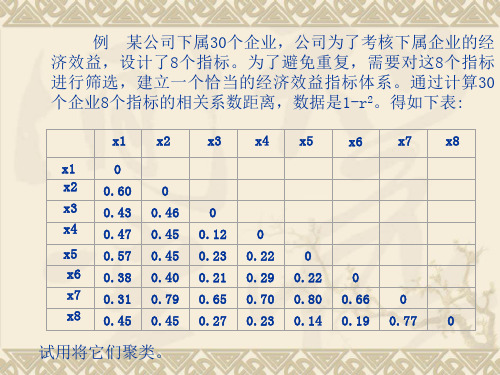
数据挖掘案例分析聚类分析
完整版数据挖掘中的聚类分析方法

完整版数据挖掘中的聚类分析方法聚类分析方法是数据挖掘领域中常用的一种数据分析方法,它通过将数据样本分组成具有相似特征的子集,并将相似的样本归为一类,从而揭示数据中隐藏的模式和结构信息。
下面将从聚类分析的基本原理、常用算法以及应用领域等方面进行详细介绍。
聚类分析的基本原理聚类分析的基本原理是将数据样本分为多个类别或群组,使得同一类别内的样本具有相似的特征,而不同类别之间的样本具有较大的差异性。
基本原理可以总结为以下三个步骤:1.相似性度量:通过定义距离度量或相似性度量来计算数据样本之间的距离或相似度。
2.类别划分:根据相似性度量,将样本分组成不同的类别,使得同一类别内的样本之间的距离较小,不同类别之间的距离较大。
3.聚类评估:评估聚类结果的好坏,常用的评估指标包括紧密度、分离度和一致性等。
常用的聚类算法聚类算法有很多种,下面将介绍常用的几种聚类算法:1. K-means算法:是一种基于划分的聚类算法,首先通过用户指定的k值确定聚类的类别数,然后随机选择k个样本作为初始聚类中心,通过迭代计算样本到各个聚类中心的距离,然后将样本划分到距离最近的聚类中心对应的类别中,最后更新聚类中心,直至达到收敛条件。
2.层次聚类算法:是一种基于树状结构的聚类算法,将样本逐步合并到一个大的类别中,直至所有样本都属于同一个类别。
层次聚类算法可分为凝聚式(自底向上)和分裂式(自顶向下)两种。
凝聚式算法首先将每个样本作为一个初始的类别,然后通过计算样本之间的距离来逐步合并最近的两个类别,直至达到停止准则。
分裂式算法则是从一个包含所有样本的初始类别开始,然后逐步将类别分裂成更小的子类别,直至达到停止准则。
3. 密度聚类算法:是一种基于样本密度的聚类算法,通过在数据空间中寻找具有足够高密度的区域,并将其作为一个聚类。
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)算法是密度聚类算法的代表,它通过定义距离和邻域半径来确定样本的核心点、边界点和噪声点,并通过将核心点连接起来形成聚类。
数据挖掘软件的分类算法和聚类算法应用案例

数据挖掘软件的分类算法和聚类算法应用案例第一章介绍数据挖掘软件的分类算法数据挖掘是从大量数据中提取有价值信息的过程,分类算法是其中最常用也最基本的技术手段之一。
下面我们将介绍几种常见的分类算法及其应用案例。
1.1 决策树算法决策树算法是一种基于树形结构的分类方法,通过一系列问题的回答来判断数据属于哪个类别。
常见应用场景是客户流失预测。
例如,在电信行业中,根据用户的个人信息、通话记录等数据,可以使用决策树算法预测某个用户是否会流失,从而采取相应措施。
1.2 朴素贝叶斯算法朴素贝叶斯算法是一种基于贝叶斯定理的概率分类方法,它假设特征之间相互独立。
常见应用场景是垃圾邮件过滤。
例如,根据邮件的关键词、发件人等特征,可以使用朴素贝叶斯算法判断某封邮件是否为垃圾邮件。
1.3 支持向量机算法支持向量机算法是一种常用的二分类算法,它将数据映射到高维空间中,通过学习一个分隔超平面来进行分类。
常见应用场景是图像识别。
例如,在人脸识别领域,可以使用支持向量机算法将不同人脸的特征进行分类,从而实现人脸识别功能。
第二章介绍数据挖掘软件的聚类算法聚类算法是将数据对象划分成不同的类别或簇的过程,属于无监督学习的范畴。
下面我们将介绍几种常见的聚类算法及其应用案例。
2.1 K均值算法K均值算法是一种基于距离度量的聚类方法,将数据划分为K个簇,每个簇的中心点称为聚类中心。
常见应用场景是客户细分。
例如,在市场营销领域中,可以使用K均值算法对用户的消费数据进行聚类,将用户划分为不同的细分群体,从而有针对性地推送广告和优惠信息。
2.2 层次聚类算法层次聚类算法是一种基于距离或相似度的聚类方法,它将数据对象自底向上或自顶向下逐渐合并,形成聚类层次结构。
常见应用场景是文本分析。
例如,在文本挖掘中,可以使用层次聚类算法对大量文件进行聚类,将相似的文件放在同一个簇中,进而快速找到相关文档。
2.3 密度聚类算法密度聚类算法是一种基于密度的聚类方法,它将数据对象划分为具有足够高密度的区域,并与邻近的高密度区域分离开来。
数据挖掘案例分析

