AIX的vmstat命令详解
AIX 5L 内存性能优化之使用 ps、sar、svmon 和 vmstat 监视内存的使用

AIX 5L 内存性能优化之使用ps、sar、svmon 和vmstat 监视内存的使用AIX 5L 内存性能优化之使用ps、sar、svmon 和vmstat 监视内存的使用,通过命令监控AIX系统的内存使用状况,进而进行系统内存的性能优化,是一个系统管理员对系统优化要做的基本工作!内存子系统中最重要的优化部分并不涉及到实际的优化工作。
在对您的系统进行优化之前,必须弄清楚主机系统的实际运行情况。
要做到这一点,AIX® 管理员必须知道应该使用何种工具,以及如何对他或她将要捕获的数据进行分析。
再次说明近期发表的一些其他优化文章中所介绍的内容,您在对系统进行正确地优化之前,必须首先监视主机,无论它是在逻辑分区(LPAR) 运行还是在自己的物理服务器上运行。
您可以使用许多命令来捕获和分析数据,所以您需要了解这些命令,以及其中的哪个命令最适合于将要进行的工作。
在捕获了相关的数据之后,您需要对结果进行分析。
有些问题乍看起来像是一个中央处理单元(CPU) 的问题,而经过分析之后,可以正确地诊断为内存或I/O 问题,前提是您使用了合适的工具捕获数据,并且知道如何进行分析工作。
仅当正确地完成了这些工作之后,您才可以考虑对系统进行实际的更改。
如果医生不了解您的病史和目前的症状,就无法诊治疾病,同样地,您也需要在优化子系统之前对其进行诊断。
如果在出现CPU 或者I/O 瓶颈的情况下,对内存子系统进行优化,这将是毫无帮助的,甚至可能会影响主机的正常运行。
本文将帮助您了解正确地实施诊断工作的重要性。
您将看到,性能优化并不仅仅只是进行实际的优化工作。
在您将要学习的工具中,有一些是通用的监视工具,所有版本的UNIX 都提供了这些工具,另外还有一些工具是专门为AIX 编写的。
有些工具为AIX Version 5.3 进行了优化,同时还专门为AIX 5.3 系统开发了一些新的工具。
生成基准数据是非常重要的,这一点无论重申多少次都不为过。
Aix服务器检查命令

Aix服务器检查命令AIX系统巡检注意事项巡检一般又厂商或者代理商来做。
第一:首先是机房温度以及湿度的检查,当然这些一般情况都没问题。
参考值:温度(摄氏℃)10 ℃-40℃湿度 8% -80%第二:就是关于电源的检测,这个只要不是新装机,一般没问题。
参考值:零-地电压小于1V火-地电压 200-240V补充:当然59系列的机器相间380V,相地240V。
第三:关于报错。
主要查看硬件的永久性报错#errpt -dH | pg软件的永久性报错#errpt -dS | pg还有系统又没又报警灯(如果不正常,在后面的帖子将会细讲)第三:机器的序列号:#uname -Mu第四:操作系统版本:#oslevel -r注:又时候不能使用是因为系统版本低的原因第五:其他检测执行sysdumpdev –l 检查dump是否设置为always allow sysdump执行sysdumpdev –e检查当前dump大小应该为主dump设备的大小的80%以下执行lsvg -l rootvg检查有否"stale"状态的逻辑卷执行lsps -s检查内存交换区占用情况执行df –k检查文件系统的分配状况,一般不要超过80%执行lsdev –Ccdisk检查硬盘状态为available执行lsdev –Ccadapter检查PCI卡状态为available执行lsdev –Cctape检查磁带机状态为available执行lsdev – Ccprocessor检查CPU状态为available执行 lsattr –El sys0|grep autorestart检查系统crash后是否自动重新启动执行lsattr –El sys0|grep cpuguard检查CPU GUARD是否开启执行lsattr –El mem0检查内存状态正常size=goodsize执行 vmstat 2iostat,topas观察us,sy,pi,po,内存占用率,硬盘读写速度等检查是否有性能瓶颈执行netstat –in和netstat –rn观察网络状态执行entstat –d enX检测网卡运行速率与交换机速率是否匹配(网卡速率由10M半工改为自适应时,缺省网关会丢失。
AIX 第十一章 系统性能监视

监视系统整体性能(4) -sar
例:观察10分种内的CPU活动情况,并存储数据: #sar –o tempfile 60 10 在该时间段后检查磁盘和磁带活动: #sar -d -f tempfile 之后,检查多处理器系统的CPU利用率: #sar -u -M -f tempfile 例:使用-b选项sar命令可监视缓冲存储器的行为, 这对于数据库应用程序是非常有用的: #sar –b 1 5
第十一章 系统性能监视学习要点Fra bibliotek
监视系统整体性能 uptime命令 sar命令 top命令 ps命令 监视内存 vmstat命令 监视磁盘性能 iostat命令
监视系统整体性能(1)-uptime
使用uptime命令监视系统性能
uptime命令可以大致分析系统的工作负载。当系统 性能发生问题时,应首先使用该命令查看负载及用户数 等。 该命令显示当前系统时间,系统运行了多久,多少用 户登录及过去1分钟、5分钟、15分钟的平均负载。
# sar –u 1 5
监视系统整体性能(3) -sar
可以将sar命令的监视结果保存到磁盘文件中。 下面的命令每10秒钟在sar.data文件中保存系 统的行为数据,30分钟内180次: # sar –o /home/sar.data 10 180 通过如下命令,可分析sar.data文件中所保 存的数据。 # sar –f /home/sar.data
监视磁盘性能(1)-iostat
使用iostat命令可以统计CPU的使用情况, 并且统计出磁盘和终端中所发生的I/O次数。 命令格式: iostat [-t] [interval时间间隔] [count次数]
IBM-AIX系统常用命令

