归档日志异常增长处理方法
归档日志空间满

归档⽇志空间满和 ORA-03113 解决今天有⼀个⽤户因为归档⽇志空间满,造成数据库宕机。
在alert⾥⾯会看到类似下⾯的内容:1. ORA-19815: 警告: db_recovery_file_dest_size 字节 (共 4294967296 字节) 已使⽤ 100.00%, 尚有 0 字节可⽤。
2. ************************************************************************3. You have following choices to free up space from recovery area:4. Consider changing RMAN RETENTION POLICY. If you are using Data Guard,5. then consider changing RMAN ARCHIVELOG DELETION POLICY.6. Back up files to tertiary device such as tape using RMAN7. BACKUP RECOVERY AREA command.8. Add disk space and increase db_recovery_file_dest_size parameter to9. reflect the new space.10. Delete unnecessary files using RMAN DELETE command. If an operating11. system command was used to delete files, then use RMAN CROSSCHECK and12. DELETE EXPIRED commands这时,如果只是把快速恢复区的归档⽇志删除,启动数据库会报错ORA-03113⽅法之⼀,按照上⾯第8条的提⽰,增加db_recovery_file_dest_size需要把数据库启动到mount状态sql>startup mountsql>system set db_recovery_file_dest_size=8192m题外话:出现这个问题的原因是开启归档⽇志,⽽快速恢复区(Flash Recovery Area)默认安装的时候⼀般只有4096M,所以很容易就满,按照Oracle的建议,⼀般这个区域的⼤⼩是数据库⽂件⼤⼩总和的两倍,所以建议⼤⼩都设置⼤⼀些。
ORACLE数据库归档日志满后造成系统宕机的处理方法

第一次宕机时,初始以为是系统内存溢出,于是重启应用服务器,发现应用服务器在启动时报错,错误为无法连接到数据库。
于是连接数据库服务器,打开EM后发现系统报错如图:提示归档日志写入失败,检查服务器发现磁盘空间满了,于是清理磁盘空间后,重启数据库问题解决。
随后把服务器磁盘空间扩容,直接给了oracle数据所在盘1TB的磁盘空间。
第二次又出现此问题,经过仔细检查,并与同事确认后,发现是由于ORACLE数据库的归档日志被启用了,而我们系统默认是没有启用ORACLE数据库归档日志这个功能的。
使用sql命令查看:Sql>sqlplus / as nolog;---------------------启动sql*PlusSql> connect sys/password@orcl as sysdba;Sql> archive log list;数据库日志模式存档模式自动存档启用存档终点USE_DB_RECOVERY_FILE_DEST最早的联机日志序列4888下一个存档日志序列4890当前日志序列4890Sql> show parameter db_recovery_file_dest;NAME TYPE VALUE------------------------------------ ----------- ------------------------------db_recovery_file_dest string D:\oracle\product\10.2.0/flash_recovery_area db_recovery_file_dest_size big integer 20G发现默认的归档路径为D:\oracle\product\10.2.0/flash_recovery_area。
而且限制使用空间为20G。
由于每天产生的oracle归档日志差不多就占用2个G的磁盘空间,而且oracle自身并不会自动清理也没有相关设置自动清理归档日志的功能,一段时间不进行清理,20G空间很快就满了。
归档日志满、硬盘满、表空间满的空间不够处理方法

