判别分析的SPSS操作
spss教程_13-1(判别分析)

y
( ) i
ax
'
k n
( ) i
, 1,2, k , i 1,2, n ,
Hale Waihona Puke ( ) iS 总 ( y
1 i 1
K
y )( y
( ) i
y ) a Ta,
' '
S 类间 n ( y
1
k
( )
y )( y y
( )
( )
判别分析
分类: 1、按判别的组数来分,有两组判别分析和多 组判别分析 2、按区分不同总体所用的数学模型来分,有 线性判别和非线性判别 3、按判别对所处理的变量方法不同有逐步判 别、序贯判别。 4、按判别准则来分,有费歇尔判别准则、贝 叶斯判别准则
判别分析
判别分析和前面的聚类分析有什么不同呢? 主要不同点就是,在聚类分析中一般人们事 先并不知道或一定要明确应该分成几类,完 全根据数据来确定。 而在判别分析中,至少有一个已经明确知道 类别的“训练样本”,利用这个数据,就可 以建立判别准则,并通过预测变量来为未知 类别的观测值进行判别了。
费歇尔判别法
费歇尔判别方法是历史上最早提出的判别方 法之一,也叫线性判别法 费歇尔判别的思想是通过将多维数据投影到 某个方向上,投影的原则是将类与类之间尽 可能的分开,然后再选择合适的判别准则, 将待判的样本进行分类判别。
费歇尔判别法
一、判别原理 设有k个总体G1,G2,…,Gk,每类中含有样本数 分别为n1,n2,…,nk 假定所建立的判别函数为
ax ax (k ) ax ax (l )
则x属于第k组
逐步判别分析
一、逐步判别原理 逐步判别分析从模型没有变量开始,每一步 都对模型进行检验,把模型外对模型的判别 力贡献最大的变量加到模型中,同时考虑已 经在模型中但又不符合留在模型中条件的变 量从模型中剔除。
2024版SPSS判别分析方法案例分析

01 查看判别分析的结果输出,包括判别函数系数、 结构矩阵、分类结果等。
02 根据输出结果,解读判别分析的结果,如判别函 数的贡献、分类准确率等。
03 结合专业知识和实际背景,对结果进行合理解释 和讨论。
05
案例分析:某公司客户流失预测 模型构建
案例背景及问题描述
01
某大型电信公司面临客户流失问题,需要构建客户流失
04
SPSS判别分析操作过程
导入数据并建立数据集
1
打开SPSS软件,选择“文件”->“打开”>“数据”,导入需要分析的数据文件。
2
在数据视图中检查数据的完整性和准确性,确保 数据质量。
3
根据需要,对数据进行预处理,如缺失值处理、 异常值处理等。
选择合适的判别分析方法
根据研究目的和数据特点,选择合适 的判别分析方法,如线性判别分析、 二次判别分析等。
决策树与随机森林
基于贝叶斯定理和多元正态分 布假设,通过最大化类间差异 和最小化类内差异来建立线性 判别函数。适用于正态分布且 各类别协方差矩阵相等的情况。
放宽了LDA的假设条件,允许各 类别具有不同的协方差矩阵。 通过构建二次判别函数进行分 类。适用于更一般的数据分布 情况。
基于距离度量的方法,将新样 本分配给与其最近的K个已知样 本中最多的类别。适用于多类 别、非线性可分问题。
数据变换与标准化
数据变换
根据分析需求,对数据进行适当的变换,如对数变换、平 方根变换等,以改善数据的分布形态或满足分析要求。
数据标准化
对数据进行标准化处理,消除量纲和数量级的影响,使不 同变量具有可比性。常用的标准化方法包括Z分数标准化、 最小最大标准化等。
数据离散化
SPSS统计分析第八章聚类分析与判别分析

SPSS统计分析第八章聚类分析与判别分析聚类分析与判别分析是SPSS统计分析中非常重要的两个方法。
聚类分析是寻找数据之间的相似性,将相似的数据划分为一个簇,从而实现对数据的归类和分组。
判别分析则是寻找数据之间的差异性,帮助我们理解不同因素对于数据的影响程度,从而实现对数据的分类预测。
首先,我们来介绍聚类分析。
聚类分析是根据数据之间的相似性进行归类的一种方法,通过度量数据之间的相似性,将相似的数据归为一类。
它在寻找数据内在组织结构和特点上具有很大的作用。
在SPSS中进行聚类分析的步骤如下:1.载入数据集:在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行聚类分析的数据集。
2.选择聚类变量:在"分析"->"分类"->"聚类"中,选择需要进行聚类分析的变量。
可以选择一个或多个变量作为聚类变量,决定了聚类的维度。
3.设置聚类参数:在设置参数的对话框中,可以选择使用不同的距离测度和聚类算法。
距离测度可以选择欧氏距离、曼哈顿距离、切比雪夫距离等,而聚类算法可以选择层次聚类、K均值聚类等。
根据具体的数据特点,选择合适的参数。
4.进行聚类分析:点击"确定"按钮,SPSS会自动进行聚类分析,并生成聚类的结果。
聚类结果可以通过树状图、散点图等形式展示,便于我们对数据的理解和分析。
接下来,我们来介绍判别分析。
判别分析是一种通过建立数学模型,根据不同的预测变量对数据进行分类和预测的方法。
判别分析可以帮助我们理解不同因素对于数据分类的重要性,从而进行有针对性的分析和预测。
在SPSS中进行判别分析的步骤如下:1.载入数据集:同样,在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行判别分析的数据集。
判别分析的SPSS实现

