聚类分析案例分析
聚类分析在市场细分中的应用案例分析

聚类分析在市场细分中的应用案例分析市场细分是市场营销中的关键战略之一,通过将市场划分为不同的细分市场,企业可以更加准确地满足不同消费者的需求,提供个性化的产品和服务。
而聚类分析作为一种常用的数据挖掘技术,可以在市场细分过程中发挥重要作用,帮助企业实现更精确的市场细分。
在本文中,我们将通过分析一个真实的案例来探讨聚类分析在市场细分中的应用。
该案例涉及到一家汽车制造商,该公司希望根据消费者的购车偏好将市场细分为不同的群体,以便更好地定位和营销其产品。
首先,为了进行聚类分析,我们需要收集大量的消费者数据。
在这个案例中,我们采集了来自不同地区的1000名消费者的数据,包括他们的年龄、性别、收入、家庭人口数量、购车目的和首选汽车品牌等信息。
这些数据将被用作聚类分析的输入。
接下来,我们使用聚类算法对收集到的数据进行分析。
在这个案例中,我们选择了k-means聚类算法来进行分析。
该算法将数据分为预定义数量的簇,每个簇之间的差异最小化。
我们选择了5个簇来表示不同的消费者群体。
通过聚类分析,我们将消费者分为了5个不同的簇。
下面是每个簇的特征描述:1. 簇1:该簇包括了年龄较大、收入较高的消费者群体,他们的购车目的主要是追求舒适性和品牌形象,在购车时更倾向于选购豪华品牌的汽车。
2. 簇2:该簇包括了年轻人群,他们的收入相对较低,购车目的主要是为了实用和经济,他们更倾向于购买价格相对较低且经济燃油的汽车。
3. 簇3:该簇包括了家庭人口较多的消费者群体,他们的购车目的主要是为了家庭出行,他们更倾向于购买多功能、空间较大的SUV或MPV类型的汽车。
4. 簇4:该簇包括了对环保和可持续性较为关注的消费者群体,他们更倾向于购买电动汽车或混合动力汽车。
5. 簇5:该簇包括了喜欢运动和驾驶激情的消费者群体,他们的购车目的主要是追求驾驶的乐趣和速度,他们更倾向于购买跑车或运动型汽车。
通过对聚类结果的分析,汽车制造商可以更好地了解不同消费者群体的需求和偏好。
案例分析 江苏省各市经济发展水平的聚类分析

案例分析江苏省各市经济发展水平的聚类分析标题:案例分析:江苏省各市经济发展水平的聚类分析一、引言江苏省作为中国的重要经济大省,其各市的经济发展水平一直以来备受。
对江苏省各市经济发展水平进行准确的评估,不仅有助于我们理解各市的经济现状,也有助于制定针对性的经济发展策略。
本文采用聚类分析的方法,对江苏省各市的经济发展水平进行分类,并对其结果进行深入剖析。
二、数据来源与方法1、数据来源我们选取了江苏省各市的GDP、人均GDP、工业增加值、固定资产投资、社会消费品零售总额、出口总额、地方财政收入等经济指标作为数据来源。
这些数据均来自江苏省统计局发布的年度报告,具有权威性和准确性。
2、方法选择考虑到数据的复杂性和多元性,我们选择采用聚类分析的方法对江苏省各市的经济发展水平进行分类。
聚类分析是一种无监督学习的方法,能够根据数据的相似性将数据集划分为不同的类别。
在聚类分析中,我们使用了K-means算法,这是一种常见的聚类算法,能够根据设定的类别数,将数据集划分为不同的类别。
三、结果与分析1、数据预处理在进行聚类分析之前,我们首先对收集到的数据进行预处理,包括缺失值填充、异常值处理以及标准化处理等。
经过预处理后的数据,能够更好地反映江苏省各市的经济发展水平。
2、聚类分析结果我们设定类别数为3,对江苏省各市的经济发展水平进行聚类分析。
经过多次尝试和调整,最终得到了较为合理的聚类结果。
该结果将江苏省各市划分为三个类别:高发展水平市、中发展水平市和低发展水平市。
3、结果分析(1)高发展水平市:这一类别的城市主要包括南京、苏州和无锡等城市。
这些城市的经济发展水平较高,各项经济指标均高于全省平均水平。
这些城市的经济结构较为合理,工业增加值和地方财政收入较高,显示出较强的经济实力和竞争力。
(2)中发展水平市:这一类别的城市主要包括常州、南通、徐州等城市。
这些城市的经济发展水平处于全省平均水平之上,但相较于高发展水平市还存在一定差距。
聚类分析的应用案例

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以帮助我们对数据进行分类和分组,发现数据中的潜在模式和规律。
在现实生活和工作中,聚类分析有着广泛的应用,下面我们将介绍几个聚类分析的应用案例。
首先,聚类分析在市场营销领域有着重要的应用。
在市场营销中,我们常常需要对顾客进行分类,以便针对不同类别的顾客制定不同的营销策略。
通过聚类分析,我们可以根据顾客的消费行为、偏好等特征将顾客进行分类,从而更好地理解顾客群体的特点,并针对性地开展营销活动,提高营销效果。
其次,聚类分析在医学领域也有着重要的应用。
在医学研究中,我们常常需要对疾病患者进行分类,以便更好地了解不同类型患者的病情特点和治疗效果。
通过聚类分析,我们可以根据患者的临床表现、病情指标等特征将患者进行分类,从而更好地指导临床诊断和治疗方案的制定,提高治疗效果和患者生存率。
此外,聚类分析还在推荐系统中有着重要的应用。
在电子商务平台和社交媒体平台上,推荐系统可以根据用户的行为和偏好向其推荐商品、信息等内容。
而聚类分析可以帮助推荐系统对用户进行分类,从而更好地理解用户的兴趣和偏好,提高推荐的准确性和个性化程度,增强用户体验。
最后,聚类分析还在金融领域有着重要的应用。
在金融风控和信用评估中,我们常常需要对客户进行分类,以便更好地评估客户的信用风险和制定个性化的信贷方案。
通过聚类分析,我们可以根据客户的财务状况、信用记录等特征将客户进行分类,从而更好地了解客户的信用状况,提高风险控制的精准度和效果。
总之,聚类分析在各个领域都有着重要的应用,它可以帮助我们更好地理解数据和问题的本质,发现数据中的潜在规律和价值信息,为决策提供科学依据。
随着数据科学和人工智能技术的不断发展,相信聚类分析的应用领域会越来越广泛,对我们的生活和工作产生越来越大的影响。
聚类分析案例范文

