数据库原理第五章
数据库原理与应用第五章课件

5.2 需求分析
5.2.2 需求分析的方法
需求分析常用的调查方法有以下几种: (1)亲自参与业务活动,了解业务处理的基本情况。 (2)请专人介绍。 (3)在对用户的需求了解过程中一定会存在许多疑问,可以通
过与用户座谈、询问等方式来解决这些疑问。 (4)设计调查表请用户填写。如果调查表设计得合理接受。 (5)查问记录。即查问原系统有关的数据记录。 (6)学习文件。及时了解掌握与用户业务相关的政策和业务规
5.6 数据库实施
所谓数据库的实施,就是根据数据库的逻辑结构 设计和物理结构设计的结果,在具体RDBMS支持的计算 机系统上建立实际的数据库模式、装人数据、并进行 测试和试运行的过程。 (1)散数据库的建立与调整 (2)数据库的调整 (3)应用程序编制与调试 (4)数据库系统的试逻辑结构设计阶段 物理结构设计阶段 数据库实施阶段 数据库运行和维护阶段
5.2 需 求 分 析
5.2.1 需求分析的任务
需求分析的任务是通过详细调查所要处理的对象(组织、 部门、企业等),充分了解原有系统的工作概况,明确用户的 各种数据需求、完整性约束条件、事务处理和安全性条件等, 然后在此基础上确定新系统的功能。新系统必须充分考虑今后 可能的扩充和改变,不能仅仅按当前应用需求来设计数据库。
(1)一个实体型转换为一个关系模式; (2)实体的属性就是关系的属性,实体的码就是关系的码。
5.5 物 理 设 计
数据库物理设计阶段主要包括以下4个过程: (1)分析影响物理数据库设计的因素。 (2)为关系模式选择存取方法。 (3)设计关系、索引等数据库文件的物理存储结构。 (4)评价物理结构。
(1)数据库的转储和恢复。 (2)维持数据库的完整性与安全性。 (3)监测并改善数据库性能。 (4)数据库的重组和重构。
数据库原理及应用课件:第5章 ACCESS 数据库—面向对象的程序设计语言(VBA)

13
2022/10/3
– 用户自定义型 所占字节数与元素个数有关,用 户可以使用Type语句定义任何数据类型。语法 如下:
– [Private/Public] Type 类型名
– 元素名 As 数据类型
–…
– End Type
例如:自定义一个教师的基本信息数据类型,其 中包括姓名、性别、年龄的信息。
4
2022/10/3
– 对象(Object)—是类的一个实例,是组成一个 系统的基本逻辑单元,是具有某些特征的具体的 事物的抽象。每个对象都具有属性和行为。
– 数据抽象(Data Abstraction)—指仅表现核心 的特性而不描述背景细节的行为。
– 继承(Inheritance)—是可以让某个类型的对象 获得另一个类型的对象的属性的方法。
24
2022/10/3
例:已知两个数x和y,比较它们的大小,使 得x大于y。
– 方法一:if x<y then
t=x
x=y
y=t
end if
– 方法二: if x<y then t=x:x=y:y=t
25
2022/10/3
– If …Then…Else语句(双分支结构)。此语句 也有两种形式:块结构和行结构。
– I说f…明T:hen语句(单分支结构)。有两种形
式1):表块达结式构一和般行为结关构系表达式、逻辑表达 块式0结为,构F也a形l可s式e以。:为If<算表术达表式达>式Th,e非n 0为True,
2)语句块可以语是句一块句或多句,若用行结 构来表示,则En只d 能If是一句语句,若多句, 行语结句构间形需式用:冒If号<表隔达开式,>而T且he必n须<语在句一>行上 书写。
数据库系统工程师:数据库原理选择题

数据库系统工程师:数据库原理选择题(五)第五章1. 在数据库设计中,将ER图转换成关系数据模型的过程属于()(2001年10月全国卷)A. 需求分析阶段B. 逻辑设计阶段C. 概念设计阶段D. 物理设计阶段2.在数据库设计中,表示用户业务流程的常用方法是( )(2003年1月全国卷)A.DFDB.ER图C.程序流程图D.数据结构图3.把ER模型转换成关系模型的过程,属于数据库的( )(2002年10月全国卷)A.需求分析B.概念设计C.逻辑设计D.物理设计4.在ER模型中,如果有6个不同实体集,有9个不同的二元联系,其中3个1∶N 联系,3个1∶1联系,3个M∶N联系,根据ER模型转换成关系模型的规则,转换成关系的数目是( )(2002年10月全国卷)A.6B.9C.12D.155.数据库设计属于()。
A、程序设计范畴B、管理科学范畴C、系统工程范畴D、软件工程范畴6.设计数据流程图(DFD)属于数据库设计的()A、可行性分析阶段的任务B、需求分析阶段的任务C、概念设计阶段的任务D、逻辑设计阶段的任务7.在数据库的概念设计中,最常用的模型是()A、实体联系模型B、数学模型C、逻辑模型D、物理模型8.数据库设计中,概念模型是()A、依赖于DBMS和硬件B、依赖于DBMS独立于硬件C、独立于DBMS依赖于硬件D、独立于DBMS和硬件9.ER图是数据库设计的工具之一,它适用于建立数据库的()。
A、需求模型B、概念模型C、逻辑模型D、物理模型10.ER方法中用属性描述事物的特征,属性在ER图中表示为()A、椭圆形B、矩形C、菱形D、有向边11.在关系数据库设计中,设计关系模式的任务属于()A、需求设计B、概念设计C、逻辑设计D、物理设计12.设计子模式属于数据库设计的()A、需求设计B、概念设计C、逻辑设计D、物理设计13.设计DB的存储结构属于数据库设计的()A、需求设计B、概念设计C、逻辑设计D、物理设计14.数据库设计中,外模型是指()A、用户使用的数据模型B、DB以外的数据模型C、系统外面的模型D、磁盘上数据的组织15.概念结构设计的目标是产生数据库的概念结构,这结构主要反映()A、组织机构的信息需求B、应用程序员的编程需求C、DBA的管理信息需求D、DBS的维护需求16.在DB的概念设计和逻辑设计之间起桥梁作用的是()A、数据结构图B、功能模块图C、ER图D、DFD17.在DB的需求分析和概念设计之间起桥梁作用的是()A、DFDB、ER图C、数据结构图D、功能模块图18.ER模型转换成关系模型时,一个M:N联系转换为一个关系模式,该关系模型的关键字是()A、M端实体的关键字B、N端实体的关键字C、M端实体的关键字和N端实体的关键字的组合D、重新选取的其他属性19.在一个ER图中,如果共有20个不同实体类型,在这些实体类型之间存在着9个不同的二元联系(二元联系是指两个实体之间的联系)其中3个是1:N联系,6个是M:N联系,还存在1个M:N的三元联系,那么根据ER模型转换成关系模型的规则,这个ER结构转换成的关系模型个数为()A、24B、27C、29D、3020.在数据库设计中,弱实体是指()A、属性只有一个的实体B、不存在关键码的实体C、只能短时期存在的实体D、以其他实体存在为先决条件的实体21.关于ER图,下列说法中错误的是()A、现实世界的事物表示为实体,事物的性质表示为属性B、事物之间的自然联系表示为实体之间的联系C、在ER图中,实体和属性的划分是绝对的、一成不变的D、在ER图中,实体之间可以有联系,属性和实体之间不能有联系22.在ER模型转换成关系模型的过程中,下列叙述不正确的是()A、每个实体类型转换成一个关系模型B、每个联系类型转换成一个关系模式C、每个M:N联系转换成一个关系模式D、在1:N联系中,“1”端实体的主键作为外键放在“N”端实体类型转换成的关系模式中23.在数据库设计中,超类实体与子类实体的关系是()A、前者继承后者的所有属性B、后者继承前者的所有属性C、前者只继承后者的主键D、后者只继承前者的主键24.综合局部ER图生成总体ER图过程中,下列说法错误的是()A、不同局部ER图中出现的相同实体,在总体ER图中只能出现一次。
《数据库原理及应用》第五章SQL查询