●Smallest F ratio.使任何两类间的最小的F值最大化 法.
●Rao' V 使 RaoV统计量最大化.可以对一个要加入到 模型中的变量的V值指定一个最小增量.选择此种方 法后,应该在该项下面的"V to dntce'"后的矩形框中输 这个增量的指定值.
②选择逐步判别停止的判据
选择逐步判别停止的判据在criteria组的矩形框中进 行.可供选择的判据有:
Indepents对话框
数据变量 输入框
数据判别分析
完成前面四步骤的操作即可使用各种系统默认值对工作数据 集的数据进行判别分析了.可以使用的方法有两种: 1直接运行:在主对话框中按用鼠标单击"Ok"按钮
2生成SPSS命令程序后再运行:在主对话框中按"Paste"按钮, 激活"Syntax"窗,在该窗中按"Run"按钮执行该语句窗中的程 序.
运行带有选择项的判别分析过程
运行Descriminant过程有两种方法: 1在主对话框中按"Ok"按钮,直接运行Descriminant过程. 2 在 主 对 话 框 中 按 "Paste" 按 钮 , 将 以 上 操 作 结 果 转 换 成 Descriminant过程的命令程序,显示在"Syntax"窗中.
5缺失值处理方式 在classification子对话框的最下面有一
个选择项,用以选择对缺失值的处理方法.
Replace missing value with mean用 该变量的均值代替缺失值.该选择项前面 的小矩形框中出现"x"时表示选定所示的 处理方法. 以上五项都给予了确定的选择 后,单击"continue"按钮,返回主对话框.
判别分析的一般步骤和SPSS实现

判别分析的一般步骤和SPSS实现判别分析是一种统计学方法,用于确定一组预测变量对于区分不同组别的目标变量的重要性。
它可以帮助我们理解和解释数据,以及预测未来的观察结果。
下面将介绍判别分析的一般步骤和如何使用SPSS软件来实现。
步骤一:数据收集和准备首先,收集需要的数据,并进行数据清洗和整理。
确保数据的完整性和准确性。
此外,还需要对数据进行标准化,以消除不同变量之间的度量单位差异。
步骤二:设定模型确定分析的目标变量和预测变量。
目标变量是我们想要预测或解释的变量,而预测变量则是用来预测目标变量的变量。
根据实际情况,选择适当的判别分析方法,如线性判别分析或二次判别分析。
步骤三:进行判别函数的计算计算出判别函数,用于将样本分成不同的组别。
判别函数是由预测变量的加权和组成的。
对于线性判别分析,判别函数的形式为:D = a1X1 + a2X2 + ... + anXn + c其中,D是判别分数,X是预测变量,a是权重,n是预测变量的数量,c是常数。
通过计算判别函数,可以根据判别分数将样本分到不同的组别。
步骤四:进行判别分析的检验判别分析的检验包括Wilks' Lambda检验和方差分析。
Wilks' Lambda检验用于检验判别函数是否统计显著,以判断预测变量的组合是否能够显著解释目标变量的变异性。
方差分析用于检验各个预测变量在不同组别之间的差异是否显著。
步骤五:解释和评估结果在判别分析的最后一步,需要对结果进行解释和评估。
根据判别分析的结果,可以判断哪些预测变量对于区分不同组别的目标变量最为重要。
此外,还可以对模型的准确性进行评估,比如使用十折交叉验证等方法。
使用SPSS软件进行判别分析的步骤如下:步骤一:导入数据首先,在SPSS软件中打开数据文件或导入数据。
确保数据的格式正确,包括变量类型、缺失值处理等。
步骤二:设定模型在SPSS中,选择"分析"菜单中的"分类"选项,然后选择"判别分析"。
判别分析的SPSS实现

判别分析的SPSS实现判别分析(Discriminant Analysis)是一种统计分析方法,用于识别和分类不同群体之间的差异。
它通过建立数学模型来寻找最佳判别函数,将样本划入事先定义好的不同类别中。
SPSS是一种流行的统计软件,可以用于进行多种数据分析,包括判别分析。
在SPSS中进行判别分析的步骤如下:1.导入数据:打开SPSS软件,并导入需要进行判别分析的数据集。
选择“文件”-“打开”-“数据”命令,找到数据文件并点击“打开”按钮。
2. 选择变量:从数据文件中选择需要用于判别的变量。
在数据视图中,点击变量名旁边的方框来选定变量。
可以按住Ctrl键并单击多个变量来进行选择。
3.运行判别分析:选择“分析”-“分类”-“判别分析”命令,打开判别分析对话框。
在对话框的“变量”选项卡中,将选择的变量移入“输入变量”框中。
如果有分类变量,可以选择将其移入“说明变量”框中。
4.设置判别函数模型:在对话框的“选项”选项卡中,可以设置判别分析的具体模型。
可以选择线性判别函数或二次判别函数,并设置解释变量和额外变量。
5.运行分析:点击对话框底部的“确定”按钮,运行判别分析。
SPSS将计算出最佳的判别函数,并用于分类和预测。
6.解释结果:判别分析完成后,可以查看结果并进行解释。
SPSS将输出各个变量的判别系数、判别函数结果、群体统计信息等。
可以根据这些结果来理解不同变量对分类的重要性。
7.进行预测:判别分析还可以用于对新样本进行分类和预测。
在对话框的“选项”选项卡中,选择“保存变量”选项,并指定一个新的变量名。
运行分析后,可以查看新变量的值,以得到新样本的分类结果。
8.检验结果:可以使用SPSS提供的各种统计方法来检验判别分析结果的显著性。
例如,可以进行方差分析来检验不同群体之间的差异性。
判别分析是一种有效的统计方法,可以用于各种不同的研究领域。
在SPSS中,通过简单的几个步骤就可以实现判别分析,并得到结果。
同时,SPSS还提供了丰富的数据可视化和结果解释功能,可以帮助用户更好地理解和解释判别分析的结果。
判别分析的SPSS操作

