表碎片起因及解决办法
如何处理MySQL数据库的表碎片问题

如何处理MySQL数据库的表碎片问题为了保持MySQL数据库的高性能和稳定运行,处理表碎片问题是至关重要的。
表碎片是指表中数据不连续存储的现象,导致数据库的性能下降、查询效率下降、磁盘空间浪费等问题。
本文将介绍如何处理MySQL数据库的表碎片问题,并提供一些有效的解决方案。
一、理解表碎片问题的原因在了解如何处理表碎片问题之前,我们先来了解一下表碎片问题的原因。
MySQL数据库中的表是由若干个数据页组成的,当表中的数据发生频繁的更新、插入、删除操作时,可能会导致数据页的碎片化。
这是因为MySQL会为新数据分配新的数据页,而删除和更新操作会留下空白的数据页。
随着操作的不断进行,这些碎片化的数据页会逐渐积累,导致表的碎片化问题。
二、常见的表碎片处理方法1. 重新组织表重新组织表是指对表进行优化,并重新整理表的数据页,以减少碎片的数量。
通过执行"optimize table"命令或使用MySQL提供的工具如phpMyAdmin来实现。
2. 分区表分区表是指将表分成若干个较小的子表,每个子表存储一定范围的数据。
通过将数据分散到不同的子表中,可以减少每个表的数据量,降低碎片化的可能性。
分区表需要根据具体的需求和数据特点进行设计和实现,可以提高数据库的性能和管理效率。
3. 定期重建表定期重建表是指定期将表中的数据导出为备份文件,然后删除原表,重新创建新表,并将备份文件导入新表中。
这样可以消除表中的碎片,同时还可以对表的结构进行优化。
4. 使用碎片整理工具MySQL提供了一些碎片整理工具,如mysqldump和mysqlcheck等,可以通过这些工具来检查和优化数据库表。
它们可以对表进行检查,发现碎片化的问题,并自动优化表。
三、使用策略处理表碎片问题除了上述常见的处理方法,还可以根据具体的情况制定一些有效的策略来处理表碎片问题。
以下是一些常用的策略:1. 定期进行维护定期进行维护是保持数据库性能稳定的重要手段。
oracle表碎片详解

oracle表碎片详解Oracle表碎片是指表中的数据在物理存储上出现不连续的情况,这可能会影响数据库性能和管理。
表碎片化可能发生在多种情况下,比如频繁的数据插入、更新和删除操作,或者由于表的存储空间不足而发生的数据移动等。
下面我将从多个角度对Oracle表碎片进行详细解释。
1. 形成原因,表碎片化可能由于多种原因导致。
比如,当表中的数据频繁插入、更新和删除时,会导致数据在磁盘上不连续存储,从而产生碎片。
此外,如果表的存储空间不足,Oracle数据库可能会将表的数据分散存储在不同的区域,也会导致表碎片化。
2. 影响,表碎片化可能会对数据库性能和管理造成影响。
首先,碎片化的表可能导致查询性能下降,因为数据库需要在不连续的存储空间中查找数据。
其次,碎片化还可能增加数据库的存储空间占用,因为碎片化的表需要更多的存储空间来存储数据。
3. 解决方法,针对Oracle表碎片化问题,可以采取一些解决方法来优化表的存储结构。
比如,可以使用Oracle提供的表重组(Table Reorganization)功能来重新组织表的存储结构,从而减少碎片化。
此外,还可以定期进行表空间的整理和重建,以优化表的存储结构,减少碎片化的发生。
4. 管理工具,Oracle数据库提供了一些管理工具来帮助识别和解决表碎片化问题。
比如,可以使用Oracle Enterprise Manager来监控表的碎片化情况,并采取相应的措施来优化表的存储结构。
此外,还可以使用Oracle提供的存储管理工具来管理表空间,以减少表碎片化的发生。
总的来说,Oracle表碎片化是指表中的数据在物理存储上出现不连续的情况,可能由于多种原因导致,并可能对数据库性能和管理造成影响。
针对表碎片化问题,可以采取一些解决方法来优化表的存储结构,并可以使用Oracle提供的管理工具来帮助识别和解决表碎片化问题。
希望以上回答能够全面解释Oracle表碎片化问题。
oracle需要碎片整理的表

一、背景介绍Oracle数据库作为业界著名的关系型数据库管理系统,在处理大型数据和复杂查询时表现出色。
然而,随着数据库使用时间的增长,数据库内产生的碎片也越来越多,这些碎片将严重影响数据库的性能和查询速度。
对于存在碎片的数据库表,需要进行碎片整理以提高数据库的性能和效率。
二、碎片整理的定义数据库中的碎片是指由于删除、更新等操作而导致数据在磁盘上不连续存储的现象。
碎片整理即是对数据库中的碎片进行清理和重组,使数据在磁盘上存储更加连续,以提高数据库的性能和效率。
三、为何需要碎片整理1. 提高查询速度:碎片整理可以减少数据在磁盘上的碎片化,使得数据库的数据存储更加紧凑,从而提高查询的速度。
2. 节省存储空间:碎片整理可以释放由于碎片化造成的存储空间,减少对磁盘空间的占用。
3. 降低数据库的维护成本:经常进行碎片整理可以减少数据库的维护成本,提高数据库的稳定性和可靠性。
四、如何进行碎片整理1. 使用Oracle自带工具:Oracle提供了一些自带的工具来进行碎片整理,例如DBMS_REDEFINITION包、GATHER_DICTIONARY_STATS过程等。
2. 使用第三方工具:市面上也有一些第三方的数据库碎片整理工具,可以根据具体需求选择适合的工具进行碎片整理操作。
3. 手动整理:在一些特殊情况下,可以选择手动进行碎片整理。
需要建立临时表将数据重新整理后再将数据导入新表来进行碎片整理。
五、碎片整理的注意事项1. 在进行碎片整理前,建议先备份数据库,以防操作出现问题造成数据丢失。
2. 碎片整理操作可能会对数据库的性能产生影响,建议在业务低峰期进行操作,以减少对业务的影响。
3. 在进行碎片整理之前,需要进行全面的评估和规划,确保整理操作的顺利进行。
六、碎片整理的效果评估1. 碎片整理后,需要对数据库进行性能的评估,包括查询速度、存储空间占用等方面进行评估。
2. 如果整理效果不理想,需要及时调整整理策略,并重新进行评估,直到达到预期的整理效果。
MySQL表空间碎片的概念及相关问题解决

MySQL表空间碎⽚的概念及相关问题解决⽬录背景什么是表空间碎⽚?怎么查看表空间碎⽚怎么解决表空间碎⽚问题对于回收空间的问题背景经常使⽤ MySQL 的话,会发现 MySQL 数据⽂件的磁盘空间⼀般会不停的增长,⽽且有时候删了数据或者插⼊⼀批数据的时候,磁盘空间有时候还会毫⽆变化。
引发这个其妙现象的就是 MySQL 的表空间碎⽚。
什么是表空间碎⽚?表空间碎⽚指的是表空间中存在碎⽚,形象⼀点来⽐喻的话,就像是⼀张 A4 纸,“表空间碎⽚”就像是把这张 A4 纸撕碎,再重新拼起来,各个碎⽚之间都会有⼀些缝隙存在,这些缝隙就是“表空间碎⽚”。
重新拼起来的碎⽚实际上会⽐完整的 A4 纸⼤上⼀圈,这也代表着表空间容易引发的问题:空间浪费。
对于背景中描述的现象,可以⽤⼀张图来进⾏解释:图中的数字代表真实的数据⾏,圆⾓矩形代表⼀个表的表空间。
从左往右,第⼀次操作是删除数据,由于 MySQL 在设计上是不会主动释放空间的,因此当表中的数据⾏被删除时,虽然数据被“删除”了,但是实际上这部分空间是没有释放的,依旧会被Table A 占⽤,因此也就出现了这样⼦的情景:删除了⽇志表的很多数据,但是 MySQL 的磁盘空间并没有降低。
PS:这种不释放空间的设计多半和惰性删除有关,早期设计数据库时,使⽤的 IO 设备⼀般是机械盘,读写性能⽐ SSD 差很多,所以删除操作⼀般不会直接触发磁盘上的数据删除。
可以看到数据删除之后,原本连续的空间中出现了两个空⽩的区域,这种⼀般就叫做表空间空洞,空洞太多了就叫做表空间碎⽚化(对应的是表空间连续)。
这部分的空间虽然不会释放,但是会被标记为可重复利⽤,参考最右边的表空间⽰意图(第三个圆⾓矩形),当新插⼊数据的时候新数据会重新写⼊到表空间空洞中,这也代表着:在⼤规模删除过数据的表上,写⼊数据时,表空间可能不会明显增长或者不会增长。
实际上产⽣表空间空洞的操作并不只有 delete,update 也会引起这个问题,⽐如在 varchar 这种变长的字符型列中修改数据,改短⼀些的时候就会出现⾮常⼩的空洞,改长的话就有可能会因为空间不⾜导致把数据⾏的⼀些数据迁移到其他地⽅去。
SQL Server2005索引碎片分析和解决方法

SQL Server2005索引碎片分析和解决方法毫无疑问,给表添加索引是有好处的,你要做的大部分工作就是维护索引,在数据更改期间索引可能产生碎片,所以一些维护是必要的。
碎片可能是你查询产生性能问题的来源。
怎样确定索引是否有碎片?SQLServer提供了一个数据库命令:DBCC SHOWCONTIG,来确定一个指定的表或索引是否有碎片。
下面举一个例子:对't_exam' 表执行DBCC SHOWCONTIG,结果如下:- 扫描页数.....................................: 20229- 扫描扩展盘区数...............................: 2543- 扩展盘区开关数...............................: 15328- 每个扩展盘区上的平均页数.....................: 8.0- 扫描密度〔最佳值:实际值〕....................: 16.50%〔2529:15329〕【如果小于100,则存在碎片。
16.50%说明有很多碎片】- 逻辑扫描碎片.................................: 46.23% 【如果为0是最好)】- 扩展盘区扫描碎片.............................: 45.10%- 每页上的平均可用字节数.......................: 3240.1- 平均页密度(完整)...........................: 59.97% 【如果为100%是最好】以上结果显示:逻辑扫描碎片和扩展盘区扫描碎片都非常大,需要对索引碎片进行处理。
DBCC DBREINDEX 和DBCC INDEXDEFRAG命令常用来整理索引碎片。
这里需要注意的是,非常低的碎片级别(小于5%)不应通过这些命令来解决,因为删除如此少量的碎片所获得的收益始终远低于重新组织或重新生成索引的开销。
truncate table 索引碎片 -回复

truncate table 索引碎片-回复索引碎片整理是数据库管理中的一项关键任务。
在数据库中,索引是用于加快数据检索速度的一种数据结构。
当数据在表中进行插入、更新和删除操作时,索引可能会产生碎片。
所谓索引碎片是指索引存储的位置不连续,导致查询效率下降。
为了维持索引的高效性,我们需要定期对索引进行碎片整理。
本文将一步一步回答“truncate table 索引碎片”这个问题。
首先,我们需要了解truncate table语句的含义。
这是一种用于快速删除表中所有数据的命令。
与普通的DELETE语句不同,truncate table会直接删除整个表,而不是一行一行地删除。
接下来,我们需要明确索引的作用和原理。
在数据库中,索引是一种特殊的数据结构,用于加速数据的查找和访问。
索引是根据数据表中的某一列或多列来创建的,它通过构建一个有序列表,将数据存储在特定的数据页或磁盘块上,从而快速定位需要查询的数据。
然而,随着数据在表中的插入、更新和删除操作,索引可能会产生碎片。
这种碎片化会导致索引存储的位置不连续,进而降低查询效率。
具体来说,当数据被删除时,索引会留下空洞;而当数据被插入时,索引会产生分散的片段。
这些碎片化的索引需要进行整理,以维持数据库的高效运行。
索引碎片整理的目的是通过重新组织索引来消除碎片,以提高查询性能。
下面是一些常见的索引碎片整理方法:1. Rebuild:这是一种完全重建索引的方法。
它会删除原始索引,然后根据表中的数据重新创建索引。
这个过程可能需要较长的时间,尤其是对于大型表来说。
但是,通过重新组织数据,重建索引可以有效地消除碎片,提高查询性能。
2. Reorganize:与重建索引相比,重新组织索引是一种更轻量级的方法。
它会重新组织索引的物理结构,但不会删除和重新创建索引。
通过重新组织数据页和磁盘块,重新组织索引可以消除碎片,提升查询性能。
相对于重建索引,重新组织索引的时间更短,适用于频繁更新的表。
解决Excel中数据丢失和损坏的问题

解决Excel中数据丢失和损坏的问题在当今数字化时代,Excel已成为企业和个人管理数据的重要工具。
然而,很多人在使用Excel时常常遇到数据丢失或损坏的问题,这不仅浪费时间和精力,还可能导致信息的不准确性和重要数据的丢失。
本文将为您介绍几种解决Excel中数据丢失和损坏问题的方法。
一、定期备份数据数据备份是防范数据丢失和损坏的必要手段。
请注意,在进行任何Excel操作之前,都应该及时备份数据,并将备份文件存储在安全可靠的地方。
这样,即使出现数据丢失或损坏问题,您也可以随时恢复以前的数据,避免遭受不必要的损失。
二、避免频繁存储和关闭文件频繁的存储和关闭Excel文件可能会导致数据在保存和关闭过程中丢失。
为避免这种情况发生,建议您在对Excel进行编辑和操作时,尽可能减少文件的存储和关闭操作。
只有在确保数据完整无误后再进行存储和关闭,可以大大降低数据丢失和损坏的概率。
三、修复损坏的Excel文件如果您的Excel文件已损坏,可以尝试使用Excel自带的修复功能进行修复。
具体操作如下:1. 打开Excel软件,并点击“文件”选项卡;2. 在下拉菜单中选择“打开”;3. 在打开文件对话框中,找到需要修复的Excel文件并选中;4. 同时按下“Ctrl”和“Shift”键,然后点击“打开”按钮;5. 在弹出的修复对话框中,选择适当的修复方式进行修复。
四、使用第三方的修复工具除了Excel自带的修复功能外,市面上也有许多第三方的Excel修复工具可供选择。
这些工具往往能够更全面地检测和修复Excel文件中的问题。
您可以通过搜索引擎查找并选择适合您需求的工具进行修复。
请注意,在使用第三方修复工具之前,应谨慎选择和确认工具的安全性和可靠性。
最好选择一些知名度高、用户口碑好的工具,以确保数据的安全和有效修复。
五、寻求专业的技术支持如果您在解决数据丢失和损坏问题时遇到了困难,或者无法通过以上方法解决问题,建议您寻求专业的技术支持。
Oracle表碎片整理操作步骤详解

Oracle表碎⽚整理操作步骤详解⾼⽔位线(HWL)下的许多数据块都是⽆数据的,但全表扫描的时候要扫描到⾼⽔位线的数据块,也就是说oracle要做许多的⽆⽤功!因此oracle提供了shrink space碎⽚整理功能。
对于索引,可以采取rebuild online的⽅式进⾏碎⽚整理,⼀般来说,经常进⾏DML操作的对象DBA要定期进⾏维护,同时注意要及时更新统计信息!,使⽤HR⽤户,创建T1表,插⼊约30W的数据,并根据object_id创建普通索引,表占存储空间34M复制代码代码如下:SQL> conn /as sysdba已连接。
SQL> select default_tablespace from dba_users where username='HR';DEFAULT_TABLESPACE------------------------------------------------------------USERSSQL> conn hr/hr已连接。
SQL> insert into t1 select * from t1;已创建 74812 ⾏。
SQL> insert into t1 select * from t1;已创建 149624 ⾏。
SQL> commit;提交完成。
SQL> create index idx_t1_id on t1(object_id);索引已创建。
SQL> exec dbms_stats.gather_table_stats('HR','T1',CASCADE=>TRUE);PL/SQL 过程已成功完成。
SQL> select count(1) from t1;COUNT(1)----------299248SQL> select sum(bytes)/1024/1024 from dba_segments where segment_name='T1';SUM(BYTES)/1024/1024--------------------34.0625SQL> select sum(bytes)/1024/1024 from dba_segments where segment_name='IDX_T1_ID';SUM(BYTES)/1024/1024--------------------6,这个值应当越低越好,表使⽤率越接近⾼⽔位线,全表扫描所做的⽆⽤功也就越少!DBMS_STATS包⽆法获取EMPTY_BLOCKS统计信息,所以需要⽤analyze命令再收集⼀次统计信息复制代码代码如下:SQL> SELECT blocks, empty_blocks, num_rows FROM user_tables WHERE table_name ='T1';BLOCKS EMPTY_BLOCKS NUM_ROWS---------- ------------ ----------4302 0 299248SQL> analyze table t1 compute statistics;表已分析。
SQLServer索引碎片和解决方法

SQLServer索引碎片和解决方法毫无疑问,给表添加索引是有好处的,你要做的大部分工作就是维护索引,在数据更改期间索引可能产生碎片,所以一些维护是必要的。
碎片可能是你查询产生性能问题的来源。
那么到底什么是索引碎片呢?索引碎片实际上有2种形式:外部碎片和内部碎片。
不管哪种碎片基本上都会影响索引内页的使用。
这也许是因为页的逻辑顺序错误(即外部碎片)或每页存储的数据量少于数据页的容量(内部错误)。
无论索引产生了哪种类型的碎片,你都会因为它而面临查询的性能问题。
外部碎片当索引页不在逻辑顺序上时就会产生外部碎片。
索引创建时,索引键按照逻辑顺序放在一组索引页上。
当新数据插入索引时,新的键可能放在存在的键之间。
为了让新的键按照正确的顺序插入,可能会创建新的索引页来存储需要移动的那些存在的键。
这些新的索引页通常物理上不会和那些被移动的键原来所在的页相邻。
创建新页的过程会引起索引页偏离逻辑顺序。
下面的例子将比实际的言论更加清晰的解释这个概念。
假定在任何另外的数据插入你的表之前存在索引上的结构如下(注:下面图片里应该是7和8,原文里是6和8):INSERT语句往索引里添加新的数据,假定添加的是5。
INSERT将引起新页创建,为了给5在原来的页上留出空间,7和8被移到了新页上。
这个创建将引起索引页偏离逻辑顺序。
在有特定搜索或者返回无序结果集的查询的情况下,偏离顺序的索引页不会引起问题。
对于返回有序结果集的查询,搜索那些无序的索引页需要进行额外的处理。
有序结果集的例子如查询返回4到10之间的记录。
为了返回7和8,查询不得不进行额外的页切换。
虽然一个额外的页切换在一个长时间运行里是无关紧要的,然而想象一下一个有好几百页偏离顺序的非常大的表的情形。
内部碎片当索引页没有用到最大量时就产生了内部碎片。
虽然在一个有频繁数据插入的应用程序里这也许有帮助,然而设置一个fill factor(填充因子)会在索引页上留下空间,服务器内部碎片会导致索引尺寸增加,从而在返回需要的数据时要执行额外的读操作。
oracle表碎片详解

oracle表碎片详解Oracle数据库是一种关系型数据库管理系统,用于存储和管理大量数据。
在Oracle中,表碎片是指表的数据和索引在物理存储上被分散到不同的数据块或数据文件中。
本文将详细介绍Oracle表碎片的概念、原因、影响以及解决方法。
一、概念表碎片是指表的数据和索引在物理存储上被分散到不同的数据块或数据文件中。
这种分散导致了数据的存储不连续,影响了查询和维护的性能。
二、原因1. 数据插入、更新和删除操作导致表的数据和索引发生变化,使得数据不连续。
2. 数据迁移或表空间重组操作可能导致表碎片。
3. 数据库备份和恢复操作也可能导致表碎片的产生。
三、影响表碎片会影响数据库的性能和存储空间利用率,具体表现为:1. 查询性能下降:由于数据分散在不同的数据块或数据文件中,查询时需要跨越多个数据块或数据文件,增加了IO操作的次数,导致查询性能下降。
2. 空间浪费:表碎片导致数据存储不连续,使得表的存储空间利用率降低,造成空间浪费。
3. 维护困难:表碎片会增加数据库的维护工作量,包括碎片整理、空间释放等操作。
四、解决方法为了解决表碎片问题,可以采取以下方法:1. 碎片整理:通过执行碎片整理操作,将表的数据和索引重新组织,使其连续存储,提高查询性能。
2. 表空间重组:对于存在大量碎片的表空间,可以进行表空间重组操作,重新分配数据块,减少碎片。
3. 定期维护:定期进行数据库维护工作,包括碎片整理、空间释放等操作,保持数据库的良好状态。
4. 合理设计:在数据库设计阶段,可以考虑合理的数据分区策略,减少表碎片的产生。
总结:表碎片是Oracle数据库中常见的问题,会对数据库的性能和存储空间利用率产生影响。
通过合理的数据库维护和设计,可以有效地解决表碎片问题,提高数据库的性能和可用性。
为了保持数据库的健康状态,管理员应该定期进行碎片整理和维护工作,以提高数据库的性能和可靠性。
sql索引碎片产生的原理解决碎片的办法(sql碎片整理)
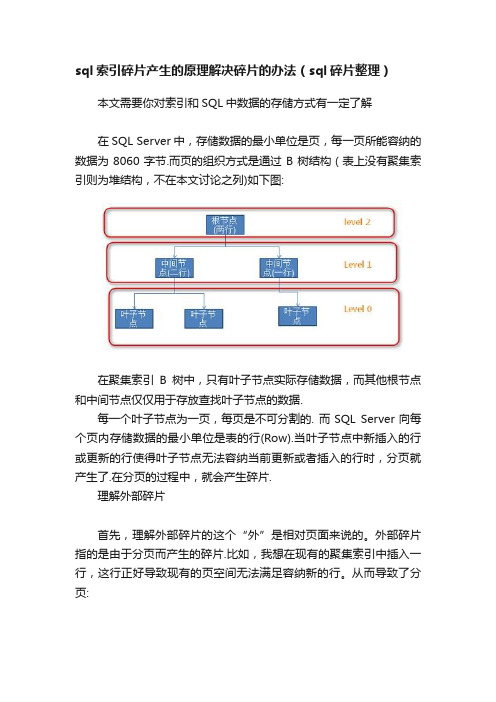
sql索引碎片产生的原理解决碎片的办法(sql碎片整理)本文需要你对索引和SQL中数据的存储方式有一定了解在SQL Server中,存储数据的最小单位是页,每一页所能容纳的数据为8060字节.而页的组织方式是通过B树结构(表上没有聚集索引则为堆结构,不在本文讨论之列)如下图:在聚集索引B树中,只有叶子节点实际存储数据,而其他根节点和中间节点仅仅用于存放查找叶子节点的数据.每一个叶子节点为一页,每页是不可分割的. 而SQL Server向每个页内存储数据的最小单位是表的行(Row).当叶子节点中新插入的行或更新的行使得叶子节点无法容纳当前更新或者插入的行时,分页就产生了.在分页的过程中,就会产生碎片.理解外部碎片首先,理解外部碎片的这个“外”是相对页面来说的。
外部碎片指的是由于分页而产生的碎片.比如,我想在现有的聚集索引中插入一行,这行正好导致现有的页空间无法满足容纳新的行。
从而导致了分页:因为在SQL SERVER中,新的页是随着数据的增长不断产生的,而聚集索引要求行之间连续,所以很多情况下分页后和原来的页在磁盘上并不连续.这就是所谓的外部碎片.由于分页会导致数据在页之间的移动,所以如果插入更新等操作经常需要导致分页,则会大大提升IO消耗,造成性能下降.而对于查找来说,在有特定搜索条件,比如where子句有很细的限制或者返回无序结果集时,外部碎片并不会对性能产生影响。
但如果要返回扫描聚集索引而查找连续页面时,外部碎片就会产生性能上的影响.在SQL Server中,比页更大的单位是区(Extent).一个区可以容纳8个页.区作为磁盘分配的物理单元.所以当页分割如果跨区后,需要多次切区。
需要更多的扫描.因为读取连续数据时会不能预读,从而造成额外的物理读,增加磁盘IO.理解内部碎片和外部碎片一样,内部碎片的”内”也是相对页来说的.下面我们来看一个例子:我们创建一个表,这个表每个行由int(4字节),char(999字节)和varchar(0字节组成),所以每行为1003个字节,则8行占用空间1003*8=8024字节加上一些内部开销,可以容纳在一个页面中:当我们随意更新某行中的col3字段后,造成页内无法容纳下新的数据,从而造成分页:分页后的示意图:而当分页时如果新的页和当前页物理上不连续,则还会造成外部碎片内部碎片和外部碎片对于查询性能的影响外部碎片对于性能的影响上面说过,主要是在于需要进行更多的跨区扫描,从而造成更多的IO操作.而内部碎片会造成数据行分布在更多的页中,从而加重了扫描的页树,也会降低查询性能.下面通过一个例子看一下,我们人为的为刚才那个表插入一些数据造成内部碎片:通过查看碎片,我们发现这时碎片已经达到了一个比较高的程度:通过查看对碎片整理之前和之后的IO,我们可以看出,IO大大下降了:对于碎片的解决办法基本上所有解决办法都是基于对索引的重建和整理,只是方式不同1.删除索引并重建这种方式并不好.在删除索引期间,索引不可用.会导致阻塞发生。
MYSQL数据表损坏的原因分析和修复方法

MYSQL数据表损坏的原因分析和修复方法表损坏的原因分析以下原因是导致mysql 表毁坏的常见原因:1、服务器突然断电导致数据文件损坏。
2、强制关机,没有先关闭mysql 服务。
3、 mysqld 进程在写表时被杀掉。
4、使用myisamchk 的同时,mysqld 也在操作表。
5、磁盘故障。
6、服务器死机。
7、 mysql 本身的bug 。
3lian素材 /doc/a716392433.html,2. 表损坏的症状一个损坏的表的典型症状如下:1 、当在从表中选择数据之时,你得到如下错误:Incorrect key file for table: '...'. Try to repair it2 、查询不能在表中找到行或返回不完全的数据。
3 、Error: Table 'p' is marked as crashed and should be repaired 。
4 、打开表失败:Can’t open file: ‘×××.MYI’ (errno: 145) 。
5 、3. 预防 MySQL 表损坏可以采用以下手段预防mysql 表损坏:1 、定期使用myisamchk 检查MyISAM 表(注意要关闭mysqld ),推荐使用check table 来检查表(不用关闭mysqld )。
2 、在做过大量的更新或删除操作后,推荐使用OPTIMIZE TABLE 来优化表,这样既减少了文件碎片,又减少了表损坏的概率。
3 、关闭服务器前,先关闭mysqld (正常关闭服务,不要使用kill -9 来杀进程)。
4 、使用ups 电源,避免出现突然断电的情况。
5 、使用最新的稳定发布版mysql ,减少mysql 本身的bug 导致表损坏。
6 、对于InnoDB 引擎,你可以使用innodb_tablespace_monitor 来检查表空间文件内文件空间管理的完整性。
mysql表碎片整理

mysql表碎片整理MySQL是最常用的关系型数据库管理系统之一,它的性能和稳定性对于数据存储和查询非常重要。
然而,在长时间运行的数据库中,表碎片的产生可能会对数据库的性能产生负面影响。
因此,定期进行MySQL表碎片整理是必要的。
本文将介绍MySQL表碎片的定义、产生原因以及整理方法,以帮助读者更好地维护数据库的健康运行。
一、MySQL表碎片的定义和产生原因表碎片是指数据库表中存在的未被连续占用的空间,它产生的原因包括:删除的记录、更新的记录导致行长度变短、表的自动增长导致行迁移等等。
当表出现碎片时,MySQL在进行数据读取和写入操作时需要额外的时间和资源来定位和处理碎片,从而导致数据库性能下降。
二、整理MySQL表碎片的方法1. 使用OPTIMIZE TABLE命令OPTIMIZE TABLE命令可以对表进行碎片整理和优化,它会重新创建表并将数据按照物理存储顺序重新整理。
在MySQL中,可以通过以下语法使用OPTIMIZE TABLE命令:OPTIMIZE TABLE table_name;2. 使用ALTER TABLE命令ALTER TABLE命令也可以用于整理MySQL表碎片,它通过重建表的方式来达到整理碎片的目的。
在MySQL中,可以通过以下语法使用ALTER TABLE命令:ALTER TABLE table_name ENGINE=InnoDB;3. 使用mysqldump和mysql命令使用mysqldump命令将数据库中的表导出为SQL文件,然后使用mysql命令重新导入SQL文件,这个过程会重新创建表并整理碎片。
4. 使用专业的数据库管理工具除了上述方法外,还可以使用一些专业的数据库管理工具来整理MySQL表碎片,这些工具可以提供更方便和快捷的操作方式,并且可以定期进行碎片整理。
三、注意事项和建议1. 定期进行碎片整理为了保证数据库的性能和稳定性,建议定期进行MySQL表碎片整理,以避免碎片对数据库性能的负面影响。
MySQL中的索引碎片和表碎片的处理

MySQL中的索引碎片和表碎片的处理数据库是现代软件开发中不可或缺的一环,而MySQL作为最常用的关系型数据库管理系统(RDBMS),承载了大量的数据存储和查询任务。
然而,随着数据库的使用,索引碎片和表碎片问题逐渐凸显出来,对数据库性能产生了负面影响。
本文将深入探讨MySQL中索引碎片和表碎片的产生原因以及相应的处理方法。
1. 索引碎片的产生原因在MySQL中,索引碎片是指索引空间中的数据不是紧密排列的情况,造成数据物理上的分散。
主要原因如下:1.1 索引的插入和删除操作。
当新数据被插入到索引中或者已有的数据被删除时,会导致数据的移动和重组,从而引发索引碎片的产生。
1.2 索引的更新操作。
当索引列的值被修改时,索引数据也需要随之更新。
如果某个索引列的值被频繁修改,那么更新操作可能会导致索引碎片增加。
1.3 索引的分裂操作。
当一棵B树索引达到一定数量的节点时,MySQL会将该索引进行分裂,将一部分节点移动到新的磁盘页中。
这个分裂操作也有可能造成索引碎片。
2. 表碎片的产生原因表碎片是指数据表中数据在磁盘上的存储位置不是相邻的情况。
表碎片产生的主要原因如下:2.1 数据的插入和删除操作。
当新数据被插入到表中或者已有的数据被删除时,会导致数据的移动和重组,从而使得表的数据在磁盘上分散存储,形成表碎片。
2.2 数据的更新操作。
当表中的数据被修改时,原有的数据可能会被移动到新的位置,再插入新的数据,这也会导致表碎片的产生。
2.3 数据的移动和重组操作。
有时候为了优化表的查询性能,数据库管理员会对数据表进行重组和整理,这也会导致表的碎片化。
3. 索引碎片和表碎片对性能的影响索引碎片和表碎片的产生对数据库的性能会产生一系列的不利影响:3.1 索引碎片会增加索引的访问成本。
当索引碎片严重时,查询操作需要访问更多的磁盘页面,增加了IO操作的花费,从而导致查询性能下降。
3.2 表碎片会增加磁盘IO操作的数量。
随着表碎片的产生,数据库需要多次读取不相邻的磁盘页面才能获取完整的数据,导致磁盘IO的开销增加。
索引碎片的产生以及解决方案

创建索引是为了在检索数据时能够减少时间,提高检索效率。
创建好了索引,并且所有索引都在工作,但性能却仍然不好,那很可能是产生了索引碎片,你需要进行索引碎片整理。
1、什么是索引碎片?由于表上有过度地插入、修改和删除操作,索引页被分成多块就形成了索引碎片,如果索引碎片严重,那扫描索引的时间就会变长,甚至导致索引不可用,因此数据检索操作就慢下来了。
有两种类型的索引碎片:内部碎片和外部碎片。
内部碎片:为了有效的利用内存,使内存产生更少的碎片,要对内存分页,内存以页为单位来使用,最后一页往往装不满,于是形成了内部碎片。
外部碎片:为了共享要分段,在段的换入换出时形成外部碎片,比如5K的段换出后,有一个4k的段进来放到原来5k的地方,于是形成1k的外部碎片。
2、如何知道是否发生了索引碎片?执行下面的SQL语句就知道了(下面的语句可以在SQL Server 2005及后续版本中运行,用你的数据库名替换掉这里的AdventureWorks):SELECTobject_name(dt.object_id) Tablename,IndexName,dt.avg_fragmentation_in_percent ASExternalFragmentation,dt.avg_page_space_used_in_percent ASInternalFragmentationFROM(SELECTobject_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks'),null,null,null,'DETAILED' )WHERE index_id <>0) AS dt INNERJOIN sys.indexes si ON si.object_id=dt.object_idAND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>10AND dt.avg_page_space_used_in_percent<75ORDERBY avg_fragmentation_in_percent DESC执行后显示AdventureWorks数据库的索引碎片信息。
MYSQL优化之数据表碎片整理详解