SQL语言
SQL功能 命令动词
数据查询
数据定义 数据操纵
SELECT
CREATE、DROP、ALTER INSERT、UPDATE、DELETE
数据控制
GRANT、REVOKE
SQL语言
SQL语言的优点在于SQL不是面向过程的 语言,使用SQL语言只需描述做什么,而 不需要描述如何做,为使用者带来极大的 方便。本章将以讨论SQL的数据查询语言 为主,同时介绍数据定义语言和数据操纵 语言。本章中大部分例题使用“学生管理” 数据库,并假定数据库在Access的当前目录 下。
简单查询----选择记录
WHERE子句通过指定查询条件,可以在表中找出满足条件 的记录。查询条件可以是任意复杂的逻辑表达式。 当WHERE子句需要指定一个以上的查询条件时,要使用逻 辑运算符AND、OR和NOT将其连接成复合的逻辑表达式。 其优先级由高到低为:NOT、AND、OR,可以使用括号改 变优先级。 条件查询还可以使用LIKE或NOT LIKE进行部分匹配查询。* 表示任意长度的字符串;?表示任意单个字符。 在查询中还可以使用查询谓词,查询谓词IN 和NOT IN用于 检索属于(IN)或不属于(NOT IN)指定集合的记录。 例10 查询成绩在60分以下(不包括60分)、90分以上(含 90分)学生的学号。
连接查询(多表查询)
例13 查询会计系学生选修课程及成绩,要求查询结果中含 属性学号、姓名、课程名称和成绩。 SELECT student.学号,姓名,课程名称,成绩 FROM student,course,grade WHERE 所属院系='会计学院' and student.学号=grade. 学号 and grade.课程编号=course.课程编号 这个查询涉及到两个表,查询所要求的结果来自两个表,查 询的条件也涉及到两个表,所以有“FROM student,grade”; 这两个表之间是有联系的,这种联系是通过父表的主关键字 (student中的学号)和子表的外部关键字(grade表的学号) 建立的,所以有命令子句WHERE中的筛选条件“student. 学号=grade.学号”。 由于student表和grade表都有学号属性,因此在SELECT子 句中要用前缀的形式“student.学号”指明取自哪个表中的 学号;此例中用“grade.学号”的形式,查询结果是一样的。
数据库系统原理课后答案 第五章

5.1 名词解释(1)SQL模式:SQL模式是表和授权的静态定义。
一个SQL模式定义为基本表的集合。
一个由模式名和模式拥有者的用户名或账号来确定,并包含模式中每一个元素(基本表、视图、索引等)的定义。
(2)SQL数据库:SQL(Structured Query Language),即‘结构式查询语言’,采用英语单词表示和结构式的语法规则。
一个SQL数据库是表的汇集,它用一个或多个SQL模式定义。
(3)基本表:在SQL中,把传统的关系模型中的关系模式称为基本表(Base Table)。
基本表是实际存储在数据库中的表,对应一个关系。
(4)存储文件:在SQL中,把传统的关系模型中的存储模式称为存储文件(Stored File)。
每个存储文件与外部存储器上一个物理文件对应。
(5)视图:在SQL中,把传统的关系模型中的子模式称为视图(View),视图是从若干基本表和(或)其他视图构造出来的表。
(6)行:在SQL中,把传统的关系模型中的元组称为行(row)。
(7)列:在SQL中,把传统的关系模型中的属性称为列(coloumn)。
(8)实表:基本表被称为“实表”,它是实际存放在数据库中的表。
(9)虚表:视图被称为“虚表”,创建一个视图时,只把视图的定义存储在数据词典中,而不存储视图所对应的数据。
(10)相关子查询:在嵌套查询中出现的符合以下特征的子查询:子查询中查询条件依赖于外层查询中的某个值,所以子查询的处理不只一次,要反复求值,以供外层查询使用。
(11)联接查询:查询时先对表进行笛卡尔积操作,然后再做等值联接、选择、投影等操作。
联接查询的效率比嵌套查询低。
(12)交互式SQL:在终端交互方式下使用的SQL语言称为交互式SQL。
(13)嵌入式SQL:嵌入在高级语言的程序中使用的SQL语言称为嵌入式SQL。
(14)共享变量:SQL和宿主语言的接口。
共享变量有宿主语言程序定义,再用SQL 的DECLARE语句说明, SQL语句就可引用这些变量传递数据库信息。
精品课件-数据库原理及应用-第5章

