C语言版图的深度和广度优先遍历源代码
图的深度优先遍历(DFS)c++非递归实现

图的深度优先遍历(DFS)c++⾮递归实现深搜算法对于程序员来讲是必会的基础,不仅要会,更要熟练。
ACM竞赛中,深搜也牢牢占据着很重要的⼀部分。
本⽂⽤显式栈(⾮递归)实现了图的深度优先遍历,希望⼤家可以相互学习。
栈实现的基本思路是将⼀个节点所有未被访问的“邻居”(即“⼀层邻居节点”)踹⼊栈中“待⽤”,然后围绕顶部节点猛攻,每个节点被访问后被踹出。
读者可以⾃⼰画图分析⼀下,难度并不⼤。
代码写的⽐较随意,仅供参考。
~#include <iostream>#include <stack>using namespace std;#define MaxNode 20#define MAX 2000#define StartNode 1int map[MaxNode+1][MaxNode+1];void dfs_stack(int start, int n){int visited[MaxNode],s_top;for(int i = 0;i <= MaxNode; i++){visited[i] = 0;}visited[start] = 1;stack <int> s;cout<<start<<"";for(int i = 1; i <= n; i++){if(map[i][start] == 1 && !visited[i] ){visited[i] = 1;s.push(i);}}while(!s.empty()){s_top = s.top();visited[s_top] = 1;cout<<s_top<<"";s.pop();for(int i = 1; i <= n; i++){if(map[i][s_top] == 1 && !visited[i] ){visited[i] = 1;s.push(i);}}}}int main(int argc, const char * argv[]) {int num_edge,num_node;int x,y;cout<<"Input number of nodes and edges >"<<endl;cin>>num_node>>num_edge;for(int i =0;i<num_node;i++){for(int j=0;j<num_node;j++){map[i][j] = 0;}}for(int i = 1; i <= num_edge; i++){cin>>x>>y;map[x][y] = map[y][x] = 1;}dfs_stack(StartNode, num_node);return0;}。
c语言中常用的查找

c语言中常用的查找C语言中常用的查找引言:在编程中,查找是一项非常常见且重要的操作。
无论是在数组、链表、树还是图等数据结构中,都需要进行查找操作来寻找特定的数据或者确定某个元素的存在与否。
C语言提供了多种查找算法和数据结构,本文将介绍C语言中常用的查找方法。
一、线性查找线性查找是最简单的查找方法之一,也称为顺序查找。
其基本思想是从数据集合的起始位置开始逐个比较待查找元素与集合中的元素,直到找到目标元素或者遍历完整个集合。
在C语言中,可以使用for循环或者while循环实现线性查找。
线性查找的时间复杂度为O(n),其中n为数据集合中元素的个数。
二、二分查找二分查找又称为折半查找,是一种高效的查找算法,但要求数据集合必须是有序的。
其基本思想是将数据集合分为两部分,然后通过与目标元素的比较来确定目标元素在哪个部分中,从而缩小查找范围。
重复这个过程直到找到目标元素或者确定目标元素不存在于数据集合中。
二分查找的时间复杂度为O(logn),其中n为数据集合中元素的个数。
三、哈希表查找哈希表是一种通过哈希函数将关键字映射到存储位置的数据结构,它能够以常数时间复杂度O(1)进行查找操作。
在C语言中,可以使用数组和链表的结合来实现哈希表。
哈希表的关键之处在于哈希函数的设计,良好的哈希函数能够将关键字均匀地映射到不同的存储位置,从而提高查找效率。
四、二叉搜索树查找二叉搜索树是一种常用的数据结构,它满足以下性质:对于任意节点,其左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
在C语言中,可以使用指针和递归的方式来实现二叉搜索树。
通过比较目标值与当前节点的值,可以确定目标值位于左子树还是右子树中,从而缩小查找范围。
五、图的遍历在图的数据结构中,查找操作通常是指遍历操作。
图的遍历有两种方式:深度优先搜索(DFS)和广度优先搜索(BFS)。
深度优先搜索通过递归的方式依次访问图中的每个节点,直到找到目标节点或者遍历完整个图。
深度优先搜索示例代码

深度优先搜索示例代码深度优先搜索(Depth First Search,DFS)是一种用于遍历或搜索树或图的算法。
它通过从根节点或某个指定节点开始,尽可能深地探索每个分支,直到找到目标节点或到达叶子节点为止。
本文将给出一个深度优先搜索的示例代码,帮助读者理解算法的实现过程。
示例代码如下:```class Graph:def __init__(self):self.graph = {}def add_edge(self, vertex, edge):if vertex in self.graph:self.graph[vertex].append(edge)else:self.graph[vertex] = [edge]def dfs(self, start):visited = set()self.dfs_helper(start, visited)def dfs_helper(self, vertex, visited):visited.add(vertex)print(vertex)if vertex in self.graph:for neighbor in self.graph[vertex]:if neighbor not in visited:self.dfs_helper(neighbor, visited)```在示例代码中,首先定义了一个`Graph`类,用于表示图结构。
`Graph`类包含了两个方法:`add_edge`用于添加边,`dfs`用于执行深度优先搜索。
`add_edge`方法用于向图中添加边,其中`vertex`表示起始节点,`edge`表示目标节点。
`dfs`方法用于执行深度优先搜索,其中`start`表示搜索的起始节点。
在深度优先搜索的实现中,我们使用了一个`visited`集合来记录已经访问过的节点,避免重复访问。
`dfs_helper`方法用于递归地进行深度优先搜索,其中`vertex`表示当前访问的节点,`visited`表示已访问节点的集合。
