3)British Academic Spoken English corpus (BASE) Another category of corpora captures the language use of language learners. eg: 1)Cambridge Learner Corpus, 2)Longman Learners’ Corpus, 3) International Corpus of Learner English (ICLE), 4) Vienna-Oxford International Corpus of English (VOICE), 5) English as a Lingua Franca in Academic Settings (ELFA)
语料库笔记

语料库简单DIY 第一讲语料库--语料库语言学的工具主讲叶城日本国立广岛大学综合科学研究中心计算机辅助语言教学博士一年联系方式: QQ 47354211 E-mail: sery2004@在语言学QQ群里面混迹了多年,经常潜水走马观花似的看着群里面的朋友们针对语料库提出各种各样的问题和困惑,总结起来,大家的问题无非离不开对于语料库的理解,应用,以及研究。
不过,因为群里面的朋友大多数都是文科的文学,语言学,以及对外汉语专业。
对于计算机辅助语言研究,语料库语言学等概念接触的机会并不是很多。
加上群里的女性朋友居多,她们对于电脑操作系统本身的使用都存在诸多头疼的问题,就更不要提数据量超大的语料数据库了。
本人不是计算机专业的毕业生,本科是日语专业,硕士是比较语言学,博士是计算机辅助对日汉语教学。
所以对于语料库本身的程序和数据库,认识只是停留在应用和架设阶段,实在说不清楚里面很多细节的问题,也请朋友们原谅。
我有说的不对的地方,欢迎来信或者QQ群里直接批判,我一定虚心接受。
谢谢!首先,我们来个扫盲活动,把对于语料库的认识梳理清楚。
第一个内容:语料库是干嘛的?CORPUS =The body of written or spoken material upon which a linguistic analysis is based .这里的CORPUS就是我们说的语料库,它实际上也等于CORPSE或者Dead Body。
就是死尸的意思。
好奇怪,这里怎么搞个死尸进来呢?其实这个概念是在构造主义时期1956年由英国的语言学会提出来的。
他们认为,人类研究语言的时候,需要诸多实体例子,这样的例子最好是最纯净的,最朴实的,甚至是最低俗低劣但是最普及的。
并且我们需要一个庞大的地方放置我们日常的言行,报纸杂志上刊登的新闻,以及各种各样的文学体裁等等。
而放置这些语言信息的地方,则被称为没有活力没有变化没有生机勃勃,像停尸房一样的地方----语料库。
构建语料库的方法

构建语料库的方法《构建语料库的超酷方法,独家分享!》嘿,宝子!今天我要跟你唠唠构建语料库这个超有用的事儿,就像我要把我压箱底的独家秘籍传给你一样,可别外传哦(开个小玩笑啦)。
一、明确语料库的用途(这就像确定目的地一样重要)首先呢,你得知道为啥要构建这个语料库。
是为了写学术论文,还是搞创作写小说,或者是为了学习外语呢?比如说我有一次想写个科幻小说,结果我构建语料库的时候,都不知道要收集啥,后来发现我连科幻小说里常见的一些科学术语、星际旅行的词汇都没搞清楚,就瞎收集,那肯定不行啊。
就像你要去旅游,你得先知道你要去海边还是山里吧。
要是为了学术论文,那就要围绕你研究的领域,像我一朋友研究古代历史的,他构建语料库的时候就专门收集古代文献、考古报告这些相关的语料。
二、确定语料的来源(找食材的过程)这一步就像我们做饭找食材一样。
来源可多啦。
1. 书籍去图书馆或者网上找相关的书籍。
如果你是搞文学创作,那各种经典小说、散文都是你的宝库。
我有次构建关于爱情主题的语料库,就从《霍乱时期的爱情》《简·爱》这些书里扒出了好多超感人的句子和词汇。
2. 网络资源这可是个大宝库。
