基于Python技术的校园网搜索引擎的设计与实现
基于python技术面向校园网原型搜索引擎设计

基于python技术面向校园网原型搜索引擎设计作者:焦萍萍来源:《电脑知识与技术》2017年第09期摘要:随着学校数字化建设的加快,校园的各种信息也不断增加,对信息进行查找和定位也逐渐变得的困难。
大多学校还是使用一般搜索引擎进行站内信息的搜索,利用这样的搜索引擎一般不能及时地得到新消息。
而且如果一些学校使用的二级域名或是用,P地址直接作为网站,那么很难被通用的搜索引擎给搜索到。
所以本文将基于Python技术对校园的搜索引擎进行分析,提供一些设计方案仅供参考。
关键词:校园搜索引擎;python技术;设计当今时代是一个信息化的社会,人们通过互联网可以看到各种信息,随着互联网的普遍使用,网络信息也不断地增长。
想要提高信息搜索的效率,主要的就是对搜索引擎进行改进。
而随着校园的信息化建设,建立一个高效搜索引擎变得非常重要。
所以,本文将结合python语言对搜索引擎的设计进行分析,探讨一下该语言在校园网中的建设。
1.搜索引擎建立的流程分析1.1框架的分析建立校园搜索引擎首先就是要进行设计流程的分析;其次就是分析Python语言中Scrapy 相关的开源爬虫结构设计,其中在Scrapy爬虫框架中有关URL的去重功能的分析;再则就是基于Python语言中关于Whoosh索引检索库的分析;最后就是对建立的系统进行测试。
根据多种的搜索引擎设计案例,总结出设计搜索引擎的基本流程:首先就是建立一个文件集合(collection),之后利用索引器(indexer)对这些文件进行索引建设。
接着用户就可以进行关键词(query)的输入,这样系统就可以利用索引进行检索。
而且索引模块可以对查询的结果进行分析排序,最后将搜索结果按照用户的要求进行排列呈现出来。
在这之前要通过网络爬虫程序将这些集合文件下载好。
因此,建立搜索引擎需要完成这几个模块:首先就是网络爬虫系统的建立,其次就是索引查询系统的建立,最后就是显示答案的模块。
1.2网络爬虫在1993年,“互联网漫游者”诞生,它是世界上首个网路爬虫程序,也被称为是网络机器人。
Python爬虫代码实例高校信息查询

Python爬虫代码实例高校信息查询Python爬虫是一种功能强大的工具,可以用来自动化地从互联网上收集数据。
在本文中,我们将使用Python爬虫来查询高校的信息,并逐步思考如何实现这个目标。
步骤1:分析目标网站首先,我们需要分析目标网站的结构和内容。
找到我们需要查询的高校信息所在的页面,并查看网页源代码。
了解网页的结构和标签,以便后续编写爬虫代码。
步骤2:导入库和模块在开始编写爬虫代码之前,我们需要导入所需的库和模块。
在Python中,常用的爬虫库有requests、beautifulsoup和pandas。
requests 库用于发送HTTP请求,beautifulsoup库用于解析网页内容,pandas库用于处理和分析数据。
步骤3:发送HTTP请求使用requests库发送HTTP请求来获取目标网页的内容。
我们可以使用requests库中的get()函数,并将目标网页的URL作为参数传入。
步骤4:解析网页内容使用beautifulsoup库解析网页内容。
通过将上一步获取到的网页内容作为参数传入beautifulsoup库的BeautifulSoup()函数,我们可以将网页内容解析成可操作的对象。
步骤5:定位目标信息在解析网页内容之后,我们需要找到包含我们需要查询的高校信息的标签或元素。
可以通过查看网页源代码,观察高校信息所在的标签的特征,例如类名、id等,然后使用beautifulsoup库的find()或find_all()函数来定位这些标签。
步骤6:提取信息并存储定位到目标信息后,我们可以使用beautifulsoup库提供的方法来提取这些信息。
根据需要,可以提取高校的名称、地点、排名等信息,并将其存储到一个变量中。
步骤7:数据处理和分析如果我们想要对查询到的高校信息进行进一步的处理或分析,可以使用pandas库来处理数据。
例如,我们可以将数据存储到一个DataFrame中,然后使用pandas库提供的功能来对数据进行排序、筛选等操作。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现校园网搜索引擎是一种通过网络检索校园网中信息的工具,它能够将分布在校园网上的信息资源进行整合、分类和检索,方便用户快速找到所需的信息。
随着校园网信息资源的日益丰富和多样化,校园网搜索引擎的重要性也日益凸显。
本文将介绍基于Python技术的校园网搜索引擎的设计与实现。
我们将分析校园网搜索引擎的需求和特点,然后介绍Python技术在搜索引擎开发中的优势,最后详细介绍校园网搜索引擎的设计和实现过程。
一、校园网搜索引擎的需求和特点1. 需求随着互联网技术的发展,校园网上的信息资源越来越丰富,包括学术论文、课程资料、教学资源等各种类型的信息。
