日常nbu检查
NBU用户监控指南

NBU用户监控指南目录1VERITAS Netbackup日常维护知识 (2)1.1 检查NetBackup的进程 (2)1.2 检查带机的状态 (2)1.3 检查备份作业的完成情况 (2)1.4 检查磁带的使用情况 (2)1.5 VERITAS Netbackup Trouble Shooting (2)2任务监视器(Activity Monitor) (3)2.1 Activity Monitor的界面 (3)2.2 使用Activity Monitor (3)2.2.1 任务监视器作用 (3)2.2.2 查看任务细节 (4)3NetBackup报告 (5)4设备管理(device manager) (5)5介质管理 (6)5.1 如何启动介质管理 (6)6管理NetBackup进程 (8)6.1 用bpps显示NetBackup目前正在运行的进程 (8)6.2 启动NetBackup进程 (8)6.3 停止NetBackup进程 (8)1VERITAS Netbackup日常维护知识NetBackup的日常维护包括检查NetBackup的进程,检查带机的状态;检查备份作业的完成情况;检查磁带的使用情况。
1.1 检查NetBackup的进程# /usr/openv/netbackup/bin/bpps –a使用这条命令可以察看到NetBackup的所有进程状况是否正在运行。
1.2 检查带机的状态检查带机可以通过图形界面来察看。
在NetBackup的JA V A界面上,点击Device Monitor图标,选择需要察看带机的media server,在control栏目下显示了带机的状态。
1.3 检查备份作业的完成情况检查备份作业的完成情况也可以通过图形界面来察看。
在NetBackup的JA V A界面点击Activity Monitor图标,可以看到所有列出来的备份作业的情况,包括正在进行的作业和已经完成的作业;另外可以通过reports里面的Backup Status选项来察看备份作业完成后的返回值。
ICU常见检查项目及分析ppt课件

含量 35% 18% 35% 7% 5%
意义:受血浆蛋白、Hb、呼吸因素和电解质影响,目前认为不能 确切反映代谢酸碱内稳情况
血气酸碱分析的临床应用
• 单纯性酸碱失衡 • 双重性酸碱失衡
呼吸性酸中毒
代谢性酸中毒
呼吸性碱中毒
代谢性碱中毒
混合性代谢性酸中毒:高AG代酸+高氯性代酸
临床血气分析符号、名称和 正常值
符号 PH PaO2 PaCO2 HCO3- (AB) SB BB BE CO2 CP SaO2
名称 酸碱度 动脉血氧分压 动脉血二氧化碳分压 碳酸氢根浓度 标准碳酸氢根浓度 缓冲碱 剩余碱 二氧化碳结合力 氧饱和度(动脉血)
正常范围 7.35-7.45 80-100mmHg 35-45mmHg 22-27mmol/L 24mmol/L 45-55mmol/L ±3mmol/L 22-29mmol/L 98%
龄)mmHg 年龄参考公式: A-aDO2 = 2.5 +(0.21×年
意义: 1) 判断肺换气功能( 静动脉分流、V/Q、呼吸膜弥散)
2)判断低氧血症的原因:
a)显著增大,且PaO2 明显降低(<60mmHg),吸纯氧时 不能纠正,考虑肺内短路,如肺不张 和 ARDS
b)轻中度增大,吸纯氧可纠正,如慢阻肺
• 三重性酸碱失衡(TABD) :一种呼吸性失衡,同时有 高AG代酸和代碱
酸碱平衡判断的四步骤
据pH、PaCO2、HCO3-变化判断原发因素
据所判断的原发因素选用相关的代偿公式
据实测HCO3-/PaCO2与相关公式所计算出的代偿区间 相比,确定是单纯常或规混检验合项酸目碱失衡
高度怀疑三重酸碱失衡(TABD)的,同时测电解质, 计算AG和潜在HCO3-,判断TABD
nbu备份解决方案

引言在当今的信息化时代,数据备份成为企业必不可少的一项工作。
而NBU (NetBackup)作为一款优秀的备份解决方案,被广泛应用于各行各业。
本文旨在介绍NBU备份解决方案的基本原理和使用方法,以及常见问题的解决方案。
1. NBU备份解决方案概述1.1 NBU是什么?NBU是Symantec公司开发的一款备份和恢复软件,它能够提供稳定可靠的数据备份和恢复功能。
通过NBU,用户可以方便地实现数据的保护和灾难恢复。
1.2 NBU的工作原理NBU的工作原理可以简单概括为以下几个步骤:1.定义备份策略:用户可以通过NBU的管理界面定义备份策略,包括备份的时间、频率、备份对象等。
2.执行备份作业:根据备份策略,在预定的时间点开始执行备份作业。
NBU 会自动调度和管理备份作业的执行过程。
3.数据传输:NBU通过网络将备份数据传输到备份服务器,然后存储到磁盘库或者磁带库中。
4.数据恢复:当需要恢复数据时,用户可以通过NBU的管理界面选择相应的备份集进行恢复操作。
1.3 NBU的优势NBU备份解决方案具有以下几个优势:•高效稳定:NBU采用了并行备份技术,能够快速备份大量数据,提高备份效率。
•灵活可靠:NBU支持多种备份介质,包括磁盘和磁带,并提供了多种备份策略的选择,满足用户不同需求。
•安全性强:NBU支持数据加密和身份验证等安全措施,保护备份数据的机密性和完整性。
2. NBU备份解决方案的使用方法2.1 安装和配置NBU首先,用户需要在服务器上安装NBU软件,并根据实际情况进行基本配置,包括存储介质的选择、备份策略的定义等。
2.2 创建备份策略在NBU管理界面中,用户可以通过创建备份策略来定义备份对象、备份时间和频率等。
同时,用户还可以选择备份类型,如全量备份、增量备份或差异备份。
2.3 执行备份作业根据预定的备份策略,NBU会自动调度和执行备份作业。
在备份过程中,用户可以监控和管理备份作业,如暂停、终止或重新排队等。
ICU常见检查项目及分析课件

ICU常见检查项目及分析课件一、概览当我们谈论ICU,也就是重症加强护理病房的时候,可能很多人都会觉得这是一个充满医学高科技和生命奇迹的地方。
确实ICU是医院里对病情严重、需要密切观察和治疗的病人的特殊护理区域。
在这里医生们会进行一系列的检查来评估病人的状况,以便进行针对性的治疗。
今天我们就来简单了解一下ICU中常见的检查项目及分析。
走进ICU,你可能会看到各种复杂的设备和仪器,这些都是为了帮助医生更好地了解病人的病情。
心电图、血压计、呼吸机等都是常见的检查工具。
它们看似复杂,但其实都是为了帮助我们更深入地了解病人的身体状况。
1. 介绍ICU(重症加强护理病房)的概念与重要性ICU并不是普通人想象中那么神秘和遥不可及的地方。
简单地说它是医院里一个特殊的病房,专门为病情严重的病人准备的。
在这里病人可以得到全方位的监护和治疗,就像被重点照顾的VIP一样。
医生和护士会密切监测病人的生命体征,比如心跳、呼吸、血压等,确保病情随时得到控制和处理。
当我们的身体出现重大问题时,ICU就像是我们的强力后盾,给我们足够的时间和机会恢复健康。
ICU的专业性在于它的先进设备和训练有素的医护团队,在这里抢救成功率会比普通病房高很多。
特别是在某些紧急情况下,ICU的重要性就体现得淋漓尽致了。
比如重大手术后的病人、意外受伤的危重患者等,都需要ICU的精准治疗和精心护理。
所以说啊ICU是医院里不可或缺的一部分,它关乎着每一个生命的安全与健康。
在这里我们能够感受到医疗技术的进步与生命的尊严并行,我们要认识到ICU的重要性,它关乎我们的生命安全啊。
接下来我们会介绍ICU里常见的检查项目以及它们的意义。
让我们更加了解这个特殊的地方。
2. 阐述常见检查项目在ICU中的作用及意义当我们谈论ICU时,这不仅仅是一个医学名词那么简单,它背后涉及到的是关乎生命的种种细节。
ICU中的检查项目,每一个都有其独特的作用和意义。
现在让我们深入了解几个常见的检查项目在ICU 中的重要作用。
NBU故障解决

