[课件]薛薇第四版SPSS第五章PPT
薛薇SPSS统计分析方法及应用相关分析和线性回归分析PPT课件

其中,ry1、ry2、r12分别表示
y和x1的相关系数,y和x
的相关系数,
2
x1和x
的相关系数
2
偏相关系数的取值范围及大小含义与相关系数相同.
第41页/共110页
• 第二,对样本来自的两总体是否存在显著的 净相关进行推断
• 检验统计量为:
tr
nq2
1 r2
• 其中,r为偏相关系数,n为样本数,q为阶数。 T统计量服从n-q-2个自由度的t分布。
• 例如,在研究商品的需求量和价格、消费者收入 之间的线性关系时,需求量和价格之间的相关关 系实际还包含了消费者收入对价格和商品需求量 的影响。
第39页/共110页
• 偏相关分析也称净相关分析,它在控制其他变 量的线性影响的条件下分析两变量间的线性关 系,所采用的工具是偏相关系数。
• 控制变量个数为1时,偏相关系数称一阶偏相 关;当控制两个变量时,偏相关系数称为二阶 偏相关;当控制变量的个数为0时,偏相关系 数称为零阶偏相关,也就是简单相关系数。
第7页/共110页
1、简单散点图
选中简单分布, 单击定义Define 按钮,打开窗口
相关回归分析(高校科研研究).sav
第8页/共110页
• Y轴Y Axis:选择Y轴要绘制的变量 • X轴X Axis:选择X轴要绘制的变量 • 设置标记Set Markers by:选择分组变量,
SPSS根据该变量的值将观测量分成几组,每 组采用不同的符号标注 • 标注个案Label Cases by:观测量标签变量
• 书中的第19章,统计图形.
第22页/共110页
相关系数
利用相关系数进行变量间线性关系的分析通常需要 完成以下两个步骤: • 第一,计算样本相关系数r;
薛薇SPSS统计方法及应用聚类介绍PPT学习教案

第6页/共33页
3、二值(Binary)变量个体间
注:聚类分析的几点说明 ➢ 所选择的变量应符合聚类的要求:所选变量应能够从不同 的侧面反映我们研究的目的; ➢ 各变量的变量值不应有数量级上的差异(对数据进行标准 化处理):聚类分析是以各种距离来度量个体间的“亲疏” 程度的,从上述各种距离的定义看,数量级将对距离产生 较大的影响,并影响最终的聚类结果。 ➢ 各变量间不应有较强的线性相关关系
种类型,分别是Q型聚类和R型聚类;层次聚类的聚类方式又有两种,分别是凝聚方式聚 类和分解方式聚类。
Q型聚类:对样本进行聚类,使具有相似特征的样本 聚集在一起,差异性大的样本分离开来。 R型聚类:对变量进行聚类,使具有相似性的变量聚 集在一起,差异性大的变量分离开来,可在相似变量 中选择少数具有代表性的变量参与其他分析,实现减 少变量个数,达到变量降维的目的。
第21页/共33页
Dendrogram选项表示输出聚类分析树形图;在Icicle 框中指定输出冰挂图,其中,All clusters表示输出 聚类分析每个阶段的冰挂图,Specified range of clusters表示只输出某个阶段的冰挂图,输入从第几 步开始,到第几步结束,中间间隔几步;在 Orientation框中指定如何显示冰挂图,其中, Vertical表示纵向显示,Horizontal表示横向水平显示。
第24页/共33页
9.2.4 层次聚类的应用举例 1、利用31个省市自治区小康和现代化指数数据进
行层次聚类分析。 利用SPSS层次聚类Q型聚类对31个省市自治区进行
分类分析。其中个体距离采用平方欧式距离,类间 距离采用平均组间链锁距离,由于数据不存在数量 级上的差异,因此无需进行进行标准化处理。 2、利用裁判打分数据进行聚类分析。
SPSS第五章 方差分析PPT课件

SPSS统计软件应用
温有锋
第五章 方差分析
