统计学上机作业
统计学上机作业

统计学第一次上机实验一、上机项目名称:EXCEL、SPSS绘制统计图表二、上机时间:2011年10月 13日,下午14:00—15:50上机地点:基础楼综合实验室三、上机目的、内容、步骤及结果目的:掌握EXCEL、SPSS统计图表的基本操作内容:教材29页4题EXCEL;30页6题SPSS步骤及结果:○1 29页4题EXCEL:1、打开Nielsen的excel表格,并在相应位置输入TV Show、Millionaire、Frasier、Charmed、Chicago Hope、total、 frequency、relative frequency、percent frequency。
2、在Millionaire后的frequency中输入——函数——COUNTIF——range(所有的数组)——CRITERIE(C2)——确定,单元格中显示Millionaire的频数,并以此用此法求出Frasier、Charmed、Chicago Hope的频数。
3、在Millionaire后的relative frequency中输入=Millionaire 的frequency数值/50,得到Millionaire的相对频数。
并依次据此求出Frasier,Charmed,Chicago Hope,total的相对频数。
4、在Millionaire后的umulative frequency中输入=Millionaire 的relative frequency数值*100,得到Millionaire的百分频数,并据此求出Frasier,Chicago Hope,Charmed的百分频率。
5、选中名称列及频数所在的列单击插入——图表,分别插入二维柱形图和饼形图。
EXCEL 表格如下:Bar graph如下:Pie chart 如下:○2 30页6题SPSS: 1、打开spss ,打开——数据,更改数据格式为xls ,打开数据找到book 文件并打开。
《统计学基础》(专)网上作业1

《统计学基础》(专)网上作业一一、单项选择题。
1.一个统计总体( )A.只能有一个标志B.只能有一个指标C.可以有多个标志D.可以有多个指标2.下列变量中,()属于离散变量A.一包谷物的重量B.一个轴承的直径C.职工的月均工资D.一个地区接受失业补助的人数3.某研究部门准备在全市200万个家庭中抽取2 000个家庭,推断该城市所有职工家庭的年人均收入。
这项研究的总体是()A.2000个家庭B. 200万个家庭C.2000个家庭的人均收入D. 200万个家庭的人均收入4.设某地区有800家独立核算的工业企业,要研究这些企业的产品生产情况,总体单位是()。
A.全工业企业B.800家工业企业C.每一件产品D.800家工业企业的全部工业产品5.有200家公司每位职工的工资资料,如果要调查这200家公司的工资水平情况,则统计总体为()。
A.200家公司的全部职工B.200家公司C.200家公司职工的全部工资D.200家公司每个职工的工资6.某市拟对占全市储蓄额4/5的几个大储蓄所进行调查,以了解全市储蓄的一半情况,则这种调查属于()。
A.统计报表B. 重点调查C.全面调查D. 抽样调查7.某连续变量分为五组:第一组40~50,第二组50~60,第三组60~70,第四组70~80,第五组80以上,以习惯规定()。
A.50在第一组,70在第四组B. 60在第二组,80在第五组C.70在第四组,80在第五组D. 80在第四组,50在第二组8.对职工的生活水平状况进行分组研究,正确地选择分组标志应当用()。
A.职工月工资总额B.职工人均收入额C.职工家庭成员平均收入额多少D.职工的人均月岗位津贴及奖金的多少9.分配数列有两个构成要素,它们是()。
A.一个是单位数,另一个是指标数B.一个是指标数,一个是分配次数C.一个是分组,另一个是次数D.一个是总体总量,另一个是标志总量10.为了解居民对小区物业服务的意见和看法,管理人员挑选了由代表性的5户居民,上门通过问卷进行调查。
应用统计学上机

应用统计学上机工商管理学院《应用统计学》实验作业班级学号姓名上课教师2017年11月实验二建立数据文件1.建立一个数据文件记录试录入以下数据,并按要求进行变量定义。
数据:学号姓名性别生日身高(cm)体重(kg)英语(总分100分)数学(总分100分)生活费($人民币)200 201 刘一迪男1982.01.12156.4247.5475 79 345.0200 202 许兆辉男1982.06.05155.7337.8378 76 435.0200 203 王鸿屿男1982.05.17144.638.6665 88 643.5200江男1982.16141.79 82 235.5204 飞08.31 .5 68 0200 205 袁翼鹏男1982.09.17161.343.3682 77 867.0200 206 段燕女1982.12.21158 47.3581 74200 207 安剑萍女1982.10.18161.547.4477 69 1233.00200 208 赵冬莉女1982.07.06162.7647.8767 73 767.8200 209 叶敏女1982.06.01164.333.8564 77 553.9200 210 毛云华女1982.09.12144 33.8470 80 343.0200 211 孙世伟男1981.10.13157.949.2384 85 453.8200 212 杨维男1981.12.6176.154.5485 80 843.0清200 213 欧阳飞男1981.11.21168.550.6779 79 657.4200 214 贺以礼男1981.09.28164.544.5675 80 1863.90200 215 张放男1981.12.08153 58.8776 69 462.2200 216 陆晓蓝女1981.10.07164.744.1480 83 476.8200 217 吴挽君女1981.09.09160.553.3479 82200 218 李利女1981.09.14147 36.4675 97 452.8200 219 韩琴女1981.10.15153.230.1790 75 244.7200 220 黄捷蕾女1981.12.02157.940.4571 80 253.0要求:将录入结果截图粘贴在作业题目答案处(变量视图和数据视图)。