dfs和bfs算法代码

dfs和bfs算法代码深度优先搜索(DFS)和广度优先搜索(BFS)是常用的图遍历算法,它们可以帮助我们解决很多实际问题。
本文将详细介绍这两种算法的实现原理和应用场景。
一、深度优先搜索(DFS)深度优先搜索是一种递归的搜索算法,它从图的某个顶点开始,沿着一条路径尽可能深地搜索,直到无法继续为止,然后回溯到上一级节点,继续搜索其他路径。
DFS一般使用栈来实现。
DFS的代码实现如下:```def dfs(graph, start):visited = set() # 用一个集合来记录已访问的节点stack = [start] # 使用栈来实现DFSwhile stack:node = stack.pop() # 取出栈顶元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点stack.extend(neighbors) # 将邻居节点入栈return visited```DFS的应用场景很多,比如迷宫问题、拓扑排序、连通分量的计算等。
在迷宫问题中,我们可以使用DFS来寻找从起点到终点的路径;在拓扑排序中,DFS可以用来确定任务的执行顺序;在连通分量的计算中,DFS可以用来判断图是否连通,并将图分割成不同的连通分量。
二、广度优先搜索(BFS)广度优先搜索是一种逐层遍历的搜索算法,它从图的某个顶点开始,先访问该顶点的所有邻居节点,然后再访问邻居节点的邻居节点,依次进行,直到遍历完所有节点。
BFS一般使用队列来实现。
BFS的代码实现如下:```from collections import dequedef bfs(graph, start):visited = set() # 用一个集合来记录已访问的节点queue = deque([start]) # 使用队列来实现BFSwhile queue:node = queue.popleft() # 取出队首元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点queue.extend(neighbors) # 将邻居节点入队return visited```BFS的应用场景也很广泛,比如寻找最短路径、社交网络中的人际关系分析等。
深度优先遍历算法实现及复杂度分析

深度优先遍历算法实现及复杂度分析深度优先遍历算法(Depth First Search, DFS)是一种常用的图遍历算法,用于查找或遍历图的节点。
本文将介绍深度优先遍历算法的实现方法,并进行对应的复杂度分析。
一、算法实现深度优先遍历算法的基本思想是从图的某个节点出发,沿着深度方向依次访问其相邻节点,直到无法继续下去,然后返回上一层节点继续遍历。
下面是深度优先遍历算法的伪代码:```1. 初始化访问标记数组visited[],将所有节点的访问标记置为false。
2. 从某个节点v开始遍历:- 标记节点v为已访问(visited[v] = true)。
- 访问节点v的相邻节点:- 若相邻节点w未被访问,则递归调用深度优先遍历算法(DFS(w))。
3. 遍历结束,所有节点都已访问。
```二、复杂度分析1. 时间复杂度深度优先遍历算法的时间复杂度取决于图的存储方式和规模。
假设图的节点数为V,边数为E。
- 邻接表存储方式:对于每个节点,需要访问其相邻节点。
因此,算法的时间复杂度为O(V+E)。
- 邻接矩阵存储方式:需要检查每个节点与其他节点的连通关系,即需要遍历整个邻接矩阵。
因此,算法的时间复杂度为O(V^2)。
2. 空间复杂度深度优先遍历算法使用了一个辅助的访问标记数组visited[]来记录每个节点的访问状态。
假设图的节点数为V。
- 邻接表存储方式:访问标记数组visited[]的空间复杂度为O(V)。
- 邻接矩阵存储方式:访问标记数组visited[]的空间复杂度同样为O(V)。
综上所述,深度优先遍历算法的时间复杂度为O(V+E),空间复杂度为O(V)。
三、应用场景深度优先遍历算法在图的遍历和搜索问题中广泛应用。
以下是一些典型的应用场景:1. 连通性问题:判断图中两个节点之间是否存在路径。
2. 非连通图遍历:对于非连通图,深度优先遍历算法可以用于遍历所有连通分量。
3. 寻找路径:在图中寻找从起始节点到目标节点的路径。
深度优先搜索算法详解及代码实现

深度优先搜索算法详解及代码实现深度优先搜索(Depth-First Search,DFS)是一种常见的图遍历算法,用于遍历或搜索图或树的所有节点。
它的核心思想是从起始节点开始,沿着一条路径尽可能深入地访问其他节点,直到无法继续深入为止,然后回退到上一个节点,继续搜索未访问过的节点,直到所有节点都被访问为止。
一、算法原理深度优先搜索算法是通过递归或使用栈(Stack)的数据结构来实现的。
下面是深度优先搜索算法的详细步骤:1. 选择起始节点,并标记该节点为已访问。
2. 从起始节点出发,依次访问与当前节点相邻且未被访问的节点。
3. 若当前节点有未被访问的邻居节点,则选择其中一个节点,将其标记为已访问,并将当前节点入栈。
4. 重复步骤2和3,直到当前节点没有未被访问的邻居节点。
5. 若当前节点没有未被访问的邻居节点,则从栈中弹出一个节点作为当前节点。
6. 重复步骤2至5,直到栈为空。
深度优先搜索算法会不断地深入到图或树的某一分支直到底部,然后再回退到上层节点继续搜索其他分支。
因此,它的搜索路径类似于一条深入的迷宫路径,直到没有其他路径可走后,再原路返回。
二、代码实现以下是使用递归方式实现深度优先搜索算法的代码:```pythondef dfs(graph, start, visited):visited.add(start)print(start, end=" ")for neighbor in graph[start]:if neighbor not in visited:dfs(graph, neighbor, visited)# 示例数据graph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']}start_node = 'A'visited = set()dfs(graph, start_node, visited)```上述代码首先定义了一个用于实现深度优先搜索的辅助函数`dfs`。
图的深度广度优先遍历C语言程序

scanf("%d",&L->num);
printf("请输入各顶点的信息(单个符号):");
for(i=0;i<L->num;i++)
{
fflush(stdin);
scanf("%c",&L->vexs[i]);
}
