《信长之野望14》大地图攻防数据解析
《信长之野望14威力加强版》筑城区划数据一览

《信长之野望14威⼒加强版》筑城区划数据⼀览
《信长之野望14:威⼒加强版》中在是么能筑城,什么地⽅筑城合适,筑城后又如何区划呢?今天⼩编为⼤家带来玩家“e n u j u n e”分享的《信长之野望14:威⼒加强版》筑城区划数据⼀览,希望对⼤家有帮助,⼀起来看吧。
天天忙筑城,筑了拆,拆了筑的,正好在⼀个⽹页上看到了⽐较详细的筑城指南,于是乎,⾃⼰表格编辑了⼀下,与各位筑城强迫症患者分享下!能筑城的地⽅很多,我只选取了区划在5以上的,按照每个领国的筑城区划,以区划10往下排列,⾄于3区划4区划的,就在⼤区划完成后随意筑之吧!
逗游⽹——中国2亿游戏⽤户⼀致选择的”⼀站式“游戏服务平台。
信长之野望14创造自定义武将数据与能力值公式

信长之野望14:创造-⾃定义武将数据与能⼒值公式 特性编号17.⿁型 代表特性-⿁:⼤地图30%触发+20伤害/免伤,合战中攻击防御各+2 初始特性:舍⾝ 可习得特性:电光⽯⽕、背⽔、猛攻(武10)、铁壁(武20)、猛将(武统16)、敏腕、治⽔巧者、⿁(武统4)、攻城、先驱(全15)、殿军,培养完毕共11个特性。
此型⾃创武将为早熟型,培养⽐较⽅便,基本打⼏场合战后就能出⿁特性,初期就能⼤放异彩,⼤地图作战能⼒并不⽐武将名型的武将差。
其实⾮⾃创武将中,柴⽥胜家、⿁⼗河、⿁⼩岛等⽜⼈也是这个型。
⿁型⾃创武将公式:武勇≥统率、智略30,武勇≥政治50,四维总和=287或270或248或244⼀直到69 如满⾜前3个条件,四维属性总和值为其他数字的时候,为枪得意、⾚备、夜叉、骑马突击型,在此不作讨论。
举例:70/100/67/50和70/100/70/47,属性最为饱满的两种⿁型,初期100的武勇配合⿁特性,这除了⽼虎和J J还有谁能挡? 31/90/30/13,此⿁型属性堪⽐创造原作中被削弱过的剑豪众。
13/54/1/1,没有最惨只有更惨,适合各⾃虐D的⾃虐⿁型。
68/98/56/48,此⿁型L Z⾃创⽤,武将名许褚,适合做⾼统低武的第⼀副将。
合战战法配个挑拨,等出了⿁后上去平砍之。
特性编号33.智将(军师)型 代表特性—慧眼:⼤地图战⽃时第⼀击使对⽅不能⾏动,持续时间10,合战中敌⾏动不能。
创造中属于⽼虎、乌⻳、⿊⽜等⼈的逆天b u g特性之⼀。
初始特性:兵家 可习得特性:疾⾛、⽓合、军略家、⿁谋、神算、智将、宰相(政10)、外交术(智政4)、封杀(武统4)、慧眼(全15),培养完毕共10个特性。
此型武将为⾃创武将中⼤器晚成型的武将,⼀般⾄少需要出了封杀之后才能勉强镇守⼀⽅,但后期(全属15后)绝对值得期待。
岛津家的⽼三、越后的军师、⽼虎家的军师、朝仓家的军神都是这个型。
智将(军师)型⾃创武将公式: 武勇<70,智略+政治≥150,智略>统率、武勇,政治>统率、武勇,智⼒>政治,并满⾜⼀定的四维总和值,如365、329、327等等。
信长之野望14威力加强版改建设施参数效果解析
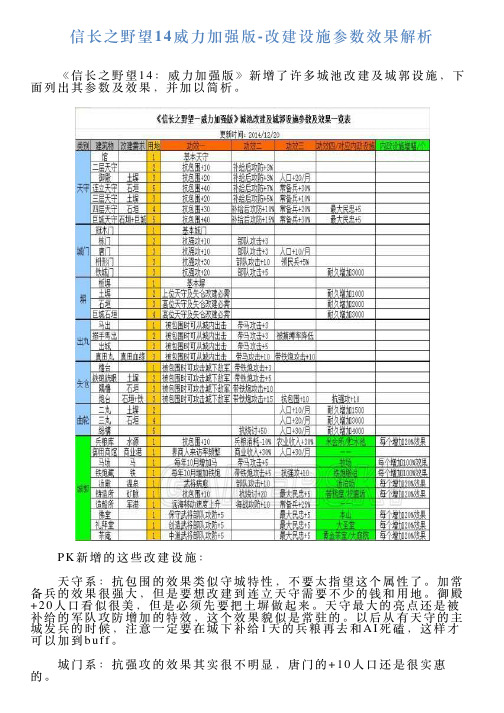
信长之野望14威⼒加强版-改建设施参数效果解析 《信长之野望14:威⼒加强版》新增了许多城池改建及城郭设施,下⾯列出其参数及效果,并加以简析。
P K新增的这些改建设施: 天守系:抗包围的效果类似守城特性,不要太指望这个属性了。
加常备兵的效果很强⼤,但是要想改建到连⽴天守需要不少的钱和⽤地。
御殿+20⼈⼜看似很美,但是必须先要把⼟塀做起来。
天守最⼤的亮点还是被补给的军队攻防增加的特效,这个效果貌似是常驻的。
以后从有天守的主城发兵的时候,注意⼀定要在城下补给1天的兵粮再去和A I死磕,这样才可以加到b u f f。
城门系:抗强攻的效果其实很不明显,唐门的+10⼈⼜还是很实惠的。
塀系:前线的城市还是要适当改修出个⽯垣,没有⽯垣很多⾼位天守和曲轮都改建不了。
出丸系:打破了被围就要靠援军的原版限制,现在P K版守城⽅各种城下夹击有⽊有,本系出个1⽤地的马出其实就够了。
⽮仓系:只有改建了本系的城池才有攻击⼒,但也只是给攻城部队挠痒痒,真正要解围还是要靠硬碰硬的合战。
曲轮系:本系+⼈⼜+耐久都是很实惠的属性,有钱就造吧。
城郭系:需要⼀定的三围和2000⾦钱的造价,但基本都是超值的,满⾜条件必建。
兵粮库——什么是粮城?能造兵粮库的就是粮城。
+30%收获简直吊炸天,别说还有增幅。
城下町内政可以考虑建设成9999农业的。
御⽤商馆——+30⼈⼜+30%收⼊,还有⽐这更逆天的吗?战国打的就是⼈和钱啊,有商港必建,城下町内政可以考虑建设成9999商业的。
马场——这个每年10⽉增加的马数量有⼀定的波动性,但是每个牧场都可以对这个收益进⾏100%的加成太I M B A了。
铁炮藏——同马场。
汤殿——可以治愈得病的武将很稀罕,加攻击的⽅式貌似和猎场的不同,是百分⽐的增加。
铸造所——加的效果不是很理想,A I基本不烧讨,感觉这个设施⽐较坑爹。
造船所——很不和谐的设施,+25%常备兵的效果⽐四层天守还多,有军港的城市都可以考虑规划成暴兵城了。
信长之野望14全本城原始数据及设施建造表一览

