数据集成中间件
系统集成各子系统详细介绍

系统集成子系统详细介绍
系统集成主要包括以下几个子系统:
1.硬件集成:主要涉及计算机、网络设备、存储设备、安全设备等各种硬件
设备的集成,以形成一个高效的系统。
2.软件集成:将各种软件应用进行整合,包括操作系统、数据库、中间件、
应用软件等,形成一个统一、协同的工作环境。
3.数据集成:将不同数据源的数据进行整合,包括结构化数据、非结构化数
据、实时数据等,确保数据的准确性和一致性。
4.网络集成:将各种网络设备、网络协议、网络安全等进行整合,形成稳定、
安全、可靠的网络环境。
5.解决方案集成:将各种解决方案进行整合,包括硬件、软件、数据、网络
等各种技术领域,形成综合性的解决方案。
6.服务集成:将各种服务进行整合,包括咨询、实施、运维、培训等服务领
域,进行服务的组合和优化,确保服务的整体质量和效果。
7.安全集成:将各种安全设备、安全策略进行整合,形成统一、完善的安全
体系。
每个子系统都有其特定的功能和作用,并且相互之间需要协同工作,以实现整个系统的最佳性能。
在实际的系统集成工作中,还需要考虑用户的需求和行业的特性,对各个子系统进行定制和优化,以满足用户的特定需求。
集成中间件的构成和用途

应用部署框架SynchroFrame
应用层
工作流引擎 管理 流程部署 引擎性能监 控 引擎日志管 理 工作流群集 管理 HA群集管 理 工作流对象API DLL API 功能模块管理 流程动态监控 流程统计分析 流程示例 Office文档在线编辑 部门管 理 组织机构建 模
工作流引擎SynchroFLOW
协同消息中间件SynchroMQ
• 高可靠和容错特性
JMS Client JMS Client
• 可靠组播服务器互连
SynchroMQ Server JMS Client
• 完全符合JMS 标准 • 高伸缩性和扩展性
JMS Client
SynchroMQ Server
• 高性能、灵活的数据库
SynchroMQ Server JMS Client
政府行业用户
▲ 中国质量认证中心认证业务管理系统 ▲ 铁道部全网电务管理系统 ▲ 中山市电子政务——网上审批系统(涉及49家委、办、局, 600多项审批业务 ) ▲ 国家总局无线局协同办公平台 ▲ 广东省财政局财务管理系统(20个地市) ▲ 北京市文化局网上审批系统 ▲ 大庆数字化城市管理系统 ▲ 广东省经贸委综合办公系统 ▲ 福建省消防总队综合业务系统(包括省总队和9个地市支队) ▲ 黑龙江省政府采购网 ▲ 江苏省中级人民法院——业务审批系统 ▲ 北京市司法局电子政务网上审批服务系统 ▲ 中国音乐出版社综合信息系统 ▲ 南京市秦淮区政府电子政务系统
应用系统 数据
SynchroPortal 的价值
• • • • •
在一个界面上展现多个不同的系统 一次登录,统一授权认证 界面个性化布局 界面皮肤可随时调整 实现了界面展现与流程、数据、业务的 分离
系统集成及中间件--1 集成系统概述

李瑞轩
rxli@ /~rxli/ 华中科技大学计算机学院
1
主要内容
第一章 第二章 第三章 第四章 第五章 第六章 第七章 第八章 第九章 概述 集成系统的建模方法 数据交换标准 中件/群件/ 中件/群件/组件概论 中间件技术 分布式对象技术 数据集成技术 XML技术 XML技术 Web服务 Web服务
3、基本组成: 、基本组成
生产指挥系统 产品工程设计系统 柔性制造系统 质量保证系统 以Net.DB为基础的支撑系统 为基础的支撑系统
14
第二章 集成系统的建模技术
2.1 几何数据模型 1、线框模型,表面模型,立休模型 、线框模型,表面模型, 2、几何的CSG (Constructive Solid 、几何的 Geometry)与B-rep (Boundary 与 Representation)表示方法 表示方法
18
曼德勃罗集的原始图形,从它出发, 曼德勃罗集的原始图形,从它出发,每一个细部都可以 演绎出美丽无比的梦幻般的仙境似的图形
19
20
分形应用
用分形理论看当前股市 分形分维的经络形态及解剖结构 用分形方法预测2020年我国乙烯年产量 用分形方法预测 年我国乙烯年产量 分形与神经网络方法在卫星数字图像分类中的 应用 分形理论在刀具磨损研究中的应用 变维分形模型预测台风路径 分形理论在社会科学中的应用 …….
21
二、多媒体数据建模方法
多媒体录像:以镜头为单位的检索(连续检索) 多媒体录像:以镜头为单位的检索(连续检索) 解决的问题:时间同步(图像与声音) 解决的问题:时间同步(图像与声音) 建模时加入时间维
1、基于文档的模型(超文本模型) 基于文档的模型(超文本模型) SMIL(Synchronized Multimedia Integration Language) 连续媒体模型(切入时钟) 2、连续媒体模型(切入时钟) 3、Amsterdam Model {(1)+(2)} 4、基于对象的分层模型 MPEG4, 如: MPEG4,MPEG7
数据集成和数据传递双模式访问异构数据库中间件框架设计

