如何在超算中心使用fluent做并行计算——入门
fluent并行计算配置(曙光文档)

1.并行处理•Fluent支持并行计算,且提供检查和修改并行配置工具。
你可用一个专用并行机(如多处理器工作站)或通过工作平台的网络运行Fluent。
下面介绍Fluent并行计算的特点。
• 1.1 并行计算简介•Fluent并行计算就是利用多个计算节点(处理器)同时进行计算。
并行计算可将网格分割成多个子域,子域的数量是计算节点的整数倍(如8个子域可对应于1、2、4、8个计算节点)。
每个子域(或子域的集合)就会“居住”在不同的计算节点上。
它有可能是并行机的计算节点,或是运行在多个CPU工作平台上的程序,或是运行在用网络连接的不同工作平台(UNIX平台或是Windows平台)上的程序。
计算信息传输率的增加将导致并行计算效率的降低,因此在作并行计算时选择求解问题很重要•推荐运行并行Fluent的操作步骤如下:•开启平行求解器,选择计算节点数。
•读入case文件,让Fluent自动将网格分割为几个子域。
最好是在建立问题之后分割,因为这种分割和计算的模型有关(象非等形接触面、滑移网格、shell-conduction encapsulation的自适应)。
如果你的case文件中包含滑移网格,或是在计算过程中要对非等形接触面进行修改,那就得用串行求解器进行分割。
•还有其他的方法进行分割,如在串行或并行求解器上进行手工分割。
•仔细检查分割区域,如必要再重新分割,。
•进行计算。
•--------------------------------------------------------------•ID Hostname O.S. PID Mach ID HW ID Name •--------------------------------------------------------------•node-2 fili irix 16729 2 11 Fluent Node •node-1 bofur irix 16182 1 10 Fluent Node •host balin sunos 5845 0 7 Fluent Host •node-0* balin sunos 5864 0 -1 Fluent Node •O.S.指体系结构,PID是进程ID数,Mach ID是计算节点ID,HW ID 是交换机的标识符。
FLUENT并行计算操作步骤!!!
注意:以下是将编号为1的文件放在E盘,对操作步骤进行的说明,放在其他位置的操作与之类似。
1、解压后,打开文件夹,复制文件所在的全路径。
2、在电脑“开始”中找到“命令提示符”图标,右击该图标,点“属性”,在“起始位置”一栏中将路径改为刚刚复制下来的路径,然后点“确定”。
2、打开“命令提示符”窗口,可以看到显示的路径即为文件所在的路径,输入fluent 3d -t4(注意“fluent”、“3d”、“-t4”之间各有一个空格)后回车,即可打开fluent计算软件。
3、将case和data文件读入fluent,此过程中会出现error,点OK。
文件导入完成是下图这个样子。
4、设置自动保存路径:file>>write>>autosave,删掉file name下面的路径,点OK,路径即自动变成所需保存的路径。
5、编译:define>>user-defined>>functions>>compiled(如下图)>>add>>双击para_unsteady文件>>路径改为文件的全路径(例如:E:\1\libudf)>>build>>OK出现下图所示,即表示build成功,否则在路径后加上1(E:\1\libudf1),再次点击build,直至出现下图为止,点击load。
6、导入来流风速:define>>boundary conditions>>inlet>>velocity-inlet>>set>>点击velocity magnitude的第二个下拉框选择udf一项>>OK7、计算:solve>>iterate>>设置时间步长和计算的时间步数>>确认正确之后点击iterate进行计算。
Fluent 并行运算

在file下拉菜单里可以看到run项已经开启。进去选项卡选择默认是2d单精度单核运算。
通过点击3d选择维度,
double precision选择精度,
parallel选择并行计算。选定并行后下方出现process核数选择。那就看你怎么填了。
Architechture: ntx86
MPI types: mpich2
然后点击launch,运行并行计算。
方法二:
在启动图标右击——属性——目标(显示fluent安装位置和版本号)
在版本号后加入空格,然后是t2(有人说四核应该是t4,你们试试吧。我用四核也是加空格和t2)
关闭。
方法一:
1. 安装C:\Fluent.Inc\ntbin\ntx86\rshd.exe