校园网搜索引擎需要能够对这些信息资源进行高效检索,方便用户查找所需信息。
2. 特点校园网搜索引擎与传统的互联网搜索引擎相比,有一些独特的特点:(1)信息资源相对集中:校园网上的信息资源大多来自学校的官方网站、教师和学生发布的学术论文等,相对来说信息资源比较集中。
(2)用户群体明确:校园网搜索引擎的用户主要是学校师生,其搜索需求相对集中,主要包括学术资料、教学资源等。
(3)安全性要求高:校园网搜索引擎需要对搜索结果和用户信息进行严格的控制和保护,确保信息安全。
二、Python技术在搜索引擎开发中的优势Python是一种简单易学、功能强大的编程语言,适用于各种类型的应用开发。
在校园网搜索引擎的设计与实现中,Python技术具有以下优势:1. 强大的数据处理能力:Python语言有着丰富的数据处理库和工具,能够快速高效地对大数据进行处理和分析。
2. 多样的网络编程库:Python支持多种网络编程库,能够方便地实现Web页面抓取、信息提取等功能。
3. 丰富的第三方库支持:Python有着丰富的第三方库支持,能够满足搜索引擎开发中各种需求,大大提高开发效率。
4. 易于维护和扩展:Python语言具有清晰简洁的语法结构,易于维护和扩展,能够快速响应需求变化。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现【摘要】这篇文章将介绍基于Python技术的校园网搜索引擎的设计与实现。
在我们将探讨建立该搜索引擎的动机和意义。
在系统架构设计中,我们将讨论系统的整体结构和各个模块之间的关系。
数据抓取与处理部分将介绍如何从校园网站抓取数据并进行预处理。
索引建立与检索部分将展示如何构建搜索索引并实现检索功能。
用户界面设计将介绍搜索引擎的界面设计和交互功能。
性能优化部分将探讨如何提升搜索引擎的性能和用户体验。
结论部分将总结设计与实现过程的经验和成果,展望搜索引擎的未来发展方向。
这篇文章将全面介绍基于Python技术的校园网搜索引擎的设计与实现过程。
【关键词】Python技术、校园网搜索引擎、设计、实现、系统架构设计、数据抓取与处理、索引建立与检索、用户界面设计、性能优化、引言、结论1. 引言1.1 引言在当今信息爆炸的时代,校园网已经成为学生们获取资讯、交流学习的重要平台。
随着校园网信息量的不断增加,如何高效地获取所需信息成为了一个挑战。
设计一种高效的校园网搜索引擎成为了迫切需要解决的问题。
基于Python技术的校园网搜索引擎通过使用Python语言编写程序,充分利用其简洁、易读、强大的特点,实现了对校园网中信息的快速检索和准确定位。
本系统采用了先进的数据抓取和处理技术,能够及时获取并更新校园网上的信息。
通过建立有效的索引系统,用户可以快速地找到他们所需要的信息。
在用户界面设计上,我们注重简洁易用的原则,让用户能够轻松地进行搜索和浏览。
为了进一步提升系统的性能,我们还对搜索引擎进行了性能优化,确保用户能够获得更快速、更准确的搜索结果。
通过本文将详细介绍基于Python技术的校园网搜索引擎的设计与实现过程,希望能为学生们提供一个更便捷、高效的校园网信息检索工具。
2. 正文2.1 系统架构设计系统架构设计是校园网搜索引擎设计中至关重要的一环,其合理性和稳定性直接影响到整个系统的性能和效果。
第5章 爬虫应用——校园网搜索引擎

• 本程序中tf={文档号:出现次数}存储是某个词在文档中出现次数。如王 宗敏的tf={12:1,35:3,88:2}即某个词“王宗敏”出现在网页ID为12 、35、88号网页里,12号页面1次,35号页面3次,88号页面2次。
网页排名和搜索模块
• 网页排名采用TF/IDF统计。TF-IDF是一种用于信息检索与数据挖掘的常 用加权技术。TF/IDF统计用以评估一词对于一个文件集或一个语料库中 的其中一份文件的重要程度。TF意思是词频(Term Frequency),IDF意思是 逆文本频率指数(Inverse Document Frequency)。TF表示词条t在文档d中出现 的频率。IDF的主要思想是:如果包含词条t的文档越少,则词条t的IDF越 大,则说明词条t具有很好的类别区分能力。
• score={文档号:文档得分}用于存储命中(搜到)文档的得分。
• 这里我们指定中原工学院新闻门户URL地址 '/index/xwdt.htm'为初始的URL。
• 使用unvisited队列存储待爬取URL链接的集合并使用广度优先搜索。使用 visited集合存储已访问过的URL链接。 unvisited=deque() #待爬取链接的列表,使用广度优先搜索 visited=set() #已访问的链接集合
• 在数据库中建立两个table,其中一个是doc表,存储每个网页ID和URL链接 create table doc (id int primary key,link text)
爬取信息的存储
• 另一个是word表,即为倒排表,存储词语和其对应的网页ID序号的list。 create table word (term varchar(25) primary key,list text)
