聚类分析的案例分析教程
聚类分析在市场细分中的应用案例分析

聚类分析在市场细分中的应用案例分析市场细分是市场营销中的关键战略之一,通过将市场划分为不同的细分市场,企业可以更加准确地满足不同消费者的需求,提供个性化的产品和服务。
而聚类分析作为一种常用的数据挖掘技术,可以在市场细分过程中发挥重要作用,帮助企业实现更精确的市场细分。
在本文中,我们将通过分析一个真实的案例来探讨聚类分析在市场细分中的应用。
该案例涉及到一家汽车制造商,该公司希望根据消费者的购车偏好将市场细分为不同的群体,以便更好地定位和营销其产品。
首先,为了进行聚类分析,我们需要收集大量的消费者数据。
在这个案例中,我们采集了来自不同地区的1000名消费者的数据,包括他们的年龄、性别、收入、家庭人口数量、购车目的和首选汽车品牌等信息。
这些数据将被用作聚类分析的输入。
接下来,我们使用聚类算法对收集到的数据进行分析。
在这个案例中,我们选择了k-means聚类算法来进行分析。
该算法将数据分为预定义数量的簇,每个簇之间的差异最小化。
我们选择了5个簇来表示不同的消费者群体。
通过聚类分析,我们将消费者分为了5个不同的簇。
下面是每个簇的特征描述:1. 簇1:该簇包括了年龄较大、收入较高的消费者群体,他们的购车目的主要是追求舒适性和品牌形象,在购车时更倾向于选购豪华品牌的汽车。
2. 簇2:该簇包括了年轻人群,他们的收入相对较低,购车目的主要是为了实用和经济,他们更倾向于购买价格相对较低且经济燃油的汽车。
3. 簇3:该簇包括了家庭人口较多的消费者群体,他们的购车目的主要是为了家庭出行,他们更倾向于购买多功能、空间较大的SUV或MPV类型的汽车。
4. 簇4:该簇包括了对环保和可持续性较为关注的消费者群体,他们更倾向于购买电动汽车或混合动力汽车。
5. 簇5:该簇包括了喜欢运动和驾驶激情的消费者群体,他们的购车目的主要是追求驾驶的乐趣和速度,他们更倾向于购买跑车或运动型汽车。
通过对聚类结果的分析,汽车制造商可以更好地了解不同消费者群体的需求和偏好。
案例分析 江苏省各市经济发展水平的聚类分析

案例分析江苏省各市经济发展水平的聚类分析标题:案例分析:江苏省各市经济发展水平的聚类分析一、引言江苏省作为中国的重要经济大省,其各市的经济发展水平一直以来备受。
对江苏省各市经济发展水平进行准确的评估,不仅有助于我们理解各市的经济现状,也有助于制定针对性的经济发展策略。
本文采用聚类分析的方法,对江苏省各市的经济发展水平进行分类,并对其结果进行深入剖析。
二、数据来源与方法1、数据来源我们选取了江苏省各市的GDP、人均GDP、工业增加值、固定资产投资、社会消费品零售总额、出口总额、地方财政收入等经济指标作为数据来源。
这些数据均来自江苏省统计局发布的年度报告,具有权威性和准确性。
2、方法选择考虑到数据的复杂性和多元性,我们选择采用聚类分析的方法对江苏省各市的经济发展水平进行分类。
聚类分析是一种无监督学习的方法,能够根据数据的相似性将数据集划分为不同的类别。
在聚类分析中,我们使用了K-means算法,这是一种常见的聚类算法,能够根据设定的类别数,将数据集划分为不同的类别。
三、结果与分析1、数据预处理在进行聚类分析之前,我们首先对收集到的数据进行预处理,包括缺失值填充、异常值处理以及标准化处理等。
经过预处理后的数据,能够更好地反映江苏省各市的经济发展水平。
2、聚类分析结果我们设定类别数为3,对江苏省各市的经济发展水平进行聚类分析。
经过多次尝试和调整,最终得到了较为合理的聚类结果。
该结果将江苏省各市划分为三个类别:高发展水平市、中发展水平市和低发展水平市。
3、结果分析(1)高发展水平市:这一类别的城市主要包括南京、苏州和无锡等城市。
这些城市的经济发展水平较高,各项经济指标均高于全省平均水平。
这些城市的经济结构较为合理,工业增加值和地方财政收入较高,显示出较强的经济实力和竞争力。
(2)中发展水平市:这一类别的城市主要包括常州、南通、徐州等城市。
这些城市的经济发展水平处于全省平均水平之上,但相较于高发展水平市还存在一定差距。
聚类分析案例范文

