操作Nhibernate
Hibernate

3.Hibernate映射类型
在hbm.xml中指定的type属性值.Java属性值<--映射类型-->表字段值映射类型负责属性值和字段值之间相互转化。type可以指定两种格式:
1)Java类型 例如:ng.String
*2)Hibernate类型
字符串:string
i.清除DAO中关闭session的代码
j.测试Struts2+Hibernate程序
--根据数据表编写POJO
--定义POJO和表的映射文件 [POJO类名].hbm.xml (在hibernate.cfg.xml中采用<mapping>元素定义)
--采用Hibernate API操作
//1.按主键做条件查询
session.load(查询类型,主键值);
session.get(查询类型,主键值);
//2.添加,根据hbm.xml定义
//自动生成主键值
session.save(obj);
//3.更新,按id当条件将obj属性
//更新到数据库
session.update(obj);
//4.删除,按id当条件删除
session.delete(obj);
**4.主键生成方式
Hibernate框架提供了一些内置的主键值生成方法。使用时通过hbm.xml文件<id>元素的<generator>指定。
*1)sequence
采用指定序列生成主键值。适用Oracle数据库。
<generator class="sequence"><param name="sequence">序列名</param></generator>
hibernate的基本用法

hibernate的基本用法Hibernate是一个开源的Java框架,用于简化数据库操作。
它为开发人员提供了一个更加简单、直观的方式来管理数据库,同时也提高了应用程序的性能和可维护性。
本文将逐步介绍Hibernate的基本用法,包括配置、实体映射、数据操作等。
一、配置Hibernate1. 下载和安装Hibernate:首先,我们需要下载Hibernate的压缩包并解压。
然后将解压后的文件夹添加到Java项目的构建路径中。
2. 创建Hibernate配置文件:在解压后的文件夹中,可以找到一个名为"hibernate.cfg.xml"的文件。
这是Hibernate的主要配置文件,我们需要在其中指定数据库连接信息和其他相关配置。
3. 配置数据库连接:在"hibernate.cfg.xml"文件中,我们可以添加一个名为"hibernate.connection.url"的属性,用于指定数据库的连接URL。
除此之外,还需要指定数据库的用户名和密码等信息。
4. 配置实体映射:Hibernate使用对象关系映射(ORM)来将Java类映射到数据库表。
我们需要在配置文件中使用"mapping"元素来指定实体类的映射文件。
这个映射文件描述了实体类与数据库表之间的对应关系。
二、实体映射1. 创建实体类:我们需要创建一个Java类,用于表示数据库中的一行数据。
这个类的字段通常与数据库表的列对应。
同时,我们可以使用Hibernate提供的注解或XML文件来配置实体的映射关系。
2. 创建映射文件:可以根据个人喜好选择使用注解还是XML文件来配置实体类的映射关系。
如果使用XML文件,需要创建一个与实体类同名的XML文件,并在其中定义实体类与数据库表之间的映射关系。
3. 配置实体映射:在配置文件中,我们需要使用"mapping"元素来指定实体类的映射文件。
基于NHibernate的客户登录系统的实现

s2_●基于N H i b er nat e的客户登录系统的实现云微(长春大学理学院吉林长春130022)信息科学【■薹]研究一个客户登录系统的实现,该系统是在vi s ual st udi o.net2005下使用c蟠亩、SO L ser ve r2000数据库进行开发.首先介绍系统的开发背景以及研究价值,其次.介绍开发环境、语言及数据库,最后,叙述系统设计的实现.【关键词】N H i be r nat e对象/关系映射登录。
中图分类号:TP3文献标识码:^文章编号:1671--7597(2008)1220065--01i、引■2l世纪的今天,信息技术的发展更是日新月异,信息技术将成为一种越来越重要的战略资源.为了提高信息处理速度、能力和决策水平,迫切需要实现信息的实时管理。
因此,如何将其设计得更加易于部署、易于使用和管理,有效降低客户的运营成本,成为了产业发展的一项重心。
此系统正是本着这一概念出发,充分利用现有的基础设施,同时整合已有的技术和平台,从而实现对登录系统的研究与实现。
=、开置平台、曩■置t曩库帕介■(一)N H i ber nat eN H i ber nat e是一个面向.N E T环境的对象/关系数据库映射工具.是大型关系型可扩展数据库的首选。
对象/关系数据库映射(O R M)表示一种技术,用来把对象模型表示的对象映射到基于SOL的关系模型数据结构中去.简单地说就是能实现把一个对象存储为数据表中的一条记录和由一条记录创建一个相应的对象,数据表中的数据就是对象的属性。
N Hi ber nat e的目标主要是用于与数据持久化相关的编程任务,能够使开发人员从原来枯燥的SO L语句的编写中解放出来,解放出来的精力可以让开发人员投入到业务逻辑的实现上.(二)钟c{I是一种现代的面向对象的程序开发语言。
充分体现了构件化的程序设计思想。
c#为程序员提供了快捷的程序开发方式,具有强大的控制能力:同时,由于是M i cr osof t公司的产品,它又同vB一样简单..ne t的各种优点在c{l中表现得淋漓尽致.c#与.net得到了完美结合.c{I是.net框架应用程序开发的最好语言。
hibernate配置