聚类分析案例范文聚类分析是一种无监督机器学习算法,它通过将数据集中的观测值分成不同的组或簇来发现数据之间的内在结构和相似性。
这种方法可以帮助我们理解数据集,发现隐藏的模式和关联性,并且可以应用于各种领域,包括市场细分、社交网络分析、生物信息学和图像处理等。
以下是一个关于使用聚类分析方法的案例研究,该案例介绍了如何使用聚类分析来帮助一家电商企业在众多商品中挖掘潜在的市场细分。
背景介绍:电商企业销售了大量商品,这些商品拥有不同的特征和属性。
该企业希望利用这些数据来了解他们的客户,并为不同的产品类型制定个性化的推广和营销策略。
为了实现这一目标,他们决定使用聚类分析方法来将客户细分成不同的群组,并理解他们的相似性和差异性。
数据收集:该企业从其销售系统中收集了一份包含多个属性的数据集。
这些属性包括:年龄、性别、购买历史、购买频率、平均订单金额等。
这些属性可以反映客户的购买行为和偏好。
数据预处理:在进行聚类分析之前,需要对数据进行预处理。
这包括对缺失值进行处理、进行数值归一化等。
然后,根据业务需求,选择适当的聚类算法和合适的距离度量方法。
聚类分析过程:在本案例中,采用了一种常见的聚类方法--K均值聚类算法,该算法通过计算数据点之间的欧氏距离来度量它们之间的相似度。
首先,选择合适的K值(聚类簇的个数)。
然后,在初始阶段,随机选择K个点作为聚类中心。
再通过计算每个数据点与聚类中心的距离,并将其归类到最近的聚类簇。
接下来,根据已经分配到每个聚类中的数据点,重新计算新的聚类中心。
这个过程将迭代,直到达到停止准则,如聚类中心不再变化或达到最大迭代次数。
聚类结果分析:在完成聚类过程后,可以根据每个聚类中心的特征和属性,对数据集进行可视化和解释。
这将帮助企业理解各个群组的特征和差异,并从中提取有价值的洞察力。
进而,企业可以根据不同群组的特征制定个性化的营销策略,提高销售和客户满意度。
总结:通过使用聚类分析方法,该电商企业成功地将其客户细分为几个不同的群组。
层次聚类分析案例

层次聚类分析案例层次聚类分析是一种常用的数据挖掘技术,它通过对数据集进行分层聚类,将相似的数据点归为一类,从而实现对数据的有效分类和分析。
本文将以一个实际案例为例,介绍层次聚类分析的应用过程和方法。
案例背景。
某电商平台希望对其用户进行分类,以便更好地进行个性化推荐和营销活动。
为了实现这一目标,我们将运用层次聚类分析方法对用户进行分类,并找出具有相似特征的用户群体。
数据准备。
首先,我们需要收集用户的相关数据,包括用户的购买记录、浏览记录、点击记录、收藏记录等。
这些数据将构成我们的样本集合,用于进行层次聚类分析。
数据预处理。
在进行层次聚类分析之前,我们需要对数据进行预处理,包括数据清洗、数据标准化等工作。
通过数据预处理,我们可以排除异常值和噪声,使得数据更加适合进行聚类分析。
层次聚类分析。
在数据预处理完成之后,我们将使用层次聚类分析算法对用户进行分类。
该算法通过计算不同用户之间的相似度,将相似度较高的用户归为一类。
通过层次聚类分析,我们可以得到用户的不同分类结果,从而实现对用户群体的有效划分。
结果分析。
最后,我们将对层次聚类分析的结果进行分析和解释。
通过对不同用户群体的特征和行为进行分析,我们可以更好地理解用户群体的特点和需求,为电商平台的个性化推荐和营销活动提供有力的支持。
总结。
通过本案例的介绍,我们可以看到层次聚类分析在用户分类和群体分析中的重要作用。
通过对数据的分层聚类,我们可以更好地理解用户群体的特征和行为,为个性化推荐和营销活动提供有力的支持。
希望本文能够对层次聚类分析的应用有所启发,为相关领域的研究和实践提供参考和借鉴。
结语。
层次聚类分析是一种强大的数据挖掘工具,它在用户分类、群体分析等领域具有广泛的应用前景。
通过本文的介绍,相信读者对层次聚类分析有了更深入的理解,希望大家能够在实际应用中灵活运用层次聚类分析方法,为相关问题的解决提供更好的支持。
聚类分析案例

聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。
聚类分析应用案例

聚类分析应用案例
简介
聚类分析是一种无监督研究方法,旨在将数据样本划分为具有相似特征的群组或类别。
在许多领域中,聚类分析被广泛应用于数据分析、模式识别和信息检索等任务。
本文将介绍聚类分析在实际应用中的一些案例。
零售行业中的市场细分
零售行业需要了解其客户群体的特征以制定有效的营销策略。
通过聚类分析,可以将顾客细分为不同的群组,例如消费惯相似的群体、购买力相近的群体等。
基于这些细分结果,零售商可以有针对性地开展宣传活动、提供个性化服务,从而提高市场竞争力。
医疗领域中的疾病分类
在医疗领域,聚类分析可以用于疾病分类和诊断。
通过对患者的症状、体征和病史等信息进行聚类,可以将患者群体划分为具有相似疾病特征的子群。
这有助于医生进行更精确的诊断和制定个性化的治疗方案。
社交媒体分析中的用户群体划分
在社交媒体分析中,聚类分析可用于划分用户群体,了解不同用户的兴趣、行为模式和需求。
以这些群体为基础,企业可以更好地理解目标用户,并设计出更精准的推广活动和产品策略。
金融领域中的风险管理
在金融领域,聚类分析可以用于风险管理。
通过对客户的财务信息、投资偏好和风险承受能力等进行聚类,可以将客户划分为不同的风险群体。
这可以帮助金融机构识别高风险客户,并采取相应的风险控制措施。
总结
聚类分析是一种强大而灵活的数据分析工具,在各个领域都有广泛的应用。
本文介绍了其在零售行业、医疗领域、社交媒体分析和金融领域中的应用案例。
聚类分析可以帮助我们理解数据的内在结构、找到相似的群体,并基于这些群体进行个性化的决策和策略制定。
聚类分析的应用案例

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以将数据集中的对象分成不同的类别或簇,使得同一类内的对象相似度较高,而不同类别之间的对象相似度较低。
聚类分析广泛应用于市场分析、社交网络分析、生物信息学、医学诊断等领域。
本文将介绍几个聚类分析的应用案例,以便更好地理解聚类分析在实际问题中的应用。
首先,聚类分析在市场分析中的应用。
在市场营销中,企业需要了解消费者的偏好和行为,以便更好地制定营销策略。
通过对消费者数据进行聚类分析,可以将消费者分成不同的群体,从而更好地理解他们的需求和行为模式。
例如,一家零售商可以通过聚类分析将消费者分成价格敏感型、品牌忠诚型、功能导向型等不同的群体,从而有针对性地进行促销活动和产品定位。
其次,聚类分析在社交网络分析中的应用。
随着社交网络的兴起,人们在社交网络上的行为数据变得越来越丰富。
通过对社交网络数据进行聚类分析,可以发现不同的社交群体和用户行为模式。
例如,一家社交网络平台可以通过聚类分析将用户分成信息分享型、社交互动型、内容创作型等不同的群体,从而更好地满足用户需求,提高用户留存和活跃度。
再次,聚类分析在生物信息学中的应用。
生物信息学是研究生物学数据的计算机科学领域,其中大量的生物数据需要进行分析和挖掘。
通过对生物数据进行聚类分析,可以发现不同的基因型、蛋白质结构等生物特征。
例如,通过对癌症患者的基因数据进行聚类分析,可以发现不同的癌症亚型和治疗方案,为临床诊断和治疗提供重要参考。
最后,聚类分析在医学诊断中的应用。
在医学诊断中,医生需要根据患者的症状和检查数据进行疾病诊断。
通过对患者数据进行聚类分析,可以发现不同的疾病类型和临床表现。
例如,通过对心脏病患者的临床数据进行聚类分析,可以发现不同的心脏病亚型和治疗方案,为临床诊断和治疗提供重要参考。
综上所述,聚类分析在市场分析、社交网络分析、生物信息学、医学诊断等领域都有重要的应用价值。
通过对不同领域的应用案例进行分析,可以更好地理解聚类分析的原理和方法,为实际问题的解决提供重要参考。
聚类分析法经典案例

聚类分析法经典案例
聚类分析是一种常用的数据分析方法,它能够将相似的观察对象分为一组,并将不相似的对象分为不同的组。
下面将介绍一个经典的聚类分析案例。
在电信行业,客户流失是一个非常重要的问题。
为了降低客户流失率,一家电信公司希望通过聚类分析来识别客户流失的特征,以便进行有针对性的营销策略。
首先,该公司收集了一些客户数据,如客户的年龄、性别、月平均消费金额、通话时长等。
然后,利用聚类分析方法,将客户分为不同的组。
在这个案例中,我们可以采用k-means聚类算法。
通过聚类分析,该公司发现了三个客户群体。
第一组客户是高消费高通话客户,他们的平均消费金额和通话时长都很高。
第二组客户是低消费低通话客户,他们的平均消费金额和通话时长都很低。
第三组客户是高消费低通话客户,他们的平均消费金额很高,但通话时长很低。
利用聚类分析的结果,该公司能够采取有针对性的营销策略。
对于高消费高通话客户,他们可能是该公司的忠诚客户,可以通过提供一些优惠或奖励来保持他们的忠诚度。
对于低消费低通话客户,可以通过提供更具吸引力的套餐或增加服务内容来激发他们的消费需求。
对于高消费低通话客户,可以通过了解他们的通话行为,推出更适合他们的通话套餐,以增加他们的通话时长。
通过这个案例,我们可以看到聚类分析在客户流失预测和营销策略中的重要作用。
它可以帮助企业快速识别不同类型的客户,有针对性地制定相应的营销策略,提高客户满意度和忠诚度,降低客户流失率。
聚类分析还可以应用于其他领域,如金融、医疗等,具有广泛的应用前景。
聚类分析及其应用案例