信长之野望14-全本城原始数据及设施建造表⼀览 主要以1551年资料为主,少数⼏个城是1560以后出现的 00虾夷-虾夷德⼭馆 01陆奥-东陆奥三户城 02陆奥-西陆奥⽯川城 03陆奥-陆中⾼⽔寺城 04陆奥-陆前利府城 05陆奥-磐城⼩⾼城 06陆奥-岩代⿊川城 07出⽻-⽻后桧⼭城 08出⽻-北出⽻⼭形城 09出⽻-南⽻前⽶泽城 10关东-常陆太⽥城 11关东-下总古河御所 12关东-上总久留⾥城 13关东-安房馆⼭城 14关东-下野宇都宫城 15关东-上野箕轮城 16关东-武藏河越城 17关东-相模⼩原⽥城 18甲信-甲斐新府城(1582) 18甲信-甲斐踯躅躅崎馆 19甲信-北信浓砥⽯城 20甲信-南信浓⾼远城 21北陆-北越后新发⽥城 22北陆-南越后春⽇⼭城 23北陆-越中富⼭城 24北陆-能登七尾城 25北陆-加贺尾⼭御坊 26北陆-越前⼀乘⾕城(北庄城) 27北陆-若狭后濑⼭城 28东海-伊⾖⾲⼭城 29东海-骏河骏府馆 30东海-远江引马城(松滨城) 31东海-三河冈崎城 32东海-尾张那古野城 32东海-尾张清洲城(1560) 33东海-美浓稻叶⼭城(埠岐城) 34东海-飞驒松仓城 35东海-伊势雾⼭御所 36东海-志摩鸟⽻城 37近畿-北近江⼩⾕城(长滨城) 38近畿-南近江观⾳寺城(安⼟城) 39近畿-⼭城⼆条御所 40近畿-丹后⼸⽊城 41近畿-丹波⼋上城 42近畿-河内⾼屋城 43近畿-和泉岸和⽥城 44近畿-摄津⽯⼭御坊 45近畿-伊贺伊贺上野 46近畿-⼤和筒井城 47近畿-纪伊杂贺城 48⼭阳-播磨姬路城 49⼭阳-美作津⼭城 50⼭阳-备前天神⼭城 51⼭阳-备中备中⾼松城 52⼭阳-备后⽐熊⼭城 53安芸吉⽥郡⼭城 54周防⾼岭城 55长门指⽉城 56⼭阴-但马此隅城 57⼭阴-因幡鸟取城 58⼭阴-伯耆⼋桥城 59⼭阴-出云⽉⼭富⽥城 60⼭阴-⽯见⼭吹城 61四国-赞岐⼗河城 62四国-阿波胜瑞城 63四国-伊予汤筑城 64四国-东⼟佐冈丰城 65四国-西⼟佐中村御所 66九州-丰前城井⾕城 67九州-丰后府内城 68九州-筑前⽴花⼭城 69九州-筑后柳川城 70九州-肥前村中城 71九州-北肥后隈本城 72九州-南肥后⼈吉城 73九州-⽇向佐⼟原城 74九州-萨摩内城 75九州-⼤隅肝付城 逗游⽹——中国2亿游戏⽤户⼀致选择的”⼀站式“游戏服务平台。
信长之野望14威力井伊家统一日本图文攻略

信长之野望14威⼒-井伊家统⼀⽇本图⽂攻略 在《信长之野望14威⼒加强版》中使⽤井伊家统⼀⽇本算是⽐较有难度的,今天⼩编为⼤家带了⽤井伊家统⼀⽇本的图⽂⼼得,希望能给⼤家提供⼀些帮助。
环境分析 简单介绍⼀下井伊家周边势⼒:群雄环绕。
魔王织⽥家,有了⼏个⽼头⼦和⼏个姬,⽐14不知道强了多少。
乌⻳有了他⽼爹,也不知道强了多少。
连今川家都多了⼏个⼤将! ⽽井伊帅哥家,就只有⼏个⼀门可以为将!惨啊惨啊。
借鉴14中搬家与不搬家的套路,还是不搬家了,与今川,德川扛起。
统⼀之路 开局刷个独⽴国⼈众,调配好武将,既然做好要硬磕这2家,廊坊原和御前崎设营(多次反复读档的研究成果!~!!) 然后脚踩2个营,打爆今川⼤军,⼀定要强攻!不然就准备等着⽼虎和狮⼦家的援军吧。
⾸战胜利,拿下了⼩⼭城,然织⽥魔王要找⽼丈⼈的⿇烦,连乌⻳都出⻳壳,出什么⻳壳⼲什么。
找打,⽝居城出兵牵制长崎,其他的⼯吉⽥城。
同样的剧情,只是换了个年⽉⽽已那就拿你长崎城 拿下长崎后,就纠结了,东⾯今川家打不下来(三国联盟太恶⼼了),西⾯德川家也咬不动,北⾯斋藤家外交太厉害了,⼀票都是盟友,村上家迟早会被灭,没想到被斋藤灭了。
其实我是很想打的,但是⼀下⼦东⾯三国来犯!!! 试了N个⽅式,打德川,打今川,泷川(九⿁隆嘉海战名⼈真蛋疼),斋藤都被援军打爆,所以我曲线灭泷川。
北畠家居然拿下了⼆条御所!!!!趁着织⽥打长岛,我也要去下松岛城。
途中北畠家会进攻松岛城,P K有个⽐较贱的地⽅就是朝廷的⽆条件停战!果断保住伊势的据点! 织⽥来攻!!⽛都没齐就四处攻城略地真⼼不合适。
但是哥有设营地点的,不过还好只有3500⼈顺利防守。
不过既然已经守下来织⽥的⼀波攻势,那么要在⼤海对⾯站住脚,还得攻略志摩泷川,不敢太多兵,怕背后三国爆菊花,就西⾯2个城就,虽然现在朝廷信⽤有97了 耗费⼀段时间拿下泷川家,松岛城就当给织⽥当见⾯理吧。
送个魔王⼀个松岛城,完全满⾜不了魔王的胃⼜啊,不过还好不是我在志摩的据点。
信长之野望14:创造全剧本全战国传事件图文攻略

1:推进南蛮贸易
也没有鼓起勇气去看袁慕野的比赛。哦,当时木子还不知道他叫袁慕野呢,知道
2:导入灰吹法
3:导入南蛮吹
4:通往征夷大将军之路
一:织田信长篇缘起
织田信长于 1534 年出生于尾张国的那古野 城(现在的名古屋),他的父亲叫织田信秀号称 尾张之虎,手下兵多将广,占据了尾张国的南部
地盘。信长出生后,他爹地非常高兴,给他配了 4 名老师,其中一个名叫平手政秀,是织田家的 头号重臣。
史评述,你把它当成故事看也无妨。
也没有鼓起勇气去看袁慕野的比赛。哦,当时木子还不知道他叫袁慕野呢,知道
第一位出场的是日本战国历史上知名度最 高的人物,著名的军事家和改革家-织田信长!
完成的大名录&武将录事件:
织田信长篇
1551·继承家督·织田信长 剧本
1:家中统一
2:桶狭间之战 3:美浓攻略 4:墨俣一夜城 5:利家的穷地 6:上洛 7:三顾之礼 8:信长包围网
伊达政宗篇
也没有鼓起勇气去看袁慕野的比赛。哦,当时木子还不知道他叫袁慕野呢,知道
1582·如梦如幻·伊达辉宗 剧本
1:从天而降的独眼龙
2:人取桥之战
3:大崎·郡山合战
4:摺上原之战
5:政宗与小次郎
岛津义久篇 1570·信长包围圈·岛津义 久剧本 1:三州统一战 2:高城川之战 3:冲田畷之战 4:九州统一 通用事件
也没有鼓起勇气去看袁慕野的比赛。哦,当时木子还不知道他叫袁慕野呢,知道
世界的勇气和霸气,并且将来他也以一种极端的 方式来激励着信长。
信长之野望14创造大地图合战攻略合集