目录
1 Hibernate概述 2 第一个Hibernate程序 3 Hibernate的配置文件 4 深入理解持久化对象 5 Hibernate的映射文件 6持久化对象 如果PO 实例与Session实例关联起来,且该实例关联到数据库的记录
脱管对象 如果PO实例曾经与Session实例关联过,但是因为Session的关闭等原 因,PO实例脱离了Session 的管理
Hibernate全面解决方案架构解释
事务(Transaction) 代表一次原子操作,它具有数据库事务的概念 但它通过抽象,将应用程序从底层的具体的JDBC、JTA和CORBA 事务中隔离开。 一个Session 之内可能包含多个Transaction对象。 所有的持久化操作都应该在事务管理下进行,即使是只读操作。
管态,对该对象操作无须锁定数据库,不会造成性能的下降。
持久化对象的状态迁移
持久化实体: 1、Serializable save(object obj) 将对象变为持久化状态 2、void persist(object obj) 将对象转化为持久化状态 3、Serializable save(object obj,object pk) 将obj对象转化为持久化状态,该对象保存到数据库,指定主键值 4、void persist(object obj,object pk) 也加了一个设定主键
Hibernate工作原理
Configuration cfg = new Configuration().configure();
开始
启动hibernate
构建Configuration 实例,初始 化该实例中的所有变量
hibernate executeupdate的返回值

hibernate executeupdate的返回值在Hibernate 中,executeUpdate 方法用于执行更新操作(如插入、修改和删除),并返回受影响的行数。
返回值类型为int,表示更新操作执行后受影响的行数。
具体的返回值含义如下:-如果返回值大于0,则表示更新操作成功,并返回受影响的行数;-如果返回值等于0,则表示更新操作执行但没有影响任何行;-如果返回值小于0,则表示更新操作执行失败。
示例代码如下:```javaString hql = "UPDATE User SET name = :newName WHERE id = :userId"; Query query = session.createQuery(hql);query.setParameter("newName", "John");query.setParameter("userId", 123);Transaction transaction = session.beginTransaction();int rowsAffected = query.executeUpdate();mit();System.out.println("受影响的行数:" + rowsAffected);```在上面的示例中,首先构造一个HQL(Hibernate Query Language)更新语句,然后创建Query 对象,并设置参数。
接着开启事务,执行更新操作,并通过executeUpdate 方法获取受影响的行数。
最后提交事务并输出受影响的行数。
需要注意的是,executeUpdate 方法返回的是受影响的行数,而不是实际更新的对象。
如果需要获取更新后的对象,可以在执行更新操作后,再通过查询获取更新后的数据。
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
事务——Nhibernate操作原生SQL以及查询DataTable

Nhibernate操作原生SQL以及查询DataTable使用Nhibernate时我们很方便实现实体映射,但是如果遇到复杂查询则显得力不从心,这是我们可以利用Nhibernate来操作原生sql来查询到DataTable来实现我们复杂的查询及其它操作。
以下实例已经过调试,现与大家分享。
///<summary>///执行ExecuteNonQuery///</summary>///<param name="sql"></param>public void ExecuteNonQuery(string sql){ISession session = null;ITransaction transaction = null;try{session = NHibernateHelper.GetCurrentSession();transaction = session.BeginTransaction();IDbCommand command = session.Connection.CreateCommand();transaction.Enlist(command);//注意此处要把command添加到事物中mandText = sql;command.ExecuteNonQuery();mit();}catch (Exception ex){if (transaction != null){transaction.Rollback();}throw ex;}finally{if (session != null){session.Close();}}}///<summary>///填充DataSet///</summary>///<param name="sql"></param>///<returns></returns>public static DataSet ExecuteDataset(string sql){ISession session = null;DataSet ds = new DataSet();try{session = NHibernateHelper.GetCurrentSession();IDbCommand command = session.Connection.CreateCommand(); mandText = sql;IDataReader reader = command.ExecuteReader();DataTable result = new DataTable();//result.Load(reader);//此方法亦可DataTable schemaTable = reader.GetSchemaTable();for (int i = 0; i < schemaTable.Rows.Count; i++){string columnName = schemaTable.Rows[i][0].ToString(); result.Columns.Add(columnName);}while (reader.Read()){int fieldCount = reader.FieldCount;object[] values = new Object[fieldCount];for (int i = 0; i < fieldCount; i++){values[i] = reader.GetValue(i);}result.Rows.Add(values);}ds.Tables.Add(result);}catch (Exception ex){Debug.Assert(false);}finally{if (session != null){session.Close();}}return ds;}///<summary>///填充DataSet(此方法亦可)///</summary>///<param name="sql"></param>///<returns></returns>public DataSet ExecuteDataset(string sql){ISession session = null;DataSet ds = new DataSet();try{session = NHibernateHelper.GetCurrentSession();IDbCommand command = session.Connection.CreateCommand(); mandText = sql;SqlDataAdapter da = new SqlDataAdapter(cmd as SqlCommand); da.Fill(ds);}catch (Exception ex){Debug.Assert(false);}finally{if (session != null){session.Close();}}return ds;}。
NHibernate与EF的区别