数据挖掘案例分析数据挖掘是指从大量的数据中发现未知的、之前不可预测的、对决策有潜在价值的模式、关系和规律的过程。
在当今信息爆炸的时代,数据挖掘已经成为了企业决策和发展的重要工具。
本文将通过一个实际案例,来分析数据挖掘在企业中的应用。
案例背景,某电商企业在市场竞争中遇到了一些问题,销售额增长放缓,用户流失率较高。
为了解决这些问题,企业决定利用数据挖掘技术对用户行为数据进行分析,以期找到潜在的解决方案。
首先,企业收集了大量的用户行为数据,包括用户浏览商品的记录、购买记录、收藏记录、评论记录等。
然后,利用数据挖掘技术对这些数据进行了分析。
通过对用户浏览商品的记录进行关联规则分析,企业发现了一些有趣的规律。
比如,有一部分用户在浏览了某些商品之后,会购买另外一些商品。
这些规律为企业提供了一些启发,可以通过推荐系统将这些相关商品进行捆绑销售,从而提高销售额。
此外,通过对用户购买记录的数据进行聚类分析,企业发现了不同用户群体的特点。
比如,有一部分用户更倾向于购买高价位的商品,而另一部分用户更倾向于购买低价位的商品。
通过针对不同群体的用户制定不同的营销策略,企业可以更好地满足用户的需求,提高用户满意度,降低用户流失率。
另外,通过对用户评论记录的情感分析,企业了解到了用户对商品的真实反馈。
有些商品可能在外观上很吸引人,但实际使用后用户体验并不好。
通过及时调整这些商品的设计和质量,企业可以提升用户对商品的满意度,从而提高用户忠诚度。
综合以上分析,企业采取了一系列针对性的措施,包括推荐系统优化、营销策略调整、产品质量改进等。
这些措施取得了显著的效果,销售额得到了提升,用户流失率也得到了降低。
通过这个案例的分析,我们可以看到数据挖掘在企业中的重要作用。
它不仅可以帮助企业发现潜在的商机,还可以帮助企业更好地了解用户需求,优化产品和服务,提升竞争力。
因此,对于企业来说,数据挖掘已经不再是可有可无的选择,而是必须要重视和应用的技术工具。
数据挖掘中的聚类分析方法

数据挖掘中的聚类分析方法数据挖掘是一种通过智能计算和算法挖掘数据价值的技术。
而数据挖掘中的聚类分析方法则是其中的一个重要分支。
聚类分析是指将相似的数据组合在一起,不同的数据分开,形成不同的类别。
聚类分析在机器学习、数据分析、数据挖掘、图像处理等领域有广泛的应用。
本文将从聚类分析的定义、算法、分类等方面进行讲解。
一、聚类分析的定义聚类分析是一种无监督学习算法,它主要用于将样本根据各自的相似性分成若干类别。
聚类分析主要有两种方法:层次聚类和划分聚类。
层次聚类是一种自下而上的聚类方法,将每个样本视为一个初始聚类,然后将聚类依次合并,形成更大的聚类,直到所有样本都组成一个聚类。
层次聚类的结果是一个聚类树状结构,通过剪枝可以获得不同的聚类结果。
划分聚类是一种自上而下的聚类方法,将所有样本看作一个大的聚类,然后逐渐将其划分成更小的聚类,最终得到所需的聚类数目。
划分聚类主要有K均值聚类和高斯混合模型聚类二、聚类分析的算法(一) 层次聚类算法层次聚类常用的算法是自底向上的聚合算法和自顶向下的分裂算法。
自底向上的聚合算法是指先构造n个初始聚类,然后迭代合并最接近的两个聚类,直到达到某个停止条件。
这个停止条件可以是达到了所需的聚类数目,也可以是聚类之间距离的最大值。
自顶向下的分裂算法则是从所有样本开始,将其划分成两个聚类,然后逐步分裂聚类,得到所需的聚类数目。
(二) K均值聚类K均值聚类是一种划分聚类算法,它需要先指定K个聚类中心,然后根据距离来将样本点分配给不同的聚类中心。
然后将每个聚类内部的样本的均值作为该聚类的新中心,重新计算每个样本点和聚类中心的距离,直到聚类中心不再改变或达到一定的迭代次数。
K均值聚类的优势在于简单快速,具有很好的可扩展性和聚类效果。
但是这种算法需要预先确定聚类中心数,且对初始聚类中心的选择比较敏感。
(三) 高斯混合模型聚类高斯混合模型聚类是一种基于概率密度估计的算法,它假设每个聚类的密度函数是一个高斯分布。
数据仓库与数据挖掘的应用案例分析