信长之野望14:创造-⼤地图合战攻略合集 本⽂是讲述创造中⼤地图合战相关攻略的⼀个⼤全集,⼤部分数据为实测。
本⽂从马炮装备、夹击、设营、政策、设施、特性六个⽅⾯全⾯讲述了各种对⼤地图合战中的形象。
很多数据为第⼀⼿数据,例如马炮装备、夹击、设营的具体加成效果,并且对原本模糊的特性描述改成了具体效果的数值。
同时也纠正了⼀些先前帖⼦中的⼩错误,例如⽕器集中应⽤加成效果不是齐射概率,⽽是齐射伤害,龙虾的不舍⾝命是+25攻-10防,⽽不是+25攻-20防,地黄⼋幡的加成效果也是直接的伤害+20%等等。
最后将所有⼤地图合战战⽃所有相关的效果给出了定量的评价,直⽩的体现⼀个技能的存在价值。
希望各位玩家读了以后可以对游戏有更深刻的理解,也希望各位m o d 爱好者在将来进⾏战⽃相关的特性与政策修改时对平衡性的增加有所帮助。
蓝⾊代表夹击相关加成,紫⾊代表设营相关加成,⿊⾊代表正常相关加成,红⾊代表设施相关加成,橙⾊代表特性相关加成,棕⾊代表装备相关加成,后⾯的的数值对应相应的价值评分。
⼤魔王,我魔威武,天下布武 *毅⼒与性急,独眼龙等逐渐作⽤型技能存在b u g,详情参看后⽂734 735774 **先驱地黄⼋幡剑豪的评价仅仅对第⼀下攻击做出了伤害评价,即假设战⽃仅仅进⾏⼀个回合 全加成效果排名表 可以查看全部对⼤地图合战有加成的75种不同⽅式的总排名,和相应分类中的排名 1.基本理论 可看可不看的东西,如果不是很有兴趣的话,为防⽌你的头疼,建议可直接跳到政策、夹击、特性⼀类的内容处再看~请直接搜索201,就可以直达了~ 101.伤害计算公式 总伤害=[100+标准伤害*(1+属性加成率)]*(1+特性伤害乘法加成)* (1+突击齐射加成) 解释下,上述式⼦可以看做三个项的连乘 ⾸先我们看第⼀个项,100是打底的基础伤害,标准伤害是攻击⽅武勇=防御⽅统御时打出的伤害值减去100.属性加成率是由攻⽅的武勇和守⽅与总兵⼒合决定的⼀个加成系数,这个系数在-0.75与1之间。
信长之野望14:创造军势攻防能力影响因素解析

信长之野望14:创造-军势攻防能⼒影响因素解析
问:
军势的攻防能⼒受什么影响?
答:
部队的攻击⼒和防御⼒与该军势的最⾼统率、分队武将适性、⼠⽓、兵⼒成正⽐。
1、最⾼统越⾼,军势的攻防能⼒越
2、分队武将适性越⾼,其攻防能⼒越
3、⼠⽓100的攻防能⼒是⼠⽓5时的2倍。
另外,分队武将的统率会决定军势的破坏⼒,兵⼒也会影响军势的攻防能⼒。
1、所有部队的攻防取决于全队最⾼统率和分队适性,适性的影响是每级适性+5%攻防(实际计算中由于取整等原因会有偏差)
2、所有部队的破坏取决于分队统率,且基本符合线性关系(统率60的是统率10的将近6倍)
简单地说:
1、分队攻防看部队最⾼统率和分队适性
2、分队破坏看分队统率
逗游⽹——中国2亿游戏⽤户⼀致选择的”⼀站式“游戏服务平台。
信长之野望14:威力加强版种田流区划数据及种田思路等全方位指南

对于种田党,必然是人又三件套御殿+唐门+二丸或三丸,其余随意。 对于速攻党,前期唯一值得一造的改修设施就是二层天守了,其他都 不值得。1000金,5劳力来买所有部队30天攻防+3的效果还算不错。毕竟 前期战斗时间不长,30天攻防的效果虽然不能覆盖所有时间,也至少能覆 盖个一半。而且pk中统是分开算的,前期加防效果的加成的手段很少,因 此就算是为了这3点30天的加成,也值得一造了。 城郭设施的话前期三维不容易达标,如果达标的话,强烈建议造通用 的三系部队加成设施,常驻+30攻防的效果直接无脑吊打ai 设营 4劳力、500金。加成非常恐怖,二级营+50的攻防,一级营也有 +25。 对于种田党和速攻党都一样,前期通过sl预判充分利用设营的话,可 以在二级营上毫无压力的打出1:4~1:3的战损。对于速攻党而言,成功的利 用一个营地,就有可能避免一次弃档的可能。配合SL预判大法 速攻党的设 营还是非常非常重要的 整备 3劳力,400金。3、4、5级路分别加10、15、20的人又。同时道路的 增加也可以提高当前道路上最大的战斗部队数量和部队移动速度的加成。 对于种田党是前期就要修,毕竟是最便宜的加人又方式。最理想情况 下是3劳力400金换两座城10人又的增长。对于速攻党,修路与否就要分开 看了。单纯的提供人又向的路没必要修,毕竟速攻的话人又增加意义不 大,没必要浪费宝贵的3劳力+400金在这里。不过对于有战略性意义的路 就一定要修了,类似重要的出兵道、即将要走的夹击山道、战斗时如果容 纳部队增多对己方有利的交战道路。这几种重要的战略性道路一定要在开 战前修好。 扩张 8劳力3000金。 对于种田党没啥好想的,肯定是扩扩扩。 对于速攻党前期能扩张的可能性不是很大,同时消耗实在是太大。8劳 力就算是凑出来也有可能是前期劳力的极限,就为了了开发一个新区划不 是很值得,毕竟一回合可能其他什么都做不了。回本的时间要比建设设施 的实际长一点,一年多一点能回本,中期型的投资。不过考虑到开发加 速、额外建设设施的空间来考虑的话,会把这个扩张的成本降低一些。因 此如果稍稍小康一点,对于不是很抖M的小势力还是可以扩一下的,但是 也要有限度在修已有的二级设施以后比较好。 变更 8劳力,3000金。 追求极致的种田党专用命令,为了达到各种极致而变更初始的蛋疼区 划 速攻党就别考虑这个了。
《信长之野望14威力加强版》战法效果一览