聚类分析案例范文聚类分析是一种无监督机器学习算法,它通过将数据集中的观测值分成不同的组或簇来发现数据之间的内在结构和相似性。
这种方法可以帮助我们理解数据集,发现隐藏的模式和关联性,并且可以应用于各种领域,包括市场细分、社交网络分析、生物信息学和图像处理等。
以下是一个关于使用聚类分析方法的案例研究,该案例介绍了如何使用聚类分析来帮助一家电商企业在众多商品中挖掘潜在的市场细分。
背景介绍:电商企业销售了大量商品,这些商品拥有不同的特征和属性。
该企业希望利用这些数据来了解他们的客户,并为不同的产品类型制定个性化的推广和营销策略。
为了实现这一目标,他们决定使用聚类分析方法来将客户细分成不同的群组,并理解他们的相似性和差异性。
数据收集:该企业从其销售系统中收集了一份包含多个属性的数据集。
这些属性包括:年龄、性别、购买历史、购买频率、平均订单金额等。
这些属性可以反映客户的购买行为和偏好。
数据预处理:在进行聚类分析之前,需要对数据进行预处理。
这包括对缺失值进行处理、进行数值归一化等。
然后,根据业务需求,选择适当的聚类算法和合适的距离度量方法。
聚类分析过程:在本案例中,采用了一种常见的聚类方法--K均值聚类算法,该算法通过计算数据点之间的欧氏距离来度量它们之间的相似度。
首先,选择合适的K值(聚类簇的个数)。
然后,在初始阶段,随机选择K个点作为聚类中心。
再通过计算每个数据点与聚类中心的距离,并将其归类到最近的聚类簇。
接下来,根据已经分配到每个聚类中的数据点,重新计算新的聚类中心。
这个过程将迭代,直到达到停止准则,如聚类中心不再变化或达到最大迭代次数。
聚类结果分析:在完成聚类过程后,可以根据每个聚类中心的特征和属性,对数据集进行可视化和解释。
这将帮助企业理解各个群组的特征和差异,并从中提取有价值的洞察力。
进而,企业可以根据不同群组的特征制定个性化的营销策略,提高销售和客户满意度。
总结:通过使用聚类分析方法,该电商企业成功地将其客户细分为几个不同的群组。
聚类分析案例

聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。
聚类分析及其应用实例ppt课件

Outlines
聚类的思想 常用的聚类方法 实例分析:层次聚类
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
3. 实例分析:层次聚类算法
定义:对给定的数据进行层次的分解
第4 步
➢
凝聚的方法(自底向上)『常用』
思想:一开始将每个对象作为单独的
第3 步
一组,然后根据同类相近,异类相异 第2步 的原则,合并对象,直到所有的组合
并成一个,或达到一个终止条件。 第1步
a, b, c, d, e c, d, e d, e
X3 Human(人) X4 Gorilla(大猩猩) X5 Chimpanzee(黑猩猩) X2 Symphalangus(合趾猿) X1 Gibbon(长臂猿)
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
离差平方和法( ward method ):
各元素到类中心的欧式距离之和。
Gp
Cluster P
Cluster M
Cluster Q
D2 WM Wp Wq
G q
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
凝聚的层次聚类法举例
Gp G q
Dpq max{ dij | i Gp , j Gq}
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
利用聚类分析进行网络流行度预测的案例分析(六)

利用聚类分析进行网络流行度预测的案例分析近年来,随着互联网和社交网络的普及,网络流行度成为了一个备受关注的话题。
对于企业、机构和个人而言,了解网络流行度的趋势和预测是一项重要的任务。
为了帮助大家更好地理解如何利用聚类分析来进行网络流行度预测,本文将通过一个案例分析来进行说明。
案例:某音乐平台的歌曲热度预测假设我们是某音乐平台的数据科学家,要预测新歌曲在发布后的热度走势。
我们可以使用聚类分析来对用户行为进行分析,进而预测新歌曲的流行度。
第一步:数据收集与清洗首先,我们需要收集大量历史歌曲的数据。
这些数据包括歌曲的播放量、评论数、点赞数、分享数等。
同时,还需要收集用户的相关信息,比如性别、年龄、地域等。
收集到的原始数据会包含一些噪声和异常值,我们需要对其进行清洗和预处理,确保数据的准确性和完整性。
第二步:特征提取与选择在进行聚类分析之前,我们需要对数据进行特征提取与选择。
以歌曲的播放量、评论数、点赞数、分享数等为例,我们可以计算出它们的比例、增长率等特征。
此外,我们还可以根据用户信息提取出用户的兴趣偏好、行为习惯等特征。
在特征选择时,我们需要注意不选择过多冗余的特征,以免影响分析的效果。
第三步:聚类分析在聚类分析中,我们可以使用各种聚类算法,比如K-means、层次聚类等。
对于我们的案例,K-means算法是一种比较常用的选择。
通过对数据进行聚类分析,我们可以将具有相似特征的歌曲或用户归为一类,从而得到不同类别的群体。
第四步:群体特征分析一旦完成了聚类分析,我们可以对每个聚类群体的特征进行分析。
比如,对于某个聚类群体来说,如果大部分歌曲都在发布后的第一周内获得了大量的播放量和点赞数,那么我们可以判断这个群体中的歌曲有很大的潜力成为热歌。
通过对不同群体的特征分析,我们可以得出一些网络流行度的规律和趋势。
第五步:预测与应用最后,我们可以利用聚类分析得到的规律和趋势来进行流行度的预测和应用。
比如,在新歌曲发布之前,我们可以根据聚类分析的结果来对歌曲进行分类,有针对性地制定推广计划和营销策略。
聚类分析法经典案例

