第9章 内部排序答案
chapter 9 内部排序

3.算法分析
辅助空间:O(1)
时间:
(1)关键字的比较次数
n−1
∑ 最好(“正序”): 1 = n −1 i=1
∑n−1
最坏(“逆序”):
i
=1+
2
+3
+L+
(n
−1)
=
n(n
−1)
i=1
2
取平均值:
1
n2 (
−
n
+
n
− 1)
=
1
(n 2
+
n
−
2)
≈
1
n2
22
4
4
(2)记录的移动次数
开始时,将要插入的记录→temp,移动1次 最后,将记录插入适当位置,即 temp→a[j+1] ,移动1次 比较后,若temp.key<a[j].key,则 a[j]→a[j+1]
5
3
13
26
5Hale Waihona Puke 1220 22 35
27 23 10 15
是堆 (小顶堆或小根堆)
不是堆
◆ 若序列{ K0, K1, …, Kn-1 }是堆,则堆顶元素(完全 二叉树的根结点)必是序列中n个元素的最小值(或最 大值)。
◆ 从根结点到每个叶结点的路径上,数据元素组成的
Chapter 9 内部排序
9.1 引言 9.2 插入排序 9.3 选择排序 9.4 交换排序 9.5 归并排序 9.6 基数排序 9.7 各种内部排序方法的比较讨论
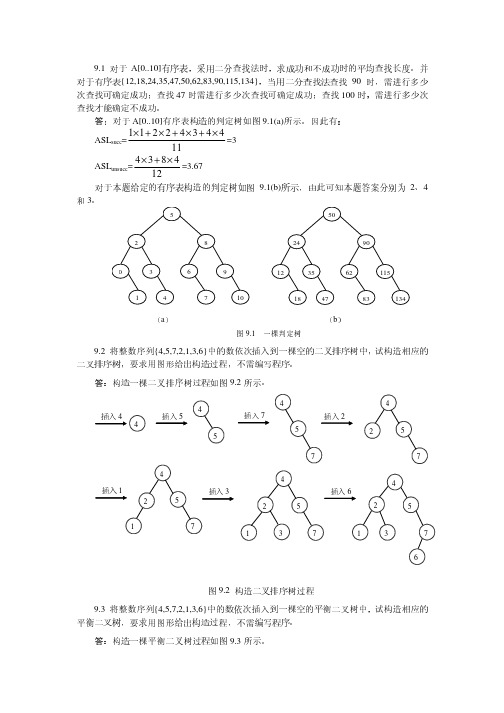
9.1 引言
一、什么叫排序(Sorting) ?
排序是将一个数据元素(或记录)的任意序列,重新 排列成一个按关键字有序的序列的操作过程。其确切定义 如下:
数据结构第九章排序习题及答案

资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载数据结构第九章排序习题及答案地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容习题九排序一、单项选择题1.下列内部排序算法中:A.快速排序 B.直接插入排序C. 二路归并排序D. 简单选择排序E. 起泡排序F. 堆排序(1)其比较次数与序列初态无关的算法是()(2)不稳定的排序算法是()(3)在初始序列已基本有序(除去n个元素中的某k个元素后即呈有序,k<<n)的情况下,排序效率最高的算法是()(4)排序的平均时间复杂度为O(n•logn)的算法是()为O(n•n)的算法是()2.比较次数与排序的初始状态无关的排序方法是( )。
A.直接插入排序 B.起泡排序 C.快速排序 D.简单选择排序3.对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为(1) 84 47 25 15 21 (2) 15 47 25 84 21(3) 15 21 25 84 47 (4) 15 21 25 47 84则采用的排序是 ( )。
A. 选择B. 冒泡C. 快速D. 插入4.下列排序算法中( )排序在一趟结束后不一定能选出一个元素放在其最终位置上。
A. 选择B. 冒泡C. 归并D. 堆5.一组记录的关键码为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为()。
A.(38,40,46,56,79,84) B. (40,38,46,79,56,84)C.(40,38,46,56,79,84) D. (40,38,46,84,56,79)6.下列排序算法中,在待排序数据已有序时,花费时间反而最多的是( )排序。
《数据结构》第九章习题参考答案

《数据结构》第九章习题参考答案《数据结构》第九章习题参考答案一、判断题(在正确说法的题后括号中打“√”,错误说法的题后括号中打“×”)1、快速排序是一种稳定的排序方法。
(×)2、在任何情况下,归并排序都比简单插入排序快。
(×)3、当待排序的元素很大时,为了交换元素的位置,移动元素要占用较多的时间,这是影响时间复杂度的主要因素。
(√)4、内排序要求数据一定要以顺序方式存储。
(×)5、直接选择排序算法在最好情况下的时间复杂度为O(n)。
( ×)6、快速排序总比简单排序快。
( ×)二、单项选择题1.在已知待排序文件已基本有序的前提下,效率最高的排序方法是(A)。
A.直接插入排序B.直接选择排序C.快速排序D.归并排序2.下列排序方法中,哪一个是稳定的排序方法?(B)A.直接选择排序B.折半插入排序C.希尔排序D.快速排序3、比较次数与排序的初始状态无关的排序方法是( B)。
A.直接插入排序B.起泡排序(时间复杂度O(n2))C.快速排序D.简单选择排序4、对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为(1)84 47 25 15 21 (2)15 47 25 84 21 (3)15 21 25 84 47 (4)15 21 25 47 84 则采用的排序是( A)。
A. 选择B. 冒泡C. 快速D. 插入5、快速排序方法在(D)情况下最不利于发挥其长处。
A. 要排序的数据量太大B. 要排序的数据中含有多个相同值C. 要排序的数据个数为奇数D. 要排序的数据已基本有序6、用某种排序方法对线性表{25,84,21,47,15,27,68,35,20}进行排序,各趟排序结束时的结果为:(基准)20,21,15,25,84,27,68,35,47(25)15,20,21,25,47,27,68,35,84(左20右47)15,20,21,25,35,27,47,68,84(左35右68)15,20,21,25,27,35,47,68,84 ;则采用的排序方法为(C)。
数据结构第九章排序习题与答案