聚类分析及其应用案例聚类分析是一种常见的数据分析方法,它能将一组数据根据相似性进行分组。
通过聚类分析,我们可以发现数据集中的隐藏模式、结构和关系,从而为决策提供有力支持。
本文将介绍聚类分析的基本原理,并通过一个应用案例来说明其在实际问题中的应用。
一、聚类分析的基本原理聚类分析的目标是将数据集中的对象(如样本、观测值)分成不同的组,使得组内的对象相似度较高,而组间的对象相似度较低。
聚类分析的基本原理有两种方法:基于原型的聚类和基于密度的聚类。
1. 基于原型的聚类基于原型的聚类方法假设数据集中的每个组都有一个原型,这个原型可以是一个样本或一个向量。
常见的基于原型的聚类方法有K均值聚类和K中心点聚类。
K均值聚类是一种常用的聚类方法,它将数据集中的对象分成K个组,每个组都有一个中心点,使得组内对象到中心点的距离最小。
K均值聚类的过程包括初始化K个中心点、计算每个对象与中心点的距离、更新中心点的位置,直到达到收敛条件。
K中心点聚类是K均值聚类的变种,它将中心点定义为每个组中对象到其他组的最小距离。
K中心点聚类的优点是对异常值不敏感,但计算复杂度较高。
2. 基于密度的聚类基于密度的聚类方法通过计算对象之间的密度来确定聚类结果。
常见的基于密度的聚类方法有DBSCAN和OPTICS。
DBSCAN是一种基于密度的聚类方法,它通过定义一个对象的邻域半径和最小邻居数来确定核心点、边界点和噪声点。
DBSCAN的聚类结果不受数据集中对象的顺序影响,并且能够发现任意形状的聚类。
OPTICS是DBSCAN的改进算法,它通过计算对象之间的可达距离来确定聚类结果。
OPTICS能够发现不同密度的聚类,并且不需要预先指定邻域半径和最小邻居数。
二、聚类分析的应用案例聚类分析在实际问题中有广泛的应用,例如市场细分、社交网络分析和生物信息学等领域。
以下是一个以市场细分为例的应用案例。
假设某公司想要将其客户分成不同的市场细分,以便更好地进行定向营销。
聚类分析及判别分析案例
聚类分析及判别分析案例⼀、案例背景随着现代⼈⼒资源管理理论的迅速发展,绩效考评技术⽔平也在不断提⾼。
绩效的多因性、多维性,要求对绩效实施多标准⼤样本科学有效的评价。
对企业来说,对上千⼈进⾏多达50~60个标准的考核是很常见的现象。
但是,⽬前多标准⼤样本⼤型企业绩效考评问题仍然困扰着许多⼈⼒资源管理从业⼈员。
为此,有必要将当今国际上最流⾏的视窗统计软件SPSS应⽤于绩效考评之中。
在分析企业员⼯绩效⽔平时,由于员⼯绩效⽔平的指标很多,各指标之间还有⼀定的关联性,缺乏有效的⽅法进⾏⽐较。
⽬前较理想的⽅法是⾮参数统计⽅法。
本⽂将列举某企业的具体情况确定适当的考核标准,采⽤主成分分析以及聚类分析⽅法,⽐较出各员⼯绩效⽔平,从⽽为企业绩效管理提供⼀定的科学依据。
最后采⽤判别分析建⽴判别函数,同时与原分类进⾏⽐较。
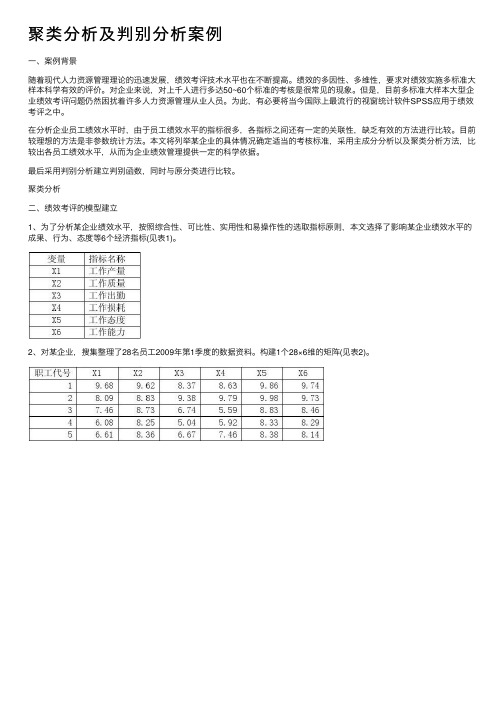
聚类分析⼆、绩效考评的模型建⽴1、为了分析某企业绩效⽔平,按照综合性、可⽐性、实⽤性和易操作性的选取指标原则,本⽂选择了影响某企业绩效⽔平的成果、⾏为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员⼯2009年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应⽤SPSS数据统计分析系统⾸先对变量进⾏及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备⽤。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227 -.295Zscore(X2) .228 -.221Zscore(X3) .224 -.297Zscore(X4) .177 -.173Zscore(X5) .186 .572Zscore(X6) .185 .587提取⽅法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值⼤于1,分别为3.944和1.08,所以选取两个主成分。
根据累计贡献率超过80%的⼀般选取原则,主成分1和主成分2的累计贡献率已达到了83.74%的⽔平,表明原来6个变量反映的信息可由两个主成分反映83.74%。
文章透彻解读聚类分析及案例实操

文章透彻解读聚类分析及案例实操目录一、聚类分析概述 (3)1. 聚类分析定义 (4)1.1 聚类分析是一种无监督学习方法 (4)1.2 目的是将相似的对象组合在一起 (5)2. 聚类分析分类 (6)2.1 根据数据类型分为数值聚类和类别聚类 (7)2.2 根据目标函数分为划分聚类和层次聚类 (9)二、聚类分析理论基础 (10)1. 距离度量方法 (11)1.1 欧氏距离 (13)1.2 曼哈顿距离 (14)1.3 余弦相似度 (15)1.4 皮尔逊相关系数 (16)2. 聚类有效性指标 (17)三、聚类分析算法 (18)1. K-均值聚类 (19)1.1 算法原理 (21)1.2 算法步骤 (22)1.3 收敛条件和异常值处理 (24)2. 层次聚类 (25)2.1 算法原理 (26)2.2 算法步骤 (27)2.3 凝聚度量和链接度量 (28)四、案例实操 (30)1. 客户分群 (31)1.1 数据准备 (33)1.2 聚类结果分析 (34)1.3 结果应用 (35)2. 商品推荐 (36)2.1 数据准备 (37)2.2 聚类结果分析 (38)2.3 结果应用 (39)3. 新闻分类 (40)3.1 数据准备 (41)3.2 聚类结果分析 (42)3.3 结果应用 (44)五、聚类分析应用场景 (45)1. 市场细分 (46)2. 社交网络分析 (47)3. 生物信息学 (48)4. 图像识别 (49)六、讨论与展望 (51)1. 聚类分析的局限性 (52)2. 未来发展方向 (53)一、聚类分析概述聚类分析是一种无监督学习方法,旨在将相似的对象组合在一起,形成不同的组或簇。
它根据数据的内在结构或特征,而非预先定义的类别对数据进行分组。
这种方法在数据挖掘、机器学习、市场细分、社交网络分析等领域具有广泛的应用。
特征选择:从数据集中选择合适的特征,以便更好地表示数据的分布和模式。
距离度量:确定一个合适的距离度量方法,用于衡量数据点之间的相似程度。
聚类分析法经典案例