归档日志满、硬盘满、表空间满的空间不够处理方法一、归档日志满,清理归档日志方法 (2)二、硬盘存储空间充足,但数据库表空间不足的扩容方法 (3)三、硬盘存储空间不足,对硬盘进行扩容或增加 (4)四、暂不能增加磁盘,但磁盘已满的处理方法 (6)一、归档日志满,清理归档日志方法archive log 日志已满ORA-00257: archiver error. Connect internal only, until freed 错误的处理方法1. 用sys用户登录sqlplus sys/pass@tt as sysdba2. 看看archiv log所在位置SQL> show parameter log_archive_dest;NAME TY PE VALUE------------------------------------ ----------- ------------------------------ log_archive_dest stringlog_archive_dest_1 stringlog_archive_dest_10 string3. 一般VALUE为空时,可以用archive log list;检查一下归档目录和log sequence SQL> archive log list;Database log mode Archive ModeAutomatic archival EnabledArchive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 360Next log sequence to archive 360Current log sequence 3624. 检查flash recovery area的使用情况,可以看见archivelog已经很大了,达到96.62 SQL> select * from V$FLASH_RECOVERY_AREA_USAGE;FILE_TYPE PERCENT_SPACE_USEDPERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES------------ ------------------ ------------------------- --------------- CONTROLFILE .13 0 1ONLINELOG 2.93 0 3ARCHIVELOG 96.62 0 1415. 计算flash recovery area已经占用的空间SQL> select sum(percent_space_used)*3/100 from v$flash_recovery_area_usage;SUM(PERCENT_SPACE_USED)*3/100-----------------------------2.99046. 找到recovery目录, show parameter recoverSQL> show parameter recover;NAME TYPE VALUE--------------------------- ----------- ------------------------------db_recovery_file_dest string /u01/app/oracle/flash_recovery_areadb_recovery_file_dest_size big integer 5Grecovery_parallelism integer 07 上述结果告诉我们,归档位置用的是默认值,放在flash_recovery_area下(db_recovery_file_dest目录=/u01/app/oracle/flash_recovery_area)[*************.0]#echo$ORACLE_BASE/u01/app/oracle [root@sha3 10.2.0]# cd $ORACLE_BASE/flash_recovery_area/tt/archivelog转移或清除对应的归档日志, 删除一些不用的日期目录的文件,注意保留最后几个文件(比如360以后的)8. 登陆rman准备删除归档日志,rman target sys/pass[root@sha3 oracle]# rman target sys/pass9. 检查一些无用的archivelogRMAN> crosscheck archivelog all;10. 删除过期的归档RMAN> delete expired archivelog all;删除7天前的归档:DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7';删除全部归档(noprompt不交互):DELETE noprompt ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-0';删除从7天前到现在的全部日志:DELETE ARCHIVELOG FROM TIME 'SYSDATE-7';11. 再次查询,发现使用率正常,已经降到23.03SQL> select * from V$FLASH_RECOVERY_AREA7_USAGE;FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES 二、硬盘存储空间充足,但数据库表空间不足的扩容方法表空间使用情况查询:SELECT a.tablespace_name "表空间名",total/1024/1024/1024 || 'G' 表空间大小,free/1024/1024/1024 || 'G' 表空间剩余大小,(total - free)/1024/1024/1024 || 'G' 表空间使用大小,ROUND((total - free) / total, 4) * 100 "使用率 %"FROM (SELECT tablespace_name, SUM(bytes) freeFROM DBA_FREE_SPACEGROUP BY tablespace_name) a,(SELECT tablespace_name, SUM(bytes) totalFROM DBA_DATA_FILESGROUP BY tablespace_name) bWHERE a.tablespace_name = b.tablespace_name扩容语句,执行如下SQL:alter tablespace MSSCPMIS add datafile '/u02/app/oradata/orcl/msscpmis02.dbf' size 5720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS12.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS13.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS14.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS15.dbf' size 30720M 备注:也可以放在不同的硬盘上附录数据文件最大值上限跟数据块大小相关,数据块大小的默认值一般都是8KB。
数据库日志增长解决方法

数据库⽇志增长解决⽅法
数据库⽇志增长过快解决⽅法:
1: 删除LOG
1:分离数据库企业管理器->服务器->数据库->右键->分离数据库
2:删除LOG⽂件
3:附加数据库企业管理器->服务器->数据库->右键->附加数据库
此法⽣成新的LOG,⼤⼩只有500多K
再将此数据库设置⾃动收缩
或⽤代码:
下⾯的⽰例分离 pubs,然后将 pubs 中的⼀个⽂件附加到当前服务器。
EXEC sp_detach_db @dbname = 'pubs '
EXEC sp_attach_single_file_db @dbname = 'pubs ',
@physname = 'c:\Program Files\Microsoft SQL Server\MSSQL\Data\pubs.mdf '
2:清空⽇志
DUMP TRANSACTION 库名 WITH NO_LOG
再:
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩⽂件--选择⽇志⽂件--在收缩⽅式⾥选择收缩⾄XXM,这⾥会给出⼀个允许收缩到的最⼩M数,直接输⼊这个数,确定就可以了
3: 果想以后不让它增长
企业管理器->服务器->数据库->属性->事务⽇志->将⽂件增长限制为2M
1、设置数据库为简单模式
--> 数据库的属性
--> “选项”页
--> “模型”选为“简单”
2、截断⽇志,收缩数据库
backup log 数据库名 with no_log
go
dbcc shrinkdatabase(数据库名)
go。
归档日志异常增长处理方法
案例描述:近日湖北运维反应湖北数据库归档日志生成过快,导致磁盘空间占满,引起数据库宕机。
问题看起来很简单,只要清理下归档日志然后重启就能解决,但这只是治标不治本的方法,显然是要找到归档日志增长异常频繁的原因。
最后通过LogMiner分析归档日志发现是运维部署了频繁update的语句,停了后归档日志变为正常.下面是详细步骤1.通过v$archived_log视图查看最近归档日志状态select to_char(COMPLETION_TIME,’yyyymmdd'), count(*)from v$archived_log twhere t。
COMPLETION_TIME 〉sysdate — 20group by to_char(COMPLETION_TIME,’yyyymmdd')order by to_char(COMPLETION_TIME, ’yyyymmdd');2.查看今天的归档日志情况,看到8点左右归档日志增长最大select to_char(FIRST_TIME,'yyyymmddhh24'), count(*)from sys。
v_$archived_log twhere t。
FIRST_TIME 〉 trunc(sysdate)group by to_char(FIRST_TIME,’yyyymmddhh24')order by to_char(FIRST_TIME,'yyyymmddhh24’)3.查看今天八点的归档日志的路径select name, COMPLETION_TIME, t.FIRST_TIME, t.RESETLOGS_TIME from sys.v_$archived_log twhere to_char(FIRST_TIME,’yyyymmddhh24') = 2015081108order by t.FIRST_TIME desc;4.打开toad,连接数据库,打开日志分析工具logminer(database→diagnose→logminer)5.点击next6.把第三步得到的归档日志的路径输入file to mine7。
归档日志满的解决办法

