高可用架构实云数据库
聊聊常见的数据库架构设计方案
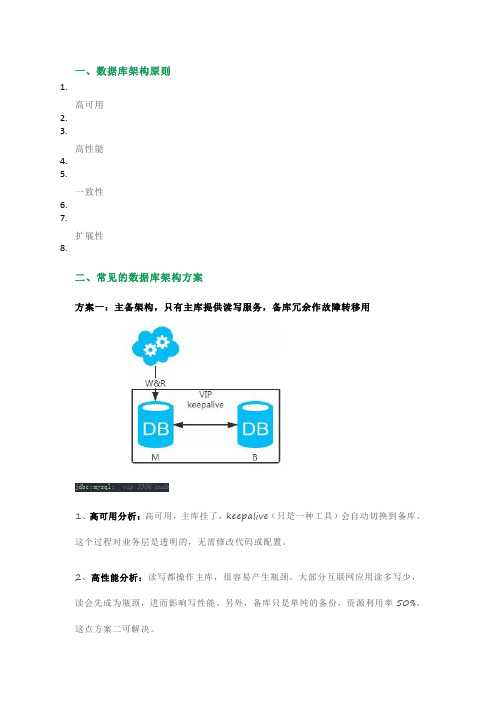
一、数据库架构原则1.高可用2.3.高性能4.5.一致性6.7.扩展性8.二、常见的数据库架构方案方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用jdbc:mysql://vip:3306/xxdb1、高可用分析:高可用,主库挂了,keepalive(只是一种工具)会自动切换到备库。
这个过程对业务层是透明的,无需修改代码或配置。
2、高性能分析:读写都操作主库,很容易产生瓶颈。
大部分互联网应用读多写少,读会先成为瓶颈,进而影响写性能。
另外,备库只是单纯的备份,资源利用率50%,这点方案二可解决。
3、一致性分析:读写都操作主库,不存在数据一致性问题。
4、扩展性分析:无法通过加从库来扩展读性能,进而提高整体性能。
5、可落地分析:两点影响落地使用。
第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。
这也是通用的方案。
第二,扩展性差,这点可以通过分库分表来扩展。
方案二:双主架构,两个主库同时提供服务,负载均衡jdbc:mysql://vip:3306/xxdb1、高可用分析:高可用,一个主库挂了,不影响另一台主库提供服务。
这个过程对业务层是透明的,无需修改代码或配置。
2、高性能分析:读写性能相比于方案一都得到提升,提升一倍。
3、一致性分析:存在数据一致性问题。
请看,一致性解决方案。
4、扩展性分析:当然可以扩展成三主循环,但笔者不建议(会多一层数据同步,这样同步的时间会更长)。
如果非得在数据库架构层面扩展的话,扩展为方案四。
5、可落地分析:两点影响落地使用。
第一,数据一致性问题,一致性解决方案可解决问题。
第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。
方案三:主从架构,一主多从,读写分离jdbc:mysql://master-ip:3306/xxdbjdbc:mysql://slave1-ip:3306/xxdbjdbc:mysql://slave2-ip:3306/xxdb1、高可用分析:主库单点,从库高可用。
海量并发下高可用库存中心的设计与实现

海量并发下高可用库存中心的设计与实现在海量并发下实现高可用的库存中心的设计至关重要,这可以确保系统能够稳定地处理大量的库存操作请求,并保证数据的准确性和一致性。
下面是一个可能的设计与实现方案:一、基础架构设计:1.库存中心采用分布式架构,包括多个库存节点,每个节点负责一部分库存数据的管理和处理。
2.使用主从复制的方式保证库存数据的可靠性和高可用性,每个节点都可以接收读操作请求,而写操作只能由主节点处理。
3.引入负载均衡的机制,将请求均匀地分发到各个库存节点,提高系统的吞吐量和并发处理能力。
二、一致性设计:1.引入分布式事务处理机制,确保库存操作的一致性。
通过如分布式锁、分布式事务协调器等技术来实现。
2.库存中心记录每次操作的流水日志,并定期对所有库存节点的数据进行校验和同步,以保证数据的准确性和一致性。
三、高可用性设计:1.使用可插拔式组件,将库存中心与外部系统解耦,以避免单点故障的问题。
2.设置监控系统和告警机制,及时发现和修复系统的故障,提高系统的可用性。
3.使用集群和冗余机制,确保系统在节点故障时仍能正常运行,同时要有自动重启和故障转移的机制。
四、性能优化设计:1.使用内存缓存技术,将热点数据保存在内存中,提高读写操作的性能。
2.利用异步处理和批处理机制,将一些耗时的操作异步化,并以批量方式执行,提高系统的吞吐量和并发能力。
3.优化数据库设计和索引,减少库存查询和更新的耗时,提高数据库的读写性能。
五、故障恢复设计:1.定期备份库存数据,以便在系统故障时能够及时恢复。
2.设计有效的灾难恢复机制,确保在灾难性事件发生时,能够快速将系统恢复到正常运行状态。
六、安全性设计:1.引入身份认证和权限控制机制,保护库存中心免受未经授权的访问和操作。
2.使用加密技术,保护库存数据在传输和存储过程中的安全性。
3.建立日志系统,记录所有的操作记录,以便进行安全审计和追踪。
总结:以上是一个可能的海量并发下高可用库存中心设计与实现的方案。
数据库的高可用性架构与故障恢复

