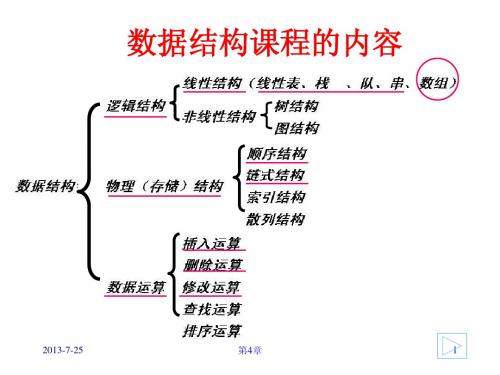
数据结构第五章
数据结构第5章 串和广义表

5.1 串的定义和基本运算
• (4)串的连接StrCat(S,T)。 • 初始条件:串S和T存在。 • 操作结果:将串T的值连接在串S的后面。 • (5)求子串SubString(Sub,S,pos,len)。 • 初始条件:串S存在,1≤pos≤StrLength(S)且
1≤len≤StrLength(S)-pos+1。 • 操作结果:用Sub返回串S的第pos个字符起长度为len的
1≤len≤StrLength(S)-pos+1。 • 操作结果:从串S中删除第pos个字符起长度为len的子串。 • (9)串的替换StrReplace(S,T,V)。 • 初始条件:串S,T和V存在,且T是非空串。 • 操作结果:用V替换串S中出现的所有与T相等的不重叠子
串。 • (10)判断串空StrEmpty(S)。 • 初始条件:串S存在。 • 操作结果:若串S为空串,则返回1;否则返回0。
• (1)非紧凑存储。设串S="Hello boy",计算机字长为32 位(4个Byte),用非紧凑格式一个地址只能存一个字符, 如图5-2所示。其优点是运算处理简单,但缺点是存储空 间十分浪费。
• (2)紧凑存储。同样存储S="Hello boy",用紧凑格式一 个地址能存四个字符,如图5-3所示。紧凑存储的优点是 空间利用率高,缺点是对串中字符处理的效率低。
•}
5.3 串的基本运算的实现
• (3)求子串操作。求串S从第pos位置开始,长度为len的 子串,并将其存入到串Sub中。操作成功返回1,不成功 返回0。其算法描述如下:
• int SubString(String *S,String *Sub,int pos,int len)
数据结构第五章 数组与广义表

压缩存储方法:只需要存储下三角 (含对角线)上的元素。可节省一 半空间。
可以使用一维数组Sa[n(n+1)/2]作为n阶对称矩阵A的存 储结构,且约定以行序为主序存储各个元素,则在Sa[k]和矩
阵元素aij之间存在一一对应关系: (下标变换公式)
i(i+1)/2 + j 当i≥j k = j(j+1)/2 + i 当i<j
q = cpot[col];
T.data[q].i = M.data[p].j; T.data[q].j = M.data[p].i; T.data[q].e = M.data[p].e; ++cpot[col]; }
分析算法FastTransposeSMatrix的时间 复杂度:
for (col=1; col<=M.nu; ++col) … … for (t=1; t<=M.tu; ++t) … … for (col=2; col<=M.nu; ++col) … … for (p=1; p<=M.tu; ++p) … …
//对当前行中每一个非零元
处
brow=M.data[p].j;
理
if (brow < N.nu ) t = N.rpos[brow+1];
M
else { t = N.tu+1 }
的
for (q=N.rpos[brow]; q< t; ++q) { ccol = N.data[q].j; // 乘积元素在Q中列号
一、三元组顺序表
对于稀疏矩阵,非零元可以用三元组表示, 整个稀疏矩阵可以表示为所有非零元的三元组所 构成的线性表。例如:
《刘大有数据结构》 chapter 5 数组字符串和集合类

再例如三维数组 再例如三维数组D[3][3][4],可以把它看作一维 , 数组 B1[3] = { D[0][3][4],D[1][3][4],D[2][3][4] } , ,
下面我们给出一个 下面我们给出一个Array类的应用例子 类的应用例子. 类的应用例子 例5.1 编写一个函数,要求输入一个整数 , 编写一个函数,要求输入一个整数N, 用动态数组A来存放 来存放2~ 之间所有 之间所有5或 的倍数 的倍数, 用动态数组 来存放 ~N之间所有 或7的倍数, 输出该数组. 输出该数组 说明 : 因为 由用户给出 , 编写程序时无法知 说明:因为N由用户给出 由用户给出, 道需要多大的数组来存放数据, 道需要多大的数组来存放数据,因此采用动态 数组(初始时大小为10) 数组(初始时大小为 ),每当数组满时就调 整数组大小,给它增加10个元素 个元素. 整数组大小,给它增加 个元素
数组在内存中一般是以顺序方式存储的 数组在内存中一般是以顺序方式存储的. 设一维数组 设一维数组A[n]存放在 个连续的存储单元中 , 存放在n个连续的存储单元中 存放在 个连续的存储单元中, 每个数组元素占一个存储单元(不妨设为C个 每个数组元素占一个存储单元 ( 不妨设为 个 连续字节) 如果数组元素A[0]的首地址是 , 的首地址是L, 连续字节). 如果数组元素 的首地址是 则 A[1] 的 首 地 址 是 L+C , A[2] 的 首 地 址 是 L+2C,… …,依次类推,对于 0 ≤ i ≤ n 1 有: , ,依次类推,
B[i]={ A[i][0],A[i][1],…,A[i][n-2],A[i][n-1] } -
数据结构:第5章 数组与广义表1-数组

中的元素均为常数。下三角矩阵正好相反,它的主对
数据结构讲义
第5章 数组与广义表
—数组
数组和广义表
数组和广义表可看成是一种特殊的 线性表,其特殊在于,表中的数据 元素本身也是一种线性表。
几乎所有的程序设计语言都有数组 类型。本节重点讲解稀疏矩阵的实 现。
5.1 数组的定义
由于数组中各元素具有统一的类型,并且 数组元素的下标一般具有固定的上界和下 界,因此,数组的处理比其它复杂的结构 更为简单。
nm
aa1221
aa2222
…………....