聚类分析法经典案例
聚类分析是一种常用的数据分析方法,它能够将相似的观察对象分为一组,并将不相似的对象分为不同的组。
下面将介绍一个经典的聚类分析案例。
在电信行业,客户流失是一个非常重要的问题。
为了降低客户流失率,一家电信公司希望通过聚类分析来识别客户流失的特征,以便进行有针对性的营销策略。
首先,该公司收集了一些客户数据,如客户的年龄、性别、月平均消费金额、通话时长等。
然后,利用聚类分析方法,将客户分为不同的组。
在这个案例中,我们可以采用k-means聚类算法。
通过聚类分析,该公司发现了三个客户群体。
第一组客户是高消费高通话客户,他们的平均消费金额和通话时长都很高。
第二组客户是低消费低通话客户,他们的平均消费金额和通话时长都很低。
第三组客户是高消费低通话客户,他们的平均消费金额很高,但通话时长很低。
利用聚类分析的结果,该公司能够采取有针对性的营销策略。
对于高消费高通话客户,他们可能是该公司的忠诚客户,可以通过提供一些优惠或奖励来保持他们的忠诚度。
对于低消费低通话客户,可以通过提供更具吸引力的套餐或增加服务内容来激发他们的消费需求。
对于高消费低通话客户,可以通过了解他们的通话行为,推出更适合他们的通话套餐,以增加他们的通话时长。
通过这个案例,我们可以看到聚类分析在客户流失预测和营销策略中的重要作用。
它可以帮助企业快速识别不同类型的客户,有针对性地制定相应的营销策略,提高客户满意度和忠诚度,降低客户流失率。
聚类分析还可以应用于其他领域,如金融、医疗等,具有广泛的应用前景。
多元统计聚类分析方法实例

多元统计聚类分析方法实例
一、概述
多元统计聚类分析是一种建立数据从不同特征维度上的理解和描述的
方法。
它是通过对多维数据进行聚类分析,将具有共同特征的不同数据项
归纳到一组中,以便进一步分析和解释这些数据项之间的相似性和差异性,从而达到更深入地理解和把握数据特征的目的。
二、基本多元统计聚类分析步骤
1、数据准备
首先,在开始进行多元统计聚类分析之前,需要准备足够的数据,以
便进行模型的建立和应用。
在进行数据准备时,要注意把握数据的准确性,避免数据准备过程中的错误,以保证后续步骤正确的进行。
2、聚类分析
在进行聚类分析时,需要根据实际的数据情况,确定聚类的参数,并
计算不同类簇之间的距离,作为聚类的依据。
在此过程中,要根据聚类的
具体目的,采用相应的聚类分析方法,以便达到更理想的聚类效果。
3、聚类评价
接下来,需要对聚类结果进行评价,以识别聚类的质量和准确性,并
可以根据评价结果,对聚类的方法和参数进行调整,以获得更理想的聚类
结果。
4、聚类结果应用
最后,在聚类分析完成后,可以将聚类结果应用到实际的问题中,以获得有效的决策依据。
聚类分析法ppt课件全

8/21/2024
25
1.2.2 动态聚类分析法
1.2 聚类分析的种类
(3)分类函数
按照修改原则不同,动态聚类方法有按批修改法、逐个修改法、混合法等。 这里主要介绍逐步聚类法中按批修改法。按批修改法分类的原则是,每一步修 改都将使对应的分类函数缩小,趋于合理,并且分类函数最终趋于定值,即计 算过程是收敛的。
8/21/2024
23
1.2.2 动态聚类分析法
1.2 聚类分析的种类
(2)初始分类 有了凝聚点以后接下来就要进行初始分类,同样获得初始分类也有不同的
方法。需要说明的是,初始分类不一定非通过凝聚点确定不可,也可以依据其 他原则分类。
以下是其他几种初始分类方法: ①人为分类,凭经验进行初始分类。 ②选择一批凝聚点后,每个样品按与其距离最近的凝聚点归类。 ③选择一批凝聚点后,每个凝聚点自成一类,将样品依次归入与其距离
8/21/2024
14
1.2 聚类分析的种类
(2)系统聚类分析的一般步骤 ①对数据进行变换处理; ②计算各样品之间的距离,并将距离最近的两个样品合并成一类; ③选择并计算类与类之间的距离,并将距离最ቤተ መጻሕፍቲ ባይዱ的两类合并,如果累的个
数大于1,则继续并类,直至所有样品归为一类为止; ④最后绘制系统聚类谱系图,按不同的分类标准,得出不同的分类结果。
8/21/2024
18
1.2 聚类分析的种类
(7)可变法
1 2 D kr
2 (8)离差平方和法
(D k 2 pD k 2 q)D p 2q
D k 2 rn n ir n n p i D i2 pn n ir n n q iD i2 qn rn in iD p 2 q
8/21/2024
聚类分析及其应用案例