IBM-AIX系统常用命令原文引自:/luckyrobbie/archive/2006/03/27/37543.htmlAix的系统备份命令是mksysb, make system backup ,有点类似ghost.Aix5.3支持微分区技术,所谓微分区就是1台机器上装多个OS(操作系统),把这台机器上的cpu资源进行划分,然后分配给每一个os使用,最小粒度是0.1个cpu.有点类似vmware软件.让一个机器跑多个操作系统.这项技术早在ibm的大机上就已经实现了.只不过最近才在小机和pc机器上发布.TIVOLI是系统管理软件.关闭aix的命令:shutdown ->正常关机,关闭所有服务. halt -> 相当于直接关闭电源.重启aix:shutdown -Fr查看出错信息:errpt errpt -a | more -> 分页显示errpt -a > /tmp/err01 输出到文件.清除错误信息:errclear 0smit 用鼠标操作 smitty 用键盘来操作,一般用smitty为好.ping -f 全速ping ,利用所有的服务器资源来ping,如果是多个服务器ping一个ip,可以把机器ping死.几个关于磁盘的名词:lv: logical volume 逻辑卷pv: physical volume 物理卷vg: volume group 卷组pp: physical partition 物理分区lp: logical partition 逻辑分区pv对应的是物理硬盘或者是磁盘阵列上划分的lun,一个vg最多可以有1016个pp.pv的上面是vg,一个vg可以包含多个pv.vg的上面是lv,lv如果不作任何处理就是裸设备,也可以作成文件系统.lv被分为多个lp,默认情况下,lp与pp是一一对应的,也可以做成一对多的.这样就相当于用多个pp来作raid0备份.lsdev -C | grep disk 可以查看物理磁盘的硬件信息lspv 查看pv的信息 -p hdisk0 查看具体数据存放的位置:例如,数据在第m到n个pp上面.lsvg 查看vg的信息 -l vg的列表 -c 被使用的vg -l rootvg 查看rootvg的详情.lslv -m lv1 查看lv1 的lp与pp的映射.getlvcv -AT lv1 看到lv1的控制信息.fsck -y /dev/newlv 检查lv.smit vg 可以管理vgsmit lv 管理lvvarryonvg rootvg 激活rootvg卷组,varryoffvg newvg 使newvg卷组脱机.nbpi:number of bytes per inode 每个i节点拥有的字节数,这个参数越小,文件系统的可用的inode越多.如果inode用完,即使有剩余空间,系统也会报空间不够.此时要调小nbpi的值.一般是4k df -k 中iused 指的是i节点的使用情况.设置从cd启动,bootlist -m normal cd0启动时按ESC+1或者F1,可以进入启动菜单.选择启动方式.用smitty crfs 创建完文件系统以后还要mount./etc/filesystems 文件记录文件系统的信息.如想把某个lv映射到不同的文件系统路径上面,可以直接修改这个文件.用logform /dev/testloglv 将lv格式化成jfs的log的格式.file 文件名可以看某个文件的信息,包括文件类型,可执行文件,文本文件,等等.uname -a 可以看到os的信息.fsck 检查文件系统的信息,在umount的时候是准确的, 相当于windows的磁盘扫描.碎片整理 smitty jfslsfs /root 显示文件系统的属性各个组件的关系:lsps -a 查看page space的使用情况vgda:vg description area 每个vg的头部存放vg的描述信息, 如果包含2个pv,那么第一个pv会在头部和另一个位置存放2个vgda,第2个pv也会存放一个.如果包含3个pv,那么每个pv上都有1个vgda.vg的信息在odm中也会存储,但必须和vgda中的信息一致,否则无法varryonvg,有下面4个命令来管理odm中的vg信息.importvg:从vgda中读取信息到odm中exportvg:从odm中删除vg信息varyonvg:激活(online)vgvaryoffvg:卸载(offline)vg修改vg的factor,这样可以将vg的max pp 从默认的1016 增大1倍,到2032,但由于vgda的总大小不变,这些信息都是记录到里面的.所以vg的最大文件数要减小1倍,实际上是个等式:max pp * max file = 固定的一个值,factor增大,实际上是max pp * factor,max file / factor.具体做法:chvg -t 2 rootvg 修改factor为2.vgda 用cfgmgr,来刷新,来认出新assign的hdisk.cfgmgr -v 检查新设备,新硬件.-i /dev/cd0 从光盘自动安装新硬件驱动.当作双机时,2个服务器server1 和server2 来连接同一个盘阵,server1对磁盘分配一个pvid,当第一次切换到server2时,要用ckdev命令来读出server1配置的pvid.系统是通过pvid来识别pv的.ckdev -l hdisk1 -a pv = clear 清除pvidckdev -l hdisk1 -a pv = yes 新置pvidlsdev 查看物理设备lsdev -C 显示所有设备状态rmdev -l cd0 逻辑删除 cd0mkdev -l cd0 安装cd0rmdev -d -l cd0 删除cd0设备驱动查看cpu的信息lsattr -El proc0lsdev -C | grep proc查看内存的信息lsattr -El mem0查看光驱的信息lsattr -El cd0查看硬盘的信息lsattr -El hdisk0lscfg -vp | more 分页看全部硬件信息prtconf | more 列出硬件信息查看谁在使用cdrom fuser /cdrom -k 直接杀掉用户进程telnet的登陆信息存放在/etc/motd文件中.想查看最近有谁登陆,用last命令.查看登录失败的信息: /etc/security/failedlogin存放用户密码的文件:/etc/security/passwd用户登录需要运行的脚本:1 /etc/profile2 /etc/environment 在这个文件中设置中文环境,LANG=zh_CN3 用户profile ,分2种情况:如果是命令行登录,则运行/home/user/.profile如果是图形登录,则运行/home/user/.dtprofile 需要将次文件中,#DTSOURCEPROFILE=TRUE 的# 去掉,否则还是使用.profile.在/dev下面有2种设备,一种是block设备,一种是char(字符)设备.这取决于不同的应用.vmstat的某些行的解释:vmstat->faults->cs: user calls 用户调用的次数cpu->wa: >40 说明io繁忙kthr: kernel threadkthr->r 在运行队列中等待执行的进程b 正在等待io的进程memory->avm:active vitual memory 物理内存+使用的虚拟内存,以4k为单位.page->re:是pin 和 pout 的总和.sr:search的内存块数.fr:释放的内存块数.每次作page out时,系统要搜索物理内存以找到可以释放的块,sr 和fr分别代表搜索的和通过搜索找到的可以释放的块数.如果2者很接近,说明内存中有很多用于file cache,内存的数量是够用的.如果fr/sr的值很小,说明内存不够.tty:代表终端iostat:%tm_act 实际transaction的百分比tps 每秒发生的次数kbps 每秒的速率名词:thrasing: 应用程序频繁交换,导致paging过多./usr/samples/kernel/vmtune -f 120 -F 128-f 120 代表minfree mem < 120 时要进行page out-F 128 代表maxfree mem > 128 时要进行page in-p -P 也跟page out 有关,具体不清楚,还需明确.sar->avque:平均的请求数对文件系统作监视:filemonfilemon -o /tmp/a.txt -O all -v运行之后系统会一直监视文件系统的使用情况并记录日志,-T 64000 是使用的buffer cache,在大型系统上,这个值可以调大.运行一段时间后,要停掉filemon,使用trcstop 或者 kill -9 进程.从a.txt中可以看到使用最频繁的文件等信息,有些类似statspack 的报告.对于后缀是Z的文件用uncompress来解压缩. uncompress a.tar.Z用strings 命令来看2进制文件如何调大page space,直接设置对应lv的大小.如果对应lv的vg 空间不够的话,可以向vg中加硬盘.dd的用法:dd if=/dev/rnewfs of=/dev/rcopyfs bs=1024 count=10240bs: block size 块大小,1024字节count: block count 块的数量if是input file ,of 是output file将任务切换到后台执行: ctrl+z ,然后 bg+回车查看后台执行的程序:jobs把后台执行的程序切换到前台执行:fg %n n是后台的job 编号ip抓包工具:iptrace 和 tcpdumpiptrace -a a.out停止iptrace:kill -9tcpdump -i en1 -w a.out a.out 是输出文件把进程与cpu绑定:bindprocessor -U 进程号 cpuidbindprocessor -U 12345 0odm库:env | grep objODMDIR=/etc/objrepos 这是odm库的存储路径在disk0上生成引导区bosboot -a -d /dev/hdisk0用kdb 查看os 的 dumpethernet channel 把2个网卡绑定到1个ip,可以作网络负载均衡.crontab 设置定时任务crontab -l list the crontabcrontab -e edit the crontabcrontab的格式:分钟小时月中的天数月份星期命令minute:0 到 59hour:0 到 23day_of_month:1 到 31month:1 到 12weekday:星期日到星期六的 0 到 6 时要在每星期日上午 2 时运行 fwlogmgmt 命令,请将下列各行添加至 crontab 文件底部:0 2 * * 0 /usr/bin/fwlogmgmt -1发送邮件,aix和redhad linux 都默认安装了smtp邮件服务,可以直接给internet发邮件.mail -s "test mail" *************************<$ORACLE_BASE/admin/$ORACLE_SID/bdump/alert$ORACLE_SI D.logmail-s"testmail"*************************<<EOF******** MAIL CONTENT *******FJLADSFJLAKHFGALFJALDSKFJAFASLJFLASF*****************************EOF有了crontab和mail,就可以定时监控数据库,然后把报告发送邮件到管理员的信箱.kill -9 9 是kill命令传送的一个信号,一共15个信号可以发送./etc/ftpusers 限制登录ftp的用户,谁在这个文件里面,谁就登不进去.网络服务 /etc/inetd.conf 刷新 refresh src -dlslpp -l | grep http 查看安装的软件检查瓶颈:利用vmstat iostat 查看总体情况,ps aux 可以看到具体进程占用资源的情况.如果是io瓶颈,可以利用filemon -o /tmp/a.txt -O all; sleep 10;trcstop 来查看io资源的使用情况.辨别僵尸进程:ps -ef pid 那列是 defunc的为僵尸进程.。
aix 常用命令