数据库的高可用性架构与故障恢复随着计算机技术的不断进步,数据库已经成为现代社会中重要的数据存储和处理工具之一。
在大型企业和组织中,数据库的高可用性架构和故障恢复是确保业务连续性和数据完整性的重要组成部分。
本文将探讨数据库的高可用性架构和故障恢复的一些关键概念和方法。
首先,我们需要理解高可用性架构的概念。
高可用性是指在面对硬件、软件或网络故障时,系统仍然能够继续运行并提供服务。
数据库的高可用性架构旨在确保数据库系统在故障发生时能够快速恢复并保持数据的连续性。
为达到这一目标,常见的架构模式包括备份和恢复、主从复制和集群。
备份和恢复是数据库高可用性架构中最常见的一种方式。
它通过定期备份数据库,并在发生故障时恢复备份文件以恢复数据完整性。
备份可以以全量备份或增量备份的方式进行,全量备份是指备份整个数据库,而增量备份则是只备份发生变更的部分。
通过组合使用不同类型的备份,可以保证不同程度的数据丢失。
另一种常见的高可用性架构是主从复制。
主从复制是通过建立一个主数据库和一个或多个从数据库的关系。
主数据库负责处理读写操作,而从数据库则复制主数据库的数据,只处理读操作。
当主数据库发生故障时,从数据库可以接管并提供服务,实现快速故障恢复。
主从复制还可以用于水平扩展,通过增加从数据库来提高处理能力。
除备份和恢复和主从复制外,还有一种被广泛采用的高可用性架构是集群。
集群是指通过多个服务器(节点)组成的系统,这些节点共享相同的硬件和软件配置,并提供相同的数据库服务。
集群通过分布数据和计算负载来提供高可用性和扩展性。
常见的集群技术包括主备集群和主主集群。
主备集群是指在多个节点中,只有一个节点处于活动状态,其他节点处于待命状态,一旦活动节点失败,待命节点可以快速接管。
主主集群则是所有节点都处于活动状态,数据进行双向同步,提供更好的性能和数据一致性。
当数据库发生故障时,快速恢复数据是至关重要的。
数据库的故障恢复可以通过以下步骤来实现。
一种基于占位虚拟机的云数据中心高可用方案

大数据 云计算数码世界 P .155一种基于占位虚拟机的云数据中心高可用方案黄颖 徐岚 中国电子科技集团公司第二十八研究所摘要:本文针对分布式云数据中心间“数据跨中心备份、服务按需接管”的中心级高可用能力,提出一种基于占位虚拟机的云高可用方案,并将系统技术架构分为网络层、云平台层、数据层、服务层、访问接入层五个层次,分析了每层的高可用技术应用策略,该方案具备较好的应用推广前景。
关键词:高可用 占位虚拟机 云数据中心1 高可用相关概念随着虚拟化、网络化、服务化技术的快速发展,云架构已在各个领域大量运用,数据中心作为云资源的提供者承载了大量不同类型的应用。
目前单一的数据中心已发展为分布式云数据中心模式,对分布式云数据中心构成一体化高可用能力的需求也越来越迫切。
在业界通常概念定义中,高可用性(High Availability ,HA)用来描述一个系统经过专门的设计,以减少停工时间,而保持其服务的高度可用性。
业界通常说的数据中心双活,也属于高可用能力的范畴。
描述系统高可用能力,一般有两个重要指标:系统恢复时间(RTO)和数据恢复点目标(RPO)。
RTO 是针对服务丢失,从业务系统故障开始,到业务系统恢复正常之间的时间段。
RPO 是针对数据丢失,指业务系统和应用数据恢复正常后,系统及生产数据能恢复到过去的哪个时间点。
一般来说,数据中心高可用能力根据备用中心活跃程度由低到高,可定义为5个等级,如图1所示。
对于最高等级的全集双活,两中心技术架构应是完全对称、去中心化的,需要从底层网络到上层应用进行一体化设计,实现起来难度很大,性价比不高。
在大多数工程实践中,一般结合高可用性需求在冷备、热备、只读、分片4个等级中选择,也可采用混合架构,对系统进行分层,不同层采用不同的高可用技术策略。
图1 高可用能力等级示意图2 高可用方案简述在某大型系统建设了相距100公里以内的两个数据中心,作为逻辑一体的后台,共同对前台客户端提供服务。
基于OpenStack私有云平台构建及高可用实现

本文介绍了开源云平台OpenStaek的基本架构以及各个 组件的功能,并利用MirantisFud自动化部署工具搭建了一个 包括1个控制节点,3个计算节点的OpenStaek的私有云平 台,在此基础上,说明了如何实现OpenStack在软件和硬件两 方面的高可用,并采用Galera插件和负载均衡的方案实现了 2.配置OpenStack数据库集群。在配置OpenStack数据 库集群时,可以根据OpenStack官方文档的说明进行配置, OpenStaek云平台后端数据库的高可用性,避免数据库因单点 故障而导致其他服务的失效,提高了云平台的实用性。
等,其中0penStack的关注度最高且发展最快速。 OpenStack是一个由美国国家航空航天局(NAsA)和美
国Rackspace公司合作研究发起的项目,OpenStack是一个
haS(Infrastructureasaservice)层的软件,其目标是提供可靠的 云部署方案及良好的扩展性。项目每半年发布一个新版本, 版本号以字母表顺序命名,从第一版的Austin(2010.1 01到最
到二次开发。
一、OpenStack的基本架构 OpenStaek云平台基本架构嗍(如图1),分为5个部分:仪 表板(Dashboard)、计算(Computing)、网络(Networking)、存储 (Storage)和共享服务(Shared services)。 计算服务(Nova),其作用是在OpenStaek环境中管理虚拟 机的生命周期,包括虚拟机的生成、调度、停止等。 存储服务,分为块存储(Cinder)和对象存储(Sw蠲。块存储 是为运行的虚拟机提供持久的逻辑卷服务,对象存储服务则 用于存储和检索任意的非结构化数据,并具有强大的扩展、
高可用架构设计及实现方法