1引言
随着 We b技 术 的不 断发 展 ,信 息 共享 和 数据 交换 的 范 围不 断扩 大 ,传 统 的关 系数 据 库 也面 临着 挑 战 , 种 不 同的数 据 库管 理系 统之 间的异 构性 及其 所 依赖 操 作系 统 的异构 性 , 各 严
重 限制 了信 息共 享和 数据 交 换范 围【2 。】 .。
个统一 的用户界面 ,为对异构数据库进行直接的 We b访问提供了新的解决方案n1 。 。
2 9
3期
一 总 5 1
21 M . X L的特 点
X ML具有跨平台、直接动态支持 We 操作、在数据描述方面灵活、可扩展、自描述 的 b
优点 ∞ ML在支持异构数据库系统方面有很多自身的优点:OX 。 ,X d ML结构性强、语义性
3
51
※编程 技术
应 用 实践 ※
数据 集成和数据 传递双 模式访 问异构数据 库 中间件框 架设计
邓念 东
( 安 科技 大学 地质 与环 境 工程 系 陕西 西安 7 0 5 ) 西 0 4 1
【 摘要 】本 文对 基于 Jv 和 X aa ML技术 的异 构数据库访 问中间件进行框架 设计。该中间件可根
据数据 用户的不 同需求,灵活 自动 的选择数据集 成或数据传 递访 问模式 ,能高效率 、低消耗地 实现异 构数据库信 息共享。 由于其 具有可扩展性 、可配置性 、通用性 、松 散耦合性等特 性 ,使
其 易于 部 署 在 不 同 w b应 用 环 境 下 。 e
【 关键词 】X ML ;中间件 ;异构数据库 ;数 据集 成 ;数据传递
异 构数 据库 的 异 构性 主要 体 现在 以下几 个方 面 【 】 计算 机 体系 结 构 的异 构 :各 个参 l :① I 2 与 的数据 库 可 以分别运 行 在 大型 机 、小型 机 、工 作站 、P 或 嵌入 式系 统 中 ;② 操 作系 统 的 C 异构 :各个 数据 库 系统 的操 作系 统可 以是 S l i、Wid ws iu 等 ;(DMBS的异构 : oa s r no 、Ln x  ̄ )
企业级应用集成的架构设计技巧(一)

企业级应用集成的架构设计技巧引言在当今数字化时代,企业面临着海量的数据和各种复杂的业务流程。
为了提高业务效率和降低成本,企业需要将各种应用系统进行集成,以实现数据的共享和流程的协同。
本文将探讨企业级应用集成的架构设计技巧,并分析其在实践中的应用。
一、选择适合的集成模式企业级应用集成可以采用多种不同的集成模式,如点对点集成、中间件集成和服务总线集成等。
在选择集成模式时,需要根据企业的需求和现有系统架构来确定最合适的模式。
点对点集成模式适用于简单的应用集成,适合少量系统之间的数据交互。
中间件集成则通过引入中间层来管理应用之间的交互,提供消息传递和数据转换等功能。
而服务总线集成则更加灵活,可以集成多个系统,并提供更复杂的消息路由和数据转换功能。
二、规划合理的数据集成策略在进行企业级应用集成时,数据集成是一个重要的环节。
首先,需要对企业的数据进行分类和标准化,确保不同应用系统的数据结构和命名规范一致。
其次,需要选择合适的数据传输方式,如批量传输、实时传输或增量传输,以满足不同的业务需求。
另外,还需要考虑数据的安全性和合规性,确保数据在传输和存储过程中的保密性和完整性。
三、实施弹性的应用集成架构为了适应企业不断变化的需求和业务流程,企业级应用集成架构需要具备一定的弹性。
首先,应用集成架构应采用松耦合的设计,使得不同模块之间可以独立演化和部署。
其次,应用集成架构可以引入微服务的概念,将应用拆分成多个独立的微服务,以实现更高的可伸缩性和灵活性。
此外,还可以采用容器化的部署方式,如Docker,以便更灵活地管理和扩展应用的资源。
四、引入适当的集成工具和平台在实施企业级应用集成时,选择合适的集成工具和平台可以极大地提升开发和维护的效率。
常用的集成工具包括企业服务总线(ESB)、数据集成工具和流程引擎等。
这些工具可以帮助开发人员实现数据转换、消息传递和流程管理等功能,提高系统的稳定性和可维护性。
五、确保合理的安全性和监控机制在进行企业级应用集成时,安全性和监控是非常重要的考虑因素。
集成OPC实时数据的消息中间件的开发与实现

场总线 、 通讯 协议 和接 口各 不 相 同 ; 同时 各种企 业 管 理 系统 往 往运 行 于 不 同的 网络 硬 件 平 台 、 同 不
的操作 系统 , 以及采 用不 同的 网络协议 , 因此如何
用 高 效可靠 的消息传 递机 制进 行 与平 台无关 的数
对控制层不同系统的实时数据进行整合 、 处理 , 并
文章编号 :10 4 2 ( 0 1 0 0 7 0 0 6— 79 2 1 ) 2— 19— 4
集 成 O C 实 时 数 据 的 消 息 中 间 件 的 开 发 与 实 现 P
孟 逢 逢
( 上海 电力学院 计 算机与信 息工 程学 院 , 上海 摘 20 9 ) 0 00
要 :介绍 了一种基 于发 布/ 阅模式的消息 中间件的开发实现 , 订 阐述了利用消息 中间件将遵 循 O C接 口 P
统 、制 造 执 行 系 统 ( nfc r g xctn Mauati E eui un o
S s m, S 和 能 源 管 控 系 统 ( nry Maae yt ME ) e E eg n g—
C M, C M 技 术 为 基 础 定 义 的 一 组 接 口规 范. O D O
m n yt et s m,E ) 这些 信 息系 统 均需 要 横 向大 S e MS . 范 围 的生 产 实 时数 据 集 成 , 以及 纵 向 与 上层 MI S
MENG ng fng Fe —e
( co lfC m ue a dI om t nE gne n , h nh i n e i Sh o o o p t n n rai n ie ig S ag a U i mt r f o r v y o l tcP w r S n h i 20 9 C i ) fEe r o e, h g a 0 00, hn ci a a
中间件