各种新闻网站、博客、论坛啥的。
不过要小心筛选哦,就像你在菜市场买菜,有些菜看着新鲜,其实可能有农药残留呢。
比如你要构建关于时尚的语料库,时尚博主的文章就很有用,但有些小网站可能会有错误信息。
像我之前在一个不靠谱的小论坛上找美食语料,结果好多错字,还把一些食材名字都写错了,差点闹笑话。
3. 学术数据库(如果是学术用途)学校或者机构的学术数据库里有很多专业的研究论文、报告。
这些就像高级食材,特别适合学术研究这个“大餐”。
三、收集语料(开始疯狂囤货啦)现在开始把你找到的语料收集起来。
可以用笔记软件,像印象笔记就超好用。
你可以把文字复制粘贴进去,要是看到纸质书上的好内容,那就打字输入进去呗。
我刚开始的时候可傻了,我看到一本超棒的诗集里的句子想放进语料库,我就手抄,抄了半天,手都酸了,后来才发现可以拍照识别文字,再稍微修改下就好,真是笨死了。
语料库基础知识

/yingyong/courses/corpusbase.htm语料库研究与应用综述语料库研究与应用综述 一 概述 语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
经过科学选材和标注、具有适当规模的语料库能够反映和记录语言的实际使用情况。
人们通过语料库观察和把握语言事实,分析和研究语言系统的规律。
语料库已经成为语言学理论研究、应用研究和语言工程不可缺少的基础资源。
语料库有多种类型,确定类型的主要依据是它的研究目的和用途,这一点往往能够体现在语料采集的原则和方式上。
有人曾经把语料库分成四种类型:(1)异质的(Heterogeneous ):没有特定的语料收集原则,广泛收集并原样存储各种语料;(2)同质的(Homogeneous ):只收集同一类内容的语料;(3)系统的(Systematic ):根据预先确定的原则和比例收集语料,使语料具有平衡性和系统性,能够代表某一范围内的语言事实;(4)专用的(Specialized ):只收集用于某一特定用途的语料。
除此之外,按照语料的语种,语料库也可以分成单语的(Monolingual )、双语的(Bilingual )和多语的(Multilingual )。
按照语料的采集单位,语料库又可以分为语篇的、语句的、短语的。
双语和多语语料库按照语料的组织形式,还可以分为平行(对齐)语料库和比较语料库,前者的语料构成译文关系,多用于机器翻译、双语词典编撰等应用领域,后者将表述同样内容的不同语言文本收集到一起,多用于语言对比研究。
语料库建设中涉及的主要问题包括:(1) 设计和规划:主要考虑语料库的用途、类型、规模、实现手段、质量保证、可扩展性等。
(2) 语料的采集:主要考虑语料获取、数据格式、字符编码、语料分类、文本描述,以及各类语料的比例以保持平衡性等。
(3) 语料的加工:包括标注项目(词语单位、词性、句法、语义、语体、篇章结构等)标记集、标注规范和加工方式。
Chapter 1b

对于语言学的研究可以追溯到古希腊时期。
公元前五到四世纪,希腊著名哲学家苏格拉底、伯拉图、亚里斯多德在他们的研究中对语言的研究就站和大地位。
伯拉图的一篇《对话》,《克雷特里斯》(Cratylus)讨论到词为什么具有意义。
克雷特里斯认为:一个对象的名称是由于它的性质而产生的所以语言自然而然地具有意义。
赫莫吉尼斯:反对这种观点,认为名称之所以能指称生物是由于惯例的原因,也就是语言使用者达成的协议。
然后苏格拉底论述两种观点的有缺点。
他说,一个句子分成两部分,名词部分和动词部分。
亚里斯多德是古希腊最著名的哲学家、思想家。
他在《解释篇》、《修辞学》、《诗学》等著作中讨论了有关语言的问题。
他认为:由于形成于惯例,因为名称没有天然产生之理。
语言的词汇只是这些思想的标记。
他进一步讨论名词部分和动词部分,指出名词没有时间成分,而动词有时间成分。
斯多噶派是盛行于公元前四世纪的一批哲学家和逻辑学家。
(他是亚里斯多德的反对者)他们区分了五大词类:名词、动词、连词、冠词和关系代词。