高可用架构设计及实现方法随着互联网技术的逐渐普及,许多企业开始注重技术的发展和架构的设计。
高可用架构是一种可以保证业务持续稳定运行的设计方案,而在实现高可用架构的过程中,涉及到的技术和策略也是非常关键的。
本文将就高可用架构的设计及实现方法做一些简单的介绍。
一、高可用架构设计概述高可用架构通俗的说法就是“高冗余度”架构,即通过多个节点、多个通道等方式提高整个系统的可靠性和稳定性。
在实际应用中,高可用的架构设计往往考虑的因素非常多,涉及的技术和策略都非常复杂。
其中,以下几个方面是设计高可用架构时必须要考虑的:1.节点冗余设计:我们可以通过备份多个节点来实现系统的整体冗余,即使一台服务器节点出现故障,也可以及时补充其他的节点保证业务的正常进行。
2.数据冗余设计:在系统存储层面,我们也可以通过备份数据、多副本等方式实现数据的冗余,保证我们的数据一旦丢失,可以快速从备盘中恢复。
3.链路冗余设计:在系统通讯方面,我们可以通过多个通道进行数据传输,避免单点故障导致业务中断。
4.负载均衡设计:一台服务器不可能承载所有的请求,因此我们需要将请求均衡地分配到多台服务器中去,以达到负载均衡的效果。
5.监控报警设计:在系统运行过程中,我们需要时刻监控各个节点和关键指标的状态,及时报警并做出相应的处理。
6.可扩展性设计:随着业务规模的不断扩大,我们需要预留足够的扩展空间和具备系统水平扩展的能力,因此在架构设计时需要考虑这方面的问题。
以上这些方面都是设计高可用架构时必须要考虑的,还需要考虑系统的应用场景、业务类型、技术选型等因素,最终综合考虑实现合适的高可用架构。
二、高可用架构的实现方法在高可用架构实现过程中,需要考虑执行上述方面的策略和技术,以下是实现高可用架构常用的方法:1.节点冗余实现方法:为了实现节点冗余,我们可以采用主备模式、双活模式、N+1等方式。
在主备模式下,我们将采用冗余服务器来备份主服务器,这样当主服务器宕机之后,冗余服务器会立即上线并提供服务。
高可用性云计算平台的研究与实现

高可用性云计算平台的研究与实现第一章:引言随着信息技术的迅速发展,云计算作为一种新型的计算模式,已经成为各行各业应用的重要手段。
高可用性云计算平台作为云计算的基础设施之一,具有极大的应用潜力。
本文旨在对高可用性云计算平台的研究与实现进行探讨,以期为相关研究和实践提供参考。
第二章:高可用性云计算平台的概述2.1 云计算平台的特点云计算平台作为一种分布式计算模式,具有灵活性、弹性和可扩展性等特点。
高可用性是云计算平台的重要特征之一,为用户提供可靠性和稳定性的服务。
2.2 高可用性云计算平台的定义高可用性云计算平台是指能够提供连续可靠性服务的云计算基础设施,具备自动和快速恢复能力,以实现对故障的快速响应,并保证用户的业务不受影响。
第三章:高可用性云计算平台的关键技术3.1 负载均衡技术负载均衡技术是实现高可用性云计算平台的关键技术之一。
通过将用户请求分配到集群中的多个节点上,实现资源的均衡利用,提高系统的整体性能和可用性。
3.2 容错技术容错技术是保障高可用性云计算平台正常运行的重要手段。
通过使用冗余的硬件、软件和网络设备等手段,实现故障的隔离和恢复。
3.3 弹性扩展技术弹性扩展技术是高可用性云计算平台实现规模性增长和弹性调整的关键技术。
通过监控系统的负载情况,及时调整资源配置,以满足用户的需求变化。
第四章:高可用性云计算平台的实现方法4.1 虚拟化技术虚拟化技术是实现高可用性云计算平台的基础。
通过将物理设备虚拟化成虚拟机,提供资源池的共享和弹性调度,实现对硬件故障的隔离和恢复。
4.2 分布式存储技术分布式存储技术是高可用性云计算平台实现数据备份和容灾的重要手段。
通过将数据分散存储在多个节点上,并实现数据的冗余备份和数据一致性保证。
4.3 容器技术容器技术是高可用性云计算平台实现应用部署和管理的重要技术。
通过将应用程序及其所有依赖项打包到容器中,实现应用的快速迁移和部署。
第五章:高可用性云计算平台的应用案例分析5.1 亚马逊AWS亚马逊AWS是目前应用最广泛的高可用性云计算平台之一。
Oracle 最高可用性架构 MAA

商务采购的灵活性、是否可以利旧、网络带宽需求、灾备中心的集成 密度等。
更高的集成密度;灾备中心及其系统应当为企业提供容灾之外更高的 附加价值,例如为生产系统报表减负、降低计划内停机时间等。
Copyright © 2016, Oracle and/or its affiliates. All rights reserved. |
闪回表
@T2 Row-1 Row-2 Row-3 Row-n
Col-1 tom ben charlie tom
Col-.. 1234 8834 9837 8793
Col-n vp vp vp vp
Batch Update
DB @ T1
闪回数据库
DB @ T2
错误更新
Copyright © 2016, Oracle and/or its affiliates. All rights reserved. |
Row-2
ben
8834
mgr
有效避免错误操作,实现更高可用性
Row-3 Row-n
Charlie tom
9837 8793
officer vp
错误更新
• 快速实时恢复,无需复杂昂贵的恢复 过程
• 错误调查
– 按照时间点或交易查看数据
• 逻辑错误恢复
– 回退交易 – 回退错误的表更新 – 回滚整套数据库
Copyright © 2016, Oracle and/or its affiliates. All rights reserved. |
5天 不可用
5
可用性意味着什么
每小时服务中断的平
数据库的容灾与高可用性架构设计

数据库的容灾与高可用性架构设计在现代企业中,数据库作为存储和管理重要数据的关键组件,在保障数据安全和可用性方面起着至关重要的作用。
为了在遇到灾难性故障时能够实现数据的恢复和系统的快速恢复,数据库的容灾与高可用性架构设计成为不可忽视的问题。
本文将从容灾和高可用性两个方面来探讨数据库架构的设计。
一、容灾架构设计容灾是指在遭受灾害或故障时,能够保证系统和数据的连续性、完整性和可用性的能力。
常见的容灾架构设计方案有备份和恢复、冷备份、热备份、以及异地多活等。
以下将介绍这些方案的特点和适用场景。
1. 备份和恢复备份和恢复是最基本也是最常用的容灾方案。
通过定期对数据库进行备份,并将备份文件保存在不同地点,以便在数据库故障时能够快速恢复。
备份可以是完整备份或增量备份,具体根据数据量和恢复的时间要求来决定。
备份和恢复需要有明确的策略和计划,包括备份频率、备份存储位置、备份验证等。
2. 冷备份冷备份是指在数据库故障时,将备份数据拷贝到目标服务器上,并启动该数据库实例的过程。
由于数据库备份是离线状态进行的,所以恢复数据库的时间较长。
冷备份适用于数据量较大、恢复时间要求相对宽松的情况。
3. 热备份热备份是指在数据库故障时,将备份数据拷贝到目标服务器上,并将该数据文件应用到实时数据库中。
这种方式下数据库恢复的时间较短,可以保证业务的连续性。
热备份适用于恢复时间要求比较短的情况。
4. 异地多活异地多活是指在两个或多个地理位置上构建相同的数据库环境,并通过数据同步来保持数据一致性。
当一个地点的数据库出现故障时,可以切换到另一个地点的数据库继续提供服务。
异地多活适用于对系统可用性要求较高的场景,但需要考虑数据同步和网络延迟等问题。
二、高可用性架构设计高可用性是指系统能够在故障发生时保持功能正常和高效运行的能力。
在数据库高可用性架构设计中,常见的方案有主从复制、主从复制+读写分离、集群等。
1. 主从复制主从复制是指将主数据库的数据实时复制到一个或多个从数据库上,从数据库作为备份和故障切换的目标。
五大常见MySQL高可用方案