习题九排序一、单项选择题1.下列内部排序算法中:A.快速排序 B.直接插入排序C. 二路归并排序D.简单选择排序E. 起泡排序F.堆排序(1)其比较次数与序列初态无关的算法是()(2)不稳定的排序算法是()(3)在初始序列已基本有序(除去n 个元素中的某 k 个元素后即呈有序, k<<n)的情况下,排序效率最高的算法是()(4)排序的平均时间复杂度为O(n?logn)的算法是()为 O(n?n) 的算法是()2.比较次数与排序的初始状态无关的排序方法是( )。
A.直接插入排序B.起泡排序C.快速排序D.简单选择排序3.对一组数据( 84, 47, 25, 15, 21)排序,数据的排列次序在排序的过程中的变化为(1) 84 47 25 15 21(2) 15 47 25 84 21(3) 15 21 25 84 47(4) 15 21 25 47 84则采用的排序是 ()。
A. 选择B.冒泡C.快速D.插入4.下列排序算法中 ( )排序在一趟结束后不一定能选出一个元素放在其最终位置上。
A. 选择B.冒泡C.归并D.堆5.一组记录的关键码为(46,79,56, 38,40, 84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为()。
A. (38,40,46,56,79,84) B. (40,38,46,79,56,84)C. (40,38,46,56,79,84) D. (40,38,46,84,56,79)6.下列排序算法中,在待排序数据已有序时,花费时间反而最多的是()排序。
A.冒泡 B. 希尔C. 快速D. 堆7.就平均性能而言,目前最好的内排序方法是() 排序法。
A. 冒泡B.希尔插入C.交换D.快速8.下列排序算法中,占用辅助空间最多的是:()A. 归并排序B.快速排序C.希尔排序D.堆排序9.若用冒泡排序方法对序列 {10,14,26,29,41,52}从大到小排序,需进行()次比较。
数据结构-9-内部排序

49 2
25* 3 25*
16
4
08 5
i=1
gap = 3
0
21
49
16
08
21
25
49
25*
16
08
21
25
49
25*
16
08
21
16
1
08 2
25* 3
25 4
49 5
i=2
gap = 2
0
21
16
08
25*
25
49
21
16
08
25*
25
49
08
16
21
25*
25
49
08
16
1
21 2
25* 3
排序之前,对象r[i]排在r[j]前面。如果在排序
之后,对象r[i]仍在对象r[j]的前面,则称这个 排序方法是稳定的,否则称这个排序方法是不 稳定的。
内排序与外排序: 内排序是指在排序期间数据 对象全部存放在内存的排序;外排序是指在排 序期间全部对象个数太多,不能同时存放在内 存,必须根据排序过程的要求,不断在内、外 存之间移动的排序。 排序的时间开销: 排序的时间开销是衡量算法 好坏的最重要的标志。排序的时间开销可用算 法执行中的数据比较次数与数据移动次数来衡 量。各节给出算法运行时间代价的大略估算一 般都按平均情况进行估算。对于那些受对象关 键字序列初始排列及对象个数影响较大的,需 要按最好情况和最坏情况进行估算。
希尔排序方法又称为“缩小增量”排序。
该方法的基本思想是:先将整个待排对象序列 按照一定间隔分割成为若干子序列,分别进行 直接插入排序,然后缩小间隔,对整个对象序 列重复以上的划分子序列和分别排序工作,直 到最后间隔为1,此时整个对象序列已 “基本 有序”,进行最后一次直接插入排序。
数据结构第三版第九章课后习题参考答案
}
}
设计如下主函数:
void main()
{ BSTNode *bt;
KeyType k=3;
int a[]={5,2,1,6,7,4,8,3,9},n=9;
bt=CreatBST(a,n);
//创建《教程》中图 9.4(a)所示的二叉排序树
printf("BST:");DispBST(bt);printf("\n");
#define M 26 int H(char *s)
//求字符串 s 的哈希函数值
{
return(*s%M);
}
构造哈希表 void Hash(char *s[]) //
{ int i,j;
char HT[M][10]; for (i=0;i<M;i++)
//哈希表置初值
HT[i][0]='\0'; for (i=0;i<N;i++) { j=H(s[i]);
//求每个关键字的位置 求 // s[i]的哈希函数值
while (1)
不冲突时 直接放到该处 { if (HT[j][0]=='\0') //
,
{ strcpy(HT[j],s[i]);
break;
}
else
//冲突时,采用线性线性探测法求下一个地址
j=(j+1)%M;
}
} for (i=0;i<M;i++)
printf("%2d",path[j]);
printf("\n");
}
else { path[i+1]=bt->key;
数据结构 第9章(内排序)