提出“白板说”“自然说”。
亚历山大大帝建立了两个殖民地:埃及亚历山大、土耳其帕加马,亚里斯多德将自己的藏书都赠给了亚历山大,许多学者来此定居从事科学研究成了有名的亚历山大学派、帕加马学派。
辩论的开始围绕:自然界是如何构成的,自然界的运动情况如何反映到人类语言之中?(公元300--146)斯拉克思《语法科学》总结了亚历山大派的语法研究工作,在第一部中进行了语音研究语法部分他认为词汇分8种。
名词、动词、冠词、代词、介词、副词、连词,分词。
文艺复兴前只是对古希腊和拉丁语的研究,14,15 世纪开始将语言学范围扩大。
开始对希伯来语阿拉伯语的研究。
因为《圣经》原文是希伯来语。
古罗马与古希腊来往已久,公元前三世纪罗马帝国征服希腊城之后,希腊科学文化直接影响罗马的发展。
罗马帝国西部拉丁语是官方语言,东部希腊语事官方语言。
希腊的文化科学乘机而入。
著名语言学家瓦罗将语言研究分为三大部分:词源学、形态学、句法学。
从语料库中挖掘知识-北语1

语言信息处理与汉语知识研讨会,2010/5/29-30,北京语言大学从语料库中挖掘知识Mining Knowledge from Corpus冯志伟提要:本文主要介绍中国传媒大学依存树库研究团队从依存树库中获取语言学知识的一些工作,如,汉语名词语法功能的研究,20种语言中心词居前与中心词居后的分布研究,汉语复杂网络的研究。
这些工作都是在汉语依存树库的基础上进行的。
本文也简要地介绍了国外从语料库中获取非语言学知识的研究。
20世纪90年代以前,从事计算语言学系统开发的绝大多数学者,都把自己的目的局限于某个十分狭窄的专业领域之中,他们采用的主流技术是基于规则的句法-语义分析,尽管这些应用系统在某些受限的“子语言”(sub-language)中也曾经获得一定程度的成功,但是,要想进一步扩大这些系统的覆盖面,用它们来处理大规模的真实文本,仍然有很大的困难。
因为从自然语言系统所需要装备的语言知识来看,其数量之浩大和颗粒度之精细,都是以往的任何系统所远远不及的。
而且,随着系统拥有的知识在数量上和程度上发生的巨大变化,系统在如何获取、表示和管理知识等基本问题上,不得不另辟蹊径。
这样,就提出了大规模真实文本的自动处理问题。
1990年8月在芬兰赫尔辛基举行的第13届国际计算语言学会议(即COLING'90)为会前讲座确定的主题是:“处理大规模真实文本的理论、方法和工具”,这说明,实现大规模真实文本的处理将是计算语言学在今后一个相当长的时期内的战略目标。
为了实现战略目标的转移,需要在理论、方法和工具等方面实行重大的革新。
1992年6月在加拿大蒙特利尔举行的第四届机器翻译的理论与方法国际会议(TMI-92)上,宣布会议的主题是“机器翻译中的经验主义和理性主义的方法”。
所谓“理性主义”,就是指以生成语言学为基础的方法,所谓“经验主义”,就是指以大规模语料库的分析为基础的方法。
从中可以看出当前计算语言学关注的焦点。
常见语料库使用入门

——语言研究中的小技能get√
华中师范大学语言研究所2015级 秦志君
0 PPT模板下载:/moban/ 行业PPT模板:/hangye/
节日PPT模板:www.1p pt.co m/ jieri/
PPT素材下载:/sucai/
统
离散与连续
计
样本与总体
由收集验证到实证分析
需要学点统计学
频率与分布
估计与检验 描述与图示
置信区间 T检验
12 公共语料库检索
由收集验证到实证分析
需要学点统计学
集中趋势的特征数:
平均数、众数、中位数、调和平均数、几何平均数
变异程度的特征数:
极差、四分位差、平均差、方差、标准差
参数估计与假设检验
——以样本对总体的推断
——以BCC语料库为例
构 式
30 公共语料库检索
自 定 义 搜 索
公共语料库的检索说明
——以BCC语料库为例
31 公共语料库检索
检 索 结 果
公共语料库的检索说明
——以BCC语料库为例
32 公共语料库检索
历 时 检 测
公共语料库的检索说明
——以BCC语料库为例