五大常见的MySQL高可用方案首发于1. 概述我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面:∙如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
∙用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时或者保持一致。
∙当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
关于对高可用的分级在这里我们不做详细的讨论,这里只讨论常用高可用方案的优缺点以及高可用方案的选型。
2. 高可用方案2.1. 主从或主主半同步复制使用双节点数据库,搭建单向或者双向的半同步复制。
在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。
常见架构如下:通常会和proxy、keepalived等第三方软件同时使用,即可以用来监控数据库的健康,又可以执行一系列管理命令。
如果主库发生故障,切换到备库后仍然可以继续使用数据库。
优点:1.架构比较简单,使用原生半同步复制作为数据同步的依据;2.双节点,没有主机宕机后的选主问题,直接切换即可;3.双节点,需求资源少,部署简单;缺点:1.完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;2.需要额外考虑haproxy、keepalived的高可用机制。
2.2. 半同步复制优化半同步复制机制是可靠的。
如果半同步复制一直是生效的,那么便可以认为数据是一致的。
但是由于网络波动等一些客观原因,导致半同步复制发生超时而切换为异步复制,那么这时便不能保证数据的一致性。
所以尽可能的保证半同步复制,便可提高数据的一致性。
该方案同样使用双节点架构,但是在原有半同复制的基础上做了功能上的优化,使半同步复制的机制变得更加可靠。
可参考的优化方案如下:双通道复制半同步复制由于发生超时后,复制断开,当再次建立起复制时,同时建立两条通道,其中一条半同步复制通道从当前位置开始复制,保证从机知道当前主机执行的进度。
MongoDB数据库高性能、高可用架构设计

MongoDB数据库高性能、高可用架构设计随着企业服务窗口的不断增加,业务中断对很多企业意味着毁灭性的灾难,因此,跨多个数据中心的应用部署成为了当下最热门的话题之一。
如今,在跨多个数据中心的应用部署最佳实践中,数据库通常负责处理多个地理区域的读取和写入,对数据变更的复制,并提供尽可能高的可用性、一致性和持久性。
但是,并非所有的技术在选择上都是平等的。
例如,一种数据库技术可以提供更高的可用性保证,却同时只能提供比另一种技术更低的数据一致性和持久性保证。
本文先分析了在现代多数据中心中应用对于数据库架构的需求。
随后探讨了数据库架构的种类及优缺点,最后专门研究MongoDB如何适用于这些类别,并最终实现双活的应用架构。
双活的需求当组织考虑在多个跨数据中心(或区域云)部署应用时,他们通常会希望使用“双活”的架构,即所有数据中心的应用服务器同时处理所有的请求。
图1:“双活”应用架构如图1 所示,该架构可以实现如下目标:∙通过提供本地处理(延迟会比较低),为来自全球的请求提供服务。
∙即使出现整个区域性的宕机,也能始终保持高可用性。
∙通过对多个数据中心里服务器资源的并行使用,来处理各类应用请求,并达到最佳的平台资源利用率。
“双活”架构的替代方案是由一个主数据中心(区域)和多个灾备(DR)区域(如图2 所示)所组成的主-DR(也称为主-被)架构。
图2:主-DR 架构在正常运行条件下,主数据中心处理请求,而DR 站点处于空闲状态。
如果主数据中心发生故障,DR 站点立即开始处理请求(同时变为活动状态)。
一般情况下,数据会从主数据中心复制到DR 站点,以便在主数据中心出现故障时,能够迅速实施接管。
如今,对于双活架构的定义尚未得到业界的普遍认同,上述主-DR 的应用架构有时也被算作“双活”。
区别在于从主站到DR 站点的故障转移速度是否够快(通常为几秒),并且是否能够自动化(无需人为干预)。
在这样的解释中,双活体系架构意味着应用停机时间接近于零。
高可用性软件架构设计和实现论文

高可用性软件架构设计和实现论文摘要:硬件冗余可以极大地提高计算机应用系统的可用性,然而,一旦关键硬件出现故障或数据库宕机,正在进行中的业务流程通常会中断。
探讨了一种如何实现应用系统高可用性的软件架构的设计方案,以弥补纯硬件冗余应用系统的不足。
关键词:高可用性;软件容错;分布式数据库在业内,计算机应用系统的可用性定义为计算机应用系统保持正常运行时间的百分比,通常用表1所示的“9”的个数来划分可用性的类型。
通常,硬件冗余(容错计算机、双机或多机集群、磁盘阵列、SAN等)、数据复制、合理的灾难备份和恢复策略都可以极大地提高计算机应用系统的可用性。
正因为如此,当前,对于计算机应用系统的高可用性、业务的可持续性要求,业内通常以硬件系统的高可用性来应对或代替。
常见的解决方案是双机(或多机)集群方案或直接采用容错计算机来保障系统的高可用性,应用软件的设计和开发往往仅注重业务流程的分析和过程控制。
在这种完全依赖硬件来保障整个系统的可用性的系统里,一旦关键硬件出现故障或数据库宕机,正在进行中的业务流程(如需较长执行时间的事务处理、后台批处理过程等)必然会中断,这是因为双机切换也需要时间。
对此,应用软件本身并无多少作为,该类业务必须等待系统重新恢复后全部或部分重做。
本文以基于大型数据库的应用系统为例,从“软件容错”设计的概念出发,参考“分布式”数据库结构设计,以“系统服务总线”为核心,给出了一种可行的高可用性软件架构的设计方案,可以极大地提高应用软件的可用性和业务系统的可持续性。
无论是传统的C/S架构,还是近年来流行的B/S架构,本文中给出的设计方案都有一定的参考意义。
1软件结构模型任何基于大型数据库的应用系统,都可以抽象为对数据的“读”和“写”操作。
至于客户端如何展现“读”到的数据,以及“客户端”与“服务端”基于何种通信协议通信,不在本文讨论之列。
软件结构的设计其实就是针对“读”和“写”的一系列流程的设计。
如何最大限度地保证系统中的所有“硬件”和“软件”协同工作,正确完成每一次“读”和“写”的操作,也就是对系统“高可靠性”和“高可用性”的要求。
云数据库的特点与架构分析