3. 将R[j+1]=R[0] 实现整个序列的排序。
North China Electric Power University
排序算法如下:
void insort(List r, int n) {//r为给定的表,其记录为r[i],i=0,1,…,n,x为暂存单元。 for (i=2; i<=n; i++) { r[0]=r[i]; //r[0]作为标志位 j=i-1; while (r[0].key<r[j].key) { r[j+1]=r[j]; j--; } //j从i-1至0,r[j].key与r[i].key进行比较 r[j+1]=r[0]; } }//insort
North China Electric Power University
例如:
第二趟希尔排序,设增量d = 3
第三趟希尔排序,设增量d = 1
North China Electric Power University
希尔排序的算法描述如下:
void ShellInsert (List r,int d) //本算法对直接插入算法作了以下修改: // 1. 前后记录位臵的增量是d,而不是1; // 2. r[0]只是暂存单元,不是哨兵。当j<=0时,插入位臵已找到。 for (i=2;i<= n ; i++) { { r[0]=r[i]; for(i=d+1;i<=n;i++) j=i-1; if ( r[i] < r[i-d]) //需将r[i]插入有序增量子表 while ( r[0].key<r[j].key) { r[0] = r[i]; //暂存在R[0] { r[j+1]=r[j]; j=i-d ; j=j-1; while ((j>0) and (r[0] < r[j])) } { r[j+d] = r[j]; //记录后移,查找插入位臵 r[j+1]=r[0]; j=j-d; } } r[j+d] = r[0];//插入 } }
数据结构 第9章 内部排序(作业)

第9章 内部排序
为了讨论方便,假设待排记录的关键字均为整数,均从 数组中下标为1的位置开始存储,下标为0的位置存储监视哨, 或空闲不用。 typedef int KeyType; typedef struct { KeyType key; OtherType other-data; } RecordType;
类: 一类是整个排序过程完全在内存中进行,称为内部排序; 另一类是由于待排序记录数据量太大,内存无法容纳全部数 据, 排序需要借助外部存储设备才能完成,称为外部排序。
第9章 内部排序
假设Ki=Kj(1≤i≤n,1≤j≤n,i≠j), 若在排序前的序列中Ri
领先于Rj(即i<j),经过排序后得到的序列中Ri仍领先于Rj, 则 称所用的排序方法是稳定的;反之,当相同关键字的领先关系 在排序过程中发生变化,则称所用的排序方法是不稳定的。 无论是稳定的还是不稳定的排序方法,均能排好序。在应 用排序的某些场合,如选举和比赛等,对排序的稳定性是有特 殊要求的。
算法21--内部排序--归并排序

实现这种递归调用的关键是为过程建立递归调用工作栈。通 常,在一个过程中调用另一过程时,系统需在运行被调用过 程之前先完成3件事:
(1)将所有实参指针,返回地址等信息传递给被调用过程; (2)为被调用过程的局部变量分配存储区; (3)将控制转移到被调用过程的入口。 在从被调用过程返回调用过程时,系统也相应地要完成3件事: (1)保存被调用过程的计算结果; (2)释放分配给被调用过程的数据区; (3)依照被凋用过程保存的返回地址将控制转移到调用过程.
实际的意义:可以把一个长度为n 的无序序列看成 是 n 个长度为 1 的有序子序列 ,首先做两两归 并,得到 n/2 个长度为 2 的子序列;再做两两 归并,…,如此重复,直到最后得到一个长度为 n
的有序序列。
归并排序
初始序列
[49] [38] [65] [97 [76] [13] [27]
第一步 第二步
T(1)=1 T(n)=kT(n/m)+f(n)
2019/10/20
归并排序时间复杂性分析
• 合并趟数: log2n • 每趟进行比较的代价 n • 总的代价为 T(n) = O ( nlog2n ) • 在一般情况下:
c
n=1
T(n) =
T( n/2 ) + T( n/2 ) + cn n>1
优缺点:Ω的这个定义的优点是与O的定义对称,缺点 是当 f(N) 对自然数的不同无穷子集有不同的表达式, 且有不同的阶时,未能很好地刻画出 f(N)的下界。
2019/10/20
f(n) cg(n)
n0
n
2019/10/20
代入法解递归方程
方法的关键步骤在于预先对解答作出推测,然后用 数学归纳法证明推测的正确性。
算法与数据结构课后答案9-11章