数据仓库与数据挖掘的应用案例分析随着信息化时代的到来,数据已经成为企业管理和决策的重要资源。
数据的采集、存储、管理和分析对于企业的发展至关重要,因此数据仓库和数据挖掘成为了企业管理中不可或缺的一部分。
本篇文章将从实际应用的角度,分析数据仓库和数据挖掘在企业管理中的应用案例,并对相应的应用过程进行深入剖析。
一、企业数据仓库的建设随着企业规模的扩大,企业的数据量也越来越大,如何高效地管理企业的数据,使企业管理者更好地利用数据进行决策已成为现代企业面临的重要问题。
在这个背景下,企业数据仓库应运而生。
企业数据仓库是一个按照主题组织的、集成的、非易失性的、随时间变化而更新的数据集合,用于支持企业管理决策。
建设企业数据仓库,首先需要确定数据仓库的目标、内容、结构和技术等方面的问题。
下面,以某电商企业的数据仓库建设为例,进行具体分析。
1. 确定数据仓库的目标该电商企业定位在提供高品质的商品和服务上,因此数据仓库的主要目标是为企业领导层提供决策支持服务,使企业能够更好地了解市场变化、用户需求、商品销售情况等,从而制定更加精准的市场营销策略和商品运营方案。
2. 确定数据仓库的内容该企业的数据仓库包括以下内容:(1)用户数据:包括用户的基本信息、购买记录、心理特征等方面的数据。
(2)商品数据:包括商品的基本信息、销售记录、库存等方面的数据。
(3)营销数据:包括销售额、订单量、优惠券使用情况、促销活动效果等方面的数据。
(4)财务数据:包括收入、成本、盈利等方面的数据。
3. 确定数据仓库的结构该企业数据仓库的结构采用星型或雪花型的结构,以主题为中心,将不同的数据源集成在一起,数据仓库中的不同表之间通过主键和外键进行关联。
4. 确定数据仓库的技术方案该企业采用的数据仓库技术方案包括ETL工具、数据清洗工具、数据集成工具、数据质量管理工具等。
在数据仓库的建设过程中,需要对数据进行清洗、转换和整合等处理,以保证数据的一致性和准确性。
数据仓库与数据挖掘案例分析

数据仓库与数据挖掘案例分析在当今数字化的时代,数据已成为企业和组织最宝贵的资产之一。
如何有效地管理和利用这些海量数据,以获取有价值的信息和洞察,成为了摆在众多企业面前的重要课题。
数据仓库和数据挖掘技术的出现,为解决这一问题提供了有力的手段。
接下来,让我们通过一些具体的案例来深入了解这两项技术的应用和价值。
一、零售行业的数据仓库与数据挖掘以一家大型连锁超市为例,该超市每天都会产生大量的销售数据,包括商品的种类、价格、销售数量、销售时间、销售地点等。
通过建立数据仓库,将这些分散在不同系统和数据库中的数据整合起来,形成一个统一的、集成的数据源。
数据挖掘技术则可以帮助超市发现隐藏在这些数据中的模式和趋势。
例如,通过关联规则挖掘,可以发现哪些商品经常被一起购买,从而优化商品的摆放和促销策略。
如果顾客经常同时购买面包和牛奶,那么将这两种商品摆放在相邻的位置,或者推出面包和牛奶的组合促销活动,可能会提高销售额。
通过聚类分析,可以将顾客分为不同的群体,根据每个群体的消费习惯和偏好,进行个性化的营销。
比如,将经常购买高端进口食品的顾客归为一类,针对他们推送相关的新品推荐和优惠信息;而对于注重性价比的顾客群体,则推送一些打折促销的商品信息。
二、金融行业的数据仓库与数据挖掘在金融领域,银行和证券公司也广泛应用数据仓库和数据挖掘技术。
一家银行拥有大量的客户数据,包括客户的基本信息、账户交易记录、信用记录等。
利用数据仓库,银行可以对这些数据进行整合和管理,实现对客户的全面了解。
数据挖掘可以帮助银行进行客户细分,识别出高价值客户和潜在的流失客户。
对于高价值客户,提供个性化的服务和专属的金融产品,提高客户的满意度和忠诚度;对于潜在的流失客户,及时采取措施进行挽留,比如提供优惠政策或者改善服务质量。
在风险管理方面,数据挖掘可以通过建立信用评估模型,预测客户的违约风险。
通过分析客户的历史交易数据、收入情况、负债情况等因素,评估客户的信用等级,为贷款审批提供决策依据,降低不良贷款率。
数据挖掘算法_聚类数据挖掘

10 9 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10
基于质心的 k-means聚类算法
坐标表示 5 个点{ X1,X2,X3,X4,X5}作为一个聚类分析的二维
样 本 : X1=(0,2),X2=(0,0),X3=(1.5,0),X4= (5,0),X5=(5,2)。假设要求的簇的数量k=2。
聚类分析的应用实独立变量 数目增加时, 发现簇的难 度开始增加
美陆军委托他人研究如何重新设计女兵服装,目 的在于减少不同尺码制服的库存数,但必须保证 每个士兵都有合体的制服。 选取了3000名女性,每人有100多个度量尺寸。
常见的聚类方法--划分聚类方法
典型的应用
作为一个独立的分析工具,用于了解数据的分布; 作为其它算法的一个数据预处理步骤;
应用聚类分析的例子
市场销售: 帮助市场人员发现客户中的不同群体, 然后用这些知识来开展一个目标明确的市场计划; 土地使用: 在一个陆地观察数据库中标识那些土地 使用相似的地区;
保险: 对购买了汽车保险的客户,标识那些有较高 平均赔偿成本的客户;
第1步:由样本的随机分布形成两个簇: C ={X1,X2,X4}和C2={X3,X5}。 这两个簇的质心M1和M2是:
1
1 2
M ={(0+0+5)/3,(2+0+0)/3}={1.66,0.66};
M ={(1.5+5)/2,(0+2)/2}={3.25,1.00};
基于质心的 k-means聚类算法
﹒.· .
﹒.┇ . .· · . . · · . · ﹒.﹒. ﹒.﹒.﹒.· ﹒. ﹒. ﹒. 类别3
数据挖掘实验报告-聚类分析