aix 常用命令AIX常用命令AIX(Advanced Interactive eXecutive)是IBM公司的一款UNIX操作系统,广泛应用于企业级服务器系统中。
本文将介绍AIX 常用命令,帮助读者更好地理解和使用该操作系统。
一、系统管理命令1. whoami:查询当前登录用户的用户名;2. hostname:查看主机名;3. uname -a:显示系统的各种信息,如内核版本、硬件平台等;4. uptime:查看系统的运行时间和负载情况;5. date:显示当前日期和时间;6. topas:实时监控系统性能,包括CPU利用率、内存使用情况等;7. lparstat -i:显示LPAR(Logical Partition)信息,包括分区的配置和资源利用情况;8. lsdev:列出设备列表;9. errpt:查看系统错误日志,用于排查故障;10. ps -ef:显示当前系统的进程列表;11. mksysb:创建系统备份;12. bootlist:设置系统启动顺序。
二、文件和目录管理命令1. ls:列出当前目录下的文件和子目录;2. pwd:显示当前工作目录的路径;3. cd:切换工作目录;4. mkdir:创建新的目录;5. rm:删除文件或目录;6. cp:复制文件或目录;7. mv:移动文件或目录;8. find:按照指定条件查找文件;9. du:查看目录或文件的磁盘使用情况;10. df:显示文件系统的使用情况;11. cat:查看文件内容;12. vi:编辑文本文件。
三、用户和权限管理命令1. useradd:创建新用户;2. userdel:删除用户;3. passwd:修改用户密码;4. chuser:修改用户属性;5. chown:修改文件或目录的所有者;6. chmod:修改文件或目录的权限;7. chgrp:修改文件或目录的所属组;8. groups:查看用户所属的组;9. su:切换用户身份;10. visudo:编辑sudoers文件,配置用户的sudo权限。
aix vmstat内存偏差

vmstat是一个在AIX(Advanced Interactive eXecutive)和其他UNIX-like 系统中常用的命令,用于报告系统的虚拟内存统计信息。
这些信息包括进程、内存、分页、块IO、陷阱和CPU 活动。
如果你发现vmstat报告的内存使用情况与实际观察到的现象存在偏差,可能是由以下原因造成的:
1.缓冲区与缓存:vmstat报告的内存使用情况可能包括用于缓冲和缓存的内存。
这部分内存可能会被频繁地重新分配,因此可能并不总是反映实际的物理内存使用情况。
2.共享内存:如果系统上运行有多个进程或服务,它们可能会共享一部分内存。
这部分内存可能会被多个进程或服务共同使用,因此vmstat报告的内存使用情况可能会高于实际物理内存使用情况。
3.内存映射:某些进程可能会使用内存映射文件或其他技术来访问文件。
这部分内存可能不会被vmstat完全识别或报告,因为它可能被视为文件或文件系统相关的内存,而不是直接相关的物理内存。
4.内核内存:内核分配的内存也可能影响vmstat的报告。
这部分内存是操作系统用于支持其功能和服务的,可能与实际应用程序使用的内存不同。
5.延迟与异步行为:系统的虚拟内存管理可能会引入一定的延迟和异步行为。
这可能会导致vmstat报告的内存使用情况与实际观察到的现象存在一定的偏差。
AIX小型机系统监视工具参数详解和调整内存的使用综述