归档日志满的解决办法
1、适当增大日志目录大小:在文件系统范围内扩容,增加虚拟内存空间;
2、定期删除过期存档:删除归档了一段时间的日志文件。
很多时候,由于不知道日志文件的实际用处,往往采用保守策略,定期删除较早的,周期性的删除;
3、采用刷新覆盖的方式:日志文件非常庞大时可以采用这种方式;
4、采用日志归档工具:比如ELK(Elasticsearch、Logstash、Kibana)等日志归档工具,也可以方便,快捷的实现日志收集整理上报;
5、采用云服务进行日志管理:在云环境上直接安装日志管理工具,可以免去很多日志文件定期清理等负担,让日志收集、整理和分析更加高效便捷。
归档日志增长过快处理解决

处理归档日志增加过快一例(2010-08-25 20:03:47)转载▼标签:分类:原创文章oracle归档日志增加过快处理归档日志增加过快一例摘要本文介绍了不久前作者是如何彻底解决一家医院数据库由于归档日志增长过快,导致磁盘剩余空间占满,引起宕机全过程。
通过本案例的描述,我们可以了解到当遇到数据库宕机问题时,应该如何分析现象、找到问题关键、最终彻底解决该问题的一个总体思路,最后还应该深入思考该问题产生的原因,总结出避免以后再出现该问题的建议。
关键字: ORACLE、归档日志、宕机、DML语句初步了解早上一来到公司,XZH就告诉我接到CQ公司的有一个技术申请,大致情况为一家三甲医院,采用Rac+Linux环境,启用了归档模式,但是由于日志增长过快,我们的技术人员设虽然置自动删除归档的任务,但是还是没有避免磁盘空间被占满,已经引起医院2次全院无法使用,虽然CQ公司也安排多名技术人员去现场处理,但是医院认为一直没有解决彻底,因此信息主管对此意见较大,希望公司安排技术支持部现场彻底解决该问题。
通过申请描述,我大致了解到以下几个关键点:1.医院启用了归档,也做了定期自动删除归档日志的任务。
2.由于归档日志增加过快,已经导致医院2号节点宕机。
3.我们的技术人员去了几次,都未彻底解决,用户已经意见很大了。
这只是个初步情况,往往只能了解问题的大概,具体的问题产生的原因还是得到用户那里去才能真正了解,于是立即出发,前往用户处处理问题。
现场分析问题到达医院,同系统管理员互相寒暄了几句,了解大体情况是医院昨天凌晨部分科室反映不能登录导航台,于是系统管理员深夜被叫到医院,查看服务器发现数据库已经宕机,检查磁盘空间,发现其中一个节点的剩余空间为0,于是立即删除部分过去的归档日志,重新启动服务器,下面科室才能够正常登录,谈话间不断听见系统管理员抱怨深夜到医院是如何如何不情愿,看来意见是比较大。
而且同样的问题不久前才出现过一次,当时是中午,询问同去的同事,了解到确实不久前也出现过一次同样的情况,当时认为是归档日志的定期删除保留的日志时间太长,当时保留的是30天的日志,后来改为保留5天的日志,心想不会再出现该问题,没想到还是无法避免。
如何处理高压运维中的日志异常分析和排查