1
辽宁医学院
SPSS统计软件应用
一、方差分析的概念
温有锋
在科学实验中常常要探讨不同实验条件或处 理方法对实验结果的影响。通常是比较不同 实验条件下样本均值间差异。
方差分析是检验多个样本均数间差异是否具 有统计意义的一种统计学方法。
举例:几种药物对某疾病的疗效;不同饲料 对牲畜体重增长的效果;
13
辽宁医学院
SPSS统计软件应用
实验数据
温有锋
各组平均值
第一组 0.8 0.9 0.7 0.8
红细胞增加数(百万/m3)
第二组
第三组
1.3
0.9
1.2
1.1
1.1
1.0
1.2
1.0
第四组 2.1 2.2 2.0 2.1
这是个双因素方差分析的问题,因素A与因素B。每 个因素均有用该药与不用该药两个水平,研究药物A 和B是否对红细胞的增加有显著影响是对红细胞增加 数的均值作以下比较:
温有锋
假设有m个样本,如果原假设H0:样本均数都相同 μ1=μ2=μ3=········=μm=μ,m个样本有共同的方差σ2。 则m个样本来自具有共同的方差σ2和相同的均数μ的 总体。
如果经过计算结果组间均方远远大于组内均方,则F> F0.05(df组间,df组内),p<0.05,推翻原假设,说明样本 来自不同的正态总体,是处理造成均值的差异,有统 计意义。否则,F<F0.05(df组间,df组内),P>0.05承认 原假设,样本来自相同总体,处理无作用。
14
辽宁医学院
SPSS统计软件应用
实验数据分析
温有锋
① 比较第二组的均值与第一组的均值是否有显 著性差异。
SPSS超级完整版教程PPT课件

▪ 按观察单位(按行输入)输入数据 将光标移 动要输入的观察单位,单击鼠标,将该观察单 位标记,输入变量的第一个值,按“Tab” 或 “”键,输入第二个数据。
▪ 按单元格输入数据 将光标移动到想要输入的
单元格,单击鼠标,输入变量值,按回车键。
2020/1/1也0 可按此法修改变量第一值章 。绪论
35
▪ 定义变量名标签是对变量名做进一步说明。
▪ 如果变量名已经说明了变量的内涵,则不必设置 变量名标签。如性别、血型、name,等
▪ 有时,变量名不能明确表示该变量的含义。如
date_in。变量名标签设置为“入院时间”。
▪ 变量标签不受字符位数的限制,可以用英文或中 文表示。
▪ 在统计分析的输出结果中,可显示变量的英文或 中文标签,使输出结果的可读性更好。
4
4
2 王武 1 65 10/25/200 11/28/200 0
4
4
3 陈杉 2 39 12/14/200 01/13/200 0
4
5
4 李思 2 30 11/22/200 12/29/200 1
4
4
5 欧阳山 1 57 12/01/200 01/15/200 2
4
5
6
赵杉
2020/1/10
2 13 10/01/200 11/18/200 1
▪ 本例的性别分别用数值1和2表示男性、女性。这 时的1和2已经没有数值大小的含义,故可以定义 为字符变量,测量类型为Nominal。但为了操作 方便和某些统计分析,还是经常把它定义为数值 变量,默认测量类型为Scale。
▪ 单击变量窗口左下方的Data 2020/窗1/1口0 转为数据窗口。 第一章 绪论
2020/1/10
薛薇SPSS统计分析方法及应用概述PPT课件

IBM成功收购SPSS后,其名称又发生了改变,总 称为 IBM SPSS,包括四个部分:统计分析、数据 挖掘、数据收集、企业应用服务
第15页/共21页
主窗口菜单及功能
菜单名
功能
解释
File
文件操作 对相关文件进行基本管理(如新建、打开、保存、打印等)。
Edit
数据编辑
对数据编辑窗口中的数据进行基本编辑(如撤销/恢复、剪切、复制、粘贴),并 实现数据查找、软件参数设置等功能。