1、监视和调整内存的使用一个系统的内存通常会几乎被占满。
即使当前运行的程序没有消耗掉所有的内存,操作系统也会将较早运行的程序和它们所使用的文件的文本页面驻留在内存。
这样的驻留并没有任何的开销,因为内存无论如何都不会去使用这一段内存。
在许多情况下,程序或者文件将会被再次用到,这样可以减少磁盘的输入输出。
检测有多少内存正被使用一些测试性能的工具提供了内存使用的报告。
我们最感兴趣的报告是由 vmstat ,ps ,和svmon 命令提供的。
vmstat 命令(内存)vmstat命令概括了系统中所有进程所使用的活动的虚拟内存,同时还有空闲列表上实际内存页的数量。
活动的虚拟内存被定义为虚拟内存中实际可以得到的工作的段页的数量(参考页面后分配中的定义)。
这个数字可能大于机器中实际页面的帧,因为一些动态虚拟内存也可能写到字分页空间以外去。
在检测内存是否短缺或者是否有需要调优内存,一系列时间间隔里输入vmstat命令,在结果报告中检验 pi 和 po 栏。
这两栏表明了每秒页面调入的页数和每秒调出的页数。
如果该值经常为非零值,说明可能存在内存瓶颈。
偶尔出现的非零值不用在意因为页面调度是虚拟内存的主要原理。
# vmstat 2 10kthr memory page faults cpu----- ----------- ------------------------ ------------ -----------r b avm fre re pi po fr sr cy in sy cs us sy id wa1 3 113726 124 0 14 6 151 600 0 521 5533 816 23 13 7 570 3 113643 346 0 2 14 208 690 0 585 2201 866 16 9 2 730 3 113659 135 0 2 2 108 323 0 516 1563 797 25 7 2 660 2 113661 122 0 3 2 120 375 0 527 1622 871 13 7 2 790 3 113662 128 0 10 3 134 432 0 644 1434 948 22 7 4 671 5 113858 238 0 35 1 146 422 0 599 5103 903 40 16 0 440 3 113969 127 0 5 10 153 529 0 565 2006 823 19 8 3 700 3 113983 125 0 33 5 153 424 0 559 2165 921 25 8 4 630 3 113682 121 0 20 9 154 470 0 608 1569 1007 15 8 0 770 4 113701 124 0 3 29 228 635 0 674 1730 1086 18 9 0 73注意到输出列队里的高输入输出等待,也注意到阻塞队列里线程的数量。
vmstat使用

vmstat的使用说明
vmstat是一个非常有用的命令行工具,用于监视虚拟内存和进程的活动情况。
它可以提供关于内存使用、CPU利用率、磁盘I/O等方面的实时信息。
下面将详细介绍vmstat的使用方法。
首先,要使用vmstat命令,可以在终端中输入以下命令:
其中,options是可选参数,用于指定要监视的特定信息;delay是可选参数,指定每隔多少秒更新一次信息;count是可选参数,指定更新信息的次数。
以下是一些常用的options参数:
•-a:显示活动和非活动内存区域的统计信息。
•-f:显示fork操作的统计信息。
•-s:按内存类别显示内存统计信息。
•-d:显示磁盘活动的统计信息。
•-p:显示进程活动的统计信息。
•-t:显示时间戳。
以下是一些示例用法:
1.显示实时内存和进程活动信息,每隔1秒更新一次,共更新10次:
1.显示实时磁盘活动信息,每隔2秒更新一次,共更新5次:
1.显示实时内存和进程活动信息,以及时间戳:
使用vmstat时需要注意,它提供的信息可以帮助我们了解系统的实时状态,从而更好地进行性能优化和管理。
同时,我们还可以通过查看输出中的各个字段来了解系统的各个方面的状态。
例如,在输出中可以看到内存使用情况、CPU利用率、磁盘I/O等方面的信息。
此外,我们还可以通过分析vmstat的输出,确定系统瓶颈并进行相应的优化。
总之,vmstat是一个非常有用的工具,可以帮助我们更好地管理和维护系统。
aix监控命令

4、errpt |more,系统出错日志。
errclear 0命令,清除现有的系统日志。
过90%或者和平时监控有较大出入则需要进行关注。
有点像hpux的bdf
6、lsps -a,查询交换内存空间使用情况。如果%used字段低于70%,则系统运行正常。
字段的us(用户进程的时间)及sy(系统进程的时间)项的值,两项值的和应该不超过90%,否则说明CPU能力短缺。
8、
errpt -a |more -> 分页显示
errpt -a >/tmp/err01 输出到文件
7、vmstat
检查CPU及内存运行情况,有点象hpux的sar命令
vmstat 5,表示每隔5秒钟显示系统CPU及内存运行情况。查看kthr(kernel运行队列中处于等待状态的进程数)
字段的r(运行队列中的进程数)项的显示值,如果该数值是系统实际CPU数的4倍或4倍以上,则表示CPU占用率过高,
1、 diag命令检查系统硬件运行情况
每个月用diag命令检查一下系统硬件的运行情况,及时发现硬件可能出现的故障。
2、mail –u root,
显示系统发送给root用户的mail错误报告。查看是否有硬件或软件方面的错误信息报告,并做相应处理。
3、last,显示各个login用户登陆信息。
需要考虑提高系统CPU工作频率;查看memory(虚拟和真实内存的使用信息)字段的fre(空闲页面的数量)项,如果数
值低于120,则说明系统内存短缺。有时候数值虽然高于120,也可以根据实际情况调整内存;查看page(页面活动的信息)字段的pi(从页面输入的页)
、po(输出到页面的页)、fr(空闲的页面数)及sr(通过页面置换算法搜索到的页面数)项的值,这4个值一般都为0,有时候也有可能为1;最后查看cpu(cpu的使用率)
Linux AIX系统实用监控命令详解

Linux AIX系统实用监控命令详解介绍Linux/UNIX系统提供了一些有用的监控命令如:iostat,vmstat,ps,sar,通过它们系统管理员可以方便地监测系统资源是否平衡并解决性能问题。
本文阐述了这些命令的使用方法,并以AIX系统为例附加应用实例。
为Linux/AIX系统管理员提供参考。
更多信息iostatiostat命令主要通过物理磁盘的活跃时间及它们的平均传输速度,监控系统输入/输出设备负载。
根据iostat命令产生的报告,用户可确定一个系统配置是否平衡,并据此在物理磁盘与适配器之间更好的平衡输入/输出负载,从而在用户注意到服务器运行缓慢之前提早发现输入/输出缓慢的问题。
iostat工具的主要目的是通过监控磁盘的利用率(tm_act字段),检测系统的I/O瓶颈。
此外,还可用于确定CPU问题,辅助容量规划。
vmstat和iostat联合使用,可获得与CPU,内存和I/O子系统有关的性能问题的必需数据。
下图是AIX系统iostat命令输出:iostat命令可产生如下四种类型的报告:tty和CPU利用情况磁盘利用情况系统吞吐率适配器吞吐率% tm_act:物理磁盘活动的时间百分比Kbps:某块磁盘传输数据的总量(读或写)tps:某块物理磁盘每秒钟 IO 传输的数量Kb_read:从磁盘上读取数据的总量Kb_wrtn:写入磁盘的数据总量vmstatvmstat命令报告关于核心线程,虚拟内存,自陷(trap),磁盘以及CPU行为的统计。
而且每种行为报告都被更细致地用百分比分别表示用户态、核态、空闲以及等待磁盘I/O等情况。
内核维持了对核心线程,换页以及中断行为的统计数据,而vmstat命令则通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据。
磁盘的输入/输出统计是通过设备驱动器维持的。
对于磁盘,平均传输速度是通过使用活跃时间核传输信息数目决定的。
而活跃时间百分比则是从报告期间驱动器忙的时间量计算出来的。
AIX下vmstat详解