聚类分析法经典案例聚类分析法是一种常用的数据分析方法,它通过对数据进行分类和分组,帮助我们发现数据中的内在规律和特征。
在实际应用中,聚类分析法被广泛运用于市场营销、社交网络分析、医学诊断、图像处理等领域。
下面,我们将介绍一些聚类分析法的经典案例,帮助大家更好地理解和应用这一方法。
首先,我们来看一个市场营销领域的案例。
某公司想要对其客户进行分类,以便更好地制定营销策略。
他们收集了客户的消费行为、年龄、性别、地理位置等数据,并利用聚类分析法对客户进行了分组。
通过分析,他们发现客户可以被分为三大类,高消费高端用户、中等消费稳定用户和低消费新用户。
有了这些分类信息,公司可以针对不同类型的客户制定不同的营销策略,提高市场营销效率。
其次,我们来看一个社交网络分析的案例。
一家社交媒体公司希望了解用户在平台上的行为和兴趣,以便更好地推荐内容和广告。
他们利用用户的浏览记录、点赞行为、评论信息等数据,通过聚类分析法将用户分为几个群体。
通过分析,他们发现用户可以被分为电影爱好者、音乐迷、美食达人等不同类型的群体。
有了这些分类信息,社交媒体公司可以更精准地为用户推荐内容和广告,提高用户满意度和广告点击率。
再次,我们来看一个医学诊断的案例。
医院收集了患者的临床症状、实验室检查结果、病史等数据,希望通过聚类分析法对患者进行分类,以便更好地制定治疗方案。
通过分析,他们发现患者可以被分为几个病情严重程度不同的群体。
有了这些分类信息,医生可以更好地制定个性化的治疗方案,提高治疗效果和患者生存率。
最后,我们来看一个图像处理的案例。
一家无人驾驶车辆公司希望通过图像识别技术对道路上的车辆和行人进行分类,以便更好地进行交通管理和安全预警。
他们利用摄像头采集的图像数据,通过聚类分析法将道路上的车辆和行人进行分类。
通过分析,他们可以更准确地识别不同类型的车辆和行人,并做出相应的交通管理和安全预警措施。
通过以上经典案例的介绍,我们可以看到聚类分析法在不同领域的广泛应用。
聚类分析案例

K-Means聚类分析一、实验方法K-Means聚类分析二、实验目的根据2001年全国31省市自治区各类小康和现代化指数的数据,用Spass对地区进行K-Means 聚类分析。
三、实验数据综合指数社会结构经济与技术发展人口素质生活质量法制与治安北京93.2 100 94.7 108.4 97.4 55.5上海92.3 95.1 92.7 112 95.4 57.5天津87.9 93.4 88.7 98 90 62.7浙江80.9 89.4 85.1 78.5 86.6 58广东79.2 90.4 86.9 65.9 86.5 59.4江苏77.8 82.1 74.8 81.2 75.9 74.6辽宁76.3 85.8 65.7 93.1 68.1 69.6福建72.4 83.4 71.7 67.7 76 60.4山东71.7 70.8 67 75.7 70.2 77.2黑龙江70.1 78.1 55.7 82.1 67.6 71吉林67.9 81.1 51.8 85.8 56.8 68.1湖北65.9 73.5 48.7 79.9 56 79陕西65.9 71.5 48.2 81.9 51.7 85.8河北65 60.1 52.4 75.6 66.4 76.6山西64.1 73.2 41 73 57.3 87.8海南64.1 71.6 46.2 61.8 54.5 100重庆64 69.7 41.9 76.2 63.2 77.9内蒙古63.2 73.5 42.2 78.2 50.2 81.4湖南60.9 60.5 40.3 73.9 56.4 84.4青海59.9 73.8 43.7 63.9 47 80.1四川59.3 60.7 43.5 71.9 50.6 78.5宁夏58.2 73.5 45.9 67.1 46.7 61.6新疆64.7 71.2 57.2 75.1 57.3 64.6安徽56.7 61.3 41.2 63.5 52.5 72.6云南56.7 59.4 49.8 59.8 48.1 72.3甘肃56.6 66 36.6 66.2 45.8 79.4 四、分析方法与结果表一31个省市自治区小康和现代化指数的K-Means聚类分析结果(一)初始聚类中心聚类1 2 3综合指数79.20 92.30 51.10社会结构90.40 95.10 61.90经济与技术发展86.90 92.70 31.50人口素质65.90 112.00 56.00生活质量86.50 95.40 41.00法制与治安59.40 57.50 75.60ANOVA聚类误差均方自由度均方自由度F 显著性综合指数1633.823 2 22.518 28 72.556 .000 社会结构1539.872 2 47.312 28 32.547 .000 经济与技术发展4381.296 2 56.760 28 77.190 .000 人口素质1817.856 2 74.363 28 24.446 .000 生活质量3315.174 2 59.276 28 55.928 .000 法制与治安530.188 2 76.284 28 6.950 .004由于已选择聚类以使不同聚类中个案之间的差异最大化,因此 F 检验只应该用于描述目的。
聚类分析的应用案例