MYSQL优化之数据表碎⽚整理详解⽬录在MySQL中,我们经常会使⽤VARCHAR、TEXT、BLOB等可变长度的⽂本数据类型。
不过,当我们使⽤这些数据类型之后,我们就不得不做⼀些额外的⼯作——MySQL数据表碎⽚整理。
那么,为什么在使⽤这些数据类型之后,我们就要对MySQL定期进⾏碎⽚整理呢?现在,我们先来看⼀个具体的例⼦。
在这⾥,我们使⽤如下SQL语句在MySQL⾃带的TEST数据库中创建名为DEMO的数据表并插⼊5条测试数据。
--创建DEMO表CREATE TABLE DEMO(id int unsigned,body text) engine=myisam charset=utf8;--插⼊5条测试数据INSERT INTO DEMO VALUES(1,'AAAAA');INSERT INTO DEMO VALUES(2,'BBBBB');INSERT INTO DEMO VALUES(3,'CCCCC');INSERT INTO DEMO VALUES(4,'DDDDD');INSERT INTO DEMO VALUES(5,'EEEEE');然后我们以这5条测试数据为基础,使⽤如下INSERT INTO语句重复执⾏多次进⾏复制性插⼊。
INSERT INTO DEMO SELECT id, body FROM DEMO;使⽤INSERT INTO语句多次插⼊产⽣总共约262万条数据众所周知,MySQL中MyISAM表的数据是以⽂件形式存储的,我们可以在MySQL存储数据的⽂件夹中找到数据库test⽬录下的demo.MYD⽂件。
此时,我们可以看到demo.MYD⽂件的⼤⼩约为50MB。
demo.MYD⽂件约为50MB此时,假如我们需要删除DEMO表中所有ID列⼩于3的数据(即1和2),于是我们执⾏如下SQL语句:DELETE FROM DEMO WHERE id < 3此时,我们可以看到DEMO表中的数据量只有原来的3/5:删除后,只剩下157万条记录DEMO表中的现有数据量只有原来的3/5,按理说,这个时候demo.MYD⽂件的⼤⼩也应该只有原来的3/5左右。
MySQL表的碎片整理和空间回收小结

