informatica性能调优方法
Informatica_PowerCenter 参数和变量使用指南

Informatica PowerCenter 参数和变量使用指南中国区唯一总代理神州数码(中国)有限公司2014年目录第一章参数和变量 (3)1、概述 (3)2、参数与变量存在的三种形式 (4)2.1系统级变量 (4)2.2 Mapping级参数与变量 (4)2.3 参数文件级参数与变量 (10)第二章参数文件格式 (12)1、标题格式和适用范围 (12)2、参数和变量类型 (13)3、实例 (13)第三章参数文件使用要点 (15)1、创建准则和使用注意事项 (15)2、PMCMD中使用参数文件 (17)第四章应用案例介绍 (18)1、定义M APPING的变量。
(18)2、在E XPRESSION组件中引用变量 (19)3、定义W ORKFLOW变量 (19)4、在E VENT W AIT组件中引用变量 (20)5、在S ESSION中引用变量 (21)6、在C OMMAND组件中引用变量 (22)7、参数文件定义 (22)8、S ESSION参数文件引用设置 (23)9、W ORKFLOW参数文件引用设置 (24)10、W ORKFLOW流程图 (24)第一章参数和变量1、概述参数和变量可以定义在工作流、工作集或会话中。
您可以使用WordPad 或Notepad 等文本编辑器来创建参数文件。
您在参数文件中列出参数或变量及其值。
参数文件可以包含以下类型的参数和变量:◆Integration Service变量◆Integration Service process变量◆Workflow变量◆Worklet变量◆Session参数◆Mapping参数和变量当您在工作流、工作集或会话中使用参数或变量时,PowerCenter Server将检查参数文件以确定参数或变量的开始值。
您可以使用参数文件来初始化工作流变量、工作集变量、映射参数和映射变量。
如果您不定义这些参数和变量的开始值,PowerCenter Server将在其它位置检查参数或变量的开始值。
Informatice开发参考

Informatica元数据库2009-07-12 14:00Informatica所有的元数据信息均以数据库表的方式存到了元数据库中。
当然Infa本身工具提供了很多的人性化的功能,使我们在开发时可以很方便的进行操作,但人们的需求总是万变的,需要方便的取到自己需要的信息,那就需要我们对他的元数据库有很深的了解。
Informatica通过表和视图给我们提供着所有的信息,在此将通过一个系列的帖子,将大部分常见的,且非常有用的表及视图介绍一下。
基于这些东西,我们即可以根据不同的需求查出自己需要的数据,也可以开发一些辅助的Infa应用程序。
OPB_ATTR:INFORMATICA(Designer,Workflow等)设计时及服务器设置的所有属性项的名称,当前值及该属性项的简要说明例如:ATTR_NAME:Tracing LevelATTR_VALUE:2ATTR_COMMENT:Amount of detail in the session log用途:可以通过该表快速查看到设计或设置时碰到的一些属性项的用途与说明OPB_ATTR_CATEGORY:INFORMATICA各属性项的分类及说明例如:CATEGORY_NAME:Files and DirectoriesDESCRIPTION:Attributes related to file names and directory locations 用途:查看上表所提的属性项的几种分类及说明OPB_CFG_ATTR:WORKFLOW MANAGER中的各个Folder下的Session Configuration的配置数据,每个配置对应表中一组Config_Id相同的数据,一组配置数据共23条例如:ATTR_ID:221ATTR_VALUE:$PMBadFileDir用途:查看所有的SessionConfiguration的配置项及值,并方便的进行各个不同Folder间的配置异同比较OPB_CNX:WORKFLOW MANAGER中关于源、目标数据库连接的定义,包括Relational Connection,Queue Connection,Loader Connection等例如:OBJECT_NAME:Orace_SourceUSER_NAME:oralUSER_PASSWORD:`?53S{$+*$*[X]CONNECT_STRING:Oratest用途:查看在WorkFlow Manager中进行配置的所有连接及其配置数据OPB_CNX_ATTR:上表所记录的所有数据库连接的一些相关属性值,一种属性值一条数据。
Informatica帮助文件翻译之一.

第六章 Filter Transformation(过滤器控件主要内容:z Filter控件总体介绍z书写过滤条件z制作一个过滤控件的例子z使用技巧z关于过滤器控件的错误处理Filter控件的总体介绍控件类型:连接型,积极型Filter控件的作用是在一个Mapping中过滤记录。
当你的所有数据记录从数据源控件出发,穿过Filter控件,此时,在Filter控件中设置一个过滤条件,那么,就只有那些满足过滤条件的记录会流向下一个控件。
有时候,您需要一个或多个条件来过滤数据在他们进入目标数据表之前。
例如,您有一些当前雇员的人力资源信息,您可能需要得到过滤掉零时雇员和钟点工的雇员信息下面图6-1就是一个包含Filter控件的Mapping,它将只让薪水等于或大于30000$的雇员进入目标表中。
图6-1下面这个图是Mapping的过滤条件图6-2 过滤条件可以看见,控件中的过滤条件是SALARY>30000,结果将把薪水小于等于30000的记录过滤掉。
作为一个积极型的控件,Filter控件会改变进入它的数据记录的数量。
每一条记录进入Filter控件,都要经过过滤条件的判断,然后返回真或假,如果返回真会才流出控件。
条件为假的记录被丢弃,在Session日志文件和Reject文件中也不记录。
为了改善Sesson的性能,应该让Filter控件尽量靠近源表,这样就可以在开始就将不想要的数据丢弃。
将两个控件的字段连向Filter控件是不容许的,它流入的字段只能从单独一个控件进入,Filter控件也不能设置默认的输出值。
书写过滤条件我们使用转换语言写过滤条件,过滤条件是一个返回真或假的表达式,例如:当您想把薪水少于等于30000$的雇员过滤掉,你可以这样写表达式:SALARY>30000也可以写复合的过滤条件,使用AND和OR连接单个的表达式。
如果你想过滤薪水小于30000$且大于100000$的雇员,您可以这样写过滤条件:SALARY>30000 AND SALARY<100000在表达式中没有必要指明true或false做为表达式的值,true或false被自动的从表达式或表达式集中返回,如果过滤条件等于NULL,等返回False。
Informatica调优(高级)