12-校园网web搜索引擎的设计与实现2011-8-21

校园网Web搜索引擎的设计与实现引言随着校园网建设的迅速发展,校园网内的信息内容正在以惊人的速度增加着。
如何更全面、更准确地获取最新、最有效的信息已经成为我们把握机遇、迎接挑战和获取成功的重要条件。
目前虽然已经有了像Google、百度这样优秀的通用搜索引擎,但是它们并不能适用于所有的情况和需要。
对学术搜索、校园网的搜索来说,一个公平的排序结果是非常重要的。
另外,由于互联网上信息量之巨,远远超出哪怕是最大的一个搜索引擎可以完全收集的能力范围。
因此,本着整合校园网资源的目的,为方便广大师生对校园网信息的获取和使用,设计并实现了一个灵活、可配置、具有良好可扩展性的校园网搜索引擎。
1. 搜索引擎的发展在国内很多基于主题领域的小型搜索引擎得到很好的发展。
例如一些音乐搜索引擎以及医药方面的搜索都有很好的应用;在越来越多的学校、企业、比较大型的网站如BBS都开始建立了自己的搜索引擎。
在国外,比较著名的有美国教育资源信息搜索的AskERIC,实现医药文献搜索的Highwire等。
Google公司在2007年决定向小型网站提供专门的搜索服务。
这些都表明,小型专用的搜索引擎将在人们获取Web信息中发挥更重要的作用[1]。
在小型搜索引擎快速发展的同时,越来越多的人致力于研究和发展这些小型搜索引擎开发技术,Lucene和Nutch是其中的代表成果。
Lucene是一个高性能、纯Java的全文检索引擎,完全免费、开源。
Lucene几乎适合于任何需要全文检索的应用,尤其是跨平台的应用。
Lucene为Nutch提供了文本索引和查询服务的API,而Nutch在Lucene的基础上实现了网页收集与搜索[2]。
小型搜索引擎与通用搜索引擎相比有很多优点,由于它本身的信息量小,它不可能取代通用搜索引擎。
但是,它是对通用搜索的很好的补充。
随着Web上信息的进一步扩大,小型搜索引擎也将会进一步发展,其中已经引起人们关注的垂直搜索引擎在未来的搜索将发挥更大的作用。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现校园网是学生、教师和工作人员日常生活和学习工作中必不可少的重要资源。
随着信息量的增加和网页的爆炸性增长,学校网站的信息检索变得越来越困难。
为了解决这一问题,我们需要一个高效的校园网搜索引擎。
本文将介绍一种基于Python技术的校园网搜索引擎的设计与实现。
一、设计目标1. 提高搜索效率。
校园网信息庞大,搜索引擎需要能够快速准确地搜索到用户所需的信息。
2. 提供个性化推荐。
搜索引擎需要能够根据用户的搜索历史和兴趣爱好,为用户推荐相关的内容。
3. 支持多种数据类型。
搜索引擎需要能够搜索网页、图片、视频等多种数据类型。
二、技术选型1. 数据存储:使用MySQL数据库存储网页的索引和元数据。
2. 网页爬取:使用Python的requests库进行网页爬取,并使用BeautifulSoup库进行网页内容的解析。
3. 搜索算法:使用TF-IDF算法进行搜索结果的排序。
4. 推荐算法:采用协同过滤算法根据用户的历史行为为用户推荐内容。
5. 前端界面:使用Django框架搭建搜索引擎的前端界面。
三、实现流程1. 数据收集:使用爬虫技术对学校网站上的各类信息进行抓取,并将得到的网页内容进行解析和存储。
2. 索引建立:对存储在数据库中的网页内容进行分词、去除停用词等预处理操作,并计算每个词的TF-IDF值,建立倒排索引。
3. 搜索功能实现:用户输入搜索关键词后,系统根据倒排索引和TF-IDF算法计算相似度,返回相关的搜索结果。
4. 推荐功能实现:根据用户的搜索历史和行为,系统计算用户之间的相似度,为用户推荐相关的内容。
5. 前端界面实现:使用Django框架搭建搜索引擎的前端界面,用户可以在界面上输入搜索关键词,查看搜索结果和推荐内容。
四、实现效果经过以上的设计和实现,我们的校园网搜索引擎可以高效地搜索到用户所需的信息,并根据用户的历史行为为其推荐相关的内容。
用户可以在搜索引擎的界面上方便地输入关键词,查看搜索结果和个性化的推荐内容。
用Python构建一个搜索引擎

用Python构建一个搜索引擎Python是一种非常流行的、功能强大的面向对象的编程语言,它可以用来构建有效的搜索引擎。
用Python构建一个搜索引擎需要依次考虑以下内容:1. 数据采集:为了构建搜索引擎,首先需要从网上获取丰富的数据。
Python提供了urllib和BeautifulSoup库,可以爬取网站信息,此外还有一些其他第三方库,比如Selenium,可以爬取动态网站数据,还可以使用API来获取实时数据。
收集的信息要存储到数据库中,常用的存储方式有MySQL,MongoDB,Elasticsearch等。
2. 数据处理:将爬取到的数据经过清洗,去除干扰信息,利用NLP相关技术,将文本内容分析成关键字,可以使用Python库NLTK和SpaCy等来实现文本分析。