View
窗口外观状 对窗口外观进行设置(如状态栏、表格线、变量值标签等是否显示、字体设置
第1页/共21页
SPSS原是为大中型计算机开发的,面向企事业单 位用户。
20世纪80年代初,微机开始普及以后,它率先推 出了微机版本(统称为SPSS/PC版),占领了微 机市场,大大地扩大了自己的用户量。
20世纪90年代,Microsoft推出操作系统Windows 后,SPSS迅速向Windows移植(统称为SPSSfor Windows版)。
第7页/共21页
3 . SPSS的基本操作环境-4个窗口
(1)数据编辑窗口 (2)结果输出窗口 (3)语法编辑窗口 (4)脚本窗口
第8页/共21页
一 、数据编辑窗口 窗口标题:data editor 功能:对SPSS的数据文件进行录入、 修改、管理等
基本操作的窗口。 组成:窗口主菜单、工具栏、数据编辑区、状态显示
第16页/共21页
spss基本操作PPT课件

2020/1/10
26
2.2.7 缺失值(Missing)的处理
当数据中存在明显错误或明显不合 理的数据以及存在漏填数据项时,统计 上通称为数据为不完全数据或缺失数据。
SPSS中说明缺失数据的基本方法是 指定用户缺失值。用户缺失值可以是:
o 对字符型或数值型变量,用户缺失值可以是1至 3个特定的离散值(Discrete missing values);
数据编辑窗口中的数据通常以SPSS数据文 件的形式保存在计算机磁盘上,其文件扩展名 为.sav。
数据编辑窗口由窗口主菜单、工具栏、数 据编辑区、系统状态显示区组成。
2020/1/10
5
标题栏
菜单栏
工 具 栏
2020/1/10
输
入
数据显示区:
数
变量名
据
观察序号
栏
数据编辑器的构成
状态栏
6
菜单表
功能
主窗口菜单及功能 解释
17
2020/1/10
频数数据的组织方式
职称 1 1 1 2 2 2 3 3 3 4 4 4
年龄段 1 2 3 1 2 3 1 2 3 1 2 3
人数 0 15 8 10 20 2 20 10 1 35 2 0
18
2.2 SPSS数据的结构和定义方法
SPSS数据的结构包括变量名、类型、宽度、列宽
• 数值型 (1)标准型(Numeric) (2)科学记数法型(Scientific Notation) (3)逗号型(Comma) (4)圆点型(Dot) (5)美元符号型(Dollar) (6)用户自定义型(Custom Currency)
• 字符型(String) • 日期型(Date)
spss数据统计分析(共42张PPT)

二 spss数据文件的建立和管理
键在于确定合适的分组数目。 三 绘制散点图的基本操作(教材235)
(b)是否将分析结果保存到磁盘上,扩展名
(1) 提出假设: HO :a1=a2=a3…=ak=0
最后整理数据中,成绩变量) ( 4 基本操作:data sort cases(最后整理数据)
少transform Automatic Recode (数据5中年龄)
据库(方向键使用)
⑥检查数据录入是否正确(是否存在非法值)
3.4 数据的编辑
①数据的定位:
人工定位(数据较少时使用)
(方法;拖动滚动钮或单击page up键或page down键) 自动定位(数据较多) a 按个案号码定位:
定位单元; Data---go to case; 输入要定位的个案号码。 b 按变量值定位:
职称 1 1 1 2 2 2 3 3 3 4 4 4
年龄段 1 2 3 1 2 3 1 2 3 1 1 1
人数 0 15 8 10 20 2 20 10 1 35 2 0
3.2 spss数据的结构和定义方法
①变量名(Name)