数据挖掘实验报告(三)聚类分析姓名:李圣杰班级:计算机1304学号:1311610602一、实验目的1、掌握k-means 聚类方法;2、通过自行编程,对三维空间内的点用k-means 方法聚类。
二、实验设备PC 一台,dev-c++5.11三、实验内容1.问题描述:立体空间三维点的聚类.说明:数据放在数据文件中(不得放在程序中),第一行是数据的个数,以后各行是各个点的x,y,z 坐标。
2.设计要求读取文本文件数据,并用K-means 方法输出聚类中心 3. 需求分析k-means 算法接受输入量k ;然后将n 个数据对象划分为 k 个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k-means 算法的工作过程说明如下:首先从n 个数据对象任意选择k 个对象作为初始聚类中心,而对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类。
然后,再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。
一般都采用均方差作为标准测度函数,具体定义如下:21∑∑=∈-=ki iiE C p m p (1)其中E 为数据库中所有对象的均方差之和,p 为代表对象的空间中的一个点,m i 为聚类C i 的均值(p 和m i 均是多维的)。
公式(1)所示的聚类标准,旨在使所获得的k 个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
四、实验步骤Step 1.读取数据组,从N 个数据对象任意选择k 个对象作为初始聚类中心; Step 2.循环Step 3到Step 4直到每个聚类不再发生变化为止; Step 3.根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分;Step 4.重新计算每个(有变化)聚类的均值(中心对象)。
《数据挖掘》课程PPT-聚类分析

图像处理
1 2 3
图像分割
在图像处理中,聚类分析可以用于将图像分割成 多个区域或对象,以便进行更细致的分析和处理。
特征提取
通过聚类分析,可以提取图像中的关键特征,如 颜色、形状、纹理等,以实现图像分类、识别和 检索。
图像压缩
通过聚类分析,可以将图像中的像素进行聚类, 从而减少图像数据的维度和复杂度,实现图像压 缩。
03 推荐系统
利用聚类分析对用户和物品进行分类,为用户推 荐相似或相关的物品或服务。
02
聚类分析的常用算法
K-means算法
• 概述:K-means是一种基于距离的聚类算法,通过迭代将数据划分为K个集群,使得每个数 据点与其所在集群的中心点之间的距离之和最小。
• · 概述:K-means是一种基于距离的聚类算法,通过迭代将数据划分为K个集群,使得每个数 据点与其所在集群的中心点之间的距离之和最小。
03 基于模型的聚类
根据某种模型对数据进行拟合,将数据点分配给 不同的模型,常见的算法有EM算法、高斯混合模 型等。
聚类分析的应用场景
01 客户细分
将客户按照其特征和行为划分为不同的细分市场, 以便更好地了解客户需求并提供定制化服务。
02 异常检测
通过聚类分析发现数据中的异常值或离群点,以 便及时发现潜在的问题或风险。
生物信息学
基因表达分析
在生物信息学中,聚类分析可以用于分析基因表达数据, 将相似的基因聚类在一起,以揭示基因之间的功能关联和 调控机制。
蛋白质组学分析
通过聚类分析,可以研究蛋白质之间的相互作用和功能模 块,以深入了解生物系统的复杂性和动态性。
个性化医疗
通过聚类分析,可以根据个体的基因型、表型等特征进行 分类,为个性化医疗提供依据和支持。
第四范式平台在数据挖掘领域的实际应用案例解析以及相关技术讲解

第四范式平台在数据挖掘领域的实际应用案例解析以及相关技术讲解数据挖掘作为一项重要的技术手段,已经在各个领域得到广泛应用。
而第四范式平台作为一个专注于大数据处理和分析的公司,其提供的数据挖掘解决方案也备受关注。
本文将结合实际案例,对第四范式平台在数据挖掘领域的应用进行解析,并对相关技术进行讲解。
首先,我们来看一个实际案例,以展示第四范式平台在数据挖掘领域的应用。
某电商公司想要通过数据挖掘技术来提升用户购买转化率。
他们将用户的购买数据、浏览数据、搜索数据等多种数据源整合到第四范式平台中进行分析。
通过对用户行为数据的挖掘,他们成功地找到了一些影响用户购买转化率的关键因素。
例如,用户在购买前浏览了多少商品、搜索了哪些关键词、购买前的停留时长等等。
基于这些发现,电商公司可以针对性地优化用户购买路径,提供个性化推荐,从而提升购买转化率。
在这个案例中,第四范式平台发挥了关键作用。
首先,平台提供了强大的数据处理和分析能力,能够高效地处理大规模的数据。
其次,平台提供了丰富的数据挖掘算法和模型,可以帮助用户发现隐藏在数据背后的规律和趋势。
最后,平台提供了友好的可视化界面,使用户能够直观地理解和使用挖掘结果。
接下来,我们来讲解一些与第四范式平台相关的数据挖掘技术。
其中一个重要的技术是聚类分析。
聚类分析是一种将数据分成不同组的技术,每个组内的数据具有相似的特征。
通过聚类分析,我们可以发现数据中的隐藏模式和规律。
在第四范式平台中,聚类分析可以帮助用户对大规模数据进行分类,从而更好地理解数据的特征和结构。
另一个相关技术是关联规则挖掘。
关联规则挖掘是一种发现数据中频繁出现的关联关系的技术。
通过挖掘关联规则,我们可以发现数据中的潜在关联性,从而进行更精准的推荐和推广。
在第四范式平台中,关联规则挖掘可以帮助用户发现产品之间的关联性,从而提供个性化的推荐和推广方案。
此外,第四范式平台还提供了文本挖掘、时间序列分析、图像识别等多种数据挖掘技术。
聚类分析算法在数据挖掘领域中的应用研究