长久以来,程序员和数据库总是保持着一种微妙的关系,在商用应用程序中,数据库一定是不可或缺的元件,这让程序员一定要为了连接与访问数据库而去学习SQL 指令,至少对于我而言,我觉得这是一个很不爽的事情。
因此在信息业中有很多人都在研究如何将程序设计模型和数据库集成在一起,对象关系对应(Object-Relational Mapping) 的技术就是由此而生,像Hibernate或NHibernate都是这个技术下的产物,而微软官方一直没有推出类似的框架,依旧依靠这个传统的数据访问工具。
估计微软也听到了来自程序员的抱怨,于是从一个ObjectSpace(ObjectSpace最早在2005年?被提出,可以让应用程序可以用完全对象化的方法连接与访问数据库,其技术概念与NHibernate相当类似)的概念最后在2008年随.net framework 3.5 SP1发布了 Entity Framework,一个附带有图形化设计器的面向实体数据库访问框架。
Entity Framework 利用了抽象化数据结构的方式,将每个数据库对象都转换成应用程序对象(entity),而数据字段都转换为属性(property),关系则转换为结合属性(association),让数据库的E/R 模型完全的转成对象模型,如此让程序设计师能用最熟悉的编程语言来调用访问。
而在抽象化的结构之下,则是高度集成与对应结构的概念层、对应层和储存层,以及支持Entity Framework 的数据提供者(provider),让数据访问的工作得以顺利与完整的进行。
Entity Framework 以Entity Data Model (EDM) 为主,将数据逻辑层切分为三块,分别为Conceptual Schema, Mapping Schema 与Storage Schema 三层:(1) 概念层:负责向上的对象与属性显露与访问,让上层的应用程序码可以如面向对象的方式般访问数据。
简述hibernate查询数据库的步骤

简述hibernate查询数据库的步骤Hibernate是一个开源的Java持久化框架,它可以帮助开发者简化数据库操作,提高开发效率。
在Hibernate中,查询数据库是非常常见的操作,本文将以标题的方式,简述Hibernate查询数据库的步骤。
一、配置Hibernate在开始使用Hibernate查询数据库之前,首先需要进行Hibernate 的配置工作。
包括创建Hibernate配置文件(hibernate.cfg.xml),配置数据库连接信息、数据库方言等。
同时,还需要配置实体类与数据库表之间的映射关系(Hibernate映射文件)。
二、创建SessionFactorySessionFactory是Hibernate的核心接口之一,它负责创建Session对象,是实现Hibernate查询的基础。
在Hibernate中,SessionFactory是线程安全的,通常一个应用程序只需要一个SessionFactory实例。
三、打开Session在进行数据库查询之前,需要先打开一个Session。
Session是Hibernate中的一个重要概念,它代表一个与数据库的会话。
可以通过SessionFactory的openSession方法来打开一个Session。
四、开始事务在进行数据库查询操作之前,通常需要开启一个事务。
通过调用Session的beginTransaction方法,开始一个事务。
事务的开启可以保证数据的一致性和完整性。
五、执行查询操作在Hibernate中,有多种查询方式可以选择。
常见的查询方式包括HQL查询、QBC查询和Native SQL查询。
HQL(Hibernate Query Language)是Hibernate提供的一种面向对象的查询语言,类似于SQL语句。
QBC(Criteria Query)是一种基于Criteria的查询方式,可以通过CriteriaBuilder来构建查询条件。
nhibernate between and or的用法