②变量类型(Type)、宽度(Width)、列宽度( Columns)
分析多个变量不同取值下的分布,掌握多变量的联合 分布特征,进行分析变量之间的相互影响和关系 (2)基本任务
根据收集到的样本数据,产生交叉列联表;在交叉 列联表的基础上,对两两变量间是否存在一定的相关 性进行分析。
职称
年龄段
35岁以下 36-49岁
50岁以上 Total
教授(1)
Count
0
%within职称 0
指定目标单元(单击鼠标右键,选择paste)
【课件】SPSS 5-6

二、输出窗口
对数据文件进行统计分析的结果,包括各种表格、图表等均 显示在输出窗口中。 输出窗口为非激活窗口,程序刚启动时,屏幕上并不显示输 出窗口,只有执行了一个具体分析过程后,输出窗口才自动打开。 图5-1是一个输出窗口。 屏幕的第一行是标题栏。 屏幕的第二行是菜单栏。 屏幕的第三行和第四行是工具栏。 屏幕最下面一行是状态栏,显示当前输出窗口的状态。 屏幕中间的两个矩形框,左边的一个是大纲视图,以树形结 构显示所有输出项的大纲。右边显示输出的图表、表格和文字性 的内容。
5.2 输出窗口中的基本操作
在标准输出窗口中可以进行以下操作: 1、查看输出对象。 2、编辑输出内容。 3、在其他应用程序中使用输出对象。 本章只介绍前两个问题。
一、查看输出对象
(一)展开和折叠大纲视图
在输出窗口中: 1、展开大纲视图 在输出窗口中,单击大纲视图中的“+”。 2、折叠大纲视图 在输出窗口中单击大纲视图中的“-”。 如图5-3所示。
打开交互式图表的方法: 1、在输出窗口中,双击一个交互式图表。 2、在输出窗口中,单击选定的交互式图表,然后从主 菜 单 Edit 中 选 择 “ SPSS Interactive Graph Object” →”Open”。 3、在输出窗口中,右键单击选定的交互式图表,然后 从 弹 出 的 快 捷 菜 单 中 选 择 “ SPSS Interactive Graph Object” →”Open”。
第5章 SPSS的基本操作
5.1 认识窗口
一、数据编辑窗口
在默认状态下,SPSS启动后屏幕的主画面显示的激活 窗口是数据编辑窗口。在数据窗口中可以新建一个数据文件、 导入现存的数据文件和对数据文件进行编辑。 在一个SPSS期间只能打开一个数据编辑窗口。如果想 打开一个新的数据窗口,原来的数据文件会自动关闭。 数据编辑窗口是程序的主窗口,用户在使用SPSS程序 期间不能关闭数据窗口,一旦关闭数据窗口,即退出SPSS 程序。 关于数据编辑窗口及其操作前面已经作了详细介绍。
第五章 spss的参数检验 人大薛薇版
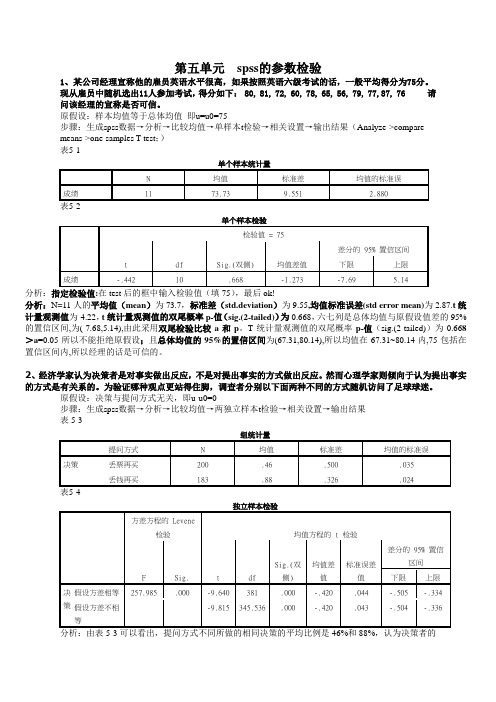
第五单元spss的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->comparemeans->one-samples T test;)分析:分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
然而心理学家则倾向于认为提出事实的方式是有关系的。
为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
原假设:决策与提问方式无关,即u-u0=0步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果决策与提问方式有关。
由表5-4看出,独立样本在0.05的检验值为0,小于0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。
3、一种植物只开兰花和白花。
按照某权威建立的遗传模型,该植物杂交的后代有75%的几率开兰花,25%的几率开白花。