之前备份是正常的。
虚拟带库重启后,备份时提示:Robotic library is down on server“驱动器显示”里驱动器是UP状态,但在驱动器控制这一栏由原先的TLD变为了AVR查看驱动器时提示“Unable to update drive path infromation. A SCSI inquiry sent to the device has Failed(16)”。
重启过MasterServer,但问题依旧。
原因是虚拟带库重启后,与之相连的两台小机Media Server不能正常找到虚拟带库的驱动器及机械手。
进入两台小机,输入-ioscan -fuC tape和-ioscan后,就找到了与其相连虚拟带库上的驱动器及机械手。
(如果还找不到就多试几次)重启Master Server及Media Server上的NBU服务,并在主服务器上“Robots”那里右键—》“inventory Robot”之后,就可以正常备份了。
nbu备份报robotic library is down on serverRobotic library is down 表示磁带库有问题,检查一下磁带库的状态是否正常,机房人员检查之后确认是正常的4、在nbu的图形界面,重新扫描硬件,点击Configure Storage Devices后,一直点击next,直到finish手工发起备份报错如下06/19/2008 09:02:29 - requesting resource r3prd-hcart2-robot-tld-006/19/2008 09:02:29 - requesting resource bkup.NBU_CLIENT.MAXJOBS.r3prd06/19/2008 09:02:29 - requesting resource bkup.NBU_POLICY.MAXJOBS.r3_db_arch06/19/2008 09:02:30 - awaiting resource r3prd-hcart2-robot-tld-0. Waiting for resources.Reason: Robotic library is down on server, Media server: r3prd,Robot Type(Number): TLD(0), Media ID: N/A, Drive Name: N/A,Volume Pool: DB_r3_arch, Storage Unit: r3prd-hcart2-robot-tld-0, Drive Scan Host: N/A提示机械臂down掉了,使用ioscan检查带库状态#[/]ioscan -fnCtapeClass I H/W Path Driver S/W State H/W Type Description==========================================================================tape 0 0/1/1/1.2.0 stape CLAIMED DEVICE HP C5683A/dev/rmt/0m /dev/rmt/0mnb /dev/rmt/c3t2d0BESTn /dev/rmt/c3t2d0DDSb/dev/rmt/0mb /dev/rmt/c3t2d0BEST/dev/rmt/0mn /dev/rmt/c3t2d0BESTb /dev/rmt/c3t2d0DDS /dev/rmt/c3t2d0DDSnbtape 3 0/4/1/0.97.26.255.1.3.0 stape CLAIMED DEVICE HP Ultrium 2-SCSI/dev/rmt/3m /dev/rmt/3mn /dev/rmt/c18t3d0BEST /dev/rmt/c18t3d0BESTn/dev/rmt/3mb /dev/rmt/3mnb /dev/rmt/c18t3d0BESTb /dev/rmt/c18t3d0BESTnbtape 7 0/4/1/0.97.26.255.1.3.1 stape CLAIMED DEVICE HP Ultrium 2-SCSI/dev/rmt/4m /dev/rmt/4mn /dev/rmt/c18t3d1BEST /dev/rmt/c18t3d1BESTn/dev/rmt/4mb /dev/rmt/4mnb /dev/rmt/c18t3d1BESTb /dev/rmt/c18t3d1BESTnbtape 5 0/4/1/1.97.25.255.1.3.1 stape NO_HW DEVICE HP Ultrium 2-SCSI/dev/rmt/5m /dev/rmt/5mn /dev/rmt/c13t3d1BEST /dev/rmt/c13t3d1BESTn/dev/rmt/5mb /dev/rmt/5mnb /dev/rmt/c13t3d1BESTb /dev/rmt/c13t3d1BESTnbtape 6 0/4/1/1.97.25.255.1.3.2 stape NO_HW DEVICE HP Ultrium 2-SCSI/dev/rmt/6m /dev/rmt/6mn /dev/rmt/c13t3d2BEST /dev/rmt/c13t3d2BESTn/dev/rmt/6mb /dev/rmt/6mnb /dev/rmt/c13t3d2BESTb /dev/rmt/c13t3d2BESTnb发现其中一块光纤卡上的两个设备连接不上了,再查看光纤卡的状态#[/]ioscan -fnCfcClass I H/W Path Driver S/W State H/W Type Description=================================================================fc 0 0/4/1/0 fcd CLAIMED INTERFACE HP 2Gb Dual Port PCI/PCI-X Fibre Channel Adapter (Port 1)/dev/fcd0fc 1 0/4/1/1 fcd CLAIMED INTERFACE HP 2Gb Dual Port PCI/PCI-X Fibre Channel Adapter (Port 2)/dev/fcd1光纤卡状态正常。
solaris系统日常维护命令

solaris系统日常维护命令solaris系统日常维护命令(一)一、 Cluster操作命令:1、 scstat -i检查公共网络的状态2、 ccp clustername启动gui控制台3、 click cconsole. crlogin. ctelnet启动管理界面4、 scsetupcli的管理界面5、 showrev -p显示 Sun Cluster 修补程序信息6、 scinstall -pv显示Sun Cluster 发行版本号以及所有Sun Cluster 软件包的版本信息7、 scrgadm –p显示为群集schost 配置的资源类型(RT Name)、资源组(RG Name) 和资源(RS Name)8、 scstat -p群集组件状态信息9、 scconf -p群集配置,10、 sccheck检查配置11、 scshutdown -g0 -y关闭整个cluster 到ok 态12、 boot单系统启动,接着将分配配额13、 scstat -n#验证引导节点时未发生错误,而且节点现在处于联机状态。
scstat(1M) 命令报告节点状态。
-D 列出磁盘设备组的配置14、 scswitch -S -h nodelist-S 从指定的节点中清空所有的设备服务和资源组。
-h nodelist 指定从中切换资源组和设备组的节点。
15、 scswitch -F -D disk-device-group-F 使磁盘设备组脱机。
-D disk-device-group 指定要脱机的设备组。
16、 pnmstat -l检验该NAFO 组的状态17、 scstat –g资源组oracle及其所有资源状态18、 scstat –D磁盘资源ipasdg状态19、 vxdg listvolume状态20、资源组切换命令把C网数据库资源组切换到hnappscswitch -z -g c-ora-rg -h hnapp把C网数据库资源组切换到hnorascswitch -z -g c-ora-rg -h hnora#把c网应用资源组切换到hngorascswitch -z -g c-app-rg -h hngora#把c网应用资源组切换到hnapproot@hnapp # scswitch -z -g c-app-rg -h hnapp #把G网应用资源组切换到hnapproot@hngora # scswitch -z -g g-app-rg -h hnapp#把G网应用资源组切换到hngoraroot@hngora # scswitch -z -g g-app-rg -h hngora #把G网数据库资源组切换到hngoraroot@hngora # scswitch -z -g g-ora-rg -h hngora21、启动/关闭资源组的资源启动G网数据库资源及监控功能# scswitch -e -j g-ora-server-rs# scswitch -e -j g-ora-lsnr-rs# scswitch -e –M –j g-ora-server-rs# scswitch -e –M –j g-ora-lsnr-rs关闭资源# scswitch -n -j g-ora-server-rs# scswitch -n -j g-ora-lsnr-rs# scswitch -n -j g-ora-server-rs# scswitch -n -j g-ora-lsnr-rs22、启动/关闭/重启资源组# scrgadm –Z –g test-ora-rg/ scswitch –F/-R –g test-ora-rg23、 scswitch –Z –g oracle启动资源组oracle24、 pnmstat -p查看NAFO情况。
Veritas NBU系统检查