聚类分析算法在数据挖掘领域中的应用研究数据分析已经成为了现代社会中非常重要的一部分,它可以用来发现现象之间的联系、挖掘规律和进行预测。
而聚类分析算法则是数据分析领域中非常重要的一种算法,它可以用来对数据集进行分类,并提取出数据中的规律与模式。
在本文中,我们将探讨聚类分析算法在数据挖掘领域中的应用研究。
一、聚类分析算法的概念与类型聚类分析算法,顾名思义,是将数据集中的元素进行分类的算法。
其通过将数据集划分成不同的簇(Cluster),从而将同类数据点聚集在一起,不同类数据点分开归类。
聚类分析算法可以分为以下几种类型:1. 手动聚类:手动聚类是人工输入分类规则并按照该规则划分数据。
2. 层次聚类:层次聚类是根据距离或相似性,将数据点逐步聚合成更大的簇。
3. K-means聚类:K-Means聚类是一种基于质心的聚类算法,它将数据点分为K个簇,并将每个点分配到最近的簇中。
4. 密度聚类:密度聚类是基于密度的聚类算法,它可以识别任意形状、大小和方向的簇。
二、聚类分析算法在数据挖掘领域中的应用研究1. 数据挖掘中的聚类分析在数据挖掘领域中,聚类分析算法经常被用来对大规模数据集进行分类。
通过将数据点划分为不同的簇,可以进一步了解数据集的结构并提取出数据中的隐藏模式。
而且聚类分析算法还可以用来将不同的数据集融合为一个更大的、更全面的数据集。
这个过程可以帮助用户发现数据集中的异常点和噪音,从而更好地理解和分析数据集。
2. 聚类分析在市场分析中的应用在市场分析中,聚类分析算法可以用来帮助企业发现不同类别的用户群体。
通过将买家分为不同的群体,企业可以了解消费者的需求、购买行为和偏好,从而针对性地进行市场营销策略。
基于聚类分析的市场分析可以找到新的销售机会,加强客户忠诚度,最终帮助企业提高销售额和利润率。
3. 聚类分析在医学影像诊断中的应用聚类分析算法在医学影像领域中应用广泛。
它可以用来对患者进行分类、发现不同类型肿瘤病变,并针对性地做出诊断和治疗方案。
聚类分析与关联规则挖掘

聚类分析与关联规则挖掘聚类分析和关联规则挖掘是数据挖掘领域中两个重要的技术方法。
它们能够从大量的数据中发现隐藏的模式和关系,对于决策支持和业务发展具有重要意义。
本文将分别介绍聚类分析和关联规则挖掘的概念、应用以及挖掘过程,并探讨它们在不同领域中的实际应用案例。
一、聚类分析聚类分析是将一组对象划分为具有相似特征的多个类别的过程。
它能够帮助我们发现数据中的内在结构,将相似的对象进行分组,从而更好地理解数据和模式。
聚类分析的过程包括选择适当的聚类算法、确定合适的距离度量,以及评估和解释聚类结果。
聚类分析在许多领域中都有广泛的应用。
在市场营销领域,我们可以使用聚类分析来对消费者进行细分,帮助企业了解不同群体的需求和偏好,从而优化产品定位和营销策略。
在医学领域,聚类分析可以帮助医生对患者进行分类,预测疾病的发展趋势,优化治疗方案。
在社交网络分析中,聚类分析可以帮助我们识别社区结构,了解不同群体之间的联系和影响。
二、关联规则挖掘关联规则挖掘是一种寻找数据项之间频繁关联关系的方法。
它能够挖掘出频繁出现的数据项组合,并通过计算支持度和置信度等指标来评估关联性的强度。
关联规则通常采用“如果...那么...”的形式,能够帮助我们发现特定条件下的潜在关系和规律。
关联规则挖掘在市场篮子分析、推荐系统、网络流量分析等领域有着广泛的应用。
在市场篮子分析中,我们可以通过挖掘购买商品之间的关联规则,提供交叉销售的策略建议。
在推荐系统中,关联规则挖掘可以帮助我们推荐用户可能感兴趣的物品或内容。
在网络流量分析中,关联规则挖掘可以帮助我们发现异常或恶意的网络活动,提高网络安全性。
三、聚类分析与关联规则挖掘的应用案例1. 零售行业的市场篮子分析在零售行业中,使用聚类分析和关联规则挖掘可以帮助商家了解不同商品的潜在关联性,优化产品陈列和促销策略。
例如,通过挖掘顾客购买记录的关联规则,商家可以发现“购买尿布的顾客也经常购买啤酒”,进而将尿布和啤酒放在相邻位置,增加销售额。
数据挖掘的实战案例