中间件
中间件包括
⒈面向对象中间件(object-oriented midware): ⒉面向消息中间件(message-oriented midware简记为MOM):
面向消息中间件(MOM)
MOM是一种面向分布式应用的中间件,它通 过消息队列(Message Queue,简记为MQ) 为分布应用提供一种可靠的消息通信机制,特 别适合于松散耦合应用集成。 MOM基本结构如下图所示。所有队列包括持 久(persistence)队列和内存队列都是由队列 管理器(Queue Manager ,简记为QM)管理 。队列管理器负责从发送方接收消息,转发给 另一个队列管理器。另一个队列管理器则负责 接收到来的消息,并放入接收方用户的队列。
物理层
ISO OSI/RM数据传输方式
¢ Í ø Ì ²Ë ½ ³ ¦ à ã Ó Ó ² í ¾ ã ±Ê ² Ô °ã ¶ » ² « ä ã ´ Ê ² ø ç ã Í Â ² ý Ý ´ ²ã Ê ¾ Á  ² ï í ã Î À ²
DH NH TH TH SH PH AH AH
Data
TCP/IP的分层与协议
TCP/IP的分层与协议
应用层 应用层 表示层
对话层 传输层 传输层 网络层 网络层 链路层 数据链路层
物理层 T C P /IP 模 型
物理层 IS O O S I/R M
操作系统在分层中的位臵
操作系统在分层中的位臵
三种分布式系统的比较
类别 分布式操作系统 网络操作系统 局部OS同构 是 否 通信方式 消息 文件 资源管理 全局,分布 结点 透明性 高 低 分布性 低 高 开放性 低 高 特性
第二章 进程通信
2.2 不同节点上的进程间通信
中间件异构数据库集成中基于半连接的查询优化算法

子查 询 , 然后 按一 定 调度 规则 , 序 执行 子查 询 , 交 给 顺 提
每 个 数 据 源 执 行 ,最 后 每 个 数 据 源 将 执 行 结 果 返 回 给 中
用
全
子
户 全
局 查 询
局 查
询 分 船
查 r 询 、 、
1 优 , 1
卜 查 、 询 、
调 度
间件 的集 成 器.其查 询 调度 过 程 如 图 1 .
1 2 作 是 由 投 影 和 连 接 操 作 导 出 smi on 操 j
图 1 查 询调 度 图
收 稿 日期 :2 0 0 —0 0 9— 9 4 作 者 简 介 :吴 俊 霖 ( 9 5一 ,女 , 四川 达 州 人 ,硕 士 研 究 生 ,主 要 从 事 数 据 库 技 术 研 究 18 ) 通 讯 作 者 :余 建 桥 ,教 授 ,博 士 ,研 究 生导 师 .
1 1 中 间件 异 构 数 据 库 集 成 中 的 查 询 .
在 中 间件 的信息 集成 系统 中 ,每个 数 据源 都是 独 立 自治 的.其 查询 过程 如 下 :用 户提 交 的基 于 全 局 视
图 的 查 询 ,由 中 间件 的 分 解 器 分 解 为 针 对 每 个 数 据 源 的
难 点 问 题 … .考 虑 到 目前 绝 大 多 数 异 构 数 据 库 是 关 系 型 数 据 库 , 在 分 布 式 查 询 中 ,连 接 操 作 是 最 常 用 而
应用程序集成

应用程序集成应用程序集成(Application Integration)是指将多个独立的应用程序或系统整合为一个统一的整体。
通过应用程序集成,不同的应用程序能够共享数据和功能,实现信息的流动和交互,提高工作效率和信息准确性。
本文将探讨应用程序集成的定义、作用、主要方法以及未来的发展趋势。
一、定义应用程序集成是一种通过软件和技术手段将不同的应用程序或系统整合起来,以实现数据和功能的互操作性。
它让不同的应用程序通过共享数据和功能进行协同工作,提供更加灵活和高效的业务应用。
二、作用应用程序集成的作用主要体现在以下几个方面:1. 数据共享:通过集成不同的应用程序,可以实现数据的共享和交换,避免数据孤岛的问题,提高数据的一致性和准确性。
2. 功能互连:不同的应用程序可以通过集成来实现功能的互连,实现信息的流动和交互。
比如,将客户关联的信息从CRM系统传递给ERP系统,实现订单的自动化处理。
3. 流程优化:通过应用程序集成,可以优化业务流程,实现自动化和标准化。
集成不同的应用程序可以将繁琐的人工操作转为自动化的流程,提高工作效率和质量。
4. 系统整合:企业通常会使用多个独立的软件系统,如ERP、CRM、HR等,通过应用程序集成可以实现系统的整合,减少管理和维护成本,提高系统的稳定性和可靠性。
三、主要方法应用程序集成有多种方法和技术,常用的方法包括:1. 数据集成:通过数据集成实现不同系统之间的数据共享和交换。
可以使用数据仓库、ETL工具、Web服务等技术,将数据从一个系统抽取、转换和加载到另一个系统中。
2. 系统接口:通过系统接口实现应用程序之间的集成。
可以使用API(Application Programming Interface)、Web服务、消息队列等技术,实现系统间的数据传输和功能调用。
3. 中间件:中间件作为一种软件层,扮演着应用程序集成的关键角色。
中间件可以提供应用程序之间的通信和交互,实现系统的整合和协同工作。
数据集成的基本概念