云数据库的特点与架构分析随着云计算的迅猛发展,云数据库作为一种新兴的数据库解决方案,正在逐渐取代传统的本地数据库。
云数据库具有许多独特的特点和架构设计,本文将对云数据库的特点和架构进行深入分析。
一、云数据库的特点1. 高可用性:云数据库具备高可用性的特点,能够实时提供持续稳定的数据库服务。
云数据库使用分布式架构,通过数据的冗余备份、主从复制和自动故障转移等机制,能够保证数据库在硬件或软件故障时的快速恢复,从而确保数据的可靠性和稳定性。
2. 弹性扩展:云数据库具备很强的扩展性,可以根据需要迅速调整数据库容量和性能。
云数据库使用了水平扩展的架构模式,通过增加服务器节点或调整服务器配置,可以实现数据库的规模扩展和负载均衡,从而满足不同规模和需求的应用对数据库的要求。
3. 自动备份与恢复:云数据库具备自动备份与恢复的功能,可以定期或实时备份数据,并能够快速恢复到指定的备份点。
云数据库的备份是基于分布式存储的,数据备份之后会存储在不同的物理节点上,从而避免了数据丢失的风险。
同时,云数据库还提供了数据快照功能,用户可以根据需要随时创建数据快照,以保护数据的安全性和完整性。
4. 跨地域容灾:云数据库支持跨地域容灾,通过在不同的地理区域部署数据库节点,能够提供灾难恢复和故障转移能力。
当某个地域发生故障或不可用时,系统可以自动切换到其他可用地域的数据库节点,从而确保业务的连续性和高可用性。
二、云数据库的架构1. 分布式架构:云数据库采用了分布式架构,将数据库存储和计算能力分散到多个物理服务器上,提高数据访问效率和负载能力。
在云数据库的架构中,数据被划分为多个分片,每个分片存储在不同的物理节点上,并通过分布式协调器进行管理和调度。
2. 多副本复制:云数据库使用多副本复制机制,将数据的多个副本存储在不同的服务器节点上。
当某个节点发生故障时,系统可以自动将副本切换到其他可用节点,从而实现快速故障转移和无缝恢复。
多副本复制还能够提供数据的高可靠性和容灾能力,确保数据的安全性和可用性。
数据库高可用性方案汇总
数据库⾼可⽤性⽅案汇总⼀. ⼤纲本篇介绍常见数据库的⾼可⽤⽅案,侧重于架构及功能介绍,不涉及详细原理,主要为了帮助⼤家对于常见数据库的⾼可⽤⽅案做个汇总性的了解。
⾸先我们先了解下⾼可⽤⽅案的常见类型,下⾯主要从两个⽅⾯来划分。
按底层存储架构主要划分为两种:1. Shared Storage:多个数据库实例之间共享⼀份数据存储,常见分案有Oracle RAC,SQL故障转移群集2. Shared Nothing: 每个数据库实例各⾃维护⼀份数据副本,常见分案有MySQL MHA,Oracle ADG,SQL镜像按功能实现主要划分为三种:1. Load balancing(负载均衡):常见实现⽅式为读写分离,典型⽅案有读写分离中间件,数据源拆分2. Auto Failover(⾃动故障转移):典型⽅案有MySQL MHA,SQL镜像(带见证服务器),AlwaysON3. Load balancing & Auto Failover(两者兼具):典型⽅案为Oracle RACPS:公司⽬前由于项⽬众多,环境参差不齐,且性能上基本单实例可以满⾜,因此侧重于故障转移,鲜有⽤到负载均衡的⽅案。
⼆. MySQL篇MySQL作为当今最流⾏的开源数据库之⼀,⾼可⽤⽅案可谓五花⼋门,下⾯依次介绍!PS:下述MySQL常见架构中的从库,⼀般都可以进⾏只读操作,程序上如果进⾏数据源拆分基本都可以达到分担压⼒的效果,所以下述中所涉及到的负载更多是意味着该⽅案能否在不拆分数据源的情况下,依靠⽅案本⾝达到负载均衡的⽬的!同理的话,故障转移也是,最简单的主从复制其实就可以实现⼿动故障转移,再配合keepalived(中间件)也可以达到⾃动故障转移的功能,所以下述中所涉及到的故障转移均意味着⽅案在不借助中间件的情况下可以实现⾃动故障转移,且对业务程序透明!主从复制是MySQL数据库使⽤率⾮常⾼的⼀种技术,它使⽤某个数据库服务器为主库(Master),然后实时在其他数据库服务器上进⾏数据复制,后⾯复制的数据库也称从库(Slave),架构上可以根据业务需求⽽进⾏多种变化组合,因此引申出了主主复制,⼀主多从,多主⼀从,联级复制等⾼可⽤架构。
阿里云产品容灾-高可用介绍及架构方案