在“Method”选项组中选择进行逐步判别分析的方法,可供 选择的判别分析方法有5种:
1.Wilks’lambda Wilks’lambda方法。默认选项,每步 都是Wilk的概计量最小的进入判别函数。
2.Unexplained variance 不可解释方差方法。选择该项, 表示每步都是使各类不可解释的方差和最小变量进入判别函数。
对已知类别的样品判别分类
对已知类别的样品(通常称 为训练样品)用线性判别函 数进行判别归类,结果如 下表,全部判对。
(5)对判别效果作检验
判别分析是假设两组样品取自不同总体,如果两个总体的均值向量在统计上 差异不显著,作判别分析意义就不大:所谓判别效果的检验就是检验两个正态总体 的均值向量是否相等,取检验的统计量为:
1
《人类发展报告》中公布的。该报告建议,目前对人文发展的衡量应
当以人生的三大要素为重点,衡量人生三大要素的指示分别采用出生
时的预期寿命、成人识字率和实际人均GDP,将以上三个指示指标
的数值合成为一个复合指数,即为人文发展指数。资料来源UNDP
《人类发展报告》1995年。
2 今从1995年世界各国人文发展指数的排序中,选取高发展水平、中 等发展水平的国家各五个作为两组样品,另选四个国家作为待判样品 作判别分析。
单击添加副标题
判别分析的SPSS 操作
§1. 基本原理
§2.实例分析
§1. 基本原理
判别分析的目的是得到体现分类的函数关系式,即判别 函数。基本思想是在已知观测对象的分类和特征变量值的前 提下,从中筛选出能提供较多信息的变量,并建立判别函数; 目标是使得到的判别函数在对观测量进行判别其所属类别时 的错判率最小。
Fisher’s 选择该项,表示可以用于对新样本进行判别分 类的fisher系数,对每一类给出一组系数,并给出该组中判别分数 最大的观测量。
SPSS-判别分析

判别分析的参数指标
1. 2. 3. 4. 5. 6.
判别系数(函数系数)---function 判别系数(函数系数)---function coefficient Bayes判别系数 Bayes判别系数 结构系数---structural 结构系数---structural coefficient 组重心---group 组重心---group centroid 方差百分比)---percent 判别指数 (方差百分比)---percent of variance 剩余判别指标---Wilks’ 剩余判别指标---Wilks’ Lambda
Territorial map 4. Display---Summary table, Casewise results, , Leave-one-out classification
各组重心坐标值
Functions at Group Centroids Function GROUP 1 1 -2.178 2 1.867 Unstandardized canonical discriminant functions evaluated at group means
利用Fisher判别函数计算出各观测值具体坐标后, 判别函数计算出各观测值具体坐标后, 利用 判别函数计算出各观测值具体坐标后 再计算出离各重心的距离, 再计算出离各重心的距离,则可得知分类情况
判别系数(函数系数) 判别系数(函数系数) ---function coefficient ---function
非标准化判别系数(unstandardized 非标准化判别系数(unstandardized discriminant coefficient) ---非标准化判别函数是用来计算判别值 ---非标准化判别函数是用来计算判别值 (discriminant score)的 score)的 标准化判别系数(standardized 标准化判别系数(standardized discriminant coefficient) coefficient)
spss判别分析

判别分析1.基本理解判别分析用于处理已知分类情况的数据集,将未知分类数据归入已知的分类中。
判别分析过程基于对变量的函数组合,变量应能够充分地体现各个类别之间的差异。
从已知变量类别的样本中拟合判别函数,后根据判别函数将新样本进行类别归类。
在P维空间中,有K个相关已知类别的总体G1,G2,G3,....Gk,单个的预测样本记为Xi =(Xi1,Xi2,Xi3,....,Xip),i=1,2,3,....n,样本属于K个总体的一个,P个变量为判别指标,判别函数就是确定样本属于哪一类别。
判别函数的两种判别方法:(1)贝叶斯判别:是一种概率型的判别函数,开始需要知道各个类别的先验概率或分布密度,后计算每个样本属于某个类别的最大概率或最小错判损失,并以此归类。
类别概率计算公式:P(Gi|D)=P(D|Gi)P(Gi)/ΣP(D|Gi)P(Gi),其中P(Gi)为属于i类的先验概率,P(D|Gi)为在第i类中得D分的条件概率,而P(Gi|D)为在第i类中得D分的后验概率。
(2)Fisher判别:是一种依据方差分析原理建立的判别方法,基本思路为投影。
对P维空间中的点Xi =(Xi1,Xi2,Xi3, (X)in),i=1,2,3,....,n,找到一组线性函数Ym (Xi)=×B,m=1,2,3,....,m,一般m<p,依据组间均方差与组内均方差之比最大的原则,选择最优的线性函数。
判别分析的一般步骤:(1):依据已知类别的观测集建立分类规则或判别规则。
(2):运用所建规则对样本进行分类检验,得到各样本的判别准确率。
(3):选择拥有较高准确率的判别规则,应用于新样本的类别判断。
2.判别分析操作步骤判别函数第一步:首先将已确定分类情况的数据到spss软件中,点击分析、分类、判别式。
图1第一步第二步:进入判别分析勾选框后首先将变量列表中的变量放入右侧的变量框中,将因变量(已知分组情况变量)放入分组变量框并定义好范围,点击继续,将自变量放入自变量框中。
判别分析的SPSS实现