数据集成数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
在企业数据集成领域,已经有了很多成熟的框架可以利用。
目前通常采用联邦式、基于中间件模型和数据仓库等方法来构造集成的系统,这些技术在不同的着重点和应用上解决数据共享和为企业提供决策支持。
目录编辑本段背景近几十年来,科学技术的迅猛发展和信息化的推进,使得人类社会所积累的数据量已经超过了过去5 000年的总和,数据的采集、存储、处理和传播的数量也与日俱增。
企业实现数据共享,可以使更多的人更充分地使用已有数据资源,减少资料收集、数据采集等重复劳动和相应费用。
但是,在实施数据共享的过程当中,由于不同用户提供的数据可能来自不同的途径,其数据内容、数据格式和数据质量千差万别,有时甚至会遇到数据格式不能转换或数据转换格式后丢失信息等棘手问题,严重阻碍了数据在各部门和各软件系统中的流动与共享。
因此,如何对数据进行有效的集成管理已成为增强企业商业竞争力的必然选择。
由于现代企业的飞速发展和企业逐渐从一个孤立节点发展成为不断与网络交换信息和进行商务事务的实体,企业数据交换也从企业内部走向了企业之间;同时,数据的不确定性和频繁变动,以及这些集成系统在实现技术和物理数据上的紧耦合关系,导致一旦应用发生变化或物理数据变动,整个体系将不得不随之修改。
因此,我们进行数据集成将面临着如何适应现代社会发展的复杂需求、有效扩展应用领域、分离实现技术和应用需求、充分描述各种数据源格式以及发布和进行数据交换等问题。
编辑本段数据集成模型分类数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
在企业数据集成领域,已经有了很多成熟的框架可以利用。
目前通常采用联邦式、基于中间件模型和数据仓库等方法来构造集成的系统,这些技术在不同的着重点和应用上解决数据共享和为企业提供决策支持。
在这里将对这几种数据集成模型做一个基本的分析。
中间件_1综述
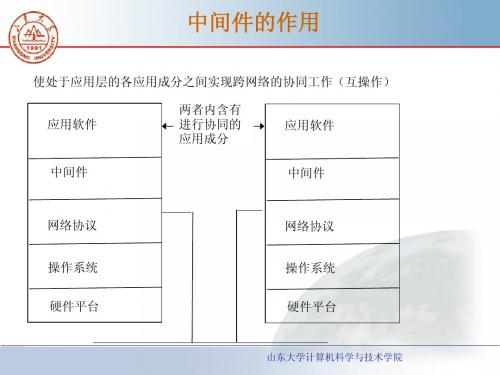
山东大学计算机科学与技术学院
消息中间件
(Message-Oriented Middleware,
MOM)
山东大学计算机科学与技术学院
动机:RPC调用的缺点 (1)客户端与服务器端需要同时在线; (2)客户端需要知道服务器端的调用接口,若调用接口发生改
变,客户端需要做相应变化,如通过ODBC连接访问数据库,客户 端需要知道远程数据库的类型,若类型发生改变,还需要重新装 载相应的驱动程序。
( Coordiantor), 其 他 节 点 称 为 事 务 参 与 者 (Participants)。协调者掌握提交或撤消事务的决定 权,而其它参与者则各自负责本地数据的更新,并向协 调者提出撤消或提交子事务的意向。一般一个结点对应
一个子事务。
山东大学计算机科学与技术学院
常见的TPM产品有
BEA的Tuxedo Microsoft的MTS SUN的JTS OMG的OTS 东方通的TongLINK/TongEasy
结点或结点间通信的失效都可能导致分布式事务的失败。 因此,为了保证事务的完整性,分布式事务通常采用两 阶段提交协议(Two Phase Commitment Protocol,简称 2PC)来提交。 两阶段提交协议的思路是 TM向所有RM发出正式提交请 求之前,先询问所有RM是否已准备好提交,仅当所有的 RM都给出肯定的回答时,TM才发出提交的请求;如果其 中有一个RM给出否定地回答,TM就指示所有的RM进行回 卷。
山东大学计算机科学与技术学院
远程过程调用中间件
山东大学计算机科学与技术学院
本地过程调用的扩展,可透明地调用远地提供的服务 数据表示、可靠传递、服务定位等 分布式计算环境,DCE
山东大学计算机科学与技术学院
软件中间件-东方通全线产品描述

1、SOA集成中间件TongIntegrator v4企业和政府现有的管理信息系统,由于投入的时间、使用的部门、生产的厂家及实现技术等各不相同,造成企业和政府现有的应用信息系统各自独立运行,数据不能共享,各自业务流程不能自动衔接,造成企业和政府内部许多自成体系的信息化孤岛,各个应用系统不能相互协作,形成统一高效的有机整体。
Tongintegratorv4作为东方通科技公司的企业应用集成产品,可以接上上述问题,其主要适用场景就是在两个或更多的异构系统(如不同的数据库、消息中间件、ERP或CRM等)之间进行资源整合(数据整合、应用整合、流程整合),实现互连互通、数据共享、业务流程协调统一等功能,构建灵活可扩展的分布式企业应用。
2、数据集成中间件Tongintegrator v2如何实现应用系统的快速构建,迁移和伸缩,以满足不断变化的市场需求。
如何能够让已有的多种应用系统无缝的集成起来。
如何设计现代IT架构,使系统不仅功能强大和可靠,而且还有强大的灵活性和可扩展性,以满足不断增长的新需求。
TI2能够为需要数据集成的应用提供数据流服务,即需要解决数据从何而来,哪个应用对其感兴趣,以及如何被每个系统使用。
TI2通过把信息提供者和消费者隔离,来构建灵活的系统,使得这些系统不会受到数据的物理位置的影响,也不会受到需要存取数据信息的应用个数的影响。
这样,对于每一个系统就不需要进行特别的定制处理,就可以在系统之间实现信息的集成了。
3、消息中间件TongLINK/Q随着计算机技术的发展,分布式应用系统的应用日益广泛,在这样的环境中,无论硬件还是软件平台都不可能做到统一。
大规模的应用软件通常要求在软、硬件各不相同的分布式网络上运行,由此出现了不同硬件平台、不同网络环境、不同数据库之间的互操作。
为了更好地开发和应用能够运行在这种异构平台上的软件,迫切需要一种基于标准的、独立于计算机硬件及操作系统的开发和运行环境,这就需要中间件技术了。
软件中间件

