计组answer05
王道计组课后题讲解

王道计组课后题讲解
(原创实用版)
目录
1. 王道计组的概述
2. 课后题的类型及重要性
3. 课后题的解答方法与技巧
4. 总结
正文
一、王道计组的概述
王道计组是一种计算机编程学习方法,主要用于解决计算机编程中的各种问题。
王道计组将复杂的编程问题分解成一个个小问题,然后通过编写小程序来解决这些小问题。
这种方法不仅可以帮助学生更好地理解编程原理,还可以提高他们的编程能力。
二、课后题的类型及重要性
课后题是王道计组学习方法中的一个重要组成部分,主要用于检验学生对课程内容的理解程度。
课后题的类型有很多,包括选择题、填空题、编程题等。
这些题目不仅可以帮助学生巩固所学知识,还可以提高他们的编程技巧。
三、课后题的解答方法与技巧
解答课后题需要掌握一定的方法和技巧,以下是一些常用的解答方法:
1.仔细阅读题目,理解题意。
2.分析题目,找出解题的关键点。
3.根据题目要求,编写程序代码。
4.调试程序,确保程序的正确性。
5.对于难度较大的题目,可以先解决其中的一部分,然后再逐步完善。
四、总结
课后题是王道计组学习方法中的一个重要组成部分,它不仅可以帮助学生检验所学知识,还可以提高他们的编程技巧。
第7章习题答案 计算机组成原理课后答案(清华大学出版社 袁春风主编)

• 159 •
7. 假定以下 MIPS 指 令序列在图 7.18 所示 的流 水线数据通路中 执行:
addu $s3, $s1, $s0
subu $t2, $s0, $s3
流水线深度( Pipeline Depth) 流 水 线 冒 险 ( Hazar d) 控制冒险(Control hazard) 流水线阻塞( Pipeline stall) 空 操 作 ( nop) 分支预测(Branch predict) 动态分支预测(Dynamic predict) 分支 延迟槽(Delayed branch slot) 旁 路 ( Bypassing) IPC(Instructions Per Cycle) 动态多发射(Dynamic multiple issue) 超长指令字 VLIW 动态流水线(Dynamic pipelining) 指令分发(Instruction dispatch) 无序发射( out-of-order issue) 重排序缓冲(Reorder buffer) 乱序执行( out-of-order execution) 无序完成( out-of-order completion)
(1)插入 一个流水段寄 存器,得到 一个两级 流水线 (2)插 入两个流水段 寄存器,得 到一个三 级流水线 (3)插入 三个流水段寄 存器,得到 一个四级 流水线 (4)吞 吐量最大的流 水线 参考答案:
(1)两级流水线的平衡点在 C 和 D 之间,其前面一个流水段的组合逻辑延时为 80+30+60=170ps,后 面一 个流水 段的 组合逻 辑延时 为 50+70+10=130ps。这 样每个 流水段 都 以 最 长 延 时 调 整 为 170+20=190ps , 故 时 钟 周 期 为 190ps , 指 令 吞 吐 率 为 1/190ps=5.26GOPS,每条 指令的执行时 间为 2x190=380ps。
2011_2012answer

7 答案: 这个程序先读入文件 original 中的内容, 然后对每个字母进行后移 2 位的编码转 换工作,最后把重新编码后的字符串写 到文件 savetoo 内。 文件“savetoo”内存储的内容: Write a program. Ytkvg c rtqitco.
四.
for i in range( len(str) ): (num) num = ord(str[i]) output..append print output
2. i3 = i3 + 1 while i1 < len(lst1): lst3[i3] = lst1[i1] i1 = i1 + 1 i3 = i3 + 1 while i2 < len(lst2): lst3[i3] = lst2[i2] i2 = i2 + 1 i3 = i3 + 1 def mergeSort(lst): n = len(lst) if n > 1: m=n/2 lst1, lst2 = lst[:m], lst[m:] mergeSort(lst1) mergeSort(lst2) merge(lst1, lst2, lst) 3. def f(a,b,c): max = min = a return max, min 4. from random import randrange from string import * def main(): lines=input("please input the lines of triangle: ") for i in range(lines): space=' '*(lines-i-1) character='' for j in range(2*i+1): if randrange(2)==0: mark='*' else: mark='#' character=character+mark print space+character main() # item added to lst3
Noip2007、2009普及组复赛答案