SPSS经典基础教程ppt课件

21
2 第 章 数据录入与数据获取
本章主要解决两个问题: 第一个问题,根据问题类型的不同,将会从开放题、单选题和多选题的 录入方式为例进行介绍。 第二个问题,重点介绍如何用SPSS直接读取Excel类型和文本格式的数 据,以及如何用ODBC接口读取数据库文件。
22
2.1 数据格式概述
2.1.1 统计软件中数据的录入格式 (1)不同观测对象的数据不能在同一记录中出现,即同一
观测数据应当独占一行。 (2)每一个观测量指标或影响因素只能占据一列的位置,
即同一指标的数量观测值都应当录入到同一个变量中去。 即:一个观测占一行,一个变量占一列
23
2.1.2 变量属性介绍
在录入数据时,归纳为以下三步: 第一步:定义变量名; 第一步:指定每个变量的各种属性; 第一步:录入数据。 变量名不能与spss保留字相同,spss的保留字有ALL、 END、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、 TO、WITH。
草稿结果是结果的一种简化文本格式。实际上就是WORD所兼容 的rtf超文本格式,因此可以在没有安装SPSS的PC机上使用文字 编辑软件打开。
11
(4)语法编辑窗口(SPSS Syntax Editor)
12
(5)脚本窗口(SPSS Script Editor)
13
1.2.3 SPSS的四种运行方式
生存分析等 对应分析、感知图、Proxscal等 多阶段复杂抽样技术等 正交设计、联合分析等,适用于市场研究 精确P值计算、随机抽样P值计算等 在地图上展示数据等
缺失数据的报告与填补等
Logistic回归、非线性回归、Probit回归等
交互式创建各种表格(如堆积表、嵌套表、分层 表等)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主要内容
单个总体的均值检验 两个总体的均值比较 利用两个独立样本 利用两个配对样本
统计学的范畴:推论统计 根据样本数据推断总体的分布或均值方差等总体 统计参数 方法: 参数检验 非参数检验
统计方法
描述统计 推断统计
参数估计 假设检验
假设检验概述
H0:两总体方差无显著差异.
方法:计算各观测与所属组均值之差的绝对值; 对绝对离差进行单因素方差分析.
两独立样本t检验
结论:
首先,如果F检验的P≤α ,则拒绝F检验的H0,认为方 差不齐性;其次看方差不齐行的t检验概率.如果≤α , 则拒绝t检验的H0,认为两总体均值有显著差异;如果 >α ,则不拒绝t检验的H0.
假设检验的基本原理
基本信念:利用小概率原理进行反证明。小概率 事件在一次实验中不可能发生。
例如:对大学男生平均身高进行推断 H0:平均身高为173 样本平均身高为178,由于存在抽样误差,不能直接拒 绝H0。而需要考虑:在H0成立的条件下,一次抽样得 到平均身高为178的可能性有多大。如果可能性较大, 是个大概率事件(与相比较),则认为H0正确。否则 ,如果可能性较小,是个小概率事件,但确实发生了 ,则只能认为H0不正确。 概率P值即为观测结果或更极端现象在零假设成立时出 现的概率
单样本t检验
SPSS中的选项
置信区间:指定输出-0的置信区间.默认值为 95%. 缺失值的处理策略
当涉及缺失值变量的计算时剔除包含缺失值 的样本
剔除所有含缺失值的个案后再计算
两独立样本t检验
目的:对两总体的均值是否有显著差异进行推断 例:男女生的月平均工资是否存在显著差异 手段:利用两个独立样本的均值差对两总体的均值 差进行检验 独立样本:抽取一个样本对抽取另一个没有影响 理论依据:两独立样本均值差的抽样分布