聚类分析及其应用案例聚类分析是一种常见的数据分析方法,它能将一组数据根据相似性进行分组。
通过聚类分析,我们可以发现数据集中的隐藏模式、结构和关系,从而为决策提供有力支持。
本文将介绍聚类分析的基本原理,并通过一个应用案例来说明其在实际问题中的应用。
一、聚类分析的基本原理聚类分析的目标是将数据集中的对象(如样本、观测值)分成不同的组,使得组内的对象相似度较高,而组间的对象相似度较低。
聚类分析的基本原理有两种方法:基于原型的聚类和基于密度的聚类。
1. 基于原型的聚类基于原型的聚类方法假设数据集中的每个组都有一个原型,这个原型可以是一个样本或一个向量。
常见的基于原型的聚类方法有K均值聚类和K中心点聚类。
K均值聚类是一种常用的聚类方法,它将数据集中的对象分成K个组,每个组都有一个中心点,使得组内对象到中心点的距离最小。
K均值聚类的过程包括初始化K个中心点、计算每个对象与中心点的距离、更新中心点的位置,直到达到收敛条件。
K中心点聚类是K均值聚类的变种,它将中心点定义为每个组中对象到其他组的最小距离。
K中心点聚类的优点是对异常值不敏感,但计算复杂度较高。
2. 基于密度的聚类基于密度的聚类方法通过计算对象之间的密度来确定聚类结果。
常见的基于密度的聚类方法有DBSCAN和OPTICS。
DBSCAN是一种基于密度的聚类方法,它通过定义一个对象的邻域半径和最小邻居数来确定核心点、边界点和噪声点。
DBSCAN的聚类结果不受数据集中对象的顺序影响,并且能够发现任意形状的聚类。
OPTICS是DBSCAN的改进算法,它通过计算对象之间的可达距离来确定聚类结果。
OPTICS能够发现不同密度的聚类,并且不需要预先指定邻域半径和最小邻居数。
二、聚类分析的应用案例聚类分析在实际问题中有广泛的应用,例如市场细分、社交网络分析和生物信息学等领域。
以下是一个以市场细分为例的应用案例。
假设某公司想要将其客户分成不同的市场细分,以便更好地进行定向营销。
聚类分析案例

SPSS软件操纵实例——某挪动公司客户细分模型之杨若古兰创作数据筹办:数据来源于telco.sav,如图1所示,Customer_ID暗示客户编号,Peak_mins暗示工作日上班时期电话时长,OffPeak_mins暗示工作日放工时期电话时长等.分析目的:对挪动手机用户进行细分,了解分歧用户群体的花费习气,以更好的对其进行定制性的营业推销,所以须要应用聚类分析.操纵步调:1,从菜单当选择【文件】——【打开】——【数据】,在打开数据窗口当选择数据地位和文件类型,将数据telco.sav导入SPSS软件中,如图2所示.图2 打开数据菜单选项2,从菜单当选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将须要尺度化的变量选到右侧的“变量列表”,勾选“将尺度化得分另存为变量”,点确定,如图3所示.图3 数据尺度化3,从菜单当选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将尺度化以后的结果选入右侧“变量列表”,客户编号选入“个案标识表记标帜根据”,聚类数改为5.点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续.点击保管按钮,在保管窗口勾选“聚类成员”、“与聚类中间的距离”,点击继续.点击选项按钮,在选项窗口勾选“ANOVA 表”、“每个个案的聚类信息”,点击继续.点击确定按钮,运转聚类分析,如图4所示.图4 聚类分析操纵结果分析表1 终极聚类中间聚类12345 Zscore: 工作日上班时期电话时长.61342.37303 Zscore: 工作日放工时期电话时长.46081Zscore: 周末电话时长.35845Zscore: 国际电话时长.04673.02351Zscore: 总通话时长.41420.10398.21627 Zscore: 平均每次通话时长由终极聚类中间表可得终极分成的5个类它们各自的均值.第一类:根据总通话时间长,上班通话时间长,国际通话时间长等特征,将第一类命名为高端商用客户.第二类:根据其在各项目标中均较低,将第二类命名为不常使用客户.第三类:根据总通话和上班通话时间居中等特征,将第三类命名为中端商用客户.第四类:根据放工通话时间最长等特征,将第四类命名为日常客户.第五类:根据平均每次通话时间最长等特征,将第五类命名为长聊客户.有贡献,本例题中主要程度排序为:总通话时长>工作日上班时期电话时长>工作日放工时期电话时长>平均每次通话时长>国际电话时长>周末电话时长.同时Sig.值都为0,说明各变量对聚类均有明显地贡献(经经常使用Sig.值是否小于0.05来检验聚类结果是否好).结论经过数据尺度化和K-均值聚类分析,终极我们基本实现了本次分析的目的,较为成功的对某挪动电话客户进行了细分,初步了解了各类型用户的手机话费花费习气,对日后经营有必定的指点意义.该挪动运营商,可参考分歧类型用户群体的手机话费习气提出有针对性的话费服务,使经营目标达到最优.。
文章透彻解读聚类分析及案例实操