中间件定义:中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源,中间件位于客户机服务器的操作系统之上,管理计算资源和网络通信。
中间件特点:1.满足大量应用的需要2.运行于多种硬件、数据库及操作系统平台3.支持分布式计算,提供跨网络、底层平台的透明性应用或服务的交互功能4.支持标准协议5.支持标准的接口中间件能为我们软件开发带来那些帮助?中间件屏蔽了底层操作系统和数据库的复杂性,使程序开发人员面对一个简单而统一的开发环境,减少程序设计的复杂性,将注意力集中在自己的业务上,不必再为程序在不系统软件上的移植而重复工作,大大减少技术上的负担;也减少了系统的维护、运行和管理的工作量及计算机总体费用的投入。
Client/Server模式:客户机和服务器结构,通过它可以利用两端硬件环境的优势,将任务合理分配到Client 端和Server端来实现,降低了系统的通信开销。
Browser/Server模式:在B/S体系结构中,用户通过浏览器向分布在网络上众多服务器发出请求,服务器对浏览器的请求进行处理,将用户所需信息返回到浏览器。
C/S模式特点:1无论是客户端还是服务端都需要特定的软件支持。
没能提供用户期望的开放环境,适用于Intranet。
2服务器端运行负荷较轻。
3数据的存储管理功能较为透明。
4C/S体系结构的劣势是高昂的维护成本且投资大B/S模式特点:1.简化了客户端的工作,瘦客户端结构。
2.对数据库的访问和应用程序的执行将在Server上完成。
3.把技术维护人员从繁重的维护升级工作中解脱出来传统B/S模式的不足方面:1浏览器应用于Web应用系统时,许多功能不能实现或实现困难。
2复杂的应用构造困难。
3HTTP可靠性低,采用浏览器进行系统维护不安全。
4Web服务器同时要处理客户请求以及与数据库联接,负载过重。
5业务逻辑和数据安全不足多层应用体系结构特点:1安全性:中间层隔离了客户直接对数据库的访问,保护数据。
信息系统集成名词解释

信息系统集成名词解释信息系统集成(Information Systems Integration)指在信息系统实施的过程中,将原有信息系统(现有系统)和新增系统、以及多种客户端技术、网络系统、企业应用等系统和环境集成起来,实现从数据收集、数据存储到数据检索、应用开发、报表展示等一体化的综合应用解决方案。
集成流程(Integration Process)是集成任务的主要步骤,属于信息系统的实施过程之一,可以帮助信息系统实施专家全方位掌握整个集成过程的样式、过程安排、设计技术、软件开发、测试机制、实施管理机制等,并以此为基础,对集成任务进行实施管理与规划。
集成技术(Integration Technology)集成技术是指把原有的系统、新建的系统与企业应用、客户端技术、网络系统等系统及环境,以各种集成技术整合起来,达到目标系统的构建及其有效运营的技术准备。
数据插入技术(Data Insertion Technology)是指在集成的过程中,将数据从系统的外部导入到系统内,实现信息的传递和数据的共享。
消息总线(Message Bus)是一个非常重要的信息集成技术,也可称为应用集成技术,消息总线可以实现不同应用之间的信息接口,使各个应用之间可以共享数据,实现信息的无缝集成。
中间件(Middleware)是在不同操作系统间的应用软件层面实现系统集成的一种技术。
它们能够在系统之间搭建一个桥梁,实现对各种系统架构和技术的支持,在各系统之间进行数据交换,并为系统之间的集成提供灵活的、安全的通信服务。
数据交换(Data Exchange)技术是介于各应用系统之间的一种技术,通过数据交换技术可以实现应用系统之间的数据联通,从而实现信息集成。
系统迁移(System Migration)是指将现有的企业系统或应用系统迁移到新的技术平台上,也可以将应用系统之间进行数据迁移,以实现企业信息系统集成的任务。
中间件技术在异构数据库集成中的应用研究

应用软件中利用这种软件可以实现不同技术之间 的资源共享 。本文在综合定 义的基础上 , 综述 了中问件 的作用 , 并
研 究 中间 件 的发 展 趋 势 。
关键 词: 据库集成 ; 构数据库 ; 数 异 中间 件
巾 图 分类 号 :P 1 .1 T 3 113
文 献 标 识码 : A
文 章 编 号 :0 8 8 8 (0 1O — 15 0 10 — 8 l2 1 )10 3 — 3
21中 间件 技 术 的 产 生 .
大约 在 2 0 0 0年前 后 , 联 网快速 发 展 起来 , 互 随
着互 联 网快 速 发展 一个 新 的产 品产 生 了 , 就 是 应 那
集 成 解 决方 法 近年 来 发 展 起 来 的 主要 有 三 种 : 1 ()
用 。但 是这 种 服务 器 系统 属 于二 层体 系结 构 , 在 存
于 应 用程 序 及 系统 内部 工 作 方 式 之 间 的 一 种 程 序
软件 。其 的主要思 路 是在各 前端 应用 程序 和后端 数 据 源 之 间 建立 一个 抽 象 层 。 中 问件 位 于 应 用 程 序 ( 即应用 层 ) 和异构 数 据库 系统 ( 即数 据层 ) 间 , 之 它
一
直保 存在 原 来 的存储 位 置 不变 ; 的缺 点是 数 据 它
联 邦查 询 反 应 比较 慢 , 太适 合 频 繁 的查 询 , 且 不 并 容易 出现资 源 冲突等 问题 。( ) 2 数据 仓库 法 。 此方 法 把 数 据存 放 在 物理地 址 中 , 且建 立 数 据仓 库 时 并 并
性、 完整性 、 成性 和访 问 的安 全性 。 集 异 构数 据 库 集 成 以后 要 求 完 全 透 明 的 对 数 据 库 资源 实现 访 问 ,特 别强 调 了其 开 放性 和通 用性 。
基于Web中间件的异构数据库数据集成与同步