printf("请输入边权矩阵的信息:");
{ *e=sq.data[(sq.front)]; return 1;}
}
/*******************************************************************பைடு நூலகம்*********/
int QueueIn (SEQQUEUE *sq,DATATYPE x)
for(v2=0;v2<g.num;v2++)
{
if(g.arcs[v1][v2]!=0&&mark[v2]==0)
{
QueueIn(&q,v2);
mark[v2]=1;
printf("%c ",g.vexs[v2]);
}
}
//如果顺序循环队列sq为空,成功返回1,否则返回0
{
if (sq.rear==sq.front)
return(1);
else
return(0);
}
/*****************************************************************************/
广度优先算法和深度优先算法

广度优先算法和深度优先算法
广度优先算法和深度优先算法是最常用的两种图遍历算法,它们都能
够遍历整个图的节点,但在具体应用场景中选择哪种算法需要根据实
际需求来判断。
广度优先算法(BFS)将当前节点的所有邻居节点都遍历一遍后再遍历下一层,可以确保找到最短路径。
具体实现方式是使用一个队列来存
储被访问过但还未被遍历过的节点,同一层的节点都在队列中,不同
层的节点通过队列的先进先出特性被访问。
BFS遍历图通常需要记录
每个节点是否被访问过,以防止重复遍历。
深度优先算法(DFS)是一种递归算法,从某一节点出发一直向下遍
历到底(即遍历到一个叶子节点),然后返回到上一层节点继续遍历,直到遍历完整个图。
DFS相较于BFS具有更好的空间复杂度,但不能
保证找到最短路径。
DFS遍历图时通常需要记录每个节点是否被访问过,并保证不重复访问。
广度优先算法和深度优先算法在选择上需要根据具体算法应用需求。
如果需要找到最短路径,则选择广度优先算法,如果需要搜索所有可
能路径,则选择深度优先算法。
例如,在迷宫的寻找最短路径场景中,BFS可以从迷宫入口出发,按照层级一层一层的向外扩展搜索,最终
一定能够找到终点,但会消耗较大的空间;而DFS则可以搜索所有可能的路径,但不能确保找到最短路径。
综上所述,广度优先算法和深度优先算法都各有优缺点,在选择上需要根据实际应用场景判断。
【算法】广度优先算法和深度优先算法

【算法】⼴度优先算法和深度优先算法⼴度(BFS)和深度(DFS)优先算法这俩个算法是图论⾥⾯⾮常重要的两个遍历的⽅法。
下⾯⼀个例⼦迷宫计算,如下图解释:所谓⼴度,就是⼀层⼀层的,向下遍历,层层堵截,看下⾯这幅图,我们如果要是⼴度优先遍历的话,我们的结果是V1 V2 V3 V4 V5 V6 V7 V8。
⼴度优先搜索的思想: ①访问顶点vi ; ②访问vi 的所有未被访问的邻接点w1 ,w2 , …wk ; ③依次从这些邻接点(在步骤②中访问的顶点)出发,访问它们的所有未被访问的邻接点; 依此类推,直到图中所有访问过的顶点的邻接点都被访问; 说明: 为实现③,需要保存在步骤②中访问的顶点,⽽且访问这些顶点的邻接点的顺序为:先保存的顶点,其邻接点先被访问。
这⾥我们就想到了⽤标准模板库中的queue队列来实现这种先进现出的服务。
步骤: 1.将V1加⼊队列,取出V1,并标记为true(即已经访问),将其邻接点加进⼊队列,则 <—[V2 V3] 2.取出V2,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[V3 V4 V5]3.取出V3,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[V4 V5 V6 V7]4.取出V4,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[V5 V6 V7 V8]5.取出V5,并标记为true(即已经访问),因为其邻接点已经加⼊队列,则 <—[V6 V7 V8]6.取出V6,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[V7 V8]7.取出V7,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[V8]8.取出V8,并标记为true(即已经访问),将其未访问过的邻接点加进⼊队列,则 <—[]区别:深度优先遍历:对每⼀个可能的分⽀路径深⼊到不能再深⼊为⽌,⽽且每个结点只能访问⼀次。
C语言DFS(深度优先搜索算法)详解

C语言DFS(深度优先搜索算法)详解DFS(深度优先)是一种用于遍历或图形或树结构的算法。
它从起点开始,沿着一条路径尽可能远地遍历图形,直到无法继续前进为止,然后返回到上一个节点,探索其他路径。
DFS基本上是一个递归的过程,它使用栈来实现。
DFS的基本思想是递归地遍历图形。
算法通过维护一个visited数组来跟踪已经访问过的节点,以避免无限循环。
首先,我们访问起点节点,并将其标记为已访问。
然后,对于起点的每个未访问的邻居节点,我们递归地调用DFS。
这样,我们沿着一条路径一直走到无法继续为止,然后返回上一个节点继续探索其他未访问的邻居。
我们重复这个过程,直到我们访问了所有的节点。
在实现DFS时,我们需要用到一个栈来存储节点。
首先,将起点节点入栈。
然后,当栈不为空时,我们将栈顶节点出栈,并将其标记为已访问。
接下来,我们将栈顶节点的所有未访问邻居入栈。
重复这个过程,直到栈为空。
需要注意的是,在使用栈时,我们应该按照相反的顺序将邻居节点入栈,这样在出栈时才能按照正确的顺序进行访问。
DFS可以用来解决很多问题,例如图的连通性、寻找路径、生成所有可能的子集等。
对于连通性问题,如果我们可以从起点节点访问到所有的节点,那么该图是连通的。
对于寻找路径问题,我们可以使用DFS来找到从起点到终点的路径。
对于生成所有可能的子集问题,我们可以使用DFS来枚举所有的子集。