aam2n2 ………………..
aamm11 aamm22 ………….... aammnn LLoocc(a( iaj)ij=)L=Loco(ca(a111)1+)[+([j(-i1-)1m)n++((i-j1-1)])*]*l l
aa1mn 1 aa2mn2 …………....
其存储形式如图所示:
15137 50800 18926 30251
a00 a10 a 11 a20 a21 a23 ………………..
70613
an-1 0 a n-1 1 a n-1 2 …a n-1 n-1
图 5.1 对称矩阵
在这个下三角矩阵中,第i行恰有i+1个元素,元素总
数为:
n(n+1)/2
5.2 数组的顺序表示和实现
由于计算机的内存结构是一维的,因此用 一维内存来表示多维数组,就必须按某种 次序将数组元素排成一列序列,然后将这 个线性序列存放在存储器中。
又由于对数组一般不做插入和删除操作, 也就是说,数组一旦建立,结构中的元素 个数和元素间的关系就不再发生变化。因 此,一般都是采用顺序存储的方法来表示 数组。
数据结构第5章课件 中国石油大学(华东)

二叉链表
leftChild
data rightChild
22
二叉树的链表表示(三叉链表)
每个结点增加一个指向双亲的指针parent,使 得查找双亲也很方便。
leftChild data parent rightChild
三叉链表
data
leftChild
27
BinTreeNode *LeftChild (BinTreeNode *current ) { return (current != NULL )? current->leftChild :NULL; } BinTreeNode *RightChild (BinTreeNode *current ) { return ( current!= NULL) ? current->rightChild : NULL; } int Height( ){return Height(root);} int Size( ){return Size(root);} BinTreeNode *GetRoot ( ) const { return root; } void preOrder( ) {preOrder(root);} //前序遍历 void inOrder( ) {inOrder(root);} //中序遍历 void postOrder( ) {postOrder(root);} //后序遍历 void levelOrder( ) ; // 不需要递归,所以直接对外接 口调用即可。层序遍历 28
b
f
c
d
g
6
e
a
b.嵌套集合表示法: b 根据树的集合定义,写出集合划分。 { a, {b,{e},{f}}, {c}, {d,{g}} } e c d
《数据结构与算法》第五章-数组和广义表学习指导材料

《数据结构与算法》第五章数组和广义表本章介绍的数组与广义表可视为线性表的推广,其特点是数据元素仍然是一个表。
本章讨论多维数组的逻辑结构和存储结构、特殊矩阵、矩阵的压缩存储、广义表的逻辑结构和存储结构等。
5.1 多维数组5.1.1 数组的逻辑结构数组是我们很熟悉的一种数据结构,它可以看作线性表的推广。
数组作为一种数据结构其特点是结构中的元素本身可以是具有某种结构的数据,但属于同一数据类型,比如:一维数组可以看作一个线性表,二维数组可以看作“数据元素是一维数组”的一维数组,三维数组可以看作“数据元素是二维数组”的一维数组,依此类推。
图5.1是一个m行n列的二维数组。
5.1.2 数组的内存映象现在来讨论数组在计算机中的存储表示。
通常,数组在内存被映象为向量,即用向量作为数组的一种存储结构,这是因为内存的地址空间是一维的,数组的行列固定后,通过一个映象函数,则可根据数组元素的下标得到它的存储地址。
对于一维数组按下标顺序分配即可。
对多维数组分配时,要把它的元素映象存储在一维存储器中,一般有两种存储方式:一是以行为主序(或先行后列)的顺序存放,如BASIC、PASCAL、COBOL、C等程序设计语言中用的是以行为主的顺序分配,即一行分配完了接着分配下一行。
另一种是以列为主序(先列后行)的顺序存放,如FORTRAN语言中,用的是以列为主序的分配顺序,即一列一列地分配。
以行为主序的分配规律是:最右边的下标先变化,即最右下标从小到大,循环一遍后,右边第二个下标再变,…,从右向左,最后是左下标。
以列为主序分配的规律恰好相反:最左边的下标先变化,即最左下标从小到大,循环一遍后,左边第二个下标再变,…,从左向右,最后是右下标。