33 公共语料库检索
检 索 统 计
检 索 式 示 例
公共语料库的检索说明
——以BCC语料库为例
18 公共语料库检索
检 索 式 示 例
公共语料库的检索说明
特 殊 含 义 符 号
公共语料库的检索说明
——以BCC语料库为例
20 公共语料库检索
特 殊 含 义 符 号
公共语料库的检索说明
——以BCC语料库为例
10 公共语料库检索
程娟老师现代汉语词汇课堂笔记

我空间有很多北语语用,文字,汉教专业课笔记。
更多北语语用,文字,汉教专业课笔记欢迎访问我空间了解。
我的新浪微博是@那些年追过的梦想,上面有分享很多专业课资料,已经备考心得,欢迎访问!祝你金榜题名程娟老师现代汉语词汇课堂笔记语素、词、词汇(一)语素(morepheme)1.什么是语素2.1按语音形式划分(1)单音语素:手灯/走观/红绿/男女/一千/条个/吗的(2)多音语素:乌鲁木齐新加坡香港(源自莞香装运地/源自海盗香姑的名字)2.2按语言功能划分(1)成词语素(2)非词语素不能独立成词的语素,包含半自由语素与不自由语素两种类型。
①半自由语素:皆为实词性语素,与成词语素相比,不能在句中独立使用。
例如:视伟威艰荐民②不自由语素:绝大多数是虚词性语素,即词缀语素。
例如:老子头2.3按意义性质划分(1)词根语素▲特点:意义实在;位置不固定:比如视:视力/重视;伟:伟大/雄伟判断:教师与老师(2)词缀语素▲特点:意义虚化;位置固定。
①前缀(5)老:老爸老妈老外老记老公/老人阿:阿妹第:第三初:初一小:小张▲前缀的特点:意义虚化;语音读本调a 改变词汇意义:把基数词该为序数词,比如“一”与“第一”;b增加色彩意义:爸与阿爸(方言色彩);c适应汉语词汇双音化的需要:虎与老虎②后缀(17单音后缀;2个双音后缀)子:名词:桌子椅子瓶子鼻子凳子稻子刀子动词:推子疯子盖子形容词:胖子瘦子儿:名词:刀儿皮儿花儿鸟儿动词:画儿盖儿扣儿托儿(医托/布托)形容词:亮儿短儿尖儿明儿头:名词:舌头石头动词:看头想头听头吃头搞头玩头形容词:甜头苦头家:姑娘家小孩家巴:有分歧名词:泥巴盐巴尾巴嘴巴;形容词:干巴瘦巴;动词:砸巴哑巴眨巴洗巴扫巴者:马列主义者科学工作者作者读者学者患者记者长者//第三者强者乎:合乎热乎似乎于:敢于勇于在于搭:甩搭扭搭化:美化绿化现代化然:竟然忽然(副词后缀)/突然(形容词后缀)其:尤其极其地:忽地霍地特地价:成天价震天价着:本着沿着得:免得值得舍得乐得乎乎:脏乎乎黑乎乎兮兮:神经兮兮“们”表示语法意义复数,但不是后缀。
语料库辅助EFL自主学习的多维探索 第1章

自主学习(Autonomous Learning)是与传 统的接受学习相对应的一种现代化学习方 式,它以学生作为学习的主体,通过学生 独立的分析、探索、实践、质疑、创造等 方法来实现学习目标。
爱因斯坦说:“发展独立思考和独立判断能 力,应始终放在首位,不应当把获得知识放在 首位。” 自主学习的核心是自主探索、自主发现,以培 养独立思考和独立决断的能力。
Johns( 1991)将数据驱动语言学习过程分为 三个阶段: 提出问题( Identify) 材料分类( Classify) 归纳总结( Generalize)
语料库辅助EFL自主学习的优势
现代信息技术为语料库的利用提供了无可 比拟的方便快捷。 第一,计算机高速处理信息,大大提高学 习者的学习效率; 第二,计算机提供的检索结果,其呈现方 式十分直观,便于观察分析。 第三,计算机的量化统计便于得出对语言 本质和运用规律的更深刻更全面的认识。 第四,与其他网络学习资源链接很方便, 学习者可以充分利用无穷无尽的网络资源。
However, a linguistic corpus, in technical terms, refers to a systematic collection of computerized texts which represents a language, or a variety of language.