Noip2007普及组复赛答案1——奖学金typeaa=recordy,s,w:integer;end;bb=recordf,h:integer;end;var a:array[1..300]of aa;b:array[1..5]of bb;n,i,j,k,t:integer;f:boolean;beginreadln(n);for i:=1 to 5 dowith b[i] do beginf:=0;h:=0;end;for i:=1 to n do beginwith a[i] do read(y,s,w);j:=1;f:=true;t:=a[i].y+a[i].s+a[i].w;while (j<=5)and f do beginif (t>b[j].f)or((t=b[j].f)and(a[i].y>a[b[j].h].y)) then begin for k:=5 downto j+1 do beginb[k].f:=b[k-1].f;b[k].h:=b[k-1].h;end;b[j].f:=t;b[j].h:=i;f:=false;end else if (t=b[j].f)and(a[i].y=a[b[j].h].y) then beginfor k:=5 downto j+2 do beginb[k].f:=b[k-1].f;b[k].h:=b[k-1].h;end;b[j+1].h:=i;b[j+1].f:=t;f:=false;end;j:=j+1;end;for i:=1 to 5 dowith b[i] do writeln(h,' ',f);end.Noip2007普及组复赛答案2——纪念品var a:array[1..30000]of byte;b:array[1..30000]of boolean;w,n,i,zu,k,ma,t:integer;beginreadln(w);readln(n);for i:=1 to 30000 do b[i]:=true;for i:=1 to n do read(a[i]);zu:=0;for i:=1 to n do beginma:=0;t:=0;if b[i] then for k:=i+1 to n doif (a[i]+a[k]<=w)and(a[i]+a[k]>ma)and b[i] and b[k] then begin ma:=a[i]+a[k];t:=k;end;if t<>0 then beginb[i]:=false;b[t]:=false;zu:=zu+1;end;end;for i:=1 to n do if b[i] then zu:=zu+1;writeln(zu);end.Noip2007普及组复赛答案3——守望者的逃离var maxs,mintime,t,m,s,t1,m1,s1:longint;procedure aa(m1,s1,t1:integer);beginif (s1>0)and(t1>0) then begins1:=s1-m1 div 10*60;t1:=t1-m1 div 10;m1:=m1 mod 10;m1:=m1+4;t1:=t1-1;aa(m1,s1,t1);m1:=m1-4;aa(m1,s1,t1);end else beginif maxs<s-s1 then maxs:=s-s1;if (t1>=0)and(mintime>t-t1) then mintime:=t-t1;end;end;beginreadln(m,s,t);maxs:=0;mintime:=2000000;t1:=t;m1:=m;s1:=s;aa(m1,s1,t1);if maxs<s then beginwriteln('No');writeln(maxs);end else beginwriteln('Yes');writeln(mintime);end;end.(pascal语言)Noip2007普及组复赛答案4——Hanoi双塔问题2007年11月21日星期三18:40var a:array[1..62]of integer;i,j,n:integer;f:boolean;beginreadln(n);for i:=2 to 62 do a[i]:=0;a[1]:=2;for i:=2 to n do beginfor j:=1 to 62 doa[j]:=a[j]*2;a[1]:=a[1]+2;for j:=1 to 62 doif a[j]>9 thenbegina[j+1]:=a[j+1]+1;a[j]:=a[j] mod10;end;end;f:=false;for i:=62 downto 1 dobeginif a[i]<>0 thenf:=true;if f then write(a[i]);end;writeln;end.(pascal语言)Noip2007普及组复赛答案4——Hanoi双塔问题2007年11月21日星期三18:40var a:array[1..62]of integer;i,j,n:integer;f:boolean;beginreadln(n);for i:=2 to 62 do a[i]:=0;a[1]:=2;for i:=2 to n do beginfor j:=1 to 62 doa[j]:=a[j]*2;a[1]:=a[1]+2;for j:=1 to 62 doif a[j]>9 thenbegina[j+1]:=a[j+1]+1;a[j]:=a[j] mod10;end;end;f:=false;for i:=62 downto 1 dobeginif a[i]<>0 thenf:=true;if f then write(a[i]);end;writeln;end.问题转述:给出一个一元多项式各项的次数和系数,按照规定的格式要求输出该多项式。
PC homewer answer 5

12345 接口5.1 什么叫端口?通常有哪几类端口?计算机对I/O端口编址时通常采用哪两种方法?在8086/8088系统中,用哪种方法对I/O端口进行编址?接口中可被CPU访问的寄存器称为端口。
通常有:数据端口、状态端口、控制端口。
对端口编址的两种方法为:内存和I/O端口统一编址,内存和I/O端口分别进行编址。
在8086/8088系统中采用内存和I/O端口统一编址。
5.2 CPU和输入/输出设备之间传送的信息有哪几类?数据信息、状态信息、控制信息。
5.3 一般的IO接口电路中有哪三类寄存器?它们各自的作用是什么?数据寄存器:存放CPU与外设之间传送的数据信息。
状态寄存器:存放当前外设所处的工作状态。
控制寄存器:存放CPU通过接口向外设传送控制信息。
5.4 简述CPU与外设进行数据交换的几种常用方式。
CPU与外设之间的数据传输有以下三种方式:程序方式、中断方式、DMA方式。
其中程序方式又分为无条件传送方式和查询方式两种方式。
无条件传送方式用于简单外设,如LED显示器。
查询方式用于外设较少的情形,接口简单,但CPU效率低。
在实时系统以及多个外设的系统中,采用中断传送方式。
这种方式CPU利用率高,速度快,但需要专门的中断控制电路。
如果要求实现高速数据传输,采用直接存储器传输方式,即DMA方式。
5.5 无条件传送方式用在哪些场合?画出无条件传送方式的工作原理图并说明。
无条件传送方式适用于对一些简单的外设的操作中,如:开关、七段LED显示管等。
当CPU执行输入指令是,读信号RD有效,选择信号M/IO处于低电平,因而三态缓冲器被选通,使其中早已准备好的输入数据进入数据总线,再到达CPU。
CPU执行输出指令时,M/IO和WR信号有效,于是接口中的输出锁存器被选中,CPU输出的信息经过数据总线打入输出锁存器,输出锁存器保持这个数据,直到外设取走。
5.6 查询方式的工作原理是怎样的?主要用在什么场合?画出查询方式输出过程的流程图。
计网第五次作业