3. 索引:在存储所有数据之前,需要将这些数据根据某种规则进行索引,以便后续检索。
此外,还可以使用Python自带的collections库,自定义字典等数据结构来存储索引数据。
4. 搜索引擎核心处理:然后利用诸如TF-IDF等机器学习技术,构建一个搜索引擎核心处理方法,该方法将会根据用户输入的关键词,对索引进行检索,根据检索结果呈现出最匹配的结果给用户。
可以使用Python库scikit-learn,Keras 搭建机器学习模型,来训练搜索引擎。
5. 用户界面:最后,可以使用Python的web框架Django来构建一个搜索引擎的用户界面,以方便用户使用,以及实现自然语言处理,工具提示等功能。
步骤完成之后,就可以把各个模块都连接起来,从而构建出一个有效的搜索引擎。
从数据采集到最终展示结果,Python提供了足够的支持和功能,能够让我们轻松地构建出一个搜索引擎。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现校园网搜索引擎是一种能够在校园网中进行信息搜索和检索的工具,可以帮助用户快速找到所需的信息资源。
本文将介绍基于Python技术的校园网搜索引擎的设计与实现。
一、设计目标校园网搜索引擎的设计目标是提供一个高效、准确、全面的搜索服务,满足用户在校园网中查找信息的需求。
具体目标如下:1. 提供快速的搜索速度,能够在短时间内返回搜索结果。
2. 提供准确的搜索结果,能够根据用户的搜索关键词匹配并展示相关的信息资源。
3. 提供全面的搜索范围,能够搜索和检索校园网中的各种类型的信息资源。
二、系统架构校园网搜索引擎的系统架构包括四个主要组件:爬虫模块、索引模块、查询模块和界面模块。
1. 爬虫模块:该模块负责在校园网中爬取信息资源,并将其存储在数据库中。
使用Python的第三方库(如BeautifulSoup、Requests等)可以方便地实现网页内容的抓取和解析。
2. 索引模块:该模块负责将抓取到的信息资源进行索引,以便后续的检索。
可以使用Python的第三方库(如Whoosh等)来构建搜索引擎的索引。
3. 查询模块:该模块负责接收用户的查询请求,并根据用户的搜索关键词在索引中进行匹配。
根据匹配结果,将相关的信息资源返回给用户。
4. 界面模块:该模块负责将查询模块返回的结果进行展示,使用户可以方便地查看和浏览搜索结果。
可以使用Python的web框架(如Flask、Django等)来实现搜索引擎的界面。
三、实现步骤基于上述的系统架构,我们可以按照以下步骤来实现校园网搜索引擎:2. 设计和编写索引模块,使用Python的第三方库实现信息资源的索引构建,并将构建好的索引存储在数据库中。
5. 将上述模块进行整合和测试,确保搜索引擎的各个功能正常运行,并满足设计目标。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现随着学校网络的发展和普及,校园网已经成为学生生活中不可或缺的一部分。
在校园网中,我们经常需要查找和获取各种信息,比如学习资料、教务信息、学校通知等。
为了方便学生们获取各种信息,我们可以设计一个基于Python技术的校园网搜索引擎。
我们需要明确搜索引擎的功能和需求。
在校园网搜索引擎中,我们希望能够提供快速、准确的搜索结果,包括学习资料、教务信息、学校通知等。
为了实现这个功能,我们可以采用以下的步骤来设计和实现校园网搜索引擎:1. 确定搜索范围:校园网中的信息非常庞大,我们需要确定搜索的范围。
根据实际情况,我们可以选择搜索学习资源、教务信息和学校通知等。
2. 收集和建立索引:为了实现快速搜索,我们需要先收集校园网中的信息并建立索引。
可以通过爬虫技术来收集各类信息,并将其存储到数据库中。
建立索引的过程可以借助Python技术中的第三方库,比如Whoosh和Elasticsearch等。
3. 设计查询接口:为了方便用户查询,我们需要设计一个查询接口。
可以通过Web界面来实现用户输入查询关键词,并将查询结果展示给用户。
这个过程可以使用Python的Web开发框架,比如Flask或Django等。
4. 实现搜索算法:根据用户输入的查询关键词,我们需要设计一个搜索算法来获取和返回相关的结果。
可以采用TF-IDF等常用的搜索算法,根据关键词和建立的索引来匹配和排序搜索结果。
5. 优化搜索效果:为了提高搜索效果,我们可以对搜索算法进行优化。
比如可以加入相关性算法,根据用户的搜索历史和点击记录等来调整搜索结果的排序。
通过以上的设计和实现,我们可以得到一个基于Python技术的校园网搜索引擎。
这个搜索引擎可以帮助学生们快速查找和获取校园网中的各类信息,并提供准确的搜索结果。
通过优化搜索效果,可以提高搜索的准确性和用户体验。
这样的搜索引擎将会大大便利学生们的学习和生活。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现校园网搜索引擎在现代大学生活中占据着越来越重要的地位,它可以帮助学生快速找到自己需要的信息,提高信息查找的效率。