判别分析的SPSS实现判别分析是一种常用的统计方法,也是一种分类的机器学习方法。
它的目的是使用已知的分类信息来训练一个分类模型,然后根据这个模型来预测新的未知实例的分类。
SPSS是一种常用的统计软件,提供了方便易用的界面来进行判别分析。
下面将介绍如何在SPSS中进行判别分析。
首先,打开SPSS软件并加载要进行判别分析的数据。
可以通过"File"->"Open"来打开数据文件,或者直接将数据文件拖动到SPSS界面中。
然后,选择"Analyze"->"Classify"->"Discriminant",进入判别分析的界面。
在界面中,需要选择要进行判别分析的变量,包括一个或多个预测变量和一个分类变量。
预测变量是判别分析模型的输入,而分类变量是判别分析模型的输出。
可以使用鼠标将变量从"Available"列表拖动到"Predictors"和"Target"列表中。
接下来,可以点击"Statistics"按钮来选择统计量。
在判别分析中,有几个常用的统计量可以选择。
例如,可以选择"Wilks' lambda"来衡量判别分析模型的预测准确率,或者选择"Group centroids"来了解不同分类的均值差异。
然后,点击"Options"按钮来设置其他选项。
在"Options"界面中,可以选择是否标准化变量,即将变量标准化为均值为0和标准差为1的形式。
标准化可以使得不同变量的尺度一致,有助于提高判别分析的性能。
此外,还可以选择输出判别函数的系数和判别函数值,以及设定分类概率的阈值等。
最后,点击"OK"按钮开始进行判别分析。
判别分析的一般步骤及SPSS实现

判别分析的一般步骤及SPSS实现判别分析是一种用于分类变量的统计方法,它可以用于确定一个或多个预测变量对于区分不同组之间差异的程度。
判别分析由一系列步骤组成,包括问题的定义、数据的准备、模型的建立、模型的评估和结果的解释。
以下是判别分析的一般步骤以及如何在SPSS中实现这些步骤的详细说明。
第一步:问题的定义在进行判别分析之前,需要明确研究的目的和问题。
例如,我们可能希望根据顾客的一些特征(如性别、年龄、收入等)来预测顾客是否购买一些产品。
这样的问题可以通过判别分析解决。
第二步:数据的准备在进行判别分析之前,需要确保数据满足分析的要求。
数据应包括一个或多个预测变量和一个分类变量。
如果数据中存在缺失值,需要进行缺失值的处理。
如果数据中存在异常值,可以选择忽略或进行适当的修正。
第三步:模型的建立在SPSS中,可以使用“分类函数”来建立判别分析模型。
选择“分析”菜单中的“分类”选项,然后选择“判别”子菜单。
在“判别”对话框中,选择一个或多个预测变量,并将分类变量指定为“因变量”。
此外,还可以选择是否进行卡方检验以及是否使用交叉验证等选项。
卡方检验可以用于评估预测变量与分类变量之间的关联性,而交叉验证可以用于评估模型对于不同样本的预测效果。
第四步:模型的评估在SPSS中,判别分析的模型评估结果可以在“判别”输出中找到。
主要关注以下几个指标:1.方差贡献表:可以查看每个预测变量对于判别函数的贡献程度,以及它们之间的相关性。
2.群组描述:可以查看不同组之间的平均值,以确定最能区分不同组的预测变量。
3.准确性表:可以查看模型的整体分类准确率以及每个组的分类准确率。
4.标准化系数表:可以查看每个预测变量对于判别函数的贡献程度,使用标准化系数来比较不同预测变量的影响。
第五步:结果的解释对于判别分析的结果进行解释是非常重要的,以帮助我们理解预测变量如何影响分类变量,并从中得出有用的结论。
可以通过参考判别函数的系数、标准化系数和方差贡献来解释结果。
判别分析实验报告 SPSS

判别分析实验报告 SPSS一、实验目的判别分析是一种用于分类和预测的统计方法。
本次实验旨在通过使用 SPSS 软件,掌握判别分析的基本原理和操作流程,能够运用判别分析方法对实际数据进行分类,并对分类结果进行评估和解释。
二、实验数据本次实验使用的数据集包含了两个类别(类别 A 和类别 B)的样本,每个样本具有若干个特征变量,如年龄、收入、教育程度等。
数据集共有 200 个样本,其中类别 A 有 100 个样本,类别 B 有 100 个样本。
三、实验步骤1、数据导入首先,打开 SPSS 软件,选择“文件”菜单中的“打开”选项,将实验数据文件导入到 SPSS 中。
2、变量定义在 SPSS 数据视图中,对各个变量进行定义,包括变量名称、变量类型、变量标签等。
3、判别分析操作选择“分析”菜单中的“分类”子菜单,然后点击“判别分析”选项。
在弹出的判别分析对话框中,将类别变量选入“分组变量”框中,将其他特征变量选入“自变量”框中。
4、选择判别方法SPSS 提供了多种判别方法,如费希尔判别法、贝叶斯判别法等。
本次实验选择费希尔判别法。
5、模型评估在判别分析结果中,查看判别函数的系数、判别函数的显著性检验、分类结果的准确性等指标,以评估模型的性能。
四、实验结果与分析1、判别函数系数判别函数的系数反映了各个自变量对判别函数的贡献程度。
通过查看系数的大小和符号,可以了解各个变量在区分不同类别中的重要性。
例如,年龄变量的系数为正,说明年龄越大,越有可能属于某个类别;而收入变量的系数为负,说明收入越低,越有可能属于另一个类别。
2、判别函数的显著性检验通过对判别函数的显著性检验,可以判断判别函数是否能够有效地区分不同的类别。
如果检验结果显著,说明判别函数具有统计学意义,可以用于分类。
3、分类结果SPSS 会给出每个样本的分类结果,以及分类的准确性。
通过比较实际类别和预测类别,可以评估模型的分类效果。
如果分类准确性较高,说明模型能够较好地对样本进行分类;如果分类准确性较低,则需要进一步分析原因,可能是数据质量问题、变量选择不当或者判别方法不合适等。
判别分析的SPSS操作