如何处理高压运维中的日志异常分析和排查在运维工作中,日志异常分析和排查是我们经常要面对的挑战之一。
当系统出现异常或故障时,日志记录着系统运行的各个细节,能够帮助我们快速定位问题和解决方案。
然而,在高压运维环境下,日志异常的数量庞大,可能需要花费大量时间和精力来分析和排查。
本文将介绍一些处理高压运维中日志异常的有效方法。
一、收集和整理日志在处理日志异常之前,首先需要收集和整理日志。
通常,运维团队需要配置日志收集系统,将各个服务器上的日志中心化管理。
这样一来,我们可以通过一个统一的界面来查看和搜索日志,极大地提高了处理效率。
在收集和整理日志的过程中,我们需要关注以下几个方面:1. 确保日志采集的全面性:所有关键的系统和组件都要包含在日志采集范围中,以便全面监控和分析。
2. 确认日志的准确性:检查日志记录的格式和内容,确保其准确性和完整性。
3. 创建合适的索引:在日志收集系统中创建适当的索引,以便快速搜索和过滤日志。
二、使用日志分析工具在高压运维环境下,手动分析大量的日志是一项耗时而复杂的任务。
因此,我们可以借助日志分析工具来加速分析过程,提高排查效率。
常用的日志分析工具包括但不限于:1. ELK Stack: 包括Elasticsearch、Logstash和Kibana,可以实现实时日志收集、存储和可视化分析。
2. Splunk: 提供丰富的搜索和可视化功能,可以帮助快速定位和处理日志异常。
这些工具可以帮助我们对日志数据进行搜索、过滤和可视化分析,使得排查工作更加高效和准确。
三、建立异常日志报警机制为了及时发现和响应日志异常,建立一个有效的日志报警机制至关重要。
我们可以通过以下方式来建立异常日志报警机制:1. 设定关键指标和阈值:根据业务需求和系统特点,设定异常指标和阈值,如异常日志数量超过某个阈值或者特定错误码的出现频率超过设定值。
2. 实时监控和报警:利用监控系统或日志分析工具,实时监控日志异常并发送报警通知。
Db2数据库归档日志很频繁

Db2数据库归档日志频繁解决方法问题现象:数据库dbbde执行命令:Db2 db2stop forceDb2 db2start运行一段时间后发现,归档日志目录中日志增长很快,日志个数很多,但是日志均未写满。
每个日志只有约3M.如图S0224497.LOG-S0*******.LOG查看实际配置Log file size (4KB) (LOGFILSIZ) = 10000Number of primary log files (LOGPRIMARY) = 10Number of secondary log files (LOGSECOND) = 20一个归档日志的大小为:4KB*10000=40M 由配置看归档日志大小正常,则可能是犹豫数据库提交事物过于频繁导致归档频率加快。
解决方法:db2 activate database dbbde归档日志恢复正常。
整理:由activate database命令初始化的数据库可以由deactivate database命令关闭,也可以通过stop database manager(或db2stop)命令关闭。
如果使用activate database命令初始化一个数据库,那么最后一个与数据库断开连接的应用就不会关闭数据库。
由于命令db2stop关闭了数据库实例,重新启动数据库没有进行激活操作activate会导致每一个连接断开后会提交事物并归档,导致了日志归档频率大的问题。
同时,如果在database没有激活之前,就在应用中使用connect to database_name或隐式连接,那么应用就必须要进行等待,直到数据库管理器启动了你要连接的数据库。
一般第一个应用会引发等待数据库管理器执行数据库启动的所有开销。
可以使用activate database database_name这样的命令启动特定的数据库。
这个命令就会免除第一个应用程序连接上来的时候等候数据库初始化所花费的时间。
[terry笔记]ArchiveLog归档日志激增解决思路
![[terry笔记]ArchiveLog归档日志激增解决思路](https://img.taocdn.com/s3/m/b9243cb1294ac850ad02de80d4d8d15abe2300a2.png)
[terry笔记]ArchiveLog归档⽇志激增解决思路归档⽇志激增的危害是巨⼤的,最严重的结果就是数据库⽆法正常⼯作,导致整个系统⽆法正常⼯作,其次就算数据库可以正常⼯作,但激增的归档会对磁盘产⽣⼤量消耗,导致性能下降。
归档⽇志激增⼀般是因为异常的dml导致,异常的dml使数据被频繁的增删改,以⾄redo⽇志频繁切换,再⾄归档⽇志激增,最终磁盘爆满,数据库⽆法正常⼯作。
1.⾸先查询每天的redo⽇志切换频率,定位异常的时间点,并且还可以粗滤计算出⽇志量(就算⽆法解决程序问题,也可以暂时扩⼤磁盘容量,先让数据库正常归档⼯作,甚⾄切换到⽆归档模式)。
select to_char(first_time,'mmdd hh24'),count(*) from v$log_history group by to_char(first_time,'mmdd hh24') order by1;2.查询产⽣⽇志最多的会话,基本可以确定是什么⽅向的应⽤col program for a30col machine for a30select a.sid,a.logon_time,ername,a.program,a.machine,a.status,round(b.value/1024/1024) mb from v$session a,(select*from (select*from v$sesstat where statistic# = (select statistic# from v$statname where name='redo size 3.截取归档⽇志激增时候的AWR报告,在sql统计中仔细排查dml类型sql,并查询嫌疑的sql的执⾏计划、统计信息等(@?/rdbms/admin/awrsqrpi),还可以找出嫌疑sql所对应的表信息是否有异常。
还可以对应之前正常时候其sql的统计信息进⾏对⽐。
日志归档解决方案