数据挖掘的实战案例在当今信息爆炸的时代,大量的数据被生成并存储在各个领域。
这些数据中蕴含着宝贵的信息,如果能够有效地挖掘出来,将会为企业决策、市场分析、产品改进等方面带来巨大的价值。
数据挖掘作为一种从大规模数据集中提取知识和信息的技术,逐渐被应用于现实生活中的各个领域。
本文将以几个实际案例来介绍数据挖掘的应用。
案例一:金融领域的客户分类随着金融行业的快速发展,银行等金融机构积累了大量的客户数据。
如何利用这些数据来提高客户服务水平和投资策略成为一个亟待解决的问题。
通过数据挖掘技术,可以对客户进行分类,以便更好地了解客户需求和风险承受能力。
在这个案例中,我们可以将客户数据进行聚类分析,找出不同群体的共同特征,并针对性地开展营销活动。
案例二:电子商务领域的用户购买行为分析在电子商务平台上,用户的购买行为是一项重要的研究对象。
通过对用户购买历史、浏览记录等数据进行挖掘,可以揭示用户的偏好、购买动机等信息。
例如,通过关联规则挖掘,我们可以发现购买某一产品的用户可能还会购买另外一类产品,从而可以有针对性地进行销售推荐。
通过购买行为分析,电商企业可以提高销售额和客户满意度。
案例三:医疗领域的疾病诊断医疗领域是一个充满挑战和机遇的领域。
数据挖掘在医疗领域的应用可以帮助医生进行疾病诊断和预测,提高精准医疗水平。
通过对患者的病例、病史和检查数据进行分析,可以建立诊断模型,辅助医生做出准确的诊断。
此外,数据挖掘还可以对大规模医学数据库进行分析,发现疾病的发生规律和可能的风险因素,为疾病预防和公共卫生政策制定提供科学依据。
案例四:交通领域的交通流预测交通拥堵是许多城市面临的一个普遍问题。
通过对交通数据进行挖掘和分析,可以准确预测交通流量,并制定合理的交通管理策略。
例如,通过分析历史交通数据和天气数据,可以建立交通流量预测模型,预测未来某一时段某个交通路段的流量,从而合理安排交通管制和调度。
综上所述,数据挖掘在各个领域的实际应用案例丰富多样。
聚类分析的应用案例

聚类分析的应用案例聚类分析是一种常用的数据挖掘技术,它可以将数据集中的对象按照其相似性进行分类,从而找出数据中的潜在模式和结构。
聚类分析在各个领域都有着广泛的应用,例如市场营销、医学诊断、社交网络分析等。
本文将介绍几个聚类分析在实际应用中的案例,帮助读者更好地理解和应用这一技术。
首先,聚类分析在市场营销中的应用案例。
假设一个公司希望对其客户进行细分,以便更好地定制营销策略。
通过聚类分析,可以将客户按照其购买行为、偏好等特征进行分类,从而识别出不同的客户群体。
比如,通过聚类分析可以将客户分为价值型客户、潜在客户、忠诚客户等不同的群体,然后针对不同的群体制定相应的营销策略,提高营销效果。
其次,聚类分析在医学诊断中的应用案例也非常广泛。
医学领域的数据往往包含大量的特征和变量,通过聚类分析可以将患者按照其症状、生理指标等特征进行分类,从而辅助医生进行诊断和治疗。
例如,通过聚类分析可以将患者分为不同的疾病类型或病情严重程度,帮助医生更好地制定个性化的治疗方案,提高治疗效果。
另外,聚类分析在社交网络分析中也有着重要的应用价值。
随着社交网络的快速发展,人们在社交网络上产生了大量的数据,通过聚类分析可以将用户按照其兴趣、行为等特征进行分类,从而挖掘出不同的用户群体和社交圈子。
这对于社交网络平台来说,可以帮助他们更好地推荐好友、内容等,提高用户的粘性和使用体验。
综上所述,聚类分析在市场营销、医学诊断、社交网络分析等领域都有着重要的应用价值。
通过聚类分析,可以帮助人们更好地理解和利用数据,发现数据中的潜在模式和结构,为决策提供科学依据。
随着数据挖掘技术的不断发展,相信聚类分析在更多的领域将会有着更广泛的应用。
数据挖掘的算法和应用案例

数据挖掘的算法和应用案例数据挖掘是一种从大量数据中提取潜在模式和知识的过程。
它结合了统计学、人工智能和机器学习等多个领域的技术和方法,在各个行业和领域都有广泛的应用。
本文将介绍一些常见的数据挖掘算法和应用案例。
一、关联规则挖掘关联规则挖掘是寻找数据中项与项之间的关联关系。
这种技术广泛应用于市场营销、购物篮分析和推荐系统中。
以购物篮分析为例,通过挖掘顾客购买商品之间的关联规则,商家可以了解客户的购物习惯和喜好,从而进行更加精准的商品推荐和促销活动。
二、分类与回归分类与回归是一类有监督学习的数据挖掘算法,它用于将数据分为不同的类别或预测数据的数值。
在医疗领域中,可以利用分类算法对患者的病情进行预测和诊断。
例如,通过对患者的病历数据进行训练,建立一个分类模型,可以在未来的新病例中预测患者是否得某种疾病。
三、聚类分析聚类分析是一种无监督学习的数据挖掘算法,其目标是将相似的对象归为一类。
在市场细分和社交网络分析中,聚类分析被广泛应用。
例如,一家电商公司可以利用聚类分析将用户划分为不同的群体,然后针对不同群体的用户制定个性化的营销策略。
四、异常检测异常检测用于识别与普通模式不符的异常数据。
在金融领域,异常检测可以用于发现金融欺诈行为。
通过对历史交易数据进行异常检测,银行可以及时发现不寻常的交易模式,并采取相应措施保护客户的资金安全。
五、文本挖掘文本挖掘用于从大量的文本数据中提取有价值的信息和知识。
在舆情分析和情感分析中,文本挖掘被广泛应用。
例如,通过对社交媒体上用户的评论进行情感分析,可以了解用户对某个产品或事件的态度和观点。
六、推荐系统推荐系统是通过分析用户的历史行为和偏好,为用户提供个性化的推荐。
在电商和视频网站中,推荐系统能够根据用户的兴趣和喜好,为他们推荐符合其口味的商品或视频。
通过挖掘用户的行为数据,推荐系统可以不断优化推荐效果,提高用户满意度。
综上所述,数据挖掘算法在各个行业和领域都有广泛的应用。
Python中的数据挖掘案例分析