例如一个2×3二维数组,逻辑结构可以用图5.2表示。
以行为主序的内存映象如图5.3(a)所示。
分配顺序为:a11 ,a12 ,a13 ,a21 ,a22,a23 ; 以列为主序的分配顺序为:a11 ,a21 ,a12 ,a22,a13 ,a23 ; 它的内存映象如图5.3(b)所示。
数据结构第5章

第5章:数组和广义表 1. 了解数组的定义;填空题:1、假设有二维数组A 6×8,每个元素用相邻的6个字节存储,存储器按字节编址。
已知A 的起始存储位置(基地址)为1000,则数组A 的体积(存储量)为 288 B ;末尾元素A 57的第一个字节地址为 1282 。
2、三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的 行下标 、 列下标 和 元素值 。
2. 理解数组的顺序表示方法会计算数组元素顺序存储的地址;填空题:1、已知A 的起始存储位置(基地址)为1000,若按行存储时,元素A 14的第一个字节地址为 (8+4)×6+1000=1072 ;若按列存储时,元素A 47的第一个字节地址为 (6×7+4)×6+1000)=1276 。
(注:数组是从0行0列还是从1行1列计算起呢?由末单元为A 57可知,是从0行0列开始!) 2、设数组a[1…60, 1…70]的基地址为2048,每个元素占2个存储单元,若以列序为主序顺序存储,则元素a[32,58]的存储地址为 8950 。
答:不考虑0行0列,利用列优先公式: LOC(a ij )=LOC(a c 1,c 2)+[(j-c 2)*(d 1-c 1+1)+i-c 1)]*L 得:LOC(a 32,58)=2048+[(58-1)*(60-1+1)+32-1]]*2=8950选择题:( A )1、假设有60行70列的二维数组a[1…60, 1…70]以列序为主序顺序存储,其基地址为10000,每个元素占2个存储单元,那么第32行第58列的元素a[32,58]的存储地址为 。
(无第0行第0列元素)A .16902B .16904C .14454D .答案A, B, C 均不对 答:此题(57列×60行+31行)×2字节+10000=16902( B )2、设矩阵A 是一个对称矩阵,为了节省存储,将其下三角部分(如下图所示)按行序存放在一维数组B[ 1, n(n-1)/2 ]中,对下三角部分中任一元素a i,j (i ≤j), 在一维数组B 中下标k 的值是:A .i(i-1)/2+j-1B .i(i-1)/2+jC .i(i+1)/2+j-1D .i(i+1)/2+j3、从供选择的答案中,选出应填入下面叙述 ? 内的最确切的解答,把相应编号写在答卷的对应栏内。
数据结构——第五章查找:01静态查找表和动态查找表

数据结构——第五章查找:01静态查找表和动态查找表1.查找表可分为两类:(1)静态查找表:仅做查询和检索操作的查找表。
(2)动态查找表:在查询之后,还需要将查询结果为不在查找表中的数据元素插⼊到查找表中;或者,从查找表中删除其查询结果为在查找表中的数据元素。
2.查找的⽅法取决于查找表的结构:由于查找表中的数据元素之间不存在明显的组织规律,因此不便于查找。
为了提⾼查找效率,需要在查找表中的元素之间⼈为地附加某种确定的关系,⽤另外⼀种结构来表⽰查找表。
3.顺序查找表:以顺序表或线性链表表⽰静态查找表,假设数组0号单元留空。
算法如下:int location(SqList L, ElemType &elem){ i = 1; p = L.elem; while (i <= L.length && *(p++)!= e) { i++; } if (i <= L.length) { return i; } else { return 0; }}此算法每次循环都要判断数组下标是否越界,改进⽅法:加⼊哨兵,将⽬标值赋给数组下标为0的元素,并从后向前查找。
改进后算法如下:int Search_Seq(SSTable ST, KeyType kval) //在顺序表ST中顺序查找其关键字等于key的数据元素。
若找到,则函数值为该元素在表中的位置,否则为0。
{ ST.elem[0].key = kval; //设置哨兵 for (i = ST.length; ST.elem[i].key != kval; i--) //从后往前找,找不到则返回0 { } return 0;}4.顺序表查找的平均查找长度为:(n+1)/2。