聚类分析的应用案例聚类分析是一种常用的数据挖掘技术,它可以将数据集中的对象按照其相似性进行分类,从而找出数据中的潜在模式和结构。
聚类分析在各个领域都有着广泛的应用,例如市场营销、医学诊断、社交网络分析等。
本文将介绍几个聚类分析在实际应用中的案例,帮助读者更好地理解和应用这一技术。
首先,聚类分析在市场营销中的应用案例。
假设一个公司希望对其客户进行细分,以便更好地定制营销策略。
通过聚类分析,可以将客户按照其购买行为、偏好等特征进行分类,从而识别出不同的客户群体。
比如,通过聚类分析可以将客户分为价值型客户、潜在客户、忠诚客户等不同的群体,然后针对不同的群体制定相应的营销策略,提高营销效果。
其次,聚类分析在医学诊断中的应用案例也非常广泛。
医学领域的数据往往包含大量的特征和变量,通过聚类分析可以将患者按照其症状、生理指标等特征进行分类,从而辅助医生进行诊断和治疗。
例如,通过聚类分析可以将患者分为不同的疾病类型或病情严重程度,帮助医生更好地制定个性化的治疗方案,提高治疗效果。
另外,聚类分析在社交网络分析中也有着重要的应用价值。
随着社交网络的快速发展,人们在社交网络上产生了大量的数据,通过聚类分析可以将用户按照其兴趣、行为等特征进行分类,从而挖掘出不同的用户群体和社交圈子。
这对于社交网络平台来说,可以帮助他们更好地推荐好友、内容等,提高用户的粘性和使用体验。
综上所述,聚类分析在市场营销、医学诊断、社交网络分析等领域都有着重要的应用价值。
通过聚类分析,可以帮助人们更好地理解和利用数据,发现数据中的潜在模式和结构,为决策提供科学依据。
随着数据挖掘技术的不断发展,相信聚类分析在更多的领域将会有着更广泛的应用。
聚类分析案例

聚类分析案例聚类分析是一种数据分析方法,用于将数据集中的对象分成不同的群组,使得群组内的对象相似度较高,而不同群组之间的相似度较低。
以下是一个聚类分析的案例。
假设一个公司试图了解他们的客户群体,以便更好地进行市场细分和定位。
该公司采集了一系列与客户相关的特征,比如年龄、性别、购买行为等。
他们打算使用聚类分析来将这些客户划分为不同的群组,以便更好地了解每个群组的特征和需求。
首先,该公司需要对数据进行预处理。
他们将删除一些不相关或重复的特征,并对缺失数据进行填充。
然后,他们需要选择一个合适的聚类算法来检测潜在的群组结构。
在这个案例中,他们选择了k-means算法,因为它是一个简单而高效的方法,适用于大规模数据集。
接下来,他们需要选择聚类的数量。
为了确定最佳的聚类数量,他们使用了“肘部法则”。
该方法计算了不同聚类数量下的聚类误差平方和(SSE),并绘制了一个聚类数量和SSE的折线图。
根据折线图,他们选择了一个聚类数量,使得SSE的降幅明显减缓的那个点。
在这个案例中,他们选择了5个聚类。
最后,他们使用选定的聚类数量运行k-means算法,并获取每个客户所属的聚类。
然后,他们对每个聚类进行分析,比如计算平均年龄、男女比例、购买偏好等。
通过对聚类结果的比较,他们可以发现不同群组之间的差异和相似之处,从而得出关于每个群组的特征和需求的结论。
通过这个聚类分析,该公司发现客户群体可以分为以下几个群组:青年女性购买群体、中年男性购买群体、中老年女性购买群体、青年男性购买群体和普通购买群体。
他们发现不同群组的平均年龄、男女比例和购买偏好存在显著差异,这为他们的市场细分和推广战略提供了有力的支持。
综上所述,聚类分析是一个有用的数据分析方法,可以帮助企业了解客户群体的特征和需求,从而更好地进行市场细分和定位。
通过对数据的预处理、选择合适的聚类算法和聚类数量,以及对聚类结果的分析,企业可以获得有关客户群体的深入洞察,并为营销决策提供有力的支持。
数据挖掘案例分析

数据挖掘案例分析聚类分析是数据挖掘中常见的一种技术,它用于将相似的数据点划分为不同的组或簇,以便我们可以更好地理解和分析数据。
在本篇文章中,我们将通过一个实际的案例来探讨聚类分析的应用。
案例背景:一家在线零售商希望了解其客户的消费行为,以便更好地进行市场定位和推广活动。
为了实现这一目标,该公司收集并整理了大量的客户购买记录数据,包括客户ID、购买时间、购买金额等。
目标:通过聚类分析客户的购买行为,将客户划分为不同的群组,从而得到客户的消费特点和行为模式。
方法:我们将使用一种常见的聚类算法- K-means算法来进行分析。
K-means算法是一种基于距离的聚类算法,它通过在数据空间中找到k个簇的方式来划分数据。
其中k值需要手动设定,我们将通过实验选择最佳的k值。
步骤:1.数据预处理:首先,我们需要对数据进行预处理。
这包括去除无效数据、处理缺失值和异常值,并进行特征工程,以便更好地表达数据的特征。
在这个案例中,我们将使用购买金额作为特征。
2.特征选择:在这个案例中,我们只选择购买金额作为特征。
在实际应用中,可以根据具体情况选择更多的特征。
3.选择聚类数k:为了找到最佳的k值,我们可以使用“肘部法则”或“轮廓系数”等方法。
肘部法则通过绘制不同k值对应的误差平方和(SSE)的曲线,选择拐点所对应的k值。
轮廓系数通过计算不同聚类间的距离和聚类内的距离,从而得到一个综合的评估指标,选择轮廓系数最大的k值。
4. 构建模型:根据选择的k值,我们使用K-means算法构建聚类模型。
K-means算法通过迭代优化的方式不断调整簇的中心点,最终使得样本点到所属簇中心的距离最小化。
在这个案例中,我们可以得到不同客户群组,比如高消费客户群组、低消费客户群组、潜在高消费客户群组等。
通过对不同群组的行为模式分析,该在线零售商可以制定相应的市场定位策略和推广计划,以获得更好的销售业绩。
聚类分析是一项非常强大的数据挖掘技术,它可以帮助我们发现数据中的隐藏模式和规律,从而更好地理解和利用数据。
聚类分析案例

