k近邻算法
1.简述k最近邻算法的原理、算法流程以及优缺点

1.简述k最近邻算法的原理、算法流程以及优缺点一、什么是K近邻算法k近邻算法又称knn算法、最近邻算法,是一种用于分类和回归的非参数统计方法。
在这两种情况下,输入包含特征空间中的k个最接近的训练样本,这个k可以由你自己进行设置。
在knn分类中,输出是一个分类族群。
一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小),所谓的多数表决指的是,在k个最近邻中,取与输入的类别相同最多的类别,作为输入的输出类别。
简而言之,k近邻算法采用测量不同特征值之间的距离方法进行分类。
knn算法还可以运用在回归预测中,这里的运用主要是指分类。
二、k近邻算法的优缺点和运用范围优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用范围:数值型和标称型、如手写数字的分类等。
三、k近邻算法的工作原理假定存在一个样本数据集合,并且样本集中的数据每个都存在标签,也就是说,我们知道每一个样本数据和标签的对应关系。
输入一个需要分类的标签,判断输入的数据属于那个标签,我们提取出输入数据的特征与样本集的特征进行比较,然后通过算法计算出与输入数据最相似的k个样本,取k个样本中,出现次数最多的标签,作为输入数据的标签。
四、k近邻算法的一般流程(1)收集数据:可以使用任何方法,可以去一些数据集的网站进行下载数据。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式(3)分析数据:可以使用任何方法(4)训练算法:此步骤不适用于k近邻算法(5)测试算法:计算错误率(6)使用算法:首先需要输入样本数据和结构化的输出结构(统一数据格式),然后运行k近邻算法判定输入数据属于哪一种类别。
五、k近邻算法的实现前言:在使用python实现k近邻算法的时候,需要使用到Numpy科学计算包。
如果想要在python中使用它,可以按照anaconda,这里包含了需要python需要经常使用到的科学计算库,如何安装。
k-近邻算法梳理(从原理到示例)

k-近邻算法梳理(从原理到⽰例)https:///kun_csdn/article/details/88919091k-近邻算法是⼀个有监督的机器学习算法,k-近邻算法也被称为knn算法,可以解决分类问题。
也可以解决回归问题。
本⽂主要内容整理为如下:knn算法的原理、优缺点及参数k取值对算法性能的影响;使⽤knn算法处理分类问题的⽰例;使⽤knn算法解决回归问题的⽰例;使⽤knn算法进⾏糖尿病检测的⽰例;1 算法原理knn算法的核⼼思想是未标记样本的类别,由距离其最近的k个邻居投票来决定。
具体的,假设我们有⼀个已标记好的数据集。
此时有⼀个未标记的数据样本,我们的任务是预测出这个数据样本所属的类别。
knn的原理是,计算待标记样本和数据集中每个样本的距离,取距离最近的k个样本。
待标记的样本所属类别就由这k个距离最近的样本投票产⽣。
假设X_test为待标记的样本,X_train为已标记的数据集,算法原理的伪代码如下:遍历X_train中的所有样本,计算每个样本与X_test的距离,并把距离保存在Distance数组中。
对Distance数组进⾏排序,取距离最近的k个点,记为X_knn。
在X_knn中统计每个类别的个数,即class0在X_knn中有⼏个样本,class1在X_knn中有⼏个样本等。
待标记样本的类别,就是在X_knn中样本个数最多的那个类别。
1.1 算法优缺点优点:准确性⾼,对异常值和噪声有较⾼的容忍度。
缺点:计算量较⼤,对内存的需求也较⼤。
1.2 算法参数其算法参数是k,参数选择需要根据数据来决定。
k值越⼤,模型的偏差越⼤,对噪声数据越不敏感,当k值很⼤时,可能造成⽋拟合;k值越⼩,模型的⽅差就会越⼤,当k值太⼩,就会造成过拟合。
1.3 变种knn算法有⼀些变种,其中之⼀是可以增加邻居的权重。
默认情况下,在计算距离时,都是使⽤相同权重。
实际上,可以针对不同的邻居指定不同的距离权重,如距离越近权重越⾼。
机器学习经典分类算法——k-近邻算法(附python实现代码及数据集)

机器学习经典分类算法——k-近邻算法(附python实现代码及数据集)⽬录⼯作原理存在⼀个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每⼀数据与所属分类的对应关系。
输⼊没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进⾏⽐较,然后算法提取样本集中特征最相似数据(最近邻)的分类特征。
⼀般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不⼤于20的整数。
最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
举个例⼦,现在我们⽤k-近邻算法来分类⼀部电影,判断它属于爱情⽚还是动作⽚。
现在已知六部电影的打⽃镜头、接吻镜头以及电影评估类型,如下图所⽰。
现在我们有⼀部电影,它有18个打⽃镜头、90个接吻镜头,想知道这部电影属于什么类型。
根据k-近邻算法,我们可以这么算。
⾸先计算未知电影与样本集中其他电影的距离(先不管这个距离如何算,后⾯会提到)。
现在我们得到了样本集中所有电影与未知电影的距离。
按照距离递增排序,可以找到k个距离最近的电影。
现在假定k=3,则三个最靠近的电影依次是He's Not Really into Dudes、Beautiful Woman、California Man。
python实现⾸先编写⼀个⽤于创建数据集和标签的函数,要注意的是该函数在实际⽤途上没有多⼤意义,仅⽤于测试代码。
def createDataSet():group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels = ['A','A','B','B']return group, labels然后是函数classify0(),该函数的功能是使⽤k-近邻算法将每组数据划分到某个类中,其伪代码如下:对未知类别属性的数据集中的每个点依次执⾏以下操作:(1)计算已知类别数据集中的点与当前点之间的距离;(2)按照距离递增次序排序;(3)选取与当前点距离最⼩的k个点;(4)确定前k个点所在类别的出现频率;(5)返回前k个点出现频率最⾼的类别作为当前点的预测分类。
机器学习--K近邻(KNN)算法的原理及优缺点