假设检验是一种根据样本数据推断总体的分布或 均值、方差等总体统计参数的方法。 根据样本来推断总体的原因: 总体数据不可能全部收集到。如:质量检测问 题 收集到总体全部数据要耗费大量的人力和财力 假设检验包括: 参数检验 非参数检验
假设检验的基本步骤
提出基本假设H0 构造服从某种理论分布的检验统计量 利用样本数据和基本假设计算检验统计量的观测 值,并得到概率P值(检验统计量在特定极端区域 取值在H0成立时的概率) 如果概率P值小于用户给定的显著性水平a,则拒 绝H0;否则,不拒绝H0
SPSS中的参数检验方法
单样本t检验 两独立样本t检验 两配对样本t检验
单样本t检验
目的:对某个总体的均值与指定的检验值之间是否 存在显著差异进行检验
例:大学毕业生的月平均工资与3500元是否有显著差 异
手段:利用单个样本的均值对总体均值进行检验 理论依据:样本均值的抽样分布 抽样分布:样本统计量的概率分布 结果来自容量相同的所有可能样本 提供了有关样本统计量的概率信息,是推断的 理论基础,是抽样推断科学性的重要依据
基本步骤: H0:u=u0,总体均值与检验值之间不存在显著差异 选择检验统计量 计算t统计量的观测值和概率P值 结论:P≤α ,拒绝H0,认为总体均值与检验值之间有 显著差异.P>α ,不能拒绝H0
•注意:SPSS给出 的双侧检验的概率P 值
单样本t检验
基本操作步骤
(1)菜单选项:分析->比较均值->单样本T检验 (2)指定检验值: 在检验值框中输入原假设值
两总体方差未知且相等:
(X X ( 1 2) 1 2) t ~t(f ) 2 2 S S 1 2 n n 1 2
S 12 S 22 2 ( ) n1 n2 f S 12 2 S 22 2 ( ) ( ) n1 n2 n1 1 n2 1
基本步骤: H0:u1-u2=0,两总体均值不存在显著差异 选择检验统计量 计算t统计量的观测值和概率P值 SPSS给出方差齐性和异方差下的两个检验结果 首先判断方差是否齐性;然后对t检验做决策 SPSS方差齐性F检验:Levene F检验
两配对样本t检验
目的:对两总体的均值是否有显著差异进行推断 例:研究某减肥产品的减肥效果,对比减肥前与 减肥后的体重总体 手段:利用两配对样本的均值差对两总体的均值差 进行检验 配对样本:抽取一个样本对抽取另一个有影响
•当总体服从正态分布 N~(μ,σ2) 时,来自该总体的所 有容量为 n 的样本的均值 X 也服从正态分布 , X的 数学期望为μ,方差为σ2/n。即X~N(μ,σ2/n) •设从均值为,方差为 2的一个任意总体中抽取容 量为n的样本,当n充分大时,样本均值的抽样分布 近似服从均值为μ、方差为σ2/n的正态分布
首先,如果F检验的P >α ,则不能拒绝F检验的H0,认 为方差齐性;其次看方差齐行的t检验概率.其余同上
两独立样本t检验
基本操作步骤 (1)菜单选项:分析->比较均值->独立样本T检验 (2)选择若干变量作为检验变量到检验变量框 (3)选择代表不同总体的变量作为分组变量到分组变 量框 (4)定义分组变量的分组情况: 定义分组变量的分组标志值分别是什么 若分组变量为连续变量.输入一个数字,将大于等 于该值的分成一组,小于该值的分成另一组.
两独立样本t检验
理论依据:两独立样本均值差的抽样分布
理论依据:两独立样本均值差的抽样分布 两总体方差已知: (X X ) ( )
Z
1 2 1 2
n n 1 2
2 1
2 2
~N ( 0 , 1 )
两总体方差未知且相等:
2 2 ( X X ) ( ) ( n 1 ) S ( n 1 ) S 1 2 1 2 2 1 1 2 2 t ~ t ( n n 2 ) S 1 2 p 1 1 n n 2 S 1 2 p n 1 n 2