/Veritas NBU系统检查(Release 4.5GA)用户:贵州移动创建日期:2005年7月14 日创建人:北京华胜天成科技股份有限公司文档控制部分修改记录审阅分发控制基本信息记录主机信息ACS:Automated Cartridge System-StorageTekHost Bus Adapters(备注:LAN备份)Bridges and Routers(备注:无)Switchs(备注:无)/oracle/app/oracle9/product/9.2.0/scripts/hot_archiver_backup.sh/oracle/app/oracle9/product9.2.0/scripts/hot_tablespace_backup_tools.sh/oracle/app/oracle9/product/9.2.0/scripts/hot_archiver_backup.sh/oracle/app/oracle9/product/9.2.0/scripts/hot_tablespace_backup_SYSTEM.sh/oracle/hot_database_backup.shOracle数据库:Oracle归档日志Archive_log:归档日志备份完毕后删除此归档日志。
<收集><收集>系统现状态分析/usr/openv/netbackup/logs系统分析:考虑用户/usr/openv/…建立在根slice,系统根区的利用率50%-70%。
因此需要用户注意此部分的log信息。
当log占满系统的根区后,对操作系统而言,无法再启动新的Process 和Jobs,会影响用户系统备份。
建议:用户在有条件情况下,建议重新规划系统的分区。
/usr/openv/netbackup/bin/bpps –a<记录2005年7月12日>root@GZBACKUP # ./bpps -aNB Processes------------root 824 1 0 Jul 05 ? 0:28 /usr/openv/netbackup/bin/bprdroot 897 1 0 Jul 05 ? 0:36 /usr/openv/netbackup/bin/bpdbmroot 1484 954 0 16:26:46 pts/9 0:01 xbproot 993 954 0 16:20:23 pts/9 0:01 xbproot 899 897 0 Jul 05 ? 0:11 /usr/openv/netbackup/bin/bpjobdroot 20302 1 0 15:00:23 ? 0:01 /usr/openv/netbackup/bin/bpjava-susvc root 0 -1 C /usr/openv/java/auth.conf 1 2root 758 1 0 16:18:45 ? 0:00 /usr/openv/netbackup/bin/bpjava-susvc root 0 -1 C /usr/openv/java/auth.conf 1 7root 20261 20239 0 15:00:07 pts/2 2:08 /usr/openv/java/jre/bin/../bin/sparc/native_threads/java -Djava.library.path=/uroot 722 699 0 16:18:26 pts/7 0:22 /usr/openv/java/jre/bin/../bin/sparc/native_threads/java -Djava.library.path=/uMM Processes------------root 811 1 0 Jul 05 ? 0:20 /usr/openv/volmgr/bin/ltidroot 903 811 0 Jul 05 ? 0:55 avrd -vroot 843 1 0 Jul 05 ? 0:20 vmd -vroot 900 811 0 Jul 05 ? 0:02 tldd -vroot 952 1 0 Jul 05 ? 0:02 tldcd –v#/usr/openv/volmgr/bin/tpconfig –dl<记录2005年7月12日16:31>带库维修中root@GZBACKUP # ./tpconfig -dlCurrently defined drives and robots are:Drive Name QUANTUMDLT80000Index 0NonRewindDrivePath /dev/rmt/9cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=1Drive Name QUANTUMDLT80001Index 1NonRewindDrivePath /dev/rmt/5cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=2Drive Name QUANTUMDLT80002Index 2NonRewindDrivePath /dev/rmt/8cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=3Drive Name QUANTUMDLT80003 Index 3 NonRewindDrivePath /dev/rmt/7cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=4Drive Name QUANTUMDLT80004 Index 4 NonRewindDrivePath /dev/rmt/4cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=5Drive Name QUANTUMDLT80005 Index 5 NonRewindDrivePath /dev/rmt/11cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=6Drive Name QUANTUMDLT80006 Index 6 NonRewindDrivePath /dev/rmt/3cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=7Drive Name QUANTUMDLT80007 Index 7 NonRewindDrivePath /dev/rmt/10cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=8Drive Name QUANTUMDLT80008Index 8NonRewindDrivePath /dev/rmt/2cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=9Drive Name QUANTUMDLT80009Index 9NonRewindDrivePath /dev/rmt/12cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=10Drive Name QUANTUMDLT800010Index 10NonRewindDrivePath /dev/rmt/1cbnType dlt2Status DOWNShared Access NoTLD(0) Definition DRIVE=11Drive Name QUANTUMDLT800011Index 11NonRewindDrivePath /dev/rmt/6cbnType dlt2Status UPShared Access NoTLD(0) Definition DRIVE=12Currently defined robotics are:TLD(0) robotic path = /dev/sg/c16t0l0,volume database host = GZBACKUP/usr/openv/volmgr/bin/vmpool –listall<记录2005年7月12日>root@GZBACKUP # ./vmpool -listall=========================================================== pool number: 0pool name: Nonedescription: the None pool (for anyone)pool host: ANYHOSTpool user: ANYpool group: NONE===========================================================pool number: 1pool name: NetBackupdescription: the NetBackup poolpool host: ANYHOSTpool user: 0 (root)pool group: NONE===========================================================pool number: 4pool name: scratchdescription: Scratch Poolpool host: ANYHOSTpool user: 0 (root)pool group: NONE===========================================================pool number: 2pool name: tempdescription: Temporary Poolpool host: ANYHOSTpool user: ANYpool group: NONE===========================================================pool number: 3pool name: rawbilldescription: Raw Bill Poolpool host: ANYHOSTpool user: ANYpool group: NONE===========================================================pool number: 5pool name: filesystemdescription: Config & File Data Poolpool host: ANYHOSTpool user: ANYpool group: NONE===========================================================pool number: 6pool name: oradatadescription: Oracle Database Poolpool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 7pool name: errordescription: ----pool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 8pool name: test-e12kdescription: test backup e12k file and dbpool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 10pool name: oradata3description: ----pool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 11pool name: DataStoredescription: the DataStore poolpool host: ANYHOSTpool user: 0 (root)pool group: NONE=========================================================== pool number: 12pool name: sybasedatadescription: jinqianka backuppool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 13pool name: newcust1860description: it is for 1860pool host: ANYHOSTpool user: ANYpool group: NONE=========================================================== pool number: 14pool name: oradata_newdescription: oradata_newpool host: ANYHOSTpool user: ANYpool group: NONE========================================================== pool number: 16pool name: oradata4description: NSALESDB backuppool host: ANYHOSTpool user: ANYpool group: NONE===========================================================/usr/sbin/modinfo | grep sg<记录:2005年7月13日>140 784bc000 302d 273 1 sg (SCSA Generic Revision: 3.4d)系统Driver状态<记录:2005年7月13日15:54>DLT80008 Driver_DownDLT800010 Driver_Down/usr/openv/netbackup/bin/admincmd/bpconfig –l/usr/openv/netbackup/bin/admincmd/bpdbjobs<记录2005年7月12日16:31>root@GZBACKUP # ./bpconfig -l*NULL* 10 12 99 2 28 0 0 0 0 1 24 1 0 2bpdbjobs_list检查policy的信息/usr/openv/netbackup/bin/admincmd/bpimmedia –policy <policy_name><记录2005年7月日>Policy_Name:rawbill_gzbill_ap1_arcbpimmedia_Policy信息记录问题描述:检查Netbackup的备份和归档文件/usr/openv/netbackup/bin/bplist –l<记录2005年7月日>root@GZBACKUP # ./bplist -ldrwxr-xr-x root bin 0 Jul 10 18:07 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jul 10 01:10 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jul 10 00:06 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jul 03 01:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jul 03 00:00 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jun 26 00:09 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jun 19 00:03 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jun 12 18:06 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jun 12 00:02 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jun 05 00:02 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 29 00:10 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 22 00:09 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 15 18:20 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 15 00:05 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 08 00:05 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 May 01 00:05 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Apr 24 00:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Apr 17 18:08 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Apr 17 00:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Apr 10 00:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Mar 26 22:57 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Mar 20 18:03 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Mar 20 00:00 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Mar 13 00:00 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Mar 06 00:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Feb 27 00:00 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Feb 20 18:04 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Feb 20 00:00 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Feb 13 00:09 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Feb 06 00:09 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jan 30 00:09 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jan 23 18:10 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jan 22 22:35 /opt/openv/netbackup/bin/ drwxr-xr-x root bin 0 Jan 16 00:09 /opt/openv/netbackup/bin/检查Netbackup的介质状态/usr/openv/netbackup/bin/admincmd/bpmedialist –summary/usr/openv/netbackup/bin/admincmd/bpmedialist –mlist/usr/openv/netbackup/bin/admincmd/bpmedialist –count<记录2005年7月日>./bpmedialist –summary<记录>bpmedialist_summary./bpmedialist –mlist<记录>bpmedialist_mlistSummary by retention level of ALL mediaLevel # Media Megabytes0 2 1866.31 110 11804431.53 1 507.44 4 269876.29 168 5641494.6检查Netbackup的Policy的特性信息/usr/openv/netbackup/bin/admincmd/bpplinfo <policy_name> -L|-l <记录2005年7月12日>root@GZBACKUP # ./bpplinfo rawbill_gzbill_ap1_arc -LPolicy Type: Standard (0)Active: yesEffective: 01/01/1970 08:00:00Follow NFS Mounts: noCross Mount Points: noClient Compress: noCollect TIR info: noPolicy Priority: 0Ext Security Info: noFile Restore Raw: noClient Encrypt: noMax Jobs/Policy: UnlimitedMult. Data Stream: noFrozen Image: noBackup Copy: 0Disaster Recovery: 0Max Frag Size: 0 MB (unlimited)Residence: TapeLib-L700V olume Pool: rawbillPolicy Type: Standard (0)Active: yesEffective: 01/01/1970 08:00:00Follow NFS Mounts: noCross Mount Points: noClient Compress: noCollect TIR info: noPolicy Priority: 0Ext Security Info: noFile Restore Raw: noClient Encrypt: noMax Jobs/Policy: UnlimitedMult. Data Stream: noFrozen Image: noBackup Copy: 0Disaster Recovery: 0Max Frag Size: 0 MB (unlimited)Residence: TapeLib-L700V olume Pool: rawbill………………………………….<记录:2005年7月日15:03>采样100次,每次间隔1秒:tin tout kps tps serv kps tps serv kps tps serv kps tps serv us sy wt id0 80 0 0 0 0 0 0 0 0 0 0 0 0 37 29 28 60 236 0 0 0 0 0 0 0 0 0 0 0 0 38 24 27 100 80 0 0 0 0 0 0 0 0 0 0 0 0 38 27 27 80 80 0 0 0 0 0 0 0 0 0 0 0 0 36 21 31 120 80 0 0 0 0 0 0 0 0 0 0 0 0 36 23 31 100 80 0 0 0 0 0 0 24 1 15 0 0 0 37 24 30 100 80 0 0 0 0 0 0 0 0 0 0 0 0 40 22 30 80 80 0 0 0 0 0 0 1 1 15 0 0 0 41 26 24 80 80 0 0 0 0 0 0 8 1 13 0 0 0 52 21 21 60 80 0 0 0 0 0 0 9 1 18 0 0 0 50 29 18 30 80 0 0 0 0 0 0 109 14 12 0 0 0 52 28 17 30 80 0 0 0 0 0 0 17 2 7 0 0 0 34 24 30 120 80 0 0 0 0 0 0 0 0 0 0 0 0 38 24 28 90 80 0 0 0 0 0 0 43 5 27 0 0 0 40 22 28 90 80 0 0 0 0 0 0 0 0 0 0 0 0 37 22 31 100 80 0 0 0 0 0 0 96 3 23 0 0 0 35 27 27 100 80 0 0 0 0 0 0 0 0 0 0 0 0 38 22 33 70 80 0 0 0 0 0 0 0 0 0 0 0 0 37 25 27 110 80 0 0 0 0 0 0 0 0 0 0 0 0 38 25 28 9 运行备份任务n_ora9_sales1_arcrawbill_gzblc_arc……系统各个Policy的Policy Priority均为0,因此,系统若在备份情况下,当多个Policy 启动Jobs,会出现系统资源互相竞争问题。
NBU基础知识整理
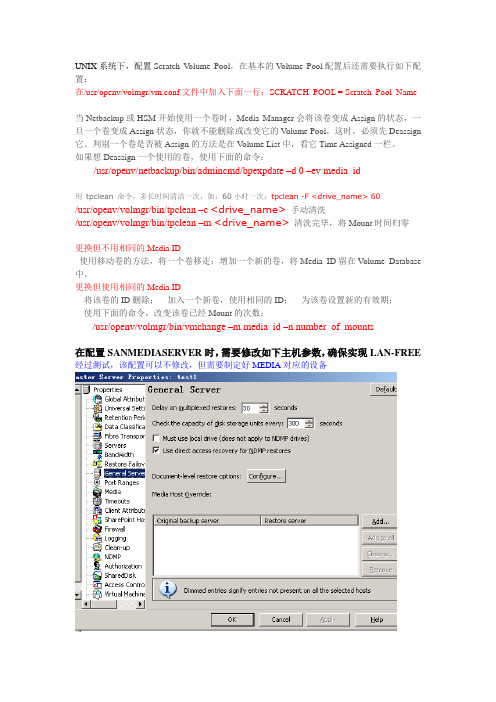
UNIX系统下,配置Scratch V olume Pool,在基本的V olume Pool配置后还需要执行如下配置:在/usr/openv/volmgr/vm.conf文件中加入下面一行:SCRATCH_POOL = Scratch_Pool_Name当Netbackup或HSM开始使用一个卷时,Media Manager会将该卷变成Assign的状态,一旦一个卷变成Assign状态,你就不能删除或改变它的V olume Pool,这时,必须先Deassign 它。
判别一个卷是否被Assign的方法是在Volume List中,看它Time Assigned一栏。
如果想Deassign一个使用的卷,使用下面的命令:/usr/openv/netbackup/bin/admincmd/bpexpdate –d 0 –ev media_id用tpclean 命令,多长时间清洁一次,如:60小时一次:tpclean -F <drive_name> 60/usr/openv/volmgr/bin/tpclean –c <drive_name>手动清洗/usr/openv/volmgr/bin/tpclean –m <drive_name>清洗完毕,将Mount时间归零更换但不用相同的Media ID使用移动卷的方法,将一个卷移走;增加一个新的卷,将Media ID留在V olume Database 中。
更换但使用相同的Media ID将该卷的ID删除;加入一个新卷,使用相同的ID;为该卷设置新的有效期;使用下面的命令,改变该卷已经Mount的次数:/usr/openv/volmgr/bin/vmchange –m media_id –n number_of_mounts在配置SANMEDIASERVER时,需要修改如下主机参数,确保实现LAN-FREE 经过测试,该配置可以不修改,但需要制定好MEDIA对应的设备Check_converage:确认备份策略备份内容2.相关检查命令启动NBU的图形管理界面:/usr/openv/netbackup/bin/jnbSA &1) 检查NBU进程状态:需要每天监控activity monitor,确认在备份服务器上运行的进程有:avrd、vmd、tldd、ltid、bprd、nbdbd、bpdbm、bpsched、bpjobd。
数据库日巡检记录单checklist_0812