日志归档解决方案1. 引言在现代计算机应用程序中,日志是一项重要的功能。
通过记录关键信息和故障排除过程,日志可以帮助开发人员和运维人员更好地理解系统的运行状况和问题。
对于大型系统和分布式应用程序来说,日志管理和归档是一项挑战,因为大量的日志数据需要处理和存储。
在本文档中,将介绍一种日志归档解决方案,以帮助团队有效地管理和存储日志数据。
2. 日志归档的挑战在开始介绍日志归档解决方案之前,我们先了解一下日志归档面临的主要挑战:2.1 数据量大随着系统规模的增长,日志数据的数量也随之增加。
大量的日志数据需要存储和处理,这对存储和计算资源提出了挑战。
2.2 数据的时效性日志数据通常从不同的源头生成,并且需要按照一定的时序进行归档。
由于数据的大量增长和实时性要求,及时处理和归档日志数据是一项挑战。
2.3 数据的安全性保护日志数据的安全性对于许多组织来说至关重要。
日志数据可能包含敏感信息,必须采取适当的安全措施,确保数据不被未经授权的人访问。
3. 日志归档解决方案为了解决上述挑战,我们提出了以下日志归档解决方案:3.1 数据收集为了处理大量的日志数据,我们需要一种可靠的方法来收集和聚合数据。
可以使用各种日志收集器,如Logstash、Fluentd、Filebeat等。
这些工具可以将日志数据从不同的源头收集到一个中央位置,以便后续的处理和归档。
3.2 数据存储一旦日志数据被收集,我们需要一个可靠和可扩展的存储解决方案来存储数据。
常见的选择包括使用分布式文件系统(如Hadoop HDFS)或分布式数据库(如Elasticsearch)。
使用这些存储系统,我们可以有效地存储和查询大量的日志数据。
3.3 数据归档为了满足数据的时效性要求,我们可以采用归档策略来处理历史数据。
归档可以将旧的日志数据移动到长期存储,从而释放宝贵的存储资源。
可以使用批处理作业定期执行归档任务,也可以采用自动化策略,根据数据的时间戳或其他条件自动触发归档操作。
Oracle数据库归档日志日常管理及建议

Oracle数据库归档日志日常管理与建议1.简介近日,项目组偶有发生归档日志占满归档目录空间导致数据库hang住(无响应),导致系统不能正常应用的情况。
针对此类问题,笔者从 Oracle 数据库归档模式、归档模式的优缺点、归档日志日常管理方法等各方面浅析并整理出归档日志日常管理与建议。
请各项目组依据实际情况,规范管理归档日志,排查相关隐患,以保证系统的正常高效运营。
另外,对于已开启数据库归档模式的项目组,若数据库管理权限不在我方,可将相关归档管理建议与当地运维部门充分沟通,避免归档的不当管理引起事故。
2.数据库归档模式与归档日志2.1 数据库运行模式简介Oracle数据库包括归档模式与非归档模式两种运行模式。
一般情况下 Oracle数据库的联机重做日志会记录对数据库所做的所有的修改,如创建对象;插入、删除、更新对象;删除对象等,这些操作都会记录在联机重做日志里。
Oracle数据库至少要有 2 个联机重做日志组。
当一个联机重做日志组被写满(假设为1)的时候,就会发生日志切换,这时联机重做日志组2(假设为 2)成为当前使用的日志,当联机重做日志组 2 写满的时候,又会发生日志切换,去写联机重做日志组1,这样反复进行。
如果数据库处于非归档模式,联机日志在切换时就会被丢弃。
而在归档模式下,当发生日志切换的时候,被切换的联机日志会被归档。
如当前在使用联机重做日志1,当 1 被写满时,发生日志切换,开始写联机重做日志2,这时联机重做日志 1 的内容会被拷贝到一个指定的目录下。
这个目录为归档目录,这个过程称之为归档,拷贝的文件叫归档日志。
2.2 归档模式优点与归档日志作用数据库运行在归档模式时,后台进程 ARCH 会将联机日志的内容拷贝到归档目录生成归档日志。
当数据库出现介质失败时,使用数据文件备份,归档日志和重做日志可以完全恢复数据库。
因此,开启归档模式及归档日志的益处与作用是非常明显的:1.可以进行完全、不完全恢复。
Oracle数据库频繁归档问题的解决办法