下面是一个用C语言实现的DFS的示例代码:```c#include <stdio.h>#define MAX_SIZE 10int graph[MAX_SIZE][MAX_SIZE];int visited[MAX_SIZE];void dfs(int node)visited[node] = 1;printf("%d ", node);for (int i = 0; i < MAX_SIZE; i++) if (graph[node][i] && !visited[i]) dfs(i);}}int mai//初始化图for (int i = 0; i < MAX_SIZE; i++) for (int j = 0; j < MAX_SIZE; j++) graph[i][j] = 0;}}//添加边graph[0][1] = 1;graph[1][0] = 1;graph[1][2] = 1;graph[2][1] = 1;graph[2][3] = 1;graph[3][2] = 1;graph[3][4] = 1;graph[4][3] = 1;// 初始化visited数组for (int i = 0; i < MAX_SIZE; i++) visited[i] = 0;}//从节点0开始进行DFSdfs(0);return 0;```在这个示例代码中,我们使用一个10x10的二维数组表示图形,其中1表示两个节点之间有连接,0表示没有连接。
树的深度与广度优先搜索(伪代码)

node = nodeStack.pop(); (node); List<Map<String, Object>> list = getChildren(node); if (!CollectionUtil.isBlank(list)) {
for (Map<String, Obk.add(child);
博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
树的深度与广度优先搜索(伪代码)
深度优先搜索
public void depthFirstSearch() {
Stack<Map<String, Object>> nodeStack = new Stack<Map<String, Object>>(); Map<String, Object> node = new HashMap<String, Object>(); /** * 第一个节点放入 */ nodeStack.add(node); while (!nodeStack.isEmpty()) {
} } }
}
广度优先搜索
public void breadthFirstSearch() { ArrayDeque<Map<String, Object>> nodeDeque = new ArrayDeque<Map<String, Object>>(); Map<String, Object> node = new HashMap<String, Object>(); /** * 第一个节点放入 */ nodeDeque.add(node); while (!nodeDeque.isEmpty()) { node = nodeDeque.pop(); (node); List<Map<String, Object>> list = getChildren(node); if (!CollectionUtil.isBlank(list)) { for (Map<String, Object> child : list) { nodeDeque.add(child); }
数据结构c语言版课后习题答案

数据结构c语言版课后习题答案数据结构是计算机科学中的一个重要概念,它涉及到组织、管理和存储数据的方式,以便可以有效地访问和修改数据。
C语言是一种广泛使用的编程语言,它提供了丰富的数据结构实现方式。
对于学习数据结构的C语言版课程,课后习题是巩固理论知识和提高实践能力的重要手段。
数据结构C语言版课后习题答案1. 单链表的实现在C语言中,单链表是一种常见的线性数据结构。
它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。
实现单链表的基本操作通常包括创建链表、插入节点、删除节点、遍历链表等。
答案:- 创建链表:定义一个链表结构体,然后使用动态内存分配为每个节点分配内存。
- 插入节点:根据插入位置,调整前后节点的指针,并将新节点插入到链表中。
- 删除节点:找到要删除的节点,调整其前后节点的指针,然后释放该节点的内存。
- 遍历链表:从头节点开始,使用指针遍历链表,直到达到链表尾部。
2. 二叉树的遍历二叉树是一种特殊的树形数据结构,其中每个节点最多有两个子节点。
二叉树的遍历是数据结构中的一个重要概念,常见的遍历方式有前序遍历、中序遍历、后序遍历和层序遍历。
答案:- 前序遍历:先访问根节点,然后递归遍历左子树,最后递归遍历右子树。
- 中序遍历:先递归遍历左子树,然后访问根节点,最后递归遍历右子树。
- 后序遍历:先递归遍历左子树,然后递归遍历右子树,最后访问根节点。
- 层序遍历:使用队列,按照从上到下,从左到右的顺序访问每个节点。
3. 哈希表的实现哈希表是一种通过哈希函数将键映射到表中一个位置来访问记录的数据结构。
它提供了快速的数据访问能力,但需要处理哈希冲突。
答案:- 哈希函数:设计一个哈希函数,将键映射到哈希表的索引。
- 哈希冲突:使用链地址法、开放地址法或双重哈希法等解决冲突。
- 插入操作:计算键的哈希值,将其插入到对应的哈希桶中。
- 删除操作:找到键对应的哈希桶,删除相应的键值对。
4. 图的表示和遍历图是一种复杂的非线性数据结构,由顶点(节点)和边组成。
C语言算法及三种基本程序结构

C语言算法及三种基本程序结构C语言是一种广泛应用于系统程序开发和嵌入式开发的编程语言。
在编写C语言程序时,我们需要掌握各种算法和程序结构,以实现不同的功能和解决各种问题。
本文将介绍C语言中的常用算法以及三种基本程序结构。
一、常用算法1. 排序算法:排序是计算机编程中最常见的问题之一、C语言提供了多种排序算法,包括冒泡排序、选择排序、插入排序、快速排序等。
排序算法根据其时间复杂度和稳定性可以进行选择。
例如,冒泡排序是一种简单但效率较低的算法,时间复杂度为O(n^2),而快速排序是一种高效的排序算法,平均时间复杂度为O(nlogn)。
2. 查找算法:查找是在一组数据中寻找特定元素的过程。
C语言提供了多种查找算法,包括线性查找、二分查找、哈希查找等。
线性查找是最简单的查找算法,但效率较低,时间复杂度为O(n);而二分查找是一种高效的查找算法,时间复杂度为O(logn),但要求数据必须有序。
3.图算法:图是由节点和边组成的数据结构,用于描述各种实际问题。
C语言提供了多种图算法,包括深度优先、广度优先、最短路径算法、最小生成树算法等。
这些算法可以解决许多实际问题,如网络路由、社交网络分析等。
4.动态规划:动态规划是一种解决多阶段决策问题的算法。
C语言中可以用动态规划来解决各种优化问题,如背包问题、最长公共子序列等。
动态规划算法需要构建状态转移方程,并利用已求解的子问题结果来求解当前问题。
1.顺序结构:顺序结构是最基本的程序结构,其中的代码按照顺序执行。