计⽹第五次作业Review Questions:1. What are some of the possible services that a link-layer protocol can offer to the network layer? Which of these link-layer services have corresponding services in IP? In TCP?链路层协议提供给⽹络层的服务有哪些?哪些是给IP的?哪些是给TCP 的?Link access, framing, reliable delivery between adjacent nodes, flow control, error detection, error correction, half-duplex and full-duplex.In IP: framing, error detection.In TCP: framing, reliable delivery between adjacent nodes, error detection, half-duplex and full-duplex.2. If all the links in the Internet were to provide reliable delivery service, would the TCP reliable delivery service be redundant? Why or why not? 不会多余,因为TCP保证的是传输层的数据传送,⽽link提供稳定可靠传输保证链路层的传输稳定,⼆者不完全重叠,所以TCP可靠传输也不会多余。
3. In Section 5.3, we listed four desirable characteristics of a broadcast channel. Which of these characteristics does slotted ALOHA have? Which of these characteristics does token passing have?4. Suppose two nodes start to transmit at the same time a packet of length Lover a broadcast channel of rate R. Denote the propagationdelay between the two nodes as dprop. Will there be a collision if dprop< L / R? Why or why not?因为L / R = 包传递的时间,如果dprop < L / R,也就意味着A的信号跑到B 的时候B的最后⼀个分组还没离开B,所以发⽣碰撞。
南理工计算机系数据结构2005年级b卷答案
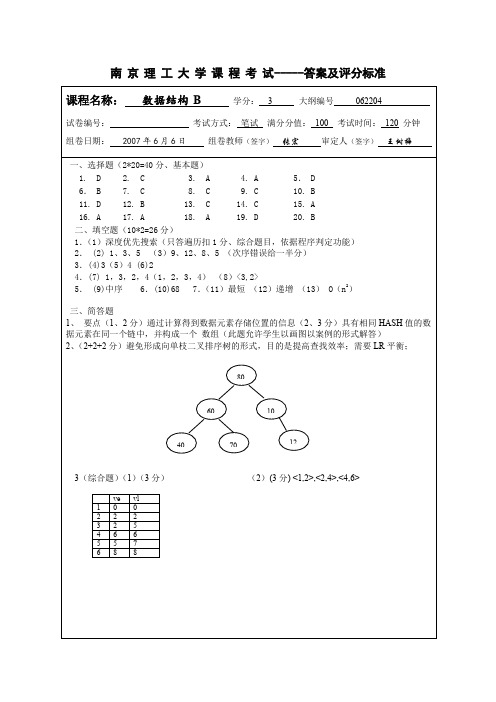
4 2
1 null
1
6
1
null
6
1
null
(没有写出权的扣一分,分开的扣一分) 四、 (7+7 分) (因为程序编制方法较多,答案供参考,题目有综合性) (1) void insert (tree,x) { if(tree!=NULL) { if(x<tree->data) insert(tree->lchild,x) elseinsert(tree->rchild,x); } else { tree=new TreeNode; tree->lchild=tree->rchild=NULL; tree->data=x; } }(综合题,没有空间分配扣一分,无递归扣 1 分,左右指针没置空扣 1 分) (2)void DelArc(adj,u,v) { p=adj[u-1].firstarc; q=NULL; while(p->vex!=v) { q=p; p=p->nextarc;} if(q= =NULL) adj[u-1].firstarc=p->nextarc; else q->nextarc=p->nextarc; delete p; } (提高题) 空间没释放扣 1 分,没考虑第一个删除点扣 1 分。
80
Байду номын сангаас
60
100
40
70
120
3(综合题) (3 分) (1) (2)(3 分) <1,2>,<2,4>,<4,6>
1 2 3 4 5 6 ve 0 2 2 6 5 8 vl 0 2 5 6 7 8
(3) 分) (3
1 2 3 4 5 6
2005年下半年计算机软考程序员下午真题及答案(word)+

05下半年软考程序员下午试题及答案试题一(15分,每空3分)阅读下列说明和流程图,将应填入___(n)___处的字句写在答题纸的对应栏内。
[流程图说明]流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符的空白。
例如,原字符串" File Name ",处理变成"File Name" 。
流程图1-2、流程图1-3 、流程图1-4分别详细描述了流程图1-1中的框A、B、C。
假设原字符串中的各个字符依次存放在字符数组ch 的各元素ch(1) 、ch(2) 、?、ch(n) 中,字符常量KB表示空白字符。
流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j) ,然后将ch(i) 、?、ch(j) 依次送入ch(1) 、ch(2)、?中。
如果字符串中没有字符或全是空白字符,则输出相应的说明。
在流程图中,strlen 是取字符串长度函数。
[流程图1-1][流程图1-2][流程图1-3][流程图1-4][问题]在流程图1-1中,判断框P中的条件可表示为:i > ___(5)___试题二(15,每空3分)阅读以下函数说明和C语言函数,将应填入___(n)___处的字句写在答题纸的对应栏内。
[说明]函数int find_Max_Min(int a[ ],int n) 的功能是:找出n个元素的数组a中的最大元素和最小元素并输出,返回查找过程中元素的比较次数。
查找方法如下:比较a[0] 和a[n-1], 若a[0] 大,则交换a[0] 和a[n-1] 的值;再比较a[1] 和a[n-2] ,若a[1] 大,则交换a[1] 和a[n-2] 的值;依此类推,直到所有的元素都比较完。
然后在数组的前半区从前往后找出小元素,在后半区从后往前找出大元素。
[函数]int find_Max_Min(int a[ ],int n) {/* 找出n个元素的数组a中的最大元素、最小元素并输出,返回查找过程中元素的比较次数*/int i,Count = 0;int temp,Maxnum,Minnum;for(i = 0; i < n/2; i++){Count = Count + 1; /*元素比较次数计数*/if(a[i]>a[_____(1)_____ ]{ /* 数组元素交换代码略*/ }}Maxnum=a[n-1];Minnum=a[0];for(i = 1; i < n/2+ n%2; i++){Count = _____(2)_____ ; /* 元素比较次数计数*/Minnum = _____(3)_____ ? a[i]:Minnum; /*找出最小元素*/Maxnum = _____(4)_____ ? _______(5)_____:Maxnum; /* 找出最大元素*/} printf("Max=%d\n,Maxnum"); printf("Min=%d\n",Minnum); return Count;}[NextPage]试题三(15分,每空3分)阅读以下说明和C语言函数,将应填入___(n)___处的字句写在答题纸的对应栏内。
计算机组成原理课堂提问共106页文档

46、我们若已接受最坏的,就再没有什么损失。——卡耐基 47、书到用时方恨少、事非经过不知难。——陆游 48、书籍把我们引入最美好的社会,使我们认识各个时代的伟大智者。——史美尔斯 49、熟读唐诗三百首,不会作诗也会吟。——孙洙 50、谁和我Байду номын сангаас样用功,谁就会和我一样成功。——莫扎特
计算机组成原理课堂提问
36、“不可能”这个字(法语是一个字 ),只 在愚人 的字典 中找得 到。--拿 破仑。 37、不要生气要争气,不要看破要突 破,不 要嫉妒 要欣赏 ,不要 托延要 积极, 不要心 动要行 动。 38、勤奋,机会,乐观是成功的三要 素。(注 意:传 统观念 认为勤 奋和机 会是成 功的要 素,但 是经过 统计学 和成功 人士的 分析得 出,乐 观是成 功的第 三要素 。
计组

第七章 精简指令系统计算机..................................................... 91 7.1 计算机的指令系统 ....................................................... 91 7.2 基于 RISC 技术的模型计算机设计实验 .................................... 92 7.3 完整指令集的 RISC 模型计算机设计实验................................... 98
附件 1 键、指示灯说明.......................................................... 131 1 指示灯.................................................................. 131 2 按 键.................................................................. 132
第九章 流水线处理机.......................................................... 121 9.1 流水线的原理及基本思想 ................................................ 121 9.1.1 流水的基本概念 .................................................. 121 9.1.2 流水的特点..................................................... 122 9.1.3 相关处理....................................................... 122 9.2 基于流水技术的模型计算机设计实验 ..................................... 123
深入理解计算机系统家庭作业答案