接下来的这些条目是INFOR MATICA 的高级调优建议。
请极其谨慎地处理,每次试用一条建议。
在没有试着使用初级和中级建议来提高INFORMATICA 的性能以前,不要尝试使用如下的高级建议。
这些建议的实施可能需要系统管理员(SA)、数据库管理员(DBA)以及网络管理员之类的专家级人物的配合才可以,所以要细心。
高级调优最重要的方面就是能够精确的查明瓶颈是什么,并且有能力定位这些瓶颈是如何引起的。
根据常理,这些高级建议放在最后,并且是在系统级上的建议。
还有其他的适用于数据仓库调优的高级建议,可以依据你的软硬件资源存在的问题去寻找相应的帮助。
1、将MAPPING 分解。
保留一个数据目标。
如果必要每个数据目标保留一个数据源。
为什么要这么做呢?在一个MAPPING 中减少数据目标的个数会大幅度的提高运行的速度。
基本的情况是这样的:每个MAPPING/TARGET 对应一个SESSION。
每个SESSION 都会建立它自己的数据库连接。
因为对每个目标表建立一个单独的数据库连接,数据库管理器(DBMS)能将插入、更新和删除等操作需求并行地处理。
在一个SESSION 中进行一个特定目的的操作也是很有帮助的(例如不在把以数据驱动地操作和直接插入操作混合地插入到同一个数据目标中)。
如果实际情况运行,每个SESSION 可以被放置到标记为“CONCURRENT”的BATCH(译者注:旧版本的术语)中。
如果能够这样做,MAPPING和SESSION 的并行执行的情况就很显而易见了。
关于并行处理的研究一再地表明:与直接将原本的操作单元简单地顺序执行相比,同一时刻开始的并行执行有时只需花费一半的时间。
当一个MAPPING 中包含多个数据目标时,就会使得每个数据库连接去处理多个不同地数据库操作语句,有时会影响这个数据目标的性能,有时又是那个。
请想一下,在这情况下,INFORMATICA (包括其他的任何工具)都很难进行BULK(并行)操作,即使在SESSION中已经设定了BULK 属性。
informatica文档