C语言中的语句就是按照从上到下的顺序执行的。
例如,以下代码实现了计算两个整数的和并输出结果的功能。
```#include <stdio.h>int maiint a = 10, b = 20;int sum = a + b;printf("Sum is %d", sum);return 0;```2. 选择结构:选择结构根据条件的真假来执行不同的语句块。
数据结构 C语言版(严蔚敏版)第7章 图

1
2
4
1
e6 2 4
2016/11/7
29
7.3 图的遍历
从已给的连通图中某一顶点出发,沿着一 些边访遍图中所有的顶点,且使每个顶点 仅被访问一次,就叫做图的遍历 ( Graph Traversal )。 图中可能存在回路,且图的任一顶点都可 能与其它顶点相通,在访问完某个顶点之 后可能会沿着某些边又回到了曾经访问过 的顶点。 为了避免重复访问,可设置一个标志顶点 是否被访问过的辅助数组 visited [ ]。
2
1 2
V2
V4
17
结论:
无向图的邻接矩阵是对称的; 有向图的邻接矩阵可能是不对称的。 在有向图中, 统计第 i 行 1 的个数可得顶点 i 的出度,统计第 j 行 1 的个数可得顶点 j 的入度。 在无向图中, 统计第 i 行 (列) 1 的个数可得 顶点i 的度。
2016/11/7
18
2
邻接表 (出度表)
adjvex nextarc
data firstarc
0 A 1 B 2 C
2016/11/7
1 0 1
逆邻接表 (入度表)
21
网络 (带权图) 的邻接表
6 9 0 2 1 C 2 8 3 D
data firstarc Adjvex info nextarc
2016/11/7
9
路径长度 非带权图的路径长度是指此路径 上边的条数。带权图的路径长度是指路径 上各边的权之和。 简单路径 若路径上各顶点 v1,v2,...,vm 均不 互相重复, 则称这样的路径为简单路径。 回路 若路径上第一个顶点 v1 与最后一个 顶点vm 重合, 则称这样的路径为回路或环。
深度优先搜索和广度优先搜索

深度优先搜索和广度优先搜索深度优先搜索(DFS)和广度优先搜索(BFS)是图论中常用的两种搜索算法。
它们是解决许多与图相关的问题的重要工具。
本文将着重介绍深度优先搜索和广度优先搜索的原理、应用场景以及优缺点。
一、深度优先搜索(DFS)深度优先搜索是一种先序遍历二叉树的思想。
从图的一个顶点出发,递归地访问与该顶点相邻的顶点,直到无法再继续前进为止,然后回溯到前一个顶点,继续访问其未被访问的邻接顶点,直到遍历完整个图。
深度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 递归访问该顶点的邻接顶点,直到所有邻接顶点均被访问过。
深度优先搜索的应用场景较为广泛。
在寻找连通分量、解决迷宫问题、查找拓扑排序等问题中,深度优先搜索都能够发挥重要作用。
它的主要优点是容易实现,缺点是可能进入无限循环。
二、广度优先搜索(BFS)广度优先搜索是一种逐层访问的思想。
从图的一个顶点出发,先访问该顶点,然后依次访问与该顶点邻接且未被访问的顶点,直到遍历完整个图。
广度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 将该顶点的所有邻接顶点加入一个队列;4. 从队列中依次取出一个顶点,并访问该顶点的邻接顶点,标记为已访问;5. 重复步骤4,直到队列为空。
广度优先搜索的应用场景也非常广泛。
在求最短路径、社交网络分析、网络爬虫等方面都可以使用广度优先搜索算法。
它的主要优点是可以找到最短路径,缺点是需要使用队列数据结构。
三、DFS与BFS的比较深度优先搜索和广度优先搜索各自有着不同的优缺点,适用于不同的场景。
深度优先搜索的优点是在空间复杂度较低的情况下找到解,但可能陷入无限循环,搜索路径不一定是最短的。
广度优先搜索能找到最短路径,但需要保存所有搜索过的节点,空间复杂度较高。
需要根据实际问题选择合适的搜索算法,例如在求最短路径问题中,广度优先搜索更加合适;而在解决连通分量问题时,深度优先搜索更为适用。
深度优先遍历算法和广度优先遍历算法实验小结

深度优先遍历算法和广度优先遍历算法实验小结一、引言在计算机科学领域,图的遍历是一种基本的算法操作。
深度优先遍历算法(Depth First Search,DFS)和广度优先遍历算法(Breadth First Search,BFS)是两种常用的图遍历算法。
它们在解决图的连通性和可达性等问题上具有重要的应用价值。
本文将从理论基础、算法原理、实验设计和实验结果等方面对深度优先遍历算法和广度优先遍历算法进行实验小结。
二、深度优先遍历算法深度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,沿着一条路径一直向前直到不能再继续前进为止,然后退回到上一个节点,尝试下一个节点,直到遍历完整个图。
深度优先遍历算法通常使用栈来实现。
以下是深度优先遍历算法的伪代码:1. 创建一个栈并将起始节点压入栈中2. 将起始节点标记为已访问3. 当栈不为空时,执行以下步骤:a. 弹出栈顶节点,并访问该节点b. 将该节点尚未访问的邻居节点压入栈中,并标记为已访问4. 重复步骤3,直到栈为空三、广度优先遍历算法广度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,先访问起始节点的所有相邻节点,然后再依次访问这些相邻节点的相邻节点,依次类推,直到遍历完整个图。
广度优先遍历算法通常使用队列来实现。
以下是广度优先遍历算法的伪代码:1. 创建一个队列并将起始节点入队2. 将起始节点标记为已访问3. 当队列不为空时,执行以下步骤:a. 出队一个节点,并访问该节点b. 将该节点尚未访问的邻居节点入队,并标记为已访问4. 重复步骤3,直到队列为空四、实验设计本次实验旨在通过编程实现深度优先遍历算法和广度优先遍历算法,并通过对比它们在不同图结构下的遍历效果,验证其算法的正确性和有效性。
具体实验设计如下:1. 实验工具:使用Python编程语言实现深度优先遍历算法和广度优先遍历算法2. 实验数据:设计多组图结构数据,包括树、稠密图、稀疏图等3. 实验环境:在相同的硬件环境下运行实验程序,确保实验结果的可比性4. 实验步骤:编写程序实现深度优先遍历算法和广度优先遍历算法,进行多次实验并记录实验结果5. 实验指标:记录每种算法的遍历路径、遍历时间和空间复杂度等指标,进行对比分析五、实验结果在不同图结构下,经过多次实验,分别记录了深度优先遍历算法和广度优先遍历算法的实验结果。
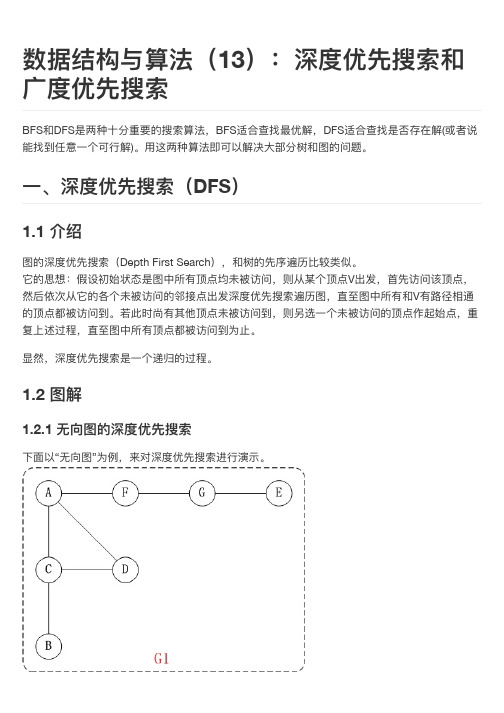