统计学上机题作业
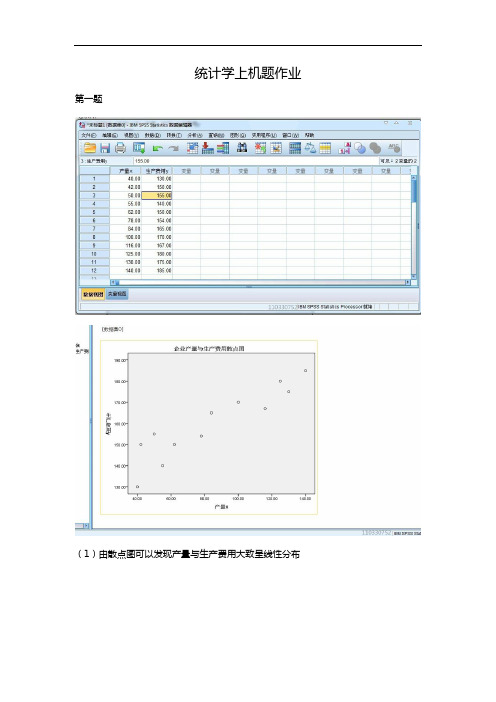
统计学上机题作业第一题
(1)由散点图可以发现产量与生产费用大致呈线性分布
(2)由上面的图表分析,可以发现产量与生产费用的线性相关系数为0.921
2、设月租金为自变量,出租率为因变量,进行回归分析,并对结果进行解释和分析散点图:
在模型汇总中,可得出相关系数r=0.795,判定系数R2=0.632,然后查表检验。
另外,在方差分析表(见上图)中可以查到SST=352.986,SSE=129.845,SSR=223.140,有公式R2=SSR/SST可以算出判定系数R2值为0.632。
①F-检验:然后在上表中我们可以看到F值:F=30.933,查表检验。
②t-检验:在系数表中,我们可以得出t=12.961,查表检验。
③DW检验:在模型汇总表中我们可以得到DW=2.001,。
④标准离差检验:在模型汇总表可以读出标准离差(误差)S=2.68582;在残差统计表中(下表)得到因变量y的均值为70.215。
因此有公式课得出δ=S/y(均值)
=2.68582/70.215=0.038
观测数据可得小于10%-15%,因此检验可以通过。
由此可见,在系数表中,容易得出回归系数:截距β0=49.318,斜率β1=0.249,如上图所示。
应用统计学上机
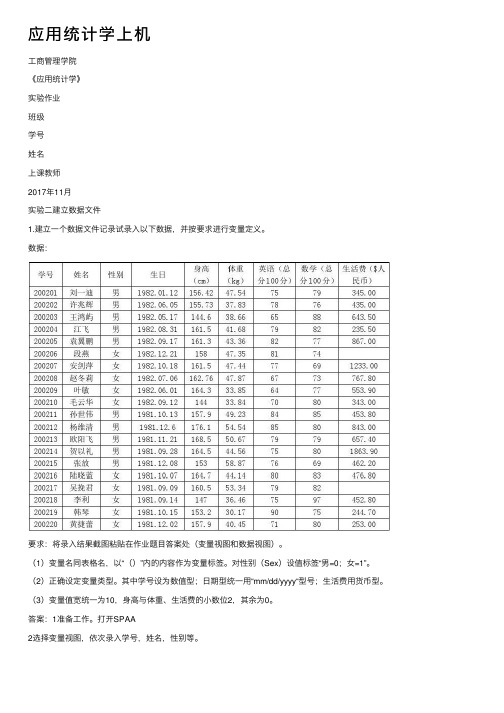
应⽤统计学上机⼯商管理学院《应⽤统计学》实验作业班级学号姓名上课教师2017年11⽉实验⼆建⽴数据⽂件1.建⽴⼀个数据⽂件记录试录⼊以下数据,并按要求进⾏变量定义。
数据:要求:将录⼊结果截图粘贴在作业题⽬答案处(变量视图和数据视图)。
(1)变量名同表格名,以“()”内的内容作为变量标签。
对性别(Sex)设值标签“男=0;⼥=1”。
(2)正确设定变量类型。
其中学号设为数值型;⽇期型统⼀⽤“mm/dd/yyyy“型号;⽣活费⽤货币型。
(3)变量值宽统⼀为10,⾝⾼与体重、⽣活费的⼩数位2,其余为0。
答案:1准备⼯作。
打开SPAA2选择变量视图,依次录⼊学号,姓名,性别等。
2.对⼤学⽣创业问题设计⼀份调查问卷。
要求格式正确,题⽬类型包括开放题、封闭题(单选、多选都有)、半封闭题三种类型,题⽬个数10-15个。
答案:3.⽤第2题得到的调查问卷进⾏模拟调查(10份),并将得到的结果录⼊到SPSS中,(1)将录⼊结果保存为xxx.sav⽂件,并将录⼊结果截图粘贴在作业题⽬答案处(变量视图和数据视图)。
答案:实验三数据的整理1. 某地区农科所为了研究该地区种植的两个⼩麦品种“中麦9号”、“豫展1号”产量的差异,从该地区的两个村庄各选5块⽥地,分别种植两个品种⼩麦,使⽤相同的⽥间管理,收获后,测得各个地块⽣产的⼩麦的千粒重(g)数据资料如表3-1所⽰。
表3-1 某地区⼩麦种植要求:量,并建⽴数据⽂件,完成分类汇总⼯作。
步骤:1.准备⼯作。
打开3-1⽂件,通过⽂件--打开,将⽂件放⼊打开窗⼝。
2.选择数据---分类汇总。
3.打开分类汇总窗⼝,将⼩麦品种放⼊分组变量对话框中,将千粒重放⼊变量摘要对话框中。
4.选择函数选项,在函数对话框中选择均值选项5.选择继续--确定,得出结果。
以此⽅式得出村对⼩麦千粒重的分类汇总。
2.某地20家企业的情况如表3-2所⽰。
表3-2 企业年产值与年⼯资总额要求:根据上述资料建⽴数据⽂件,并完成下列统计整理⼯作,并回答有关问题:(1)调⽤排序命令对企业按部门、年产值的主次顺序进⾏排序。
统计学上机实验报告

统计图表一、上机项目名称:EXCEL、SPSS绘制统计图表二、上机时间、地点:2010年9月16日,上午10:20—12:10基础楼综合实验室三、上机目的、内容、步骤及结果目的:掌握EXCEL、SPSS统计图表的基本操作内容:教材29页4题EXCEL;30页6题SPSS步骤及结果:29页4题EXCEL1.复制各个名称→在F1插入函数→选择统计中的frequency→在F2插入函数COUNTI →分别填$A$2:$A$51和D2→拖拽复制公式至E51→在G1输入函数relative f→输入公式:=F2/50→拖拽复制公式至F51→抽取D2:E51中的所有不同数据→复制到I2:K5,得出如下表格由大到小TV show frequency relative f1 Millionaire 24 0.482 Frasier 15 0.33 Chicago Hope 7 0.144 Charmed 4 0.08total 50 12.在工具栏选择插入菜单图表→柱形图→选择柱形图格式→下一步→选择相应的区域→按下一步→设置图表的名称、横轴和竖轴的名称→选中完成,得出如下图表:3. 选择插入菜单→选择图表→选中饼图→选择相应的图形格式,在在对话框选择下一步→选择相应的区域→按下一步→设置图表的名称→选中完成,得出图表如下:4.选中各个节目的frequency值,在工具栏中选降序排序,得到market share的相应排序。
29页6题SPSS1.打开SPSS软件,打开相对应的文件。
2.选择图形→选中图形模板→完成相对应的对话框→确定完成,在输出窗口可看到相应的图形四、上机心得体会:以前以为excel只是建个表格,现在发现它还有这么多功能。
通过观看老师演示,了解Excel和SPSS制作图表的基本过程,再通过练习课后题掌握了这一技能,并且也对Excel和SPSS的强大功能有了初步了解。
描述性一、上机项目名称:EXCEL、SPSS做单变量描述性统计指标计算二、上机时间、地点:2010年9月16 日,上午10:20—12:10基础楼综合实验室三、上机目的、内容和步骤目的:掌握统计软件单变量描述性指标计算的功能内容:教材80页5题或81页7题EXCEL单变量值结果输出;教材88页19题EXCEL和SPSS描述性统计指标统一输出.步骤:80页5题1.打开EXCEL→导入相应的数据→在E列各行输入mean、median、mode、q1、q32.点击下一个单元格→插入函数→选择统计→选择函数average→点击确定→再选择salary那列的数据→点击确定。
统计学上机练习

3.248
3.248
.