文章透彻解读聚类分析及案例实操目录一、聚类分析概述 (3)1. 聚类分析定义 (4)1.1 聚类分析是一种无监督学习方法 (4)1.2 目的是将相似的对象组合在一起 (5)2. 聚类分析分类 (6)2.1 根据数据类型分为数值聚类和类别聚类 (7)2.2 根据目标函数分为划分聚类和层次聚类 (9)二、聚类分析理论基础 (10)1. 距离度量方法 (11)1.1 欧氏距离 (13)1.2 曼哈顿距离 (14)1.3 余弦相似度 (15)1.4 皮尔逊相关系数 (16)2. 聚类有效性指标 (17)三、聚类分析算法 (18)1. K-均值聚类 (19)1.1 算法原理 (21)1.2 算法步骤 (22)1.3 收敛条件和异常值处理 (24)2. 层次聚类 (25)2.1 算法原理 (26)2.2 算法步骤 (27)2.3 凝聚度量和链接度量 (28)四、案例实操 (30)1. 客户分群 (31)1.1 数据准备 (33)1.2 聚类结果分析 (34)1.3 结果应用 (35)2. 商品推荐 (36)2.1 数据准备 (37)2.2 聚类结果分析 (38)2.3 结果应用 (39)3. 新闻分类 (40)3.1 数据准备 (41)3.2 聚类结果分析 (42)3.3 结果应用 (44)五、聚类分析应用场景 (45)1. 市场细分 (46)2. 社交网络分析 (47)3. 生物信息学 (48)4. 图像识别 (49)六、讨论与展望 (51)1. 聚类分析的局限性 (52)2. 未来发展方向 (53)一、聚类分析概述聚类分析是一种无监督学习方法,旨在将相似的对象组合在一起,形成不同的组或簇。
它根据数据的内在结构或特征,而非预先定义的类别对数据进行分组。
这种方法在数据挖掘、机器学习、市场细分、社交网络分析等领域具有广泛的应用。
特征选择:从数据集中选择合适的特征,以便更好地表示数据的分布和模式。
距离度量:确定一个合适的距离度量方法,用于衡量数据点之间的相似程度。
聚类分析案例

K-Means聚类分析一、实验方法K-Means聚类分析二、实验目的根据2001年全国31省市自治区各类小康和现代化指数的数据,用Spass对地区进行K-Means 聚类分析。
三、实验数据综合指数社会结构经济与技术发展人口素质生活质量法制与治安北京93.2 100 94.7 108.4 97.4 55.5上海92.3 95.1 92.7 112 95.4 57.5天津87.9 93.4 88.7 98 90 62.7浙江80.9 89.4 85.1 78.5 86.6 58广东79.2 90.4 86.9 65.9 86.5 59.4江苏77.8 82.1 74.8 81.2 75.9 74.6辽宁76.3 85.8 65.7 93.1 68.1 69.6福建72.4 83.4 71.7 67.7 76 60.4山东71.7 70.8 67 75.7 70.2 77.2黑龙江70.1 78.1 55.7 82.1 67.6 71吉林67.9 81.1 51.8 85.8 56.8 68.1湖北65.9 73.5 48.7 79.9 56 79陕西65.9 71.5 48.2 81.9 51.7 85.8河北65 60.1 52.4 75.6 66.4 76.6山西64.1 73.2 41 73 57.3 87.8海南64.1 71.6 46.2 61.8 54.5 100重庆64 69.7 41.9 76.2 63.2 77.9内蒙古63.2 73.5 42.2 78.2 50.2 81.4湖南60.9 60.5 40.3 73.9 56.4 84.4青海59.9 73.8 43.7 63.9 47 80.1四川59.3 60.7 43.5 71.9 50.6 78.5宁夏58.2 73.5 45.9 67.1 46.7 61.6新疆64.7 71.2 57.2 75.1 57.3 64.6安徽56.7 61.3 41.2 63.5 52.5 72.6云南56.7 59.4 49.8 59.8 48.1 72.3甘肃56.6 66 36.6 66.2 45.8 79.4 四、分析方法与结果表一31个省市自治区小康和现代化指数的K-Means聚类分析结果(一)初始聚类中心聚类1 2 3综合指数79.20 92.30 51.10社会结构90.40 95.10 61.90经济与技术发展86.90 92.70 31.50人口素质65.90 112.00 56.00生活质量86.50 95.40 41.00法制与治安59.40 57.50 75.60ANOVA聚类误差均方自由度均方自由度F 显著性综合指数1633.823 2 22.518 28 72.556 .000 社会结构1539.872 2 47.312 28 32.547 .000 经济与技术发展4381.296 2 56.760 28 77.190 .000 人口素质1817.856 2 74.363 28 24.446 .000 生活质量3315.174 2 59.276 28 55.928 .000 法制与治安530.188 2 76.284 28 6.950 .004由于已选择聚类以使不同聚类中个案之间的差异最大化,因此 F 检验只应该用于描述目的。
聚类分析例子
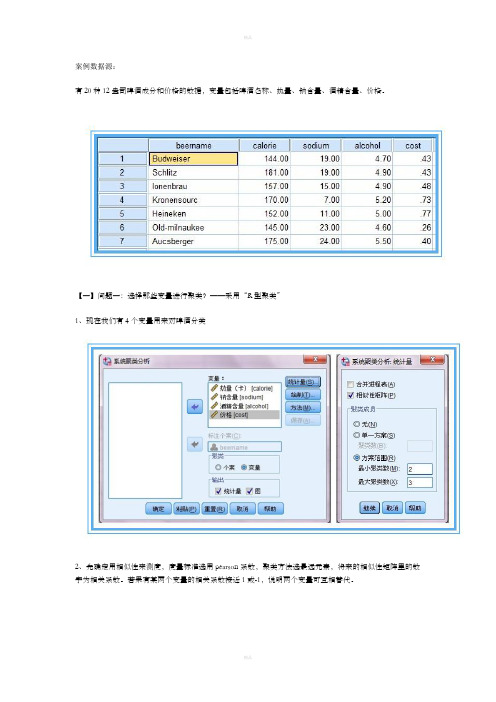
案例数据源:有20种12盎司啤酒成分和价格的数据,变量包括啤酒名称、热量、钠含量、酒精含量、价格。
【一】问题一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类2、先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
3、只输出“树状图”就可以了,从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
【二】问题二:20中啤酒能分为几类?——采用“Q型聚类”1、现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
【三】问题三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
2、这个过程一般用单因素方差分析来判断。
注意此时,因子变量选择聚为4类的结果,而将三个聚类变量作为因变量处理。
方差分析结果显示,三个聚类变量sig值均极显著,我们用于分类的3个变量对分类有作用,可以使用,作为聚类变量是比较合理的。
【四】问题四:聚类结果的解释?——采用”均值比较描述统计“1、聚类分析最后一步,也是最为困难的就是对分出的各类进行定义解释,描述各类的特征,即各类别特征描述。
聚类分析及判别分析案例