深入理解计算机系统(第二版)家庭作业答案(总109页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--所以,a,b异号,t,b同号即可判定为溢出。
int tsub_ovf(int x, int y){int w = sizeof(int)<<3;int t = x - y;x>>=(w-1);y>>=(w-1);t>>=(w-1);return (x != y) && (y == t);}顺便整理一下汇编中CF,OF的设定规则(个人总结,如有不对之处,欢迎指正)。
t = a + b;CF: (unsigned t) < (unsigned a) 进位标志OF: (a<0 == b<0) && (t<0 != a<0)t = a - b;CF: (a<0 && b>=0) || ((a<0 == b<0) && t<0) 退位标志OF: (a<0 != b<0) && (b<0 == t<0)汇编中,无符号和有符号运算对条件码(标志位)的设定应该是相同的,但是对于无符号比较和有符号比较,其返回值是根据不同的标志位进行的。
详情可以参考第三章节。
根据2-18,不难推导, (x'*y')_h = (x*y)_h + x(w-1)*y + y(w-1)*x。
unsigned unsigned_high_prod(unsigned x, unsigned y){ int w = sizeof(int)<<3;return signed_high_prod(x, y) + (x>>(w-1))*y + x*(y>>(w-1));}当然,这里用了乘法,不属于整数位级编码规则,聪明的办法是使用int进行移位,并使用与运算。
offer5课题汇总

offer5课题汇总
offer5是一个常见的编程问题集合,它包含了各种不同难度的算法和数据结构问题。
以下是一些offer5中常见的课题:
1. 数组和链表:包括数组的查找、排序、插入和删除操作,链表的节点插入、删除和遍历等。
2. 栈和队列:包括栈的实现、队列的实现以及它们的各种操作。
3. 树和图:包括二叉树、二叉搜索树、图的各种遍历算法等。
4. 排序和查找:包括各种排序算法(如冒泡排序、选择排序、插入排序、快速排序等)和查找算法(如二分查找、哈希查找等)。
5. 动态规划:包括各种经典的动态规划问题,如背包问题、最长公共子序列等。
6. 字符串处理:包括字符串的匹配、替换、加密和解密等操作。
7. 系统设计:包括分布式系统设计、数据库设计和缓存系统设计等。
8. 数据结构优化:包括各种数据结构的优化,如使用哈希表优化数据结构等。
这些课题都是计算机科学和软件工程领域中非常重要的知识点,熟练掌握这些课题对于提高编程能力和解决实际问题非常重要。
计组课后作业答案

《运算器》P61 3.4写出下列各机器数的二进制真值X:(1)[X]补=0,1001 X=1001(2)[X]补=1,1001 X=-111(3)[X]原=0,1101 X=1101(4)[X]原=1,1101 X=-1101(5)[X]反=0,1011 X=1011(6)[X]反=1,1011 X=-100(7)[X]移=0,1001 X=-111(8)[X]移=1,1001 X=+1001(9)[X]补=1,0000000 X=-10000000B,X=-128(10)[X]反=1,0000000 X=-1111111B,X=-127(11)[X]原=1,0000000 X=-0(12)[X]移=1,0000000 X=0P107 4.1X=0.1101 Y=-0.0110(设机器数长度为8位)[X]补=0.1101000[-X]补=1.0011000[2X]补=溢出[-2X]补=溢出[X/2]补=0.0110100[-X/2]补=1.1001100[Y]补=1.1010000[-Y]补=0.0110000[2Y]补=1.0100000[-2Y]补=0.1100000[Y/2]补=1.1101000[-Y/2]补=0.0011000[-Y/4]补=0.0001100P61:5、(1) X=-25/64=-0.011001B ,Y=2.875=10.111B[X]浮=0,11111 1.11001=7F9H [Y]浮=1,00010 0.10111=897H (2) [Z]浮=9F4H=1,00111 1.10100=-80P61:6、机器数字长16位 (1) 无符号整数:12~016-(2) 原码表示的定点整数:1,111…11~0,111…11即12~)12(1515--- (3) 补码表示的定点整数:1,00…000~0,111…11即12~21515--(4) 补码表示的定点小数:1.00…000~0.111…11即1521~1---(5) 非规格化浮点数:ER M N ⨯=最大数=12772)21(--⨯-最小数=12721-⨯-最大负数=72722--⨯-最小正数=72722--⨯(6) 最大数=12772)21(--⨯-最小数=12721-⨯-最大负数=72712)22(---⨯+-最小正数=72122--⨯P107:2、(1)(2)P108:4-14-2P108:55-1补码BOOTH算法5-2补码BOOTH算法P108:6、6-1原码恢复余数算法6-2原码加减交替算法P108 7-1补码加减交替算法7-2补码加减交替算法P108:8-1(1)X=-1.625=-1.101B Y=5.25=101.01B X+YX-Y:1、对阶同上2、尾数相减:11.1100110+ 11.01011[E X-Y]补= 11.00100103、结果不需规格化4、舍入处理:[E X-Y]补=1.00101[X-Y] = 0,0011 1,00101X=0.2344 = 0.00111 Y= -0.1133=-0.00011X-Y:1、对阶同上2、尾数相减:00.11100+ 00.01100[E X-Y]补= 01.01000 发生正溢尾数右移,阶码加1[E X-Y]补= 0.10100[M x-y] = 1.11113、结果不需规格化4、舍入处理:[E X-Y]补=0.10100[X-Y] = 1,1111 0,10100(1)X=5.25=101.01B Y=-1.625=-1.101B X*Y9-1 X/Y:9-2 X*Y9-2 X/Y《存储体系》P225:2、 (1) 片641641161664=⨯=⨯⨯K K(2) s msμ625.151282=(3) s ns μ64500128=⨯ P225:3、(1) 最大主存容量=bit 16218⨯(2) 共需片6416416416218=⨯=⨯⨯bitK bit芯片;若采用异步刷新,则刷新信号的周期为s msμ625.151282= (3) 每块8字节,则Cache 容量为行925128162==⨯BytebitK ,即c=9,Cache 采用2路组相联映射,则r=1。
计算机组成与设计 第五版答案_CH06_Solution