数据结构与算法(13):深度优先搜索和广度优先搜索
2.2.2 有向图的广广度优先搜索
下面面以“有向图”为例例,来对广广度优先搜索进行行行演示。还是以上面面的图G2为例例进行行行说明。
第1步:访问A。 第2步:访问B。 第3步:依次访问C,E,F。 在访问了了B之后,接下来访问B的出边的另一一个顶点,即C,E,F。前 面面已经说过,在本文文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访 问E,F。 第4步:依次访问D,G。 在访问完C,E,F之后,再依次访问它们的出边的另一一个顶点。还是按 照C,E,F的顺序访问,C的已经全部访问过了了,那么就只剩下E,F;先访问E的邻接点D,再访 问F的邻接点G。
if(mVexs[i]==ch)
return i;
return -1;
}
/* * 读取一一个输入入字符
*/
private char readChar() {
char ch='0';
do {
try {
ch = (char)System.in.read();
} catch (IOException e) {
数据结构与算法(13):深度优先搜索和 广广度优先搜索
BFS和DFS是两种十十分重要的搜索算法,BFS适合查找最优解,DFS适合查找是否存在解(或者说 能找到任意一一个可行行行解)。用用这两种算法即可以解决大大部分树和图的问题。
一一、深度优先搜索(DFS)
1.1 介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比比较类似。 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点V出发,首首先访问该顶点, 然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至至图中所有和V有路路径相通 的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一一个未被访问的顶点作起始点,重 复上述过程,直至至图中所有顶点都被访问到为止止。 显然,深度优先搜索是一一个递归的过程。
马的遍历问题c语言

马的遍历问题c语言马的遍历问题是一道经典的算法问题,也是计算机科学中常见的图论问题。
在这个问题中,我们需要找到一种方法来让一个马在一个棋盘上遍历所有的格子,且每个格子只能被访问一次。
这个问题可以使用深度优先搜索或广度优先搜索等算法来解决。
一、问题描述1.1 题目描述在一个8x8的棋盘上,有一个马初始位置为(x0,y0),现在需要将马移动到棋盘上所有格子恰好经过一次且仅经过一次。
请问是否存在这样的移动方案?如果存在,请输出任意一种方案。
1.2 输入输出格式输入格式:两个整数x0和y0表示马初始位置坐标。
输出格式:若存在移动方案,则输出任意一种方案;否则输出“无解”。
二、解题思路2.1 深度优先搜索算法深度优先搜索算法是从根节点开始,沿着树的深度遍历树的节点,直到找到目标节点或者遍历完整棵树。
该算法可以使用递归方式实现,也可以使用栈来实现。
对于本题,在每个节点上,我们需要判断当前位置是否已经被访问过,并且还需要判断当前位置是否越界。
如果当前位置符合要求,则将该位置标记为已访问,并且继续递归搜索下一个节点。
如果搜索到最后一个节点,则说明找到了一种方案。
2.2 广度优先搜索算法广度优先搜索算法是从起始节点开始,按照层次遍历树的节点,直到找到目标节点或者遍历完整棵树。
该算法可以使用队列来实现。
对于本题,在每个节点上,我们需要判断当前位置是否已经被访问过,并且还需要判断当前位置是否越界。
如果当前位置符合要求,则将该位置标记为已访问,并且将该节点加入队列中。
接着从队列中取出下一个节点,继续搜索下一层的所有节点。
如果搜索到最后一个节点,则说明找到了一种方案。
三、代码实现3.1 深度优先搜索算法代码实现```#include <stdio.h>#include <stdlib.h>#define N 8 // 棋盘大小#define MAX_STEP N*N // 最大步数int board[N][N]; // 棋盘int dx[8] = {1, 2, 2, 1, -1, -2, -2, -1}; // 马可以走的8个方向int dy[8] = {2, 1, -1, -2, -2, -1, 1, 2};void print_board() // 打印棋盘{int i, j;for(i=0; i<N; i++) {for(j=0; j<N; j++) {printf("%d ", board[i][j]);}printf("\n");}}int dfs(int x, int y, int step) // 深度优先搜索{int k, nx, ny;if(step == MAX_STEP) { // 找到一种方案print_board();return 1;}for(k=0; k<8; k++) { // 枚举马可以走的8个方向nx = x + dx[k];ny = y + dy[k];if(nx>=0 && nx<N && ny>=0 && ny<N && board[nx][ny]==0) { // 判断是否越界和是否已经访问过 board[nx][ny] = step+1;if(dfs(nx, ny, step+1)) { // 递归搜索下一个节点 return 1;}board[nx][ny] = 0;}}return 0;}int main(){int x, y;printf("请输入马初始位置坐标(范围:0~7):\n"); scanf("%d %d", &x, &y);if(x<0 || x>=N || y<0 || y>=N) {printf("输入坐标不合法!\n");return -1;}board[x][y] = 1; // 标记初始位置已访问过if(!dfs(x, y, 1)) { // 搜索所有节点printf("无解!