一、案例背景随着现代人力资源管理理论的迅速开展,绩效考评技术水平也在不断提高。
绩效的多因性、多维性,要求对绩效实施多标准大样本科学有效的评价。
对企业来说,对上千人进展多达50~60个标准的考核是很常见的现象。
但是,目前多标准大样本大型企业绩效考评问题仍然困扰着许多人力资源管理从业人员。
为此,有必要将当今国际上最流行的视窗统计软件SPSS应用于绩效考评之中。
在分析企业员工绩效水平时,由于员工绩效水平的指标很多,各指标之间还有一定的关联性,缺乏有效的方法进展比拟。
目前较理想的方法是非参数统计方法。
本文将列举某企业的具体情况确定适当的考核标准,采用主成分分析以及聚类分析方法,比拟出各员工绩效水平,从而为企业绩效管理提供一定的科学依据。
最后采用判别分析建立判别函数,同时与原分类进展比拟。
聚类分析二、绩效考评的模型建立1、为了分析某企业绩效水平,按照综合性、可比性、实用性和易操作性的选取指标原那么,本文选择了影响某企业绩效水平的成果、行为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员工2021年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应用SPSS数据统计分析系统首先对变量进展及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备用。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227Zscore(X2) .228Zscore(X3) .224Zscore(X4) .177Zscore(X5) .186 .572Zscore(X6) .185 .587提取方法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值大于1,分别为3.944和1.08,所以选取两个主成分。
根据累计奉献率超过80%的一般选取原那么,主成分1和主成分2的累计奉献率已到达了83.74%的水平,说明原来6个变量反映的信息可由两个主成分反映83.74%。
聚类分析案例

聚类分析案例聚类分析是一种数据分析方法,用于将数据集中的对象分成不同的群组,使得群组内的对象相似度较高,而不同群组之间的相似度较低。
以下是一个聚类分析的案例。
假设一个公司试图了解他们的客户群体,以便更好地进行市场细分和定位。
该公司采集了一系列与客户相关的特征,比如年龄、性别、购买行为等。
他们打算使用聚类分析来将这些客户划分为不同的群组,以便更好地了解每个群组的特征和需求。
首先,该公司需要对数据进行预处理。
他们将删除一些不相关或重复的特征,并对缺失数据进行填充。
然后,他们需要选择一个合适的聚类算法来检测潜在的群组结构。
在这个案例中,他们选择了k-means算法,因为它是一个简单而高效的方法,适用于大规模数据集。
接下来,他们需要选择聚类的数量。
为了确定最佳的聚类数量,他们使用了“肘部法则”。
该方法计算了不同聚类数量下的聚类误差平方和(SSE),并绘制了一个聚类数量和SSE的折线图。
根据折线图,他们选择了一个聚类数量,使得SSE的降幅明显减缓的那个点。
在这个案例中,他们选择了5个聚类。
最后,他们使用选定的聚类数量运行k-means算法,并获取每个客户所属的聚类。
然后,他们对每个聚类进行分析,比如计算平均年龄、男女比例、购买偏好等。
通过对聚类结果的比较,他们可以发现不同群组之间的差异和相似之处,从而得出关于每个群组的特征和需求的结论。
通过这个聚类分析,该公司发现客户群体可以分为以下几个群组:青年女性购买群体、中年男性购买群体、中老年女性购买群体、青年男性购买群体和普通购买群体。
他们发现不同群组的平均年龄、男女比例和购买偏好存在显著差异,这为他们的市场细分和推广战略提供了有力的支持。
综上所述,聚类分析是一个有用的数据分析方法,可以帮助企业了解客户群体的特征和需求,从而更好地进行市场细分和定位。
通过对数据的预处理、选择合适的聚类算法和聚类数量,以及对聚类结果的分析,企业可以获得有关客户群体的深入洞察,并为营销决策提供有力的支持。
聚类分析案例