算法与数据结构课后答案9-11章第9章集合一、基础知识题9.1 若对长度均为n 的有序的顺序表和无序的顺序表分别进行顺序查找,试在下列三种情况下分别讨论二者在等概率情况下平均查找长度是否相同?(1)查找不成功,即表中没有和关键字K 相等的记录;(2)查找成功,且表中只有一个和关键字K 相等的记录;(3)查找成功,且表中有多个和关键字K 相等的记录,要求计算有多少个和关键字K 相等的记录。
【解答】(1)平均查找长度不相同。
前者在n+1个位置均可能失败,后者失败时的查找长度都是n+1。
(2)平均查找长度相同。
在n 个位置上均可能成功。
(3)平均查找长度不相同。
前者在某个位置上(1<=i<=n)查找成功时,和关键字K 相等的记录是连续的,而后者要查找完顺序表的全部记录。
9.2 在查找和排序算法中,监视哨的作用是什么?【解答】监视哨的作用是免去查找过程中每次都要检测整个表是否查找完毕,提高了查找效率。
9.3 用分块查找法,有2000项的表分成多少块最理想?每块的理想长度是多少?若每块长度为25 ,平均查找长度是多少?【解答】分成45块,每块的理想长度为45(最后一块长20)。
若每块长25,则平均查找长度为ASL=(80+1)/2+(25+1)/2=53.5(顺序查找确定块),或ASL=19(折半查找确定块)。
9.4 用不同的输入顺序输入n 个关键字,可能构造出的二叉排序树具有多少种不同形态? 【解答】 9.5 证明若二叉排序树中的一个结点存在两个孩子,则它的中序后继结点没有左孩子,中序前驱结点没有右孩子。
【证明】根据中序遍历的定义,该结点的中序后继是其右子树上按中序遍历的第一个结点,即右子树上值最小的结点:叶子结点或仅有右子树的结点,没有左孩子;而其中序前驱是其左子树上按中序遍历的最后个结点,即左子树上值最大的结点:叶子结点或仅有左子树的结点,没有右孩子。
命题得证。
9.6 对于一个高度为h 的A VL 树,其最少结点数是多少?反之,对于一个有n 个结点的A VL 树,其最大高度是多少? 最小高度是多少?【解答】设以N h 表示深度为h 的A VL 树中含有的最少结点数。
数据结构第九章习题

第九章内部排序
1.以关键字序列(503,087,512,061,908,170,897,275,653,426)为例,手工执行以下排序方法,写出每一趟排序结束时的关键字状态。
(1)直接插入排序;(2)希尔排序(增量5,3,1);(3)快速排序;
(4)堆排序;(5)归并排序;(6)基数排序。
2.对长度为n的记录序列进行快速排序时,所需进行的比较次数依赖于这n个元素的初始序列。
(1)n=7时的最好情况下需进行多少次比较?说明理由。
(2)对n=7给出一个最好情况的初始排序实例。
3.已知一个单链表由3000个元素组成,每个元素是一个整数,其值在1~1000000之间。
试考察在所学的几种排序方法中,哪些方法可用于解决这个链表的排序问题?哪些不能,简述理由。
4.比较各种排序方法的时间复杂度、空间复杂度和稳定性。
《数据结构》习题汇编09-第九章-排序-试题

《数据结构》习题汇编09-第九章-排序-试题数据结构课程(本科)第九章试题一、单项选择题1.若待排序对象序列在排序前已按其排序码递增顺序排列,则采用()方法比较次数最少。
A. 直接插入排序B. 快速排序C. 归并排序D. 直接选择排序2.如果只想得到1024个元素组成的序列中的前5个最小元素,那么用()方法最快。
A. 起泡排序B. 快速排序C. 直接选择排序D. 堆排序3.对待排序的元素序列进行划分,将其分为左、右两个子序列,再对两个子序列施加同样的排序操作,直到子序列为空或只剩一个元素为止。
这样的排序方法是()。
A. 直接选择排序B. 直接插入排序C. 快速排序D. 起泡排序4.对5个不同的数据元素进行直接插入排序,最多需要进行()次比较?A. 8B. 10C. 15D. 255.如果输入序列是已经排好顺序的,则下列算法中()算法最快结束?A. 起泡排序B. 直接插入排序C. 直接选择排序D. 快速排序6.如果输入序列是已经排好顺序的,则下列算法中()算法最慢结束?A. 起泡排序B. 直接插入排序C. 直接选择排序D. 快速排序7.下列排序算法中()算法是不稳定的。
A. 起泡排序B. 直接插入排序C. 基数排序D. 快速排序8.假设某文件经过内部排序得到100个初始归并段,那么如果要求利用多路平衡归并在3 趟内完成排序,则应取的归并路数至少是()。
A. 3B. 4C. 5D. 69.采用任何基于排序码比较的算法,对5个互异的整数进行排序,至少需要()次比较。
A. 5B. 6C. 7D. 810.下列算法中()算法不具有这样的特性:对某些输入序列,可能不需要移动数据对象即可完成排序。
A. 起泡排序B. 希尔排序C. 快速排序D. 直接选择排序11.使用递归的归并排序算法时,为了保证排序过程的时间复杂度不超过O(nlog2n),必须做到()。
A. 每次序列的划分应该在线性时间内完成B. 每次归并的两个子序列长度接近C. 每次归并在线性时间内完成D. 以上全是12.在基于排序码比较的排序算法中,()算法的最坏情况下的时间复杂度不高于O(nlog2n)。
数据结构与算法(C++语言版)》第9章 内部排序