Chapter 6 Solutions S-3 6.1 Th ere is no single right answer for this question. Th e purpose is to get studentsto think about parallelism present in their daily lives. Th e answer should have atleast 10 activities identifi ed.6.1.1 Any reasonable answer is correct here.6.1.2 Any reasonable answer is correct here.6.1.3 Any reasonable answer is correct here.6.1.4 Th e student is asked to quantify the savings due to parallelism. Th e answershould consider the amount of overlap provided through parallelism and should beless than or equal to (if no parallelism was possible) to the original time computedif each activity was carried out serially.6.26.2.1 For this set of resources, we can pipeline the preparation. We assume thatwe do not have to reheat the oven for each cake.Preheat OvenMix ingredients in bowl for Cake 1Fill cake pan with contents of bowl and bake Cake 1. Mix ingredients forCake 2 in bowl.Finish baking Cake 1. Empty cake pan. Fill cake pan with bowl contents forCake 2 and bake Cake 2. Mix ingredients in bowl for Cake 3.Finish baking Cake 2. Empty cake pan. Fill cake pan with bowl contents forCake 3 and bake Cake 3.Finish baking Cake 3. Empty cake pan.6.2.2 Now we have 3 bowls, 3 cake pans and 3 mixers. We will name them A, B,and C.Preheat OvenMix incredients in bowl A for Cake 1Fill cake pan A with contents of bowl A and bake for Cake 1. Mix ingredientsforCake 2 in bowl A.Finish baking Cake 1. Empty cake pan A. Fill cake pan A with contents ofbowl A for Cake 2. Mix ingredients in bowl A for Cake 3.Finishing baking Cake 2. Empty cake pan A. Fill cake pan A with contentsof bowl A for Cake 3.S-4 ChapterSolutions6Finish baking Cake 3. Empty cake pan A.Th e point here is that we cannot carry out any of these items in parallelbecause we either have one person doing the work, or we have limitedcapacity in our oven.6.2.3 Each step can be done in parallel for each cake. Th e time to bake 1 cake, 2cakes or 3 cakes is exactly the same.6.2.4 Th e loop computation is equivalent to the steps involved to make one cake.Given that we have multiple processors (or ovens and cooks), we can executeinstructions (or cook multiple cakes) in parallel. Th e instructions in the loop (orcooking steps) may have some dependencies on prior instructions (or cookingsteps) in the loop body (cooking a single cake).Data-level parallelism occurs when loop iterations are independent (i.e., noloop carried dependencies).Task-level parallelism includes any instructions that can be computed onparallel execution units, are similar to the independent operations involvedin making multiple cakes.6.36.3.1 While binary search has very good serial performance, it is diffi cult toparallelize without modifying the code. So part A asks to compute the speedupfactor, but increasing X beyond 2 or 3 should have no benefi ts. While we canperform the comparison of low and high on one core, the computation for midon a second core, and the comparison for A[mid] on a third core, without somerestructuring or speculative execution, we will not obtain any speedup. Th e answershould include a graph, showing that no speedup is obtained aft er the values of 1,2, or 3 (this value depends somewhat on the assumption made) for Y.6.3.2 In this question, we suggest that we can increase the number of cores (toeach the number of array elements). Again, given the current code, we really cannotobtain any benefi t from these extra cores. But if we create threads to compare theN elements to the value X and perform these in parallel, then we can get idealspeedup (Y times speedup), and the comparison can be completed in the amountof time to perform a single comparison.6.4. Th is problem illustrates that some computations can be done in parallelif serial code is restructured. But more importantly, we may want to provide forSIMD operations in our ISA, and allow for data-level parallelism when performingthe same operation on multiple data items.Chapter 6 Solutions S-5 6.4.1 Th is is a straightforward computation. Th e fi rst instruction is executedonce, and the loop body is executed 998 times.Version 1—17,965 cyclesVersion 2—22,955 cyclesVersion 3—20,959 cycles6.4.2 Array elements D[j] and D[jϪ1] will have loop carried dependencies. Th esewill $f4 in the current iteration and $f0 in the next iteration.6.4.3 Th is is a very challenging problem and there are many possibleimplementations for the solution. Th e preferred solution will try to utilize the twonodes by unrolling the loop 4 times (this already gives you a substantial speedupby eliminating many loop increment, branch and load instructions). Th e loopbody running on node 1 would look something like this (the code is not the mosteffi cient code sequence):addiu $s1, $zero, 996l.d $f0, –16($s0)l.d $f2, –8($s0)loop:add.d $f4, $f2, $f0add.d $f6, $f4, $f2Send (2, $f4)Send (2, $f6)s.d $f4, 0($s0)s.d $f6, 8($s0)Receive($f8)add.d $f10, $f8, $f6add.d $f0, $f10, $f8Send (2, $f10)Send (2, $f0)s.d. $f8, 16($s0)s.d $f10, 24($s0)s.d $f0 32($s0)Receive($f2)s.d $f2 40($s0)addiu $s0, $s0, 48bne $s0, $s1, loopadd.d $f4, $f2, $f0add.d $f6, $f4, $f2add.d $f10, $f8, $f6s.d $f4, 0($s0)s.d $f6, 8($s0)s.d $f8, 16($s0)S-6 Chapter6SolutionsTh e code on node 2 would look something like this:addiu $s2, $zero, 0loop:Receive ($f12)Receive ($f14)add.d $f16, $f14, $f12Send(1, $f16)Receive ($f12)Receive ($f14)add.d $f16, $f14, $f12Send(1, $f16)Receive ($f12)Receive ($f14)add.d $f16, $f14, $f12Send(1, $f16)Receive ($f12)Receive ($f14)add.d $f16, $f14, $f12Send(1, $f16)addiu $s2, $s2, 1bne $s2, 83, loopBasically Node 1 would compute 4 adds each loop iteration, and Node 2would compute 4 adds. Th e loop takes 1463 cycles, which is much better thanclose to 18K. But the unrolled loop would run faster given the current sendinstruction latency.6.4.4 Th e loop network would need to respond within a single cycle to obtain aspeedup. Th is illustrates why using distributed message passing is diffi cult whenloops contain loop-carried dependencies.6.56.5.1 Th is problem is again a divide and conquer problem, but utilizes recursionto produce a very compact piece of code. In part A the student is asked to computethe speedup when the number of cores is small. When forming the lists, we spawn athread for the computation of left in the MergeSort code, and spawn a thread for thecomputation of the right. If we consider this recursively, for m initial elements in thearray, we can utilize 1 ϩ 2 ϩ 4 ϩ 8 ϩ 16 ϩ …. log2(m) processors to obtain speedup.6.5.2 In this question, log2 (m) is the largest value of Y for which we can obtainany speedup without restructuring. But if we had m cores, we could perform sorting using a very diff erent algorithm. For instance, if we have greater than m/2 cores, we can compare all pairs of data elements, swap the elements if the left element is greater than the right element, and then repeat this step m times. So this is one possible answer for the question. It is known as parallel comparison sort. Various comparison sort algorithms include odd-even sort and cocktail sort.Chapter 6 Solutions S-76.66.6.1 Th is problem presents an “embarrassingly parallel” computationand asks the student to fi nd the speedup obtained on a 4-core system. Th ecomputations involved are: (m ϫ p ϫ n) multiplications and (m ϫ p ϫ(n Ϫ 1)) additions. Th e multiplications and additions associated with a singleelement in C are dependent (we cannot start summing up the results of themultiplications for an element until two products are available). So in this question,the speedup should be very close to 4.6.6.2 Th is question asks about how speedup is aff ected due to cache misses causedby the 4 cores all working on diff erent matrix elements that map to the same cacheline. Each update would incur the cost of a cache miss, and so will reduce thespeedup obtained by a factor of 3 times the cost of servicing a cache miss.6.6.3 In this question, we are asked how to fi x this problem. Th e easiest way tosolve the false sharing problem is to compute the elements in C by traversing thematrix across columns instead of rows (i.e., using index-j instead of index-i). Th eseelements will be mapped to diff erent cache lines. Th en we just need to make surewe process the matrix index that is computed ( i, j) and (i ϩ 1, j) on the same core.Th is will eliminate false sharing.6.76.7.1 x ϭ 2, y ϭ 2, w ϭ 1, z ϭ 0x ϭ 2, y ϭ 2, w ϭ 3, z ϭ 0x ϭ 2, y ϭ 2, w ϭ 5, z ϭ 0x ϭ 2, y ϭ 2, w ϭ 1, z ϭ 2x ϭ 2, y ϭ 2, w ϭ 3, z ϭ 2x ϭ 2, y ϭ 2, w ϭ 5, z ϭ 2x ϭ 2, y ϭ 2, w ϭ 1, z ϭ 4x ϭ 2, y ϭ 2, w ϭ 3, z ϭ 4x ϭ 3, y ϭ 2, w ϭ 5, z ϭ 46.7.2 We could set synchronization instructions aft er each operation so that allcores see the same value on all nodes.6.86.8.1 If every philosopher simultaneously picks up the left fork, then there will beno right fork to pick up. Th is will lead to starvation.S-8 ChapterSolutions66.8.2 Th e basic solution is that whenever a philosopher wants to eat, she checksboth forks. If they are free, then she eats. Otherwise, she waits until a neighborcontacts her. Whenever a philosopher fi nishes eating, she checks to see if herneighbors want to eat and are waiting. If so, then she releases the fork to one ofthem and lets them eat. Th e diffi culty is to fi rst be able to obtain both forks withoutanother philosopher interrupting the transition between checking and acquisition.We can implement this a number of ways, but a simple way is to accept requestsfor forks in a centralized queue, and give out forks based on the priority defi nedby being closest to the head of the queue. Th is provides both deadlock preventionand fairness.6.8.3 Th ere are a number or right answers here, but basically showing a casewhere the request of the head of the queue does not have the closest forks available,though there are forks available for other philosophers.6.8.4 By periodically repeating the request, the request will move to the head ofthe queue. Th is only partially solves the problem unless you can guarantee thatall philosophers eat for exactly the same amount of time, and can use this time toschedule the issuance of the repeated request.6.9A3B1, B4A1, A2B1, B4A1, A4B2A1B3A1A2A1A1B1B2B1A3A4B2B4Chapter 6 Solutions S-9A1B1A1B1A1B2A2B3A3B4A46.10 Th is is an open-ended question.6.116.11.1 Th e answer should include a MIPS program that includes 4 diff erentprocesses that will compute ¼ of the sums. Assuming that memory latency is notan issue, the program should get linear speed when run on the 4 processors (thereis no communication necessary between threads). If memory is being consideredin the answer, then the array blocking should consider preserving spatial locality sothat false sharing is not created.6.11.2 Since this program is highly data parallel and there are no datadependencies, a 8ϫ speedup should be observed. In terms of instructions, theSIMD machine should have fewer instructions (though this will depend upon theSIMD extensions).6.12 Th is is an open-ended question that could have many possible answers. Th ekey is that the student learns about MISD and compares it to an SIMD machine.6.13 Th is is an open-ended question that could have many answers. Th e key isthat the students learn about warps.6.14 Th is is an open-ended programming assignment. Th e code should be testedfor correctness.6.15 Th is question will require the students to research on the Internet both theAMD Fusion architecture and the Intel QuickPath technology. Th e key is thatstudents become aware of these technologies. Th e actual bandwidth and latencyvalues should be available right off the company websites, and will change as thetechnology evolves.6.166.16.1 For an n-cube of order N (2N nodes), the interconnection network cansustain NϪ1 broken links and still guarantee that there is a path to all nodes in thenetwork.6.16.2 Th e plot below shows the number of network links that can fail and stillguarantee that the network is not disconnected.S-10 Chapter 6Solutions11010010000100000Network order N u m b e r o f f a u l t y l i n k s6.176.17.1 Major diff erences between these suites include:Whetstone—designed for fl oating point performance specifi callyPARSEC—these workloads are focused on multithreaded programs6.17.2 Only the PARSEC benchmarks should be impacted by sharing and synchronization. Th is should not be a factor in Whetstone.6.186.18.1 Any reasonable C program that performs the transformation should be accepted.6.18.2 Th e storage space should be equal to (R ϩ R) times the size of a single precision fl oating point number ϩ (m + 1) times the size of the index, where R is the number of non-zero elements and m is the number of rows. We will assume each fl oating-point number is 4 bytes, and each index is a short unsigned integer that is 2 bytes. For Matrix X this equals 111 bytes.6.18.3 Th e answer should include results for both a brute-force and a computation using the Yale Sparse Matrix Format.6.18.4 Th ere are a number of more effi cient formats, but their impact should be marginal for the small matrices used in this problem.6.196.19.1 Th is question presents three diff erent CPU models to consider when executing the following code:if (X[i][j] > Y[i][j])count++;Chapter 6 Solutions S-11 6.19.2 Th ere are a number of acceptable answers here, but they should considerthe capabilities of each CPU and also its frequency. What follows is one possibleanswer:Since X and Y are FP numbers, we should utilize the vector processor (CPU C) toissue 2 loads, 8 matrix elements in parallel from A and 8 matrix elements from B,into a single vector register and then perform a vector subtract. We would thenissue 2 vector stores to put the result in memory.Since the vector processor does not have comparison instructions, we would haveCPU A perform 2 parallel conditional jumps based on fl oating point registers. Wewould increment two counts based on the conditional compare. Finally, we couldjust add the two counts for the entire matrix. We would not need to use core B.6.19.3 Th e point of the problem is to show that it is diffi cult to perform an operationon individual vector elements when utilizing a vector processor. What might be a niceinstruction to add would be a vector comparison that would allow for us to comparetwo vectors and produce a scalar value of the number of elements where one vectorwas larger the other. Th is would reduce the computation to a single instruction forthe comparison of 8 FP number pairs, and then an integer computation for summingup all of these values.6.20 Th is question looks at the amount of queuing that is occurring in the systemgiven a maximum transaction processing rate, and the latency observed on averageby a transaction. Th e latency includes both the service time (which is computed bythe maximum rate) and the queue time.6.20.1 So for a max transaction processing rate of 5000/sec, and we have 4 corescontributing, we would see an average latency of .8 ms if there was no queuingtaking place. Th us, each core must have 1.25 transactions either executing or insome amount of completion on average.So the answers are:1 ms5000/sec 1.252 ms5000/sec 2.51 ms10,000/sec 2.52 ms10,000/sec56.20.2 We should be able to double the maximum transaction rate by doublingthe number of cores.6.20.3 Th e reason this does not happen is due to memory contention on theshared memory system.。
王道计组课后题讲解