5.上述顺序查找表的查找算法简单,但平均查找长度较⼤,不适⽤于表长较⼤的查找表。
若以有序表表⽰静态查找表,则查找过程可以基于折半进⾏。
算法如下:int Search_Bin(SSTable ST, KeyType kval){ low = 1; high = ST.length; //置区间初值 while (low <= high) { mid = (low + high) / 2; if (kval == ST.elem[mid].key) { return mid; //找到待查元素 } else if (kval < ST.elem[mid].key) { high = mid - 1; //继续在前半区间查找 } else { low = mid + 1; //继续在后半区间查找 } } return 0; //顺序表中不存在待查元素} //表长为n的折半查找的判定树的深度和含有n个结点的完全⼆叉树的深度相同6.⼏种查找表的时间复杂度:(1)从查找性能看,最好情况能达到O(logn),此时要求表有序;(2)从插⼊和删除性能看,最好情况能达到O(1),此时要求存储结构是链表。
《数据结构》第五章习题参考答案

《数据结构》第五章习题参考答案一、判断题(在正确说法的题后括号中打“√”,错误说法的题后括号中打“×”)1、知道一颗树的先序序列和后序序列可唯一确定这颗树。
( ×)2、二叉树的左右子树可任意交换。
(×)3、任何一颗二叉树的叶子节点在先序、中序和后序遍历序列中的相对次序不发生改变。
(√)4、哈夫曼树是带权路径最短的树,路径上权值较大的结点离根较近。
(√)5、用一维数组存储二叉树时,总是以前序遍历顺序存储结点。
( ×)6、完全二叉树中,若一个结点没有左孩子,则它必是叶子结点。
( √)7、一棵树中的叶子数一定等于与其对应的二叉树的叶子数。
(×)8、度为2的树就是二叉树。
(×)二、单项选择题1.具有10个叶结点的二叉树中有( B )个度为2的结点。
A.8 B.9 C.10 D.112.树的后根遍历序列等同于该树对应的二叉树的( B )。
A. 先序序列B. 中序序列C. 后序序列3、二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG 。
该二叉树根的右子树的根是:( C )A. EB. FC. GD. H04、在下述结论中,正确的是( D )。
①具有n个结点的完全二叉树的深度k必为┌log2(n+1)┐;②二叉树的度为2;③二叉树的左右子树可任意交换;④一棵深度为k(k≥1)且有2k-1个结点的二叉树称为满二叉树。
A.①②③B.②③④C.①②④D.①④5、某二叉树的后序遍历序列与先序遍历序列正好相反,则该二叉树一定是( D )。
A.空或只有一个结点B.完全二叉树C.二叉排序树D.高度等于其结点数三、填空题1、对于一棵具有n个结点的二叉树,对应二叉链接表中指针总数为__2n____个,其中___n-1_____个用于指向孩子结点,___n+1___个指针空闲着。
2、一棵深度为k(k≥1)的满二叉树有_____2k-1______个叶子结点。
数据结构-第5章--数组练习题

数据结构-第5章--数组练习题第5章数组一、选择题3.设有数组A[i,j],数组的每个元素长度为3字节,i的值为1到8,j的值为1到10,数组从内存首地址BA开始顺序存放,当用以列为主存放时,元素A[5,8]的存储首地址为(A)。
A.BA+141B.BA+180C.BA+222D.BA+2254.假设以行序为主序存储二维数组A=array[1..100,1..100],设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]=(A)。
A.808B.818C.1010D.10205.数组A[0..5,0..6]的每个元素占五个字节,将其按列优先次序存储在起始地址为1000的内存单元中,则元素A[5,5]的地址是()。
1195A.1175B.1180C.1205D.12107.将一个A[1..100,1..100]的三对角矩阵,按行优先存入一维数组B[1‥298]中,A中元素A6665(即该元素下标i=66,j=65),在B数组中的位置K为()。
供选择的答案:A.198B.195C.1972+64某3=19410.若对n阶对称矩阵A以行序为主序方式将其下三角形的元素(包括主对角线上所有元素)依次存放于一维数组B[1..(n(n+1))/2]中,则在B中确定aij(iA.i某(i-1)/2+jB.j某(j-1)/2+iC.i某(i+1)/2+jD.j某(j+1)/2+i11.设A是n某n的对称矩阵,将A的对角线及对角线上方的元素以列为主的次序存放在一维数组B[1..n(n+1)/2]中,对上述任一元素aij(1≤i,j≤n,且i≤j)在B中的位置为(C)。