插入排序
插入排序
• 以上述静态链表类型作为待排记录序列的存储结构,并设 数组中下标为0的分量为表头结点,并令表头结点记录的关 键码取最大整数MAXNUM。 • 表插入的排序过程是,首先将静态链表中数组下标为1的分 量(结点)和表头结点构成一个循环链表,然后依次将下 标为2~n的分量(结点)按记录关键码非递减有序插入到 循环链表中,算法如以下程序所示。
插入排序
例9-3
• 以关键码序列{52, 43, 68, 89, 77, 16, 24, 52*, 80, 31}为例,表 插入排序的过程如下列图所示。
插入排序
• 从上面的过程可看出,表插入排序与直接插入排序的不同 之处在于,表插入排序以修改2n次指针值来代替记录的移 动,但和关键码的比较次数相同,因此表插入排序的时间 复杂度仍为O(n2)。
i=n
交换排序
• 快速排序 • 快速排序(quick sort)是Hoare于1962年提出的一种分区交 换排序。它采用了一种分而治之的策略,是对冒泡排序的 一种改进。其算法思想是,首先将待排序记录序列中的所 有记录作为当前待排序区域,选取第一个记录的关键码值 为基准(轴值),从待排序记录序列左、右两端开始向中 间靠拢,交替与轴值进行比较,若左侧记录的关键码值大 于轴值,则将该记录移到基准记录的右侧,若右侧记录的 关键码值小于轴值,则将该记录移到基准记录的左侧,最 后让基准记录到达它的最终位置,此时,基准记录将待排 序记录分成了左右两个区域,位于基准记录左侧的记录都 小于或等于轴值,位于基准记录右侧的所有记录的关键码 都大于或等于轴值,这就是一趟快速排序。
例9-5
• 如图所示为冒泡排序的一个示例。冒泡排序的效率分析: ① 若初始序列为“正序”序列,则只需进行一趟排序,在 排序过程中进行n−1次关键码的比较,且不移动记录;② 若 初始序列为“逆序”序列,则需进行n−1趟排序,需进行 2 ∑ (i − 1) = n(n − 1) / 2次比较。因此,总的时间复杂度为O(n2)。
第9章自测题答案

第9章排序自测卷答案姓名班级一、填空题(每空1分,共24分)1. 大多数排序算法都有两个基本的操作:比较(两个关键字的大小)和移动(记录或改变指向记录的指针)。
2. 在对一组记录(54,38,96,23,15,72,60,45,83)进行直接插入排序时,当把第7个记录60插入到有序表时,为寻找插入位置至少需比较3次。
(可约定为,从后向前比较)3. 在插入和选择排序中,若初始数据基本正序,则选用插入排序(到尾部);若初始数据基本反序,则选用选择排序。
4. 在堆排序和快速排序中,若初始记录接近正序或反序,则选用堆排序;若初始记录基本无序,则最好选用快速排序。
5. 对于n个记录的集合进行冒泡排序,在最坏的情况下所需要的时间是O(n2) 。
若对其进行快速排序,在最坏的情况下所需要的时间是O(n2) 。
6. 对于n个记录的集合进行归并排序,所需要的平均时间是O(nlog2n) ,所需要的附加空间是O(n) 。
7.【计研题2000】对于n个记录的表进行2路归并排序,整个归并排序需进行log2n 趟(遍),共计移动n log2n次记录。
(即移动到新表中的总次数!共log2n趟,每趟都要移动n个元素)8.设要将序列(Q, H, C, Y, P, A, M, S, R, D, F, X)中的关键码按字母序的升序重新排列,则:冒泡排序一趟扫描的结果是H, C, Q, P, A, M, S, R, D, F, X ,Y;初始步长为4的希尔(shell)排序一趟的结果是P, A, C, S, Q, D, F, X , R, H,M, Y;二路归并排序一趟扫描的结果是H, Q, C, Y,A, P, M, S, D, R, F, X ;快速排序一趟扫描的结果是F, H, C, D, P, A, M, Q, R, S, Y,X;堆排序初始建堆的结果是A, D, C, R, F, Q, M, S, Y,P, H, X。
9. 在堆排序、快速排序和归并排序中,若只从存储空间考虑,则应首先选取堆排序方法,其次选取快速排序方法,最后选取归并排序方法;若只从排序结果的稳定性考虑,则应选取归并排序方法;若只从平均情况下最快考虑,则应选取快速排序方法;若只从最坏情况下最快并且要节省内存考虑,则应选取堆排序方法。
数据结构习题汇编09 第九章 排序 试题

数据结构课程(本科)第九章试题一、单项选择题1.若待排序对象序列在排序前已按其排序码递增顺序排列,则采用()方法比较次数最少。
A. 直接插入排序B. 快速排序C. 归并排序D. 直接选择排序2.如果只想得到1024个元素组成的序列中的前5个最小元素,那么用()方法最快。
A. 起泡排序B. 快速排序C. 直接选择排序D. 堆排序3.对待排序的元素序列进行划分,将其分为左、右两个子序列,再对两个子序列施加同样的排序操作,直到子序列为空或只剩一个元素为止。
这样的排序方法是()。
A. 直接选择排序B. 直接插入排序C. 快速排序D. 起泡排序4.对5个不同的数据元素进行直接插入排序,最多需要进行()次比较?A. 8B. 10C. 15D. 255.如果输入序列是已经排好顺序的,则下列算法中()算法最快结束?A. 起泡排序B. 直接插入排序C. 直接选择排序D. 快速排序6.如果输入序列是已经排好顺序的,则下列算法中()算法最慢结束?A. 起泡排序B. 直接插入排序C. 直接选择排序D. 快速排序7.下列排序算法中()算法是不稳定的。
A. 起泡排序B. 直接插入排序C. 基数排序D. 快速排序8.假设某文件经过内部排序得到100个初始归并段,那么如果要求利用多路平衡归并在3 趟内完成排序,则应取的归并路数至少是()。
A. 3B. 4C. 5D. 69.采用任何基于排序码比较的算法,对5个互异的整数进行排序,至少需要()次比较。
A. 5B. 6C. 7D. 810.下列算法中()算法不具有这样的特性:对某些输入序列,可能不需要移动数据对象即可完成排序。
A. 起泡排序B. 希尔排序C. 快速排序D. 直接选择排序11.使用递归的归并排序算法时,为了保证排序过程的时间复杂度不超过O(nlog2n),必须做到()。
A. 每次序列的划分应该在线性时间内完成B. 每次归并的两个子序列长度接近C. 每次归并在线性时间内完成D. 以上全是12.在基于排序码比较的排序算法中,()算法的最坏情况下的时间复杂度不高于O(nlog2n)。
数据结构(内部排序)习题与答案