聚类分析案例聚类分析是一种常用的数据挖掘技术,它可以帮助我们将数据集中具有相似特征的对象进行分组,从而揭示数据内在的结构和规律。
在本文中,我们将通过一个实际的案例来介绍聚类分析的应用。
案例背景:某电商平台希望对其用户进行分群,以便更好地了解用户的特征和行为习惯,从而精准推荐商品、提高用户满意度和促进销售额的增长。
为了实现这一目标,我们将运用聚类分析技术对用户数据进行分析。
数据准备:我们收集了一定时间内的用户行为数据,包括用户的浏览记录、购买记录、点击广告的次数、收藏商品的数量等信息。
这些数据将作为聚类分析的输入。
聚类分析步骤:1. 数据预处理,首先,我们需要对收集到的原始数据进行清洗和预处理,包括去除异常值、缺失值处理、数据标准化等工作,以确保数据的质量和可靠性。
2. 特征选择,在进行聚类分析之前,我们需要对数据进行特征选择,选择能够代表用户特征和行为的变量作为聚类的特征,例如购买频率、浏览深度、活跃时段等。
3. 模型选择,根据业务需求和数据特点,我们可以选择合适的聚类分析模型,常用的包括K均值聚类、层次聚类、密度聚类等。
4. 聚类分析,在选择好模型后,我们可以利用数据挖掘工具(如Python中的scikit-learn库)进行聚类分析,将用户分成若干个群体,并对每个群体的特征进行分析和解释。
案例结果:经过聚类分析,我们将用户分成了三个群体,高消费用户、低消费用户和潜在用户。
高消费用户的购买频率和客单价较高,对促销活动和新品推荐比较敏感;低消费用户购买频率较低,但对特价商品和折扣活动有一定的响应;潜在用户则具有较高的点击广告次数和浏览深度,但购买行为较少。
通过对不同群体的特征分析,电商平台可以有针对性地制定营销策略,提高用户的满意度和促进销售额的增长。
结论:通过本案例的聚类分析,我们可以看到聚类分析在电商领域的重要应用价值。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户的特征和行为习惯,从而精准推荐商品、提高用户满意度和促进销售额的增长。
聚类分析例子
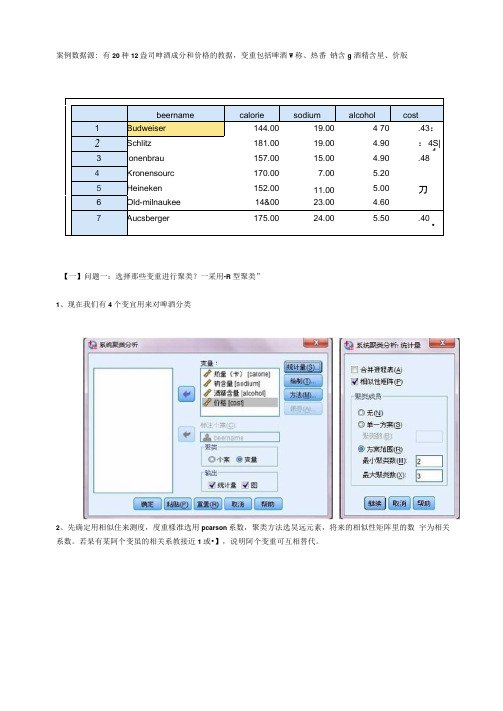
案例数据源: 有20种12盎司呻酒成分和价格的教据,变重包括啤酒W称、热番钠含g 酒精含星、价版beername calorie sodium alcohol cost 1Budweiser144.0019.00 4 70.43:2Schlitz181.0019.00 4.90:4S|4 3lonenbrau157.0015.00 4.90.484Kronensourc170.007.00 5.205Heineken152.0011.00 5.00刀6Old-milnaukee14&0023.00 4.607Aucsberger175.0024.00 5.50.40•【一】问题一:选择那些变重进行聚类?一采用-R型聚类”1、现在我们有4个变宜用来对啤酒分类2、先确定用相似住来测度,度重樣准选用pcarson系数,聚类方法选昊远元素,将来的相似性矩阵里的数宇为相关系数。
若杲有某阿个变虽的相关系教接近1或•】,说明阿个变重可互相替代。
3、只输出“树状图”就可以了,从proximity mnirix表中可以看出热重ft酒靖含量两个变虽相关系教0.903, 最大,二者选其一即可,没有必要都作为聚类变重,导致成本埴和。
至于热重和酒箱含虽选择哪一个作为典型指極来代替原来的两个变蚩,可以帳据专业知识或测定的难易程度决定。
(与因于分析不同,是完全踢掉其中一个变重以达到降淮的目的。
)这里选用酒精含重,至此,确定出用于聚类的变重为:酒精含童钠含重,价格。
Cluster Membership【二】问题二:20中啤酒能分为几类?——采用“Q型聚类”1、现在开绐对20中啤酒进行聚类。
开绐不确定应该分为几类,暂时用一个类范闫来i或探,这一回用欧式距离平方进行测度。
站矣疑关分折:统计量匚合并进您瑕⑹J16似性矩吨)◎无迥)©单一方累①)@方索爼S1迟)银小比类玫廻):卜|噩犬JK类数迖):同|[址绶J丨聯肖邸肋,2、主要通过树状圏和冰柱国来理解类别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《应用多元统计分析》
――报告
班级:
学号:
姓名:
聚类分析的案例分析
摘要
本文主要用SPSS软件对实验数据运用系统聚类法和K均值聚类法进行聚类分析,从而实现聚类分析及其运用。
利用聚类分析研究某化工厂周围的几个地区的气体浓度的情况,从而判断出这几个地区的污染程度。
经过聚类分析可以得到,样本6这一地区的气体浓度值最高,污染程度是最严重的,样本3和样本4气体浓度较高,污染程度也比较严重,因此要给予及时的控制和改善。
关键词:SPSS软件聚类分析学生成绩
数据来源
、数学模型
聚类分析的基本思想是认为各个样本与所选择的指标之间存在着不同程度的 相似性。
可以根据这些相似性把相似程度较高的归为一类, 从而对其总体进行分
析和总结,判断其之间的差距。
系统聚类法的基本思想是在这几个样本之间定义其之间的距离, 在多个变量之 间定义其相似系数,距离或者相似系数代表着样本或者变量之间的相似程度。
根 据相似程度的不同大小,将样本进行归类,将关系较为密切的归为一类,关系较 为疏远的后归为一类,用不同的方法将所有的样本都聚到合适的类中, 这里我们 用的是最近距离法,形成一个聚类树形图,可据此清楚的看出样本的分类情况。
K 均值法是将每个样品分配给最近中心的类中,只产生指定类数的聚类结果。
《应用多元统计分析》第一版164页第6题