机器学习--K近邻(KNN)算法的原理及优缺点⼀、KNN算法原理 K近邻法(k-nearst neighbors,KNN)是⼀种很基本的机器学习⽅法。
它的基本思想是:在训练集中数据和标签已知的情况下,输⼊测试数据,将测试数据的特征与训练集中对应的特征进⾏相互⽐较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
由于KNN⽅法主要靠周围有限的邻近的样本,⽽不是靠判别类域的⽅法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN⽅法较其他⽅法更为适合。
KNN算法不仅可以⽤于分类,还可以⽤于回归。
通过找出⼀个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有⽤的⽅法是将不同距离的邻居对该样本产⽣的影响给予不同的权值(weight),如权值与距离成反⽐。
KNN算法的描述: (1)计算测试数据与各个训练数据之间的距离; (2)按照距离的递增关系进⾏排序; (3)选取距离最⼩的K个点; (4)确定前K个点所在类别的出现频率 (5)返回前K个点中出现频率最⾼的类别作为测试数据的预测分类。
算法流程: (1)准备数据,对数据进⾏预处理。
(2)选⽤合适的数据结构存储训练数据和测试元组。
(3)设定参数,如k。
(4)维护⼀个⼤⼩为k的的按距离由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存⼊优先级队列。
(5)遍历训练元组集,计算当前训练元组与测试。
元组的距离,将所得距离L 与优先级队列中的最⼤距离Lmax。
(6)进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列。
(7)遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
k邻近值算法

k邻近值算法k邻近值算法是一种常用的机器学习算法,被广泛应用于分类和回归问题中。
它的核心思想是通过在特征空间中寻找最近邻的训练样本来预测未知样本的标签或值。
首先,我们需要了解k邻近值算法的基本原理。
该算法的步骤如下:首先,计算待预测样本与训练样本之间的距离,常用的计算距离的方法有欧氏距离、曼哈顿距离等。
然后,选择距离最近的k个训练样本,通常我们可以通过设置参数k的值来确定最近邻的个数。
接下来,根据这k个样本的标签或值,采用多数投票或加权平均的方法来预测待预测样本的标签或值。
最后,将预测结果返回。
k邻近值算法的优点在于简单且易于实现,无需训练过程,并且能够处理多分类和回归问题。
此外,该算法对数据的分布没有假设,在处理具有非线性关系的数据时表现良好。
它还可以适用于多种数据类型,包括数值型、离散型和连续型。
然而,k邻近值算法也存在一些缺点。
首先,该算法对邻居样本的选择很敏感,如果选择不当,可能会导致预测结果出现错误。
其次,由于该算法需要计算样本间的距离,对于大规模数据集来说,计算量会非常大,导致算法的效率下降。
此外,该算法对特征空间中的各个维度的度量是均等对待的,这意味着对于具有不同重要性的特征,其权重是一样的,可能会影响到预测的准确性。
针对k邻近值算法的缺点,我们可以采取一些策略来提高算法的性能。
首先,我们可以通过选择合适的距离度量方法,来优化样本的选择过程。
其次,合理选择k的值是很重要的,在一定范围内,增大k 可以减少错误的预测。
此外,对于特征空间的归一化处理,也可以提高算法的效率和准确性。
最后,我们可以使用特征选择的方法,来排除掉对于预测结果没有贡献的特征,以降低计算开销。
总之,k邻近值算法是一种简单、易于实现且广泛应用的机器学习算法。
通过选择最近邻的方式来进行预测,能够在多分类和回归问题中获得良好的效果。
然而,该算法也存在一些缺点,如对邻居样本选择的敏感性和计算复杂度较高等。
通过选择合适的策略和参数设置,我们可以优化算法的性能,并在实际应用中取得更好的效果。
k近邻算法解决实际问题

k近邻算法(k-Nearest Neighbors,简称kNN)是一种非常实用的机器学习算法,可以用于解决各种实际问题。
以下是一些使用kNN算法解决实际问题的例子:1.垃圾邮件识别:通过分析邮件的内容和元数据,使用kNN算法训练模型,
可以识别垃圾邮件。
具体地,可以将邮件内容作为输入特征,标签为正常邮件或垃圾邮件,使用kNN算法进行分类。
2.电影推荐:使用kNN算法可以基于用户的历史行为和偏好,推荐类似风格
的电影。
例如,可以根据电影的导演、演员、类型、主题等特征,使用kNN算法对用户进行分类,并推荐与用户所在类别最相似的电影。
3.信用卡欺诈检测:通过分析大量的信用卡交易数据,使用kNN算法可以检
测出异常交易,预防欺诈行为。
可以将交易金额、时间、地点等作为输入特征,标签为正常交易或欺诈交易,使用kNN算法进行分类。
4.疾病诊断:在医疗领域,可以使用kNN算法根据患者的症状、病史、检查
结果等数据,进行疾病诊断。
可以将患者的各种特征作为输入,标签为某种疾病或健康状态,使用kNN算法进行分类。
5.语音识别:在语音识别领域,可以使用kNN算法进行语音到文字的转换。
具体地,可以将语音信号的某些特征作为输入,标签为相应的文字,使用kNN 算法进行分类,并对分类结果进行优化和调整。
总之,k近邻算法是一种非常实用的机器学习算法,可以用于解决各种实际问题。
在实际应用中,需要根据具体问题的特点选择合适的特征和参数,并对模型进行合理的评估和调整。
第二章-K近邻算法