对于 异构数 据库 数据 库, 中最 重要 的是DB 本 身 的异构 , 重点做 下 说 其 MS 现
明:
第一 , 结构 的区 别, 同 D M 采 用 的数据 类 型和 数据 结构 。 第 二, 则 不 BS 规 的不同, 同的数 据模 型造 成 了不 同的规 则 。 三, 不 第 查询 语言 的 不 同, 同的数 不 据 模 型 必然 造 成 不 同 的数 据类 型 。 2异构 数 据库 需 要解 决 的问题 () 1数据 共 享 问题 对 于异构数 据库 系统, 实现数 据共享 应当达 到两 点 : 是实现 数据库 转换 : 一 二 是 实现 数 据 的透 明 访 问 。 () 2 数据 转 换过程 的冲 突 问题 在 转换 的过程 中, 确定两 种 模型 中所存 在 的各种 语法 和语 义上 的冲 突, 要 这些冲 突 可能包 括 : 命 名冲突 : 即源模 型 中的标 识符可 能是 目的模 型 中的保 留 字, 时就 需要 这 重新 命名 。 格式 冲突 : 同一种数 据类 型可 能有 不 同的表示 方法 和语 义差 异, 这需要 定 义两种 模 型之 间的 变换 函数 。 结构 冲突 : 果两种 数据 库系 统之 问的数 据定 义模 型不 同, 如 如分 别为关 系 模 型和 层 次模 型,需要 重新 定 义 实体 属性 和 联 系 。 3异 构数 据 库连 接与 存取 的相 关 技 术 面对 当前信 息 资源复杂 性, 要实 现异 构数 据库 的数据 集成 和 同步, 传统 的 D M ( 库管 理 系统) B S数据 已经很 难 解决 。 近几 年许 多新 的相 关技 术相 继推 出, 纵 览 近年来 的进 展, 主要包 括 以下相 关 技术 : () 1开放 式数 据库 互连 技术 O B DC O B ( p n D t b s o n c o ) 由m o o t 出的基 于 C 言的 D C O e a aa eC n e tr 是 ir s f 推 c 语 开放 数据库 互连 技术 , 主要 针对 客户 端 / 务器 结 构的数 据库 。 包含 访 问不 服 它 同数 据库 所 要求 的 O B D C驱动 程序 及 驱 动程 序所 支 持 的函数 。 ( ) A A 数据 库互 连技 术 J B 2 JV DC J B (a a D t b s o n c o ) J v S f 公 司设 计 的 J v 语言 的 D CJ v a a a eC n e tr 是 a ao t aa 数据 库 A I 应用 编程 接 口) 主 要针对 浏 览器 / 务器 结构 的 W B 据库 。与 P( , 服 E数 其他 的数据 库存 取技 术相 比, J B D C是连 接 I tr e 上异 构 数据库 的最 好方 n ent 法 。使用 J BC能够 方 便地 向任 何 关系 数 据库 发送 S L语句 。 D Q ()M 3 X L中间件 技术 X L 由 W C组织 于 1 9 年 2月 制定 的一种 通用 语 言规 范, 是专 门为 M是 3 98 它 W b应用程 序而 设计 的 S M e GL的简化 子集 。X L最大 的优 点在 于它 的数据 描述 M 和 传 送 能力 , 备很 强 的 开放 性 。 具
基于XML的异构数据库集成中间件的研究

配置模块 面 向管理 接 口, 主要 向集 成 中间件 管 理 员提供 异构数 据库 的元 数据信 息 。通过 配置模块
主要生成 三类文 件 : 全局 视 图文件 , 数据库 连接池配
供统 一 的查 询接 口, 如图 1 示 。 所
XML d t ,ti d l w r h ed l df rn e s e t o a as u c cu i gt e p afr ,s s m a a h smi d e a es il s l i e e c si a p c f t o r e i l dn lt m a f n s d n h o yt e
数据访 问接 口。
要 实现数 据 的集 成 , 主 要 的是 找 到一 种 解 决 最 异构性 的交互媒 介 。X ML具有 平 台性无 关 、 扩 展 可
基金项目:重庆市 自然科学基金项 目( S C 0 7 B 18 CT20 B27 ) 作者 简 介 :张 建 江 ( 9 1 , , 士 研 究 生 , 要 研 究 方 向 为计 算 1 8 一) 男 硕 主 机网络及数据库 。
图1 X ML集 成 中 I 模 型 司件
连接池 配置文件 : 通过 J D 将 生成的连 接池信 NI
息写入 配 置 文件 ( e e.m sr rx l和 ap poet s , v p . rp re ) 记 i 录相应 的配置信 息并保存 为 X L文件 。 M
X ML集 成 中间件 将 各 个异 构 数据 库 的元 数 据
存储( 异构 数据库 系统 ) 和基 于数据 的查询应 用 ( 应
用 程序 ) 间 , 方 面 汇 集 了分在 各 个 异 构 数 据 库 之 一
企业级应用集成与电子商务的集成方式(二)