6.262
6.262
.
2682.826
2682.826
.
7130.199
7130.199
.
16.376
16.376
6.262 2682.826 7130.199
16.376
拟合统计量 平稳的 R 方 R方 RMSE MAPE MaxAPE MAE MaxAE 正态化的 BIC
模型拟合 百分位
9ห้องสมุดไป่ตู้
西安邮电学大学 经济与管理 学院
《统计学》课内实验 过程考核表
学生姓名 承担任务实验室(单位) 经济与管理院学院
实施时间
班级/学号 所在部门
实验一
EXCEL 频数分布表
具体内容
实验二
EXCEL 描述统计
实验三
EXCEL 相关与回归
指导教师(师傅)姓名
指导教师(师傅) 对学生的评价
刘飞 学习态度 学习纪律 实践能力
13395.23
2007
109655.2
16386.04
2008
120332.7
18903.64
2009
135822.8
21715.25
2010
159878.3
26396.47
2011
183084.8
31649.29
输入/移去的变量 b
模型
输入的变量 移去的变量
方法
1
财政收入 a
. 输入
a. 已输入所有请求的变量。
90
95
1.957E-15 .995
3274.261 3.248 6.262
2682.826 7130.199
统计学上机实验题目

A.1. 要求筛选出(1)统计学成绩等于75分的学生;(2)数学成绩高的前3名学生;(3)4门课程成绩都大于70分的学生。
2. 要求筛选出(1)数学成绩等于60分的学生;(2)经济学成绩高的前4名学生;(3)4门课3. 要求筛选出(1)英语成绩等于85分的学生;(2)统计学成绩高的前4名学生;(3)4门课4. 要求筛选出(1)统计学成绩等于90分的学生;(2)经济学成绩高的前3名学生;(3)4门5. 要求筛选出(1)数学成绩等于85分的学生;(2)英语成绩高的前3名学生;(3)4门课程B.1. 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.较差;E.差。
调查结果如下所示;B EC C AD C B AE D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C要求编制品质数列,列出频率、频数,并选用适当的统计图如:圆形图、条形图等形象地显示资料整理的结果。
(要求展现整理过程)2. 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为: A.好;B.较好;C.一般;D.较差;E.差。
调查结果如下所示;A E C DB DC B A ED B D B C DE C E D A D B C C A E D B B B A C D E A B D D B C B C E C B C B B C D A C A C D E C E B B E C C A D D B A E B A C D E A B D E C A D B C C A E D B B C B C E D B D C A B要求编制品质数列,列出频率、频数,并选用适当的统计图如:圆形图、条形图等形象地显示资料整理的结果。
统计学上机——精选推荐

统计学上机实验报告班级:工商管理1302班**:***学号:**********实验一用Excel搜集与整理数据一.用excel搜集数据【例13-1】假定有100个总体单位,每个总体单位给一个编号,共有从1到100个编号,输入工作表后如图所示:总体各单位编号表等距抽样结果二.用excel进行统计分组【例13-2】我们采用第三章例3-1,把50名工人的月产量资料输入工作表,如图所示:工人月产量资料应当注意,上图实际上是一个条形图,而不是直方图。
调整后的直方图三.用excel作统计图【例13-3】我们这里采用第三章表3-13的资料,看一下如何作饼图。
首先把数据输入到工作表中,如图所示:河北省主要市2001年人口情况饼图实验二用EXCEL计算描述统计量一、用函数计算描述统计量(一)众数【例13-4】:为了解某经济学院新毕业大学生的工资情况,随机抽取30人,月工资如下:15601340160014101590141016101570171015501490 16901380168014701530156012501560135015601510 15501460155015701980161015101440(二)中位数(三)算术平均数(四)标准差函数计算描述统计量(大学生工资情况)二.描述统计工具量的使用描述统计输出结果Excel 实验二补充第一部分:用EXCEL1.为研究人们对不同类型软饮料的偏好情况,一家调查公司在某超市随机调查了50名消费者。
右表是顾客性别及其所偏好的饮料类型记录。
生成频数分布表,观察不同性别的消费者及其所偏好的饮料类型的分布状况,并进行描述性分析1)生成频数分布表EXCEL用数据透视表生成定性数据的频数分布2【例】2011年北京、天津、上海和重庆地区按收入法计算的地区生产总值(按当年价格计算)数据。
绘制环形图比较四个地区的生产总值构成利用表中数据绘制环形图并进行说明.如下张图制作的环形图:由上图通过比较不同色环形的总面积可得,上海的地区生产总值最高,其次为北京,而重庆为最低。
《统计学》上机实验例题(一)

• •
2010年
生成频数分布表
(列联表—Excel)
不同类型饮料和顾客性别的频数分布
绿色 健康饮品
2010年
分类数据的图示—条形图
(bar Chart)
2010年
分类数据的图示—复式条形图