一、单选题1、对关键字序列(21,19,37,5,2),经直接插入排序法由小到大排序,第一趟后所得结果为()。
A.(19,21,5,2,37)B.(19,21,37,5,2)C.(19,21,2,5,37)D.(19,21,5,37,2)正确答案:B2、对关键字序列(21,19,37,5,2),经冒泡排序法由小到大排序,第一趟后所得结果为()。
A.(19,21,37,5,2)B.(19,21,2,5,37)C.(19,21,5,37,2)D.(19,21,5,2,37)正确答案:D3、对关键字序列(149,138,165,197,176,113,127),采用基数排序的第一趟之后所得结果为()。
A.(113,165,176,197,127,138,149)B.(113,165,176,127,197,138,149)C.(113,127,138,149,165,176,197)D.(149,138,165,197,176,113,127)正确答案:A4、下列各项键值()序列不是堆的。
A.(5,23,68,16,94)B.(5,23,16,94,68)C.(5,16,23,68,94)D.(5,23,16,68,94)正确答案:A5、假设一组待排序的关键字序列为(24,62,36,19),要求从小到大进行排序,()是归并排序的过程。
A.(24,62,36,19)(24,36,62,19)(19,24,36,62)B.(24,62,19,36)(19,24,36,62)C.(62,24,36,19)(19,24,36,62)D.(24,19,36,62)(24,19,36,62)(19,24,36,62)正确答案:B6、在第一趟排序之后,不能确保将数据表中某一个元素放在其最终位置上的排序算法是()。
A.归并排序B.快速排序C.冒泡排序D.选择排序正确答案:A7、对于下列排序,()的时间效率与关键字初始序列有直接关系。
计算机操作系统课后答案第9章习题解答

第9章习题解答一、填空1.MS-DOS操作系统由BOOT、IO.SYS、MSDOS.SYS以及 所组成。
2.MS-DOS的一个进程,由程序(包括代码、数据和堆栈)、程序段前缀以及环境块三部分组成。
3.MS-DOS向用户提供了两种控制作业运行的方式,一种是批处理方式,一种是命令处理方式。
4.MS-DOS存储管理规定,从地址0开始每16个字节为一个“节”,它是进行存储分配的单位。
5.MS-DOS在每个内存分区的前面都开辟一个16个字节的区域,在它里面存放该分区的尺寸和使用信息。
这个区域被称为是一个内存分区所对应的内存控制块。
6.MS-DOS有4个存储区域,它们是:常规内存区、上位内存区、高端内存区和扩充内存区。
7.“簇”是MS-DOS进行磁盘存储空间分配的单位,它所含扇区数必须是2的整数次方。
8.当一个目录表里仅包含“.”和“..”时,意味该目录表为空。
9.在MS-DOS里,用文件名打开文件,随后就通过句柄来访问该文件了。
10.在MS-DOS里,把字符设备视为设备文件。
二、选择1.下面对DOS的说法中,B 是正确的。
A.内、外部命令都常驻内存B.内部命令常驻内存,外部命令非常驻内存C.内、外部命令都非常驻内存D.内部命令非常驻内存,外部命令常驻内存2.DOS进程的程序,在内存里 D 存放在一起。
A.总是和程序段前缀以及环境块B.和谁都不C.总是和进程的环境块D.总是和程序段前缀3.MS-DOS启动时能够自动执行的批处理文件名是: C 。
A.CONFIG.SYS B.MSDOS.SYSC.AUTOEXEC.BAT D.4.下面所列的内存分配算法, D 不是MS-DOS采用的。
A.最佳适应法B.最先适应法C.最后适应法D.最坏适应法5.在MS-DOS里,从1024K到1088K的存储区域被称为 D 区。
A.上位内存B.扩展内存C.扩充内存D.高端内存6.MS-DOS的存储管理是对A的管理。
A.常规内存B.常规内存和上位内存C.常规内存和扩展内存D.常规内存和扩充内存7.在下面给出的MS-DOS常用扩展名中,B 不表示一个可执行文件。
数据结构第9章内部排序