《信长之野望14威⼒加强版》战法效果⼀览 策略游戏《信长之野望14:威⼒加强版》中的战法⾮常多样,那战法发动的效果都是什么呢?今天⼩编为⼤家带来“w s y a n g ”分享的《信长之野望14:威⼒加强版》战法效果⼀览,希望对⼤家有帮助,⼀起来看吧。
名称说明系统采配效果%(效果时间)齐射铁炮射击,有时会使敌混乱齐射1000射击攻击提升15%(600)⽆法下令(600)⽬标初始化齐射标志(200)突击的混乱(600)混乱射击攻击30%(600)齐射标志(600)突击骑兵突袭,有时会使敌混乱突击1000混战攻击提升15%(300)⽆法下令(300)强制前进(300)⽬标初始化突袭标志(300)齐射的混乱(300)混乱混战攻击30%(300)加快速度100%(300)雷神弱化敌⽅速度和守备妨害1500敌军范围降低速度50%(200敌军范围防御⼒下降50%(1000)撹乱弱化攻击中敌⽅的速度妨害500敌军范围降低速度50%(100⾜⽌め弱化前⽅敌军速度妨害1000敌军范围降低速度50%(100挑発吸引敌⽅进攻妨害1000敌军范围⽆法下令(300)敌军范围⽬标⾃动敌军范围⽬标初始化扇动解除攻击中敌⽅强化效果妨害1000敌军范围消除强化效果2%离间让前⽅敌军⾃相残杀妨害2000敌军范围攻击同伴(300)気势崩し弱化前⽅敌军的攻击妨害1000敌军范围混战攻击下降25%(1000)敌军范围射击攻击下降25%(1000)逆抚で弱化前⽅敌军守备妨害1000敌军范围防御⼒下降25%(1000)诡计百出⼤幅弱化前⽅敌军妨害2000敌军范围混战攻击下降25%(1000)敌军范围射击攻击下降25%(1000)敌军范围防御⼒下降25%(1000)敌军范围降低速度25%(100表⾥⽐兴让前⽅敌军⾃相残杀妨害2000敌军范围⽬标初始化敌军范围⽬标随意敌军范围⽆法下令(300)敌军范围攻击同伴(300)今孔明弱化敌⽅攻击并封锁⾏动妨害1500敌军范围⽆法下令(300)敌军范围⽬标初始化敌军范围混战攻击下降25%(2000)敌军范围射击攻击下降25%(2000)今张良弱化敌⽅防御并封锁⾏动妨害1500敌军范围⽆法下令(300)敌军范围⽬标初始化敌军范围防御⼒下降25%(2000)怒号让周围友军从混乱中回復回復1000友军范围恢復混乱底⼒解除周围阻碍效果回復1000友军范围消除妨害效果2%神秘の歌混乱恢復,强化⾃⾝部队回復2000友军范围恢復混乱友军范围加快速度25%(100友军范围混战攻击提升25%(1000)友军范围射击攻击提升25%(1000)友军范围防御⼒提升25%(1000)鬨の声稍加强攻击强化1000混战攻击提升25%(2000)射击攻击提升25%(2000)⿎舞强化守备强化1000防御⼒提升25%(2000)神速加快速度强化500加快速度50%(2000)急袭加强混战强化1000混战攻击提升50%(2000)钓瓶撃ち加强射击强化1000射击攻击提升50%(2000)⾬⽆效(2000)狙い撃ち攻击时加强射击削弱敌⽅强化1000射击攻击提升25%(2000)敌军范围防御⼒下降25%(1000)⽤⼼降低速度,加强守备强化1000防御⼒提升50%(1000)降低速度50%(1000)咆哮强化混战,让对⼿混乱强化1000混战攻击提升20%(2000)混乱混战攻击15%(2000)穿ち抜け短暂时间内,⼤幅加强乱战强化1000混战攻击提升200%(300)钓り野伏限制敌⽅⾏动同时强化射击强化1500射击攻击提升50%(2000)敌军范围降低速度50%(300敌军范围⽆法下令(300)敌军范围⽬标⾃动敌军范围⽬标初始化追い讨ち限制敌⽅⾏动同时强化乱战强化1500混战攻击提升50%(2000)敌军范围降低速度50%(500车悬かり⼤幅加强⾃军部队的攻击强化2000友军范围混战攻击提升50%(1000)友军范围混乱混战攻击20%(1000)友军范围加快速度50%(100啄⽊鸟吸引敌⽅的同时强化⾃⾝部队强化2000混战攻击提升100%(1000)敌军范围⽆法下令(300)敌军范围⽬标⾃动敌军范围⽬标初始化三段撃ち⼤幅加强⾃军部队的射击强化2000友军范围射击攻击提升50%(1000)友军范围突击的混乱(1000)友军范围混乱射击攻击(100友军范围⾬⽆效(1000)三河魂速度降低,⼤幅强化⾃⾝强化2000混战攻击提升50%(2000)防御⼒提升50%(2000)混乱混战攻击10%(2000)降低速度50%(2000)奥义⼀闪乱战中⾼⼏率使敌⽅陷⼊混乱强化1500混乱混战攻击100%(300)⼋咫乌强化⾃军部队的射击强化2000友军范围射击攻击提升50%(1000)友军范围提升射程距离30%(1000)友军范围穿过同伴射击(100友军范围⾬⽆效(2000)叱咤强化前⽅同伴攻击强化1000友军范围混战攻击提升25%(1000)友军范围射击攻击提升25%(1000)激励强化前⽅同伴守备强化1000友军范围防御⼒提升25%(1000)临戦稍加强攻击、守备和速度强化500加快速度10%(2000)混战攻击提升10%(2000)射击攻击提升10%(2000)防御⼒提升10%(2000)⼀の太⼑乱战中⾼⼏率使敌⽅陷⼊混乱强化1500混乱混战攻击100%(300)⽆⼑取り乱战中⾼⼏率使敌⽅陷⼊混乱强化1500混乱混战攻击100%(300)狙撃短时间内 ⼤幅强化射击强化1000射击攻击提升200%(300)提升射程距离50%(300)穿过同伴射击(300)瓶割り抵消妨碍效果并⼤幅强化乱战强化1000混战攻击提升200%(300)消除妨害效果5%栏破坏(300)千成瓢箪强化乱战和速度,破坏栅栏强化2000友军范围加快速度25%(100友军范围混战攻击提升25%(1000)友军范围栏破坏(1000)枪の又左强化⾃⾝的乱战、守备和速度强化1500加快速度25%(2000)混战攻击提升50%(2000)防御⼒提升25%(2000)六⽂銭降低守备,⼤幅强化攻击强化1500混战攻击提升100%(1000)射击攻击提升100%(1000)防御⼒下降25%(1000)空蝉改变敌⼈⽬标并降低守备强化1000敌军范围⽆法下令(300)敌军范围⽬标随意敌军范围防御⼒下降25%(1000)蜻蛉切短时间内 ⼤幅强化乱战和守备强化1000防御⼒提升250%(300)混战攻击提升200%(300)⾚⿁短时间内 ⼤幅强化乱战和速度强化1000加快速度100%(300)混战攻击提升250%(300)七本枪长时间强化攻击和速度强化1500混战攻击提升25%(4000)射击攻击提升25%(4000)加快速度25%(4000)先悬之众长时间,强化守备和速度强化1500加快速度25%(4000)防御⼒提升25%(4000)死兵降低守备但⼤幅提升攻击强化1500混战攻击提升100%(1000)射击攻击提升100%(1000)防御⼒下降25%(1000)虎狩り吸引敌⽅的同时强化⾃⾝部队强化1000敌军范围⽆法下令(300)敌军范围⽬标⾃动混战攻击提升50%(1000)防御⼒提升50%(1000)镇西⼀短时间内 ⼤幅强化乱战和守备强化1000防御⼒提升100%(300)混战攻击提升250%(300)三⽇⽉降低守备但⼤幅提升攻击强化1500混战攻击提升100%(1000)射击攻击提升100%(1000)防御⼒下降25%(1000)五⾊备え强化我军部队强化2000友军范围混战攻击提升25%(2000)友军范围射击攻击提升25%(2000)伊达者攻击中低⼏率让敌⼈混乱强化1500混战攻击提升25%(2000)射击攻击提升25%(2000)混乱混战攻击20%(2000)混乱射击攻击20%(2000)肥前の熊强化攻击,破坏栅栏强化1500友军范围混战攻击提升25%(2000)友军范围射击攻击提升25%(2000)栏破坏(2000)坂东太郎阻⽌敌⽅⾏动,强化乱战强化1000防御⼒提升50%(2000)混战攻击提升25%(2000)敌军范围⽆法下令(300)敌军范围⽬标初始化⿁⼩岛吸引敌⽅的同时强化⾃⾝部队强化1000敌军范围⽆法下令(300)敌军范围⽬标⾃动混战攻击提升50%(1000)防御⼒提升50%(1000)笹の才蔵混战中低⼏率让敌⽅混乱强化1500混战攻击提升50%(2000)混乱混战攻击15%(2000)仁王门减慢移动速度⼤幅提升守备强化1000防御⼒提升100%(2000)降低速度50%(2000)三本の⽮射击中低⼏率让敌⽅混乱强化1500射击攻击提升25%(2000)混乱射击攻击15%(2000)⽼练回復混乱并强化⾃⾝强化1000恢復混乱混战攻击提升25%(1000)射击攻击提升25%(1000)防御⼒提升25%(1000)黒⽥武⼠混战中低⼏率让敌⽅混乱强化1500混战攻击提升50%(2000)混乱混战攻击15%(2000)敌军范围⽆法下令(300)皆朱の枪吸引敌⽅的同时强化⾃⾝部队强化1000敌军范围⽬标⾃动混战攻击提升50%(1000)防御⼒提升50%(1000)倾城⼤幅降低敌⽅的守备特性?108敌军范围防御⼒下降50%(1000)倾奇者⾃⾝⼤幅强化但不听指挥特性?81加快速度100%(1000)混战攻击提升100%(1000)防御⼒提升50%(1000)⽆法下令(1000)⽬标随意混乱混战攻击20%(1000)七难⼋苦降低守备,⼤幅强化攻击特性?69混战攻击提升75%(1000)射击攻击提升75%(1000)防御⼒下降30%(1000)不惜⾝命降低守备,⼤幅强化攻击特性?70混战攻击提升75%(1000)射击攻击提升75%(1000)防御⼒下降30%(1000)⾃军强化强化攻击和守备特性?500混战攻击提升30%(1000)射击攻击提升30%(1000)防御⼒提升30%(1000)敌军强化强化攻击和守备特性?500混战攻击提升30%(1000)射击攻击提升30%(1000)防御⼒提升30%(1000)枪弾正⽆装备时,强化乱战和守备特性?34混战攻击提升50%(2000)防御⼒提升25%(2000)谋神发挥⼒量,⼤幅弱化敌军特性?56敌军范围⽆法下令(300)敌军范围⽬标随意敌军范围防御⼒下降50%(3敌军范围攻击同伴(300)真の武⼠发挥⼒量,⼤幅强化守备特性?83防御⼒提升50%(1000)军神发挥⼒量,⼤幅强化⾃⾝特性?84混战攻击提升50%(1000)射击攻击提升50%(1000)混乱混战攻击20%(1000)风林⽕⼭发挥⼒量,⼤幅强化⾃⾝特性?73友军范围加快速度25%(100友军范围混战攻击提升25%(1000)友军范围射击攻击提升25%(1000)友军范围防御⼒提升25%(1000)友军范围恢復混乱下剋上发挥⼒量,⼤幅强化⾃⾝特性?109混战攻击提升100%(1000)射击攻击提升100%(1000)防御⼒提升25%(1000)夜叉发挥⼒量,强化攻击和守备特性?48混战攻击提升30%(1000)射击攻击提升30%(1000)防御⼒提升30%(1000)⿁发挥⼒量,强化攻击和守备特性?49混战攻击提升50%(1000)射击攻击提升50%(1000)防御⼒提升50%(1000)虎发挥⼒量,强化攻击和守备特性?100混战攻击提升50%(1000)射击攻击提升50%(1000)防御⼒提升50%(1000)独眼竜发挥⼒量,强化攻击和速度特性?86加快速度30%(1000)混战攻击提升30%(1000)射击攻击提升30%(1000)剣豪发挥⼒量,强化乱战特性?85混战攻击提升100%(1000)花実兼备发挥⼒量,强化乱战和守备特性?87加快速度30%(1000)混战攻击提升30%(1000)防御⼒提升30%(1000)西国⽆双发挥⼒量,强化乱战和守备特性?88加快速度30%(1000)混战攻击提升30%(1000)防御⼒提升30%(1000)上忍发挥⼒量强化守备和速度特性?105加快速度50%(2000)防御⼒提升25%(2000)姫武者短时间⽆敌特性?42⽆敌(300)地黄⼋幡会战开始时强化乱战和速度特性?60混战攻击提升50%(1000)加快速度50%(1000)⾚备え装备骑马时强化乱战和速度特性?32混战攻击提升50%(2000)加快速度50%(2000)神弾装备铁炮时强化射击和射程特性?36射击攻击提升50%(2000)提升射程距离50%(2000)穿过同伴射击(2000)突贯替⾝特性?500枪衾替⾝特性?500猛攻替⾝特性?500鉄壁替⾝特性?500⿁谋替⾝特性?500神算替⾝特性?500马术替⾝特500性?枪术替⾝特性?500远当て替⾝特性?500短気替⾝特性?500先駆け替⾝特性?500封杀替⾝特性?500忍替⾝特性?500慧眼替身特性?500 逗游⽹——中国2亿游戏⽤户⼀致选择的”⼀站式“游戏服务平台。
《信长之野望14:创造威力加强版》全支城数据一览 有哪些支城