判别分析的SPSS操作判别分析(Discriminant Analysis)是一种用于确定样本所属类别的统计分析方法。
它通过构建线性方程来将样本分类到不同的组中,该线性方程称为判别函数。
在进行判别分析之前,首先需要收集关于不同类别的样本数据,并且这些样本必须是可信的、有代表性的。
SPSS是一种常用的统计软件,可以进行判别分析。
下面将介绍使用SPSS进行判别分析的步骤。
一、数据准备在进行判别分析之前,需要针对每个样本收集一些特征变量的数据。
这些特征变量可以是连续变量或者分类变量。
同时,还需要收集样本的类别信息,类别信息必须是分类变量。
将这些数据输入到SPSS中的数据文件中。
二、进行判别分析1. 打开 SPSS 软件,在主界面点击 "Analyze"(分析),然后选择"Classify"(分类),再点击 "Discriminant"(判别)。
2. 在 "Discriminant Function"(判别函数)对话框中,选择"Variables"(变量)。
将所有的特征变量移动到 "Predictors"(预测变量)列表中,将类别信息移动到 "Grouping Variable"(分组变量)中。
3. 在 "Options"(选项)中,可以选择 "Statistics"(统计量)和"Save classification results"(保存分类结果)。
4.单击"OK"开始进行判别分析。
三、结果解读1. 判别分析将给出一些统计结果,其中最重要的是 "Canonical Discriminant Function Coefficients"(标准化判别系数)和"Structure Matrix"(结构矩阵)。
判别分析的一般步骤及SPSS实现

判别分析的SPSS实现
表7.3 Bayes判别法的输出结果
C l as si fic ati on Fu ncti o n C oe ffi ci e n ts
GROUP
1.00
X1
-14 3.85 1
X2
15 3.13 6
6
2
2 1.000
.469 9.674
.231
7
2
2 1.000
.868 8.332 -.613
8
2
2 1.000
5.98 5 10 .1 28 -2.51 8
9
2
2 1.000
4.793 8.342 1.760
10
2
2 1.000
.101 9.491 -.145
11
3
3 1.000
.139 -6.687 -.394
Dist a nce t o Funct ion Funct ion
Cent roid
1
2
.297 -2.177 1.364
2
1
1 1.000
.236 -2.270 1.375
3
1
1 1.000
.117 -2.741 1.323
4
1
1 .998
.507 -3.199
.638
5
1
1 1.000
.418 -2.582
标准化的典型判别函数是由标准化的自变量通过Fisher判别法得到的,所以 要得到标准化的典型判别得分,代入该函数的自变量必须是经过标准化的。
2. Canonical Discriminant Function Coefficients(给出未标准化的典型判别 函数系数)
SPSS判别分析

SPSS判别分析SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,也提供了强大的判别分析功能。
本文将介绍SPSS中判别分析的步骤、应用以及结果的解读。
一、判别分析的步骤1.数据准备:首先,将已知类别的样本数据录入SPSS中,每个样本对应一个实例,每个实例有一组预测变量和一个类别变量。
2.变量选择:选择要作为预测变量的特征或属性,并将其加入模型。
通常,只有连续型或分类型的自变量(预测变量)可以用于判别分析。
3.数据分割:将已知类别的样本数据分为训练集和测试集,一般按照70%的比例划分。
4.判别模型:使用SPSS中的判别分析功能建立判别模型。
在SPSS中,可以通过路径“分析-分类-判别”打开判别分析对话框。
5.模型评估:使用测试集来评估模型的准确性和性能。
可以查看分类结果的混淆矩阵,计算预测准确率、召回率、F1值等指标。
6.结果解读:根据模型的解读提示,分析各个预测变量对判别结果的重要性,找出主要影响判别的变量。
二、判别分析的应用领域判别分析广泛应用于各个领域,包括社会科学、医学、市场营销等。
以下是几个常见的应用案例:1.疾病诊断:通过患者的生物特征(如血液检测结果、基因表达谱等)来判断是否患有其中一种疾病。
2.风险评估:用于评估贷款申请者的信用风险,根据一些个人特征(如年龄、收入、居住地等)来预测违约概率。
3.市场细分:根据消费者的特征(如年龄、性别、购买行为等)将市场区分为不同的细分市场,以制定更精准的市场营销策略。
4.情感识别:通过分析文本数据(如社交媒体评论、产品评论等)来判断用户的情感倾向,以评估产品或服务的满意度。
三、结果解读判别分析的结果包括判别函数、判别系数和预测结果。
判别函数可以看作是一组线性加权的预测变量,用于将实例划分到不同的类别中。
判别系数表示了每个预测变量对判别结果的贡献程度,可以用于解释影响判断的主要变量。
SPSS中判别分析方法的正确使用