\n");}return 0;}```3.2 广度优先搜索算法代码实现```#include <stdio.h>#include <stdlib.h>#define N 8 // 棋盘大小#define MAX_STEP N*N // 最大步数int board[N][N]; // 棋盘int dx[8] = {1, 2, 2, 1, -1, -2, -2, -1}; // 马可以走的8个方向int dy[8] = {2, 1, -1, -2, -2, -1, 1, 2};void print_board() // 打印棋盘{int i, j;for(i=0; i<N; i++) {for(j=0; j<N; j++) {printf("%d ", board[i][j]);}printf("\n");}}int bfs(int x0, int y0) // 广度优先搜索{int queue[N*N][3];int head = 0;int tail = 0;int i;queue[tail][0] = x0;queue[tail][1] = y0;queue[tail][2] = 1; // 初始位置已访问过tail++;while(head<tail) { // 遍历队列中的所有节点int x = queue[head][0];int y = queue[head][1];int step = queue[head][2];if(step == MAX_STEP) { // 找到一种方案print_board();return 1;}for(i=0; i<8; i++) { // 枚举马可以走的8个方向int nx = x + dx[i];int ny = y + dy[i];if(nx>=0 && nx<N && ny>=0 && ny<N && board[nx][ny]==0) { // 判断是否越界和是否已经访问过 board[nx][ny] = step+1;queue[tail][0] = nx;queue[tail][1] = ny;queue[tail][2] = step+1;tail++;}}head++;}return 0;}int main(){int x, y;printf("请输入马初始位置坐标(范围:0~7):\n"); scanf("%d %d", &x, &y);if(x<0 || x>=N || y<0 || y>=N) {printf("输入坐标不合法!\n");return -1;}board[x][y] = 1; // 标记初始位置已访问过if(!bfs(x, y)) { // 搜索所有节点printf("无解!\n");}return 0;}```四、总结本文介绍了马的遍历问题,包括问题描述、解题思路和代码实现。
c语言dfs函数

c语言dfs函数DFS(Depth First Search)是图遍历的一种算法,它以深度优先的方式进行搜索。
在计算机科学中,图是由节点(顶点)和连接节点的边组成的抽象数据类型。
DFS算法通过递归的方式遍历图中的节点,并记录已经访问过的节点,以避免重复访问。
在DFS算法中,首先选择一个起始节点作为根节点,然后从该节点开始向下遍历,直到达到最深的节点。
在遍历的过程中,如果遇到已经访问过的节点或者无法继续向下遍历的节点,则回溯到上一个节点,继续遍历其他路径。
这种遍历方式可以通过递归或者栈来实现。
DFS算法的核心思想是尽可能深入地探索图中的路径,直到找到目标节点或者无法继续深入为止。
它与BFS(Breadth First Search)算法相对应,BFS算法是以广度优先的方式进行搜索,先遍历当前节点的所有相邻节点,再依次遍历下一层的节点。
在实际应用中,DFS算法被广泛应用于解决各种问题,如寻找图中的连通分量、解决迷宫问题、生成括号序列等。
以下是几个应用DFS算法的具体例子:1. 寻找图中的连通分量:通过DFS算法可以遍历图中的所有节点,并将属于同一个连通分量的节点标记为已访问。
这样可以快速找到图中的所有连通分量,用于分析网络结构、社交关系等。
2. 解决迷宫问题:迷宫问题可以看作是一个由节点和连接节点的边构成的图。
通过DFS算法可以从起始节点开始遍历迷宫,直到找到终点或者无法继续深入为止。
这种方式可以找到从起点到终点的最短路径。
3. 生成括号序列:给定一个整数n,表示括号的对数,通过DFS算法可以生成所有有效的括号序列。
在生成序列的过程中,需要满足左括号的数量不能超过n,右括号的数量不能超过左括号的数量,这样才能保证生成的序列是有效的。
除了上述几个例子,DFS算法还可以应用于解决其他问题,如求解图的最小生成树、求解图的割点和桥等。
在实际应用中,选择使用DFS算法还是BFS算法取决于具体的问题需求和图的结构。
深度优先算法和广度优先算法c语言

深度优先算法和广度优先算法是计算机科学中常见的两种图遍历算法。
它们在处理图数据结构时起着至关重要的作用,在实际应用中被广泛使用。
本文将探讨深度优先算法和广度优先算法在C语言中的实现和应用。
一、深度优先算法深度优先算法(Depth First Search)是一种用于遍历或搜索树或图的算法。
其基本思想是从起始顶点开始,尽可能沿着一条路径一直向下,直到无法再继续为止,然后回溯到前一个节点,继续向下搜索。
深度优先算法可以通过递归或栈来实现。
在C语言中,我们可以使用递归方法来实现深度优先算法。
```c#define MAXVEX 100typedef struct {int vertex[MAXVEX]; // 顶点表int arc[MAXVEX][MAXVEX]; // 邻接矩阵int vexnum, aum; // 图的顶点数和边数} MGraph;int visited[MAXVEX]; // 访问标志数组void DFS(MGraph G, int v) {int i;visited[v] = 1; // 标记v已访问printf("d ", v); // 访问顶点vfor (i = 0; i < G.vexnum; i++) {if (G.arc[v][i] == 1 !visited[i]) {DFS(G, i); // 对v的尚未访问的邻接顶点i进行递归访问}}}```二、广度优先算法广度优先算法(Breadth First Search)同样是一种用于图的遍历或搜索的算法,不同于深度优先算法,广度优先算法的基本思想是从起始顶点开始,先访问其所有的直接邻接顶点,然后依次访问这些邻接顶点的邻接顶点。
广度优先算法可以通过队列来实现。
在C语言中,我们可以使用队列来实现广度优先算法。
```ctypedef struct {int vertex[MAXVEX]; // 顶点表int arc[MAXVEX][MAXVEX]; // 邻接矩阵 int vexnum, aum; // 图的顶点数和边数} MGraph;int visited[MAXVEX]; // 访问标志数组void BFS(MGraph G, int v) {int i, j;int queue[MAXVEX]; // 定义队列int front = 0, rear = 0; // 队头和队尾指针 printf("d ", v); // 访问顶点vvisited[v] = 1; // 标记v已访问queue[rear++] = v; // 入队while (front < rear) {v = queue[front++]; // 出队for (i = 0; i < G.vexnum; i++) {if (G.arc[v][i] == 1 !visited[i]) {printf("d ", i); // 访问顶点ivisited[i] = 1; // 标记i已访问queue[rear++] = i; // 入队}}}}```三、深度优先算法与广度优先算法的比较1. 时间复杂度:深度优先算法和广度优先算法的时间复杂度均为O(V+E),其中V为顶点数,E为边数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