1
当p=2时,LP为欧l几n1 x里i(l)得距x(jl离) PP
当p=1时,为曼哈顿距离 当p=+∞时,为切比雪夫距离
LPm l axi(l)xx(jl)
注意:使用的距离不同,k近邻的结果也会不同的, 即“由不同的距离度量所确定的最邻近点是不同的”
Company Logo
Company Logo
K近邻算法存在的问题 接上 解决方法:当计算两个实例间的距离时对每个属性 加权。
用复杂的数据结构,如搜索树去加速最近邻的确 定。这个方法经常通过设定“几乎是最近邻”的目 标去提高搜索速度
Company Logo
K近邻算法应用实践
knn()函数
基本形式: knn(tarin,test,cl,k,l,prob,use.all)
在应用中k一般取一个比较小的值,通常采用交叉验 证法来选取最优的k值
Company Logo
分类决策规则
k近邻法的分类决策规则往往是多数表决,即由输入 实例的k个近邻训练实例多数所属的类来决定
如果损失函数为0-1损失,则分类函数表示为:
误f分 类I ( 的c 概 率y ) :: R N c 1 , c 2 , c 3 ,. c K ..,
解决方法:当计算两个实例间的距离时对每个属性 加权。 这相当于按比例缩放欧氏空间中的坐标轴,缩短 对应于不太相关属性的坐标轴,拉长对应于更相关 的属性的坐标轴。每个坐标轴应伸展的数量可以通 过交叉验证的方法自动决定。
Company Logo
K近邻算法存在的问题
问题二:K-近邻算法必须保存全部数据集,如果训 练数据集的很大,必须使用大量的存储空间。此外, 由于必须对数据集中的每个数据计算距离值,实际 使用时可能非常耗时
KNN(K近邻法)算法原理
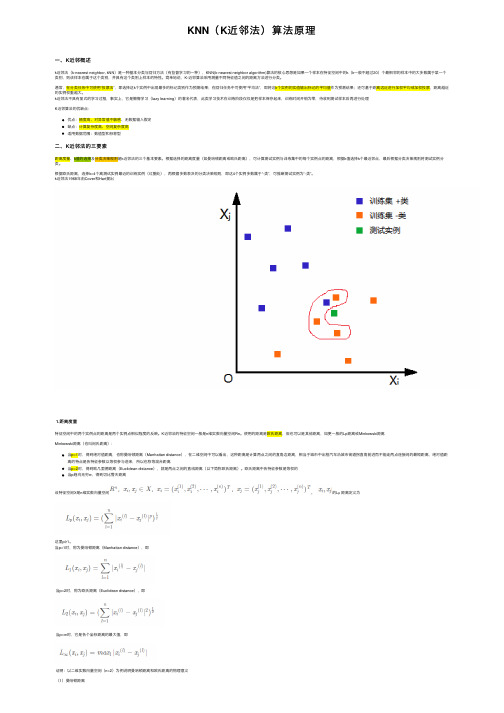
KNN(K近邻法)算法原理⼀、K近邻概述k近邻法(k-nearest neighbor, kNN)是⼀种基本分类与回归⽅法(有监督学习的⼀种),KNN(k-nearest neighbor algorithm)算法的核⼼思想是如果⼀个样本在特征空间中的k(k⼀般不超过20)个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
简单地说,K-近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类。
通常,在分类任务中可使⽤“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使⽤“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进⾏加权平均或加权投票,距离越近的实例权重越⼤。
k近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进⾏处理K近邻算法的优缺点:优点:精度⾼、对异常值不敏感、⽆数据输⼊假定缺点:计算复杂度⾼、空间复杂度⾼适⽤数据范围:数值型和标称型⼆、K近邻法的三要素距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
根据选择的距离度量(如曼哈顿距离或欧⽒距离),可计算测试实例与训练集中的每个实例点的距离,根据k值选择k个最近邻点,最后根据分类决策规则将测试实例分类。
根据欧⽒距离,选择k=4个离测试实例最近的训练实例(红圈处),再根据多数表决的分类决策规则,即这4个实例多数属于“-类”,可推断测试实例为“-类”。
k近邻法1968年由Cover和Hart提出1.距离度量特征空间中的两个实例点的距离是两个实例点相似程度的反映。
K近邻法的特征空间⼀般是n维实数向量空间Rn。
使⽤的距离是欧⽒距离,但也可以是其他距离,如更⼀般的Lp距离或Minkowski距离Minkowski距离(也叫闵⽒距离):当p=1时,得到绝对值距离,也称曼哈顿距离(Manhattan distance),在⼆维空间中可以看出,这种距离是计算两点之间的直⾓边距离,相当于城市中出租汽车沿城市街道拐直⾓前进⽽不能⾛两点连接间的最短距离,绝对值距离的特点是各特征参数以等权参与进来,所以也称等混合距离当p=2时,得到欧⼏⾥德距离(Euclidean distance),就是两点之间的直线距离(以下简称欧⽒距离)。
k近邻算法的原理和实现过程