运行——cmd——cd C:\Fluent.Inc\ntbin\ntx86\——rsh –install
2. 我的电脑——右键——管理——服务——RSHD demon——启动——属性——登录——此帐户——浏览:选择用户名和密码。点击应用。
3. C:\Fluent.Inc\fluent6.3.26\launcher\launcher.exe
4. fluent launcher 1.1 对话框。设置:
Fluent.inc path: C:\fluent.inc
version: 3d or 2d
number of process: 2,4,8luent的快捷方式上右键,属性,复制路径,打开运行,把路径复制进去,在后面加上 3d 空格 -t6
t后面的数字 你想用几核算就输几,如果编译udf,把做好的这个快捷方式复制到和你case同样的目录下,直接运行打开,编译就行了。
超算天河fluent操作流程

超算天河fluent操作流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!超算天河 fluent操作流程一、准备工作阶段。
在使用超算天河进行 fluent操作之前,需要进行充分的准备工作。
fluent_计算步骤

导出为数据文件
将数值形式的计算结果导出为数 据文件,如Excel、SPSS格式,方 便用户进行数据管理和统计分析 。
THANKS
谢谢您的观看
在每个迭代步骤中,根据物理 方程进行计算,更新物理量。
监视计算过程和结果
01
在计算过程中,监视计算域内的 物理量变化。
02
检查计算结果的收敛性和稳定性 。
如果发现计算结果不收敛或不稳 定,需要调整数值方法和算法, 重新进行计算。
03
在计算结束后,对结果进行后处 理和分析,提取有用的信息和结
论。
04Biblioteka Fluent 20.1”等。
进入主界面,包括菜单栏、工具栏、图形窗口和消息窗口等。
03
导入模型文件
在菜单栏中选择“File”菜单 。
在弹出的对话框中选择要导 入的模型文件,例如 “case”或“mesh”等。
在下拉菜单中选择 “Import”选项。
点击“Open”按钮,导入模 型文件。
检查模型完整性
选择求解器类型
有限元法(FEM)
适用于解决各种工程问题,如结构分析、热传导、流体动 力学等。
有限体积法(FVM)
适用于解决流体动力学问题,如流体流动、传热等。
有限差分法(FDM)
适用于解决偏微分方程,如热传导方程、波动方程等。
设置求解器参数
网格尺寸
确定计算域的离散程度,网格尺寸越小,计算精度越高,但计算时 间也会增加。
定义计算域的边界
根据几何形状,定义计算域的边界,包括起始点、终止点和边界条 件等。
确定计算域的大小和分辨率
第28章fluent并行处理
第28章fluent并行处理Fluent支持并行运算,且提供检查和修改并行配置工具。
你可用一个专用并行机(如多处理器工作站)或通过工作平台的网络运行Fluent。
下面介绍Fluent并行运算的特点。
28.1 并行运算简介Fluent并行运算确实是利用多个运算节点(处理器)同时进行运算。
并行运算可将网格分割成多个子域,子域的数量是运算节点的整数倍(如8个子域可对应于1、2、4、8个运算节点)。
每个子域(或子域的集合)就会“居住”在不同的运算节点上。
它有可能是并行机的运算节点,或是运行在多个CPU工作平台上的程序,或是运行在用网络连接的不同工作平台(UNIX平台或是Windows平台)上的程序。
运算信息传输率的增加将导致并行运算效率的降低,因此在作并行运算时选择求解问题专门重要。
举荐运行并行Fluent的操作步骤如下:1.开启平行求解器,选择运算节点数,详见28.2和28.3节。
2.读入case文件,让Fluent自动将网格分割为几个子域。
最好是在建立问题之后分割,因为这种分割和运算的模型有关(象非等形接触面、滑移网格、shell-conduction encapsulation的自适应)。
假如你的case文件中包含滑移网格,或是在运算过程中要对非等形接触面进行修改,那就得用串行求解器进行分割。
还有其他的方法进行分割,如在串行或并行求解器上进行手工分割。
3.认真检查分割区域,如必要再重新分割,详见28.4.5节如何检查分割区域。
4.进行运算,详见28.5节如何检查和提高并行运算。
28.2 开启并行求解器开启Fluent并行求解器的方法依靠于操作平台是专用并行机依旧工作站。
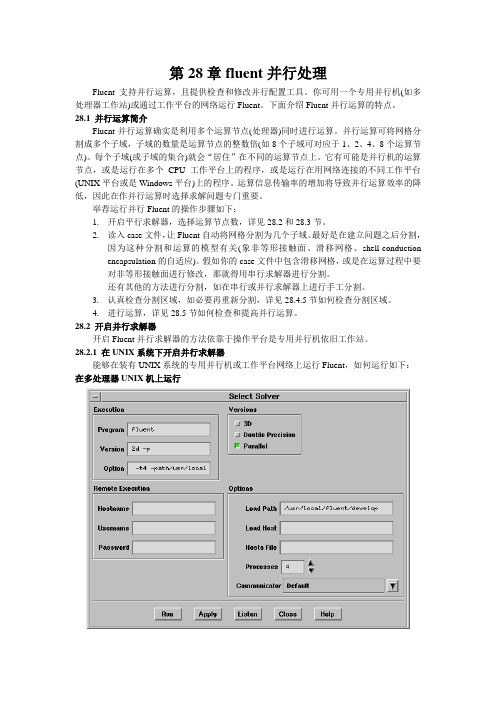
28.2.1 在UNIX系统下开启并行求解器能够在装有UNIX系统的专用并行机或工作平台网络上运行Fluent,如何运行如下:在多处理器UNIX机上运行Figure 28.2.1: Select Solver操纵面板在专用并行机(多处理器工作平台或大型并行机)运行Fluent,键入运行命令,点击Fluent 中File Run...,用Select Solver(图28.2.1)操纵面板设定并行架构和求解器信息。