算法步骤: (1)将整个待排序的记录序列划分成有序 区和无序区,初始时有序区为待排序记 录序列的第一个记录,无序区包括所有 剩余待排序的记录; (2)将无序区的第一个记录插入到有序 区的合适位置中,从而使无序区减少一 个记录,有序区增加一个记录; (3)重复执行(2),直到无序区中没有 记录为止。
希尔排序算法: void shell_sort(Sqlist *L, int dk[], int t)
/*按增量序列dk[0 … t-1],对顺序表L进行希尔排序*/
{ int m ; for (m=0; m<=t; m++) shell_pass(L, dk[m]) ; }
希尔排序可提高排序速度: (1) 分组后n值减小,n² 更小,而T(n)=O(n² ), 所以T(n)从总体上看减小了; (2) 关键字较小的记录可以以增量为单位跳 跃式前移,当进行最后一趟增量为1的插 入排序时,序列已基本有序。 增量序列取法: (1) 无除1以外的公因子; (2) 增量递减,最后一个增量值必须为1。
算法分析:
⑴ 最好情况:待排序记录按关键字从小到大排 列,算法中的内循环无须执行,每一趟排序时, 关键字比较1次,记录不需移动。所以整个排 序的关键字比较次数为n-1,记录移动次数为 0。 ⑵ 最坏情况:待排序记录按关键字从大到小排 列,每一趟排序时,算法中的内循环体执行i-1 次,关键字比较次数i次,记录移动次数i+1。 一般地,认为待排序的记录在各个位置的插入 概率相同,则取以上两种情况的平均值,作为 排序的关键字比较次数和记录移动次数,约为 n2/4,由此,直接插入排序的平均时间复杂度 为O(n2)。
插入排序
插入排序是一类借助“插入”操作进行 排序的方法,其主要思想是:每次将一 个待排序的记录按其关键字的大小插入 到一个已经排好序的有序序列中,直到 全部记录排好序。
第9章习题答案