各Transformation的功能说明1.Source Qualifier(数据源编辑,Relational)1.Source Qualifier有下列用途:A.连接同源的数据集;B.过滤源数据;C.指定连接条件(等连,非等连,like)和类型(内连,外连);D.指定排序栏位(当Mapping中用到Aggregator或者Joiner时,排序可以改进性能);E.Distinct;F.Override Select;2.Source Qualifier执行从数据库数据类型到Powercenter数据类型间的转换;3.当一个Mapping中有多个Source Qualifier连到多个Target时可用Target Load Order指定装载顺序;4.在Source Qualifier中的多个地方可以使用参数或变量,传入SQL语句用的是字符串格式,所以大部分时候都需要用引号;5.Source Qualifier只为连出的Port产生SQL语句,需要注意的是,Override SQL是和连出线的Port顺序相关的,而且,其它属性如Join,Filter,Sorted Ports,Distinct 会失效;6.这些属性都可以在Session 属性中被Override(覆盖)。
7.一切检索的内容都是以SQL Query最高优先级,如果没有sql query就找User Join Define和filter,如果有SQL Query那么SQ拉出的端口必须与SQL Query 的Select 个数一样多, sql query多表时,select到的field的table的Source是一定需带上的,当需要多个schema作为源的话,则一定需要sql querry8.Pre SQL和Post SQL在seesion执行前或者结束时会触发。
比如可以把session 执行的时间写入到某些地方,获取执行电脑的ip地址等用处.2.Update Strategy1.Powercenter的更新策略包括两个方面:A.在Mapping中:用Update Strategy Transformation标识行为Insert,Update,Delete或者Reject;B.在Session中:配置Treat source row as 属性(Insert,Update,Delete或者Data driven),配置Target的属性(Insert,Update [as Update](只是更新) | [as Insert](把更新视为新增) | [else Insert](先更新,更新不到则新增) ,Delete,Truncate target table option);2.在Update Strategy Expression中可以输入常量(DD_INSERT, DD_UPDATE, DD_DELETE,DD_REJECT)或者数字值(0,1,2,3),其它数字值被解析为0,可以用IIF或者DECODE 函数构建逻辑表达式来区别每一行的更新策略;3.Forward Rejected Rows:勾选时被Rejected的行会存入对应Target配置的Reject文件中去,不选时,可能会写入Session Log中去,根椐当前Transformation的Tracing Level的属性来决定;如果在会话属性中配置了出错行日志属性,则不会生成Reject文件;3.Expression1.用来执行单行计算,在计算表达式中,可以使用输入端口,输入/输出端口,可以使用函数以及非连接的Lookup,也可以使用变量端口;2.数据来源只能一个4.Lookup1.Lookup根椐输入值从数据库或者平面文件中查找数据;2.Lookup分为连接型和非连接型的:A.连接型的可以传送多个返回值给其它的Transformation,非连接型的只能有一个返回端口,在表达式中用Lookup函数(:LKP())来调用;B.连接型的可以利用到默认值,当没有匹配记录时,非连接型的总是返回空;3.Lookup可以配置成使用CACHE,对平面文件这项必选,Informatica Server在条件栏位上建立索引CACHE,在其它栏位上建立数据CACHE,如果分配的CACHE空间不够就存放在CACHE文件中;4.CACHE文件可以是临时的,也可以是固定化的;5.当Lookup配置成动态时,对应的表是Target,如果输入行连接栏位在CACHE中没有找到匹配记录,就在CACHE中插入一行,如果找到了就更新CACHE或者不更新CACHE,取决于比较栏位是否匹配,给标志栏位NewLookupRow赋值0(Unchange),1(Insert),2(Update);6.Lookup的端口除了I,O之外,还有L和R;7.多匹配行处理策略:返回第一行,返回最一行,报错;8.在数据库Lookup使用CACHE的前提下可以使用Override SQL,下面情形下适于使用Override SQL:A.增加一个Where子句;B.指定不同于默认SQL的Order By子句,在带有Order By子句的Override SQL后加上--,目的是屏蔽掉系统自动产生的Order By子句;(PowerCenter 服务器是默认是按lookup的栏位来Order By的,如果你在Override里面想要覆盖它的Order By方式,一定必须在结尾输入’--‘注释符来覆盖,否则lookup会失败,而且在新的Order by 里面要有LookUp Condition包含的栏位,而且顺序需要一致)C.Lookup表名或者栏位中包含保留字或者栏位名中含/时,用引号将保留字引起来;(如果look up栏位里面包含了db的保留字,那么需要在pm目录下建立一个含有那些保留字的reswords.txt的文件,pm会在保留字周围放置一些引用,来解决和服务器冲突的问题.)D.需要在Lookup查询中使用参数或者变量时;E.其它情况,比如从一个连接中返回结果或者要对返回作函数处理后的结果作为CACHE;9.关于Lookup的条件匹配:A.条件两边的端口必须匹配;B.输入端口允许在条件中出现多次;C.多个条件间的关系是AND;D.相等条件可以匹配空值(NULL=NULL);E.如果条件中有等于和不等于,将所有等于放在前面;10.如果允许,可以在Lookup表的连接条件栏位上建立索引,以改进性能;11.LookUp一定要有输入port,SQL Overrid不能覆盖condition的作用12.Dynamic LookUp一般用于查找目标表是否已经有Source传过来的记录,然后根据更新标志(flag)做处理.也就是把目标表的所有数据先用文件作为缓存存放起来,然后Source传过来的记录与缓存文件的数据比较并且由属性(insert else update,update else insert)决定是否更新缓存文件.13.理解Associated Port的意义;关联端口,当Dynamic Look Up Cache时,PM如何把in port的资料和cache里面的资料来对比和关联,然后产生新的cache和NewLookUpRow就是需要用Associated Port来关联in port端口的资料或者Sequrence了。
Informatica_(4)工作流

Informatica_(4)⼯作流三、workflow执⾏、监控workflow是PowerCenter的执⾏单元;⼀个workflow包括⼀个或者多个session(或task)。
1.sessionsession是mapping的实例化。
session是给mapping提供配置⽂件的场所或机制。
有了这些配置信息,mapping就可以执⾏了,所以说session是mapping的⼀个可执⾏实例。
session的两种类型:Reusable session(可重复使⽤)和⾮Reusable session(不可重复使⽤)。
1.1 Reusable session(可重复使⽤session)创建⼀次,可以被多次重⽤。
选中“Task Developer”,打开菜单“Tasks--》create”,输⼊session名点“create”,选择对应的mapping.Reusable session可⽤以多个workflow或者worklet。
1.2 ⾮Reusable session(不可重复使⽤session)先创建workflow,再创建session。
选中“workflow designer”,打开菜单“workflows--》create”,输⼊workflow名点“OK”,workflow的起始点“Start”创建成功;再在workflow的⼯作区内创建session,即⾮Reusable session。
⾮Reusable session可以转换为Reusable session,双击session,选中“make reuseable”。
2.workflow2.1 并⾏执⾏⼀个workflow同时链接多个session,并且多个session之间没有依赖关系,可以并⾏执⾏以提升效率。
2.2 串⾏执⾏⼀个workflow同时链接多个session,并且多个session之间存在依赖关系,需要按照依赖关系顺序依次执⾏。
Informatica 参数的使用