MySQL表的碎⽚整理和空间回收⼩结MySQL表碎⽚化(Table Fragmentation)的原因关于MySQL中表碎⽚化(Table Fragmentation)产⽣的原因,简单总结⼀下,MySQL Engine不同,碎⽚化的原因可能也有所差别。
这⾥没有深⼊理解、分析这些差别。
此⽂仅以InnoDB引擎为主。
总结如有不⾜或错误的地⽅,敬请指出。
InnoDB表的数据存储在页(page)中,每个页可以存放多条记录。
这些记录以树形结构组织,这颗树称为B+树索引。
表中数据和辅助索引都是使⽤B+树结构。
维护表中所有数据的这颗B+树索引称为聚簇索引,通过主键来组织的。
聚簇索引的叶⼦节点包含⾏中所有字段的值,辅助索引的叶⼦节点包含索引列和主键列。
在InnoDB中,删除⼀些⾏,这些⾏只是被标记为“已删除”,⽽不是真的从索引中物理删除了,因⽽空间也没有真的被释放回收。
InnoDB的Purge线程会异步的来清理这些没⽤的索引键和⾏。
但是依然没有把这些释放出来的空间还给操作系统重新使⽤,因⽽会导致页⾯中存在很多空洞。
如果表结构中包含动态长度字段,那么这些空洞甚⾄可能不能被InnoDB重新⽤来存新的⾏,因为空间空间长度不⾜。
关于这个你可以参考博客。
另外,删除数据就会导致页(page)中出现空⽩空间,⼤量随机的DELETE操作,必然会在数据⽂件中造成不连续的空⽩空间。
⽽当插⼊数据时,这些空⽩空间则会被利⽤起来.于是造成了数据的存储位置不连续。
物理存储顺序与逻辑上的排序顺序不同,这种就是数据碎⽚。
对于⼤量的UPDATE,也会产⽣⽂件碎⽚化, Innodb的最⼩物理存储分配单位是页(page),⽽UPDATE也可能导致页分裂(page split),频繁的页分裂,页会变得稀疏,并且被不规则的填充,所以最终数据会有碎⽚。
First at all you must understand that Mysql tables get fragmented when a row is updated, so it's a normal situation. When a table is created, lets say imported using a dump with data, all rows are stored with no fragmentation in many fixed size pages. When you update a variable length row, the page containing this row is divided in two or more pages to store the changes, and these new two (or more) pages contains blank spaces filling the unused space.表的数据存储也可能碎⽚化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
表碎片起因及解决办法跟表碎片有关的基础知识:什么是水线(High Water Mark)?----------------------------所有的oracle段(segments,在此,为了理解方便,建议把segment作为表的一个同义词) 都有一个在段内容纳数据的上限,我们把这个上限称为"high water mark"或HWM。
这个HWM是一个标记,用来说明已经有多少没有使用的数据块分配给这个segment。
HWM通常增长的幅度为一次5个数据块,原则上HWM只会增大,不会缩小,即使将表中的数据全部删除,HWM还是为原值,由于这个特点,使HWM很象一个水库的历史最高水位,这也就是HWM的原始含义,当然不能说一个水库没水了,就说该水库的历史最高水位为0。
但是如果我们在表上使用了truncate命令,则该表的HWM会被重新置为0。
HWM数据库的操作有如下影响:a) 全表扫描通常要读出直到HWM标记的所有的属于该表数据库块,即使该表中没有任何数据。
b) 即使HWM以下有空闲的数据库块,键入在插入数据时使用了append关键字,则在插入时使用HWM以上的数据块,此时HWM会自动增大。
如何知道一个表的HWM?a) 首先对表进行分析:ANALYZE TABLE <tablename> ESTIMATE/COMPUTE STATISTICS;b) SELECT blocks, empty_blocks, num_rowsFROM user_tablesWHERE table_name = <tablename>;BLOCKS 列代表该表中曾经使用过得数据库块的数目,即水线。
EMPTY_BLOCKS 代表分配给该表,但是在水线以上的数据库块,即从来没有使用的数据块。
让我们以一个有28672行的BIG_EMP1表为例进行说明:1) SQL> SELECT segment_name,segment_type,blocksFROM dba_segmentsWHERE segment_name='BIG_EMP1';SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS----------------------------- ----------------- ---------- ------- BIG_EMP1 TABLE 1024 21 row selected.2) SQL> ANALYZE TABLE big_emp1 ESTIMATE STATISTICS;Statement processed.3) SQL> SELECT table_name,num_rows,blocks,empty_blocksFROM user_tablesWHERE table_name='BIG_EMP1';TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS------------------------------ ---------- ---------- ------------ BIG_EMP1 28672 700 3231 row selected.注意:BLOCKS + EMPTY_BLOCKS (700+323=1023)比DBA_SEGMENTS.BLOCKS少个数据库块,这是因为有一个数据库块被保留用作segment header。
DBA_SEGMENTS.BLOCKS 表示分配给这个表的所有的数据库块的数目。
USER_TABLES.BLOCKS表示已经使用过的数据库块的数目。
4) SQL> SELECT COUNT (DISTINCTDBMS_ROWID.ROWID_BLOCK_NUMBER(rowid)||DBMS_ROWID.ROWID_RELATIVE_FNO(rowid)) "Used"FROM big_emp1;Used----------7001 row selected.5) SQL> DELETE from big_emp1;28672 rows processed.6) SQL> commit;Statement processed.7) SQL> ANALYZE TABLE big_emp1 ESTIMATE STATISTICS;Statement processed.8) SQL> SELECT table_name,num_rows,blocks,empty_blocksFROM user_tablesWHERE table_name='BIG_EMP1';TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS------------------------------ ---------- ---------- ------------ BIG_EMP1 0 700 3231 row selected.9) SQL> SELECT COUNT (DISTINCTDBMS_ROWID.ROWID_BLOCK_NUMBER(rowid)||DBMS_ROWID.ROWID_RELATIVE_FNO(rowid)) "Used"FROM big_emp1;Used----------0 -- 这表名没有任何数据库块容纳数据,即表中无数据1 row selected.10) SQL> TRUNCATE TABLE big_emp1;Statement processed.11) SQL> ANALYZE TABLE big_emp1 ESTIMATE STATISTICS;Statement processed.12) SQL> SELECT table_name,num_rows,blocks,empty_blocks2> FROM user_tables3> WHERE table_name='BIG_EMP1';TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS------------------------------ ---------- ---------- ------------ BIG_EMP1 0 0 5111 row selected.13) SQL> SELECT segment_name,segment_type,blocksFROM dba_segmentsWHERE segment_name='BIG_EMP1';SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS----------------------------- ----------------- ---------- ------- BIG_EMP1 TABLE 512 11 row selected.注意:TRUNCATE命令回收了由delete命令产生的空闲空间,注意该表分配的空间由原先的1024块降为512块。
为了保留由delete命令产生的空闲空间,可以使用TRUNCATE TABLE big_emp1 REUSE STORAGE用此命令后,该表还会是原先的1024块。
行链接(Row chaining) 与行迁移(Row Migration)当一行的数据过长而不能插入一个单个数据块中时,可能发生两种事情:行链接(row chaining)或行迁移(row migration)。
行链接当第一次插入行时,由于行太长而不能容纳在一个数据块中时,就会发生行链接。
在这种情况下,oracle会使用与该块链接的一块或多块数据块来容纳该行的数据。
行连接经常在插入比较大的行时才会发生,如包含long, long row, lob等类型的数据。
在这些情况下行链接是不可避免的。
行迁移当修改不是行链接的行时,当修改后的行长度大于修改前的行长度,并且该数据块中的空闲空间已经比较小而不能完全容纳该行的数据时,就会发生行迁移。
在这种情况下,Oracle会将整行的数据迁移到一个新的数据块上,而将该行原先的空间只放一个指针,指向该行的新的位置,并且该行原先空间的剩余空间不再被数据库使用,这些剩余的空间我们将其称之为空洞,这就是产生表碎片的主要原因,表碎片基本上也是不可避免的,但是我们可以将其降到一个我们可以接受的程度。
注意,即使发生了行迁移,发生了行迁移的行的rowid 还是不会变化,这也是行迁移会引起数据库I/O性能降低的原因。
其实行迁移是行链接的一种特殊形式,但是它的起因与行为跟行链接有很大不同,所以一般把它从行链接中独立出来,单独进行处理。
行链接和行迁移引起数据库性能下降的原因:引起性能下降的原因主要是由于引起多余的I/O造成的。
当通过索引访问已有行迁移现象的行时,数据库必须扫描一个以上的数据块才能检索到改行的数据。
这主要有一下两种表现形式:1) 导致row migration 或row chaining INSERT 或 UPDATE语句的性能比较差,因为它们需要执行额外的处理2) 利用索引查询已经链接或迁移的行的select语句性能比较差,因为它们要执行额外的I/O如何才能检测到行迁移与行链接:在表中被迁移或被链接的行可以通过带list chained rows选项的analyze语句识别出来。
这个命令收集每个被迁移或链接的行的信息,并将这些信息放到指定的输出表中。
为了创建这个输出表,运行脚本UTLCHAIN.SQL。
SQL> ANALYZE TABLE scott.emp LIST CHAINED ROWS;SQL> SELECT * FROM chained_rows;当然你也可以通过检查v$sysstat视图中的'table fetch continued row'来检查被迁移或被链接的行。
SQL> SELECT name, value FROM v$sysstat WHERE name = 'table fetch continued row';NAME VALUE-------------------------------------------------------------------------table fetch continued row 308尽管行迁移与行链接是两个不同的事情,但是在oracle内部,它们被当作一回事。