言研究、对比研究、翻译研究、教 学研究词典编纂,以及机器翻译和 软件开发等。
COBUILD语料库(The COBUILD Corpus) 朗文语料库网络(The Longman Corpus Network) 英国国家语料库(BNC,British National Corpus) 国际英语语料库(ICE,International Corpus of English) 美国当代英语语料库(COCA,Corpus of Contemporary American English) 美国国家语料库(ANC,American National Corpus)
语料库标注说明

“HSK动态作文语料库”语料标注及代码说明“HSK动态作文语料库”从字、词、句、篇、标点符号等角度,对所收入的作文语料中存在的外国人使用汉语的中介语偏误进行全面标注。
1 、字处理(包括标点符号)[C]:错字标记,用于标示考生写的不成字的字。
用[C]代表错字,在[C]前填写正确的字。
例如:地球[C](“球”是错字)、这[C]。
[B]:别字标记,用于标示把甲字写成乙字的情况。
别字包括同音的、不同音而只是形似的、既不同音也不形似但成字的等等。
把别字移至[B]中B的后面,并在[B]前填写正确的字。
例如:提[B题]高、考虑[B虎]。
[L]:漏字标记,用于标示作文中应有而没有的字。
用[L]表示漏掉的字,并在[L]前填写所漏掉的字。
例如:后悔[L],表示“悔”在原文中是漏掉的字。
农[L]药,表示“农”在原文中是漏掉的字。
[D]:多字标记,用于标示作文中不应出现而出现的字。
把多余的字移至[D]中D的后面。
例如:我的[D的],表示括号中的“的”是多余的字(原文中写了两个“的”)。
[F]:繁体字标记,用于标示繁体字。
把繁体字移至[F]中F的后面,并在[F]前填写简体字。
例如:记忆[F憶]、单{F單}纯、养{F養}分{F份}。
注意:1)繁体字标记标示的是使用正确的繁体字,如果该繁体字同时又是别字,则先标繁体字标记,再标别字标记。
例如:俭朴[F樸[B僕]]。
2)繁体字写错了,标为:后[F後[C]]。
[Y]:异体字标记,用于标示异体字。
把异体字移至[Y]中Y的后面,并在[Y]前填写简体字。
例如:偏[Y徧]、沉[Y沈]。
[P]:拼音字标记,用于标示以汉语拼音代替汉字的情况。
把拼音字移至[P]中P的后面,并在[P]前填写简体字。
例如:缘[Pyúan]分、保护[Phù]。
[#]:无法识别的字的标记,用于标示无法识别的字。
每个不可识别的字用一个[#]表示。
例如:更[#][#]保存自己的生命,……[BC]:错误标点标记,用于标示使用错误的标点符号。
语料库翻译学

语料库翻译学一引言二语料库/语料库翻译学三语料库翻译学的研究内容四Content译学研究语料库的种类一、引言Example:Start or begin?在口语中哪个更常用?在BNC等语料库中查到,在口语中,start更常用。
一、引言◆在口头表达、写作或翻译中如何确定某些用法是地道的?◆学习者一般要有多大词汇量才能读懂英文报纸?◆哪些是商务英语中最常用的单词和短语?◆某种考试中,哪些单词、词组等语言现象出现频率偏高?◆如何通过量化统计来分析文学作品的写作风格?语料库的方法基于真实的语言使用情况。
一、引言语料库具有以下特征:➢语料库建设有系统的语言学理论为指导,开发有明确又具体的目的。
➢语料是按照明确的语言学原则采用随机抽样的方法得到的语言运用的自然语料,不是随意的语言材料的堆积,更不是由某人杜撰的。
语料库的容量和语料采用方法保证了语料具有代表性,也由此保证语料库的语言研究科学性、客观性。
一、引言➢语料库以先进的计算机技术为技术手段,语料通过电子文本形式存储并且是通过计算机处理的,具有资源优势和处理速度优势。
➢基于语料库的研究以量化研究为基石,以概率统计为手段,以数据驱动为基本理念。
➢语料库既是一种研究方法,又代表着一种新的研究思维。
二、语料库通俗意义:语言材料库严格意义:语料库是指按照一定的语言学原则,运用随机抽样方法,收集自然出现的连续的语言运用文本或话语片断而建成的具有一定容量的大型电子文本库。
以语料库为基础,真实的双语语料或翻译语料为研究对象,数据统计和理论分析为研究方法,依据语言学、文学和文化理论及翻译理论,系统分析翻译本质、翻译过程和翻译现象等内容的研究。
语料库翻译学语料库语料库建设有特定研究目的和具体用途,在语料抽样范围和文类覆盖方面力求平衡,在收集语料时需要考虑到每一文类、体裁、语域、主题类型等的抽样比例。
大型电子文档目标在于搜集任何可获得的语言材料或所限定的语种文类语料,其语言材料之间关系松散。
《语料库语言学视角下的英汉意义演化研究》读书笔记模板

5.6.1哲学系统论的理论思想 5.6.2意义演化的系统过程分析
6.1建构语言演化模 型的标准
6.2广义选择理论
6.3基于意义单位复 制与选择的意义演化 模型
6.4本章小结
6.2.1主体架构 6.2.2复制过程 6.2.3选择过程 6.2.4具体应用
6.3.1模型要素的确定 6.3.2模型过程的阐述 6.3.3模型的整体展示与特性归纳
目录分析
1.2研究内容
1.1研究背景
1.3研究方法
1.4研究意义
1.5本书结构
2.1国外意义演化研 究综述
2.2国内汉语意义演 化研究
2.3对当前意义演化 研究的思考
2.4本章小结
2.1.1布雷亚对意义演化的开创性研究 2.1.2 20世纪上半叶的意义演化研究 2.1.3意义演化研究的认知范式 2.1.4意义演化研究的语用范式
精彩摘录
这是《语料库语言学视角下的英汉意义演化研究》的读书笔记模板,可以替换为自己的精彩内容摘录。