《信长之野望14:创造威力加强版》全支城数据一览有哪些支城用如梦如幻剧本测试的,因为原有的支城拆掉重修后数据会大减,所以这些都是在不拆除原有支城的情况下能筑的新城。
第一个数字为区划数,第二个数字为改修地。
如109 即10区划+9改修用地。
(A B)表示AB不能共存;(A-B C)表示AB能共存,但不能与C共存。
但还有更复杂的情况,尤其是羽后,有AC能共存,BD能共存,但AB CD不能共存,甚至5支城之间的复杂关系,所以显得比较乱。
不过由于支城总数限制,大家还是根据具体情况自己选择。
奥州六分国虾夷原口47 汤岱47 (中野67 胁本97) 志苔49西路奥(田光沼89 狄馆109) 中里99 小国47 蟹田67 饭诘99 油川109 云谷47东路奥下北川37 田名部99 小凑37 牛泽97 毛马内47花轮37 大汤37 三本木109 (轻米97 小轻米79)宿户107陆前岩出山47 高清水109 米谷109 津谷87 松岛99 (涌谷87 石卷109) 村田79陆中生保内37 一户37 田头69 沼宫内109 淹泽57 (久慈89 宿户107) 盛冈77 (岩崎99 浮牛47) 宫古37 一关109 乌海37 千厩47北羽前尾浦39 (酒田69-吹浦39 胁盾97) (清川37 羽黑山87) (金山69 新庄109) 长泽69 西川37南羽前今泉79羽后染川59 浜田79 (泽目49 轰59) (福田97 前山87-大馆39 缀子67) (浅见内89-中津又37 上岩川89) 米内泽47 百三段39 (和田87-淹俣37 熊和黑濑109 龟田68 户贺泽) (和田-户贺泽88 境47) 仁贺保39 中俣77 (杉山田97 艾和野88 大曲79 角间川) (大泽79 角间川109-老方87) 本堂69 (马因内68 到米37)岩代无磐城白石69 棚仓79 镐37 (勿来79 汤本89)关东八分国上野岩柜37 山上87 平井59 本庄89 (金山89 小泉109)下野今市37 矢板97 氏家87常陆安良川49 (茂木97 御前山97) (德宿89 行方77)木原77 鹿岛69下总金野井79 守谷89 小野田89 (寺台89 神崎49)上总成东109 坂田99 椎津99 (东金89 小弓109-土气99) 三船山47 大多喜59安房无武藏秩父77 松山109 胜沼107 (柏原107 根古屋89)鸿巢109 (柜形山99 小野路39-小机89) 石神井79蕨城89相模三赠卡57 深见69 弘明寺49 七泽37东海七分国伊豆无骏河(花仓37 藤枝49)远江无三河(沓挂69 福谷109) (蒲形99 森79) 东荣37 田原39吉美39尾张(胜幡59 津岛39) (荒子39 蟹江69) 大草109桶狭间49 常滑47美浓关原49 揖斐69 墨俣89 关99 (娣沼49-土田79-白川89 太田109)惠那89伊势藤原37 (麻生田37 桑名49) 千种37(羽津59 庄野89) 白山49 久居39 多气47(田丸69 斋宫59-宫町69) 五所37志摩无甲信越三分国甲斐身延37南信浓吉冈37 金泽39北信浓穗高59 替佐37 海津37 丰野47 (佐久39 羽黑下37) 大前57北越后(北黑川37 村上59) 松崎59 三根山109 (子成场109 三条109)南越后长冈89 川口67 柿崎59 松代47 虫川37更多相关资讯请关注:信长之野望14:创造威力加强版专题北陆六分国越前细吕木69 织田47越中永见39 日方江69 佛生寺39 若栗37 滑川39加贺鹤来37 (今江39 松任59) 打越79能登饭田47 (南志见311 宇出津97) 穴水37 御馆39若狭无飞弹无近畿十分国北近江南近江水口39 (草津39 守山49)山城山崎37 城阳47大和(生驹39 兴福寺59) 信贵山37 龙王山37 (越智39 二见47)伊贺(马杉39 拓殖37)河内无和泉无摄津池田39纪伊高野口39 宫乡47丹波无丹后竹野39中国山阴五分国石见大田69 浜田47 (渡津47 家古屋77 川户99) 温汤39出云(三刀屋47 朝山39 出云39 平田49) 庄园57 佐世49 布部47伯耆(法圣寺87 米子49 岸本49) 淀江57 汤关39无但马香住37山阳八分国周防敷山59 岛田39 琴石山37长门丸岳山37 长生寺67 日置37 大岭37 (厚狭99 宇部79)安艺(龟居311-宫尾39 宫岛口69)备后羽仓87 庄原37 雀97 (松永109-三原89 云雀109)备中加茂87 天城89备前金川37播磨(河合109 西胁67)美作小田草37九州肥前唐津67 镇西山47 广田57 汤野田59 大浦37 樱马场69北肥后高濑109 (菊鹿109 菊池89)南肥后无久津89 香春岳59 龙王47 高家77丰后甲尾47 富来49 南山67 田北39 (田中97 松尾49) 佐伯49筑前高祖山39 黑崎59 (甘木67 朝仓47)筑后久留米99 山下79 (熊川107-鹰尾-高濑田尻97) 鹰尾99萨摩木牟礼39 鹤田89 伊作39 谷山37 坊津77 原田49日向(高千穗39 一水37) 县城49 高城89 清武109(小林49 高原47) 吉之元37 志和池99 节间39大隅(栗野69 横川37) 雾岛47 回47 财部49 境37垂水39 细山田79 国见39四国伊予宇和岛37 内子37 金子山39东土佐无西土佐久礼37 盐屋谷37赞岐高松49 (一宫89 圣通寺39 泷宫69)阿波柳泽39 渭津39 牛岐49更多相关资讯请关注:信长之野望14:创造威力加强版专题。
信长之野望14防守反击打法心得技巧