1、定义参数文件Mapping Parameters(参数) 和 Variables(变量)的使用如果你在一个mapping中多次用到同一个值,又或者mapping中要用到一个在session运行才能决定的值,这时候可以使用mapping parameters或variable。
Mapping参数变量的命名方式:$$NAME存放参数变量的.txt文件的格式:[folder_name.session_name]parameter_name=valuevariable_name=valuemapplet_name.parameter_name=value[folder_name.session2_name]parameter_name=valuevariable_name=valuemapplet_name.variable_name=value[folder2_name.session_name]parameter_name=valuevariable_name=valuemapplet_name.parameter_name=value例如:[Common_Dimension.s_M_Inventory]$$BeginDate=2007-07-01$$EndDate=2007-07-31$$IsCurrentDay=0$DBConnection_Source=EM$DBConnection_Target=DC$PMSessionLogDir=C:\para2、添加参数或变量的方法是:选择Mappings-Parameters and Variables,在窗口新增变量或者参数,并对它的数据类型,数据大小,初始值进行设置。
添加的参数和变量在本mapping 的transformation的表达式中就可以使用了。
这些参数和变量的值还可以设置在.txt文件中,建session或者batch的时候把这个文件的路径设置在Parameter输入框中就行了。
Informatica邮件功能配置(MAPI)

Informatica E-mail config instruction(MAPI) Informatica邮件发送功能配置(MAPI)说明书(以测试环境为例)Configuring MAPI on Windows1.先安装Microsoft Outlook (如果之前安装了,就不用在安装)2.配置邮箱服务,单击控制面板中的查看x86控制面板图标3.双击邮件图标4.点击上步操作出现后窗口的显示配置文件图标5.点击添加按钮6.在配置名称栏中填写合适的名称7.输入名称后点击确定8.上步确定后会出现邮件账户向导,选择exchange服务器选项,点击下一步9.选择手动配置服务器,点击下一步10.选择Microsoft Exchange 点击下一步11.出现下面的提示框12.填写exchange服务器名称和用户名,用户名就是发送邮件的邮箱名,点击下一步邮件服务器地址接收邮件的邮箱地址13.点击完成如果操作系统是64位,那么需要进行14-19步骤,32位不需要14.打开informatica的控制台15.点击是(Y)16.输入informatica的用户名和密码登陆17.点击左侧test_int(Integration Service)18.点击右侧最下方有Custom Properties的edit按钮19.点击add 添加以下属性值点击OKSMTPFromAddress XXX@SMTPServerAddress XXX_SMTPPortNumber 25至此邮箱服务器配置完成下面步骤是如何在informatica中使用发送邮件功能20.打开informatica的workflow Manager21.右击我们要使用的Repository 点击出现的connect22.输入用户名与密码登陆23.右击我们指定的文件夹,点击Open24.在工具栏中点击Tasks然后点击Create25.选择Email,然后输入需要的名称点击Create26.双击上步骤中生成的email_test27.点击Properties,会有Email user name,Emil Subject,Email TestEmail user name 是您需要发送的邮件地址,多个地址中间用分号(;)隔开Emil Subject 是您发送的邮件中的主题Email Test 是您发送的邮件中的内容28.在邮件内容窗口中可以输入我们需要的文本内容,但是左边的Variables暂时不可用(下面步骤中有讲到如何使用)29.选择一个可以使用的session,双击这个session,然后点击Components,窗口中有On Success E-Mail(意思是session如果成功则发邮件),然后选择type为Reusable,On Failure E-Mail(session如果失败则发邮件) 同上30.点击右侧小箭头的按钮31.会出现Email的列表,因为我们只做了一个,所以只显示一个,选择需要的Email Browser, 点击OK (可以点击Override按钮进行重写此邮件的配置,重写功能我们在下面一步中进行讲解)32.点击右击笔形按钮33.选择Properties,然后点击右侧的箭头按钮34.可以在Text的窗口中重新编辑邮件内容,可以选择左侧Variable框中的函数,也可以手工输入代表左侧函数的编码,如%w意思是此session所在的workflow的名称%a 可以发送本服务器中指定目录的附件例%a<G:\blat276\test.xlsx> 则发送G:\blat276目录下的test.xlsx文件作为附件%g 意思是把本session的日志文件作为附件发送%s 意思是本session的名称…设置完毕后点击OK至此session中的设置已经全部完成,后面步骤会有运行示例35.在一个可用的workflow中右击窗口,点击start workflow,运行workflow36.W orkflow运行完成后,查看您所要发送的邮箱,会发现邮件已经到达,附件,日志等等设置的内容也测试成功。
Informix 性能调优实例讲解

概述在实际的生产运行环境中,笔者在国内很多客户现场都看到开发人员和系统管理人员遇到很多有关于Informix 数据库引起的性能问题,进而被多次问起如何进行Informix 数据库性能调优,笔者根据自己在工作中对Informix 数据库的使用经验积累写下这篇文章。
性能优化原则包括:∙性能规划:深入了解应用与数据库的交互特征,确立良好的设计、开发、测试迭代过程,上线前消除模型上的性能瓶颈。
∙实例调优:建立性能基准,对比调节数据库、操作系统、存储、网络等的配置,主动监控、消除瓶颈。
∙SQL 调优:书写高效SQL,优化相关数据库对象,充分借助优化器,确定最佳执行计划。
性能优化流程1. 首先执行下面的初始检查:o获取直接用户的使用反馈,确定性能目标和范围。
o获取性能表现好与坏时的操作系统、数据库、应用统计信息。
o对数据库做一次全面健康检查。
2. 根据收集的信息,以及对应用特性的了解,构建性能概念模型,明确性能瓶颈所在,以及导致性能的根本原因。
o首先应该排除操作系统、硬件资源造成的瓶颈。
o然后针对数据库系统性能进行分析o必要时,还需要检查应用日志,因为系统性能问题也可能由于应用非SQL 部分造成瓶颈。
3. 提出一系列针对的优化措施,并根据它们对性能改善的重要程度排序,然后逐一加以实施。
不要一次执行所有的优化措施,必须逐条尝试,逐步对比。
4. 通过获取直接用户的反馈验证调节是否已经产生预期的效果,否则,需要重新提炼性能概念模型,直到对应用特性了解进一步准确。
5. 重复上述,直到性能达到目标或由于客观约束无法进一步优化。
当从操作系统层面判断系统存在瓶颈并且是数据库引起的,那么可以从下面的流程图来解决图 1. 性能诊断优化流程典型性能问题案例案例1:数据库应用突然变慢问题特征数据库应用突然变慢,查看系统信息,发现CPU 空闲突然很低,IO 性能没有明显恶化。
处理步骤首先,需要排除操作系统上其他应用程序的问题。
通过top(HP)/topas(AIX/Linux) 命令可以看到当前占用CPU 资源最多的进程,确认是oninit进程。
影响Informix数据库性能的主要参数...

