合肥工业大学数据结构与算法实验报告1
数据结构与算法实验报告(线性表)

一、实验目的1、深刻理解线性结构的特点以及线性表的概念。
2、熟练掌握线性表的顺序存储结构、链式存储结构及基本运算算法的实现,特别是查找、插入和删除等算法。
二、实验环境1) 硬件:每个学生需配备计算机一台,操作系统:Windows2000/XP。
2) 软件:visual c++6.0。
三、实验题目和实验内容实验题目:线性表的顺序、链式表示及其应用实验内容:1、基本题:实验2.1、实验2.2、实验2. 4、实验2.72、附加题:实验2.3、实验2.6(没做)四、实验数据和实验结果2.1a,b,c,d,e2.2a,b,c,d,e22.4a,b,c,d,e2.7第一个多项式:2x+6x^2-4x^3+3x^4 第二个多项式1x-3x^2+6x^3-3x^4五、附录(程序代码)2.1#include<iostream.h>#include<malloc.h>#define MaxSize 50typedef struct{char data[MaxSize];int length;}SqList;void CreateList(SqList *&L,char a[],int n) {int i;L=(SqList *)malloc(sizeof(SqList));for(i=0;i<n;i++)L->data[i]=a[i];L->length=n;}void InitList(SqList *&L){L=(SqList *)malloc(sizeof(SqList));L->length=0;}void DestroyList(SqList *&L){free(L);}int ListEmpty(SqList *L){return (L->length==0);}int ListLength(SqList *L){return (L->length);}void DispList(SqList *L){int i;for(i=0;i<L->length;i++)cout<<L->data[i];cout<<endl;}char GetElem(SqList *L,int i,char &e){if(i<1||i>L->length)return 0;e=L->data[i-1];return e;}第3 页共15 页int LocateElem(SqList *L,char e){int i=0;while(i<L->length&&L->data[i]!=e) i++;if(i>=L->length)return 0;elsereturn i+1;}int ListInsert(SqList*&L,int i,char e) {int j;if(i<1||i>L->length+1)return 0;i--;for(j=L->length;j>i;j--)L->data[j]=L->data[j-1];L->data[i]=e;L->length++;return 1;}int ListDelete(SqList *&L,int i,char &e) {int j;if(i<1||i>L->length)return 0;i--;e=L->data[i];for(j=i;j<L->length-1;j++)L->length--;return 1;}void main (){SqList *p;char b[10],e;int k;cout<<"元素个数:";cin>>k;cout<<"输入元素:";for(int m=0;m<k;m++)cin>>b[m];InitList(p);4CreateList(p,b,k);cout<<"输出顺序表:";DispList(p);cout<<"顺序表长度是:"<<ListLength(p)<<endl;if(ListEmpty(p))cout<<"顺序表为空"<<endl;elsecout<<"顺序表不为空"<<endl;cout<<"顺序表第3位元素是:"<<GetElem(p,3,e)<<endl;cout<<"元素a的位置是:第"<<LocateElem(p,'a')<<"位"<<endl;ListInsert(p,4,'f');cout<<"在第4个元素上插入元素f:";DispList(p);cout<<"删除顺序表第3个元素:";ListDelete(p,3,e);DispList(p);DestroyList(p);}2.2#include<iostream.h>#include<malloc.h>typedef struct LNode{char data;struct LNode *next;}LinkList;void CreateListR(LinkList *&L,char a[],int n){LinkList *s,*r;int i;L=(LinkList *)malloc(sizeof(LinkList));r=L;for(i=0;i<n;i++){s=(LinkList *)malloc(sizeof(LinkList));s->data=a[i];r->next=s;r=s;}r->next=NULL;}第5 页共15 页void InitList(LinkList *&L){L=(LinkList *)malloc(sizeof(LinkList));L->next=NULL;}void DestroyList(LinkList *&L){LinkList *pre=L,*p=pre->next;while(p){free(pre);pre=p;p=pre->next;}free(pre);}int ListEmpty(LinkList *L){return(L->next==NULL);}int ListLength(LinkList *L){int n=0;LinkList *p=L;while(p->next){n++;p=p->next;}return(n);}void DispList(LinkList *L){LinkList *p=L->next;while(p){cout<<p->data;p=p->next;}cout<<endl;}char GetElem(LinkList *L,int i,char &e) {int j=0;6LinkList *p=L;while(j<i&&p!=NULL){j++;p=p->next;}if(!p)return 0;else{e=p->data;return e;}}int LocateElem(LinkList *L,char e){int i=1;LinkList *p=L->next;while(p&&p->data!=e){p=p->next;i++;}if(!p)return(0);elsereturn(i);}int ListInsert(LinkList *&L,int i,char e){int j=0;LinkList *p=L,*s;while(j<i-1&&p){j++;p=p->next;}if(!p)return 0;else{s=(LinkList *)malloc(sizeof(LinkList));s->data=e;s->next=p->next;第7 页共15 页p->next=s;return 1;}}int ListDelete(LinkList *&L,int i,char &e){int j=0;LinkList *p=L,*q;while(j<i-1&&p){j++;p=p->next;}if(!p)return 0;else{q=p->next;if(!q)return 0;e=q->data;p->next=q->next;free(q);return 1;}}void main(){LinkList *h;char b[10],e;int k;cout<<"元素个数:";cin>>k;cout<<"输入元素:";for(int m=0;m<k;m++)cin>>b[m];InitList(h);CreateListR(h,b,k);cout<<"输出单链表:";DispList(h);cout<<"单链表长度是:"<<ListLength(h)<<endl;if(ListEmpty(h))cout<<"单链表为空"<<endl;else8cout<<"单链表不为空"<<endl;cout<<"单链表第3位元素是:"<<GetElem(h,3,e)<<endl;cout<<"元素a的位置是:第"<<LocateElem(h,'a')<<"位"<<endl;ListInsert(h,4,'f');cout<<"在第4个元素上插入元素f:";DispList(h);cout<<"删除单链表第3个元素:";ListDelete(h,3,e);DispList(h);DestroyList(h);}2.4#include<iostream.h>#include<malloc.h>typedef struct LNode{char data;struct LNode *next;}LinkList;void CreateListR(LinkList *&L,char a[],int n){LinkList *s,*r;int i;L=(LinkList *)malloc(sizeof(LinkList));r=L;for(i=0;i<n;i++){s=(LinkList *)malloc(sizeof(LinkList));s->data=a[i];r->next=s;r=s;}r->next=L;}void InitList(LinkList *&L){L=(LinkList *)malloc(sizeof(LinkList));L->next=NULL;}void DestroyList(LinkList *&L){第9 页共15 页LinkList *pre=L->next,*p=pre->next;L->next=NULL;while(p){free(pre);pre=p;p=pre->next;}free(pre);}int ListEmpty(LinkList *L){return(L->next==NULL);}int ListLength(LinkList *L){int n=0;LinkList *p=L;while(p->next!=L&&p->next){n++;p=p->next;}return(n);}void DispList(LinkList *L){LinkList *p=L->next;while(p!=L&&p){cout<<p->data;p=p->next;}cout<<endl;}char GetElem(LinkList *L,int i,char &e) {int j=1;LinkList *p=L->next;while(j<i&&p!=L&&p){j++;p=p->next;}10return 0;else{e=p->data;return e;}}int LocateElem(LinkList *L,char e){int i=1;LinkList *p=L->next;while(p!=L&&p->data!=e&&p){p=p->next;i++;}if(!p)return(0);elsereturn(i);}int ListInsert(LinkList *&L,int i,char e){int j=1;LinkList *p=L->next,*s;while(j<i-1&&p&&p!=L){j++;p=p->next;}if(!p)return 0;else{s=(LinkList *)malloc(sizeof(LinkList));s->data=e;s->next=p->next;p->next=s;return 1;}}int ListDelete(LinkList *&L,int i,char &e) {第11 页共15 页LinkList *p=L->next,*q;while(j<i-1&&p&&p!=L){j++;p=p->next;}if(!p)return 0;else{q=p->next;if(!q||q==L->next)return 0;e=q->data;p->next=q->next;free(q);return 1;}}void main(){LinkList *h;char b[10],e;int k;cout<<"元素个数:";cin>>k;cout<<"输入元素:";for(int m=0;m<k;m++)cin>>b[m];InitList(h);CreateListR(h,b,k);cout<<"输出循环单链表:";DispList(h);cout<<"循环单链表长度是:"<<ListLength(h)<<endl;if(ListEmpty(h))cout<<"循环单链表为空"<<endl;elsecout<<"循环单链表不为空"<<endl;cout<<"循环单链表第3位元素是:"<<GetElem(h,3,e)<<endl;cout<<"元素a的位置是:第"<<LocateElem(h,'a')<<"位"<<endl;ListInsert(h,4,'f');cout<<"在第4个元素上插入元素f:";DispList(h);12cout<<"删除循环单链表第3个元素:";ListDelete(h,3,e);DispList(h);DestroyList(h);}2.7#include<iostream.h>#include<malloc.h>typedef struct polynomial{int coef; //系数int index; //指数struct polynomial *next;}LinkList;void CreateList(LinkList *&L, int n){LinkList *s,*r;int i;L=(LinkList *)malloc(sizeof(LinkList));r=L;for(i=0;i<n;i++){s=(LinkList*)malloc(sizeof(LinkList));cout<<"依次输入多项式系数和指数:";cin>>s->coef>>s->index;s->next = NULL;r->next=s;r=s;}}void InitList(LinkList *&L){L=(LinkList *)malloc(sizeof(LinkList));L->next=NULL;}void AddList(LinkList *&list1,LinkList *&list2,int m,int n) {LinkList *s,*r,*t;int i;s=list1->next;r=list2->next;t=list1;第13 页共15 页for(i=0;i<n;i++){if(s==NULL){s=list1->next;t=list1;}while(s!=NULL){if(s->index!=r->index){s=s->next;t=t->next;}else break;}if(!s){s=(LinkList*)malloc(sizeof(LinkList));s->coef=r->coef;s->index=r->index;s->next=NULL;t->next=s;s=s->next;r=r->next;continue;}else{if(s->index==r->index)s->coef=s->coef+r->coef;if(s->coef==0){LinkList *temp1;temp1=s;s=s->next;t->next=s;delete temp1;}}r=r->next;s=NULL;}cout<<"多项式相加的结果是:";14list1=list1->next;while(list1){cout<<list1->coef<<"x^"<<list1->index;if(list1->next!=NULL)cout<<"+";list1=list1->next;}}void DispList(LinkList *L){L=L->next;while(L){cout<<L->coef<<"x^"<<L->index;if(L->next!=NULL)if(L->next->coef>0)cout<<"+";L=L->next;}}void main(){LinkList *list1,*list2;InitList(list1);InitList(list2);int m,n;cout<<"请输入第一个多项式的项数:";cin>>m;CreateList(list1,m);cout<<"多项式表示是:";DispList(list1);cout<<endl;cout<<"请输入第二个多项式的项数:";cin>>n;CreateList(list2,n);cout<<"多项式表示是:";DispList(list2);cout<<endl;AddList(list1,list2,m,n);cout<<endl;}第15 页共15 页。
算法与及数据结构实验报告

第一学期实验报告课程名称:算法与数据结构实验名称:城市链表一、实验目的本次实验的主要目的在于熟悉线性表的基本运算在两种存储结构上的实现,其中以熟悉各种链表的操作为侧重点。
同时,通过本次实验帮助学生复习高级语言的使用方法。
二、实验内容(一)城市链表:将若干城市的信息,存入一个带头结点的单链表。
结点中的城市信息包括:城市名,城市的位置坐标。
要求能够利用城市名和位置坐标进行有关查找、插入、删除、更新等操作。
(二) 约瑟夫环m 的初值为20;密码:3,1,7,2,6,8,4(正确的结果应为6,1,4,7,2,3,5)。
三、实验环境VS2010 、win8.1四、实验结果(一)城市链表:(1)创建城市链表;(2)给定一个城市名,返回其位置坐标;(3)给定一个位置坐标P 和一个距离D,返回所有与P 的距离小于等于D 的城市。
(4)在已有的城市链表中插入一个新的城市;(5)更新城市信息;(6)删除某个城市信息。
(二) 约瑟夫环m 的初值为20;密码:3,1,7,2,6,8,4输出6,1,4,7,2,3,5。
五、附录城市链表:5.1 问题分析该实验要求对链表实现创建,遍历,插入,删除,查询等操作,故使用单链表。
5.2 设计方案该程序大致分为以下几个模块:1.创建城市链表模块,即在空链表中插入新元素。
故创建城市链表中包涵插入模块。
2.返回位置坐标模块。
3.计算距离模块4.插入模块。
5.更新城市信息模块6.删除信息模块。
5.3 算法5.3.1 根据中心城市坐标,返回在距离内的所有城市:void FindCityDistance(citylist *L){//根据距离输出城市……//输入信息与距离L=L->next;while(L != NULL){if(((L->x-x1)*(L->x-x1)+(L->y-y1)*(L->y-y1)<=dis *dis)&&(((L->x-x1)+(L->y-y1))!=0 )){printf("城市名称%s\n",L->Name);printf("城市坐标%.2lf,%.2lf\n",L->x,L->y);}L=L->next;}}该算法主要用到了勾股定理,考虑到不需要实际数值,只需要大小比较,所以只用横坐标差的平方+纵坐标差的平方<= 距离的平方判定。
算法与及数据结构实验报告

算法与及数据结构实验报告算法与数据结构实验报告一、实验目的本次算法与数据结构实验的主要目的是通过实际操作和编程实现,深入理解和掌握常见算法和数据结构的基本原理、特性和应用,提高我们解决实际问题的能力和编程技巧。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
同时,为了进行算法性能的分析和比较,使用了 Python 的 time 模块来计算程序的运行时间。
三、实验内容1、线性表的实现与操作顺序表的实现:使用数组来实现顺序表,并实现了插入、删除、查找等基本操作。
链表的实现:通过创建节点类来实现链表,包括单向链表和双向链表,并完成了相应的操作。
2、栈和队列的应用栈的实现与应用:用数组或链表实现栈结构,解决了表达式求值、括号匹配等问题。
队列的实现与应用:实现了顺序队列和循环队列,用于模拟排队系统等场景。
3、树结构的探索二叉树的创建与遍历:实现了二叉树的先序、中序和后序遍历算法,并对其时间复杂度进行了分析。
二叉搜索树的操作:构建二叉搜索树,实现了插入、删除、查找等操作。
4、图的表示与遍历邻接矩阵和邻接表表示图:分别用邻接矩阵和邻接表来存储图的结构,并对两种表示方法的优缺点进行了比较。
图的深度优先遍历和广度优先遍历:实现了两种遍历算法,并应用于解决路径查找等问题。
5、排序算法的比较插入排序、冒泡排序、选择排序:实现了这三种简单排序算法,并对不同规模的数据进行排序,比较它们的性能。
快速排序、归并排序:深入理解并实现了这两种高效的排序算法,通过实验分析其在不同情况下的表现。
6、查找算法的实践顺序查找、二分查找:实现了这两种基本的查找算法,并比较它们在有序和无序数据中的查找效率。
四、实验步骤及结果分析1、线性表的实现与操作顺序表:在实现顺序表的插入操作时,如果插入位置在表的末尾或中间,需要移动后续元素以腾出空间。
删除操作同理,需要移动被删除元素后面的元素。
在查找操作中,通过遍历数组即可完成。
数据结构与算法分析》实验报告

数据结构与算法分析》实验报告《数据结构与算法分析》实验报告一、实验目的本次实验旨在通过实际操作和分析,深入理解数据结构与算法的基本概念和原理,掌握常见数据结构的实现和应用,以及算法的设计和性能评估。
通过实验,提高编程能力和解决实际问题的能力,培养逻辑思维和创新精神。
二、实验环境操作系统:Windows 10编程语言:Python 3x开发工具:PyCharm三、实验内容1、线性表顺序表的实现与操作链表的实现与操作2、栈和队列栈的实现与应用(表达式求值)队列的实现与应用(排队系统模拟)3、树和二叉树二叉树的遍历算法实现(前序、中序、后序)二叉搜索树的实现与操作4、图图的存储结构(邻接矩阵和邻接表)图的遍历算法(深度优先搜索和广度优先搜索)5、排序算法冒泡排序插入排序选择排序快速排序归并排序6、查找算法顺序查找二分查找四、实验步骤及结果1、线性表顺序表的实现与操作定义一个顺序表类,使用数组来存储元素。
实现插入、删除、查找等基本操作。
进行性能测试,分析在不同位置插入和删除元素的时间复杂度。
实验结果表明,在顺序表的前端或中间进行插入和删除操作时,时间复杂度较高,而在末尾操作时效率较高。
链表的实现与操作定义链表节点类和链表类。
实现链表的插入、删除、查找等操作。
比较顺序表和链表在不同操作下的性能差异。
结果显示,链表在频繁插入和删除元素的情况下表现更优,而顺序表在随机访问元素时速度更快。
2、栈和队列栈的实现与应用(表达式求值)用栈来实现表达式求值的算法。
输入表达式,如“2 + 3 ( 4 1 )”,计算并输出结果。
经过测试,能够正确计算各种复杂的表达式。
队列的实现与应用(排队系统模拟)模拟一个简单的排队系统,顾客到达和离开队列。
输出队列的状态和平均等待时间。
实验发现,队列长度和顾客等待时间与到达率和服务率密切相关。
3、树和二叉树二叉树的遍历算法实现(前序、中序、后序)构建一棵二叉树。
分别实现前序、中序、后序遍历算法,并输出遍历结果。
合工大数据分析报告(3篇)

第1篇一、引言随着信息技术的飞速发展,大数据已经成为推动社会进步的重要力量。
我国政府高度重视大数据产业的发展,将其列为国家战略性新兴产业。
合肥工业大学(以下简称“合工”)作为一所知名高等学府,在大数据领域有着丰富的教学、科研和实践经验。
本报告将对合工大数据发展现状进行分析,并提出相关建议。
二、合工大数据发展现状1. 教育教学(1)专业设置:合工在大数据领域设有多个相关专业,如数据科学与大数据技术、计算机科学与技术、软件工程等。
这些专业培养了大量具备大数据理论知识与实践能力的人才。
(2)课程体系:合工大数据相关课程体系完善,涵盖了数据挖掘、机器学习、数据分析、数据库技术等多个方面,为学生提供了全面的学习机会。
(3)实践教学:合工注重实践教学,通过实验室、实习基地、创新创业项目等途径,提高学生的实践能力。
2. 科研成果(1)科研项目:合工在大数据领域承担了多项国家级、省部级科研项目,如国家自然科学基金、国家重点研发计划等。
(2)学术论文:合工在大数据领域的学术论文发表数量和质量均位居国内前列,为我国大数据产业发展提供了有力支持。
(3)专利成果:合工在大数据领域拥有多项专利成果,为产业发展提供了技术保障。
3. 企业合作(1)产学研合作:合工与多家企业建立了产学研合作关系,共同开展大数据技术研究与应用。
(2)人才培养:合工为企业培养了大量大数据人才,满足了企业对人才的需求。
(3)技术服务:合工为企业提供大数据技术咨询服务,助力企业解决实际问题。
三、合工大数据发展存在的问题1. 人才培养与市场需求不匹配:虽然合工大数据专业设置较为完善,但部分课程设置与市场需求存在一定差距,导致毕业生就业面临压力。
2. 研发投入不足:相较于国外知名高校,合工在大数据领域的研发投入相对较少,影响了科研水平的提升。
3. 产业协同不足:合工与大数据企业的合作深度和广度有待提高,产业协同效应尚未充分发挥。
四、合工大数据发展建议1. 优化专业设置:根据市场需求,调整和优化大数据相关专业课程设置,提高人才培养质量。
数据结构与算法的实验报告

数据结构与算法的实验报告数据结构与算法第二次实验报告电子105班赵萌2010021526实验二:栈和队列的定义及基本操作一、实验目的:. 熟练掌握栈和队列的特点. 掌握栈的定义和基本操作,熟练掌握顺序栈的操作及应用. 掌握对列的定义和基本操作,熟练掌握链式队列的操作及应用, 掌握环形队列的入队和出队等基本操作. 加深对栈结构和队列结构的理解,逐步培养解决实际问题的编程能力二、实验内容:定义顺序栈,完成栈的基本操作:空栈、入栈、出栈、取栈顶元素;实现十进制数与八进制数的转换;定义链式队列,完成队列的基本操作:入队和出队;1.问题描述:(1)利用栈的顺序存储结构,设计一组输入数据(假定为一组整数),能够对顺序栈进行如下操作:. 初始化一个空栈,分配一段连续的存储空间,且设定好栈顶和栈底;. 完成一个元素的入栈操作,修改栈顶指针;. 完成一个元素的出栈操作,修改栈顶指针;. 读取栈顶指针所指向的元素的值;. 将十进制数N 和其它d 进制数的转换是计算机实现计算的基本问题,其解决方案很多,其中最简单方法基于下列原理:即除d 取余法。
例如:(1348)10=(2504)8N N div 8 N mod 81348 168 4168 21 021 2 52 0 2从中我们可以看出,最先产生的余数4 是转换结果的最低位,这正好符合栈的特性即后进先出的特性。
所以可以用顺序栈来模拟这个过程。
以此来实现十进制数与八进制数的转换; . 编写主程序,实现对各不同的算法调用。
(2)利用队列的链式存储结构,设计一组输入数据(假定为一组整数),能够对链式队列进行如下操作:. 初始化一个空队列,形成一个带表头结点的空队;. 完成一个元素的入队操作,修改队尾指针;. 完成一个元素的出队操作,修改队头指针;. 修改主程序,实现对各不同的算法调用。
其他算法的描述省略,参见实现要求说明。
2.实现要求:对顺序栈的各项操作一定要编写成为C(C++)语言函数,组合成模块化的形式,每个算法的实现要从时间复杂度和空间复杂度上进行评价。
HFUT 数据结构试验一预习报告

数据结构试验报告试验一 单链表试验1、试验目的(1)理解线性表的链式存储结构(2)熟练掌握动态链表结构及有关算法设计。
(3)根据具体问题的需要,设计出合理的表示数据的链表结构,并设计相关算法。
二、实验环境:Windows xp Dev C++三、实验内容:(1)编写链表类,实现基本的操作。
(2)实现以下功能:求链表中第i个结点的指针(函数);在第i个结点前插入值为x的结点;删除链表中第i个元素结点;在一个递增有序的链表L中插入一个值为x的元素,并保持其递增有序特性;将单链表L中的奇数项和偶数项结点分解开,并分别连成一个带头结点的单链表,然后再将这两个新链表同时输出在屏幕上,并保留原链表的显示结果;将单链表L中的奇数项和偶数项结点分解开,并分别连成一个带头结点的单链表,然后再将这两个新链表同时输出在屏幕上,并保留原链表的显示结果;求两个递增有序链表L1和L2中的公共元素,并以同样方式连接成链表L3。
四、试验准备(1)类结构:错误代码(枚举)enum error_code{sucess=0,overflow=1,downflow=2,rangeerror=3};节点(结构体)template <class Element_type> struct node{Element_type data;node *next;};链表类template <class Element_type>class List{public:List();//构造函数~List();//析构函数bool empty()const;//判断函数是否为空,空则返回trueerror_code show()const;//输出链表内容int length()const;//链表长度error_code get_element(const int i,Element_type &x)const;//取出第i个位置的值并赋给xnode<Element_type>* locate(const Element_type x)const;//返回值为x 的节点地址node<Element_type>* locate_node(const int i)const;//返回第i个节点的地址node<Element_type>* return_top()const;//返回链表的首节点error_code insert(const int i ,const Element_type x);//在第i个位置插入值为x的节点error_code insert(const Element_type x);//按顺序插入值为x的节点 error_code delete_element(const int i);删除第i个位置的节点error_code clear();//置为空private:node<Element_type> *top;};5、试验过程(1)具体实现:一些辅助函数:(2)试验目标的程序实现:<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
合肥工业大学数据结构试验一实验报告

计算机与信息学院数据结构实验报告专业班级学生姓名及学号课程教学班号任课教师实验指导教师实验地点2015 ~2016 学年第 2 学期说明实验报告是关于实验教学内容、过程及效果的记录和总结,因此,应注意以下事项和要求:1.每个实验单元在4页的篇幅内完成一份报告。
“实验单元”指按照实验指导书规定的实验内容。
若篇幅不够,可另附纸。
2、各实验的预习部分的内容是进入实验室做实验的必要条件,请按要求做好预习。
3.实验报告要求:书写工整规范,语言表达清楚,数据和程序真实。
理论联系实际,认真分析实验中出现的问题与现象,总结经验。
4.参加实验的每位同学应独立完成实验报告的撰写,其中程序或相关的设计图纸也可以采用打印等方式粘贴到报告中。
严禁抄袭或拷贝,否则,一经查实,按作弊论取,并取消理论课考试资格。
5.实验报告作为评定实验成绩的依据。
实验序号及名称:实验一单链表实验实验时间∶2016年 5 月二、实验内容与步骤(过程及数据记录):<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
实验测试数据基本要求:第一组数据:链表长度n≥10,i分别为5,n,0,n+1,n+2第二组数据:链表长度n=0,i分别为0,2node* list::address(int i){node *p = head->next;int n = 1;while (n != i&&p != NULL){p = p->next;n++;}if (p!=NULL) return p;else return NULL;}第一组数据第二组数据<2>在第i个结点前插入值为x的结点。
实验测试数据基本要求:第一组数据:链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2 第二组数据:链表长度n=0,x=100,i=5errorcode list::insert(const int i, const int x){node *p;p = head;int n = 1;while (n != i&&p != NULL){p = p->next;n++;}if (i<1 || i>length() + 1) return rangeerror;node *s = new node;s->data = x;s->next = p->next;p->next = s;count++;return success;}<3>删除链表中第i个元素结点。
合肥工业大学数据结构与算法实验报告1

数据结构实验报告实验一顺序表实验1.实验目标(1)熟练掌握线性表的顺序存储结构。
(2)熟练掌握顺序表的有关算法设计。
(3)根据具体问题的需要,设计出合理的表示数据的顺序结构,并设计相关算法。
2.实验内容和要求(1)顺序表结构和运算定义,算法的实现以库文件方式实现,不得在测试主程序中直接实现;(2)实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求;(3)程序有适当的注释;(4)设计算法实现各实验。
3.数据结构设计(1)以结构体,类为基础,和函数调用实现各实验;4.算法设计(除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想)5.运行和测试(1)各个实验运行正常,符合实验要求;(2)达到实验目的。
6.总结和心得[7. 附录](源代码清单。
纸质报告不做要求。
电子报告,可直接附源文件,删除编译生成的所有文件)<1>求顺序表中第i个元素(函数),若不存在,报错。
题1查找元素.cpp<2>在第i个结点前插入值为x的结点。
题2插入元素.cpp<3>删除顺序表中第i个元素结点。
题3删除元素.cpp<4>在一个递增有序的顺序表L中插入一个值为x的元素,并保持其递增有序特性。
题4递增插入.cpp<5>将顺序表L中的奇数项和偶数项结点分解开(元素值为奇数、偶数),分别放入新的顺序表中,然后原表和新表元素同时输出到屏幕上,以便对照求解结果。
题5求奇偶.cpp<6>求两个递增有序顺序表L1和L2中的公共元素,放入新的顺序表L3中。
题6求交集.cpp<7>删除递增有序顺序表中的重复元素,并统计移动元素次数,要求时间性能最好。
题7删除相同元素.cpp。
合肥工业大学数据结构试验一实验报告

计算机与信息学院数据结构实验报告专业班级学生姓名及学号课程教学班号任课教师实验指导教师实验地点2015 ~2016 学年第 2 学期说明实验报告是关于实验教学内容、过程及效果的记录和总结,因此,应注意以下事项和要求:1.每个实验单元在4页的篇幅内完成一份报告。
“实验单元”指按照实验指导书规定的实验内容。
若篇幅不够,可另附纸。
2、各实验的预习部分的内容是进入实验室做实验的必要条件,请按要求做好预习。
3.实验报告要求:书写工整规范,语言表达清楚,数据和程序真实。
理论联系实际,认真分析实验中出现的问题与现象,总结经验。
4.参加实验的每位同学应独立完成实验报告的撰写,其中程序或相关的设计图纸也可以采用打印等方式粘贴到报告中。
严禁抄袭或拷贝,否则,一经查实,按作弊论取,并取消理论课考试资格。
5.实验报告作为评定实验成绩的依据。
实验序号及名称:实验一单链表实验实验时间∶ 2016年 5 月二、实验内容与步骤(过程及数据记录):<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
实验测试数据基本要求:第一组数据:链表长度n≥10,i分别为5,n,0,n+1,n+2第二组数据:链表长度n=0,i分别为0,2node* list::address(int i){n ode *p = head->next;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (p!=NULL) return p;e lse return NULL;}第一组数据第二组数据<2>在第i个结点前插入值为x的结点。
实验测试数据基本要求:第一组数据:链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2第二组数据:链表长度n=0,x=100,i=5errorcode list::insert(const int i, const int x){n ode *p;p = head;i nt n = 1;w hile (n != i&&p != NULL){p = p->next;n++;}i f (i<1 || i>length() + 1) return rangeerror;n ode *s = new node;s->data = x;s->next = p->next;p->next = s;c ount++;r eturn success;}<3>删除链表中第i个元素结点。
合工大计算方法实验报告参考模板

《计算方法》试验报告班级:学号:姓名:实验一、牛顿下山法1 实验目的(1)熟悉非线性方程求根简单迭代法,牛顿迭代及牛顿下山法 (2)能编程实现简单迭代法,牛顿迭代及牛顿下山法 (3)认识选择迭代格式的重要性 (4) 对迭代速度建立感性的认识;分析实验结果体会初值对迭代的影响2 实验内容(1)用牛顿下山法解方程013=--x x (初值为0.6)输入:初值,误差限,迭代最大次数,下山最大次数输出:近似根各步下山因子(2)设方程f(x)=x 3- 3x –1=0 有三个实根 x *1=1.8793 , x *2=-0.34727 ,x *3=-1.53209现采用下面六种不同计算格式,求 f(x)=0的根 x *1 或x *2 x = 213xx +; x = 313-x ;x = 313+x ; x = 312-x ;x = x 13+;x = x - ()1133123---x x x输入:初值,误差限,迭代最大次数输出:近似根、实际迭代次数 3 算法基本原理求非线性方程组的解是科学计算常遇到的问题,有很多实际背景.各种算法层出不穷,其中迭代是主流算法。
只有建立有效的迭代格式,迭代数列才可以收敛于所求的根。
因此设计算法之前,对于一般迭代进行收敛性的判断是至关重要的。
牛顿法也叫切线法,是迭代算法中典型方法,只要初值选取适当,在单根附近,牛顿法收敛速度很快,初值对于牛顿迭代至关重要。
当初值选取不当可以采用牛顿下山算法进行纠正。
一般迭代:)(1k k x x φ=+ 0)()(=⇔=x f x x φ 牛顿公式:)()(1k k k k x f x f x x '-=+ 牛顿下山公式:)()(1k k k k x f x f x x '-=+λ图3.1一般迭代算法流程图 下山因子 ,,,,322121211=λ 下山条件|)(||)(|1k k x f x f <+4 算法描述一般迭代算法见流程图牛顿下山算法见流程图:5、代码:#include <iostream>#include <fstream>#include <cmath>using namespace std;class srrt{private:int n;double *a, *xr, *xi;public:图3.2牛顿下山算法流程图⇐⇐⇐⇐srrt (int nn){n = nn;a = new double[n+1]; //动态分配内存xr = new double[n];xi = new double[n];}void input (); //由文件读入代数方程系数void srrt_root (); //执行牛顿下山法void output (); //输出根到文件并显示~srrt (){ delete [] a, xr, xi; }};void srrt::input () //由文件读入代数方程系数{int i;char str1[20];cout <<"\n输入文件名: ";cin >>str1;ifstream fin (str1);if (!fin){ cout <<"\n不能打开这个文件" <<str1 <<endl; exit(1); } for (i=n; i>=0; i--) fin >>a[i]; //读入代数方程系数fin.close ();}void srrt::srrt_root () //执行牛顿下山法{int m,i,jt,k,is,it;double t,x,y,x1,y1,dx,dy,p,q,w,dd,dc,c;double g,u,v,pq,g1,u1,v1;m=n;while ((m>0)&&(fabs(a[m])+1.0==1.0)) m=m-1;if (m<=0){cout <<"\n程序工作失败!" <<endl;return;}for (i=0; i<=m; i++) a[i]=a[i]/a[m];for (i=0; i<=m/2; i++){w=a[i]; a[i]=a[m-i]; a[m-i]=w;}k=m; is=0; w=1.0;jt=1;while (jt==1){pq=fabs(a[k]);while (pq<1.0e-12){xr[k-1]=0.0; xi[k-1]=0.0; k=k-1;if (k==1){xr[0]=-a[1]*w/a[0]; xi[0]=0.0;return;}pq=fabs(a[k]);}q=log(pq); q=q/(1.0*k); q=exp(q);p=q; w=w*p;for (i=1; i<=k; i++){ a[i]=a[i]/q; q=q*p; }x=0.0001; x1=x; y=0.2; y1=y; dx=1.0;g=1.0e+37;l40:u=a[0]; v=0.0;for (i=1; i<=k; i++){p=u*x1; q=v*y1;pq=(u+v)*(x1+y1);u=p-q+a[i]; v=pq-p-q;}g1=u*u+v*v;if (g1>=g){if (is!=0){it=1;if (it==0){is=1;dd=sqrt(dx*dx+dy*dy);if (dd>1.0) dd=1.0;dc=6.28/(4.5*k); c=0.0;}while(1==1){dx=dd*cos(c); dy=dd*sin(c);x1=x+dx; y1=y+dy;if (c<=6.29) { it=0; break; }dd=dd/1.67;if (dd<=1.0e-07) { it=1; break; }c=0.0;}if (it==0) goto l40;}else{it=1;while (it==1){t=t/1.67; it=0;x1=x-t*dx;y1=y-t*dy;if (k>=50){p=sqrt(x1*x1+y1*y1);q=exp(85.0/k);if (p>=q) it=1;}}if (t>=1.0e-03) goto l40;if (g>1.0e-18){it=0;if (it==0){is=1;dd=sqrt(dx*dx+dy*dy);if (dd>1.0) dd=1.0;dc=6.28/(4.5*k); c=0.0;}while(1==1){c=c+dc;dx=dd*cos(c); dy=dd*sin(c);x1=x+dx; y1=y+dy;if (c<=6.29) { it=0; break; }dd=dd/1.67;if (dd<=1.0e-07) { it=1; break; }}if (it==0) goto l40;}}if (fabs(y)<=1.0e-06){ p=-x; y=0.0; q=0.0; }else{p=-2.0*x; q=x*x+y*y;xr[k-1]=x*w;xi[k-1]=-y*w;k=k-1;}for (i=1; i<=k; i++){a[i]=a[i]-a[i-1]*p;a[i+1]=a[i+1]-a[i-1]*q;}xr[k-1]=x*w; xi[k-1]=y*w;k=k-1;if (k==1){ xr[0]=-a[1]*w/a[0]; xi[0]=0.0; } }else{g=g1; x=x1; y=y1; is=0;if (g<=1.0e-22){if (fabs(y)<=1.0e-06){ p=-x; y=0.0; q=0.0; }else{p=-2.0*x; q=x*x+y*y;xr[k-1]=x*w;xi[k-1]=-y*w;k=k-1;}for (i=1; i<=k; i++){a[i]=a[i]-a[i-1]*p;a[i+1]=a[i+1]-a[i-1]*q;}xr[k-1]=x*w; xi[k-1]=y*w;k=k-1;if (k==1){ xr[0]=-a[1]*w/a[0]; xi[0]=0.0; }}else{u1=k*a[0]; v1=0.0;for (i=2; i<=k; i++){p=u1*x; q=v1*y; pq=(u1+v1)*(x+y);u1=p-q+(k-i+1)*a[i-1];v1=pq-p-q;}p=u1*u1+v1*v1;if (p<=1.0e-20){it=0;if (it==0){is=1;dd=sqrt(dx*dx+dy*dy);if (dd>1.0) dd=1.0;dc=6.28/(4.5*k); c=0.0;}while(1==1){c=c+dc;dx=dd*cos(c); dy=dd*sin(c);x1=x+dx; y1=y+dy;if (c<=6.29) { it=0; break; }dd=dd/1.67;if (dd<=1.0e-07) { it=1; break; }c=0.0;}if (it==0) goto l40;if (fabs(y)<=1.0e-06){ p=-x; y=0.0; q=0.0; }else{p=-2.0*x; q=x*x+y*y;xr[k-1]=x*w;xi[k-1]=-y*w;k=k-1;}for (i=1; i<=k; i++){a[i]=a[i]-a[i-1]*p;a[i+1]=a[i+1]-a[i-1]*q;}xr[k-1]=x*w; xi[k-1]=y*w;k=k-1;if (k==1){ xr[0]=-a[1]*w/a[0]; xi[0]=0.0; }}else{dx=(u*u1+v*v1)/p;dy=(u1*v-v1*u)/p;t=1.0+4.0/k;it=1;while (it==1){t=t/1.67; it=0;x1=x-t*dx;y1=y-t*dy;if (k>=50){p=sqrt(x1*x1+y1*y1);q=exp(85.0/k);if (p>=q) it=1;}}if (t>=1.0e-03) goto l40;if (g>1.0e-18){it=0;if (it==0){is=1;dd=sqrt(dx*dx+dy*dy);if (dd>1.0) dd=1.0;dc=6.28/(4.5*k); c=0.0;}while(1==1){c=c+dc;dx=dd*cos(c); dy=dd*sin(c);x1=x+dx; y1=y+dy;if (c<=6.29) { it=0; break; }dd=dd/1.67;if (dd<=1.0e-07) { it=1; break; }c=0.0;}if (it==0) goto l40;}if (fabs(y)<=1.0e-06){ p=-x; y=0.0; q=0.0; }else{p=-2.0*x; q=x*x+y*y;xr[k-1]=x*w;xi[k-1]=-y*w;k=k-1;}for (i=1; i<=k; i++){a[i]=a[i]-a[i-1]*p;a[i+1]=a[i+1]-a[i-1]*q;}xr[k-1]=x*w; xi[k-1]=y*w;k=k-1;if (k==1){ xr[0]=-a[1]*w/a[0]; xi[0]=0.0; }}}}if (k==1) jt=0;else jt=1;}}void srrt::output () //输出根到文件并显示{int k;char str2[20];cout <<"\n输出文件名: ";cin >>str2;ofstream fout (str2);if (!fout){ cout <<"\n不能打开这个文件" <<str2 <<endl; exit(1); } for (k=0; k<n; k++){fout <<xr[k] <<" " <<xi[k] <<endl;cout <<xr[k] <<" +j " <<xi[k] <<endl;}fout.close ();}void main () //主函数{srrt root(6);root.input (); //由文件读入代数方程系数root.srrt_root (); //执行牛顿下山法root.output (); //输出根到文件并显示}6、输入输出输出结果如下:7、分析体会牛顿下山法作为计算方法课程中重要的知识点,在看书学习时较易大致理解其思路,但上级编写代码时却是有难度的。
数据结构与算法综合设计实验-1实验报告

电子科技大学实验报告学生姓名:苏魏明学号:指导教师:实验地点:实验时间:一、实验室名称:软件实验室二、实验项目名称:数据结构与算法—线性表三、实验学时:4四、实验原理:在链式存储结构中,存储数据结构的存储空间可以不连续,各数据结点的存储顺序与数据元素之间的逻辑关系可以不一致,而数据元素之间的逻辑关系是由指针域来确定的。
链式存储方式即可以用于表示线性结构,也可用于表示非线性结构。
一般来说,在线性表的链式存储结构中,各数据结点的存储符号是不连续的,并且各结点在存储空间中的位置关系与逻辑关系也不一致。
对于线性链表,可以从头指针开始,沿各结点的指针扫描到链表中的所有结点。
线性表的链接存储中,为了方便在表头插入和删除结点的操作,经常在表头结点(存储第一个元素的结点)的前面增加一个结点,称之为头结点或表头附加结点。
这样原来的表头指针由指向第一个元素的结点改为指向头结点,头结点的数据域为空,头结点的指针域指向第一个元素的结点。
五、实验目的:本实验通过定义单向链表的数据结构,设计创建链表、插入结点、遍历结点等基本算法,使学生掌握线性链表的基本特征和算法,并能熟练编写C程序,培养理论联系实际和自主学习的能力,提高程序设计水平。
六、实验内容:使用数据结构typedef struct node {Elemtype data;struct node *next;} ListNode, *ListPtr;typedef struct stuInfo {char stuName[10]; /*学生姓名*/int Age /*年龄*/} ElemType实现带头结点的单向链表的创建、删除链表、插入结点等操作,并能实现年龄递增的两个单向链表合并一个链表,合并后的链表按年龄递减,可认为同名同年龄是同一个学生,每个学生在合并后的链表中仅出现一次。
最后打印输出合并后的链表元素,验证结果的正确性。
七、实验器材(设备、元器件):PC机一台,装有C语言集成开发环境。
合肥工业大学数据结构试验一实验报告

计算机与信息学院数据结构实验报告专业班级学生姓名及学号课程教学班号任课教师实验指导教师实验地点2015 ~2016 学年第 2 学期说明实验报告就是关于实验教学内容、过程及效果的记录与总结,因此,应注意以下事项与要求:1.每个实验单元在4页的篇幅内完成一份报告。
“实验单元”指按照实验指导书规定的实验内容。
若篇幅不够,可另附纸。
2、各实验的预习部分的内容就是进入实验室做实验的必要条件,请按要求做好预习。
3.实验报告要求:书写工整规范,语言表达清楚,数据与程序真实。
理论联系实际,认真分析实验中出现的问题与现象,总结经验。
4.参加实验的每位同学应独立完成实验报告的撰写,其中程序或相关的设计图纸也可以采用打印等方式粘贴到报告中。
严禁抄袭或拷贝,否则,一经查实,按作弊论取,并取消理论课考试资格。
5.实验报告作为评定实验成绩的依据。
实验序号及名称:实验一单链表实验实验时间∶2016年 5 月二、实验内容与步骤(过程及数据记录):<1>求链表中第i个结点的指针(函数),若不存在,则返回NULL。
实验测试数据基本要求:第一组数据:链表长度n≥10,i分别为5,n,0,n+1,n+2第二组数据:链表长度n=0,i分别为0,2node* list::address(int i){node *p = head->next;int n = 1;while (n != i&&p != NULL){p = p->next;n++;}if (p!=NULL) return p;else return NULL;}第一组数据第二组数据<2>在第i个结点前插入值为x的结点。
实验测试数据基本要求:第一组数据:链表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2 第二组数据:链表长度n=0,x=100,i=5errorcode list::insert(const int i, const int x){node *p;p = head;int n = 1;while (n != i&&p != NULL){p = p->next;n++;}if (i<1 || i>length() + 1) return rangeerror;node *s = new node;s->data = x;s->next = p->next;p->next = s;count++;return success;}<3>删除链表中第i个元素结点。
合肥工业大学数据结构二叉树实验报告

btree(char a[]);
//visit
T visit(bnode<T> *t);
//取根
bnode<T> *get_root();
//构造树
void create_btree(T x);
//先序构造
bnode<T>* pre_create();
void test(bnode<T> *t);
int ltag, rtag;
};
int max_x(int x, int y)
{
return x >= y ? x : y;
}
//二叉树类---------------------------------
template<class T>
class btree
{
bnode<T> *root;
int count_bnode, count_leaf;
errorcode queue<T>::append(T x)
{
if (full()) return overflow;
data[rear % maxlen] = x;
rear++;
flag = 1;
return success;
}
template<class T>
errorcode queue<T>::serve()
合肥工业大学数据结构二叉树实验代码
2014211590李亚鸣
#include<iostream>
#include<fstream>
合肥工业大学计算机专业计算方法实验报告
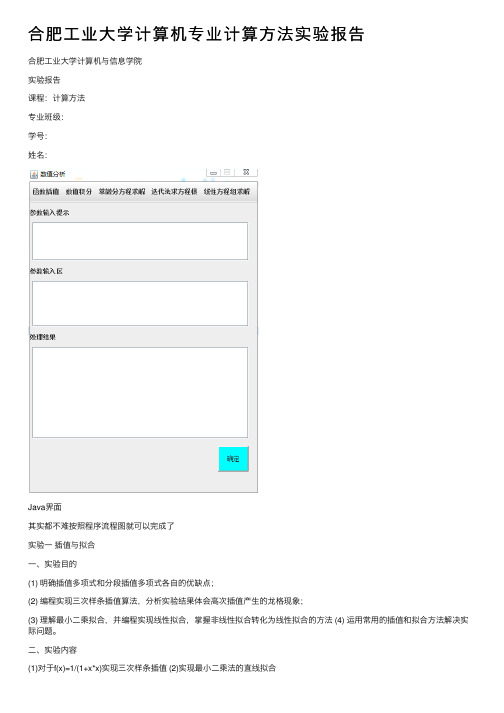
合肥⼯业⼤学计算机专业计算⽅法实验报告合肥⼯业⼤学计算机与信息学院实验报告课程:计算⽅法专业班级:学号:姓名:Java界⾯其实都不难按照程序流程图就可以完成了实验⼀插值与拟合⼀、实验⽬的(1) 明确插值多项式和分段插值多项式各⾃的优缺点;(2) 编程实现三次样条插值算法,分析实验结果体会⾼次插值产⽣的龙格现象;(3) 理解最⼩⼆乘拟合,并编程实现线性拟合,掌握⾮线性拟合转化为线性拟合的⽅法 (4) 运⽤常⽤的插值和拟合⽅法解决实际问题。
数据如下:j x 165 123 150 123 141 j y187126172125148三、基本原理(计算公式)(1)三次样条插值在每个内节点上具有2阶导数。
(2)最⼩⼆乘法拟合直线为y=a+bx ,⽽a ,b 有如下等式(N 为给出的数据点的总个数)i i y x b N =+∑a ; ∑∑∑=+i i i i y x x b x 2a四、算法设计与实现(流程图,关键点)最⼩⼆乘法直线拟合:输⼊数据后,按照公式计算a,b。
⽤得到的拟合直线计算预测点的近似函数值。
五、输⼊与输出(1)三次样条插值输⼊:区间长度,n+1个数据点,预测点输出:预测点的近似函数值,精确值,及误差(2)最⼩⼆乘法直线拟合六、结果讨论和分析代码三次样条插值#include#include#define N 10using namespace std; double u0(double x){ return (x-1)*(x-1)*(2*x+1);return x*x*(3-2*x);}double v0(double x){return x*(x-1)*(x-1);}double v1(double x){return x*x*(x-1);}double s3(double x,double y,double y1,double m,double m1,double h){ return u0(x)*y+u1(x)*y1+h*v0(x)*m+h*v1(x)*m1; }double f(double x){return 1/(1+x*x);}int main(){ifstream fin;fin.open("E:\\t.txt");if(!fin){cout<<"error opening input stream"<system("pause");return 0;}double x[N+1],y[N+1],m[N+1],A[N],B[N],C[N];double h[N];double a[N],b[N];double f0,fn;double temp;int i;for(i=0;i<=N;i++){fin>>x[i]>>y[i];}fin>>f0>>fn;h[0]=x[1]-x[0];for(i=1;ib[i]=3*((1-a[i])*(y[i]-y[i-1])/h[i-1]+a[i]*(y[i+1]-y[i])/h[i]);}m[1]=b[1]-(1-a[1])*f0;m[N-1]=b[N-1]-a[N-1]*fn;for(i=2;im[i]=b[i];}for(i=1;iB[i]=2;C[i]=a[i];}for(i=2;iA[i]=1-a[i];}C[1]=C[1]/B[1];m[1]=m[1]/B[1];double t;for(i=2;i!=N-2;i++){t=B[i]-C[i-1]*A[i];C[i]=C[i]/t;m[i]=(m[i]-m[i-1]*A[i])/t;}m[N-1]=(m[N-1]-m[N-2]*A[N-1])/(B[N-1]-C[N-2]*A[N-1]); for(i=N-2;i>0;i--){m[i]=m[i]-C[i]*m[i+1];}cout<<"please:(输⼊插值节点在"<while(cin>>temp){double tt=temp;if(tempx[N]){cout<<"插值节点为"<continue;}}temp=(temp-x[i-1])/h[i-1];temp=s3(temp,y[i-1],y[i],m[i-1],m[i],h[i-1]); cout<<"插值节点为"<}system("pause");fin.close();return 0;}最⼩⼆乘法的直线拟合#include#include#define n 5using namespace std;double sum(double x[],int k){int i;double sum=0;for(i=0;isum=sum+x[i];return sum;}double sum2(double x[],int k){int i;double sum=0;for(i=0;isum=sum+x[i]*x[i];return sum;}double sumxy(double x[],double y[],int k){ int i;double sum=0;for(i=0;isum=sum+x[i]*y[i];int main(){ifstream fin;fin.open("E:\\t.txt");if(!fin){cout<<"error opening input stream"<system("pause");return 0;}double x[n],y[n],a,b;double x0,y0;int i;for(i=0;ifin>>x[i]>>y[i];}b=(n*sumxy(x,y,n)-sum(x,n)*sum(y,n))/(n*sum2(x,n)-sum(x,n)*sum(x,n));a=(sum(y,n)-b*sum(x,n))/n;cout<<"最⼩⼆乘法直线拟合得到a: "<cout<<"请输⼊插值节点x:";while(cin>>x0){y0=a+b*x0;cout<<"当x="<cout<<"请输⼊插值节点x:";}system("pause");fin.close();return 0;}实验⼆数值积分⼀、实验⽬的(1)熟悉复化梯形⽅法、复化Simpson⽅法、梯形递推算法、龙贝格算法;(2)能编程实现龙贝格算法和中点加速;(3)理解并掌握⾃适应算法和收敛加速算法的基本思想;(4)分析实验结果体会各种⽅法的精确度,建⽴计算机求解定积分问题的感性认识x1sin (2)⽤中点加速⽅法计算xe 的⼀阶导数三、基本原理(计算公式)(1)龙贝格算法梯形递推公式∑-=++=10212)(22n k k n n x f h T T加权平均公式:n n n S T T =--1442 n n n C S S =--144222 n nn R C C =--144323 (2)中点加速中点公式: G(h)=(f(a+h)-f(a-h))/2/h 加权平均:G1(h)=4*G(h/2)/3-G(h)/3 G2(h)=16*G1(h/2)/15-G1(h)/15 G3(h)=64*G2(h/2)/63-G2(h)/63四、算法设计与实现(流程图,关键点)中点加速:输⼊数据后根据公式计算导数值五、输⼊与输出图2.2梯形递推算法流程图图2.3龙贝格算法流程图(1) ⽤龙贝格算法计算dx xx1sin 输⼊:积分区间,误差限输出:序列Tn ,Sn,Cn,Rn 及积分结果 (2)⽤中点加速⽅法计算xe 的⼀阶导数输⼊:求导节点,步长输出:求得的导数值,精确值六、结果讨论和分析代码#includeusing namespace std;double f(double x){if(x==0)return 1;return sin(x)/x;}int main(){ifstream fin;fin.open("E:\\t.txt");if(!fin){cout<<"error opening input stream"< system("pause");return 0;}double a,b,e,t1,t2,s1,s2,c1,c2,r1,r2; double x,h,s;fin>>a>>b>>e;cout<<"积分区间为["<cout<<"k T2 S2 C2 R2"<h=b-a;t1=(f(a)+f(b))*h/2;cout<<0<<" "<int k;for(k=1;k<=10;k++,h=h/2,t1=t2,s1=s2){ s=0;x=a+h/2;do{s=s+f(x);x=x+h;}while(xt2=t1/2+h*s/2;s2=t2+(t2-t1)/3;}c2=s2+(s2-s1)/15;if(k==2){cout<c1=c2;continue;}r2=c2+(c2-c1)/63;cout<if(k==3){r1=r2;c1=c2;continue;}if(fabs(r2-r1)cout<<"数值积分结果为"< break;}r1=r2;c1=c2;}system("pause");return 0;}中点加速算法#include#include#includeusing namespace std; double f(double x){ return exp(x);}}double g(double x,double h){return (f(x+h)-f(x-h))/2/h;}double g1(double x,double h){return 4*g(x,h/2)/3-g(x,h)/3;}double g2(double x,double h){return 16*g1(x,h/2)/15-g1(x,h)/15;}double g3(double x,double h){return 64*g2(x,h/2)/63-g2(x,h)/63;}int main(){ifstream fin;fin.open("E:\\t.txt");if(!fin){cout<<"error opening input stream"<system("pause");return 0;}double a,h;while(fin>>a>>h)cout<<"当x="<<a<< ",步长h="<< h<<",x处⼀阶导数值精确值为"<<f1(a)<<",中点加速求得x处⼀阶导数值为"<<g3(a,h)<<",误差为"<<f1(a)-g3(a,h)<<endl;</p>system("pause");fin.close();return 0;}实验三⾮线性⽅程求根迭代法⼀、实验⽬的(1)熟悉⾮线性⽅程求根简单迭代法,⽜顿迭代及⽜顿下⼭法(2)能编程实现⽜顿下⼭法(3)认识选择迭代格式的重要性(4)对迭代速度建⽴感性的认识;分析实验结果体会初值对迭代的影响⼆、实验内容⽤⽜顿下⼭法解⽅程013=--x x (初值为0.6)三、基本原理(计算公式)求⾮线性⽅程组的解是科学计算常遇到的问题,有很多实际背景.各种算法层出不穷,其中迭代是主流算法。
算法与数据结构实验报告