Python中的数据挖掘案例分析数据挖掘是指从大量数据中发现规律、模式和趋势的过程,用以帮助人们做出决策或预测未来的趋势。
在当今信息爆炸的时代,数据挖掘技术正发挥越来越重要的作用。
Python作为一种强大的编程语言,在数据挖掘中广泛应用,并且拥有丰富的库和工具,方便进行各种数据分析任务。
本文将通过几个实际案例,展示Python中的数据挖掘应用。
案例一:销售预测一家电子商务公司希望预测未来一段时间内的销售情况,以便有效管理库存和制定营销策略。
他们拥有大量的销售数据,包括时间、地点、价格、促销活动等信息。
使用Python中的数据挖掘技术,可以对这些数据进行分析和建模,以预测未来的销售量。
具体步骤包括数据清洗、特征选择、模型训练和评估等。
通过Python的机器学习库,如scikit-learn,可以方便地完成这些任务。
案例二:用户行为分析一个社交媒体平台希望了解用户的行为模式,以改善用户体验和精准推荐相关内容。
他们通过Python中的数据挖掘技术,分析用户的点击、评论、分享等行为数据,探索用户的兴趣和喜好。
通过数据可视化工具,如matplotlib和seaborn,可以将分析结果以图表形式展示,直观地了解用户的行为特征。
案例三:航空公司客户细分一家航空公司需要进行客户细分,以精确制定营销策略。
他们拥有大量的乘客数据,包括航班信息、消费金额、会员等级等。
使用Python中的数据挖掘技术,可以对这些数据进行聚类分析,将乘客划分为不同的细分群体,如商务旅客、休闲旅客、高消费乘客等。
通过这样的细分,航空公司可以有针对性地开展推广活动和服务改进。
案例四:信用评分银行机构需要对申请贷款的个人或企业进行信用评分,以决定是否批准贷款以及贷款额度。
他们可以通过Python中的数据挖掘技术,分析个人或企业的信息,如年龄、收入、借款记录等,建立信用评分模型。
通过Python的统计分析库,如pandas和numpy,可以方便地进行数据处理和特征工程。
数据挖掘 聚类分析(第六章)
❖ 具体过程如表:
m1
m2
K1
K2
2
4
{2,3}
{4,10,12,20,30,11,25}
2.5
16
{2,3,4}
{10,12,20,30,11,25}
3
18
{2,3,4,10}
{12,20,30,11,25}
4.75
19.6 {2,3,4,10,11,12}
{20,30,25}
7
25
{2,3,4,10,11,12}
❖ 2、考虑下一个数据项,把它分配到目前 某个类中或一个新类中。给分配是基于 一些准则的,例如新数据项到目前类的 重心的距离。在这种情况下,每次添加 一个新数据项到一个目前的类中时,需 要重新计算重心的值。
❖ 3、重复步骤2,直到所有的数据样本都 被聚类完毕。
❖ 例如: 设 x1=(0,2),x2=(0,0),x3=(1.5,0),x4=(5,0),X5=(5,2) 假定样本的顺序是:X1,X2,X3,X4,X5, 类间相似度的 阈值水平是s=3。
❖ 聚类结果的质量也取决于它发现隐藏模式的 能力。.
K-均值聚类
❖ K-均值聚类方法是最简单、最常用的使 用使用准则的方法。
❖ K-均值聚类是属于划分方法中的基于质 心技术的一种方法。划分的思路是以k 为参数,把n个对象分为k 个类,以使类 内具有较高的相似度,而类间的相似度 较低。相似度的计算根据一个类中对象 的平均值(被看作类的重心)来进行。
1、第一个样本X1将变成第一个类C1={x1}.x1的坐标就 是重心坐标M1={0,2}。
2、开始分析其他样本。 a)把第2个样本x2和M1比较,距离d为:
d(x2,M1)= 02 22 =2.0<3
数据挖掘聚类的例子

数据挖掘聚类的例子数据挖掘聚类是数据分析领域中的一项重要技术,通过对大量数据进行探索性分析和模式识别,将相似的数据对象聚集到一起,从而帮助人们更好地理解数据背后的规律和趋势。
本文将通过几个具体的例子,从不同领域展示数据挖掘聚类的应用。
首先,我们来看一个市场调研的例子。
在市场调研中,人们经常需要将消费者根据其购买行为进行分群。
通过数据挖掘聚类,可以将拥有类似购买偏好的消费者聚集到一起,帮助企业精准地制定营销策略。
例如,一家运动品牌的市场调研人员可以通过分析消费者的购买记录和喜好,将他们分为运动型、休闲型、时尚型等群体,以便更好地推广不同款式的产品。
其次,数据挖掘聚类在医疗领域也有着广泛的应用。
医院可以通过分析患者的病历和医疗数据,将相似病例聚类到一起,从而发现潜在的病因和治疗方法。
例如,一家肿瘤医院可以通过分析癌症患者的基因数据,将他们分为不同的亚型,从而提供更加个性化的治疗方案。
此外,通过将患者聚类到具有相似病情的群体中,医院还可以针对不同群体的患者制定更加精准和有效的康复计划。
另一个令人感兴趣的领域是社交媒体分析。
随着社交媒体的普及,人们在社交平台上产生了大量的数据,包括用户的个人资料、点赞、评论等。
通过数据挖掘聚类,我们可以将具有相似兴趣和行为的用户聚集到一起,以便更好地理解他们的需求和行为习惯。
例如,一家电商公司可以通过分析用户在社交媒体上的行为数据,将他们分为购买型、分享型、评论型等不同类型的用户,从而更好地进行个性化推荐和精准营销。
除了以上领域,数据挖掘聚类还可以应用于交通运输、金融、教育等多个领域。
在交通运输方面,通过分析交通流量数据,可以将不同时段、不同道路上的车辆聚类,为交通管理提供科学依据。
在金融领域,可以通过分析客户的交易记录和信用评级,将客户分为高风险、中风险、低风险等群体,从而制定个性化信贷政策。
在教育领域,通过分析学生的学习行为和成绩,可以将学生分为高成绩型、中等成绩型、低成绩型等群体,以便针对不同群体制定个性化的教学计划。
六种相似基本模型在数据挖掘中的应用案例