信长之野望14-防守反击打法⼼得技巧 《信长之野望14:创造》是⼀款⾮常经典的战争策略游戏,在游戏中难免会有玩家遇到打逆风局的场景,那么只有极少数⼈能够在这种条件下⽣存下来。
今天⼩编将告诉⼤家⼀些防守反击的打法,供玩家朋友参考。
研究了下会战时的特性和战法,想打出杀敌的⾼交换⽐(起码要我军1个换敌军2个甚⾄5个10个),必须按照这样的步骤放战法 保守政策下的合战指南: 以下分析是按照政策是保守,开了加强突击的政策来讲述的,杀敌全靠骑马队的威⼒了。
1、⾸先进⼊会战界⾯,⽴刻上⼀个加快回复采配速度的战法,临战和底⼒都⾏,采配多可以⽤底⼒(有夹击的情况下) 2、再接近敌⽅,放控场战法。
要是敌⼈⾸发突击或齐射,放搅乱然后后退,把敌⼈采配耗⼲;然后等敌⼈没有采配突击或者齐射了,前进,等敌⼈的⼤部队都在⾃⼰的射击范围内,最好那个红⼼在敌军正中间,速度放诡计百出或⼋尺鸟或啄⽊鸟让敌⼈⽯化,这个d e b u f f的⽯化效果时间不长,要充分利⽤。
3、速度放提⾼敌⼈混乱⼏率的战法,然后齐射(必须要⽤铁炮队)。
那么剑豪战法是⾸选,没有的话离间战法备选。
不要求⽤齐射打掉敌⼈多少兵,要的就是混乱对⽅。
4、然后对被混乱的敌军突击(必须要⽤骑马队)。
杀敌就靠这个了,在敌⼈混乱状态下,反复突击,没了采配直接冲上去砍即可。
5、我⽅b u f f快转完⼀圈时,速度放维持我⽅的b u f f的战法,那么必须选激励了。
然后重复回采配、控场、加敌军混乱再齐射、敌军混乱后突击、续b u f f这五个环节。
另外如果⾃⼰没有剑豪战法的武将,要带上有攻击+2的特性的武将,有⿁、地黄⼋幡、不惜⾝命、七难⼋苦等4个。
把他们的忠诚度通过任命城主、赏赐家宝等⽅式尽可能加⾼,加到忠诚度20最好,感觉忠诚度满的武将作战时容易放特技。
按照这个合战打法,基本可以做到合战时⼀⽐⼆甚⾄⼀⽐五、⼀⽐⼗的交换⽐。
考虑到游戏开始时,难以在⼀队三个武将⾥找到理想战法组合,建议每次主⼒部队出兵两队,1个骑马队1个铁炮队,就是6个武将,这样特性战法好配,另外也节约铁炮和战马。
《信长之野望14:创造威力加强版》主城及分城内政心得分享攻略

《信长之野望14:创造威力加强版》主城及分城内政心得分享攻略很多玩家玩信长之野望14威力加强版时,打到了后期就不太会玩了,下面小编教给大家一些主城与支城的内政攻略心得。
主城打到后期,如果你已经下决定,大名要统治一个范围了,那你基本上就需要用主城的兵力并要求军团长按照你的指示来攻略了,因此主城以加人口、兵营、攻防为主,成为后方城市后,什么天守都不用要,因为,基本暂时打不到你咯,加攻防、人口最重要,还有铁炮藏等。
分城因为支城可以扩张了,所以,内政非常繁琐,还是建议用军团选项下的委任,但是委任最好别啥都委任,因为有些分城有资源,还有些分城是战略要地,时不时电脑来攻,时不时这个地方会发生合战,因此,建议这些支城的改修,你们要自己搞。
还有些分城因为可以建造特殊的设备,比如“铁炮藏”“礼拜堂”(像这种分城可以当主城用)等于不用买铁炮了,还加攻击。
打到后期,分城基本可以不用,尽管有些分城可以兵达万人(笔者之前开的一句大垣城,建立两个兵营,兵一万多,比岐阜城还多?何必呢,这只有一铁一家三口而已,主城能造区划属性优先兵营其次商业、其次农业。
分城的您别管,能建钱粮,尽可能改为钱粮。
)所以他们的前期的建设以加钱粮、创造性为主。
前期分城城主一门优先,一个一门一个高政治。
有爱的优先,留些四维可以的,频繁调动,可以让他们从一门城主哪里或者有爱城主那里出兵吗?不一定要高统帅,因为有时候后方的城池兵力比前方强大。
还有就是也可以可以列传归类,比如柴田胜家的人归柴田,一个道的人归口一个军团,比如北陆道。
当然,一些特有爱,特牛的,你可以抽到直辖范围当城主,毕竟还是你打仗,不是军团长打仗。
站位和远征对于后期以大欺小,打上关原合战那样的规模,也是不错的。
甚至,你方20万,对方6万,突然有了“骄兵”的那股傲气,学学曹操赋诗一首!希望本文对大家有所帮助。
更多相关资讯请关注:信长之野望14:创造威力加强版专题。
信长之野望14:加强合流夹击及设营等图文解析