备份文件大小截图(每周至少一次)
PMS
数据库状态及备份状态
备份文件大小截图(每周至少一次)
Vertica
数据库运行状态
本机备份状态查看(7/15号自动备份)
9/17号备份到NBU
异常说明
巡检日期:年月日巡检人:
系统
日巡检项
是否正常
邮件系统
存储容量/License
垃圾邮件监控
邮件归档
是否收到归档邮件
存储容量
本地NBU
java控制台查看状态
170查看磁盘使用率
V7000
V7000-172.16.7.21
V7000-192.168.8.111
V7000-1据库172.18.8.2
Basis/cert/cert4a/ylyy/eaiprd每天一次)
备份状态检查(bi/fe_app5/fe_base5每月15/30号备份,1/16号FTP到82上)
备份文件大小截图及日志保存
CRM69
alert日志
备份状态检查
备份文件大小截图及日志保存(每周一次)
云平台
数据库状态及备份状态
P2PS
FTP中间备份服务器192.168.8.110
北京NBU备份172.21.190.5
RAC
crontab日志
运行状态检查
AWR正常报告(每周至少一次)
AIX110
备份状态检查(qrcode/crmif一周一次)
备份状态检查(n9yl/ylyy_ehr/
ylyy_bpm/ccense/zbcg/osbdev_mem/
NBU维护手册