nhibernatebetweenandor的用法标题:《NHibernate中BETWEEN和OR的用法详解》在NHibernate中,BETWEEN和OR都是非常重要的操作符,它们在查询语句中发挥着重要的作用。
这篇文章将详细介绍这两种操作符的使用方法。
一、BETWEEN操作符BETWEEN操作符用于在某个范围中进行查找。
在NHibernate中,可以使用它来过滤数据,包括单个值、范围、列表等。
例如,以下语句将会返回“年龄”在18-30之间的记录:```scssfromPersonwhereagebetween18and30```这里需要注意,BETWEEN操作符是不包含两端值的。
也就是说,它会返回从18到30之间的所有数字,但不包括18和30本身。
二、OR操作符OR操作符用于在查询中添加多个条件,其中至少有一个条件满足时,记录就会被返回。
在NHibernate中,OR操作符的使用也非常常见。
例如,以下语句将会返回名字为“John”或者“Mary”的记录:```scssfromPersonwherename='John'orname='Mary'```这里需要注意的是,OR操作符是逻辑或的关系,也就是说,只要满足其中一个条件,就会返回对应的记录。
三、使用技巧在使用BETWEEN和OR时,还有一些技巧可以帮助提高查询效率。
例如:*尽量避免使用嵌套的BETWEEN操作符,因为这可能会导致查询效率低下。
可以考虑使用其他方式来替代。
*对于多个条件之间的逻辑关系,可以使用AND或OR来组合,但要避免过多的嵌套条件。
*尽量避免使用多个AND连接的多个条件,这可能会降低查询效率。
*在使用OR时,确保所有条件之间都有逻辑关系,以避免出现逻辑错误。
四、总结在NHibernate中,BETWEEN和OR都是非常重要的操作符,它们可以用来过滤和组合查询条件。
在使用时,需要仔细考虑条件之间的关系和顺序,以避免出现逻辑错误和提高查询效率。
hibernatetemplate 语法

hibernatetemplate 语法摘要:一、介绍HibernateTemplate 语法二、HibernateTemplate 的优势三、HibernateTemplate 的使用方法四、HibernateTemplate 的常见方法五、HibernateTemplate 的注意事项六、总结正文:HibernateTemplate 是Hibernate 框架中的一个核心类,它提供了一种简化Hibernate 操作的语法。
HibernateTemplate 可以帮助我们简化Hibernate 的增删改查操作,使开发者无需手动编写SQL 语句,只需使用HibernateTemplate 类的方法即可完成相应的操作。
HibernateTemplate 的优势在于它提供了一种更符合面向对象编程思想的操作方式。
通过HibernateTemplate,我们可以将业务逻辑与数据访问逻辑分离,使代码结构更加清晰。
同时,HibernateTemplate 还具有自动事务管理功能,可以有效地管理事务,避免出现因事务处理不当而引发的问题。
使用HibernateTemplate 非常简单,首先需要创建一个HibernateTemplate 对象,然后通过这个对象调用相应的方法进行操作。
下面是一个简单的示例:```java// 获取HibernateTemplate 对象Session session = HibernateUtil.getSessionFactory().openSession();HibernateTemplate hibernateTemplate = new HibernateTemplate(session);// 使用HibernateTemplate 插入数据User user = new User();user.setName("张三");user.setAge(25);hibernateTemplate.insert(user);// 使用HibernateTemplate 更新数据User user2 = (User) hibernateTemplate.load(User.class, 1);user2.setName("李四");hibernateTemplate.update(user2);// 使用HibernateTemplate 删除数据hibernateTemplate.delete(user);// 使用HibernateTemplate 查询数据List<User> users = hibernateTemplate.loadAll(User.class);```HibernateTemplate 提供了许多常用的方法,如insert、update、delete、load、loadAll 等,可以满足我们日常开发中的大部分需求。
NHibernate在.NET开发中的应用

o e ma y t o e o e t m n n 。 n —o n ,n -o a y等几 种 。 — -
O e t oe n—o n :一对一是一种常见的数据模 型 。它有 两种情 — 况 : 种 是 主 键 (r rK y关 联 ; 一 种 是 外 健 (oegK y 一 Pi y e) ma 另 Fri e1 n 关 联。 在使用外健的时候 耍保证其唯一性 。在主键关联 的情况下. 必 须 有 一个 主键 是根 据别 一 个 主键 而 来 的。N HB是通 过 一 种 特 殊 的方 式 来 处理 这 种 情 况 的。 注 意 两 个 主健 名 称 必 须 同 名 。 要 而 外健 关 联 需要 在 oe t- n n -o oe配 置 中定 义 一 个 p et-e 属 性 . mp r r y f 这个 属性 在 当前 版 本 的 N HB中还 没 有 实 现 。 业 务概 念 。 m n—o oe 是 描述 多对 一 的一 种 数 据模 型 . 指 定 may ay t_n : 它 n 11 . 持久化操作 方 是不 能独立存在的 . ay t—n 是 N m n—oo e HB中保证数据有效 开发商业 项 目简单 的说就是将各种数据持久化 .目前常用 性的最有用 的一种映射 .通过使用 may t o e n—o n 能有效 的防治 — 的持久化方法有 以下三种 : 孤儿 记 录被 写入 到数 据 表 中 在业务类中硬编码 S L S L直接写在业 务类 中. Q :Q 这种方法 oe t m n : 对多也是一种 常见的数据模 型 . n—o a y一 — 在按范式 写代码效率很高 . 于小型应用程序 , 对 是可行的 。但是将业 务类 设计 的数据库中随处可见。在 NI I B中通过 oe t m n n —o ay可以非 — 与 关 系数 据 库 结 构 直 接 耦 合 在一 起 。 何 小 的 改变 ( 如对 某一 常 方 便 的处 理 这 种模 型 . 任 例 同时 N B还 提 供 了级 联 更 新 和 删 除 的 H 列 重 命名 或 者 移 植 到 另 外 一 种数 据 库 )都 将 导 致 源代 码 级 的修 功能 , 以保证数据完整 性。【 3 】
hibernate的flush方法