企业级应用集成与电子商务的集成方式随着电子商务的快速发展,越来越多的企业开始意识到将企业级应用与电子商务进行集成的重要性。
通过集成,企业可以实现业务的无缝对接,提高工作效率,降低成本,提升竞争力。
本文将讨论企业级应用集成与电子商务的集成方式,从技术角度探究最佳实践。
I. 数据集成数据集成是企业级应用集成与电子商务的基础。
企业级应用通常包括客户关系管理(CRM)、供应链管理(SCM)和企业资源计划(ERP)等系统,而电子商务涉及电子支付、在线订单处理等。
要实现数据的畅通流动,可以采用以下几种集成方式:1. 手工集成:数据手工导入和导出是最简单的方式,但也是最耗时的。
手工集成容易出错,并且无法满足大规模数据交流的需求。
2. 批量集成:通过批量导入和导出数据来实现集成。
企业可以定期导出数据文件,通过FTP等方式进行传输。
然后,利用数据映射工具将数据导入到目标应用中。
这种方式适用于数据量较大且集成频率不高的场景。
3. 实时集成:利用企业级应用集成中间件(EAI)工具,可以实现实时数据集成。
当源应用中的数据发生变化时,EAI工具会自动将数据传输到目标应用。
这种集成方式可以实现即时更新和实时数据同步,提高工作效率。
II. 进程集成除了数据的集成,企业级应用集成与电子商务还需要实现进程的无缝对接。
其中,业务流程集成和工作流引擎是两种常见的集成方式。
1. 业务流程集成:企业级应用集成与电子商务可以通过业务流程集成来实现进程的无缝对接。
企业可以使用业务流程管理系统(BPMS)来设计和执行业务流程。
通过集成BPMS和电子商务平台,企业可以实现从订单生成到支付完成的整个流程的自动化。
2. 工作流引擎:工作流引擎可以帮助企业定义、执行和监控工作流程。
通过将工作流引擎与电子商务平台集成,企业可以实现订单管理、库存管理等流程的自动化。
例如,在接收到新订单时,工作流引擎可以自动触发库存更新和支付处理等操作。
III. 系统集成系统集成是企业级应用集成与电子商务的关键环节。
LabMap软件总线中间件和ODBC数据库的集成