第5章 关系数据库设计理论
(4) 示例模式4。 Teach(Cname,Tname,Rbook); 该关系模式用来存放课程、教师及课程参考书信息。其中, Teach为关系模式名,Cname为课程名,Tname为教师名, Rbook为某课程的参考书名。
第5章 关系数据库设计理论
现实系统的数据及语义可以通过高级语义数据模型(如实 体关系数据模型、对象模型)抽象后得到相应的数据模型。为 了通过关系数据库管理系统实现该数据模型,需要使其向关系 模型转换,变成相应的关系模式。然而,这样得到的关系模式, 还只是初步的关系模式,可能存在这样或那样的问题。因此, 需要对这类初步的关系模式,利用关系数据库设计理论进行规 范化,以逐步消除其存在的异常,得到一定规范程度的关系模 式,这就是本章所要讲述的内容。
第5章 关系数据库设计理论
实际上,设计任何一种数据库应用系统,不论是层次的、 网状的还是关系的,都会遇到如何构造合适的数据模式即逻辑 结构的问题。由于关系模型有严格的数学理论基础,并且可以 向别的数据模型转换,因此,人们就以关系模型为背景来讨论 这个问题,形成了数据库逻辑设计的一个有力工具——关系数 据库的规范化理论。规范化理论虽然是以关系模型为背景,但 是对于一般的数据库逻辑设计同样具有理论上的意义。
第5章 关系数据库设计理论
关系系统当中,数据冗余产生的重要原因就在于对数据依 赖的处理,从而影响到关系模式本身的结构设计。解决数据间 的依赖关系常常采用对关系的分解来消除不合理的部分,以减 少数据冗余。在例5.1中,我们将Teaching关系分解为三个关 系模式来表达:Student (Sno,Sname,Ssex,Sdept), Course(Cno,Cname,Tname)及Score(Sno,Cno,Grade),其 中Cno为学生选修的课程编号;分解后的部分数据如表5.2、 表5.3和表5.4所示。
《MySQL数据库原理、设计与应用》第5章课后习题答案

第五章一、填空题1.逗号或,2. 33.FLOOR(3+RAND()*(11-3+1))或FLOOR(3+RAND()*9)4.NULL5.ON DUPLICATE KEY二、判断题1.错2.对3.错4.对5.对三、选择题1. D2. B3. D4. A5. C四、简答题1.请简述DELETE与TRUNCA TE的区别。
答:①实现方式不同:TRUNCATE本质上先执行删除(DROP)数据表的操作,然后再根据有效的表结构文件(.frm)重新创建数据表的方式来实现数据清空操作。
而DELETE语句则是逐条的删除数据表中保存的记录。
②执行效率不同:在针对大型数据表(如千万级的数据记录)时,TRUNCATE清空数据的实现方式,决定了它比DELETE语句删除数据的方式执行效率更高。
③对AUTO_INCREMENT的字段影响不同,TRUNCATE清空数据后,再次向表中添加数据,自动增长字段会从默认的初始值重新开始,而使用DELETE语句删除表中的记录时,则不影响自动增长值。
④删除数据的范围不同:TRUNCATE语句只能用于清空表中的所有记录,而DELETE语句可通过WHERE指定删除满足条件的部分记录。
⑤返回值含义不同:TRUNCATE操作的返回值一般是无意义的,而DELETE语句则会返回符合条件被删除的记录数。
⑥所属SQL语言的不同组成部分:DELETE语句属于DML数据操作语句,而TRUNCA TE通常被认为是DDL数据定义语句。
2.请简述WHERE与HA VING之间的区别。
1答:①WHERE操作是从数据表中获取数据,用于将数据从磁盘存储到内存中,而HA VING是对已存放到内存中的数据进行操作。
②HA VING位于GROUP BY子句后,而WHERE位于GROUP BY 子句之前。
③HA VING关键字后可以跟聚合函数,而WHERE则不可以。
通常情况下,HA VING关键字与GROUPBY一起使用,对分组后的结果进行过滤。
数据库原理第五章关系数据库的规范化设计

12
模式分解是关系规范化的 主要方法(二)
与TDC相比,分解为三个关系模式后,数据的冗余度明显 降低。 当新插入一个系时,只要在关系D中添加一条记录。 当某个教师尚未讲课,只要在关系T中添加一条教师记录, 而与TC授课关系无关,这就避免了插入异常。 当某个系的教师不再讲课时,只需在TC中删除该教师的 全部授课记录,而关系D中有关该系的信息仍然保留,从 而不会引起删除异常。 同时,由于数据冗余度的降低,数据没有重复存储,也不 会引起更新异常。
24
2.2 完全函数依赖和部分函数依赖
例如:学生成绩表中
姓名 王一 王二 王三 王一
学号 1 2 3 4
年龄 16 15 16 16
籍贯 河北 山东 北京 天津
姓名不能推出年龄,学号也不能推出年龄,但是 姓名 + 学号能推出年龄,故完全依赖;
学号能直接推出籍贯,故是部分依赖
25
2.3 传递函数依赖
当关系中的元组增加、删除或更新后都不能被破 坏这种函数依赖。因此,必须根据语义来确定属 性之间的函数依赖,而不能单凭某一时刻关系中 的实际数据值来判断。
20
函数依赖的定义和性质(六)
函数依赖可以保证关系分解的无损连接性
设R(X,Y,Z),X,Y,Z为不相交的属性集合,如果X Y或X Z,则有R(X,Y,Z)=R[X,Y]*R[X,Z],其中,R[X,Y]表示关 系R在属性(X,Y)上的投影,即 R等于其投影在X上的自然连 接,这样便保证了关系R分解后不会丢失原有的信息,称为 关系分解的无损连接性
《数据库系统原理》PPT电子课件教案-第五章 数据库保护