而基于Python技术的校园网搜索引擎具有灵活、高效、易扩展等特点,能够为大学生提供更好的信息查找体验。
本文将介绍基于Python技术的校园网搜索引擎的设计与实现。
一、校园网搜索引擎的需求分析1.1 校园网信息资源广泛现代大学的校园网中包含了大量的信息资源,如学术论文、课程资料、教学视频等。
学生在日常学习和科研中需要查阅这些信息资源,因此需要一个高效的校园网搜索引擎来帮助他们。
1.2 需要快速、精准的搜索结果校园网搜索引擎需要能够快速、精准地返回学生所需的搜索结果,以满足他们对信息的高效获取需求。
1.3 需要支持多种数据格式校园网中的信息资源通常涉及多种数据格式,包括文本、图片、视频等,因此搜索引擎需要支持多种数据格式的检索和展示。
1.4 需要灵活的搜索策略不同的学生对信息的需求和检索策略可能有所不同,搜索引擎需要提供灵活的检索策略,以满足不同学生的个性化需求。
2.1 数据采集与存储校园网搜索引擎需要通过爬虫技术对校园网中的信息资源进行采集,并将采集到的数据进行结构化存储,以便后续的索引和检索。
2.2 索引与检索搜索引擎需要建立信息资源的全文索引,并提供高效的检索算法,以便在用户输入关键词时能够快速返回搜索结果。
2.3 搜索结果的展示搜索引擎需要提供友好的用户界面,能够对搜索结果进行合理的排版和展示,使用户能够快速获取所需信息。
2.4 支持个性化定制搜索引擎需要提供个性化的搜索策略和定制功能,使用户能够根据自己的需求调整搜索参数,获取更加符合自己需求的搜索结果。
3.1 数据采集与存储Python语言具有强大的网络爬虫库,如requests、BeautifulSoup等,可以用于快速、高效地对校园网中的信息资源进行采集。
采集到的数据可以使用Python的数据库库,如MySQLdb、pymongo等进行存储。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现作者:熊辉来源:《科技视界》2019年第28期【摘要】面对高速发展的经济以及科技新突破给我国带来的翻天覆地变化,互联网已经普及国内外,人们的生活也因科技的作用而便利了很多,但科技是一把“双刃剑”,互联网的高速发展与各种信息的传播也让给我们带来了“信息污染”,一时间很难辨别信息的正确性。
对于校园数字化建设来说,也同样不可避免的会受到“信息污染”的干扰,各种无效信息使我们对正确信息的查找与定位变得艰难,而调查发现对于很多学校来说,大多是运用很普通的搜索引擎检索信息,而普通的搜索引擎难以搜集到有效、正确的信息。
针对上述问题,为了还学校一个高效、清净的信息环境,笔者将结合Python技术对校园网的搜索引擎进行相关介绍和设计,设计方案仅供参考。
【关键词】Python技术;校园网搜索引擎;设计;信息化;信息污染中图分类号: TP391.3;TP393.18 文献标识码: A 文章编号: 2095-2457(2019)28-0173-002DOI:10.19694/ki.issn2095-2457.2019.28.079【Abstract】In the face of the rapid development of the economy and new breakthroughs in science and technology to bring about great changes in our country, the Internet has been popularized at home and abroad, people's lives are also because of the role of science and technology and facilitate a lot, but science and technology is a "double-edged sword", the rapid development of the Internet and the dissemination of various information has also brought us "information pollution", It's hard to tell the correctness of information for a while. For the campus digital construction, is also inevitable by the "information pollution" interference, all kinds of invalid information makes us to find and locate the correct information become difficult, and the survey found that for many schools, most