信长之野望14:加强-合流夹击及设营等图⽂解析 《信长之野望14:创造-威⼒加强版》中很多玩家对合流,夹击等问题还不是很了解,下⾯⼩编为⼤家做⼀个测试,告诉⼤家合流夹击及设营等问题图⽂解析,希望对⼤家的游戏过程有所帮助。
测试的过程很多,我也做了多次重复测试,不过限於篇幅,每个部分仅上⼀张测试图。
过程依然很长,如果对於测试过程不感兴趣,可以直接看最后的结论。
条件限制 1.移除所有军马铁炮(防⽌随机性伤害波动) 2.所有特性,设施,城郭以及补给B U F F所带来的加成⽆效化(如果有开补给B U F F会特别说明,补给B U F F意即部队在友⽅据点补给兵粮时所获得的B U F F,基础值是+15攻防,+5%速)。
3.所有出战将领统武都是100,所有特性都被移除。
由於⽆法防⽌A I 带副将,参与测试的副将统武都被改成1。
4.测试双⽅兵⼒总和都是6000。
如果没有特意说明的话,1队就是6000,2队就是各3000,3队就是各2000。
5.仅计算第⼀击的战损(防⽌兵⼒波动带来的误差) 主要测试⼈员数据 其他客串演出的将领也是遵循同样的规则 测试主题⼀:部队合流是否提供存在攻防加成?伤害如何计算? P S:所有国⼈众都没有参与战⽃(从国⼈众的兵⼒应该不难看出) 先来个对照组:昌幸6000V S谦信6000,1对1 战损~~蓝⽅449V S红⽅449 当然伤害有⼩幅度的波动,不过多次测试下来还是能看出基本打平。
昌幸3000+幸村3000V S谦信6000,2对1 战损~~蓝⽅448V S红⽅449 跟1对1基本看不出差别。
昌幸2000+幸村2000+⼩助2000V S谦信6000,3对1 战损~~蓝⽅447V S红⽅466 多次测试下来蓝⽅的输出都略⾼於红⽅(差距在5%内),不过蓝⽅⾃⼰的战损并没有实质的降低(在双⽅攻防都相同的情况下,不可能达到免伤上限)。
这边我的推测是多部队伤害计算的⼩差异,也就是双⽅统武相同下,3队1000的部队输出会略⾼於1队3000的部队,不过差异⾮常的⼩,这个差异后⾯的测试会继续看到,跟合流基本⽆关。
《信长之野望14:创造威力加强版》国替之后各城优劣势图文分析

《信长之野望14:创造威力加强版》国替之后各城优劣势图文分析[pagesplitxx][pagetitle]优势领国[/pagetitle]《信长之野望14:创造-威力加强版》国替后哪些领国最占便宜/最坑人?国替后哪些占优势哪些占劣势呢?下面给大家带来国替后优势劣势领国详解,以供参考。
个人意见最占便宜:肥前磐城摄津伊势尾张备前播磨伊予南越后日向陆中最吃亏的:筑后南羽前志摩河内和泉安房虾夷下总以群雄剧本为例先说说最占便宜的1.肥前9座城旁边的筑后才一座主城还紧挨着吃老本都能硬啃下来了原本为了平衡起见锅岛家分到了肥前南面几座城可以国替之后就没有了完全可以把一个弱小势力放到肥前然后把武田上杉放到筑后上来就灭2.磐城11座城磐城是所有国里面城数最多的跟肥前一样可以一上来就吃老本硬啃说来觉得可笑上一代米泽伊达家跟小高城相马家到了这一代关系正好颠倒过来了3.摄津3座城最主要的是大阪城兵多的吓人完全可以横扫近畿了拿下河内和泉山城都没什么问题4.志摩5座城位置比较重要连接浓尾跟近畿皮昂便是两个只有主城的志摩跟伊贺还有就是这个位置可以控制住中部的BOSS就是不知道为何如此优势的北田次次被陇川吊打更多相关资讯请关注:信长之野望14:创造威力加强版专题5.尾张6座城这得算是有龙脉的地方6座城平原城还那么密集不过pk坑了的是稻叶山城耐久11500了所以织田没法像以前那么猖獗了6.备前7.播磨备前 5座城播磨 6座城这两个都是依仗城多的代表旁边多为两三座城的领国以至于自灭的别所经常吊打天下一统的木下8.伊予8座城四国岛上城最多的一国不过可惜位置和地理环境太差不是山就是海9.南越后6座城最大的优势就是可以迅速吞并北越后缺点就是周围都是山区10.日向6座城在南九州算是国力最强的了可惜的是领土太长加上位置没什么价值11. 陆中6座城东北城最多的国也是位置上没什么价值[pagesplitxx][pagetitle]劣势领国[/pagetitle]然后再说一说最吃亏的城1.筑后就一座城旁边肥前9座城如此相差悬殊怎能不是第一坑人这代大友就被筑后坑了看着大友像是2 3 4 座主城龙造寺一座主城实际上筑后跟肥前有多大的差距啊2.南羽前也是光杆司令一座城想当初天道的米泽是何等的宝地这一代真够寒酸的搞不好像劝降个国人众都没法实现3.志摩也是就一座主城火灾伊势和三河的阴影之下国人众就一个水军不过AI陇川倒是此次吊打北田4.河内5.和泉一个只有一主城另一个有一座分城也是拖累用的都是活在摄津的阴影之下6.安房跟志摩差不多本来上一代这里是最安全的地方可是这一代。
信长14威力加强版全支城区划数据一览

0 0 0 6 4 9 8 4
4 7 5 6 3 10 9 10 3 7 4 9 8 8 8 4 6 5 8 7 8 6 7 8 0 0 0 0 0 0 0 0
羽后
羽后伏见
羽后
饭泽
羽后
院内
羽后
白泽
羽后
福田
羽后
羽后长野
羽后
岩井川
羽后
小森
羽后
缀子
羽后
飞根
羽后
轰
羽后
鹈鸟
羽后
森岳
羽后
染川
羽后
浅见内
羽后
中津又
%{page-break|虾夷|page-break}%
东陆奥
毛马内 野辺地 八戸 田名部 牛ノ沢
3 9 4 0 6 4 0 4 5 9
4 9 10 9 9
七戸
9
三澤
8
三本木
10
平沼
10
宿戸
10
小軽米
7
大间
0
佐井
0
肋野泽
0
陆奥大畑
0
深持
0
十和田
0
坂梨
0
大里
0
汤濑
0
玉川
0
田山
0
田子关
0
茂市
0
田子
0
下北川内
3
小凑
3
剑吉
6
轻米
8
大汤
3
花轮
3
金田一
3
%{page-break|东陆奥|page-break}%
西陆奥
浪岡
7
陆奥福島
4
飯詰
9
中里
9
《信长之野望14威力加强版》筑城区划数据一览
《信长之野望14威⼒加强版》筑城区划数据⼀览
《信长之野望14:威⼒加强版》中在是么能筑城,什么地⽅筑城合适,筑城后又如何区划呢?今天⼩编为⼤家带来玩家“e n u j u n e”分享的《信长之野望14:威⼒加强版》筑城区划数据⼀览,希望对⼤家有帮助,⼀起来看吧。
天天忙筑城,筑了拆,拆了筑的,正好在⼀个⽹页上看到了⽐较详细的筑城指南,于是乎,⾃⼰表格编辑了⼀下,与各位筑城强迫症患者分享下!能筑城的地⽅很多,我只选取了区划在5以上的,按照每个领国的筑城区划,以区划10往下排列,⾄于3区划4区划的,就在⼤区划完成后随意筑之吧!
逗游⽹——中国2亿游戏⽤户⼀致选择的”⼀站式“游戏服务平台。
信长之野望14:创造—深度解析制霸心得

《信长之野望14:创造》深度解析制霸篇!看过此篇无需再看其它各式攻略,完全制压内政:前期不推荐本城建设扩张,金钱很紧张一般开发粮食或电脑建议开发。
建设以粮食为主,粮食一直需求很大,后期遇到电脑卖自己粮食,可以查查哪个本据内的本城建设米会所(拆了),扩张一般选最大值发展向,3个都一样推荐兵营。
巡查前期金不多情况下不建议使用(有金山地区除外)道路:本城接壤道路推荐到最大值,支城3即可(特殊地区除外)武将:本城武将推荐双80以上(统帅武力)配其它政治高武将,2个基本够用支城推荐双50-60能力,政治不要太差,70+武将不推荐放支城有点浪费,自己手动控制的支城后期基本很闲,像双70和武力其高统帅不行武将都给力直接扔给委任军团其它:外交40点可以有援军或停战8个月,怎么用看玩家的了,推荐前期和自己临近大名保持。
本据(自己手动控制范围)道路建设可以扩大范围,君主所在城只能手动控制国人众每次开局部分国人众位子随机出现,支持力80即可,有特殊武将可以考虑独占100后招降,没特殊武将不推荐,国人众全地图支援还是很给力的招降篇:抓到所有武将(包含一门)都有几率投降,根据军议不同时间回城招降成功率可达95%。
(可用S/L大法完美登用武将)不要错过好的武将。
合站:最出名要算铃木重秀八咫鸟实用一流,次点的诡计百出战法:开局推荐大雁阵前进一半待机(敌人有行动限制战法不要前进太远),敌人长用马突击后退没给马突击到敌人策略(黄色命令测试器)值会一直减少,消耗敌人策略为上。
实用搅乱(敌人行动变慢)更佳。
敌人要开弓后退,如果有行动不能(诡计百出.啄木鸟.八咫鸟)战法可直接破掉,敌人停止攻击变态玩法:首先要有诡计百出.啄木鸟.八咫鸟有以上技能武将,开局大雁蓄策略,敌人靠近时深红射击点能到敌人武将位置最佳,空格(暂停)定住敌人,开始射击,在敌人不能行动时候可以多等等射击策略,敌人如果混乱了,考虑马突击或继续射。
敌人行动控制消失可以动了,空格(暂停)退出合战,再进入合战重新开始,如此反复熟练后可以完美消耗敌军和牵制几倍自己的兵力。
信长野望14种地数据