第9章习题答案第9章排序习题91.在各种排序方法中,哪些是稳定的?哪些是不稳定的?对不稳定的排序方法举出一个不稳定的例子。
解:排序方法直接插入排序折半插入排序二路插入排序表插入排序起泡排序直接选择排序希尔排序快速排序堆排序 2-路归并排序基数排序平均时间最坏情况辅助空间稳定性稳定稳定稳定稳定稳定不稳定不稳定 2不稳定排序举例 2,2,13,2,2,1(d=2,d=1) 2,2,1 2,1,1(大顶堆) O(n) O(n) O(n) O(n) O(n) O(n)O(n1.3222222O(n) O(n) O(n) O(n) O(n) O(n) O(n1.32222222O(1) O(1) O(n) O(1) O(1) O(1) O(1) ) 222) O(nlogO(nlogO(nlogn) n) n) O(n) O(log22n) 不稳定不稳定稳定稳定 O(nlogO(nlogn) n) O(1) O(n) O(d*(rd?n)) O(d*(rd?n)) O(rd) 2.若不考虑基数排序,则排序的两种基本操作是什么?解:关键字的比较和记录的移动。
3.外排序的基本操作是什么?解:生成有序归并段,归并。
4.分别采用堆排序、快速排序、起泡排序和归并排序,对初始状态为有序的表,则最省时间的是哪种排序方法?最费时间的是哪种排序方法?解:起泡排序,快速排序。
5.不受待排序初始序列的影响的排序算法是哪种?其时间复杂度是多少?解:简单选择排序,时间复杂度是O(n)。
6.直接插入排序设置监视哨的作用是什么?解:免去查找过程中每一步都要检测整个表是否查找完毕,提高了查找效率。
7.从平均时间性能而言,哪种排序方法最佳?解:快速排序。
8.设待排序的记录有10个,其关键字分别为{75,23,98,44,57,12,29,64,38,82}。
手工执行以下排序算法(按字典序比较关键字的大小),写出每一堂排序结束时的关键字的状态:(1)直接插入排序 (2)折半插入排序12第9章排序(3)起泡排序 (4)简单选择排序 (5)快速排序 (6)希尔排序 (7)2-路归并排序 (8)基数排序解:略9.已知记录序列R[1..n]中的关键字各不相同,可按如下所述实现计数排序:另设数组C[1..n],对每个记录R[i],统计序列中关键字比它小的记录个数存于C[i],则C[i]=0的记录必为关键字最小的记录,然后依C[i]值的大小对R中记录进行重新排列,试编写实现上述排序的算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
while(p->data>key) p=p->pre; L.sp=p; } else if(p->data<key) { while(p->data<key) p=p->next; L.sp=p; } return p; }//Search_DSList 分析:本题的平均查找长度与上一题相同,也是 n/3.
9.31
int last=0,flag=1;
int Is_BSTree(Bitree T)//判断二叉树 T 是否二叉排序树,是则返回 1,否则返回 0 {
if(T->lchild&&flag) Is_BSTree(T->lchild); if(T->data<last) flag=0; //与其中序前驱相比较 last=T->data; if(T->rchild&&flag) Is_BSTree(T->rchild); return flag; }//Is_BSTree
ST.elem[ST.length+1].key=key; for (i=1; ST.elem[i].key>key; ++i); if (ST.elem[i].key==key)&&(i<=ST.length) return i else return 0 ;
}//Search-Seq
9.31 TelemType Maxv(Bitree T){
第九章答案 9.1 (1)无序表:顺序查找不成功时,查找长度为 n+1;成功时,平均查找长度为 1/(n+1)*(1+2+… +(n+1))=(n+2)/2;两者不相同。 (2)表中只有一个关键字等于给定值 k 的记录,无序表、有序表:顺序查找成功时,平均 查找长度均为 1/(n)*(1+2+…+n)=(n+1)/2;两者相同。 (3)表中只有 m 个关键字等于给定值 k 的记录,无序表:ASL=n+1;有序表:ASL=(n+1) /2+m;两者不相同。
}//Minv
Status IsBST(Bitree T){ //判别 T 是否为二叉排序树 if (!T) return OK; else if
((!T->lchild)||((T->lchild)&&(IsBST(T->lchild)&&(Maxv(T->lchild)<T->data))) &&((!T->rchild)||((T->rchild)&&(IsBST(T->rchild)&&(Minv(T->rchild)>T-
9.33
void Print_NLT(BiTree T,int x)//从大到小输出二叉排序树 T 中所有不小于 x 的元素 {
if(T->rchild) Print_NLT(T->rchild,x); if(T->data<x) exit(); //当遇到小于 x 的元素时立即结束运行 printf("%d\n",T->data); if(T->lchild) Print_NLT(T->lchild,x); //先右后左的中序遍历 }//Print_NLT
return mid; else if(key<r[mid].key) high=mid; else low=mid; } //本算法不存在查找失败的情况,不需要 return 0; }//Locate_Bin
9.28
typedef struct { int maxkey; int firstloc;
9.34
void Delete_NLT(BiTree &T,int x)//删除二叉排序树 T 中所有不小于 x 元素结点,并释放空间 {
if(T->rchild) Delete_NLT(T->rchild,x); if(T->data<x) exit(); //当遇到小于 x 的元素时立即结束运行 q=T; T=T->lchild; free(q); //如果树根不小于 x,则删除树根,并以左子树的根作为新的树根 if(T) Delete_NLT(T,x); //继续在左子树中执行算法 }//Delete_NLT
} Index;
typedef struct { int *elem; int length; Index idx[MAXBLOCK]; //每块起始位置和最大元素,其中 idx[ 0 ]不利用,其内容初始化为{0,0}以
利于折半查找 int blknum; //块的数目
} IdxSqList; //索引顺序表类型
for(p=L.h,i=1;p->data!=key;p=p->next,i++); else
for(p=L.t,i=L.tpos;p->data!=key;p=p->next,i++); L.t=p; //更新 t 指针 return p; }//Search_CSList 分析:由于题目中假定每次查找都是成功的,所以本算法中没有关于查找失败的处理.由微积分可得,在等概率 情况下,平均查找长度约为 n/3.
printf("a=%d\n",last); if(last<=x&&T->data>x) //找到了大于 x 的最小元素
printf("b=%d\n",T->data); last=T->data; if(T->rchild) MaxLT_MinGT(T->rchild,x); }//MaxLT_MinGT
9.19
22 67 41 30
53 46
13
01
0 1 2 3 4 5 6 7 8 9 10
ASL=(4*1+2*2+3+6)/8=17/8
9.25 int Search-Seq(SSTable ST, KeyType key){ //在顺序表 ST 中顺序查找其关键字等于 key 的数据元素,ST 按关键字自大至小有序, //若找到,则函数值为该元素在表中的位置,否则为 0
9.29
typedef struct { LNode *h; //h 指向最小元素 LNode *t; //t 指向上次查找的结点
} CSList;
LNode *Search_CSList(CSList &L,int key)//在有序单循环链表存储结构上的查找算法,假定每次查找都成 功 {
if(L.t->data==key) return L.t; else if(L.t->data>key)
int *r; r=ST.elem; if(key<r.key) return 0; else if(key>=r[ST.length].key) return ST.length; low=1;high=ST.length; while(low<=high) {
mid=(low+high)/2; if(key>=r[mid].key&&key<r[mid+1].key) //查找结束的条件
9.32
int last=0;
void MaxLT_MinGT(BiTree T,int x)//找到二叉排序树 T 中小于 x 的最大元素和大于 x 的最小元素 {
if(T->lchild) MaxLT_MinGT(T->lchild,x); //本算法仍是借助中序遍历来实现 if(last<x&&T->data>=x) //找到了小于 x 的最大元素
5
2
1
3
8
6
9
4
7
10
9.3 ASL=1/10(1+2*2+4*3+3*4)=2.9
9.11
9.14
删除 50 后
30
20
20 30
20
50
30
20
50 52
30 52
20
50
60
30 52
20
50
60 68
52
30
68
20
50 60
70
52 68
20 30
ቤተ መጻሕፍቲ ባይዱ
60
70
52
删除 68 后
20 30
60 70
9.26
int Search_Bin_Digui(SSTable ST,int key,int low,int high)//折半查找的递归算法 {
if(low>high) return 0; //查找不到时返回 0 mid=(low+high)/2; if(ST.elem[mid].key==key) return mid; else if(ST.elem[mid].key>key)
mid=(low+high)/2; if(key<=L.idx[mid].maxkey&&key>L.idx[mid-1].maxkey)
found=1; else if(key>L.idx[mid].maxkey)
low=mid+1; else high=mid-1; } i=L.idx[mid].firstloc; //块的下界 j=i+blksize-1; //块的上界