Oracle数据库频繁归档问题的解决办法Oracle数据库频繁归档问题的解决办法第一步检查top 输出 CPU 使用率很低iostat 读 M/s 写 K/s iowait %v$session 中的会话不多且都没有大的事务操作db_writer_processes=log_archive_max_processes=主日志组个每个组中个 M大小的日志文件备日志组个每个组中个 M大小的日志文件v$log 除了一个组为current 其它所有日志组状态均为active重启数据库现象依旧第二步判断根据以上检查结果判断应该不是应用层的问题初步判断是系统进程或硬件问题因为是生产系统不到万不得已不要轻易作硬件检测和更换因为那样会需要大量停止服务时间首先采取一般控制日志归档的方法第三步措施增加主日志文件alter database add logfile member /u /oradata/BOSS/redo log to groupalter database add logfile member /u /oradata/BOSS/redo log to groupalter database add logfile member /u /oradata/BOSS/redo log to groupalter database add logfile member /u /oradata/BOSS/redo log to group第四步增加归档进程数由改为alter system set log_archive_max_processes= scope=bothlishixinzhi/Article/program/Oracle/201311/17384。
Oracle数据库的归档日志写满磁盘空间解决办法

Oracle数据库的归档日志写满磁盘空间解决办法1、数据库不能启动SQL> sta rtupOR ACLE例程已经启动。
Tota l Sys tem G lobal Area 289406976 byte sFixed Size 1248576 byte sVaria ble S ize 83886784 byte sDatab ase B uffer s 197132288 byte sRedoBuffe rs 7139328 byte s数据库装载完毕。
ORA-16038: 日志 2 序列号 44无法归档OR A-19809: 超出了恢复文件数的限制O RA-00312:联机日志2 线程1:'D:\ORACL E\PRO DUCT\10.2.0\ORA DATA\ORCL\REDO02.LOG' 2、查看$ORACL E_HOM E\adm in\SI D\bdu mp\al ert_S ID.lo g日志Thu Feb19 09:45:33 2009Error s infiled:\or acle\produ ct\10.2.0\admin\orcl\bdum p\orc l_arc1_660.trc:O RA-19815:WARNI NG: d b_rec overy_file_dest_size of 2147483648bytesis 99.95% used, and has1129472 re maini ng by tes a vaila ble.Th u Feb 19 09:45:33 2009Erro rs in file d:\o racle\prod uct\10.2.0\admi n\orc l\udu mp\or cl_or a_4708.trc: ORA-19815:警告:db_re cover y_fil e_des t_siz e 字节(共 2147483648 字节) 已使用99.95%,尚有 1129472字节可用。
解决oracle归档日志写满了(ORA00257)的问题-电脑资料

解决oracle归档日志写满了(ORA00257)的问题-电脑资料解决ORA-00257: archiver error. Connect internal only, until freed此问题属于归档日志满了,。
解决办法:SQL> select * from V$FLASH_RECOVERY_AREA_USAGE;FILE_TYPE PERCENT_SPACE_USEDPERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES------------ ------------------ ------------------------- ---------------CONTROLFILE 0 0 0ONLINELOG 0 0 0ARCHIVELOG 99.9 0 255BACKUPPIECE 0 0 0IMAGECOPY 0 0 0FLASHBACKLOG 0 0 0注:可以看出,ARCHIVELOG日志已经达到99.9%了,电脑资料《解决oracle归档日志写满了(ORA00257)的问题》(https://)。
要把它清除掉!SQL> quitC:\Documents and Settings\Administrator>rmanRMAN> connect target system/myoracle@orcl注:system为oracle用户,myoracle为oracle用户密码,orcl 为连接的数据库名称SID。
RMAN> crosscheck archivelog all;RMAN> delete expired archivelog all;注:删除过期的归档这样就把归档文件删除了。
再进入sqlplus 查看ARCHIVELOG日志使用率!第二种方法就是增大闪回日志文件的最大大小。
如下:alter system set DB_RECOVERY_FILE_DEST_SIZE=10g以上处理方法是当遇到出现日志写满报错时的处理,建议最好做个任务,定时删除日志,如下:DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7'; //删除七天前的归档DELETE ARCHIVELOG FROM TIME 'SYSDATE-7'; //删除七天到现在的归档作者清晨迎朝阳。
数据库异常处理与错误日志分析技巧