k近邻算法的原理和实现过程
k近邻算法是一种基本的分类和回归算法,它的原理和实现过程如下:
原理:
1. 确定一个样本的k个最近的邻居,即选取与该样本距离最近的k个样本。
2. 根据这k个最近邻居的标签进行投票或者加权,确定该样本的预测标签。
如果
是分类问题,那么选取票数最多的标签作为预测标签;如果是回归问题,那么选
取k个最近邻居的标签的平均值作为预测标签。
实现过程:
1. 准备数据集:收集已知样本和其对应的标签。
2. 确定距离度量准则:选择合适的距离度量准则来度量样本间的距离,例如欧氏
距离、曼哈顿距离等。
3. 选择合适的k值:根据问题的要求选择适当的k值。
4. 计算样本之间的距离:对于每个未知样本,计算它与已知样本之间的距离,选
择k个最近邻居。
5. 统计k个最近邻居的标签:对于分类问题,统计k个最近邻居的标签的出现次数,并选择出现次数最多的标签作为预测标签;对于回归问题,计算k个最近邻
居的标签的平均数作为预测标签。
6. 将样本进行分类或预测:根据预测标签将未知样本进行分类或预测。
需要注意的是,在实际应用中,可以采取一些优化措施来提高k近邻算法的效率,比如使用kd树来加速最近邻搜索过程。
还可以对特征进行归一化处理,以避免
某些特征的权重过大对距离计算的影响。
k 近邻算法

k 近邻算法
k近邻算法(k-nearest neighbors,KNN)是一种用于分类和回
归的机器学习算法。
它的基本思想是在特征空间中,在训练数据集中寻找k个与待预测样本最相似的样本,然后根据这k个样本的标签来预测待预测样本的类别或值。
具体步骤如下:
1. 计算待预测样本与每个训练样本之间的距离,通常使用欧氏距离或曼哈顿距离等测量方法。
2. 选择k个距离最近的训练样本。
3. 根据这k个训练样本的标签,确定待预测样本的类别或值。
对于分类问题,通常采用少数服从多数的投票机制来确定类别。
对于回归问题,通常采用k个样本的平均值来预测待预测样本的值。
k近邻算法的优点包括简单易理解、无需训练过程、对数据没
有假设等;但它也存在一些缺点,如需要存储全部的训练数据、计算复杂度较高等。
在应用k近邻算法时,需要确定的重要参数是k的取值,通常通过交叉验证等方法来选择。
另外,数据预处理和特征选择等步骤通常会对k近邻算法的性能产生重要影响。
K-近邻算法PPT课件

.
19
示例:使用k-近邻算法
改进约会网站的配对结果
1.问题描述: 我都朋友佩琪一直使用在线约会网站寻找适 合自己的约会对象。尽管约会网站会推荐不 同的人选,但是她并不是喜欢每一个人。经 过一番总结,她发现曾交往过三种类型的人:
不喜欢的人 魅力一般的人 极具魅力的人
.
20
示例:使用k-近邻算法
改进约会网站的配对结果
(3)分析数据:可以使用任何方法。 (4)测试算法:计算错误率。 (5)使用算法:首先需要输入样本数据和结构化的输 出结果,然后运行k-近邻算法判定输入数据属于哪个分 类,最后应用对计算出的分类执行后续的处理。
.
10
准备:使用Python导入数据
1.创建名为kNN.py的Python模块
注:接下来所有的代码均保存于这个文件夹中,读者可以按照自己的习 惯在自己创建的文件夹中编写代码,也可以去网上查找源代码,但笔者 建议读者按照本PPT的顺序去创建模块并编写代码。
.
15
实施kNN分类算法
(2)以下为kNN近邻算法代码,将其保存于kNN.py中 def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis = 1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount = {} for i in range(k):
K-近邻算法

K-近邻算法⼀、概述k-近邻算法(k-Nearest Neighbour algorithm),⼜称为KNN算法,是数据挖掘技术中原理最简单的算法。
KNN 的⼯作原理:给定⼀个已知标签类别的训练数据集,输⼊没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。
可以简单理解为:由那些离X最近的k个点来投票决定X归为哪⼀类。
图1 图1中有红⾊三⾓和蓝⾊⽅块两种类别,我们现在需要判断绿⾊圆点属于哪种类别当k=3时,绿⾊圆点属于红⾊三⾓这种类别;当k=5时,绿⾊圆点属于蓝⾊⽅块这种类别。
举个简单的例⼦,可以⽤k-近邻算法分类⼀个电影是爱情⽚还是动作⽚。
(打⽃镜头和接吻镜头数量为虚构)电影名称打⽃镜头接吻镜头电影类型⽆问西东1101爱情⽚后来的我们589爱情⽚前任31297爱情⽚红海⾏动1085动作⽚唐⼈街探案1129动作⽚战狼21158动作⽚新电影2467?表1 每部电影的打⽃镜头数、接吻镜头数和电影分类表1就是我们已有的数据集合,也就是训练样本集。
这个数据集有两个特征——打⽃镜头数和接吻镜头数。
除此之外,我们也知道每部电影的所属类型,即分类标签。
粗略看来,接吻镜头多的就是爱情⽚,打⽃镜头多的就是动作⽚。
以我们多年的经验来看,这个分类还算合理。
如果现在给我⼀部新的电影,告诉我电影中的打⽃镜头和接吻镜头分别是多少,那么我可以根据你给出的信息进⾏判断,这部电影是属于爱情⽚还是动作⽚。
⽽k-近邻算法也可以像我们⼈⼀样做到这⼀点。
但是,这仅仅是两个特征,如果把特征扩⼤到N个呢?我们⼈类还能凭经验“⼀眼看出”电影的所属类别吗?想想就知道这是⼀个⾮常困难的事情,但算法可以,这就是算法的魅⼒所在。
我们已经知道k-近邻算法的⼯作原理,根据特征⽐较,然后提取样本集中特征最相似数据(最近邻)的分类标签。
那么如何进⾏⽐较呢?⽐如表1中新出的电影,我们该如何判断他所属的电影类别呢?如图2所⽰。
k- 最近邻算法