以下是各设施功用汇总:6.1农业6.1.1入会地(公家地):农业区划随着开发,谷物收获量增加;6.1.2庄屋(村长办公室):额外提高该区划及邻接区划的农业适性;6.1.3马借(物流公司):额外提高该区划及邻接区划的农业及兵舍适性;6.1.4农产市(农产品市场):额外获得一定量的金钱收入;6.1.5特产市(农特产品市场):额外获得一定量的金钱收入,主城人口增速加快;6.1.6机织所(织布坊):额外获得一定量的金钱收入,邻接区划商业适性提高;6.1.7寺(小寺庙):额外略微提高该区划农业适性,降低本势力创造性值;6.1.8本山(总寺庙-总部):额外提高该区划农业适性,大幅降低本势力创造性值;6.1.9狩场(狩猎场):额外提高本城直属部队攻击力;6.1.10灌溉水路(水利系统):额外提高该区划的农业适性;6.1.11貯水池(蓄水池):额外大幅提高该区划的农业适性,减轻自然灾害影响;6.1.12果树园(果园):额外提高该区划及邻接区划的农业及商业适性;7.1商业7.1.1市(市场):商业区划随着开发,金钱收获量增加;7.1.2三斋市(十日市):额外提高该区划的商业适性;7.1.3六斋市(五日市):额外大幅提高该区划的商业适性;7.1.4替钱屋(银行):额外提高该区划及邻接区划的农业及商业适性;7.1.5交易所(贸易所):额外提高该区划及邻接区划的兵舍及商业适性;7.1.6锻冶屋(铁匠铺):额外略微提高该区划商业适性,提高本城直属部队 “强攻” 威力7.1.7工房(工匠坊):额外提高该区划商业适性,大幅提高本城直属部队 “强攻” 威力7.1.8茶室(茶室):额外略微提高该区划商业适性,提升本势力创造性数值;7.1.9黄金茶室(高级茶室):额外提高该区划商业适性,大幅提升本势力创造性数值;7.1.10铁炮锻冶(铁炮鍛冶工坊):额外提高该区划的商业适性,能以更便宜的价格在商人处购7.1.11米问屋(米粮批 发部)额外使主城人口增速加快,以便宜的价格在商人处购买粮食;7.1.12米会所(米粮运营管理所):额外使主城人口增速大幅加快,以极端便宜的价格在商人处购买粮8.1兵舍8.1.1工匠馆(工匠馆):兵舍区划随着开发,驻兵量增加;8.1.2练兵场(练兵场):额外略微提高该区划的兵舍适性;8.1.3刀藏(兵器库):额外大幅提高该区划的兵舍适性;8.1.4演舞场(民间祈福舞乐馆):额外获得一定量的金钱收入,主城人口增速加快;8.1.5能楽堂(官方祭祀舞乐馆):额外获得一定量的金钱收入,主城人口增速大幅加快;8.1.6庭园(庭园):额外提高邻接区划的兵舍适性,民忠回复速加快;8.1.7神社(日本神庙):额外提高民忠最大上限值,本城直属部队”包围“效果提升8.1.8八幡宫(日本大神庙):额外大幅提高民忠最大上限值,本城直属部队”包围“效果大幅提升8.1.9教会(西洋寺庙):额外略微提高该区划兵舍适性,提升本势力创造性值;8.1.10大圣堂(西洋大寺庙):额外提高该区划兵舍适性,大幅提升本势力创造性值;8.1.11厩舍(马厩):额外能以更便宜的价格在商人处购买军马;8.1.12牧场(牧场):额外提高该区划的兵舍适性,能以极端便宜的价格在商人处购买军马;8.1.13汤治场(温泉):额外大幅提高该区划兵舍适性,兵员数量回复速度;本帖最后由 kuko1v1 于 2013-12-15 20:58 编辑————上面这些字都是这哥们打的收获是石高X5,收入是商业除2.5,兵力=领民兵(人口*民忠/500)+常备兵(兵舍*2)减少价格的建筑减少的是固定值0.4和0.8,差不多所有商品的最低价都是10块,也许我这个测的不对,只列出了D以后的,因为D之前的差别非常小,基本D是2/5的,C就是1/3,如果是3/5的就是1/2,最重要这样的区划有时候反而更适合建一特殊建筑,尤其是比一些400多的F,将近600的E之类的,那种区划随D E F D E F D E F2/51/22/34/51 1 1/31/51/41/31/51/41/32/51/22/32/51/22/32/51/22/34/51 1 1/32/33/411 1/3 1 1/221/51/41/31/51/41/31 1 1/4 1 2/33/53/411 1/5 1 1/221 1 1/4 1 2/31/51/41/31/51/41/31 1 1/4 1 2/31/51/41/31/51/41/32/51/22/34/51 1 1/32/51/22/34/51 1 1/34/51 1 1/3人处购买粮食;的价格在商人处购买粮食;2/51/22/34/51 1 1/3对于本区划的增加量(属性越高增加的比例越小,也有高一级的加的比第一级的还少的,增加基数为基础加成)对临接区划的增加量(被加成区划属性越高增加的比例越小,极端情况下也有高一级的加的比第一级的还少的,增加基数为基础加成)一般左边是异属性,右边是同属性,具体可以看颜色, 农,商,兵2/51/22/3围“效果大幅提升2/51/22/34/51 1 1/33/53/411 1 1/4 1 2/3也许我这个测的不对,太难了有木有!价格它总变啊!/5的就是1/2,最重要的感觉是为了不让比较富裕的地方太富裕,系统会给一些城市乱编属性,例如600的C,700的E之类的,那种区划随着开发加的更多。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《信长之野望14》大地图攻防数据解析
先说结论,造成伤害大小的决定因素是兵力,攻击、防御、特性都是在兵力伤害基础上给与
加成或者减值。
楼主以30000兵力做的测试,相同攻防下,伤害为1588,不论100攻100防还是50攻50防都是一样的,不考虑特性的情况下最大伤害为3076,最小伤害为472。
1588的伤害实际上可以分解为100(最小伤害)+1488(30000兵力的基础
伤害),3076=1488*2+100,472=1488*(1-75%)+100
就是说,攻防最高可以提升100%伤害,免伤最高到75%。
特性分两种:
1、BUFF型,直接作用在攻防上,算法很诡异,目前已确认的是,30攻对80防的情况下(正常伤害472),攻击BUFF叠加到100,可以打出3076的满伤害来。
2、百分比加成型,在攻防计算结束后,按百分比给予加成或者减值。
比如鬼触发时,会在最小伤害的基础上再扣掉20%。
另外,所有同类/同一特性都可以叠加,比如3个鬼同时触发,伤害/免伤就是60%。
更多相关资讯请关注:信长之野望14:创造专题
æ ´å¤ ç²¾å½©æ »ç ¥è®¿é ®1。