影响Informix数据库性能的主要参数...影响CPU使用率的配置参数和环境变量Online 配置文件onconfig中的下列参数对CPU的利用率有明显的影响:NUMCPUVPSSINGLE_CPU_VPMULTIPROCESSORAFF_NPROCSAFF_SPROCNUMAIOVPSOPTCOMPANDNETTYPENUMCPUVPS、MULTIPROCESSOR和SINGL_CPU_VPNUMCPUVPS参数规定了Online 开始启动的CPU VP的数量。
分配的CPU VP的个数不要超过可以为它们服务的CPU的个数。
对于单处理器的计算机系统,Informix 建议使用一个CPU VP。
对于有4个以上CPU,主要用做数据库服务器的多处理器系统,Informix 建议设置NUMCPUVPS的值等于处理器总数减一。
对于双处理器系统,运行两个CPU VP可能会改善性能。
这需要监控操作系统的CPU使用情况。
可以使用操作系统命令sar 或vmstat。
如果运行多个CPU VP,应将MULTIPROCESSOR 设置为1,当设置MULTIPROCESSOR为1时,Online 以对应于多处理器的方式执行锁定。
否则,设置该参数为0。
注意:如果设置SINGLE_CPU_VP参数为,则NUMCPUVPS 参数的值也必须是1,如果后者大于1,Online就不能初始化并显示下面的错误信息:Cannot have 'SINGLE_CPU_VP' now-zero and 'NUMCPUVPS'greater than 1AFF_NPROCS 和 AFF_SPROC在支持Online和客户应用的系统上,可以通过操作系统把应用连接到某些特定的CPU。
这样做可以有效地保留剩余的CPU给Online CPU VP使用,它们是用AFF--NPROCES和AFF_SPROC配置参数连接到剩余CPU的。
Informatica_功能特性介绍

Informatica主要功能特性介绍1.Pre-Session和Post-Session调用数据库SQL以及存储过程。
2.列/行转换:一行记录转换为多条记录,使用Normalizer组件(见:Normalizer)。
3.行/列转换+条件汇总功能:多条记录合并为一条记录,使用Aggregator组件(结合其条件汇总功能) (见:ReversibleNormalizer)。
关于条件汇总的两种写法,注意它们的不同,如下:1) sum(iif(COMMITMONTH=$$v_yearmonth,PREMIUM,0))2) sum(PREMIUM, COMMITMONTH=$$v_yearmonth)4.增量汇总:将上次汇总的结果保存在Informatica系统目录下,以后对于增量的数据再做汇总的结果跟上次汇总的结果合并,大大提高汇总效率。
要结合Aggregator组件和Session的增量汇总属性(见:IncrementalAggregation)。
最新汇总数据的集合文件,会在Informatica Server的Cache子目录下生成,文件名如:PMAGG493_4.idx,PMAGG493_4.dat。
5.Mapping的参数(Parameter)和变量(Variable):参数和变量的值可以在参数文件中指定;变量的值可以在Session运行结束后动态更改(用法举例:动态生成抽取源表的Where语句,来实现对增量数据的抽取(见:ParameterAndVariable)。
可以使用的Variable函数:SetCountVariable SetMaxVariable SetMinVariable SetVariable。
参数文件的格式举例:[tdbu.s_m_ParameterAndVariable]$$PID=12$$VID=8$InputFile1=sales.txt$DBConnection_target=sales$PMSessionLogFile=D:/session logs/firstrun.txt6.读文件列表(FileList):针对多个结构相同,但是文件名不同的文件数据源,采用该方式可以大大提高ETL设计的灵活性,减少不必要的重复性操作。
informatica面试常见问题