我国山区有一某大型化工厂,在该厂区的邻近地区中挑选其中最具有代表性的
8个大气取样点,在固定的时间点每日4次抽取6种大气样本,测定其中包含的 8个取样
点中每种气体的平均浓度,数据如下表。
试用聚类分析方法对取样点及 大气污染气体进行分类。
二氧化硫
环召豆1丙
环己烷
1 0. 056 0.084
0. 031 「0. 038
0. 0081 0. 022
2
0. 049 0. 055 0. 1
0. 11
0. 022 0.0073^ 匚 3
C. 038 0, 13 0. 079 F
17
0. 05S
0, 0i3 4
r 0- 034 0. 095 CL 058 -616 0. 2 0. 029^ 号
r 0.094 0,066 0, 029
厂 0, 32
012 0. Oil 6 0. 064 0. 072 CL 1 P 0.21 0. 0Z8 1, 38 7
0. 040 0. 089 0. OG2 0. 26
0. 033 0. 1 3
0. 069
0. 0S7
0. 027
F 0.05
0.
斶
0. 021
三、建立数学模型
、运行过程
(一)系统聚类分析
在SPSS界面对上述数据进行系统聚类分析如图1和图2所示,进行最近距离分类。
Cluster Mem tership-
© Non e
O Single solution
number of dusters:
@迟沏我ofsolutioris
Llinimum number of cluste rs2
Maximum number of clusters:4坐Hierarchical Cluster Analyst: Save UontinciE]Cancel
(二)K均值聚类分
析
对数据进行K均值聚类分析,如下图所示:
毕Cluster N,
呈Cluster membership
Q DistanfEfrom 匚luster cenier
f --------------- / ------------------ f -------------- \
Continue Cancel Help
图4
K Means Cluster Ana^sis:
Statistics
V India cluster centers
I' ATJOYAiaDlK
V Cius:9r nfcrT.atijn lorsach OSQ
-Mis Jing Value; ---------------------
◎ Esc Lld^ C3£&^ Il5twis-
C 匚述ud? caiss pairwise
Cgm训| Cancel | H创匚
二、运行结果
(一)聚类树形图
41:卑閣阴F黑齡書盒井
W 1S- 53
由图可以看出,将数据进行聚类分析,根据设定的分为了二类到三类。
若分为两类则样本6为一类,其他为一类;若分为三类则将样本四分离出来,其他分为一类。
(二)新变量
itl K2X3X4J(S CLUJ 1CLLl2_i
1
1.0160.own.0310”038 D.02201
2.1500.1100.007311
3IJdQ170D a MO11
21 1-0340-.OT50.0580160D.2000.0290
50E40.mo.0290顾QI却.041011
6QUO07701Q0O2100Q河 1 XQQ3?
70450G5202SC'O0^003GO11 OfiflO OST0Q?70050 D om521011
该图显示将分类结果的新变量,分别为CLU3_1和CLU2_1可以清楚的看到将
数据聚为2类和3类的分类情况
(三)新变量迭代过程中类中心的变化量
迭代历史记录a
a.由于聚类中心内没有改动或改动较小而达到收敛。
任何中心的最大绝对坐标更
改为.000。
当前迭代为2。
初始中心间的最小距离为.230。
从表中可以看出本次聚类过程共进行了两次迭代。
由于我们在Iterate 子对话框中设置最大迭代次数为10和收敛判据为0,所以在第二次迭代后,类中心的变化为0,从而迭代停止。
(四)各观测量所属类成员表
聚类成员
(五)最终类中心表
图10
根据结果(五)和结果(六)可以看出,将8个样本聚为了4类。
第一类包括样本1、样本2和样本8,根据图1中聚类1这一列可以看出,这一类为这四类中气体浓度值最低的一类,也就是说该类的环境污染不严重,属于优;第二类包括样本5和样本7,该类气体浓度也是比较低的一类,环境污染有些严重,属于良;第三类包括样本6,这一气体浓度最高,环境污染最严重,属于差;第四类包括样本3 和样本4,环境污染较严重,属于中。
(六)新变量
K1X2K3X4XS XG CLU CLU|QCL 1QCL_2 1帖閱094003 rO0380OMi022011M656
20MD.100011M.0220.0073■111为也
3.C3B0.13DD.07901700.0430'114D?44l}
40340.05801600_2M0.0290214.07440
5CS4Q•Q2W-OT2Q■ W1011 2 04247
6064007?010QHJ0-2801323QEJOOQ
708900620260003800%D12
3瞒D0087002700500QtSQ0210i1106017
如图所示,QCL_1为分类情况,而QCL_2为所属类中心距离
四、结论
通过在SPSS软件中对聚类分析案例的运用将不同的样本聚为不同的类,并算
出其间的距离更加清楚方便的将多项不同的样本进行聚类分析,并对其的总体情
况进行估计,最后能够得到各类别的气体浓度总体情况,从而判断出环境污染的严重情况。
经过这次实验学到了很多东西,遇到的问题也一一得到解决。