hibernate的flush方法Hibernate是一个开源的对象关系映射工具,提供了数据库操作的抽象层,使开发者可以使用面向对象的方式进行数据库操作。
Hibernate的flush方法是用于将Hibernate会话中的变化同步到数据库的操作。
在Hibernate中,会话(Session)是表示开发者与数据库之间的一次连接。
开发者可以通过向会话中添加、修改和删除对象来操作数据库。
而flush方法则是将这些变化同步到数据库。
在什么情况下需要使用flush方法呢?1. 当开发者需要保证数据的完整性时,可以使用flush方法。
当开发者添加、修改或删除了对象之后,调用flush方法会立即将这些变化同步到数据库。
2. 当开发者需要检查数据是否已经被持久化时,可以使用flush方法。
在调用flush方法之后,数据将被立即同步到数据库,可以通过查询数据库来验证数据是否已经被保存。
3. 当开发者需要在事务之外使用最新的数据时,可以使用flush方法。
在Hibernate中,默认情况下,事务提交之前,所有的数据变化只是在会话缓存中进行维护,而不会立即同步到数据库。
但是,如果开发者需要在事务之外查询到最新的数据,可以在查询之前调用flush方法,确保数据已经更新到数据库中。
4. 当开发者需要将数据库操作的异常抛出时,可以使用flush方法。
在执行数据库操作过程中,如果发生了异常,Hibernate会自动回滚事务,但不会抛出异常。
如果开发者希望在发生异常时得到通知,可以在执行数据库操作之前调用flush方法,如果操作失败,会抛出异常。
实际上,flush方法执行的操作如下:1.将会话中的持久化对象的状态同步到数据库。
持久化对象的状态包括新增、修改和删除。
2.将会话中的变化同步到数据库的操作也会级联到关联对象。
如果一些持久化对象发生了变化,与之关联的其他对象也会受到影响。
3. 执行flush操作不会结束当前事务,会话仍然处于打开状态,可以继续进行操作。
NHibernate常见错误

