网络数据包收发流程1
网络数据包传输过程总结

网络数据包传输过程总结一、概述网络数据包传输是指在计算机网络中,数据通过网络传输的过程。
在网络通信中,数据被分割成小的数据包,并通过网络传输到目标主机。
本文将详细介绍网络数据包传输的过程。
二、数据包的组成网络数据包由首部和数据两部份组成。
首部包含了源地址、目标地址、协议类型等信息,用于标识数据包的发送和接收方以及数据包的类型。
数据部份则是实际要传输的数据。
三、数据包传输过程1. 数据封装在传输数据之前,数据被封装成数据包。
首先,数据被划分为较小的数据块,每一个数据块称为一个数据包。
然后,每一个数据包都会被添加之首部信息,包括源地址、目标地址、协议类型等。
最后,数据包被发送到网络层进行传输。
2. 数据包的路由选择一旦数据包被封装好,它将被发送到网络层。
在网络层,数据包将根据目标地址进行路由选择。
路由选择是指选择合适的路径将数据包从源主机发送到目标主机。
路由选择是通过路由器进行的,路由器根据路由表中的信息选择最佳路径。
3. 数据包的传输一旦路由选择完成,数据包将被发送到下一跳路由器。
数据包通过物理层的传输介质(如网线、光纤等)进行传输。
在传输过程中,数据包可能会经过多个路由器,每一个路由器都会根据路由表将数据包转发到下一个路由器,直到到达目标主机。
4. 数据包的接收和解封装当数据包到达目标主机后,目标主机将接收到数据包。
目标主机会根据数据包的首部信息判断该数据包是否属于自己,并进行相应的处理。
如果数据包属于目标主机,目标主机会将数据包的数据部份提取出来,进行解封装,还原成原始的数据。
5. 数据包的应用处理一旦数据包被解封装,数据将被传递到应用层进行进一步的处理。
应用层根据协议类型和数据内容对数据进行处理,如显示在用户界面上、存储到数据库中等。
四、数据包传输的特点1. 可靠性网络数据包传输过程中,数据包可能会丢失或者损坏。
为了确保数据的可靠性,网络传输协议通常会采用一些机制,如校验和、确认应答等。
2. 延迟数据包传输过程中,数据包需要经过多个路由器进行转发,这会导致一定的传输延迟。
收发流程图

数据包收发流程图一、PCI设备大多数网卡都是一个PCI设备,PCI设备都包含了一个标准的配置寄存器,寄存器中,包含了PCI设备的厂商ID、设备ID等等信息,驱动程序使用来描述这些寄存器的标识符。
这样,在驱动程序中,常常就可以看到定义一个struct pci_device_id 类型的数组,告诉内核支持不同类型的PCI设备的列表。
在内核中,一个PCI设备,使用struct pci_driver结构来描述。
设备的探测函数:因为在系统引导的时候,PCI设备已经被识别,当内核发现一个已经检测到的设备同驱动注册的id_table 中的信息相匹配时,它就会触发驱动的probe函数,以e100为例:static int __devinit e100_probe(struct pci_dev *pdev, const struct pci_device_id *ent){1.分配网络设备2.设置各成员指针函数3.设置网络设备名称4.设置网络设备名称5.网络设备指针,指向自己6.将PCI设备的私有数据区指向网络设备7.激活PCI设备8.判断I/O区域是否是I/O内存,如果不是,则报错退出9. 分配I/O内存区域10分配完成后,映射I/O内存11设置设备私有数据结构的大部份默认参数12 初始化自旋锁,锅的初始化必须在调用hw_reset 之前执行13 硬件复位,通过向指定I/O端口设置复位指令实现.14添加两个内核定时器,watchdog和blink_timer15注册网络设备16 return}二、打开设备在探测函数中,设置了netdev->open = e100_open; 指定了设备的open函数为e100_open:static int e100_open(struct net_device *netdev){struct nic *nic = netdev_priv(netdev);//取得设备统计信息int err = 0;netif_carrier_off(netdev);// 关闭载波信号if((err = e100_up(nic)))// 函数启动网卡DPRINTK(IFUP, ERR, "Cannot open interface, aborting.\n");return err;}信号载波(carrier)的存在,载波的存在意味着设备可以工作netif_carrier_off:关闭载波信号;netif_carrier_on:打开载波信号;netif_carrier_ok:检测载波信号;对于探测网卡网线是否连接,这一组函数被使用得较多;接着,调用e100_up函数启动网卡,这个"启动"的过程,最重要的步骤有:1、调用request_irq向内核注册中断;2、调用netif_wake_queue函数来重新启动传输队列这样,中断函数e100_intr将被调用;三、网卡中断在内核中断处理中,会检测中断与我们刚才注册的中断号匹配,于是,注册的中断处理函数就被调用了。
openstack ovs-dpdk原理

openstack ovs-dpdk原理OpenStack OVS-DPDK原理OpenStack是目前最流行的开源云计算管理平台之一,它提供了云计算中常见的计算、网络、存储等服务,可以帮助用户快速搭建自己的云计算环境。
而Open Virtual Switch (OVS)是OpenStack中常用的网络虚拟化技术,可以为VM (虚拟机)提供灵活的网络服务,同时保证了数据的安全性和可靠性。
而DPDK (Data Plane Development Kit)是Intel提供的一款数据平面开发工具包,可以帮助开发者实现高性能数据处理的应用程序。
本文主要介绍OpenStack OVS-DPDK原理,包括OVS和DPDK的概念、OVS-DPDK的架构、OVS-DPDK的工作原理以及如何配置使用OVS-DPDK等方面。
1. OVS和DPDK概念1.1 OVSOpen vSwitch(OVS)是一款开源的虚拟交换机,可以在虚拟机之间提供流量控制、QoS、负载均衡等网络功能。
OVS是使用C语言编写的,支持多种协议,例如VXLAN、GRE、STT、IPsec等。
OVS以插件的方式与OpenStack集成,并且可以与其他虚拟化软件和硬件配合使用,例如QEMU、XEN、DPDK等。
1.2 DPDKData Plane Development Kit(DPDK)是一个数据平面开发工具包,可以帮助开发者实现高性能数据处理的应用程序。
DPDK运行在x86、ARM和Power8等平台上,使用用户空间设备驱动程序(User Space Device Driver)和高效率的队列管理,可以在不使用内核网络协议栈的情况下,实现高速数据包的收发和处理。
2. OVS-DPDK架构OVS-DPDK是将OVS和DPDK结合起来实现的一种高性能的数据平面虚拟化技术。
OVS-DPDK的架构如图1所示:图1 OVS-DPDK架构从图1中可以看出,OVS-DPDK的架构由三部分组成,分别是:1. 用户态进程(OVS-DPDK)。
ping和数据包发送流程