SPSS中判别分析方法的正确使用判别分析是一种经典的统计方法,用于将一组观测值分配到不同的已知类别中。
它被广泛应用于分类问题,如客户群体分类、药物分类等。
在SPSS中,判别分析方法可以通过以下步骤正确使用:第一步:准备数据首先,需要准备一个用于判别分析的数据集。
该数据集应包含预测变量(也称为自变量)和所属类别(也称为因变量)两部分。
预测变量是用来解释类别分布的变量,而所属类别是需要预测或分类的变量。
确保数据集中不含有缺失值或异常值。
第二步:设置分析方法在SPSS中,可以通过点击“分析”菜单,然后选择“分类”子菜单中的“判别”选项来设置判别分析。
在弹出的对话框中,将需预测的类别(也称为因变量)移动到“因变量”框中,将预测变量(也称为自变量)移动到“自变量”框中。
可以选择要使用的分析方法,如方差判别分析、线性判别分析等,然后点击“确定”开始分析。
第三步:解读输出结果SPSS将生成一个判别分析的结果报告,包括描述性统计、判别函数、马氏距离以及判别图等。
可以通过阅读输出结果了解到判别函数如何区分不同的类别,以及判别图如何表示不同的类别之间的差异。
此外,还可以观察描述性统计结果,比较不同类别之间的平均值、方差等指标,进一步理解类别分布的特征。
第四步:交叉验证为了验证判别分析的准确性和稳定性,可以使用交叉验证方法。
在SPSS中,可以选择在判别分析对话框的“交叉验证”选项中设置交叉验证方法。
交叉验证将数据集分为几个部分,然后使用其中一部分数据来估计判别函数,再使用剩余的数据来验证判别函数的准确性。
通过交叉验证可以得到判别分析的预测正确率,以及其它评估指标。
第五步:解读结果根据判别分析的结果报告和交叉验证的准确性评估,可以判断判别分析方法的准确性和稳定性。
如果预测正确率较高且稳定,那么可以认为判别分析是一个有效的分类方法。
此外,还可以利用判别函数的系数和贡献度等信息,评估不同预测变量对类别分布的贡献程度。
总结:判别分析是一种常用的分类方法,可用于解决各种分类问题。
分类算法:判别分析 spss操作流程介绍
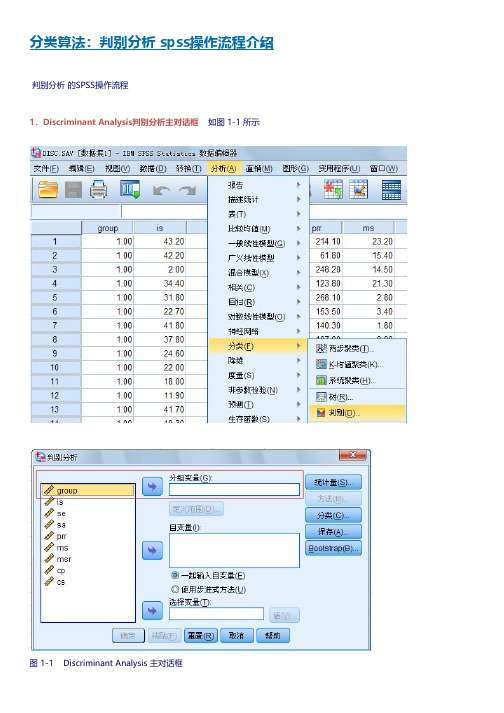
分类算法:判别分析 spss操作流程介绍 判别分析 的SPSS操作流程1.Discriminant Analysis判别分析主对话框 如图 1-1 所示图 1-1 Discriminant Analysis 主对话框(1)选择分类变量及其范围在主对话框中左面的矩形框中选择表明已知的观测量所属类别的变量(一定是离散变量),按上面的一个向右的箭头按钮,使该变量名移到右面的Grouping Variable 框中。
此时矩形框下面的Define Range 按钮加亮,按该按钮屏幕显示一个小对话框如图1-2 所示,供指定该分类变量的数值范围。
图 1-2 Define Range 对话框在Minimum 框中输入该分类变量的最小值在Maximum 框中输入该分类变量的最大值。
按Continue 按钮返回主对话框。
(2)指定判别分析的自变量图 1-3 展开 Selection Variable 对话框的主对话框在主对话框的左面的变量表中选择表明观测量特征的变量,按下面一个箭头按钮。
把选中的变量移到Independents 矩形框中,作为参与判别分析的变量。
(3) 选择观测量图 1-4 Set Value 子对话框如果希望使用一部分观测量进行判别函数的推导而且有一个变量的某个值可以作为这些观测量的标识,则用Select 功能进行选择,操作方法是单击Select 按钮展开Selection Variable。
选择框如图1-3 所示。
并从变量列表框中选择变量移入该框中再单击Selection Variable 选择框右侧的Value按钮,展开Set Value(子对话框)对话框,如图1-4 所示,键入标识参与分析的观测量所具有的该变量值,一般均使用数据文件中的所有合法观测量此步骤可以省略。
(4) 选择分析方法在主对话框中自变量矩形框下面有两个选择项,被选中的方法前面的圆圈中加有黑点。
这两个选择项是用于选择判别分析方法的l Enter independent together 选项,当认为所有自变量都能对观测量特性提供丰富的信息时,使用该选择项。
SPSS数据的判别分析

SPSS数据的判别分析判别分析(Discriminant Analysis)是一种统计分析方法,用于确定一组变量如何能够最好地区分或判别不同的群体。
该方法可以用于解决分类问题,即将多个已知类别的观测对象分配到新的未知类别中。
SPSS是一种功能强大的统计软件,可以进行各种统计分析,包括判别分析。
在SPSS中,进行判别分析的步骤如下:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单下的“判别分析”选项。
3.在弹出的对话框中,将要分类的变量(被解释变量)放入“因子”框中,用于判别的变量(解释变量)放入“变量”框中。
点击“分类图”按钮可以选择是否绘制分类图表。
4.点击“确定”按钮,进行判别分析。
判别分析的目标是找到一个线性组合,能够最好地将样本区分开来。
在SPSS的结果中,输出了多种统计量,包括判别系数,判别函数的系数,标准化判别函数系数等信息。
这些统计量可以帮助我们理解分类问题的解释力和判别函数的重要性。
判别函数是判别分析的核心输出,它可以根据变量的值来预测被解释变量的分类。
判别函数通常以线性函数的形式表示,例如:D = a1X1 + a2X2 + ... + anXn + b其中,D是判别函数的值,X1, X2, ..., Xn是解释变量的值,a1,a2, ..., an是判别函数的系数,b是常数项。
通过计算判别函数的值,就可以将新的观测对象分配到相应的分类中。
在SPSS中,可以使用“分类评估”功能来检验判别函数的准确性。
该功能可以计算被正确分类的对象的百分比,以及各个分类中的正确分类的百分比。
同时,SPSS还提供了一些可视化工具来帮助我们理解判别分析的结果。
例如,通过绘制分类图表,可以直观地了解不同分类之间的分隔情况。
此外,还可以通过散点图来展示解释变量和被解释变量之间的关系,以及如何影响判别函数的值。
判别分析在实际应用中具有广泛的应用。
例如,在医学领域,可以使用判别分析将患者分为不同的疾病分类,以便进行诊断和治疗。
用SPSS软件来实现判别分析