袋鼠云出品——阿里云高可用-容灾解决方案这两天,一篇名为《IT之家因无法忍受阿里云而迁移至XX云》的文章引起了整个云计算行业的热议。
(袋鼠云CTO江枫还专门写了一篇热评)从目前得到的信息看,其应该是在青岛区域购买了一台云服务器ECS,基于.net和自建SQL Server,并且应用和数据库跑在同一台云服务器上。
IT之家,所有应用都部署在单台ECS上,不具备高可用的特性。
即便阿里云产品本身就有容灾、高可用的特征,但是因为一些用户对阿里云产品的不了解和自身应用架构不够合理,也根本无法使其发挥该优势。
其实,IT之家的事情不是个例,有很多其他企业在这方面很头疼。
所以,袋鼠云技术专家结合以往实践经验,总结出了一套切实可行的《阿里云高可用-容灾解决方案》,希望能和各位阿里云上用户一起探讨。
一、阿里云产品容灾-高可用介绍1、SLB 容灾-高可用介绍阿里云SLB产品使用开源软件LVS+keeplived实现4层的负载均衡。
采用淘宝的Tengine实现7层的负载均衡。
所有负载均衡均采用集群部署,集群之间实时会话同步,以消除服务器单点,提升冗余,保证服务稳定。
在各个地域采用多物理机房部署,实现同城容灾。
SLB在整体设计上让其可用性高达99.99%。
且能够根据应用负载进行弹性扩容,在任意一台SLB故障或流量波动等情况下都能做到不中断对外服务。
图一2、ECS 容灾-高可用介绍云服务器ECS实例是一个虚拟的计算环境,包含了CPU、内存、操作系统、磁盘、带宽等最基础的服务器组件,是ECS提供给每个用户的操作实体,就如同我们平时使用的虚机。
但需要确认的是,ECS自身是没有容灾和高可用方面的功能。
所以当我们在单台ECS服务器上部署各种应用时,特别是对于那些将应用服务,数据库服务等都打包安装在单台ECS服务器时就更要注意这点了。
那ECS自身没有容灾-高可用这样的功能,对于在单台ECS上部署各种服务,一旦ECS 故障就只能眼睁睁的看着它down机对外停止服务么?此时,如果产品自身没有容灾和高可用功能,我们可以从架构上来弥补这个短板。
云计算平台部署与运维作业指导书

云计算平台部署与运维作业指导书第1章云计算基础概念 (4)1.1 云计算服务模型概述 (4)1.1.1 软件即服务(Software as a Service,SaaS) (4)1.1.2 平台即服务(Platform as a Service,PaaS) (5)1.1.3 基础设施即服务(Infrastructure as a Service,IaaS) (5)1.2 云计算部署模型介绍 (5)1.2.1 公共云 (5)1.2.2 私有云 (5)1.2.3 混合云 (5)1.2.4 社区云 (5)1.3 云计算关键技术简述 (6)1.3.1 虚拟化技术 (6)1.3.2 分布式计算与存储 (6)1.3.3 资源调度与优化 (6)1.3.4 数据中心网络技术 (6)1.3.5 安全与隐私保护技术 (6)第2章部署前准备 (6)2.1 确定业务需求 (6)2.1.1 分析业务目标:明确业务在云计算平台上的目标,包括提升业务效率、降低成本、提高系统可用性等。
(6)2.1.2 评估业务规模:根据业务发展现状和预期,预测云计算资源需求,包括计算、存储、网络等方面的需求。
(6)2.1.3 确定关键业务流程:识别业务中的关键环节,以保证在部署云计算平台时,这些环节能够得到有效支持。
(7)2.1.4 业务连续性和安全性要求:明确业务在云计算环境下的连续性和安全性需求,以保证业务稳定运行。
(7)2.2 评估资源预算 (7)2.2.1 估算基础设施成本:根据业务需求,对云计算平台的计算、存储、网络等资源进行估算,以确定基础设施成本。
(7)2.2.2 评估运维成本:考虑云计算平台部署与运维过程中的人力、培训、监控、优化等成本。
(7)2.2.3 预测业务增长:根据业务发展预期,预留一定的资源预算,以应对业务增长带来的额外需求。
(7)2.2.4 优化预算分配:在保证业务需求的前提下,合理分配预算,以实现成本效益最大化。
云数据库的HA架构设计

云数据库的HA架构设计所谓HA架构,即高可用性架构,是指在系统设计中采用一系列技术和策略,以确保系统能够在各种异常情况下保持稳定可用的能力。
对于云数据库而言,实现高可用性架构是非常重要的,以确保数据在任何时候都能够安全可靠地存储和访问。
以下是一个适用于云数据库的HA架构设计示例:一、概述云数据库的HA架构设计旨在提供高可用性、高性能和可扩展性的数据库服务。
该架构包括主从复制、自动切换和负载均衡等关键技术,以确保数据的持久性、可靠性和可用性。
二、主从复制主从复制是一种常见的数据库同步技术,适用于云数据库的HA架构设计。
该技术通常是通过将主数据库的数据变更实时同步到多个从数据库来实现的。
在该架构中,主库负责处理写入操作,而从库则负责处理读取操作。
主从复制的工作原理是,主库接收到写入请求后,将数据变更记录在二进制日志(Binlog)中,并将其同步到从库。
从库通过读取主库的Binlog,并将其中的数据变更应用到自身的数据库中。
通过这样的复制机制,从库能够实现与主库的数据同步,从而保证了数据的一致性。
三、自动切换自动切换是云数据库HA架构设计中的另一个关键技术。
当主库发生故障或不可用时,自动切换机制能够快速将从库切换为主库,以确保系统的持续可用性。
在自动切换机制中,通常会采用心跳检测的方式来监测主库的状态。
当主库无法正常响应时,自动切换机制会立即启动,并将系统切换到可用的从库上。
同时,还需要确保新的主库能够接收和处理写入请求,以保证系统的正常运行。
四、负载均衡负载均衡是云数据库HA架构设计中不可或缺的一环。
通过负载均衡技术,可以将用户的请求均匀地分发到不同的数据库节点上,以实现请求的并行处理和数据的平衡负载。
在负载均衡的实现中,通常会采用多个数据库节点来共同处理用户的请求。
通过将用户请求导入到不同的节点上,并根据节点的负载情况进行动态调整,可以实现对数据库系统的优化和提升。
五、容灾备份容灾备份是云数据库HA架构设计中的重要环节。
高并发时序数据库的设计与实现研究