ping和数据包发送流程学习⾃:ICMP 协议ICMP 是什么?ICMP 全称是 Internet Control Message Protocol,也就是互联⽹控制报⽂协议。
⽹络包在复杂的⽹络传输环境⾥,常常会遇到各种问题。
当遇到问题的时候,需要传出消息,报告遇到了什么问题,这样才可以调整传输策略,以此来控制整个局⾯。
ICMP 功能都有啥?ICMP 主要的功能包括:确认 IP 包是否成功送达⽬标地址、报告发送过程中 IP 包被废弃的原因和改善⽹络设置等。
在 IP 通信中如果某个 IP 包因为某种原因未能达到⽬标地址,那么这个具体的原因将由 ICMP 负责通知。
⽐如说是未发现⽬的主机,即⽬标不可达。
ICMP 的通知消息会使⽤ IP 进⾏发送。
ICMP 包头格式:ICMP 报⽂是封装在 IP 包⾥⾯,它⼯作在⽹络层,是 IP 协议的助⼿。
ICMP 包头的类型字段,⼤致可以分为两⼤类:⼀类是⽤于诊断的查询消息,也就是「查询报⽂类型」另⼀类是通知出错原因的错误消息,也就是「差错报⽂类型」查询报⽂类型回送消息 —— 类型 0 和 8:回送消息⽤于进⾏通信的主机或路由器之间,判断所发送的数据包是否已经成功到达对端的⼀种消息, ping 命令就是利⽤这个消息实现的。
可以向对端主机发送回送请求的消息( ICMP Echo Request Message ,类型 8 ),也可以接收对端主机发回来的回送应答消息( ICMP Echo Reply Message ,类型 0 )。
相⽐原⽣的 ICMP,这⾥多了两个字段:标识符:⽤以区分是哪个应⽤程序发 ICMP 包,⽐如⽤进程 PID 作为标识符;序号:序列号从 0 开始,每发送⼀次新的回送请求就会加 1 ,可以⽤来确认⽹络包是否有丢失。
在选项数据中, ping 还会存放发送请求的时间值,来计算往返时间,说明路程的长短。
差错报⽂类型⼏个常⽤的 ICMP 差错报⽂的例⼦:⽬标不可达消息 —— 类型为 3原点抑制消息 —— 类型 4重定向消息 —— 类型 5超时消息 —— 类型 11⽬标不可达消息(Destination Unreachable Message) —— 类型为 3:IP 路由器⽆法将 IP 数据包发送给⽬标地址时,会给发送端主机返回⼀个⽬标不可达的 ICMP 消息,并在这个消息中显⽰不可达的具体原因,原因记录在 ICMP 包头的代码字段。
网络传输的分解过程

网络传输的分解过程网络传输的分解过程随着互联网的快速发展,网络传输已经成为我们日常生活中不可或缺的一部分。
无论是浏览网页、发送电子邮件、观看在线视频还是进行在线游戏,网络传输都扮演着重要角色。
但是,许多人对网络传输的具体过程知之甚少。
在这篇文章中,我将详细介绍网络传输的分解过程。
网络传输的分解过程可以分为以下几个关键步骤:数据切割、封装、发送、接收和重组。
首先,数据切割是将要传输的数据切割成更小的数据包的过程。
这是因为大多数网络传输都是基于数据包的形式进行的,将大的数据分割成小的数据包可以提高传输的效率。
切割的大小通常由传输协议决定。
例如,在传输文件时,文件会被切割成几个数据包,以便更快地发送。
接下来是封装步骤。
封装是将数据包转换为适合网络传输的格式的过程。
在这个过程中,每个数据包都被添加上标识符和其他必要的信息,以便接收方能正确地识别和重组数据包。
该过程还包括对数据进行压缩和加密,以确保传输的安全性和完整性。
然后是发送过程。
在发送过程中,数据包被发送到目标地址。
这涉及到将数据包发送到本地网络的路由器上,然后通过公共互联网将数据包发送到目标主机。
这个过程中,数据包经过多个网络节点的转发,最终到达目标地址。
接收是接收方的一部分,接收方通过网络接收到已经发送的数据包。
接收方首先会检查数据包的完整性和有效性,以确保数据的准确性。
然后,接收方会将数据包存储在本地,并准备进行下一步的重组。
最后是重组过程。
重组是将接收到的数据包按正确的顺序重新组装成完整的数据的过程。
这通常涉及到根据数据包的标识符和其他信息将它们按顺序排列。
一旦数据包重新组装完毕,接收方就可以使用这些数据进行相关操作,比如显示网页、播放视频或者保存文件。
总的来说,网络传输的分解过程可以概括为数据切割、封装、发送、接收和重组。
这个过程是网络传输的基础,确保数据能够在网络中准确地传输和接收。
理解这个过程有助于我们更好地利用网络资源并确保数据的安全性和完整性。
virtio_net数据包的收发

virtio-net数据包的收发virtio设备创建vring的创建流程Ring的内存分布发送接收virtio设备创建在virtio设备创建过程中,形成的数据结构如图所示:从图中可以看出,virtio-netdev关联了两个virtqueue,包括一个send queue和一个receive queue,而具体的queue的实现由vring来承载。
针对virtqueue 的操作包括:int virtqueue_add_buf( struct virtqueue *_vq, struct scatterlist sg[], unsigned int out, unsigned int in, void *data, gfp_t gfp)add_buf()用于向queue中添加一个新的buffer,参数data是一个非空的令牌,用于识别buffer,当buffer内容被消耗后,data会返回。
virtqueue_kick()Guest 通知host 单个或者多个buffer 已经添加到queue 中,调用virtqueue_notify(),notify 函数会向queue notify(VIRTIO_PCI_QUEUE_NOTIFY)寄存器写入queue index 来通知host。
void *virtqueue_get_buf(struct virtqueue *_vq, unsigned int *len)返回使用过的buffer,len为写入到buffer中数据的长度。
获取数据,释放buffer,更新vring描述符表格中的index。
virtqueue_disable_cb()Guest不再需要知道一个buffer已经使用了,也就是关闭device的中断。
驱动会在初始化时注册一个回调函数,disable_cb()通常在这个virtqueue回调函数中使用,用于关闭再次的回调函数调用。
virtqueue_enable_cb()与disable_cb()刚好相反,用于重新开启设备中断的上报。
UDP数据包的接收与发送

网络通信基础如果网络中两个主机上的应用程序要相互通信,其一要知道彼此的IP,其二要知道程序可监听的端口。
因为同一主机上的程序使用网络是通过端口号来区分的。
UDP Socket的使用过程:1.初始化网络库2.创建SOCK_DGRAM类型的Socket。
3.绑定套接字。
4.发送、接收数据。
5.销毁套接字。
6.释放网络库。
广播数据包的原理:专门用于同时向网络中所有工作站进行发送的一个地址叫做广播地址。
在使用TCP/IP 协议的网络中,主机标识段host ID 为全1 的IP 地址为广播地址。
如果你的IP为:192.168.1.39,子网掩码为255.255.255.0,则广播地址为:192.168.1.255;如果IP为192.168.1.39,子网掩码为:255.255.255.19则广播地址为:192.168.1.63。
如果只想在本网络内广播数据,只要向广播地址发送数据包即可,这种数据包可以被路由,它会经由路由器到达本网段内的所有主机,此种广播也叫直接广播;如果想在整个网络中广播数据,要向255.255.255.255发送数据包,这种数据包不会被路由,它只能到达本物理网络中的所有主机此种广播叫有限广播。
使用UDP协议发送、接收广播包的过程。
假如我们要向192.168.0.X,子网掩码为:255.255.255.0的子网中发送广播包。
其步骤如下:1.初始化Winsock库。
2.创建SOCK_DIRAM类型的Socket。
3.设置Socket的属性允许其广播。
4.发送数据包到192.168.0.2555.接收自己广播的广播包。
6.关闭Socket7.释放网络库。
注意事项如下:1.接收方一定要知道广播方的口号,然后绑定此端口号才能正确接收。
2.接收方的Socket不需要设置成广播属性。
3.绑定的IP不可以使用“127.0.0.1”,可以使用真实IP地址或者INADDR_ANY。
否则接收失败。
tcp网络连接的三个基本流程

tcp网络连接的三个基本流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!TCP 网络连接的三个基本流程是:建立连接、数据传输和断开连接。
计算机网络中的数据包的传输过程

计算机网络中的数据包的传输过程在计算机网络中,数据包传输过程是实现数据通信的核心环节之一。
数据包是由源节点发送到目标节点的数据单元,通过一系列的传输步骤和协议来完成传输。
本文将逐步介绍计算机网络中数据包传输的过程。
一、数据包的生成数据包的生成是数据传输的起始阶段。
当源节点发送数据时,操作系统将数据转化为数据包。
数据包一般包括一个报头和数据字段。
报头包含了目标地址、源地址、数据包序号、校验和等信息,用于标识和验证数据包。
二、数据包的封装在数据包生成后,需要将数据包进一步封装,以适合在网络中进行传输。
封装的过程通常包括添加物理地址、链路层地址和目标网络地址。
这些信息是数据包在网络中传输和路由的依据。
三、数据包的分组为了在网络中进行高效传输,数据包往往被分组。
分组的过程将数据包按照一定的规则和长度划分为多个片段,每个片段都打上报头,以便在目标节点重新组装。
分组可以提高数据在网络中的传输效率,减少传输延迟。
四、数据包的路由一旦数据包完成了分组,它将进入数据网络并开始通过路由器进行传输。
路由器是计算机网络中的关键设备,负责将数据包从源节点传输到目标节点。
路由器根据数据包的目标地址和路由表中的信息,选择合适的路径和下一跳路由器,以实现数据包的传输。
五、数据包的传输在数据包到达路由器后,路由器将根据目标地址和路由表的信息,将数据包发送给下一跳路由器。
这个过程是逐跳进行的,直到数据包抵达目标节点。
中间的路由器通过转发数据包实现了源节点到目标节点的连接。
六、数据包的接收和解封当数据包到达目标节点后,目标节点的操作系统将接收到数据包。
然后,目标节点将对数据包进行解封和还原操作,恢复数据原始状态。
解封的过程包括校验和验证、报头解析和数据字段还原。
七、数据包的处理接收节点的操作系统将对收到的数据包进行处理,根据需要进行相应的操作。
处理的方法可以是存储数据,进行数据处理和计算,或者调用相应的应用程序。
八、数据包的应答在数据包的传输过程中,源节点通常希望得到目标节点的应答,以确认数据传输的成功。
信息传输的过程

信息传输的过程一般要经过编码、传送、接收、译码等过程。
以QQ发送信息为例,信息传输的过程为:QQ把信息先进行编码,变为QQ报文头加信息的ASCII码,然后交给传输层的UDP协议,变为UDP报文头加QQ报文头加信息的ASCII码,之后IP协议把报文交给链路层协议的以太协议,报文变为以太报文头加IP报文头加UDP报文头加QQ报文头加信息的ASCII码,然后报文被分割为好几个帧,以0101的形式通过物理层发送到网络上,交换机收到这些帧后还原成以太报文,根据以太报文头里的MAC地址查找自己的MAC地址表,找到出接口把报文发送出去,这个过程不断重复,直到找到对方的网关,最后网关根据IP报文头里的IP地址把报文送到对方QQ上,对方QQ再进行译码,变为原来的信息。
RTL8139网卡驱动数据包接收流程

网卡驱动数据包接收流程基于RTL8139网卡目录网卡驱动数据包接收流程 (1)1. 中断函数 (1)2. 发送完成事件处理 (4)3. 软中断处理函数 (5)4. 8139 poll函数实现 (8)5. rtl8139_rx的实现 (9)6. netif_receive_skb (12)1. 中断函数static irqreturn_t rtl8139_interrupt (int irq, void *dev_instance)所有有网卡产生的中断都会引起该中断函数的调用,这是在static int rtl8139_open (struct net_device *dev){struct rtl8139_private *tp = netdev_priv(dev);int retval;void __iomem *ioaddr = tp->mmio_addr;/* 注册中断处理函数,中断号为共享*/retval = request_irq (dev->irq, rtl8139_interrupt, IRQF_SHARED, dev->name, dev);完成的。
中断函数处理的事件可以大致分为几类:A 数据包到达产生的中断(RxAckBits = RxFIFOOver | RxOverflow | RxOK);B 异常事件,通常都是出错的情况(RxAckBits = RxFIFOOver | RxOverflow | RxOK)C发送完成事件(TxOK | TxErr)下面我们看看具体的代码static irqreturn_t rtl8139_interrupt (int irq, void *dev_instance){/* 参数dev_instance是在上面注册中断处理函数的时候传入的*/struct net_device *dev = (struct net_device *) dev_instance;/* tp 为网卡驱动自定义的驱动特有的数据,和dev一起分配的*/struct rtl8139_private *tp = netdev_priv(dev);void __iomem *ioaddr = tp->mmio_addr;u16 status, ackstat;int link_changed = 0; /* avoid bogus "uninit" warning */int handled = 0;/* 对驱动数据加锁*/spin_lock (&tp->lock);/*读中断状态寄存器,获取中断状态*/status = RTL_R16 (IntrStatus);/* 这时由共享此中断号的其它设备产生的中断*/if (unlikely((status & rtl8139_intr_mask) == 0))goto out;handled = 1;/* 硬件错误*/if (unlikely(status == 0xFFFF))goto out;/* 设备已关闭*/if (unlikely(!netif_running(dev))) {/* 屏蔽所有中断*/RTL_W16 (IntrMask, 0);goto out;}/* Acknowledge all of the current interrupt sources ASAP, butan first get an additional status bit from CSCR. */if (unlikely(status & RxUnderrun))link_changed = RTL_R16 (CSCR) & CSCR_LinkChangeBit;ackstat = status & ~(RxAckBits | TxErr);if (ackstat)RTL_W16 (IntrStatus, ackstat);下一步处理数据包到达事件/* Receive packets are processed by poll routine.If not running start it now. */if (status & RxAckBits){if (netif_rx_schedule_prep(dev, &tp->napi)) {RTL_W16_F (IntrMask, rtl8139_norx_intr_mask);__netif_rx_schedule(dev, &tp->napi);}}先强调下8139网卡驱动的数据接收方式采用的是Linux内核的NAPI新机制。
udp通信流程

udp通信流程UDP通信流程UDP(User Datagram Protocol)是一种无连接的传输协议,它以简单、快速和高效的方式进行数据传输。
与TCP不同,UDP不提供可靠性和错误检测,但它具有低延迟和高吞吐量的优势。
在本文中,我们将介绍UDP通信的基本流程。
UDP通信流程可以概括为以下几个步骤:1. 创建UDP套接字:在进行UDP通信之前,首先需要创建一个UDP套接字。
套接字是网络通信的基础,它负责发送和接收数据。
通过调用系统函数创建一个UDP套接字,我们可以利用该套接字进行数据传输。
2. 绑定IP地址和端口号:在进行UDP通信之前,需要将套接字绑定到本地的IP地址和端口号上。
IP地址用于标识网络中的设备,端口号用于标识设备中的进程。
通过将套接字与特定的IP地址和端口号绑定,我们可以确保数据传输的正确性和安全性。
3. 发送数据:一旦套接字绑定到了本地的IP地址和端口号上,就可以通过套接字发送数据了。
发送数据时,需要指定目标设备的IP地址和端口号。
UDP是无连接的,因此可以直接发送数据,而无需建立连接。
4. 接收数据:在发送数据之后,目标设备将接收到发送的数据。
接收数据时,需要创建一个用于接收数据的缓冲区,并指定最大接收数据的长度。
一旦接收到数据,就可以对数据进行处理和分析。
5. 关闭套接字:在完成数据传输后,需要关闭套接字以释放资源。
通过调用系统函数关闭套接字,可以确保资源的有效使用,并避免资源泄露的问题。
尽管UDP通信不提供可靠性和错误检测,但它在某些场景下非常有用。
例如,在实时应用中,如音频和视频传输,UDP可以提供低延迟和高吞吐量的优势。
此外,在某些应用中,如DNS(Domain Name System)查询,UDP也被广泛使用。
总结:UDP通信流程的基本步骤包括创建UDP套接字、绑定IP地址和端口号、发送数据、接收数据和关闭套接字。
尽管UDP不提供可靠性和错误检测,但它具有低延迟和高吞吐量的优势。
ppp pppd chat关系及数据收发流程

ppp/pppd/chat关系及数据收发流程参考:/absurd 李先静<xianjimli at hotmail dot com>一、协议相关介绍PPP(Point-to-Point Protocol点到点协议)是为在同等单元之间传输数据包这样的简单链路设计的链路层协议。
这种链路提供全双工操作,并按照顺序传递数据包。
设计目的主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种共通的解决方案。
链路控制协议LCP(Link Control Protocol);网络控制协议NCP(Network Control Protocol);认证协议:口令验证协议PAP(Password Authentication Protocol)和挑战握手验证协议CHAP (Challenge-Handshake Authentication Protocol)。
LCP协商,协商内容包括除RFC1661中所定义的选项之外,还要考虑PPPOA和PPPOE协议中规定的内容。
LCP协商过后就到了Establish阶段,开始PAP或CHAP认证。
PAP为两次握手认证,口令为明文。
PAP认证过程如下:发送用户名同口令到认证方,认证方查看是否有此用户,口令是否正确,然后发送相应的响应。
CHAP为三次握手认证,口令为密文(密钥)CHAP认证由认证方发送一些随机产生的报文,交给被认证,被认证方用自己的口令字用MD5算法进行加密,传回密文,认证方用自己保存的口令字及随机报文用MD5算法加密,比较二者的密文,根据比较结果返回响应的响应。
认证成功即进行Network阶段协商(NCP),在IP接入中主要是IPCP协商(如IP地址和DNS地址的协商等)。
任何阶段的协商失败都将导致链路的拆除。
协商成功,则链路建立成功,可以开始传输网络层数据报文。
PPPoE(PPP over Ethernet),PPPoA(PPP over ATM)二、应用关系IP协议等网络层TCP/IPPPP协议(PPPD协助) PPP以太网和串口等物理层串口pppd是一个后台服务进程(daemon),是一个用户空间的进程,所以把策略性的内容从内核的PPP协议处理模块移到pppd中是很自然的事了。
计算机网络课程设计--数据包发送和接受程序的实现

计算机网络课程设计一数据包发送和接受程序的实现《计算机网络》课程设计数据包发送和接受程序的实现计算机学院软件工程10级⑷班3110006379陈泳蒸2012年12月21日数据包发送和接受程序的实现一、设计题目与要求1.设计题目发送TCP数据包2.设计要求本设计的功能孚填充一个TCP数据包,并发送给目的主机。
1)以命令行形式运行:SendTCP sourcejp source_port destjp dest_port, 其中SendTCP是程序名,source_ip为源端IP地址,source_port为源端口号, destjp为目的地址,dest_port为目的端口号。
2)其他的TCP头部参数请自行设定。
3)数据字段为a Thls is my homework of network J am happy!4)成功发送后在屏幕上输出"send OK”。
三、详细设计本课程设计的目标是发送一个TCP数据包,可以利用原始套接字来完成这个工作。
整个程序由初始化原始套接字和发送TCP数据包两个部分组成。
当应用进程需要通过TCP发送时,它就将此应用层报文传送给执行TCP协议的传输实体。
TCP 传输实体将用户数据加上TCP报头,形成TCP数据包,在TCP数据包上增加IP头部,形成IP包。
如图-1显示的是TCP数据包和IP包得关系。
TCP 协议的数据传输单位称为报文段,其格式如图-2所示。
报文段报头的长度是20B~60B,选项部分长度最多为40Bo TCP报文段主要包括以下字段。
端口号:端口号字段包括源端口号和目的端口号。
每个端口号的长度是16位,分别表示发送该TCP包的应用进程的端口号和接收该TCP包的应用进程的端口号。
-1 TCP IP IP序号:长度为32位。
由于TCP协议是面向数据流的,它所传送的报文段可以视为连续的数据流,因此需要给每一字节编号。
序号字段的“序号”指的是本报文段数据的第一个字节的序号。
网络中数据传输的过程

⽹络中数据传输的过程1. 数据传输的背景(1) 现在互联⽹中使⽤的是基于OSI七层模型的TCP/IP模型。
TCP/IP模型包括五层,即物理层,数据链路层,⽹络层,传输层,应⽤层;其中数据链路层⼜可以分为两个⼦层,即LLC(逻辑链路控制层)和MAC(介质访问控制层)。
这些层的分⼯合作是数据正确传输的基础。
(2) ARP协议(地址解析协议),它的主要功能是将⽹络层IP地址转化为数据链路层MAC地址。
从IP地址到物理地址的映射有两种⽅式:表格⽅式和⾮表格⽅式。
在以太⽹中或者在同⼀局域⽹中,所有对IP地址的访问都转换为对数据链路层⽹卡MAC地址的寻找。
如果主机A的ARP 列表中没有主机B的IP地址和对应的MAC地址,那么在传输数据时是不可能到达主机B的。
(3)DNS(域名服务器),它的主要功能是将域名转换为对应的IP地址。
在不同⽹段的数据传输中,主机A要先根据主机B的IP地址与⼦⽹掩码做与运算所得的结果——主机B所在的⽹络号找到主机B所在的⽹络,再根据MAC地址找到主机B。
2. 同⼀⽹段的数据传输假设在同⼀⽹段中的两台主机A和B想要通信,A如果想给B发送数据,必须先将B的IP地址与它的⼦⽹掩码做与运算得出B所在的⽹络号,A将所得的B的⽹络号和⾃⼰的做⽐较,以判断B和A是否在同⼀⽹段中,如果相同,则在同⼀⽹段,如果不同,则不在同⼀⽹段。
如果A和B在同⼀⽹段,但是A没有B的IP地址所对应的MAC地址信息,则利⽤第⼆层⼴播形式发送ARP请求报⽂,在报⽂中包含了A(源主机)和B(⽬标主机)的IP地址信息。
同⼀⽹段中的所有主机都可以收到并分析ARP报⽂,如果发现⽬标主机的IP地址和⾃⼰的不同,则丢弃报⽂,否则,就向A(源主机)发送ARP请求响应报⽂,报⽂的内容包括B(⽬标主机)的MAC地址。
为了减少⼴播量,⽹络设备通过ARP表在缓存中保存IP与MAC地址的映射信息。
在⼀次 ARP的请求与响应过程中,通信双⽅都把对⽅的MAC地址与IP地址的对应关系保存在各⾃的ARP表中,以在后续的通信中使⽤。
TCP协议实现文件传输

TCP协议实现文件传输TCP(Transmission Control Protocol)是一种基于连接的协议,用于在计算机网络中可靠地传输数据。
它对数据分割、传输顺序、丢包、拥塞控制等问题进行了有效的处理。
因此,TCP协议非常适合用于文件传输。
1.建立连接:发送方(客户端)首先向接收方(服务器)发送一个特殊的请求,即SYN包,该请求用于建立连接。
服务器收到请求后,向发送方发送一个SYN-ACK包,确认连接的建立。
发送方再发送一个ACK包,确认收到服务器的确认。
这个过程称为三次握手。
2.传输数据:连接建立后,发送方将文件拆分为数据包,并将其按顺序发送给接收方。
接收方根据数据包的顺序将它们重新组装成完整的文件。
如果发送方发送了一个数据包,但没有及时收到接收方的确认,发送方会重新发送该数据包,以确保数据的可靠传输。
通过TCP的拥塞控制机制,它可以根据网络状况来动态调整发送数据包的速率,确保网络的稳定性。
3.关闭连接:在文件传输完成后,发送方向接收方发送一个特殊的请求,即FIN包,表示关闭连接。
接收方收到FIN包后,向发送方发送一个ACK包进行确认。
发送方再发送一个FIN包给接收方,接收方收到后再发送一个ACK包进行确认。
这个过程称为四次挥手。
然而,正是因为TCP协议在可靠性和流量控制方面的强大能力,导致了它的传输效率相对较低。
TCP协议会对每个数据包进行确认和重传,这样会增加传输的延迟。
对于大文件的传输,TCP协议可能会造成网络拥塞,导致传输速度下降。
为了解决这个问题,可以采用一些优化策略,如使用分段传输、窗口大小调整、数据压缩等技术。
此外,还可以使用UDP(User Datagram Protocol)协议实现文件传输。
相比TCP,UDP协议不提供可靠性和流控制机制,但传输速度更快。
因此,根据具体的应用场景和需求,可以选择合适的协议来实现文件传输。
总结起来,TCP协议实现文件传输具有可靠性高的优点,但传输效率相对较低。
数据传输是怎么传输的?传输过程详解
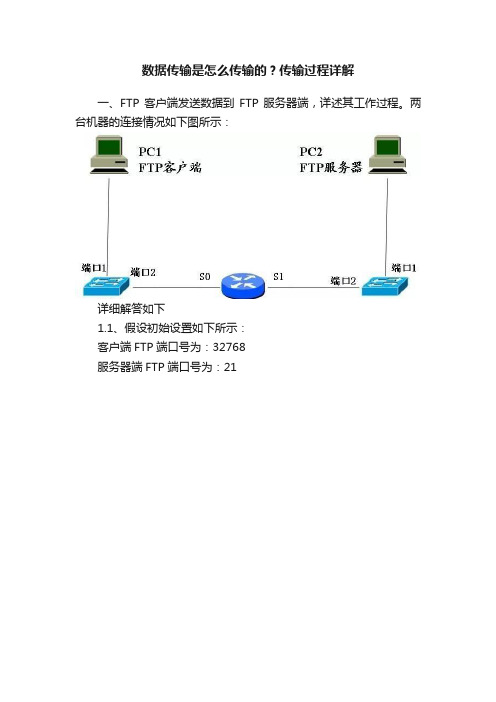
数据传输是怎么传输的?传输过程详解一、FTP客户端发送数据到FTP服务器端,详述其工作过程。
两台机器的连接情况如下图所示:详细解答如下1.1、假设初始设置如下所示:客户端FTP端口号为:32768服务器端FTP端口号为:211.2、不同网络段上的两台计算机通过TCP/IP协议通讯的过程如下所示:协议是水平的,服务是垂直的。
物理层,指的是电信号的传递方式,透明的传输比特流。
链路层,在两个相邻结点间的线路上无差错地传送以帧为单位的数据。
网络层,负责为分组交换网上的不同主机提供通信,数据传送的单位是分组或包。
传输层,负责主机中两个进程之间的通信,数据传输的单位是报文段。
网络层负责点到点(point-to-point)的传输(这里的“点”指主机或路由器),而传输层负责端到端(end-to-end)的传输(这里的“端”指源主机和目的主机)。
1.3、数据包的封装过程不同的协议层对数据包有不同的称谓,在传输层叫做段(segment),在网络层叫做数据报(datagram),在链路层叫做帧(frame)。
数据封装成帧后发到传输介质上,到达目的主机后每层协议再剥掉相应的首部,最后将应用层数据交给应用程序处理。
两台计算机在不同的网段中,那么数据从一台计算机到另一台计算机传输过程中要经过一个或多个路由器。
1.4、工作过程(1)在PC1客户端,将原始数据封装成帧,然后通过物理链路发送给Switch1的端口1。
形成的帧为:注:发送方怎样知道目的站是否和自己在同一个网络段?每个IP 地址都有网络前缀,发送方只要将目的IP地址中的网络前缀提取出来,与自己的网络前缀比较,若匹配,则意味着数据报可以直接发送。
也就是说比较二者的网络号是否相同。
本题中,PC1和PC2在两个网络段。
(2)Switch1收到数据并对数据帧进行校验后,查看目的MAC 地址,得知数据是要发送给PC2,所以Switch1就对数据帧进行存储转发,查看自己的MAC地址列表后,从端口2将数据转发给路由器的S0端口。
virtio_net数据包的收发
virtio-net数据包的收发virtio设备创建vring的创建流程Ring的内存分布发送接收virtio设备创建在virtio设备创建过程中,形成的数据结构如图所示:从图中可以看出,virtio-netdev关联了两个virtqueue,包括一个send queue和一个receive queue,而具体的queue的实现由vring来承载。
针对virtqueue 的操作包括:int virtqueue_add_buf( struct virtqueue *_vq, struct scatterlist sg[], unsigned int out, unsigned int in, void *data, gfp_t gfp)add_buf()用于向queue中添加一个新的buffer,参数data是一个非空的令牌,用于识别buffer,当buffer内容被消耗后,data会返回。
virtqueue_kick()Guest 通知host 单个或者多个buffer 已经添加到queue 中,调用virtqueue_notify(),notify 函数会向queue notify(VIRTIO_PCI_QUEUE_NOTIFY)寄存器写入queue index 来通知host。
void *virtqueue_get_buf(struct virtqueue *_vq, unsigned int *len)返回使用过的buffer,len为写入到buffer中数据的长度。
获取数据,释放buffer,更新vring描述符表格中的index。
virtqueue_disable_cb()Guest不再需要知道一个buffer已经使用了,也就是关闭device的中断。
驱动会在初始化时注册一个回调函数,disable_cb()通常在这个virtqueue回调函数中使用,用于关闭再次的回调函数调用。
virtqueue_enable_cb()与disable_cb()刚好相反,用于重新开启设备中断的上报。
Ipv4协议收发实验