王道计组课后题讲解摘要:1.王道计组课后题讲解概述2.王道计组课后题的主要内容3.王道计组课后题的解析方法4.王道计组课后题的答案与解析5.总结正文:王道计组课后题讲解概述王道计组课后题是一套针对计算机科学与技术专业的编程题目,旨在帮助学生巩固课堂所学知识,提高编程能力和解决问题的能力。
本文将对王道计组课后题的主要内容、解析方法以及答案与解析进行详细讲解。
王道计组课后题的主要内容王道计组课后题的内容涵盖了计算机科学与技术专业的各个方面,包括数据结构、算法、操作系统、计算机网络等。
题目类型多样,有选择题、填空题、判断题和编程题等,难易程度适中,适合学生巩固课堂所学知识。
王道计组课后题的解析方法对于王道计组课后题,我们可以采用以下几种方法进行解析:1.理论分析:对于选择题、填空题和判断题,可以通过理论分析得出正确答案。
这需要我们对相关知识点有深入的理解,能够快速判断选项的正确性。
2.实例分析:对于编程题,可以通过编写具体的程序来验证答案的正确性。
这需要我们具备一定的编程能力,能够熟练运用所学知识解决实际问题。
3.对比分析:对于有一定难度的题目,可以采用对比分析的方法,即将多个选项或答案进行比较,找出正确答案。
这需要我们对相关知识点有较好的掌握,能够快速判断选项的优劣。
王道计组课后题的答案与解析由于篇幅有限,本文无法给出所有题目的答案与解析。
但是,我们可以通过以下方式获取答案与解析:1.参考教材:王道计组课后题的答案与解析可以在教材中找到。
我们可以参考教材中的相关内容,找出答案与解析。
2.在线资源:互联网上有许多关于王道计组课后题的解答资源。
我们可以搜索相关资源,获取答案与解析。
3.请教老师和同学:如果对题目的解答有疑问,可以向老师和同学请教,获取答案与解析。
总结王道计组课后题是帮助学生巩固课堂所学知识的有效手段。
通过分析题目内容、解析方法和答案与解析,我们可以更好地完成课后题,提高自己的编程能力和解决问题的能力。
logistic计组代码 -回复