informatica面试常见问题
1. 请介绍一下Informatica的工作原理和主要功能。
2. 你在之前的项目中如何使用Informatica ETL工具?
3. 如何处理Informatica作业的错误和异常?
4. 如何进行Informatica数据质量检查和数据清洗?
5. 请列举一些常用的Informatica转换(transformation)和它们的作用。
6. 如何进行Informatica数据加载和抽取?
7. 你在之前的项目中遇到的最大的数据质量问题是什么,你是如何解决的?
8. 如何进行Informatica性能优化和调优?
9. 如何进行Informatica作业的监控和日志记录?
10. 请描述一下Informatica的工作流(workflow)和会话(session)的关系。
11. 如何在Informatica中处理事实表和维度表的加载?
12. 你在Informatica中使用过哪些源系统和目标系统?
13. 如何进行Informatica作业的自动化调度和自动重启?
14. 在使用Informatica过程中,你遇到过哪些具体的技术难题,你是如何解决的?
15. 你对Informatica未来的发展有何看法?
16. 你具备哪些Informatica相关的认证?
17. 请简要介绍一下你的Informatica项目经验和技术能力。
18. 你对数据仓库设计和数据模型有哪些了解?如何将其应用到Informatica中?
19. 请谈谈你在Informatica中的团队合作经验。
20. 你对Informatica的竞争对手有何了解,为什么选择使用Informatica?。
informatica基本使用方法

informatica基本使用方法1. INFORMATICA CLIENT的使用1.1 Repository Manager 的使用1.1.1 创建Repository。
前提:a. 在ODBC数据源管理器中新建一个数据源连接至你要创建Repository的数据库(例:jzjxdev)b. 要在你要连接的数据库中新建一个用户(例:name: ETL password:ETL)现在你可以创建一个Repository了。
选择Repository –Create Repository,输入Repository Name(例:JZJX),Database Username(例:etl),Database Password(例:etl),ODBC Data Source(例:jzjxdev),Native Connect String(数据库所在ip例:141.20.52.108)1.1.2 添加Repository。
通过这一步你可以添加别人已经建好的Repository。
选择Repository – Add Repository,输入Repository Name(例:JZJX),Username(例:etl),点击ok就可以看到名为JZJX的Repository在左边的浏览器中,但是此时还看不到它的内容,要看到它的内容或者对它进行操作必须先连接它。
1.1.3 添加Folder选择Folder – Create,输入文件夹名称即可。
1.2 Designer 的使用首先连接Repository,可以看到该Repository在Repository Manager中创建的文件夹。
1.2.1 SourcesSources文件夹下的表是抽取的来源表。
导入方法:选择T ools菜单下的Source Analyzer,然后选择Sources菜单下的Import from database,连接想要连接的数据库,连接上后选择你要抽取的表点击ok你所选择的表就会出现在Sources文件夹下。
InformaticaPowercenter使用手册_V1.0

InformaticaPowercenter使⽤⼿册_V1.0—Informatica Powercenter使⽤⼿册⽂档作者:BI项⽬组创建⽇期:2010-01-24更新⽇期:2010-01-24控制编码:当前版本: 1.0⽂档控制变更记录2审核分发未决与已结问题未决问题已结问题⽬录1概述 (7)1.1项⽬范围 (7)1.2读者对象 (7)1.3参考⽂档 (7)2软件简介 (8)2.1概念 (8)2.2作⽤ (8)3⼯具设置 (9)3.1R EPOSITORY M ANAGER (9) 3.1.1登陆Repository Manager (10) 3.1.2修改密码 (10)3.1.3添加外部⼯具 (10)3.2D ESIGNER (11)3.2.1登陆Desiger (12)3.2.2修改密码 (12)3.2.3添加外部⼯具 (12)3.2.4设置样式 (12)3.2.5其他选项 (14)3.3W ORKFLOW M ANAGER (14) 3.3.1登陆WorkFlow Manager (14) 3.3.2添加外部⼯具 (14)3.3.3设置样式 (15)3.3.4其他选项 (15)3.4W ORKFLOW M ONITOR (15) 3.4.1登陆WorkFlow Monitor (15) 4ETL开发 (17)4.1创建资料库 (17)4.2配置ODBC数据源 (18)4.3导⼊数据源表 (22)4.4导⼊⽬标源表 (26)4.6创建W ORK F LOW (31)4.7运⾏W ORKFLOW (34)4.8监视查看运⾏ (34)5转换组件 (36)5.1概览 (36)5.2S OURCE Q UALIFIER (38)5.3U PDATE S TRATEGY (39)5.4E XPRESSION (40)5.5L OOKUP (40)5.6A GGREGATOR (41)5.7F ILTER (42)5.8J OINER (42)5.9N ORMALIZER (43)5.10R OUTER (44)5.11S EQUENCE (44)5.12S ORTER (45)5.13U NION (45)5.14R ANK (46)5.15P ROCEDURE (46)5.16T RANSACTION C ONTROL (46)5.17SQL (48)5.18XML (49)5.19J AVA (56)5.20C USTOMER T RANSFORMATION (57)6特定实例 (60)6.1维度表 (60)6.1.1导⼊数据源和⽬标源 (60)6.1.2创建mapping (60)6.1.3创建WorkFlow (66)6.1.4运⾏WorkFLow (69)6.2事实表 (70)8附件 (75)1 概述本⽂档可作系统管理员安装PowerCenter时参考指南,安装⼈员最好具备⼀定操作系统、关系数据库、数据库引擎相关知识。
Informatica调优(高级)

接下来的这些条目是INFOR MATICA 的高级调优建议。
请极其谨慎地处理,每次试用一条建议。
在没有试着使用初级和中级建议来提高INFORMATICA 的性能以前,不要尝试使用如下的高级建议。
这些建议的实施可能需要系统管理员(SA)、数据库管理员(DBA)以及网络管理员之类的专家级人物的配合才可以,所以要细心。
高级调优最重要的方面就是能够精确的查明瓶颈是什么,并且有能力定位这些瓶颈是如何引起的。
根据常理,这些高级建议放在最后,并且是在系统级上的建议。
还有其他的适用于数据仓库调优的高级建议,可以依据你的软硬件资源存在的问题去寻找相应的帮助。
1、将MAPPING 分解。
保留一个数据目标。
如果必要每个数据目标保留一个数据源。
为什么要这么做呢?在一个MAPPING 中减少数据目标的个数会大幅度的提高运行的速度。
基本的情况是这样的:每个MAPPING/TARGET 对应一个SESSION。
每个SESSION 都会建立它自己的数据库连接。
因为对每个目标表建立一个单独的数据库连接,数据库管理器(DBMS)能将插入、更新和删除等操作需求并行地处理。
在一个SESSION 中进行一个特定目的的操作也是很有帮助的(例如不在把以数据驱动地操作和直接插入操作混合地插入到同一个数据目标中)。
如果实际情况运行,每个SESSION 可以被放置到标记为“CONCURRENT”的BATCH(译者注:旧版本的术语)中。
如果能够这样做,MAPPING。
和SESSION 的并行执行的情况就很显而易见了。
关于并行处理的研究一再地表明:与直接将原本的操作单元简单地顺序执行相比,同一时刻开始的并行执行有时只需花费一半的时间。
当一个MAPPING 中包含多个数据目标时,就会使得每个数据库连接去处理多个不同地数据库操作语句,有时会影响这个数据目标的性能,有时又是那个。
请想一下,在这情况下,INFORMATICA (包括其他的任何工具)都很难进行BULK(并行)操作,即使在SESSION中已经设定了BULK 属性。
Informatica开发规范

神州数码(中国)有限公司Informatica项目开发规划冷鹏2006年9月1.引言以前看到过whyu小记写过Informatica的一个开发规范,觉得不错,也碰到外面一些项目组在参考他写的规范,非常好!我也碰到很多公司的项目组有非常不错的DW项目规范文档,只是很少有拿出来给大家参考共享的,觉得非常的遗憾!反观自己当时做JA V A、C、Web时,项目标准和规范都是成套的有下载。
所以在这里我呼吁大家可以将项目里敏感的内容去掉,将文档的骨头拿出来,让大家做项目吸取更多的经验,少走弯路,走更正规的路,毕竟大家都在这个圈子里混,都是做技术的,这个圈子如果长久都停留在这个水平,自己也不会走出圈子里这个水平。
我扒拉的这篇规范也算不上是什么规范,结合了whyu小记、Informatica里的一些内容希望在这里给大家抛砖引玉。
希望大家总结出DW项目的更多管理规范、更多产品的开发方法以提高你我。
2.命名约定在进行Informatica开发规划时,对引用PowerCenter内的组件、变量、参数等最好参考一个统一的命名规则,官方的样例也有一些命名规划,我认为可以分个级别如Mapping、Session、Task这样的分为一个级别,统一以1个小写字母加下划线为规范,转换组件可以也可以为分为一个级别,以3个小写字母加下划线为规范。
如果不用命名规范也没多大关系,因为这些内容各自都有对应的Folder进行管理,比较好辨认。
2.1.组件命名2.2.其它命名3.主题说明往往在一个数据仓库项目内ETL都占了很大的开发量,在一个ETL过程中会涉及到多个操作步骤,如从不同数据源中提取出到本地,通过网络发送数据到目标域,装入Staging Area,再转换到ODS Area,进入数据仓库,通过层层汇总,再刷进Cube,因此在ETL开发时分主题就有很多方法,可以按ETL操作步骤来分为Source→Staging Area→ODS→DW→View DM→OLAP SERVER,也可以按照各数据源中数据类型,也可从目标事实表出发以完成一个目标主题为主,或者多种方法综合使用来进行ETL主题划分。
Informatica 10.4.0 剖析入门指南说明书