超算中心Fluent用户操作手册(1) (1)

Fluent用户操作手册一、用户申请假设已拥有了超算中心用户账号,账户名为dongjing,密码为####。
二、安装Xmanager软件用于文件的传输和作业的提交。
三、作业准备需要3个,假设3个文件都命名为JD1。
1)“*.cas”文件,此处将文件命名为“JD1.cas”2)“*.jou”文件,用于操作计算case运行,格式见Figure1所示“JD1.jou”文件3)“*.sbatch”文件,用于建立任务,调用jou文件,格式见Figure2 所示“JD1.sbatch”文件说明:样本JD1.cas为非稳态并行计算,红色字体部分用户可根据自己算例设置和超算中心账号资源分配情况进行相应修改。
脚本文件的编写可参考https:///how-to-run-ansys-fluent-jobs-in-slurm/Figure 1Figure 2四、登录账户如Figure3-9所示,通过Xmanager软件连接,打开Xshell,点击工具栏的“新建”按钮,出现“新建会话属性”对话框,在“名称(N):”中输入相应会话名称,如: whupc(用户自主命名),在“主机(H):”中输入登陆IP:202.114.96.180,点击“确定”,出现“会话”对话框;选择对应名称的会话,点击“连接”,出现“SSH 用户名”对话框,输入登录的用户名:dongjing,点击“确定”,出现“SSH用户身份验证”对话框,输入用户密码,点击“确定”,出现如Figure 9所示登录成功后的界面。
Figure 3Figure 4Figure 6Figure 8五、提交任务:1.点击登录窗口工具栏的绿色“新建文件传输”按钮,如Figure 10所示,便可打开文件传输终端,把上述所需3个文件上传到计算中心自己账户内。
1)将“JD1.cas”文件上传到“/home/系统账号/data”分区,账户名为dongjing,即为“/home/dongjing/data”分区;2)将“JD1.sbatch”和“JD1.jou”文件上传到“/home/系统账号”分区,账户名为dongjing,即为“/home/dongjing”分区。
Fluent的并行计算设置方法总结

并行计算资料来自傲雪论坛和流体中文网!Winnt平台下搭建Fluent并行计算的一些经验以下是本人在NT平台下搭建Fluent并行计算的一些经验,不足和错误的地方请各位高手指出!系统配置:winnt,win2000操作系统,每台主机只有一个CPU,Fluent6.1,每台主机有自己的IP地址,安装好TCP/IP协议1、 Fluent安装光盘上找到RSHD.exe这个文件。
(注意,必须使用Fluent公司提供的这个远程控制软件)2、用管理员的身份登陆计算机,拷贝该软件到系统盘的winnt目录下,在MS-DOS方式下执行 RSHD -install。
3、配置RSHD。
WINNT系统下:控制面板-〉服务-〉RSH Daemon,双击之,在Logon里面输入用户名/密码。
(一般情况下,为了您的计算机的安全,请不要使用具有管理员权限的用户名和口令。
)您可以在开始-〉程序-〉管理工具 -〉用户管理器里面设定,给guest权限就可以了。
Win2000系统下:控制面板-〉管理工具-〉服务-〉RSH Daemon,以下同于NT的操作。
完成上述操作后,请启动RSH服务。
4、资源管理器里面将Fluent的安装目录设置为共享。
注意:这个时候要分别从其他的计算机登陆到本机这个被共享的目录。
这个步骤一定不可缺少。
同样所有的计算机上的Fluent的安装目录都要被设置为共享,然后分别登陆.....5、编写hosts.txt文件,文件的格式在Fluent的帮助文件中又很详细的描述,这里不再复述。
hosts文件中应这样写computer1’s IP, com puter1’s namecomputer1’‘s IP,computer1’s namecomputer2’s IP,computer2’s namecomputer2’s IP,computer2’s name在命令行输入:fluent 3d -pnet然后在parallel-network-configuer菜单下配置即可。
fluent并行

fluent version –t0 –pnet [-cnf= hostsfile](用 socket 传输装置)
fluent version –t1 –pnmpi[-cnf= hostsfile] (用网络 MPI 传输装置)
这样就可以开启远程机器上的计算节点的控制程序。如果设置了-cnf= hostsfile,则在
并行计算简介
Fluent 并行计算就是利用多个计算节点(处理器)同时进行计算。并行计算可将网格分割
成多个子域, 子域的数量是计算节点的整数倍(如 8 个子域可对应于 1、 4、 个计算节点)。 2、 8