A.i(i-l)/2+jB.j(j-l)/2+iC.j(j-l)/2+i-1D.i(i-l)/2+j-112.A[N,N]是对称矩阵,将下面三角(包括对角线)以行序存储到一维数组T[N(N+1)/2]中,则对任一上三角元素a[i][j]对应T[k]的下标k是(AB)。
《数据结构(Python语言描述)》第5章 广义表

广义表是由n个类型相同的数据元素(a1、a2、……、an)组成的有限序列。广义表的元素可以是单个 元素,也可以是一个广义表。通常广义表记作:
GL=(a1,a2,…,an) 广义表有两种数据元素,分别是原子和子表,因此需要两种结构的节点,一种是表节点,用来表 示子表,如图5-1所示;一种是原子节点,用来表示原子,如图5-2所示。
OPTION
在广义表GL中,如果ai也是一个 广义表表,则称ai为广义表GL的 子表。
03 表头
OPTION
在广义表中GL中,a1如果不为空, 则称a1为广义表的表头。
04 表尾
OPTION
在广义表GL中,除了表头a1的其余 元素组成的表称为表尾。
05 深度
OPTION
广义表GL中括号嵌套的最大层数。
图5-3 广义表表节点
表节点由三个域组成:标志域tag,指向表头节点的指针域ph,指向表尾节 点的指针域pt。表节点的标志域tag=1。
5.3 存储结构
7
图5-4 广义表原子节点
原子节点由两个域组成:标志域tag,值域atom。原子节点的标志域tag=0。
节点的定义:
class Node:
def __init__(self, ph, pt, tag, atom):
表节点由三个域组成,即标志域tag、指向表头节点的指针域ph、指向表尾节点的指针域pt。表节点 的标志域tag=1。
原子节点由两个域组成,即标志域tag、值域atom。原子节点的标志域tag=0。
5.2 基本用语
4
01 原子
OPTION
在广义表GL中,如果ai为单个元 素,则称ai称为原子
02 子表
数据结构第五章
5.3.1 特殊矩阵
是指非零元素或零元素的分布有一定规律的矩阵。
1、对称矩阵 在一个n阶方阵A中,若元素满足下述性质: aij = aji 0≦i,j≦n-1 则称A为对称矩阵。
对称矩阵中的元素关于主对角线对称,故只 要存储矩阵中上三角或下三角中的元素,这样, 能节约近一半的存储空间。
2013-7-25 第4章 18
5.3 矩阵的压缩存储
在科学与工程计算问题中,矩阵是一种常用 的数学对象,在高级语言编制程序时,常将 一个矩阵描述为一个二维数组。 当矩阵中的非零元素呈某种规律分布或者矩 阵中出现大量的零元素的情况下,会占用许 多单元去存储重复的非零元素或零元素,这 对高阶矩阵会造成极大的浪费。 为了节省存储空间,我们可以对这类矩阵进 行压缩存储:
5.2 数组的顺序表示和实现 由于计算机的内存结构是一维的, 因此用一维内存来表示多维数组,就必 须按某种次序将数组元素排成一列序列 ,然后将这个线性序列存放在存储器中 。 又由于对数组一般不做插入和删除 操作,也就是说,数组一旦建立,结构 中的元素个数和元素间的关系就不再发 生变化。因此,一般都是采用顺序存储 的方法来表示数组。
即为多个相同的非零元素只分配一个存储空间; 对零元素不分配空间。
课堂讨论: 1. 什么是压缩存储? 若多个数据元素的值都相同,则只分配一个元素值的 存储空间,且零元素不占存储空间。 2. 所有二维数组(矩阵)都能压缩吗? 未必,要看矩阵是否具备以上压缩条件。 3. 什么样的矩阵具备以上压缩条件? 一些特殊矩阵,如:对称矩阵,对角矩阵,三角矩阵, 稀疏矩阵等。 4. 什么叫稀疏矩阵? 矩阵中非零元素的个数较少(一般小于5%)
通常有两种顺序存储方式:
⑴行优先顺序——将数组元素按行排列,第i+1个行 向量紧接在第i个行向量后面。以二维数组为例,按 行优先顺序存储的线性序列为: a11,a12,…,a1n,a21,a22,…a2n,……,am1,am2,…,amn 在PASCAL、C语言中,数组就是按行优先顺序存 储的。 ⑵列优先顺序——将数组元素按列向量排列,第j+1 个列向量紧接在第j个列向量之后,A的m*n个元素按 列优先顺序存储的线性序列为: a11,a21,…,am1,a12,a22,…am2,……,an1,an2,…,anm 在FORTRAN语言中,数组就是按列优先顺序存储的。