AIX下vmstat详解
AIX下vmstat详解
vmstat 是用来实时查看内存使用情况,反映的情况比用top直观一些.
如果直接使用,只能得到当前的情况,最好用个时间间隔来采集
vmstat T 其中T用具体的时间标示,单位是秒例如:vmstat 5 表格每隔5秒采集一次.
这样在刷新的时候就能比较系统的看到那个列不正常的
procs:
r-->;在运行队列中等待的进程数
b-->;在等待io的进程数
w-->;可以进入运行队列但被替换的进程
memoy
swap-->;现时可用的交换内存(k表示)
free-->;空闲的内存(k表示)
pages
re--》回收的页面
mf--》非严重错误的页面
pi--》进入页面数(k表示)
po--》出页面数(k表示)
fr--》空余的页面数(k表示)
de--》提前读入的页面中的未命中数
sr--》通过时钟算法扫描的页面
disk 显示每秒的磁盘操作。
s表示scsi盘,0表示盘号
fault 显示每秒的中断数
in--》设备中断
sy--》系统中断
cy--》cpu交换
cpu 表示cpu的使用状态
cs--》用户进程使用的时间
sy--》系统进程使用的时间
id--》cpu空闲的时间
其中:
如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
如果pi,po 长期不等于0,表示内存不足。
如果disk 经常不等于0,且在 b中的队列大于3,表示 io性能不好。
AIX系统CPU性能评估

1、vmstat使用vmstat 来进行性能评估,该命令可获得关于系统各种资源之间的相关性能的简要信息。
当然我们也主要用它来看CPU 的一个负载情况。
的一个负载情况。
下面是我们调用vmstat 命令的一个输出结果:命令的一个输出结果:$vmstat 1 2System configuration: lcpu=16 mem=23552MBkthr memory page faults cpu----- ----------- ------------------------ ----------------- -----------r b avm fre re pi po fr sr cy in sy cs us sy id wa0 0 3091988 2741152 0 0 0 0 0 0 1849 26129 4907 8 1 88 3 0 0 3091989 2741151 0 0 0 0 0 0 2527 32013 6561 15 2 77 6 对上面的命令解释如下:对上面的命令解释如下:Kthr 段显示内容¨ r 列表示可运行的内核线程平均数目,包括正在运行的线程和等待 CPU 的线程。
如果这个数字大于的线程。
如果这个数字大于 CPU CPU CPU 的数目,则表明有线程需要等待的数目,则表明有线程需要等待CPU CPU。
¨ ¨ b b 列表示处在非中断睡眠状态的进程数。
包括正在等待文件系统 I/O I/O 的的线程,或由于内存装入控制而被挂起的线程。
Memory 段显示内容¨ avm 列表示活动虚拟内存的页面数,每页一般4KB¨ fre 空闲的页面数,每页一般4KBPage 段显示内容¨ re –该列无效¨ re –该列无效¨ pi 从磁盘交换到内存的交换页pi 从磁盘交换到内存的交换页((调页空间调页空间))数量,数量,4KB/4KB/4KB/页。
vmstat命令详解

vmstatvmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。
该命令通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。
vmstat反馈的与CPU相关的信息包括:(1)多少任务在运行(2)CPU使用的情况(3)CPU收到多少中断(4)发生多少上下文切换下面只介绍Vmstat与CPU相关的参数vmstat的语法如下:vmstat [delay [count]]参数的含义如下:参数解释delay 相邻的两次采样的间隔时间count 采样的次数,count只能和delay一起使用当没有参数时,vmstat则显示系统启动以后所有信息的平均值。
有delay 时,第一行的信息自系统启动以来的平均信息。
从第二行开始,输出为前一个delay时间段的平均信息。
当系统有多个CPU时,输出为所有CPU的平均值。
与CPU有关的输出的含义 (采用进一法)参数解释从/proc/stat获得数据任务的信息r 在internal时间段里,运行队列里等待CPU的任务(任务)的个数,即不包含vmstat进程 procs_running-1b 在internal时间段里,被资源阻塞的任务数(I/0,页面调度,等等.),通常情况下是接近0的 procs_blockedCPU信息所有值取整(四舍五入)total*100δnice)/δuser+δus 在internal时间段里,用户态的CPU时间(%),包含 nice值为负进程 (total*100δsoftirq)/δirq+δsystem+δsy 在internal时间段里,核心态的CPU时间(%) (total*100δidle/δid 在internal时间段里,cpu空闲的时间,不包括等待i/o的时间(%)total*100δiowait/δwa 在internal时间段里,等待i/o的时间(%)系统信息intr/intervalδin 在internal时间段里,每秒发生中断的次数ctxt/intervalδcs 在internal时间段里,每秒上下文切换的次数,即每秒内核任务交换的次数CODE:范例1:average mode (粗略信息)当vmstat不带参数时,对应的输出值是从系统启动以来的平均值,而r和b则对应的是完成这一命令时,系统的值。
AIX系统计性能命令

AIX系统计性能命令一:vmstatvmstat命令用来获得UNIX系统有关进程、虚存、页面交换空间及CPU活动的信息。
这些信息反映了系统的负载情况。
vmstat首次运行时显示自系统启动开始的各项统计信息,之后运行vmstat将显示自上次运行该命令以后的统计信息。
用户可以通过指定统计的次数和时间来获得所需的统计信息。
有关进程的信息有:(kthr)r :在就绪状态等待的进程数。
b :在等待状态等待的进程数。
有关内存的信息有:(memory)avm:使用的页面数。
fre :空闲队列中的页面数。
有关页面交换空间的信息有:(page)re :在指定时间间隔内每秒要求收回的页面数。
po :在指定时间间隔内换入到页面交换空间的页面数。
pi :由页面交换空间换出的页面数。
fr :在指定时间间隔内释放的页面数。
sr :在指定时间间隔内检查的页面数(以确定该页面是否可以释放)。
cy :按时钟算法每秒扫描的页面数。
有关故障的信息有:(faults)in :在指定时间内的每秒中断次数。
sy :在指定时间内每秒系统调用次数。
cs :在指定时间内每秒上下文切换的次数。
有关CPU的信息有:(cpu)us :在指定时间间隔内CPU在用户态的利用率。
sy :在指定时间间隔内CPU在核心态的利用率。
id :在指定时间间隔内CPU空闲时间比。
wa :在指定时间间隔内CPU因为等待I/O而空闲的时间比。
vmstat 可以用来确定一个系统的工作是受限于CPU还是受限于内存:如果CPU的sy和us值相加的百分比接近100%,或者运行队列(r) 中等待的进程数总是不等于 0,则该系统受限于CPU;如果pi、po的值总是不等于0,则该系统受限于内存。
vmstat运用举例:vmstat –f :显示系统中的子进程数。
vmstat –s :显示系统中不同的事件。
vmstat –i :显示系统的中断数。
vmstat hdisk0 hdisk1:显示hdisk0 、hdisk1的使用情况。
vmstat命令详解