算法与数据结构实验报告算法与数据结构实验报告引言算法与数据结构是计算机科学中的两个重要概念。
算法是解决问题的一系列步骤或规则,而数据结构是组织和存储数据的方式。
在本次实验中,我们将探索不同的算法和数据结构,并通过实际的案例来验证它们的效果和应用。
一、排序算法排序算法是计算机科学中最基础的算法之一。
在本次实验中,我们实现了冒泡排序、插入排序和快速排序算法,并对它们进行了比较。
冒泡排序是一种简单但低效的排序算法。
它通过多次遍历待排序的元素,每次比较相邻的两个元素并交换位置,将较大的元素逐渐“冒泡”到数组的末尾。
尽管冒泡排序的时间复杂度为O(n^2),但它易于实现且适用于小规模的数据集。
插入排序是一种更高效的排序算法。
它将待排序的元素依次插入已排好序的部分中,直到所有元素都被插入完毕。
插入排序的时间复杂度为O(n^2),但对于部分有序的数据集,插入排序的效率会更高。
快速排序是一种常用的排序算法,它采用分治的思想。
快速排序的基本思路是选择一个基准元素,将小于基准的元素放在基准的左边,大于基准的元素放在基准的右边,然后对左右两部分分别进行快速排序。
快速排序的时间复杂度为O(nlogn),但在最坏情况下会退化为O(n^2)。
通过实际的实验数据,我们发现快速排序的效率远高于冒泡排序和插入排序。
这是因为快速排序采用了分治的策略,将原始问题划分为更小的子问题,从而减少了比较和交换的次数。
二、查找算法查找算法是在给定数据集中寻找特定元素的算法。
在本次实验中,我们实现了线性查找和二分查找算法,并对它们进行了比较。
线性查找是一种简单但低效的查找算法。
它通过逐个比较待查找的元素和数据集中的元素,直到找到匹配的元素或遍历完整个数据集。
线性查找的时间复杂度为O(n),适用于小规模的数据集。
二分查找是一种更高效的查找算法,但要求数据集必须是有序的。
它通过将数据集划分为两部分,并与中间元素进行比较,从而确定待查找元素所在的部分,然后再在该部分中进行二分查找。
合肥工业大学计算机体系结构实验报告

实验一主板架构的测试一、实验目的及要求了解Internet系列主板的基本构架二、实验设备(环境)及要求多核计算机,windows os ,CPU-Z,GPU-Z。
三、实验内容与步骤1.执行计算机硬件检测程序CPU-Z,GPU-Z;2.记录所用计算机的CPU ID号,Cache大小,指令集,CPU型号,电压,内存,主板,SPD和GPU等所有显示的信息;3.在任务和设备管理器中查看CPU是否为双核?四、实验结果与数据处理1.执行计算机硬件检测程序CPU-Z,GPU-Z;2.记录所用计算机的CPU ID号,Cache大小,指令集,CPU型号,电压,内存,主板,SPD和GPU等所有显示的信息;3.在任务和设备管理器中查看CPU是否为双核?在任务管理器中可以看到CPU为双核:在设备管理器中可以看到CPU为4线程:五、分析与讨论结论:对电脑的构架有的更深的了解。
1.此台电脑CPU是Inter i5,3.20GHz,三级缓存;2.从CPU-Z中的核心时钟频率可以判断计算机的性能,时钟频率越高越好;3.从任务管理器和系统属性上并不能准确的判断CPU的核数,需要用CPU-Z进行检测才能真正确定计算机的核数。
实验一熟悉WinDLX的使用一、实验目的1.熟练掌握WinDLX模拟器的操作和使用2.熟悉DLX指令集结构及其特点二、实验内容1.用WinDLX模拟器执行求阶乘程序fact.s。
这个程序说明浮点指令的使用。
该程序从标准输入读入一个整数,求其阶乘,然后将结果输出。
该程序中调用了input.s中的输入子程序,这个子程序用于读入正整数。
2.用WinDLX模拟器执行求最大公约数程序gcm.s。
该程序从标准输入读入两个整数,求他们的最大公约数,然后将结果写到标准输出。
该程序中调用了input.s中的输入子程序。
3.通过上述使用WinDLX,总结WinDLX的特点。
三、实验报告认真记录实验数据或显示结果。
如实填写实验报告。
数据结构与算法课内实验实验报告

(三)内容提要:
1、数据采集
本次实验,每位同学对自己采集到的数据进行处理。数据采集的要求如下:
1)采集时间:(1)11.15~11.16(数据结构专题实验第4次实验);
(2)11.24(第11周周末);
(3)第5次数据结构专题实验时间;
2)对于每段移动,计算平均速度在m个样本上的速度平均值,16段移动可以得到16个速度平均值,对这16个速度平均值进行排序,给出最大和最小速度对应的段ID和平均速度。
3)对于每段移动,计算移动持续时间在m个样本上的移动持续时间平均值,16段移动可以得到16个移动持续时间平均值,对这16个移动持续时间平均值进行排序,给出最长和最短移动持续时间对应的段ID和移动持续时间。
Record record[16]; //文件中的十六段记录
}Sample;
typedef struct Data //读取原始数据时的中间存储结构
{
int x; //x坐标
int y; //y坐标
int time; //时间戳
int type; //操作类型
}Data;
typedef struct Result //统计结果的存储结构
(4)课内实验验收时间待定
2)采集地点:西一楼307;
3)采集时长:每位同学5~10分钟;
4)采集内容:每位同学认真完成指定的鼠标操作,包括鼠标的移动、鼠标单击和鼠标双击(见下述提示1)。
2、数据处理
采集到的数据会以文本的形式保存,一个文本文件称为一个样本。每位同学需要m个样本完成实验。读取文本文件并对数据进行如下操作:
2、文件的基本操作。文件的打开及读取数据,写入数据等。
数据结构实验报告(合工大)

数据结构实验报告实验一:栈和队列实验目的:掌握栈和队列特点、逻辑结构和存储结构熟悉对栈和队列的一些基本操作和具体的函数定义。
利用栈和队列的基本操作完成一定功能的程序。
实验任务1.给出顺序栈的类定义和函数实现,利用栈的基本操作完成十进制数N与其它d进制数的转换。
(如N=1357,d=8)实验原理:将十进制数N转换为八进制时,采用的是“除取余数法”,即每次用8除N所得的余数作为八进制数的当前个位,将相除所得的商的整数部分作为新的N值重复上述计算,直到N为0为止。
此时,将前面所得到的各余数反过来连接便得到最后的转换结果。
程序清单#include<iostream>#include<cstdlib>using namespace std;typedef int DATA_TYPE;const int MAXLEN=100;enum error_code{success,overflow,underflow};class stack{public:stack();bool empty()const;error_code get_top(DATA_TYPE &x)const;error_code push(const DATA_TYPE x);error_code pop();bool full()const;private:DATA_TYPE data[MAXLEN];int count;};stack::stack(){count=0;}bool stack::empty()const{return count==0;}error_code stack::get_top(DATA_TYPE &x)const {if(empty())return underflow;else{x=data[count-1];return success;}}error_code stack::push(const DATA_TYPE x){if(full())return overflow;else{data[count]=x;count++;}}error_code stack::pop() {if(empty())return underflow;else{count--;return success;}}bool stack::full()const {return count==MAXLEN; }void main(){stack S;int N,d;cout<<"请输入一个十进制数N和所需转换的进制d"<<endl; cin>>N>>d;if(N==0){cout<<"输出转换结果:"<<N<<endl;}while(N){(N%d);N=N/d;}cout<<"输出转换结果:"<<endl;while(!()){(N);cout<<N;();}cout<<endl;}while(!()){(x);cout<<x;();}}测试数据:N=1348 d=8运行结果:2.给出顺序队列的类定义和函数实现,并利用队列计算并打印杨辉三角的前n行的内容。