(bar Chart)
• 饮料类型和顾客性别的条形图
2010年
分类数据的图示—帕累托图
(pareto chart)
(a)向上累积
非常 不满意 一般 满意 不满意 (b)向下累积
甲城市家庭对住房状况评价的累积频数分布
环形图
(例题分析)
13% 10% 7% 8% 非常不满意
15%
21% 36% 33% 不满意
一般
31% 26% 甲乙两城市家庭对住房状况的评价 满意 非常满意
用Excel制作图形
2.3 数值型数据的整理与展示 2.3.1 2.3.2 数据分组 数值型数据的图示
温度 / 0C 6 8 降雨量 /mm 25 40 产量/ ( kg/hm2 ) 2250 3450
位面积产量与降雨量 和温度等有一定关系 。为了解它们之间的 关系形态,收集数据 如表。试绘制小麦产 量与降雨量的散点图 ,并分析它们之间的 关系。
10
13 14 16 21
58
68 110 98 120
一、数值型数据:用数据分析中的直方 图编制频数分布表;绘制直方图折线图
【 例 2.5】 (
见教材38~ 42页) 表中
是某电脑公 司 2002 年 前 四个月各天 的销售量数 据(单位:台) 。试对数据 进行分组
等距分组表
(上下组限重叠)
分组数据的图示
(直方图的绘制)
统计学上机实验一、二

数据的收集、整理与显示统计数据的收集、整理与显示是统计分析的基础和初步,其中涉及到抽样方法的选择,数据的筛选、排序,数据的分类和分组以及频数分布的制作等。
本章主要介绍如何使用Excel 进行相应处理,其中第一节统计数据的收集,介绍“抽样”工具的使用;第二节数据的预处理,介绍“筛选”、“排位和百分比排位”工具的使用;第三节品质数据的整理与显示,介绍如何使用“直方图”工具制作品质型数据的频数分布;第四节数值型数据的整理与显示,介绍如何使用“直方图”工具制作数值型数据的频数分布以及多变量数据的雷达图制作。
第一节统计数据的收集数据的处理是数据整理的先前步骤,是在对数据分类或分组之前所做的必要处理,包括数据的审核、筛选、排序等。
本节主要介绍Excel中筛选和排序功能的使用。
一、数据筛选数据筛选包括两方面内容:一是将某些不符合要求的数据或有明显错误的数据予以剔除;二是将符合某种特定条件的数据筛选出来,对不符合特定条件的数据予以剔除。
下面举例说明Excel进行数据筛选的过程。
表1-28名学生的考试成绩数据单位:分表1-2是八名学生四门课程的考试成绩数据,使用Excel“筛选”命令分别找出统计成绩等于75分的学生;英语成绩前三名的学生;数学成绩大于80小于90的学生;统计成绩和数学成绩大于80分,或者英语成绩大于90分的学生。
Excel提供了两种筛选命令:“自动筛选”(适用于简单的条件)和“高级筛选”(适用于复杂的条件)。
接下先来介绍“自动筛选”的使用。
首先,将表格中的数据区域选定或者只需确保活动单元格处于数据区域既可(如表1-2所示,活动单元格为B3)。
选择“数据”菜单,并选择“自动筛选”命令。
如图1.6所示。
图1.6从“数据”菜单中选择“筛选自动”这时会在第一行(列标题)出现下拉箭头,用鼠标点击箭头会出现如下结果,如图 1.7所示。
图1.7“自动筛选”命令图1.8统计成绩75分的学生图1.9英语成绩前三名的学生图1.10数学成绩大于80小于90的学生要筛选出统计学成绩为75分的学生,可选择75,得到图1.8的结果;要筛选出英语成绩最高的前三名学生,可在英语成绩下拉箭头选项中选择“前10个”,并在对话框中输入“3”,得到如图1.9所示结果。
统计学上机习题

统计学上机习题1.打开“tab1.xls”工作簿,进行如下操作:(1)在“原始成绩”工作表的第1行前面插入一行,加上一个“2007~2008学年第一学期商专10601班学生成绩一览表” 的标题。
(2)将序号“1”-“9”前面加“0”,变为“01”-“09”。
(3)将A9行底色添加为淡黄色。
(4)应用条件格式,将90分以上的成绩显示为兰色,将80~90分的成绩显示为绿色,将60分以下的成绩显示为红色。
(5)在“原始成绩”工作表的最后加上5行,分别计算各门课程的最高分、最低分、考试总分、平均分数和标准差,其中平均成绩和标准差要求保留两位小数。
(注:可分别利用MAX()、MIN()、SUM()、A VERAGE()及STDEVP()函数) 求。
)(6)另建一个工作表,取名为“汇总成绩”,在“汇总成绩”表中计算“原始成绩”工作表中每个学生的成绩总分及平均成绩,其中平均成绩保留两位小数。
(注:跨工作表引用格式为:“=表名!单元格名称” )(7)在“汇总成绩”工作表中按照平均成绩由高到低排名次,将名次结果记录在增加的一列“名次”中。
(8)在“汇总成绩”工作表中,先将C列“姓名”复制到G列,然后在H列将平均成绩60分以上的显示成“及格”,60分以下的显示成“不及格”;在I列将平均成绩60分以下、60-70分、70-80分、80-90分、90分以上的分别显示成“不及格”、“及格”、“中等”、“良好”及“优秀”。
(9)对“汇总成绩”工作表中的总分与平均分两列数据进行保护设置。
然后对“tab1.xls”进行打开权限和工作表修改权限的保护设置。
(10)按照统计表的一般规范化要求对“原始成绩”工作表进行格式设置,编制统计报表,将该班同学的成绩打印出来。
(要求熟悉字体、边框、行高、列宽、打印标题行及标题列等的设置。
)2.打开工作簿“tab2.xls”,按要求在工作表sheet1中完成下述工作:(1) 计算每位职工的实发工资(其中医疗保险、养老金、储蓄和其它扣款为扣除款项),填入实发工资相应单元格中。
统计学上机实习学号2009100...