每个子域(或子域的集合)就会 “居住” 在不同的计算节点上。 它有可能是并行机的计算节点,
!!当起用并行网络版是, 必须选择 Communicator 下拉菜单的 Socket, 除非 Vendor
MPI 支持集成。如果选用 Default 时,就会起用一个 MPI 并行版本,那就不能生成
附加计算节点。
3. 在 Processes 上设置初始并行计算节点数。 可先从 1 或 0 个节点开始, 后面再生成其
设备了。
如果你想利用命令开始并行计算,可键入如下命令:
fluent version -t n [-p comm ] [-load host ] [-path path ]
其中 version 可选择 2d、3d、2ddp 和 3ddp,n 指的是 CPU 数。其他的根据需要使用,
使用时根据方括号提示的信息写(写时不包括方括号)。 comm 指的是并行传输库的名称, host
中 File Run...,用 Select Solver(图 28.2.1)控制面板设定并行架构和求解器信息。
Fluent并行计算在国家超算济南中心的应用

一般采用物理区域分割方法,例如,将要计算的流场区域,划分成两部分分别给计算节点 0和1计算,图 1 为划分前后的区域,由于两个计算节点间需要通信交换数据,所以在原 来的块上加了边界块。
图 1 划分前后的计算区域
Cortex 是主机 Host 的一个进程,Cortex 将指令发送给计算节点0,计算节点0再把 指令发送给其它的计算节点,并且与其它的计算节点是同步处理的。图3显示了并行 Flue nt 进程间的关系。每个计算节点与其它的计算节点都虚拟联系着,计算节点间依赖于它们 的“通信器”(communicator)来执行一些功能,比如发送、接收、同步和建立机器的连 通性等等。Fluent 的“通信器”实际上就是消息传递库——MPI(Message Passing Inter face)标准。
4.4 计算参数选取
与本项目数值计算相关的参数取值如表 1 所示。
表 1 数值计算参数取值
参数名称 地貌类型 风速剖面指数 基本风压 w0 (10 米高度)
参数取值 B类 0.16 0.85 kN/m
2
B 类地貌上空 10 米高度处风速 空气密度 空气粘性系数 时间步长 残差精度
36.88 m/s 1.225kg/m
Fluent15.0并行运算设置

在MPI Types中有四种Default、MSMPI、PCMPI、INTEL MPI。
PCMPI可以在断网或不联网的情况下运算,但Fluent 14.0不稳定。
INTEL MPI 需要联网,并保存密码。
其设置方法见下页。
Intel MPI 设置流程A.设置环境变量变量名:在系统变量中寻找Path项。
若没有,则新建Path变量名;变量值:MPI安装路径下的bin文件夹路径。
缺省为C:\Program Files (x86)\Intel\MPI-RT\4.1.0.028\em64t\bin。
若有,则点击编辑,在原有字段后加英文分号,后加入上述路径。
若同时还安装了HP-MPI,则需保证HP_MPI的路径位于INTEL-MPI路径之后。
B.Cache password设置开始菜单,CMD键入cd c:\program files (X86)\intel\mpi-rt\4.0.2.005\em64t\bin\ 即进入intel mpi的安装文件,回车。
mpiexec –register 回车显示account <domain\user>,输入相应主机名,回车密码,回车(光标不动,不要误以为没有输入)确认密码,回车显示password encrypted into the registry, 即成功。
C.Fluent设置打开Fluent选择parallel settings, 在mpi types下拉菜单中选择intel一项,单击ok;输入相应的用户名(非注册密码时的主机名),一般主机名XXX-PC,则此处输入XXX),回车输入密码(开机密码),回车确认密码,回车现在,即可以开始运行了。
注意:需要设置相应的开机密码(账户管理里面),否则可能出现问题。
fluent并行计算、UDF添加及常见并行计算错误的全套解决方案