Ipv4协议收发实验实验说明:由于tcp/ipv4协议已经集成在系统和网卡的驱动程序中,自己单独编写实现基于ipv4协议收发的实验,要求对系统及硬件的相关接口能够理解和应用。
其中的工作量是很大的,在网上也没有相关可以利用的实现平台。
只查到了基于NetRiver2000实验系统的tcp协议收发实验例程,该系统提供了操作系统和硬件底层的接口用来实现函数的的编写及调用。
这里,限于知识储备,我对相关的函数及ipv4数据包的格式,分组,封装实现及收发流程做了分析和研究,对tcp/ipv4的协议有了更好的理解。
1.实验目的IPv4协议是互联网的核心协议,它保证了网络节点(包括网络设备和主机)在网络层能够按照标准协议互相通信。
IPv4地址唯一标识了网络节点。
在我们日常使用的计算机的主机协议栈中,IPv4协议必不可少,它能够接收网络中传送给本机的分组,同时也能根据上层协议的要求将报文封装为IPv4分组发送出去。
本实验通过设计实现主机协议栈中的IPv4协议,让学生深入了解网络层协议的基本原理,学习IPv4协议基本的分组接收和发送流程。
另外,通过本实验,学生可以初步接触互联网协议栈的结构和计算机网络实验系统,为后面进行更为深入复杂的实验奠定良好的基础。
2.实验原理TCP协议簇本身4层:主机-网络层(接口层)、互连层、传输层、应用层。
IP协议在第二层(OSI的第三层:网络层)TCP在第三层。
(OSI的第四层:传输层)Ipv4数据包格式:3 实验要求在理解TCP/Ipv4协议数据格式及处理流程的基础上,根据计算机网络实验系统所提供的上下层接口函数和协议中分组收发的主要流程,设计实现一个简单的IPv4分组收发模块。
要求实现的主要功能包括:1)IPv4分组的基本接收处理;2)IPv4分组的封装发送;3)理解对IPv4协议中的选项和分片处理的原理4 .实验内容1)实现IPv4分组的基本接收处理功能对于接收到的IPv4分组,检查目的地址是否为本地地址,并检查IPv4分组头部中其它字段的合法性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网络数据包收发流程(1):从驱动到协议栈2013-06-26 14:47:19标签:控制器数据包以太网网络流量原文出处:/uid-24148050-id-464587.html一、硬件环境intel82546:PHY与MAC集成在一起的PCI网卡芯片,很强大bcm5461:PHY芯片,与之对应的MAC是TSECTSEC:Three Speed Ethernet Controller,三速以太网控制器,PowerPc 架构CPU里面的MAC 模块注意,TSEC内部有DMA子模块话说现在的CPU越来越牛叉了,什么功能都往里面加,最常见的如MAC功能。
TSEC只是MAC功能模块的一种,其他架构的cpu也有和TSEC类似的MAC功能模块。
这些集成到CPU芯片上的功能模块有个学名,叫平台设备,即platform device。
二、网络收包原理网络驱动收包大致有3种情况:no NAPI:mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。
netpoll:在网络和I/O子系统尚不能完整可用时,模拟了来自指定设备的中断,即轮询收包。
缺点是实时性差NAPI:采用中断+ 轮询的方式:mac收到一个包来后会产生接收中断,但是马上关闭。
直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断通过sysctl来修改dev_max_backlog或者通过proc修改/proc/sys/net/core/netdev_max_backlog下面只写内核配置成使用NAPI的情况,只写TSEC驱动。
(非NAPI的情况和PCI网卡驱动以后再说)内核版本linux 2.6.24三、NAPI 相关数据结构每个网络设备(MAC层)都有自己的net_device数据结构,这个结构上有napi_struct。
每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量上。
这样在软中断时,net_rx_action会遍历cpu私有变量的poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。
四、内核启动时的准备工作4.1 初始化网络相关的全局数据结构,并挂载处理网络相关软中断的钩子函数start_kernel()--> rest_init()--> do_basic_setup()--> do_initcall-->net_dev_init__init net_dev_init(){//每个CPU都有一个CPU私有变量_get_cpu_var(softnet_data)//_get_cpu_var(softnet_data).poll_list很重要,软中断中需要遍历它的for_each_possible_cpu(i) {struct softnet_data *queue;queue = &per_cpu(softnet_data, i);skb_queue_head_init(&queue->input_pkt_queue);queue->completion_queue = NULL;INIT_LIST_HEAD(&queue->poll_list);queue->backlog.poll = process_backlog;queue->backlog.weight = weight_p;}open_softirq(NET_TX_SOFTIRQ,net_tx_action, NULL); //在软中断上挂网络发送handleropen_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL); //在软中断上挂网络接收handler}4.2 加载网络设备的驱动NOTE:这里的网络设备是指MAC层的网络设备,即TSEC和PCI网卡(bcm5461是phy)在网络设备驱动中创建net_device数据结构,并初始化其钩子函数open(),close() 等挂载TSEC的驱动的入口函数是gfar_probe// 平台设备TSEC 的数据结构static struct platform_driver gfar_driver = {.probe = gfar_probe,.remove = gfar_remove,.driver = {.name = "fsl-gianfar",},};int gfar_probe(struct platform_device *pdev){dev = alloc_etherdev(sizeof (*priv)); // 创建net_device数据结构dev->open = gfar_enet_open;dev->hard_start_xmit = gfar_start_xmit;dev->tx_timeout = gfar_timeout;dev->watchdog_timeo = TX_TIMEOUT;#ifdef CONFIG_GFAR_NAPInetif_napi_add(dev, &priv->napi,gfar_poll,GFAR_DEV_WEIGHT); //软中断里会调用poll钩子函数#endif#ifdef CONFIG_NET_POLL_CONTROLLERdev->poll_controller = gfar_netpoll;#endifdev->stop = gfar_close;dev->change_mtu = gfar_change_mtu;dev->mtu = 1500;dev->set_multicast_list = gfar_set_multi;dev->set_mac_address = gfar_set_mac_address;dev->ethtool_ops = &gfar_ethtool_ops;}五、启用网络设备5.1 用户调用ifconfig等程序,然后通过ioctl系统调用进入内核socket的ioctl()系统调用--> sock_ioctl()--> dev_ioctl() //判断SIOCSIFFLAGS--> __dev_get_by_name(net, ifr->ifr_name) //根据名字选net_device--> dev_change_flags() //判断IFF_UP--> dev_open(net_device) //调用open钩子函数对于TSEC来说,挂的钩子函数是gfar_enet_open(net_device)5.2 在网络设备的open钩子函数里,分配接收bd,挂中断ISR(包括rx、tx、err),对于TSEC 来说gfar_enet_open--> 给Rx Tx Bd 分配一致性DMA内存--> 把Rx Bd的“EA地址”赋给数据结构,物理地址赋给TSEC寄存器--> 把Tx Bd的“EA地址”赋给数据结构,物理地址赋给TSEC寄存器--> 给tx_skbuff 指针数组分配内存,并初始化为NULL--> 给rx_skbuff 指针数组分配内存,并初始化为NULL--> 初始化Tx Bd--> 初始化Rx Bd,提前分配存储以太网包的skb,这里使用的是一次性dma映射(注意:#define DEFAULT_RX_BUFFER_SIZE 1536保证了skb能存一个以太网包)rxbdp = priv->rx_bd_base;for (i = 0; i < priv->rx_ring_size; i++) {struct sk_buff *skb = NULL;rxbdp->status = 0;//这里真正分配skb,并且初始化rxbpd->bufPtr, rxbdpd->lengthskb = gfar_new_skb(dev, rxbdp);priv->rx_skbuff[i] = skb;rxbdp++;}rxbdp--;rxbdp->status |= RXBD_WRAP; // 给最后一个bd设置标记WRAP标记--> 注册TSEC相关的中断handler:错误,接收,发送request_irq(priv->interruptError, gfar_error, 0, "enet_error", dev)request_irq(priv->interruptTransmit, gfar_transmit, 0, "enet_tx", dev)//包发送完request_irq(priv->interruptReceive,gfar_receive, 0, "enet_rx", dev) //包接收完-->gfar_start(net_device)// 使能Rx、Tx// 开启TSEC的DMA 寄存器// Mask 掉我们不关心的中断event最终,TSEC相关的Bd等数据结构应该是下面这个样子的六、中断里接收以太网包TSEC的RX已经使能了,网络数据包进入内存的流程为:网线--> Rj45网口--> MDI 差分线--> bcm5461(PHY芯片进行数模转换) --> MII总线--> TSEC的DMA Engine 会自动检查下一个可用的Rx bd--> 把网络数据包DMA 到Rx bd 所指向的内存,即skb->data接收到一个完整的以太网数据包后,TSEC会根据event mask触发一个Rx 外部中断。