LabMap软件总线中间件和ODBC数据库的集成C. Bruce-Boye, W. Kanewski,D. Kazakov, Yaohui Wu摘要:在这篇论文里我们想到了一个方法,这个方法是在LabMap软件总线中间件的基础上,把数据提取与控制自动化系统和企业版数据库方案集成在一起。
我们提出了一个数据库接口与LabMap独立的体系结构。
LabMap的各个应用可以透明地进入数据库,就象把数据库当作另一个虚拟硬件设备。
这个方法的优点是数据库可以平滑地提供给用户应用软件,而且费用低,不用重新设计软件。
LabMap[1]是一个软件中间件总线系统,被用作软实时系统中的数据提取和控制。
它已成功地配置在自动化、医疗和其他领域中。
越来越多的工序自动化系统需要数据库方案的支持。
通过与数据库管理系统互操作,使得LabMap进一步集成到了客户系统软件中。
开发数据库互连(ODBC)[2]通过特定数据库驱动服务,提供了与不同数据库互连的体系结构。
ODBC在数据库APIs(应用程序接口)上是基于来自X/Open和ISO/IEC的呼叫-等级接口(CLI)规范,同时ODBC把结构化查询语言(SQL)[3]当作数据库存取语言。
目前ODBC 在存取数据库上是一个被广泛接受的技术,受大多DBMS(数据库管理系统)用户支持。
为了把数据提取和自动化控制集成到企业系统里,用户独立的数据库存取是一个重要的需求。
为此,LabMap提供了基于ODBC的数据库支持。
因此,使用LabMap中间件的应用软件可以享受来自所有DBMSs的完全独立的数据库以及所有功能和高性能,并且能实现最大的互操作性——也就是说,就象同一个应用在存取DBMSs。
通过LabODBC接口,LabMap提供到ODBC数据库引擎的完全透明的存取。
这就意味着,LabMap用户可以把数据库看作与自动化系统里的其他硬件和软件组件类似的一个组件。
图1描绘了基于LabMap把数据库集成到自动化系统的一个例子。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.7. 支持增量更新
对于经常用到的增量更新数据集成中间件做了专门的支持,有效的解决了完全抽取和增量抽取的问题。数据集成中间件中提供多种控件来支持增量更新,增量更新的设计方法也是根据应用场景来选取的。增量更新按照数据种类的不同大概可以分成:1. 只增加,不更新;2. 只更新,不增加;3. 即增加也更新;4. 有删除,有增加,有更新。其中1 ,2, 3种大概都是相同的思路,使用的控件可能略有不同,通用的方法是在原数据库增加一个时间戳,然后在转换之后的对应表保留这个时间戳,然后每次抽取数据的时候,先读取这个目标数据库表的时间戳的最大值,把这个值当作参数
1.1. 图形化界面,使用简单
数据集成中间件充分考虑了用户使用的便捷性和易用性,提供了图形化的开发、管理和监控界面,使非技术人员通过简单的培训也能掌握要高级技术人员通过编程完成的功能。便捷性主要体现在整个抽取、转换、加工整合只要通过简单的拖拽就可以实现。易用性体现在对于任何用户,即便对计算机使用较少的人,只要明白业务需求,通过培训即可轻易自主使用各种图形控件设计自己的业务需求。数据集成中间件完全通过图形化控件实现了具体的业务需求,完成了业务问题的图形化转变。
1.8. 完善的运行、调试、分析、日志管理
数据集成中间件提供了对ETL统一处理过程,包括完整地运行、调试、管理功能以及不同层次级别的日志管理功能、完善的数据审计功能。数据集成中间件有相关的监控预警机制,为作业设计人员,提供了良好的设计环境,使设计人员能全面地观察执行过程。数据集成中间件只是从业务数据源读取数据,即便执行失败也不会对源数据任何做修改,保证了作业正常进行,不影响数据源系统和经营分析系统的正常工作。日志管理功能分出了七个日志级别,从没有日志,到非常详细,为设计人员调试作业、转换提供了多层次的备选方案。
数据集成中间件的开放性、可扩展性为特殊个性化服务提供了解决办法。
1.6. 支持java script内嵌脚本和存储过程等数据库对象
数据集成中间件支持内嵌脚本语言、存储过程、插件及外部程序来处理复杂的处理。数据集成中间件支持java script内嵌脚本语言,提高了常用的字符串验证、日期格式转换等常用函数,用户可以像使用web编程一样,将复杂的业务处理通过编写java script实现,这为用户的高级应用提供了支持。数据集成中间件是基于元数据的设计的,完全屏蔽数据库厂商的差异性,用户不必担心数据库的变更、或升级带来的已有的作业不可用,同时也有效地支持了数据库各自的特性,用户可以轻松的调用自己编写的或者数据库系统自带的存储过程、函数等对象。数据集成中间件基于元数据,在屏蔽数据库差异性的同时,很好的支持数据库的特性。
数据集成中间件供灵活的作业开发的参数支持。无论是转换还是作业,构成他们的每个图形化控件都提供了完善参数支持,大大提高了设计人员的效率和灵活性,同时也使作业易用修改重复利用。这些参数包括:对于数据纪录数目,开始时间,文件
名,数据长度等。
在线数据集成主要是为了针对客户已有的信息系统的数据进行集成。根据不同的要求将数据抽取到平台的业务数据库中来,并完成数据的清洗和建仓。由于目标信息系统仍然在运行和生产数据,在线数据集成能够根据定时实现对增量数据的同步工作。
1.5. 灵活的可扩充性,支持二次开发
数据集成中间件通过组件化设计、接口化设计实现了灵活的可扩充性,对于各个模块支持二次开发控件的即插即用。这样可以有效地对数据转换模块进行二次开发,为用户业务发展、业务变更等提供了可扩充性,使用户花费很小的成本,即可享用定制化的服务。比如用户需要一个合并纪录的业务要求,那么我们可以在短时间内开发一个“合并纪录”的转换控件,直接放到数据集成中间件中即可使用。
1.4. 丰富的数据转换功能
数据集成中间件包含了丰富的数据转换功能,包含了二十多种转换控件,比如值影射、拆分字段、字段选择、计算器、增加常量、排序纪录、过滤纪录、去除重复纪录、是否为null、行转为列、分组等等。这些转换控件支持ETL过程中数据转换环节执行顺序、支持的数据平滑化、规范化、聚类等转换操作。即便对于新出现的特殊转换,我们也可以开发出个性化的转换控件,放入数据集成中间件即可实现即插即用的功能。
数据集成中间件影响分析,除了能够分析转换性能的瓶颈外,还提供分析报表的功能,为设计高效的转换提供了良好的支持。
数据集成中间件设计的转换、作业可以存放在物理文件系统,也可以存放在常见的关系数据库中。为用户管理提供良好的支撑。
1.9. 高效的性能
数据集成中间件拥有良好的性能。通过流水线作业技术和缓冲技术,分批分量的读取数据,降低数据源系统的IO操作,最大限度的降低了对业务数据的影响,使业务系统的分析平台、报表平台不受影响。 在保证不对源系统造成影响的前提下,依然能达到每秒一万条数据的传输转换速度。
数据集成中间件支持VFS文件和远程执行,构建出了基于网络的转换平台。只要用户有网络连接即可实现各种数据源的加工整合。
1.3. 基于工作流支持过程驱动方法和自顶向下的设计
数据集成中间件设计基于工作流,提供了灵活的作业设计方法,支持过程驱动方法和自顶向下的设计。数据集成中间件作业设计包含转换和作业两个核心对象,转换实现数据加载、计算、清洗、转移等功能,作业是把转换或者作业作为一个工作流中的一个节点来看待,实现了更加复杂的数据处理。通过转换和作业可以实现自顶向下的设计,数据集成中间件基于工作流作业设计,完美的支持了过程驱动方法。数据集成中间件还提供了作业件的同步异步控制,为用户提供了全面的设计方案。
1.2. 支持各种平台和广泛的数据源
数据集成中间件完全由java实现,由此具备了跨平台性,支持各种字符集的转换,能够运行在各种操作系统之上,如UNIX、Windows NT/2000/2003、Linux等。数据集成中间件采用高性能的数据抽取接口,通过JDBC、ODBC、JNDI、OCI等技术支持的各种数据源,包括各种关系数据库、web数据库、xml数据、以及各种结构化数据和非格式化数据。支持常见的数据库,如Oracle、DB2、Sybase、SQL Server、mysql、excel等主流数据库,同时为方便用户各种电子文件数据整合,还支持txt、csv、xls、zip、xml文件作为输入或输出,这为提取多数据源数据提供了完备的保障。
数据集成中间件作业设计思路是这样的,创建一个与原表结构类似的表结构,然后创建一个三种类型的触发器,分别对应insert , update , delete 操作,然后维护这个新表,在你进行ETL的过程的时候,将增量备份或者数据复制停止,然后开始读这个新表,在读完之后将这个表里面的数据删除掉就可以了。这些操作都可以通过数据集成中间件控件实现。
传给原数据库的相应表,根据这个时间戳来做限定条件来抽取数据,抽取之后同样要保留这个时间戳,并且原数据库的时间戳一定是指定默认值为当前时间(以原数据库的时间为标准),抽取之后的目标数据库的时间戳要保留原来的时间戳,而不是抽取时候的时间。第四种情况有些复杂,但利用数据集成中间件控件也是能完全能够实现的。