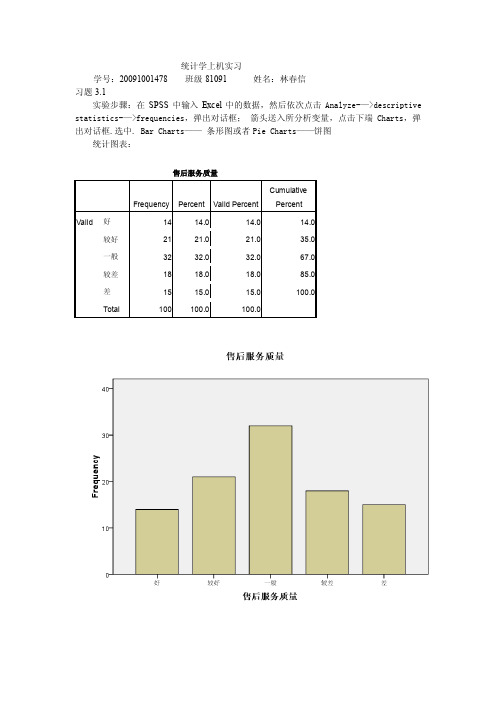
统计学上机实习学号:20091001478 班级81091 姓名:林春信习题3.1实验步骤:在SPSS中输入Excel中的数据,然后依次点击Analyze-—>descriptive statistics-—>frequencies,弹出对话框;箭头送入所分析变量,点击下端Charts,弹出对话框.选中. Bar Charts——条形图或者Pie Charts——饼图统计图表:结果分析:习题3.10实验步骤:依次点击Analyze->descriptive statistics->explore, 弹出对话框;箭头送入所分析变量,系统自动生成茎叶图与箱线图,单击主菜单OK键统计图表:考试成绩 Stem-and-Leaf PlotFrequency Stem & Leaf1.00 Extremes (=<44)2.00 5 . 796.00 6 . 0112335.00 6 . 5667910.00 7 . 001233344413.00 7 . 55555667778893.00 8 . 0024.00 8 . 55665.00 9 . 022231.00 9 . 6Stem width: 10Each leaf: 1 case(s)结果分析:习题3.14实验步骤:先把第一产业,第二产业,第三产业的Type中的String改为Numeric,然后依次点击Graphs->Legacy diaglos->Line,在弹出的对话框中选择Multiple和Summaries of separate variables,然后点击Define。
在弹出的对话框把第一产业,第二产业,第三产业和国内生产总值放入Lines Represent,把年份放入Category Axis。
最后点击OK统计图表:结果分析:习题电脑销量实验步骤:依次点击Graphs->Legacy diaglos->Histogram,然后把电脑销量放入variables,再点击OK统计图表:结果分析:根据顾客购买饮料的记录,编制频数分布表实验步骤:依次点击Analyze-—>descriptive statistics-—>frequencies,弹出对话框,把顾客性别,饮料类型放入variables中,再点击OK统计图表:结果分析:基本描述统计量计量分析实验步骤:依次点击Analyze-—>descriptive statistics-—> descriptive,弹出对话框;统计图表:结果分析:交叉分组下的频数分析:实验步骤:练习1:某年中国10省市人均国民收入(3577,2981,1148,1124,1080,1383,1628,4822,1696,1717),单位:元,试建立该组数据的95%置信区间。
统计学原理 网上作业及答案

统计学原理作业第1套您已经通过该套作业,请参看正确答案1、中国人口普查属于那种调查方式:()A.全面调查B.抽样调查C.重点调查D.典型调查参考答案:A2、下述表述不正确的是()A.推断统计学是研究如何根据样本数据去推断总体数量特征的方法。
B.根据计量学的一般分类方法,按照对事物计量的精确程度,常将所采用的计量尺度分为两个尺度,即定类尺度和定序尺度C.表述频数分布的图形可用直方图、折线图、曲线图、茎叶图D.定性数据也称品质数据,它说明的是事物的品质特征,是不能用数值表示的,其结果通常表现为类别,这类数据是由定类尺度和定序尺度计量形成的参考答案:B3、抽样误差是指()。
A.在调查过程中由于观察.测量等差错所引起的误差B.在调查中违反随机原则出现的系统误差C.随机抽样而产生的代表性误差D.人为原因所造成的误差参考答案:C4、对某种连续生产的产品进行质量检验,要求每隔一小时抽出10 分钟的产品进行检验,这种抽查方式是()。
A.简单随机抽样B.类型抽样C.等距抽样D.整群抽样参考答案:C5、中国人口普查的调查单位是:()A.该国的全部人口C.该国的每一户家庭B.该国的每一个人D.该国的全部家庭参考答案:B6、采取组距分组时,为解决“不重”的问题,统计分组时习惯上规定:()A.下组限不在内C.上、下组限均不计在内B.上组限不在内D.根据实际情况来确定参考答案:B7、统计数据的准确性是指()。
A.最低的抽样误差C.满足用户需求B.最小的非抽样误差D.保持时间序列的可比性参考答案:B8、上、下四分位数在数据中所处的位置分别是()。
A.25%,50%C.50%,25% B.25%,75%D.75%,25%参考答案:D9、以下关于集中趋势测度描述错误的是:()A.众数是一组数据中出现次数最多的变量值B.中位数是一组数据按大小排序后,处于政中间位置上的变量值C.均值是全部数据的算术平均D.集合平均数是N 个变量值之和的N 次方根参考答案:D10、已知某企业1 月.2 月.3 月.4 月的平均职工人数分别为190 人.195 人.193 人和201 人。
统计学的上机实训报告

一、实习背景随着科学技术的飞速发展,统计学在各个领域的应用日益广泛。
为了提高我们对统计学软件的熟练程度,加深对统计学理论知识的理解,我们进行了为期两周的统计学上机实训。
本次实训以SPSS软件为主要工具,通过实际操作,掌握统计学数据处理和分析的基本技能。
二、实习目的1. 熟练掌握SPSS软件的基本操作,包括数据录入、数据管理、数据转换等。
2. 学习运用SPSS进行描述性统计、推断性统计和多元统计分析。
3. 培养统计学思维,提高数据分析和解决问题的能力。
三、实习内容1. 数据录入与数据管理(1)在SPSS中录入数据,包括数值型数据和分类数据。
(2)学习数据管理的基本操作,如数据筛选、排序、合并等。
(3)了解SPSS的数据视图和变量视图,掌握变量的定义和编辑。
2. 描述性统计(1)学习SPSS进行描述性统计,包括计算均值、标准差、中位数等。
(2)掌握描述性统计图表的制作,如直方图、饼图、散点图等。
(3)学习描述性统计的假设检验,如t检验、方差分析等。
3. 推断性统计(1)学习SPSS进行推断性统计,包括参数估计、假设检验等。
(2)掌握t检验、方差分析、卡方检验等常用统计方法。
(3)学习如何根据实际需求选择合适的统计方法,并进行结果解释。
4. 多元统计分析(1)学习SPSS进行多元统计分析,包括相关分析、回归分析等。