四、用户定义的安全性措施 除了系统级的安全性措施外,Oracle还允许用户用数 据库触发器定义特殊的更复杂的用户级安全性措施。例 如,规定只能在工作时间内更新Student表,可以定义如 下触发器,其中sysdate为系统当前时间: CREATE OR REPLACE TRIGGER secure student BEFORE INSERT OR UPDATE OR DELETE ON Student BEGIN IF(TO_CHAR(sysdate,’DY’) IN(‘SAT’,’SUN’)) OR(TO_NUMBER(sysdate HH24') NOT BETWEEN 8 AND l7) THEN
常用的方法:
1)用一个用户名或者用户标识号来标明用户身份, 系统鉴别此用户是否是合法用户。 2)口令(Password)。为进一步核实用户,系统要求 用户输入口令 3)系统提供一个随机数,用户根据预先约定好的某 一过程或函数进行计算,系统根据计算结果是否正 确进一步鉴定用户身份。
2. 存取控制
(2)行级安全性 Oracle行级安全性由视图实现。用视图定义表的水 平子集,限定用户在视图上的操作,就为表的行级提供 了保护。视图上的授权与回收与表级完全相同。 例如,只允许用户U2查看Student表中信息系学生的 数据,则首先创建信息系学生视图S_ IS,然后将该视图 的SELECT权限授予U2用户。 (3)列级安全性 Oracle列级安全性可以由视图实现,也可以直接在基 本表上定义。 用视图定义表的垂直子集就可以实现列级安全性,方 法与上面类似。
Oracle对数据库对象的权限采用分散控制方式, 允许具有WITH GRANTOPTION的用户把相应权限或 其子集传递授予其他用户,但不允许循环授权,即被 授权者不能把权限再授回给授权者或其祖先, U1 U2 U3 U4 × 循环授权 Oracle把所有权限信息记录在数据字典中。当用 户进行数据库操作时,Oracle首先根据数据字典中的 权限信息,检查操作的合法性。在Oracle中,安全性 检查是任何数据库操作的第一步。
数据库原理 第五章

Database Theory
Integrity Constraints in Create Table
SCT
Student
Not NULL
Primary Key (A1, ..., An) Check (P), where P is a predicate …… E.g.
Create Table Student (Sno char(10) Not NULL, Sname char(20),
DCL (Data Control Language)
Grant Revoke
4 Finance & Economics Zhejiang University of
Database Theory
Data Definition Language (DDL) Allows the specification of not only a set of relations but also information about each relation, including:
char(n) – Fixed length character string, with user-specified length n. varchar(n). – Variable length character strings, with user-specified maximum length
Database Theory
Operations of SQL
DDL (Data Definition Language)
Create
Alter Drop
DML (Data Manipulation Language)
数据原理 第5章 数据预处理

©
第五章
数据预处理:11
5.1.1.3清洗脏数据
❖ 异构数据源数据库中的数据并不都是正确的,常常 不可避免地存在着不完整、不一致、不精确和重复 的数据,这些数据统称为“脏数据”。脏数据能使 挖掘过程陷入混乱,导致不可靠的输出。
©
第五章
数据预处理:12
清洗脏数据可采用下面的方式:
手工实现方式 用专门编写的应用程序 采用概率统计学原理查找数值异常的记录 对重复记录的检测与删除
第五章
数据预处理:24
©
5.1.4.4 概念分层
❖ 概念分层通过收集并用较高层的概念替换较低层的 概念来定义数值属性的一个离散化。
❖ 概念分层可以用来归约数据,通过这种概化尽管细 节丢失了,但概化后的数据更有意义、更容易理解, 并且所需的空间比原数据少。
❖ 对于数值属性,由于数据的可能取值范围的多样性 和数据值的更新频繁,说明概念分层是困难的。
©
第五章
数据预处理:40
❖ 第二,算法简单。对于给定的决策表,预处理过程所使用的 算法可以是分辨矩阵或逐个属性、逐条规则进行检验,算法 简单,易于计算机的实现,方便挖掘系统的自动操作;
❖ 第三,可以有效地去除冗余的属性或属性的值。
©
第五章
数据预处理:34
5.2.2复共线性数据的预处理方法
❖ 常规方法进行函数发现时一般要作出一个假设:数 据满足统计不相关。而传统的函数发现算法中,常 常忽略对数据是否满足该假设的检验。若数据不满 足统计不相关的假设(也称数据变量之间存在复共 线性),在这种情况下,函数发现算法挖掘出来的 函数关系表达式可能会存在系统误差,该表达式将 不是我们要发现的理想函数。
©
第五章
数据预处理:32
数据库原理及应用李唯唯第五章实验

数据库原理及应用李唯唯第五章实验数据库原理及应用是一门涉及数据库设计、管理和应用的学科,主要包括数据库理论和数据库技术的学习与应用。
在学习数据库原理及应用的第五章实验中,我主要学习了数据库的事务管理和并发控制。
事务是数据库管理系统中的一个重要概念,它是由一系列数据库操作组成的逻辑单位,具有原子性、一致性、隔离性和持久性四个特性。
事务的管理可以保证数据库的数据完整性和一致性,在实际应用中起到了非常重要的作用。
在这一章节的实验中,我首先学习了事务的概念和特性,并了解了事务的隔离级别。
数据库的隔离级别包括读未提交、读已提交、可重复读和串行化四个级别,每个级别在并发访问数据库时有不同的表现和效果。
了解了这些隔离级别之后,我在实验中通过设置不同的隔离级别,进行了相关的实验和测试。
在实验中,我使用MySQL数据库进行了相关的操作和设置。
首先,我创建了一个测试用的数据库和表,并插入了一些测试数据。
接着,我通过SQL语句和MySQL的事务命令进行了不同的操作,例如插入、更新、删除等。
在进行操作的过程中,我对不同的隔离级别进行了设置,并观察了不同隔离级别下的数据库表现。
通过实验,我对事务管理和并发控制有了更深入的了解。
在并发访问数据库时,由于多个事务同时进行,可能会导致一些问题,例如脏读、不可重复读和幻读等。
通过设置合适的隔离级别,可以避免这些问题的发生。
在实验中,我观察到在读未提交的隔离级别下,可以发生脏读现象;在读已提交的隔离级别下,脏读得到了避免,但不可重复读问题依然存在;而在可重复读和串行化的隔离级别下,不仅脏读和不可重复读问题都得到了避免,还能够避免幻读问题。
通过这次实验,我不仅学习了事务管理和并发控制的相关知识,还学会了如何使用MySQL进行相关的实际操作。
数据库的事务管理和并发控制在实际应用中非常重要,特别是在多用户环境下,合理设置隔离级别可以保证数据库的数据完整性和一致性。
因此,学习和掌握这些知识对于我今后的工作和学习都具有重要的意义。
数据库原理与应用 第5章答案解析肖海蓉、任民宏