logistic计组代码-回复题目:logistic计组代码的步骤详解与应用场景分析引言:在计算机科学领域,logistic计组代码是一种常用的编码技术,广泛应用于数据传输和数据存储等领域。
本文将详细介绍logistic计组代码的步骤,并分析其在实际应用中的场景和优势。
一、概述1.1 什么是logistic计组代码?logistic计组代码是使用logistic函数对输入进行编码和解码的一种方式。
它将输入映射到[0,1]的区间上,实现了信息的压缩和恢复。
1.2 logistic计组代码的优势相较于其他编码技术,logistic计组代码具有以下优势:- 通过使用logistic函数,可以将输入限定在[0,1]的范围内,避免了数值溢出和失真。
- 将数据映射到[0,1]的区间上,可以实现数据的归一化和压缩,提高数据的存储和传输效率。
- 由于logistic函数的非线性特性,logistic计组代码可以更好地处理非线性关系的数据。
- 经过logistic编码的数据,在解码时可以恢复原始的数据信息。
二、logistic计组代码步骤详解2.1 数据预处理在进行logistic计组代码之前,首先需要对数据进行预处理。
通常包括以下几个步骤:- 数据清洗:去除重复值、缺失值以及异常值,确保数据的质量和准确性。
- 特征选择:选取与目标密切相关的特征作为编码依据,提高编码的效果。
- 特征缩放:对特征进行归一化处理,使其数值范围在[0,1]之间。
2.2 logistic函数logistic函数是logistic计组代码的核心部分,它用于将输入映射到[0,1]的范围上。
logistic函数的表达式为:f(x) = 1 / (1 + e^(-x))其中,x为输入值,f(x)为经过logistic编码后的值。
2.3 编码与解码logistic计组代码的编码和解码过程如下:- 编码过程:将原始数据通过logistic函数进行映射,得到编码后的数据。
IT系统分析员考题 v1-answer