(2)掌握相关系数、回归系数等参数的计算方法。
(3)学习如何根据实际需求进行回归分析,并进行结果解释。
四、实习过程1. 前期准备(1)熟悉SPSS软件界面和基本操作。
(2)收集实际数据,进行数据预处理。
2. 实训操作(1)按照实习内容,依次进行数据录入、数据管理、描述性统计、推断性统计和多元统计分析。
(2)在操作过程中,遇到问题及时查阅资料,与同学和老师交流。
3. 结果分析与总结(1)对统计结果进行解释,分析数据背后的规律和现象。
(2)总结实训过程中的经验和教训,提高统计学应用能力。
五、实习成果1. 熟练掌握了SPSS软件的基本操作,能够独立进行数据录入、数据管理和统计分析。
统计学spss上机实验
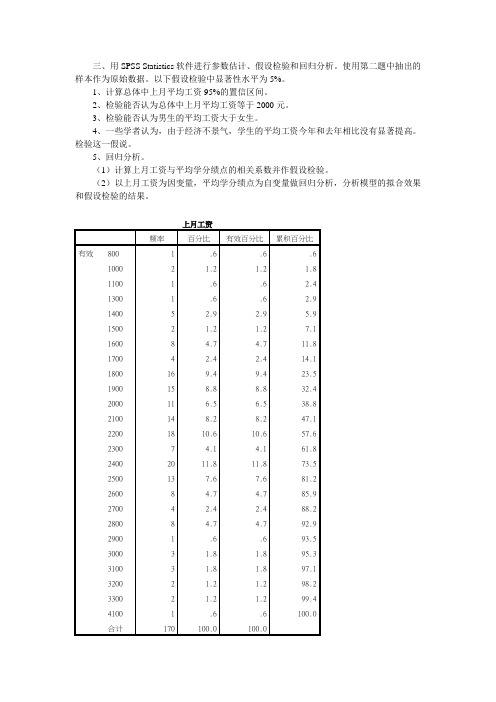
三、用SPSS Statistics软件进行参数估计、假设检验和回归分析。
使用第二题中抽出的样本作为原始数据。
以下假设检验中显著性水平为5%。
1、计算总体中上月平均工资95%的置信区间。
2、检验能否认为总体中上月平均工资等于2000元。
3、检验能否认为男生的平均工资大于女生。
4、一些学者认为,由于经济不景气,学生的平均工资今年和去年相比没有显著提高。
检验这一假说。
5、回归分析。
(1)计算上月工资与平均学分绩点的相关系数并作假设检验。
(2)以上月工资为因变量,平均学分绩点为自变量做回归分析,分析模型的拟合效果和假设检验的结果。
上月工资频率百分比有效百分比累积百分比有效800 1 .6 .6 .61000 2 1.2 1.2 1.81100 1 .6 .6 2.41300 1 .6 .6 2.91400 5 2.9 2.9 5.91500 2 1.2 1.2 7.11600 8 4.7 4.7 11.81700 4 2.4 2.4 14.11800 16 9.4 9.4 23.51900 15 8.8 8.8 32.42000 11 6.5 6.5 38.82100 14 8.2 8.2 47.12200 18 10.6 10.6 57.62300 7 4.1 4.1 61.82400 20 11.8 11.8 73.52500 13 7.6 7.6 81.22600 8 4.7 4.7 85.92700 4 2.4 2.4 88.22800 8 4.7 4.7 92.92900 1 .6 .6 93.53000 3 1.8 1.8 95.33100 3 1.8 1.8 97.13200 2 1.2 1.2 98.23300 2 1.2 1.2 99.44100 1 .6 .6 100.0合计170 100.0 100.0描述统计量标准误上月工资均值2188.24 37.059 均值的 95% 置信区间下限2115.08上限2261.395% 修整均值2183.01中值2200.00方差233470.240标准差483.188极小值800极大值4100范围3300四分位距600偏度.264 .186峰度 1.187 .370统计量上月工资N 有效170缺失0。
统计学上机习题
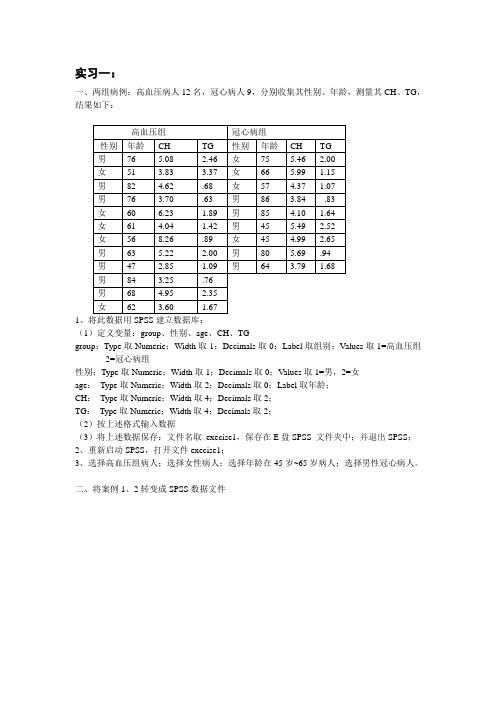
一、两组病例:高血压病人12名,冠心病人9,分别收集其性别、年龄,测量其CH、TG,结果如下:1(1)定义变量:group、性别、age、CH、TGgroup:Type取Numeric;Width取1;Decimals取0;Label取组别;Values取1=高血压组2=冠心病组性别:Type取Numeric;Width取1;Decimals取0;Values取1=男,2=女age:Type取Numeric;Width取2;Decimals取0;Label取年龄;CH:Type取Numeric;Width取4;Decimals取2;TG:Type取Numeric;Width取4;Decimals取2;(2)按上述格式输入数据(3)将上述数据保存:文件名取execise1,保存在E盘SPSS 文件夹中;并退出SPSS;2、重新启动SPSS,打开文件execise1;3、选择高血压组病人;选择女性病人;选择年龄在45岁~65岁病人;选择男性冠心病人。
二、将案例1、2转变成SPSS数据文件1.现检测出11名鼻咽癌患者的血清病毒VCA-LOG抗体滴度(kg)如下,请计算其倒数的对数值x;1:5 1:20 1:40 1:80 1:80 1:80 1:160 1:160 1:320 1:320 1:6402、某地80例健康男子血清总胆固醇值测定结果如下,请绘制频数表.4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.715.69 4.125.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.694.38 4.89 6.255.32 4.50 4.63 3.61 4.44 4.43 4.254.035.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.974.735.216.12 3.55 4.67 5.01 6.18 5.47 4.39 5.024.895.33 4.786.03 4.23 4.61 5.02 4.85 6.14 3.451、某农村地区1999年130名14岁女孩的身高资料(cm),请进行描述性统计分析。
统计学上机练习题

一、某医院收集了一批糖尿病患者,随机分成2组,对2组慢性肾炎病人分别用A药(group=1),和B药(group=0),评价指标为连续性变量,用Y表示(Y值越低表明疗效越好),结果见Stata文件(ex1X.dta,X=1,2,…,100)。
问这2种药物治疗慢性肾炎的疗效是否相同?依题意,本题属完全随机设计,所得指标数据为计量资料,且相互独立,在满足各自应具备的条件的前提下,可以对其进行两组计量资料的t检验或者完全随机设计资料的方差分析以推断两个样本所代表的两总体均数μ1,μ2是否相等。