lying through a very common search engine to retrieve information, and ordinary search engines difficult to collect effective, The right information. In view of the above-mentioned problems, in order to return the school an efficient and clean information environment, the author will combine Python technology on the campus network search engine related introduction and design, design design for reference only.【Key words】Python technology; Campus web search engine; Design; Information; Information pollution21世纪是一个经济高速发展,高度信息化的社会,互联网在我国境内几乎已经全覆盖,通过它人们不出门就能够获取各种各样的信息,但如今随着它的高速发展,各种各样的网络信息也随处都是,人们有时候很难在第一时间找到自己想要的信息,因此要想让自己的信息搜索效率提高就需要改进搜索引擎,好的搜索引擎能够极大的帮助人们获取自己想要的信息。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现【摘要】本文探讨了基于Python技术的校园网搜索引擎的设计与实现。
在分析了研究背景、研究目的和研究意义。
接着,通过解释校园网搜索引擎的概念和原理,以及Python技术在搜索引擎中的应用,为读者提供了相关知识基础。
然后,详细介绍了校园网搜索引擎的设计与实现过程,包括数据爬取与处理技术和用户界面设计与优化。
在评估了基于Python技术的校园网搜索引擎的效果与展望,探讨了未来发展方向,并总结了本文的重要内容。
通过本文,读者能够了解基于Python技术的校园网搜索引擎的技术原理和实施方法,为相关领域的研究和应用提供参考。
【关键词】校园网搜索引擎、Python技术、数据爬取、用户界面设计、效果、展望、发展方向、总结、研究背景、研究目的、研究意义、概念与原理、设计与实现过程1. 引言1.1 研究背景校园网搜索引擎在当今信息化时代具有重要的意义。
随着社会的发展和信息量的爆炸增长,学生们在日常学习和生活中需要获取各种各样的信息,而校园网搜索引擎的推出为他们提供了便捷高效的检索途径。
目前市面上的搜索引擎大多面向全网搜索,对于校园网内的特定信息并不适用,开发基于Python技术的校园网搜索引擎显得尤为重要。
研究背景:当前大部分学校的校园网信息量巨大,包括课程资料、学术论文、教授信息等,但学生们往往需要花费大量时间在繁琐的信息搜索过程中,搜索效率低下。
利用Python技术设计一款高效的校园网搜索引擎,将有助于提升学生们的信息检索效率,节约他们宝贵的时间。
研究基于Python技术的校园网搜索引擎,也将推动Python技术在教育领域的应用和发展,具有积极的促进作用。
就是为了便捷高效地检索校园网内的信息,提升学生们的学习和生活质量。
则在于推动校园网信息化建设,促进教育信息化进程。
1.2 研究目的校园网搜索引擎的研究目的主要包括以下几个方面:1. 提高信息检索效率:校园网搜索引擎的研究目的之一是提高学生和教师在校园网内的信息检索效率。
基于Python技术的校园网搜索引擎的设计与实现

基于Python技术的校园网搜索引擎的设计与实现
随着互联网的快速发展,信息已成为一种稀缺资源。
在校园网中,学生教工往往需要
查找各种信息,如学术论文、科研成果、学院通知等。
然而,由于校园网上信息繁多、分散,学生教工往往需要花费很长时间在网站中浏览查找需要的信息。
为解决这一问题,本
文设计并实现了一个基于Python技术的校园网搜索引擎。
首先,本搜索引擎使用Python语言作为开发工具,利用Python中的各类库和框架来
实现搜索引擎的功能。
其次,本搜索引擎采用爬虫技术,对校园网上的各类网站进行爬取,提取有关信息进行分析,建立索引。
这样,用户只需在搜索框中输入关键词,搜索引擎就
能够根据建立的索引在几秒钟内返回结果。
最后,为保证搜索结果的相关性和准确性,本
搜索引擎采用了多种算法进行优化,如TF-IDF算法、PageRank算法等。
本搜索引擎具有以下特点:
1. 精准度高:本搜索引擎通过爬虫技术获取校园网上的各类网站,能够准确地搜索
出符合用户输入关键词的相关信息。
2. 速度快:本搜索引擎采用多种算法进行优化,在查询结果方面具有较高速度和准
确性,能够快速地将用户需要的信息返回。
3. 强扩展性:本搜索引擎采用模块化开发方式,模块之间独立,可以对各个模块进
行增删改查的操作,具有更好的扩展性。