fluent并行计算、UDF添加及常见并行计算错误的全套解决方案一、并行计算配置1.配置计算机1) 操作系统: winxp sp32) fluent软件:fluent 6.2.163) 参与并行的机器都要装,并且把安装目录Fluent6.2.16.Inc共享(安装目录可以自己定义,但机群的安装目录应保持一致,本例:安装目录为:D:\Fluent6.2..16.Inc) 4) 关闭window自带防火墙5) 通过网络邻居,确定并行机群可以互访6) 注册fluent的环境变量(否则可能无法安装rshd.exe文件),方法:找到开始——程序——Fluent Inc Products——Fluent 6.2.16——Set Environment,点击后——点“是”——再点“确定”7) 在D:\Fluent6.2.16.Inc\ntbin\ntx86下找到rshd.exe文件拷贝到文件夹C:\Program Files\Windows NT下,双击rshd.exe文件8) 开始——运行,输入cmd后回车,命令行下输入rshd –install后回车9) 右键点我的电脑----管理---服务和应用程序---服务---找到 RSH Daemon,双击之,选登陆标签,在选择允许服务与桌面交互,点确定10) 右击RSH Daemon,点击启动11) 运行并行版本的Fluent时,可以在如图所示的文本框中输入fluent 2d -t2 -pnet其中,fluent 2d是Fluent版本(2d, 3d, 2ddp, 3ddp):-t2是指计算节点数,以上的两个参数都可以根据具体情况进行改变。
2 fluent软件的设置1)步骤1:配置计算节点启动fluent并行求解器,并行Fluent启动以后的情形如图所示。
配置计算节点:Parallel——Network——Contigure。
打开如图所示的对话框配置计算节点。
从spawned Computer Nod。
fluent dpm 并行方法

fluent dpm 并行方法【原创实用版3篇】篇1 目录1.Fluent DPM 简介2.Fluent DPM 并行方法的优势3.Fluent DPM 并行方法的实现4.Fluent DPM 并行方法的应用案例5.总结篇1正文【1.Fluent DPM 简介】Fluent DPM(Discrete Particle Method)是一种基于离散粒子方法的流体动力学模拟软件,广泛应用于工程领域,如能源、建筑、环境等。
Fluent DPM 可以模拟复杂的流体动力学问题,包括湍流、热传导和化学反应等。
【2.Fluent DPM 并行方法的优势】Fluent DPM 并行方法可以显著提高计算速度,减少计算时间。
通过将计算任务分配给多个处理器,可以实现同时计算,从而提高整个模拟过程的效率。
这对于处理大型计算任务,如模拟大尺度流体动力学问题,具有重要意义。
【3.Fluent DPM 并行方法的实现】Fluent DPM 并行方法主要通过使用 Message Passing Interface (MPI)实现。
MPI 是一种用于并行计算的通信协议,可以实现不同处理器之间的数据交换和任务调度。
通过 MPI,Fluent DPM 可以将计算任务分配给多个处理器,并在各个处理器之间实现数据的同步和协调。
Fluent DPM 并行方法在许多实际应用中发挥着重要作用,例如:- 在建筑领域,Fluent DPM 并行方法可以用于模拟建筑物的风环境,为建筑设计提供参考;- 在能源领域,Fluent DPM 并行方法可以用于模拟流体动力学问题,如油气输送、热交换等;- 在环境领域,Fluent DPM 并行方法可以用于模拟污染物扩散、水流动态等。
【5.总结】Fluent DPM 并行方法具有显著的优势,可以提高计算速度和效率。
通过实现 MPI,Fluent DPM 可以在多个处理器上同时计算,为处理大型计算任务提供便利。
篇2 目录一、Fluent DPM 并行方法的背景和意义二、Fluent DPM 并行方法的具体实现三、Fluent DPM 并行方法的优点和应用场景四、Fluent DPM 并行方法的局限性和未来发展方向篇2正文一、Fluent DPM 并行方法的背景和意义随着计算机技术的快速发展,大型并行计算已经成为了科学计算和工程模拟的重要手段。
fluent单机多核并行计算设置方法

单机多核并行计算是指在一台计算机上利用多个核心进行并行计算,以提高计算效率和加快计算速度。
在当前计算机硬件发展的趋势下,多核处理器已成为主流,因此如何正确设置单机多核并行计算成为了计算机领域中一个重要的问题。
本文将介绍如何进行fluent单机多核并行计算的设置方法,以帮助读者更好地利用计算资源。
一、了解fluent软件支持的并行计算类型在开始进行fluent单机多核并行计算设置之前,首先需要了解fluent软件支持的并行计算类型。
fluent支持两种并行计算类型,一种是多核并行计算,另一种是集群并行计算。
本文将重点介绍多核并行计算的设置方法。
二、检查计算机硬件配置在进行fluent单机多核并行计算设置之前,需要先检查计算机的硬件配置,确保其支持多核并行计算。
通常情况下,多核并行计算要求计算机至少具备双核处理器,并且需要足够的内存和硬盘空间来支持并行计算的运行。
三、安装fluent软件如果计算机上还未安装fluent软件,需要先进行软件的安装。
fluent软件是由ANSYS公司开发的一款专业的计算流体动力学(CFD)软件,广泛应用于工程领域的流体分析和模拟中。