首先,分别对两组计量资料进行正态性检验:(文件ex14)H0:资料正态分布H1:资料非正态分布α=0.05. sktest y if group==1Skewness/Kurtosis tests for Normality------- joint ------Variable | Pr(Skewness) Pr(Kurtosis) adj chi2(2) Prob>chi2-------------+-------------------------------------------------------y | 0.300 0.787 1.25 0.5357. sktest y if group==0Skewness/Kurtosis tests for Normality------- joint ------Variable | Pr(Skewness) Pr(Kurtosis) adj chi2(2) Prob>chi2-------------+-------------------------------------------------------y | 0.556 0.779 0.44 0.8028两组资料的正态性检验的P值均大于0.05,故认为两组资料分别服从正态分布。
其次,对两样被资料作方差齐性检验H0:σ12 =σ22 A 药组和B药组总体方差相同H1: σ12≠σ22 A药组和B药组总体方差不同α=0.10. sdtest y,by(group)------------------------------------------------------------------------------Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]---------+--------------------------------------------------------------------0 | 17 -.0260403 .4078132 1.681457 -.8905656 .8384851 | 22 .00305 .4315776 2.024279 -.8944648 .9005648---------+--------------------------------------------------------------------combined | 39 -.0096304 .2976478 1.85881 -.6121869 .5929261------------------------------------------------------------------------------Ho: sd(0) = sd(1)F(16,21) observed = F_obs = 0.690F(16,21) lower tail = F_L = F_obs = 0.690F(16,21) upper tail = F_U = 1/F_obs = 1.449Ha: sd(0) < sd(1) Ha: sd(0) ~= sd(1) Ha: sd(0) > sd(1)P < F_obs = 0.2265 P < F_L + P > F_U = 0.4368 P > F_obs = 0.7735两样本方差比F=0.690,P=0.4368>0.10,按α=0.10水准不拒绝H0,差别无统计学意义,尚不能认为两组总体方差不同。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学第一次上机实验一、上机项目名称:EXCEL、SPSS绘制统计图表二、上机时间:2011年10月 13日,下午14:00—15:50上机地点:基础楼综合实验室三、上机目的、内容、步骤及结果目的:掌握EXCEL、SPSS统计图表的基本操作内容:教材29页4题EXCEL;30页6题SPSS步骤及结果:○1 29页4题EXCEL:1、打开Nielsen的excel表格,并在相应位置输入TV Show、Millionaire、Frasier、Charmed、Chicago Hope、total、 frequency、relative frequency、percent frequency。
2、在Millionaire后的frequency中输入——函数——COUNTIF——range(所有的数组)——CRITERIE(C2)——确定,单元格中显示Millionaire的频数,并以此用此法求出Frasier、Charmed、Chicago Hope的频数。
3、在Millionaire后的relative frequency中输入=Millionaire 的frequency数值/50,得到Millionaire的相对频数。
并依次据此求出Frasier,Charmed,Chicago Hope,total的相对频数。
4、在Millionaire后的umulative frequency中输入=Millionaire 的relative frequency数值*100,得到Millionaire的百分频数,并据此求出Frasier,Chicago Hope,Charmed的百分频率。
5、选中名称列及频数所在的列单击插入——图表,分别插入二维柱形图和饼形图。
EXCEL 表格如下:TV Show frequencyrelativefrequencypercentfrequency Millionaire 24 0.48 48% Frasier 15 0.3 30% Charmed 4 0.08 8% ChicagoHope 7 0.14 14% total 50 1 100% Bar graph如下:Pie chart如下:○2 30页6题SPSS:1、打开spss,打开——数据,更改数据格式为xls,打开数据找到book文件并打开。
2、依次点击分析——描述统计——频率,得到如下的SPSS表格。
3、从如下表格中找到相应的频数和频率。
Book频率百分比有效百分比累积百分比有效7 Habits 10 16.7 16.7 16.7 Dad 13 21.7 21.7 38.3Dummies 2 3.3 3.3 41.7Milliona16 26.7 26.7 68.3ireMotley 9 15.0 15.0 83.31 1.7 1.7 85.0ParachuteTax3 5.0 5.0 90.0Guide6 10.0 10.0 100.0WSJGuide合计60 100.0 100.0四、上机心得体会:在学习统计学知识之前,在中学时期也多少接触过excel的函数应用等知识,并用此来计算平均数、加和等简单的函数计算。