聚类分析案例聚类分析是一种常用的数据挖掘技术,它可以帮助我们将数据集中具有相似特征的对象进行分组,从而揭示数据内在的结构和规律。
在本文中,我们将通过一个实际的案例来介绍聚类分析的应用。
案例背景:某电商平台希望对其用户进行分群,以便更好地了解用户的特征和行为习惯,从而精准推荐商品、提高用户满意度和促进销售额的增长。
为了实现这一目标,我们将运用聚类分析技术对用户数据进行分析。
数据准备:我们收集了一定时间内的用户行为数据,包括用户的浏览记录、购买记录、点击广告的次数、收藏商品的数量等信息。
这些数据将作为聚类分析的输入。
聚类分析步骤:1. 数据预处理,首先,我们需要对收集到的原始数据进行清洗和预处理,包括去除异常值、缺失值处理、数据标准化等工作,以确保数据的质量和可靠性。
2. 特征选择,在进行聚类分析之前,我们需要对数据进行特征选择,选择能够代表用户特征和行为的变量作为聚类的特征,例如购买频率、浏览深度、活跃时段等。
3. 模型选择,根据业务需求和数据特点,我们可以选择合适的聚类分析模型,常用的包括K均值聚类、层次聚类、密度聚类等。
4. 聚类分析,在选择好模型后,我们可以利用数据挖掘工具(如Python中的scikit-learn库)进行聚类分析,将用户分成若干个群体,并对每个群体的特征进行分析和解释。
案例结果:经过聚类分析,我们将用户分成了三个群体,高消费用户、低消费用户和潜在用户。
高消费用户的购买频率和客单价较高,对促销活动和新品推荐比较敏感;低消费用户购买频率较低,但对特价商品和折扣活动有一定的响应;潜在用户则具有较高的点击广告次数和浏览深度,但购买行为较少。
通过对不同群体的特征分析,电商平台可以有针对性地制定营销策略,提高用户的满意度和促进销售额的增长。
结论:通过本案例的聚类分析,我们可以看到聚类分析在电商领域的重要应用价值。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户的特征和行为习惯,从而精准推荐商品、提高用户满意度和促进销售额的增长。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
yangweipyf@
西安建筑科技大学
“人以类聚, 物以群分”。对事物进行分类,是人们认识事物 的出发点,也是人们认识世界的一种重要方法。因此,分类学 已成为人们认识世界的一门基础学科。
聚类分析又称群分析,它是研究(样品或指标)分类问题的一 种多元统计方法,所谓类,通俗地说,就是指相似元素的集合。
矩阵D中的第3行第2列为12763,表示上海与山西的欧氏 距离为12763, 其余类推.
若想得到下三角阵,则有命令:
S = tril(squareform(d1))
S=1.0e+004 *
0
0
0
0
0
0.3462 0
0
0
0
1.0293 1.2763 0
0
0
1.1575 1.3932 0.1428
0
0
(3) C C
相似系数中最常用的是相关系数与夹角余弦.
例1.2. 计算例1.1中各指标之间的相关系数与夹角余弦
解:x=[…];
%与例6.1.1数据相同
R=corrcoef(x); %指标之间的相关系数
Cij
(x x )( y y) (x x)2 (y y)2
其中x表示第i行元素,y表示第j行元素。
陕西
8354.63
638.76
65.33
2610.61
新疆
9422.22
938.15
141.75
1976.49
为了研究上述5个省、区、市的城镇居民收入差异, 需要利用统计资料对其进行分类,指标变量有4个, 计算各省、区、市之间的前6种距离
解:x=[18738.96 778.36 452.75 7707.87
Dp2k
nq nk nr nk
Dq2k
nk nr nk
Dp2q
2谱系聚类与K均值聚类
2.1 谱系聚类
谱系聚类法是目前应用较为广泛的一种聚类法. 谱系聚 类是根据生物分类学的思想对研究对象进行 分类的方法. 在 生物分类学中,分类的单位是: 门、纲、目、科、属、种, 其中种是分类的基本单位,分类单位越小,它所包含的生物 就越少,生物之间的共同特征就越多. 利用这种思想,谱系 聚类首先将各样品自成一类,然后把最相似(距离最近或相似 系数最大)的样品聚为小类,再将已聚合的小类按各类之间的 相似性(用类间距离度量)进行再聚合,随着相似性的减弱, 最后将一切子类都聚为一大类,从而得到一个按相似性大小 聚结起来的一个谱系图.
D= squareform(d1); % 注意此时d1必须 是一个行向量,结果为实对称矩阵
D = 1.0e+004 * 0 0.3462 1.0293 1.1575 1.0944
0.3462 0 1.2763 1.3932 1.3080 1.0293 1.2763 0 0.1428 0.1639 1.1575 1.3932 0.1428 0 0.1280 1.0944 1.3080 0.1639 0.1280 0
本次主要介绍谱系聚类、K均值聚类、模糊C均值聚类和模糊 减法聚类及其MATLAB实现.
1 距离聚类
1.1聚类的思想 在社会经济领域中存在着大量分类问题,比如对我
国30个省市自治区独立核算工业企业经济效益进行分 析,一般不是逐个省市自治区去分析,而较好地做法 是选取能反映企业经济效益的代表性指标,如:百元 固定资产实现利税、资金利税率、产值利税率、百元 销售收入实现利润、全员劳动生产率等等,根据这些 指标对30个省市自治区进行分类,然后根据分类结果 对企业经济效益进行综合评价,就易于得出科学的分 析。
表 省(区、市)城镇居民人均家庭收入