vmstat命令详解各种unix平台下iostat与vmstst说明vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控⼯具。
该命令通过使⽤knlist⼦程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。
vmstat反馈的与CPU相关的信息包括:(1)多少任务在运⾏(2)CPU使⽤的情况(3)CPU收到多少中断(4)发⽣多少上下⽂切换Linux下vmstat输出释疑:Vmstatprocs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----r b swpd free buff cache si so bi bo in cs us sy id wa0 0 100152 2436 97200 289740 0 1 34 45 99 33 0 0 99 0procsr 列表⽰运⾏和等待cpu时间⽚的进程数,如果长期⼤于1,说明cpu不⾜,需要增加cpu。
b 列表⽰在等待资源的进程数,⽐如正在等待I/O、或者内存交换等。
cpu 表⽰cpu的使⽤状态us 列显⽰了⽤户⽅式下所花费 CPU 时间的百分⽐。
us的值⽐较⾼时,说明⽤户进程消耗的cpu时间多,但是如果长期⼤于50%,需要考虑优化⽤户的程序。
sy 列显⽰了内核进程所花费的cpu时间的百分⽐。
这⾥us + sy的参考值为80%,如果us+sy ⼤于 80%说明可能存在CPU不⾜。
wa 列显⽰了IO等待所占⽤的CPU时间的百分⽐。
这⾥wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘⼤量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显⽰了cpu处在空闲状态的时间百分⽐system 显⽰采集间隔内发⽣的中断数in 列表⽰在某⼀时间间隔中观测到的每秒设备中断数。
AIX系统资源使用情况查看技巧

AIX系统资源使用情况查看技巧
在AIX系统中,您可以使用一些命令来查看系统资源的使用情况。
以下是一些常用的命令:
1.vmstat:显示虚拟内存统计信息,包括进程状态、内存使用、分页活动等。
2.topas:显示进程活动统计信息,包括CPU使用率、内存使用、I/O活动
等。
3.pstat:显示系统性能统计信息,包括CPU使用率、内存使用、I/O活动等。
4.vmstat结合grep命令可以查看特定进程的资源使用情况。
例如,vmstat
| grep PID可以查看特定进程(PID)的资源使用情况。
5.topas结合grep命令可以查看特定进程的资源使用情况。
例如,topas |
grep PID可以查看特定进程(PID)的资源使用情况。
6.pstat结合grep命令可以查看特定进程的资源使用情况。
例如,pstat -p
PID可以查看特定进程(PID)的资源使用情况。
另外,如果您需要更详细的系统资源使用情况,您可以使用AIX的系统管理工具(如SMIT或SMF),这些工具可以提供更详细的系统资源使用报告和图形化的界面。
Vmstat命令大全和命令详解

vmstat 命令详解procs:r-->在运行队列中等待的进程数b-->在等待io的进程数w-->可以进入运行队列但被替换的进程memoyswap-->现时可用的交换内存(k表示)free-->空闲的内存(k表示)pagesre--》回收的页面mf--》非严重错误的页面pi--》进入页面数(k表示)po--》出页面数(k表示)fr--》空余的页面数(k表示)de--》提前读入的页面中的未命中数sr--》通过时钟算法扫描的页面disk 显示每秒的磁盘操作。
s表示scsi盘,0表示盘号fault 显示每秒的中断数in--》设备中断sy--》系统中断cy--》cpu交换cpu 表示cpu的使用状态cs--》用户进程使用的时间sy--》系统进程使用的时间id--》cpu空闲的时间(1)通过VMSTA T识别CPU瓶颈如果r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us) 系统则面临着CPU资源的短缺. r(运行队列)展示了正在执行和等待CPU资源的任务个数。
当这个值超过了CPU数目,就会出现瓶颈了。
当r值超过了CPU个数,就会出现CPU瓶颈,解决办法大体几种:1. 最简单的就是增加CPU个数2. 通过调整任务执行时间,如大任务放到系统不繁忙的情况下进行执行,进尔平衡系统任务3. 调整已有任务的优先级首先需要声明一点的是,vmstat中CPU的度量是百分比的。
当us+sy的值接近100的时候,表示CPU正在接近满负荷工作。
但要注意的是,CPU满负荷工作并不能说明什么,UNIX总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化。
唯一能够确定CPU瓶颈的还是r (运行队列)的值。
(2)通过VMSTA T识别RAM瓶颈如果pi,po 长期不等于0,表示内存不足。
内存的瓶颈是由scan rate (sr)来决定的.scan rate是通过每秒的始终算法来进行页扫描的.如果scan rate(sr)连续的大于每秒200页则表示可能存在内存缺陷.同样的如果page项中的pi 和po这两栏表示每秒页面的调入的页数和每秒调出的页数.如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个别的时候不为0的话,属于正常的页面调度这个是虚拟内存的主要原理. 数据库服务器都只有有限的RAM,出现内存争用现象是Oracle的常见问题。
AIX系统检测