涉猎了系统的统计学知识后,我常常为那些繁琐的计算头疼。
其实统计学并不难,只要细心,并能够踏实的计算下去,学好统计学不算难,通过了上机老师的教授和实际的操作,我发现原来统计学可以用如此简洁的方法获得结果,在惊叹excel、spss等工具带来巨大方便的同时,也对统计学产生了更为浓厚的兴趣。
统计学第二次上机实验一、上机项目名称:EXCEL、SPSS做单变量描述性统计指标计算二、上机时间:2011年10 月 20日,下午14:00—15:50上机地点:基础楼综合实验室三、上机目的、内容、步骤及结果目的:掌握统计软件单变量描述性指标计算的功能内容:教材80页5题或81页7题EXCEL单变量值结果输出;教材88页19题EXCEL和SPSS描述性统计指标统一输出。
步骤及结果:○1 80页5题EXCEL:1、打开acctsal的excel文件,件,任选一列,依次输入mean,median, mode, sample variance, sample standard deviation, Q1, Q3, IQR,5th percentile.2、插入—函数—统计—average—选择要计算的数值区域—确定—meanMedian—选择要计算的数值区域—确定—MedianMode—选择要计算的数值区域—确定— modequartile —选择要计算的数值区域+1—确定—Q1quartile —选择要计算的数值区域+3—确定—Q3percentile—选择要计算的数值区域+0.2—percentile(20)skewness—选择要计算的数值区域—确定—skewness所得图表如下,从该图表中可以读出想要的结果。
○2 88页19题EXCEL和SPSS:1、打开notebook、依次点击“工具”、“数据分析”、“描述统计”、选择数据源,标志位于第一行,默认95%的置信区间点击“确定”。
得到如下表格:2、打开spss,打开,数据,更改数据格式——xls,打开数据找到notebook文件并打开,点击分析——描述统计——探索——overall rating转入因变量,得到如下表格:统计量标准误Overall Rating 均值78.47 1.400 均值的 95% 置信区间下限75.46上限81.475% 修整均值78.35中值78.00方差29.410标准差 5.423极小值67极大值92范围25四分位距 3偏度.542 .580峰度 2.983 1.121四、上机心得体会:通过了不断的上机操作演练,我开始将上课老师讲到的一步步的检验,并取得了很大的成效。
在越来越熟悉excel和spss环境的同时,我学到了更多的分析数据、处理数据的操作方法,并能够整体的分析样本的数据特征,收获颇丰。
统计学第三次上机实验一、上机项目名称:EXCEL二项、正态概率计算和随机抽样二、上机时间:2010年10 月27 日,下午14:00—15:50上机地点:基础楼综合室三、上机目的、内容、步骤及结果目的:掌握和体会EXCEL统计软件的强大计算功能内容:教材197页27题结果输出;教材231页24题结果输出步骤及结果:○1197页27题:1、打开一个excel表格,任选一列单元格,依次输入x 0—20。
2、在x右边的单元格中输入f(x),再在旁边输入p(x≤X).3、在f(x)列插入函数BINOMDIST(taials=20,probability-s=0.7,cumulative=false)4、在p(x≤X)列插入函数BINOMDIST(taials=20,probability-s=0.7,cumulative=TRUE)——(1)5、p(x≥X)=1-p(x≤X).○2231页24题:1、打开excel,新建一个空白表格。
2、输入相应的数据。
其中mean——AVERAGE,standard deviation——STDEV p(x≤800)——NORMDIST(X=800,cumulative=TRUE)p(X≤x0)=0.95——NORMINV(probability=0.95)3、输出以下表格,并从中找到结果。
四、上机心得体会:在本次实验操作中,我学会了利用excel进行更为复杂的数据分析和计算。
通过对这个软件的不断深入学习,我对于统计学的兴趣越来越深,同时因为省掉了大量繁琐的计算,我开始习惯于用excel 进行一些复杂的计算,节省了大量的时间和精力。
统计学第四次上机实验一、上机项目名称:用EXCEL、SPSS进行均值的区间估计二、上机时间:2010年11 月3 日,下午14:00—15:50上机地点:基础楼综合实验室三、上机目的、内容、步骤及结果目的:掌握统计软件进行区间估计的功能内容:教材294页9、11题、302页19题EXCEL结果输出;教材294页12题、302页22题SPSS结果输出步骤和结果:○1 294页9、11题:1、打开EXCEL,新建一个空白电子表格,导入老师提供的相应数据。
2、插入AVERAGE函数,计算样本均值sample mean。
3、插入STDEV函数,计算margin of error。
4、插入Confidence函数,计算lower limit,upper limit。
5、得到结果如下图所示:第 9 题.第11题.○2294页12题:1、打开SPSS,导入老师提供的相应数据。
2、依次点击分析——描述统计——探索,出现对话框。
把“两者都”换成“统计量”,根据题目要求更改置信区间,点击确定。
3、得到结果如下图所示:案例处理摘要描述○3302页22题:1.打开SPSS,导入老师提供相应数据“sleep.xls”。
2.依次点击分析——比较均值——单样本T检验,点击选项,根据题目要求更改置信区间,点击继续,确定。
3.得到结果如下图所示:T检验单个样本统计量单个样本检验四、上机心得体会:总共四节的上机操作课就此结束。
在这四节课中,我对excel、spss有了大致的了解,我渐渐的在数据之中摸索到规律,在学习中队数据产生了极大的兴趣与理解。
我相信,无论是在今后的学习还是生活中,统计学都会起着举足轻重的地位,所以,掌握好这些知识的重要性自然凸显出来,对它的掌握将是受益终身。