[繁体字转换简体方法]打开文档---菜单栏---审阅---繁转简---转换完成IT系統分析員、軟體開發員考題題庫(V1.0)說明:選題個數可在9~11個間,答題時間80分鐘~120分鐘。
一、基礎IT技術部分(每題8~10分)說明:1、2、3、4、5、14必選,6~13可選2或不選1、某集團下屬單位共800名員工,分佈在15個部門,要設計一個含部門、姓名、崗位、年齡、工資、部門領導6項內容的人員資料庫系統,請用ER圖作一數據規劃。
Answer: ER圖如下:2、請編一帶迴圈條件的程式,可分部門遍曆上例中的每一條記錄。
Answer:Declare cursor cur_DepartmentSelect Deptcode from Department order by deptcodeFetch cur_Department into @DeptcodeWhile @@Fetch_status= 0BeginSelect ‘部門’, ‘姓名’, A.Station ‘崗位’, A.Age ‘年齡’, A.Salary ‘工資’, (select staffname from staff where staff.staffcode = b.staffcode ) 部門領導from staff A, Department BWhere A.Deptcode = @Deptcode and A.Deptcode = B.DeptcodeFetch next cur_Department into @DeptcodeEndClose cursor cur_DepartmentDeallocate cursor cur_Department3、在編寫SQL語句時為了提高性能,與資料庫索引匹配時應注意哪些?舉例說明。
Answer:1. 匹配所有的索引2. 匹配盡可能多的主健3.高級(主)的表放在等式左邊,而低級(次)的表放在等式右邊。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
“计算机组织结构”作业 05参考答案
1.存储器中有一个8 位字11000010,假设在海明码中采用偶校验,请写出加
入校验码后的数据。
因为是8位字,校验码的长度为4,分别为C4C3C2C1
根据公式计算可得:
C1=0⊕1⊕0⊕0⊕1=0
C2=0⊕0⊕0⊕0⊕1=1
C3=1⊕0⊕0⊕1=0
2.一个8 位字00111001,采用海明码生成校验位后存储。
假定由存储器读出
数据时,计算出的校验位是1101,那么由存储器读出的数据字是什么?
假设采用偶校验,00111001计算出的校验码为0111(方法见题1),而读出的校验码为1101。
因此,数据字读出时发生了错误,而校验码读出时没有发生错误(这建立在最多只有一位发生错误的假设上)。
计算出故障字为0111⊕1101=1010。
可见是第10位(D6)出错。
原先的数据字为00111001,所以读出的数据字为00011001。
注:本题也可以假设采用奇校验。
3.已知下列字符的ACSII 编码:A=1000001,a=1100001,0=0110000,求E、e、
f、7、G、Z、5 的7 位ACSII 码和第7位前加入奇校验位后的8 位编码。
字母是根据排序编码的,若将A看作第1个,E为第5个,即E的编码为100 0101。
加入奇校验后的8位编码为0100 0101。
同理可知:
e:110 0101(7位),1110 0101(8位)
f:110 0110(7位),1110 0110(8位)
7:011 0111(7位),0011 0111(8位)
G:100 0111(7位),1100 0111(8位)
Z:101 1010(7位),1101 1010(8位)
5:011 0101(7位),1011 0101(8位)
4.某计算机在信息传输中采用基于偶校验的海明码,对每个字节生成校验位。
假设所传输信息的十六进制表示为8F3CAB96H,且将信息与校验码按照故障字的顺序排列后一起传输。
如果传输中没有发生任何错误,写出所接收到信息(含校验码)的十六进制表示。
根据海明码的计算规则:
C1 = D1 ⊕D2 ⊕D4 ⊕D5 ⊕D7
C2 = D1 ⊕D3 ⊕D4 ⊕D6 ⊕D7
C3 = D2 ⊕D3 ⊕D4 ⊕D8
C4 = D5 ⊕D6 ⊕D7 ⊕D8
对各个字节计算出校验码:
8FH = 1000 1111B,校验码(C4C3C2C1)为1011
3CH = 0011 1100B,校验码(C4C3C2C1)为0010
ABH = 1010 1011B,校验码(C4C3C2C1)为0111
96H = 1001 0110B,校验码(C4C3C2C1)为0110
所以,将信息和校验码按照故障字的顺序排列后的二进制表示为:
1000 1111 0111 0011 0110 0010 1010 0101 1111 1001 0011 1010
十六进制表示为:8F7362A5F93AH
5.假设要传送的数据信息为100011,若约定的生成多项式位G(x) = x3 + 1,则
生成的循环冗余校验码是多少?
生成多项式G(x)为1001,所以将数据左移3位后,进行模2除法:
100111
1001 / 100011000
1001
0011
0000
0111
0000
1110
1001
1110
1001
1110
1001
111
校验码为111。
6.假定有两个用来存储10TB数据的RAID系统,每个磁盘的大小均为2TB。
系
统A使用RAID 1技术,系统B使用RAID 5技术。
请问:[刘璟,121250083]
a)系统A需要比系统B多用多少存储容量?
A系统需20TB存储容量;B系统采用6个磁盘,需12TB存储容量,多用8TB
b)假定一个应用需要向磁盘写入一块数据,若磁盘读或写一块数据的时间
为30ms,则最坏情况下,在系统A和系统B上写入一块数据分别需要多
少时间?
A: 30ms
B: 120ms(最坏情况:两读两写)
c)哪个系统更加可靠?为什么?
A更加可靠。
RAID1通过镜像对整个数据进行了备份,只要其中一份数据所在磁盘出现了问题,通过另一份数据就可以很方便的进行恢复;而B系统中,如果两块磁盘同一对应位置同时存在故障,相应的数据就无法进行恢复了。
7.假定在一个使用RAID 5的系统中,采用先更新数据块、再更新校验快的信息
更新方式。
如果在更新数据块和更新校验块的操作之间突然发生了断电现象,那会出现什么问题?是否可以通过更改信息更新方式来避免这一问题的发生?如果可以的话,请说明如何更改及更改后的方式如何发挥作用。
如果突然断电,那么校验块与其他数据块会出现不匹配,此时无法通过校验位对其他数据块进行正确的恢复操作。
可以。
先更新校验块,如果发生断电情况,可以通过已更新的校验块来恢复出需要更新的数据块。