高并发时序数据库的设计与实现研究近年来,随着云计算、大数据、物联网等技术的兴起,时序数据的应用越来越广泛。
例如,智能家居、物流监控、金融交易等领域都需要对时序数据进行存储、查询和分析。
然而,随着数据规模的增大和查询频率的提高,传统的关系型数据库已经无法满足高并发时序数据处理的需求。
因此,高并发时序数据库成为了一个热门的研究领域。
一、时序数据库的特点时序数据库的特点主要包括三个方面:高并发、高容量和高性能。
首先,时序数据的采集非常频繁,一般以毫秒或微秒为单位进行采集。
因此,处理这些数据的数据库需要具备高并发处理能力,可以支持上万次的并发读写操作。
其次,时序数据的存储量非常大,一般以天、月、年为单位进行统计和分析。
因此,时序数据库需要具备高容量存储能力,可以支持PB级别的数据存储。
最后,由于时序数据的查询、分析和处理需要实时性能,因此时序数据库需要具备高性能的查询能力,可以在毫秒或秒级别内完成复杂的数据查询和分析操作。
二、高并发时序数据库的架构设计高并发时序数据库的架构设计需要考虑多个方面,包括数据采集、存储、索引、缓存、查询等。
下面我们将分别对这些方面进行详细的描述。
1. 数据采集数据采集是高并发时序数据库的关键,一般通过网络或传感器等方式采集数据。
在采集时,需要考虑采样频率、采样精度和数据压缩等问题。
采样频率的选择需要结合实际应用场景进行规划,一般一秒钟或一毫秒进行一次采集。
采样精度和数据压缩则需要根据存储容量和数据处理能力来进行规划。
2. 数据存储数据存储是高并发时序数据库的核心,一般采用分布式存储的方式进行存储。
由于时序数据的写入和查询比较频繁,因此需要采用高可扩展性的存储架构。
常用的分布式存储技术包括基于Hadoop的HBase、基于Cassandra的ScyllaDB、基于InfluxDB的Kapacitor等。
3. 索引机制时序数据的查询一般以时间为关键词进行查询,因此索引机制是高并发时序数据库的另一个重要方面。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
高可用架构实践云数据库UCloud云数据库(UDB)团队对UDB底层架构进行重构,对其性能和数据一致性等内核方面做了大量深入的工作。
“高可用”英文翻译为“High Availability”,从字面上理解就是要做到服务full-time的持续可用。
但老实说,要做到full-time是不现实的,因为能够影响系统服务可用性的因素实在太多了,除软件BUG、硬件故障外,还包括系统所依赖的一些如运营商提供的带宽等第三方服务,,甚至还包括天灾人祸。
因此,所谓的高可用意味着“更少的停服时间”,而工业界也有一套测量系统可用性的标准,即大家所熟知的SLA(Service Level Agreement),也就是几个9的可用性(如下表):在工业应用场景中,例如做在线服务的各大互联网公司,号称7*24小时不间断服务,如果只是达到一个“9”的可用性,将会是一种什么样的灾难。
然而,要做到5个“9”的可用性,就意味着全年只有一次服务宕机,而且必须在5分钟左右就恢复,其难度不言而喻,因此只是采用技术手段不足以做到,还需要有一整套完备严谨的工程管理防范措施、配套工具及工程运维人员等。
云计算号称互联网公司的水和电,高可用犹如云服务商的生命线。
因为云端成千上万个用户数据库实例所面临的问题会更加五花八门,所以云数据库作为该领域的一项重要服务,更是承受着不同维度的考验。
下面将先介绍MySQL领域的关键技术及适用场景,并在此基础上介绍和分享UDB的高可用方案。
数据库服务和很多工业服务在高可用技术方案是相通的,为了实现高可用,首先实现服务的”冗余”,即服务的集群化。
如果服务有冗余备份,宕机后还有其它备份服务(热备和冷备)可以顶上,所以实现数据库服务的”冗余”也是高可用数据库的核心准则。
不过,有了”冗余”备份后还不够,因为如果每次宕机都需要人工恢复切换至备份服务,那么恢复时间得不到保证,同时人为的故障恢复过程中可能会引入新的风险(人为事故),从而降低了服务的可用性,因此必须还具备”自动故障转移”功能。
数据库服务相比于其它系统的高可用,在上述两个关键技术点的实现上会更加困难,因为传统RDMS对数据、事务的持久性与稳定性要求非高,因此也提高了对冗余数据的一致性要求和实现难度。
下图是Oracle官方对MySQL几种典型高可用方案的可用性总结,由于时间相对较早,并且随着近年来分布式一致性协议在工业界的实践和发展,MySQL高可用方案又有了全新的发展方向以及相对成熟的方案,下面将一并罗列与解析。
(1)MySQL Replication 就是通过MySQL原生复制技术来实现数据的冗余,该方案也是较易实现和通用的方案,相关原理介绍不再详细赘述。
其实现原理主要是通过2PC来实现本地BINLOG与本地数据的一致性,并在此基础上通过IO 线程和SQL线程来实现远端数据与本地数据同步,根据数据一致性程度不同,复制技术又可以分为异步复制、半同步复制以及同步复制。
另外,在此冗余技术上,一般会搭配使用MySQLProxy、keepalived、MHA等第三方软件来实现自动容灾,该技术方案如果不做一定优化,可用性一般不到2个“9”。
(2)MySQL Fabric 是Oracle官方提供的一种MySQL高可用方案,通过数据分片下的读写分离模式,该方案的可用性达到2个“9”。
(3)分布式块设备复制(Distributed Relicated Block Deivce,DRBD)是一种基于软件、网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷等生成数据镜像。
当用户将数据写入本地磁盘时,还会把数据发送到网络中另一台主机的磁盘上,使本地主机(主节点)与远程主机(备节点)数据实时同步,当本地主机出现问题时,远程主机上还保留着一份相同的数据,仍能继续使用,保证了数据安全,但该方案的缺点是IO性能影响严重,可用性不到3个“9”。
(4)Solaris Clustering方案代表着另一种技术方向,即以共享存储为基础,实现数据库服务器和存储设备的解耦,其结果是数据库服务器之间的冗余与数据无关,数据冗余通过SAN共享储存或分布式存储系统来实现。
当然,除此之外,Solaris Clustering还提供操作系统、硬件等各个层面的监控机制。