cpu保存现场,根据中断向量,开始执行外部中断处理函数do_IRQ()do_IRQ 伪代码{上半部处理硬中断查看中断源寄存器,得知是网络外设产生了外部中断执行网络设备的rx中断handler(设备不同,函数不同,但流程类似,TSEC是gfar_receive)1. mask 掉rx event,再来数据包就不会产生rx中断2. 给napi_struct.state加上NAPI_STATE_SCHED 状态3. 挂网络设备自己的napi_struct结构到cpu私有变量_get_cpu_var(softnet_data).poll_list4. 触发网络接收软中断下半部处理软中断依次执行所有软中断handler,包括timer,tasklet等等执行网络接收的软中断handler net_rx_action1. 遍历cpu私有变量_get_cpu_var(softnet_data).poll_list2. 取出poll_list上面挂的napi_struct 结构,执行钩子函数napi_struct.poll()(设备不同,钩子函数不同,流程类似,TSEC是gfar_poll)3. 若poll钩子函数处理完所有包,则打开rx event mask,再来数据包的话会产生rx中断4. 调用napi_complete(napi_struct *n)把napi_struct 结构从_get_cpu_var(softnet_data).poll_list 上移走同时去掉napi_struct.state 的NAPI_STATE_SCHED 状态}6.1 TSEC的接收中断处理函数gfar_receive{#ifdef CONFIG_GFAR_NAPI// test_and_set当前net_device的napi_struct.state 为NAPI_STATE_SCHED// 在软中断里调用net_rx_action 会检查状态napi_struct.stateif (netif_rx_schedule_prep(dev, &priv->napi)) {tempval = gfar_read(&priv->regs->imask);tempval &= IMASK_RX_DISABLED; //mask掉rx,不再产生rx中断gfar_write(&priv->regs->imask, tempval);// 将当前net_device的napi_struct.poll_list 挂到// CPU私有变量__get_cpu_var(softnet_data).poll_list 上,并触发软中断// 所以,在软中断中调用net_rx_action 的时候,就会执行当前net_device的// napi_struct.poll()钩子函数,即gfar_poll()__netif_rx_schedule(dev, &priv->napi);}#elsegfar_clean_rx_ring(dev, priv->rx_ring_size);#endif}6.2 网络接收软中断net_rx_actionnet_rx_action(){struct list_head *list = &__get_cpu_var(softnet_data).poll_list;//通过napi_struct.poll_list,将N多个napi_struct 链接到一条链上//通过CPU私有变量,我们找到了链头,然后开始遍历这个链int budget = netdev_budget; //这个值就是dev_max_backlog,通过sysctl来修改while (!list_empty(list)) {struct napi_struct *n;int work, weight;local_irq_enable();//从链上取一个napi_struct 结构(接收中断处理函数里加到链表上的,如gfar_receive)n = list_entry(list->next, struct napi_struct, poll_list);weight = n->weight;work = 0;if (test_bit(NAPI_STATE_SCHED, &n->state)) //检查状态标记,此标记在接收中断里加上的work = n->poll(n, weight); //使用NAPI的话,使用的是网络设备自己的napi_struct.poll//对于TSEC是,是gfar_pollWARN_ON_ONCE(work > weight);budget -= work;local_irq_disable();if (unlikely(work == weight)) {if (unlikely(napi_disable_pending(n)))__napi_complete(n); //操作napi_struct,把去掉NAPI_STATE_SCHED状态,从链表中删去elselist_move_tail(&n->poll_list, list);}netpoll_poll_unlock(have);}out:local_irq_enable();}static int gfar_poll(struct napi_struct *napi, int budget){struct gfar_private *priv = container_of(napi, struct gfar_private, napi);struct net_device *dev = priv->dev; //TSEC对应的网络设备int howmany;//根据dev的rx bd,获取skb并送入协议栈,返回处理的skb的个数,即以太网包的个数howmany = gfar_clean_rx_ring(dev, budget);// 下面这个判断比较有讲究的// 收到的包的个数小于budget,代表我们在一个软中断里就全处理完了,所以打开rx硬中断// 要是收到的包的个数大于budget,表示一个软中断里处理不完所有包,那就不打开rx 硬中断,// 此次软中断的下一轮循环里再接着处理,直到包处理完(即howmany<budget),再打开rx 硬中断if (howmany < budget) {netif_rx_complete(dev, napi);gfar_write(&priv->regs->rstat, RSTAT_CLEAR_RHALT);//打开rx 硬中断,rx 硬中断是在gfar_receive()中被关闭的gfar_write(&priv->regs->imask, IMASK_DEFAULT);}return howmany;}gfar_clean_rx_ring(dev, budget){bdp = priv->cur_rx;while (!((bdp->status & RXBD_EMPTY) || (--rx_work_limit < 0))) {rmb();skb = priv->rx_skbuff[priv->skb_currx];//从rx_skbuff[]中获取skbhowmany++;dev->stats.rx_packets++;pkt_len = bdp->length - 4; //从length中去掉以太网包的FCS长度gfar_process_frame(dev, skb, pkt_len);dev->stats.rx_bytes += pkt_len;dev->last_rx = jiffies;bdp->status &= ~RXBD_STATS; //清rx bd的状态skb = gfar_new_skb(dev, bdp); // Add another skb for the futurepriv->rx_skbuff[priv->skb_currx] = skb;if (bdp->status & RXBD_WRAP) //更新指向bd的指针bdp = priv->rx_bd_base; //bd有WARP标记,说明是最后一个bd了,需要“绕回来”elsebdp++;priv->skb_currx = (priv->skb_currx + 1) & RX_RING_MOD_MASK(priv->rx_ring_size);}priv->cur_rx = bdp; /* Update the current rxbd pointer to be the next one */return howmany;}gfar_process_frame()-->skb->protocol = eth_type_trans(skb, dev); //确定网络层包类型,IP、ARP、VLAN等等-->RECEIVE(skb) //调用netif_receive_skb(skb)进入协议栈#ifdef CONFIG_GFAR_NAPI#define RECEIVE(x) netif_receive_skb(x)#else#define RECEIVE(x) netif_rx(x)#endif------------------------------------ 华丽的分割线--------------------------------------- 呼,netif_receive_skb(skb) 可算到协议栈了,歇会儿....以太网的FCS会在网卡中断(如gfar_clean_rx_ring)中忽略掉/* Remove the FCS from the packet length */pkt_len = bdp->length - 4;至于填充数据,是在协议栈中被忽略掉的,比如ip协议ip_rcv()/* Our transport medium may have padded the buffer out. Now we know it * is IP we can trim to the true length of the frame.* Note this now means skb->len holds ntohs(iph->tot_len).*/if (pskb_trim_rcsum(skb, len)) {IP_INC_STATS_BH(IPSTATS_MIB_INDISCARDS);goto drop;}。