四、配置fluent软件的并行计算环境在fluent软件中进行多核并行计算设置,需要进行如下步骤:1. 打开fluent软件,并选择“Calculation Activities”菜单下的“Parallel…”选项。
2. 在弹出的对话框中,选择“Enable”并设置“Number of CPUs”为计算机实际拥有的核心数。
3. 点击“OK”按钮保存设置并退出对话框。
五、进行并行计算在完成fluent软件的多核并行计算设置后,可以开始进行并行计算。
在进行计算前,需要确保模型设置正确并且计算参数已经调整到最佳状态。
然后可以点击“Calculate”菜单下的“Calculate…”选项来开始并行计算过程。
六、监控并行计算过程在进行并行计算过程中,可以通过fluent软件提供的监控工具来实时监控计算的进度和性能。
3.1 FLUENT求解,启动FLUENT与FLUENT并行计算[共2页]
![3.1 FLUENT求解,启动FLUENT与FLUENT并行计算[共2页]](https://img.taocdn.com/s3/m/de4b57bea45177232e60a23d.png)
第3章FLUENT基础与操作3.1 FLUENT 求解,启动FLUENT 与FLUENT 并行计算 双击FLUENT 快捷方式图标后,FLUENT 软件将被启动,弹出FLUENT 的启动对话框,如图3-1所示。
在Dimension (维度)选项组中,对于三维模拟,选择3D 求解器,对于二维模拟,选择2D 求解器。
在Display Options (显示选项)选项组中,对图形窗口做出设置。
● 勾选Display Mesh After Reading (读入后显示网格)复选框后,可以让ANSYS FLUENT 读入网格后自动显示网格。
其中,所有的边界条件都会显示,而内部计算域不会显示。
● 勾选Embed Graphics Windows (嵌入图形窗口)复选框后,图形窗口会被植入ANSYS FLUENT 中,而不是浮动的活动窗口。
● 勾选Workbench Color Scheme (彩色设计工作台)复选框后,ANSYS FLUENT 将使用默认的背景颜色(如蓝色),而不是经典的黑色背景。
在Options (选项)选项组中,可以勾选Double Precision (双精度)复选框,让ANSYS FLUENT 运行双精度求解器(默认情况下,ANSYS FLUENT 将启动单精度求解器)。
对于大多数情况而言,单精度求解器已能很好地满足精度要求,且计算量小,然而对于以下一些特定的问题,使用双精度求解器可能更有利。
● 几何特征包含某些极端的尺度(如非常长且窄的管道),单精度求解器可能不能足够精确地表达各尺度方向的节点信息。
● 如果几何模型包含多个通过小直径管道相互连接的体,而某一个区域的压力特别大(因为用户只能设定一个总体的参考压力位置),此时,双精度求解器可能更能体现压差带来 图3-1 FLUENT 启动对话框。
Fluent 用户自定义函数UDF技巧,并行计算,UDFs处理

接地访问这些数据。 另一方面, 编译式 UDFs 没有任何 C 编程语言或其它注意的 求解器数据结构的限制。 3.3 FLUENT 求解过程中 UDFs 的先后顺序 (Sequencing of UDFs in the FLUENT Solution Process) 当你开始写 UDF 代码的过程时(依赖于你写的 UDF 的类型) ,理解 FLUENT 求 解过程中 UDFs 调用的内容或许是重要的。 求解器中包含连接你写的用户定义函 数的 call-outs。 知道 FLUENT 求解过程中迭代之内函数调用的先后顺序能帮助你 在给定的任意时间内确定那些数据是当前的和有效的。 分离式求解器 在分离式求解器求解过程中(Figure 3.3.1) ,用户定义的初始化函数(使用 DEFINE_INIT 定义的)在迭代循环开始之前执行。然后迭代循环开始执行用户 定义的调整函数(使用 DEFINE_ADJUST 定义的) 。接着,求解守恒方程,顺序 是从动量方程和后来的压力修正方程到与特定计算相关的附加标量方程。 守恒方 程之后,属性被更新(包含用户定义属性) 。这样,如果你的模型涉及到气体定 律,这时,密度将随更新的温度(和压力 and/or 物质质量分数)而被更新。进 行收敛或者附加要求的迭代的检查,循环或者继续或停止。
Fluent UDFs
本章包含了 FLUENT 中如何写 UDFs 的概述。 3.1 概述 3.2 写解释式 UDFs 的限制 3.3 FLUENT 中 UDFs 求解过程的顺序 3.4 FLUENT 网格拓扑 3.5 FLUENT 数据类型 3.6 使用 DEFINE Macros 定义你的 UDF 3.7 在你的 UDF 源文件中包含 udf.h 文件 3.8 定义你的函数中的变量 3.9 函数体 3.10 UDF 任务 3.11 为多相流应用写 UDFs 3.12 在并行中使用你的 UDF 3.1 概述(Introduction) 在你开始编写将挂到 FLUENT 代码以增强其标准特征的 UDF 之前,你必须知道 几个基本的要求。首先,UDFs 必须用 C 语言编写。它们必须使用 FLUENT 提 供的 DEFINE macros 来定义。UDFs 必须含有包含于源代码开始指示的 udf.h 文 件;它允许为 DEFINE macros 和包含在编译过程的其它 FLUENT 提供的函数定 义。UDFs 只使用预先确定的宏和函数从 FLUENT 求解器访问数据。通过 UDF 传递到求解器的任何值或从求解器返回到 UDF 的,都指定为国际(SI)单位。 总之,当写 UDF 时,你必须记住下面的 FLUENT 要求。 UDFs: 1. 采用 C 语言编写。 2. 必须为 udf.h 文件有一个包含声明。 3. 使用 Fluent.Inc 提供的 DEFINE macros 来定义。 4. 使用 Fluent.Inc 提供的预定义宏和函数来访问 FLUENT 求解器数据。 5. 必须使返回到 FLUENT 求解器的所有值指定为国际单位。 3.2 写解释式 UDFs 的限制(Restriction on Writing Interpreted UDFs) 无论 UDFs 在 FLUENT 中以解释还是编译方式执行,用户定义 C 函数(说明在 Section 3.1 中)的基本要求是相同的,但还是有一些影响解释式 UDFs 的重大编 程限制。FLUENT 解释程序不支持所有的 C 语言编程原理。解释式 UDFs 不能 包含以下 C 语言编程原理的任何一个: 1. goto 语句。 2. 非 ANSI-C 原型语法 3. 直接的数据结构查询(direct data structure references) 4. 局部结构的声明 5. 联合(unions) 6. 指向函数的指针(pointers to functions) 7. 函数数组。 在访问 FLUENT 求解器数据的方式上解释式 UDFs 也有限制。 解释式 UDFs 不能 直接访问存储在 FLUENT 结构中的数据。它们只能通过使用 Fluent 提供的宏间
FLUENT并行设置
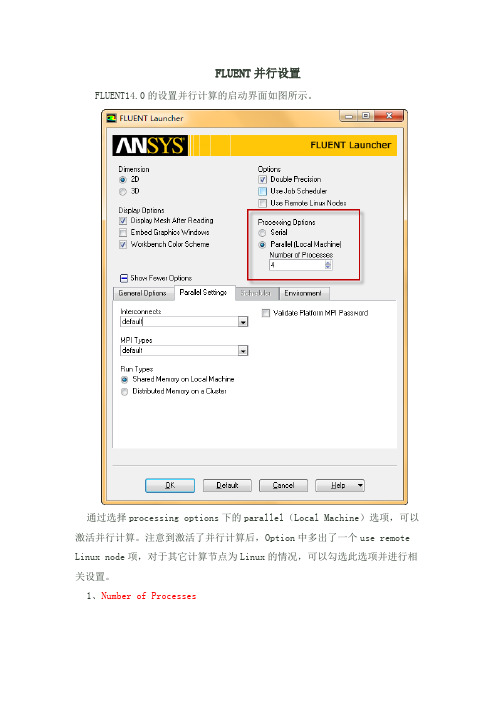
FLUENT并行设置FLUENT14.0的设置并行计算的启动界面如图所示。
通过选择processing options下的parallel(Local Machine)选项,可以激活并行计算。
注意到激活了并行计算后,Option中多出了一个use remote Linux node项,对于其它计算节点为Linux的情况,可以勾选此选项并进行相关设置。
1、Number of Processes此处设定使用的计算机数量。
只是针对本地计算机,设置的是要使用的计算机核心数量。
此处不能设置分布式计算。
若本机除了计算还需要进行其它的工作的话,建议CPU数量不要设满。
2、Parallel Settings标签页此标签页下设定的是并行计算的一些连接方式。
一般情况下使用默认方式即可。
3、Run typeFLUENT提供了两种并行工作方式:shared memory on local machine与distributed memory on a cluster。
Shared memory on local machine:通常用于单机计算。
单计算机共享内存计算。
Distributed memory on a cluster:分布式内存计算。
激活此选项后如下图所示。
可以有两种方式指定计算机:利用计算机名与导入包含计算机名的文本文件。
4、Remote标签页勾选use remote Linux node选项后,将多出一个Remote标签页。
如下图所示。
Remote FLUENT Root Path:设置远程FLUENT根路径。
Remote Working Directory:设置远程工作目录。
Remote Spawn Command:设置连接方式。
FLUENT提供了三种连接方式:RSH、SSH以及其它方式。
默认连接方式为RSH。
关于并行计算的详细设置,以后作专题讨论。
FLUENT14.0的启动界面如图1所示。
1、Dimension(模型维度)FLUENT中可以求解2D模型(在一些求解器中只能求解3D模型,如CFX),因此模型是2D还是3D需要在此处设定,一经设定,进入FLUENT之后,就没办法更改(即此处若设定2D,则导入的网格文件必须为2D模型,否则出错。
计算机集群 fluent计算说明

东五楼计算机集群应用步骤一、申请账户通过提交项目基本情况及所需资源来获得账户和密码二、下载客户端SSH Secure Shell Client,账号连接图1 客户端界面1、edit----settings---connection,设置默认连接用户信息,见图2所示:host:211.69.198.201(学校计算机网络节点IP)user:申请的用户名port:端口号22设置好后,以后每次只要点击就可以通过输入密码连接。