总之,基于Python技术的校园网搜索引擎在为用户提供优质搜索体验的同时,也为
校园网信息的整合和共享提供了新的思路和方法。
基于python的检索系统设计与实现

基于python的检索系统设计与实现
随着信息量的快速增长,建立高效的检索系统已经成为一项十分重要的任务。
Python作为一种流行的编程语言,可以很好地用于设计和实现各种检索系统。
在设计检索系统之前,需要确定系统的目标和功能。
例如,该系统是用于检索文本、图像、音频还是视频等。
同时,也需要确定检索的范围和深度,以及所需的数据和参数。
在此基础上,可以采用以下步骤来设计和实现Python检索系统:
1. 数据收集和预处理:收集需要检索的数据,例如文本文件、图片文件等,并进行预处理,例如转换为机器可读的格式,标准化文本内容等。
2. 索引构建:创建一个索引来快速查找和检索数据。
可以使用许多不同的索引方法,例如倒排索引、哈希表等。
3. 查询处理:接收用户查询,并处理并解析查询。
可以使用自然语言处理(NLP)技术来处理查询,并提取关键词和短语。
4. 检索和排序:使用索引来查找与查询相关的数据,并按照相关性进行排序。
可以使用各种检索算法和排序算法来实现此过程,例如TF-IDF、余弦相似度等。
5. 结果展示:将结果以易于理解的方式呈现给用户,例如通过网页展示、保存结果等。
Python有许多强大的库和工具可用于实现这些步骤,例如NLTK、Scikit-learn、PyTorch、TensorFlow等。
通过利用这些工具,我们可以快速地构建高效的检索系统。
总的来说,设计和实现Python检索系统需要深入了解数据的结构和特征,同时也需要掌握Python编程语言和相关工具和库的使用。
一旦完成了这些步骤,我们就可以为各种应用程序构建高效的检索系统,帮助用户快速找到所需的信息。
校园网搜索引擎系统的设计与实现

三、实现细节
1.索引存储 为了提高搜索速度和效率,我们需要将索引存储在内存中。可以使用Python 中的字典(dict)或集合(set)等数据结构来实现索引的存储和查询。另外, 我们也可以使用分布式缓存系统(如Redis)来分布式存储索引,以支持大规模 数据处理和高并发访问。
三、实现细节
2.索引更新 由于校园网中的网页是动态更新的,因此我们需要定期更新索引以保持搜索 引擎的准确性和时效性。可以使用定时任务(如Celery)来实现索引的定时更新 和维护。
二、搜索引擎设计
3.搜索算法 在建立好索引之后,我们需要实现搜索算法来匹配用户的搜索请求。常见的 搜索算法包括全文搜索和K-最近邻算法等。全文搜索算法可以根据关键词在倒排 索引中进行匹配,并按照一定的排序规则返回搜索结果。K-最近邻算法则是将搜 索结果按照相似度进行排序,并返回与用户搜索请求最相似的K个结果。
谢谢观看
二、搜索引擎设计
二、搜索引擎设计
1.数据采集 要实现一个校园网搜索引擎,首先需要获取校园网中的网页数据。我们可以 使用Python中的requests库来发送HTTP请求并获取网页内容。对于校园网内的 网页,我们可以通过爬虫程序自动发现和爬取所有网页链接和内容。对于校园网 外的网页,我们需要通过其他方式获取数据。
二、搜索引擎设计
2.数据处理 获取到网页数据后,需要对数据进行处理,以便建立索引。首先,我们需要 使用HTML解析库(如BeautifulSoup或lxml)提取出网页中的文本信息和非结构 化数据。然后,我们需要对文本信息进行分词处理,并使用倒排索引将关键词与 对应的网页链接关联起来。同时,我们还需要对网页进行去重和去噪处理,以避 免重复和无关的信息干扰搜索结果。
2、文本处理
用python做一个搜索引擎(Pylucene)的实例代码
⽤python做⼀个搜索引擎(Pylucene)的实例代码1.什么是搜索引擎?搜索引擎是“对⽹络信息资源进⾏搜集整理并提供信息查询服务的系统,包括信息搜集、信息整理和⽤户查询三部分”。
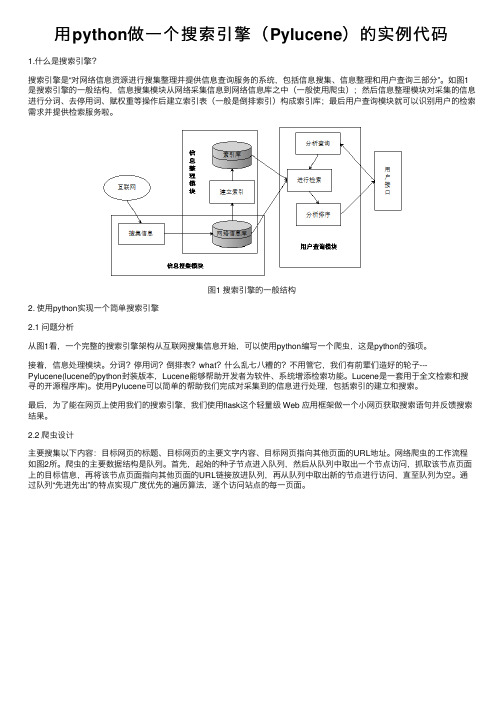
如图1是搜索引擎的⼀般结构,信息搜集模块从⽹络采集信息到⽹络信息库之中(⼀般使⽤爬⾍);然后信息整理模块对采集的信息进⾏分词、去停⽤词、赋权重等操作后建⽴索引表(⼀般是倒排索引)构成索引库;最后⽤户查询模块就可以识别⽤户的检索需求并提供检索服务啦。
图1 搜索引擎的⼀般结构2. 使⽤python实现⼀个简单搜索引擎2.1 问题分析从图1看,⼀个完整的搜索引擎架构从互联⽹搜集信息开始,可以使⽤python编写⼀个爬⾍,这是python的强项。
接着,信息处理模块。
分词?停⽤词?倒排表?what?什么乱七⼋糟的?不⽤管它,我们有前辈们造好的轮⼦---Pylucene(lucene的python封装版本,Lucene能够帮助开发者为软件、系统增添检索功能。
Lucene是⼀套⽤于全⽂检索和搜寻的开源程序库)。
使⽤Pylucene可以简单的帮助我们完成对采集到的信息进⾏处理,包括索引的建⽴和搜索。