AIX系统性能监控vmstat:报告关于内核进程,虚拟内存,磁盘,cpu的的活动状态的工具主要有几个用法:1.vmstat 间隔测试数量输出如下kthr memory page faults cpu----- ----------- ------------------------ ------------ -----------r b avm fre re pi po fr sr cy in sy cs us sy id wa0 0 26258 18280 0 0 0 7 20 0 127 227 64 1 2 96 1其中:kthr--内核进程的状态--r 运行队列中的进程数,在一个稳定的工作量下,应该少于5--b 等待队列中的进程数(等待I/O),通常情况下是接近0的.memory--虚拟和真实内存的使用信息--avm 活动虚拟页面,在进程运行中分配到工作段的页面空间数.--fre 空闲列表的数量.一般不少于120,当fre少于120时,系统开始自动的kill进程去释放free listpage--页面活动的信息--re 页面i/o的列表--pi 从页面输入的页(一般不大于5)--po 输出到页面的页--fr 空闲的页面数(可替换的页面数)--sr 通过页面臵换算法搜索到的页面数--cy 页面臵换算法的时钟频率faults--在取样间隔中的陷阱及中断数--in 设备中断--sy 系统调用中断--cs 内核进程前后交换中断cpu--cpu的使用率--us 用户进程的时间--sy 系统进程的时间--id cpu空闲的时间--wa 等待i/o的时间一般us+sy 在单用户系统中不大于90,在多用户系统中不大于80. wa时间一般不大于40.aix CPU 性能监视CPU 性能监视处理单元是系统中最快的组件之一。
在某一时间对单个程序来说保持100% 的CPU 占用率(也就是说,空闲0%,等待0%)超过几秒钟是相对少见的。
AIX操作系统关键性能指标监控
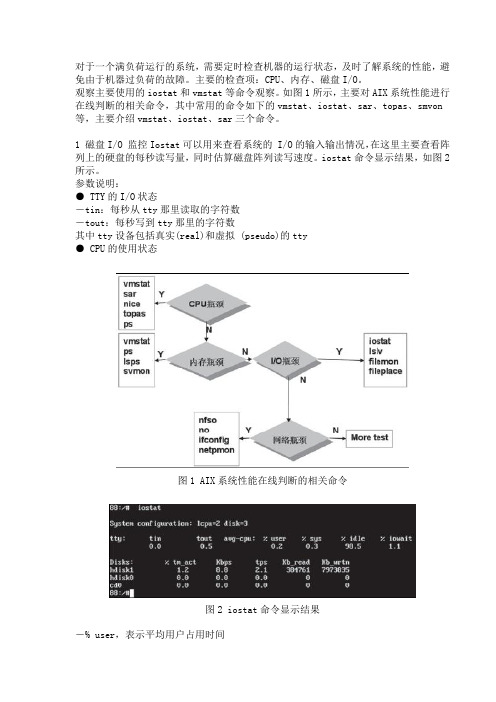
对于一个满负荷运行的系统,需要定时检查机器的运行状态,及时了解系统的性能,避免由于机器过负荷的故障。
主要的检查项:CPU、内存、磁盘I/O。
观察主要使用的iostat和vmstat等命令观察。
如图1所示,主要对AIX系统性能进行在线判断的相关命令,其中常用的命令如下的vmstat、iostat、sar、topas、smvon 等,主要介绍vmstat、iostat、sar三个命令。
1 磁盘I/O 监控Iostat可以用来查看系统的 I/O的输入输出情况,在这里主要查看阵列上的硬盘的每秒读写量,同时估算磁盘阵列读写速度。
iostat命令显示结果,如图2所示。
参数说明:● TTY的I/O状态-tin:每秒从tty那里读取的字符数-tout:每秒写到tty那里的字符数其中tty设备包括真实(real)和虚拟 (pseudo)的tty● CPU的使用状态图1 AIX系统性能在线判断的相关命令图2 iostat命令显示结果-% user,表示平均用户占用时间-% sys,表示系统花费CPU时间-% idle,表示CPU空闲时间-% iowait,表示CPU等待I/O所花费时间如果%idle数值都很高而且%iowait数值也很高,大于25,这个说明系统存在I/O或者硬盘瓶颈。
注意:出现瞬间高的值是可能的,比如系统写CDR话单文件的时候。
高数值的%iowait有可能下面几个原因:(1)内存不够而引起频繁的swap空间的数据交换,导致数据存取存在交换空间的 I/O 瓶颈;(2)硬盘上面数据不合理的分布;(3)数据的fragment不合理。
● 硬盘使用状态-% tm_ a c t :表示某个硬盘处于active状态的百分比-tps:表示每秒某个硬盘有多少个数据传输次数-Kb_readKb_wrtn:分别显示从开机到运行iostat这个命令这段时间内对硬盘的read 和write的总数据量,单位kb。
2 内存使用情况监控VMSTAT由于AIX操作系统的内存管理机制与其它UNIX内存管理机制不同,因此其内存分配机制也不一样,在VMSTAT中看到的FREE MEM值并不是真正内存的FREE值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
AIX的vmstat命令详解(原创)vmstat概述vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和CPU 活动的统计信息。
由vmstat 命令生成的报告可以用于平衡系统负载活动。
系统范围内的这些统计信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
Interval 参数指定每个报告之间的时间量(以秒计)。
第一个报告包含系统启动后时间的统计信息。
后续报告包含自从前一个报告起的时间间隔过程中所收集的统计信息。
如果没有指定Interval 参数,vmstat 命令生成单个报告然后退出。
Count 参数只能和Interval 参数一起指定。
如果指定了Count 参数,其值决定生成的报告数目和相互间隔的秒数。
如果Interval 参数被指定而没有Count 参数,则连续生成报告。
Count 参数不允许为0。
内核为内核线程、调页和中断活动维护统计信息,vmstat 命令通过使用perfstat 内核扩展来对其进行访问。
磁盘输入/输出统计信息由设备驱动程序维护。
对于磁盘,利用活动时间和传送信息数量来确定平均传送速率。
活动时间的百分数根据报告期间驱动器忙的时间量来计算。
vmstat命令输出详解输出样例#vmstat 1 2System configuration: lcpu=8 mem=15360MBkthr memory page faults cpu----- ---------------------------- ---------------------- ------------ ----------------------------------------r b avm fre re pi po fr sr cy in sy cs us sy id wa 1 0 1614482 971363 0 0 0 0 0 0 56 4997 2739 1 1 97 00 0 1614484 971361 0 0 0 0 0 0 23 4435 2677 1 1 97 0Kthrkernel thread state(内核线程状态,表示每秒钟在采样间隔时间上对各种队列的内核线程数求得的平均值) r: 取样期间可运行的内核线程的平均数,包括正在运行的线程和指准备运行但尚在等待运行的进程。
1.)如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
2.)如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
3.)如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。
解决方法当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的CPU. 一般情况下,应用程序的问题会比较大一些.比如一些sql语句不合理等等都会造成这样的现象.b:表示每秒VMM等待队列中的内核线程平均数(等待资源或I/O),这里参考值为2,大于2表示被阻塞列线程数目太多。