数据结构 第5章_递归

2 m=Fibona(2)+Fibona(1); 1 return(m);
(13)
1
(15)
S3
(8) 2
m=Fibona(2)+Fibona(1);
(9)
(10)
1
(14)
return(1)
return(m);
return(1)
return(1)
(4)
return(1)
(5) 1
(6)
(7) 1 Fibona(5)的执行过程
退出
5.3 递归程序到非递归程序的转换
采用递归方式实现问题的算法程序具有结构清 晰、可读性好、易于理解等优点,但递归程序较之 非递归程序无论是空间需求还是时间需求都更高, 因此在希望节省存储空间和追求执行效率的情况下, 人们更希望使用非递归方式实现问题的算法程序; 另外,有些高级程序设计语言没有提供递归的 机制和手段,对于某些具有递归性质的问题(简称 递归问题)无法使用递归方式加以解决,必须使用 非递归方式实现。因此,本小节主要研究递归程序 到非递归程序的转换方法。
退出
例5 采用非递归方式实现求正整数n的阶乘值。 仍使用Fact(n)表示n的阶乘值。要求解Fact(n) 的值,可以考虑i从0开始,依次取1,2,……,一直到n, 分别求Fact(i)的值,且保证求解Fact(i)时总是以前 面已有的求解结果为基础;当i=n 时,Fact(i)的值即 为所求的Fact(n)的值。
退出
排列问题
设计一个递归算法生成n个元素{r1,r2,…,rn}的全排列。
设R={r1,r2,…,rn}是要进行排列的n个元素,Ri=R-{ri}。 集合X中元素的全排列记为perm(X)。 (ri)perm(X)表示在全排列perm(X)的每一个排列前加 上前缀得到的排列。R的全排列可归纳定义如下:
数据结构第五章 数组和广义表

5.3.1
特殊矩阵
1、对称矩阵 在一个n阶方阵A中,若元素满足下述性质: aij = aji 1≤i,j≤n 则称A为对称矩阵。 a11 1 5 1 3 7 a21 a 22 5 0 8 0 0 a31 a32 a33 1 8 9 2 6 ……………….. 3 0 2 5 1 an 1 a n 2 a n 3 …a n n 7 0 6 1 3
第5章
数组和广义表
5.1 数组的定义
5.2 数组的顺序表示和实现
5.3 矩阵的压缩存储
5.3.1 特殊矩阵
5.3.2 稀疏矩阵
5.4 广义表的定义
5.1 数组的定义
数组-----线性表的扩展 A =(a0,a1,a2,…,an-1)
a00 a10 ┇ Am×n= ai0 ┇ am-1,0 a01 … a0j … a11 … a1j … ┇ ai2 … aij … ┇ am-1,2 … am-1,j … a0,n-1 a1,n-1 ai,n-1 am-1,n-1 α0 α1 ┇ Am×n= α i ┇ α m-1
Assign( &A, e, index1, ..., indexn) 赋值操作 初始条件:A是n维数组,e为元素变量,随后是n个下标值。 操作结果:若下标不超界,则将e的值赋给所指定的A的元 素,并返回OK。 对于数组来说一旦维数确定了,每个元素的下标确定了, 那么整个数组就确定了,这样的一个数组结构除了能改变 某元素的值,其他的不能再改变。
5.2 数组的顺序表示和实现
数组类型特点: 1) 只有引用型操作,没有加工型操作; 2) 数组是多维的结构,而存储空间是一个一维的结构。 有两种顺序映象的方式。
有两种顺序映像方法: 1)以行序为主序(行优先,先行后列):先存储行号较小 的元素,行号相同者先存储列号较小的元素;
数据结构讲义第5章-数组和广义表

5.4 广义表
5)若广义表不空,则可分成表头和表尾,反之,一对表头和表尾 可唯一确定广义表 对非空广义表:称第一个元素为L的表头,其余元素组成的表称 为LS的表尾; B = (a,(b,c,d)) 表头:a 表尾 ((b,c,d)) 即 HEAD(B)=a, C = (e) D = (A,B,C,f ) 表头:e 表尾 ( ) TAIL(B)=((b,c,d)),
5.4 广义表
4)下面是一些广义表的例子; A = ( ) 空表,表长为0; B = (a,(b,c,d)) B的表长为2,两个元素分别为 a 和子表(b,c,d); C = (e) C中只有一个元素e,表长为1; D = (A,B,C,f ) D 的表长为4,它的前三个元素 A B C 广义表, 4 A,B,C , 第四个是单元素; E=( a ,E ) 递归表.