用SPSS软件来实现判别分析判别分析是一种统计模型和机器学习方法,可用于研究两个或更多群体之间的差异。
通过使用SPSS软件,我们可以对数据进行判别分析,并评估自变量的贡献程度,以及如何使用这些自变量来预测因变量。
要进行判别分析,首先需要准备数据。
在SPSS中,数据应该被整理为一个数据框,每一行代表一个样本,每一列代表一个特征或变量。
在判别分析中,我们需要明确选择一个因变量和若干个自变量。
在SPSS软件中,进行判别分析的步骤如下:步骤1:导入数据在SPSS中,首先需要导入我们的数据集。
点击“文件(File)”选项卡,选择“打开(Open)”,然后选择数据文件。
确保数据文件是一个包含正确数据格式的数据框。
如果数据集过大,可以选择只导入部分数据进行分析,可以通过“变量视图(Variable View)”进行选择。
步骤2:选择判别分析方法点击“分析(Analyze)”选项卡,选择“描述统计(Descriptive Statistics)”,选择“判别(Discriminant)”。
步骤3:设置因变量和自变量在弹出的“判别函数(Discriminant Function)”对话框中,将被解释的变量(因变量)从左边的“因变量(Dependent)”栏拖到右边的“因变量(Dependent)”栏。
然后,将讲自变量(特征)从左边的“自变量(Independent(s))”栏拖到右边的“自变量(Independent(s))”栏。
函数使用的哪些变量将取决于数据中可用的变量数。
步骤4:选择分类方法在“类型(Method)”选项中,选择判别分析的分类方法。
SPSS提供了两种方法:“协方差矩阵相等(Covariance matrices equal)”和“协方差矩阵不等(Covariance matrices not equal)”。
前者使用默认参数,即假设所有群体具有相同的协方差矩阵。
后者提供了更具灵活性的选项,可以允许不同群体拥有不同的协方差矩阵。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5.Rao's V Rao V统计量.选择该项,表示每步都使 统计量. 统计量 选择该项,表示每步都使Rao V统计量产生最大增量的变量进入判别函数,可以对一个要加 统计量产生最大增量的变量进入判别函数, 统计量产生最大增量的变量进入判别函数 入到模型中的变量的V值指定一个最小增量.选择该方法时需 入到模型中的变量的 值指定一个最小增量. 值指定一个最小增量 要在该项下面的" 要在该项下面的"V-to-enter"(输入 值)文本框中输入这个 (输入V值 增量的指定值,当某变量导致的V值增量大于指定值的变量进 增量的指定值,当某变量导致的 值增量大于指定值的变量进 入判别函数. 入判别函数. "Criteria"(准则 选项组用于选择逐步判别停止的判据,可 准则)选项组用于选择逐步判别停止的判据 准则 选项组用于选择逐步判别停止的判据, 供选择的判据包括以下几项: 供选择的判据包括以下几项:
对话框, 图1.1 "Discriminate Analysis"对话框, 对话框
Step2:选择分组变量和自变量 : 在变量列表中选择指定分组变量,单击右向箭头按钮, 在变量列表中选择指定分组变量,单击右向箭头按钮, 将其移动至右侧的" 将其移动至右侧的&分组)文本框中, (分组)文本框中, 并单击" 并单击"Define Range"(定义范围)按钮,出现图 所示 (定义范围)按钮,出现图1.2所示 的"Discriminant Analysis:Define Range"(判别分析定 : ( 义范围)对话框,在"Minimum"文本框中输入该分组变量 义范围)对话框, 文本框中输入该分组变量 的最小值, 的最小值,在"Maximum"文本框中输入该分组变量的最大 文本框中输入该分组变量的最大 单击" 按钮, 值,单击"Continue"按钮,返回主对话框. 按钮 返回主对话框.
图1.3 "Discriminant Analysis:Set Value" :
Step5:执行操作. :执行操作. 选择完毕后,单击" 按钮, 选择完毕后,单击"OK"按钮,执行判别分析操作. 按钮 执行判别分析操作.
§3. 选项设置
§3.1 Method选项 选项 选择" 方法进行判别分析时, 选择"Use stepwise method"方法进行判别分析时, 方法进行判别分析时 按钮, "Method"(方法)按钮将被激活,单击"Method"按钮,打开 (方法)按钮将被激活,单击" 按钮 "Discriminant Analysis:Stepwise Method"(判别分析:逐 : (判别分析: 步分析方法)对话框,如图1.4所示 步分析方法)对话框,如图 所示
代人判别函数: 代人判别函数:
得两组的判别函数分别为: 得两组的判别函数分别为:
将原各组样品进行回判结果如下一灯片表: 将原各组样品进行回判结果如下一灯片表: 待判样品判别结果如下: 待判样品判别结果如下:
3,利用距离判别法中例l的人文发展指数的数据作 ,利用距离判别法中例 的人文发展指数的数据作 Fisher判别分析: 判别分析: 判别分析 (1)建立判别函数 建立判别函数 利用前例计算的结果,可得 利用前例计算的结果,可得Fisher判别函数的系数 判别函数的系数