MemoryMemory包括了虚拟内存和实际内存的信息avm: 活动的虚拟页面(Active virtual pages,以4k为单位),该值较高并不意味着性能不好。
记住,虚拟内存的概念是提供给我们寻址大于实内存容量的能力(一些在RAM 内存中,而另一些在调页空间中)。
但是如果虚拟内存远大于实内存,可能造成过度的页面调度,从而导致延时。
如果avm小于RAM,那么当RAM 中填满文件页时就会引起调页空间的页面调度。
这种情况下,调整minperm、maxperm 和maxclient 的值可以减少调页空间的页面调度量。
fre: 自由表(free list)的大小。
真实内存的大部分被用作文件系统数据的缓存。
因此,自由表(free list)的大小保持比较小并不稀奇。
Page页面错误和分页活动的信息。
此值为指定时间周期内每秒给定单位的平均值。
re 页面调度程序(Pager)输入输出列表(input/output)列表。
pi 表示每秒钟从Paging Space置换到内存的页数,调页空间是驻留在磁盘上的虚拟内存的一部分。
当内存过量使用时,它用作溢出。
调页空间由用于存储从实内存中窃取到的工作组页面的逻辑卷组成。
当进程访问一个窃取页时,产生了一个缺页故障,这一页必须从调页空间读入内存。
这里pi的参考值为5,大于5说明内存不足。
po 表示每秒钟从内存置换到Paging Space的页数,无论什么时候窃取工作存储器的一页,如果它仍未驻留在调页空间中或已被修改,那它会被写入调页空间。
如果不被再次访问,它会留在页面调度设备中直到进程终止或放弃空间。
如果包含在出故障页面中的后续地址引用导致缺页故障,那么这些页面将会由系统个别调进。
当一个进程正常终止,任何分配给该进程的调页空间将被释放。
如果这两列持续大于5,则系统的性能瓶颈很可能是内存不足,而导致交换频繁。
fr 表示每秒钟页面置换算法释放的页数。
当VMM 页面替换例程扫描页面帧表(Page Frame Table,PFT)时,它使用一些条件选取要窃取的页面以插入到可用内存帧的空闲列表中。
sr 表示每秒钟页面置换算法检查的页数,页面替换算法在可以窃取足够的页面以满足页面替换线程的需要之前可能不得不扫描许多页面帧。
cy 页面置换算法所使用的时钟周期。
即表示每秒页面替换代码扫描了PFT 多少次。
因为插入空闲列表可以不需要完全扫描PFT,并且因为所有的vmstat 字段报告为整数,这一字段通常为0。
Faults 故障列:样例时间周期中,每秒陷阱(Trap )和中断率的平均值。
in 设备中断次数,iostat命令输出更有参考意义。
sy 系统调用次数,通过明确的系统调用,用户进程可以使用资源。
这些调用指示内核执行调用线程的操作,并在内核和该进程之间交换数据。
因为工作负载和应用程序变化很大,不同的调用执行不同的功能,所以不可能定义每秒钟有多少系统调用才算太多。
这里设置参考值为10000,超过10000,用户需要注意。
cs 内核线程上下文交换Kernel thread context switches。
即时间片用完后,再轮到时的上下文计算,如果太高,则要仔细观察CPUCPU 使用时间百分比细目分类us 用户进程CPU占用,一个UNIX 进程可以在用户方式下执行,也可以在系统(内核)方式下执行。
当在用户方式下时,进程在它自己的应用程序代码中执行,不需要内核资源来进行计算、管理内存或设置变量。
sy 系统进程CPU占用,这包括内核进程(kprocs)和其它需要访问内核资源的进程所消耗的CPU 资源。
如果一个进程需要内核资源,它必须执行一个系统调用,并由此切换到系统方式从而使该资源可用。
例如,对一个文件的读或写操作需要内核资源来打开文件、寻找特定的位置,以及读或写数据,除非使用内存映射文件。
这里us + sy的参考值为80%,如果us+sy 大于80%说明可能存在CPU不足。
id 系统空闲CPU idle timewa 表示IO等待时间,即系统等待未完成的disk/NFS I/O 请求期间的CPU 空闲时间,如果us与sy之和持续超过90%时,CPU出现了瓶颈。
如果wa长期很高>50,则表示IO太忙,具体看是应用IO多,还是交换分页多,如果是后者,则显示内存不足;如果是前者,则应关注应用的IO性能状况,优化应用与磁盘设备pc 消耗物理处理器的数目。
只在使用共享处理器运行的分区显示(只在微分区环境中显示)ec 消耗授权容量的百分比。
只在使用共享处理器运行的分区显示(只在微分区环境中显示)Active Memory Sharing 增加的新字段mmode如果分区以共享内存模式运行,就显示shared。
到编写本文时,对于专用内存分区,不显示这个字段。
mpsz显示共享内存池的大小。
hpi显示分区的系统管理程序页面换入数量。
如果系统管理程序已经把引用的页面换出到磁盘,所以它们在真实内存中不存在,就会发生系统管理程序页面换入。
如果在执行vmstat 命令时没有指定时间间隔,那么显示的值是从引导时开始计算的。
hpit显示分区的系统管理程序分页花费的时间(以毫秒为单位)。
如果在执行vmstat 命令时没有指定时间间隔,那么显示的值是从引导时开始计算的。
pmem显示支持逻辑内存的物理内存量(以GB 为单位)。
loan显示借给系统管理程序的逻辑内存量(以GB 为单位)。
可以通过vmo 可调项ams_loan_policy 调整借出的内存量。
vmstat参数列表-f 报告从系统启动后的派生数目。
-h 显示系统管理程序分页信息-i 显示从系统启动后每个设备造成的中断数目。
-I 用新的输出栏显示I/O 定向视图,p 在标题kthr 下;栏fi 和fo 在标题页面下,而不是栏下;re 和cy 在页标题中。
-s 将总数结构中的内容写入到标准输出,该结构包含从系统初始化后调页事件的绝对计数。
如下描述了这些事件:地址翻译错误每次发生地址转换页面故障时增加。
解决页面故障可能需要I/O,也可能不需要。
存储保护页面故障(失去锁定)不包含在此计数之内。
入页随虚拟内存管理器读入的每页增加。
计数随调页空间和文件空间的入页增加。
它和出页统计信息一起表示实际I/O (由虚拟内存管理器启动)的总量。
出页随虚拟内存管理器写出的每页增加。
计数随调页空间和文件空间的出页而增加。
它和入页统计信息一起表示实际I/O(由虚拟内存管理器启动)的总量。
调页空间入页只随VMM 启动的来自调页空间的入页而增加。
调页空间出页只随VMM 启动的来自调页空间的出页而增加。
总回收当不启用一个新的I/O 请求也可以满足地址翻译错误时增加。
如果页面以前已经被VMM 请求过的,但是I/O 还没有完成;或者页面被预读算法提前提取,但是被故障段隐藏了;或者如果页面已经被放入空闲列表中,但还没有重新使用,则会发生此情况。
零填充页面故障如果页面故障针对的是工作存储器,且可以通过指定一个帧并以零填充帧来满足它的话,则该值增加。
可执行填充页面故障随着每个指令页面故障而增加。
用时钟检查页面VMM 利用时钟算法实施伪最近最少使用(1ru)的页面替换模式。
时钟检查过的页面是aged 。
为每个时钟检查过的页面增加此计数值。
时钟指针的转动随着每次VMM 时钟旋转而增加(即在每一次完整的内存扫描后)。
用时钟释放的页面随着时钟算法从实内存中选择释放的每一个页面而增加。
回溯随着解决前一个页面故障时出现的每一个页面故障而增加。