k- 最近邻算法摘要:1.K-最近邻算法的定义和原理2.K-最近邻算法的计算方法3.K-最近邻算法的应用场景4.K-最近邻算法的优缺点正文:1.K-最近邻算法的定义和原理K-最近邻(K-Nearest Neighbors,简称KNN)算法是一种基于相似度度量的聚类分析方法。
该算法的基本思想是:在数据集中,每个数据点都与距离它最近的K 个数据点属于同一类别。
这里的K 是一个超参数,可以根据实际问题和数据情况进行调整。
KNN 算法的主要步骤包括数据预处理、计算距离、确定最近邻和进行分类等。
2.K-最近邻算法的计算方法计算K-最近邻算法的过程可以分为以下几个步骤:(1)数据预处理:将原始数据转换为适用于计算距离的格式,如数值型数据。
(2)计算距离:采用欧氏距离、曼哈顿距离等方法计算数据点之间的距离。
(3)确定最近邻:对每个数据点,找到距离最近的K 个数据点。
(4)进行分类:根据最近邻的数据点所属的类别,对目标数据点进行分类。
3.K-最近邻算法的应用场景K-最近邻算法广泛应用于数据挖掘、机器学习、模式识别等领域。
常见的应用场景包括:(1)分类:将数据点划分到不同的类别中。
(2)回归:根据特征值预测目标值。
(3)降维:通过将高维数据映射到低维空间,减少计算复杂度和噪声干扰。
4.K-最近邻算法的优缺点K-最近邻算法具有以下优缺点:优点:(1)简单易懂,易于实现。
(2)对数据规模和分布没有特殊要求。
(3)对噪声不敏感,具有较好的鲁棒性。
缺点:(1)计算复杂度高,尤其是大规模数据集。
(2)对离群点和噪声敏感。
k-近邻算法 欧式距离

k-近邻算法欧式距离
k-近邻算法是一种常用的机器学习算法,它可以用于分类和回归问题。
在k-近邻算法中,我们通过计算样本点之间的欧式距离来确定最近的k个邻居。
欧式距离是一种常用的距离度量方法,也叫欧几里得距离。
它是在坐标空间中测量两个点之间的直线距离。
欧式距离计算公式为:
距离 = sqrt((x2-x1)^2 + (y2-y1)^2)
其中,(x1, y1)和(x2, y2)分别表示两个样本点的坐标。
通过计算每个样本点与目标点的欧式距离,我们可以找到与目标点最近的k个邻居。
然后,根据这k个邻居的分类标签或者数值,我们可以预测目标点的分类或者数值。
需要注意的是,k-近邻算法中的k值是一个重要的参数。
较小的k值可能会导致对噪声敏感,而较大的k值可能会导致低估样本点的局部特性。
总的来说,k-近邻算法通过欧式距离计算来确定最近的k个邻居,并根据邻居的标签或者数值进行预测。
这种算法在许多实际问题中都有应用,如图像识别、推荐系统等。
kneighborsclassifier 算法介绍

k-nearest neighbors(k-近邻)是一种简单而有效的监督式学习算法。
该算法在分类和回归问题上都有广泛的应用,并且易于理解和实现。
k-nearest neighbors算法的核心思想是基于输入样本的特征,来预测新样本的分类标签或者数值输出。
k-nearest neighbors算法的原理如下:1. 数据集准备:将训练数据集中的样本按照特征进行标记,这些特征用来决定样本的类别或者数值。
另外,还需要准备测试数据集,用于模型的验证和评估。
2. 计算距离:在预测过程中,计算测试样本与训练样本之间的距离。
通常使用的距离度量包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
3. 选择k值:选择一个合适的k值,该值表示在预测时将考虑最接近的k个训练样本。
选择合适的k值对算法的性能有着重要影响。
4. 预测:根据测试样本与训练样本的距离,选择最接近的k个训练样本,根据这k个训练样本的标签或数值进行预测。
通常采用投票法(对分类问题)或者平均法(对回归问题)来确定最终的预测结果。
k-nearest neighbors算法的优缺点如下:优点:1. 简单、直观:算法实现简单,易于理解和解释。
2. 适用于多类别问题:对于多分类问题,k-nearest neighbors算法表现良好。
3. 适用于非线性数据:对于非线性数据集,k-nearest neighbors算法也能够取得不错的预测效果。
缺点:1. 计算复杂度高:在大型数据集中,由于需要计算相互之间的距离,算法的计算开销比较大。
2. 对异常值敏感:k-nearest neighbors算法对异常值比较敏感,因此在使用该算法时需要注意异常值的处理。
3. 需要合适的k值:k值的选择对算法的性能有着重要的影响,选择不当会导致预测效果下降。
在使用k-nearest neighbors算法时,需要注意以下几点:1. 数据预处理:在应用k-nearest neighbors算法之前,需要对数据进行一定的预处理。
kneighborsclassifier 算法

kneighborsclassifier 算法K-最近邻算法(K-Nearest Neighbors Algorithm,简称KNN)是一种常见的分类算法之一,它可以对未知样本进行分类,它的基本原理是将未知样本与已知样本进行比较,以最近的K个样本为参考,将该未知样本归类到与最近的K个样本类别相同的类别中。
KNN算法的主要特点包括简单易用、非常适用于多类别样本分类问题,但是对于大规模数据的分类问题,计算量会变得非常大。
KNN算法的基本步骤包括:1. 选择和确定分类方式:可以是分析每个特征变量并按照最小误差或者最大分类准确率的方式进行;2. 选择要用于分类的近邻数量:这就是K的值,对于不同的问题要结合经验和理解来选择;3. 计算未知样本和已知样本之间的距离:可以使用欧式距离计算;4. 找到最近的K个样本:根据已知样本和未知样本之间的距离,找到最近的K个样本;5. 进行分类:通过统计K个样本中每个类别的数量,将未知样本归类到数量最大的类别中。
KNN算法是一个非常直观且易于理解的算法,但也存在一些缺点。
其中最明显的问题是需要大量的计算资源,特别是在样本数量非常大的时候。
算法需要存储所有的已知样本,也会占用大量的存储空间。
KNN算法的优点是对于高维数据,它不需要假设数据的任何分布类型。
这使得该算法适用于具有复杂结构和分布的数据集。
它适用于多分类问题和二分类问题。
在Python编程中,我们可以使用scikit-learn库中的KNeighborsClassifier来实现KNN算法。
下面是一个简单的代码示例:在使用KNN算法时,需要注意的一个关键问题是如何设置K值。
如果K值设置过小,那么模型会过于敏感,产生过拟合的现象;如果K值设置过大,那么模型会过于简单,容易出现欠拟合的情况。
K值的选择需要结合实际问题和模型评价指标进行综合考虑。
KNN算法是一个简单而有效的分类算法,可以用于多类别分类问题,尤其适用于非线性和高维数据。
k近邻算法的三个基本要素

k近邻算法的三个基本要素k近邻算法(k-Nearest Neighbors, k-NN)是一种简单而有效的分类和回归方法。
它是监督学习中最基础的算法之一,常被用于模式识别、数据挖掘和推荐系统等领域。
k近邻算法的核心思想是通过测量不同样本之间的距离来进行分类或回归预测。
1. 距离度量在k近邻算法中,选择合适的距离度量方法对分类或回归结果影响重大。
常用的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
1.1 欧氏距离欧氏距离是最常用的距离度量方法,它衡量两个样本之间在各个维度上的差异。
对于二维空间中的两个点P(x1,y1)和Q(x2,y2),它们之间的欧氏距离可以表示为:d euclidean(P,Q)=√(x2−x1)2+(y2−y1)21.2 曼哈顿距离曼哈顿距离是另一种常用的距离度量方法,它衡量两个样本之间在各个维度上的绝对差异。
对于二维空间中的两个点P(x1,y1)和Q(x2,y2),它们之间的曼哈顿距离可以表示为:d manℎattan(P,Q)=|x2−x1|+|y2−y1|1.3 闵可夫斯基距离闵可夫斯基距离是欧氏距离和曼哈顿距离的一种推广形式,可以根据具体情况调整参数。
对于二维空间中的两个点P(x1,y1)和Q(x2,y2),它们之间的闵可夫斯基距离可以表示为:d minkowski(P,Q)=(∑|x2i−x1i|pni=1+|y2i−y1i|p)1p其中p为参数,当p=1时为曼哈顿距离,当p=2时为欧氏距离。
2. k值选择k值是k近邻算法中的另一个重要参数,它决定了要考虑多少个最近邻样本的类别或属性。
选择合适的k值对于算法的性能和准确性至关重要。
k值过小会使得模型过于敏感,容易受到噪声和异常值的干扰,导致过拟合现象;而k值过大会使得模型过于简单,无法捕捉到样本之间的局部特征,导致欠拟合现象。
通常情况下,我们可以通过交叉验证或者网格搜索等方法来选择最优的k值。
在实际应用中,一般选择较小的奇数作为k值,以确保分类结果能够得到明确判断。
k最邻近算法