NHibernate常见错误1.NHibernateSample.Data.Test.QueryHQLFixture.WhereTest:NHibernate.Hql.Ast.ANTLR.QuerySyntaxException : 引发类型为“Antlr.Runtime.NoViableAltException”的异常。
near line 1, column 7 [selectfrom NHibernateSample.Domain.Entities.Customer c where c.Firstname='scenery']错误语法:select from customer正确语法:from customereSQL_GetCustomersWithOrdersTest:NHibernate.Exceptions.GenericADOException : could not execute query[ select distinct customer.* from Customer customer inner join [Order] o on o.CustomerId=customer.CustomerId where o.OrderDate> @p0 ]Name:orderDate - Value:2011-9-5 0:00:00[SQL: select distinct customer.* from Customer customer inner join [Order] o on o.CustomerId=customer.CustomerId where o.OrderDate> @p0]---->System.IndexOutOfRangeException :CustomerId0_0_错误写法:return _session.CreateSQLQuery("select distinct {customer}.* from Customer {customer}" +" inner join [Order] o ono.CustomerId={customer}.CustomerId whereo.OrderDate> :orderDate").AddEntity("customer", typeof(Customer)).SetDateTime("orderDate", orderDate).List<Customer>();正解写法:return _session.CreateSQLQuery("select distinct {customer.*} from Customer {customer}" +" inner join [Order] o ono.CustomerId={customer}.CustomerId whereo.OrderDate> :orderDate").AddEntity("customer", typeof(Customer)).SetDateTime("orderDate", orderDate).List<Customer>();eCriteriaAPI_GetCustomerswithOrdersHavingProductTest: NHibernate.Exceptions.GenericADOException : couldnot execute query[ SELECT this_.CustomerId as CustomerId0_2_, this_.Version as Version0_2_, this_.Firstname as Firstname0_2_,this_.Lastname as Lastname0_2_, order1_.OrderId as OrderId1_0_, order1_.OrderDate as OrderDate1_0_,order1_.CustomerId as CustomerId1_0_, products5_.[Order] as Order1_, product2_.ProductId as Product,product2_.ProductId as ProductId3_1_, product2_.Name as Name3_1_, product2_.Cost as Cost3_1_ FROM Customer this_ inner join [Order] order1_ onthis_.CustomerId=order1_.CustomerId inner join OrderProduct products5_ onorder1_.OrderId=products5_.[Order] inner join Productproduct2_ on products5_.Product=product2_.ProductId WHERE this_.Firstname = @p0 and order1_.OrderDate >@p1 and product2_.Name = @p2 ]Positional parameters: #0>scenery #1>2008-10-1 0:00:00 #2>shirt[SQL: SELECT this_.CustomerId as CustomerId0_2_,this_.Version as Version0_2_, this_.Firstname as Firstname0_2_, this_.Lastname as Lastname0_2_,order1_.OrderId as OrderId1_0_, order1_.OrderDate as OrderDate1_0_, order1_.CustomerId as CustomerId1_0_, products5_.[Order] as Order1_, product2_.ProductId as Product, product2_.ProductId as ProductId3_1_,product2_.Name as Name3_1_, product2_.Cost as Cost3_1_ FROM Customer this_ inner join [Order] order1_ onthis_.CustomerId=order1_.CustomerId inner join OrderProduct products5_ onorder1_.OrderId=products5_.[Order] inner join Product product2_ on products5_.Product=product2_.ProductId WHERE this_.Firstname = @p0 and order1_.OrderDate >@p1 and product2_.Name = @p2]---->System.Data.SqlClient.SqlException : 列名'Order' 无效。
nhibernate generator hilo用法

nhibernate generator hilo用法NHibernate的hilo生成器是一种用于生成数据库表的唯一标识符的机制。
它使用一个hi值,来跟踪当前生成的值,并保持在数据库表中。
以下是NHibernate hilo生成器的用法:1.在映射文件(.hbm.xml)中定义标识符生成器:```xml<class name="YourClassName" table="YourTableName"><id name="Id" column="YourColumnName"><generator class="hilo"/></id>...</class>```2.在配置文件(hibernate.cfg.xml)中配置hilo生成器的参数:```xml<hibernate-configuration><session-factory>...<propertyname="hibernate.id.new_generator_mappings">true</property> <propertyname="hibernate.id.optimizer.pooled.preferred">hilo</property> <propertyname="hibernate.id.optimizer.pooled.lo">10</property>...</session-factory></hibernate-configuration>```3.在代码中使用Session.Save()来保存实体对象:```csharpUsing (var session = sessionFactory.OpenSession()){using (var transaction = session.BeginTransaction()){YourClassName obj = new YourClassName();session.Save(obj);mit();}}```使用hilo生成器时,它会根据你在配置文件中设置的值(如lo和table等)自动生成唯一标识符。
hibernate 调用存储过程 传参 获取返回值

Hibernate调用存储过程传参获取返回值简介Hibernate是一个流行的Java持久化框架,它提供了一种将Java对象映射到关系型数据库的方式。
在某些情况下,我们可能需要调用存储过程来执行一些复杂的数据库操作。
本文将介绍如何使用Hibernate调用存储过程,并传递参数和获取返回值。
准备工作在开始之前,我们需要完成以下准备工作:1.安装Java JDK和Hibernate框架。
2.配置Hibernate的数据库连接信息,包括数据库驱动、URL、用户名和密码等。
3.创建数据库存储过程,并确保它已经在数据库中正确地定义和测试。
Hibernate映射文件在使用Hibernate调用存储过程之前,我们需要创建一个Hibernate映射文件来定义存储过程的调用。
下面是一个示例的映射文件:<hibernate-mapping><sql-query name="callStoredProcedure" callable="true">{ call my_stored_procedure(:param1, :param2) }</sql-query></hibernate-mapping>在上面的示例中,我们定义了一个名为”callStoredProcedure”的SQL查询,其中”callable”属性被设置为”true”,表示这是一个调用存储过程的查询。
存储过程的调用语法是{ call procedure_name(:param1, :param2) },其中”:param1”和”:param2”是存储过程的输入参数。
调用存储过程一旦我们有了Hibernate映射文件,我们就可以在Java代码中使用Hibernate来调用存储过程。
下面是一个示例代码:Session session = HibernateUtil.getSessionFactory().getCurrentSession(); Transaction tx = session.beginTransaction();Query query = session.getNamedQuery("callStoredProcedure");query.setParameter("param1", value1);query.setParameter("param2", value2);query.executeUpdate();mit();在上面的示例中,我们首先获取Hibernate的Session对象,并开启一个事务。
CodeSmith图形界面基本操作(一)