最后,为了能在⽹页上使⽤我们的搜索引擎,我们使⽤flask这个轻量级 Web 应⽤框架做⼀个⼩⽹页获取搜索语句并反馈搜索结果。
2.2 爬⾍设计主要搜集以下内容:⽬标⽹页的标题、⽬标⽹页的主要⽂字内容、⽬标⽹页指向其他页⾯的URL地址。
⽹络爬⾍的⼯作流程如图2所。
爬⾍的主要数据结构是队列。
⾸先,起始的种⼦节点进⼊队列,然后从队列中取出⼀个节点访问,抓取该节点页⾯上的⽬标信息,再将该节点页⾯指向其他页⾯的URL链接放进队列,再从队列中取出新的节点进⾏访问,直⾄队列为空。
通过队列“先进先出”的特点实现⼴度优先的遍历算法,逐个访问站点的每⼀页⾯。
图22.3 pylucene的使⽤Pylucene中关于建⽴索引的类主要有Directory、Analyzer、IndexWriter、Document、Filed。
Python技术与搜索引擎优化的结合应用

Python技术与搜索引擎优化的结合应用随着互联网的快速发展,搜索引擎成为人们获取信息的重要途径。
而在如此庞大的互联网世界中,如何确保自己的网站能够优化到搜索引擎的前列,成为了很多网站管理员亟需解决的问题。
Python技术则作为一门高效、灵活的编程语言,正逐渐被广大网站开发人员所崇尚和利用。
在此背景下,将Python技术与搜索引擎优化相结合应用,不仅能够有效提升网站的优化程度,还能够帮助网站管理员更好地了解和掌握搜索引擎的工作原理。
首先,Python技术在搜索引擎优化中的应用体现在网站数据分析和关键词优化方面。
通过使用Python编写的程序,网站管理员可以方便地对自己网站的数据进行收集、分析和处理。
例如,使用Python的数据分析库,可以对访问日志进行解析,提取出有关访问者的信息,如访问来源、访问时间、访问频率等,并将这些数据进行可视化处理,从而更好地了解用户的行为和需求。
基于这些数据,网站管理员可以有针对性地进行关键词优化,提升网站的排名和曝光度。
通过分析搜索引擎的热门关键词和用户搜索习惯,结合自己网站的主题和内容,选择合适的关键词进行优化,使得网站更容易被搜索引擎收录和展示。
其次,Python技术在搜索引擎优化中的应用还表现在网站的自动化操作和爬虫程序的开发方面。
搜索引擎对网站的排名依赖于很多因素,如网页质量、网页结构等,而这些因素对网站管理员来说往往需要大量的时间和精力去手动操作和维护。
而借助Python技术,可以编写自动化脚本,实现对网站的自动操作和维护。
例如,通过Python的网络爬虫技术,网站管理员可以定期爬取搜索引擎上关于自己网站的数据,并进行分析,找出可能影响排名的问题。
通过自动化操作,可以有效减少人力成本,提升工作效率。
除此之外,Python技术在搜索引擎优化中还可应用于网站速度优化和移动端适配等方面。
作为一门高性能的编程语言,Python能够快速处理复杂的计算和逻辑问题,从而在网站代码的优化和性能调优中发挥重要作用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Python技术的校园网搜索引擎的设计与实现
随着网络的不断发展,各大学校都建立了自己的信息化平台,为师生提供更加便利的
服务。
然而,在信息海量的背景下,如何快速精准地搜索到所需信息成为一个难题。
因此,设计一款基于Python技术的校园网搜索引擎便成为了一项重要的任务。
该搜索引擎的基本架构如下图所示:
该搜索引擎主要由三个模块组成:
1. 爬虫模块:负责从校园网上爬取相关信息并进行处理。
2. 索引模块:将爬取的信息进行处理后生成索引库。
3. 搜索模块:读取索引库并进行查询操作。
具体实现如下:
爬虫模块:
该模块主要使用Python中的urllib模块进行网页爬取,对爬取到的网页进行解析并
提取出所需的信息。
爬虫模块负责的主要任务包括:
1. 通过网络连接器获取校园网上的相关网页。
2. 对网页进行解析,提取出所需的信息存入列表。
3. 过滤无用信息并对其进行加工处理。
4. 将处理后的信息保存至索引库中。
索引模块:
该模块主要对爬虫模块爬取的信息进行处理,生成大量的索引文件供搜索模块使用。
索引模块负责的主要任务包括:
1. 将爬虫模块爬取到的信息进行加工处理,去除HTML标签、特殊字符等无用信息。
2. 将处理后的信息进行关键词提取,并将其转化成一个词频统计表。
3. 将词频统计表中的关键词与文档进行对应,生成一个文档关键词对照表。
4. 读取文档关键词对照表,生成多个倒排索引表。
5. 将所有倒排索引表合并成一个总索引表。
1. 读取索引库中的所有倒排索引表。
2. 对用户输入的关键字进行分词操作,生成多个搜索词语。
3. 对搜索词语进行匹配,找到所有含有关键词的文档。
4. 对匹配到的文档进行排序,按相关度高低进行排序。
5. 输出与搜索词语相关的所有文档链接。
总结:
本文介绍了一款基于Python技术的校园网搜索引擎的设计与实现。
该搜索引擎分为爬虫模块、索引模块和搜索模块三个部分,主要使用urllib库进行网络连接及网页爬取,对所爬取的信息进行加工处理并生成索引库,实现了快速精准的搜索功能。