k最邻近算法k最邻近算法(K-NearestNeighbors,KNN)是一种常见的机器学习算法,它是一种监督学习算法,用于分类和回归。
KNN算法是一种基于实例的学习,它的基本思想是通过比较一个未知样本与训练集中所有样本的相似度,来确定该未知样本的类别。
本文将介绍KNN算法的基本原理、应用场景、优缺点以及改进方法等。
基本原理KNN算法的基本原理是通过计算未知样本与训练集中所有样本的距离(或相似度),然后选取k个距离最近的样本,根据这k个样本的类别来预测未知样本的类别。
KNN算法的核心思想是“近朱者赤,近墨者黑”,即认为距离较近的样本更有可能属于同一类别。
KNN算法的具体步骤如下:1. 计算未知样本与训练集中所有样本的距离(或相似度)。
2. 选取k个距离最近(或相似度最高)的样本。
3. 根据这k个样本的类别来预测未知样本的类别。
应用场景KNN算法广泛应用于分类和回归问题中。
其中,分类问题是指将未知样本分为多个类别中的一种,而回归问题是指根据已知的数据来预测未知的数值。
下面分别介绍KNN算法在分类和回归问题中的应用场景。
1. 分类问题KNN算法在分类问题中的应用非常广泛,例如:1.1 电子商务中的商品推荐系统。
根据用户的历史购买记录和浏览记录,推荐其可能感兴趣的商品。
1.2 医学诊断。
根据患者的症状和病史,预测其可能患有的疾病。
1.3 信用评估。
根据申请人的个人信息和信用记录,判断其申请贷款的可靠性。
2. 回归问题KNN算法在回归问题中的应用也比较广泛,例如:2.1 股票价格预测。
根据历史交易数据,预测某只股票未来的价格。
2.2 房价预测。
根据历史交易数据和房屋的基本信息,预测某个地区房价的趋势。
2.3 汽车油耗预测。
根据汽车的基本信息和历史油耗数据,预测某个车型的油耗。
优缺点KNN算法的优点:1. 简单易懂。
KNN算法的基本原理非常简单,易于理解和实现。
2. 适用性广。
KNN算法可以用于分类和回归问题,适用性非常广。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
k近邻算法(knn, k nearest neighbor)前两天受朋友之托,帮忙与两个k近邻算法,k近邻的非正式描述,就是给定一个样本集exset,样本数为M,每个样本点是N维向量,对于给定目标点d,d也为N维向量,要从exset中找出与d距离最近的k个点(k<=N),当k=1时,knn问题就变成了最近邻问题。
最naive的方法就是求出exset中所有样本与d的距离,进行按出小到大排序,取前k个即为所求,但这样的复杂度为O(N),当样本数大时,效率非常低下. 我实现了层次knn(HKNN)和kdtree knn,它们都是通过对树进行剪枝达到提高搜索效率的目的,hknn的剪枝原理是(以最近邻问题为例),如果目标点d与当前最近邻点x的距离,小于d与某结点Kp中心的距离加上Kp的半径,那么结点Kp中的任何一点到目标点的距离都会大于d 与当前最近邻点的距离,从而它们不可能是最近邻点(K近邻问题类似于它),这个结点可以被排除掉。
kdtree对样本集所在超平面进行划分成子超平面,剪枝原理是,如果某个子超平面与目标点的最近距离大于d与当前最近点x的距离,则该超平面上的点到d的距离都大于当前最近邻点,从而被剪掉。
两个算法均用matlab实现(应要求),把代码帖在下面,以备将来查用或者需要的朋友可以参考.function y = VecDist(a, b)%%返回两向量距离的平方assert(length(a) == length(b));y = sum((a-b).^2);end下面是HKNN的代码classdef Node < handle%UNTITLED2 Summary of this class goes here% Detailed explanation goes here% Node 层次树中的一个结点,对应一个样本子集KppropertiesNp; %Kp的样本数Mp; %Kp的样本均值,即中心Rp; %Kp中样本到Mp的最大距离Leafs; %生成的子节点的叶子,C * k矩阵,C为中心数量,k是样本维数。
如果不是叶结点,则为空SubNode; %子节点, 行向量endmethodsfunction obj = Node(samples, maxLeaf)global SAMPLES%samples是个列向量,它里面的元素是SAMPLES的行的下标,而不是SAMPLES行向量,使用全局变量是出于效率上的考虑= length(samples);if <= maxLeaf)= samples;else% opts = statset('MaxIter',100);% [IDX] = kmeans(SAMPLES(samples, :), maxLeaf, 'EmptyAction','singleton','Options',opts); [IDX] = kmeans(SAMPLES(samples, :), maxLeaf, 'EmptyAction','singleton');for k = 1:maxLeafidxs = (IDX == k);samp = samples(idxs);newObj = Node(samp, maxLeaf);= [ newObj];%SubNode为空说明当层的Centers是叶结点endend= mean(SAMPLES(samples, :), 1);dist = zeros(1, ;for t = 1:dist(t) = VecDist(SAMPLES(samples(t), :), ; end= max(dist);endendendfunction SearchKnn(Node)global KNNVec KNNDist B DEST SAMPLES m = length;if m ~= 0%叶结点%是叶结点for k = 1:mD_X_Xi = VecDist(DEST, SAMPLES(k), :));if (D_X_Xi < B)[Dmax, I] = max(KNNDist); KNNDist(I) = D_X_Xi; KNNVec(I) = (k);B = max(KNNDist);endendelse%非叶结点tab = ;D = zeros(size(tab));delMark = zeros(size(tab));for k = 1:length(tab)D(k) = VecDist(DEST, tab(k).Mp); if (D(k) > B + tab(k).Rp) delMark(k) = 1;endendtab(delMark == 1) = [];for k = 1:length(tab)SearchKnn(tab(k));endend下面是kdtree的代码classdef KDTree < handle%UNTITLED2 Summary of this class goes here% Detailed explanation goes herepropertiesdom_elt; %A point from Kd_d space, point associated with the current node split_pos;%分割位置,比如对于K维向量,这个位置可以是从1到k left;%左子树right;%右子树bNULL;%标识这个结点是否是NULLendmethods (Static)function [sample, index, split] = ChoosePivot1(samples)global SAMPLESdimVar = var(SAMPLES(samples, :));[maxVar, split] = max(dimVar);%分界点的维,即从第多少维处分[sorted, IDX] = sort(SAMPLES(samples, split));n = length(IDX);index = IDX(round(n/2));sample = samples(index);endfunction [sample, index, split] = ChoosePivot2(samples)%第二种pivot选择策略,选择范围最长的那维作为pivot%注意:这个选择策略是以树的不平衡性换取剪枝时的效果,对于有些数据分布,性能可能反而下降global SAMPLES[upper, I] = max(SAMPLES(samples, :), [], 1);%按列取最大值[bottom, I] = min(SAMPLES(samples, :), [], 1);%range = upper-bottom;%行向量[maxRange, split] = max(range);%分界点的维,即从第多少维处分[sorted, IDX] = sort(SAMPLES(samples, split));n = length(IDX);index = IDX(round(n/2));sample = samples(index);endfunction [exleft, exright] = SplitExset(exset, ex, pivot)global SAMPLESvec = SAMPLES(exset, pivot);%列向量flag = (vec <= SAMPLES(ex, pivot));exleft = exset(flag);flag = ~flag;exright = exset(flag);endendmethodsfunction obj = KDTree(exset)%输入向量集,SAMPLES的下标if isempty(exset)= true;else= false;[ex, index, split] = (exset);%[ex, index, split] = (exset);= ex;= split;exset_ = exset;%exset除去先作分割点的那个点exset_(exset == ex) = [];%将exset_分成左右两个样本集[exsetLeft, exsetRight] = (exset_, ex, split);%递归构造左右子树= KDTree(exsetLeft);= KDTree(exsetRight);endendendendfunction SearchKNN(kd, hr)%SearchKNN Summary of this function goes here% Detailed explanation goes here% kd 是 kdtree% hr是输入超平面图,它是由两个点决定,类比平面和二维点,所有二维点都在平面上,% 而平面上的一个矩形区域,可以由平面上的两个点决定% 首次迭代,输入超平面为一个能覆盖所有点的超平面。
对于二维,可以想像p1 = (-infinite, -infinite)% 到p2 = (infinite, infinite)的平面可以覆盖二维平面所有点。
可以推测一个可以覆盖K维空间所有点的的超平面图% 应该是(-inf, -inf....-inf),k维,到正的相应无穷点global SAMPLES DEST MAX_DIST_SQD %global in%DIST_SQD, SQD是指距离的平方global KNNVec KNNDist %global outif%kd是空的return;end%kd不为空pivot = ;%下标s = ;%分割输入超平面%分割面是经过pivot并且cui直于第s维%还原是以二维情况联想,可以得到分割后的两个超平面图left_hr_right_point = hr(2,:);left_hr_right_point(s) = SAMPLES(pivot,s);left_hr = [hr(1,:);left_hr_right_point];%得到分割后的left 超平面right_hr_left_point = hr(1,:);right_hr_left_point(s) = SAMPLES(pivot, s);right_hr = [right_hr_left_point;hr(2,:)];%得到right 超平面% 判断目标点在哪个超平面上% 始终以二维情况来理解,不然比较抽象bTarget_in_left = (DEST(s) <= SAMPLES(pivot, s));nearer_kd = [];nearer_hr = [];further_kd = [];further_hr = [];if bTarget_in_left%如果在左边超平面上%那么最近点在kd的左孩子上nearer_kd = ;nearer_hr = left_hr;further_kd = ;further_hr = right_hr;else%在右孩子上nearer_kd = ;nearer_hr = right_hr;further_kd = ;further_hr = left_hr;endSearchKNN(nearer_kd, nearer_hr);% A nearer point could only lie in further_kd if there were some% part of further_hr within distance sqrt(MAX_DIST_SQD) of target sqrt_Maxdist = sqrt(MAX_DIST_SQD);% 剪枝就在这里bIntersect = CheckInterSect(further_hr, sqrt_Maxdist, DEST);if ~bIntersect%如果不相交,没有必要继续搜索了return;end%如果超平面与超球有相交部分d = VecDist(SAMPLES(pivot, :), DEST);if d < MAX_DIST_SQD[Dmax, I] = max(KNNDist);KNNVec(I) = pivot;KNNDist(I) = d;MAX_DIST_SQD = max(KNNDist);endSearchKNN(further_kd, further_hr);endfunction bIntersect = CheckInterSect(hr, radius, t)%检查以点t为中心,radius为半径的圆,与超平面hr是否相交,为方便%在超平面上找到一个距t最近的点,如果这个距离小于等于radius,则相交%如何确定超平面上到t最近的点p:%假设超平面hr在第i维的上限和下限分别是hri_max, hri_min,则有% hri_min, if ti <= hri_min% pi = ti, if hri_min < ti < hri_max% hri_max, if ti >= hri_maxp = zeros(size(t));%超平面上与t最近的点,待求minHr = hr(1,:);maxHr = hr(2,:);% for k = 1:length(t)% if (t(k) <= minHr(k))% p(k) = minHr(k);% elseif (t(k) >= maxHr(k))% p(k) = maxHr(k);% else% p(k) = t(k);% end% endflag1 = (t <= minHr);p(flag1) = minHr(flag1);flag2 = (t >= maxHr);p(flag2) = maxHr(flag2);flag3 = ~(flag1 | flag2);p(flag3) = t(flag3);if (VecDist(p, t) >radius^2)bIntersect = false;elsebIntersect = true;endendOK,就这么多了,需要的朋友可以随便下载使用~。