六种相似基本模型在数据挖掘中的应用案例1. 聚类模型聚类模型在数据挖掘中被广泛应用。
它是一种将相似对象分组到同一类别中的方法。
以下是一些聚类模型在数据挖掘中的应用案例:- 市场细分分析:通过聚类分析可以将市场细分为不同的群体,从而有针对性地制定营销策略。
- 社交网络分析:聚类模型可以帮助识别社交网络中的社群,从而了解人际关系和社交影响力。
- 金融风险评估:通过聚类模型可以将客户分组,进而评估客户的信用风险和潜在欺诈风险。
2. 分类模型分类模型是一种将事物分类到预定义类别的方法,在数据挖掘中应用广泛。
以下是一些分类模型在数据挖掘中的应用案例:- 垃圾邮件过滤:通过分类模型可以将垃圾邮件与正常邮件进行区分。
- 疾病诊断:通过分类模型可以将患者的症状与已知疾病进行匹配,帮助医生进行诊断。
- 欺诈检测:分类模型可以帮助银行或信用卡公司识别可疑的交易行为,减少欺诈风险。
3. 关联规则模型关联规则模型是用来发现数据集中的频繁项集和关联规则的方法。
以下是一些关联规则模型在数据挖掘中的应用案例:- 购物篮分析:关联规则模型可以分析顾客的购物篮,发现购买行为中的相关性,从而提供个性化的推荐。
- 医药领域:通过关联规则模型可以发现药物之间的关联性,帮助科学家进行新药研发和副作用分析。
- 网络安全:关联规则模型可以帮助分析网络流量的模式,发现可能的攻击行为。
4. 预测模型预测模型是用来对未来事件进行预测的方法。
以下是一些预测模型在数据挖掘中的应用案例:- 销售预测:通过历史销售数据和其他相关因素,预测未来的销售趋势,帮助企业制定生产和供应链策略。
- 股票市场分析:预测模型可以通过分析过去的股票数据,预测未来的股价走势,辅助投资决策。
- 气象预测:通过预测模型可以分析历史气象数据,预测未来的天气情况,帮助人们做出相应安排。
5. 异常检测模型异常检测模型用于识别与正常模式不符的数据点。
以下是一些异常检测模型在数据挖掘中的应用案例:- 网络入侵检测:通过异常检测模型可以发现可能的网络入侵行为,提高网络安全性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验项目名称ﻩ:对全国31个地区农村居民人均年食品消费量(09年)的聚类分析ﻩﻩﻩﻩﻩ
信息技术学院 软件技术与数据库教研室
实验概述:对全国不同地区农村居民每人年食品消费量的聚类分析
1.实验目的
运用数据挖掘技术中的聚类分析方法,对全国不同地区农村居民每人年食品消费量的数据进行分类。
2.实验要求
对他们购买的食物进行分类.
其中,食物的英文表示:Rice Vegetable Oil Meat Bird Egg Seafood Sugar Wine Fruit Nuts
分别对应为:粮食 蔬菜及制品 食用油 猪牛羊肉 家禽 蛋类及其制品 水产品 食糖 酒消 瓜果 坚果及制品
所以,聚类的对象我选择按列聚类。
可见,农村居民的主要食品消费主要集中在粮食和蔬菜;瓜果,肉类,酒类其次;油、鸡蛋,禽、海鲜,糖、坚果相对较少。
2.疑难与需解决的问题
此数据使用关联规则方法不太好找出关联食品.
3.实验体会
此数据使用关联规则方法不太好找出关联食品。
实验数据的选取很重要,它对实验结果的得出有直接意义。
教师评语及成绩
验内容与关键步骤
1.实验结果
通过STATISTICA软件进行聚类分析后,得出的分类为:
一、对于农村地区居民食品消费的数量而言,食用油和蛋类及其制品属于一类,家禽和海鲜属于一类,食糖和坚果属于一类,这三类可以应归结为消费较少的第一类;
二、肉类,瓜果,酒类属于第二类,,消费数量较多;
三、粮食,蔬菜属于第三类,消费数量最多,远远高于其它两类.
用聚类分析方法分析数据,对数据进行分类。
3.实验预备知识
统计学知识,数据库知识,数据挖掘聚类分析方法
实验内容
1.实验方案设计
用全国31个地区(北京、天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆)的农村居民人均年食品消费量这一数据,