第5 章网络数据库管理系统SQL Server 2012课后习题参考答案1、简答题(1)简述组成SQL Server 2012 数据库的三种类型的文件。
答:SQL Server 数据库文件根据其作用的不同,可以分为主数据文件、次数据文件、事务日志文件3 种类型。
①主数据文件(primary file):主数据文件是数据库的起点,指向数据库文件的其他部分。
主数据文件是用来存放数据和数据库的初始化(启动)信息和部分或全部数据,是SQL Server 数据库的主体,它是每个数据库不可缺少的部分,每个数据库有且仅有一个主数据文件,用户数据和对象也可以存储在此文件中,主数据文件的文件扩展名为.mdf。
②次数据文件(secondary file):用来存储主数据文件没有存储的其他数据和对象。
如果数据库中的数据量很大,除了将数据存储在主数据文件中以外,还可以将一部分数据存储在次数据文件中;如果主数据文件足够大,能够容纳数据库中的所有数据,则该数据库不需要次数据文件。
使用次数据文件是因为数据量太过庞大,可以将数据分散存储在多个不同磁盘上以方便进行管理、提高读取速度。
次数据文件的扩展名为.ndf。
③事务日志文件(transaction log file):用来记录数据库更新情况的文件,SQL Server 2012具有事务功能,可以保证数据库操作的一致性和完整性,用事务日志文件来记录所有事务及每个事务对数据库进行的插入、删除和更新操作。
事务日志是数据库的重要组件,如果数据库遭到破坏,可以根据事务日志文件分析出错的原因;如果数据丢失,可以使用事务日志恢复数据库内容。
每个数据库至少拥有一个事务日志文件,也可以拥有多个日志文件。
事务日志文件的文件扩展名为.ldf。
(2)SQL Server 2012 有哪些系统数据库,它们的作用是什么?SQL Server 2012 中主要包括master、model、tempdb 和msdb 四个系统数据库。
数据库原理及应用第5章课后习题答案

习题51、 理解并给出下列术语的定义:1)设R(U)是一个属性集U 上的关系模式,X 和Y 是U 的子集。
若对于R(U)的任意一个可能的关系r ,r 中不可能存在两个元组在X 上的属性值相等, 而在Y 上的属性值不等, 则称 X 函数确定Y 或 Y 函数依赖于X ,记作X →Y 。
2) 完全函数依赖在R(U)中,如果X →Y ,并且对于X 的任何一个真子集X ’,都有Y 不函数依赖于X ’ ,则称Y 对X 完全函数依赖,记作Y X F −→−3) 部分函数依赖若X →Y ,但Y 不完全函数依赖于X ,则称Y 对X 部分函数依赖,记作Y X p −→−4) 传递函数依赖在R(U)中,如果X →Y ,(Y ⊆X) , Y →X ,Y →Z , 则称Z 对X 传递函数依赖。
记为:Z X T−→−注: 如果Y →X , 即X ←→Y ,则Z 直接依赖于X 。
5)候选码设K 为R (U,F )的属性或属性组合。
若U K F →, 则K 称为R 的侯选码。
6)主码:若候选码多于一个,则选定其中的一个作为主码。
7)外码:关系模式 R 中属性或属性组X 并非 R 的码,但 X 是另一个关系模式的码,则称 X 是R 的外部码(Foreign key )也称外码8)如果一个关系模式R 的所有属性都是不可分的基本数据项,则R ∈1NF.9)若R ∈1NF ,且每一个非主属性完全函数依赖于码,则R ∈2NF 。
10)如果R(U,F )∈2NF ,并且所有非主属性都不传递依赖于主码,则R(U,F )∈3NF 。
11)关系模式R (U ,F )∈1NF ,若X →Y 且Y ⊆ X 时X 必含有码,则R (U ,F ) ∈BCNF 。
12)关系模式R<U ,F>∈1NF ,如果对于R 的每个非平凡多值依赖X →→Y (Y ⊆ X ),X 都含有码,则R ∈4NF 。
2、 关系规范化的操作异常有哪些?1) 数据冗余大2) 插入异常3) 删除异常4) 更新异常3、 第一范式、第二范式和第三范式关系的关系是什么?4、 已知关系模式R(A,B,C,D,E)及其上的函数依赖集合F={A->D,B->C,E-> A},该关系模式的候选码是什么?候选码为:(E,B)5、 已知学生表(学号,姓名,性别,年龄,系编号,系名称),存在的函数依赖集合是{学号->姓名,学号->性别,学号->年龄,学号->系编号,系编号->系名称},判断其满足第几范式。
数据库系统原理教程第五章清华大学

存取控制(续)
– 关系数据库中授权的数据对象粒度 • 数据库 •表 • 属性列 •行
– 能否提供与数据值有关的授权反映了授权子 系统精巧程度
存取控制(续)
实现与数据值有关的授权
– 利用存取谓词 • 存取谓词可以很复杂 – 可以引用系统变量,如终端设备号, 系统时钟等,实现与时间地点有关的 存取权限,这样用户只能在某段时间 内,某台终端上存取有关数据
DBMS中的数据加密
– 有些数据库产品提供了数据加密例行程序 – 有些数据库产品本身未提供加密程序,但提
供了接口
数据加密(续)
数据加密功能通常也作为可选特征,允 许用户自由选择
– 数据加密与解密是比较费时的操作 – 数据加密与解密程序会占用大量系统资源 – 应该只对高度机密的数据加密
5.1 安全性
享
例:军事秘密、 国家机密、 新产品实验数据、 市场需求分析、市场营销策略、销售计划、 客户档案、 医疗档案、 银行储蓄数据
安全性(续)
– 数据库中数据的共享是在DBMS统一的严格 的控制之下的共享,即只允许有合法使用权 限的用户访问允许他存取的数据
– 数据库系统的安全保护措施是否有效是数据 库系统主要的性能指标之一
例:DBA建立一用户U12后,欲将ALTER
TABLE、CREATE VIEW、CREATE INDEX、 DROP TABLE、DROP VIEW、DROP INDEX, GRANT,REVOKE、INSERT 、 SELETE、UPDATE、DELETE、AUDIT、 NOAUDIT等系统权限授予U12,则可以只简 单地将CONNECT角色授予U12即可:
空
3. 定义视图
视图机制把要保密的数据对无权存取这些数据 的用户隐藏起来,从而自动地对数据提供一定 程度的安全保护。
第五章 关系的规范化(数据库原理与应用)

DataBase
关系规范化
关系规范化是从微观角度研究关系模式中属性与 属性之间的函数依赖性,判断关系模式中设计的 合理性,解决数据库设计的优化问题 规范化是通过一组不同级别的范式判定关系规范 化的程度,确认产生数据异常的原因,并通过关 系模式的分解方法,消除数据异常 规范化设计理论主要包括三方面内容:数据依赖, 范式和模式设计方法
魏英 tutor_wei@
7952616
DataBase
第一范式
将非规范化关系转换成1NF:P131
工资(工程号,工程名称,职工号,姓名,职务,小 时工资率,工时)
工程号 工程名称 职工号 A1 A1 A1 A2 花园大厦 花园大厦 花园大厦 立交桥 1001 1002 1004 1001 姓名 职务 小时工资率 工时 65 60 60 65 13 16 19 15 齐光明 工程师 李思岐 技术员 葛宇洪 律师 齐光明 工程师
律师
60
14
840
设计一个关系模式
R(工程号,工程名称,职工号,姓名,职务,小时工资率, 工时)
魏英 tutor_wei@ 7952616
DataBase
关系规范化
典型问题
数据冗余:如果一个职工参与多个工程项目,那么这 个职工的职工号,姓名,职务和小时工资率就要重复 几次存储。 操作异常
魏英 tutor_wei@
7952616
DataBase
函数依赖
例5.1:学生关系模式为学生(学号,姓名,性 别,系名称,系地址)
学号 姓名 性别 系名称 系地址 101 张三 男 计算机 C 102 李四 男 计算机 C 103 王五 女 计算机 C 经管 104 赵六 女 B 学生关系的FD集为: FD={ 学号→姓名, 学号→性别, 学号→系名称, 学号→系地址 系名称→系地址}
数据库原理第五章PPT课件

9
记录一般不会刚好填满物理块,会留下不用的零头 空间:
B―p×R<R
记录1 记录2 记录3 记录4
为了利用这部分空间,可以利用记录的跨块存储组 织(spanned organization)。
10
定长记录(跨块)
块i
记录1
记录2
记录3 记录4
区 址最 高 键
相对地址
1 121
2 134 3 167 4 182
5 203 6 211 7 223
8
9 229 10 231 11 237 12
241
索引键
13 255 14 259 15 267 16 271 …
…
37
查找索引键为211的记录的存储地址
211
271 430 601
182 4 201
Student(SNO,SNAME,SEX,BIRTHDATE, DEPT)
散列函数 H(SNO)=Address
90041 李林 … 计算机系 2
H(900412)=@addr
@addr
90041 李林 … 2
计算机系
存储空间
29
直接文件存在的问题: 键所映射的地址范围固定(地址范围设的太大或 太小都不好,为什么?)。 地址重叠问题(处理地址重叠增加了开销)。 直接文件只对散列键的访问有效。 不便于处理变长记录。 对于通用的DBMS很难找到通用的散列函数。 上述原因导致直接文件目前在数据库系统中使用不多。
0001 Nanjing 0002 Nanjing 0003 Nanjing 0004 Shanghai 0005 Shanghai
数据库管理系统原理 第五章测验 测验答案 慕课答案 UOOC优课 课后练习 深圳大学
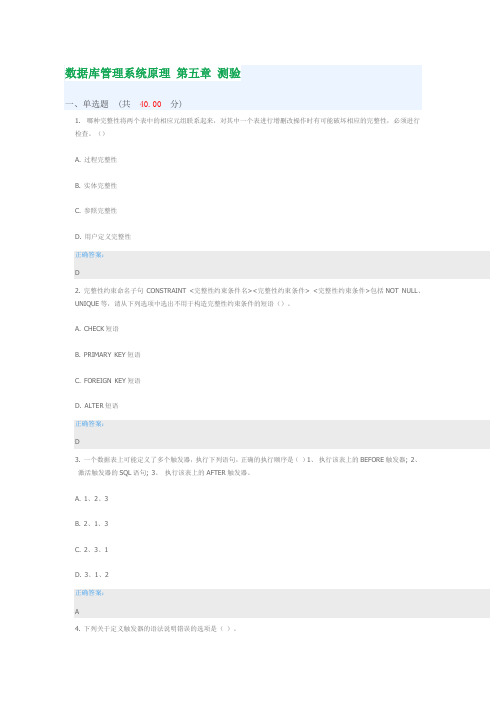
数据库管理系统原理第五章测验一、单选题(共40.00分)1. 哪种完整性将两个表中的相应元组联系起来,对其中一个表进行增删改操作时有可能破坏相应的完整性,必须进行检查。
()A. 过程完整性B. 实体完整性C. 参照完整性D. 用户定义完整性正确答案:D2. 完整性约束命名子句CONSTRAINT <完整性约束条件名><完整性约束条件> <完整性约束条件>包括NOT NULL、UNIQUE等,请从下列选项中选出不用于构造完整性约束条件的短语()。
A. CHECK短语B. PRIMARY KEY短语C. FOREIGN KEY短语D. ALTER短语正确答案:D3. 一个数据表上可能定义了多个触发器,执行下列语句,正确的执行顺序是()1、执行该表上的BEFORE触发器; 2、激活触发器的SQL语句; 3、执行该表上的AFTER触发器。
A. 1、2、3B. 2、1、3C. 2、3、1D. 3、1、2正确答案:A4. 下列关于定义触发器的语法说明错误的选项是()。
A. 表的拥有者才可以在表上创建触发器B. 触发器可以定义在基本表上,也可以定义在视图上C. 同一模式下,触发器名必须是唯一的,触发器名和表名必须在同一模式下D. 触发器只能定义在基本表上,不能定义在视图上正确答案:B二、多选题(共33.00分)1. 触发器类型()。
A. 行级触发器(FOR EACH ROW)B. 列级触发器(FOR EACH COLUMN)C. 语句级触发器(FOR EACH STATEMENT)D. 表级触发器(FOR EACH TABLE)正确答案:A C2. CREATE TABLE DEPT ( Deptno NUMERIC(2), Dname CHAR(9) UNIQUE NOT NULL)关于关键子句“ UNIQUE NOT NULL”描述正确的选项()。
A. 实体完整性B. 要求Dname列值唯一, 或者不能取空值C. 用户定义的完整性D. 要求Dname列值唯一, 并且不能取空值正确答案:C D3. 数据的安全性描述正确的选项()。
数据库第五章

数据库第五章在学习数据库的过程中,第五章往往是一个关键的转折点。
这一章通常会涉及到一些更深入、更复杂的概念和技术,为我们进一步理解和应用数据库打下坚实的基础。
首先,第五章可能会着重探讨数据库的索引结构。
索引就像是一本书的目录,它能够帮助我们快速地找到所需的数据。
想象一下,如果没有目录,我们要在一本厚厚的书中找到特定的内容,那将是多么耗时费力。
数据库中的索引也是如此,它可以大大提高数据检索的效率。
常见的索引类型包括 B 树索引、哈希索引等。
B 树索引适用于范围查询,而哈希索引则在精确匹配查询时表现出色。
了解不同索引类型的特点和适用场景,对于优化数据库性能至关重要。
其次,数据库的存储结构也是这一章的重要内容。
数据在磁盘上的存储方式会直接影响到数据的读写速度和存储空间的利用效率。
比如,连续存储可以提高读取的性能,但不利于数据的插入和删除;而链式存储则在插入和删除操作上更具优势,但读取时可能需要更多的时间来遍历链表。
此外,还会涉及到数据的压缩技术,通过合理的压缩算法,可以减少数据存储空间,降低存储成本。
第五章可能还会讲到数据库的查询优化。
当我们向数据库发送一个查询请求时,数据库系统需要决定如何以最有效的方式执行这个查询。
这涉及到对查询语句的分析、执行计划的生成和选择。
比如,在一个包含多个表的复杂查询中,选择合适的连接方式(内连接、外连接等)以及确定表的访问顺序,都能对查询性能产生巨大的影响。
为了实现查询优化,数据库管理员需要了解数据库系统的内部机制,能够通过查看执行计划来判断查询的效率,并根据实际情况进行调整。
另外,事务处理也是这一章不容忽视的部分。
事务是数据库操作的基本单位,它具有原子性、一致性、隔离性和持久性这四个重要特性,通常被称为ACID 特性。
原子性确保事务中的所有操作要么全部成功,要么全部失败,不会出现部分成功的情况;一致性保证事务执行前后数据库的状态始终是合法的;隔离性使得多个并发事务之间相互隔离,不会相互干扰;持久性则保证事务一旦提交,其结果就会永久保存,不会因为系统故障而丢失。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
记录8 记录7 记录6 记录5 记录4 记录3 记录2 记录1
记录8 记录7
作删除 标记
记录6 记录5 记录4 记录3 记录2 记录1
集中删除 记录,并 进行记录 重排
记录8 记录7 记录5 记录3 记录1
2.直接文件
直接文件中,将记录的某一属性用散列函数直 接映射成记录的地址,被散列的属性称为散列键。
…
计算机系
900417 900418
陈燕
…
计算机系
…
存储空间
学生表的索引文件
索引与散列的区别——索引文件有记录才占用 存储空间,使用散列空文件也占用全部文件空间。 索引本省占用空间,但索引一般较记录小得多
针对非散列键和非索引属性的访问,都不能有效发挥直 接文件或索引文件的优势。散列或索引失效时,两者谁的访 问代价更大?
Shanghai
问题:索引法对串型的长度有什么要求?
5.3 文件结构和存取路径
5.3.1 访问文件的方式
传统的数据模型都以记录为基础,记录的集合构成 文件。文件须按一定的结构组织和存储记录,按一定 的存取路径访问有关记录。 对数据库的操作最终要落实到对文件的操作。 文件结构及其所提供的存储路径直接影响数据访问 的速度,通常针对不同的数据访问采用不同的文件结 构。
19 24 28 31
289 311 419 430
单元存 储区
5 203 6 211 211 7 223 8 9 10 231 11 237 12 241 229
最单 高元 键存 值储 区
值单 相元 对存 地储 址最 高 键
最 指溢 高 针出 键 链 值 头
13 14 15 16 …
255
259
267 271 …
变长记录(跨块)
记录1 记录2 记录3
块i
块i+1
记录3(剩 余部分)
记录4
记录5
5.2.3 物理块在磁盘上的分配
早期的DBMS中,通常由操作系统分配数 据库所需的物理块,逻辑上相邻的数据可能 被分散到磁盘的不同区域。使得访问数据时, 性能下降。 现代DBMS中,都改由DBMS初始化时向操 作系统一次性的申请所需的存储空间。
相对地址
稠密索引(dense index)
每个键值对应一个索引项——稠密索引。 稠密索引的预查找功能(用记录的地址代替记录参与 集合运算,减少I/O次数)。 索引溢出的问题
稠密索引中,每增加一个键值,就要增加一个索引项。 索引也会有溢出的可能。 解决方法:1.在每个索引块中预留发展的空间 2.建立索引溢出区
为了便于检索,索引项总是按索引键排序。
文件中的记录按索引键排序吗?
注意:索引项记录,并不是文件中的记录 按索引键排序 受按门牌号找住户的启示(住户在“物理” 上按门牌号码排序),提出非稠密索引。
非稠密索引与稠密索引
1.不为每个键值设立索引项的索引——非稠密索引 2.可以节省索引的存储空间,代价是文件要按索引 键排序 3.对一个文件,只能为一个索引键(一般为主键) 建立非稠密索引(为什么?)
1、连续分配法(contiguous allocation)
将一个文件的块分配在磁盘的连续空间上, 块的次序就是其存储的次序,有利于顺序存取 多块文件,不利于文件的扩充。 2、链接分配法(linked allocation)
物理块未必分配在磁盘的连续存储空间上, 各物理块用指针链接,有利于文件的扩展,但 效率较差。
溢出区
271
16
271
1 2 3 4 5 6 7 8 9 10 11 12
121 134 167 182 203 211 223 229 231 237 241 13 14 15 16 … 255