Informatica®10.4.0剖析入门指南Informatica 剖析入门指南10.4.02019年12 月© 版权所有 Informatica LLC 2010, 2020本软件和文档仅根据包含使用与披露限制的单独许可协议提供。
未事先征得 Informatica LLC 同意,不得以任何形式、通过任何手段(电子、影印、录制或其他手段)复制或传播本文档的任何部分。
Informatica 和 Informatica 标志是 Informatica LLC 在美国和世界其他许多司法管辖区的商标或注册商标。
欲获得 Informatica 商标的最新列表,请访问 https:// /trademarks.html。
其他公司和产品名称可能是其各自所有者的商业名称或商标。
美国政府权利交付给美国政府客户的程序、软件、数据库及相关文档和技术数据是指适用的联邦采购条例和政府机构特定补充条例中定义的"商业计算机软件"或"商业技术数据"。
因此,使用、复制、披露、修改和改编应遵循适用的政府合同中规定的限制和许可条款、政府合同条款的适用范围以及 FAR 52.227-19 商用计算机软件许可中规定的额外权利。
本软件和/或文档中的若干部分受第三方版权约束。
所需的第三方声明随产品一起提供。
本文档中的信息如有更改,恕不另行通知。
如发现本文档中有什么问题,请通过以下电子邮件地址向我们报告:**********************************。
Informatica 产品根据对应协议的条款和条件进行担保。
INFORMATICA 按"原样"提供本文档中的信息,无任何明示或暗示的担保,包括但不限于任何适销性和特定用途适用性担保,也没有任何非侵权担保或条件。
发布日期: 2020-02-04目录前言 (6)Informatica 资源 (6)Informatica Network (6)Informatica 知识库 (6)Informatica 文档 (6)Informatica 产品可用性矩阵 (7)Informatica Velocity (7)Informatica Marketplace (7)Informatica 全球客户支持部门 (7)第 1章: 入门概览 (8)剖析概览 (8)介绍 Informatica Analyst (9)Informatica Analyst 用户界面 (9)Informatica Developer 用户界面 (11)Informatica Developer 欢迎页 (12)备忘单 (12)Informatica Developer 任务 (13)教程讲解 (13)教程结构 (13)教程先决条件 (14)Informatica Analyst 教程 (14)Informatica Developer 教程 (15)第 I部分: Informatica Analyst 入门 (16)第 2章: 课程 1。
informaticapowercenter快速上手,入门指导
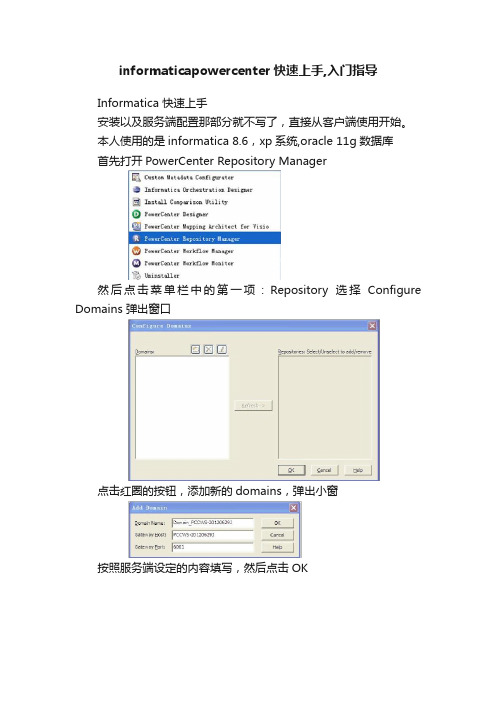
informaticapowercenter快速上手,入门指导Informatica 快速上手安装以及服务端配置那部分就不写了,直接从客户端使用开始。
本人使用的是informatica 8.6,xp系统,oracle 11g数据库首先打开PowerCenter Repository Manager然后点击菜单栏中的第一项:Repository选择Configure Domains 弹出窗口点击红圈的按钮,添加新的domains,弹出小窗按照服务端设定的内容填写,然后点击OK会出现你刚刚新添加的domains,然后右边选择你需要的资料库,勾上。
回到主界面左边的Repository Navigator里面已经有资料库了,双击你需要的那个数据库,出现弹窗这里填入你服务端里面设置的用户名密码,一般有默认的Administrator,密码也是Administrator,且权限最高,其他用户需要他赋予权限才能使用powercenter内容,所以这里直接使用Administrator用户,点击connect登录。
登陆后,进入资料库资料库里面是按文件夹存储的点击菜单栏中的Folder——create,来创建新的文件夹,跳出弹窗把Name改一下,这里是做入门上手练习,所以取名Practise然后点击确定,这时,资料库中会多出Practise文件夹,我们选中,然后点击工具栏中的D图标,进入PowerCenter Designer因为选中了Practise,所以进入PowerCenter Designer之后,会直接打开此文件夹,然后就能进行入门练习了。
但之前我们还有一步要做,就是导入表。
导入练习所需要的表,sql脚本在客户端bin文件夹内smpl_db2.sqlsmpl_inf.sqlsmpl_ms.sqlsmpl_ora.sqlsmpl_syb.sqlsmpl_tera.sql以oracle为例,执行脚本smpl_ora.sql,但是因为脚本使用的是us时间制,所以先改变数据库会话的时间格式:alter session set nls_language=American;alter session set nls_date_format = 'DD-MON-YYYY';然后执行脚本,如果有什么限制的,请赋给用户dba权限之后,再执行脚本,之后就能开始练习了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、Suorce调优
1.文本文件:
-调优Line Sequential Buffer Length(1024)
2.关系型数据库:
-在Source Qualify优化SQL
-在源数据增加索引
-增加Database Network Packet size
-当DB与informatica在同一台机器上使用IPC协议
二、Target调优
1.目标为文本文件:
-调优Line Sequential Buffer Length(1024)
2.目标位关系型数据库
-删除目标索引和约束
-增加checkpoit interval
-使用Bulk Loading和External loading
-增加Database networkPacketsize
三、Mapping调优
>最少化转化组件
>减少不必要的link
>对Aggregator、Joiner、Rank、Lookup等组件,减少连接的input/output和output字段
>Single Pass:读一次数据,多处使用
>减少数据类型转换:数值的比较比字符串要快
>减少转换错误:使用session tracing terse
>组件调优:Lookup组件、Filter组件、Aggregator组件、Joiner组件调优、调优Sequence Generator
>调优表达式
>增加Partition
>调优Session参数
四、System调优
>增加network speed:本地速度一般是网络的5-20倍;文件拷贝到本地
>使用informatica Grid
>当只处理7-bit ASCII或EBCDIC数据时,选用ASCII data movement mode :只是用一个字节存储数据。
>减少Paging(虚拟内存):在Unix系统下,使用processor binding将资源分配给informatica。