CodeSmith图形界⾯基本操作(⼀)CodeSmith图形界⾯操作 先从⽤法开始:以NHibernate模板⽣成为例: 1、启动CodeSmith,界⾯如下: 2、导⼊模板,点击左上⾓的⽂件夹⼀样的按钮,打开⽂件选择框,选择模板⽂件所在⽂件夹: 3、回到主界⾯就可以看到,模板⽂件已经被添加进来了。
4、展开⽂件夹,看到有个.cst后缀的⽂件,双击它,就会展开如下所⽰界⾯: 解释⼀下个选项的意思: OutputDirectory:⽣成的代码⽂件输出到的⽂件夹。
SourceDataBase:数据库名称 Assembly:就是⽣成代码⽂件的程序集。
ForceId:是否⽣成主键,如果选中,当表中没有主键时会报错。
NameSpace:⽣成代码⽂件的命名空间。
RemoveTablePrifix:要去除的表名前缀。
5、选择数据库 在上⾯的⼏个选项中,经常要⽤到选择数据库,点击SourceDataBase选项后⾯的三个点。
弹出选择数据库对话框: 如果你在下拉菜单中,没有看到⾃⼰的数据库,那么就可以再次点击后⾯的两个点,进⾏配置。
点击后看到如下界⾯: 如果在这⾥没有你⾃⼰想要选择的数据库,你可以点击Add按钮进⾏添加。
其中Name是你要连接的数据库名,然后有个Provider Type的下拉列表框,在这个框⾥⾯可以选择需要操作的数据库,如下图: 对于SqlServer应该选择SqlSchemaProvider。
ConnectionString:数据库连接字符串,你可以点击后⾯的三个点的按钮来进⾏⽣成,点击后界⾯如下: 是不是很有亲切感,很熟悉啊。
选择好路径,点击Test Connection测试连接,如果没有问题就连接上数据库了。
然后就⼀路选择OK返回。
回到主界⾯后,点击Generate(⽣成),稍等⼀会,待进度条全部变成绿⾊,代码⽂件就会⽣成到你设置的⽬录⾥⾯了。
代码⽣成之后,CodeSmith会显⽰如下界⾯: 最后到刚刚设置的输出⽬录去看看⽣成的代码⽂件。
hibernate createnativequery 使用

hibernate createnativequery 使用摘要:一、Hibernate 简介1.Hibernate 介绍2.Hibernate 的作用二、Hibernate 的NativeQuery 使用1.NativeQuery 概述2.NativeQuery 的使用场景3.NativeQuery 的优点和缺点三、Hibernate CreateNativeQuery 方法1.CreateNativeQuery 方法定义2.方法参数说明3.方法使用示例四、Hibernate CreateNativeQuery 应用实例1.实例一:使用CreateNativeQuery 查询数据2.实例二:使用CreateNativeQuery 更新数据3.实例三:使用CreateNativeQuery 删除数据正文:Hibernate 是一个开源的持久化框架,主要用于将Java 对象映射到关系型数据库中,从而实现数据持久化。
它将Java 对象与数据库表之间的映射关系以及数据库操作进行了抽象,简化了开发者在数据库操作方面的复杂性。
在Hibernate 中,有一个非常重要的功能就是NativeQuery 的使用。
NativeQuery 允许开发者使用JDBC 语句直接操作数据库,这在某些特定场景下非常有用。
例如,当需要执行复杂查询、存储过程或事务处理时,使用NativeQuery 可以提供更大的灵活性。
Hibernate 提供了CreateNativeQuery 方法,用于创建一个NativeQuery 对象。
CreateNativeQuery 方法接收一个字符串参数,即SQL 语句或命名查询,根据这个参数创建一个NativeQuery 对象。
然后,可以通过这个NativeQuery 对象执行查询、更新、删除等数据库操作。
Hibernate批处理操作优化(批量插入、更新与删除)