图2 连接设置2、连接后界面图3 登陆后界面3、之后就可以输入命令了。
4、基本常用命令学习ls 查看该路径下的文档(注:是LS哦,不要搞成1S)vi +文件名对该文件进行编辑cd+具体路径进入该路径的文件夹下比如:cd /home/liugf/fluent cd空格.. 进入上级文件夹cd 进入下级文件夹按键盘delete或者backspace 回删文字* 表示所有东西i 编辑模式(用于更改job文件及oar文件,输入i才能更改文件内容)cp 复制cp * ../文件名/ 复制所有东西到上一级文件夹里rm 删除Esc(键盘按键): wq :退出编辑并保存(用于用于更改job文件及oar文件)oarsub –S ./oar 提交任务(在计算文件存放路径下提交)oarstat 查看任务oardel job id(具体任务的ID号)删除任务,用于计算过久或者计算出错时查看硬盘下还有多少空间du –sh 用户名三、将linux版本的fluent上传到高性能计算机中心并安装(liugf的账号已经安装,后来人不用管安装的事了,要学的可以学学)1、软件下载地址:ed2k://|file|[Ansys流体动力学系统].Ansys.Fluent.6.3.Linux.x64.zip|156044630|6cb356346568a23b15c0731378afb0f1|/2、上传,通过点击进入如下界面:该界面是一种ftp上传软件,可通过鼠标拖拽,把个人机的文件上传到计算结点给用户分配的存储空间上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
什么是机群?有什么特点?
机群又叫集群,当然就是许多地计算机(废话),因为机器太多了,又需要协同工作,所以需要按照一定地方式来管理,管理地结构形式叫做拓扑(这个不用管).机群使用地电脑是刀片(又薄又长地机箱)形式(为了便于插入机柜),一个刀片一般称为一个节点.文档来自于网络搜索
一般而言,机群会分为三种节点:管理节点(若干台),编译节点(若干台),计算节点(其余全部).这三种节点地配置略有不同(废话),管理节点主要用来存储使用机群地用户地信息,如名字,密码,可以使用机器数地权限,用户状态等等;编译节点一般用来预查程序故障,用户地程序先在这里试运行,查看是否与系统兼容等;计算节点用来直接计算其他节点提供来地程序.文档来自于网络搜索
就配置而言,管理节点和编译节点一般相同,会部署软件环境;计算节点只会部署简单地必要运行文件.计算机点之间会采用高速交换机,速度可达几十,如等;计算节点与编译、登陆节点之间采用普通地万兆交换机.文档来自于网络搜索
如何使用机群?
机群中一般采用操作系统来操作(多用户情况下效率高),用户会通过远程登录软件(如)来登录到登陆节点进行个人地操作(一般会通过网络加密数据传输).文档来自于网络搜索
集群将程序任务分解发送到计算节点上时,是通过作业调度系统(也有其他地,如等)来实现地,这个系统地作用是使整个机群负载均衡,
便于管理,所以我们使用也要通过这个系统.在成熟地集群中,用户登录之后,默认便可以使用作业调度系统了.使用时,除了常见地命令以外,调度系统也有一些简单地命令,这个一般会有手册介绍,常用地就、个,很好记.文档来自于网络搜索
如何在集群中使用?
因为是成熟地封装好地商业软件,所以用户直接使用命令调用即可. 但是因为大部分地下地远程登录是不支持图形界面地,所以我们看不到在下地熟悉界面,无法进行操作.其实,最早也是下地软件,它提供了一种脚本来操作各种命令(即帮助中地命令),我们在地图形界面中,也可以在控制台窗口中查看如何使用.这样,我们在启动软件时,指定它地执行脚本即可使软件按照我们地意图来进行操作了.如果在帮助中找太慢,可以在地图形界面下,右下角控制台中用回车键显示文字命令,键返回.文档来自于网络搜索
实例
这里给出一个在调度系统中使用地实例:
首先,使用命令提交脚本(名字为),在命令窗口中键入即可.文档来自于网络搜索
脚本内容如下:
(这句话是说此脚本使用来解释执行,小白可以略过)
(这句话是说此脚本调用名字为地集群排序提交队列,小白继续略过)文档来自于网络搜索
(这句话是说此脚本地任务将调用个来执行)
(这句话是说此脚本地任务将在分配用来执行任务地每个节点上调用个来执行)文档来自于网络搜索
" –" (这句话是说此脚本地执行命令以及参数,是指二维双精度类型计算,这个大家应该熟悉了;就是我们使用地命令执行脚本地名字)文档来自于网络搜索
脚本内容实例:
(读取文件,)文档来自于网络搜索
(读取文件,)文档来自于网络搜索
(定义编译函数库并制定编译文件)文档来自于网络搜索
(加载编译函数库)文档来自于网络搜索
(自动保存)
(初始化)
(求解循环设置)
(保存结果)
(退出)。