选项组中选择进行逐步判别分析的方法, 在"Method"选项组中选择进行逐步判别分析的方法,可供 选项组中选择进行逐步判别分析的方法 选择的判别分析方法有5种 选择的判别分析方法有 种: 1.Wilks'lambda Wilks'lambda方法.默认选项,每步都是 方法. 方法 默认选项, Wilk的概计量最小的进入判别函数. 的概计量最小的进入判别函数. 的概计量最小的进入判别函数 2.Unexplained variance 不可解释方差方法.选择该项, 不可解释方差方法.选择该项, 表示每步都是使各类不可解释的方差和最小变量进入判别函数. 表示每步都是使各类不可解释的方差和最小变量进入判别函数. 3.Mahalanobis'distance Mahalanobis距离方法.选择该 距离方法. 距离方法 表示每步都使靠的最近的两类间Mahalanobis距离最大的变 项,表示每步都使靠的最近的两类间 距离最大的变 量进入判别函数. 量进入判别函数. 4.Smallest F ratio最小 值方法.选择该项,表示每步都使 最小F值方法 最小 值方法.选择该项, 任何两类间的最小的F值最大变量进入判别函数 值最大变量进入判别函数. 任何两类间的最小的 值最大变量进入判别函数.
Step4:选择变量值标识. :选择变量值标识. 如果需要使用一部分个案参与判别函数的推导, 如果需要使用一部分个案参与判别函数的推导,而且有一个变 量的某个值可以作为这些观测量的标识,则用Select Variable功 量的某个值可以作为这些观测量的标识,则用 功 能进行选择.方法为在变量列表中选择变量,单击右向箭头按钮, 能进行选择.方法为在变量列表中选择变量,单击右向箭头按钮, 将其移动至" 将其移动至"Selection"(选择变量)文本框;然后单击 (选择变量)文本框; 文本框右侧的" 按钮, "Selection"文本框右侧的"Value"按钮,显示"Discriminant 文本框右侧的 按钮 显示" Analysis:Set Value"(判别分析:设定值)子对话框,如图 : (判别分析:设定值)子对话框, 1.3所示,输入选择变量的标识.单击"Continue"按钮,返回主 所示, 按钮, 所示 输入选择变量的标识.单击" 按钮 对话框. 对话框.
所以判别函数为
(2)计算判别临界值 0. 计算判别临界值y 计算判别临界值 由于
所以
(3)判别准则 判别准则
(4)对已知类别的样品判别归类 对已知类别的样品判别归类
上述回判结果表明:总的回代判对率为 %,这与统计资料 上述回判结果表明:总的回代判对率为100%,这与统计资料 %, 的结果相符,而且与前面用距离判别法的结果也一致. 的结果相符,而且与前面用距离判别法的结果也一致. (5)对判别效果作检验 对判别效果作检验 由于 检验水平下判别有效. 所以在 检验水平下判别有效. (6)待判样品判别结果如下:判别结果与实际情况吻合. 待判样品判别结果如下: 待判样品判别结果如下 判别结果与实际情况吻合.
判别分析的SPSS操作 操作 判别分析的
§1. 基本原理 §2. 基本操作 §3. 选项设置 §4. 实例分析
§1. 基本原理
判别分析的目的是得到体现分类的函数关系式, 判别分析的目的是得到体现分类的函数关系式,即判别 函数. 函数.基本思想是在已知观测对象的分类和特征变量值的前 提下,从中筛选出能提供较多信息的变量,并建立判别函数; 提下,从中筛选出能提供较多信息的变量,并建立判别函数; 目标是使得到的判别函数在对观测量进行判别其所属类别时 的错判率最小. 的错判率最小. 判别函数的一般形式是: 判别函数的一般形式是:Y = a1 x1 + a 2 x2 + + a n x n 其中, 为判别函数判别值; 其中,Y 为判别函数判别值;x1 , x 2 ,, x n 为反映研究对象 特征的变量; 特征的变量;1 , a 2 ,, a n 为各变量的系数,即判别系数. a 为各变量的系数,即判别系数. 常用的判别法有距离判别法, 判别法和Bayes判别法. 判别法. 常用的判别法有距离判别法,Fisher判别法和 判别法和 判别法
(5)对判别效果作检验 对判别效果作检验 判别分析是假设两组样品取自不同总体, 判别分析是假设两组样品取自不同总体,如果两个总体的均值 向量在统计上差异不显著,作判别分析意义就不大: 向量在统计上差异不显著,作判别分析意义就不大:所谓判别效果 的检验就是检验两个正态总体的均值向量是否相等, 的检验就是检验两个正态总体的均值向量是否相等,取检验的统计 量为: 量为:
图1.2 "Discriminate Analysis:Define Range"对 : 对 话框
在变量列表中选择判别分析的变量,单击右向箭头按钮, 在变量列表中选择判别分析的变量,单击右向箭头按钮, 将其移动至" 将其移动至"Independents"(自变量)列表框中. (自变量)列表框中. Step3:选择判别分析方法. :选择判别分析方法. 在主对话框中,自变量列表框下侧显示两个单选框, 在主对话框中,自变量列表框下侧显示两个单选框,用 于指定选择判别分析的方法. 于指定选择判别分析的方法. Enter independents together 默认选项.当认为所有自变 默认选项. 量都能对观测特性提供丰富的信息时,使用该选项, 量都能对观测特性提供丰富的信息时,使用该选项,选择该项 将不加uanz地使用所有自变量进行判别分析,建立全模型,且 地使用所有自变量进行判别分析, 将不加 地使用所有自变量进行判别分析 建立全模型, 不需要进一步选择. 不需要进一步选择. Use stepwise method 逐步分析方法.当认为不是所有自 逐步分析方法. 变量都能对观测量特性提供丰的信息时,选择该项, 变量都能对观测量特性提供丰的信息时,选择该项,因此需要 判别贡献的大小再进行选择.选中该单选按钮时, 判别贡献的大小再进行选择.选中该单选按钮时,"Method" 按钮被激活,可以进一步选择判别分析方法. 按钮被激活,可以进一步选择判别分析方法.
(2)计算样本协差阵,从而求出 计算样本协差阵, 计算样本协差阵
类似地
经计算
(3)求线性判别函数 求线性判别函数W(X) 求线性判别函数 解线性方程组 得