Hibernate批处理操作优化(批量插入、更新与删除)在项目的开发过程之中,由于项目需求,我们常常需要把大批量的数据插入到数据库。
数量级有万级、十万级、百万级、甚至千万级别的。
如此数量级别的数据用Hibernate做插入操作,就可能会发生异常,常见的异常是OutOfMemoryError(内存溢出异常)。
首先,我们简单来回顾一下Hibernate插入操作的机制。
Hibernate要对它内部缓存进行维护,当我们执行插入操作时,就会把要操作的对象全部放到自身的内部缓存来进行管理。
谈到Hibernate的缓存,Hibernate有内部缓存与二级缓存之说。
由于Hibernate对这两种缓存有着不同的管理机制,对于二级缓存,我们可以对它的大小进行相关配置,而对于内部缓存,Hibernate就采取了“放任自流”的态度了,对它的容量并没有限制。
现在症结找到了,我们做海量数据插入的时候,生成这么多的对象就会被纳入内部缓存(内部缓存是在内存中做缓存的),这样你的系统内存就会一点一点的被蚕食,如果最后系统被挤“炸”了,也就在情理之中了。
我们想想如何较好的处理这个问题呢?有的开发条件又必须使用Hibernate来处理,当然有的项目比较灵活,可以去寻求其他的方法。
笔者在这里推荐两种方法:(1):优化Hibernate,程序上采用分段插入及时清除缓存的方法。
(2):绕过Hibernate API ,直接通过 JDBC API 来做批量插入,这个方法性能上是最好的,也是最快的。
对于上述中的方法1,其基本是思路为:优化Hibernate,在配置文件中设置hibernate.jdbc.batch_size参数,来指定每次提交SQL的数量;程序上采用分段插入及时清除缓存的方法(Session实现了异步write-behind,它允许Hibernate显式地写操作的批处理),也就是每插入一定量的数据后及时的把它们从内部缓存中清除掉,释放占用的内存。
Hibernete基本概念
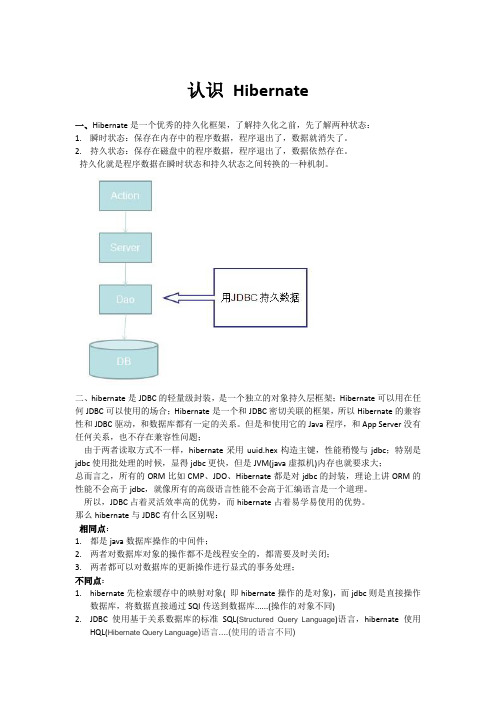
认识Hibernate一、Hibernate是一个优秀的持久化框架,了解持久化之前,先了解两种状态:1.瞬时状态:保存在内存中的程序数据,程序退出了,数据就消失了。
2.持久状态:保存在磁盘中的程序数据,程序退出了,数据依然存在。
持久化就是程序数据在瞬时状态和持久状态之间转换的一种机制。
二、hibernate是JDBC的轻量级封装,是一个独立的对象持久层框架;Hibernate可以用在任何JDBC可以使用的场合;Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系。
但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题;由于两者读取方式不一样,hibernate采用uuid.hex构造主键,性能稍慢与jdbc;特别是jdbc使用批处理的时候,显得jdbc更快,但是JVM(java虚拟机)内存也就要求大;总而言之,所有的ORM比如CMP、JDO、Hibernate都是对jdbc的封装,理论上讲ORM的性能不会高于jdbc,就像所有的高级语言性能不会高于汇编语言是一个道理。
所以,JDBC占着灵活效率高的优势,而hibernate占着易学易使用的优势。
那么hibernate与JDBC有什么区别呢:相同点:1.都是java数据库操作的中间件;2.两者对数据库对象的操作都不是线程安全的,都需要及时关闭;3.两者都可以对数据库的更新操作进行显式的事务处理;不同点:1.hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库,将数据直接通过SQl传送到数据库......(操作的对象不同)2.JDBC使用基于关系数据库的标准SQL(Structured Query Language)语言,hibernate使用HQL(Hibernate Query Language)语言....(使用的语言不同)3.Hibernate操作的数据是可持久化的,也就是持久化的对象属性的值,可以和数据库中保持一致,而jdbc操作数据的状态是瞬时的,变量的值无法和数据库中一致....(数据状态不同)三、ORM(Object Relational Mapping)对象关系映射完成对象数据到关系型数据映射的机制,称为:对象·关系映射,简ORM总结:Hibernate是一个优秀的对象关系映射机制,通过映射文件保存这种关系信息;在业务层以面向对象的方式编程,不需要考虑数据的保存形式。