数据库异常处理与错误日志分析技巧数据库在应用开发中扮演着重要的角色,承载着大量的数据,所以我们需要保证数据库的稳定性和可靠性。
然而,难免会出现一些异常情况和错误,这时候我们就需要掌握数据库异常处理和错误日志分析的技巧。
异常处理在数据库中是一项非常重要的任务。
数据库异常可能会导致数据的错误或丢失,给系统的稳定性和可靠性带来严重影响。
下面将介绍一些处理数据库异常的技巧:首先,要建立合适的异常处理机制。
对于数据库操作,我们应该合理地利用事务进行错误回滚。
在任何时候出现异常时,事务会被回滚到操作之前的状态,确保数据库的一致性。
其次,要养成良好的编码习惯。
编写清晰、可读性强的代码,对各种异常情况进行预测和处理。
使用Try-Catch语句捕捉异常,并及时处理或记录。
良好的编码习惯可以大大减少数据库异常的发生。
另外,及时排查并修复数据库异常。
定期进行数据库检查,发现异常情况要及时修复。
设置监控系统,监测数据库的性能和运行状态,当数据库异常时能够及时报警和处理。
对于错误日志的分析也是数据库管理中的重要任务。
错误日志记录了数据库的运行情况和产生的错误信息,通过分析错误日志可以找到数据库异常的根源,并采取相应的措施进行修复。
下面将介绍一些错误日志分析的技巧:首先,要关注数据库错误级别。
错误日志中一般会记录了不同级别的错误,如严重错误、警告和信息。
我们应该优先处理严重错误和警告,因为它们可能会对数据库功能和性能造成重大影响。
其次,要注意查找错误的原因。
错误日志中会提供出错语句的相关信息,如表名、字段名等,我们需要根据这些信息来查找出错的原因。
对于常见的错误信息,可以通过互联网搜索解决方案,对于特定的错误,可以参考数据库文档或官方论坛。
另外,建议定期备份错误日志并进行归档。
错误日志通常是一个不断增长的文件,过多的错误日志会影响数据库的运行性能。
我们可以定期备份错误日志并根据需要进行归档,以便后续的错误分析和排查。
最后,要注意错误日志的监控和分析。
Oracle 10g 归档日志满了的解决办法

已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup;
ORACLE 例程已经启动。
闪回区满
初始化参数 DB_RECOVERY_FILE_DEST 的值清空即可。”
但是还是不明白怎么做,指点一下吧!谢谢! [/B]
alter system set db_recovery_file_dest=0 scope=both
4.查看归档日志的状态
RMAN> list archivelog all;
5.手工删除归档日志文件
6.更新归档日志
RMAN> crosscheck archivelog all;
RMAN> delete expired archivelog all; --中间会提示确认,输入"yes"即可
Oracle 10g 归档日志满了的解决办法
Oracle.如果Oracle的归档日志满了,应用连接数据库就会出错,这时需要手工删除过期的归档日志,方法如下:
1.指定数据库实例
$ export ORACLE_SID=db1
2.进入rman
$ rman
3.连接数据库
RMAN> connect target sys/password;
7.退出rman
RMAN> exit
SQL> alter database clear unarchived logfile 'D:\ORACLE\PRODUCT\10.2.0\ORADATA\scmerp\REDO01.LOG';
数据库已更改。
归档日志量增长异常分析_结论为物化视图无法使用增量刷新导致