索引键
单元存 储区
259
267 271 …
最单 高元 键存 值储 区
值单 相元 对存 地储 址最 高 键
4.非稠密索引中,若干个记录组成一个单元存储区,单 元存储区中的记录按索引键排序。 5.单元存储区装满后,可向溢出区溢出(用指针指向溢 出区),但溢出太多时,指针链接次数增加,将导致数 据库性能下降。 6.可以建立多级非稠密索引(通常最高一级索引应尽量 保证可以常驻内存)。
示例
191
182 223 241 271 430 601 289 311 419 430 19 24 28 31 289 311 419 430 4 7 12 201 223 251 249 201 251
3、簇集分配法(clustered allocation) 上述两种方法的结合。 4、索引分配法(indexed allocation) 每个文件有一个逻辑块号与其物理块地址对 照的索引。
数据压缩技术
1.消零或空格符法(null suppression) 例如,bbbbb可以用#5表示; 000000可以用@6表示等。 2.串型代替法(pattern substitution)
5.2.2 记录在物理块上的分配
磁盘上,记录必须分配到物理块中。
记录跨快存储(spanned) 记录不垮块存储(unspanned)
设B为物理块的有效空间大小,R为固定长记 录的大小,若B>R,则每个物理块可容纳的记录 数为: p=[B/R] p称为块因子(Blocking Factor)。
传统文件系统不能提供实现DBMS功能所需的附 加信息。DBMS为了实现其功能,须在文件目录、 文件描述块、物理块等部分附加一些信息。 传统文件系统主要面向批处理,数据库系统要 求即时访问、动态修改。这就要求文件的结构能 适应数据的动态变化,提供快速访问路径。
传统文件系统服务对象特殊,用途单一,共享 度低;数据库中的文件供所有用户共享,有些用 途甚至是不可知的。
5 12 18
2.相对法——每个字段没有固定的长度,而是用特 殊的字符分隔开
LI? MING? MALE? 1967#
问题:字段中也需要用到这些分隔符时,如何进行 表示?
3.计数法——每个字段的开始加上表示该字段长度 的字段
02LI04MING04MALE041967
问题:计数法对字段的实际长度有什么要求?
1.主索引——以主键为索引键(primary index)。 2.次索引——以非主键为索引键(secendary index),建立次索引可以提高查询的效率,但增 加了索引维护的开销。 3.倒排文件——主索引+次索引的极端情况(文件 的所有属性上都建立索引),有利于多属性值的 查找,但数据更新时开销很大。
文件访问方式按设计文件结构的观点分5类
1.查询文件的全部或相当多的记录(≥15%) 2.查询某一特定记录 3.查询某些记录 4.范围查询 5.记录的更新
5.3.2 数据库对文件的要求
一些DBMS就以OS的的文件管理系统作为 其物理层的基础,更多的DBMS不用OS的文件 管理系统,而是独立设计其存储结构。原因 如下:
Student(SNO,SNAME,SEX,BIRTHDATE,DEPT)
散列函数 H(SNO)=Address
900412 李林 … 计算机系
@addr
H(900412)=@addr
900412
李林
…
计算机系
存储空间
直接文件存在的问题:
键所映射的地址范围固定(地址范围设的太大或 太小都不好,为什么?)。 地址重叠问题(处理地址重叠增加了开销)。 直接文件只对散列键的访问有效。 不便于处理变长记录。 对于通用的DBMS很难找到通用的散列函数。 上述原因导致直接文件目前在数据库系统中使用不多。
最 指溢 高 针出 键 链 值 头
相对地址
查找索引键为211的记录的存储地址
191
182 223 4 7 7 12 201 223 251 249 201 251
211
271 430 601
241
溢出区
271
16
271
1 2 3 4
121 134 167 182
索引键
289 311 419 430
减少DBMS对OS的依赖,提高DBMS的可移植性。
传统文件系统一旦建立以后,数据量比较稳定; 数据库中文件的数据量变化较大。
5.3.3 文件的基本类型
不同类型的访问各有其使用的文件结构和 存取路径。DBMS通常提供多种文件结构,供数 据库设计者选用。
1.堆文件(heap file) 2.直接文件(direct file) 3.索引文件(indexed file)
OS与DBMS都有各自的缓冲区。 不少DBMS采用延迟写与提前读技术,减少 I/O,改善性能。
5.2 记录的存储结构
记录是目前商用数据库的基本数据单元,有定 长和变长之分。 记录的存储结构
1.定位法——每个字段按其最大可能长度分配定长的 位臵
LIbbb MINGbbb MALEbb 1967
以物理块为交换单位的优点: 1).减少I/O的次数,从而减少寻道和等待的时间。 2).减少间隙的数目,提高磁盘空间利用率。 物理快的大小由OS决定。
一般,在磁盘和内存之间设立缓冲区以解决 二者的速度不匹配问题。
由于有多个缓冲块可供申请使用,磁盘的读写 操作和读写数据的处理可以重叠进行。
i块缓冲块A 读出: 处理: i+1块缓冲块B i+2块缓冲块A 处理A中i块 处理B中i+1块
第五章 数据库的存储结构
5.1 数据库存储介质的特点
数据库是大量、持久数据的集合,在现阶段 用内存作为数据库的存储介质是不合适的。
采用多级存储器,用的最多的辅存是磁盘。 光盘由于速度和价格上的原因,近期无法取 代硬盘。 磁带是顺序存取存储器,通常用作后备存储 器。