13 使用和维护步骤 ........................................................................................................................41
14 NetBackup 常见问题 ................................................................................................................43
3
3 NBU 管理界面
NetBackup 提供了三种管理界面: 1) /usr/openv/netbackup/bin/jnbSA — Java 界面
2) /usr/openv/netbackup/bin/bpadm /usr/openv/netbackup/bin/vmadm — 字符菜单界面 bpadm 的字符界面
4
3) CLI — Netbackup 常用命令介绍 NetBackup 安装目录为/usr/openv(Unix) 命令行/usr/openv/netbackup/bin 普通操作命令
/usr/openv/netbackup/bin/admincmd 管理命令 /usr/openv/netbackup/bin/goodies 管理脚本 /usr/openv/volmgr/bin 磁带管理命令 NetBackup 安装目录为 c:\program files\veritas\(NT)
15 附件一:备份系统的基本知识 ..................................................................................................43
ICU常规检查

常规检查1.新转入病人化验——三大常规——血气分析——生化全套——全胸片——有人工气道者或合并肺部病变者痰培养——发热原因不明者血尿培养——术中大量失血或长期使用抗凝药物者检查凝血三项。
2.常规化验(1)血常规——最近一次检查中Hb、WBC、Plt均无异常者每周一、周四各检查一次。
——最近一次检查中Hb、WBC、Plt有一项异常者至少隔天查一次。
——Hb、WBC、Plt任一项进行性下降者至少每天查一次。
——接受血制品(红细胞,血小板)输注后应尽快复查一次。
——检查结果与临床不符当日复查(2)PT、APTT、INR——Plt低于正常至少隔天查一次——Plt进行性下降者至少每天检查一次(如PT、PTT、INR异常需要DIC指标)——符合脓毒症表现患者每天查一次——血浆输注>400ml/24小时者次日查一次——CVVH应用抗凝隔天一次——肝硬化失代偿期每周至少查两次凝血功能——手术操作前需要查凝血功能(如气管切开,急诊手术等),尿标本(3)生化全套——病情稳定者每周日、周四检查一次——脓毒症、重症感染、或肝肾功能不全者至少隔天查一次——肾功能衰竭或CVVH治疗患者肾功能至少每日一次(4)全胸片——人工辅助呼吸(包括有创、无创)者至少隔天查1次——以明确存在肺部病变转入者,在病情稳定前每天查1次——COPD但病情稳定(呼吸节律平稳、体温正常、痰液性状无明显改变)每周日、周四查1次(5)血气分析——新转入患者前3天至少每天查1次——机械通气开始3天内至少每天查1次——其他根据需要随时检查(6)痰培养——转入大于3天,至少每天查1次——COPD但病情稳定者每周日、周四查一次——明确存在肺部病变者,在病情稳定前隔天查1次——新发现发热后连查3天(7)乳酸——任何血流动力学不稳定而原因不明——持续的代谢性酸中毒——休克原因明确但缺少有创监测或复苏效果不肯定时——应动态观察,需多次复查,间隔时间依具体情况定,可能需要<2小时3.新出现发热的处理(1)T>38.5℃——血培养2次(不同部位)——血常规1次——全胸片1次(2)是否存在可能感染源(如胸腹部外伤、手术等)——是:感染部位体液培养+抗生素调整——无:T<39℃,观察48小时(3)出现以下任一情况:①T>39℃②48小时内连续发热③出现感染表现——中心静脉管留置>48小时:拔除+培养——尿常规异常:中段尿培养——腹泻:大便常规——抗生素调整——药物+强物理降温(酒精冷水擦浴、冰袋或解热镇痛药,特殊情况下激素)4.药物浓度监测——万古霉素:用药开始72小时后。
整理的一些nbu命令及用法