以二维数组为例:二维数组中的每个元素都受两个线性关 系的约束即行关系和列关系,在每个关系中,每个元素aij 都有且仅有一个直接前趋,都有且仅有一个直接后继. 在行关系中 aij直接前趋是 aij直接后继是 在列关系中 aij直接前趋是 aij直接后继是
a00 a01 a10 a11
a0 n-1 a1 n-1
a11 a21 ┇ a12 a22 ┇ ai2 ┇ … amj … amn … aij … ain … … a1j a2j … … a1n a2n β1 β2 ┇ βi ┇ βm
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Loc(aij)=Loc(a11)+[(j-1)*m+(i-1)]*K (尽管是方阵,但公式仍不同)
例3:〖00年计算机系考研题〗设数组a[1…60, 1…70]的
基地址为2048,每个元素占2个存储单元,若以列序为主序 顺序存储,则元素a[32,58]的存储地址为 8950 。 答:请注意审题!利用列优先通式: LOC(aij)=LOC(ac1,c2)+[(j-c2)*(d1-c1+1)+i-c1)]*L 得:LOC(a32,58)=2048+[(58-1)*(60-1+1)+32-1)]*2=8950
9
一、稀疏矩阵的压缩存储
二、稀疏矩阵的操作
问题: 如果只存储稀疏矩阵中的非零元素,那这些元素的 位置信息该如何表示? 解决思路: 对每个非零元素增开若干存储单元,例如存放其所 在的行号和列号,便可准确反映该元素所在位置。 实现方法: 将每个非零元素用一个三元组(i,j,aij)来表示, 则每个稀疏矩阵可用一个三元组表来表示。
18
压缩转置算法的效率分析: 1、主要时间消耗在查找M.data[p].j=col的元素,由两重循 环完成: for(col=1; col<=M.nu; col++) 循环次数=nu {for(p=1; p<=M.tu; p++) 循环次数=tu 所以该算法的时间复杂度为O(nu*tu) ----即M的列数与M中非零元素的个数之积 最恶劣情况:M中全是非零元素,此时tu=mu*nu, 时间复杂度为 O(nu2*mu ) 注:若M中基本上是非零元素时,即使用非压缩传统转置算法 的时间复杂度也不过是O(nu*mu) (程序见教材P99) 结论:压缩转置算法不能滥用。 前提:仅适用于非零元素个数很少(即tu<<mu*nu)的情况。
行数 总列数,即 第2维长度 元素个数
ij
补充:计算二维数组元素地址的通式
设一般的二维数组是A[c1..d1, c2..d2],这里c1,c2不一定是0。
单个元素 长度
二维数组列优先存储的通式为: LOC(aij)=LOC(ac1,c2)+[(j-c2)*(d1-c1+1)+i-c1)]*L
6
例1〖软考题〗:一个二维数组A,行下标的范围是1到6,列
法1:用线性表表示:
(( 1,2,12) ,(1,3,9), (3,1,-3), (3,5,14), (4,3,24), (5,2,18) ,(6,1,15), (6,4,-7))
11
法2:用三元组矩阵表示:
0 1 2 3
i 6 1 1 3 3 4
j 6 2 3 1 5 3
value 8 12 9 -3 14 24
第5章 数组和广义表(Arrays & Lists)
数组和广义表的特点:一种特殊的线性表
① 元素的值并非原子类型,可以再分解,表中元素也是一 个线性表(即广义的线性表)。 ② 所有数据元素仍属同一数据类型。
பைடு நூலகம்
5.1 5.2 5.3 5.4 5.5
数组的定义 数组的顺序表示和实现 矩阵的压缩存储 广义表的定义 广义表的存储结构
15
三 元 组 表 a.data
(1, 3, 9 ) (3, 1, -3) (3, 5, 14) (4, 3, 24) (5, 2, 18) (6, 1, 15) (6, 4, -7)
三 元 组 表 b.data
提问: 若采用三元组压缩技术存储稀疏矩阵,只要把每个 元素的行下标和列下标互换,就完成了对该矩阵的转置运 算,这种说法正确吗? 答:肯定不正确! 除了: (1)每个元素的行下标和列下标互换(即三元组 中的i和j互换); 还应该:(2)T的总行数mu和总列数nu与M值不同(互换); (3)重排三元组内元素顺序,使转置后的三元组 也按行(或列)为主序有规律的排列。
0 1 2 3 4 5
1 2 1
2 0 3
3 2 3
4 1 5
5 1 6
6 2 7
6
规律:POS(1)=1 POS(i)=POS(i-1)+NUM(i-1)
7 8
12 0 0 0 18 0 i 6 1 1 3 3 4 5 6 6
9 0 0 24 0 0
0 0 0 0 0 -7 j 6 2 3 1 5 3 2 1 4
Amn=
N维数组的特点: n个下标,每个元素受到n个关系约束
一个n维数组可以看成是由若干个n-1维数组组成的线性表。
3
N维数组的数据类型定义
n_ARRAY = (D, R)
其中:
数据对象:D = {aj1,j2…jn| ji为数组元素的第i 维下标 ,aj1,j2…jn Elemset} 数据关系:R = { R1 ,R2,…. Rn } Ri = {<aj1,j2,…ji…jn , aj1,j2,…ji+1…jn >| aj1,j2,…ji…jn , aj1,j2,…ji+1…jn D } 基本操作:构造数组、销毁数组、读数组元素、写数组元素
数组的抽象数据类型定义略,参见教材P90
疑问:为何书中写成i=2,…n?