邻接表表示的图:
#include""
#include""
#define MaxVertexNum 50 ertex=a; irstedge=NULL; irstedge;
G->adjlist[i].firstedge=s; irstedge;
G->adjlist[j].firstedge=s; ertex); irstedge; ertex); irstedge; ertex); //访问Vj
visited[p->adjvex]=TRUE;
r=r+1; cq[r]=p->adjvex; //访问过的Vj入队
}
p=p->next; //找Vi的下一个邻接点
}
}//endwhile
}
//==========主函数===========
void main()
{
//int i;
ALGraph *G;
G=(ALGraph *)malloc(sizeof(ALGraph));
CreatALGraph(G);
printf("Print Graph DFS: ");
DFS(G);
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3);
printf("\n");
}
邻接矩阵表示的图:
#include""
#include""
#define MaxVertexNum 100 //定义最大顶点数
typedef struct{
char vexs[MaxVertexNum]; //顶点表
int edges[MaxVertexNum][MaxVertexNum]; //邻接矩阵,可看作边表int n,e; //图中的顶点数n和边数e
}MGraph; //用邻接矩阵表示的图的类型
//=========建立邻接矩阵=======
void CreatMGraph(MGraph *G)
{
int i,j,k;
char a;
printf("Input VertexNum(n) and EdgesNum(e): ");
scanf("%d,%d",&G->n,&G->e); //输入顶点数和边数
scanf("%c",&a);
printf("Input Vertex string:");
for(i=0;i<G->n;i++)
{
scanf("%c",&a);
G->vexs[i]=a; //读入顶点信息,建立顶点表
}
for(i=0;i<G->n;i++)
for(j=0;j<G->n;j++)
G->edges[i][j]=0; //初始化邻接矩阵
printf("Input edges,Creat Adjacency Matrix\n");
for(k=0;k<G->e;k++) { //读入e条边,建立邻接矩阵
scanf("%d%d",&i,&j); //输入边(Vi,Vj)的顶点序号
G->edges[i][j]=1;
G->edges[j][i]=1; //若为无向图,矩阵为对称矩阵;若建立有向图,去掉该条语句
}
}
//=========定义标志向量,为全局变量=======
typedef enum{FALSE,TRUE} Boolean;
Boolean visited[MaxVertexNum];
//========DFS:深度优先遍历的递归算法======
void DFSM(MGraph *G,int i)
{ //以Vi为出发点对邻接矩阵表示的图G进行DFS搜索,邻接矩阵是0,1矩阵
int j;
printf("%c",G->vexs[i]); //访问顶点Vi
visited[i]=TRUE; //置已访问标志
for(j=0;j<G->n;j++) //依次搜索Vi的邻接点
if(G->edges[i][j]==1 && ! visited[j])
DFSM(G,j); //(Vi,Vj)∈E,且Vj未访问过,故Vj为新出发点
}
void DFS(MGraph *G)
{
int i;
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
if(!visited[i]) //Vi未访问过
DFSM(G,i); //以Vi为源点开始DFS搜索
}
//===========BFS:广度优先遍历=======
void BFS(MGraph *G,int k)
{ //以Vk为源点对用邻接矩阵表示的图G进行广度优先搜索
int i,j,f=0,r=0;
int cq[MaxVertexNum]; //定义队列
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
cq[i]=-1; //队列初始化
printf("%c",G->vexs[k]); //访问源点Vk
visited[k]=TRUE;
cq[r]=k; //Vk已访问,将其入队。
注意,实际上是将其序号入队while(cq[f]!=-1) { //队非空则执行
i=cq[f]; f=f+1; //Vf出队
for(j=0;j<G->n;j++) //依次Vi的邻接点Vj
if(!visited[j] && G->edges[i][j]==1) { //Vj未访问
printf("%c",G->vexs[j]); //访问Vj
visited[j]=TRUE;
r=r+1; cq[r]=j; //访问过Vj入队
}
}
}
//==========main=====
void main()
{
//int i;
MGraph *G;
G=(MGraph *)malloc(sizeof(MGraph)); //为图G申请内存空间CreatMGraph(G); //建立邻接矩阵
printf("Print Graph DFS: ");
DFS(G); //深度优先遍历
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3); //以序号为3的顶点开始广度优先遍历
printf("\n");
}。