整理的一些nbu命令及用法tpreq请求挂卷及和指定的驱动名相关链C:\Program Files\VERITAS\Volmgr\bin>tpreq.exeFile Name and media ID must be specifiedUsage: tpreq -m media_id [-a (r/w)] [-d density] [-p poolname] [-f] filename tpunmount.exe从目录中移走磁带文件,并移走磁带卷从驱动器中C:\Program Files\VERITAS\Volmgr\bin>tpunmount.exeUsage: tpunmount [-f] filename [-force]Do_not_eject_standalone option is specified in the vm.confVmrule管理微码C:\Program Files\VERITAS\Volmgr\bin>vmruleUsage: vmrule [-h volume_database_host]{-listall [-b] |-add <barcode_tag> <media_type> <pool_name> <max_mounts> "<description>" |-change <barcode_tag> <media_type> <pool_name> <max_mounts> "<description>" | -delete <barcode_tag>}bpbakcup往备份服务器上备份文件C:\Program Files\VERITAS\NetBackup\bin\goodies>bpbackupSpecify either a listfile or a list of files on the command line.USAGE: bpbackup [-p policy] [-s schedule] [-k "keyword phrase"][-L progress_log [-en]] [-S master_server...][-t policy_type] [-w [hh:mm:ss]]-f listfile | filenamesbpbackup -i [-p policy] [-s schedule] [-k "keyword phrase"][-h hostname] [-L progress_log [-en]] [-S master_server...][-t policy_type] [-w [hh:mm:ss]]EXIT STATUS 144: invalid command usageBpbackupdb备份目录信息C:\Program Files\VERITAS\NetBackup\bin\admincmd>bpbackupdb -help USAGE: bpbackupdb [{-dpath disk_path} |{-tpath tape_device_path [-m media_ID]} |{-opath optical_device_path [-m media_ID]}][-nodbpaths] [-v] [path...]bpdbjobs[/color和NBU job数据库交互C:\Program Files\VERITAS\NetBackup\bin\admincmd>bpdbjobs -help bpdbjobs: [-report] [-M <master servers>][-file <pathname>] [-append] [ -vault | -lvault | -all_columns ] bpdbjobs: -summary [-M <master servers>][-file <pathname>] [-append] [ -U | -L | -all_columns ]bpdbjobs: -delete [-M <master servers>] <jobs,comma,separated>bpdbjobs: -cancel [-M <master servers>] <jobs,comma,separated>bpdbjobs: -cancel_all [-M <master servers>][-M <master servers>]bpdbjobs: -clean [-M <master servers>][-keep_hours <hours>] or [-keep_days <days>][-keep_successful_hours <hours>] or [-keep_successful_days <days>][-verbose]<hours> = [ 3..720 ] <days> = [ 1..30 ]bpdbjobs: -versionbpdbjobs: -helpbpduplicate创建一个备份拷贝bperror显示NBU状态及trouleshoot信息从NBU错误目录中得到C:\Program Files\VERITAS\NetBackup\bin\admincmd>bperrorUSAGE: bperror {-S|-statuscode status_code}[-r|-recommendation] [-p|-platform Unx|NTx] [-v]bperror [-all|-problems|-media|{-backstat [-by_statcode]}][-L|-l|-U] [-columns ncols][-d mm/dd/yyyy HH:MM:SS|-hoursago hours] [-e mm/dd/yyyy HH:MM:SS] [-client client_name] [-server server_name][-jobid job_id][-M master_server,...] [-v]bperror [-s {severity[+]}|severity ...] [-t type ...][-L|-l|-U] [-columns ncols][-d mm/dd/yyyy HH:MM:SS|-hoursago hours] [-e mm/dd/yyyy HH:MM:SS][-client client_name] [-server server_name][-jobid job_id][-M master_server,...] [-v]-by_statcode is used only with both -U and -backstatValid values for ncols:40 or moreValid values for severity:ALL, DEBUG, INFO, WARNING, ERROR, CRITICALValid values for type:ALL, ARCHIVE, BACKSTAT, BACKUP, GENERAL,MEDIADEV, RETRIEVE, SECURITYBpexpdate改变备份介质目录的过期日期C:\Program Files\VERITAS\NetBackup\bin\admincmd>bpexpdate.exebpexpdate: -m <media id> -d <mm/dd/yyyy HH:MM:SS | 0 | infinity>[-host <name>] [-force][-M <master_server,...,master_server>]bpexpdate: -deassignempty [-m <media id>] [-host <name>] [-force][-M <master_server,...,master_server>]bpexpdate: -backupid <backup id> -d <mm/dd/yyyy HH:MM:SS | 0 | infinity> [-client <name>] [-copy <number>] [-force][-M <master_server,...,master_server>]bpexpdate: -recalculate [-backupid <backup id>] [-copy <number>][-d <mm/dd/yyyy HH:MM:SS | 0 | infinity>] [-client <name>][-policy <name>] [-ret <retention level>] [-sched <type>][-M <master_server,...,master_server>]legal values for sched: 0=full,1=differential incr,2=user,3=arch4=cumulative incrbpimport引入备份C:\Program Files\VERITAS\NetBackup\bin\admincmd>bpimport -helpbpimport: -create_db_info -id <media_id> [-server <name>] [-L <output_file> [-en]] [-passwd] [-local]bpimport: [-l] [-p] [-pb] [-PD] [-PM] [-v] [-local] [-client <name>][-M master_server][-Bidfile <file_name>][-backup_copy <backup_copy_value>][-st <sched_type>] [-sl <sched_label>] [-L <output_file> [-en]][-policy <name>] [-s <startdate>] [-e <enddate>][-pt <policy_type>] [-hoursago <hours>] [-cn <copy number>][-backupid <backup_id>] [-id <media_id>]Valid values for sched_type:FULL, INCR, CINC, UBAK, UARC, NOT_ARCHIVEValid values for policy_type:Standard Apollo-wbak NetWare MS-Windows-NTOS/2 AFSBprecover恢复相关的nbu目录C:\Program Files\VERITAS\NetBackup\bin\admincmd>bprecover -helpbprecover: -l -m media_ID -d density [-v]-l -tpath <raw_tape_device_path> [-v]-l -dpath <disk_device_path> [-v]-l -opath <optical_device_path> [-v]-r [ALL|image_number] -m media_ID -d density [-stdout] [-dhost <destination_host>] [-v] -r [ALL|image_number] -tpath <raw_tape_device_path> [-stdout] [-dhost <destination_host>][-v]-r [ALL|image_number] -dpath <disk_device_path> [-stdout] [-dhost <destination_host>] [-v ]-r [ALL|image_number] -opath <optical_device_path> [-stdout] [-dhost <destination_host>] [-v]bprestore还原文件C:\Program Files\VERITAS\NetBackup\bin\admincmd>bprestoreUSAGE: bprestore [-A | -B] [-K] [-l | -H | -y] [-r] [-T][-L progress_log [-en]] [-R rename_file] [-C client][-D client] [-S master_server] [-t policy_type][-p policy] [-k "keyword phrase"] [-cm] [-md][-td temp_dir] [-BR be_redirection_path] [-F file_options][-s mm/dd/yyyy [HH:MM:SS]] [-e mm/dd/yyyy [HH:MM:SS]][-w [hh:mm:ss]] -f listfile | filenamesEXIT STATUS 144: invalid command usageBpstuadd创建nbu storage unit group or a storage unitC:\Program Files\VERITAS\NetBackup\bin\admincmd>bpstuaddUSAGE: bpstuadd -group group_name [stunit name]orUSAGE: bpstuadd -label storage_unit_label-path path_nameor-density density_type [-rt robot_type -rn robot_number][-host host_name][-cj max_jobs][-odo on_demand_only][-mfs max_fragment_size][-maxmpx mpx_factor][-nh NDMP_attach_host][-verbose][-fastrax][-M master_server,...]Valid values for mpx_factor: 1..32max_fragment_size in MB:For removable media, 0 if unlimited or greater than 50For disk, between 20 and 2000 (2GB)Bpstudel删除storage unitC:\Program Files\VERITAS\NetBackup\bin\admincmd>bpstudelbpstudel: -label <storage unit label> [-verbose][-M <master_server,...,master_server>]or1. Solaris下:/usr/openv/volmgr/bin/sgscan changer 查看本机所有Robot设备;/usr/openv/volmgr/bin/sgscan tape 查看本机所有的磁带驱动器。
常见NetBackup通讯问题及排错一般步骤

常见NetBackup通讯问题及排错一般步骤摘要:大约有20%以上的NetBackup备份/恢复失败是由通讯故障引起的,而不是NetBackup自身的问题。
而且在处理这些故障时,用户往往忽略通讯问题的可能。
本文从通讯的角度对可能引起NBU备份/恢复失败的因素进行分析及列举了一些排错方法。
内容:大约有20%以上的NetBackup备份/恢复失败是由通讯故障引起的,而不是NetBackup自身的问题。
而且在处理这些故障时,用户往往忽略通讯问题的可能。
这是因为一般的应用系统在安装NetBackup之前已经有业务系统(如Oracle)在正常运行,用户一般会进行简单的名字解析配置,并使用ping 命令验证通过。
但事实上,上述这些并不能完全保证NetBackup备份/恢复任务正常运行,因为:? NetBackup进程流较一般应用程序更为复杂,要求精心规划和实施名字解析、端口使用及防火墙策略。
? 备份应用会产生海量猝发网络流量,要求更为健壮的网络环境。
症状常见的通讯问题可能表现为:? 同一个客户端,文件系统备份正常,数据库备份失败。
? 新加的Media Server或Client,不能正常工作。
? 备份任务挂起。
常见的通讯问题引起的NetBackup错误代码有:23、24、25、40、41、42等。
要深入分析并解决备份和恢复中的通讯问题,必须深入了解NetBackup的进程流,但如果遵循一些简单有效的原则,就可以避免、解决大部分的通讯问题。
正确设置NetBackup通讯相关项首先,要正确设置NetBackup通讯相关项,包括:1. 确认NetBackup主机名称。
a. NetBackup主机名可以从hostname (短名)、FQDN (Fully Qualified Domain Name,正式域名、长名 )及 virtual name (集群网络资源名)中选择。
b. 一旦确定,坚持统一在所有NetBackup场合(Policy, Server Lists)使用,并保持大小写一致。
symantec_nbu备份一体机运维巡检手册

NBU 备份一体机中文运维手册2012/11Symantec咨询服务部文件信息版本目录1.运维巡检内容 (5)2.检查硬件状态 (6)2.1 检查SAS硬盘状态 (6)2.2 检查面板状态 (7)2.3 检查2口10G的网卡状态 (8)2.4检查4口1G的网卡状态 (9)2.5检查2口8G的光纤卡状态 (9)2.6 检查存储扩展柜硬盘状态 (10)2.7检查存储扩展柜电源状态 (11)2.8 检查存储扩展柜SAS连接状态 (12)3.使用命令行检查 (14)3.1查看 CPU状态 (14)3.2查看 disk状态 (14)3.3.查看RAID group状态 (15)3.4查看 fan状态 (16)3.5查看 power supply状态 (16)3.6查看温度 (17)3.7查看 8Gb FC HBA card (17)3.8全部硬件自检 (17)4.关于NBU软件的SNMP报警 (18)5.关于NBU A ppliance的SNMP报警 (19)6.关于CallHome (20)1.运维巡检内容每日基本检查2. 检查硬件状态2.1 检查SAS硬盘状态The eight SAS disk drive modules each contain one disk drive. Each module has2 LEDs, one red and one green. The green LED flashes when drive activity occursand is lit when no activity occurs. The red LED is lit when drive faults occur.Slot 7是hot spare盘One disk inside a carrier defines the “Disk Module.” There are two LEDs on eachDisk module. One LED indicates disk status. The other LED indicates Power and/orActivity.The control panel of the appliance provides systemactivity and fault information.2.2 检查面板状态A Hard Disk Activity LEDRandom flashing green light indicates hard disk drive activity (SAS).No light indicates no hard disk drive activity.B andC NIC 1 and NIC2 Activity LEDContinuous green light indicates a link between the appliance and the computer or network to which it is connected.Flashing green light indicates computer or network activity.D Appliance Status LEDSolid amber indicates a critical or non-recoverable condition.Solid green indicates normal operation.Flashing green indicates degraded performance.Flashing amber indicates a non-critical condition.No light indicates POST is running or the appliance is off.E Power/Sleep LEDContinuous green light indicates the appliance has power applied to it or the appliance is S0 state.Flashing green indicates the appliance is in sleep or ACPI S1 state.No light indicates the power is off or the appliance is in ACPI S4 or S5 state.F Appliance identificationSolid blue indicates appliance identification is active.No light indicates appliance identification is not activated.2.3 检查2口10G的网卡状态2.4检查4口1G的网卡状态2.5检查2口8G的光纤卡状态Note: Each port on the 8Gb FC HBA card shows three LEDs, labeled “8”, “4” and“2.” These numbers correspond to the rate of data transfer (8Gbit/s, 4Gbit/s or2Gbit/s).2.6 检查存储扩展柜硬盘状态右下角第16个盘是hot spare2.7检查存储扩展柜电源状态2.8 检查存储扩展柜SAS连接状态3. 使用命令行检查通过web页面中的Monitor->Hardware也可以查看如下状态3.1查看 CPU状态nb-app.Main_Menu>Monitor->Hardware CPUStatus The state of the CPU.Presence detected indicates that the CPU works normally.Failure detected indicates that the CPU is absentError Status■ 0: Normal.■ 1: Abnormal.3.2查看 disk状态nb-app.Main_Menu>Monitor->Hardware diskStatusThe typical running states of the disk are as follows:■ Online -- A drive that can be accessed by the RAID controller and is part of the virtual drive.■ Unconfigured (Good) -- A drive that is functioning normallybut is not configured as a part of a virtual drive or as a hot spare. ■ Hot Spare --Adrive that is turned on and ready for use as a spare in case an online drive fails.■ Failed -- A drive that was originally configured as Online or Hot Spare, but on which the firmware detects an unrecoverable error.■Rebuild -- A drive to which data is being written to restore full redundancy for a virtual drive.■Unconfigured (Bad) -- A drive on which the firmware detectsan unrecoverable error; the drive was Unconfigured Good or thedrive cannot be initialized.■Missing -- A drive that was Online but which has been removedfrom its location.■Offline -- A drive that is part of a virtual drive but which has invalid data as far as the RAID configuration is concerned.Error Status■0: Normal.■1: Abnormal.3.3.查看RAID group状态nb-app.Main_Menu>Monitor->Hardware RAIDStatusA RAID group may be in the one of the following states:■Optimal -- The virtual drive operating condition is good. All configured drives are online.■Degraded -- The virtual drive operating condition is not optimal. One of the configured drives has failed or is offline.■Partial Degraded --The operating condition in aRAID6 virtualdrive is not optimal. One of the configured drives has failed or is offline. RAID 6 can tolerate up to two drive faults.■Failed -- The virtual drive has failed.■Offline -- The virtual drive is not available to theRAIDcontroller.Error Status■0: Normal.■ 1: Abnormal.3.4查看 fan状态nb-app.Main_Menu>Monitor->Hardware fanStatusThe fan state.■ Device Present indicates that the fan works normally.■ Device Absent indicates that the fan works abnormallyError Status■ 0: Normal.■ 1: Abnormal.3.5查看 power supply状态nb-app.Main_Menu>Monitor->Hardware powerStatusThe running state of the power supply.■ Presence detected indicates that the power supply works normally.■ Failure detected indicates that the power supply is absent or faulty.Error Status■ 0: Normal.■ 1: Abnormal3.6查看温度nb-app.Main_Menu>Monitor->Hardware temperatureError Status■0: Normal.■1: Abnormal.3.7查看 8Gb FC HBA cardnb-app.Main_Menu>Monitor->Hardware FibreChannelStatusThe running state of FC HBA:■Online indicates that the FC HBA works normally.■Link Down indicates that the FC HBA link is faulty.■No HBA(s) indicates that no FC HBA detected.Error Status■0: Normal.■1: Abnormal.3.8全部硬件自检nb-app.Main_Menu>Support->Test Hardware需要约50分钟4.关于NBU软件的SNMP报警可以通过NBU OpsCenter中的SNMP发送功能配置NBU软件问题报警。
NBU常见故障处理

解释:服务器太长时间没有收到来自该客户机的任何信息。
推荐的操作: NetBackup
服务器上使用
“主机属性”,更改客户机连接超时
(Client connect timeout)或客户机读取超时(Client read timeout)。默认
为 300 秒。 如果更改上面属性后备份仍然报错,请检查网络通信是否异常
(对于磁盘存储单元),而且最多并行驱动器数
(Maximum
concurrent drives) 属性没有设置为 0(对于介质管理器存储单元)。 如果存储单元是磁带或光盘,请验证是否至少有一个驱动器处于
“启动”状态。可使用设备监视器。
验证存储单元配置中的机械手编号和主机是否与介质管理Байду номын сангаас设备配 置中指定的内匹配。
NBU 常见错误及故障解决
典型故障一
标题
NBU 备份服务器主机备份故障
发生日期
发现日期
现象:备份主服务器 nbu 的 bpemm 进程意外停止,导致备份服务器备份任务无法正常运行。
检查与分析:
1. 所有备份任务报 800 号错误,备份任务无法正常完成备份任务。
2. 检查磁带机设备状态,发现有 5 号驱动器处于 DOWN 状态,手动 UP 后仍处于 DOWN 状
加适当类型的日程表,或者创建具有此客户机和适当类型日程表的
新策略。
13. NetBackup 状态码: 219
消息:必需的存储单元不可用
解释:备份的策略或日程表需要特定的存储单元,但该存储单元当前不
可用。在当前备份会话中,使用该存储单元的其他尝试也将导致此错误。
推荐的操作:
在作业详细信息窗口中查找失败的作业。 验证日程表是否指定了正确的存储单元以及该存储单元是否存在。 验证介质管理器设备后台驻留程序 (ltid) 是否正在运行 (如果服
ICU常用实验室检查

通过实验室检查,医生可以了解患者 的生理状态,评估病情严重程度,发 现潜在的并发症和感染,以及监测治 疗效果和调整治疗方案。
实验室检查的重要性
01
02
03
诊断依据
实验室检查可以为医生提 供客观的指标,帮助医生 准确诊断病情,避免漏诊 和误诊。
监测病情变化
通过定期进行实验室检查, 医生可以及时发现病情的 变化,以便采取相应的治 疗措施。
样本采集
确保采集的样本质量,遵循正确的采 集方法和时间,避免样本污染或变质。
仪器校准
实验室检查所使用的仪器应定期进行 校准和维护,以确保结果的准确性和 可靠性。
质量控制
实验室应建立严格的质量控制标准, 对检查结果进行定期审核和校验,以 确保结果的准确性。
局限性
检查结果的时效性
实验室检查结果仅代表患者当时的生理状态, 不能预测未来的病情变化。
诊断疾病
诊断感染性疾病
诊断血液系统疾病
通过血常规、血培养、尿培养等检查, 确定病原体类型,为治疗提供依据。
通过血常规、凝血功能、骨髓穿刺等 检查,诊断贫血、白血病、凝血障碍 等血液系统疾病。
诊断代谢性疾病
通过血糖、血脂、电解质等检查,评 估患者的代谢状况,诊断糖尿病、高 血脂等代谢性疾病。
监测病情
指导治疗
实验室检查结果可以为医 生提供治疗依据,帮助医 生制定个性化的治疗方案, 调整药物剂量和种类。
icu常用实验室检查的项目与分类
血液检查
尿液检查
粪便检查
其他检查
包括血常规、血生化、 血气分析、凝血功能等。
包括尿常规、尿培养等。
包括粪便常规、粪便培 养等。
包括脑钠肽、心肌酶谱、 血培养、痰培养等。
nbu故障处理流程

nbu故障处理流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!NetBackup 故障处理流程。
1. 收集信息。
确定故障类型(备份失败、还原失败、介质问题等)。
kub检查流程和注意事项

kub检查流程和注意事项
嘿呀!今天咱们就来好好聊聊“KUB 检查流程和注意事项”呢!
首先,咱得知道啥是KUB 检查呀?简单说,KUB 就是腹部平片检查,能帮咱们瞅瞅腹部里的情况哟!
那KUB 检查的流程是啥呢?
1. 检查前准备可重要啦!哎呀呀,患者得提前禁食禁水一段时间,具体多久呢?这得听医生的安排呀!为啥要这样呢?因为这样能让检查结果更准确呀!
2. 到了检查的时候啦,患者要乖乖躺在检查床上,按照医生的指示调整姿势,可别乱动哟!
3. 然后呢,机器就开始工作啦,这个过程很快的,别紧张哇!
接下来,再说说KUB 检查的注意事项。
1. 身上可不能有金属物品呀,啥项链、耳环、手表,都得摘下来哟!不然会影响检查结果的,这可不得了哇!
2. 要是怀孕了或者可能怀孕的女性朋友,一定要提前告诉医生呀!这可马虎不得呢!
3. 检查后,也别大意哟!要多喝点水,促进体内的造影剂排出呢。
哇!总之,KUB 检查虽然不复杂,但是流程和注意事项咱们可得牢记在心呀!这样才能让检查顺利进行,得到准确的结果,帮助医生做出正确的诊断,咱们也能早点恢复健康啦!你说是不是呀?。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、NBU中添加环境变量的方法
Linux系统
修改/etc/.bash_profile,添加
PATH=$PATH:/usr/openv/netbackup/bin
PATH=$PATH:/usr/openv/netbackup/bin/admincmd PATH=$PATH:/usr/openv/netbackup/bin/goodies
PATH=$PATH:/usr/openv/volmgr/bin
export PATH
MANPATH=$MANPATH,/usr/openv/man/
export MANPATH
二、NBU服务自启动、停止脚本位置
4、 Linux Red Hat
/etc/rc.d/init.d/netbackup
/etc/rc.d/rc0.d/K01netbackup
/etc/rc.d/rc1.d/K01netbackup
/etc/rc.d/rc2.d/S77netbackup
/etc/rc.d/rc3.d/S77netbackup
/etc/rc.d/rc5.d/S77netbackup
/etc/rc.d/rc6.d/K01netbackup
/etc/rc.d/init.d/nbclient
/etc/rc.d/rc0.d/K01nbclient
/etc/rc.d/rc1.d/K01nbclient
/etc/rc.d/rc2.d/S95nbclient
/etc/rc.d/rc3.d/S95nbclient
/etc/rc.d/rc5.d/S95nbclient
/etc/rc.d/rc6.d/K01nbclient
三、NBU启动、关闭的方法
1、 Master主机的关闭NBU的方法:
/usr/openv/netbackup/bin/bp.kill_all 或者/usr/openv/netbackup/bin/goodies/netabckup stop
2、Master主机的启动NBU的方法:
/usr/openv/netbackup/bin/bp.start_all 或者/usr/openv/netbackup/bin/goodies/netabckup start
3、media server主机关闭nbu方法
/usr/openv/netbackup/bin/bp.kill_all 或者/usr/openv/netbackup/bin/goodies/netabckup stop
4、media server主机开启nbu方法
/usr/openv/netbackup/bin/bp.start_all 或者/usr/openv/netbackup/bin/goodies/netabckup start
四、检查
1、使用bpps检查进程启动情况
/usr/openv/netbackup/bin/bpps –x
2、备份索引完整性检查(3个月)
#bpcatlist –online –since-months 3 记录所有备份操作在NBU的catalog的记录
Backupid Backup Date Files Size Sched Policy Catarcid S C Files file dms1_1195384006 Nov 18 11:06:46 2007 1 288k Default-Application-Backup dms1rmanfull 0 1 0 dms1rmanfull_1195384006_UBAK.f
3、主机全局变量配置检查
#bpconfig –U 该命令显示NetBackup全局配置属性。
这些属性影响所有策略和客户机的操作;
Admin Mail Address:
Job Retry Delay: 30 minutes Max Simultaneous Jobs/Client: 99
Backup Tries: 2 time(s) in 12 hour(s)
Keep Error/Debug Logs: 28 days
Max drives this master: 0
Keep TrueImageRecovery Info: 1 days
Compress Image DB Files: (not enabled)
Media Mount Timeout: 0 minutes (unlimited)
Shared Media Mount Timeout:0 minutes (unlimited)
Display Reports: 24 hours ago
Preprocess Interval: 4 hours (default)
Maximum Backup Copies: 2
Image DB Cleanup Interval: 12 hours
Policy Update Interval: 10 minutes
4、备份异常事件检查#bperror –U –d /mm/dd/yyyy –e /mm/dd/yyyy
5、NBU配置检查#bpgetconfig –L 用于获取配置信息的助手程序
6、供紧急恢复时的备份镜像保存信息#bpimagelist -U bpimagelist 使用指定的格式来报告与从命令选项发送的属性相匹配的目录库映像或可移动介质;注:-policy -st来检查关键数据的全备和增量镜像所在介质号
7、检查磁带机清洗状况tpclean -L 输出内容举例如下:
输出内容举例如下:
Drive Name Type Mount Time Frequency Last Cleaned Comment
**** ********** ********* **************** *******
HP.ULTRIUM3-SCSI.001 hcart3* 0.1 0 N/A
HP.ULTRIUM3-SCSI.000 hcart3* 0.0 0 N/A
IBM.ULTRIUM-TD2.003 hcart2* 0.3 0 N/A
8、检查磁带介质是否都正常#bpmedialist bpmedialist 查询一个或多个NetBackup 介质目录库,并生成NetBackup 介质状态报告;经检查,部分磁带介质有被frozen的现象,此操作并不影响正常备份,可以在将来方便的时候(比如系统周期维护日)对其状态进行重置,如继续发现读写错误,建议更换磁带;
9、检查是否还有足够可用磁带#available_media 部分磁带介质有被frozen的现象,此操作并不影响正常备份,可以在将来方便的时候(比如系统周期维护日)对其状态进行重置,如继续发现读写错误,建议更换磁带
10、SAN环境下检查所有Media Server健康状态在MasterServer上运行:#vmdareq –display 输出内容举例如下:
11、检查磁带库设备状态#tpconfig –l 输出内容举例如下:
12、检查存储单元配置#bpstulist -U -show_available bpstulist 命令显示NetBackup 存储单元或存储单元组的属性。
13、根据实际情况和时间确认是否要进行数据检查#bpverify bpverify 通过读取备份卷,并将其内容与NetBackup 目录库进行比较来验证一个或多个备份的内容。
该操作并不将卷数据与客户机磁盘的内容进行比较。
它读取映像中的每个块以验证卷是否为可读。
14、卷池信息一致性检查#vmpool –listall 列出卷池;经检查,符合要求。
输出结果,举例说明如下:
15、NBU系统全面性检查:support support命令检查全面的系统运行状况。
第5章磁带出入库操作。