作者介绍
这是《语料库语言学视角下的英汉意义演化研究》的读书笔记模板,暂无该书作者的介绍。
谢谢观看
7.2研究的启示
7.1研究取得的成 果和发现
7.3研究局限和未 来展望
7.2.1对意义演化自动发现的启示 7.2.2对外宣工作的启示 7.2.3对舆情工作的启示 7.2.4对词典编纂的启示 7.2.5对词汇教学的启示
读书笔记
这是《语料库语言学视角下的英汉意义演化研究》的读书笔记模板,可以替换为自己的心得。
语料库语言学视角下的英汉意义演 化研究
读书笔记模板
01 思维导图
03 目录分析 05 精彩摘录
目录
02 内容摘要 04 读书笔记 06 作者介绍
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基本观点
词汇中心教学法坚持以词项(lexis)单词短 语结构为基本单位的语言观;重视频率在大缸 设计及教学中的作用;词汇中心教学法本质上 采取的是交际法,它强调将词项置于真实语言 素材中,并贯穿于真实任务中加以学习。同时 提倡学生自主的发现式学习。
Step1 打开Sub-corpus creator,导入seccel(只能导入 单个文件夹),显示文本文件,勾选case sensitive(区 分大小写),file contains “T1=”,获得男生/女生文本,保 存生成子库。
Step2 用PowerConc对两个子库进行比较。
2 趋势
small & specific
标记(mark-up)与标注
Sinclair和他的clean text policy (Sinclair认为语料库语言学应摒弃旧理论一切重来)
语料库语言学界对标注的态度(大部分研究者认为应该标 注),世界最大的语料库Bank of English可以进行词类检 索。
标注的主题
1. 人工标注 (Brown语料库) 2. 机器标注(准确率97-98%)
Step1:新建文件夹1:observeText 新建文件夹2:referenceCorpus
Step2:安装PowerGREP Step3: 设置PowerGREP (preferencegeneral,勾选1、2空格)
Step4: 格式转换(UTF-8转换成ANSI):
1) 找到04Academic,单击右键,出现search with PowerGREP(若有子文件,选第search subfolders)
语言学习观:行为主义 (行为主义)
教学实施方案:句型操练
两大教学法之二:交际法
语言观组活动
What and how
教什么 怎么教
词汇中心教学法
The Lexical Approach 许家金,2009,词汇中心教学法的交际观:理
8.2上午
(一)梁茂成 手工标注
1)自动标注 TreeTagger
word_Pos word-Pos_Lemma(原形)
2) 手工标注: BFSU Qualitative Coder
语料库的手工标注
BFSU Qualitative Coder 1.1 1)根据codelist,修改制定需要的mycodelist 2)打开BFSU Qualitative Colder 3) 打开需标注的.txt文档,导入mycodelist,进 行手工标注 4)BFSU中可做统计(点statistics,跳出网页) 5)保存为.txt文档后,用powerconc检索分析, 如:检索<LIT> free hand</LIT>
Why concordancing? 上下看强形式搭配,左右看综合分析用法。
基本概念 type (独特词形),token,KW/SW/Node word span (一个span可视作一个mini text) collocates (观察从collocationcolligationsemantic meaning) cotext, context, co-occurrence(同现),recurrence(复现)
基本观点
然而,由于过分依赖频率信息,语言观和语言 教学完全基于词项,将词汇中心教学法嫁接于 任务型教学且缺乏创新,归纳式的自主。。。
实例演示
新闻英语教学设计 以新闻英语常用动词教学设计为例 powerConc with China Daily Political new 2011
Words cluster as people do
e.g. Search: no attempt 用法 Regex: \bno\b\s\battempts?(ed/ing)\b 观察collocation and co-occurrence
作业:hair: 单数与复数的隐喻 body metaphor
出结果后,点击keyness,出现load Ref.wordlist,导入 academicOnewordlist, count ④自设主题词临界值,如前20词,按照by value进行比较。
理据
我们对真实世界的理解表达为知识 知识表现为不同的语义场 语义场表现为各种词语场 各种词语场实现为各个词群(单词或短语) 特定话题触发独特词群 具有特定话题的文本包含独特词群,该词群一
replace
e.g.replace:空格1不填,空格2填 ST$,出现从1开始排序的新文件名。
3. 文本清理,元信息标记、语言学标记
8.1下午
(三)梁茂成 语料库的标注
标注与干净文本原则 标注的常见类型 词性标注 手工标注
标注与干净文本原则
标注(annotation): The process of applying additional information to corpus data.
contrastive studies 3 建库准备
建库原则,文本收集,文本分类,文本处理, 标记(外部信息),标注(annotating notes, 语言学标注)
e.g. <Year>1990</Year><Sex>Male</sex>
8.1下午
(二)许家金 语料库采集与整理
1. 基本要素
① Text format: . txt ② Filename: short&alphanumeric(字母数字组
得出结论: reporting verbs:
said told added
检索make,2-gram词表
make +adj
教学实施要点
真实语言材料,真实语境 频率优先原则(材料的编排与选择) 归纳式、发现式学习
8.2上午
(二)李文中 主题词分析
分析文本时注意备份,把需分析的语料放入 新建的文件夹中。
练习:使用语料: 04Academic/4Genres_RAW/Four_Genres/01 _General_corpora/Data
1. 创建2个对比文件夹,用PowerGREP转换 格式,并把text放入这2个文件夹
合,不超过8词,不用汉字,不出现空格) ③ encoding ANSI:英语,汉语
三种格式: UTF8:平行语料库 Unicode:其他语言
④ versions of corpora: RAW, POS, with metadata
2. 批量文件名修改
insert
SuperbBatchRenamer
般不在其它话题中出现
因此
某个特定话题的文本包含的独特词群具有异常 高频
参照语料库代表了某一类型语言运用的常态 对比两个词表,可以提取那些超常高频的词群
比什么:条件控制
控制相似变量 突出差异焦点
描述
观察文本 具有明确主题的完整文本或一致主题的文本集
参照语料库 具有足够的代表性 足够大 同质语料
① 打开PowerConc, 导入referencecorpus进行N-gram统计, 结果save到PowerConc根目录下,命名为 academicOnewordlist.
② 打开academicOnewordlist, 删除前4行,保存。 ③ 再打开PowerConc,导入observetext,N-gram,count,
标注的客体
1. 语音与音调的标注 2. 词性标注(part-of-speech tagging) 3. 句法标注(parsing,斯坦福大学做的较好) 4. 语义标注(semantic tagging) 5. 错误标注(error tagging 学习者语言,人工) 6. 停顿标注等。。。
标注的常见类型
④ context
二、为什么要研究语料库语言学
1)使语言学研究更具科学性 2)可验证,不是玩具 3)大数据,更具说服力 4)enables you to look at a lot of language at once
8.1上午
(二)李文中
Brown-Raw 语料库范例 Span 跨距 (KWIC,一般左5右5) 检索排序(sort),以necessarily为例,观 察得出结论:经常与not连用。
标注必须基于科学、合理的分类体系 1. 与研究目的相关 2. 分类的穷尽性 3. 各子类不应该相互重叠 4. 关于“其他”类(应该是最小类)
标注的常见类型
标注集/赋码集(tagset)是标注中所使用的代 码集,是对分类体系的操作化。
Tagset: A collection of tags (or coldes) in a tagging scheme.
<by value>: datamin10, 即过滤掉频率<10的词 <by Regex>: I\S+|C\S+表示介词+连词 √ exclude 表排除
不勾选表示选中 “Save distribution” 保存分布信息,即按文本单独保存。
8.1下午
(一)李文中
1. 标注信息的添加与使用
e.g. 用PowerConc检索 dataleanerseccl 问题:男生与女生在口语中使用情态动词有无差异
8.1上午
(三)许家金
PowerConc设计原则 most powerful least effort doing more with less
基本操作
N-gram list:n词词表 Hits:相当于 Token概念 Items:相当于Type概念 Size:包括单词、符号、数字 Filter mode:过滤掉不需要的