归档⽇志量增长异常分析_结论为物化视图⽆法使⽤增量刷新导致对于客户的问题故障进⾏总结1)问题现象归档⽇志,每⼩时切换最低60于次,每天产⽣归档⽇志720g,由于归档⽇志过多,定时清理归档不及时,导致Arch磁盘组空间极易消耗殆尽,导致业务⽆法操作,业务连续性收到影响。
2)短期处理⼿⼯处理,临时清理⼀天前归档,保障业务连续性RMAN>DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-1';3)问题定位使⽤Logminer⼯具进⾏挖掘,在2019年03⽉05⽇晚上9点,与2019年03⽉06⽇早上7点,⽇志挖掘top3输出结果相同。
对于数据库来说,不同时间段,业务连续性的对同⼀个表insert,delete,JOB定时调⽤可能实现。
USERNAME OWNER NAME TYPE_NAME OPERATION COUNTBJ_SELECTION BJ_SELECTION YD_BARGAIN_PRICE TABLE INSERT 1481521BJ_SELECTION BJ_SELECTION YD_BARGAIN_PRICE TABLE DELETE 1481521BJ_SELECTION INTERNAL 4444594JOB视图查询SQL> select job,log_user,last_date,next_date,broken,interval,what from dba_jobs where WHAT like '%YD_BARGAIN_PRICE%';JOB LOG_USER LAST_DATE NEXT_DATE B INTERVAL WHAT---------- ----------------------------- ----------------------------- -------------------1365 BJ_SELECTION 2019-03-0609:29:532019-03-0609:29:59 NSYSDATE + NUMTODSINTERVAL(2,'SECOND')dbms_refresh.refresh('"BJ_SELECTION"."YD_BARGAIN_PRICE"');1366 BJ_TEST_SELECTION 2019-03-0609:30:022019-03-0609:30:04 NSYSDATE + NUMTODSINTERVAL(2,'SECOND')dbms_refresh.refresh('"BJ_TEST_SELECTION"."YD_BARGAIN_PRICE"');JOB间隔2s,执⾏物化视图刷新。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
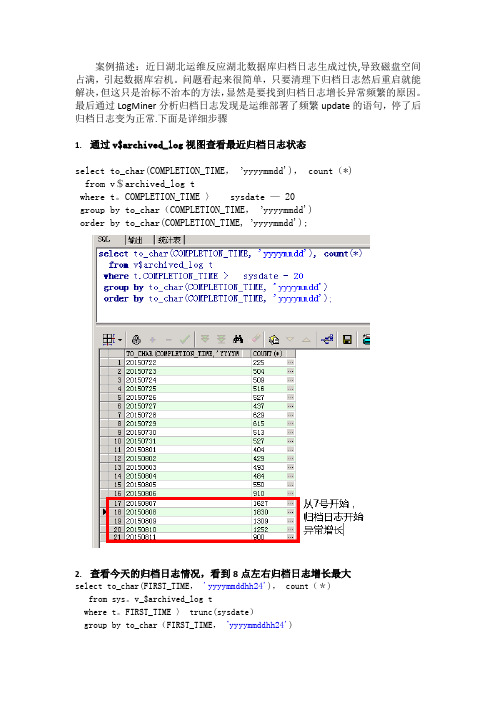
案例描述:近日湖北运维反应湖北数据库归档日志生成过快,导致磁盘空间占满,引起数据库宕机。
问题看起来很简单,只要清理下归档日志然后重启就能解决,但这只是治标不治本的方法,显然是要找到归档日志增长异常频繁的原因。
最后通过LogMiner分析归档日志发现是运维部署了频繁update的语句,停了后归档日志变为正常。
下面是详细步骤
1.通过v$archived_log视图查看最近归档日志状态
select to_char(COMPLETION_TIME, 'yyyymmdd'), count(*)
from v$archived_log t
where PLETION_TIME > sysdate - 20
group by to_char(COMPLETION_TIME, 'yyyymmdd')
order by to_char(COMPLETION_TIME, 'yyyymmdd');
2.查看今天的归档日志情况,看到8点左右归档日志增长最大
select to_char(FIRST_TIME, 'yyyymmddhh24'), count(*)
from sys.v_$archived_log t
where t.FIRST_TIME > trunc(sysdate)
group by to_char(FIRST_TIME, 'yyyymmddhh24')
order by to_char(FIRST_TIME, 'yyyymmddhh24')
3.查看今天八点的归档日志的路径
select name, COMPLETION_TIME, t.FIRST_TIME, t.RESETLOGS_TIME from sys.v_$archived_log t
where to_char(FIRST_TIME, 'yyyymmddhh24') = 2015081108
order by t.FIRST_TIME desc;
4.打开toad,连接数据库,打开日志分析工具logminer
(database→diagnose→logminer)
5.点击next
6.把第三步得到的归档日志的路径输入file to mine
7.点击运行图标,分析日志,得到sql语句。