省(市)
工薪收入 (元/人)
经营净收入(元/ 人)
财产性收入(元/ 人)
转移性收入(元/ 人)
北京
18738.96
778.36
452.75
7707.87
上海
21791.11
1399.14
369.12
6199.77
安徽
9302.38
959.43
293.92
3603.72
由于要考察的物价指数很多,通常先对这些物价指数进行 分类。总之,需要分类的问题很多,因此聚类分析这个有 用的数学工具越来越受到人们的重视,它在许多领域中都 得到了广泛的应用。
聚类问题的一般提法是:设有n 个样品的 p元观测数据
组成一个数据矩阵
X
xx1211
x 12
x 22
xn1 xn2
x1p x2p
d3=pdist(x, 'minkowski',3); %计算明氏距离,d3为1行10列 的行向量 d4=pdist(x,'chebychev') %计算切氏距离. d5=pdist(x,'seuclidean') %计算方差加权距离. d6=pdist(x,'mahalanobis') %计算马氏距离
其中 为样品的协方差矩阵.
在MATLAB中,计算距离的命令是pdist. 调用格式 Y =pdist(X,distance)
输入的 X是一个矩阵,行为个体,列为指标,distance 是距离的类型。若缺省distance,则输出的Y是一个行向量 ,向量的长度为(N-1)*N/2,其中N是样本的容量,Y的元素 分别为个体(1,2),(1,3),..., (1,N), (2,3),...(2,N),.....(N-1,N)之 间的欧氏距离。
向量的距离
设有 n 个样品的 p 元观测数据
xi (xi1, xi2, , xip )T , i 1, 2, , n.
这时,每个样品可看成 n 元空间的一个点,也即一 个 维向量,两个向量之间的距离记为,满足如下 条件:
(1)(非负性) d (xi , x j ) 0, 且d (xi , x j ) 0当且仅当 xi x j
xnp
其中每一行表示一个样品,每一列表示一个指标,xij 表示
第 i个样品关于第 j项指标的观测值,要根据观测值矩阵X
对样品或指标进行分类。
分类的思想:在样品之间定义距离,在指标之间定义相 似系数. 样品距离表明样品之间的相似度,指标之间的相似 系数刻画指标之间的相似度.
聚类分析的基本思想: 将样品(或变量)按相似度的大小逐 一归类,关系密切的聚集到较小的一类,关系疏远的聚集到 较大的一类,直到所有的样品(或变量)都聚集完毕。
设 d ij 表示两个样品 xi,xj 之间的距离,
G p , Gq 分别表示两个类别,各自含有 np,nq 个样品.
(1)最短距离
Dpq
min
iGp , jGq
dij
即用两类中样品之间的距离最短者作为两类间距离.
(2)最长距离
Dpq
max iGp , jGq
dij
即用两类中样品之间的距离最长者作为两类间距离.
(3)类平均距离
1
Dpq npnq iGp jGq dij
即用两类中所有两两样品之间距离的平均作为 两类间距离.
(4)重心距离
Dpq d (x p , xq ) (x p xq )T (x p xq )
其中 x p , xq 分别是G p , Gq 的重心,这是用 两类重心之间的欧氏距离作为类间距离. 一组数据 的平均数即为这组数据的重心。
%计算夹角余弦
J=
1.0000 0.9536 0.9609 0.9797
0.9536 1.0000 0.9026 0.8990
0.9609 0.9026 1.0000 0.9833
0.9797 0.8990 0.9833 1.0000
3类间距离与递推公式 前面,我们介绍了两个向量之间的距离,下面我们 介绍两个类别之间的距离:
2.绝对距离
p
d (xi , x j ) | xik x jk | k 1
3.明可夫斯基(Minkowski) 距离
p
d (xi , x j ) [ | xik x jk |m ]1/ m k 1
其中m(m>0)为常数。
4.切贝雪夫(Chebyshev)距离
d (xi , x j ) max | xik x jk |
(2)(对称性)
d (xi , x j ) d (x j , xi )
(3)(三角不等式) d (xi , x j ) d (xi , xk ) d (xk , x j )
在聚类分析中最常用的是欧氏距离。
1.欧氏(Euclidean)距离
p
d (xi , x j ) [ (xik x jk )2 ]1/ 2 k 1
R= [1.0000 0.6183 0.8138 0.8931 0.6183 1.0000 0.4287 0.2927 0.8138 0.4287 1.0000 0.9235 0.8931 0.2927 0.9235 1.0000]
x1=normc(x); % 将x的各列化为单位向量
J=x1'*x1
1k p
5.方差加权(seuclidean)距离
p
d (xi , x j ) [ (xik x jk )2 / sk2 ]1/ 2 k 1
其中
s
2 k
1 n 1
n
(x jk
j 1
Xk )2, Xk
1 n
n
x jk .
j 1
6.马氏(mahalanobis)距离
d(xi , xj ) (xi xj )T 1(xi xj )
聚类分析方法不仅可以对样品进行分类,而且可以对变量进 行分类,在对变量进行分类时,常常采用相似系数来度量变量
之间的相似性。对 p个指标变量进行聚类时,用相似系数来衡
量变量之间的相似程度(关联度),若用C 表示变量 , 之间 的相似系数,则应满足: