k近邻分类算法
K-近邻算法(KNN)

K-近邻算法(KNN) ⽂本分类算法、简单的机器学习算法、基本要素、距离度量、类别判定、k取值、改进策略 kNN算法是著名的模式识别统计学⽅法,是最好的⽂本分类算法之⼀,在机器学习分类算法中占有相当⼤的地位,是最简单的机器学习算法之⼀。
外⽂名:k-Nearest Neighbor(简称kNN) 中⽂名:k最邻近分类算法 应⽤:⽂本分类、模式识别、图像及空间分类 典型:懒惰学习 训练时间开销:0 提出时间:1968年 作者:Cover和Hart提出 关键字:kNN算法、k近邻算法、机器学习、⽂本分类思想: 官⽅:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个"邻居"的信息来进⾏预测。
通俗点说:就是计算⼀个点与样本空间所有点之间的距离,取出与该点最近的k个点,然后统计这k个点⾥⾯所属分类⽐例最⼤的(“回归”⾥⾯使⽤平均法),则点A属于该分类。
k邻近法实际上利⽤训练数据集对特征向量空间进⾏划分,并作为其分类的“模型”。
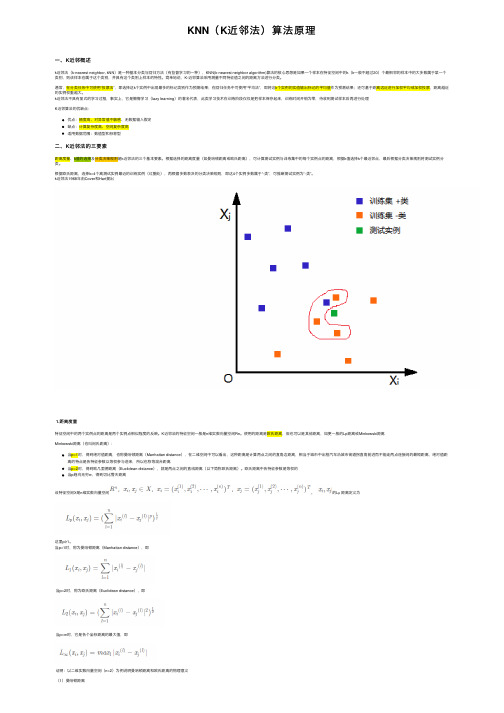
三个基本要素:k值的选择、距离度量、分类决策规则图例说明:上图中,绿⾊圆要被决定赋予哪个类,是红⾊三⾓形还是蓝⾊四⽅形?如果K=3,由于红⾊三⾓形所占⽐例为2/3,绿⾊圆将被赋予红⾊三⾓形那个类,如果K=5,由于蓝⾊四⽅形⽐例为3/5,因此绿⾊圆被赋予蓝⾊四⽅形类。
算法计算步骤 1、算距离:给定测试对象,计算它与训练集中的每个对象的距离; 2、找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻; 3、做分类:根据这k个近邻归属的主要类别,来对测试对象分类;距离的计算⽅式(相似性度量): 欧式距离: 曼哈顿距离:类别的判定: 投票法:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对邻近的投票进⾏加权,距离越近则权重越⼤(权重为距离平⽅的倒数)。
优点: 1、简单,易于理解,易于实现,⽆需估计参数,⽆需训练; 2、适合对稀有事件进⾏分类; 3、特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN⽐SVM的表现要好。
k近邻算法原理

k近邻算法原理
K近邻算法(K Nearest Neighbors, 简称KNN),是一种监督学习算法,其中,监督
学习意味着学习过程必须包含由特征(feature)对应的正确答案(label)。
KNN算法通
过对未标记的样本空间进行半有监督学习,识别出具有特定结构的分类边界,从而实现预
测分类。
KNN算法假设点之间的距离可以衡量样本之间的相似度,并将未知的目标实例与已知
的训练样本进行比较,而实际上,KNN算法会寻找与当前对象最为相近的K训练样本,通
过对K个最邻近样本进行投票(一般采用多数表决原则),来确定当前对象的类别。
KNN算法的基本思想是:如果一个样本在特征空间中的k个最相邻的样本中的大多数
属于某一个类别,则该样本也属于这个类别。
KNN算法的决策基于函数:
设有一个样本集合S={x1,x2,…,xi,…xn}, y为对应的未知类别,现设定一个实例P,计算 dij的距离[d(x i,P)], i=1,…,n。
将距离从小到大排序,按以下公式计算P的类别:
y = (1/K) {∑[ K(d (xi ,P))]}, i=1,…,K
其中 K(d (x,P))返回类别,可以采用众数法或者加权统计法。
KNN算法执行预测分类,它只会找到最近邻居,而不会对其他输入作出假设,这也就
是KNN算法的“惰性(lazy)”性质的来源。
KNN算法的优点在于具有较高的精度,而缺
点在于计算量较大,时间消耗较多,特征空间也需要较大。
KNN(k近邻)机器学习算法详解

KNN(k近邻)机器学习算法详解KNN算法详解一、算法概述1、kNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。
这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。
该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
2、代表论文Discriminant Adaptive Nearest Neighbor ClassificationTrevor Hastie and Rolbert Tibshirani3、行业应用客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)二、算法要点1、指导思想kNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
计算步骤如下:1)算距离:给定测试对象,计算它与训练集中的每个对象的距离?2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻?3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类2、距离或相似度的衡量什么是合适的距离衡量?距离越近应该意味着这两个点属于一个分类的可能性越大。
觉的距离衡量包括欧式距离、夹角余弦等。
对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适。
3、类别的判定投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)三、优缺点简单,易于理解,易于实现,无需估计参数,无需训练适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢可解释性较差,无法给出决策树那样的规则。
K最近邻算法

K最近邻算法K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
kNN方法在类别决策时,只与极少量的相邻样本有关。
由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
KNN算法的机器学习基础显示相似数据点通常如何彼此靠近存在的图像大多数情况下,相似的数据点彼此接近。
KNN算法就是基于这个假设以使算法有用。
KNN利用与我们童年时可能学过的一些数学相似的想法(有时称为距离、接近度或接近度),即计算图上点之间的距离。
例如,直线距离(也称为欧氏距离)是一个流行且熟悉的选择。
KNN通过查找查询和数据中所有示例之间的距离来工作,选择最接近查询的指定数字示例( K ),然后选择最常用的标签(在分类的情况下)或平均标签(在回归的情况下)。
在分类和回归的情况下,我们看到为我们的数据选择正确的K是通过尝试几个K并选择最有效的一个来完成的。
KNN算法的步骤1.加载数据2.将K初始化为你选择的邻居数量3.对于数据中的每个示例4.3.1 根据数据计算查询示例和当前示例之间的距离。
5.3.2 将示例的距离和索引添加到有序集合中6.按距离将距离和索引的有序集合从最小到最大(按升序)排序7.从已排序的集合中挑选前K个条目8.获取所选K个条目的标签9.如果回归,返回K个标签的平均值10.如果分类,返回K个标签的模式'为K选择正确的值为了选择适合你的数据的K,我们用不同的K值运行了几次KNN算法,并选择K来减少我们遇到的错误数量,同时保持算法在给定之前从未见过的数据时准确预测的能力。
机器学习:K-近邻算法(KNN)

机器学习:K-近邻算法(KNN)机器学习:K-近邻算法(KNN)⼀、KNN算法概述KNN作为⼀种有监督分类算法,是最简单的机器学习算法之⼀,顾名思义,其算法主体思想就是根据距离相近的邻居类别,来判定⾃⼰的所属类别。
算法的前提是需要有⼀个已被标记类别的训练数据集,具体的计算步骤分为⼀下三步:1、计算测试对象与训练集中所有对象的距离,可以是欧式距离、余弦距离等,⽐较常⽤的是较为简单的欧式距离;2、找出上步计算的距离中最近的K个对象,作为测试对象的邻居;3、找出K个对象中出现频率最⾼的对象,其所属的类别就是该测试对象所属的类别。
⼆、算法优缺点1、优点思想简单,易于理解,易于实现,⽆需估计参数,⽆需训练;适合对稀有事物进⾏分类;特别适合于多分类问题。
2、缺点懒惰算法,进⾏分类时计算量⼤,要扫描全部训练样本计算距离,内存开销⼤,评分慢;当样本不平衡时,如其中⼀个类别的样本较⼤,可能会导致对新样本计算近邻时,⼤容量样本占⼤多数,影响分类效果;可解释性较差,⽆法给出决策树那样的规则。
三、注意问题1、K值的设定K值设置过⼩会降低分类精度;若设置过⼤,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。
通常,K值的设定采⽤交叉检验的⽅式(以K=1为基准)经验规则:K⼀般低于训练样本数的平⽅根。
2、优化问题压缩训练样本;确定最终的类别时,不是简单的采⽤投票法,⽽是进⾏加权投票,距离越近权重越⾼。
四、python中scikit-learn对KNN算法的应⽤#KNN调⽤import numpy as npfrom sklearn import datasetsiris = datasets.load_iris()iris_X = iris.datairis_y = iris.targetnp.unique(iris_y)# Split iris data in train and test data# A random permutation, to split the data randomlynp.random.seed(0)# permutation随机⽣成⼀个范围内的序列indices = np.random.permutation(len(iris_X))# 通过随机序列将数据随机进⾏测试集和训练集的划分iris_X_train = iris_X[indices[:-10]]iris_y_train = iris_y[indices[:-10]]iris_X_test = iris_X[indices[-10:]]iris_y_test = iris_y[indices[-10:]]# Create and fit a nearest-neighbor classifierfrom sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier()knn.fit(iris_X_train, iris_y_train)KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=5, p=2,weights='uniform')knn.predict(iris_X_test)print iris_y_testKNeighborsClassifier⽅法中含有8个参数(以下前两个常⽤):n_neighbors : int, optional (default = 5):K的取值,默认的邻居数量是5;weights:确定近邻的权重,“uniform”权重⼀样,“distance”指权重为距离的倒数,默认情况下是权重相等。
k近邻算法的基本原理

k近邻算法的基本原理KNN算法(K-Nearest Neighbor,K近邻算法)是一种从已有数据中学习的基本分类与回归方法的死记硬背型,它的思想是:如果一个样本在特征空间中的k个最相似(即特征空年中Coolicoding数量最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法中,K通常是不大于20的整数。
KNN算法是基于实例的学习,它的思想很简单,即找到最临近的K个样例,来推断测试样例的分类或回归值。
KNN算法属于非参数方法,没有先验假设,其分类结果是基于训练集已知的类别标签。
KNN算法是一种懒惰学习,属于监督学习,当给定测试样例时,该算法不会建立分类模型,而是等到真正进行分类时才进行运算,KNN算法实际上是对训练集进行记忆,没有真正“学习”发生,即该算法属于懒惰学习,它不建立模型,而是用待分类的测试样例,穷举与它的距离最近的训练样例,以此来作出判断。
KNN算法的核心是计算样本之间的距离,这个距离的计算主要有欧氏距离、皮尔森距离、余弦距离等,其中以欧氏距离应用最多,计算两个样本之间的欧氏距离,需要对每个特征进行比较,然后对这些特征值进行平方和取平方根。
它表示两点在n维空间中的绝对距离,其公式为(xi,yi是两个样本点,p为维数):S=√∑(xi-yi)^2KNN算法将待测样本与训练集中的样本进行比较,计算距离值,然后选取距离最小的K个样本,这K个样本的类别投票为待分类样本的类别。
如果K=1,则它很简单,直接将K 个最近邻点的标签赋予待分类点即可;如果K>1 ,则只需统计K个最近邻点中出现次数最多的标签,并将其赋予待分类点即可。
另外,KNN还可以应用在回归问题中,例如:计算待分类点的回归值时,用待分类点的K个最近邻的加权和来计算,其中距离越近,贡献的值就越大。
总之,KNN算法是一种相对简单的机器学习算法,它不需要训练时的额外操作,算法的主要操作就是计算待分类样例与训练集中的样例之间的距离,按距离的顺序选取K个最邻近的样本点,然后以它们中个数最多的类别作为分类结果。
机器学习--K近邻(KNN)算法的原理及优缺点

机器学习--K近邻(KNN)算法的原理及优缺点⼀、KNN算法原理 K近邻法(k-nearst neighbors,KNN)是⼀种很基本的机器学习⽅法。
它的基本思想是:在训练集中数据和标签已知的情况下,输⼊测试数据,将测试数据的特征与训练集中对应的特征进⾏相互⽐较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
由于KNN⽅法主要靠周围有限的邻近的样本,⽽不是靠判别类域的⽅法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN⽅法较其他⽅法更为适合。
KNN算法不仅可以⽤于分类,还可以⽤于回归。
通过找出⼀个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有⽤的⽅法是将不同距离的邻居对该样本产⽣的影响给予不同的权值(weight),如权值与距离成反⽐。
KNN算法的描述: (1)计算测试数据与各个训练数据之间的距离; (2)按照距离的递增关系进⾏排序; (3)选取距离最⼩的K个点; (4)确定前K个点所在类别的出现频率 (5)返回前K个点中出现频率最⾼的类别作为测试数据的预测分类。
算法流程: (1)准备数据,对数据进⾏预处理。
(2)选⽤合适的数据结构存储训练数据和测试元组。
(3)设定参数,如k。
(4)维护⼀个⼤⼩为k的的按距离由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存⼊优先级队列。
(5)遍历训练元组集,计算当前训练元组与测试。
元组的距离,将所得距离L 与优先级队列中的最⼤距离Lmax。
(6)进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列。
(7)遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
KNN(K近邻法)算法原理
KNN(K近邻法)算法原理⼀、K近邻概述k近邻法(k-nearest neighbor, kNN)是⼀种基本分类与回归⽅法(有监督学习的⼀种),KNN(k-nearest neighbor algorithm)算法的核⼼思想是如果⼀个样本在特征空间中的k(k⼀般不超过20)个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
简单地说,K-近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类。
通常,在分类任务中可使⽤“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使⽤“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进⾏加权平均或加权投票,距离越近的实例权重越⼤。
k近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进⾏处理K近邻算法的优缺点:优点:精度⾼、对异常值不敏感、⽆数据输⼊假定缺点:计算复杂度⾼、空间复杂度⾼适⽤数据范围:数值型和标称型⼆、K近邻法的三要素距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
根据选择的距离度量(如曼哈顿距离或欧⽒距离),可计算测试实例与训练集中的每个实例点的距离,根据k值选择k个最近邻点,最后根据分类决策规则将测试实例分类。
根据欧⽒距离,选择k=4个离测试实例最近的训练实例(红圈处),再根据多数表决的分类决策规则,即这4个实例多数属于“-类”,可推断测试实例为“-类”。
k近邻法1968年由Cover和Hart提出1.距离度量特征空间中的两个实例点的距离是两个实例点相似程度的反映。
K近邻法的特征空间⼀般是n维实数向量空间Rn。
使⽤的距离是欧⽒距离,但也可以是其他距离,如更⼀般的Lp距离或Minkowski距离Minkowski距离(也叫闵⽒距离):当p=1时,得到绝对值距离,也称曼哈顿距离(Manhattan distance),在⼆维空间中可以看出,这种距离是计算两点之间的直⾓边距离,相当于城市中出租汽车沿城市街道拐直⾓前进⽽不能⾛两点连接间的最短距离,绝对值距离的特点是各特征参数以等权参与进来,所以也称等混合距离当p=2时,得到欧⼏⾥德距离(Euclidean distance),就是两点之间的直线距离(以下简称欧⽒距离)。
基于K近邻的分类算法研究

基于K近邻的分类算法研究沈阳航空航天大学Shenyang Aerospace University算法分析题目:基于K-近邻分类算法的研究院系计算机学院专业计算机技术姓名学号指导教师2015年 1 月摘要数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。
K 近邻算法(KNN)是基于统计的分类方法,是数据挖掘分类算法中比较常用的一种方法。
该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。
本文主要研究了K 近邻分类算法。
首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,其次指出了K 近邻算法的计算速度慢、分类准确度不高的原因,提出了两种新的改进方法。
针对K 近邻算法的计算量大的缺陷,构建了聚类算法与K 近邻算法相结合的一种方法。
将聚类中的K -均值和分类中的K 近邻算法有机结合。
有效地提高了分类算法的速度。
针对分类准确度的问题,提出了一种新的距离权重设定方法。
传统的KNN 算法一般采用欧式距离公式度量两样本间的距离。
由于在实际样本数据集合中每一个属性对样本的贡献作用是不尽相同的,通常采用加权欧式距离公式。
本文提出一种新的计算权重的方法。
实验表明,本文提出的算法有效地提高了分类准确度。
最后,在总结全文的基础上,指出了有待进一步研究的方向。
关键词:K 近邻,聚类算法,权重,复杂度,准确度ABSTRACTData mining is a widely field of machine learning, and it integrates the artificial intelligence technology and database technology. It helps people extract valuable knowledge from a large data intelligently and automatically to meet different people applications. KNN is a used method in data mining based on Statistic. The algorithm has become one of the ways in data mining theory and application because of intuitive, without priori statistical knowledge, and no study features.The main works of this thesis is k nearest neighbor classification algorithm. First, it introduces mainly classification algorithms of data mining and descripts theoretical base and application. This paper points out the reasons of slow and low accuracy and proposes two improved ways.In order to overcome the disadvantages of traditional KNN, this paper use two algorithms of classification and clustering to propose an improved KNN classification algorithm. Experiments show that this algorithm can speed up when it has a few effects in accuracy.According to the problem of classification accuracy, the paper proposes a new calculation of weight. KNN the traditional method generally used Continental distance formula measure the distance between the two samples. As the actual sample data collection in every attribute of a sample of the contribution is not the same, often using the weighted Continental distance formula. This paper presents a calculation of weight,that is weighted based on the characteristics of KNN algorithm. According tothis Experiments on artificial datasets show that this algorithm can improve the accuracy of classification.Last, the paper indicates the direction of research in future based on the full-text.Keywords: K Nearest Neighbor, Clustering Algorithm, Feature Weighted, Complex Degree, Classification Accuracy.前言K最近邻(k-Nearest neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
k近邻算法的原理和实现过程

k近邻算法的原理和实现过程
k近邻算法是一种基本的分类和回归算法,它的原理和实现过程如下:
原理:
1. 确定一个样本的k个最近的邻居,即选取与该样本距离最近的k个样本。
2. 根据这k个最近邻居的标签进行投票或者加权,确定该样本的预测标签。
如果
是分类问题,那么选取票数最多的标签作为预测标签;如果是回归问题,那么选
取k个最近邻居的标签的平均值作为预测标签。
实现过程:
1. 准备数据集:收集已知样本和其对应的标签。
2. 确定距离度量准则:选择合适的距离度量准则来度量样本间的距离,例如欧氏
距离、曼哈顿距离等。
3. 选择合适的k值:根据问题的要求选择适当的k值。
4. 计算样本之间的距离:对于每个未知样本,计算它与已知样本之间的距离,选
择k个最近邻居。
5. 统计k个最近邻居的标签:对于分类问题,统计k个最近邻居的标签的出现次数,并选择出现次数最多的标签作为预测标签;对于回归问题,计算k个最近邻
居的标签的平均数作为预测标签。
6. 将样本进行分类或预测:根据预测标签将未知样本进行分类或预测。
需要注意的是,在实际应用中,可以采取一些优化措施来提高k近邻算法的效率,比如使用kd树来加速最近邻搜索过程。
还可以对特征进行归一化处理,以避免
某些特征的权重过大对距离计算的影响。
k近邻分类法的步骤

k近邻分类法的步骤
4. 确定k值:选择一个合适的k值,表示在分类时考虑的最近邻样本的数量。k值的选择需 要根据具体问题和数据集进行调整。一般来说,较小的k值会使分类结果更敏感,而较大的k 值会使分类结果更平滑。
5. 选择最近邻:根据计算得到的距离,选择与未知样本最近的k个已知样本作为最近邻。
6. 进行投票:对于这k个最近邻样本,根据它们的类别标签进行投票。一般采用多数表决 的方式,将得票最多的类别作为未知样本的预测类别。
7. 输出结果:根据投票结果,将未知样本分类到预测的分类法是一种常用的机器学习算法,用于对未知样本进行分类。其步骤如下:
1. 数据准备:首先,需要准备一个已知类别的训练数据集,其中包含了已知样本的特征和 对应的类别标签。同时,还需要准备一个未知样本的测试数据集,用于进行分类预测。
2. 特征选择:根据问题的需求和数据的特点,选择合适的特征进行分类。特征应该具有区 分不同类别的能力,并且能够提供足够的信息用于分类。
K-近邻算法

K-近邻算法⼀、概述k-近邻算法(k-Nearest Neighbour algorithm),⼜称为KNN算法,是数据挖掘技术中原理最简单的算法。
KNN 的⼯作原理:给定⼀个已知标签类别的训练数据集,输⼊没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。
可以简单理解为:由那些离X最近的k个点来投票决定X归为哪⼀类。
图1 图1中有红⾊三⾓和蓝⾊⽅块两种类别,我们现在需要判断绿⾊圆点属于哪种类别当k=3时,绿⾊圆点属于红⾊三⾓这种类别;当k=5时,绿⾊圆点属于蓝⾊⽅块这种类别。
举个简单的例⼦,可以⽤k-近邻算法分类⼀个电影是爱情⽚还是动作⽚。
(打⽃镜头和接吻镜头数量为虚构)电影名称打⽃镜头接吻镜头电影类型⽆问西东1101爱情⽚后来的我们589爱情⽚前任31297爱情⽚红海⾏动1085动作⽚唐⼈街探案1129动作⽚战狼21158动作⽚新电影2467?表1 每部电影的打⽃镜头数、接吻镜头数和电影分类表1就是我们已有的数据集合,也就是训练样本集。
这个数据集有两个特征——打⽃镜头数和接吻镜头数。
除此之外,我们也知道每部电影的所属类型,即分类标签。
粗略看来,接吻镜头多的就是爱情⽚,打⽃镜头多的就是动作⽚。
以我们多年的经验来看,这个分类还算合理。
如果现在给我⼀部新的电影,告诉我电影中的打⽃镜头和接吻镜头分别是多少,那么我可以根据你给出的信息进⾏判断,这部电影是属于爱情⽚还是动作⽚。
⽽k-近邻算法也可以像我们⼈⼀样做到这⼀点。
但是,这仅仅是两个特征,如果把特征扩⼤到N个呢?我们⼈类还能凭经验“⼀眼看出”电影的所属类别吗?想想就知道这是⼀个⾮常困难的事情,但算法可以,这就是算法的魅⼒所在。
我们已经知道k-近邻算法的⼯作原理,根据特征⽐较,然后提取样本集中特征最相似数据(最近邻)的分类标签。
那么如何进⾏⽐较呢?⽐如表1中新出的电影,我们该如何判断他所属的电影类别呢?如图2所⽰。
KNN算法原理与应用

12
KNN算法的sklearn实现
sklearn.neighbors模块集成了 k-近邻相关的类,KNeighborsClassifier用做kNN分类
树,KNeighborsRegressor用做kNN回归树。KNeighborsClassifier类的实现原型如下:
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',
testData = [0.2, 0.1]
Result = classify(testData, group, labels, 3)
print(Result)
5
KNN算法基本原理
6
• 运行效果:
•
左下角两个点属于B类用蓝色点标识,右上角
两个点属于A类用红色标识。取k值为3时通过
kNN算法计算,距离测试点(0.2, 0.1)最近的
algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1,
**kwargs)
13
KNN算法的sklearn实现
主要参数如下:
•
•
n_neighbors:整型,默认参数值为5。邻居数k值。
量的kNN搜索。
,适合于样本数量远大于特征数
KNN算法基本原理:距离计算
7
在KNN算法中,如何计算样本间距离非常重要,下面我们介绍几种常见的
距离计算方法。
闵可夫斯基距离
闵可夫斯基距离(Minkowski Distance)是一种常见的方法,用于衡量数值点之间距离。
kneighborsclassifier 算法介绍

k-nearest neighbors(k-近邻)是一种简单而有效的监督式学习算法。
该算法在分类和回归问题上都有广泛的应用,并且易于理解和实现。
k-nearest neighbors算法的核心思想是基于输入样本的特征,来预测新样本的分类标签或者数值输出。
k-nearest neighbors算法的原理如下:1. 数据集准备:将训练数据集中的样本按照特征进行标记,这些特征用来决定样本的类别或者数值。
另外,还需要准备测试数据集,用于模型的验证和评估。
2. 计算距离:在预测过程中,计算测试样本与训练样本之间的距离。
通常使用的距离度量包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
3. 选择k值:选择一个合适的k值,该值表示在预测时将考虑最接近的k个训练样本。
选择合适的k值对算法的性能有着重要影响。
4. 预测:根据测试样本与训练样本的距离,选择最接近的k个训练样本,根据这k个训练样本的标签或数值进行预测。
通常采用投票法(对分类问题)或者平均法(对回归问题)来确定最终的预测结果。
k-nearest neighbors算法的优缺点如下:优点:1. 简单、直观:算法实现简单,易于理解和解释。
2. 适用于多类别问题:对于多分类问题,k-nearest neighbors算法表现良好。
3. 适用于非线性数据:对于非线性数据集,k-nearest neighbors算法也能够取得不错的预测效果。
缺点:1. 计算复杂度高:在大型数据集中,由于需要计算相互之间的距离,算法的计算开销比较大。
2. 对异常值敏感:k-nearest neighbors算法对异常值比较敏感,因此在使用该算法时需要注意异常值的处理。
3. 需要合适的k值:k值的选择对算法的性能有着重要的影响,选择不当会导致预测效果下降。
在使用k-nearest neighbors算法时,需要注意以下几点:1. 数据预处理:在应用k-nearest neighbors算法之前,需要对数据进行一定的预处理。
近邻分类算法、

近邻分类算法、近邻分类算法(K-Nearest Neighbor,简称KNN)是机器学习领域中最常用的分类算法之一,其基本原理是通过计算样本之间的距离,并找出距离目标最近的前K个训练样本,根据这些样本的类别来预测目标样本的类别。
KNN算法简单易用,无需建立模型,具有较高的准确率和可解释性,广泛应用于模式识别、数据挖掘、推荐系统等领域中。
1. 训练阶段时间复杂度低,预测阶段时间复杂度高,但模型存储开销小。
2. 需要对距离度量进行合适的选择和优化,常见的距离度量有欧式距离、曼哈顿距离、余弦相似度等。
3. K值的选择对模型性能影响较大,通常通过交叉验证等方法确定。
KNN算法的基本流程如下:1. 计算目标样本与训练样本之间的距离。
2. 选择距离最近的前K个训练样本。
3. 根据这些样本的类别,预测目标样本的类别。
1. 优点:简单易用、无需建立模型、准确率高、可解释性强。
2. 缺点:计算复杂度高、对离群点敏感、需要对距离度量进行优化、对样本分布敏感。
KNN算法在中文文本分类中的应用:中文文本分类是自然语言处理中的一个重要任务,其目标是将中文文本分成不同的类别。
KNN算法可以通过计算文本之间的距离,并根据文本相似性来进行分类。
在中文文本分类中,常见的距离度量方法有余弦相似度、欧式距离和Jaccard距离等。
KNN算法能够处理高维稀疏特征空间中的文本分类问题,并且能够适应不同类别之间的边界,因此在中文文本分类中应用广泛。
总结:1. 分词:中文文本需要进行分词处理,将文本转换为词汇序列进行处理,通常采用词袋模型表示文本特征。
2. 特征提取:选择合适的特征对文本分类的准确性具有重要影响,通常采用TF-IDF 等方法进行特征提取。
3. 词向量化:将文本转换为对应的词向量,通过计算这些词向量之间的距离进行文本分类。
4. 参数优化:KNN算法的参数K值需要进行优化,通常采用交叉验证等方法进行确定。
5. 大规模文本分类:针对大规模中文文本分类问题,可以采用局部敏感哈希(LSH)等方法进行优化,提高算法效率。
最近邻法分类

最近邻法分类最近邻法(K-Nearest Neighbors)是一种常用的分类算法,也是最简单的机器学习算法之一。
该方法的基本思想是,对于一个未知样本点,通过计算其与训练集中的样本点的距离,并找到距离最近的K个样本点,根据这K个样本点的类别,对该样本点进行分类。
最近邻法的分类过程可以简述如下:1. 准备训练集:收集已知类别的样本数据,并将这些数据划分为训练集和测试集。
2. 计算距离:对于每一个测试样本点,计算它与所有训练样本点之间的距离,常用的距离度量包括欧氏距离、曼哈顿距离等。
3. 选择K值:确定K值,即选择距离最近的K个训练样本点。
4. 进行投票:对于选定的K个样本点,根据它们的类别进行投票,将投票结果作为该测试样本点的预测类别。
最近邻法的优点包括简单易懂、容易实现、无需模型训练等,同时还能适应复杂的决策边界。
然而,最近邻法也存在一些缺点,例如需要大量的计算、对样本数量敏感、样本不平衡时容易出现偏差等。
在应用最近邻法进行分类时,需要根据具体情况选择合适的参数和技巧。
以下是一些常用的技巧和改进措施:1. 归一化:对于具有不同尺度的特征值,可以将其进行归一化处理,例如将特征值缩放到[0, 1]范围内,以避免某些特征对分类结果的影响过大。
2. 权重调整:对于不同的样本点,可以根据其距离远近赋予不同的权重,距离越近的样本,对最终结果的影响权重越大,距离越远的样本,权重越小。
3. 特征选择:对于特征维度较高的数据集,可以采用特征选择的方法,选择对分类结果影响较大的特征,提高分类的准确性和效率。
4. 交叉验证:可以使用交叉验证来评估最近邻法的性能,通过对训练集进行划分得到多个子集,交替使用这些子集进行训练和测试,以综合评价算法的性能。
最近邻法在实际应用中有着广泛的应用,尤其在模式识别、图像处理、文本分类等领域具有较好的效果。
但也需要注意其对数据量敏感,对于大规模的数据集,最近邻法的计算开销会变得较大,因此在实际应用中可以结合其他算法或者采用一些优化策略来提高算法的效率。
机器学习-分类算法之k-近邻

机器学习-分类算法之k-近邻分类算法之k-近邻k-近邻算法采⽤测量不同特征值之间的距离来进⾏分类优点:精度⾼、对异常值不敏感、⽆数据输⼊假定缺点:计算复杂度⾼、空间复杂度⾼使⽤数据范围:数值型和标称型⼀个例⼦弄懂k-近邻电影可以按照题材分类,每个题材⼜是如何定义的呢?那么假如两种类型的电影,动作⽚和爱情⽚。
动作⽚有哪些公共的特征?那么爱情⽚⼜存在哪些明显的差别呢?我们发现动作⽚中打⽃镜头的次数较多,⽽爱情⽚中接吻镜头相对更多。
当然动作⽚中也有⼀些接吻镜头,爱情⽚中也会有⼀些打⽃镜头。
所以不能单纯通过是否存在打⽃镜头或者接吻镜头来判断影⽚的类别。
那么现在我们有6部影⽚已经明确了类别,也有打⽃镜头和接吻镜头的次数,还有⼀部电影类型未知。
电影名称打⽃镜头接吻镜头电影类型California Man3104爱情⽚He's not Really into dues2100爱情⽚Beautiful Woman181爱情⽚Kevin Longblade10110动作⽚Robo Slayer 3000995动作⽚Amped II982动作⽚1890未知那么我们使⽤K-近邻算法来分类爱情⽚和动作⽚:存在⼀个样本数据集合,也叫训练样本集,样本个数M个,知道每⼀个数据特征与类别对应关系,然后存在未知类型数据集合1个,那么我们要选择⼀个测试样本数据中与训练样本中M个的距离,排序过后选出最近的K个,这个取值⼀般不⼤于20个。
选择K个最相近数据中次数最多的分类。
那么我们根据这个原则去判断未知电影的分类电影名称与未知电影的距离California Man20.5He's not Really into dues18.7Beautiful Woman19.2Kevin Longblade115.3Robo Slayer 3000117.4Amped II118.9我们假设K为3,那么排名前三个电影的类型都是爱情⽚,所以我们判定这个未知电影也是⼀个爱情⽚。
k近邻分类算法

第2章k-近邻算法(kNN)引言本章介绍kNN算法的基本理论以及如何使用距离测量的方法分类物品。
其次,将使用python从文本文件中导入并解析数据,然后,当存在许多数据来源时,如何避免计算距离时可能碰到的一些常见的错识。
2.1 k-近邻算法概述k-近邻(k Nearest Neighbors)算法采用测量不同特征之间的距离方法进行分类。
它的工作原理是:存在一个样本数据集合,并且样本集中每个数据都存在标签,即我们知道样本每一数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的分类标签。
一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法的优点是精度高,对异常值不敏感,无数据输入假定;缺点是计算复杂度高、空间复杂度高。
适用于数值和离散型数据。
2.1.1 准备知识:使用python导入数据首先,创建名为kNN.py的python模块,然后添加下面代码:from numpy import * #引入科学计算包import operator #经典python函数库。
运算符模块。
#创建数据集def createDataSet():group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels=['A','A','B','B']return group,labels测试:>>> import kNN>>> group,labels=kNN.createDataSet()注意:要将kNN.py文件放到Python27文件夹下,否则提示找不到文件。
2.2.2 实施kNN算法使用k-近邻算法将每组数据划分到某个类中,其伪代码如下:对未知类别属性的数据集中的每个点依次执行以下操作:1.计算已知类别数据集中的点与当前点之间的距离;2.按照距离递增交序排序;3.选取与当前点距离最小的k个点;4.确定前k个点所在类别的出现频率;5.返回前k个点出现频率最高的类别作为当前点的预测分类。
k最近邻算法

k最近邻算法
k最近邻算法:
K最近邻(k-NearestNeighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第2章k-近邻算法(kNN)引言本章介绍kNN算法的基本理论以及如何使用距离测量的方法分类物品。
其次,将使用python从文本文件中导入并解析数据,然后,当存在许多数据来源时,如何避免计算距离时可能碰到的一些常见的错识。
2.1 k-近邻算法概述k-近邻(k Nearest Neighbors)算法采用测量不同特征之间的距离方法进行分类。
它的工作原理是:存在一个样本数据集合,并且样本集中每个数据都存在标签,即我们知道样本每一数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的分类标签。
一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法的优点是精度高,对异常值不敏感,无数据输入假定;缺点是计算复杂度高、空间复杂度高。
适用于数值和离散型数据。
2.1.1 准备知识:使用python导入数据首先,创建名为kNN.py的python模块,然后添加下面代码:from numpy import * #引入科学计算包import operator #经典python函数库。
运算符模块。
#创建数据集def createDataSet():group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels=['A','A','B','B']return group,labels测试:>>> import kNN>>> group,labels=kNN.createDataSet()注意:要将kNN.py文件放到Python27文件夹下,否则提示找不到文件。
2.2.2 实施kNN算法使用k-近邻算法将每组数据划分到某个类中,其伪代码如下:对未知类别属性的数据集中的每个点依次执行以下操作:1.计算已知类别数据集中的点与当前点之间的距离;2.按照距离递增交序排序;3.选取与当前点距离最小的k个点;4.确定前k个点所在类别的出现频率;5.返回前k个点出现频率最高的类别作为当前点的预测分类。
用欧氏距离公式,计算两个向量点xA和xB之间的距离:例如,点(0, 0)与(1, 2)之间的距离计算为:python函数classify()程序如下所示:#算法核心#inX:用于分类的输入向量。
即将对其进行分类。
#dataSet:训练样本集#labels:标签向量def classfy0(inX,dataSet,labels,k):#距离计算#得到数组的行数。
即知道有几个训练数据dataSetSize =dataSet.shape[0]#用欧氏距离公式计算距离diffMat =tile(inX,(dataSetSize,1))-dataSet #将inX扩展为4行2列的向量,两个矩阵相减sqDiffMat =diffMat**2 #平方sqDistances =sqDiffMat.sum(axis=1) #asis=1是按行相加distances =sqDistances**0.5 #开方sortedDistIndicies=distances.argsort() #升序排列#选择距离最小的k个点。
classCount={}for i in range(k):voteIlabel=labels[sortedDistIndicies[i]]classCount[voteIlabel]=classCount.get(voteIlabel,0)+1#排序,降序sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),revers e=True)return sortedClassCount[0][0]测试:>>>kNN .classify0([0,0],group, labels,3)2.2示例:使用k-近邻算法改进约会网站的配对结果在约会网站上使用k-近邻算法的步骤:1.收集数据:提供文本文件。
2.准备数据:使用python解析文本文件。
3.分析数据:使用Matplotlib画二维扩散图。
4.训练算法:此步骤不适用于k-近邻算法。
5.测试算法:使用部分数据作为测试样本。
测试样本与非测试样本的区别在于:测试样本是已经完成分类的数据,如果预没分类与实际类别不同,则标记为一个error.6.使用算法:产生简单的命令行程序,然后可以输入一些特征数据以判断对方是否为自己喜欢的类型。
2.2.1准备数据:从文本文件中解析数据将数据存放到文本文件,每一个样本数据占据一行。
首先,必须将特处理数据改变为分类器可以接受的格式。
在kNN.py中创建file2matrix的函数,以此来处理输入格式问题。
将文本记录转换为NumPy的解析程序如下所示:def file2matrix(filename):# 打开训练集文件fr = open(filename)# 获取文件行数,即训练集的样本个数numberOfLines = len(fr.readlines())# 初始化特征矩阵returnMat = zeros((numberOfLines,3))# 初始化标签向量classLabelVector = []# 特征矩阵的行号也即样本序号index = 0# 遍历训练集文件中的所有行for line in fr.readlines():# 去掉行头行尾的换行符,制表符。
line = line.strip()# 以制表符分割行listFromLine = line.split('\t')# 将该行特征部分数据存入特征矩阵returnMat[index,:] = listFromLine[0:3]# 将该行标签部分数据存入标签矩阵classLabelVector.append(int(listFromLine[-1]))# 样本序号+1index += 1#返回训练样本矩阵和类标签向量。
return returnMat,classLabelVector测试:>>>reload(kNN)>>>datingDataMat,datingLabels=kNN.file2matrix('datingTestSe t2.txt')注意:文件中不要包含字符串,否则运行会出错。
2.2.2分析数据:使用Matplotlib创建散点图首先我们使用Matplotlib制作原始数据的散点图.如下程序所示:import matplotlibimport matplotlib.pyplot as plt# 新建一个图对象fig = plt.figure()# 设置1行1列个图区域,并选择其中的第1个区域展示数据。
ax = fig.add_subplot(111)# 以训练集第一列(玩网游所消耗的时间比)为数据分析图的行,第二列(每年消费的冰淇淋公升数)为数据分析图的列。
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*numpy.array(datingLabels), 15.0*numpy.array(datingLabels))# 坐标轴定界ax.axis([-2,25,-0.2,2.0])# 坐标轴说明(matplotlib配置中文显示有点麻烦这里直接用英文的好了)plt.xlabel('Percentage of Time Spent Playing Online Games')1plt.ylabel('Liters of Ice Cream Consumed Per Week')# 展示数据分析图plt.show()2.2.3 准备数据:归一化数值我们分析的这三个特征,在距离计算公式中所占的权重是不同的:飞机历程肯定要比吃冰淇淋的公升数大多了。
因此,需要将它们转为同样的一个数量区间,再进行距离计算。
--- 这个步骤就叫做数据归一化。
可以使用如下公式对数据进行归一化:newValue = (oldValue - min) / (max - min)即用旧的特征值去减它取到的最小的值,然后再除以它的取值范围。
很显然,所有得到的新值取值均在0 -1 。
这部分代码如下:def autoNorm(dataSet):# 获得每列最小值minVals = dataSet.min(0)# 获得每列最大值maxVals = dataSet.max(0)# 获得每列特征的取值范围ranges = maxVals - minVals# 构建初始矩阵(模型同dataSet)normDataSet = numpy.zeros(numpy.shape(dataSet))# 数据归一化矩阵运算m = dataSet.shape[0]normDataSet = dataSet - numpy.tile(minVals, (m,1))# 注意/是特征值相除法。
/在别的函数库也许是矩阵除法的意思。
normDataSet = normDataSet/numpy.tile(ranges, (m,1))return normDataSet第四步:测试算法测试的策略是随机取10%的数据进行分析,再判断分类准确率如何。
第五步:使用算法构建完整可用系统运行结果:至此,该系统编写完毕。
2.3 示例:手写识别系统编程实现,大概分为三个步骤:(1)将每个图片(即txt文本,以下提到图片都指txt文本)转化为一个向量,即32*32的向量转化为1*1024的特征向量。
(2)训练样本中有10*10个图片,可以合并成一个100*1024的矩阵,每一行对应一个图片。
(这是为了方便计算,很多机器学习算法在计算的时候采用矩阵运算,可以简化代码,有时还可以减少计算复杂度)。
(3)测试样本中有10*5个图片,我们要让程序自动判断每个图片所表示的数字。
同样的,对于测试图片,将其转化为1*1024的向量,然后计算它与训练样本中各个图片的“距离”(这里两个向量的距离采用欧式距离),然后对距离排序,选出较小的前k个,因为这k个样本来自训练集,是已知其代表的数字的,所以被测试图片所代表的数字就可以确定为这k个中出现次数最多的那个数字。
除了书上的代码以外自己需要加的图像处理部分:#将图像转换成0和1的像素点def compress(img, h1, h2, w1, w2):for h in range(h1, h2):for w in range(w1, w2):pixel = img.getpixel((w,h))if pixel[0] == 0:return1return0#将数字以像素点32*32的向量的形式取出来def getRange(img):imgSize = img.sizehMax = 0hMin = imgSize[1]wMax = 0wMin = imgSize[0]for h in range(imgSize[1]):for w in range(imgSize[0]):if img.getpixel((w, h))[0] == 0:if w > wMax:wMax = wif w < wMin:wMin = wif h > hMax:hMax = hif h < hMin:hMin = hwRange = wMax - wMinhRange = hMax - hMinwMin = wMin - wRange/6wMax = wMax + wRange/6hMin = hMin - hRange/6hMax = hMax + hRange/6if wMin < 0:wMin = 0if wMax > imgSize[0]:wMax = imgSize[0]if hMin < 0:hMin = 0if hMax > imgSize[1]:hMax = imgSize[1]return (hMin, hMax, wMin, wMax)#将像素点转化成图像的形式存储def image2File(imagePath, filePath):img = Image.open(imagePath, 'r')(hMin, hMax, wMin, wMax) = getRange(img)wArray = linspace(wMin, wMax, 33)hArray = linspace(hMin, hMax, 33)wList = [int(x) for x in wArray]hList = [int(x) for x in hArray]fw = open(filePath,'w')for h in range(32):for w in range(32):number = compress(img, hList[h], hList[h+1]+1, wList[w], wList[w+1]+1)fw.write(str(number))fw.write('\n')fw.close()运行结果:2.4小结k-近邻算法是分类数据最简单最有效的算法,本章通过两个例子讲述了如何使用k-近邻算法构造分类器。