该方案的可用性达到接近4个“9”,但由于价格昂贵,实现代价大。
(5)MySQL Cluster是官方提供的一个开源方案,其将MySQL的集群分为SQL 节点和数据节点,数据节点通过一种内存中的存储引擎来实现自动sharding和复制。
虽然该方案号称接近5个“9”的可用性,但缺点也很多,例如对内存消耗大、使用成本高、牺牲了过多SQL语言特性、配置复杂等。
(6)Paxos 协议主要以多数派投票的方式来就分布式系统中某个值达成一致,该算法被业界认为是分布式一致性算法,包括其在内衍生出来的分布式一致性算法,如Raft,也在很多开源分布式系统得到应用。
Paxos与MySQL相结合可以实现分布式MySQL数据库较终一致性,从而保证高可用,因而使用分布式算法来解决MySQL数据库一致性问题的方法也逐渐被用户所接受,一系列产品如PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster等,越来越多的被应用到生产环境。
较近,Oracle官方推出MySQL Group Replication的GA,更使其在MySQL高可用领域成为一种民用技术,因此使用分布式协议和多副本来解决数据库一致性问题已经成为主流方向。
但此类方案还处于初级阶段,不够成熟,同时分布式一致性协议由于网络开销的原因,在性能上还有待提高和优化。
为了实现云数据库服务的高可用,基于半同步复制技术,UDB采用双主的热备架构,实现故障自动转移,并在此基础上实现了Proxy模块,该模块不仅负责数据业务的转发,同时还监控后端DB健康状况和双主数据一致性检测,实现在后端DB宕机但不影响数据一致性的情况下,完成数据业务切换。
整个架构及容灾过程如下图:也许从架构上看很简单,一主一备的架构没有什么新意,但深入到细节中会发现仍有很多问题和难点,或者说这些问题都围绕“如何保证数据一致性”这个目标。
普通异步复制对数据库性能影响较小,但主从数据一致性难以保证;强同步复制虽然保证了主从强一致,但可用性很差,因此UDB选择了折中方案——半同步复制。
不过,只是简单的使用半同步复制依然不够,通过分析半同步复制的过程和原理,UCloud发现半同步复制会存在以下缺陷,在分析缺陷的同时也将介绍UDB的解决方案与策略:1、如何解决临界事务问题?什么是临界事务?临界事务就是在宕机那个时间点主库正在提交的事务,这个事务可能已经提交,可能已经fsync到磁盘,但却没有同步到从库中去。
半同步复制对于临界事务是没法保证的,下图是MySQL5.7无损复制一次事务commit 流程(UDB基于次复制技术做了优化):如上图,UCloud对MySQL5.7版本中无损复制模式(默认模式下)的半同步复制主机commit做了细分,拆成7个可能crash的阶段,考虑到双机切换后可能会导致的数据丢失与数据一致性异常,UCloud对每个阶段做了以下分析:➢在阶段1、2、3发生了crash,由于主库重启后事务会回滚,binlog未发送到从库,所以不会发生异常;➢在阶段4发生异常,由于主库进入了commit阶段,但是binlog尚未发送到从库,在主库重启后仍然会将这个事务发送到从机;➢在阶段5、6、7发生异常,由于从库已经收到了binlog,只要主库重启后即可达到主库和备库数据一致的效果通过上述分析,无损复制模式下,只有在阶段4发生宕机会导致恢复后双主数据不一致,因为发生宕机时,该事务在此阶段并没有发送至从库。
但主库已提交至binlog和redolog,如果此时业务切至从库,主库恢复后会继续将事务commit 并同步到从库。
不过,由于从库上已经有了新事务,因此很可能会与此事务产生冲突(如主键冲突),从而导致双主数据不一致。
所以为了解决宕机时临界事务问题,UCloud通过内核层面在主库重启recovery阶段作了如下调整:有选择性的commit并复制到从库部分事务,回滚掉没有同步到原从库的事务及Truncate掉binlog中相应的event,整个过程如下图:如上图所示,主库恢复后,会向从库或者Proxy询问从本库同步过去的较后一条事务的binlog位置,并以此为基础回滚掉该binlog位置之后的临界事务。
2、如何解决半同步退化问题?由于网络抖动以及从库硬件故障等问题会导致半同步退化为异步,如果在此情况下主库发生宕机并发生切换,会导致数据丢失,对很多数据敏感业务(如金融)造成的后果将非常严重。
因此,虽然当半同步复制退化时,整个集群是不可以容灾切换业务的,但如果主机宕机无法SSH登陆,又将怎样确定主从是否退化以及从库数据是否和主库一致?为了解决此问题,防止错误切换导致数据丢失,UDB通过在Proxy和MySQL 之间以及主从之间增加链接通道,Proxy和MySQL会用专门线程通过此链接通道同步事务信息,如果主库发生宕机,从库可以在本地缓存和远端Proxy获取同步事务信息,并使用该事务信息作为从机是否可以切换的依据,如下图:同时,为了提高可用性,应对短时间网络抖动后造成双主长时间数据不一致的情况,UDB在网络恢复后,会额外启动一个复制链路来追补落后的数据,而原先的半同步复制链路则继续用于复制实时事务。
这样不仅可以提高复制数据效率,而且还避免了由于从库负载过高永远恢复半同步的风险。
3、如何保证Proxy的高可用?通过前述问题以及UDB相应解决方案的分析,可以看出Proxy在整个架构中扮演着极其重要的角色,不仅负责数据转发,同时也为数据一致性和可用性提供保障。
那么关注的另一个问题就出现了:如果Proxy宕机怎么办?为了解决Proxy 高可用问题,UDB对Proxy模块也采用了“一主一备”模式,如下图:当图中左路主Proxy宕机后,ProxyMaster模块会触发容灾处理过程,此时ProxyMaster会将虚拟IP重新绑定至Proxy(backup)并自动启动,启动后Proxy(backup)会重新链路至原MasterDB,以保证业务不间断,而ProxyMaster模块通过ZK服务分布在多个服务器上,有效的保证了Proxy的可用性。
4、其他保障措施实际上,除该双主技术架构外,为了保障服务的高可用,UDB在运维监控等层面也做了大量工作,通过对硬件、操作系统、数据库、网络等各个层面的不间断监控,较大程度及时捕获和恢复数据库服务。
同时,UDB通过自研的大型数据库备份系统,能够应对各种级别宕机故障后的数据恢复,从而保障了用户数据的安全可靠性。