4
5.2 数组的顺序存储表示和实现
问题:计算机的存储结构是一维的,而数组一般是多维的, 怎样存放? 解决办法:事先约定按某种次序将数组元素排成一列序列, 然后将这个线性序列存入存储器中。 例如:在二维数组中,我们既可以规定按行存储,也可以 规定按列存储。 注意: • 若规定好了次序,则数组中任意一个元素的存放地址便 有规律可寻,可形成地址计算公式; • 约定的次序不同,则计算元素地址的公式也有所不同; • C和PASCAL中一般采用行优先顺序;FORTRAN采用列优先。
10
例1 :三元素组表中的每个结点对应于稀疏矩阵的 一个非零元素,它包含有三个数据项,分别表示该 元素的 行下标 、 列下标 和 元素值 。
例2:写出右图所示稀疏 矩阵的压缩存储形式。
0 0 -3 0 0 15 12 0 0 0 18 0 9 0 0 24 0 0 0 0 0 0 0 -7 0 0 14 0 0 0 0 0 0 0 0 0
12
0 法三:用带辅助向量的三元组表示。 0 用途:通过三元组高效访问稀疏矩阵中 -3 任一非零元素。 0 方法: 增加2个辅助向量: 0 ① 记录每行非0元素个数,用NUM(i)表示; 15
② 记录稀疏矩阵中每行第一个非0元素在三元 组中的行号,用POS(i)表示。
i
NUM( i) POS( i )
7
若是N维数组,其中任一元素的地址该如何计算?
教材已给出低维优先的地址计算公式,见P93(5-2)式
该式称为n维数组的映像函数:
n
Loc(j1,j2,…jn)=LOC(0,0,…0)+i 1
数组基址
C j
i i
前面若干元素占用 的地址字节总数
其中Cn=L, Ci-1=bi×Ci, 1<i≤n
一个元 素长度 第i维长度 与所存元素个数有关的系 数,可用递推法求出
1
5.1 数组的定义
数组: 由一组名字相同、下标不同的变量构成
注意: 本章所讨论的数组与高级语言中的数组有所区别:高 级语言中的数组是顺序结构;而本章的数组既可以是顺序的, 也可以是链式结构,用户可根据需要选择。
讨论:“数组的处理比其它复杂的结构要简单”,对吗? 答:对的。因为: ① 数组中各元素具有统一的类型; ② 数组元素的下标一般具有固定的上界和下界,即数组一 旦被定义,它的维数和维界就不再改变。 ③数组的基本操作比较简单,除了结构的初始化和销毁之 外,只有存取元素和修改元素值的操作。
data[ ]中
int mu; int nu; int tu; }TsMatrix;
//矩阵总行数
//矩阵总列数
//矩阵中非零元素总个数 //整个三元组表的定义
14
二、稀疏矩阵的操作(以转置运算为例)
目的:
0 0 -3 0 0 15 12 0 0 0 18 0 9 0 0 24 0 0 0 0 0 0 0 -7 0 0 14 0 0 0 0 0 0 0 0 0
5
无论规定行优先或列优先,只要知道以下三要素便可随时求出任 一元素的地址(这样数组中的任一元素便可以随机存取!) ①开始结点的存放地址(即基地址) ②维数和每维的上、下界; ac1,c2 … ac1,d2 ③每个数组元素所占用的单元数 Amn= … aij … ad1,c2 … ad1,d2 则行优先存储时的地址公式为: LOC(aij)=LOC(ac1,c2)+[(i-c1)*(d2-c2+1)+j-c2)]*L aij之前的 数组基址 a 本行前面的
M
转置后
0 12 9 0 0 0
0 0 0 0 0 0
–3 0 0 0 14 0
0 0 15 0 18 0 24 0 0 0 0 -7 0 0 0 0 0 0
T
(1, 2, 12)
(1, 3, -3)
(1, 6, 15) (2, 1, 12) (2, 5, 18) (3, 1, 9) (3, 4, 24) (4, 6, -7) (5, 3, 14)
0 0 0 0 14 0 0 0 0 0 0 0 v 8 12 9 -3 14 24 18 15 -7
13
三元组表的顺序存储表示(见教材P98): #define MAXSIZE 125000 //设非零元素最大个数125000 typedef struct{ int i; //元素行号 int j; //元素列号 ElemType e; //元素值 //一个结点的结构定义 }Triple; typedef struct{ Triple data[MAXSIZE+1]; //三元组表,以行为主序存入一维向量